| Теория информации |
|---|
|
|
|
|
|

Информацио́нная энтропи́я — мера неопределённости некоторой системы (в статистической физике или теории информации), в частности, непредсказуемость появления какого-либо символа первичного алфавита. В последнем случае при отсутствии информационных потерь энтропия численно равна количеству информации на символ передаваемого сообщения.
Например, в последовательности букв, составляющих какое-либо предложение на русском языке, разные буквы появляются с разной частотностью, поэтому неопределённость появления для некоторых букв меньше, чем для других. Если же учесть, что некоторые сочетания букв (в этом случае говорят об энтропии 
Формальные определения[править | править код]
Информационная двоичная энтропия, при отсутствии информационных потерь, рассчитывается по формуле Хартли:

где 






Эта величина также называется средней энтропией сообщения. Величина 
Таким образом, энтропия системы
В общем случае, основание логарифма в определении энтропии может быть любым, большим 1 (так как алфавитом, состоящим только из одного символа, нельзя передавать информацию); выбор основания логарифма определяет единицу измерения энтропии. Для информационных систем, основанных на двоичной системе счисления, единицей измерения информационной энтропии (собственно, информации) является бит. В задачах математической статистики более удобным может оказаться применение натурального логарифма, в этом случае единицей измерения информационной энтропии является нат.
Определение по Шеннону[править | править код]
Клод Шеннон предположил, что прирост информации равен утраченной неопределённости, и задал требования к её измерению:
- мера должна быть непрерывной; то есть изменение значения величины вероятности на малую величину должно вызывать малое результирующее изменение функции;
- в случае, когда все варианты (буквы в приведённом примере) равновероятны, увеличение количества вариантов (букв) должно всегда увеличивать значение функции;
- должна быть возможность сделать выбор (в нашем примере — букв) в два шага, в которых значение функции конечного результата должно являться суммой функций промежуточных результатов.[прояснить]
Поэтому функция энтропии 
определена и непрерывна для всех
, где
для всех
и
. (Эта функция зависит только от распределения вероятностей, но не от алфавита.)
- Для целых положительных
- Для целых положительных
, где
, должно выполняться равенство


Шеннон показал,[2] что единственная функция, удовлетворяющая этим требованиям, имеет вид

где 
Шеннон определил, что измерение энтропии (
Определение энтропии Шеннона связано с понятием термодинамической энтропии. Больцман и Гиббс проделали большую работу по статистической термодинамике, которая способствовала принятию слова «энтропия» в информационную теорию. Существует связь между термодинамической и информационной энтропией. Например, демон Максвелла также противопоставляет термодинамическую энтропию информации, и получение какого-либо количества информации равно потерянной энтропии.
Определение с помощью собственной информации[править | править код]
Также можно определить энтропию случайной величины, предварительно введя понятие распределения случайной величины 


и собственной информации:

Тогда энтропия определяется как:

Единицы измерения информационной энтропии[править | править код]
От основания логарифма зависит единица измерения количества информации и энтропии: бит, нат, трит или хартли.
Свойства[править | править код]
Энтропия является количеством, определённым в контексте вероятностной модели для источника данных. Например, кидание монеты имеет энтропию:
бит на одно кидание (при условии его независимости), а количество возможных состояний равно:
возможных состояния (значения) («орёл» и «решка»).
У источника, который генерирует строку, состоящую только из букв «А», энтропия равна нулю: 

Это тоже информация, которую тоже надо учитывать. Примером запоминающих устройств, в которых используются разряды с энтропией, равной нулю, но с количеством информации, равным одному возможному состоянию, то есть не равным нулю, являются разряды данных записанных в ПЗУ, в которых каждый разряд имеет только одно возможное состояние.
Так, например, опытным путём можно установить, что энтропия английского текста равна 1,5 бит на символ, что будет варьироваться для разных текстов. Степень энтропии источника данных означает среднее число битов на элемент данных, требуемых для их (данных) зашифровки без потери информации, при оптимальном кодировании.
- Некоторые биты данных могут не нести информации. Например, структуры данных часто хранят избыточную информацию или имеют идентичные секции независимо от информации в структуре данных.
- Количество энтропии не всегда выражается целым числом битов.
Математические свойства[править | править код]
- Неотрицательность:
.
- Ограниченность:
, что вытекает из неравенства Йенсена для вогнутой функции
и
. Если все
.
- Если
независимы, то
.
- Энтропия — выпуклая вверх функция распределения вероятностей элементов.
- Если
.
Эффективность[править | править код]
Алфавит может иметь вероятностное распределение, далекое от равномерного. Если исходный алфавит содержит
Энтропия ограничивает максимально возможное сжатие без потерь (или почти без потерь), которое может быть реализовано при использовании теоретически — типичного набора или, на практике, — кодирования Хаффмана, кодирования Лемпеля — Зива — Велча или арифметического кодирования.
Вариации и обобщения[править | править код]
b-арная энтропия[править | править код]
В общем случае b-арная энтропия (где b равно 2, 3, …) источника 





В частности, при 


Условная энтропия[править | править код]
Если следование символов алфавита не независимо (например, во французском языке после буквы «q» почти всегда следует «u», а после слова «передовик» в советских газетах обычно следовало слово «производства» или «труда»), количество информации, которую несёт последовательность таких символов (а, следовательно, и энтропия) меньше. Для учёта таких фактов используется условная энтропия.
Условной энтропией первого порядка (аналогично для Марковской модели первого порядка) называется энтропия для алфавита, где известны вероятности появления одной буквы после другой (то есть вероятности двухбуквенных сочетаний):

где 

Например, для русского языка без буквы «ё» 
Через частную и общую условные энтропии полностью описываются информационные потери при передаче данных в канале с помехами. Для этого применяются так называемые канальные матрицы. Для описания потерь со стороны источника (то есть известен посланный сигнал) рассматривают условную вероятность 

 |
 |
… | |
… | 
|
|
|---|---|---|---|---|---|---|

|
 |
 |
… |  |
… | 
|

|
 |
 |
… |  |
… | 
|
| … | … | … | … | … | … | … |
|
|
 |
 |
… | |
… | 
|
| … | … | … | … | … | … | … |

|
 |
 |
… |  |
… | 
|
Вероятности, расположенные по диагонали, описывают вероятность правильного приёма, а сумма всех элементов любой строки даёт 1. Потери, приходящиеся на передаваемый сигнал

Для вычисления потерь при передаче всех сигналов используется общая условная энтропия:





Взаимная энтропия[править | править код]
Взаимная энтропия или энтропия объединения предназначена для расчёта энтропии взаимосвязанных систем (энтропии совместного появления статистически зависимых сообщений) и обозначается 


Взаимосвязь переданных и полученных сигналов описывается вероятностями совместных событий 
 |
 |
… |  |
… | 
|
 |
 |
… |  |
… | 
|
| … | … | … | … | … | … |
 |
 |
… | |
… | 
|
| … | … | … | … | … | … |
 |
 |
… |  |
… | 
|
Для более общего случая, когда описывается не канал, а в целом взаимодействующие системы, матрица необязательно должна быть квадратной. Сумма всех элементов столбца с номером 

Условные вероятности производятся по формуле Байеса. Таким образом, имеются все данные для вычисления энтропий источника и приёмника:


Взаимная энтропия вычисляется последовательным суммированием по строкам (или по столбцам) всех вероятностей матрицы, умноженных на их логарифм:

Единица измерения — бит/два символа, это объясняется тем, что взаимная энтропия описывает неопределённость на пару символов: отправленного и полученного. Путём несложных преобразований также получаем

