Новичку очень трудно найти нужный символ или слово в массе кода, однако это делается очень быстро и просто. Если не знаете как, то читайте дальше.
В следующей статье, мы приступим к редактированию шаблона, и нам придётся находить нужные элементы в коде темы.
Если кто-то ещё не видел, что из себя представляет код шаблона, то зайдите в Консоль — Внешний вид — Редактор.
Перед Вами откроется код файла style.css. Покрутите его вниз, и первое, что придёт Вам в голову будет: ё-моё, как же в этой массе английских слов, цифр и символов, найти то, что нам будет нужно.
Для полноты ощущения, можно открыть один из php файлов, которые расположены в колонке справа от поля редактора.
Только сразу отгоните мысль типа: «Я в этом до самой смерти не разберусь». Разберётесь, и я Вам в этом помогу.
Рассмотрим два варианта, в зависимости от начальных условий, нахождения нужного элемента в коде.
Вариант 1.
Условие: мы точно знаем то, что нам нужно найти.
Для примера возьмём код страницы.
Комбинация клавиш Contrl-F откроет окно поиска в правом верхнем углу, в которое можно ввести искомый элемент кода. Элемент и все его повторения подсветятся.
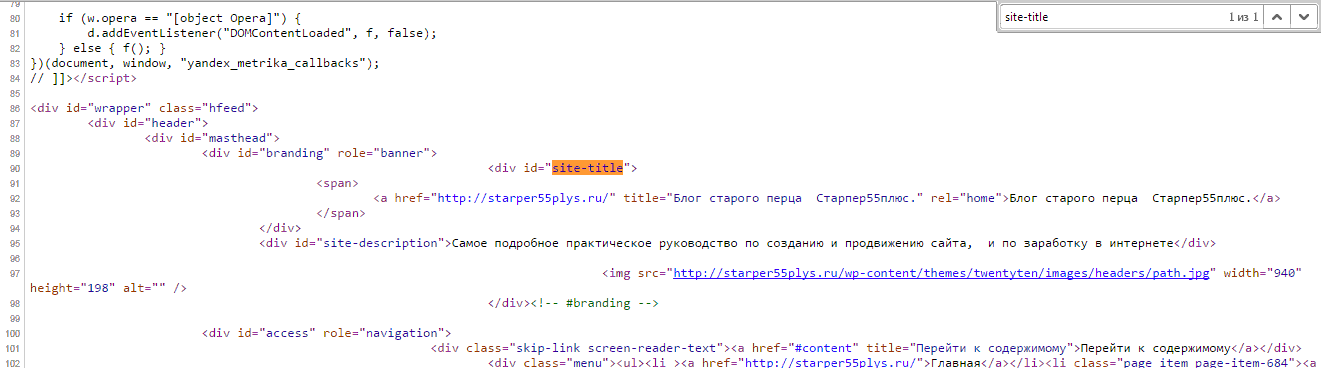
Этот поиск работает абсолютно для любого кода, открытого в браузере, то есть на странице.
Вариант 2.
Условие: мы видим элемент на странице, но не знаем ни его html, ни css.
В этом случае потребуется web-инспектор, или по другому Инструмент разработчика.
Инструмент разработчика есть во всех браузерах и открыть его можно или клавишей F12, или правой клавишей мыши, выбрав “Просмотреть код” или “Исследовать элемент”. В разных браузерах по разному.
Главное не выбирайте “Просмотреть код страницы”. Похоже, но не то.
После этого появится web-инспектор. Его интерфейс в разных браузерах немного отличается, но принцип действия везде одинаковый.
Я покажу на примере web-инспектора Chrome.
Заходим на страницу и открываем web-инспектор. По умолчанию он откроется в двух колонках, в левой будет html код всех элементов, находящихся на странице, а в правой — css оформление.
