Делайте так:
grep -rnw '/путь/к/папке/с/файлами' -e "шаблон"
-rили-R– рекурсивный поиск.-n– вывод номера строки.-w– только целые слова.-l(нижний регистр отL) – вывод имени файла, где было совпадение.
Эффективности добавят следующие флаги:
-
--exclude– Шаблон для исключения файлов, например: поиск везде, кроме файлов с расширением.o:grep --exclude=*.o -rnw '/путь/к/папке/с/файлами' -e "шаблон" -
--include– Поиск только в определённых файлах, например: только в файлах с расширениями.hи.c:grep --include=*.{c,h} -rnw '/путь/к/папке/с/файлами' -e "шаблон" -
--exclude-dirи--include-dir– то же, только для выборки директорий, например: исключить папкиодин,twoи любые, начинающиеся наа:grep --exclude-dir={один,two,а*} -rnw '/путь/к/папке/с/файлами' -e "шаблон"
Это отлично работает для подобных целей, остальные настройки для grep можно узнать, выполнив man grep.
При формировании ответа использовался ответ на вопрос «How do I find all files containing specific text on Linux?» от участника @rakib.
Команда grep означает «печать глобального регулярного выражения», и это одна из самых мощных и часто используемых команд в Linux.
grep ищет в одном или нескольких входных файлах строки, соответствующие заданному шаблону, и записывает каждую соответствующую строку в стандартный вывод. Если файлы не указаны, grep читает из стандартного ввода, который обычно является выводом другой команды.
В этой статье мы покажем вам, как использовать команду grep на практических примерах и подробных объяснениях наиболее распространенных опций GNU grep .
Командный синтаксис grep
Синтаксис команды grep следующий:
grep [OPTIONS] PATTERN [FILE...]
Пункты в квадратных скобках необязательны.
OPTIONS— Ноль или более вариантов. Grep включает ряд опций , управляющих его поведением.-
PATTERN— Шаблон поиска. -
FILE— Ноль или более имен входных файлов.
Чтобы иметь возможность искать файл, пользователь, выполняющий команду, должен иметь доступ для чтения к файлу.
Искать строку в файлах
Наиболее простое использование команды grep — поиск строки (текста) в файле.
Например, чтобы отобразить все строки, содержащие строку bash из файла /etc/passwd , вы должны выполнить следующую команду:
grep bash /etc/passwdРезультат должен выглядеть примерно так:
root:x:0:0:root:/root:/bin/bash
linuxize:x:1000:1000:linuxize:/home/linuxize:/bin/bash
Если в строке есть пробелы, вам нужно заключить ее в одинарные или двойные кавычки:
grep "Gnome Display Manager" /etc/passwdИнвертировать соответствие (исключить)
Чтобы отобразить строки, не соответствующие шаблону, используйте параметр -v (или --invert-match ).
Например, чтобы распечатать строки, не содержащие строковый nologin вы должны использовать:
grep -v nologin /etc/passwdroot:x:0:0:root:/root:/bin/bash
colord:x:124:124::/var/lib/colord:/bin/false
git:x:994:994:git daemon user:/:/usr/bin/git-shell
linuxize:x:1000:1000:linuxize:/home/linuxize:/bin/bash
Использование Grep для фильтрации вывода команды
Вывод команды может быть отфильтрован с помощью grep через конвейер, и на терминал будут напечатаны только строки, соответствующие заданному шаблону.
Например, чтобы узнать, какие процессы выполняются в вашей системе как пользовательские www-data вы можете использовать следующую команду ps :
ps -ef | grep www-datawww-data 18247 12675 4 16:00 ? 00:00:00 php-fpm: pool www
root 18272 17714 0 16:00 pts/0 00:00:00 grep --color=auto --exclude-dir=.bzr --exclude-dir=CVS --exclude-dir=.git --exclude-dir=.hg --exclude-dir=.svn www-data
www-data 31147 12770 0 Oct22 ? 00:05:51 nginx: worker process
www-data 31148 12770 0 Oct22 ? 00:00:00 nginx: cache manager process
Вы также можете объединить несколько каналов по команде. Как вы можете видеть в выходных данных выше, также есть строка, содержащая процесс grep . Если вы не хотите, чтобы эта строка отображалась, передайте результат другому экземпляру grep как показано ниже.
ps -ef | grep www-data | grep -v grepwww-data 18247 12675 4 16:00 ? 00:00:00 php-fpm: pool www
www-data 31147 12770 0 Oct22 ? 00:05:51 nginx: worker process
www-data 31148 12770 0 Oct22 ? 00:00:00 nginx: cache manager process
Рекурсивный поиск
Для рекурсивного поиска шаблона вызовите grep с параметром -r (или --recursive ). Когда используется этот параметр, grep будет искать все файлы в указанном каталоге, пропуская символические ссылки, которые встречаются рекурсивно.
Чтобы следовать по всем символическим ссылкам , вместо -r используйте параметр -R (или --dereference-recursive ).
Вот пример, показывающий, как искать строку linuxize.com во всех файлах внутри каталога /etc :
grep -r linuxize.com /etcВывод будет включать совпадающие строки с префиксом полного пути к файлу:
/etc/hosts:127.0.0.1 node2.linuxize.com
/etc/nginx/sites-available/linuxize.com: server_name linuxize.com www.linuxize.com;
Если вы используете опцию -R , grep будет следовать по всем символическим ссылкам:
grep -R linuxize.com /etcОбратите внимание на последнюю строку вывода ниже. Эта строка не печатается, когда grep вызывается с -r потому что файлы внутри каталога с sites-enabled Nginx являются символическими ссылками на файлы конфигурации внутри каталога с sites-available .
/etc/hosts:127.0.0.1 node2.linuxize.com
/etc/nginx/sites-available/linuxize.com: server_name linuxize.com www.linuxize.com;
/etc/nginx/sites-enabled/linuxize.com: server_name linuxize.com www.linuxize.com;
Показать только имя файла
Чтобы подавить вывод grep по умолчанию и вывести только имена файлов, содержащих совпадающий шаблон, используйте параметр -l (или --files-with-matches ).
Приведенная ниже команда выполняет поиск по всем файлам, заканчивающимся на .conf в текущем рабочем каталоге и выводит только имена файлов, содержащих строку linuxize.com :
grep -l linuxize.com *.confРезультат будет выглядеть примерно так:
tmux.conf
haproxy.conf
Параметр -l обычно используется в сочетании с рекурсивным параметром -R :
grep -Rl linuxize.com /tmpПоиск без учета регистра
По умолчанию grep чувствителен к регистру. Это означает, что символы верхнего и нижнего регистра рассматриваются как разные.
Чтобы игнорировать регистр при поиске, вызовите grep с параметром -i (или --ignore-case ).
Например, при поиске Zebra без какой-либо опции следующая команда не покажет никаких результатов, т.е. есть совпадающие строки:
grep Zebra /usr/share/wordsНо если вы выполните поиск без учета регистра с использованием параметра -i , он будет соответствовать как заглавным, так и строчным буквам:
grep -i Zebra /usr/share/wordsУказание «Зебра» будет соответствовать «зебре», «ZEbrA» или любой другой комбинации букв верхнего и нижнего регистра для этой строки.
zebra
zebra's
zebras
Искать полные слова
При поиске строки grep отобразит все строки, в которых строка встроена в строки большего размера.
Например, если вы ищете «gnu», все строки, в которых «gnu» встроено в слова большего размера, такие как «cygnus» или «magnum», будут найдены:
grep gnu /usr/share/wordscygnus
gnu
interregnum
lgnu9d
lignum
magnum
magnuson
sphagnum
wingnut
Чтобы вернуть только те строки, в которых указанная строка представляет собой целое слово (заключенное в символы, отличные от слов), используйте параметр -w (или --word-regexp ).
Символы слова включают буквенно-цифровые символы ( az , AZ и 0-9 ) и символы подчеркивания ( _ ). Все остальные символы считаются несловесными символами.
Если вы запустите ту же команду, что и выше, включая параметр -w , команда grep вернет только те строки, где gnu включен как отдельное слово.
grep -w gnu /usr/share/wordsgnu
Показать номера строк
Параметр -n (или --line-number ) указывает grep показывать номер строки, содержащей строку, соответствующую шаблону. Когда используется эта опция, grep выводит совпадения на стандартный вывод с префиксом номера строки.
