2.1.2. Эмпирическая функция распределения
Это статистический аналог функции распределения из теорвера. Данная функция определяется, как отношение:
, где – количество вариант СТРОГО МЕНЬШИХ, чем ,
при этом «икс» «пробегает» все значения от «минус» до «плюс» бесконечности.
Построим эмпирическую функцию распределения для нашей задачи. Чтобы было нагляднее, отложу варианты и их количество на числовой оси: 
На интервале – по той причине, что левее ЛЮБОЙ точки этого интервала вариант нет. Кроме того, функция равна нулю ещё и в точке . Почему? Потому, что значение определяет количество вариант (см. определение), которые СТРОГО меньше двух, а это количество равно нулю.
На промежутке – и опять обратите внимание, что значение не учитывает рабочих 3-го разряда, т.к. речь идёт о вариантах, которые СТРОГО меньше трёх (по определению).
На промежутке – и далее процесс продолжается по принципу накопления частот:
– если , то ;
– если , то ;
– и, наконец, если , то – и в самом деле, для ЛЮБОГО «икс» из интервала ВСЕ частоты расположены СТРОГО левее этого значения «икс» (см. чертёж выше).
Накопленные относительные частоты удобно заносить в отдельный столбец таблицы, при этом алгоритм вычислений очень прост: сначала сносим слева частоту (красная стрелка), и каждое следующее значение получаем как сумму предыдущего и относительной частоты из текущего левого столбца (зелёные обозначения): 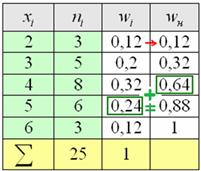
Вот ещё, кстати, один довод за вертикальную ориентацию данных – справа по надобности можно приписывать дополнительные столбцы.
Построенную функцию принято записывать в кусочном виде:
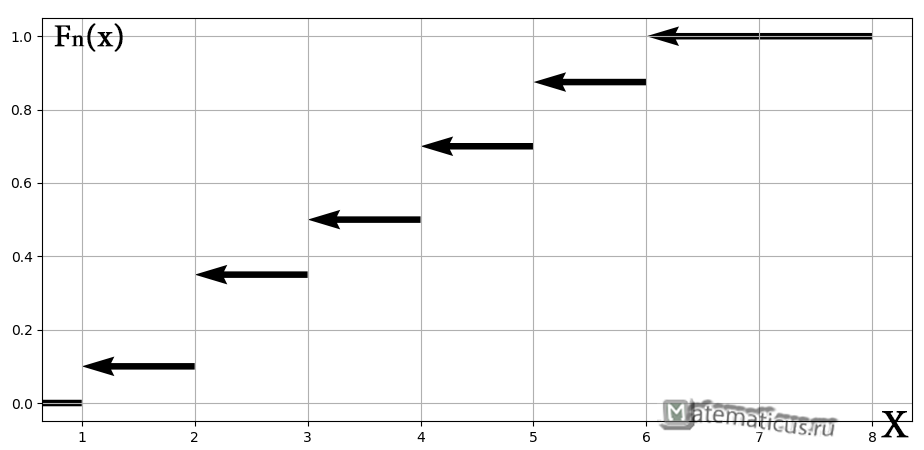
а её график представляет собой ступенчатую фигуру: 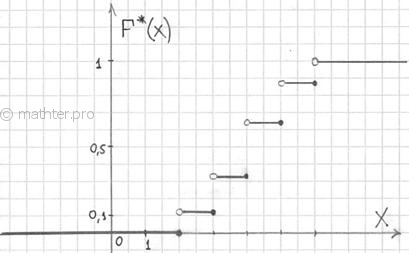
Эмпирическая функция распределения не убывает и принимает значения лишь из промежутка , и если у вас вдруг получится что-то не так, то ищите ошибку.
Теперь смотрим видео, о том, как построить эту функцию в Экселе (Ютуб).
И, конечно, вспомним основной метод математической статистики. Эмпирическая функция распределения строится по выборке и приближает теоретическую функцию распределения . Легко догадаться, что последняя появляется в результате исследования всей генеральной совокупности, но если рабочих в цехе ещё пересчитать можно, то звёзды на небе – уже вряд ли. Вот поэтому и важнА функция эмпирическая, и ещё важнее, чтобы выборка была репрезентативна, дабы приближение было хорошим.
Миниатюрное задание для закрепления материала:
Пример 5
Дано статистическое распределение совокупности: 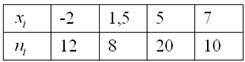
Составить эмпирическую функцию распределения, выполнить чертёж
Решаем самостоятельно – все числа уже в Экселе! Свериться с образцом можно в конце книги. По поводу красоты чертежа сильно не запаривайтесь, главное, чтобы было правильно – этого обычно достаточно для зачёта.
Из таблицы n=40, т.е.
n=4+10+6+8+7+5=40
Вычислим функцию распределения выборки 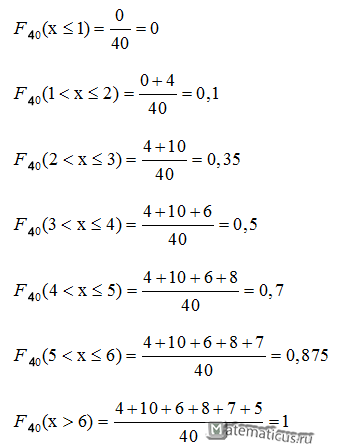
Эмпирическая функция распределения имеет вид

Построим график кусочно-постоянной эмпирической функции распределения
таким образом, по данным выборки можно приближенно построить функцию для неизвестной функции выборки.
2 комментария
У вас опечатка, где вы написали n=30, n=4+10+6+8+7+5=30 и F_30, так как n=40.
Построить эмпирическое распределение результатов тестирования в баллах для следующей выборки: 69, 85, 78, 85, 83, 81, 95, 88, 97, 92, 74, 83, 89, 77, 93.
В ячейку А1 введите слова Результаты, в диапазон А2:А16 – результаты тестирования.
Выберите ширину интервала 5 баллов. Тогда при крайних результатах 69 и 97 баллов, получится 7 интервалов. В ячейку С1 введите название интервалов Границы. В диапазон С2:С8 введите граничные значения интервалов: 70, 75, 80, 85, 90, 95, 100.
Введите заголовки создаваемой таблицы: в ячейку D1 – Абсолютные частоты, в ячейку Е1 – Относительные частоты, в F1 – Накопленные частоты.
Заполните столбец абсолютных частот. Для этого выделите для них блок ячеек D2:D8, вызовите Мастер функций, категория – Статистические, функция – Частота, в поле Массив данных введите диапазон данных тестирования А2:А16, в поле Массив интервалов введите диапазон интервалов С2:С8, нажмите комбинацию клавиш Ctrl+Shift+Enter. В столбце D2:D8 появится массив абсолютных частот.
В ячейке D9 найдите общее количество результатов тестирования, с помощью Автосумма.
Заполните столбец относительных частот. В ячейку Е2 введите формулу =$D2/$D$9 .
Протягиванием скопируйте полученное значение в диапазон Е3:Е8. Получим массив относительных частот.
Заполните столбец накопленных частот. В ячейку F2 скопируйте значение относительной частоты из ячейки Е2. В ячейку F3 введите формулу =F2+E3. Протягиванием скопируйте полученное значение в диапазон F4:F8. Получим массив накопленных частот.
В результате получим таблицу, представленную на рисунке 1.
Пусть Nх — число наблюдений, при которых значение признака Х меньше Х. При объеме выборки, равном П, относительная частота события Х XK.
Сама же функция F*(X) служит для оценки теоретической функции распределения F(X) генеральной совокупности.
Пример 3. Построить эмпирическую функцию по заданному распределению выборки:

Решение. Находим объем выборки: П = 10 + 15 + 25 = 50. Наименьшая варианта равна 2, поэтому F*(X) = 0 при Х ≤ 2. Значение Х 6. Напишем формулу искомой эмпирической функции:
4. Рассмотрим любой из критериев оценки качеств педагога-профессионала, например, «успешное решение задач обучения и воспитания». Ответ на этот вопрос анкеты типа «да», «нет» достаточно груб. Чтобы уменьшить относительную ошибку такого измерения, необходимо увеличить число возможных ответов на конкретный критериальный вопрос. В табл. 1 представлены возможные варианты ответов.
Обозначим этот параметр через х. Тогда в процессе ответа на вопрос величина х примет дискретное значение х, принадлежащее определенному интервалу значений. Поставим в соответствие каждому из ответов определенное числовое значение параметра х (см. табл. 1).
Войдите
в Мой Мир, чтобы комментировать
Красота
Войдите
в Мой Мир, чтобы комментировать
Дождевик
Супер топ
11 936
19.05.2023
Войдите
в Мой Мир, чтобы комментировать
Сразу видно самого голодного товарища в доме
Супер топ
8 390
19.05.2023
Войдите
в Мой Мир, чтобы комментировать
Вот так реставрация стола
Супер топ
3 446
19.05.2023
Нравится1Нравится1 человеку
Войдите
в Мой Мир, чтобы комментировать
Птичка
Супер топ
3 884
19.05.2023
Войдите
в Мой Мир, чтобы комментировать
Антарктика
Супер топ
3 031
19.05.2023
Войдите
в Мой Мир, чтобы комментировать
Повторил)
Супер топ
3 472
19.05.2023
Войдите
в Мой Мир, чтобы комментировать
Реалистично
Супер топ
2 537
19.05.2023
Нравится1Нравится1 человеку
Войдите
в Мой Мир, чтобы комментировать
Двухтактная мощь и ярость
Супер топ
2 706
19.05.2023
Войдите
в Мой Мир, чтобы комментировать
Лимон
Супер топ
1 941
19.05.2023
Войдите
в Мой Мир, чтобы комментировать
Пробка на 100 баллов
Супер топ
1 820
19.05.2023
Нравится1Нравится1 человеку
Войдите
в Мой Мир, чтобы комментировать
Встал в позу))
Супер топ
1 829
19.05.2023
Войдите
в Мой Мир, чтобы комментировать
Отличный маникюр
Супер топ
1 579
19.05.2023
Войдите
в Мой Мир, чтобы комментировать
Хватит дёргать
Супер топ
1 180
19.05.2023
Нравится1Нравится1 человеку
Войдите
в Мой Мир, чтобы комментировать
Какая грация
Супер топ
1 532
19.05.2023
Войдите
в Мой Мир, чтобы комментировать
Все не так, как ты думала
Супер топ
1 478
19.05.2023
Войдите
в Мой Мир, чтобы комментировать
Следил за мячиком и не уследил
Супер топ
1 456
19.05.2023
Войдите
в Мой Мир, чтобы комментировать
Время пришло
Супер топ
1 232
19.05.2023
Войдите
в Мой Мир, чтобы комментировать
Подстава
Супер топ
1 291
19.05.2023
Войдите
в Мой Мир, чтобы комментировать
Железный конь
Супер топ
1 013
19.05.2023
Войдите
в Мой Мир, чтобы комментировать
Меткий запуск
Войдите
в Мой Мир, чтобы комментировать
Микромашинка
Войдите
в Мой Мир, чтобы комментировать
Поиграла…на нервах
Супер топ
1 278
19.05.2023
Войдите
в Мой Мир, чтобы комментировать
Постановка
задачи.
Построить
график эмпирической функции распределения
с подогнанной ожидаемой функцией
распределения.
Теоретические
основы.
См.
стр. 31-32 пособия [4].
Вычисления.
Если
попытаться построить ЭФР средствами
Excel,
упорядочив сначала данные и сопоставив
затем каждому упорядоченному значению
x(k)
значение
![]() ,
,
то вместо горизонтальных получим
наклонные ступеньки. Чтобы избежать
этого недостатка, можно каждое значение
вариационного ряда повторить дважды,
при этом первому из этих значений
сопоставить ЭФР![]() ,
,
а второму
![]() .
.
Вычисление нормальной функции
распределения описано ниже в главе
“Встроенные функции Excel”.
Здесь кратко только скажем, что для
этого можно использовать функцииНОРМРАСПиНОРМСТРАСПиз
категории “Статистические”.
Функция
распределения экспоненциального закона
вычисляется с помощью простой функции
EXP.
Кроме того,
предполагается, что уже вычислены
среднее значение и дисперсия выборки
(задание 1).
Пример.

