Большая часть времени, проводимая пользователем в интернете, тратится на поиск интересующей его информации. При этом существует масса способов добыть эти данные – можно заглянуть в онлайновую энциклопедию и попробовать отыскать ответ там, можно подписаться на рассылку по интересующей теме и внимательно изучать приходящую корреспонденцию, а можно посоветоваться с компетентными людьми на форуме, задав им вопрос.
Но самый универсальный способ найти что-то в интернете – воспользоваться одной из многочисленных поисковых систем. Сервисы для осуществления поиска на миллионах и миллионах web-сайтов – это, пожалуй, основополагающее звено всемирной Сети. Без Google, Yahoo, Yandex и многих других привычных сегодня поисковых систем пребывание пользователя в Сети скорее напоминало бы хождение слепого по лесу. Значимость поисковых систем для работы в интернете трудно переоценить – у многих пользователей в качестве стартовых страниц указаны адреса поисковых систем, и именно с них для многих начинается бесконечное путешествие по различным ресурсам сети.
Однако эффективность интернет-раскопок у всех разная – один человек находит информацию мгновенно, у другого на это уходит очень много времени, ну а третий может и вовсе не найти для себя ничего полезного. В чем же причина? Ответ прост: поиск в интернете сродни рыбалке – нужно знать, где ловить и на что ловить, т.е. где искать и как искать. В сегодняшней статье мы расскажем о том, как лучше всего проводить поиск в интернете, и поведаем, какие для этого существуют поисковые системы, кроме тех, которые “у всех на устах”.
Однако начнем мы именно с тех систем, которые вы знаете. Если пользователь знает адрес поисковой системы, это еще не означает, что он умеет ею пользоваться. Давайте проверим, насколько вы хорошо разбираетесь в технологии поисковых запросов.
То, насколько точные результаты вы получите, прежде всего, зависит от того, насколько умело вы сформировали поисковый запрос. Например, если вы ищете информацию для написания курсовой работы, не нужно вводить ее тему дословно, особенно если работа имеет узкую специализацию. Гораздо больше ценных сведений вы найдете, если попробуете подобрать ключевые слова, то есть те слова, которые обязательно будут встречаться в вашей работе.
Если вы ищете утерянную инструкцию для автомагнитолы, то введя номер модели, наверняка получите огромное количество сайтов, предлагающих ее приобрести. Чтобы отсеять ненужные ссылки, можно использовать функцию поиска в найденном или исключить из поиска некоторые слова. Практически в каждом поисковике вы найдете функцию расширенного поиска. Это – еще один хороший способ отсеять ненужные результаты. Среди таких функций может пригодиться поиск страниц, которые недавно обновлялись, поиск страниц только на определенном языке или на сайтах, расположенных в указанной вами доменной зоне.
Время, которое тратится на поиск, можно существенно сэкономить, если знать и использовать синтаксис языка запросов. Каждый поисковик имеет тут свои особенности. Например, когда вы ищете что-нибудь на Яндексе, то не лишним будет использовать следующие приемы:
- Для поиска слов, которые должны встретиться на странице в одном предложении, поставьте между ними символ &
- Чтобы исключить определенное слово из результатов поиска, добавьте его к своему запросу, поставив перед ним символы ~~
- Чтобы найти страницы, в которых содержится хотя бы одно из слов, указанных в поисковом запросе, разделите их символом |
- Для поиска слова в указанной форме поставьте перед ним восклицательный знак
Свои секреты есть и у поисковой системы Google. Вот лишь некоторые из них:
- Для поиска информации на определенном сайте (и только на нем) введите в поле запроса его адрес, предварив словом site и двоеточием (например, site:http://www.3dnews.ru)
- Для поиска фразы, которая должна встретиться на странице полностью, возьмите ее в кавычки
- Для исключения из результатов поиска страниц, на которых встречается определенное слово, добавьте его к своему запросу, поставив перед ним знак минус
Это – лишь несколько штрихов, которые могут помочь сделать поиск в интернете эффективнее. Если же вы хотите добиться оптимального результата, мы советуем вам подробнее ознакомиться с синтаксисом языка запросов, который подробно описан в справочной системе вашего любимого поисковика.
В том, что Google и Yandex – это незаменимые инструменты для поиска в сети, сомневаться не приходится – поиск в этих системах удобен, гибок и очень точен. Но, тем не менее, это не означает, что альтернативные поисковые системы не имеют права на существование. Да – они индексируют меньшее количество страниц, да – их методы подбора ресурсов во многом спорны. Но у таких поисковых систем есть одно неоспоримое преимущество – они предлагают что-то новое, отличное от принятых стандартов. Поскольку альтернативные поисковые сервисы используют иной подход к подбору ресурсов, соответствующих запросу, результат поиска будет совершенно иной, чем в случае с привычными поисковыми системами. Так что, если долгие поиски по известным сервисам ни к чему не привели, это означает одно – нужно сменить тактику и попробовать другие методы поиска информации, с помощью альтернативных поисковых систем. Зачастую альтернативные поисковики используют для сбора результатов один или несколько списков с ресурсами, которые были найдены Google, Yahoo и другими крупными системами. Эти результаты фильтруются, отбираются лучшие и часто для лучшего восприятия визуализируются при помощи диаграммы, карты сайтов, облака тегов и т.д.
