На уроке рассматривается работа с файлами в Питон: текстовые и бинарные файлы, запись в файл и чтение из файла
Содержание:
- Файлы в Python
- Работа с текстовыми файлами в Питон
В целом различают два типа файлов (и работы с ними):
- текстовые файлы со строками неопределенной длины;
- двоичные (бинарные) файлы (хранящие коды таких данных, как, например, рисунки, звуки, видеофильмы);
Этапы работы с файлом:
- открытие файла;
- режим чтения,
- режим записи,
- режим добавления данных.
- работа с файлом;
- закрытие файла.
В python открыть файл можно с помощью функции open с двумя параметрами:
- имя файла (путь к файлу);
- режим открытия файла:
- «r» – открыть на чтение,
- «w» – открыть на запись (если файл существует, его содержимое удаляется),
- «a» – открыть на добавление.
В коде это выглядит следующим образом:
Fin = open ( "input.txt" ) Fout = open ( "output.txt", "w" ) # работа с файлами Fout.close() Fin.close()
Работа с текстовыми файлами в Питон
- Чтение из файла происходит двумя способами:
- построчно с помощью метода readline:
- метод read читает данные до конца файла:
- Для получения отдельных слов строки используется метод split, который по пробелам разбивает строку на составляющие компоненты:
- способ:
- способ:
- В python метод write служит для записи строки в файл:
- Запись в файл можно осуществлять, используя определенный
шаблон вывода. Например: - Аналогом «паскалевского» eof (если конец файла) является обычный способ использования цикла while или с помощью добавления строк в список:
- подходящий способ для Python:
файл input.txt:
1
2
3
str1 = Fin.readline() # str1 = 1 str2 = Fin.readline() # str2 = 2
файл input.txt:
1
2
3
str = Fin.read() ''' str = 1 2 3 '''
str = Fin.readline().split() print(str[0]) print(str[1])
Пример:
В файле записаны два числа. Необходимо суммировать их.
файл input.txt:
12 17
ответ:
27
✍ Решение:
Fin = open ( "D:/input.txt" ) str = Fin.readline().split() x, y = int(str[0]), int(str[1]) print(x+y)
... x, y = [int(i) for i in s] print(x+y)
* Функция int преобразует строковое значение в числовое.
Fout = open ( "D:/out.txt","w" ) Fout.write ("hello")
Fout.write ( "{:d} + {:d} = {:d}n".format(x, y, x+y) )
В таком случае вместо шаблонов {:d} последовательно подставляются значения параметров метода format (сначала x, затем y, затем x+y).
while True: str = Fin.readline() if not str: break
Fin = open ( "input.txt" ) lst = Fin.readlines() for str in lst: print ( str, end = "" ) Fin.close()
for str in open ( "input.txt" ): print ( str, end = "" )
Задание Python 9_1:
Считать из файла input.txt 10 чисел (числа записаны через пробел). Затем записать их произведение в файл output.txt.
Рассмотрим пример работы с массивами.
Пример:
Считать из текстового файла числа и записать их в другой текстовый файл в отсортированном виде.
✍ Решение:
- Поскольку в Python работа с массивом осуществляется с помощью структуры список, то количество элементов в массиве заранее определять не нужно.
- Считывание из файла чисел:
- Сортировка.
- Запись отсортированного массива (списка) в файл:
- Или другой вариант записи в файл:
lst = [] while True: st = Fin.readline() if not st: break lst.append (int(st))
Fout = open ( "output.txt", "w" ) Fout.write (str(lst)) # функция str преобразует числовое значение в символьное Fout.close()
for x in lst: Fout.write (str(x)+"n") # запись с каждой строки нового числа
Задание Python 9_2:
В файле записаны в целые числа. Найти максимальное и минимальное число и записать в другой файл.
Задание Python 9_3:
В файле записаны в столбик целые числа. Отсортировать их по возрастанию суммы цифр и записать в другой файл.
Рассмотрим на примере обработку строковых значений.
Пример:
В файл записаны сведения о сотрудниках некоторой фирмы в виде:
Иванов 45 бухгалтер
Необходимо записать в текстовый файл сведения о сотрудниках, возраст которых меньше 40.
✍ Решение:
- Поскольку сведения записаны в определенном формате, т.е. вторым по счету словом всегда будет возраст, то будем использовать метод split, который разделит слова по пробелам. Под номером 1 в списке будет ити возраст:
- Более короткая запись будет выглядеть так:
- Программа выглядит так:
- Но лучше в стиле Python:
st = Fin.readline() data = st.split() stAge = data[1] intAge = int(stAge)
st = Fin.readline() intAge = int(st.split()[1])
while True: st = Fin.readline() if not s: break intAge = int (st.split()[1])
for st in open ( "input.txt" ): intAge = int (st.split()[1]) if intAge < 40: Fout.write (st)
Задание Python 9_4:
В файл записаны сведения о детях детского сада:
Иванов иван 5 лет
Необходимо записать в текстовый файл самого старшего и самого младшего.