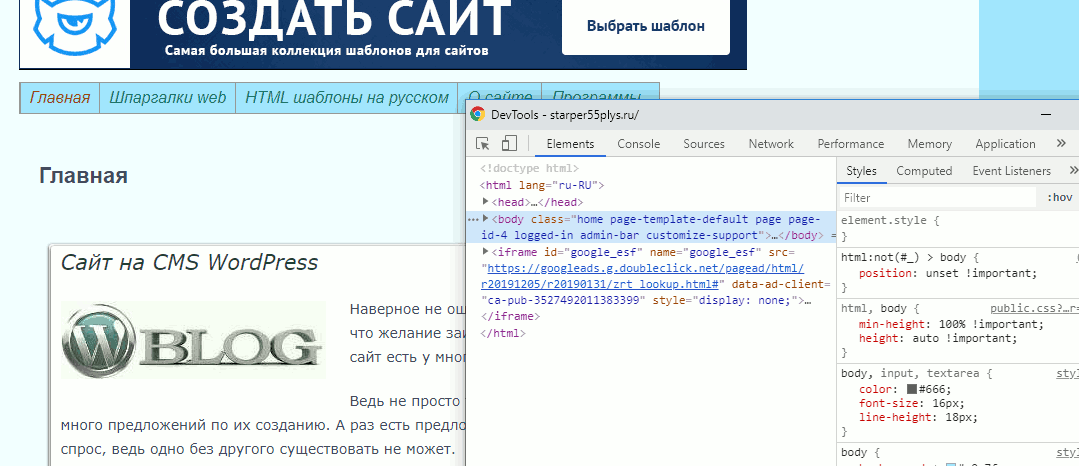
Изначально, код откроется в сложенном виде, то есть будут видны только основные элементы страницы, но если щёлкнуть по треугольничку в начале строки, то откроются все вложения, находящиеся в элементе.
И вот так, открывая вложение за вложением, можно добраться практически до любого элемента, находящегося на странице.
Определить, какой код, какому элементу соответствует, очень просто.
Надо просто вести по строкам курсором, и как только курсор оказывается на строке с кодом, так тут-же элемент, которому соответствует этот код, подсвечивается.
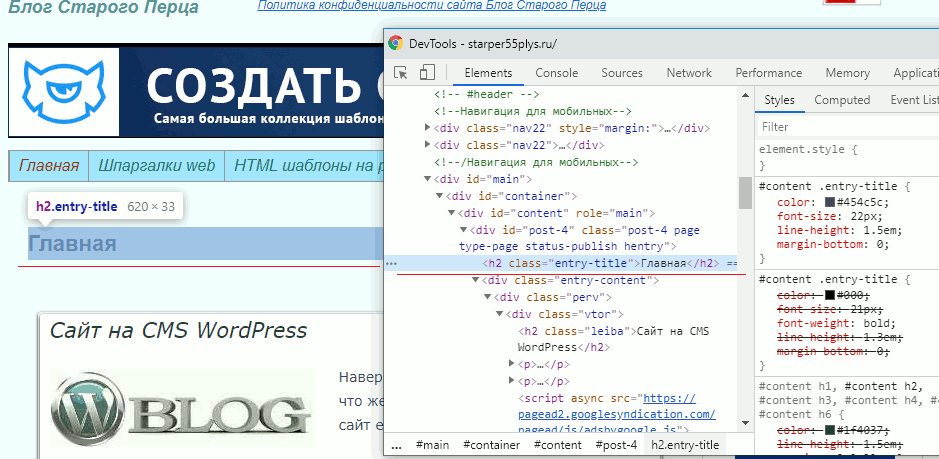
Теперь найдём css этого элемента. Для этого надо один раз щёлкнуть левой клавишей по строке с html, и в правой колонке отобразятся все стили, которые ему заданы, а так-же стили, влияющие на элемент, от родительских элементов.

Теперь, зная class или id элемента, можно спокойно идти в файл style.css, найти в нём нужный селектор, с помощью Поиска (Ctrl+F), и править внешний вид элемента.
Желаю творческих успехов.
Неужели не осталось вопросов? Спросить

Перемена
— Мам, ну почему ты думаешь, что если я была на дне рождения, то сразу пила?!