Взаимная энтропия обладает свойством информационной полноты — из неё можно получить все рассматриваемые величины.
История[править | править код]
В 1948 году, исследуя проблему рациональной передачи информации через зашумлённый коммуникационный канал, Клод Шеннон предложил революционный вероятностный подход к пониманию коммуникаций и создал первую, истинно математическую, теорию энтропии. Его сенсационные идеи быстро послужили основой разработки двух основных направлений: теории информации, которая использует понятие вероятности и эргодическую теорию для изучения статистических характеристик данных и коммуникационных систем, и теории кодирования, в которой используются главным образом алгебраические и геометрические инструменты для разработки эффективных кодов.
Понятие энтропии как меры случайности введено Шенноном в его статье «Математическая теория связи» (англ. A Mathematical Theory of Communication), опубликованной в двух частях в Bell System Technical Journal в 1948 году.
Примечания[править | править код]
- ↑ Данное представление удобно для работы с информацией, представленной в двоичной форме; в общем случае основание логарифма может быть другим.
- ↑ Shannon, Claude E. A Mathematical Theory of Communication (неопр.) // Bell System Technical Journal (англ.) (рус.. — 1948. — July (т. 27, № 3). — С. 419. — doi:10.1002/j.1538-7305.1948.tb01338.x. Архивировано 1 августа 2016 года.
- ↑ Габидулин Э. М., Пилипчук Н. И. Лекции по теории информации — МФТИ, 2007. — С. 16. — 214 с. — ISBN 978-5-7417-0197-3
- ↑ Лебедев Д. С., Гармаш В. А. О возможности увеличения скорости передачи телеграфных сообщений. — М.: Электросвязь, 1958. — № 1. — С. 68—69.
См. также[править | править код]
- Дифференциальная энтропия (энтропия для непрерывного распределения)
- Взаимная информация
- Энтропийное кодирование
- Цепь Маркова
- Расстояние Кульбака — Лейблера
Ссылки[править | править код]
- Shannon Claude E. A Mathematical Theory of Communication Архивная копия от 31 января 1998 на Wayback Machine (англ.)
- Коротаев С. М. Энтропия и информация — универсальные естественнонаучные понятия.
Литература[править | править код]
- Шеннон К. Работы по теории информации и кибернетике. — М.: Изд. иностр. лит., 2002.
- Волькенштейн М. В. Энтропия и информация. — М.: Наука, 2006.
- Цымбал В. П. Теория информации и кодирование. — К.: Вища Школа, 2003.
- Martin, Nathaniel F.G. & England, James W. Mathematical Theory of Entropy. — Cambridge University Press, 2011. — ISBN 978-0-521-17738-2.
- Шамбадаль П. Развитие и приложение понятия энтропии. — М.: Наука, 1967. — 280 с.
- Мартин Н., Ингленд Дж. Математическая теория энтропии. — М.: Мир, 1988. — 350 с.
- Хинчин А. Я. Понятие энтропии в теории вероятностей // Успехи математических наук. — Российская академия наук, 1953. — Т. 8, вып. 3(55). — С. 3—20.
- Брюллюэн Л. Наука и теория информации. — М., 1960.
- Винер Н. Кибернетика и общество. — М., 1958.
- Винер Н. Кибернетика или управление и связь в животном и машине. — М., 1968.
- Петрушенко Л. А. Самодвижение материи в свете кибернетики. — М., 1974.
- Эшби У. Р. Введение в кибернетику. — М., 1965.
- Яглом А. М., Яглом И. М. Вероятность и информация. — М., 1973.
- Волькенштейн М. В. Энтропия и информация. — М.: Наука, 1986. — 192 с.
- Верещагин Н.К., Щепин Е.В. Информация, кодирование и предсказание. — М.: ФМОП, МЦНМО, 2012. — 238 с. — ISBN 978-5-94057-920-5.
Формула Шеннона (Информационная энтропия)
Данная формула также как и формула Хартли, в информатике применяется для высчитывания общего количество информации при различных вероятностях.
В качестве примера различных не равных вероятностей можно привести выход людей из казармы в военной части. Из казармы могут выйти как и солдат, так и офицер, и даже генерал. Но распределение cолдатов, офицеров и генералов в казарме разное, что очевидно, ведь солдатов будет больше всего, затем по количеству идут офицеры и самый редкий вид будут генералы. Так как вероятности не равны для всех трех видов военных, для того чтобы подсчитать сколько информации займет такое событие и используется формула Шеннона.
Для других же равновероятных событий, таких как подброс монеты (вероятность того что выпадет орёл или решка будет одинаковой — 50 %) используется формула Хартли.
Интересуешься информатикой? Читайте нашу новую лекцию системы счисления
Теперь, давайте рассмотрим применение этой формулы на конкретном примере:
В каком сообщений содержится меньше всего информации (Считайте в битах):
- Василий сьел 6 конфет, из них 2 было барбариски.
- В комьютере 10 папок, нужный файл нашелся в 9 папке.
- Баба Люда сделала 4 пирога с мясом и 4 пирога с капустой. Григорий сьел 2 пирога.
- В Африке 200 дней сухая погода, а 165 дней льют муссоны. африканец охотился 40 дней в году.
В этой задаче обратим внимания что 1,2 и 3 варианты, эти варианты считать легко, так как события равновероятны. И для этого мы будем использовать формулу Хартли I = log2N (рис.1) А вот с 4 пунком где видно, что распределение дней не равномерно(перевес в сторону сухой погоды), что же тогда нам в этом случае делать? Для таких событий и используется формула Шеннона или информационной энтропии: I = — ( p1log2 p1 + p2 log2 p2 + . . . + pN log2 pN), (рис.3)

В которой:
- I — количество информации
- p — вероятность того что это события случиться
Далее чтобы узнать p необходимо поделить количество интересующих нас событий на общее количество возможных вариантов.
Интересующие нас события в нашей задаче это
- Было две барбариски из шести (2/6)
- Была одна папка в которой нашлась нужный файл по отношению к общему количеству (1/10)
- Всего пирогов было восемь из которых сьедено григорием два (2/8)
- и последнее сорок дней охоты по отношению к двести засушливым дням и сорок дней охоты к сто шестидесяти пяти дождливым дням. (40/200) + (40/165)
таким образом получаем что:

Где K — это интересующие нас событие, а N общее количество этих событий, также чтобы проверить себя вероятность того или иного события не может быть больше единицы. (потому что вероятных событий всегда меньше)

Вернемся к нашей задаче и посчитаем сколько информации содержится.
Кстате, при подсчёте логарифма удобно использовать сайт — https://planetcalc.ru/419/#
- Для первого случая — 2/6 = 0,33 = и далее Log2 0,33 = 1.599 бит
- Для второго случая — 1/10 = 0,10 Log2 0,10 = 3.322 бит
- Для третьего — 2/8 = 0,25 = Log2 0,25 = 2 бит
- Для четвертого — 40/200 + 40/165 = 0.2 и 0,24 соответственно, далее считаем по формуле -(0,2 * log2 0,2) +-(0,24 * log2 0.24) = 0.95856 бит
Таким образом ответ для нашей задачи получился 0.95856 бит, что значит 4 пункт.
Вот таким образом и используется формула Шеннона при подсчёте информации. Если у вас есть какие либо вопросы, или что то Вам не понятно можете задать вопросы в комментариях. (отвечаю оперативно)
Мы ежедневно работаем с информацией из разных источников. При этом каждый из нас имеет некоторые интуитивные представления о том, что означает, что один источник является для нас более информативным, чем другой. Однако далеко не всегда понятно, как это правильно определить формально. Не всегда большое количество текста означает большое количество информации. Например, среди СМИ распространена практика, когда короткое сообщение из ленты информационного агентства переписывают в большую новость, но при этом не добавляют никакой «новой информации». Или другой пример: рассмотрим текстовый файл с романом Л.Н. Толстого «Война и мир» в кодировке UTF-8. Его размер — 3.2 Мб. Сколько информации содержится в этом файле? Изменится ли это количество, если файл перекодировать в другую кодировку? А если заархивировать? Сколько информации вы получите, если прочитаете этот файл? А если прочитаете его второй раз?
По мотивам открытой лекции для Computer Science центра рассказываю о том, как можно математически подойти к определению понятия “количество информации”.
В классической статье А.Н. Колмогорова “Три подхода к определению понятия количества информации” (1965) рассматривают три способа это сделать:
-
комбинаторный (информация по Хартли),
-
вероятностный (энтропия Шеннона),
-
алгоритмический (колмогоровская сложность).
Мы будем следовать этому плану.
Комбинаторный подход: информация по Хартли
Мы начнём самого простого и естественного подхода, предложенного Хартли в 1928 году.
Пусть задано некоторое конечное множество  . Количеством информации в
. Количеством информации в  будем называть
будем называть  .
.
Можно интерпретировать это определение следующим образом: нам нужно  битов для описания элемента из
битов для описания элемента из  .
.
Почему мы используем биты? Можно использовать и другие единицы измерения, например, триты или байты, но тогда нужно изменить основание логарифма на 3 или 256, соответственно. В дальшейшем все логарифмы будут по основанию 2.
Этого определения уже достаточно для того, чтобы измерить количество информации в некотором сообщении. Пусть про  стало известно, что
стало известно, что  . Теперь нам достаточно
. Теперь нам достаточно  битов для описания
битов для описания  , таким образом нам сообщили
, таким образом нам сообщили  битов информации.
битов информации.
Пример
Загадано целое число
от
до
. Нам сообщили, что
делится на
. Сколько информации нам сообщили?
Воспользуемся рассуждением выше.
![]()
(Тот факт, что некоторое сообщение может содержать нецелое количество битов, может показаться немного неожиданным.)
Можно ещё сказать, что сообщение, уменшающее пространство поиска в  раз приносит
раз приносит  битов информации. В данном примере пространство поиска уменьшилось в 1000/166 раз.
битов информации. В данном примере пространство поиска уменьшилось в 1000/166 раз.
Интересно, что одного этого определения уже достаточно для того, чтобы решать довольно нетривиальные задачи.
Применение: цена информации
Загадано целое число
от
до
. Разрешается задавать любые вопросы на ДА/НЕТ. Если ответ на вопрос “ДА”, то мы должны заплатить рубль, если ответ “НЕТ” — два рубля. Сколько нужно заплатить для отгадывания числа
?
Любой вопрос можно сформулировать как вопрос о принадлежности некоторому множеству, поэтому мы будем считать, что все вопросы имеют вид “ ?” для некоторого множества
?” для некоторого множества  .
.
Каким образом нужно задавать вопросы? Нам бы хотелось, чтобы вне зависимости от ответа цена за бит информации была постоянной. Другими словами, в случае ответа “НЕТ” и заплатив два рубля мы должны узнать в два больше информации, чем при ответе “ДА”. Давайте запишем это формально.
Потребуем, чтобы
![]()
Пусть  , тогда
, тогда  . Подставляем и получаем, что
. Подставляем и получаем, что
![]()
Это эквивалентно квадратному уравнению  Положительный корень этого уравнения
Положительный корень этого уравнения  . Таким образом, при любом ответе мы заплатим
. Таким образом, при любом ответе мы заплатим  рублей за бит информации, а в сумме мы заплатим примерно
рублей за бит информации, а в сумме мы заплатим примерно рублей (с точностью до округления).
рублей (с точностью до округления).
Осталось понять, как выбирать такие множества . Будем выбирать в качестве  непрерывные отрезки прямой. Пусть нам известно, что
непрерывные отрезки прямой. Пусть нам известно, что  принадлежит отрезку
принадлежит отрезку ![[a,b]](https://habrastorage.org/getpro/habr/upload_files/9a0/3e7/b69/9a03e7b69911956ef048f0e4f6496a6c.svg) (изначально это отрезок
(изначально это отрезок ![[1,n]](https://habrastorage.org/getpro/habr/upload_files/6a5/ba8/1c6/6a5ba81c6f282d08594b053eb740e8a7.svg) ). В следующего множества
). В следующего множества  возмём отрезок
возмём отрезок ![[a, a+ alphacdot(b-a)]](https://habrastorage.org/getpro/habr/upload_files/9cc/487/bdb/9cc487bdbefd53d5e81016a203868ef7.svg) , где. Тогда за каждый заплаченный рубль текущий отрезок будет уменьшаться в
, где. Тогда за каждый заплаченный рубль текущий отрезок будет уменьшаться в  раз. Когда длина отрезка станет меньше единицы, мы однозначно определим . Поэтому цена отгадывания не будет превосходить
раз. Когда длина отрезка станет меньше единицы, мы однозначно определим . Поэтому цена отгадывания не будет превосходить
![]()
Приведённое рассуждение доказывает только верхнюю оценку. Можно доказать и нижнюю оценку: для любого способа задавать вопросы будет такое число , для отгадывания которого придётся заплатить не менее  рублей.
рублей.
Вероятностный подход: энтропия Шеннона
Вероятностный подход, предложенный Клодом Шенноном в 1948 году, обобщает определение Хартли на случай, когда не все элементы множества являются равнозначными. Вместо множества в этом подходе мы будем рассматривать вероятностное распределение на множестве и оценивать среднее по распределению количество информации, которое содержит случайная величина.
Пусть задана случайная величина  , принимающая
, принимающая  различных значений с вероятностями
различных значений с вероятностями  . Энтропия Шеннона случайной величины
. Энтропия Шеннона случайной величины  определяется как
определяется как