Разработчики альтернативных поисковых систем порой так далеко заходят в своих поисках нового универсального интерфейса, что, иногда трудно признать в web-странице поисковую машину. И тем не менее, это – поисковые системы. Необычные и странные, на первый взгляд…
FindSounds.com – ищет звуки
Этот ресурс предназначен для тех пользователей, которые находятся в творческом поиске. Ресурс позволяет искать звуковые файлы разных форматов – wav, mp3, aiff, au. В базе данных ресурса есть самые разнообразные звуки – крики животных, скрежет машин, звон, стук, сирены, жужжание насекомых, грохот взрывов и стрельбы, всплеск воды и т.д. Звуковые файлы могут искаться по разным критериям, например, по размеру, наличию двух или одного каналов звучания (стерео/моно), частоте дискретизации и разрядности звучания. В результатах поиска ресурс показывает не только ссылки на найденные файлы, но и их основные характеристики, а также показывает график амплитуды звука, по которой можно судить о характере звучания данного семпла.
База звуковых эффектов FindSounds может найти применение в самых разных областях – от разработки компьютерных игр и прочих приложений, до создания презентаций и всевозможных клипов. Поисковик может пригодиться, например тем, кто создает интерактивную web-графику и желает внести разнообразие на сайт, сопроводив нажатие элементов навигации страниц различными звуками.
Gnod.net – подберет музыку, книги и фильмы по вкусу
Когда у человека возникает желание почитать новую книгу, послушать какую-нибудь новую музыку или посмотреть фильм, он, как правило, обращается за советом к своему другу или знакомому, который в его глазах имеет авторитет. Однако найти того, кто согласился бы высказать свое мнение по данному вопросу, не так просто. Во-первых, не все любят давать советы, ведь рекомендуя что-то другому, человек берет на себя долю ответственности, и многих останавливает вопрос “А вдруг фильм, который я посоветую, ему не понравится?” Во-вторых, человек, который дает совет, должен понимать, что именно понравится собеседнику, а что – будет совершенно неинтересно. Ведь на вкус и цвет, как говорится…
Но есть более простой способ получить хороший совет – воспользоваться особым поисковиком, который сделан именно для этой цели. Итак, вы захотели послушать новую группу, но нет времени и желания искать хорошую музыку. Ресурс gnod.net поинтересуется у вас несколькими именами музыкальных исполнителей, которые вам нравятся, проведет анализ результатов и предложит свой вариант певца или группы, которая тоже должна вам понравиться.
Сервис имеет несколько баз данных – по музыкальным исполнителям, по фильмам, книгам и людям. Таким образом, ресурс вобрал в себя четыре сервиса: Gnod Music, Gnod Books, Gnod Movies и Flork. Последний сервис, Flork – это социальный эксперимент по обнаружению людей, которым интересно общаться друг с другом.
Мы с удовольствием протестировали музыкальный раздел этого сервиса и ввели трех исполнителей – Gerry and the Pacemakers, The Beatles и Hollies. Наша подборка не была случайной – эти три группы принадлежат к эпохе шестидесятых, к интересному явлению, которое носит название Британское вторжение (British Invasion). Все эти группы играли бит, и поисковик должен был предложить группу или исполнителя в том же стиле. Так и случилось. Результат, предложенный нам – это группа Archies, которая в конце шестидесятых была на устах у всех американцев со своей веселой песенкой Sugar Sugar.
Поиграв с поисковиком какое-то время, мы пришли к выводу, что gnod.net чаще дает правильный совет, а ошибается не очень часто. Для наглядности, результаты своего “совета” поисковик может предоставить в виде анимированного облака с названиями групп, авторов или фильмов. Базу данных можно пополнять самостоятельно, проводя “беседы” с поисковиком и отвечая на его вопросы в стиле “это мне нравится” или “это мне не нравится”.
Alldll.net – найдет файлы библиотек
Этот поисковик мы рекомендуем вам сразу занести в закладки, так как рано или поздно он обязательно пригодится. Вероятно, каждому доводилось хотя бы раз столкнуться с проблемой отсутствия в системе какой-то библиотеки dll. Обычно это приводит к тому, что программы или игры отказываются запускаться, и на экране появляется сообщение “Couldn’t find *****.dll”. Причин тому может быть много, например, отсутствие файла может быть вызвано некорректным удалением ранее установленного приложения, случайным повреждением файла и т.д. Кроме того, разработчик мог просто не включить в дистрибутив своего продукта эту библиотеку.
Исправить ситуацию очень просто – достаточно найти в интернете недостающий файл, загрузить его и скопировать в директорию той программы, которая отказывается запускаться, либо в папку ..WINDOWSsystem32… Найти и скачать отсутствующий файл можно легко и быстро с помощью данного сервиса. Ресурс www.alldll.net представляет собой поисковую базу данных по наиболее популярным библиотекам dll. Файлы рассортированы по алфавиту, присутствует функция поиска. Искомый файл можно искать, даже если вам известно только приблизительное название библиотеки. Достаточно в поле запроса начать вводить текст, и в нижней части страницы появится огромный список файлов, которые начинаются с тех букв, которые были набраны.
