Каждый объект в компьютере (или любом другом электронном устройстве) имеет свой информационный объём, то есть то количество информации, которое он занимает в памяти устройства.
Например, текстовый документ на (2)–(3) страницы может иметь информационный объём (150) Кб.
Изображение в хорошем качестве — (2)–(4) Мб.
Аудиофайл с песней на (3) минуты — около (6) Мб.
Рассмотрим измерение текстовой информации в компьютере.
Размер текстового сообщения зависит от того, с помощью какого алфавита он был написан и сколько в нём символов.
Алфавит (N) — это количество символов в некотором языке.
Чем больше алфавит, тем больше информационный вес одного символа.
Информационный вес одного символа (i) — это количество информации, которое отводится на один символ.
Обрати внимание!
Они связаны формулой:
N=2i
.
Например, в русском алфавите (33) буквы, вычислим информационный вес одного символа по формуле:
33=2i,i≈5
бит. То есть вес одного символа (буквы) — (5) бит.
Представим, что в тетрадке записана следующая строка: «Мама сидела за столом».
Как посчитать, сколько информации несёт в себе это сообщение?
Нам известно, сколько весит один символ — (5) бит, можно подсчитать количество символов в данном сообщении — (18), соответственно, чтобы найти, сколько всего информации несёт в себе это сообщение, нужно перемножить информационный вес одного символа и количество символов в сообщении.
Обрати внимание!
Можно вывести формулу:
I=K×i
,
где (I) — информационный объём сообщения;
(K) — количество символов в сообщении;
(i) — информационный вес одного символа.
Но мы будем работать с компьютерным текстом. Там алфавит намного больше.
Как ты думаешь, сколько всего символов можно ввести с клавиатуры?
Ты скажешь «много» и будешь прав: с клавиатуры можно ввести русские/английские буквы, цифры, специальные знаки и т. д. Всего (256) символов.
Посчитаем информационный вес одного символа компьютерного алфавита.
N=2i.256=2i.256=28.
Один символ компьютерного алфавита весит (8) бит или (1) байт.
Решим задачу.
Найди информационный объём текста (в битах), написанного с помощью компьютера:
«Информация — это сведения об окружающем нас мире».
Текст напечатан на компьютере, поэтому один символ весит (8) бит или (1) байт.
Всего символов в сообщении между кавычками: (48). При подсчёте символов учитываются все символы и пробелы.
Запишем решение:
I=K×i.I=48×8.I=384бит.
Ответ: (384) бита.
Задача
Найди информационный объём сообщения (в байтах), который напечатали школьники на уроке информатики, если оно содержит (2) страницы, на каждой странице по (12) строк, и в каждой строке (28) символов.
Оформим решение задачи.
|
Дано: K=2×12×28.i=1байт. |
Чтобы посчитать, сколько символов всего в сообщении, нужно умножить количество страниц на количество строк и на количество символов в каждой строке. В условии сказано, что текст напечатали, поэтому один символ равен (1) байту. I=K×i.I=2×12×28×1.I=672байта. |
| Найти: (I) — ? | Ответ: (672) байта. |
Информационный объем текста складывается из информационных весов составляющих его символов.
Современный компьютер может обрабатывать числовую, текстовую, графическую, звуковую и видео информацию. Все эти виды информации в компьютере представлены в двоичном коде, т. е. используется всего два символа 0 и 1. Связано это с тем, что удобно представлять информацию в виде последовательности электрических импульсов: импульс отсутствует (0), импульс есть (1).
Такое кодирование принято называть двоичным, а сами логические последовательности нулей и единиц — машинным языком.
Какой длины должен быть двоичный код, чтобы с его помощью можно было закодировать васе символы клавиатуры компьютера?
Достаточный алфавит
В алфавит мощностью 256 символов можно поместить практически все символы, которые есть на клавиатуре. Такой алфавит называется достаточным.
Т.к. 256 = 2 8 , то вес 1 символа – 8 бит.
Единице в 8 бит присвоили свое название — байт.
1 байт = 8 бит.
Таким образом, информационный вес одного символа достаточного алфавита равен 1 байту.
Для измерения больших информационных объемов используются более крупные единицы измерения информации:
Единицы измерения количества информации:
1 килобайт = 1 Кб = 1024 байта
1 мегабайт = 1 Мб = 1024 Кб
1 гигабайт = 1 Гб = 1024 Гб
Информационный объем текста
Книга содержит 150 страниц.
На каждой странице — 40 строк.
В каждой строке 60 символов (включая пробелы).
Найти информационный объем текста.
1. Количество символов в книге:
60 * 40 * 150 = 360 000 символов.
2. Т.к. 1 символ весит 1 байт, информационный объем книги равен
3. Переведем байты в более крупные единицы:
360 000 / 1024 = 351,56 Кб
351,56 / 1024 = 0,34 Мб
Ответ: Информационный объем текста 0,34 Мб.
Задача:
Информационный объем текста, подготовленного с помощью компьютера, равен 3,5 Кб. Сколько символов содержит этот текст?
Информационный объем текста 3,5 Мб. Найти количество символов в тексте.
1. Переведем объем из Мб в байты:
3,5 Мб * 1024 = 3584 Кб
3584 Кб * 1024 = 3 670 016 байт
2. Т.к. 1 символ весит 1 байт, количество символов в тексте равно