(По непрерывности тут нужно доопределить  .)
.)
Энтропия Шеннона оценивает среднее количество информации (математическое ожидание), которое содержится в значениях случайной величины.
При первом взгляде на это определение, может показаться совершенно непонятно откуда оно берётся. Шеннон подошёл к этой задаче чисто математически: сформулировал требования к функции и доказал, что это единственная функция, удовлетворяющая сформулированным требованиям.
Я попробую объяснить происхождение этой формулы как обобщение информации по Хартли. Нам бы хотелось, чтобы это определение согласовывалось с определением Хартли, т.е. должны выполняться следующие “граничные условия”:
Будем искать  в виде математического ожидания количества информации, которую мы получаем от каждого возможного значения .
в виде математического ожидания количества информации, которую мы получаем от каждого возможного значения .
![]()
Как оценить, сколько информации содержится в событии  ? Пусть
? Пусть  — всё пространство элементарных исходов. Тогда событие
— всё пространство элементарных исходов. Тогда событие  соответствует множеству элементарных исходов меры
соответствует множеству элементарных исходов меры  . Если произошло событие
. Если произошло событие  , то размер множества согласованных с этим событием элементарных исходов уменьшается с
, то размер множества согласованных с этим событием элементарных исходов уменьшается с  до
до  , т.е. событие
, т.е. событие  сообщает нам
сообщает нам  битов информации. Тут мы пользуемся тем, что количество информации в сообщении, которое уменьшает размер пространство поиска в
битов информации. Тут мы пользуемся тем, что количество информации в сообщении, которое уменьшает размер пространство поиска в  раз приносит
раз приносит  битов информации.
битов информации.
Примеры
Свойства энтропии Шеннона
Для случайной величины  , принимающей
, принимающей  значений с вероятностями
значений с вероятностями  , выполняются следующие соотношения.
, выполняются следующие соотношения.
-
 .
. -

 распределение
распределение  вырождено.
вырождено. -
 .
. -

 распределение
распределение  равномерно.
равномерно.
Чем распределение ближе к равномерному, тем больше энтропия Шеннона.
Энтропия пары
Понятие энтропии Шеннона можно обобщить для пары случайных величин. Аналогично это обощается для тройки, четвёрки и т.д.
Пусть совместно распределённые случайные величины  и
и  принимают значения
принимают значения  и
и  , соответственно. Энтропия пары случайных величин
, соответственно. Энтропия пары случайных величин  и
и  определяется следующим соотношением:
определяется следующим соотношением:
![H(X,Y) = sum_{i=1}^ksum_{j=1}^mPr[X = a_i, Y=b_j]cdot logfrac{1}{Pr[X = a_i, Y = b_j]}.](https://habrastorage.org/getpro/habr/upload_files/bdb/a99/dd1/bdba99dd141ec64b0456fb6ef5f765e6.svg)
Примеры
Рассмотрим эксперимент с выбрасыванием двух игральных кубиков — синего и красного.
Свойства энтропии Шеннона пары случайных величин
Для энтропии пары выполняются следующие свойства.
Условная энтропия Шеннона
Теперь давайте научимся вычислять условную энтропию одной случайной величины относительно другой.
Условная энтропия  относительно
относительно  определяется следующим соотношением:
определяется следующим соотношением:
![]()
Примеры
Рассмотрим снова примеры про два игральных кубика.
Свойства условной энтропии
Условная энтропия обладает следующими свойствами
Взаимная информация
Ещё одна информационная величина, которую мы введём в этом разделе — это взаимная информация двух случайных величин.
Информация в  о величине
о величине  (взаимная информация случайных величин
(взаимная информация случайных величин  и
и  ) определяется следующим соотношением
) определяется следующим соотношением
![]()
Примеры
И снова обратимся к примерам с двумя игральными кубиками.
Свойства взаимной информации
Выполняются следующие соотношения.
-
 . Т.е. определение взаимной информации симметрично и его можно переписать так:
. Т.е. определение взаимной информации симметрично и его можно переписать так:
![]()
-
Или так:
 .
. -
 и
и  .
. -
 .
. -
 .
.
Все информационные величины, которые мы определили к этому моменту можно проиллюстрировать при помощи кругов Эйлера.
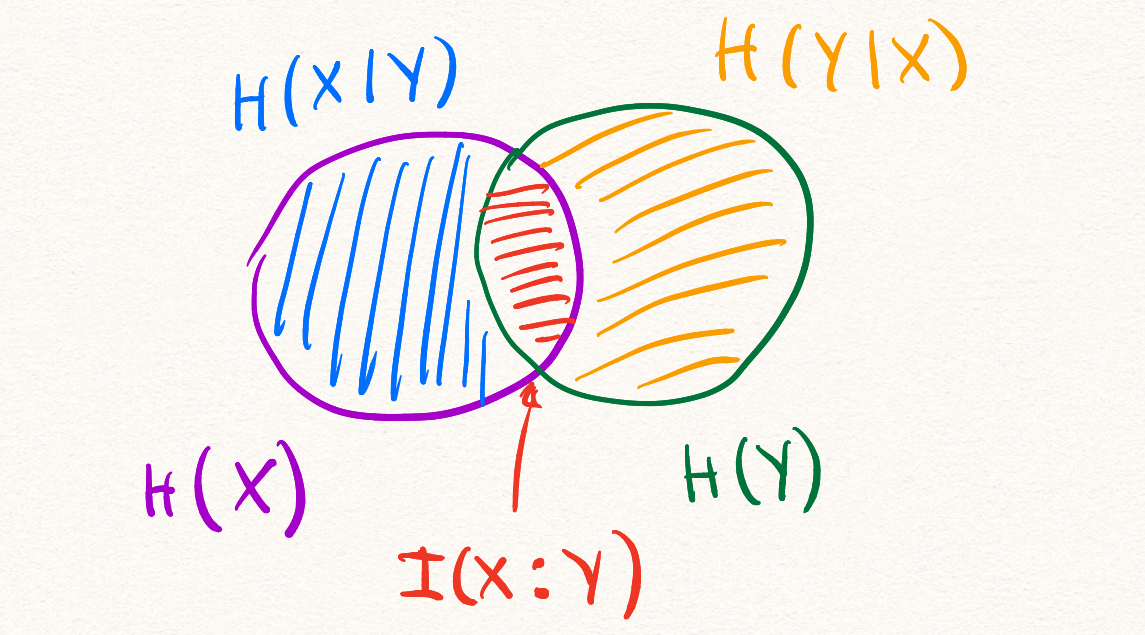
Мы пойдём дальше и рассмотрим информационную величину, зависящую от трёх случайных величин.
Пусть  ,
,  и
и  совместно распределены. Информация в
совместно распределены. Информация в  о
о  при условии
при условии  определяется следующим соотношением:
определяется следующим соотношением:
![]()
Свойства такие же как и обычной взаимной информации, нужно только добавить соответствующее условие ко всем членам.
Всё, что мы успели определить можно удобно проиллюстрировать при помощи трёх кругов Эйлера.

Из этой иллюстрации можно вывести все определения и соотношения на информационные величины.
Мы не будем продолжать дальше и рассматривать четыре случайные величины по трём причинам. Во-первых, рисовать четыре круга Эйлера со всеми возможными областями — это непросто. Во-вторых, для двух и трёх случайных величин почти все возможные соотношения можно вывести из кругов Эйлера, а для четырёх случайных величин это уже не так. И в третьих, уже для трёх случайных величин возникают неприятные эффекты, демонстрирующие, что дальше будет хуже.
Рассмотрим треугольник в пересечении всех трёх кругов  ,
,  и
и  . Этот треугольник соответствуют взаимной информации трёх случайных величин
. Этот треугольник соответствуют взаимной информации трёх случайных величин  . Проблема с этой информационной величиной заключается в том, что ей не удаётся придать какой-то “физический” смысл. Более того, в отличие от всех остальных величин на картинке
. Проблема с этой информационной величиной заключается в том, что ей не удаётся придать какой-то “физический” смысл. Более того, в отличие от всех остальных величин на картинке  может быть отрицательной!
может быть отрицательной!
Рассмотрим пример трёх случайных величин равномерно распределённых на  . Пусть
. Пусть  и
и  будут независимы, а
будут независимы, а  . Легко проверить, что
. Легко проверить, что  . При этом
. При этом  . В то же время
. В то же время  . Получается следующая картинка.
. Получается следующая картинка.