Например, чтобы отобразить строки из файла /etc/services содержащие строку bash префиксом совпадающего номера строки, вы можете использовать следующую команду:
grep -n 10000 /etc/servicesРезультат ниже показывает нам, что совпадения находятся в строках 10423 и 10424.
10423:ndmp 10000/tcp
10424:ndmp 10000/udp
Подсчет совпадений
Чтобы вывести количество совпадающих строк в стандартный вывод, используйте параметр -c (или --count ).
В приведенном ниже примере мы подсчитываем количество учетных записей, в которых в качестве оболочки используется /usr/bin/zsh .
regular expressiongrep -c '/usr/bin/zsh' /etc/passwd
4
Бесшумный режим
-q (или --quiet ) указывает grep работать в тихом режиме, чтобы ничего не отображать на стандартном выводе. Если совпадение найдено, команда завершает работу со статусом 0 . Это полезно при использовании grep в сценариях оболочки, где вы хотите проверить, содержит ли файл строку, и выполнить определенное действие в зависимости от результата.
Вот пример использования grep в тихом режиме в качестве тестовой команды в операторе if :
if grep -q PATTERN filename
then
echo pattern found
else
echo pattern not found
fi
Основное регулярное выражение
GNU Grep имеет три набора функций регулярных выражений : базовый, расширенный и Perl-совместимый.
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, где все символы, кроме метасимволов, на самом деле являются регулярными выражениями, которые соответствуют друг другу.
Ниже приведен список наиболее часто используемых метасимволов:
-
Используйте символ
^(каретка) для сопоставления выражения в начале строки. В следующем примере строкаkangarooбудет соответствовать только в том случае, если она встречается в самом начале строки.grep "^kangaroo" file.txt -
Используйте символ
$(доллар), чтобы найти выражение в конце строки. В следующем примере строкаkangarooбудет соответствовать только в том случае, если она встречается в самом конце строки.grep "kangaroo$" file.txt -
Используйте расширение
.(точка) символ, соответствующий любому одиночному символу. Например, чтобы сопоставить все, что начинается сkanзатем имеет два символа и заканчивается строкойroo, вы можете использовать следующий шаблон:grep "kan..roo" file.txt -
Используйте
[ ](скобки) для соответствия любому одиночному символу, заключенному в квадратные скобки. Например, найдите строки, содержащиеacceptили «accent, вы можете использовать следующий шаблон:grep "acce[np]t" file.txt -
Используйте
[^ ]для соответствия любому одиночному символу, не заключенному в квадратные скобки. Следующий шаблон будет соответствовать любой комбинации строк, содержащихco(any_letter_except_l)a, напримерcoca,cobaltи т. Д., Но не будет соответствовать строкам, содержащимcola,grep "co[^l]a" file.txt
Чтобы избежать специального значения следующего символа, используйте символ (обратная косая черта).
Расширенные регулярные выражения
Чтобы интерпретировать шаблон как расширенное регулярное выражение, используйте параметр -E (или --extended-regexp ). Расширенные регулярные выражения включают в себя все основные метасимволы, а также дополнительные метасимволы для создания более сложных и мощных шаблонов поиска. Вот несколько примеров:
-
Сопоставьте и извлеките все адреса электронной почты из данного файла:
grep -E -o "b[A-Za-z0-9._%+-][email protected][A-Za-z0-9.-]+.[A-Za-z]{2,6}b" file.txt -
Сопоставьте и извлеките все действительные IP-адреса из данного файла:
grep -E -o '(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)' file.txt
Параметр -o используется для печати только соответствующей строки.
Поиск нескольких строк (шаблонов)
Два или более шаблонов поиска можно объединить с помощью оператора ИЛИ | .
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, в котором метасимволы, такие как | теряют свое особое значение, и необходимо использовать их версии с обратной косой чертой.
В приведенном ниже примере мы ищем все вхождения слов fatal , error и critical в файле ошибок журнала Nginx :
grep 'fatal|error|critical' /var/log/nginx/error.logЕсли вы используете опцию расширенного регулярного выражения -E , то оператор | не следует экранировать, как показано ниже:
grep -E 'fatal|error|critical' /var/log/nginx/error.logСтроки печати перед матчем
Чтобы напечатать определенное количество строк перед совпадающими строками, используйте параметр -B (или --before-context ).
Например, чтобы отобразить пять строк ведущего контекста перед совпадающими строками, вы должны использовать следующую команду:
grep -B 5 root /etc/passwdПечатать строки после матча
Чтобы напечатать определенное количество строк после совпадающих строк, используйте параметр -A (или --after-context ).
Например, чтобы отобразить пять строк конечного контекста после совпадающих строк, вы должны использовать следующую команду:
grep -A 5 root /etc/passwdВыводы
Команда grep позволяет искать шаблон внутри файлов. Если совпадение найдено, grep печатает строки, содержащие указанный шаблон.
Подробнее о Grep можно узнать на странице руководства пользователя Grep .
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
This is my solution for the problem. It comes with the feature of also checking in sub-directories, as well as being able to handle multiple file types. It is also quite easy to add support for other ones. The downside is of course that it’s quite chunky code. But let me know what you think.
import os
import docx2txt
from pptx import Presentation
import pdfplumber
def findFiles(strings, dir, subDirs, fileContent, fileExtensions):
# Finds all the files in 'dir' that contain one string from 'strings'.
# Additional parameters:
# 'subDirs': True/False : Look in sub-directories of your folder
# 'fileContent': True/False :Also look for the strings in the file content of every file
# 'fileExtensions': True/False : Look for a specific file extension -> 'fileContent' is ignored
filesInDir = []
foundFiles = []
filesFound = 0
if not subDirs:
for filename in os.listdir(dir):
if os.path.isfile(os.path.join(dir, filename).replace("\", "/")):
filesInDir.append(os.path.join(dir, filename).replace("\", "/"))
else:
for root, subdirs, files in os.walk(dir):
for f in files:
if not os.path.isdir(os.path.join(root, f).replace("\", "/")):
filesInDir.append(os.path.join(root, f).replace("\", "/"))
print(filesInDir)
# Find files that contain the keyword
if filesInDir:
for file in filesInDir:
print("Current file: "+file)
# Define what is to be searched in
filename, extension = os.path.splitext(file)
if fileExtensions:
fileText = extension
else:
fileText = os.path.basename(filename).lower()
if fileContent:
fileText += getFileContent(file).lower()
# Check for translations
for string in strings:
print(string)
if string in fileText:
foundFiles.append(file)
filesFound += 1
break
return foundFiles
def getFileContent(filename):
'''Returns the content of a file of a supported type (list: supportedTypes)'''
if filename.partition(".")[2] in supportedTypes:
if filename.endswith(".pdf"):
content = ""
with pdfplumber.open(filename) as pdf:
for x in range(0, len(pdf.pages)):
page = pdf.pages[x]
content = content + page.extract_text()
return content
elif filename.endswith(".txt"):
with open(filename, 'r') as f:
content = ""
lines = f.readlines()
for x in lines:
content = content + x
f.close()
return content
elif filename.endswith(".docx"):
content = docx2txt.process(filename)
return content
elif filename.endswith(".pptx"):
content = ""
prs = Presentation(filename)
for slide in prs.slides:
for shape in slide.shapes:
if hasattr(shape, "text"):
content = content+shape.text
return content
else:
return ""
supportedTypes = ["txt", "docx", "pdf", "pptx"]
print(findFiles(strings=["buch"], dir="C:/Users/User/Desktop/", subDirs=True, fileContent=True, fileExtensions=False))
Иногда может понадобится найти файл, в котором содержится определённая строка или найти строку в файле, где есть нужное слово. В Linux для этого существует несколько утилит, одна из самых используемых это grep. С её помощью можно искать не только строки в файлах, но и фильтровать вывод команд, и много чего ещё.
В этой инструкции мы рассмотрим что такое команда grep Linux, подробно разберём синтаксис и возможные опции grep, а также приведём несколько примеров работы с этой утилитой.