Рис.
2
Порядок
вычислений.
-
Скопировать
исходные данные в буфер обмена; -
перейти
на лист “ЭФР”
и, установив курсор в ячейку A3,
вставить данные из буфера обмена; -
повторить
процесс восстановления данных, начиная
с ячейки A104
-
установить
курсор в ячейку A104; -
вставить данные
из буфера обмена
-
– всего
получится 202
значения с 3-й
по 204-ю
ячейки;
-
упорядочить
значения в столбце A
-
кликнуть
мышкой по кнопке
 ;
;
-
ввести
в ячейку B3
формулу
-
=(СТРОКА(B3)-1)/202-1/101
-
– функция
«СТРОКА»
возвращает номер строки указанного
аргумента, то есть в данном случае в
ячейке B3
получится значение (3-1)/202-1/101
= 0;
-
ввести
в ячейку B4
формулу
-
=(СТРОКА(B3)-1)/202
-
– получится
значение (3-1)/202
= 1/101;
-
выделить
обе ячейки B3
и B4
и скопировать их параллельно всем
данным до ячейки B204
-
– в
последней ячейке должно получиться
значение 1;
-
добавить
в ячейку A2
значение, на единицу меньшее значения
ячейки A3
и сопоставить ему значение 0
в ячейке B2; -
добавить
в ячейку A205
значение, на единицу большее значения
ячейки A204
и сопоставить ему значение 1
в ячейке B205.
Ввести формулы
вычисления нормального распределения:
-
в
ячейки F4,
F5
(те, которые скрыты графиком) скопировать
среднее и стандартное отклонение,
соответственно
-
=МОМЕНТЫ!B4
-
=МОМЕНТЫ!B6
-
в
ячейку C2
ввести формулу нормального распределения
-
=НОРМРАСП(A2;$F$4;$F$5;1)
-
в
ячейку D2
ввести формулу вычисления расхождения
между ЭФР и ожидаемой функцией
распределения
-
=ABS(C2-B2)
-
скопировать
обе ячейки C2
и D2
вплоть до 205-й строки; -
вычислить
максимальное расхождение, например, в
ячейке F6
-
=МАКС(D2:D205)
Теперь уже можно
рисовать графики:
-
выделить
все значения в ячейках A2:C205; -
вызвать
“Мастера
Диаграмм”; -
выбрать
«Точечную»
диаграмму – без маркеров со сглаживающей
линией (третья по порядку среди точечных
диаграмм); -
при
выборе представления диаграммы, после
двух нажатий кнопки
 ,
,
удалить “Легенду”
и добавить “Заголовок
по
оси Х”:
-
МАКСИМАЛЬНОЕ
РАСХОЖДЕНИЕ D=…
-
(указав
здесь полученное значение Δ из ячейки
F6);
-
 ;
; -
установить
параметры диаграммы, как в примере.
Замечание.
Если бы параметры нормальной модели
не оценивались по выборочным данным, а
были бы в точности равны этим оценкам,
то при полученном здесь расхождении
Δ=0,097 гипотезу нормальности следовало
бы принять с критическим уровнем
значимости > 0,20 (см. таблицу 6.2 сборника
таблиц [1]). Это надо воспринимать как
хороший знак и не более того. Если
неизвестные значения параметров
оцениваются по выборке, то критический
уровень значимости становится зависящим
от неизвестных параметров и трудно
ожидать, что даже в предположениях
гипотезы критерий будет иметь приемлемый
размер.
Контрольные
вопросы.
-
Сформулируйте
статистическую задачу. -
Что такое
вариационный ряд?-
31.
-
-
Дайте определение
эмпирической функции распределения?-
31.
-
-
Почему
некоторые ступеньки ЭФР высокие, а
некоторые низкие?-
31.
-
-
Почему одни
ступеньки ЭФР длинные, а другие короткие?-
31.
-
-
Постройте
ЭФР по следующим данным: 1; 2; 1; 3; 1; 5; 1; 3. -
Выпишите
формулу для функции распределения
нормального закона (равномерного,
экспоненциального).-
16-21.
-
-
Можно
ли утверждать, что ЭФР является
состоятельной оценкой истинной функции
распределения? Что сие означает?-
31.
-
-
Можно
ли утверждать, что ЭФР является
несмещенной оценкой истинной функции
распределения? Что сие означает?-
31.
-
-
Докажите
несмещенность ЭФР. -
Можно
ли по значению максимального расхождения
между ЭФР и ожидаемой функцией
распределения принять или отвергнуть
гипотезу о виде истинной функции
распределения?-
32.
-
Соседние файлы в папке Матстат
- #
- #
При изучении величины, принимающей случайные значения (результатов физических измерений в серии экспериментов, экономических показателей, параметров технологических процессов и т.п.), мы имеем дело с выборками. Выборочное наблюдение – это способ наблюдения, при котором обследуется не вся совокупность значений изучаемой величины, а лишь часть ее, отобранная по определенным правилам выборки и обеспечивающая получение данных, характеризующих всю совокупность в целом.
При выборочном наблюдении обследованию подвергается определенная, заранее обусловленная часть совокупности, а результаты обследования распространяются на всю совокупность.
Ту часть единиц, которая отобрана для наблюдения, принято называть выборочной совокупностью или выборкой, а всю совокупность единиц, из которых производится отбор, – генеральной совокупностью.
Число единиц (элементов) статистической совокупности называется ее объемом. Объем генеральной совокупности обозначается N, а объем выборочной совокупности п.
Качество результатов выборочного наблюдения зависит от того, насколько состав выборки представляет генеральную совокупность, иначе говоря, от того, насколько выборка репрезентативна (представительна).
Элементами выборки (x1 х2, . хп) являются числовые значения, называемые вариантами, которые могут быть дискретными, т.е. изолированными (например, целыми числами), или могут принимать значения из некоторого интервала (а, b).
Вариационный ряд получается из выборки упорядочением по возрастанию (или убыванию) и подсчетом частоты каждого значения. Если вариационный ряд содержит значения признака и соответствующие ему частоты,то такой ряд носит название дискретный вариационный ряд. Если нам известно, что исследуемый показатель может принимать любые значения из некоторого интервала, то строим интервальный вариационный.
Удобнее всего ряды распределения анализировать с помощью их графического изображения, позволяющего судить о форме распределения. Наглядное представление о характере изменения частот вариационного ряда дают полигон и гистограмма.
Пример 2.1.
Известны следующие данные о результатах сдачи студентами экзамена (в баллах):
| 18 | 16 | 20 | 17 | 19 | 20 | 17 |
| 17 | 12 | 15 | 20 | 18 | 19 | 18 |
| 18 | 16 | 18 | 14 | 14 | 17 | 19 |
| 16 | 14 | 19 | 12 | 15 | 16 | 20 |
Необходимо построить ряд распределения числа студентов по баллу, представить графически результаты.
Введем данные в диапазоне A1: A29, в ячейку A1 введем текст «Балл» (рис.2.6).
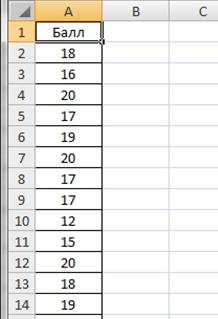
Рисунок 2.6. Баллы успеваемости студентов
Определим наименьший и наибольший балл по выборке. Для этого введем в ячейках С1 и С2 соответственно введем формулы =МИН(A2:A29) и =МАКС(A2:A29). Получим значения 12 и 20 соответственно (рис.2.7).
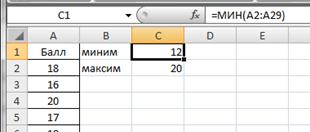
Рисунок 2.7. Минимальный и максимальный балл
Построим вариационный ряд. Для каждого значения необходимо подсчитать частоту. Так как значения признака (балл) отличаются на единицу, то можно воспользоваться следующим способом. В ячейку С4 введем формулу =С1, в С5 соответственно С4+1. Ячейку С5 протянем маркером заполнения (правый нижний угол ячейки) вниз до С12. Результаты представлены на рисунке 2.8.
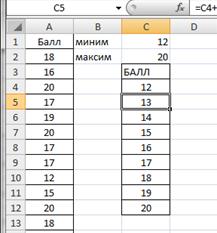
Рисунок 2.8. Значения признака
Вычислим частоту для каждого значения признака. В ячейку D4 введем формулу =СЧЕТЕСЛИ(A$2:A$29;C4) и протянем D4 маркером вниз до заполнения D12. В ячейке D13 просуммируем частоты с помощью формулы =СУММ(D4:D12).
Получим вариационный ряд (значения признака и соответствующие им частоты) на рисунке 2.9.
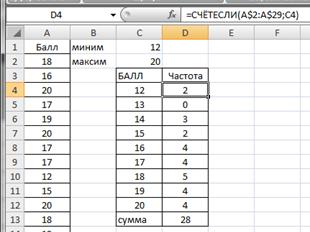
Рис.2.9. Частоты вариационного ряда
Вычислим частость (относительную частоту) для каждого значения признака. В ячейку Е4 введем формулу = D4/D$13. Протянем Е4 маркером заполнения вниз до Е12 (рис.2.10).
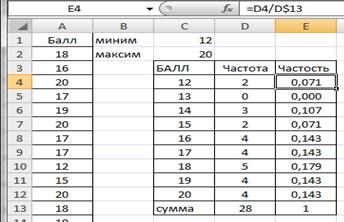
Рисунок 2.10. Частости ряда распределения
Вычислим накопленные частоты. В ячейку F4 введем формулу =D4, а в ячейку F5 – формулу = D5+F4. Протянем F5 маркером заполнения вниз до F12 (рис.2.11).
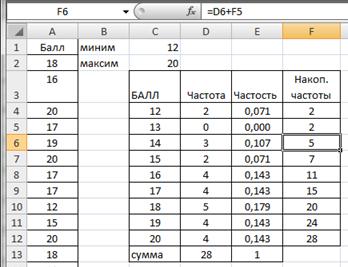
Рисунок 2.11. Накопленные частоты ряда
Построим эмпирическую функцию распределения, т.е. найдем наколенные частости. Выделим F4:F12 и маркером заполнения протянем вправо на соседний столбец (рис.2.12). В G4 получим формулу = Е4, в ячейке G5 формулу =Е5+ G4 и т.д.
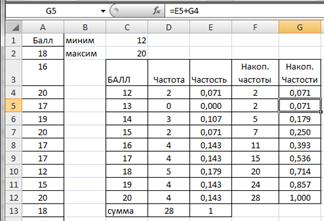
Рисунок 2.12. Накопленные частости ряда
Построим полигон распределения частот и частостей. Выделим диапазон ячеек С4:D12. Выполним команду меню «Диаграмма» и выберем тип «Точечная», вариант «Точечная с прямыми отрезками и маркерами». Полигон распределения частот представлен на рисунке 2.13.