Мы знаем, что  . При этом
. При этом  . Получается, что
. Получается, что  , а
, а  , т.е. для таких случайных величин
, т.е. для таких случайных величин .
.
Применение энтропии Шеннона: кодирование
В этом разделе мы обсудим, как энтропия Шеннона возникает в теории кодирования. Будем рассматривать коды, которые кодируют каждый символ по отдельности.
Пусть задан алфавит  . Код — это отображение из
. Код — это отображение из  в
в  . Код
. Код  называется однозначно декодируемым, если любое сообщение, полученное применением
называется однозначно декодируемым, если любое сообщение, полученное применением  к символам некоторого текста, декодируется однозначно.
к символам некоторого текста, декодируется однозначно.
Код называется префиксным (prefix-free), если нет двух символов  и
и  таких, что
таких, что  является префиксом
является префиксом  .
.
Префиксные коды являются однозначно декодируемыми. Действительно, при декодировании префиксного кода легко понять, где находятся границы кодов отдельных символов.
Теорема [Шеннон]. Для любого однозначно декодируемого кода существует префиксный код с теми же длинами кодов символов.
Таким образом для изучения однозначно декодируемых кодов достаточно рассматривать только префиксные коды.
Задача об оптимальном кодировании.
Дан текст  . Нужно найти такой код
. Нужно найти такой код  , что
, что

Пусть  . Обозначим через
. Обозначим через  частоту, с которой символ
частоту, с которой символ  встречается в
встречается в  . Тогда выражение выше можно переписать как
. Тогда выражение выше можно переписать как

Следующая теорема могла встречаться вам в курсе алгоритмов.
Теорема [Хаффман]. Код Хаффмана, построенный по  , является оптимальным префиксным кодом.
, является оптимальным префиксным кодом.
Алгоритм Хаффмана по набору частот эффективно строит оптимальный код для задачи оптимального кодирования.
Связь с энтропией
Имеют место две следующие оценки.
Теорема [Шеннон]. Для любого однозначно декодируемого кода выполняется

Теорема [Шеннон]. Для любых значений  существует префиксный код
существует префиксный код  , такой что
, такой что

Рассмотрим случайную величину  , равномерно распределённую на символах текста
, равномерно распределённую на символах текста  . Получим, что
. Получим, что  . Таким образом, эти две теоремы задают оценку на среднюю длину кода символа при оптимальном кодировании, т.е. и для кодирования Хаффмана.
. Таким образом, эти две теоремы задают оценку на среднюю длину кода символа при оптимальном кодировании, т.е. и для кодирования Хаффмана.

Следовательно, длину кода Хаффмана текста  можно оценить, как
можно оценить, как
![]()
Применение энтропии Шеннона: шифрования с закрытым ключом
Рассмотрим простейшую схему шифрования с закрытым ключом. Шифрование сообщения  с ключом шифрования
с ключом шифрования  выполняется при помощи алгоритма шифрования
выполняется при помощи алгоритма шифрования  . В результате получается шифрограмма
. В результате получается шифрограмма  . Зная
. Зная  получатель шифрограммы восстанавливает исходное сообщение
получатель шифрограммы восстанавливает исходное сообщение  :
:  .
.
Мы будем анализировать эту схему с помощью аппарата энтропии Шеннона. Пусть  и
и  являются случайными величинами. Противник не знает
являются случайными величинами. Противник не знает  и
и  , но знает
, но знает  , которая так же является случайной величиной.
, которая так же является случайной величиной.
Для совершенной схемы шифрования (perfect secrecy) выполняются следующие соотношения:
-
 , т.е. шифрограмма однозначно определяется по ключу и сообщению.
, т.е. шифрограмма однозначно определяется по ключу и сообщению. -
 , т.е. исходное сообщение однозначно восстанавливается по шифрограмме и ключу.
, т.е. исходное сообщение однозначно восстанавливается по шифрограмме и ключу. -
 , т.е. в отсутствие ключа из шифрограммы нельзя получить никакой информации о пересылаемом сообщении.
, т.е. в отсутствие ключа из шифрограммы нельзя получить никакой информации о пересылаемом сообщении.
Теорема [Шеннон].  , даже если условие
, даже если условие  нарушается (т.е. алгоритм
нарушается (т.е. алгоритм  использует случайные биты).
использует случайные биты).
Эта теорема утверждает, что для совершенной схемы шифрования длина ключа должна быть не менее длины сообщения. Другими словами, если вы хотите зашифровать и передать своему знакомому файл размера 1Гб, то для этого вы заранее должны встретиться и обменяться закрытым ключом размера не менее 1Гб. И конечно, этот ключ можно использовать только однажды. Таким образом, самая оптимальная совершенная схема шифрования — это “одноразовый блокнот”, в котором длина ключа совпадает с длиной сообщения.
Если же вы используете ключ, который короче пересылаемого сообщения, то шифрограмма раскрывает некоторую информацию о зашифрованном сообщении. Причём количество этой информации можно оценить, как разницу между энтропией сообщения и энтропией ключа. Если вы используете пароль из 10 символов при пересылке файла размера 1Гб, то вы разглашаете примерно 1Гб – 10 байт.
Это всё звучит очень печально, но не всё так плохо. Мы ведь никак не учитываем вычислительную мощь противника, т.е. мы не ограничиваем количество времени, которое противнику потребуется на выделение этой информации.
Современная криптография строится на предположении об ограниченности вычислительных возможностей противника. Тут есть свои проблемы, а именно отсутствие математического доказательства криптографической стойкости (все доказательства строятся на различных предположениях), так что может оказаться, что вся эта криптография бесполезна (подробнее можно почитать в статье о мирах Рассела Импальяццо, которая переведена на хабре), но это уже совсем другая история.
Доказательство. Нарисуем картинку для трёх случайных величин и отметим то, что нам известно.