Что такое grep?
Название команды grep расшифровывается как “search globally for lines matching the regular expression, and print them”. Это одна из самых востребованных команд в терминале Linux, которая входит в состав проекта GNU. До того как появился проект GNU, существовала утилита предшественник grep, тем же названием, которая была разработана в 1973 году Кеном Томпсоном для поиска файлов по содержимому в Unix. А потом уже была разработана свободная утилита с той же функциональностью в рамках GNU.
Grep дает очень много возможностей для фильтрации текста. Вы можете выбирать нужные строки из текстовых файлов, отфильтровать вывод команд, и даже искать файлы в файловой системе, которые содержат определённые строки. Утилита очень популярна, потому что она уже предустановлена прочти во всех дистрибутивах.
Синтаксис grep
Синтаксис команды выглядит следующим образом:
$ grep [опции] шаблон [/путь/к/файлу/или/папке…]
Или:
$ команда | grep [опции] шаблон
Здесь:
- Опции – это дополнительные параметры, с помощью которых указываются различные настройки поиска и вывода, например количество строк или режим инверсии.
- Шаблон – это любая строка или регулярное выражение, по которому будет выполняться поиск.
- Имя файла или папки – это то место, где будет выполняться поиск. Как вы увидите дальше, grep позволяет искать в нескольких файлах и даже в каталоге, используя рекурсивный режим.
Возможность фильтровать стандартный вывод пригодится, например, когда нужно выбрать только ошибки из логов или отфильтровать только необходимую информацию из вывода какой-либо другой утилиты.
Опции
Давайте рассмотрим самые основные опции утилиты, которые помогут более эффективно выполнять поиск текста в файлах grep:
- -E, –extended-regexp – включить расширенный режим регулярных выражений (ERE);
- -F, –fixed-strings – рассматривать шаблон поиска как обычную строку, а не регулярное выражение;
- -G, –basic-regexp – интерпретировать шаблон поиска как базовое регулярное выражение (BRE);
- -P, –perl-regexp – рассматривать шаблон поиска как регулярное выражение Perl;
- -e, –regexp – альтернативный способ указать шаблон поиска, опцию можно использовать несколько раз, что позволяет указать несколько шаблонов для поиска файлов, содержащих один из них;
- -f, –file – читать шаблон поиска из файла;
- -i, –ignore-case – не учитывать регистр символов;
- -v, –invert-match – вывести только те строки, в которых шаблон поиска не найден;
- -w, –word-regexp – искать шаблон как слово, отделенное пробелами или другими знаками препинания;
- -x, –line-regexp – искать шаблон как целую строку, от начала и до символа перевода строки;
- -c – вывести количество найденных строк;
- –color – включить цветной режим, доступные значения: never, always и auto;
- -L, –files-without-match – выводить только имена файлов, будут выведены все файлы в которых выполняется поиск;
- -l, –files-with-match – аналогично предыдущему, но будут выведены только файлы, в которых есть хотя бы одно вхождение;