Рисунок 2.13. Полигон распределения частот
Выделим диапазон ячеек С4:С12 и, удерживая клавишу CTRL, диапазон Е4:Е12. Выполним команду меню «Диаграмма» и выберем тип «Точечная», вариант «Точечная с прямыми отрезками и маркерами». Полигон распределения частостей представлен на рисунке 2.14.
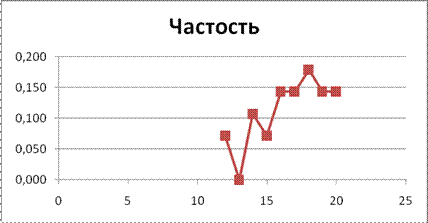
Рисунок 2.14. Полигон распределения частостей
Построим гистограмму распределения частостей, для чего выделим диапазон Е4:Е12, выберем тип диаграммы «Гистограмма». Щелкнем правой кнопкой в области диаграммы, выберем «Выбрать данные», выберете «Ряд» – «Изменить», левой кнопкой щелкнем в строке «Подписи оси Х» и выделим диапазон С4:С12 (рис.2.15).
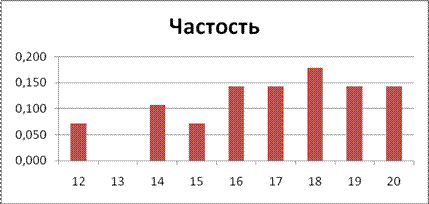
Рисунок 2.15. Гистограмма распределения частостей
Построим кумуляту частостей, для чего выделим диапазон ячеек С4:С12 и, удерживая клавишу CTRL, диапазон G4:G12. Выполним команду меню «Диаграмма» и выберем тип «Точечная», вариант «Точечная с прямыми отрезками». Кумулята представлена на рис.2.16.

Рисунок 2.16. Кумулята
Пример 2.2.
В таблице 2.7 представлены значения процентных ставок по кредитам по 30 коммерческим банкам.
Банковские процентные ставки
| № Банка | Процентная ставка, % |
| 1 | 20,3 |
| 2 | 17,1 |
| 3 | 14,2 |
| 4 | 11,0 |
| 5 | 17,3 |
| 6 | 19,6 |
| 7 | 20,5 |
| 8 | 23,6 |
| 9 | 14,6 |
| 10 | 17,5 |
| 11 | 20,8 |
| 12 | 13,6 |
| 13 | 24,0 |
| 14 | 17,5 |
| 15 | 15,0 |
| 16 | 21,1 |
| 17 | 17,6 |
| 18 | 15,8 |
| 19 | 18,8 |
| 20 | 22,4 |
| 21 | 16,1 |
| 22 | 17,9 |
| 23 | 21,7 |
| 24 | 18,0 |
| 25 | 16,4 |
| 26 | 26,0 |
| 27 | 18,4 |
| 28 | 16,7 |
| 29 | 12,2 |
| 30 | 13,9 |
Построим интервальный вариационный ряд. Для этого вычислим границы интервалов (карманов) с использованием формулы Стэрджесса.
Введем данные в диапазоне A1:A31 (рис.2.17). Определим максимальное и минимальное значения (ячейки С2 и С3 соответственно) так же как и в примере 2.1. Определим число интервалов по формуле Стэрджесса, для чего в ячейку С6 введем формулу =ЦЕЛОЕ(1+3,322*LOG10(30)) (рис.2.18).
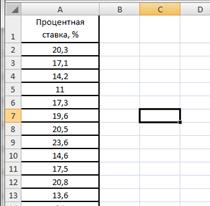
Рисунок 2.17. Процентные ставки банков

Рисунок 2.18. Число интервалов
Вычислим длину интервалов, для чего в ячейке С8 введем формулу =ОКРУГЛ((C3-C2)/C6;2) (рис.2.19).
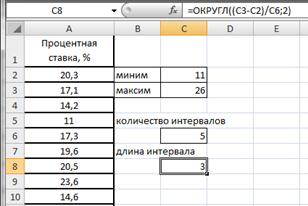
Рисунок 2.19. Длина интервала
Определим нижние и верхние границы интервалов (карманы), для чего в ячейке Е2 запишем формулу =С2, в ячейке Е3 запишем ==E2+$C$8. Протянем Е3 маркером заполнения вниз до Е7 (рис.2.20).
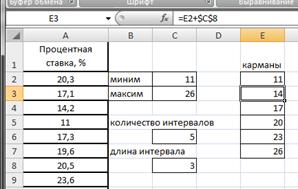
Рисунок 2.20. Границы интервалов
Подсчитаем частоты – в интервал считаем те значения, которые больше нижней границы интервала или равны ей и меньше верхней границы.
Воспользуемся функцией ЧАСТОТА. Для этого в ячейке F2 введем формулу =ЧАСТОТА(A2:A31;E2:E7). Протянем F2 маркером заполнения вниз до F8.
Формулу в этом примере необходимо ввести как формулу массива. Выделим диапазон F2:F8, нажмем клавишу F2, а затем нажмем клавиши CTRL+SHIFT+ВВОД (рис.2.21).
Если формула не будет введена как формула массива, отобразится только одно ее значение в ячейке F2.
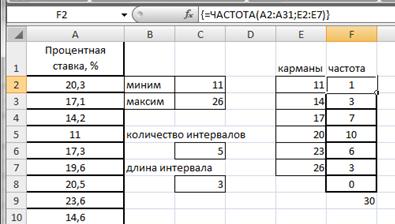
Рисунок 2.21. Частоты значений признака
Также можно воспользоваться средством Пакета анализа (Анализ данных в Office 2007) ГИСТОГРАММА (рис.2.22). Выберем входной интервал, интервал карманов, метки, интегральный процент, поместим результаты на этом же листе (укажем ячейку $H$2).
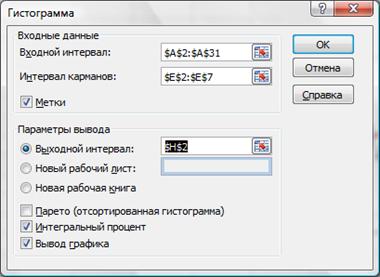
Рисунок 2.22. Построение гистограммы
Полученная гистограмма представлена на рис.2.23.
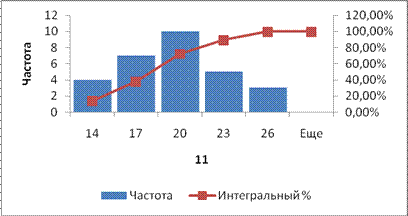
Рис.2.23. Гистограмма частот
Замечание. Если диапазон карманов не был введен, то набор отрезков, равномерно распределенных между минимальным и максимальным значениями данных, будет создан автоматически.
Дата добавления: 2018-11-12 ; просмотров: 1065 | Нарушение авторских прав
Вариационный ряд может быть:
– дискретным, когда изучаемый признак характеризуется определенным числом (как правило целым).
– интервальным, когда определены границы «от» и «до» для непрерывно варьируемого признака. Интервальный ряд также строят если множество значений дискретно варьируемого признака велико.
Рассмотрим пример построения дискретного вариационного ряда.
Пример 1. Имеются данные о количественном составе 60 семей.

