
Какие существуют методы извлечения Фамилии Имени Отчества из текста?
Какие существуют методы извлечения Фамилии Имени Отчества из текста?
Сложно конечно предположить наличиие какого-либо универсального алгоритма, скорее интересуют практические наработки и статьи, дающее представление о направлениях в каких можно двигаться.
Интересуют возможности выделения ФИО в формате “Путин В.В./Путин Владминир Владимирович/Владминир Владимирович” (в разных падежах) и т.д.
-
Вопрос заданболее трёх лет назад
-
8258 просмотров
ну вот сходу шаблон для написания regexp:
1. два или три слова (разделитель: не буква или цифра (или несколько))
2. все 1-е буквы – заглавные,
3. минимум одно слово – состоит НЕ из 1 буквы.
4. если слово из 1-й буквы – следующий символ обязательно: “.” (точка)
5 расстояние Левенштейна по словарю имен, фамилий и отчеств (через их сочетания).
Отбой. Если кому интересно Яндекс некоторое время назад опубликовал исходные тексты tomita парсера (github.com/yandex/tomita-parser). Надо признать кода очень много и изучить его работы изнутри будет достаточно интересно, но касательно заданного вопроса вывод такой: используются данные из mystem и достаточно большое кол-во правил (код на C++).
Пригласить эксперта
Попробуйте томита-парсер от Яндекса.
Гугл работает над семантическим поиском, там каждому имени и фимилии присвоен отдельный крякозябр (/m/05qt0″ – Politics, Путин есть на русском и даже Мизулина ) с чёрточками (ну и остальным словам, уже поиск работает, у меня тодже по нескольким выражениям), по английскому запросто а по русски там мало слов. v3 это типо там надо искать. Лет через 10 такой проблемы наверное не возникнет.
Должны существовать корпуса со списком всех имён/фамилий/отчеств. Как минимум, можно автоматически выбрать из википедии или dbpedia (структурированные данные из википедии).
1. Находим корпуса или формируем свой.
2. Делаем поиск на совпадение хотя бы с одним словом (лучше, на частичное совпадени — на случай опечаток и всяких склонений).
3. Когда находим, выделяем окрестность слова (пара слов влево-вправо) и анализируем его эвристиками.
Если задача серьёзная (не хобби), то раз упомянули томиту, упомяну и такую молотилку текстов: ABBYY Tagger. Словари и правила в комплекте. Но вариант не бюджетный.
Это называется задача распознавания именованных сущностей (named entity recognition). В вашем случае имен персон. Наш продукт Textocat API умеет это делать: убедитесь в этом сами на странице демо для русского языка или получите бесплатный ключ к API после регистрации на нашем сайте.
-
Показать ещё
Загружается…
18 мая 2023, в 19:39
5000 руб./за проект
18 мая 2023, в 19:22
1500 руб./за проект
18 мая 2023, в 19:20
800 руб./в час
Минуточку внимания
Время прочтения: 11 мин.
Очень часто в задачах текст майнинга требуется реализовать вытаскивание имён, года рождения, паспортных данных и т.п. из объемного текста. Для получения ФИО из текста существует библиотека “Natasha”. Но, когда имена в тексте попадаются “нестандартные” и очень редкие, библиотека, к сожалению, пасует. Также сложности появляются, когда ФИО находится не в именительном падеже, и/или имя и отчество записаны инициалами, да ещё и с неправильными знаками препинания и отступами. Плюс ко всему, мало того что “Natasha” может неверно извлечь ФИО, так ещё его нужно привести к нормальной форме (именительный падеж). Для этого существуют некоторые библиотеки, но справляются они также не со всеми именами, да и если “Natasha” неверно извлекла имя, дальнейшая лемматизация ФИО не имеет значения.
Итак, попробуем сделать алгоритм, который с лучшей точностью решает задачу извлечения имени из текста конкретно под наши данные и нужды, затем сделаем небольшое сравнение с отработкой готовых библиотек. Конечно же, как базовый инструмент использовать будем регулярные выражения :).
Следует заметить, что все дальнейшие имена в примерах были случайным образом изменены в силу политики конфиденциальности, любое совпадение с реальными людьми — случайно.
Итак, имеется огромная таблица с интересующей нас колонкой, в которой данные имеют следующий вид:

Вот в таком разнородном стиле заполнено много сотен тысяч строк с уймой опечаток, ошибок, неточностей.
Ладно, вооружимся регулярными выражениями и попробуем решить задачу. Для начала напишем несколько функций.
def text_is_upper(text):
"""Функция определения написан текст заглавными буквами и строчными"""
text = re.sub('[^А-Яа-я]', '',text) # Убираем лишние символы
try:
# % загл. букв
percent_upper = sum(map(str.isupper, text)) / len(text)
if percent_upper > 0.8: # Загл. букв больше- строка капсовая
return True
else:
return False
except Exception as e:
return False
def find_name(text):
"""Функция поиска ФИО"""
text = str(text) # Для уверенности переводим в строку
text = text.replace('Ё','Е')
text = text.replace('ё','е')
# Удаляем двойные пробелы:
text = re.sub(r's+',' ', text)
# Ищем паттерн Урова Елена Михайловна / ГЛУХИХ АННА АЛЕКСЕЕВНА
# name = None # Инициализация переменной вытянутого имени
""" Паттерн:
Первое слово - Загл. буква, далее не пробел, не точка,
не запятая, далее могут идти строчные буквы
Второе слово - Заглавная буква + строчные
или одна заглавная как инициал
После - пробел или точка для отделения инициала
Третье слово - аналогично второму.
(Урова Елена Михайловна, ГЛУХИХ АННА АЛЕКСЕЕВНА, Заяц А.О) """
pattern = r'((b[A-Я][^A-Яs.,][a-я]*)(s+)([A-Я][a-я]*)'+
'(.+s*|s+)([A-Я][a-я]*))'
# Если строка не написана капсом:
if not text_is_upper(text):
name = re.findall(pattern, text)
# Разбиваем ФИО на три строки Ф, И, О:
if name:
FIO = name[0][0].replace('.',' ')
FIO = re.sub(r's+',' ', FIO).split(' ')
if len(FIO) >= 3:
return FIO[0], FIO[1], FIO[2]
elif len(FIO) == 2:
return FIO[0], FIO[1], 'пусто'
elif len(FIO) == 1:
return FIO[0], 'пусто', 'пусто'
else:
return 'пусто','пусто','пусто'
# Если строка капсовая:
else:
# Определяем по слову перед ФИО :(
try: # Индекс, откуда начинается ФИО осужденного:
start_number_index = re.search(
r'(bосуждw{0,} )|(bосужд. )',
text, flags=re.I).end()
text_cut = text[start_number_index:]
FIO = text_cut.replace('.',' ')
FIO = re.sub(r's+',' ', FIO).split(' ')
if len(FIO) >= 3:
return FIO[0], FIO[1], FIO[2]
elif len(FIO) == 2:
return FIO[0], FIO[1], 'пусто'
elif len(FIO) == 1:
return FIO[0], 'пусто', 'пусто'
except Exception:
return 'пусто','пусто','пусто'
Ниже df[‘Purpose’] — колонка таблицы, где находится интересующий нас текст.
# Получаем общую колонку ФИО соответсвует с 3мя ответами
df['ФИО'] = df['PURPOSE'].apply(lambda text: find_name(text))
# Распределяем на три столбца
df['Ф'] = df['ФИО'].apply(lambda x: x[0])
df['И'] = df['ФИО'].apply(lambda x: x[1])
df['О'] = df['ФИО'].apply(lambda x: x[2])
df = df.drop(['ФИО'], axis=1)
Вот так с помощью “регулярок”, мы предварительно вытащили ФИО из текста и разделили по разным столбцам. Поехали дальше… Теперь хотелось бы определить в каком падеже находится наше имя (соответственно фамилия и отчество тоже будут в этом падеже). Поступим так: для начала с какого-нибудь сайта сделаем выгрузку мужских и женских имён. Пример полученного файла с именами:

В коде ниже готовые тестовые файлы со списком имён называются “мужские имена.txt” и “женские_имена.txt”. Сформируем из текстовых данных списки и добавим в них некоторые редкие имена, отсутствующие в исходном файле, но присутствующие в наших данных (это делается путём прогонки алгоритма и сортировкой результатов по неотработанным именам).
male_names = open('мужские имена.txt', encoding = 'utf-8').read()[1:]
female_names = open('женские имена.txt', encoding = 'utf-8').read()[1:]
list_male_names = male_names.lower().split('nn')
list_female_names = female_names.lower().split('nn')
# Добавим редкие имена, которые встречаются в нашей таблице:
list_male_names.extend(['эдуард', 'айдар', 'алик', 'рустам',
'ильдар', 'азамат','равиль','альбек',
'магомед','яков','радион','вугар','дамир',
'марсель','радик','ильгиз', 'аким', 'ашот',
'наиль', 'рафаииль','эрик', 'ильсур',
'роберт','ленар','кайрат','арсен',
'гаврил','камиль','феликс'])
list_female_names.extend(['зинаида', 'марса','анжела', 'зуфара',
'лиана','камила','лиа','дария','даниэла',
'леся','роза','юлианна','дина'])
list_male_names = list(map(lambda x: x.replace('ё','е'),
list_male_names))
list_female_names = list(map(lambda x: x.replace('ё','е'),
list_female_names))
Список имён получили. Далее пробуем пройтись по полученному столбцу df[‘Имя’] и преобразовать имя в именительный падеж при необходимости. Вся логика основана на окончании слова, в коде ниже есть комментарии 🙂
def percent_similarity(comparing_name, list_of_names):
""" Функция сравнения имён """
if comparing_name.lower() in list_of_names:
# если извл.имя есть в списке имён - оно в им.п.:
return comparing_name
# ПавлЕ, ПавлУ, ПавлОМ... (одно из имен не подх.под алгор.):
if comparing_name.lower().startswith('павл'):
return 'павел'
# Если имени нет в списке имен в им.падеже, ищем в др. падеже:
for name_from_list in list_of_names:
# Если извлеченное имя длинее имени из списка имен:
if len(comparing_name) > len(name_from_list):
# Ищем имя из списка:
# Родительный падеж
if comparing_name[:-1] == name_from_list: # ТимурА>Тимур
return name_from_list # им. падеж возвращаем
break
# Творительный падеж
elif (comparing_name[:-2] == name_from_list[:-1] and
comparing_name[-2:] == 'ем') or
(comparing_name[:-2] == name_from_list and
comparing_name[-2:] == 'ом'): # ВикторОМ, РоманОМ...
return name_from_list # АлексеЕМ, ВиталиЕМ...
break
# Если длина имени одинаковая и отл. буква в конце слова
elif len(comparing_name) == len(name_from_list) and
comparing_name[:-1] == name_from_list[:-1]: # ОльгЕ > ОльгА
return name_from_list
break
# Преобразуем мужское и женское имена в им.падеж
df['Имя_мужское_им.падеж'] = df['И'].apply(
lambda name: percent_similarity(name.lower(), list_male_names))
df['Имя_женское_им.падеж'] = df['И'].apply(
lambda name: percent_similarity(name.lower(), list_female_names))
df['Имя_мужское_им.падеж'] = df['Имя_мужское_им.падеж'].fillna('пусто')
df['Имя_женское_им.падеж'] = df['Имя_женское_им.падеж'].fillna('пусто')
Так, получили именительный падеж имён для мужских и женских имён. Но ведь у нас встречаются имена, которые применимы и к женщине, и к мужчине. Например, женское имя Александра может быть воспринято как мужское имя Александр в родительном падеже (У Александра есть яблоко).
Вот тут-то нам придёт на помощь отчество. Нехитрыми соображениями о том, как склоняется отчество в разных падежах, попробуем понять, о ком идёт речь в тексте: о мужчине или о женщине.
def choose_F_M_name(M_name, F_name, Patronymic):
"""Функция определения имя относится к мужчине
или женщине (напр. Александра - Александр, Евгения - Евгений)"""
# Если percent_similarity определила и женское, и мужское имя:
if M_name != 'пусто' and F_name != 'пусто':
# Как правило, предпоследняя буква отчества у женщин - "н".
# "ИгоревНе, НиколаевНа". Поэтому смотрим пред.букву
try:
if Patronymic[-2].lower() == 'н':
M_name = 'пусто' # если есть "н" - удаляем муж. имя
else:
F_name = 'пусто' # если нет "н" - удаляем жен. имя
except:
pass
return M_name, F_name
# Удаляем мужское/женское имя при дублировании
df['transit'] = df.apply(lambda x:choose_F_M_name(
x['Имя_мужское_им.падеж'],
x['Имя_женское_им.падеж'],
x['О']), axis = 1)
df['Имя_мужское_им.падеж'] = df['transit'].apply(lambda x: x[0])
df['Имя_женское_им.падеж'] = df['transit'].apply(lambda x: x[1])
df = df.drop(['transit'], axis = 1)
Получили имена в именительном падеже. Посмотрим, что у нас имеется:

Теперь нужно что-то сделать с фамилией и отчеством. Будем проверять, если имя было преобразовано в именительный падеж (значения для каждого объекта в столбцах вытянутого имени и имени в именительном падеже разнятся), тогда пытаемся преобразовать отчество и фамилия. Опять же, всё делается из соображений по окончаниям слов в разных падежах.
def surname_patronymic_nominative(M_name,F_name,F,O,I):
"""Функция преобр. фамилии и отчества в им. падеж"""
"""Если имя уже было преобразовано в именительный"""
F_new, O_new = F,O # Инициализируем текущими значениями
F, O = F.lower(), O.lower()
# Мужчина Male:
if M_name != I.lower() and M_name != 'пусто':
if F[-1:] == 'а': # Род.падеж
F_new = F[:-1] # ЕвстифеевА > Евстифеев
elif F[-2:] == 'ым': # Твор.падеж
F_new = F[:-2] # ЕвстифеевЫМ > Евстифеев
elif F[-5:] == 'ского': # Твор.падеж
F_new = F[:-5] +'ский' # РяховСКОГО > РяховСКИЙ
elif F[-5:] == 'цкого': # Твор.падеж
F_new = F[:-5] +'цкий' # МудиЦКОГО > МудиЦКИЙ
else:
F_new = F # Соловых > Соловых
if O[-1:] == 'а': # ИгоревичА > Игоревич
O_new = O[:-1]
# Женщина Female:
elif F_name != I.lower() and F_name != 'пусто':
if F[-4:] == 'ской': # Род.падеж
F_new = F[:-4]+'ская' # СлабинСКОЙ > СлабинСКАЯ
elif F[-4:] == 'цкой': # Род.падеж
F_new = F[:-4]+'цкая' # ХмельниЦКОЙ > ХмельниЦКАЯ
elif F[-2:] == 'ой': # Род.падеж обычное окончание
F_new = F[:-2]+'a' # ХлебниковОЙ > ХлебниковА
else:
F_new = F # Кличко > Кличко
if O[-1:] == 'ы': # МихайловнЫ > МихайловнА
O_new = O[:-1]+'a'
if len(F_new) > 1 and len(O_new) > 1: # Возвращаем фам. и отч.
return F_new[0].upper()+F_new[1:], O_new[0].upper()+O_new[1:]
else:
return F_new, O_new # Возвращаем инициалы
# Формируем фамилию и отчество в именительном падеже,
# Если имя было трансформировано в именительный:
df['Фамилия_Отчество_именительное'] = df.apply(
lambda x: surname_patronymic_nominative(x['Имя_мужское_им.падеж'],
x['Имя_женское_им.падеж'],
x['Ф'],x['О'],x['И']), axis=1)
df['Фам_им'] = df['Фамилия_Отчество_именительное'].apply(lambda x: x[0])
df['Отч_им'] = df['Фамилия_Отчество_именительное'].apply(lambda x: x[1])
df = df.drop(['Фамилия_Отчество_именительное'], axis=1)
Посмотрим, что мы имеем теперь. ФИО есть в именительном падеже:

Далее почистим ненужные столбцы. И посмотрим, где имя и отчество записаны как инициалы.
def Finaly_name(M_name, F_name):
"""Получаем итоговое имя"""
if M_name != 'пусто':
return M_name[0].upper()+M_name[1:] # мужское имя в им.пад
elif M_name == 'пусто' and F_name != 'пусто':
return F_name[0].upper()+F_name[1:] # женское имя в им.пад
# Получаем одну колонку имени. Мужской и женский варианты del
df['Имя_им'] = df.apply(lambda x:
Finaly_name(x['Имя_мужское_им.падеж'],
x['Имя_женское_им.падеж']),axis=1)
df = df.drop(['Имя_мужское_им.падеж', 'Имя_женское_им.падеж'],axis=1)
cols = ['PURPOSE', 'Ф', 'И', 'О', 'Фам_им',
'Имя_им', 'Отч_им', 'CLIENTDATE']
df = df[cols] # Оставили нужные нам столбцы
# Заполним имя_им, где остались пропуски, значением вытянутого
df['Имя_им'] = df['Имя_им'].fillna(df['И'])
# Посмотрим, где инициалы в ИО
df[df['И'].apply(lambda x: len(x)==1)].head()