Medpoisk.ru – поиск медицинской информации
Несмотря на то, что данная поисковая система использует движок поиска от Google, это ни в коей мере не снижает ее ценность. Medpoisk.ru – это универсальный поисковик, который предназначен для поиска исключительно на медицинских сайтах. Этот сайт – отличный инструмент для каждого медика и всех, кто желает получить ответ на любой вопрос из области медицины. Как лечить ту или иную болезнь, какие противопоказания у того или иного лекарства, к какому врачу обратиться – все это и многое другое можно узнать, “спросив” у поисковика. Поисковик включает в себя биржу труда и может использоваться для поиска работы среди медицинских работников. Ресурс также содержит каталог медицинских учреждений, рассортированных по регионам. Среди этих учреждений адреса клиник, медицинских центров разной направленности, родильные дома, диагностические центры, косметологические салоны и пр. Мы вам искренне желаем, чтобы этим поисковым сервисом вы пользовались исключительно из любопытства, а не по необходимости.
Taggalaxy.de – поиск картинок и фотографий
Возможно, вы слышали о популярном сервисе для обмена графическими файлами Flickr.com? Это тот самый сервис, который в 2007 году был заблокирован китайскими властями, после того как на его страницах появились фотографии печальных событий 1989 года на площади Тяньаньмэнь, расположенной в столице Китая Пекине. Flickr.com является одним из первых Web 2.0 сервисов, а число изображений, загружаемых на него пользователями, исчисляется миллиардами.
Количество картинок, загружаемых на серверы этого сервиса столь велико, что для того чтобы найти какое-то конкретное изображение в этом океане снимков и картин, необходима отдельная поисковая система. Сервис предлагает услугу поиска по изображениям, однако есть более интересный способ искать картинки – используя необычный поисковик taggalaxy.de.
Этот поисковый сервис представляет собой средство для поиска изображений на Flickr.com, с предварительным просмотром. А необычным его делает интерфейс поиска, который полностью сделан трехмерным. Процесс поиска по ключевому слову напоминает какую-то компьютерную игру – в космическом пространстве летают разные небесные тела, между которыми можно перемещаться в виртуальном мире.
После того, как будет выполнен запрос по ключевому слову, на экране возникнет система из солнца и планет, которые вращаются вокруг светила. Каждое небесное тело имеет свое предназначение и “подписано” словом. В центре галактики – солнце, ключевой запрос, все остальные тела – это вспомогательные слова, уточнения. Если щелкнуть мышью по солнцу, этот объект приблизится, и со всех сторон на него слетятся и окружат фотографии, содержание которых определено поисковым запросом. Эту трехмерную модель с фотографиями можно поворачивать в виртуальном пространстве, подробно рассматривая и выискивая интересующее изображение. После этого достаточно щелкнуть по картинке, чтобы она увеличилась в размере, и тогда ее можно будет лучше рассмотреть и почитать описание.
В процессе работы с этим поисковиком, можно использовать функцию скроллинга – она позволяет приближать или отдалять трехмерные планеты. Остальные планеты, которые видны в интерфейсе поисковика после запроса – это вспомогательные слова, позволяющие уточнить запрос. Например, если ввести в поле поиска “Sky”, то среди уточняющих слов-планет будут слова “сlouds”, “sunset”, “blue” и другие схожие по смыслу тэги, которые пользователи указали при использовании сервиса Flickr.com. Недостатком поисковой системы можно считать то, что taggalaxy.de не поддерживает русский язык, поэтому запросы можно вводить только латиницей.
Nigma.ru – фильтрует результаты других поисковых систем
Среди всех поисковых систем, которые можно встретить в интернете, существует особая группа поисковиков. Она отличается от всех остальных тем, что в них реализована функция мультипоиска, то есть одновременного поиска по нескольким поисковым системам. Одной из таких мультипоисковых систем является российский сервис Nigma.ru.
Nigma содержит собственную базу ресурсов, но помимо этого позволяет выполнять поиск сразу по всем наиболее популярным поисковым системам, в числе которых – Google, MSN, Yandex, Rambler, AltaVista, Yahoo и Aport. Механизм отбора результатов в этой поисковой машине отличается от большинства принятых методов обнаружения сайтов. Дело в том, что движок этого сервиса использует кластеризацию результатов. Что это означает? Представьте себе, что вы решили для себя выяснить, что такое “рендеринг”. Сопоставив результаты в разных поисковых системах, движок Nigma.ru отобрал наиболее вероятные результаты и при этом в левой части окна, рядом со списком результатов поиска, отобразил так называемые кластеры – “визуализация”, “создание”, “система”, “rendering”, “процесс”, “studio max”, “компьютерной графики” и другие слова и словосочетания. Эти кластеры представляют собой тематическую группу найденных документов. Таким образом, можно быстро сузить круг поиска или конкретизировать поисковый запрос.
В Nigma.ru можно также использовать рубрики, чтобы ограничить область, из которой будут выбираться результаты – например, выполнять поиск только с учетом музыкальных ресурсов или вывести результаты только для изображений. Еще одна возможность этого сервиса может быть интересна школьникам и студентам. Nigma.ru предлагает сервисы Nigma-математика и Nigma-химия. Первый предназначен для быстрого решения простых уравнений и различных арифметических операций, второй позволяет работать с формулами химических реакций. Поисковый сервис распознает более тысячи физических, математических констант и единиц измерения, позволяя быстро выполнять преобразование из одной размерности в другую.