SEO-анализ текста от Text.ru — это уникальный сервис, не имеющий аналогов. Возможность подсветки «воды», заспамленности и ключей в тексте позволяет сделать анализ текста интерактивным и легким для восприятия.
SEO-анализ текста включает в себя:
С помощью данного онлайн-сервиса можно определить число слов в тексте, а также количество символов с пробелами и без них.
Возможность нахождения поисковых ключей в тексте и определения их количества полезна как для написания нового текста, так и для оптимизации уже существующего. Расположение ключевых слов по группам и по частоте сделает навигацию по ключам удобной и быстрой. Сервис также найдет и морфологические варианты ключей, которые выделятся в тексте при нажатии на нужное ключевое слово.
Данный параметр отображает процент наличия в тексте стоп-слов, фразеологизмов, а также словесных оборотов, фраз, соединительных слов, являющихся не значимыми и не несущими смысловой нагрузки. Небольшое содержание «воды» в тексте является естественным показателем, при этом:
- до 15% — естественное содержание «воды» в тексте;
- от 15% до 30% — превышенное содержание «воды» в тексте;
- от 30% — высокое содержание «воды» в тексте.
Процент заспамленности текста отражает количество поисковых ключевых слов в тексте. Чем больше в тексте ключевых слов, тем выше его заспамленность:
- до 30% — отсутствие или естественное содержание ключевых слов в тексте;
- от 30% до 60% — SEO-оптимизированный текст. В большинстве случаев поисковые системы считают данный текст релевантным ключевым словам, которые указаны в тексте.
- от 60% — сильно оптимизированный или заспамленный ключевыми словами текст.
Данный параметр показывает количество слов, состоящих из букв различных алфавитов. Часто это буквы русского и английского языка, например, слово «стол», где «о» — буква английского алфавита. Некоторые копирайтеры заменяют в русских словах часть букв на английские, чтобы обманным путем повысить уникальность текста. SEO-анализ текста от Text.ru успешно выявляет такие слова.
SEO-анализ текста доступен через API. Подробнее в API-проверке.