— Дочь а нечего что я папа?
Объявление в метро: «при обнаружении подозрительных предметов сделайте подозрительное лицо.
В раздел > > > Исправляем шаблон WordPress. Веб-инспектор
Время на прочтение
8 мин
Количество просмотров 94K
Пару дней назад получил тестовое задание от компании на вакансию Front-end dev. Конечно же, задание состояло из нескольких пунктов. Но сейчас речь пойдет только об одном из них — организация поиска по странице. Т.е. банальный поиск по введенному в поле тексту (аналог Ctrl+F в браузере). Особенность задания была в том, что использование каких-либо JS фреймворков или библиотек запрещено. Все писать на родном native JavaScript.
(Для наглядности далее буду сопровождать всю статью скринами и кодом, чтоб мне и вам было понятнее, о чем речь в конкретный момент)
Поиск готового решения
Первая мысль: кто-то уже точно такое писал, надо нагуглить и скопипастить. Так я и сделал. За час я нашел два неплохих скрипта, которые по сути работали одинаково, но были написаны по-разному. Выбрал тот, в коде которого лучше разобрался и вставил к себе на старничку.
Если кому интересно, код брал тут.
Скрипт сразу заработал. Я думал, что вопрос решен, но как оказалось, не в обиду автору скрипта, в нем был огромный недостаток. Скрипт вел поиск по всему содержимому тега ... и, как вы уже наверное догадались, при поиске любого сочетания символов, которые напоминают тег или его атрибуты, ломалась вся страница HTML.
Почему скрипт работал некорректно?
Все просто. Скрипт работает следующим образом. Сперва в переменную записываем все содержимое тега body, затем ищем совпадения с регулярным выражением (задает пользователь при вводе в текстовое поле) и затем заменяем все совпадения на следующий код:
<span style="background-color: yellow;">...найденное совпадение...</span>
А затем заменяем текущий тег body на новый полученный. Разметка обновляется, меняются стили и на экране подсвечиваются желтым все найденные результаты.
Вы уже наверняка поняли, в чем проблема, но я все же объясню подробней. Представьте, что в поле поиска ввели слово «div». Как вы понимаете, внутри body есть множество других тегов, в том числе и div. И если мы всем к «div» применим стили, указанные выше, то это уже будет не блок, а непонятно что, так как конструкция ломается. В итоге после перезаписи разметки мы получим полностью сломанную веб-страницу. Выглядит это так.
Было до поиска:  Просмореть полностью
Просмореть полностью
Стало после поиска:  Просмореть полностью
Просмореть полностью
Как видите, страница полностью ломается. Короче говоря, скрипт оказался нерабочим, и я решил написать свой с нуля, чему и посвящается эта статья.
Итак пишем скрипт с нуля
Как все у меня выглядит.
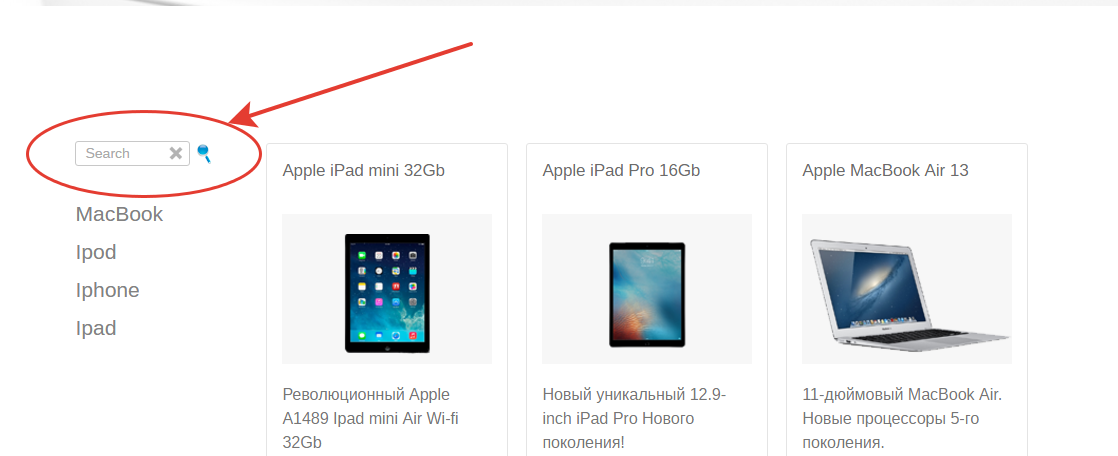
Сейчас нас интересует форма с поиском. Обвел ее красной линией.