Ефим Карпов
Профи
(622),
на голосовании
10 лет назад
Голосование за лучший ответ
Clever Bot
Просветленный
(31853)
10 лет назад
через поиск
Николай
Просветленный
(35577)
10 лет назад
в какой операционной системе?
find /I input.txt c:
Katze von Ulthar
Оракул
(60413)
10 лет назад
нажми winkey+f
CHIZZ
Мастер
(1566)
10 лет назад
Есть Отличная программа для поиска “Everything”.
Похожие вопросы
1. Ввод из файла
Пусть нужно считать файл input.txt. Будем считать, что файл input.txt лежит в той же папке, что и наша программа. Напишите в ней такой код:
fin = open('input.txt', 'r')
a = fin.readlines()
После этого в списке a окажется список из строк файла. Например, если файл input.txtбыл
abcd efgh
то команда print(a) выведет ['abcdn', 'efghn']. Последний символ в каждой строке — 'n' — это один специальный символ конца строки. Обратите внимание: это не два символа, а один.
Можно удалить эти ненужные символы с помощью метода strip(). В этом случае считывание может выглядеть так:
fin = open('input.txt', 'r')
a = [line.strip() for line in fin.readlines()]
2. Вывод в файл
Для вывода в файл нужно открыть его и связать объект файла с каким-нибудь именем.
fout = open('output.txt', 'w') # 'w' - это режим "запись" ("write")
После этого можно осуществлять вывод обычной командой print(), указывая при этом объект файла в качестве параметра file.
print("Hello, world!", file=fout)
По окончании работы с файлом необходимо закрыть его. В противном случае файл может даже не появиться на жёстком диске.
fout.close()
3. Ввод-вывод в ситуации, когда количество строк неизвестно
Пусть нужно считать входной файл, причём количество строк в нём заранее неизвестно. Выполните такой код:
from sys import stdin a = stdin.readlines()
После этого в списке a окажется список из строк входного файла. Например, если входной файл был
abcd efgh
то команда print(a) выведет ['abcdn', 'efghn']. Последний символ в каждой строке — 'n' — это один специальный символ конца строки. Обратите внимание: это не два символа, а один.
К сожалению, протестировать на правильность программы с таким вводом-вывом из среды Wing невозможно. Дело в том, что в консоли Винга нельзя сказать, что входной файл закончился. Нет возможности ввести символ конца файла. Соответственно, метод sys.stdin.readlines() никогда не завершится, поскольку будет ждать всё новые и новые строки из входа. Чтобы протестировать ваш код на системе Windows, проделайте следующие действия:
- Откройте консоль: Пуск → Выполнить →
cmd - С помощью команды
cdдойдите до папки с вашей программой. При этом не стесняйтесь обильно нажимать клавишу Tab. - Введите имя вашей программы в консоли и нажмите Enter. При этом ваша программа запустится
- Введите в консоль входные данные для программы.
- Введите конец входного файла, нажав сочетание Ctrl+Z. Нажмите Enter.
- Насладитесь выводом вашей программы.
На олимпиадах по программированию для ввода данных в программу используют, как правило, файл с названием input.txt(содержит входные данные), а для вывода используется output.txt(содержит все выходные данные). В данной статье мы разберем, как нам брать данные из файла input.txt и записывать в output.txt.

Из input.txt в output.txt
Может показаться, что это неудобно, и проще всего организовать ввод данных через консоль, попросив об этом пользователя примерно таким сообщением «Введите значение N:». Однако, использование файлов input.txt и output.txt позволяет автоматизировать проверку ответа участника олимпиады, что в разы ускоряет подведение итогов.
Если Вы любите решать олимпиадные задачи, то Вам просто необходимо иметь шаблон такой программы, чтобы каждый раз не реализовывать её. Ежели Вы впервые столкнулись с этим, то мы сейчас разберем, как это всё делается.
Мы уже говорили, как считывать данные из файла и записывать данные в файл посредством функций стандартной библиотеки <iostream> языка программирования C++. Давайте же применим наши знания в решении данной задачи.
Организуем ввод всех данных из файла input.txt в наши переменные и массивы. Я покажу, как считать разные типы данных: числа, строки, ряды чисел(для массива).
