Как находить информацию для сайта.
Сайт-блог, который мы с вами хотим сделать, полностью зависит от качественного контента. Но перед тем как заполнить свой собственный блог контентом, необходимо определиться с тем, в какой среде вы будете черпать идеи для написания своих статей и постов. Именно с проблемой поиска идей для статей чаще всего сталкиваются начинающие блоггеры, которые не знают, где взять материал для своего блога.
К счастью, в Интернете любой человек может найти практически любую, исчерпывающую информацию по своим запросам. Причем, даже если ваш тематический блог посвящен редким тропическим рыбкам, то вы все равно найдете массу интересной информации и фотографий, которыми вы сможете поделиться с читателями своего блога.
Для начала черпать идеи для блога можно, подписавшись на так называемые rss рассылки, rss каналы, которые ведут практически все блоггеры мира.
При поиске информации для русскоязычного сайта — заходим в Яндекс.блоги //blogs.yandex.ru/ и смотрим, популярные блоги на вашу тему или задаем поиск по блогам с теми ключевыми словами, которые вам интересны. Далее вам просто потребуется подписаться на интересующие вас rss ленты, чтобы получать как минимум 10 новостей в день.
Эти самые новости помогут вам наполниться самыми различными идеями и вариантами статей, которые вы сможете написать самостоятельно, опираясь на опыт других блоггеров. RSS рассылки можно получать с помощью определенных плагинов своего браузера. Например, Opera и Firefox прекрасно справляются с получением и подачей полученного по rss материала.
Или лучше использовать специализированную программу RSS Reader (или RSS Агрегатор). Их существует множество, обзор можете почитать тут
//www.kreont.name/rss/popular_rss_aggregators.html
Я рекомендую FeedDemon , бесплатный и удобный в использовании
После того как все установлено и настроено, встает вопрос о том, где искать интересные блоги и их RSS, которые имеют качественный интересный контент, из которого мы и будем черпать идеи. Наиболее удобными и интересными, на мой взгляд, являются два простых и в тоже время полезных сервиса, это:
на каждом из которых вы сможете найти просто невероятное количество блогов на любую интересующую вас тему. В этих популярных поисковиках вы вводите те ключевые слова, которые представляют для вас интерес или просто выбираете ту категорию, которая вам больше всего подходит.
Подписка на рассылку происходит следующим образом, вы копируете ссылку на rss в свой rss плагин браузера или агрегатор, и вы готовы к получению самой интересной и полезной информации.
Поиск по блогам поможет вам найти наиболее интересные и популярные блоги, на которых вы сможете научиться, как правильно вести блог, и начнете отмечать для себя, что отличает блоги опытных пользователей от блогов новичков. Вам предстоит непростая, но интересная и прибыльная работа, поэтому, не теряя времени, начинайте посещать все блоги, которые кажутся вам интересными. После того как интересный блог найден, подписывайтесь на его рассылку и приступайте к самостоятельному написанию статей, на основании информации полученной из блога-оригинала новости, идеи…
Переписывать новости и статьи красиво своими словами, после небольшой практики, сможет каждый, тем более что Интернет не требует от вас большого мастерства, вам достаточно просто писать и писать как можно больше про самые интересные и важные на ваш взгляд события и вещи в вашей нише.
Среднее число добавляемых на блог постов в неделю должно быть не менее 3-х, 4-х, общим объемом до 6-10000 тысяч символов. Написание и размещение постов будет занимать у вас около 2-2,5 часа в день. После того как вы наберетесь опыта, на эти операции вы будете затрачивать от 40 минут до часа.

Теперь очень важная информация о том, что контент для вашего блога должен быть всегда уникальным или, в крайнем случае, с претензией на уникальность. Все дело в том, что качество статей, а точнее их уникальность очень ценится не только поисковыми серверами, но и теми людьми, которые ваши статьи читают, ведь в конечном итоге вы получаете прибыль за то, что люди посещают ваш сайт. Поэтому вашей основной задачей должно стать написание качественного контента для людей.
Например, вы хотите написать статью о том, как разводить комнатные цветы. Тогда вам достаточно ввести требуемый запрос в любой поисковой системе, чтобы получить несколько сайтов, где эта тема уже раскрыта или активно обсуждается. Вам остается только собрать информацию, добавить свой собственный опыт или, в крайнем случае, просто переписать имеющийся материал своими словами, чтобы получить хорошую статью для своего собственного блога.
В начале на написание вы будете тратить немало времени, но это только в начале, потом вы либо сможете писать самостоятельно большое количество текстов, либо просто заказывать качественные тексты на различных биржах удаленной работы, яркими примерами которых являются такие ресурсы как
- //www.weblancer.net/
- //www.free-lance.ru/
На этих сайтах вы сможете устроить настоящий тендер и отобрать именно того исполнителя, который устроит вас по цене и качеству. Тем более что если вам необходимо заполнение или ведение вашего блога на английском, испанском или даже китайском языке, то на указанных выше сайтах вы сможете найти хороших и ответственных исполнителей для этой работы.
А можно воспользоваться и целыми биржами статей, на которых уже имеются готовые к размещению статьи:
- //copylancer.ru/
- //www.textsale.ru/
- //advego.ru/
Статьи на этих сайтах написаны под заказ и ждут только размещения на том или ином сайте.
И естественно, всегда проверяйте все статьи (как свои таки чужие) на уникальность. Для этого вы можете воспользоваться различными сервисами, представленными в сети, например: //copyscape.com/ или специальными программами типа DCF (DoubleCopyFinder), которые сразу находят плагиат или невысокую уникальность текста.
Иногда в своем блоге можно размещать чужие статьи, взятые с различных каталогов статей, таких как //50rus.info/ //www.topofarticles.com/ //www.artcat.com.ua/ и множество других.
Для англоязычных сайтов это //ezinearticles.com/ //www.articledashboard.com/
На подобных сайтах есть масса статей на самые различные темы, так что при должном желании в вашем блоге будет всегда свежая и актуальная информация.
Но конечно эти статьи не уникальные. Просто копированием нужный нам сайт не сделаешь.
И еще, согласно правилам хорошего тона, если вы взяли статью с конкретного сайта, то желательно всегда указывать источник. Но в случае если материал был собран с нескольких различных ресурсов и переработан вами в свою уникальную статью, то ставить ссылку на источник необязательно.
Еще что можно брать и публиковать даже без ссылок на авторов статьи с
правами PLR (Private Label Rights), это статьи, которые пишутся специально для продажи нескольким людям.
Все, кто их купит — могут публиковать их где угодно как свои.
Это больше распространено в англоязычном интернете и их легко найти
если поискать в гугле «plr articles»
Но даже если статьи новые, то их купят не только вы, поэтому они также не
будут уникальными. Их нужно обязательно переделать.
Можно конечно какое-то количество статей ставить без переделки. Но эта скопированная часть статей должна быть намного меньше чем количество уникальных статей.
Надеюсь, после прочтения этой главы вы поняли, где черпать идеи для написания хороших статей и сами статьи для своего сайта.
Главное на этом не останавливаться, а применять знания на практике!
ДАЛЬШЕ: Продвижение – Раскрутка Сайта. Внутренняя Оптимизация. —>

Обзор лучших сервисов и приложений для экспресс-аудита сайтов.
Яндекс.Вебмастер (и его аналог от Google – Search Console)
Самый очевидный вариант, но при этом достаточно эффективный. Сервисы от Google и Яндекс могут предоставить много полезной информации о ресурсе. Например, показать позиции сайта в поиске и запросы, через которые люди попадают на ваш ресурс. Тут же можно найти информацию об индексировании страниц и микроразметке, ответы сервера, информацию о безопасности сайта и т.п. Причем все это от самого надежного источника данных.
Но придется смириться с тем, что в Яндекс.Вебмастере и в Google Search Console доступны только данные по вашим сайтам. Взглянуть на то, что происходит у конкурентов, не получится.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
KeyCollector
Программа KeyCollector разрабатывалась как инструмент для быстрого и эффективного сбора семантического ядра и по ходу своего развития обрела немало дополнений, помогающих провести аудит сайта. В частности, возможности KeyCollector позволяют оценить насколько релевантны страницы ресурса, определить количество подходящих ключевых запросов и т.п.
Это помогает быстро оценить конкурентоспособность выбранного сайта, эффективность и стоимость ключевых слов, а также получить другую полезную информацию. Правда, только часть функций KeyCollector доступна в бесплатной демо-версии, за остальное придется платить. Лицензия обойдется в 1800 рублей/год.
PR-CY
Многофункциональная система аудита сайтов, позволяющая проверить любой ресурс буквально по всем важным параметрам. В их числе:
-
Список проиндексированных страниц и их посещаемость по данным Liveinternet.
-
Наличие на сайте вредоносного программного обеспечения и наличие самого сайта в списке запрещенных.
-
Рейтинг качества оптимизации страниц (оцениваются заголовки, описания, микроразметка и т.п.).
-
Техническая информация о сервере.
И еще с десяток разных критериев, включая ответы сервера и информацию о наличии SSL-сертификата. Статистика по поисковым словам тут тоже есть.