-
.
-
 , следовательно
, следовательно  , а значит
, а значит  .
. -
 (по свойству взаимной информации), следовательно
(по свойству взаимной информации), следовательно  , а значит
, а значит  .
. -
 . Таким образом,
. Таким образом,
![]()
В доказательстве мы действительно не воспользовались тем, что .
Алгоритмический подход: колмогоровская сложность
Подход Шеннона хорош для случайных величин, но если мы попробуем применить его к текстам, то выходит, что количество информации в тексте зависит только от частот символов, но не зависит от их порядка. При таком подходе получается, что в “Войне и мире” и в тексте, который получается сортировкой всех знаков в “Войне и мире”, содержится одинаковое количество информации. Колмогоров предложил подход, позволяющий измерять количество информации в конкретных объектах (строках), а не в случайных величинах.
Внимание. До этого момента я старался следить за математической строгостью формулировок. Для того, чтобы двигаться дальше в том же ключе, мне потребовалось бы предположить, что читатель неплохо знаком с математической логикой и теорией вычислимости. Я пойду более простым путём и просто буду махать руками, заметая под ковёр некоторые подробности. Однако, все утверждения и рассуждения дальше можно математически строго сформулировать и доказать.
Нам потребуется зафиксировать способ описания битовой строки. Чтобы не углубляться в рассуждения про машины Тьюринга, мы будем описывать строки на языках программирования. Нужно только сделать оговорку, что программы на этих языках будут запускаться на компьютере с неограниченным объёмом оперативной памяти (иначе мы получили бы более слабую вычислительную модель, чем машина Тьюринга).
Сложностью  строки
строки  относительно языка программирования
относительно языка программирования  называется длина кратчайшей программы, которая выводит
называется длина кратчайшей программы, которая выводит  .
.
Таким образом сложность “Войны и мира” относительноя языка Python — это длина кратчайшей программы на Python, которая печатает текст “Войны и мира”. Естественным образом сложность отсортированной версии “Войны и мира” относительно языка Python получится значительно меньше, т.к. её можно предварительно закодировать при помощи RLE.
Сравнение языков программирования
Дальше нам потребуется научиться любимой забаве всех программистов — сравнению языков программирования.
Будем говорить, что язык  не хуже языка программирования
не хуже языка программирования  и обозначать
и обозначать  , если существует константа
, если существует константа  такая, что для для всех
такая, что для для всех  выполняется
выполняется 
Исходя из этого определения получается, что язык Python не хуже (!) этого вашего Haskell! И я это докажу. В качестве константы  мы возьмём длину реализации интепретатора Haskell на Python. Таким образом, любая программа на Haskell переделывается в программу на Python просто дописыванием к ней интерпретатора Haskell на Python.
мы возьмём длину реализации интепретатора Haskell на Python. Таким образом, любая программа на Haskell переделывается в программу на Python просто дописыванием к ней интерпретатора Haskell на Python.
Соломонов и Колмогоров пошли дальше и доказали существования оптимального языка программирования.
Теорема [Соломонова-Колмогорова]. Существует способ описания (язык программирования)  такой, что для любого другого способа описания
такой, что для любого другого способа описания  выполняется
выполняется  .
.
И да, некоторые уже наверное догадались, что — это JavaScript. Или любой другой Тьюринг полный язык программирования.
Это приводит нас к следующему определению, предложенному Колмогоровым в 1965 году.
Колмогоровской сложностью строки  будем называть её сложность относительно оптимального способа описания и будем обозначать
будем называть её сложность относительно оптимального способа описания и будем обозначать  .
.
Важно понимать, что при разных выборах оптимального языка программирования колмогоровская сложность будет отличаться, но только на константу. Для любых двух оптимальных языков программирования  и
и  выполняется
выполняется  и
и  , т.е. существует такая константа
, т.е. существует такая константа  , что
, что  Это объясняет, почему в этой науке аддитивные константы принято игнорировать.
Это объясняет, почему в этой науке аддитивные константы принято игнорировать.
При этом для конкретной строки и конкретного выбора колмогоровская сложность определена однозначно.
Свойства колмогоровской сложности
Начнём с простых свойств. Колмогоровская сложность обладает следующими свойствами.
Первое свойство выполняется потому, что мы всегда можем зашить строку в саму программу. Второе свойство верно, т.к. из программы, выводящей строку  , легко сделать программу, которая выводит эту строку дважды.
, легко сделать программу, которая выводит эту строку дважды.
Примеры
Несжимаемые строки
Важнейшее свойство колмогоровской сложности заключается в существовании сложных (несжимаемых строк). Проверьте себя и попробуйте объяснить, почему не бывает идеальных архиваторов, которые умели бы сжимать любые файлы хотя бы на 1 байт, и при этом позволяли бы однозначно разархивировать результат.
В терминах колмогоровской сложности это можно сформулировать так.
Вопрос. Существует ли такая длина строки
, что для любой строки
колмогоровская сложность
меньше
?
Следующая теорема даёт отрицательный ответ на этот вопрос.
Теорема. Для любого  существует
существует  такой, что
такой, что  .
.
Доказательство. Битовых строк длины  всего
всего  . Число строк сложности меньше
. Число строк сложности меньше  не превосходит число программ длины меньше
не превосходит число программ длины меньше  , т.е. таких программ не больше чем
, т.е. таких программ не больше чем
![]()
Таким образом, для какой-то строки гарантированно не хватит программы.
Верна и более сильная теорема.
Теорема. Существует  такое, что для
такое, что для  слов длины
слов длины  верно
верно
![]()
Другими словами, почти все строки длины  имеют почти максимальную сложность.
имеют почти максимальную сложность.
Колмогоровская сложность: вычислимость
В этом разделе мы поговорим про вычислимость колмогоровской сложности. Я не буду давать формально определение вычислимости, а буду опираться на интуитивные предствления читателей.
Теорема. Не существует программы, которая по двоичной записи числа  выводит строку
выводит строку  , такую что
, такую что  .
.
Эта теорема говорит о том, что не существует программы-генератора, которая умела бы генерировать сложные строки по запросу.
Доказательство. Проведём доказетельство от противного. Пусть такая программа  существует и
существует и  . Тогда с одной стороны сложность
. Тогда с одной стороны сложность  не меньше
не меньше  , а с другой стороны мы можем описать
, а с другой стороны мы можем описать  при помощи
при помощи  битов и кода программы
битов и кода программы .
.
![]()
Это приводит нас к противоречию, т.к. при достаточно больших значениях  неизбежно станет больше, чем
неизбежно станет больше, чем  .
.
Как следствие мы получаем невычислимость колмогоровской сложности.
Следствие. Отображение  не является вычислимым.
не является вычислимым.
Опять же, предположим, что это нет так и существует программа  , которая по строку вычисляет её колмогоровскую сложность. Тогда на основе программы
, которая по строку вычисляет её колмогоровскую сложность. Тогда на основе программы  можно реализовать программу
можно реализовать программу  из теоремы выше: она будет перебирать все строки длины не более
из теоремы выше: она будет перебирать все строки длины не более  и находить лексикографически первую, для которой сложность будет не меньше
и находить лексикографически первую, для которой сложность будет не меньше  . А мы уже доказали, что такой программы не существует.
. А мы уже доказали, что такой программы не существует.
Связь с энтропией Шеннона
Теорема. Пусть  длины
длины  содержит
содержит  единиц и
единиц и  нулей, тогда
нулей, тогда

Я надеюсь, что вы уже узнали энтропию Шеннона для случайной величины с двумя значениями с вероятностями  и
и  .
.
Для колмогоровской сложности можно проделать весь путь, который мы проделали для энтропии Шеннона: определить условную колмогоровскую сложность, сложность пары строк, взаимную информацию и условную взаимную информацию и т.д. При этом формулы будут повторять формулы для энтропии Шеннона с точностью до  . Однако это тема для отдельной статьи.
. Однако это тема для отдельной статьи.
Применение колмогоровской сложности: бесконечность множества простых чисел
Начнём с довольно игрушечного применения. С помощью колмогоровской сложности мы докажем следующую теорему, знакомую нам со школы.
Теорема. Простых чисел бесконечно много.
Очевидно, что для доказательства этой теоремы никакая колмогоровская сложность не нужна. Однако на этом примере я смогу продемонстрировать основные идеи применения колмогоровской сложности в более сложных ситуациях.
Доказательство. Проведём доказательство от обратного. Пусть существует всего  простых чисел:
простых чисел:  . Тогда любое натуральное
. Тогда любое натуральное  раскладывается на степени простых:
раскладывается на степени простых:
![]()
т.е. определяется набором степеней  . Каждое
. Каждое  , т.е. задаётся
, т.е. задаётся  битами. Поэтому любое
битами. Поэтому любое  можно задать при помощи
можно задать при помощи  битов (помним, что
битов (помним, что  — это константа).
— это константа).
Теперь воспользуемся теоремой о существовании несжимаемых строк. Как следствие, мы можем заключить, что существуют  -битовые числа
-битовые числа  сложности не менее
сложности не менее  (можно взять сложную строку и приписать в начало единицу). Получается, что сложное число можно задать при помощи небольшого числа битов.
(можно взять сложную строку и приписать в начало единицу). Получается, что сложное число можно задать при помощи небольшого числа битов.
![]()
Противоречие.
Применение колмогоровской сложности: алгоритмическая случайность
Колмогоровская сложность позволяет решить следующую проблему из классической теории вероятностей.
Пусть в лаборатории живёт обезьянка, которую научили печатать на печатной машинке так, что каждую кнопку она нажимает с одинаковой вероятность. Вам предлагается посмотреть на лист печатного текста и сказать, верите ли вы, что его напечатала эта обезьянка. Вы смотрите на лист и видите, что это первая страница “Гамлета” Шекспира. Поверите ли вы? Очевидно, что нет. Хорошо, а если это не Шекспир, а, скажем, текст детектива Дарьи Донцовой? Скорей всего тоже не поверите. А если просто какой-то набор русских слов? Опять же, очень сомневаюсь, что вы поверите.
Внимание, вопрос. А как объяснить, почему вы не верите? Давайте для простоты считать, что на странице помещается 2000 знаков и всего на машинке есть 80 знаков. Вы можете резонно заметить, что вероятность того, что обезьянка случайным образом породила текст “Гамлета” порядка  , что астрономически мало. Это верно.
, что астрономически мало. Это верно.
Теперь предположим, что вам показали текст, который вас устроил (он с вашей точки зрения будет похож на “случайный”). Но ведь вероятность его появления тоже будет порядка . Как же вы определяете, что один текст выглядит “случайным”, а другой — не выглядит?
Колмогоровская сложность позволяет дать формальный ответ на этот вопрос. Если у текста отстутствует короткое описание (т.е. в нём нет каких-то закономерностей, которые можно было бы использовать для сжатия), то такую строку можно назвать случайной. И как мы увидели выше почти все строки имеют большую колмогоровскую сложность. Поэтому, когда вы видите строку с закономерностями, т.е. маленькой колмогоровской сложности, то это соответствует очень редкому событию. В противоположность наблюдению строки без закономерностей. Вероятность увидеть строку без закономерностей близка к 1.
Это обобщается на случай бесконечных последовательностей. Пусть  . Как определить понятие случайной последовательности?
. Как определить понятие случайной последовательности?
(неформальное определение)
Последовательность случайна по Мартину–Лёфу, если каждый её префикс является несжимаемым.
Оказывается, что это очень хорошее определение случайных последовательностей, т.к. оно обладает ожидаемыми свойствами.
Свойства случайных последовательностей
-
Почти все последовательности являются случайными по Мартину–Лёфу, а мера неслучайных равна
 .
. -
Всякая случайная по Мартину-Лёфу последовательность невычислима.
-
Если
 случайная по Мартин-Лёфу, то
случайная по Мартин-Лёфу, то

Заключение
Если вам интересно изучить эту тему подробнее, то я рекомендую обратиться к следующим источникам.
-
Верещагин Н.К., Щепин Е.В. Информация, кодирование и предсказание. МЦНМО. (нет в свободном доступе, но pdf продаётся за копейки)
-
В.А. Успенский, А.Х. Шень, Н.К. Верещагин. Колмогоровская сложность и алгоритмическая случайность.
-
Курс “Введение в теорию информации” А.Е. Ромащенко в Computer Science клубе.
Если вам интересны подобные материалы, подписывайтесь в соцсетях на CS клуб и CS центр, а так же на наши каналы на youtube: CS клуб, CS центр.
Энтропи́я (информационная) — мера хаотичности информации, неопределённость появления какого-либо символа первичного алфавита. При отсутствии информационных потерь численно равна количеству информации на символ передаваемого сообщения.
Так, возьмём, например, последовательность символов, составляющих какое-либо предложение на русском языке. Каждый символ появляется с разной частотой, следовательно, неопределённость появления для некоторых символов больше, чем для других. Если же учесть, что некоторые сочетания символов встречаются очень редко, то неопределённость ещё более уменьшается (в этом случае говорят об энтропии n-ого порядка, см. Условная энтропия).
Концепции информации и энтропии имеют глубокие связи друг с другом, но, несмотря на это, разработка теорий в статистической механике и теории информации заняла много лет, чтобы сделать их соответствующими друг другу. Ср. тж. Термодинамическая энтропия
Формальные определения
Информационная энтропия для независимых случайных событий x с n возможными состояниями (от 1 до n) рассчитывается по формуле:

Эта величина также называется средней энтропией сообщения. Величина 
Таким образом, энтропия события x является суммой с противоположным знаком всех произведений относительных частот появления события i, умноженных на их же двоичные логарифмы (основание 2 выбрано только для удобства работы с информацией, представленной в двоичной форме). Это определение для дискретных случайных событий можно расширить для функции распределения вероятностей.
Шеннон вывел это определение энтропии из следующих предположений:
- мера должна быть непрерывной; т. е. изменение значения величины вероятности на малую величину должно вызывать малое результирующее изменение энтропии;
- в случае, когда все варианты (буквы в приведенном примере) равновероятны, увеличение количества вариантов (букв) должно всегда увеличивать полную энтропию;
- должна быть возможность сделать выбор (в нашем примере букв) в два шага, в которых энтропия конечного результата должна будет являтся суммой энтропий промежуточных результатов.
Шеннон показал, что любое определение энтропии, удовлетворяющее этим предположениям, должно быть в форме:

где K — константа (и в действительности нужна только для выбора единиц измерения).
Шеннон определил, что измерение энтропии (H = − p1 log2 p1 − … − pn log2 pn), применяемое к источнику информации, может определить требования к минимальной пропускной способности канала, требуемой для надежной передачи информации в виде закодированных двоичных чисел. Для вывода формулы Шеннона необходимо вычислить математическое ожидания «количества информации», содержащегося в цифре из источника информации. Мера энтропии Шеннона выражает неуверенность реализации случайной переменной. Таким образом, энтропия является разницей между информацией, содержащейся в сообщении, и той частью информации, которая точно известна (или хорошо предсказуема) в сообщении. Примером этого является избыточность языка — имеются явные статистические закономерности в появлении букв, пар последовательных букв, троек и т.д. См. Цепи Маркова.
В общем случае b-арная энтропия (где b равно 2,3,… ) источника 

Определение энтропии Шеннона очень связано с понятием термодинамической энтропии. Больцман и Гиббс проделали большую работу по статистической термодинамике, которая способствовала принятию слова «энтропия» в информационную теорию. Существует связь между термодинамической и информационной энтропией. Например, демон Максвелла также противопоставляет термодинамическую энтропию информации, и получение какого-либо количества информации равно потерянной энтропии.
Условная энтропия
Если следование символов алфавита не независимо (например, во французском языке после буквы «q» почти всегда следует «u», а после слова «передовик» в советских газетах обычно следовало слово «производства» или «труда»), количество информации, которую несёт последовательность таких символов (а следовательно и энтропия) очевидно меньше. Для учёта таких фактов используется условная энтропия.
Условной энтропией первого порядка (аналогично для Марковской модели первого порядка) называется энтропия для алфавита, где известны вероятности появления одной буквы после другой (т.е. вероятности двухбуквенных сочетаний):

где 


Так, для русского алфавита без буквы «ё» 
Через частную и общую условные энтропии полностью описываются информационные потери при передаче данных в канале с помехами. Для этого применяются т.н. канальные матрицы. Так, для описания потерь со стороны источника (т.е. известен посланный сигнал), рассматривают условную вероятность 



|

|
… |
|
… | 
|
|
|---|---|---|---|---|---|---|

|

|

|
… |
|
… | 
|

|

|

|
… | 
|
… | 
|
| … | … | … | … | … | … | … |
|
|

|

|
… |
|
… | 
|
| … | … | … | … | … | … | … |

|

|

|
… | 
|
… | 
|
Очевидно, вероятности, расположенные по диагонали описывают вероятность правильного приёма, а сумма всех элементов столбца даст вероятность появления соответствующего символа на стороне приёмника — 

Для вычисления потерь при передаче всех сигналов используется общая условная энтропия:





Взаимная энтропия
Взаимная энтропия, или энтропия объединения, предназначена для рассчёта энтропии взаимосвязанных систем (энтропии совместного появления статистически зависимых сообщений) и обозначается 


Взаимосязь переданных и полученных сигналов описывается вероятностями совместных событий 

|

|
… |
|
… | 
|

|

|
… | 
|
… | 
|
| … | … | … | … | … | … |

|

|
… |
|
… | 
|
| … | … | … | … | … | … |

|

|
… | 
|
… | 
|
Для более общего случая, когда описывается не канал, а просто взаимодействующие системы, матрица необязательно должна быть квадратной. Очевидно, сумма всех элементов столбца с номером

Условные вероятности производятся по формуле Байеса. Таким образом имеются все данные для вычисления энтропий источника и приёмника:


Взаимная энтропия вычисляется последовательным суммированием по строкам (или по столбцам) всех вероятностей матрицы, умноженных на их логарифм:

Единица измерения — бит/два символа, это объясняется тем, что взаимная энтропия описывает неопределённость на пару символов — отправленного и полученного. Путём несложных преобразований также получаем

Взаимная энтропия обладает свойством информационной полноты — из неё можно получить все рассматриваемые величины.
Свойства
Важно помнить, что энтропия является количеством, определённым в контексте вероятностной модели для источника данных. Например, кидание монеты имеет энтропию 
- Некоторые биты данных могут не нести информации. Например, структуры данных часто хранят избыточную информацию, или имеют идентичные секции независимо от информации в структуре данных.
- Количество энтропии не всегда выражается целым числом бит.
Альтернативное определение
Другим способом определения функции энтропии H является доказательство, что H однозначно определена (как указано ранее), если и только если H удовлетворяет пунктам 1)—3):
1) H(p1, …, pn) определена и непрерывна для всех p1, …, pn, где pi 
2) Для целых положительных n, должно выполняться следующее неравенство:

3) Для целых положительных bi, где b1 + … + bn = n, должно выполняться равенство:

Эффективность
Исходный алфавит, встречающийся на практике, имеет вероятностное распределение, которое далеко от оптимального. Если исходный алфавит имел n символов, тогда он может может быть сравнён с «оптимизированным алфавитом», вероятностное распределение которого однородно. Соотношение энтропии исходного и оптимизированного алфавита — это эффективность исходного алфавита, которая может быть выражена в процентах.
Из этого следует, что эффективность исходного алфавита с n символами может быть определена просто как равная его n-арной энтропии.
Энтропия ограничивает максимально возможное сжатие без потерь (или почти без потерь), которое может быть реализовано при использовании теоретически — типичного набора или, на практике, — кодирования Хаффмана, кодирования Лемпеля-Зива или арифметического кодирования.
История
В 1948 году, исследуя проблему рациональной передачи информации через зашумленный коммуникационный канал, Клод Шеннон предложил революционный вероятностный подход к пониманию коммуникаций и создал первую, истинно математическую, теорию энтропии. Его сенсационные идеи быстро послужили основой разработки двух основных направлений: теории информации, которая использует понятие вероятности и эргодическую теорию для изучения статистических характеристик данных и коммуникационных систем, и теории кодирования, в которой используются главным образом алгебраические и геометрические инструменты для разработки эффективных шифров.
Понятие энтропии, как меры случайности, введено Шенноном в его статье «A Mathematical Theory of Communication», опубликованной в двух частях в Bell System Technical Journal в 1948 году.
Литература
- ↑ Д.С. Лебедев, В.А. Гармаш. О возможности увеличения скорости передачи телеграфных сообщений. — М.:Электросвязь, 1958, №1. с.68-69
- 2.Цымбал В.П. Теория информации и кодирование. — К.:Выща Школа, 1977. — 288 с.
См. также
- Энтропийное кодирование
- Цепь Маркова
- Для понимания информационной энтропии можно прибегнуть к примеру из области термодинамической энтропии получившему широко известное название Демона Максвелла.
Внешние ссылки
- http://cm.bell-labs.com/cm/ms/what/shannonday/paper.html
- С.М. Коротаев. Энтропия и информация — Универсальные естественнонаучные понятия
Эта статья содержит материал из статьи Информационная энтропия русской Википедии.
«Информация есть форма жизни», — писал американский поэт и эссеист Джон Перри Барлоу. Действительно, мы постоянно сталкиваемся со словом «информация» — ее получают, передают и сохраняют. Узнать прогноз погоды или результат футбольного матча, содержание фильма или книги, поговорить по телефону — всегда ясно, с каким видом информации мы имеем дело. Но что такое сама информация, а главное — как ее можно измерить, никто обычно не задумывается. А между тем, информация и способы ее передачи — важная вещь, которая во многом определяет нашу жизнь, неотъемлемой частью которой стали информационные технологии. Научный редактор издания «Лаба.Медиа» Владимир Губайловский объясняет, что такое информация, как ее измерять, и почему самое сложное — это передача информации без искажений.
Читайте «Хайтек» в
Пространство случайных событий
В 1946 году американский ученый-статистик Джон Тьюки предложил название БИТ (BIT, BInary digiT — «двоичное число» — «Хайтек») — одно из главных понятий XX века. Тьюки избрал бит для обозначения одного двоичного разряда, способного принимать значение 0 или 1. Клод Шеннон в своей программной статье «Математическая теория связи» предложил измерять в битах количество информации. Но это не единственное понятие, введенное и исследованное Шенноном в его статье.
Представим себе пространство случайных событий, которое состоит из бросания одной фальшивой монеты, на обеих сторонах которой орел. Когда выпадает орел? Ясно, что всегда. Это мы знаем заранее, поскольку так устроено наше пространство. Выпадение орла — достоверное событие, то есть его вероятность равна 1. Много ли информации мы сообщим, если скажем о выпавшем орле? Нет. Количество информации в таком сообщении мы будем считать равным 0.
Теперь давайте бросать правильную монету: с одной стороны у нее орел, а с другой решка, как и положено. Выпадение орла или решки будут двумя разными событиями, из которых состоит наше пространство случайных событий. Если мы сообщим об исходе одного бросания, то это действительно будет новая информация. При выпадении орла мы сообщим 0, а при решке 1. Для того, чтобы сообщить эту информацию, нам достаточно 1 бита.
Что изменилось? В нашем пространстве событий появилась неопределенность. Нам есть, что о нем рассказать тому, кто сам монету не бросает и исхода бросания не видит. Но чтобы правильно понять наше сообщение, он должен точно знать, чем мы занимаемся, что означают 0 и 1. Наши пространства событий должны совпадать, и процесс декодирования — однозначно восстанавливать результат бросания. Если пространство событий у передающего и принимающего не совпадает или нет возможности однозначного декодирования сообщения, информация останется только шумом в канале связи.
Если независимо и одновременно бросать две монеты, то разных равновероятных результатов будет уже четыре: орел-орел, орел-решка, решка-орел и решка-решка. Чтобы передать информацию, нам понадобится уже 2 бита, и наши сообщения будут такими: 00, 01, 10 и 11. Информации стало в два раза больше. Это произошло, потому что выросла неопределенность. Если мы попытаемся угадать исход такого парного бросания, то имеем в два раза больше шансов ошибиться.
Чем больше неопределенность пространства событий, тем больше информации содержит сообщение о его состоянии.
Немного усложним наше пространство событий. Пока все события, которые случались, были равновероятными. Но в реальных пространствах далеко не все события имеют равную вероятность. Скажем, вероятность того, что увиденная нами ворона будет черной, близка к 1. Вероятность того, что первый встреченный на улице прохожий окажется мужчиной, — примерно 0,5. Но встретить на улице Москвы крокодила почти невероятно. Интуитивно мы понимаем, что сообщение о встрече с крокодилом имеет гораздо большую информационную ценность, чем о черной вороне. Чем ниже вероятность события, тем больше информации в сообщении о таком событии.
Пусть пространство событий не такое экзотическое. Мы просто стоим у окна и смотрим на проезжающие машины. Мимо проезжают автомобили четырех цветов, о которых нам необходимо сообщить. Для этого мы закодируем цвета: черный — 00, белый — 01, красный — 10, синий — 11. Чтобы сообщить о том, какой именно автомобиль проехал, нам достаточно передать 2 бита информации.
Но довольно долго наблюдая за автомобилями, замечаем, что цвет автомобилей распределен неравномерно: черных — 50% (каждый второй), белых — 25% (каждый четвертый), красных и синих — по 12,5% (каждый восьмой). Тогда можно оптимизировать передаваемую информацию.
Больше всего черных автомобилей, поэтому обозначим черный — 0 — самый короткий код, а код всех остальных пусть начинается на 1. Из оставшихся половина белые — 10, а оставшиеся цвета начинаются на 11. В заключение обозначим красный — 110, а синий — 111.
Теперь, передавая информацию о цвете автомобилей, мы можем закодировать ее плотнее.