Давайте немного разберемся. Я это реализовал следующим образом (пока чистый HTML). Форма с тремя тегами.
Первый — для ввода текста;
Второй — для для отмены поиска (снять выделение);
Третий — для поиска (выделить найденные результаты).
<form>
<input type="text" value="" placeholder="Search" autofocus>
<input type="button" value=" " title="Отменить поиск">
<input type="submit" value=" " title="Начать поиск">
</form>
Итак, у нас есть поле для ввода и 2 кнопки. JavaScript буду писать в файле js.js. Предпложим, что его вы уже создали и подключили.
Первое, что сделаем: пропишем вызовы функции при нажатии на кнопку поиска и кнопку отмены. Выглядеть будет так:
<form>
<input class="place_for_search" type="text" id="text-to-find" value="" placeholder="Search" autofocus>
<input class="button_for_turn_back" type="button" onclick="javascript: FindOnPage('text-to-find',false); return false;" value=" " title="Отменить поиск">
<input class="button_for_search" type="submit" onclick="javascript: FindOnPage('text-to-find',true); return false;" value=" " title="Начать поиск">
</form>
Давайте немного поясню что тут и зачем нужно.
Полю с текстом даем id=«text-to-find» (по этому id будем обращатсья к элементу из js).
Кнопке отмены даем такие атрибуты: type=«button» onclick=«javascript: FindOnPage(‘text-to-find’,false); return false;»
— Тип: button
— При нажатии вызывается функция FindOnPage(‘text-to-find’,false); и передает id поля с текстом, false
Кнопке поиска даем такие атрибуты: type=«button» onclick=«javascript: FindOnPage(‘text-to-find’,true); return false;»
— Тип: submit (не кнопка потому, что тут можно юзать Enter после ввода в поле, а так можете и button использовать)
— При нажатии вызывается функция FindOnPage(‘text-to-find’,true); и передает id поля с текстом, true
Вы наверняка заметили еще 1 атрибут: true/false. Его будем использовать для определения, на какую именно кнопку нажали (отменить поиск или начать поиск). Если жмем на отмену, то передаем false. Если жмем на поиск, то передаем true.
Окей, двигаемся дальше. Переходим к JavaScript
Будем считать, что вы уже создали и подключили js файл к DOM.
Прежде, чем начнем писать код, давайте отвлечемся и сперва обсудим, как все должно работать. Т.е. по сути пропишем план действий. Итак, нам надо, чтоб при вводе текста в поле шел поиск по странице, но нельзя затрагивать теги и атрибуты. Т.е. только текстовые объекты. Как этого достичь — уверен есть много способов. Но сейчас будем использовать регулярные выражения.
Итак, следующее регулярное выражение будет искать только текст след. вида: “>… текст…<“. Т.е. будет проходить поиск только текстовых объектов, в то время, как теги и атрибуты будут оставаться нетронутыми.
/>(.*?)</g
Так мы будем находить нужные части кода, которые будем парсить и искать совпадения с текстом, который ввел пользователь. Затем будем добавлять стили найденным объектам и после этого заменять html — код на новый.