Sitechecker
Этот инструмент ориентирован на поиск технических проблем на сайте. Он работает в автоматическом режиме и весьма точно определяет, какие критические ошибки присутствуют в работе ресурса и над чем стоит поработать.
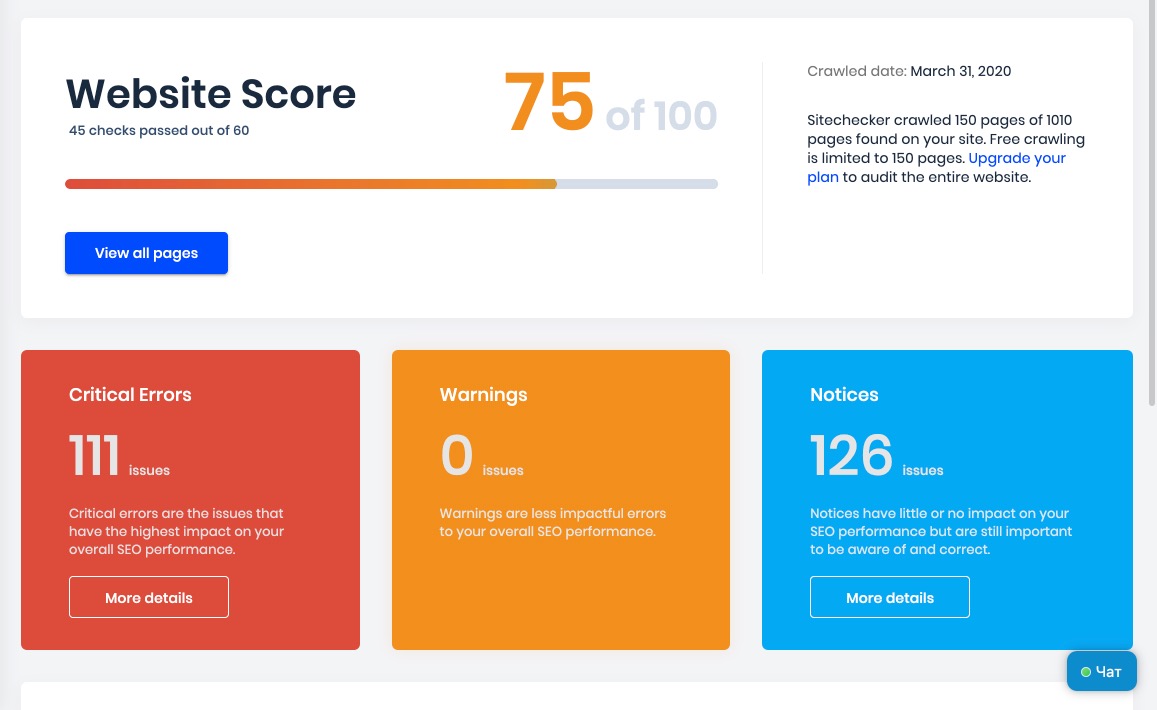
Sitechecker покажет, какие страницы и почему не поддерживают SSL-шифрование, поможет убрать дублированные теги из HTML-разметки, правильно оформить title и оптимизировать контент на странице.
Бесплатная версия программы работает в ограниченном режиме и показывает данные только по четырем страницам, но многим даже этого может быть достаточно, чтобы сделать выводы о сайте в целом.
Be1.ru
Этот сервис во многом похож на PR-CY. Показывает примерно те же данные, создавая подробный отчет о ресурсе со всеми необходимыми показателями.
be1.ru рассказывает о наличии вирусов, неполадок в работе сервера, о неправильно оформленных тегах и прочих технических особенностях.

Также здесь можно посмотреть количество входящих и исходящих ссылок, узнать, какие ключевые запросы отсутствуют в семантическом ядре (те, которые можно было бы использовать для продвижения сайта), получить подробную информацию о демографии пользователей.
А еще у сервиса шикарный маскот-робот.
Seobility
В отличие от многих конкурентов, Seobility уделяет больше внимания не техническим аспектам ресурса, а контенту, который на нем размещен.
Seobility может базово оценить контент, опубликованный на анализируемых страницах, и вынести ряд замечаний. Например, сообщить, что заголовки первого уровня не используются в тексте или, наоборот, повторяются. Или о том, что в тексте недостаточно слов. При этом сервис хвалит за наличие списков и других средств оформления текста и ругает за их отсутствие.
Также Seobility оценивает популярность сайта в социальных сетях и даже в Википедии.
Text.ru
Этот сервис знаком многим копирайтерам, так как часто используется как для проверки уникальности отдельных статей, так и для проверки таких характеристик текста, как «заспамленность» и «водность».
Через алгоритмы text.ru можно проверить страницу целиком. Он оценит уникальность контента, проверит орфографию, покажет в процентном соотношении количество спама и воды в тексте, то есть проведет базовый SEO-анализ.
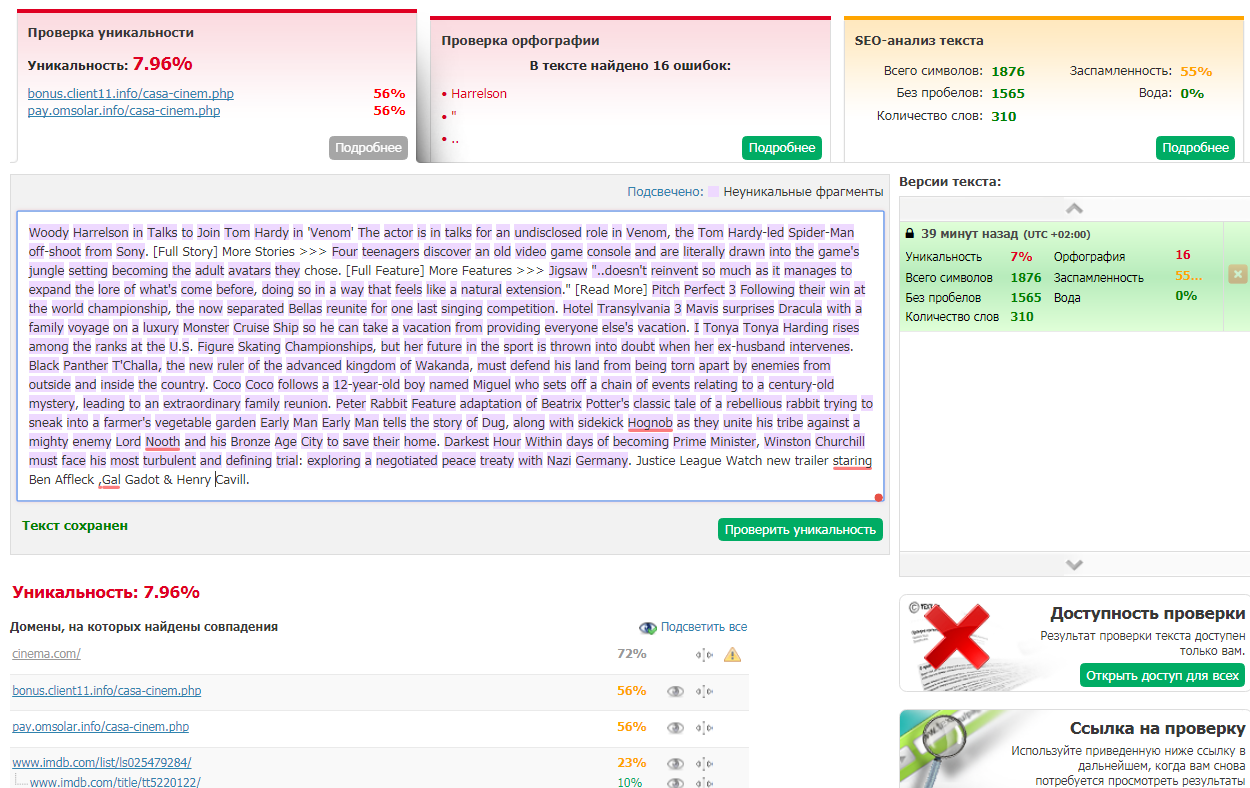
Отличный вспомогательный инструмент для анализа контента в дополнение к другим сервисам для аудита сайтов.
Nibbler
Иностранный сервис для проверки сайтов. Отчет, формирующийся в Nibbler, делится на четыре группы:
-
Насколько сайт оптимизирован для людей с ограниченными возможностями.
-
Насколько он производительный и в общих чертах приятный для пользователя.
-
Достаточно ли анализируемый ресурс популярен в сети.
-
Насколько грамотно он реализован с технической стороны (теги, SEO и все такое).
Сервис делится большим количеством полезных данных, но общая оценка у многих вебмастеров портится из-за параметров в духе отстутствия оптимизации страницы под печать. То есть вещей, которые далеко не всем ресурсам нужны и оценивать которые не стоило бы. Так что нужно более внимательно относиться к отчетам, которые генерирует Nibbler.
СайтРепорт
Как и другие подобные сервисы, СайтРепорт показывает всю необходимую базовую информацию о состоянии ресурса. Местами он ошибается и выдает менее точную информацию, чем конкуренты, но зато он может рассказать о некоторых показателях, которые редко освещаются у других.