- -m, –max-count – остановить поиск после того как будет найдено указанное количество строк;
- -o, –only-matching – отображать только совпавшую часть, вместо отображения всей строки;
- -h, –no-filename – не выводить имя файла;
- -q, –quiet – не выводить ничего;
- -s, –no-messages – не выводить ошибки чтения файлов;
- -A, –after-content – показать вхождение и n строк после него;
- -B, –before-content – показать вхождение и n строк после него;
- -C – показать n строк до и после вхождения;
- -a, –text – обрабатывать двоичные файлы как текст;
- –exclude – пропустить файлы имена которых соответствуют регулярному выражению;
- –exclude-dir – пропустить все файлы в указанной директории;
- -I – пропускать двоичные файлы;
- –include – искать только в файлах, имена которых соответствуют регулярному выражению;
- -r – рекурсивный поиск по всем подпапкам;
- -R – рекурсивный поиск включая ссылки;
Все самые основные опции рассмотрели, теперь давайте перейдём к примерам работы команды grep Linux.
Примеры использования grep
Давайте перейдём к практике. Сначала рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep.
1. Поиск текста в файле
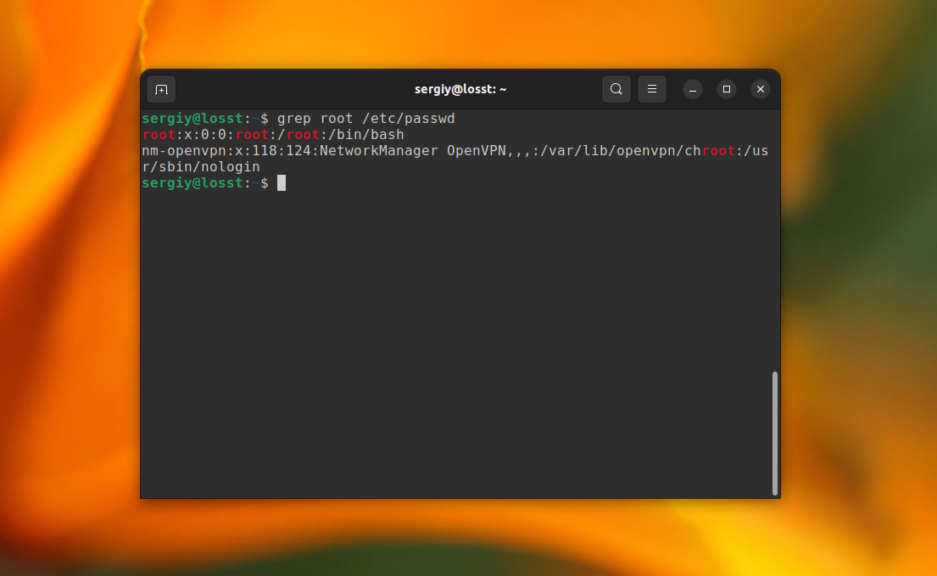
В первом примере мы будем искать информацию о пользователе root в файле со списком пользователей Linux /etc/passwd. Для этого выполните следующую команду:
grep root /etc/passwd
В результате вы получите что-то вроде этого:
С помощью опции -i можно указать, что регистр символов учитывать не нужно. Например, давайте найдём все строки содержащие вхождение слова time в том же файле:
grep -i "time" /etc/passwd
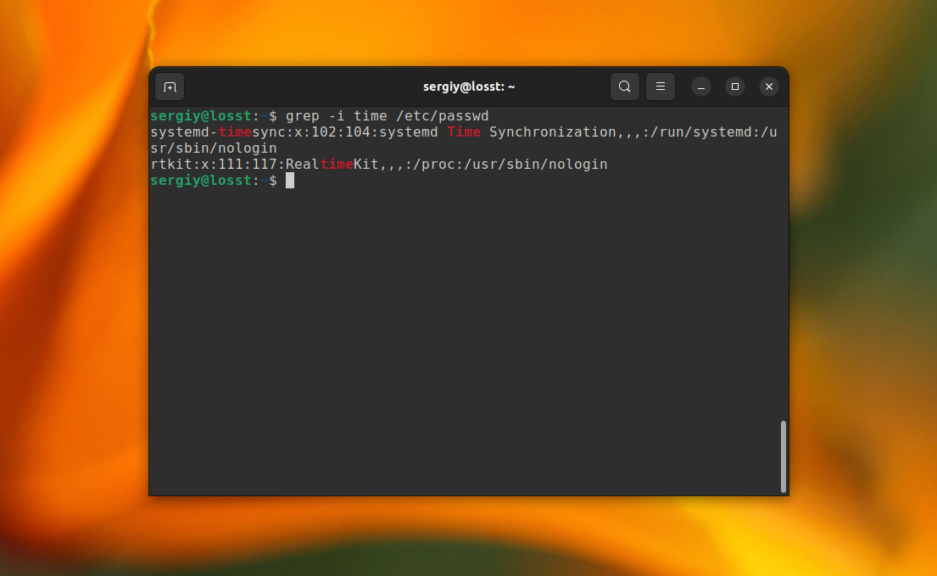
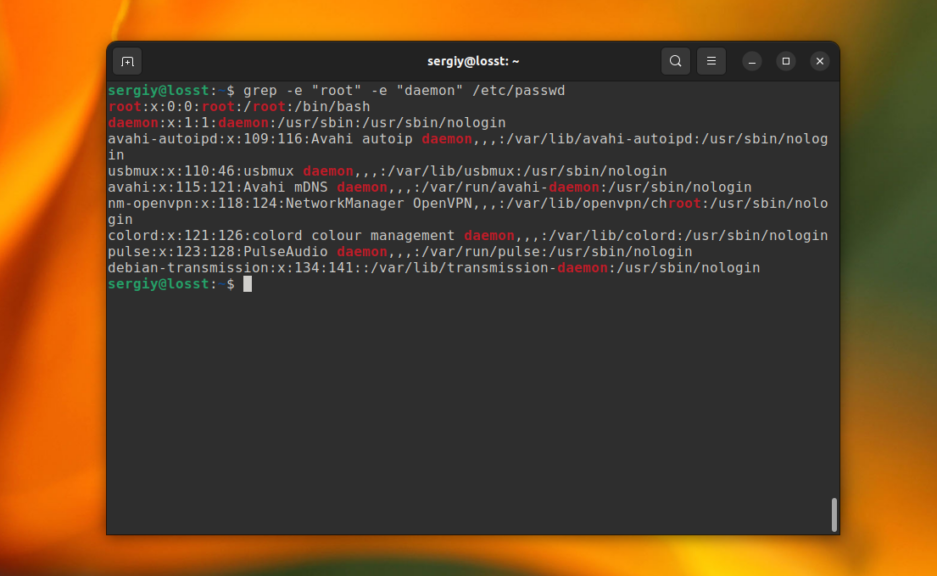
В этом случае Time, time, TIME и другие вариации слова будут считаться эквивалентными. Ещё, вы можете указать несколько условий для поиска, используя опцию -e. Например:
grep -e "root" -e "daemon" /etc/passwd
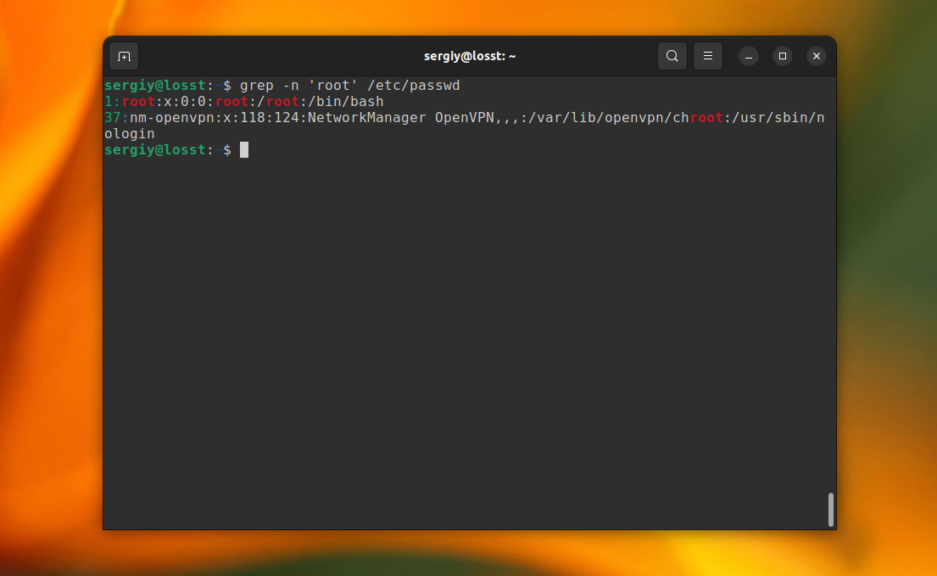
C помощью опции -n можно выводить номер строки, в которой найдено вхождение, например:
grep -n 'root' /etc/passwd
Это всё хорошо работает пока ваш поисковый запрос не содержит специальных символов. Например, если вы попытаетесь найти все строки, которые содержат символ “[” в файле /etc/grub/00_header, то получите ошибку, что это регулярное выражение не верно. Для того чтобы этого избежать, нужно явно указать, что вы хотите искать строку с помощью опции -F:
grep -F "[" /etc/grub.d/00_header
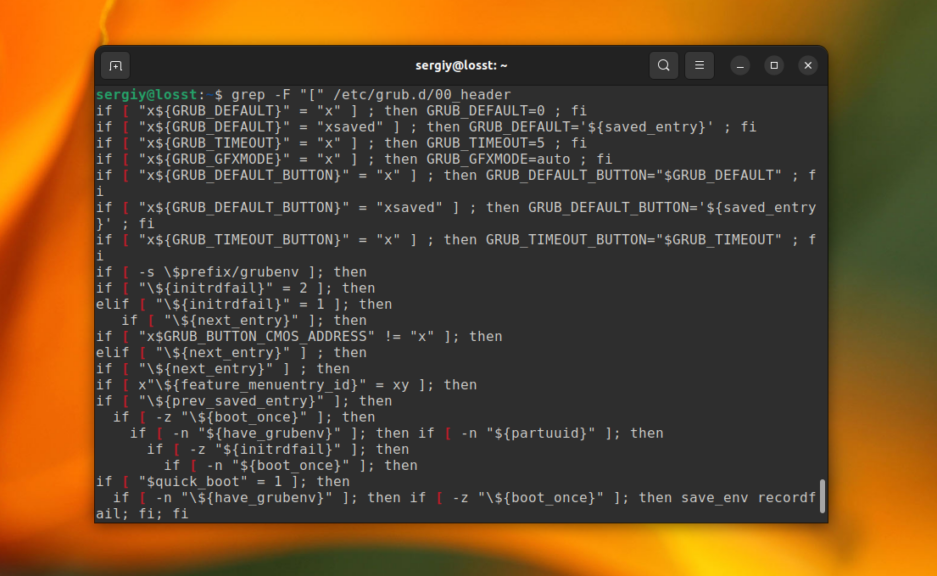
Теперь вы знаете как выполняется поиск текста файлах grep.
2. Фильтрация вывода команды
Для того чтобы отфильтровать вывод другой команды с помощью grep достаточно перенаправить его используя оператор |. А файл для самого grep указывать не надо. Например, для того чтобы найти все процессы gnome можно использовать такую команду:
ps aux | grep "gnome"
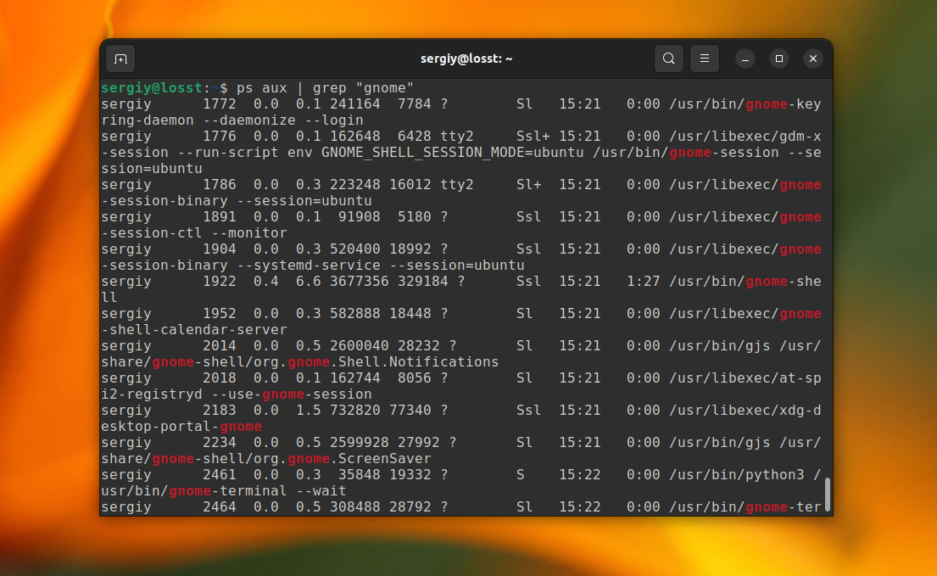
В остальном всё работает аналогично.