Приступим. Сперва переменные, которые нам понадобятся.
var input,search,pr,result,result_arr, locale_HTML, result_store;
//input - принимаем текст, который ввел пользователь
//search - делаем из строки регулярное выражение
//pr - сохраняем в нее текущий <body></body>
//result - выборка текста из pr (т.е. отсекаем теги и атрибуты)
//result_arr - аналог pr, но со стилями для подсветки
//locale_HTML - оригинал <body></body> который менять не будем, используем для обнуления стилей
И сразу определим locale_HTML значение независимо от того, ищем мы что-то или нет. Это нужно, чтоб сразу сохранить оригинал страницы и иметь взможность обнулять стили.
var input,search,pr,result,result_arr, locale_HTML, result_store;
locale_HTML = document.body.innerHTML; // сохраняем в переменную весь body (Исходный)
Ок, теперь уже стоит создать функцию, которая вызывается у нас из DOM. Сразу прикинем, что внутри у нас должны быть 2 функции, каждая из которых срабатывает в зависимости от нажатой кнопки. Ведь мы либо проводим поиск, либо обнуляем его. И контроллируется это атрибутом true/false, как вы помните. Так же надо понимать, что при повторном поиске прежние стили должны обнуляться. Таким образом получим следующее:
var input,search,pr,result,result_arr, locale_HTML, result_store;
locale_HTML = document.body.innerHTML; // сохраняем в переменную весь body (Исходный)
function FindOnPage(name, status) {
if(status) { FindOnPageBack(); FindOnPageGo(); } //чистим прошлое и Выделяем найденное
if(!status) { FindOnPageBack(); } //Снимаем выделение
}
Ок, часть логики реализована, двигаемся дальше. Необходимо проверять полученное слово на количество символов. Ведь зачем нам искать 1 букву/символ. В общем, я решил эту возможность ограничить 3+ символа.
Итак, сперва приниамем значение, которое ввел пользователь, и, в зависимости от его длины, выполняем либо основную функцию поиска, либо функцию вывода предупреждения и обнуления. Выглядеть будет так:
var input,search,pr,result,result_arr, locale_HTML, result_store;
locale_HTML = document.body.innerHTML; // сохраняем в переменную весь body (Исходный)
function FindOnPage(name, status) {
input = document.getElementById(name).value; //получаем значение из поля в html
if(input.length<3&&status==true) {
alert('Для поиска вы должны ввести три или более символов');
function FindOnPageBack() { document.body.innerHTML = locale_HTML; } //обнуляем стили
}
if(input.length>=3)
{
//выполняем поиск
}
function FindOnPageBack() { document.body.innerHTML = locale_HTML; } //обнуляем стили
if(status) { FindOnPageBack(); FindOnPageGo(); } //чистим прошлое и Выделяем найденное
if(!status) { FindOnPageBack(); } //Снимаем выделение
}
Сейчас поясню этот участок кода. Единственное, что могло стать не ясно — вот эта строка:
function FindOnPageBack() { document.body.innerHTML = locale_HTML; }
Тут все просто: метод innerHTML возвращает html код объекта. В данном случае мы просто заменяем текущий body на оригинальный, который мы сохранили при загрузке всей страницы.
Двигаемся дальше. Даем значения основным переменным.
var input,search,pr,result,result_arr, locale_HTML, result_store;
locale_HTML = document.body.innerHTML; // сохраняем в переменную весь body (Исходный)
function FindOnPage(name, status) {
input = document.getElementById(name).value; //получаем значение из поля в html
if(input.length<3&&status==true) {
alert('Для поиска вы должны ввести три или более символов');
function FindOnPageBack() { document.body.innerHTML = locale_HTML; } //обнуляем стили
}
if(input.length>=3)
{
function FindOnPageGo() {
search = '/'+input+'/g'; //делаем из строки регуярное выражение
pr = document.body.innerHTML; // сохраняем в переменную весь body
result = pr.match(/>(.*?)</g); //отсекаем все теги и получаем только текст
result_arr = []; //в этом массиве будем хранить результат работы (подсветку)
}
}
function FindOnPageBack() { document.body.innerHTML = locale_HTML; } //обнуляем стили
if(status) { FindOnPageBack(); FindOnPageGo(); } //чистим прошлое и Выделяем найденное
if(!status) { FindOnPageBack(); } //Снимаем выделение
}
Итак, на данном этапе у нас уже есть основные переменные и значения. Теперь надо придать нужным участкам кода стили с выделенным фоном. Т.е. проверка выбранного текста на регулярное выражение (по сути мы выбранный регулярным выражением текст снова парсим регулярным выражением). Для этого надо из введенного текста сделать регулярное выражение (сделали), а затем выполнить метод, переданный в виде такста. Тут нам поможет метод eval().