Searchme.com – поисковик с предпросмотром
Всем известно, что для того чтобы найти конкретную информацию в сети, необходимо потратить немало времени. Просматривая результаты поиска, пользователь, в основном, открывает ресурсы наугад, не зная наверняка, найдет ли он на новой странице то, что его интересует, или это будет пустой тратой времени. Создатели поискового сервиса searchme.com задумались над этой проблемой и придумали ее оригинальное решение. Суть этого решения состояла в том, чтобы создать такую поисковую систему, в которой пользователь мог бы посмотреть на приблизительный эскиз страницы еще до ее загрузки. Это позволило бы составить дополнительное мнение о серьезности ресурса и о его содержании.
Реализация этой идеи была просто великолепной – созданный поисковик имеет красивый анимированный трехмерный интерфейс и показывает результаты поиска в виде анимированной ленты эскизов, уменьшенных скриншотов web-страниц, включающих в себя ключевое слово поиска. Ленту с результатами, подобно пленке со старыми негативами, можно прокручивать в окне браузера, используя специальный ползунок, расположенный под вереницей изображений. Эскизы мгновенно подгружаются, поэтому никаких “тормозов” с прорисовкой результатов не наблюдается. Особенно удобно работать с результатами поиска в полноэкранном режиме – тогда вполне можно разобрать даже текст статей на эскизах результатов. Чтобы оценить удобство этой системы, достаточно попробовать просмотреть новостные ресурсы. Фотографии к главным новостям на титульной странице web-издания, тут же дадут понять, какую новость на данном ресурсе считают наиболее важной.
Torrent-finder.com – поиск торрентов
Несмотря на все старания правообладателей музыки и видео закрыть любые сервисы по обмену мультимедийным контентом, в интернете по-прежнему есть место для тех, кто не видит в этом ничего плохого. Один из способов послушать новый музыкальный альбом или посмотреть недавно вышедший на экраны фильм – скачать себе его на жесткий диск, используя программу, работающую с протоколом BitTorrent. О достоинствах этого способа обмена данных знают практически все – распределенная передача данных между всеми пользователями снижает нагрузку и зависимость от каждого клиента сети. Но вот проблема – для того, чтобы загрузить любой файл при помощи BitTorrent, необходимо скачать файл торрент, который содержит информацию о раздаваемых пользователем файлах. В интернете есть множество ресурсов, которые собирают желающих поделиться с другими своими “сокровищами”. Каждый такой ресурс имеет свой трекер – сервер, на котором хранятся файлы-торренты. Чтобы найти тот или иной файл среди тысяч и тысяч раздаваемых архивов, необходимо выполнить поиск соответствующего файла-торрента на этом трекере. Впрочем, интересующего файла может не оказаться. В таком случае придется искать другие трекеры и смотреть уже там, есть ли возможность загрузить разыскиваемый файл-торрент. На перебор сайта за сайтом часто тратится немало времени.
Выход – специализированный поисковик торрентов. Сайтов, которые ищут по торрент-ресурсам, в сети немало. Однако torrent-finder.com имеет перед остальными поисковыми системами неоспоримое преимущество – этот сервис позволяет искать файлы на огромном числе трекеров одновременно.
Astronet.ru – астрономический поисковый сервис
Этот ресурс предоставляет поиск информации по сайтам, чья тематика, так или иначе, имеет отношение к астрономии. Всего в базе данных поисковой системы около четырех сотен сайтов по астрономической тематике – сайты обсерваторий, любительские странички, библиотеки научной литературы и пр.
Тем, чья профессия связана с астрономией, можно только позавидовать – в изучении космических событий есть доля романтики. Ничто не кажется человеку столь интересным, как область неизведанного. Может быть, поэтому он так часто обращает свое внимание к космосу и пытается найти ответ на вечный вопрос “Есть ли жизнь во Вселенной?” Мы тоже не стали отличаться оригинальностью и попробовали задать поисковику легендарный вопрос “Есть ли жизнь на Марсе?” Ответов было так много, и все они были столь интересны, что, позабыв обо всем, мы погрузились в чтение гипотез и рассматривание фотографий и макетов марсианской поверхности.
Помимо функции поиска, на сайте есть масса других полезных сервисов, среди которых, например, есть Англо-Русско-Английский Астрономический словарь, биографический справочник с подробными сведениями обо всех ученых, которые внесли свой вклад в развитие астрономии, глоссарий астрономических терминов. Есть также удобная карта звездного неба, которая генерирует положение созвездий, в зависимости от широты и долготы точки наблюдения, а также времени суток.
Friv.com – бесплатные игры на любой вкус!
Поисковые сервисы нужны всем – и тем, кто использует их для написания диссертации, и тем, кто хочет узнать прогноз погоды или расписание поездов, и даже тем, кто выкроил пять минут свободного времени и хочет просто, что называется, повалять дурака, поиграть в какую-нибудь незамысловатую компьютерную игру. Для последней категории пользователей этот ресурс будет настоящим кладезем игр.