Энтропия по Шеннону
Пусть наше пространство событий состоит из n разных событий. При бросании монеты с двумя орлами такое событие ровно одно, при бросании одной правильной монеты — 2, при бросании двух монет или наблюдении за автомобилями — 4. Каждому событию соответствует вероятность его наступления. При бросании монеты с двумя орлами событие (выпадение орла) одно и его вероятность p1 = 1. При бросании правильной монеты событий два, они равновероятны и вероятность каждого — 0,5: p1 = 0,5, p2 = 0,5. При бросании двух правильных монет событий четыре, все они равновероятны и вероятность каждого — 0,25: p1 = 0,25, p2 = 0,25, p3 = 0,25, p4 = 0,25. При наблюдении за автомобилями событий четыре, и они имеют разные вероятности: черный — 0,5, белый — 0,25, красный — 0,125, синий — 0,125: p1 = 0,5, p2 = 0,25, p3 = 0,125, p4 = 0,125.

Это не случайное совпадение. Шеннон так подобрал энтропию (меру неопределенности в пространстве событий), чтобы выполнялись три условия:
- 1Энтропия достоверного события, вероятность которого 1, равна 0.
- Энтропия двух независимых событий равна сумме энтропий этих событий.
- Энтропия максимальна, если все события равновероятны.
Все эти требования вполне соответствуют нашим представлениям о неопределенности пространства событий. Если событие одно (первый пример) — никакой неопределенности нет. Если события независимы — неопределенность суммы равна сумме неопределенностей — они просто складываются (пример с бросанием двух монет). И, наконец, если все события равновероятны, то степень неопределенности системы максимальна. Как в случае с бросанием двух монет, все четыре события равновероятны и энтропия равна 2, она больше, чем в случае с автомобилями, когда событий тоже четыре, но они имеют разную вероятность — в этом случае энтропия 1,75.
Клод Элвуд Шеннон — американский инженер, криптоаналитик и математик. Считается «отцом информационного века». Основатель теории информации, нашедшей применение в современных высокотехнологических системах связи. Предоставил фундаментальные понятия, идеи и их математические формулировки, которые в настоящее время формируют основу для современных коммуникационных технологий.
В 1948 году предложил использовать слово «бит» для обозначения наименьшей единицы информации. Он также продемонстрировал, что введенная им энтропия эквивалентна мере неопределенности информации в передаваемом сообщении. Статьи Шеннона «Математическая теория связи» и «Теория связи в секретных системах» считаются основополагающими для теории информации и криптографии.
Во время Второй мировой войны Шеннон в Bell Laboratories занимался разработкой криптографических систем, позже это помогло ему открыть методы кодирования с коррекцией ошибок.
Шеннон внес ключевой вклад в теорию вероятностных схем, теорию игр, теорию автоматов и теорию систем управления — области наук, входящие в понятие «кибернетика».
Кодирование
И бросаемые монеты, и проезжающие автомобили не похожи на цифры 0 и 1. Чтобы сообщить о событиях, происходящих в пространствах, нужно придумать способ описать эти события. Это описание называется кодированием.
Кодировать сообщения можно бесконечным числом разных способов. Но Шеннон показал, что самый короткий код не может быть меньше в битах, чем энтропия.
Именно поэтому энтропия сообщения и есть мера информации в сообщении. Поскольку во всех рассмотренных случаях количество бит при кодировании равно энтропии, — значит кодирование прошло оптимально. Короче закодировать сообщения о событиях в наших пространствах уже нельзя.
При оптимальном кодировании нельзя потерять или исказить в сообщении ни одного передаваемого бита. Если хоть один бит потеряется, то исказится информация. А ведь все реальные каналы связи не дают 100-процентной уверенности, что все биты сообщения дойдут до получателя неискаженными.
Для устранения этой проблемы необходимо сделать код не оптимальным, а избыточным. Например, передавать вместе с сообщением его контрольную сумму — специальным образом вычисленное значение, получаемое при преобразовании кода сообщения, и которое можно проверить, пересчитав при получении сообщения. Если переданная контрольная сумма совпадет с вычисленной, вероятность того, что передача прошла без ошибок, будет довольно высока. А если контрольная сумма не совпадет, то необходимо запросить повторную передачу. Примерно так работает сегодня большинство каналов связи, например, при передаче пакетов информации по интернету.
Сообщения на естественном языке
Рассмотрим пространство событий, которое состоит из сообщений на естественном языке. Это частный случай, но один из самых важных. Событиями здесь будут передаваемые символы (буквы фиксированного алфавита). Эти символы встречаются в языке с разной вероятностью.
Самым частотным символом (то есть таким, который чаще всего встречается во всех текстах, написанных на русском языке) является пробел: из тысячи символов в среднем пробел встречается 175 раз. Вторым по частоте является символ «о» — 90, далее следуют другие гласные: «е» (или «ё» — мы их различать не будем) — 72, «а» — 62, «и» — 62, и только дальше встречается первый согласный «т» — 53. А самый редкий «ф» — этот символ встречается всего два раза на тысячу знаков.
Будем использовать 31-буквенный алфавит русского языка (в нем не отличаются «е» и «ё», а также «ъ» и «ь»). Если бы все буквы встречались в языке с одинаковой вероятностью, то энтропия на символ была бы Н = 5 бит, но если мы учтем реальные частоты символов, то энтропия окажется меньше: Н = 4,35 бит. (Это почти в два раза меньше, чем при традиционном кодировании, когда символ передается как байт — 8 бит).
Но энтропия символа в языке еще ниже. Вероятность появления следующего символа не полностью предопределена средней частотой символа во всех текстах. То, какой символ последует, зависит от символов уже переданных. Например, в современном русском языке после символа «ъ» не может следовать символ согласного звука. После двух подряд гласных «е» третий гласный «е» следует крайне редко, разве только в слове «длинношеее». То есть следующий символ в некоторой степени предопределен. Если мы учтем такую предопределенность следующего символа, неопределенность (то есть информация) следующего символа будет еще меньше, чем 4,35. По некоторым оценкам, следующий символ в русском языке предопределен структурой языка более чем на 50%, то есть при оптимальном кодировании всю информацию можно передать, вычеркнув половину букв из сообщения.
Другое дело, что не всякую букву можно безболезненно вычеркнуть. Высокочастотную «о» (и вообще гласные), например, вычеркнуть легко, а вот редкие «ф» или «э» — довольно проблематично.
Естественный язык, на котором мы общаемся друг с другом, высоко избыточен, а потому надежен, если мы что-то недослышали — нестрашно, информация все равно будет передана.
Но пока Шеннон не ввел меру информации, мы не могли понять и того, что язык избыточен, и до какой степени мы может сжимать сообщения (и почему текстовые файлы так хорошо сжимаются архиватором).
Избыточность естественного языка
В статье «О том, как мы ворпсиманием теcкт» (название звучит именно так!) был взят фрагмент романа Ивана Тургенева «Дворянское гнездо» и подвергнут некоторому преобразованию: из фрагмента было вычеркнуто 34% букв, но не случайных. Были оставлены первые и последние буквы в словах, вычеркивались только гласные, причем не все. Целью было не просто получить возможность восстановить всю информацию по преобразованному тексту, но и добиться того, чтобы человек, читающий этот текст, не испытывал особых трудностей из-за пропусков букв.