3. Базовые регулярные выражения
Утилита grep поддерживает несколько видов регулярных выражений. Это базовые регулярные выражения (BRE), которые используются по умолчанию и расширенные (ERE). Базовые регулярные выражение поддерживает набор символов, позволяющих описать каждый определённый символ в строке. Это: ., *, [], [^], ^ и $. Например, вы можете найти строки, которые начитаются на букву r:
grep "^r" /etc/passwd
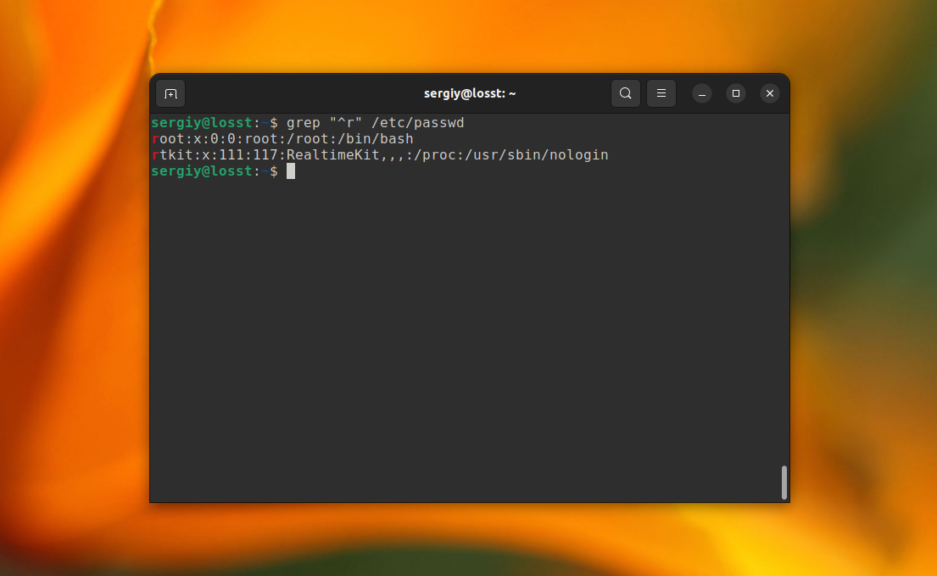
Или же строки, которые содержат большие буквы:
grep "[A-Z]" /etc/passwd
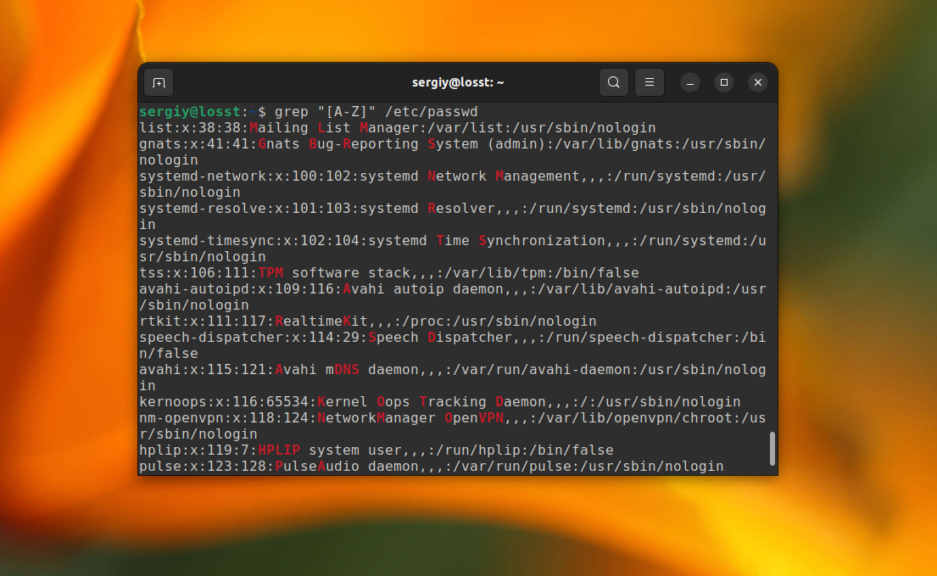
А так можно найти все строки, которые заканчиваются на ready в файле /var/log/dmesg:
grep "ready$" /var/log/dmesg
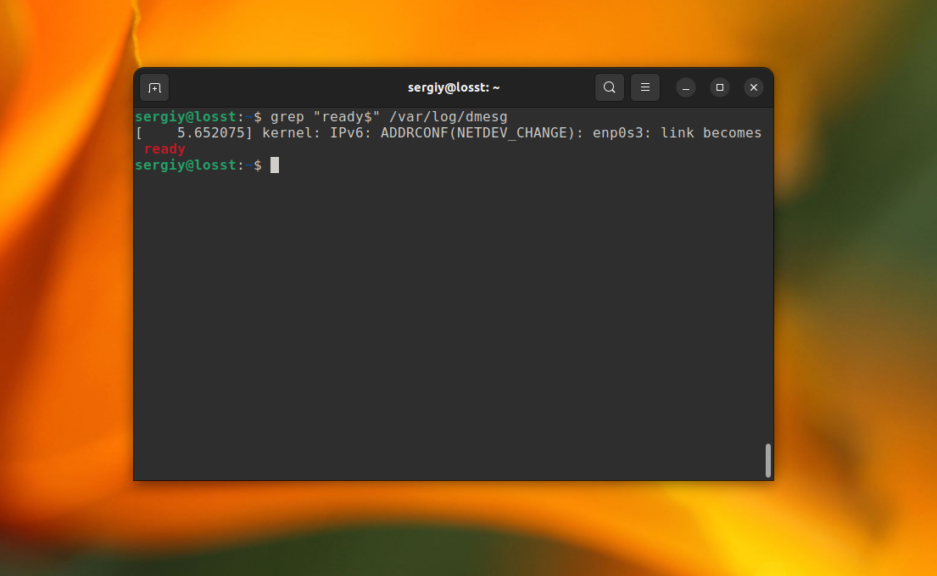
Но используя базовый синтаксис вы не можете указать точное количество этих символов.
4. Расширенные регулярные выражения
В дополнение ко всем символам из базового синтаксиса, в расширенном синтаксисе поддерживаются также такие символы:
- + – одно или больше повторений предыдущего символа;
- ? – ноль или одно повторение предыдущего символа;
- {n,m} – повторение предыдущего символа от n до m раз;
- | – позволяет объединять несколько паттернов.
Для активации расширенного синтаксиса нужно использовать опцию -E. Например, вместо использования опции -e, можно объединить несколько слов для поиска вот так:
grep -E "root|daemon" /etc/passwd
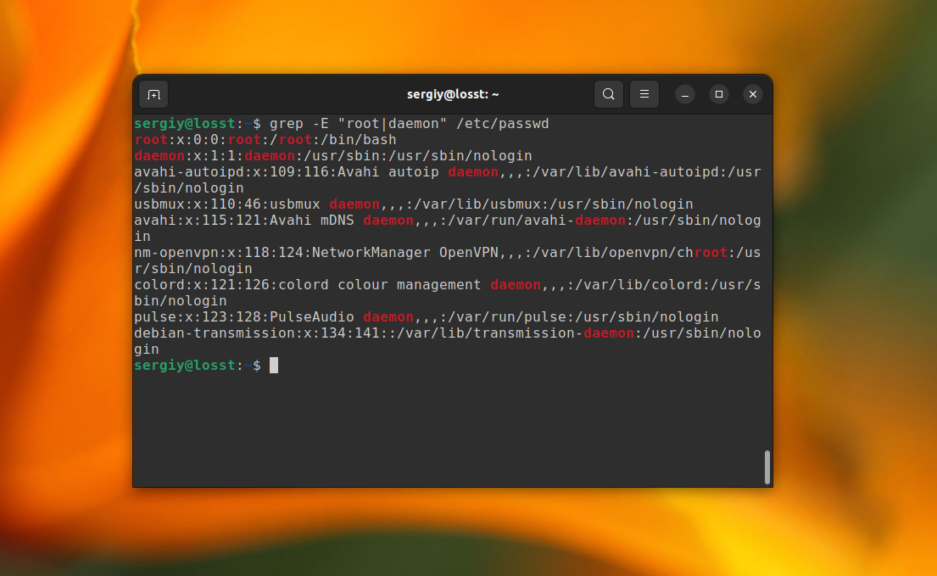
Вообще, регулярные выражения grep – это очень обширная тема, в этой статье я лишь показал несколько примеров. Как вы увидели, поиск текста в файлах grep становиться ещё эффективнее. Но на полное объяснение этой темы нужна целая статья, поэтому пока пропустим её и пойдем дальше.