Построить вариационный ряд и полигон распределения
Решение .
Алгоритм построения вариационного ряда:
1) Откроем таблицы Excel.
2) Введем массив данных в диапазон А1:L5. Если вы изучаете документ в электронной форме (в формате Word, например), для этого достаточно выделить таблицу с данными и скопировать ее в буфер, затем выделить ячейку А1 и вставить данные – они автоматически займут подходящий диапазон.
3) Подсчитаем объем выборки n – число выборочных данных, для этого в ячейку В7 введем формулу =СЧЁТ(А1:L5). Заметим, что для того, чтобы в формулу ввести нужный диапазон, необязательно вводить его обозначение с клавиатуры, достаточно его выделить.
4) Определим минимальное и максимальное значение в выборке, введя в ячейку В8 формулу =МИН(А1:L5), и в ячейку В9: =МАКС(А1:L5).
Рис.1.1 Пример 1. Первичная обработка статистических данных в таблицах Excel

5) Далее, подготовим таблицу для построения вариационного ряда, введя названия для столбца интервалов (значений варианты) и столбца частот. В столбец интервалов введем значения признака от минимального (1) до максимального (6), заняв диапазон В12:В17.
6) Выделим столбец частот, введем формулу =ЧАСТОТА(А1:L5;В12:В17) и нажмем сочетание клавиш CTRL+SHIFT+ENTER
Рис.1.2 Пример 1. Построение вариационного ряда

7) Для контроля вычислим сумму частот при помощи функции СУММ (значок функции S в группе «Редактирование» на вкладке «Главная»), вычисленная сумма должна совпасть с ранее вычисленным объемом выборки в ячейке В7.
Построим полигон:
1) выделив полученный диапазон частот, выберем команду «График» на вкладке «Вставка». По умолчанию значениями на горизонтальной оси будут порядковые числа – в нашем случае от 1 до 6, что совпадает со значениями варианты (номерами тарифных разрядов).
2) Название ряда диаграммы «ряд 1» можно либо изменить, воспользовавшись той же опцией «выбрать данные» вкладки «Конструктор», либо просто удалить.
Рис.1.3. Пример 1. Построение полигона частот
В реальных социально-экономических системах нельзя проводить активные эксперименты, поэтому данные обычно представляют собой наблюдения за происходящим процессом, например: курс валюты на бирже в течение месяца, урожайность пшеницы в хозяйстве за 30 лет, производительность труда рабочих за смену и т.д. Результаты наблюдений — это в общем случае ряд чисел, расположенных в беспорядке, который для изучения необходимо упорядочить (проранжи- ровать).
Операция, заключающаяся в расположении значений признака по возрастанию, называется ранжированием опытных данных.
После операции ранжирования опытные данные можно сгруппировать так, чтобы в каждой группе признак принимал одно и то же значение, которое называется вариантом (х,). Число элементов в каждой группе называется частотой варианта («,).
Размахом вариации называется число

где хтах — наибольший вариант;
x min — наименьший вариант.
Сумма всех частот равна определенному числу л, которое называется объемом совокупности:

Отношение частоты данного варианта к объему совокупности называется относительной частотой, или частостью, этого варианта:

Последовательность вариант, расположенных в возрастающем порядке, называется вариационным рядом (вариация — изменение).
Вариационные ряды бывают дискретными и непрерывными. Дискретным вариационным рядом называется ранжированная последовательность вариант с соответствующими частотами и (или) частостями.
Пример 1. В результате тестирования группа из 24 человек набрала баллы: 4, 0, 3, 4, 1, 0, 3, 1, 0, 4, 0, 0, 3, 1, 0, 1, 1, 3, 2, 3, 1, 2, 1, 2. Построить дискретный вариационный ряд.
Решение. Проранжируем исходный ряд, подсчитаем частоту и частость вариант: 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 4.
В результате получим дискретный вариационный ряд (табл. 3.10).
Ранжированный ряд успеваемости
Число студентов, л,
Относительная частота, А
В Excel проранжируем исходный ряд. Для этого введем все данные в диапазон А1 :А24 и воспользуемся кнопкой Щ (Сортировка по возрастанию).
Подсчитаем частоту и частость вариант. Построим таблицу в диапазоне D2:G7 (рис. 3.13).

Рис. 3.13. Контекстное меню строки состояния
Рассмотрим два варианта подсчета частот:
- 1) выделим диапазон, в котором находятся нули. Щелкнем в нижней правой части окна Excel правой кнопкой мыши и выберем в контекстном меню вид итога, который по умолчанию будет появляться в итоговой строке при выделении произвольного диапазона (см. рис. 3.13) — количество. Таким образом, последовательно выделяя диапазоны с одинаковыми значениями вариант, мы получим все частоты;
- 2) выполним команду Сервис — Анализ данных — Гистограмма. Заполним диалоговое окно в соответствии с рис. 3.14.

Рис. 3.14. Диалоговое окно инструмента пакета анализа «Гистограмма»
В результате получим таблицу с частотами вариантов и соответствующий график (рис. 3.15).