Так как фамилии с «а» в окончании могут принадлежать мужчине в родительном падеже и женщине в именительном, нужно понять, как будем это различать. Попробуем выяснить, сколько мужчин и сколько женщин получилось в нашей выборке.
df['Male_Name'] = df['Имя_им'].apply(lambda x: x.lower() in list_male_names)
df['Female_Name'] = df['Имя_им'].apply(lambda x: x.lower() in list_female_names)
print ('Соотношение мужских имён к женским:',
df['Male_Name'].value_counts()[1]/df['Female_Name'].value_counts()[1])
df = df.drop(['Male_Name', 'Female_Name'], axis=1)
![]()
Мужских имён значительно больше в нашей таблице. Будем определять окончание «а» как родительный падеж мужского имени. Осталось отделить несклоняемые фамилии от склоняемых.
def surname_nominative(F):
"""Функция преобр.фамилии в им.падеж, где имя, отч.инициальные"""
try:
# Мужские фамилии:
if F[-1] == 'а' and F[-2] != 'х': # ПетруХа: ха.. не склоняем
return F[:-1] # Муж. фамилия в род.пад
elif F[-2:] == 'ым':
return F[:-4] # Муж. фамилия в твор.пад
elif F[-5:] == 'ского':
return F[:-5] + 'ский' # Муж. фамилия в твор.пад
elif F[-5:] == 'цкого':
return F[:-5] + 'цкий' # Муж. фамилия в твор.пад
# Женские фамилии:
elif F[-4:] == 'цкой':
return F[:-4] + 'цкая' # Жен. фамилия в твор.пад
elif F[-4:] == 'ской':
return F[:-4] + 'ская' # Жен. фамилия в твор.пад
elif F[-2:] == 'ой':
return F[:-2] + 'а' # Жен. фамилия в твор.пад
else:
return F # Без изменения
except Exception as e:
return F
# Преобр. фамилию у инициальных ИО в им.падеж
list_index = df[df['Имя_им'].apply(
lambda x: len(x)) == 1].index.tolist()
df['Фам_им'][list_index] = df['Фам_им'][list_index].apply(
lambda x: surname_nominative(x))
df[df['Имя_им'].apply(lambda x: len(x)) == 1].head(5)

Готово. Теперь на некоторых более-менее ярких примерах сравним результаты отработки готовыми библиотеками и нашим алгоритмом.
Пример отработки готовыми библиотеками:

Колонки с индексом “_1” здесь несут ФИО, вытянутое “Наташей”, с индексом “_2” – финальное ФИО в именительном падеже лемматизированное какой-то библиотекой.
Нетрудно заметить, что результат очень “так-себе”.
Посмотрим, как справился с этими полями наш алгоритм:

Алгоритм отработал на данных примерах замечательно.
Так мы убедились, что под специфичные задачи иногда бывает выгодно (по соотношению трудозатраты/качество) сделать собственный алгоритм, нежели использовать какие-либо готовые решения. Конечно, текущий алгоритм не идеален, и его можно дорабатывать и дальше, но текущее качество отработки удовлетворяет требованиям, поэтому дальнейшие “допилы” нецелесообразны 😊.
{“id”:13956,”url”:”/distributions/13956/click?bit=1&hash=218824c4468d1ad16ead721c4569ab95b5415e06001032a32c34f904cb106363″,”title”:”u041au0430u043a u0440u043eu0434u0438u0442u0435u043bu044e-u0430u0439u0442u0438u0448u043du0438u043au0443 u0438u0437u0431u0430u0432u0438u0442u044cu0441u044f u043eu0442 u043cu0443u043a u0432u044bu0431u043eu0440u0430: u0441u0435u043cu044cu044f u0438u043bu0438 u0440u0430u0431u043eu0442u0430″,”buttonText”:”u0423u0437u043du0430u0442u044c”,”imageUuid”:”cbf3e8d3-863a-5b81-9dd9-f0c431721801″}
Как извлечь структурированную информацию из текста на русском языке? Знакомы ли вы с Natasha?
Одной из самых сложных, неоднозначных проблем, которая может встретиться во время работы с данными, является извлечение именованных сущностей (Named‑entity recognition, NER) – слов, обозначающих предмет или явление определенной категории.
На вход программному модулю подаётся текст, а на выходе получаются структурированные объекты. Например, имеется новостной текст, и необходимо выделить в нем сущности (локации, персоны, организации, даты и так далее). Решая задачу NER, мы сможем понять, что «ООН» – это организация, «8 апреля 1938 года» это дата, а «Kumasi» – локация.
Задача NER традиционна и хорошо изучена, особенно для английского языка. Существует большое количество как коммерческих так и открытых решений, например, NLTK, Spacy, Stanford NER, OpenNLP и другие. Для русского языка тоже существует довольно много инструментов, но почти все они являются коммерческими (DaData, Pullenti, Abbyy Infoextractor, Dictum).
Из открытых инструментов отметим Natasha – открытая библиотека для языка программирования Python, которая позволяет извлекать структурированную информацию из текстов на русском языке. Natasha отличается лаконичным интерфейсом и включает экстракторы для имён, адресов, сумм денег, дат и некоторых других сущностей.
Однажды мне нужно было решить следующую задачу: был дан набор строк, в каждой строке была дата договора. Эта дата могла быть в произвольных форматах и стоять в любом месте строки. Я потратил достаточное количество времени, чтобы написать регулярное выражение, которое находит эти даты. Применив же инструмент, решающий задачу NER, время на решение задачи составило не более 2 минут, как на рисунке 1.
На Рисунках 1 и 2 показаны примеры использования библиотеки Natasha для извлечения дат (рисунок 1) и ФИО (рисунок 2).
Рисунок 2 – Пример с именами
Сначала создаётся объект нужного нам экстрактора, в который передаётся текст. Экстрактор определит положения объектов, которые мы ищем (например, объект NamesExtractor будет искать ФИО в тексте и найдёт их в следующем виде ([105, 136), [139, 166), [297, 323), [354, 369)]). Также можно вывести данные в формате JSON с помощью функции format_json.
Таким образом, всего лишь в 5 строчек кода можно извлечь необходимую информацию (имена, даты, локации, валюты и т. д.) и сэкономить много времени.
Использование поиска операционной системы и текстового редактора
Привет, читателю. Вот мы и добрались до очередной ступени экзамена по информатике в 9 классе. Выполнив 11 заданий, вы можете рассчитывать на получение оценки “4”. Конечно, если все задания будут выполнены правильно. Хе-хе.
С одиннадцатого задания начинается практическая часть экзамена. Для её выполнения потребуются умения работать на компьютере, а для тренировки, конечно, сам компьютер.
Поехали?!
Задание 11 выглядит так:

Вместе с заданием, вам предложат файл архива на рабочем столе компьютера:
В задании говорится, что в архиве, есть каталог Проза. В нём, подкаталог Гоголь. В подкаталоге Гоголь необходимо найти персонажа с фамилией Ковалев и узнать его имя.
Подробный алгоритм выполнения задания, показан ниже.
Двойным щелчком левой кнопки мыши (л.к.м.) открываем предложенный вам архив. Видим в нем папку с таким же названием, как и у архива. Зажав л.к.м. на папке, вытаскиваем её на рабочий стол компьютера. Закрываем окно архива.
Находим в открывшемся окне папку “Проза“. Двойным щелчком л.к.м. открываем её.
Открылись несколько подкаталогов. Выбираем среди них “Гоголь” и открываем его двойным щелчком л.к.м.
Перед нами список произведений Гоголя. Что бы узнать, в каком из них есть персонаж Ковалев, нужно набрать фамилию в поисковой строке в верхнем правом углу окна. Советую набирать фамилию так, как она написана в задании. Не КовалЁв, а КовалЕв.
И вот, перед нами произведение Гоголя, в котором есть искомый персонаж. Нам предлагают одно и то же произведение в трех разных форматах. Осталось найти имя.
Для этого, открываем любой, из файлов.
Одновременно жмём на две кнопки клавиатуры: ctrl + F, и в открывшейся поисковой строке набираем фамилию “КовалЕв”. Ниже приведены примеры поиска во всех трех предложенных файлах.
Обычно, поиск подсвечивает нужное слово (здесь желтым или синим). Искомое слово в произведении встречается несколько десятков раз, поэтому пришлось пролистать текст, для того, что бы найти не просто фамилию, а фамилию с именем. В ответе к заданию пишем Платон. Задание выполнено. Заветный 11-ый балл заработан. Опять, Хе-Хе.
Данные задания могут отличаться по количеству этапов поиска и сложности поиска слова в тексте. Иногда нужное слово можно обнаружить в описании файла еще на пятом этапе (см. выше). Иногда нужное слово находится в заголовке произведения. Поэтому, доля случая будет играть в выполнении этого задания не последнюю роль, особенно в плане затраченного времени. Советую, основательно потренироваться:
https://inf-oge.sdamgia.ru/test?theme=27
Замечания, пожелания, мысли, вопросы и т.п. смело пишите в комментах.
Ссылки на разборы предыдущих 10 заданий:
Цель курса (важно). Задание 1. Задание 2.
Задание 3. Задание 4. Задание 5.
Задание 6. Задание 7. Задание 8 .
Задание 9. Задание 10.
Работая с текстом, особенно с большими объемами, зачастую необходимо найти слово или кусок текста. Для этого можно воспользоваться поиском по тексту в Ворде. Существует несколько вариантов поиска в Word:
- Простой поиска, через кнопку «Найти» (открывается панель Навигация);
- Расширенный поиск, через кнопку «Заменить», там есть вкладка «Найти».
Самый простой поиск в ворде – это через кнопку «Найти». Эта кнопка расположена во вкладке «Главная» в самом правом углу.

! Для ускорения работы, для поиска в Ворде воспользуйтесь комбинацией клавишей: CRL+F
После нажатия кнопки или сочетания клавишей откроется окно Навигации, где можно будет вводить слова для поиска.

! Это самый простой и быстрый способ поиска по документу Word.
Для обычного пользователя большего и не нужно. Но если ваша деятельность, вынуждает Вас искать более сложные фрагменты текста (например, нужно найти текст с синим цветом), то необходимо воспользоваться расширенной формой поиска.
Расширенный поиск в Ворде
Часто возникает необходимость поиска слов в Ворде, которое отличается по формату. Например, все слова, выделенные жирным. В этом как рас и поможет расширенный поиск.
Существует 3 варианта вызова расширенного поиска:
- В панели навигация, после обычного поиска

- На кнопке «Найти» нужно нажать на стрелочку вниз

- Нужно нажать на кнопку «Заменить» , там выйдет диалоговое окно. В окне перейти на вкладку «Найти»

В любом случае все 3 варианта ведут к одной форме – «Расширенному поиску».
Как в Word найти слово в тексте – Расширенный поиск
После открытия отдельного диалогового окна, нужно нажать на кнопку «Больше»

После нажатия кнопки диалоговое окно увеличится

Перед нами высветилось большое количество настроек. Рассмотрим самые важные:
Направление поиска
В настройках можно задать Направление поиска. Рекомендовано оставлять пункт «Везде». Так найти слово в тексте будет более реально, потому что поиск пройдет по всему файлу. Еще существуют режимы «Назад» и «Вперед». В этом режиме поиск начинается от курсора и идет вперед по документу или назад (Вверх или вниз)

Поиск с учетом регистра
Поиск с учетом регистра позволяет искать слова с заданным регистром. Например, города пишутся с большой буквы, но журналист где-то мог неосознанно написать название города с маленькой буквы. Что бы облегчить поиск и проверку, необходимо воспользоваться этой конфигурацией:

Поиск по целым словам
Если нажать на вторую галочку, «Только слово целиком», то поиск будет искать не по символам, а по целым словам. Т.е. если вбить в поиск только часть слова, то он его не найдет. Напимер, необходимо найти слово Ворд, при обычном поиске будут найдены все слова с разными окончаниями (Ворде, Ворду), но при нажатой галочке «Только слова целиком» этого не произойдет.