5. Вывод контекста
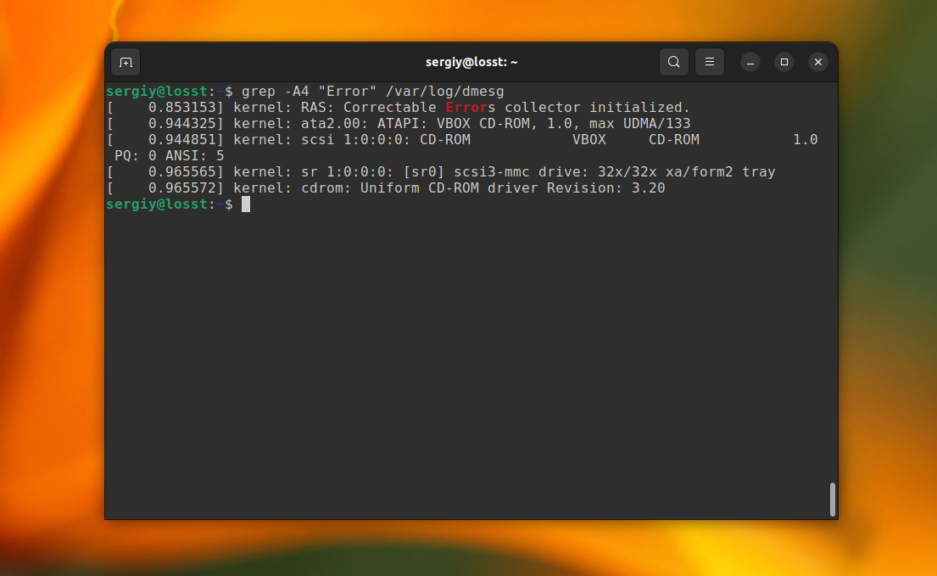
Иногда бывает очень полезно вывести не только саму строку со вхождением, но и строки до и после неё. Например, мы хотим выбрать все ошибки из лог-файла, но знаем, что в следующей строчке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк. Ошибки будем искать в /var/log/dmesg по шаблону “Error”:
grep -A4 "Error" /var/log/dmesg
Выведет строку с вхождением и 4 строчки после неё:
grep -B4 "Error" /var/log/dmesg
Эта команда выведет строку со вхождением и 4 строчки до неё. А следующая выведет по две строки с верху и снизу от вхождения.
grep -C2 "Error" /var/log/dmesg
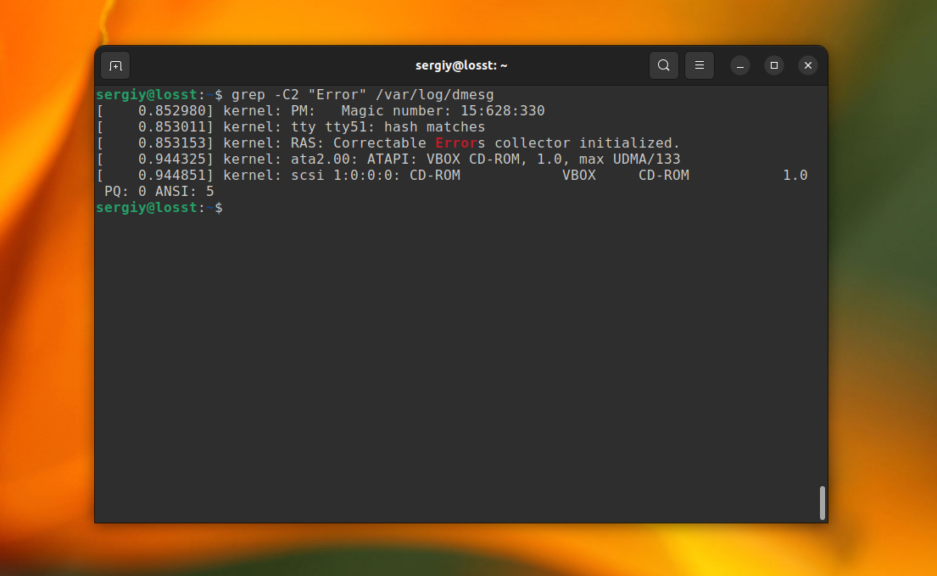
6. Рекурсивный поиск в grep
До этого мы рассматривали поиск в определённом файле или выводе команд. Но grep также может выполнить поиск текста в нескольких файлах, размещённых в одном каталоге или подкаталогах. Для этого нужно использовать опцию -r. Например, давайте найдём все файлы, которые содержат строку Kernel в папке /var/log:
grep -r "Kernel" /var/log
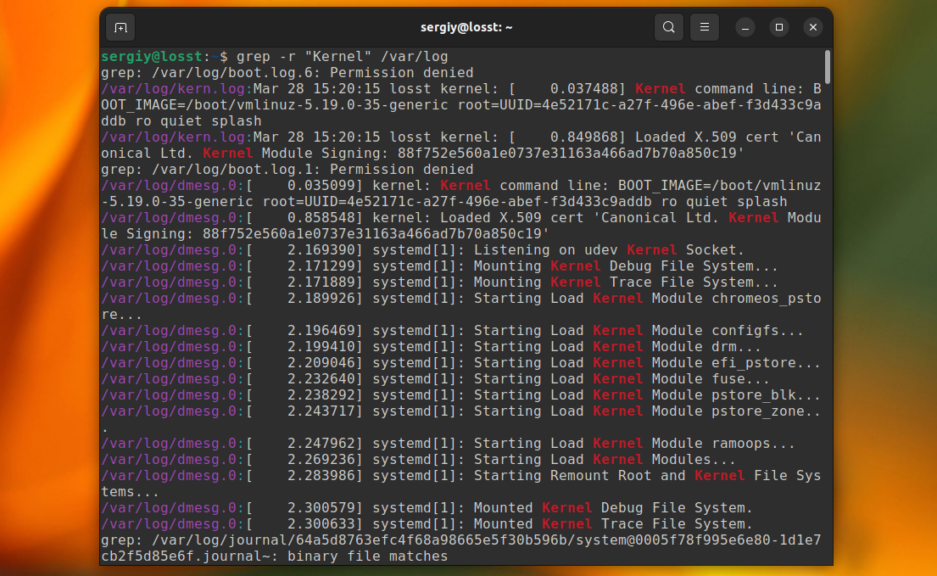
Папка с вашими файлами может содержать двоичные файлы, в которых поиск выполнять обычно не надо. Для того чтобы их пропускать используйте опцию -I:
grep -rI "Kernel" /var/log
Некоторые файлы доступны только суперпользователю и для того чтобы выполнять по ним поиск вам нужно запускать grep с помощью sudo. Или же вы можете просто скрыть сообщения об ошибках чтения и пропускать такие файлы с помощью опции -s:
grep -rIs "Kernel" /var/log
7. Выбор файлов для поиска
С помощью опций –include и –exclude вы можете фильтровать файлы, которые будут принимать участие в поиске. Например, для того чтобы выполнить поиск только по файлам с расширением .log в папке /var/log используйте такую команду:
grep -r --include="*.log" "Kernel" /var/log
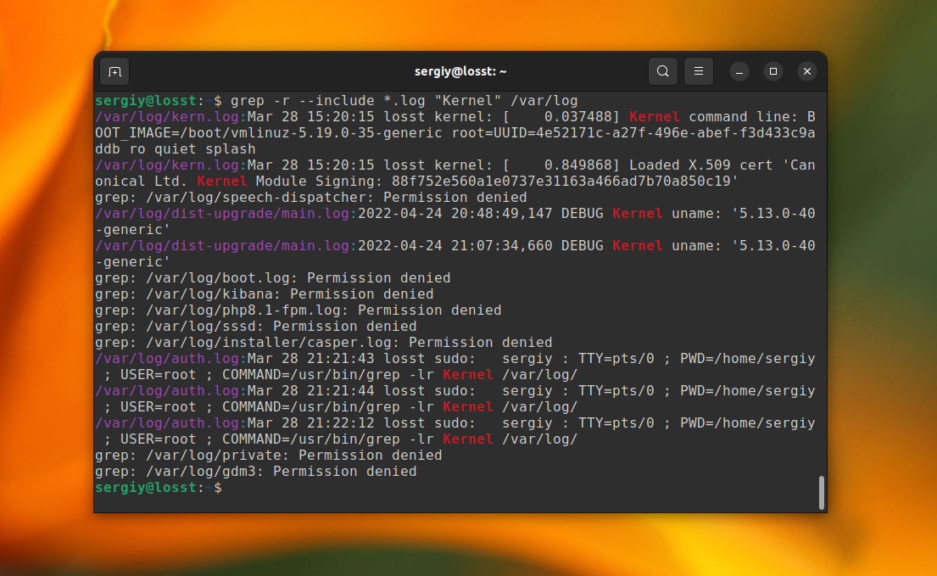
А для того чтобы исключить все файлы с расширением .journal надо использовать опцию –exclude:
grep -r --exclude="*.journal" "Kernel" /var/log
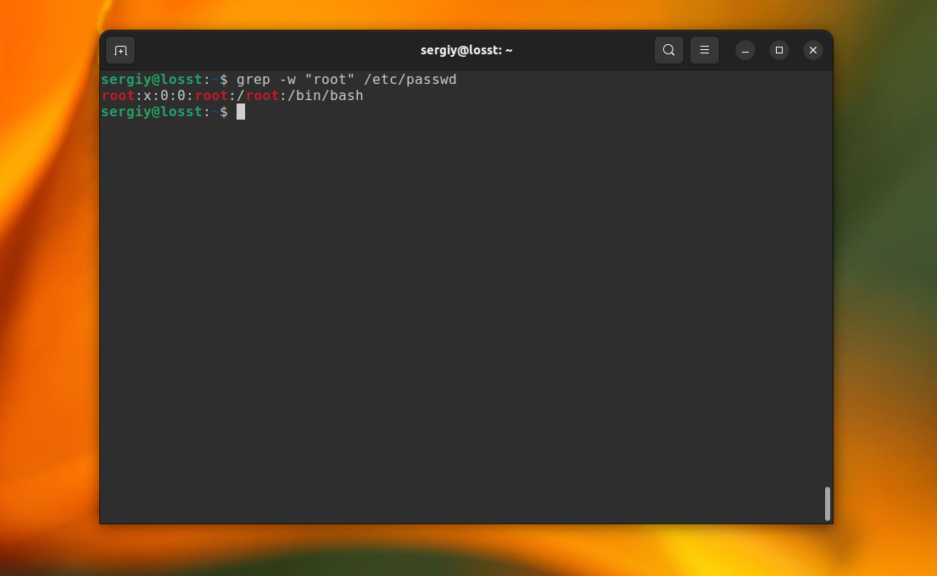
8. Поиск слов в grep
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить утилиту искать по содержимому файлов в Linux строки, которые включают только искомые слова полностью с помощью опции -w. Например:
grep -w "root" /etc/passwd
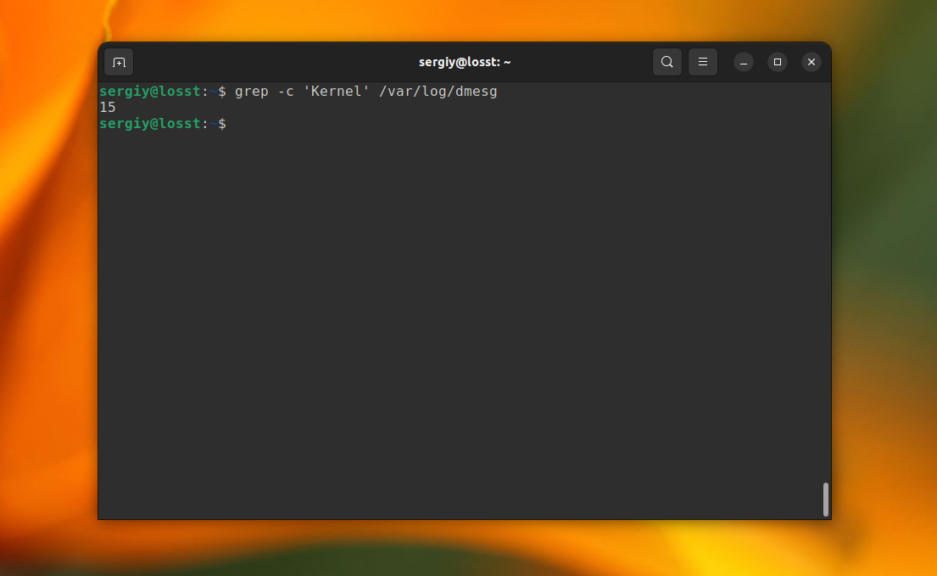
9. Количество строк
Утилита grep может сообщить, сколько строк с определенным текстом было найдено файле. Для этого используется опция -c (счетчик). Например:
grep -c 'Kernel' /var/log/dmesg
10. Инвертированный поиск
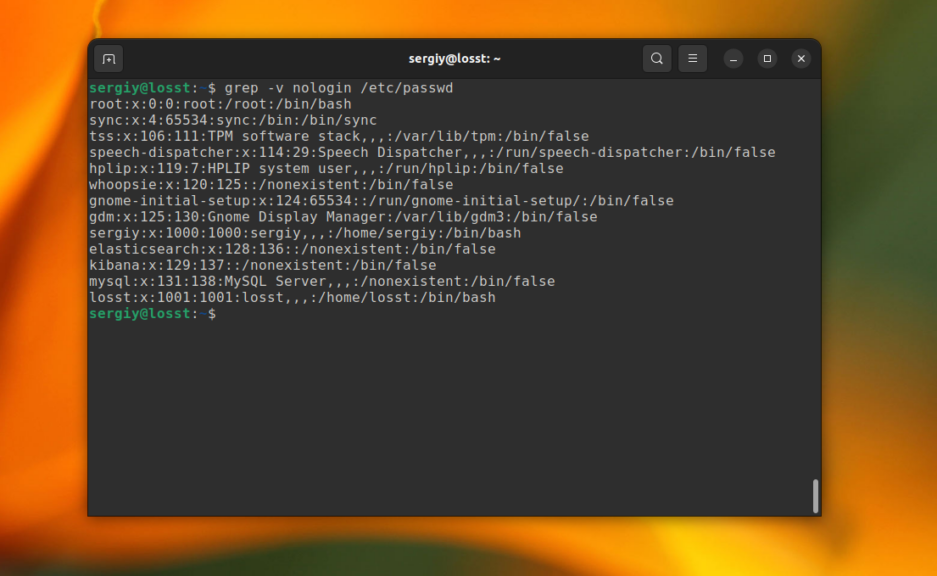
Команда grep Linux может быть использована для поиска строк, которые не содержат указанное слово. Например, так можно вывести только те строки, которые не содержат слово nologin:
grep -v nologin /etc/passwd
11. Вывод имен файлов