Это – не совсем поисковик, хотя именно так его называют западные обозреватели (Game search engine). Сайт friv.com представляет собой, скорее, каталог, сборник 264 игр на Flash, собранных на одной странице. Нажмите любую из красочных иконок и играйте на здоровье. На friv.com вы найдете любые “офисные забавы” – от тетриса и шахмат до квеста-бродилки и шутера. Сюжет многих игр сделан с большим юмором и, несомненно, понравится не только вам, но и вашим друзьям.
VisualWorld.ru – поиск с ассоциативными связями
Методика отбора правильных результатов у каждого поисковика своя, уникальная. Вот, например, эта поисковая система работает по принципу ассоциативности. Данный поисковик старается не только правильно отобрать web-ресурсы, соответствующие определенному запросу, но и подсказать ассоциативными словами направление поиска. Так, если ввести в поле запроса ключевое слово или словосочетание, результат, показываемый поисковой машиной, будет выглядеть как набор ассоциативных слов, семантическое облако, ну, и, разумеется, обычный список сайтов, отобранных поисковиком в результате поиска.
Отличительная особенность VisualWorld.ru – это визуализация ассоциативных связей, т.е. составление карты-диаграммы, демонстрирующей связи между словами, которые относятся к схожим темам. Этот граф поначалу может показаться чем-то непонятным и необычным, но после нескольких попыток поиска к нему привыкаешь и используешь его для сужения области поиска.
Поисковый сервис VisualWorld.ru может работать не только в режиме ассоциативного поиска, но и обычного. Для более быстрой работы с системой, существует “облегченная” версия сайта – viwo.ru.
Briefly.ru – краткое содержание любой книги
Можно долго спорить о том, умрет ли книга или нет, но факт остается фактом – сегодняшний читатель – это не тот, кто листает томик Лермонтова или Толстого, а, скорее, тот, кто еще умеет читать. Скоро библиофилом сможет считать себя каждый, кто знает что Бендер – это плод фантазии Ильфа и Петрова, а не герой “Футурамы”, а Гомер – это вовсе не персонаж “Симпсонов”, а вполне адекватный грек, живший пару тысяч лет назад.
Нам думается, что пропавший интерес к литературе – это явление временное, и наступят времена, когда люди вернутся к книгам. Ну а пока время диктует свои законы, и появляются такие ресурсы, как briefly.ru. Не нужно быть особенно прозорливым, чтобы догадаться, на кого рассчитан данный ресурс – конечно, на школьников и студентов. Зачем читать целую книгу, если можно в двух словах узнать, о чем там писал старина Метерлинк.
На сайте briefly.ru собрано большое количество кратких содержаний к разным книгам – от “Божественной комедии” Данте Алигьери до “Гамлета” Шекспира и “Тихого Дона” Шолохова.
Содержание произведений рассортировано на сайте по авторам, есть функция поиска. Нужно отдать должное создателям этого ресурса – они очень тщательно подошли к подбору текста для пересказа, поэтому большинство произведений пересказано литературным языком, все понятно и… интересно. Ну что ж, быть может, среди тех, кто ознакомится с содержанием этих книг, найдется и такой, кто захочет узнать книгу, прочитав ее в оригинале. И не с экрана КПК или ноутбука, а с белых листов обычной книги, пока еще есть такая возможность.
Videoinet.ru – поиск по видеороликам
Этот сервис выполняет поиск видео по различным онлайновым хранилищам видео, как отечественным, например RuTube.ru, так и по зарубежным.
Всем известно, что самый большой видеоархив – это сервис YouTube. Однако на практике оказывается, что наши отечественные сервисы для хранения видеороликов мало в чем уступают, а кое в чем и лучше сервиса, принадлежащего Google. Во-первых, отечественные сервисы более демократичны к выкладываемому видео – к счастью, в нашей стране пока никому не приходит в голову подавать в суд за то, что в сеть на всеобщее обозрение выложен музыкальный клип или фрагмент нового блокбастера. Во-вторых, содержание клипов, которые загружают на сервер наши пользователи, нам более близко и понятно. Вот, например, репортаж с одного из телеканалов, ставший уже документальным, о событиях, предварявших приезд на Украину сэра Пола Маккартни – оказывается, есть на Закарпатье село Битля, в котором местные гуцулы готовят “гарну писню” для одного из “Битлз”. А вот – другой ролик, где пьяный преподаватель одного из столичных вузов пытается провести лекцию. Шанс увидеть подобное на YouTube гораздо ниже – это то, что близко нашему зрителю, это – наш менталитет.
Поиск на сервисе videoinet.ru можно выполнять по тегам, по рейтингу и ключевым словам, которые имеют отношение к содержанию клипа. Сервис позволяет делать закладки и составлять из видеоклипов списки воспроизведения.
Kartoo.com – поиск с картой результатов
В ситуации, когда долгий поиск в Интернете не принес никакого положительного результата, логично предположить, что поисковый запрос был сделан не совсем удачно и его стоит сформулировать как-то по-другому. Но чем дольше пользователь перебирает страницы, тем труднее ему включить воображение и придумать, как иначе описать свою проблему одним-двумя словами. В этом случае нужно просто переключиться и попробовать какой-нибудь совершенно другой поисковый сервис, например, kartoo.com.