Итак, для начала создадим файл input.txt, откроем с помощью текстового редактора и заполним его различными значениями. Я разместил пару чисел на одной строке, одно число на следующей строке, 10 чисел еще на одной строке и строку текста на последней. Файл input.txt содержит следующее:
15 20 10 2 3 4 5 6 7 8 19 900001 123 Nicknixer.ru
Теперь напишем программу, которая будет брать все эти значения и заносить в нужные нам переменные.
Допустим, мне нужно занести первые два числа на первой строке(15 и 20) в переменные a и b соответственно.
Значение числа на второй строке(10) в переменную N, и при этом, договоримся, что на второй строке число указывает на количество чисел, размещенных на третей строке. То есть на третей строке у нас N чисел через пробел, их мы будем заносить в массив.
И, наконец, на четвёртой строке файла у нас расположено слово, его мы тоже занесем в переменную.
Теперь напишем программу, которая считает это всё и поместит в переменные, с которыми мы сможем работать. Я буду размещать код поэтапно, чтобы было понятно, что и где добавилось. Для начала Вы можете узнать как считывать из файла в C++.
Подключим необходимые заголовки
#include <fstream> #include <iostream> #include <cstring>
Определим переменные
int a,b,N;
Откроем файл input.txt для чтения
ifstream fin("input.txt");
Считаем первые два числа из файла input.txt в переменные a и b
fin >> a; fin >> b;
Разделителем чисел в файле служат пробелы. Поэтому просто выводим поток из fin прямо в переменные по порядку.
Считаем число со второй строчки в переменную N
fin >> N;
Указатель положения в файле сместился автоматически на следующую строчку и считал число.
То есть числа можно разделять пробелами или переносами строк, и просто выводить информацию по порядку из файла в соответствующие переменные.
Теперь определяем массив с размером N и вносим в него следующие 10 чисел из файла
int mass[N];
for(int i=0;i<N;++i)
{
fin >> mass[i];
}
В результате массив mass[] заполнился следующими 10-ю числами из файла(числами с третьей строки).
И теперь считаем следующую за всем этим слово
string msg; fin >> msg;
Теперь выведем значения всех переменных в консоль
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "N = " << N << endl;
cout << "mass = ";
for(int i=0;i<N;++i)
{
cout << mass[i] << " ";
}
cout << endl;
cout << "msg = " << msg << endl;
Компилируем и запускаем

Полученные значения из файла
Весь листинг написанной нами программы для чтения из файла и записи в переменные с последующим выводом их значений:
#include <fstream>
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
int a,b,N;
ifstream fin("input.txt");
fin >> a;
fin >> b;
fin >> N;
int mass[N];
for(int i=0;i<N;++i)
{
fin >> mass[i];
}
string msg;
fin >> msg;
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "N = " << N << endl;
cout << "mass = ";
for(int i=0;i<N;++i)
{
cout << mass[i] << " ";
}
cout << endl;
cout << "msg = " << msg << endl;
fin.close();
return 0;
}
Итак, с вводом данных из файла в переменные мы разобрались. Идем дальше.
Запись выходных данных в файл output.txt
Записывание данных в файл очень похоже на обычный вывод данных в консоль. Вы передаете в поток различные данные, как делаете это с потоком cout. Попробуем записать данные в файл output.txt, такие как число и строка. Разместим их на разных строках.
Осуществляется это аналогично, как и со считыванием.
Подключаем необходимые заголовки.
#include <fstream> #include <iostream> #include <cstring>
Определяем переменные и заносим в них наши значения, которые мы запишем в файл.
int a; string msg; a = 150; msg = "Our string";
Откроем файл output.txt для записи.
ofstream fin("output.txt");
Теперь, аналогично с обычным выводом в консоль, передаем в поток файла наши данные.
fin << a; fin << endl; // Переход на следующую строку fin << msg;
Закрываем файл.
fin.close();
Теперь компилируем и запускаем программу, после чего открываем файл output.txt с помощью текстового редактора и видим записанные в него значения наших переменных, размещенных на разных строках.

Содержимое файла output.txt
Весь код программы для записи переменных в файл:
#include <fstream>
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
int a;
string msg;
ofstream fin("output.txt");
a = 150;
msg = "Our string";
fin << a;
fin << endl;
fin << msg;
fin.close();
return 0;
}
Вот мы и разобрались с выводом данных в файл output.txt.
Шаблон считывания данных из input.txt и записи в файл output.txt
Теперь создадим шаблон программы для использования в будущих решениях олимпиадных задач, чтобы каждый раз не писать один и тот же код для получения данных из input.txt и записи в output.txt.
Синтезируем две наши написанные программы и получим следующий код.