Подстановочные знаки
Более тяжелый элемент, это подстановочные знаки. Например, нам нужно найти все слова, которые начинаются с буквы м и заканчиваются буквой к. Для этого в диалоговом окне поиска нажимаем галочку «Подстановочные знаки», и нажимаем на кнопку «Специальный», в открывающемся списке выбираем нужный знак:

В результате Word найдет вот такое значение:

Поиск омофонов
Microsoft Word реализовал поиск омофонов, но только на английском языке, для этого необходимо выбрать пункт «Произносится как». Вообще, омофоны — это слова, которые произносятся одинаково, но пишутся и имеют значение разное. Для такого поиска необходимо нажать «Произносится как». Например, английское слово cell (клетка) произносится так же, как слово sell (продавать).

! из-за не поддержания русского языка, эффективность от данной опции на нуле
Поиск по тексту без учета знаков препинания
Очень полезная опция «Не учитывать знаки препинания». Она позволяет проводить поиск без учета знаков препинания, особенно хорошо, когда нужно найти словосочетание в тексте.

Поиск слов без учета пробелов
Включенная галочка «Не учитывать пробелы» позволяет находить словосочетания, в которых есть пробел, но алгоритм поиска Word как бы проглатывает его.

Поиск текста по формату
Очень удобный функционал, когда нужно найти текст с определенным форматированием. Для поиска необходимо нажать кнопку Формат, потом у Вас откроется большой выбор форматов:

Для примера в тексте я выделил Жирным текст «как найти слово в тексте Word». Весть текст выделен полужирным, а кусок текста «слово в тексте Word» сделал подчернутым.
В формате я выбрал полужирный, подчеркивание, и русский язык. В итоге Ворд наше только фрагмент «слово в тексте». Только он был и жирным и подчеркнутым и на русском языке.

После проделанных манипуляция не забудьте нажать кнопку «Снять форматирование». Кнопка находится правее от кнопки «Формат».
Специальный поиск от Ворд
Правее от кнопки формат есть кнопка «Специальный». Там существует огромное количество элементов для поиска
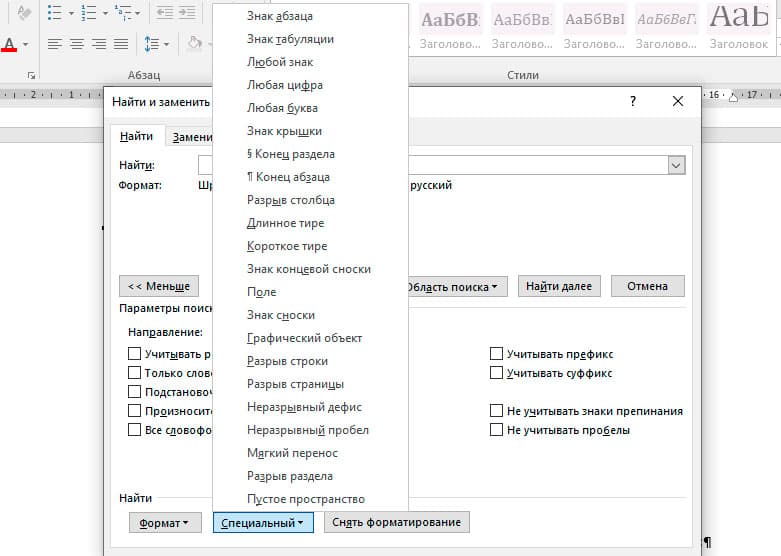
Через этот элемент можно искать:
- Только цифры;
- Графические элементы;
- Неразрывные пробелы или дефисы;
- Длинное и короткое тире;
- Разрывы разделов, страниц, строк;
- Пустое пространство (особенно важно при написании курсовых и дипломных работ);
- И много других элементов.
Опции, которые не приносят пользы
!Это мое субъективное мнение, если у вас есть другие взгляды, то можете писать в комментариях.
- Опция «произносится как». Не поддержание русского языка, делает эту опцию бессмысленной;
- Опция «все словоформы», опция полезная при замене. А если нужно только найти словоформы, то с этим справляется обычный поиск по тексту;
- Опция «Учитывать префикс» и «Учитывать суффикс» – поиск слов, с определенными суффиксами и префиксами. Этот пункт так же полезен будет при замене текста, но не при поиске. С этой функцией справляется обычный поиск.