К огда человек только начинает учиться копирайтингу, автор испытывает уйму сложностей даже в таких простых вещах, как определение объёма текста. Кажется: сущая мелочь, но и с ней надо уметь справиться.
Как узнать объём текста? Предлагаю вашему вниманию несколько удобных вариантов.
Редактор Word (или другая программа для работы с текстом). Когда вы набираете символы в Office, внизу страницы ведётся подсчёт слов и символов с пробелами.
- Чтобы посчитать объём текста частично, выделите нужный фрагмент мышкой и снова посмотрите на параметры внизу листа. Удобно, правда?
Чтоб увидеть всю статистику, кликните на надпись внизу, и перед глазами появится табличка, как на картинке (изображение увеличивается).
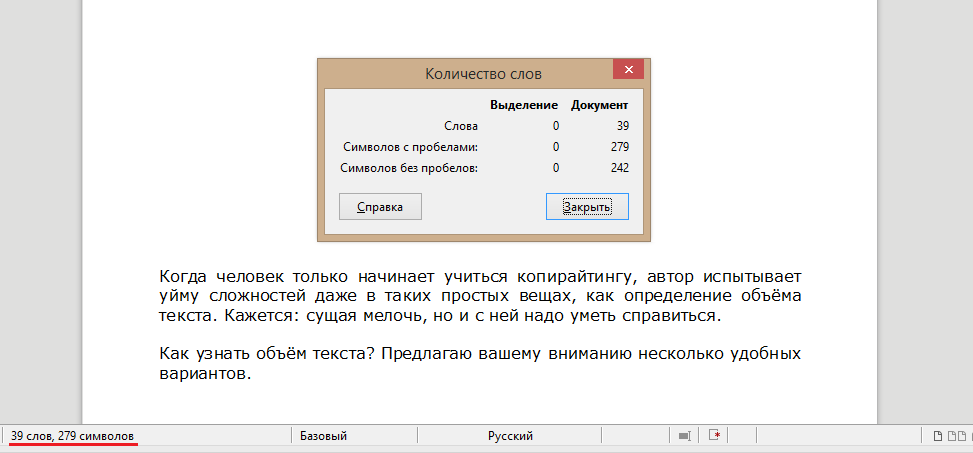
Подсчёт объёма текста в Word
TextAnalyzer. Об этом сервисе для вебмастеров я уже писала. Онлайн-инструмент выручает меня в работе над SEO-статьями. Закиньте контент в редактор, кликните на кнопку, и всего через две секунды вы сможете узнать объём текста (с пробелами и без).
Также посчитать объём текста легко в Istio.com, Content Watch, 1y.ru, text.ru или других сервисах для «сеошников», копирайтеров, журналистов.
Как видите, узнать объём текста не составляет никакого труда. В следующий раз расскажу в блоге о том, как определить объём текста с учётом ключевых слов. Этот материал будет полезен тем, кто осваивает SEO-копирайтинг. Удачи начинающим авторам!
Определить объём текста
Онлайн калькулятор легко и непринужденно вычислит объем текста в битах, байтах и килобайтах. Для перевода в другие единицы измерения данных воспользуйтесь онлайн конвертером.
Информационный вес (объем) символа текста определяется для следующих кодировок:
Unicode UTF-8
Unicode UTF-16
ASCII, ANSI, Windows-1251
|
Текст
|
|
Символов 0 Символов без учета пробелов 0 Уникальных символов 0 Слов 0 Слов (буквенных) 0 Уникальных слов 0 Строк 0 Абзацев 0 Предложений 0 Средняя длина слова 0 Время чтения 0 сек Букв 0 Русских букв 0 Латинских букв 0 Гласных букв 0 Согласных букв 0 Слогов 0 Цифр 0 Чисел 0 Пробелов 0 Остальных знаков 0 Знаков препинания 0 Объем текста (Unicode UTF-8) бит 0 Объем текста (Unicode UTF-8) байт 0 Объем текста (Unicode UTF-8) килобайт 0 Объем текста (Unicode UTF-16) бит 0 Объем текста (Unicode UTF-16) байт 0 Объем текста (Unicode UTF-16) килобайт 0 Объем текста (ASCII, ANSI, Windows-1251) бит 0 Объем текста (ASCII, ANSI, Windows-1251) байт 0 Объем текста (ASCII, ANSI, Windows-1251) килобайт 0 |
|
|
Почему на windows сохраняя текст блокноте перенос строки занимает – 4 байта в юникоде или 2 байта в анси?
Это историческое явление, которое берёт начало с дос, последовательность OD OA (nr ) в виндовс используются чтоб был единообразный вывод на терминал независимо консоль это или принтер. Но для вывода просто на консоль достаточно только n.
В юникоде есть символы которые весят 4 байта, например эмоджи: 🙃
×
Пожалуйста напишите с чем связна такая низкая оценка:
×
Для установки калькулятора на iPhone – просто добавьте страницу
«На главный экран»

Для установки калькулятора на Android – просто добавьте страницу
«На главный экран»

Задачи на определение информационного объема текста
Проверяется умение оценивать количественные параметры информационных объектов.
Теоретический материал:
N = 2i , где N – мощность алфавита (количество символов в используемом
алфавите),
i – информационный объем одного символа (информационный
вес символа), бит
I = K*i, где I – информационный объем текстового документа (файла),
K – количество символов в тексте
Задача 1.

Считаем количество символов в заданном тексте (перед и после тире – пробел, после знаков препинания, кроме последнего – пробел, пробел – это тоже символ). В результате получаем – 52 символа в тексте.
Дано:
i = 16 бит
K = 52
I – ?
Решение:
I = K*i
I = 52*16бит = 832бит (такой ответ есть – 2)
Ответ: 2
Задача 2.

Дано:
K = 16*35*64 – количество символов в статье
i = 8 бит
I – ?
Решение: Чтобы перевести ответ в Кбайты нужно разделить результат на 8 и на 1024 (8=23, 1024=210)
I=16*35*64*8 бит= =35Кбайт Ответ: 4
=35Кбайт Ответ: 4
Задача 3.

Пусть x – это количество строк на каждой странице, тогда K=10*x*64 – количество символов в тексте рассказа.
Дано:
I = 15 Кбайт
K =10*x*64
i = 2 байта
x – ?
Решение:
Переведем информационный объем текста из Кбайт в байты.
I = 15 Кбайт = 15*1024 байт (не перемножаем)
Подставим все данные в формулу для измерения количества информации в тексте.
I = K*i
15*1024 = 10*x*64*2
Выразим из полученного выражения x
x =  – количество строк на каждой странице – 4
– количество строк на каждой странице – 4
Ответ: 4
Задачи для самостоятельного решения:
Задача 1.