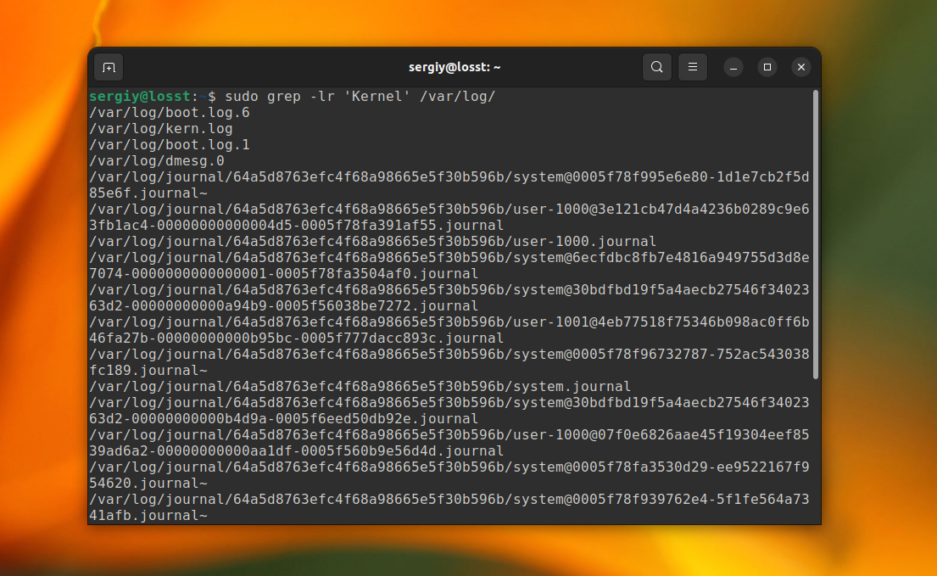
Вы можете указать grep выводить только имена файлов, в которых было хотя бы одно вхождение с помощью опции -l. Например, следующая команда выведет все имена файлов из каталога /var/log, при поиске по содержимому которых было обнаружено вхождение Kernel:
grep -lr 'Kernel' /var/log/
12. Цветной вывод
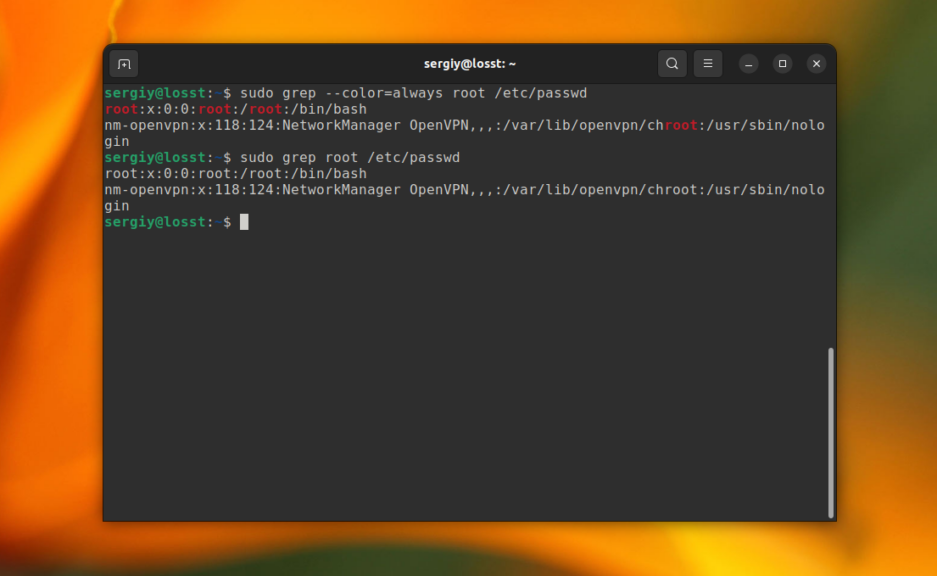
По умолчанию grep не будет подсвечивать совпадения цветом. Но в большинстве дистрибутивов прописан алиас для grep, который это включает. Однако, когда вы используйте команду c sudo это работать не будет. Для включения подсветки вручную используйте опцию –color со значением always:
sudo grep --color=always root /etc/passwd
Получится:
Выводы
Вот и всё. Теперь вы знаете что представляет из себя команда grep Linux, а также как ею пользоваться для поиска файлов и фильтрации вывода команд. При правильном применении эта утилита станет мощным инструментом в ваших руках. Если у вас остались вопросы, пишите в комментариях!
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.

Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна .
1. Немного про grep
Команда grep (global regular expression print) остается одной из наиболее универсальных команд в окружении командной строки Linux. Это происходит потому что grep является чрезвычайно мощной утилитой которая дает пользователям возможность сортировать ввод на основе сложных правил, тем самым делая ее популярным связующим звеном в конвейере команд. Grep в основном используется для поиска текста как в данных поступающих на стандартный вход, так и в указанных файлах на предмет строк содержащих указанные слова или подстроки.
2. Базовый синтаксис команды grep
Ниже представлены примеры использования grep с базовым синтаксисом:
grep 'word' filename
grep 'word' file1 file2 file3
grep 'string1 string2' filename
cat otherfile | grep 'something'
command | grep 'something'
command option1 | grep 'data'
grep --color 'data' fileName
3. Как использовать grep для поиска в файлах
Попробуем найти пользователя “vasya” в файле passwd. Для поиска в файле /etc/passwd информации о пользователе “vasya” необходимо использовать следующую команду:
grep vasya /etc/passwd
Пример результата:
vasya:x:1000:1000:vasya,,,:/home/vasya:/bin/bash
Также мы можем попросить grep осуществлять поиск игнорируя регистр букв, то есть не делая различия между большими и маленькими буквами. Для этого используется параметр -i, как показано ниже:
grep -i "vasya" /etc/passwd
4. Рекурсивное использование grep
Если у вас есть большое количество текстовых файлов в ряде директорий и поддиректорий, к примеру, конфигурационных файлов apache в /etc/apache2 и требуется найти файл где содержится определенный текст, то стоит использовать параметр -r чтобы осуществить рекурсивный поиск. То есть поиску будет осуществлен по всем файлам в иерархии директорий:
grep -r "domain.tld" /etc/apache2/
Также можно использовать этот параметр в верхнем регистре. То есть можно писать -R. Разница в том что при использовании -r не происходит обработка символических ссылок, а при использовании -R – происходит. Пример использования:
grep -R debian /etc/apache2/
/etc/apache2/sites-available/debian-help.ru: ServerName debian-help.ru
/etc/apache2/sites-available/debian-help.ru: ServerAlias www.debian-help.ru
Как можно видеть результат состоит из имени файла, где была найдена строка и самой строки. Включение в вывод имен файлов можно с легкостью подавить с помощью параметра -h, как показано ниже:
grep -r -h debian /etc/apache2/
ServerName debian-help.ru
ServerAlias www.debian-help.ru
5. Использование grep для поиска только целых слов
Когда вы ищите qwe, grep выберет все вхождения данного сочетания, к примеру, qwerty, qwe123, 345qwerty и множество других комбинаций. Вы можете указать, чтобы grep выбирал только те строки, которые содержат точное включение в виде целого слова. Для этого используйте параметр -w:
grep -w "qwe" filename
6. Как искать несколько различных слов
Для поиска двух или более различных слов вы можете использовать команду egrep следующим образом:
egrep -w 'first_word|second_word' filename
Либо вариант с просто grep:
grep -w 'first_word|second_word' filename
7. Подсчет количества строк, содержащих вхождение
grep может сообщать сколько строк содержат указанное сочетание. Для этого воспользуйтесь параметром -c (count):
grep -c 'word' filename
В дополнение, можно использовать параметр -n чтобы заставить grep выводить номера строк в файле, в которых было найдено включение:
grep -n 'www-data' /etc/passwd
13:www-data:x:33:33:www-data:/var/www:/usr/sbin/nologin
8. Инвертный поиск
grep позволяет осуществлять поиск наоборот, то есть будут выведены все строки, кроме имеющих вхождение указанного слова и для этого используется параметр -v:
grep -v 'word' filename
Можно исключить что-либо из вывода поиска применив конвейер:
grep 'first_word' filename | grep -v 'second_word'
9. Как выводить только имена файлов в которых есть включение слова
Для вывода только имен файлов нужно использовать параметр -l, к примеру, так:
grep -l 'word' *.txt
10. Поиск всех файлов содержащих слово во всех файлах и поддиректориях
Если вам нужно осуществить поиск слова в любых формах во всех файлах в этой директории и всех содержащихся в ней тоже, то используйте сочетание описанных выше параметров:
grep -rli 'word' ./*
11. Вывод строк перед и после найденного вхождения
Для вывода нескольких строк перед вхождением используется параметры -A, а после вождения -B.
К примеру, чтобы вывести 5 строк перед и 10 после найденного вхождения используйте команду:
grep -A 5 -B 10 'word' filename