Рис. 3.15. Результаты применения инструмента «Гистограмма)
Найдем объем выборки, заполнив все частоты вариант в диапазоне ЕЗ:Е7, выделим его левой кнопкой мыши и щелкнем по кнопке ? (автосумма).
В ячейку F3 введем формулу «=ЕЗ/$Е$8», за маркер заполнения (крест в правом нижнем углу ячейки) с помощью мыши скопируем до F7 и выберем кнопку автосумма, в результате получим частоты вариантов и их сумму (1). В ячейку G3 введем частоту варианта 0 — цифру 6 (или ссылку на ячейку, ее содержащую — ЕЗ), в ячейку G4 введем формулу «=G3+E4» и скопируем ее до ячейки G7, в результате получим накопленные частоты. Таким образом, мы получили дискретный вариационный ряд. Естественно, частоты необходимо округлить, но таким образом, чтобы их сумма равнялась 1. Для этого выделим левой кнопкой мыши диапазон частот (F3:F7), щелкнув по правой кнопке, откроем контекстное меню и выполним команду Формат ячеек — Числовой — Число знаков 3 — ОК. Преобразовав обозначения, получим дискретный вариационный ряд, представленный в табл. 3.11.
ВАРИАЦИОННЫЕ РЯДЫ.
ВЫБОРОЧНАЯ ФУНКЦИЯ РАСПРЕДЕЛЕНИЯ
- Авторы
- Файлы работы
- Сертификаты
Растеряев Н.В. 1, Елисеев С.А. 1
1Филиал Федерального государственного автономного образовательного учреждения высшего образования «Южный федеральный университет» в г. Новошахтинске Ростовской области (филиал ЮФУ в г. Новошахтинске)
Комментарии
Текст работы размещён без изображений и формул.
Полная версия работы доступна во вкладке “Файлы работы” в формате PDF
овладеть навыками составления дискретных и интервальных вариационных рядов выборки, построения выборочной (эмпирической) функции распределения в среде ЭТ MS.
Краткая теория
Для решения задач, связанных с анализом данных при наличии случайных непредсказуемых воздействий, разработан математический аппарат ‒ математическая статистика, что позволяет выявлять закономерности на основе случайностей, делать на их основе обоснованные выводы и прогнозы.
Важнейшими понятиями математической статистики являются понятия генеральной совокупности и выборки.
Генеральной совокупностью наблюдаемого признака (случайной величины) Х называют множество всевозможных значений, принимаемых наблюдаемым признаком Х.
Часть отобранных объектов из генеральной совокупности называется выборочной совокупностью, или выборкой. Результаты измерений изучаемого признака nобъектов выборочной совокупности порождают nзначений х1, х2, … , хn случайной величины X . Число nназывается объемом выборки.
Выборку можно рассматривать двояко:
а) как случайный вектор длины n, каждая компонента которого имеет такое же распределение, как и наблюдаемый признак;
б) как на результаты измерений, т.е. набор n чисел.
Случайная величина Х называется дискретной случайной величиной, если она принимает свое значение из некоторого конечного фиксированного набора, например, случайная величина Х ‒ число появления шестерки при двух бросках игрального кубика
Х: 0,1,2 .
Случайная величина Х называется непрерывной случайной величиной, если она принимает любое значение из некоторого интервала (в том числе ‒ ∞ и +∞), например, рост человека.
После получения выборки имеем данные, которые представляют собой множество чисел, расположенных в беспорядке. Анализ таких данных весьма затруднителен, и для изучения скрытых закономерностей их подвергают определенной обработке.
Простейшая операция – ранжирование опытных данных, результатом которого являются значения, расположенные в порядке неубывания. Если среди элементов встречаются одинаковые, то они объединяются в одну группу. Значение случайной величины, соответствующее отдельной группе сгруппированного ряда наблюдаемых данных, называется вариантом, а изменение этого значения – варьированием. Варианты будем обозначать строчными буквами с соответствующими порядковому номеру группы индексами x(1) , x(2) , …, x(N) , где N – число групп. При этом x(1)< x(2)< … < x(N).
Численность отдельной группы сгруппированного ряда данных называется частотой ni , где i – индекс варианта, а отношение частоты данного варианта к общей сумме частот называется частностью (или относительной частотой) и обозначается ωi , i = 1, …,N , т.е.
ωi=nij=1Nnj ,
при этом j=1Nnj=n ‒ объему выборки.
Дискретным вариационным рядомназывается ранжированная совокупность вариантов x(i) с соответствующими им частотами niили частностями ωi .
Если число возможных значений дискретной случайной величины достаточно велико или наблюдаемая случайная величина является непрерывной, то строят интервальный вариационный ряд, под которым понимают упорядоченную совокупность интервалов варьирования значений случайной величины с соответствующими частотами или частностями попаданий в каждый из них значений случайной величины.
Как правило, частичные интервалы, на которые разбивается весь интервал варьирования, имеют одинаковую длину Δ, которая может быть вычислена по следующей формуле
∆=RN=xmax-xminN .
где R – размах варьирования (изменения) случайной величины;
xmax , xmin – наибольшее и наименьшее значения исследуемой случайной величины;
N – число частичных интервалов группировки.
Некоторые авторы рекомендуют пользоваться следующими эмпирическими формулами для определения числа интервалов:
, N = 5.lg(n) ,
N = 1 + 3,322.lg(n) ‒ формула Стерджеса.
В рекомендациях по стандартизации Р 50.1.033-2001 “Прикладная статистика. Правила проверки согласия опытного распределения с теоретическим. Часть I. Критерии типа хи-квадрат” рекомендует следующие значения N в зависимости от объема выборки n:
|
Объем выборки n |
Число интервалов группировки N |
|
40 ‒ 100 |
7 ‒ 9 |
|
100 ‒ 500 |
8 ‒ 12 |
|
500 ‒ 1000 |
10 ‒ 16 |
|
1000 ‒ 10000 |
12 ‒ 22 |
В теории вероятностей для характеристики распределения случайной величины служит функция распределения
,
определяющую для каждого значения х вероятность того, что случайная величина Х примет значение, меньшее х, т.е. равная вероятности события , где – любое действительное число.
Одной из основных характеристик выборки является выборочная (эмпирическая) функция распределения
,
где – количество элементов выборки, меньших чем . Другими словами, есть относительная частота появления события в n независимых испытаниях. Главное различие между и состоит в том, что определяет вероятность события A, а выборочная функция распределения – относительную частоту этого события.
Свойства функции :
1. .
2. – неубывающая функция.
3.
Функция является “ступенчатой”, имеются разрывы в точках, которым соответствуют наблюдаемые значения вариантов. Величина скачка равна относительной частоте варианта.
Аналитически задается следующим соотношением:
Fn*x= 0 при x≤x1 ;j=1i-1ωj при x(i-1)x(N) ,
где – соответствующие относительные частоты;
– элементы вариационного ряда (варианты).