#include <fstream>
using namespace std;
int main()
{
ifstream fin("input.txt");
ofstream fout("output.txt");
// Здесь размещаем алгоритмы
fin.close();
fout.close();
return 0;
}
Вот и получился шаблон. Проверим его.
Допустим, нам нужно взять первое число из файла input.txt и записать его в файл output.txt.
Для этого просто определяем числовую переменную, считываем данные из потока fin, и выводим значение переменной в поток fout. Всё просто, вот так:
int temp; fin >> temp; fout << temp;
В файле input.txt у меня записано число 15, после запуска программы в файле output.txt появилось число 15. Всё работает, всё просто.
Код программы:
#include <fstream>
using namespace std;
int main()
{
ifstream fin("input.txt");
ofstream fout("output.txt");
int temp; // Определяем переменную
fin >> temp; // Получаем данные из файла input.txt
fout << temp; // Записываем данные в файл out.put.txt
fin.close();
fout.close();
return 0;
}
Итоги
Итак, мы научились получать данные из файла и записывать их в другой файл. Создали шаблон для будущих решений олимпиадных задач. Кстати, если вы решаете задачи по программированию на языке C++, то загляните в раздел с решениями задач. Если у Вас остались вопросы, то задавайте их в комментариях.
Материалы по курсу «Основы программирования»
Основные понятия: файлы, пути к файлам
Файл — именованная область в долговременной памяти (на диске). Правила,
определяющие допустимые имена файлов, зависят от используемой файловой
системы.
Если имя файла включает как минимум один знак ., то часть имени
от последнего знака . и до конца называется расширением. Как правило,
расширение указывает тип содержимого файла: .jpg — картинка в формате JPEG,
.txt — текстовый файл, .exe — исполнимый файл ОС Windows, .py — исходный
текст на языке Python и т.д.
Часто интерфейс операционной системы скрывает расширения файлов, т.е. файлы
с именами input.txt и program.py будут отображаться как input
и program. Распространённая ошибка — забыть о том, что расширения скрываются
и добавить «лишнее» расширение, создав, например, текстовый файл
input.txt.txt — в папке он будет показываться как input.txt,
т.к. расширение будет скрыто. Но при этом программа на Python не сможет найти
файл input.txt, т.к. реально его в папке нет — есть файл с именем
input.txt.txt.
Файловая система — способ хранения данных в долговременной памяти,
использующий именованные файлы.
Папка (каталог, «директория») — именованная группа файлов. Как правило,
файл находится только в одной папке. Некоторые файловые системы позволяют
одному файлу находиться в нескольких папках одновременно, но это редкая
и специфическая практика.
Папки тоже являются файлами (специального вида) и могут находиться внутри
других папок. Если папка A находится внутри папки B, то папка B для
папки A считается родительской. Корневая папка (корневой каталог) —
папка, у которой нет родительской.
Путь к файлу — строка, описывающая расположение файла в файловой системе.
У запущенной программы одна из папок файловой системы является текущей —
это своего рода неявная глобальная переменная.
Пути к файлам могут быть относительными и абсолютными. Относительный путь
к файлу указывается, начиная с текущей папки, абсолютный путь к файлу —
начиная с корневой папки.
В каждой папке (кроме корневой) неявно присутствуют две имени файла — ссылка
на текущую папку (записывается как одинарная точка .) и ссылка на родительскую
папку (записывается как две точки: ..). Они используются, чтобы
в относительном пути ссылаться на текущую папку или на родительскую.
Путь к файлу включает в себя перечисление имён папок, в которые нужно перейти
относительно текущей или корневой папки, чтобы добраться до файла плюс в конце
само имя файла.
Если файл находится в текущей папке, то относительный путь к нему состоит
из одного имени файла.
Правила записи пути к файлу зависят от операционной системы.
Особенности путей к файлам на Windows
На Windows компоненты пути разделяются знаками прямой / и обратной
косой черты. Причём в интерфейсе (командная строка, элементы графического
интерфейса) обратная косая черта работает всегда, прямая / не всегда
(из соображений совместимости по историческим причинам).
Относительный путь к файлу — перечисление имён папок с именем целевого
файла в конце, разделителем служат знаки / или . Текущих папок
на Windows может быть несколько, у каждой буквы диска — своя текущая папка,
поэтому относительный путь на Windows может начинаться с буквы диска
и двоеточия.
Абсолютный путь к файлу начинается с разделителя папок (т.е. / или ),
который может предваряться буквой диска. Если буква диска не указана,
то подразумевается текущая буква диска.
Абсолютные пути к файлу:
• D:MazdaywikDocumentsПреподаваниеL4b-02 Файловый ввод-вывод.md
• D:/Mazdaywik/Documents/Преподавание/L4/b-02 Файловый ввод-вывод.md
• MazdaywikDocumentsПреподаваниеL4b-02 Файловый ввод-вывод.md
• C:Program FilesFar ManagerFar.exe
• C:WindowsSystem32notepad.exe
Относительные пути:
• b-02 Файловый ввод-вывод.md
• D:b-02 Файловый ввод-вывод.md
• C:Far.exe
• 2020-2021rk1.pdf
• ..curricula.ref
• ../curricula.ref
Первые три примера — файл, который я сейчас пишу, а вы сейчас читаете.
Последние два примера означают переход в родительскую папку. Абсолютный путь
для него выглядит как
• D:/Mazdaywik/Documents/Преподавание/curricula.ref
(т.к. текущая папка — D:MazdaywikDocumentsПреподаваниеL4).
В именах файлов на Windows запрещены знаки ", , /, <, >, :, *,
?. Некоторые имена файлов зарезрвированы — nul, prn, con, com1,
lpt1, aux и ряд других — нельзя создать файл с этим именем и любым
расширением (например, nul.txt, con.jpg, aux.py и т.д.)
Имена файлов не чувствительны к регистру — заглавные и строчные буквы считаются
одинаковыми. Файл с именем штукатурка.txt можно открыть, используя имена
• Штукатурка.txt
• ШТУКАТУРКА.TXT
• ШтукаТурка.txt
• штукаТУРКА.tXt
• ШтУкАтУрКа.TxT
Особенности путей к файлам на unix-подобных ОС (Linux и macOS)
Здесь всё проще. Разделителем компонентов в пути является только знак /.
Корень у файловой системы один, букв диска нету. Вместо этого для подключаемых
устройств (например, флешек) создаются отдельные папки, внутри которых
отображается содержимое устройства.
Примеры путей к файлам:
Абсолютные пути:
• /usr/bin/python3
• /home/username/Documents/Таблица.docx
• /media/My Flash Drive/Music/Моргенштерн.mp3
Относительные пути:
• Documents/Таблица.docx
• ../Pictures/facepalm.jpg
На Linux в именах файлов допустимы любые знаки, кроме знака / (т.к. он
зарезервирован для разделителя путей), в отличие от Windows, зарезервированных
имён нет (кроме . — ссылки на текущую папку и .. — ссылка на родительскую).
На Linux имена файлов учитывают регистр символов — большие и маленькие буквы
считаются разными. Имена файлов hello.txt и HELLO.TXT — это имена двух
разных файлов.
На macOS регистр имён файлов, как и на Windows, не учитывается.
Текстовый файл — файл, хранящий в себе последовательность текстовых строк.
Строки в текстовом файле разделяются знаками перевода строки n. Символы,
содержащиеся в строках, представляются байтами или последовательностями
байтов при помощи так называемых кодировок — наборов правил представления
символов в виде байтов.
Однобайтовые кодировки (вроде Windows-1251 для кириллицы) представляют каждый
символ в виде одного байта, поэтому поддерживают только небольшой набор символов
(не более 256 включая управляющие символы). Например, кодировка Windows-1251
для кириллицы поддерживает только кириллические и латинские буквы, цифры, набор
основных знаков пунктуации и математических знаков.
Многобайтные кодировки (UTF-8, UTF-16, UTF-32, некоторые кодировки для азиатских
языков с иероглифами) сопоставляют одному символу несколько байтов, позволяют
хранить гораздо больший набор символов. В частности, кодировка UTF-8
представляет все символы стандарта UNICODE, в частности, буквы алфавитов
большинства языков (включая иероглифы, деванагари и прочее), разнообразные
знаки пунктуации и математические знаки, эмодзи и т.д. В UTF-8 латинские буквы,
цифры и основные знаки пунктуации кодируются 1 байтом, кириллические, греческие
буквы, иврит и некоторые другие алфавиты — 2 байтами, иероглифы и эмодзи —
3 или 4 байта.
Python поддерживает работу с символами стандарта UNICODE.
Работа с файлами в Python
Для того, чтобы взаимодействовать с файлом, его нужно сначала открыть —
создать объект файла, через который можно с ним взаимодействовать (читать
или писать).
После работы с файлом, его нужно обязательно закрыть — сообщить операционной
системе, что мы с ним больше не работаем.
Несколько программ могут одновременно открыть файл для чтения и читать его.
Но если одна из программ открыла файл для записи, то другие программы, как
правило, не могут этот файл открыть, как на чтение, так и на запись (детали
поведения зависят от операционной системы).
На Windows, в частности, если файл открыт в программе, то его нельзя удалить —
получим сообщение о том, что файл занят. Если открыт файл на флешке,
то Windows не даст эту флешку безопасно извлечь.