Задача 2.

Задача 3.

Задача 4.

Задача 5.

Задача 6.

Задача 7.

Задачи взяты с сайта fipi.ru из открытого банка заданий (с.1-7)

Добрый день, сегодня мы познакомимся с заданием №1 ОГЭ по информатике. Сама суть идёт из темы про кодирование информации. Когда мы пытаемся найти какое количество нужно выделить памяти у компьютера на один символ. Символ — это не только цифры (0-9) и буквы разных алфавитов, но и прочие специальные символы (знаки препинания, вопросительные, восклицательные знаки и т.д.). Пробел так же, как и любой другой символ занимает память при его использовании/наличии.
Само вычисление необходимого количества памяти происходит по формуле объёма информации:
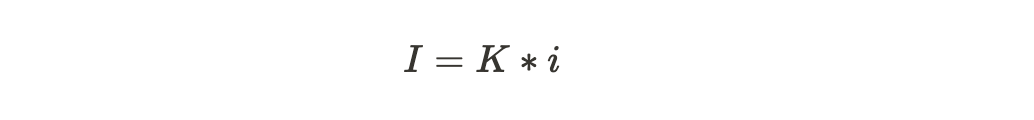
- I – объём информации (сколько весит файл/сообщение);
- K – количество символов в сообщении/в файле;
- i – количество информации (сколько памяти занимает один символ).
У этих переменных есть свои единицы измерения. Для количества символов – символы. А для объёма информации и количества информации — это бит, байт, кбайт и т.д.
Теперь, после некоторого введения в теорию мы обладаем инструментами для решения данной задачи. Осталось только определить, как применить полученные знания и каков алгоритм наших действий.
Задача №1
В кодировке КОИ-8 каждый символ кодируется 8 битами. Андрей написал текст (в нём нет лишних пробелов):
«Обь, Лена, Волга, Москва, Макензи, Амазонка — реки».
Ученик вычеркнул из списка название одной из рек. Заодно он вычеркнул лишние запятые и пробелы — два пробела не должны идти подряд. При этом размер нового предложения в данной кодировке оказался на 8 байт меньше, чем размер исходного предложения. Напишите в ответе вычеркнутое название реки.
Решение
Теперь попробуем разобрать данную задачу. У нас тут есть кодировка “КОИ-8”, которая говорит нам о том, что каждый символ весит 8 бит. А 8 бит это ровно 1 байт информации. Всё, что заключено в кавычки нас, интересует. Далее ученик вычеркнул слово (название реки) и, окружавшие его, запятую и пробел. После всех этих действий объём сообщения уменьшился на 8 байт.
Теперь мы обладаем всей полезной информацией и можем сделать некоторые выводы и суждения:
- 1 символ = 1 байту;
- удалили запятую и пробел – минус два символа, то есть 2 байта;
- 8 байт – 2 байта = 6 байт;
- 6 байт = 6 символов (в данном случае букв);
- Следовательно, необходимо найти слово (в данном случае название реки), в котором есть ровно шесть букв – Москва.
Существуют задачи, где необходимо посчитать какое количество байт будет весить файл. Попробуем разобраться с этим видом задания.
Задача №2
Статья, набранная на компьютере, содержит 20 страниц, на каждой странице 40 строк, в каждой строке 48 символов. В одном из представлений Unicode каждый символ кодируется двумя байтами. Определите информационный объём статьи в Кбайтах в этом варианте представления Unicode.
Решение
Как можем заметить тут речь идёт о файле, в котором есть 20 страниц. В каждой странице 40 строк и на каждой строке 48 символов. Исходя из этих значений найдём сколько ВСЕГО символов в файле. Также сказано что каждый символ занимает (весит) 2 байта информации. Следовательно, умножив общее количество символов на вес символа, найдём информационный объём файла (сколько он будет весить на компьютере). На словах вроде решили, теперь решим и “на бумаге”.
Для начала найдем количество символов:
После этого никто не мешает найти объем информации:
Получили достаточно большой ответ. Поскольку здесь мы умножали количество символов на байты (их вес), то и ответ получился тоже в байтах. Если бы умножали на бит, то и информационный объём тоже был бы в единицах измерения — бит. Но в самом задание сказано определить информационный объём в Кбайтах. Для этого необходимо полученное число разделить на 1024 (исходя из таблицы переводов сверху).
Вышел достаточно лаконичный ответ – 75 Кбайт.
Понравилась статья? Хочешь разбираться в информатике, программировании и уметь работать в разных программах? Тогда ставь лайк, подпишись на канал и поделись статьей с друзьями!
Читайте также:
#информатика #огэ #разбор #задания #решение #экзамен