Замечание. В случае интервального вариационного ряда под понимается середина i-го частичного интервала. Эмпирическую функцию распределения непрерывной случайной величины так же называют «накопленная частота».
Перед вычислением полезно построить дискретный или интервальный вариационный ряд.
Пример выполнения
Постановка задачи 1. На телефонной станции проводились наблюдения над числом неправильных соединений в минуту. Наблюдения в течение 30 минут дали следующие результаты (табл. 1).
Таблица 1.
|
3 |
0 |
1 |
5 |
1 |
2 |
4 |
5 |
3 |
4 |
|
2 |
4 |
2 |
0 |
2 |
3 |
1 |
3 |
2 |
1 |
|
4 |
3 |
0 |
2 |
1 |
0 |
4 |
2 |
3 |
2 |
Требуется найти дискретный вариационный ряд, выборочную (эмпирическую) функцию распределения данной выборки и построить ее график в среде ЭТ MS Excel.
Решение.
Очевидно, что число X является дискретной случайной величиной, а полученные данные есть значения этой случайной величины.
В результате выполнения операций ранжирования и группировки были получены шесть значений случайной величины (варианты): 0; 1; 2; 3; 4; 5. При этом значение 0 в этой группе встречается 4 раза, значение 1 – 5 раз, значение 2 – 8 раз, значение 3 – 6 раз, значение 4 – 5 раз, значение 5 – 2 раза. Вычисленные значения частот и частностей приведены в табл. 2.
Таблица 2.
|
Индекс |
1, 2, 3, 4, 5, 6 |
|
|
Вариант |
0, 1, 2, 3, 4, 5 |
|
|
Частота |
4, 5, 8, 6, 5, 2 |
|
|
Частность |
Используя данный дискретный вариационный ряд (см. табл. 2), вычислим значения по формуле, приведенной выше, и занесем их в табл. 3.
Таблица 3.
|
x |
|
|
x 0 |
0 |
|
0 < x 1 |
|
|
1 < x 2 |
|
|
2 < x 3 |
|
|
3 < x 4 |
|
|
4 < x 5 |
|
|
x > 5 |
По данным таблицы 3 построим график эмпирической функции распределения.
Решение задачи в среде ЭТ MSExcel. Для решения задачи в среде ЭТ MS Excel необходимо выполнить следующие действия:
1. Идентифицируйте свою работу, переименовав Лист1 в Титульный лист и записав номер лабораторной работы, ее название, кто выполнил и проверил.
2. Переименуйте Лист 2 в Дискретный. Наберите массив 30 значений исходных данных выборки.
3. Найдите величины хmax, хmin, n, используя встроенные функции Excel МАКС, МИН и СЧЕТ.
4. Сформируйте столбец вариант x(i)от 0 до 5 и с помощью функции ЧАСТОТА найдите частоту появления значений случайной величины Х в данном интервале.
Синтаксис функции:
ЧАСТОТА(массив данных;массив интервалов).
Массив данных ‒ массив или ссылка на множество данных, для которых вычисляются частоты. В нашем случае это диапазон B2:K2. Если массив данных не содержит значений, то функция ЧАСТОТА возвращает массив нулей.
Массив интервалов ‒ массив или ссылка на множество интервалов, в которые группируются значения аргумента массив данных. В нашем случае это диапазон F7:F12. Если массив интервалов не содержит значений, то функция ЧАСТОТА возвращает количество элементов в аргументе Массив данных.
Функция ЧАСТОТА вводится как формула массива после выделения интервала смежных ячеек, в которые нужно вернуть полученный массив частот.
Количество элементов в возвращаемом массиве на единицу больше числа элементов в массиве интервалов. Дополнительный элемент в возвращаемом массиве содержит количество значений, больших, чем максимальное значение в интервалах, т.е. больше 5 в нашем случае.
Поскольку данная функция возвращает массив, она должна задаваться в качестве формулы массива и работа с ней завершается трехклавишной комбинацией CTRL+SHIFT+ENTER.
Функция ЧАСТОТА игнорирует пустые ячейки и тексты.
5. Сформируйте столбец частностей, вычислив значения ωi , i = 1, …,6 по формуле
ωi=nin .
6. Сформируйте столбец значений выборочной функции распределения . При этом первое значение в ячейке I7 просто копируется из ячейки Н7.
Следующее значение вычисляется как накопленная сумма предыдущего значения ω1 из ячейки I7 и текущего значения ω2 из ячейки Н8:
=I7+H8 .
Затем данная формула копируется автозаполнением в остальные ячейки диапазона, с выходом на значение, равное 1.
7. Построим график эмпирической функции распределения. С использованием штатных средств Мастера диаграмм ЭТ MS Excel построить ступенчатый график функции распределения дискретной случайной величины нельзя.
Покажем, как в MS Excel все-таки можно построить такой график.
7.1. Расположим данные полученного дискретного вариационного ряда так, как показано на рисунке ниже.
При этом данные копируются из предыдущей таблицы. Используют контекстное меню команды Вставка: Параметры вставки → Значения
7.2. В разреженную таким образом таблицу введем ряд дополнений. В ячейку К7 введем значение -2, а в ячейку К20 значение 7, это границы интервала [-2 ;7] на котором будет построен наш график. В оставшиеся пустые ячейки введем значения, чуть меньшие значений полученных вариант (см. случай а) ниже).
Два первых значения функции F(x) в ячейках L7 и L8 примем равным нулю, т.к. при x ≤ x(1) . В оставшиеся пустые ячейки скопируем значения функции, расположенные выше (см. случай б) выше).
7.3. По данным, находящимся в диапазоне ячеек K7:L20, с помощью Мастера диаграмм, построим диаграмму типа Точечная без маркеров. Отформатируем диаграмму, убрав маркеры и задав линию, соединяющую табличные значения.
Т.к. функция ‒ непрерывна слева в любой точке x, т. е. , то устраним неоднозначность в точках разрыва, “вырезав” соответствующие значения. Для этого построим точечный график по данным первого и последнего столбца полученного дискретного вариационного ряда.
8. Постройте пунктирные линии в вырезанных точках графика. Для этого выделим точки графика и на вкладке Макет в группе Анализ нажмём кнопку Планки погрешностей, а затем выберем строку Дополнительные параметры планок погрешностей … .
В диалоговом окне Формат планок погрешностей выполните установки, представленные ниже. Установите радиокнопку – пользовательская и в появившемся окне, в поле ввода Отрицательное значение ошибки введите значения столбца F(x).
Получили график функции распределения с пунктирными линиями.
9. Сделайте выводы и сохраните работу в вашем каталоге.
Постановка задачи 2. Исследуется рост учащихся (в сантиметрах) в студенческой группе из 25 человек. Получена выборка (см. табл. 4) из следующих 25 значений.
Таблица 4.
|
184 |
182 |
182 |
180 |
177 |
|
179 |
173 |
179 |
192 |
173 |
|
190 |
163 |
177 |
186 |
170 |
|
178 |
185 |
173 |
179 |
165 |
|
179 |
173 |
179 |
166 |
170 |
Требуется: найти интервальныйвариационный ряд, выборочную (эмпирическую) функцию распределения данной выборки и построить ее график в среде ЭТ MS Excel.
Решение.
Найдем максимальное и минимальное значения в исследуемой выборке
xmax=192 , xmin=163 см.
Вычислим размах варьирования R исследуемого признака по формуле
R=xmax-xmin=29.
Для нахождения числа интервалов группировки N воспользуемся формулой