Максимально число одновременно открытых файлов ограничено, количество зависит
от настроек операционной системы (как-то я делал опыт, на Windows не удалось
открыть более 4000 файлов одновременно).
Запись в файлы буферизуется — данные, которые записываются в файл, сначала
записываются в область оперативной памяти, т.н. «буфер», когда «буфер»
заполняется, выполняется реальна запись на диск. Буфер сбрасывается при закрытии
файла.
По этим причинам файл нужно не забывать закрывать.
Открытие файлов
Файл открывается при помощи встроенной функции open(). Синтаксис:
open(‹путь-к-файлу›, ‹режим›, encoding=‹кодировка›)
- Первый параметр (обязательный) — путь к файлу (строка).
- Второй параметр — режим. Режим может быть
r(read) — чтение текстового файла,w(write) — перезапись текстового файла,a(append) — дозапись в конец текстового файла,rb,wb,ab(binary) — чтение, перезапись или дозапись двоичного
файла.- Если режим файла не указан, то подразумевается
r.
- Параметр
encodingзадаёт кодировку файла, используется для текстовых
файлов. Рекомендуется всегда указывать кодировку'utf-8'. Кодировку
можно не указывать, если в файл пишутся только символы с кодами меньше
127 (латинские буквы, цифры, основные знаки препинания)
Примеры:
# Текстовый файл открыт для чтения
f1 = open('file1.txt', 'r', encoding='utf-8')
# Тоже самое, режим 'r' подразумевается
f2 = open('file1.txt', encoding='utf-8')
# Здесь будет использована кодировка по умолчанию
# (1251 на Windows, UTF-8 на Linux и macOS)
f3 = open('file1.txt')
# Текстовый файл открыт для перезаписи
f4 = open('file2.txt', 'w', encoding='utf-8')
# Текстовый файл открыт для дозаписи в конец
f5 = open('file3.txt', 'a', encoding='utf-8')
# Двоичный файл открыт для чтения
f6 = open('picture.jpg', 'rb')
# Закрытие всех файлов
f1.close()
f2.close()
f3.close()
f4.close()
f5.close()
f6.close()
Файл закрывается при помощи вызова метода .close(). Python может сам
закрывать файлы, но не всегда, поэтому .close() лучше вызывать явно.
Чтение файлов
Мы будем рассматривать только чтение текстовых файлов.
Для чтения файлов используются следующие методы:
.read(count)— прочитатьcountсимволов из файла,.read()— прочитать всё содержимое файла от текущей позиции до конца,.readline()— прочитать очередную строку из файла,.readlines()— прочитать все строки из файла, функция возвращает
список строк.
Строки, которые возвращают .readline() и .readlines(), завершаются
символом перевода строки n. Для того, чтобы эти символы стереть,
можно использовать вызов метода .rstrip('n'), либо вообще .strip(),
если нас не интересуют ни начальные, ни конечные пробельные символы.
Сам объект текстового файла, открытого на чтение, является итератором,
который при переборе читает очередную строку (неявно вызывая .readline()).
Пример функции, которая распечатывает содержимое файла с заданным именем.
def print_file(filename):
fin = open(filename, 'r', encoding='utf-8')
for line in fin:
print(line.rstrip('n'))
fin.close()
Здесь мы не пользуемся методами для чтения файла, мы пользуемся тем, что
объект файла является итератором — может быть прочитан в цикле for. Цикл
будет перебирать все строки файла, как если бы они были прочитаны при помощи
метода .readline().
В конце прочитанных строк будет находиться знак перевода строки (n), кроме,
возможно, последней — она на знак n может не завершаться. Поэтому для
удаления n на конце мы используем метод .rstrip('n'), указывая в качестве
параметра удаляемый символ.
Альтернативное решение — вручную проверять, что если строка заканчивается
на n, то мы её обрезаем, иначе не трогаем. Обрезать последний символ без
проверки нельзя, т.к. в последней строке знак перевода может отсутствовать.
Если знаки n не обрезать, то на печать будут выводиться лишние пустые
строки, т.к. print() при печати строки сам добавляет в конец знак n.
Другой, более короткий способ прочитать всё содержимое файла — использовать
метод .read():
def print_file(filename):
fin = open(filename, 'r', encoding='utf-8')
print(fin.read())
fin.close()
Мы при помощи метода .read() читаем весь файл до конца, всё содержимое
файла загружается в оперативную память в виде одной большой строки — эту
строку распечатываем при помощи print(). Такое решение нормально работает
только с небольшими файлами — файлами, размер которых измеряется не более
чем мегабайтами. Для гигабайтных файлов так делать не надо — памяти может
не хватить.
Запись файлов
Для того, чтобы записывать в файл, его нужно открыть в соответствующем режиме.
Режимов записи два:
- Режим перезаписи файла —
'w'(от слова write). Если файл не существовал,
то он при открытии будет создан и его размер будет равен нулю. Если файл
уже существовал, то он будет перезаписан — всё его содержимое сотрётся,
его размер станет равным 0 байт. - Режим дозаписи в файл —
'a'(от слова append). Если файл не существовал,
он будет создан и будет иметь размер 0 байт. Если файл уже существовал,
то данные в нём останутся как есть, новая запись будет осуществляться
в конец файла.
Пример:
>>> f = open('example.txt', 'w', encoding='utf8')
>>> f.write('Один!')
5
>>> f.close()
>>> f = open('example.txt', 'w', encoding='utf8')
>>> f.write('Два!')
4
>>> f.close()
После этих манипуляций в файле example.txt будет записано только слово
т.к. мы открывали файл для перезаписи. После первого «сеанса» работы с файлом
(вызовы open(), .write() и .close()) в файле оказалось слово Один!.
Когда мы открыли файл второй раз для перезаписи (в режиме 'w'), всё
содержимое файла стёрлось, и вместо него мы записали слово Два!.
Если мы файл удалим, а затем сделаем тоже самое, используя уже режим 'a'
(дозапись):
>>> f = open('example.txt', 'a', encoding='utf8')
>>> f.write('Один!')
5
>>> f.close()
>>> f = open('example.txt', 'a', encoding='utf8')
>>> f.write('Два!')
4
>>> f.close()
то в файле example.txt у нас окажется
При первом открытии (несуществующего) файла файл будет создан пустым и в него
будет записано Один!. При втором открытии содержимое файла не изменится,
новая запись будет осуществляться в конец — в конце допишется Два!.
Метод .write()
Метод .write(s) принимает в качестве параметра строку и записывает её в файл.
Возвращаемое значение — количество записанных символов. Обычно возвращаемое
значение совпадает с длиной строки. Редко, если на диске закончилось доступное
место, строка может записана не полностью и возвращаемое значение будет меньше
длины. Обычно об этом не задумываются и возвращаемое значение не анализируют.
Нужно помнить, что метод .write() при записи строки в файл не добавляет
в конце знак перевода строки 'n'. Если формировать файл при помощи метода
.write(), переводы строк нужно добавлять явно.
Функция print()
С функцией print() мы уже знакомы, мы ею пользовались для вывода данных
на консоль. Однако, её можно использовать и для записи в файл.
Расширенный синтаксис функции print():
print(‹значение›, ‹значение›,… sep=‹разделитель полей›,
end=‹разделитель строк›, file=‹объект файла›)
Функция print(), помимо списка значений для записи, принимает несколько
необязательных параметров. Это параметры:
sep=‹разделитель полей›— строка, которая разделяет выводимые значения,
по умолчанию — один пробел' '.end=‹разделитель строк›— строка, которая завершает вывод строки,
по умолчанию — перевод строки'n'.file=‹объект файла›— открытый для записи (дозаписи или перезаписи)
файл или устройство вывода, по умолчанию — вывод на консольsys.stdout.
Таким образом, функция print() выводит значения, разделяя их пробелом,
в конце выводимой строки печатает перевод строки, вывод осуществляется в консоль
(т.е. на экран). Однако, это поведение можно изменить, указывая необязательные
параметры.
Вывод по умолчанию:
Сделаем разделителем другие строки:
>>> print(1, 2, 3, sep=';')
1;2;3
>>> print(1, 2, 3, sep='*****')
1*****2*****3
Выведем две строки, используя в качестве разделителя '!' — перевод на новую
строку осуществлён не будет:
>>> print(1, 2, 3); print(4, 5, 6)
1 2 3
4 5 6
>>> print(1, 2, 3, end='!'); print(4, 5, 6, end='!')
1 2 3!4 5 6!
В качестве разделителя полей укажем вместо пробела по умолчанию перевод строки —
каждое значение будет распечатано на новой строчке.
>>> print(1, 2, 3, sep='n')
1
2
3
Пример записи в файл при помощи функции print():
>>> f = open('example.txt', 'w', encoding='utf8')
>>> print('Пишем в файл при помощи print()', file=f)
>>> print(1, 2, 3, 4, 5, 6, file=f)
>>> print(1, 2, 3, 4, 5, 6, sep=',', file=f)
>>> f.close()
Функция print() сначала напечатала строчку, потом шесть чисел, разделяя их
пробелами (по умолчанию), затем шесть чисел, разделяя их запятой (явно указан
sep=','). Содержимое файла:
Пишем в файл при помощи print()
1 2 3 4 5 6
1,2,3,4,5,6
Использование функции print() для вывода в файл удобнее, чем метод .write().