В общем, после того, как мы заменим текст и получим результат со стилями, надо текущий html заменить на полученный. Делаем.
var input,search,pr,result,result_arr, locale_HTML, result_store;
locale_HTML = document.body.innerHTML; // сохраняем в переменную весь body (Исходный)
function FindOnPage(name, status) {
input = document.getElementById(name).value; //получаем значение из поля в html
if(input.length<3&&status==true) {
alert('Для поиска вы должны ввести три или более символов');
function FindOnPageBack() { document.body.innerHTML = locale_HTML; } //обнуляем стили
}
if(input.length>=3)
{
function FindOnPageGo() {
search = '/'+input+'/g'; //делаем из строки регуярное выражение
pr = document.body.innerHTML; // сохраняем в переменную весь body
result = pr.match(/>(.*?)</g); //отсекаем все теги и получаем только текст
result_arr = []; //в этом массиве будем хранить результат работы (подсветку)
for(var i=0; i<result.length;i++) {
result_arr[i] = result[i].replace(eval(search), '<span style="background-color:yellow;">'+input+'</span>'); //находим нужные элементы, задаем стиль и сохраняем в новый массив
}
for(var i=0; i<result.length;i++) {
pr=pr.replace(result[i],result_arr[i]) //заменяем в переменной с html текст на новый из новогом ассива
}
document.body.innerHTML = pr; //заменяем html код
}
}
function FindOnPageBack() { document.body.innerHTML = locale_HTML; } //обнуляем стили
if(status) { FindOnPageBack(); FindOnPageGo(); } //чистим прошлое и Выделяем найденное
if(!status) { FindOnPageBack(); } //Снимаем выделение
}
По сути все готово, и скрипт уже работает. Но добавим еще пару деталей для красоты.
1) Обрежем пробелы у текста, который вводит пользователь. Вставляем этот код:
input = numer.replace(/^s+/g,'');
input = numer.replace(/[ ]{1,}/g,' ');
После этой строки:
input = document.getElementById(name).value; //получаем значение из поля в html
2) Сделаем проверку на совпадения (если совпадений не найдено — сообщим об этом). Этот код вставляем внутрь функции function FindOnPageGo() после переменных.
var warning = true;
for(var i=0;i<result.length;i++) {
if(result[i].match(eval(search))!=null) {
warning = false;
}
}
if(warning == true) {
alert('Не найдено ни одного совпадения');
}
Посмотреть исходник можно тут.
Скачать исходник можно тут.
Теперь все. Конечно, можно добавить скролл к первому найденному результату, живой поиск ajax, да и вообще улучшать можно бесконечно. Сейчас это довольно примитивный поиск по сайту. Целью статьи было помочь новичкам, если возникет такой же вопрос как у меня. Ведь простого готового решения я не нашел.
P.S.: для корректной работы необходимо убрать переносы текста в html документе в тех местах, где есть обычный текст между тегами.
Например, вместо
<p> бла бла бла
</p>
Надо
<p> бла бла бла </p>
Это не принципиально, можно от этих переносов избаляться автоматически на сервисе, но может подскажете заодно, как это пофиксить, если поймете раньше меня.
Также, если кто писал подобное, но с живым поиском, поделитесь исходником, будет интересно разобрать.
Буду рад выслушать конструкнтиную критику, мнения, может, рекомендации.
На днях дописал немного код, сделал живой поиск по странице. Так, что вопрос снят. Код HTML не менялся. JS можете посмотреть тут.