К таким относится релевантность ключей, например. В этом отчете отображается статистика по релевантности ключей в соответствии с данными из Wordstat. Также сервис показывает «видимость» сайта для поисковика и отображает похожие на ваш ресурсы. Проще говоря, говорит о том, по каким ключам ваши страницы всплывают в первой десятке поисковой выдачи и какие конкуренты идут с вами в ногу. А еще он отображает краткую справку о производительности ресурса.
Mangools
Продвинутый сервис для аудита сайтов, собирающий точную информацию в четырех четко разграниченных отчетах:
-
В первом отчете отображается обобщенная статистика, то есть показатели в духе авторитетности и цитируемости, собранные из различных доверенных источников.
-
Во втором показываются удаленные ссылки и то как они использовались за последние несколько месяцев.
-
В третьем отчете отображается лучший контент ресурса. Это материалы, которыми чаще всего делятся и на которые ссылаются другие источники.
-
В последнем отчете указываются конкуренты, т.е. ресурсы с похожей тематикой на одном уровне популярности с анализируемым или рядом.
Advego
Еще один сервис, созданный не столько для аудита сайтов, сколько для анализа контента, размещенного на нем. Он во многом похож на text.ru, так как используется с той же целью – убедиться, что текст уникален и не заспамлен.
Конечно, критериев проверки у Advego намного больше, и многие из них куда важнее, чем названные мной, но конкретно с неуникальными участками текста он борется особенно хорошо. Как бы автор ни пытался выкрутиться, сервис сразу заметит попытки уникализировать материал нечестным путем.
Это может быть особенно полезно, если вы ведете блог на тему, которая уже раскрывалась десятки раз, и для продвижения необходимы высокоуникальные статьи.
Megaindex
Популярный сервис для сбора аналитических данных о работе сайта. Продукт пользуется спросом как среди вебмастеров, так и среди разработчиков других подобных сервисов. Они опираются на данные Megaindex в том числе.
Внутри целая серия различных инструментов для аудита веб-страниц. Можно проанализировать посещаемость ресурса, проверить, насколько он заметен в поисковых системах и по каким запросам выходит в топ. Можно проверить обратные ссылки, взглянуть на конкурентов и многое другое.
Также Megaindex отлично подходит для экспресс-аудита, так как в один клик и без дотошного анализа выводит обобщенную оценку ресурса.
Comparser
Интересный продукт для сбора информации о ресурсе тем же методом, каким обычно пользуется поисковой робот. Comparser умеет имитировать ботов Яндекса и Google и, как настоящий «краулер», собирает всяческие технические данные о ресурсе.
В Comparser много настроек, поэтому можно адаптировать механизмы поиска и анализа информации под свои нужды. Выявить страницы, находящиеся в индексе, или обнаружить те, что по какой-то причине не индексируются.
Программа собирает информацию сразу из двух поисковых систем и объединяет ее с данными, которые находит на ресурсе самостоятельно. Получается обширный отчет с большим количеством полезных данных касаемо индексации.
Букварикс
Букварикс – это аналог KeyCollector, но более скромный. Принцип работы у него похожий – Букварикс тоже подбирает базу ключевых запросов, чтобы было проще продвигать свой ресурс в обеих поисковых системах.
Алгоритм взаимодействия с сервисом следующий:
-
Сначала вы «скармливаете» ему ссылку на сайт или какой-то ключевой запрос.
-
Он подбирает подходящие фразы для AdWords и отправляет их вам Excel-файлом.
В отчетах Букварикс отображаются данные как по конкретно вашему ресурсу, так и по конкурентам, продвигающимся по схожим поисковым запросам.
PageSpeed Insights
Детище самой Google, которое фокусируется на решении исключительно одной задачи – повышении производительности вашего ресурса.
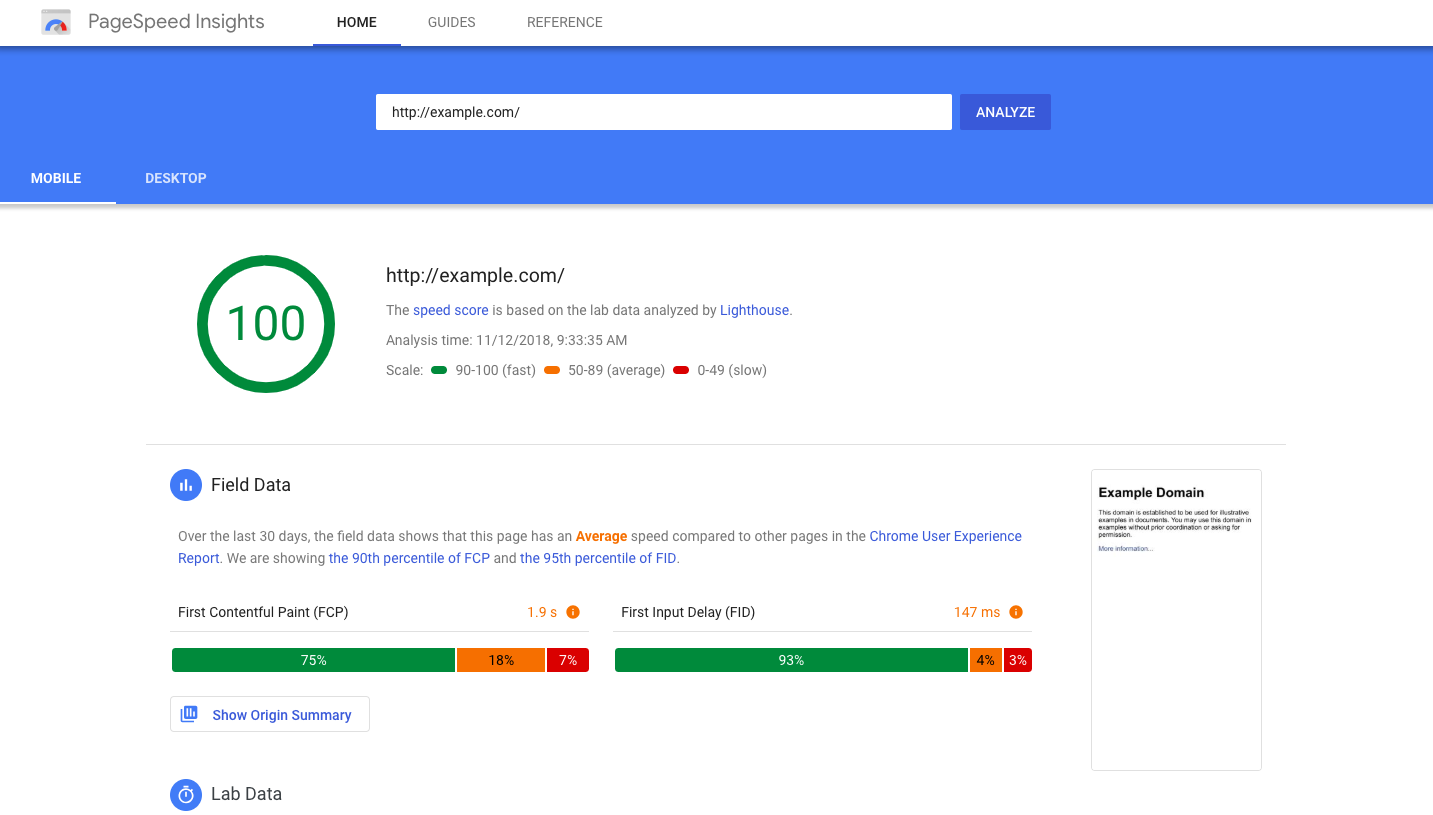
Google (да и Яндекс) очень трепетно относится к таким характеристикам страниц, как скорость их загрузки и общая производительность, поэтому медленные ссылки не получают милости со стороны поисковиков и остаются на задворках поисковой выдачи.
Если не хотите такой судьбы для своего сайта, то стоит воспользоваться PageSpeed Insights. Он подскажет, из-за чего страницы медленно загружаются и как это можно исправить, чтобы повысить рейтинг в глазах Google. Причем подскажет подобающим образом, с подробными инструкциями.
allpositions
Ресурс для базового аудита сайтов и проверки их позиций в поисковой выдаче.
allpositions нацелен на то, чтобы рассказать вебмастерам, на каком месте в Яндексе и Google появляется их сайт при вводе определенных ключевых запросов и как положение ресурса в топе поиска менялось за последнее время. Вместе с этим allpositions, конечно же, показывает успехи конкурентов, чтобы вы знали, кто вас обгоняет или уже обогнал.
Также сервис показывает различную статистику, взятую из сервиса Google Analytics.
SEOTO.ME
Востребованный онлайн-сервис для аудита сайтов. Функциональный и визуально привлекательный. Интерфейс – одно из главных достоинств этого проекта. Минималистичный и понятный.
SEOTO.ME показывает статистику по всем страницам анализируемого ресурса. В нее попадают данные из Яндекс.Метрики и Google Analytics, туда же попадают различные технические показатели и самые важные данные в духе статуса индексации или наличия неканонических URL.
Если SEOTO.ME обнаруживает проблему на анализируемом ресурсе, то отправляет сообщение о ней в отдельный раздел.
Neatpeak Spider
Это не онлайн-сервис, а отдельное приложение для ПК от российских SEO-специалистов. Программа платная и ориентирована именно на SEOшников, для кого оптимизация является основным источником дохода.
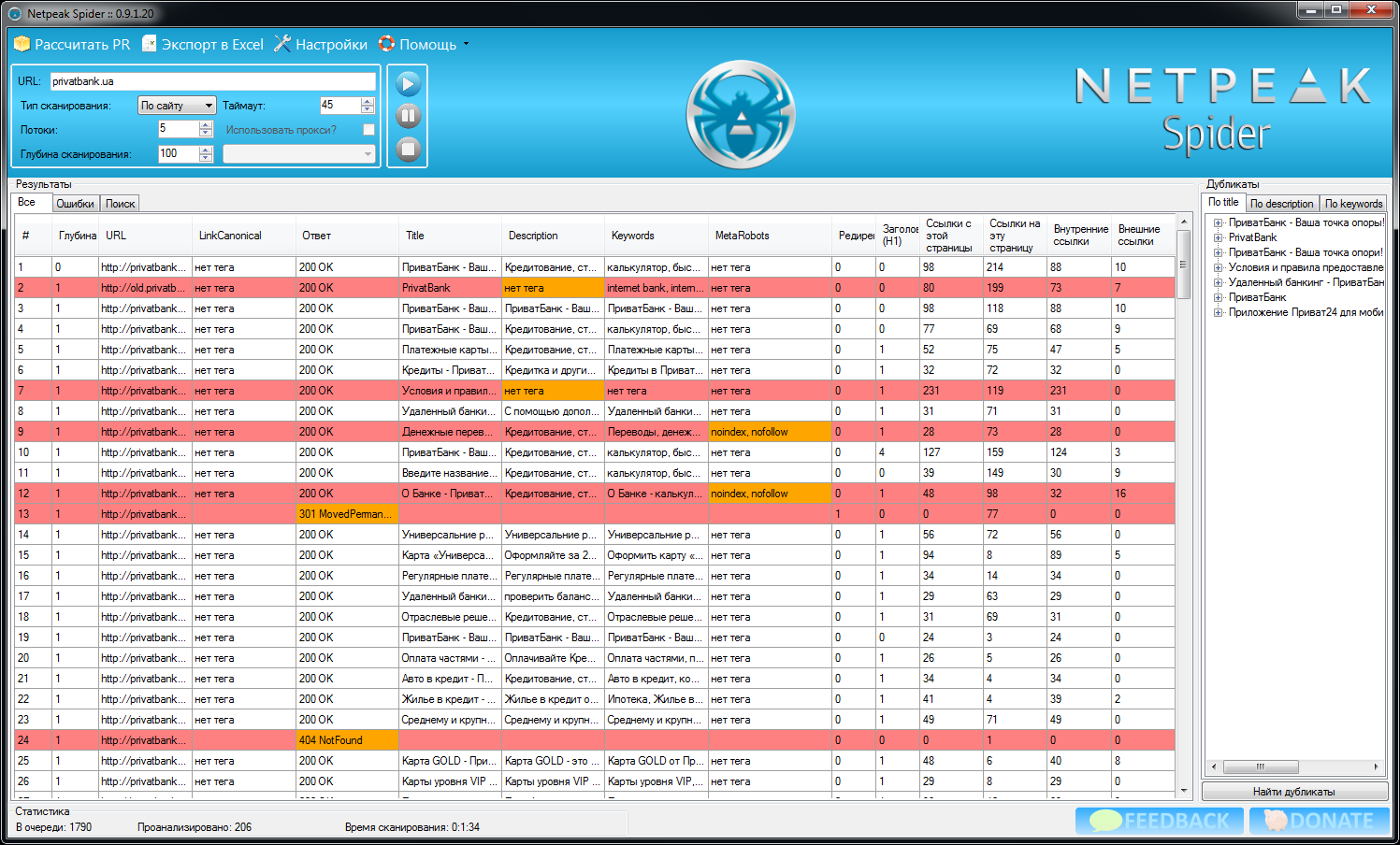
Netpeak Spider анализирует сайт досконально. Программа может обнаружить на сайте более 80 распространенных ошибок внутренней оптимизации, пагубно влияющих на позиции ресурса в поисковой выдаче.
Информация в Netpeak Spider подается в виде наглядных диаграмм, грамотно организованных рядом со списком ошибок с подробным описанием каждой из них. Приложение дает подсказки по тому, как исправить возникшую ошибку и что будет с сайтом, если ее проигнорировать.
Website Auditor
Эта программа похожа на Netpeak Spider, но отличается менее подробным анализом и отсутствием платы за использование. Поэтому она отлично подходит начинающим SEO-специалистам, а еще тем, кому нужно быстро провести аудит, чтобы получить общую информацию и особо не вникать в тему.
Также Website Auditor расскажет, какие страницы открываются с ошибкой и с какой именно, какие перенаправления настроены на сайте. Расскажет о проблемах технического характера и немного о контенте (нет ли дубликатов и некорректных тегов).
Кроме того, программа анализирует еще и медиаконтент, хранящийся на ресурсе.
Screaming Frog SEO Spider
Популярная кроссплатформенная утилита для анализа масштабных сайтов с тысячами страниц.
Screaming Frog SEO Spider проверяет все, что есть на вашем сайте: тексты, картинки, CSS-файлы, скрипты и т.п. Анализирует каждый элемент и на основе полученных данных делает вывод о «качестве» сайта.
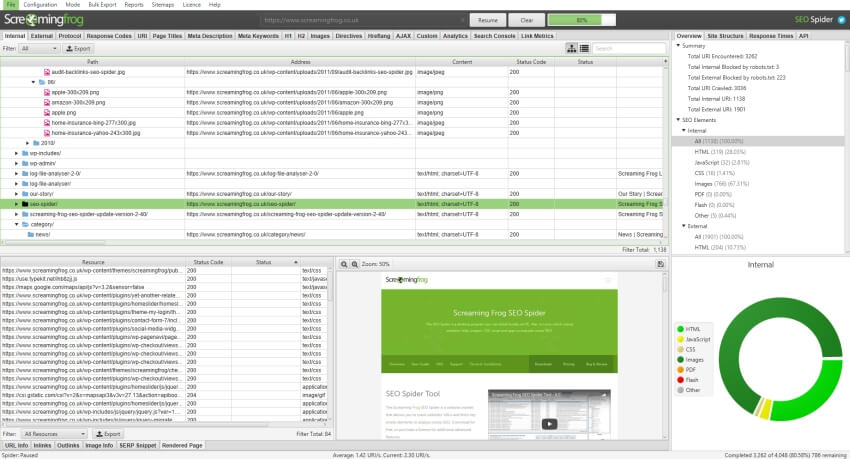
Естественно, Screaming Frog SEO Spider отдельно сообщает коды ошибок, ответы сервера, показывает некорректно оформленные ссылки, неоптимизированные заголовки, описания и другие HTML-теги.
Также приложение отдельно проверяет изображения, в частности сообщает о слишком тяжелых файлах.
Lighthouse
Lighthouse – это система анализа сайтов, разработанная компанией Google. Изначально она была расширением для Google Chrome, а позже вовсе стала частью Chrome DevTools.
Главное преимущество Lighthouse заключается как раз в том, что утилита создана крупнейшим поисковиком. И здесь как нельзя точнее указаны параметры, которым необходимо следовать, чтобы Google более лояльно относился к вашему сайту.
Lighthouse расскажет, что нужно поменять в сайте, чтобы он работал быстрее, как сделать его более адаптированным для людей с ограниченными возможностями, как сделать сайт удобным и симпатичным для большинства пользователей и т.п.
В общем, полный спектр показателей, за которыми точно необходимо следить, причем «из первых рук».
MozBar
Удобное расширение для браузера Google Chrome, показывающее три характеристики каждого посещаемого сайта:
-
Domain Authority – авторитетность домена.
-
Page Authority – авторитетность страницы.
-
Уровень «заспамленности» сайта внешними ссылками.
Если нажать на значок запуска более полного анализа, то расширение также может рассказать о проблемах в микроразметке, общей оптимизации страницы и массе других параметров.