Важность закрытия файлов, оператор with
Для примера создадим файл, запишем в него строку и пока не закроем:
>>> f = open('example.txt', 'w', encoding='utf8')
>>> print('Пишем строчку в файл', file=f)
Файл в папке появился, но он почему-то пустой. Размер отображается как 0 байт,
если откроем блокнотом, то увидим пустой файл.
Причина в том, что данные при записи буферизуются — для открытого файла
в оперативной памяти выделяется участок, куда помещаются данные, подлежащие
записи. Когда эта область памяти заполняется, происходит запись данных на диск.
Буфер необходим для ускорения работы программы, т.к. операция записи на диск
гораздо более медленная, чем запись в оперативную память и имеет смысл её
выполнять реже.
Если мы файл закроем, то содержимое буфера принудительно выпишется на диск.
После закрытия файла его размер уже не нулевой, и если откроем его блокнотом,
то увидим ожидаемое содержимое — строку
Таким образом, файлы, открытые для записи, нужно обязательно закрывать, т.к.
иначе есть риск потери данных. Если, например, интерпретатор Python’а будет
аварийно завершён, данные в буфере на диск не выпишутся.
Другая причина закрытия файлов — на Windows открытые файлы блокируются
операционной системой. Если мы откроем файл и попробуем его удалить:
>>> f = open('example.txt', 'r', encoding='utf8')
то удалить его не удастся:
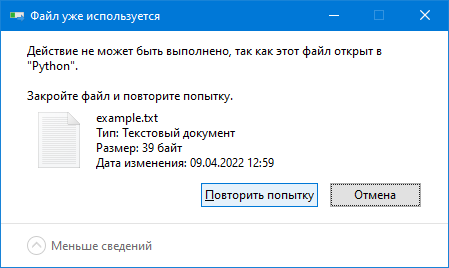
Если файл закрыть, то он успешно удалится:
На Linux и macOS удалять открытые файлы можно.
Третья причина — нельзя одновременно открыть очень много файлов. Для примера
напишем функцию:
def many_open_files(count):
files = []
for i in range(count):
files.append(open('file' + str(i) + '.txt', 'w'))
return files
Эта функция открывает для записи указанное количество файлов, имена файлов
при этом имеют вид file0.txt, file1.txt, …, функция возвращает список
открытых файлов.
При попытке открыть 10 тысяч файлов получим следующее сообщение об ошибке:
>>> fs = many_open_files(10000)
Traceback (most recent call last):
File "<pyshell#8>", line 1, in <module>
fs = many_open_files(10000)
File "D:/…/example.py", line 4, in many_open_files
OSError: [Errno 24] Too many open files: 'file8189.txt'
Таким образом, в Windows по умолчанию нельзя открыть более 8188 файлов
одновременно.
Python часто «прощает» незакрытые файлы — он их может закрыть сам. Но лучше
на это не полагаться. Не забывать каждый раз вызывать метод .close()
довольно утомительно, поэтому разработчики Python предусмотрели синтаксис,
гарантирующий обязательное закрытие файла:
with open(‹параметры›) as ‹перем›:
‹блок кода›
Здесь ‹параметры› — параметры функции open(): имя файла, режим, кодировка,
‹перем› — имя переменной, которой будет присвоен отрытый файл, ‹блок кода› —
некоторый блок кода. Семантика этой конструкции следующая.
- Открывается файл,
- объект файла присваивается переменной
‹перем›, - выполняется
‹блок кода›. - При завершении выполнения блока кода, причём любым способом — при достижении
его конца, либо завершение функции при помощиreturn, либо, если конструкция
withнаходится внутри цикла, то при прерывании итерации при помощиbreak
илиcontinue, либо при генерации исключения (возникновении ошибки) файл,
присвоенный переменной‹перем›обязательно автоматически закроется.
Пример. Подсчитаем число строк в файле.
def count_lines(filename):
with open(filename, 'r', encoding='utf8') as f:
return len(f.readlines())
Функция count_lines(filename) принимает имя файла и возвращает число строк
в нём. Для открытия файла используется конструкция with, которая присваивает
открытый функцией open() файл в переменную f. Чтобы подсчитать строки
в файле, мы считываем все строки при помощи метода .readlines()
и возвращаем длину полученного списка. Заметим, что блок кода, управляемый
with, завершается при помощи return. Однако, файл будет закрыт, т.к. with
это гарантирует.
