Задачи на определение информационного объема текста
Проверяется умение оценивать количественные параметры информационных объектов.
Теоретический материал:
N = 2i , где N – мощность алфавита (количество символов в используемом
алфавите),
i – информационный объем одного символа (информационный
вес символа), бит
I = K*i, где I – информационный объем текстового документа (файла),
K – количество символов в тексте
Задача 1.

Считаем количество символов в заданном тексте (перед и после тире – пробел, после знаков препинания, кроме последнего – пробел, пробел – это тоже символ). В результате получаем – 52 символа в тексте.
Дано:
i = 16 бит
K = 52
I – ?
Решение:
I = K*i
I = 52*16бит = 832бит (такой ответ есть – 2)
Ответ: 2
Задача 2.

Дано:
K = 16*35*64 – количество символов в статье
i = 8 бит
I – ?
Решение: Чтобы перевести ответ в Кбайты нужно разделить результат на 8 и на 1024 (8=23, 1024=210)
I=16*35*64*8 бит= =35Кбайт Ответ: 4
=35Кбайт Ответ: 4
Задача 3.

Пусть x – это количество строк на каждой странице, тогда K=10*x*64 – количество символов в тексте рассказа.
Дано:
I = 15 Кбайт
K =10*x*64
i = 2 байта
x – ?
Решение:
Переведем информационный объем текста из Кбайт в байты.
I = 15 Кбайт = 15*1024 байт (не перемножаем)
Подставим все данные в формулу для измерения количества информации в тексте.
I = K*i
15*1024 = 10*x*64*2
Выразим из полученного выражения x
x =  – количество строк на каждой странице – 4
– количество строк на каждой странице – 4
Ответ: 4
Задачи для самостоятельного решения:
Задача 1.

Задача 2.

Задача 3.

Задача 4.

Задача 5.

Задача 6.

Задача 7.

Задачи взяты с сайта fipi.ru из открытого банка заданий (с.1-7)