Поиск ведется по тегам с классом «place_for_live_search». Так что для того, чтоб алгоритм парсил нужный контент, добавляем класс и готово.
how can i search an html page for a word fast?
and how can i get the html tag that the word is in? (so i can work with the entire tag)
asked Apr 14, 2009 at 16:08
Chen KinnrotChen Kinnrot
20.5k17 gold badges79 silver badges139 bronze badges
To find the element that word exists in, you’d have to traverse the entire tree looking in just the text nodes, applying the same test as above. Once you find the word in a text node, return the parent of that node.
var word = "foo",
queue = [document.body],
curr
;
while (curr = queue.pop()) {
if (!curr.textContent.match(word)) continue;
for (var i = 0; i < curr.childNodes.length; ++i) {
switch (curr.childNodes[i].nodeType) {
case Node.TEXT_NODE : // 3
if (curr.childNodes[i].textContent.match(word)) {
console.log("Found!");
console.log(curr);
// you might want to end your search here.
}
break;
case Node.ELEMENT_NODE : // 1
queue.push(curr.childNodes[i]);
break;
}
}
}
this works in Firefox, no promises for IE.
What it does is start with the body element and check to see if the word exists inside that element. If it doesn’t, then that’s it, and the search stops there. If it is in the body element, then it loops through all the immediate children of the body. If it finds a text node, then see if the word is in that text node. If it finds an element, then push that into the queue. Keep on going until you’ve either found the word or there’s no more elements to search.
answered Apr 14, 2009 at 16:15
3
You can iterate through DOM elements, looking for a substring within them. Neither fast nor elegant, but for small HTML might work well enough.
I’d try something recursive, like: (code not tested)
findText(node, text) {
if(node.childNodes.length==0) {//leaf node
if(node.textContent.indexOf(text)== -1) return [];
return [node];
}
var matchingNodes = new Array();
for(child in node.childNodes) {
matchingNodes.concat(findText(child, text));
}
return matchingNodes;
}
answered Apr 14, 2009 at 16:14
vartecvartec
130k36 gold badges217 silver badges244 bronze badges
0
You can try using XPath, it’s fast and accurate
http://www.w3schools.com/Xpath/xpath_examples.asp
Also if XPath is a bit more complicated, then you can try any javascript library like jQuery that hides the boilerplate code and makes it easier to express about what you want found.
Also, as from IE8 and the next Firefox 3.5 , there is also Selectors API implemented. All you need to do is use CSS to express what to search for.
answered Apr 14, 2009 at 16:16
AzderAzder
4,6787 gold badges37 silver badges57 bronze badges
2
You can probably read the body of the document tree and perform simple string tests on it fast enough without having to go far beyond that – it depends a bit on the HTML you are working with, though – how much control do you have over the pages? If you are working within a site you control, you can probably focus your search on the parts of the page likely to be different page from page, if you are working with other people’s pages you’ve got a tougher job on your hands simply because you don’t necessarily know what content you need to test against.
Again, if you are going to search the same page multiple times and your data set is large it may be worth creating some kind of index in memory, whereas if you are only going to search for a few words or use smaller documents its probably not worth the time and complexity to build that.
Probably the best thing to do is to get some sample documents that you feel will be representative and just do a whole lot of prototyping based around the approaches people have offered here.
answered Apr 14, 2009 at 16:19
glenatronglenatron
10.9k13 gold badges63 silver badges109 bronze badges
form.addEventListener("submit", (e) => {
e.preventDefault();
var keyword = document.getElementById("search_input");
let words = keyword.value;
var word = words,
queue = [document.body],
curr;
while (curr = queue.pop()) {
if (!curr.textContent.toUpperCase().match(word.toUpperCase())) continue;
for (var i = 0; i < curr.childNodes.length; ++i) {
switch (curr.childNodes[i].nodeType) {
case Node.TEXT_NODE: // 3
if (curr.childNodes[i].textContent.toUpperCase().match(word.toUpperCase())) {
console.log("Found!");
console.log(curr);
curr.scrollIntoView();
}
break;
case Node.ELEMENT_NODE: // 1
queue.push(curr.childNodes[i]);
break;
}
}
}
});
answered Dec 18, 2020 at 17:39
Теги: javascript, символ, поиск, методы, строка, индекс, проверка, строковые функции, слово, indexof
Для поиска слова, символа или любой другой подстроки в строке в языке программирования JavaScript используют хорошо известный метод indexOf. В результате проверки метод возвращает позицию первого совпадения, если же совпадение по введённому вами символу найдено не будет, будет возвращено -1.