Одно только наличие необычного интерфейса поискового ресурса может подтолкнуть пользователя к идее сформулировать свой запрос по-новому. А если учесть при этом, что результаты будут совсем не те, что выдавал предыдущий поисковик, можно предположить, что шансы найти ответ в этом случае будут выше.
Поисковый сервис совершенно не похож на обычные поисковые машины – его внешний вид больше напоминает окно какого-то приложения. После ввода слова-запроса, в окне “приложения” появляется анимированный персонаж, который развлекает пользователя, пока результаты подготавливаются к выводу на экран. Далее следует построение карты Интернета, которая определяет связи между смысловым содержанием различных ресурсов. По этой карте хорошо видно, какая область ближе всего к тематике выбранного ресурса и где следует искать информацию. Интересно, что показанные на карте связи можно редактировать, определяя тем самым область поиска. На карте интернет-ресурсов сайты отмечены разными иконками – те, которые имеют больший размер иконки, скорее соответствуют поисковому запросу. Пользоваться поисковой системой kartoo.com очень непривычно, особенно вначале. Но, тем не менее, к некоторым возможностям поиска привыкаешь мгновенно – например, очень удобные пиктограммы сайтов, которые дают возможность судить о том, просматривал ты эту страницу или нет. Также поисковая система хранит историю запросов, что очень удобно, если необходимо вернуться к какому-то результату. Для этого можно просмотреть список слов, запрашиваемых в поисковике, и вспомнить, какой именно привел к тому или иному ресурсу. Поисковик, к сожалению, плохо работает с русским текстом. Поиск может производиться в одном из трех режимов – по всему интернету, только по англоязычным страницам и с использованием “родительского” фильтра. Когда страниц, соответствующих запросу, поисковая система обнаруживает много, результаты поиска делятся на страницы (как в любом поисковике) и для каждой из них создается своя карта Интернета. Любая карта результатов может быть сохранена и затем заново использована для поиска.
Webbrain.com – конкретизация области поиска
Визуальное представление результатов поиска – это частое явление среди альтернативных поисковых систем. Наиболее близкий и понятный способ демонстрации области поиска – это диаграмма, которую, так или иначе, обыгрывают в необычных интерфейсах создатели альтернативных поисковиков. Сервис webbrain.com – это попытка сделать поисковую систему, в которой пользователь мог бы не только перебирать подряд результаты, но и выбирать направление поиска. Работает поисковый сервис очень просто. Пользователь вводит запрос, после чего в верхней части страницы строится диаграмма слов, определяющих смысловую область поиска, а в нижней части окна браузера показывается стандартный список сайтов, отвечающих требованию запроса. В центре диаграммы ключевое слово, наиболее близко соответствующее тематике запроса. Иногда по центральному слову можно судить, насколько “правильно” поисковая система идентифицировала смысл запроса. Например, если ввести “3dnews.ru”, в центр диаграммы система ставит игры. Ну что ж, это верно, хотя, по правде сказать, нам кажется, что логичнее было бы увидеть в центре диаграммы другое слово, например “свежие IT-новости” или “компьютер”.
Неточность результатов этого поисковика объясняется скудной базой проиндексированных сайтов, однако сама идея интересна и, возможно, когда-нибудь получит продолжение. Для того, чтобы можно было работать с webbrain.com, необходимо иметь установленный компонент Java Virtual Maсhine, Internet Explorer, Firefox или Netscape.
Agakids.ru – детский поисковик
Когда ребенок стремится изучать компьютер – это нужно всячески поощрять. Но давать ему самостоятельно искать ответы на свои вопросы в Google или подобном “взрослом” поисковике не стоит. Ведь даже если поисковый движок имеет функцию ограничения результатов поиска с учетом нежелательного содержания, то это означает лишь то, что при включенном фильтре порнография и насилие не исчезнут полностью, а будут встречаться на страницах результатов реже. Гарантировать же полностью “чистый” список результатов не может ни один поисковый сервис. Не решают до конца эту проблему и программы для родительского контроля.
Но есть один очень хороший выход из положения – предложить ребенку поработать со специальным детским поисковиком agakids.ru. Этот сервис устроен таким образом, что осуществляет поиск исключительно по тем ресурсам, которые были добавлены в базу данных agakids.ru и были одобрены создателями сервиса. Поисковый сервис может найти полезную информацию и для родителей – расскажет, как правильно воспитывать детей, как заботиться об их здоровье и т.д. На сайте работает и детское интернет-радио, которое транслирует в эфир разные сказки, детские песни, рассказы и многое другое.
Чтобы ребенку было интересно использовать этот поисковик, работа с результатами может происходить в режиме визуального поиска, когда найденные странички показываются в виде красивой анимированной серии картинок-скриншотов заглавной страницы сайтов. Взрослым же, наверное, будет удобнее работать в текстовом режиме.
Eyeplorer.com – поиск в онлайновой энциклопедии
Создавая этот необычный поисковый движок, создатели стремились сделать его как можно более “умным”, способным точно настраиваться на поисковый вопрос. Решив, что нет более универсальной базы, чем та, которая содержится в энциклопедических статьях, создатели сервиса пришли к выводу, что новый поисковик следует создавать на основе Википедии – популярной онлайновой энциклопедии. Созданный немецкими программистами, eyeplorer.com визуализирует результаты поиска и дает возможность конкретизировать поиск. Eyeplorer.com – очень удобный инструмент, для того, чтобы быстро найти краткие сведения в определенной области.
Поисковая система выглядит как круговая диаграмма. В центре этой диаграммы находится окно поиска. После того, как запрос выполнен, на этой диаграмме начинают отмечаться точками результаты поиска, причем эти результаты выглядят как тэги-ссылки, помогающие пользователю раскрыть суть вопроса. Ссылки в этой диаграмме ведут на страницы онлайновой энциклопедии. Для большего удобства масштаб диаграммы можно менять, используя для этого специальный ползунок. Любой тэг, перемещенный в поле запроса, автоматически запускает новый поиск, и диаграмма перестраивает карту результатов. Поисковый запрос можно уточнять, добавляя дополнительные слова, уточняющие суть вопроса. Справа от этой диаграммы имеется блокнот, на который можно перетаскивать комментарии-ссылки к тэгам диаграммы, своего рода закладки онлайн.
Picollator.ru – поиск по содержимому картинок
Когда вы вводите запрос на большинстве популярных поисковых систем, предлагающих поиск графических файлов, вы получаете результаты, основанные на том, какой текст встречается на странице, а также на названиях файлов. А вот менее известный поисковик Picollator работает совершенно по-другому. Эта система идентифицирует то, что изображено на картинках. Естественно, что при таком подходе и поисковый запрос должен формулироваться не в виде слова или словосочетания, а быть картинкой.
Именно так и есть: загрузите на сервер фотографию или укажите ссылку на сайт, куда она уже загружена, и спустя несколько секунд вы увидите эскизы изображений, похожих на загруженное фото. Сервис имеет некоторые ограничения: он работает только с фотографиями людей. К тому же, чтобы получить приемлемый результат, исходное фото должно быть хорошего качества – лицо человека на нем должно быть хорошо видно, также желательно, чтобы он не было повернуто.
Kwmap.net – предложит направления поиска
Слоган этого сайта под поисковой формой “Keymap of whole Internet” полностью соответствует сути этой поисковой машины. Сервис kwmap.net визуализирует найденные результаты самым простым и наглядным образом, какой только можно придумать – в виде карты дорог, чем-то напоминающей карту метрополитена. Узловые точки этой карты – это ключевые слова, найденные поисковой системой. Точка на пересечении путей – это центральное слово, то самое, которое было введено в поле запроса поисковой машины.
Поисковая машина отчасти выполняет работу пользователя – в случае неудовлетворительного результата, можно не ломать голову над тем, какой вопрос задать более точно – достаточно взглянуть на визуальное представление результатов поиска и выбрать одно из ключевых слов. Иными словами, используя эти ключевые выражения, можно управлять направлением поиска.
Заключение
На этом список “странных” поисковых сервисов, конечно же, не заканчивается. Лучшие умы стараются разработать все более совершенный алгоритм отбора результатов поиска в интернете. Но, несмотря на все их усилия, до сих пор не было предложено такого решения, которое бы смогло вызвать большой интерес у пользователей. Это можно объяснить не только силой привычки, но и тем, что за годы существования Google, Yandex, Yahoo! и других поисковых систем, многие пользователи научились “фильтровать” результаты, умело оперируя синтаксисом поискового запроса, ничуть не хуже, чем это делают альтернативные поисковики. Полагаем, что ситуация может в корне измениться лишь тогда, когда на горизонте появится поисковый сервис, использующий не движок старших систем, а свой собственный, и который при этом сможет проиндексировать такое же огромное количество страниц, как Google.
Спор относительно того, какой из поисковиков самый лучший, определенно обречен на бесконечный диспут. Наверняка найдется немало людей, которые будут утверждать, что ничего лучше, чем Google или Yandex человек не придумал. Найдутся и такие, кто скажет, что альтернативные поисковики ищут точнее. Правы и те, и другие. В конце концов, в закладках браузера есть место для всех поисковых систем, которые могут пригодиться.
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Открываем Google, пишем то, что нужно найти в специальную строку и жмем Enter. «Все просто, чему вы меня учить собрались», — думаете вы. Ага, не тут-то было, друзья.
После сегодняшней статьи большинство из вас поймет, что делали это неправильно. Но этот навык – один из самых важных для продуктивного сотрудника. Потому что в 2021 году дергать руководство по вопросам, которые, как оказалось, легко гуглятся, — моветон.
Ну и на форумах не даст вам упасть лицом в грязь, чего уж там.
Затягивать не будем, ниже вас ждут фишки, которые облегчат вам жизнь.
Кстати, вы замечали, что какую бы ты ни ввёл проблему в Google, это уже с кем-то было? Серьёзно, даже если ввести запрос: «Что делать, если мне кинули в лицо дикобраза?», то на каком-нибудь форуме будет сидеть мужик, который уже написал про это. Типа, у нас с женой в прошлом году была похожая ситуация.