Добрый день, сегодня мы познакомимся с заданием №1 ОГЭ по информатике. Сама суть идёт из темы про кодирование информации. Когда мы пытаемся найти какое количество нужно выделить памяти у компьютера на один символ. Символ — это не только цифры (0-9) и буквы разных алфавитов, но и прочие специальные символы (знаки препинания, вопросительные, восклицательные знаки и т.д.). Пробел так же, как и любой другой символ занимает память при его использовании/наличии.
Само вычисление необходимого количества памяти происходит по формуле объёма информации:
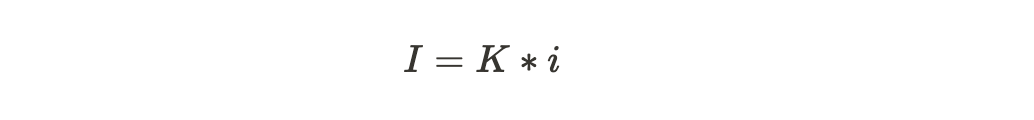
- I – объём информации (сколько весит файл/сообщение);
- K – количество символов в сообщении/в файле;
- i – количество информации (сколько памяти занимает один символ).
У этих переменных есть свои единицы измерения. Для количества символов – символы. А для объёма информации и количества информации — это бит, байт, кбайт и т.д.
Теперь, после некоторого введения в теорию мы обладаем инструментами для решения данной задачи. Осталось только определить, как применить полученные знания и каков алгоритм наших действий.
Задача №1
В кодировке КОИ-8 каждый символ кодируется 8 битами. Андрей написал текст (в нём нет лишних пробелов):
«Обь, Лена, Волга, Москва, Макензи, Амазонка — реки».
Ученик вычеркнул из списка название одной из рек. Заодно он вычеркнул лишние запятые и пробелы — два пробела не должны идти подряд. При этом размер нового предложения в данной кодировке оказался на 8 байт меньше, чем размер исходного предложения. Напишите в ответе вычеркнутое название реки.
Решение
Теперь попробуем разобрать данную задачу. У нас тут есть кодировка “КОИ-8”, которая говорит нам о том, что каждый символ весит 8 бит. А 8 бит это ровно 1 байт информации. Всё, что заключено в кавычки нас, интересует. Далее ученик вычеркнул слово (название реки) и, окружавшие его, запятую и пробел. После всех этих действий объём сообщения уменьшился на 8 байт.
Теперь мы обладаем всей полезной информацией и можем сделать некоторые выводы и суждения:
- 1 символ = 1 байту;
- удалили запятую и пробел – минус два символа, то есть 2 байта;
- 8 байт – 2 байта = 6 байт;
- 6 байт = 6 символов (в данном случае букв);
- Следовательно, необходимо найти слово (в данном случае название реки), в котором есть ровно шесть букв – Москва.
Существуют задачи, где необходимо посчитать какое количество байт будет весить файл. Попробуем разобраться с этим видом задания.
Задача №2
Статья, набранная на компьютере, содержит 20 страниц, на каждой странице 40 строк, в каждой строке 48 символов. В одном из представлений Unicode каждый символ кодируется двумя байтами. Определите информационный объём статьи в Кбайтах в этом варианте представления Unicode.
Решение
Как можем заметить тут речь идёт о файле, в котором есть 20 страниц. В каждой странице 40 строк и на каждой строке 48 символов. Исходя из этих значений найдём сколько ВСЕГО символов в файле. Также сказано что каждый символ занимает (весит) 2 байта информации. Следовательно, умножив общее количество символов на вес символа, найдём информационный объём файла (сколько он будет весить на компьютере). На словах вроде решили, теперь решим и “на бумаге”.
Для начала найдем количество символов:
После этого никто не мешает найти объем информации:
Получили достаточно большой ответ. Поскольку здесь мы умножали количество символов на байты (их вес), то и ответ получился тоже в байтах. Если бы умножали на бит, то и информационный объём тоже был бы в единицах измерения — бит. Но в самом задание сказано определить информационный объём в Кбайтах. Для этого необходимо полученное число разделить на 1024 (исходя из таблицы переводов сверху).
Вышел достаточно лаконичный ответ – 75 Кбайт.
Понравилась статья? Хочешь разбираться в информатике, программировании и уметь работать в разных программах? Тогда ставь лайк, подпишись на канал и поделись статьей с друзьями!
Читайте также:
#информатика #огэ #разбор #задания #решение #экзамен
1. Информационный объём текстового
сообщения
Расчёт
информационного объёма текстового сообщения (количества информации,
содержащейся в информационном сообщении) основан на подсчёте количества
символов в этом сообщении, включая пробелы, и на определении
информационного веса одного символа, который зависит от кодировки, используемой
при передаче и хранении данного сообщения.
Для расчёта
информационного объёма текстового сообщения используется формула
I=K*i, где
I – это информационный объём текстового сообщения,
измеряющийся в байтах, килобайтах, мегабайтах;
K – количество символов в
сообщении,
i – информационный вес одного символа, который
измеряется в битах на один символ.
Информационный
объём одного символа связан с количеством символов в алфавите формулой
N=2i, где
N – это количество символов в алфавите (мощность
алфавита),
i – информационный
вес одного символа в битах на один символ.
2. Информационный объём растрового
графического изображения
Расчёт
информационного объёма растрового графического изображения (количества
информации, содержащейся в графическом изображении) основан на подсчёте количества
пикселей в этом изображении и на определении глубины
цвета (информационного веса одного пикселя).
Для расчёта
информационного объёма растрового графического изображения используется
формула
I=K*i, где
I – это информационный объём растрового графического
изображения, измеряющийся в байтах, килобайтах, мегабайтах;
K – количество пикселей (точек) в
изображении, определяющееся разрешающей способностью носителя информации
(экрана монитора, сканера, принтера);
i – глубина цвета, которая
измеряется в битах на один пиксель.
Глубина цвета связана с
количеством отображаемых цветов формулой
N=2i, где
N – это количество цветов в палитре,
i – глубина цвета в битах на
один пиксель.
Определить объём текста
Онлайн калькулятор легко и непринужденно вычислит объем текста в битах, байтах и килобайтах. Для перевода в другие единицы измерения данных воспользуйтесь онлайн конвертером.
Информационный вес (объем) символа текста определяется для следующих кодировок:
Unicode UTF-8
Unicode UTF-16
ASCII, ANSI, Windows-1251
|
Текст
|
|
Символов 0 Символов без учета пробелов 0 Уникальных символов 0 Слов 0 Слов (буквенных) 0 Уникальных слов 0 Строк 0 Абзацев 0 Предложений 0 Средняя длина слова 0 Время чтения 0 сек Букв 0 Русских букв 0 Латинских букв 0 Гласных букв 0 Согласных букв 0 Слогов 0 Цифр 0 Чисел 0 Пробелов 0 Остальных знаков 0 Знаков препинания 0 Объем текста (Unicode UTF-8) бит 0 Объем текста (Unicode UTF-8) байт 0 Объем текста (Unicode UTF-8) килобайт 0 Объем текста (Unicode UTF-16) бит 0 Объем текста (Unicode UTF-16) байт 0 Объем текста (Unicode UTF-16) килобайт 0 Объем текста (ASCII, ANSI, Windows-1251) бит 0 Объем текста (ASCII, ANSI, Windows-1251) байт 0 Объем текста (ASCII, ANSI, Windows-1251) килобайт 0 |
|
|
Почему на windows сохраняя текст блокноте перенос строки занимает – 4 байта в юникоде или 2 байта в анси?
Это историческое явление, которое берёт начало с дос, последовательность OD OA (nr ) в виндовс используются чтоб был единообразный вывод на терминал независимо консоль это или принтер. Но для вывода просто на консоль достаточно только n.
В юникоде есть символы которые весят 4 байта, например эмоджи: 🙃
×
Пожалуйста напишите с чем связна такая низкая оценка:
×
Для установки калькулятора на iPhone – просто добавьте страницу
«На главный экран»

Для установки калькулятора на Android – просто добавьте страницу
«На главный экран»

Теоретический материал:
1) N = 2i, где N – мощность алфавита (количество символов в используемом
алфавите), i – информационный объем одного символа (информационный
вес символа), бит.
2) I = K*i, где I – информационный объем текстового документа (файла), K – количество символов в тексте
При алфавитном подходе к определению количества информации отвлекаются от содержания информации и рассматривают информационное сообщение как последовательность знаков определенной знаковой системы.
Информационная емкость знака.
Представим себе, что необходимо передать информационное сообщение по каналу передачи информации от отправителя к получателю. Пусть сообщение кодируется с помощью знаковой системы, алфавит которой состоит из N знаков {1, …, N}. В простейшем случае, когда длина кода сообщения составляет один знак, отправитель может послать одно из N возможных сообщений “1”, “2”, …, “N”, которое будет нести количество информации I (рис. 1).
Формула 1) связывает между собой количество возможных информационных сообщений N и количество информации I, которое несет полученное сообщение. Тогда в рассматриваемой ситуации N — это количество знаков в алфавите знаковой системы, а i – количество информации, которое несет каждый знак:
N = 2i.
_______________________________________________________________________________
С помощью этой формулы можно, например, определить количество информации, которое несет знак в двоичной знаковой системе:
N = 2 => 2 = 2i => 21 = 2i => i = 1 бит.
Таким образом, в двоичной знаковой системе знак несет 1 бит информации. Интересно, что сама единица измерения количества информации “бит” (bit) получила свое название ОТ английского словосочетания “Binary digiT” – “двоичная цифра”.
Информационная емкость знака двоичной знаковой системы составляет 1 бит.
Чем большее количество знаков содержит алфавит знаковой системы, тем большее количество информации несет один знак. В качестве примера определим количество информации, которое несет буква русского алфавита.
_______________________________________________________________________________
Пример.
В русский алфавит входят 33 буквы, однако на практике часто для передачи сообщений используются только 32 буквы (исключается буква “ё”). С помощью формулы 1) определим количество информации, которое несет буква русского алфавита:
N = 32 => 32 = 2i => 25 = 2i => i=5 битов.
Таким образом, буква русского алфавита несет 5 битов информации (при алфавитном подходе к измерению количества информации).
_______________________________________________________________________________
Количество информации, которое несет знак, зависит от вероятности его получения. Если получатель заранее точно знает, какой знак придет, то полученное количество информации будет равно 0. Наоборот, чем менее вероятно получение знака, тем больше его информационная емкость.
В русской письменной речи частота использования букв в тексте различна, так в среднем на 1000 знаков осмысленного текста приходится 200 букв “а” и в сто раз меньшее количество буквы “ф” (всего 2). Таким образом, с точки зрения теории информации, информационная емкость знаков русского алфавита различна (у буквы “а” она наименьшая, а у буквы “ф” – наибольшая).
Количество информации в сообщении.
Сообщение состоит из последовательности знаков, каждый из которых несет определенное количество информации. Если знаки несут одинаковое количество информации, то количество информации I в сообщении можно подсчитать, умножив количество информации i, которое несет один знак, на длину кода (количество знаков в сообщении) К:
I = i × K
Так, каждая цифра двоичного компьютерного кода несет информацию в 1 бит. Следовательно, две цифры несут информацию в 2 бита, три цифры – в 3 бита и т. д. Количество информации в битах равно количеству цифр двоичного компьютерного кода (табл. 1.1).