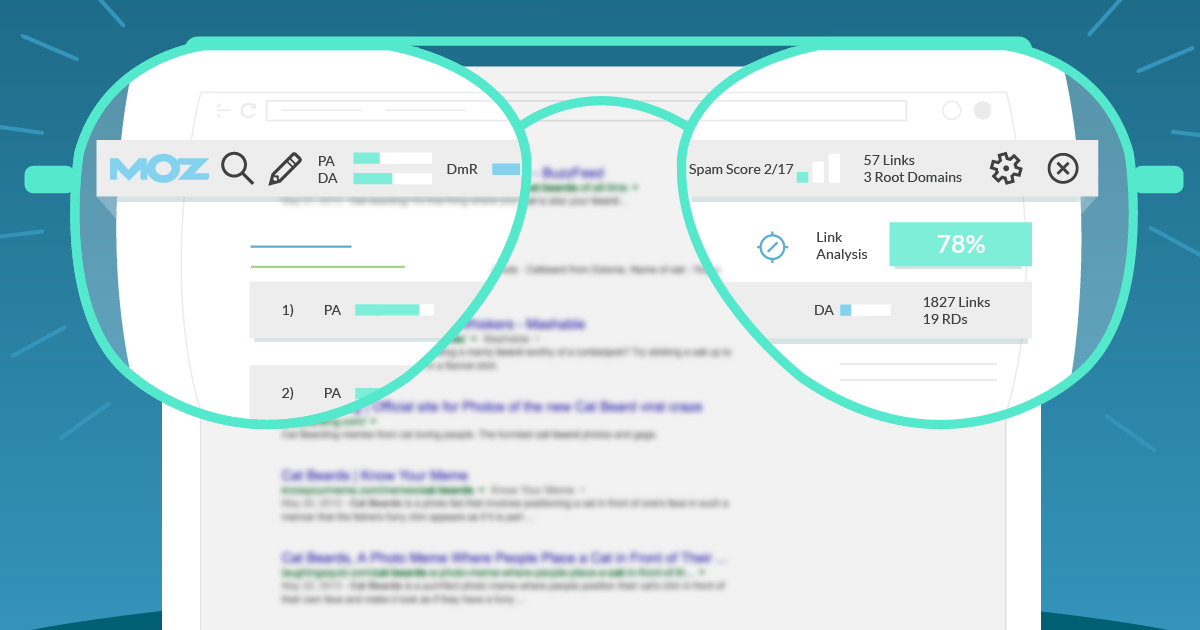
Помимо прочего, MozBar показывает и техническую информацию о посещаемом ресурсе. Если купить расширенную версию дополнения, то оно даст более подробные подсказки по поводу оптимизации страницы.
Seo-Tools
Это не совсем сервис для аудита сайта, а скорее сборник таких сервисов в удобном формате.
Расширение Seo-Tools доступно на каждой странице. При его запуске высвечивается большой список сервисов, каждый из которых может предоставить подобный отчет о наличии ошибок или недооптимизированных элементов.
При нажатии по любому из сервисов в окне расширения происходит переадресация на соответствующий ресурс, уже готовый к анализу выбранной страницы.
RDS Bar
RDS Bar почти полностью копирует функциональность Moz Bar. В чем-то он эффективнее, в чем-то отстает. Можно использовать его в качестве дополнения, чтобы наверняка убедиться в том, что показатели, которые выводят подобные приложения, верны.
Он также анализирует большое количество SEO-показателей, объединяет их в единую рейтинговую систему и сообщает, какой балл смог заработать сайт. При желании можно более подробно изучить найденные расширением ошибки и неоптимизированный контент.
Вместо заключения
На этом и закончим. Количество сервисов для аудита сайтов не заканчивается данным списком. Легко наберется еще десяток-другой подобных программ и онлайн-ресурсов. Я же выбрал для вас наиболее популярные, эффективные и удобные в использовании.
Удачи!

Наверное, многие когда-нибудь задумывались, как сделать поиск на сайте? Безусловно, для крупных сайтов с большим количеством контента поиск является просто незаменимой вещью. В большинстве случаев пользователь, впервые посетив Ваш сайт в поисках чего-либо важного, не станет разбираться в навигационных панелях, выпадающих меню и прочих элементах навигации, а в спешке попытается найти что-нибудь похожее на поисковую строку. И если такой роскоши на сайте не окажется, либо он не справится с поисковым запросом, то посетитель просто закроет вкладку. Но статья не о значении поиска для сайта и не о психологии посетителей. Я расскажу, как реализовать небольшой алгоритм полнотекстового поиска, который, надеюсь, избавит начинающих разработчиков от головной боли.
У читателя может возникнуть вопрос: зачем писать все с нуля, если все уже давно написано? Да, у крупных поисковиков есть API, есть такие клевые проекты, как Sphinx и Apache Solr. Но у каждого из этих решений есть свои преимущества и недостатки. Пользуясь услугами поисковиков, типа Google и Яндекс, Вы получите множество плюшек, таких как мощный морфологический анализ, исправление опечаток и ошибок в запросе, распознавание неверной раскладки клавиатуры, однако без ложки дегтя тут не обойдется. Во первых, такой поиск не интегрируется в структуру сайта — он внешний, и Вы не сможете указать ему, какие данные наиболее важны, а какие не очень. Во вторых, содержимое сайта индексируется только с определенным интервалом, который зависит от выбранного поисковика, так что если на сайте что-нибудь обновится, придется дожидаться момента, когда эти изменения попадут в индекс и станут доступными в поиске. У Sphinx и Apache Solr дела с интеграцией и индексированием гораздо лучше, но не каждый хостинг позволит из запустить.
Ничто не мешает написать поисковый механизм самостоятельно. Предполагается, что сайт работает на PHP в связке с каким-нибудь сервером баз данных, например MySQL. Давайте сначала определимся, что требуется от поиска на сайте?
- Поиск с учетом языковой морфологии. Независимо от падежа, окончания и
других прелестей великого и могучего языка поиск должен находить то, что нужно
пользователю. Другими словами, «яблок», «яблока», «яблоки» — это формы одного и того
же слова «яблоко», что нужно учитывать в поисковом алгоритме. Одним из способов
достижения данной цели является приведение каждого слова поискового запроса и слов
содержимого сайта к базовой форме. - Возможность указать контекст поиска. То есть, возможность самостоятельно выбрать
контент сайта, в пределах которого будет работать поисковый алгоритм, а также определить
значимость для каждого из пределов. Например, рассмотрим интернет-магазин. Предполагается,
что поисковый запрос чаще всего будет содержать название искомой продукции, поэтому поиск по
названиям товара будет иметь наивысший приоритет. В качестве следующего приоритета можно
выбрать поиск по свойствам товаров, затем поиск по описанию. - Индексирование содержимого сайта. Представьте ситуацию: одновременно около 30 человек
выполняют поисковые запросы. Сервер принимает каждое соединение, управление потоком
передается интерпретатору PHP. При каждом запросе заново инициализируется поисковый
движок, заново перерывается содержимое сайта… Сложно сказать, сколько времени и
ресурсов потребуется, чтобы обработать все эти запросы. Именно для того, чтобы не
делать одну и ту же работу по сто раз, была придумана технология индексирования.
Индексирование выполняется только при изменении или добавлении содержимого сайта,
а поиск выполняется уже по индексу, а не по содержимому. - Механизм ранжирования. Ранжирование результатов поиска — это сортировка результатов поиска, выполняемая на основе оценки значимости найденных данных. Например, в каком-нибудь блоге выполняется поисковый запрос «космос». Данное слово содержится в двух статьях: в первой 16 раз, во второй — 5 раз. Вероятнее всего, первая статья будет иметь большее значение для инициатора поиска. Также каждой разновидности содержимого сайта при индексировании задается определенный коэффициент, который будет влиять на его позиции в поисковой выдаче.
Теперь пару слов о том, что нам предстоит реализовать:
- морфологический анализатор,
- алгоритм ранжирования,
- алгоритм индексирования,
- алгоритм поиска.
В конце статьи будет показан пример реализации поиска на примере простого интернет-магазина. Тем, кому лень все это изучать и просто нужен готовый поисковик, можно смело забирать движок из репозитория GitHub FireWind.
Принцип работы
Со стороны бэкенда поиск работает так:
- содержимое сайта индексируется,
- пользователь присылает запрос,
- из запроса исключаются служебные части речи,
- получившаяся строка разбивается на массив слов, переведенных в базовую форму,
- поиск каждого слова полученного массива осуществляется в индексе,
- результаты поиска ранжируются, сортируются и отдаются пользователю.
Подготовка
Задача поставлена, теперь можно перейти к делу. Я использую Linux в качестве рабочей ОС, однако постараюсь не использовать ее экзотических возможностей, чтобы любители Windows смогли «собрать» поисковый движок по аналогии. Все, что Вам нужно — это знание основ PHP и умение обращаться с MySQL. Поехали!
Наш проект будет состоять из ядра, где будут собраны все жизненно необходимые функции, а также модуля морфологического анализа и обработки текста. Для начала создадим корневую папку проекта firewind, а в ней создадим файл core.php — он и будет ядром.
$ mkdir firewind
$ cd firewind
$ touch core.php
Теперь вооружаемся своим любимым текстовым редактором и подготавливаем каркас:
<?php
class firewind {
public $VERSION = "1.0.0";
function __construct() {
// Инициализатор //
}
}
?>
Тут мы создали основной класс, который можно будет использовать на Ваших сайтах. На этом подготовительная часть заканчивается, пора двигаться дальше.