N≈n=25=5.
Далее следует группировка выборки. При этом интервал варьирования признака [xmin, xmax] разбивается на N интервалов группировки одинаковой длины ∆, а затем подсчитывается число попаданий признака в j-й интервал группировки – ni,i=.
∆=RN=xmax-xminN =5,8≈6.
При этом каждый интервал группировки Δi= (ai;bi) характеризуется своим правым и левым концом, числом ni – попаданием признака в этот интервал. Иногда интервал характеризуют не границами, а его средним значением.
Дальнейшие вычисления удобно представить в табл. 5.
Таблица 5.
|
i |
Интервал группировки Δi |
Кол-во попаданий в интервал |
Частоты ni |
Относительные частоты ωi=nin |
Накопленные частоты |
|
1 |
162,5-168,5 |
│││ |
3 |
3/25 |
3/25 |
|
2 |
168,5-174,5 |
│││││ │ |
6 |
6/25 |
9/25 |
|
3 |
174,5-180,5 |
│││││ ││││ |
9 |
9/25 |
18/25 |
|
4 |
180,5-186,5 |
│││││ |
5 |
5/25 |
23/25 |
|
5 |
186,5-192,5 |
││ |
2 |
2/25 |
252/25 = 1 |
|
∑ |
25 |
1 |
Чтобы значение исследуемого признака не попадало на границы интервала группировки, примем минимальное значение признака не 163, а 162,5 и от этого значения начнем строить интервалы длиной Δ = 6 (см. второй столбец табл. 5).
Откладывая по оси абсцисс средние значения интервалов группировки, а по оси ординат – значения накопленных частот, строим график эмпирической функции растределения.
Решение задачи в среде ЭТ MSExcel. Для решения задачи в среде ЭТ MS Excel необходимо выполнить следующие действия:
1. Переименуйте Лист 3 в Непрерывный. Наберите массив 25 значений исходных данных выборки.
2. Найдите величины хmax, хmin, n, N, Δокругл используя встроенные функции Excel МАКС, МИН, СЧЕТ, КОРЕНЬ и ОКРУГЛ.
3. Сформируйте столбец интервалов варьирования от значения 162,5 с шагом Δ = 6. Первое значение набираем с клавиатуры, а второе вычисляем с помощью формулы
=E9+$C$13 .
Остальные значения получим копированием с помощью Автозаполнения.
4. Сформируйте столбец Частота и с помощью функции ЧАСТОТА найдите частоту появления значений исследуемой случайной величины Х в каждом из интервалов.
5. Заполните столбец относительных частот, рассчитав значение в ячейке G9 по формуле
=F9/$C$10 .
Остальные значения получим копированием формулы с помощью Автозаполнения.
6. Вычислите середины интервалов группировки, рассчитав значение в ячейке Н9 по формуле
=(E9+E10)/2 .
Остальные значения в диапазоне Н10:Н13 получим копированием формулы с помощью Автозаполнения.
7. Заполните столбец накопленных частот. При этом, значение в ячейке I9 получим, копируя значение ячейки G10 по формуле
=G10 .
Значение в ячейке I10 получим по формуле
=I9+G11 .
Остальные значения в диапазоне I11:I13 получим, копируя формулу с помощью Автозаполнения.
8. По данным двух последних столбцов построим график эмпирической функции распределения.
9. Сделайте выводы и сохраните работу в вашем каталоге.
Лист Excel лабораторной работы имеет вид, представленный на рисунке.
Исходные данные для самостоятельного решения
Задание 1. Имеется выборка непрерывной случайной величины объема n = 26 (табл. 6).
Задание 2. Имеется выборка дискретной случайной величины объема n = 30 (табл. 7).
Требуется: найти дискретный и интервальныйвариационные ряды, выборочную (эмпирическую) функцию распределения данных выборок и построить их графики в среде ЭТ MS Excel.
Таблица 6.
|
№ варианта |
Выборка |
||||||||||||
|
1 |
11,7 |
9,83 |
5,49 |
7,43 |
9,92 |
3,41 |
6,83 |
8,22 |
8,30 |
8,14 |
9,29 |
9,27 |
7,43 |
|
7,41 |
3,56 |
7,72 |
12,1 |
6,06 |
10,6 |
6,76 |
8,21 |
9,86 |
8,13 |
9,04 |
4,75 |
9,33 |
|
|
2 |
4,49 |
9,25 |
7,94 |
9,10 |
6,27 |
6,77 |
3,47 |
8,84 |
6,48 |
4,92 |
6,98 |
10,1 |
6,32 |
|
6,36 |
5,16 |
7,92 |
12,0 |
7,46 |
7,01 |
13,0 |
7,34 |
6,71 |
5,48 |
9,95 |
11,9 |
8,89 |
|
|
3 |
6,13 |
8,56 |
9,77 |
9,17 |
8,89 |
6,19 |
7,70 |
6,96 |
6,72 |
6,08 |
4,41 |
5,52 |
9,59 |
|
9,02 |
6,22 |
4,86 |
6,33 |
6,28 |
8,60 |
7,38 |
7,84 |
7,24 |
6,85 |
6,50 |
8,28 |
4,98 |
|
|
4 |
6,52 |
9,27 |
7,91 |
5,77 |
8,02 |
3,07 |
2,22 |
5,76 |
11,6 |
6,62 |
7,07 |
12,5 |
1,65 |
|
10,5 |
3,67 |
7,62 |
4,94 |
5,39 |
3,64 |
4,62 |
8,88 |
6,75 |
5,77 |
6,38 |
10,3 |
5,74 |
|
|
5 |
8,18 |
9,56 |
6,06 |
5,85 |
6,78 |
5,60 |
10,8 |
7,70 |
6,44 |
8,64 |
6,95 |
5,66 |
4,84 |
|
4,96 |
4,62 |
5,57 |
6,47 |
5,97 |
8,02 |
3,66 |
9,24 |
4,13 |
6,58 |
7,51 |
5,67 |
7,89 |
|
|
6 |
10,2 |
9,23 |
8,77 |
10,4 |
9,44 |
9,09 |
6,30 |
9,42 |
6,12 |
9,69 |
8,59 |
8,68 |
7,97 |
|
8,64 |
6,45 |
5,29 |
5,00 |
8,42 |
8,84 |
8,26 |
6,66 |
6,96 |
6,51 |
6,72 |
6,00 |
5,36 |
|
|
7 |
7,13 |
9,12 |
9,77 |
9,17 |
8,89 |
6,19 |
7,71 |
6,96 |
6,72 |
6,08 |
4,41 |
5,52 |
9,59 |
|
8,06 |
6,26 |
4,86 |
6,33 |
6,28 |
8,60 |
7,38 |
7,84 |
7,24 |
6,85 |
6,50 |
8,28 |
4,98 |
|
|
8 |
3,53 |
9,56 |
7,03 |
9,18 |
7,45 |
5,59 |
6,85 |
11,3 |
7,90 |
6,00 |
6,68 |
5,66 |
8,64 |
|
8,87 |
4,58 |
11,3 |
5,02 |
4,33 |
9,31 |
10,3 |
5,99 |
6,98 |
5,23 |
8,75 |
7,73 |
9,16 |
|
|
9 |
3,38 |
7,87 |
4,04 |
8,21 |
4,08 |
3,46 |
4,37 |
6,66 |
1,46 |
5,59 |
3,78 |
8,73 |
5,57 |
|
8,22 |
3,25 |
3,38 |
4,20 |
2,49 |
6,11 |
4,54 |
6,53 |
5,20 |
3,84 |
5,35 |
9,72 |
4,63 |
|
|
10 |
4,21 |
5,68 |
3,45 |
6,79 |
3,39 |
2,99 |
3,88 |
3,77 |
1,43 |
5,96 |
4,94 |
6,55 |
5,92 |
|
4,20 |
4,25 |
5,64 |
5,58 |
5,87 |
5,05 |
3,55 |
7,95 |
4,45 |
5,85 |
6,68 |
1,24 |
7,09 |
Таблица 7.
|
№ варианта |
Выборка |
||||||||||||||
|
1 |
4 |
0 |
2 |
5 |
1 |
2 |
4 |
5 |
3 |
4 |
4 |
0 |
1 |
5 |
1 |
|
2 |
3 |
2 |
0 |
2 |
3 |
1 |
3 |
2 |
1 |
2 |
4 |
2 |
0 |
2 |
|
|
2 |
2 |
0 |
3 |
5 |
1 |
2 |
4 |
5 |
3 |
4 |
4 |
0 |
1 |
5 |
1 |
|
1 |
3 |
4 |
0 |
2 |
3 |
1 |
3 |
2 |
1 |
2 |
4 |
2 |
0 |
2 |
|
|
3 |
2 |
3 |
2 |
0 |
2 |
3 |
1 |
1 |
2 |
3 |
2 |
4 |
2 |
0 |
2 |
|
2 |
0 |
3 |
5 |
1 |
2 |
4 |
5 |
3 |
4 |
4 |
0 |
1 |
5 |
1 |
|
|
4 |
4 |
2 |
1 |
5 |
1 |
2 |
4 |
5 |
3 |
4 |
4 |
0 |
1 |
5 |
1 |
|
3 |
3 |
4 |
0 |
2 |
3 |
1 |
3 |
2 |
1 |
2 |
4 |
2 |
0 |
2 |
|
|
5 |
2 |
3 |
4 |
0 |
2 |
1 |
2 |
3 |
2 |
1 |
2 |
2 |
4 |
0 |
2 |
|
4 |
3 |
2 |
2 |
1 |
3 |
1 |
3 |
2 |
2 |
1 |
4 |
2 |
2 |
0 |
|
|
6 |
2 |
3 |
2 |
1 |
2 |
2 |
4 |
0 |
2 |
4 |
4 |
0 |
1 |
5 |
1 |
|
1 |
3 |
2 |
2 |
1 |
4 |
2 |
2 |
0 |
1 |
2 |
4 |
2 |
0 |
2 |
|
|
7 |
4 |
3 |
2 |
2 |
5 |
3 |
1 |
3 |
2 |
2 |
1 |
4 |
2 |
2 |
0 |
|
2 |
3 |
2 |
1 |
2 |
2 |
4 |
0 |
2 |
4 |
4 |
0 |
1 |
5 |
1 |
|
|
8 |
5 |
3 |
4 |
4 |
0 |
1 |
5 |
1 |
2 |
2 |
1 |
4 |
2 |
2 |
0 |
|
3 |
2 |
1 |
2 |
4 |
2 |
0 |
2 |
2 |
0 |
4 |
0 |
1 |
5 |
1 |
|
|
9 |
2 |
3 |
2 |
1 |
2 |
2 |
4 |
0 |
2 |
4 |
4 |
0 |
1 |
5 |
1 |
|
5 |
3 |
4 |
4 |
0 |
1 |
5 |
1 |
2 |
2 |
1 |
4 |
2 |
2 |
0 |
|
|
10 |
0 |
2 |
3 |
5 |
1 |
2 |
4 |
5 |
3 |
4 |
4 |
0 |
1 |
5 |
1 |
|
4 |
2 |
1 |
5 |
1 |
2 |
4 |
5 |
3 |
4 |
4 |
0 |
1 |
5 |
1 |
Просмотров работы: 10742
Код для цитирования:
