
От автора: хотите составить для своего проекта файл с указаниями для робота, но не знаете как? Сегодня разберемся, как посмотреть robots.txt сайта и изменить его под свои нужды.
В интернете каждый день появляются готовые решения по той или иной проблеме. Нет денег на дизайнера? Используйте один из тысяч бесплатных шаблонов. Не хотите нанимать сео-специалиста? Воспользуйтесь услугами какого-нибудь известного бесплатного сервиса, почитайте сами пару статей.
Уже давно нет необходимости самому с нуля писать тот же самый robots.txt. К слову, это специальный файл, который есть практически на любом сайте, и в нем содержатся указания для поисковых роботов. Синтаксис команд очень простой, но все равно на составление собственного файла уйдет время. Лучше посмотреть у другого сайта. Тут есть несколько оговорок:
Сайт должен быть на том же движке, что и ваш. В принципе, сегодня в интернете куча сервисов, где можно узнать название cms практически любого веб-ресурса.
Это должен быть более менее успешный сайт, у которого все в порядке с поисковым трафиком. Это говорит о том, что robots.txt составлен нормально.
Итак, чтобы посмотреть этот файл нужно в адресной строке набрать: доменное-имя.зона/robots.txt
Все неверятно просто, правда? Если адрес не будет найден, значит такого файла на сайте нет, либо к нему закрыт доступ. Но в большинстве случаев вы увидите перед собой содержимое файла:

В принципе, даже человек не особо разбирающийся в коде быстро поймет, что тут написать. Команда allow разрешает что-либо индексировать, а disallow – запрещает. User-agent – это указание поисковых роботов, к которым обращены инструкции. Это необходимо в том случае, когда нужно указать команды для отдельного поисковика.
Что делать дальше?
Скопировать все и изменить под свой сайт. Как изменять? Я уже говорил, что движки сайтов должны совпадать, иначе изменять что-либо бессмысленно – нужно переписывать абсолютно все.
Итак, вам необходимо будет пройтись по строкам и определить, какие разделы из указанных присутствуют на вашем сайте, а какие – нет. На скриншоте выше вы видите пример robots.txt для wordpress сайта, причем в отдельном каталоге есть форум. Вывод? Если у вас нет форума, все эти строки нужно удалить, так как подобных разделов и страниц у вас просто не существует, зачем тогда их закрывать?
Самый простой robots.txt может выглядеть так:
|
User–agent: * Disallow: /wp–admin Disallow: /wp–includes Disallow: /wp–content Allow: /wp–content/uploads/ |
Все вы наверняка знаете стандартную структуру папок в wordpress, если хотя бы 1 раз устанавливали этот движок. Это папки wp-admin, wp-content и wp-includes. Обычно все 3 закрывают от индексации, потому что они содержат чисто технические файлы, необходимые для работы движка, плагинов и шаблонов.
Каталог uploads открывают, потому что в нем содержаться картинки, а их обыно индексируют.
В общем, вам нужно пройтись по скопированному robots.txt и просмотреть, что из написанного действительно есть на вашем сайте, а чего нет. Конечно, самому определить будет трудно. Я могу лишь сказать, что если вы что-то не удалите, то ничего страшного, просто лишняя строчка будет, которая никак не вредит (потому что раздела нет).
Так ли важна настройка robots.txt?

Конечно, необходимо иметь этот файл и хотя бы основные каталоги через него закрыть. Но критично ли важно его составление? Как показывает практика, нет. Я лично вижу сайты на одних движках с абсолютно разным robots.txt, которые одинаково успешно продвигаются в поисковых системах.
Я не спорю, что можно совершить какую-то ошибку. Например, закрыть изображения или оставить открытым ненужный каталог, но чего-то супер страшного не произойдет. Во-первых, потому что поисковые системы сегодня умнее и могут игнорировать какие-то указание из файла. Во-вторых, написаны сотни статей о настройке robots.txt и уж что-то можно понять из них.
Я видел файлы, в которых было 6-7 строчек, запрещающих индексировать пару каталогов. Также я видел файлы с сотней-другой строк кода, где было закрыто все, что только можно. Оба сайта при этом нормально продвигались.
В wordpress есть так называемые дубли. Это плохо. Многие борятся с этим с помощью закрытия подобных дублей так:
|
Disallow: /wp–feed Disallow: */trackback Disallow: */feed Disallow: /tag/ Disallow: /archive/ |
Это лишь некоторые из дублей, создаваемых wordpress. Могу сказать, что так можно делать, но защиты на 100% ожидать не стоит. Я бы даже сказал, что вообще не нужно ее ожидать и проблема как раз в том, о чем я уже говорил ранее:
Поисковые системы все равно могут забрать в индекс такие вещи.
Тут уже нужно бороться по-другому. Например, с помощью редиректов или плагинов, которые будут уничтожать дубли. Впрочем, это уже тема для отдельной статьи.
Где находится robots.txt?
Этот файл всегда находится в корне сайта, поэтому мы и можем обратиться к нему, прописав адрес сайта и название файла через слэш. По-моему, тут все максимально просто.
В общем, сегодня мы рассмотрели вопрос, как посмотреть содержимое файла robots.txt, скопировать его и изменить под свои нужды. О настройке я также напишу еще 1-2 статьи в ближайшее время, потому что в этой статье мы рассмотрели не все. Кстати, также много информации по продвижению сайтов-блогов вы можете найти в нашем курсе. А я на этом пока прощаюсь с вами.
Оптимизируйте свои подборки
Сохраняйте и классифицируйте контент в соответствии со своими настройками.
С помощью файла robots.txt вы можете указывать, какие файлы на вашем сайте будут видны поисковым роботам.
Файл robots.txt находится в корневом каталоге вашего сайта. Например, на сайте www.example.com он находится по адресу www.example.com/robots.txt. Он представляет собой обычный текстовый файл, который соответствует стандарту исключений для роботов
и содержит одно или несколько правил. Каждое из них запрещает или разрешает всем поисковым роботам или одному определенному из них доступ к определенному пути в домене или субдомене, в котором размещается файл robots.txt. Все файлы считаются доступными для сканирования, если вы не указали иное в файле robots.txt.
Ниже приведен пример простого файла robots.txt с двумя правилами.
User-agent: Googlebot Disallow: /nogooglebot/ User-agent: * Allow: / Sitemap: https://www.example.com/sitemap.xml
Пояснения:
-
Агенту пользователя с названием Googlebot запрещено сканировать любые URL, начинающиеся с
https://example.com/nogooglebot/. - Любым другим агентам пользователя разрешено сканировать весь сайт. Это правило можно опустить, и результат будет тем же. По умолчанию агенты пользователя могут сканировать сайт целиком.
-
Файл Sitemap этого сайта находится по адресу
https://www.example.com/sitemap.xml.
Более подробные сведения вы найдете в разделе Синтаксис.
Основные рекомендации по созданию файла robots.txt
Работа с файлом robots.txt включает четыре этапа.
- Создайте файл robots.txt
- Добавьте в него правила
- Опубликуйте готовый файл в корневом каталоге своего сайта
- Протестируйте свой файл robots.txt
Как создать файл robots.txt
Создать файл robots.txt можно в любом текстовом редакторе, таком как Блокнот, TextEdit, vi или Emacs. Не используйте офисные приложения, поскольку зачастую они сохраняют файлы в проприетарном формате и добавляют в них лишние символы, например фигурные кавычки, которые не распознаются поисковыми роботами. Обязательно сохраните файл в кодировке UTF-8, если вам будет предложено выбрать кодировку.
Правила в отношении формата и расположения файла
- Файл должен называться robots.txt.
- На сайте должен быть только один такой файл.
-
Файл robots.txt нужно разместить в корневом каталоге сайта. Например, на сайте
https://www.example.com/он должен располагаться по адресуhttps://www.example.com/robots.txt. Он не должен находиться в подкаталоге (например, по адресуhttps://example.com/pages/robots.txt). Если вы не знаете, как получить доступ к корневому каталогу сайта, или у вас нет соответствующих прав, обратитесь к хостинг-провайдеру. Если у вас нет доступа к корневому каталогу сайта, используйте альтернативный метод блокировки, например тегиmeta. -
Файл robots.txt можно разместить по адресу с субдоменом (например,
https://website.example.com/robots.txt) или нестандартным портом (например,https://example.com:8181/robots.txt). - Действие robots.txt распространяется только на пути в пределах протокола, хоста и порта, где он размещен. Иными словами, правило по адресу
https://example.com/robots.txtдействует только для файлов, относящихся к доменуhttps://example.com/, но не к субдомену, такому какhttps://m.example.com/, или другим протоколам, напримерhttp://example.com/. - Файл robots.txt должен представлять собой текстовый файл в кодировке UTF-8 (которая включает коды символов ASCII). Google может проигнорировать символы, не относящиеся к UTF-8, в результате чего будут обработаны не все правила из файла robots.txt.
Как написать правила в файле robots.txt
Правила – это инструкции для поисковых роботов, указывающие, какие разделы сайта можно сканировать. Добавляя правила в файл robots.txt, учитывайте следующее:
- Файл robots.txt состоит из одной или более групп (наборов правил).
-
Каждая группа может включать несколько правил, по одному на строку. Эти правила также называются директивами. Каждая группа начинается со строки
User-agent, определяющей, какому роботу адресованы правила в ней. - Группа содержит следующую информацию:
- К какому агенту пользователя относятся директивы группы.
- К каким каталогам или файлам у этого агента есть доступ.
- К каким каталогам или файлам у этого агента нет доступа.
- Поисковые роботы обрабатывают группы по порядку сверху вниз. Агент пользователя может следовать только одному, наиболее подходящему для него набору правил, который будет обработан первым. Если к одному агенту пользователя относится несколько групп, все они будут объединены в одну.
- По умолчанию агенту пользователя разрешено сканировать любые страницы и каталоги, доступ к которым не заблокирован правилом
disallow. -
Правила должны указываться с учетом регистра. К примеру, правило
disallow: /file.aspраспространяется на URLhttps://www.example.com/file.asp, но не наhttps://www.example.com/FILE.asp. -
Символ
#означает начало комментария. Во время обработки комментарии игнорируются.
Правила в файлах robots.txt, поддерживаемые роботами Google
-
user-agent:(обязательное правило, может повторяться в пределах группы). Определяет, к какому именно автоматическому клиенту (поисковому роботу) относятся правила в группе. С такой строки начинается каждая группа правил. Названия агентов пользователя Google перечислены в этом списке.
Используйте знак*, чтобы заблокировать доступ всем поисковым роботам (кроме роботов AdsBot, которых нужно указывать отдельно). Примеры:# Example 1: Block only Googlebot User-agent: Googlebot Disallow: / # Example 2: Block Googlebot and Adsbot User-agent: Googlebot User-agent: AdsBot-Google Disallow: / # Example 3: Block all crawlers except AdsBot (AdsBot crawlers must be named explicitly) User-agent: * Disallow: /
-
disallow:(каждое правило должно содержать не менее одной директивыdisallowилиallow). Указывает на каталог или страницу относительно корневого домена, которые нельзя сканировать агенту пользователя. Если правило касается страницы, должен быть указан полный путь к ней, как в адресной строке браузера. В начале строки должен быть символ/. Если правило касается каталога, строка должна заканчиваться символом/. -
allow:(каждое правило должно содержать не менее одной директивыdisallowилиallow). Указывает на каталог или страницу относительно корневого домена, которые разрешено сканировать агенту пользователя. Используется для того, чтобы переопределить правилоdisallowи разрешить сканирование подкаталога или страницы в закрытом для обработки каталоге. Если правило касается страницы, должен быть указан полный путь к ней, как в адресной строке браузера. В начале строки должен быть символ/. Если правило касается каталога, строка должна заканчиваться символом/. -
sitemap:(необязательная директива, которая может повторяться несколько раз или не использоваться совсем). Указывает на расположение файла Sitemap, используемого на сайте. URL файла Sitemap должен быть полным. Google не перебирает варианты URL с префиксами http и https или с элементом www и без него. Из файлов Sitemap роботы Google получают информацию о том, какой контент нужно сканировать и как отличить его от материалов, которые можно или нельзя обрабатывать.
Подробнее…Примеры:
Sitemap: https://example.com/sitemap.xml Sitemap: https://www.example.com/sitemap.xml
Все правила, кроме sitemap, поддерживают подстановочный знак * для обозначения префикса или суффикса пути, а также всего пути.
Строки, не соответствующие ни одному из этих правил, игнорируются.
Ознакомьтесь со спецификацией Google для файлов robots.txt, где подробно описаны все правила.
Как загрузить файл robots.txt
Сохраненный на компьютере файл robots.txt необходимо загрузить на сайт и сделать доступным для поисковых роботов. Специального инструмента для этого не существует, поскольку способ загрузки зависит от вашего сайта и серверной архитектуры. Обратитесь к своему хостинг-провайдеру или попробуйте самостоятельно найти его документацию (пример запроса: “загрузка файлов infomaniak”).
После загрузки файла robots.txt проверьте, доступен ли он для роботов и может ли Google обработать его.
Как протестировать разметку файла robots.txt
Чтобы убедиться, что загруженный файл robots.txt общедоступен, откройте в браузере окно в режиме инкогнито (или аналогичном) и перейдите по адресу файла. Пример: https://example.com/robots.txt. Если вы видите содержимое файла robots.txt, то можно переходить к тестированию разметки.
Для этой цели Google предлагает два средства:
- Инструмент проверки файла robots.txt в Search Console. Этот инструмент можно использовать только для файлов robots.txt, которые уже доступны на вашем сайте.
- Если вы разработчик, мы рекомендуем воспользоваться библиотекой с открытым исходным кодом, которая также применяется в Google Поиске. С помощью этого инструмента файлы robots.txt можно локально тестировать прямо на компьютере.
Как отправить файл robots.txt в Google
Когда вы загрузите и протестируете файл robots.txt, поисковые роботы Google автоматически найдут его и начнут применять. С вашей стороны никаких действий не требуется. Если вы внесли в файл robots.txt изменения и хотите как можно скорее обновить кешированную копию, следуйте инструкциям в этой статье.
Полезные правила
Ниже перечислено несколько правил, часто используемых в файлах robots.txt.
| Полезные правила | |
|---|---|
| Это правило запрещает сканировать весь сайт. |
Следует учесть, что в некоторых случаях URL сайта могут индексироваться, даже если они не были просканированы. User-agent: * Disallow: / |
| Это правило запрещает сканировать каталог со всем его содержимым. |
Чтобы запретить сканирование целого каталога, поставьте косую черту после его названия. User-agent: * Disallow: /calendar/ Disallow: /junk/ Disallow: /books/fiction/contemporary/ |
| Это правило позволяет сканировать сайт только одному поисковому роботу. |
Сканировать весь сайт может только робот User-agent: Googlebot-news Allow: / User-agent: * Disallow: / |
| Это правило разрешает сканирование всем поисковым роботам за исключением одного. |
Робот User-agent: Unnecessarybot Disallow: / User-agent: * Allow: / |
|
Это правило запрещает сканирование отдельной страницы. |
Например, можно запретить сканирование страниц User-agent: * Disallow: /useless_file.html Disallow: /junk/other_useless_file.html |
|
Это правило запрещает сканировать весь сайт за исключением определенного подкаталога. |
Поисковым роботам предоставлен доступ только к подкаталогу User-agent: * Disallow: / Allow: /public/ |
|
Это правило скрывает определенное изображение от робота Google Картинок. |
Например, вы можете запретить сканировать изображение User-agent: Googlebot-Image Disallow: /images/dogs.jpg |
|
Это правило скрывает все изображения на сайте от робота Google Картинок. |
Google не сможет индексировать изображения и видео, которые недоступны для сканирования. User-agent: Googlebot-Image Disallow: / |
|
Это правило запрещает сканировать все файлы определенного типа. |
Например, вы можете запретить роботам доступ ко всем файлам User-agent: Googlebot Disallow: /*.gif$ |
|
Это правило запрещает сканировать весь сайт, но при этом он может обрабатываться роботом |
Робот User-agent: * Disallow: / User-agent: Mediapartners-Google Allow: / |
Воспользуйтесь подстановочными знаками * и $, чтобы сопоставлять URL, которые заканчиваются определенной строкой.
|
Например, вы можете исключить все файлы User-agent: Googlebot Disallow: /*.xls$ |
Если не указано иное, контент на этой странице предоставляется по лицензии Creative Commons “С указанием авторства 4.0”, а примеры кода – по лицензии Apache 2.0. Подробнее об этом написано в правилах сайта. Java – это зарегистрированный товарный знак корпорации Oracle и ее аффилированных лиц.
Последнее обновление: 2023-02-24 UTC.
Роботы Яндекса корректно обрабатывают robots.txt, если:
-
Размер файла не превышает 500 КБ.
-
Это TXT-файл с названием robots — robots.txt.
-
Файл размещен в корневом каталоге сайта.
-
Файл доступен для роботов — сервер, на котором размещен сайт, отвечает HTTP-кодом со статусом 200 OK. Проверьте ответ сервера
Если файл не соответствует требованиям, сайт считается открытым для индексирования.
Яндекс поддерживает редирект с файла robots.txt, расположенного на одном сайте, на файл, который расположен на другом сайте. В этом случае учитываются директивы в файле, на который происходит перенаправление. Такой редирект может быть удобен при переезде сайта.
Яндекс поддерживает следующие директивы:
| Директива | Что делает |
|---|---|
| User-agent * | Указывает на робота, для которого действуют перечисленные в robots.txt правила. |
| Disallow | Запрещает обход разделов или отдельных страниц сайта. |
| Sitemap | Указывает путь к файлу Sitemap, который размещен на сайте. |
| Clean-param | Указывает роботу, что URL страницы содержит параметры (например, UTM-метки), которые не нужно учитывать при индексировании. |
| Allow | Разрешает индексирование разделов или отдельных страниц сайта. |
| Crawl-delay |
Задает роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей. Рекомендуем вместо директивы использовать настройку скорости обхода в Яндекс Вебмастере. |
* Обязательная директива.
Наиболее часто вам могут понадобиться директивы Disallow, Sitemap и Clean-param. Например:
User-agent: * #указывает, для каких роботов установлены директивы
Disallow: /bin/ # запрещает ссылки из "Корзины с товарами".
Disallow: /search/ # запрещает ссылки страниц встроенного на сайте поиска
Disallow: /admin/ # запрещает ссылки из панели администратора
Sitemap: http://example.com/sitemap # указывает роботу на файл Sitemap для сайта
Clean-param: ref /some_dir/get_book.plРоботы других поисковых систем и сервисов могут иначе интерпретировать директивы.
Примечание. Робот учитывает регистр в написании подстрок (имя или путь до файла, имя робота) и не учитывает регистр в названиях директив.
Использование кириллицы запрещено в файле robots.txt и HTTP-заголовках сервера.
Для указания имен доменов используйте Punycode. Адреса страниц указывайте в кодировке, соответствующей кодировке текущей структуры сайта.
Пример файла robots.txt:
#Неверно:
User-agent: Yandex
Disallow: /корзина
Sitemap: сайт.рф/sitemap.xml
#Верно:
User-agent: Yandex
Disallow: /%D0%BA%D0%BE%D1%80%D0%B7%D0%B8%D0%BD%D0%B0
Sitemap: http://xn--80aswg.xn--p1ai/sitemap.xml-
В текстовом редакторе создайте файл с именем robots.txt и укажите в нем нужные вам директивы.
-
Проверьте файл в Вебмастере.
-
Положите файл в корневую директорию вашего сайта.
Пример файла. Данный файл разрешает индексирование всего сайта для всех поисковых систем.
В Вебмастере на странице «Диагностика сайта» возникает ошибка «Сервер отвечает редиректом на запрос /robots.txt»
Чтобы файл robots.txt учитывался роботом, он должен находиться в корневом каталоге сайта и отвечать кодом HTTP 200. Индексирующий робот не поддерживает использование файлов, расположенных на других сайтах.
Чтобы проверить доступность файла robots.txt для робота, проверьте ответ сервера.
Если ваш robots.txt выполняет перенаправление на другой файл robots.txt (например, при переезде сайта), Яндекс учитывает robots.txt, на который происходит перенаправление. Убедитесь, что в этом файле указаны верные директивы. Чтобы проверить файл, добавьте сайт, который является целью перенаправления, в Вебмастер и подтвердите права на управление сайтом.
Поисковые системы ранжируют страницы согласно заданным параметрам. Если не прописать условия ранжирования с помощью специальных инструментов, в топ выдачи попадут ненужные страницы, а нужные — останутся в тени. Чтобы этого избежать, необходимо настроить robots.txt.
Создаем файл в блокноте или любой текстовой программе — подойдет Word, NotePad и т. д. Главное, чтобы вы сохранили файл в формате “.txt” и назвали его “robots”. В тексте нужно будет прописать страницы, которые можно и нельзя индексировать, указать нужные директивы.
Затем установить галочку в строке «Включить robots.txt» и внести в поле необходимые правила, нажать «Применить». Проверьте, открывается ли файл по адресу ваш_домен/robots.txt.
Как настроить файл robots.txt вручную
Для этого не нужно быть программистом или верстальщиком — достаточно разобраться, за что отвечает каждый параметр, который мы будем вносить в файл.
- User-agent. С этой директивы должен начинаться каждый robots.txt. Она показывает, для бота какой поисковой системы предназначается инструкция.
User-agent: YandexBot — для Яндекса,
User-agent: Googlebot — для Гугла,
User-Agent: * — общий для всех роботов.

SEO продвижение и сайты для предпринимателей.
Чтобы посмотреть файл robots.txt чужого сайта, нужно в адресной строке набрать: название_сайта.ru/robots.txt. Он находится в корне любого сайта.
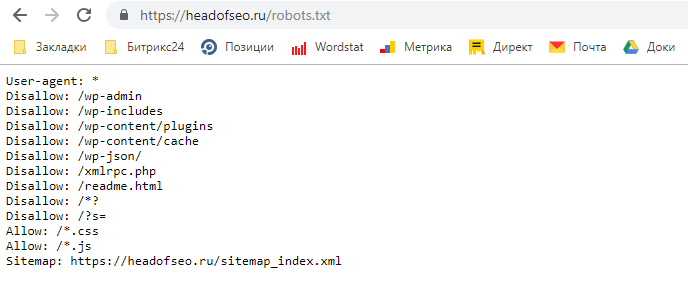
Просто копировать файл robots.txt не надо так как у вам может быть другая админка.
Мой Телеграмм канал про SEO
Мой канал про SEO. Как делать оптимизацию и продвигать сайт в топ 10 поисковых систем Яндекс и Google.
Канал для SEO-шников, как делать seo, создавать и оптимизировать сайты.
Как чилить и зарабатывать от 30 до 100к в месяц.
В общем чисто seo-щный лайф стайл. Подписывайтесь!
Подпишись >>>>
+_+_+_+_+_+_+_+_+_+_+_+_+_+_+_+_+_+_+_+_+_+_+_+_+_+
Автор статьи : Павел Гречко
Рекомендую прочитать