Морфологический анализатор
Русский язык — довольно сложная штука, которая радует своим разнообразием и шокирует иностранцев конструкциями, типа «да нет, наверное». Научить машину понимать его, да и любой другой язык, — довольно непростая задача. Наиболее успешны в этом плане поисковые компании, типа Google и Яндекс, которые постоянно улучшают свои алгоритмы и держат их в секрете. Придется нам сделать что-то свое, попроще. К счастью, колесо изобретать не придется — все уже сделано за нас. Встречайте, phpMorphy — морфологический анализатор, поддерживающий русский, английский и немецкий языки. Более подробную информацию можно получить тут, однако нас интересуют только две его возможности: лемматизация, то есть получение базовой формы слова, и получение грамматической информации о слове (род, число, падеж, часть речи и т.д.).
Нужна библиотека и словарь для нее. Все это добро можно найти тут. Библиотека находится в одноименной папке «phpmorphy», словари расположены в «phpmorphy-dictionaries». Скачиваем последние версии в корневую папку проекта и распаковываем:
# Распаковываем библиотеку
$ unzip phpmorphy-0.3.7.zip
$ mv phpmorphy-0.3.7 phpmorphy
# Распаковываем словарь в phpmorphy/dicts
$ unzip morphy-0.3.x-ru_RU-withjo-utf-8.zip -d phpmorphy/dicts/
# Удаляем исходные архивы
$ rm phpmorphy-0.3.7.zip morphy-0.3.x-ru_RU-withjo-utf-8.zip
Отлично! Библиотека готова к использованию. Пришло время написать «оболочку», которая абстрагирует работу с phpMorphy. Для этого создадим еще один файл morphyus.php в корневой директории:
<?php
require_once __DIR__.'/phpmorphy/src/common.php';
class morphyus {
private $phpmorphy = null;
private $regexp_word = '/([a-zа-я0-9]+)/ui';
private $regexp_entity = '/&([a-zA-Z0-9]+);/';
function __construct() {
$directory = __DIR__.'/phpmorphy/dicts';
$language = 'ru_RU';
$options[ 'storage' ] = PHPMORPHY_STORAGE_FILE;
// Инициализация библиотеки //
$this->phpmorphy = new phpMorphy( $directory, $language, $options );
}
/**
* Разбивает текст на массив слов
*
* @param {string} content Исходный текст для выделения слов
* @param {boolean} filter Активирует фильтрацию HTML-тегов и сущностей
* @return {array} Результирующий массив
*/
public function get_words( $content, $filter=true ) {
// Фильтрация HTML-тегов и HTML-сущностей //
if ( $filter ) {
$content = strip_tags( $content );
$content = preg_replace( $this->regexp_entity, ' ', $content );
}
// Перевод в верхний регистр //
$content = mb_strtoupper( $content, 'UTF-8' );
// Замена ё на е //
$content = str_ireplace( 'Ё', 'Е', $content );
// Выделение слов из контекста //
preg_match_all( $this->regexp_word, $content, $words_src );
return $words_src[ 1 ];
}
/**
* Находит леммы слова
*
* @param {string} word Исходное слово
* @param {array|boolean} Массив возможных лемм слова, либо false
*/
public function lemmatize( $word ) {
// Получение базовой формы слова //
$lemmas = $this->phpmorphy->lemmatize( $word );
return $lemmas;
}
}
?>
Пока реализовано только два метода. get_words разбивает текст на массив слов, фильтруя при этом HTML-теги и сущности типа “ ”. Метод lemmatize возвращает массив лемм слова, либо false, если таковых не нашлось.
Механизм ранжирования на уровне морфологии
Давайте остановимся на такой единице языка, как предложение. Наиболее важной частью предложения является основа в виде подлежащего и/или сказуемого. Чаще всего подлежащее выражается существительным, а сказуемое глаголом. Второстепенные члены в основном употребляются для уточнения смысла основы. В разных предложениях одни и те же части речи порой имеют совершенно разное значение, и наиболее точно оценить это значение в контексте текста сегодня может только человек. Однако программно оценить значение какого-либо слова все-таки можно, хоть и не так точно. При этом алгоритм ранжирования должен опираться на так называемый профиль текста, который определяется его автором. Профиль представляет из себя ассоциативный массив, ключами которого являются части речи, а значениями соответственно ранг (или вес) каждой из них. Пример профиля я покажу в заключении, а пока попробуем перевести эти размышления на язык PHP, добавив еще один метод к классу morphyus:
<?php
require_once __DIR__.'/phpmorphy/src/common.php';
class morphyus {
private $phpmorphy = null;
private $regexp_word = '/([a-zа-я0-9]+)/ui';
private $regexp_entity = '/&([a-zA-Z0-9]+);/';
// ... //
/**
* Оценивает значимость слова
*
* @param {string} word Исходное слово
* @param {array} profile Профиль текста
* @return {integer} Оценка значимости от 0 до 5
*/
public function weigh( $word, $profile=false ) {
// Попытка определения части речи //
$partsOfSpeech = $this->phpmorphy->getPartOfSpeech( $word );
// Профиль по умолчанию //
if ( !$profile ) {
$profile = [
// Служебные части речи //
'ПРЕДЛ' => 0,
'СОЮЗ' => 0,
'МЕЖД' => 0,
'ВВОДН' => 0,
'ЧАСТ' => 0,
'МС' => 0,
// Наиболее значимые части речи //
'С' => 5,
'Г' => 5,
'П' => 3,
'Н' => 3,
// Остальные части речи //
'DEFAULT' => 1
];
}
// Если не удалось определить возможные части речи //
if ( !$partsOfSpeech ) {
return $profile[ 'DEFAULT' ];
}
// Определение ранга //
for ( $i = 0; $i < count( $partsOfSpeech ); $i++ ) {
if ( isset( $profile[ $partsOfSpeech[ $i ] ] ) ) {
$range[] = $profile[ $partsOfSpeech[ $i ] ];
} else {
$range[] = $profile[ 'DEFAULT' ];
}
}
return max( $range );
}
}
?>
Индексирование содержимого сайта

Как уже говорилось выше, индексирование заметно ускоряет выполнение поискового запроса, так как поисковому движку не нужно обрабатывать контент каждый раз заново — поиск выполняется по индексу. Но что же все-таки происходит при индексировании? Если по порядку, то:
- Сначала из текста формируется массив слов, и делается это с помощью метода get_words.
- Согласно профилю, из текста отбрасываются незначимые части речи.
- Значимые оцениваются по пятибальной шкале, с помощью метода weigh.
- Для каждого сова выполняется поиск лемм, иначе говоря базовых форм.
- Рассчитывается количество повторений каждого слова и суммарный ранг.
- Все данные записываются в объект и в виде JSON записываются в базу данных.
В результате получается объект следующего формата:
{
"range" : "<коэффициент значимости индексируемых данных>",
"words" : [
// Одно из слов //
{
"source" : "<базовая версия слова>",
"range" : "<суммарный ранг>",
"count" : "<количество повторений данного слова в тексте>",
"weight" : "<ранг на основе части речи>",
"basic" : [
// Варианты лемм слова //
]
}
]
}
Пишем инициализатор и первый метод ядра поискового движка:
<?php
require_once 'morphyus.php';
class firewind {
public $VERSION = "1.0.0";
private $morphyus;
function __construct() {
$this->morphyus = new morphyus;
}
/**
* Выполняет индексирование текста
*
* @param {string} content Текст для индексирования
* @param {integer} [range] Коэффициент значимости индексируемых данных
* @return {object} Результат индексирования
*/
public function make_index( $content, $range=1 ) {
$index = new stdClass;
$index->range = $range;
$index->words = [];
// Выделение слов из текста //
$words = $this->morphyus->get_words( $content );
foreach ( $words as $word ) {
// Оценка значимости слова //
$weight = $this->morphyus->weigh( $word );
if ( $weight > 0 ) {
// Количество слов в индексе //
$length = count( $index->words );
// Проверка существования исходного слова в индексе //
for ( $i = 0; $i < $length; $i++ ) {
if ( $index->words[ $i ]->source === $word ) {
// Исходное слово уже есть в индексе //
$index->words[ $i ]->count++;
$index->words[ $i ]->range =
$range * $index->words[ $i ]->count * $index->words[ $i ]->weight;
// Обработка следующего слова //
continue 2;
}
}
// Если исходного слова еще нет в индексе //
$lemma = $this->morphyus->lemmatize( $word );
if ( $lemma ) {
// Проверка наличия лемм в индексе //
for ( $i = 0; $i < $length; $i++ ) {
// Если у сравниваемого слова есть леммы //
if ( $index->words[ $i ]->basic ) {
$difference = count(
array_diff( $lemma, $index->words[ $i ]->basic )
);
// Если сравниваемое слово имеет менее двух отличных лемм //
if ( $difference === 0 ) {
$index->words[ $i ]->count++;
$index->words[ $i ]->range =
$range * $index->words[ $i ]->count * $index->words[ $i ]->weight;
// Обработка следующего слова //
continue 2;
}
}
}
}
// Если в индексе нет ни лемм, ни исходного слова, //
// значит пора добавить его //
$node = new stdClass;
$node->source = $word;
$node->count = 1;
$node->range = $range * $weight;
$node->weight = $weight;
$node->basic = $lemma;
$index->words[] = $node;
}
}
return $index;
}
}
?>
Теперь при добавлении или изменении данных в таблицах достаточно просто вызвать данную функцию, чтобы проиндексировать их, но это не обязательно: индексирование может быть и отложенным. Первым аргументом метода make_index является исходный текст, вторым — коэффициент значимости индексируемых данных. Ранг каждого слова, кстати, расчитывается по формуле:
<?php
$range = <коэффициент значимости> * <ранг на основе части речи> * <количество повторений>;
// В коде это выглядит так: //
$index->words[ $i ]->range = $range * $index->words[ $i ]->count * $index->words[ $i ]->weight;
?>
Хранение индексированных данных
Очевидно, что индекс нужно где-нибудь хранить, да еще и привязать к исходным данным. Наиболее подходящим местом для них будет база данных. Если индексируется содержимое файлов, то можно создать отдельную таблицу в базе данных, которая будет содержать индекс название каждого файла, а для содержимого, которое уже хранится в базе, можно добавить еще одно поле типа в структуру таблиц. Такой подход позволит разделять типы содержимого при поиске, например, названия и описание статей в случае блога.
Нерешенным остался лишь вопрос формата индексированного содержимого, ведь make_index возвращает объект, и так просто в базу данных или файл его не запишешь. Можно использовать JSON и хранить его в полях типа LONGTEXT, можно BSON или CBOR, используя тип данных LONGBLOB. Два последних формата позволяют представлять данные в более компактном виде, чем первый.
Как говорится, «хозяин — барин», так-что решать, где и как все будет храниться, Вам.
Benchmark
Давайте проверим, что у нас получилось. Я взял текст своей любимой статьи «Темная материя интернета», а именно содержимое узла #content html_format и сохранил его в отдельный файл.
<?php
require_once '../src/core.php';
$firewind = new firewind;
// Читаем исходный текст //
$source = file_get_contents( './source.html' );
// Засекаем время начала //
$begin_time = microtime( true );
echo "Indexing started: $begin_timen";
// Индексирование //
$index = $firewind->make_index( $source );
// Засекаем время конца //
$finish_time = microtime( true );
echo "Indexing finished: $finish_timen";
// Результаты //
$total_time = $finish_time - $begin_time;
echo "Total time: $total_timen";
?>
На моей машине с конфигурацией:
CPU: Intel Core i7-4510U @ 2.00GHz, 4M Cache
RAM: 2×4096 Mb
OS: Ubuntu 14.04.1 LTS, x64
PHP: 5.5.9-1ubuntu4.5
Индексирование заняло около секунды:
$ php benchmark.php
Indexing started: 1417343592.3094
Indexing finished: 1417343593.5604
Total time: 1.2510349750519
Думаю, вполне неплохой результат.
Реализация поиска
Остался последний и самый главный метод, метод поиска. В качестве первого аргумента метод принимает индекс поискового запроса, в качестве второго — индекс содержимого, в котором выполняется поиск. В результате выполнения возвращается суммарный ранг, рассчитанный на основе ранга найденных слов, либо 0, если ничего не нашлось. Это позволит сортировать поисковую выдачу.
<?php
require_once 'morphyus.php';
class firewind {
public $VERSION = "1.0.0";
private $morphyus;
// ... //
/**
* Выполняет поиск слов одного индексного объекта в другом
*
* @param {object} target Искомые данные
* @param {object} source Данные, в которых выполняется поиск
* @return {integer} Суммарный ранг на основе найденных данных
*/
public function search( $target, $index ) {
$total_range = 0;
// Перебор слов запроса //
foreach ( $target->words as $target_word ) {
// Перебор слов индекса //
foreach ( $index->words as $index_word ) {
if ( $index_word->source === $target_word->source ) {
$total_range += $index_word->range;
} else if ( $index_word->basic && $target_word->basic ) {
// Если у искомого и индексированного слов есть леммы //
$index_count = count( $index_word ->basic );
$target_count = count( $target_word ->basic );
for ( $i = 0; $i < $target_count; $i++ ) {
for ( $j = 0; $j < $index_count; $j++ ) {
if ( $index_word->basic[ $j ] === $target_word->basic[ $i ] ) {
$total_range += $index_word->range;
continue 2;
}
}
}
}
}
}
return $total_range;
}
}
?>
Все! Поисковый движок готов к использованию. Но есть одно но… На самом деле это не джин-волшебник, и просто закинув его на свой сайт Вы не получите ничего. Его нужно интегрировать, причем этот процесс во многом зависит от архитектуры Вашего сайта. Рассмотрим этот процесс на примере небольшого интернет магазина.
Реализация поиска на примере интернет-магазина
Допустим, информация о продаваемой продукции хранится в таблице production:
CREATE TABLE `production` (
`uid` INT NOT NULL AUTO_INCREMENT, -- Уникальный идентификатор
`name` VARCHAR(45) NOT NULL, -- Название продукта
`manufacturer` VARCHAR(45) NOT NULL, -- Производитель
`price` INT NOT NULL, -- Стоимость продукта
`keywords` TEXT NULL, -- Индекс ключевых слов
PRIMARY KEY ( `uid` )
);
SHOW COLUMNS FROM `production`;
+--------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-------------+------+-----+---------+-------+
| uid | int(11) | NO | PRI | NULL | |
| name | varchar(45) | NO | | NULL | |
| manufacturer | varchar(45) | NO | | NULL | |
| price | int(11) | NO | | NULL | |
| keywords | text | YES | | NULL | |
+--------------+-------------+------+-----+---------+-------+
А описание в таблице description:
CREATE TABLE `description` (
`uid` INT NOT NULL AUTO_INCREMENT, -- Уникальный идентификатор
`fid` INT NOT NULL, -- Внешний ключ для привязки описания к продукту
`description` LONGTEXT NOT NULL, -- Само описание
`index` TEXT NULL, -- Индексированное описание
PRIMARY KEY ( `uid` )
);
SHOW COLUMNS FROM `description`;
+-------------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------+----------+------+-----+---------+-------+
| uid | int(11) | NO | PRI | NULL | |
| fid | int(11) | NO | | NULL | |
| description | longtext | NO | | NULL | |
| index | text | YES | | NULL | |
+-------------+----------+------+-----+---------+-------+
Поле production.keywords будет содержать индекс ключевых слов продукта, description.index будет содержать индексированное описание. И все это будут храниться в формате JSON.
Вот пример функции добавления нового продукта:
<?php
require_once 'firewind/core.php';
$firewind = new firewind;
$connection = new mysqli( 'host', 'user', 'password', 'database' );
if ( $connection->connect_error ) {
die( 'Cannot connect to database.' );
}
$connection->set_charset( 'UTF8' );
function add_product( $name, $manufacturer, $price, $description, $keywords ) {
global $firewind, $connection;
// Индексирование описания продукта //
$description_index = $firewind->make_index( $description );
$description_index = json_encode( $description_index );
// Индексирование ключевых слов //
$keywords_index = $firewind->make_index( $keywords, 2 );
$keywords_index = json_encode( $keywords_index );
// Подготовка запросов //
$production_query = $connection->prepare(
"INSERT INTO `production` ( `name`, `manufacturer`, `price`, `keywords` )
VALUES ( ?, ?, ?, ? )"
);
$description_query = $connection->prepare(
"INSERT INTO `description` ( `fid`, `description`, `index` )
VALUES ( LAST_INSERT_ID(), ?, ? )"
);
if ( !$production_query || !$description_query ) {
die( "Cannot prepare requests!n" );
}
if (
// Биндинг параметров //
$production_query -> bind_param( 'ssis', $name, $manufacturer, $price, $keywords_index ) &&
$description_query -> bind_param( 'ss', $description, $description_index ) &&
// Выполнение запросов //
$production_query -> execute() &&
$description_query -> execute()
) {
// Если запросы выполнились успешно //
echo( "Product successfully added!n" );
// Завершение запросов //
$production_query -> close();
$description_query -> close();
return true;
} else {
die( "An error occurred while executing query...n" );
}
}
?>
Здесь поисковый механизм был интегрирован в функцию добавления нового продукта магазина. А теперь обработчик поисковых запросов:
<?php
require_once '../src/core.php';
$firewind = new firewind;
$connection = new mysqli( 'host', 'user', 'password', 'database' );
if ( $connection->connect_error ) {
die( 'Cannot connect to database.' );
}
$connection->set_charset( 'UTF8' );
// Поисковый запрос //
$query = isset( $_GET[ 'query' ] ) ? trim( $_GET[ 'query' ] ) : false;
if ( $query ) {
// Обработка поискового запроса //
$query_index = $firewind->make_index( $query );
// Получение данных //
$production = $connection->query("
SELECT p.`uid`, p.`name`, p.`keywords`, d.`index`
FROM `production` p, `description` d
WHERE p.`uid` = d.`uid`
");
if ( !$production ) {
die( "Cannot get production info.n" );
}
// Выполнение поиска //
while ( $product = $production->fetch_assoc() ) {
// Распаковка индекса //
$keywords = json_decode( $product[ 'keywords' ] );
$index = json_decode( $product[ 'index' ] );
$range = $firewind->search( $query_index, $keywords );
$range += $firewind->search( $query_index, $index );
if ( $range > 0 ) {
$result[ $product[ 'uid' ] ] = $range;
}
}
// Если что-нибудь нашлось //
if ( isset( $result ) ) {
// Сортировка по убыванию //
arsort( $result );
// Вывод результатов //
$i = 1;
foreach ( $result as $uid => $range ) {
printf(
"#%d. Found product with id %d and range %d.n",
$i++,
$uid,
$range
);
}
} else {
echo( "Sorry, no results found.n" );
}
} else {
echo( "Query cannot be empty. Try again.n" );
}
?>
Данный сценарий принимает поисковый запрос в виде GET-параметра query и выполняет поиск. В результате выводятся найденные продукты магазина.
Заключение
В статье был описан один из вариантов реализации поиска для сайта. Это самая первая его версия, поэтому буду только рад узнать Ваши замечания, мнения и пожелания. Присоединяйтесь к моему проекту на Github: https://github.com/axilirator/firewind. В планах добавить туда еще кучу всяких возможностей, вроде кэширования поисковых запросов, подсказок при вводе поискового запроса и алгоритма побуквенного сравнения, который поможет бороться с опечатками.
Всем спасибо за внимание, ну и с днем информационной безопасности!
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Какой поиск для сайта предпочитаете Вы?
23.2%
Своя реализация
174
12.27%
Не использую поиск для сайта
92
Проголосовали 750 пользователей.
Воздержались 287 пользователей.
Обзор сервисов поиска для сайта
2021 / 05 / 31
Время чтения ≈
Многостраничные сайты, например, интернет-магазины, блоги и медиа важно дополнить внутренним поиском. Так пользователям будет намного быстрее и комфортнее находить информацию. Это особенно актуально, если структура портала сложная и запутанная, где не разобраться без карты сайта. Давайте рассмотрим, как сделать внутренний поиск удобным для пользователей.
Как сделать внутренний поиск по сайту
Исследовательская компания eConsultancy обнаружила, что установленный поиск по сайту улучшает пользовательский опыт и финансовые показатели компаний на 7%. При этом 30% посетителей пользуются внутренним поиском и доход от этих клиентов больше, чем от тех, кто просматривает главную и первые страницы каталога. И это неудивительно — просто представьте, что ищете товары на Wildberries или Ozon вручную без внутреннего поиска. Перспектива часами листать вкладки не радует.
Прежде чем приступать к работе над внутренним поиском, убедитесь, что поисковая строка хорошо заметна на главной странице
Важно, чтобы каждый посетитель мог легко ее найти и воспользоваться.
Далее вам понадобится реализовать некоторые обязательные функции в админке вашего ресурса:
- Поиск с учетом языковой морфологии. Независимо от падежа и склонения части речи, поиск должен находить именно ту информацию, которая нужна пользователю. А форма слова не должна влиять на выдачу. Как вариант, можно конвертировать слова в нужную форму.
- Контекст поиска. Можно выбрать контекст сайта, который будет устанавливать границы поиска и распределять запросы по приоритетам. Это значит, что вы сами выбираете контент, который будет отображаться в алгоритмах.
- Индексирование контента. Индексация всей информации на сайте должно происходить постоянно, иначе она не попадет в поисковую выдачу.
- Механизм ранжирования. Ранжирование поисковой выдачи — это сортировка его результатов, которая выполняется на основе оценки значимости найденных данных.
Существует три способа сделать внутренний поиск на сайте:
- Написать или заказать уникальный алгоритм — для этого понадобится программист, маркетолог и дизайнер.
- Использовать стандартный поиск вашей CMS — у каждой из них свой алгоритм.
- Подключить сторонний сервис — об этом мы поговорим ниже.
Сервисы поиска по сайту
Сервисы поиска выполняют различные полезные функции. Например, они могут понимать опечатки и ошибки, угадывать, что ищет пользователь, и показывать ему подсказки. Некоторые даже запоминают, что смотрел и покупал посетитель — и учитывают эти предпочтения при ранжировании результатов.
А еще поисковые модули распознают опечатки и собирают статистику. Владелец сайта может увидеть, что ищут люди на его портале, по каким кнопкам они кликают и что делают потом.
«Google Поиск»
Google Поиск стоит от 100$ до 2000$ в год. При этом вы можете тестировать бесплатную версию с ограничениями.
Из плюсов — все возможности большого Google, удобный поиск на разных языках и по картинкам. Из минусов — в бесплатной версии есть реклама и нельзя экспериментировать с оформлением. В результате пользователь может растеряться и даже не поймет, что находится на вашем сайте.
Подключить «Google Поиск» на сайт легко, для этого нужно вставить код скрипта на страницу. Эти настройки можно изменять в личном кабинете, а код больше не придется обновлять.
«Яндекс Поиск» для сайта
Яндекс Поиск бесплатный и он работает так же, как и поиск в браузере. К примеру, дает подсказки, распознает опечатки и ошибки, предлагает синонимы. В сервисе можно посмотреть статистику поисков посетителей. Еще один плюс — вы можете настроить внешний вид поисковой строки и страницы с результатами выдачи.
Подключить «Яндекс Поиск» на сайт довольно просто. Для этого вставьте код на сайт. А в личном кабинете настройте подсказки, синонимы, и просматривайте статистику.
Перечислим другие востребованные сервисы, если Google или Яндекс вам по какой-то причине не подошел.
Solr
Бесплатный сервис Solr популярен у Adobe, Disney, eBay, IBM. У него открытый исходный код, при этом сервис очень надежный и справляется с огромными нагрузками. Установить Solr самостоятельно не получится, потребуется помощь программиста.
Sphinx
Бесплатный движок с открытым исходным кодом — это Sphinx. Его называют одной из самых быстрых систем поиска. Выглядит, как отдельное приложение, которое нужно установить на сервер и подключить к сайту с помощью API. Вам для этого потребуется программист.
Detectum
Detectum — сервис для интернет-магазинов, цена рассчитывается по запросу. Удобен тем, что включает подсказки, автозаполнение и исправление опечаток, фильтрует результаты выдачи. Detectum анализирует историю покупок и показывает посетителям именно те товары, которые могут их заинтересовать.
Как видите, система поиска по сайту — это значимый элемент интерфейса. А на ресурсах, где есть хотя бы 20 страниц без нее не справится. Поэтому изучите предложения на рынке и выберите сервис, который подойдет вам по ценовой политике, простоте установки и будет отвечать вашим техническим требованиям.
На главную Блог Бизнес Обзор сервисов поиска для сайта
Любой пользователь интернета знает — то, что нужно, можно с легкостью найти в поисковой системе. Но бывают такие ситуации, когда какую-то информацию нужно найти на определенном сайте.
Какие у нас есть варианты?
Найти на конкретном сайте строку поиска.
Самый простой, но не всегда верный вариант. Дело в том, что не всегда движки сайта умеют искать информацию внутри сайта, как правило, поиск на сайтах создан примитивно.

Например, на сайте есть статья «Как поют ласточки», она спокойно найдется по фразе «поют ласточки», но не найдется по запросу «поёт ласточка», потому что, в большинстве случаев, поиск внутри сайта не учитывает морфологию слов.
Поиск внутри сайта через форму лучше осуществлять по ключевым словам, пробуя различные варианты.
Воспользоваться поисковыми системами
Основные поисковые системы умеют искать информацию на конкретном сайте. Чтобы найти нужное на сайте через Яндекс, нужно воспользоваться оператором host:
Запрос будет выглядеть так: тормозит видео в браузере host:poznyaev.ru
С помощью оператора host мы указали поисковой машине адрес сайта, на котором нужно поискать данную информацию. Если на искомом сайте есть поддомены, то лучше использовать оператор site, по аналогии с host.
В Google данная манипуляция также работает, но нужно использовать оператор site:
Поисковые машины также поддерживают оператор *, чтобы сузить границы поиска, например, если вам нужно найти информацию в определенной категории сайта: site.ru/windows/*
Кстати, если сайт хорошо ранжируется в поисковике, можно и не использовать операторы. Достаточно после запросы вписать URL адрес сайта.
Стоит понимать, что поисковая система, как правило, не индексирует на 100% все страницы сайта и также может не найти нужные данные. Индексирование зависит от многих параметров: качества страниц, скорости работы сайта, наложенных фильтров и ограничений на сайт…
Рекомендую прочесть: Робот-штатив превращает телефон в личного оператора
Факторов ранжирования сотни, все их невозможно перечислить в одной статье, поэтому на 100% гарантировать положительный результат поиска на сайте никто не может.
Если вы уверены, что информация была или должна быть на конкретном сайте, то тут единственный совет — написать владельцу сайта.
А для того, чтобы найти какой-либо текст на конкретной странице сайта, нам не нужны поисковые системы. Открываем страницу в браузере и нажимаем Ctrl + F — откроется строка поиска по странице. Естественно, никакой морфологии такой поиск учитывать не будет. В мобильном браузере форма поиска вызывается через меню браузера и действует аналогично.
А у вас были проблемы с поиском информации на сайтах? Напишите в комментарии 👇
Подписывайтесь, чтобы не пропустить новые публикации:
Телеграм-канал | Группа Вконтакте | Одноклассники