Искомое слово или символ указываются первым параметром. Что касается второго параметра, то он необязателен. Зато с его помощью мы можем передать номер (индекс) символа или буквы, с которого надо начинать поиск. Важный момент: метод indexOf() чувствителен к регистру вводимых вами букв, слов и символов.
Синтаксис метода предельно прост:
строка.indexOf(первый параметр указывает, что ищем, [второй параметр определяет, откуда начинаем поиск]);Приведем примеры поиска слова в строке JavaScript
В примере ниже у нас есть строка ‘Я учусь в OTUS’, причём мы ищем в строке слово ‘учусь’. Метод вернёт нам индекс 2, т. к. именно с этой позиции начинается слово ‘учусь’ в строке. Тут стоит вспомнить, что индексация (подсчёт позиции) начинается с нуля, а не с единицы.
let str = 'Я учусь в OTUS; console.log(str.indexOf('учусь'));В результате получим следующий вывод:
В очередном примере в строке ‘Я учу Java и учу JavaScript в OTUS’ давайте найдём слово ‘учу’, но не первое его вхождение в строку, а второе. Следовательно, начнём поиск с 5-й позиции, указав это вторым параметром.
let str = 'Я учу Java и учу JavaScript в OTUS'; console.log(str.indexOf('учу', 5));Проверка приведёт к возвращению числа 13, т. к. именно с этой позиции начинается второе слово «учу» в нашей строке.
Давайте приведем ещё парочку примеров. В коде ниже, исследуемый нами метод поиска вернёт -1, ведь подстроки ‘Go’ в нашей строке попросту нет:
let str = 'Я учусь в OTUS'; console.log(str.indexOf('Go'));В принципе, как видите, ничего сложного. Нам вернётся -1 и в случае, если мы будем искать одинаковые слова с разным регистром (OTUS не равно OtuS):
let str = 'Я учусь в OTUS; console.log(str.indexOf(' OtuS'));Вернётся -1 и в последнем примере, ведь после позиции, которую мы выбрали вторым параметром для поиска, совпадения найдены не будут:
let str = 'Я учусь в OTUS'; console.log(str.indexOf('учусь', 7));Проверка приведёт к следующему результату:
Вот и всё, что можно сказать про простейший поиск слов и символов в строке JavaScript. Напоследок стоит упомянуть метод lastIndexOf(), тоже осуществляющий поиск символа, слова или любой подстроки в строке. Разница заключается лишь в том, что этот метод начинает искать с конца строки, а не с начала — в остальном он работает аналогично.
Больше операций по поиску в строке JavaScript, включая дополнительные операции по работе с подстрокой, вы найдёте здесь.
Интересует профессиональный курс по JavaScript-разработке? Переходите по ссылке ниже:

При вводе строки по CTRL+F в коде надо помнить, что внутри строчки не должно быть никаких тегов, например изменения шрифта или стиля, иначе строчка может и не найтись в поиске по тексту HTML кода.
Например текст на странице такой:
2х2=4
Это же самое в HTML коде выглядит так:
2х2=<strong>4</strong>
Поиск ничего не даст
Такое бывает в тех случаях когда внутри строки используются теги; в этом случае надо найти и скопировать строчку на экране, затем преобразовать в HTML (фрагмент кода для преобразования приведен в ответе на вопрос Какие есть толковые способы перевести doc в html?) и только потом, зная как закодирована строчка, можно искать этот код в коде HTML.