Почему сравнительно легко читать этот испорченный текст? В нем действительно содержится необходимая информация для восстановления целых слов. Носитель русского языка располагает определенным набором событий (слов и целых предложений), которые он использует при распознавании. Кроме того, в распоряжении носителя еще и стандартные языковые конструкции, которые помогают ему восстанавливать информацию. Например, «Она бла блее чвствтльна» — с высокой вероятностью можно прочесть как «Она была более чувствительна». Но взятая отдельно фраза «Она бла блее», скорее, будет восстановлена как «Она была белее». Поскольку мы в повседневном общении имеем дело с каналами, в которых есть шум и помехи, то довольно хорошо умеем восстанавливать информацию, но только ту, которую мы уже знаем заранее. Например, фраза «Чрты ее не бли лшны приятнсти, хтя нмнго рспхли и спллсь» хорошо читается за исключением последнего слова «спллсь» — «сплылись». Этого слова нет в современном лексиконе. При быстром чтении слово «спллсь» читается скорее как «слиплись», при медленном — просто ставит в тупик.
Оцифровка сигнала
Звук, или акустические колебания — это синусоида. Это видно, например, на экране звукового редактора. Чтобы точно передать звук, понадобится бесконечное количество значений — вся синусоида. Это возможно при аналоговом соединении. Он поет — вы слушаете, контакт не прерывается, пока длится песня.
При цифровой связи по каналу мы можем передать только конечное количество значений. Значит ли это, что звук нельзя передать точно? Оказывается, нет.
Разные звуки — это по-разному модулированная синусоида. Мы передаем только дискретные значения (частоты и амплитуды), а саму синусоиду передавать не надо — ее может породить принимающий прибор. Он порождает синусоиду, и на нее накладывается модуляция, созданная по значениям, переданным по каналу связи. Существуют точные принципы, какие именно дискретные значения надо передавать, чтобы звук на входе в канал связи совпадал со звуком на выходе, где эти значения накладываются на некоторую стандартную синусоиду (об этом как раз теорема Котельникова).
Теорема Котельникова (в англоязычной литературе — теорема Найквиста — Шеннона, теорема отсчетов) — фундаментальное утверждение в области цифровой обработки сигналов, связывающее непрерывные и дискретные сигналы и гласящее, что «любую функцию F(t), состоящую из частот от 0 до f1, можно непрерывно передавать с любой точностью при помощи чисел, следующих друг за другом через 1/(2*f1) секунд.
Помехоустойчивое кодирование. Коды Хэмминга
Если по ненадежному каналу передать закодированный текст Ивана Тургенева, пусть и с некоторым количеством ошибок, то получится вполне осмысленный текст. Но вот если нам нужно передать все с точностью до бита, задача окажется нерешенной: мы не знаем, какие биты ошибочны, потому что ошибка случайна. Даже контрольная сумма не всегда спасает.
Именно поэтому сегодня при передаче данных по сетям стремятся не столько к оптимальному кодированию, при котором в канал можно затолкать максимальное количество информации, сколько к такому кодированию (заведомо избыточному) при котором можно восстановить ошибки — так, примерно, как мы при чтении восстанавливали слова во фрагменте Ивана Тургенева.
Существуют специальные помехоустойчивые коды, которые позволяют восстанавливать информацию после сбоя. Один из них — код Хэмминга. Допустим, весь наш язык состоит из трех слов: 111000, 001110, 100011. Эти слова знают и источник сообщения, и приемник. И мы знаем, что в канале связи случаются ошибки, но при передаче одного слова искажается не более одного бита информации.
Предположим, мы сначала передаем слово 111000. В результате не более чем одной ошибки (ошибки мы выделили) оно может превратиться в одно из слов:
1) 111000, 011000, 101000, 110000, 111100, 111010, 111001.
При передаче слова 001110 может получиться любое из слов:
2) 001110, 101110, 011110, 000110, 001010, 001100, 001111.
Наконец, для 100011 у нас может получиться на приеме:
3) 100011, 000011, 110011, 101011, 100111, 100001, 100010.
Заметим, что все три списка попарно не пересекаются. Иными словами, если на другом конце канала связи появляется любое слово из списка 1, получатель точно знает, что ему передавали именно слово 111000, а если появляется любое слово из списка 2 — слово 001110, а из списка 3 — слово 100011. В этом случае говорят, что наш код исправил одну ошибку.
Исправление произошло за счет двух факторов. Во-первых, получатель знает весь «словарь», то есть пространство событий получателя сообщения совпадает с пространством того, кто сообщение передал. Когда код передавался всего с одной ошибкой, выходило слово, которого в словаре не было.
Во-вторых, слова в словаре были подобраны особенным образом. Даже при возникновении ошибки получатель не мог перепутать одно слово с другим. Например, если словарь состоит из слов «дочка», «точка», «кочка», и при передаче получалось «вочка», то получатель, зная, что такого слова не бывает, исправить ошибку не смог бы — любое из трех слов может оказаться правильным. Если же в словарь входят «точка», «галка», «ветка» и нам известно, что допускается не больше одной ошибки, то «вочка» это заведомо «точка», а не «галка». В кодах, исправляющих ошибки, слова выбираются именно так, чтобы они были «узнаваемы» даже после ошибки. Разница лишь в том, что в кодовом «алфавите» всего две буквы — ноль и единица.
Избыточность такого кодирования очень велика, а количество слов, которые мы можем таким образом передать, сравнительно невелико. Нам ведь надо исключать из словаря любое слово, которое может при ошибке совпасть с целым списком, соответствующим передаваемым словам (например, в словаре не может быть слов «дочка» и «точка»). Но точная передача сообщения настолько важна, что на исследование помехоустойчивых кодов тратятся большие силы.
Сенсация
Понятия энтропии (или неопределенности и непредсказуемости) сообщения и избыточности (или предопределенности и предсказуемости) очень естественно соответствуют нашим интуитивным представлениям о мере информации. Чем более непредсказуемо сообщение (тем больше его энтропия, потому что меньше вероятность), — тем больше информации оно несет. Сенсация (например, встреча с крокодилом на Тверской) — редкое событие, его предсказуемость очень мала, и потому велика информационная стоимость. Часто информацией называют новости — сообщения о только что произошедших событиях, о которых мы еще ничего не знаем. Но если о случившемся нам расскажут второй и третий раз примерно теми же словами, избыточность сообщения будет велика, его непредсказуемость упадет до нуля, и мы просто не станем слушать, отмахиваясь от говорящего со словами «Знаю, знаю». Поэтому СМИ так стараются быть первыми. Вот это соответствие интуитивному чувству новизны, которое рождает действительно неожиданное известие, и сыграло главную роль в том, что статья Шеннона, совершенно не рассчитанная на массового читателя, стала сенсацией, которую подхватила пресса, которую приняли как универсальный ключ к познанию природы ученые самых разных специальностей — от лингвистов и литературоведов до биологов.
Но понятие информации по Шеннону — строгая математическая теория, и ее применение за пределами теории связи очень ненадежно. Зато в самой теории связи она играет центральную роль.
Семантическая информация
Шеннон, введя понятие энтропии как меры информации, получил возможность работать с информацией — в первую очередь, ее измерять и оценивать такие характеристики, как пропускная способность каналов или оптимальность кодирования. Но главным допущением, которое позволило Шеннону успешно оперировать с информацией, было предположение, что порождение информации — это случайный процесс, который можно успешно описать в терминах теории вероятности. Если процесс неслучайный, то есть он подчиняется закономерностям (к тому же не всегда ясным, как это происходит в естественном языке), то к нему рассуждения Шеннона неприменимы. Все, что говорит Шеннон, никак не связано с осмысленностью информации.
Пока мы говорим о символах (или буквах алфавита), мы вполне можем рассуждать в терминах случайных событий, но как только мы перейдем к словам языка, ситуация резко изменится. Речь — это процесс, особым образом организованный, и здесь структура сообщения не менее важна, чем символы, которыми она передается.
Еще недавно казалось, что мы ничего не можем сделать, чтобы хоть как-то приблизиться к измерению осмысленности текста, но в последние годы ситуация начала меняться. И связано это прежде всего с применением искусственных нейронных сетей к задачам машинного перевода, автоматического реферирования текстов, извлечению информации из текстов, генерированию отчетов на естественном языке. Во всех этих задачах происходит преобразование, кодирование и декодирование осмысленной информации, заключенной в естественном языке. И постепенно складывается представление об информационных потерях при таких преобразованиях, а значит — о мере осмысленной информации. Но на сегодняшний день той четкости и точности, которую имеет шенноновская теория информации, в этих трудных задачах еще нет.