Ваня Усович, Белорусский и российский стендап-комик и юморист
Фишка 1
Если вам нужно найти точную цитату, например, из книги, возьмите ее в кавычки. Ниже мы отыскали гениальную цитату из книги «Мастер и Маргарита».
Фишка 2
Бывает, что вы уже точно знаете, что хотите найти, но гугл цепляет что-то схожее с запросом. Это мешает и раздражает. Чтобы отсеять слова, которые вы не хотите видеть в выдаче, используйте знак «-» (минус).
Вот, например, поисковой запрос ненавистника песочного печенья:
Фишка 3
Подходит для тех, кто привык делать всё и сразу. Уже через несколько долей секунд вы научитесь вводить сразу несколько запросов.
*барабанная дробь*
Для этого нужна палочка-выручалочка «|». Например, вводите в поисковую строку «купить клавиатуру | компьютерную мышь» и получаете страницы, содержащие «купить клавиатуру» или «купить компьютерную мышь».
Совет: если вы тоже долго ищете, где находится эта кнопка, посмотрите над Enter.
Фишка 4
Выручит, если вы помните первое и последнее слово в словосочетании или предложении. А еще может помочь составить клевый заголовок. Короче, знак звездочка «*» как бы говорит гуглу: «Чувак, я не помню, какое слово должно там быть, но я надеюсь, ты справишься с задачей».
Фишка 5
Если вы хотите найти файл в конкретном формате, добавьте к запросу «filetype:» с указанием расширения файла: pdf, docx и т.д., например, нам нужно было отыскать PDF-файлы:
Фишка 6
Чтобы найти источник, в котором упоминаются сразу все ключевые слова, перед каждым словом добавьте знак «&». Слов может быть много, но чем их больше, тем сильнее сужается зона поиска.
Кстати, вы еще не захотели есть от наших примеров?
Фишка 7
Признавайтесь, что вы делаете, когда нужно найти значение слова. «ВВП что такое» или «Шерофобия это». Вот так пишете, да?
Гуглить значения слов теперь вам поможет оператор «define:». Сразу после него вбиваем интересующее нас слово и получаем результат.
— Ты сильный?!
— Я сильный!
— Ты матерый?!
— Я матерый!
— Ты даже не знаешь, что такое сдаваться?!
— Я даже не знаю, что такое «матерый»!
Фишка 8
Допустим, вам нужно найти статью не во всём Интернете, а на конкретном сайте. Для этого введите в поисковую строку «site:» и после двоеточия укажите адрес сайта и запрос. Вот так все просто.
Фишка 9
Часто заголовок полностью отображает суть статьи или материалов, которые вам нужны. Поэтому в некоторых случаях удобно пользоваться поиском по заголовку. Для этого введите «intitle:», а после него свой запрос. Получается примерно так:
Фишка 10
Чтобы расширить количество страниц в выдаче за счёт синонимов, указывайте перед запросом тильду «~». К примеру, загуглив «~cтранные имена», вы найдете сайты, где помимо слова «странные» будут и его синонимы: «необычные, невероятные, уникальные».
Ну и, конечно, не забывайте о расширенных инструментах, которые предлагает Google. Там вы можете установить точный временной промежуток для поиска, выбирать язык и даже регион, в которым был опубликован материал.
В комментариях делитесь, о каких функциях вы знали, а о каких услышали впервые 🙂
Кстати, еще больше интересных фишек в области онлайн-образования, подборки с полезными ресурсами и т.д., вы найдете в нашем Telegram-канале. Присоединяйтесь!
Ищем и скачиваем непопулярные и старые файлы в интернете
Время на прочтение
14 мин
Количество просмотров 194K
Преимущественно медиафайлы. На полном серьезе, без шуток.
Введение
Бывает, случается так, что вы хотите скачать альбом 2007 года исполнителя, который кроме вас известен 3.5 людям, какой-нибудь испанский ска-панк или малопопулярный спидкор европейского происхождения. Находите BitTorrent-раздачу, ставите на закачку, быстро скачиваете 14.7%, и… все. Проходит день, неделя, месяц, а процент скачанного не увеличивается. Вы ищете этот альбом в поисковике, натыкаетесь на форумы, показывающие ссылки только после регистрации и 5 написанных сообщений, регистрируетесь, флудите в мертвых темах, вам открываются ссылки на файлообменники вроде rapidshare и megaupload, которые уже сто лет как умерли.

Увы, частая ситуация в попытке хоть что-то скачать
Такое случается. В последнее время, к сожалению, случается чаще: правообладатели и правоохранительные органы всерьез взялись за файлообмен; в прошлом году закрылись или были закрыты KickassTorrents, BlackCat Games, what.cd, btdigg, torrentz.eu, EX.ua, fs.to, torrents.net.ua, и еще куча других сайтов. И если поиск свежих рипов фильмов, сериалов, музыки, мультиков все еще не представляет большой проблемы, несмотря на многократно участившееся удаления со стороны правообладателей контента из поисковых систем, торрент-трекеров и файлообменников, то поиск и скачивание оригинала (DVD или Blu-Ray) фильмов и сериалов или просто ТВ-рипов 7-летней давности на не-английском и не-русском языке — не такая уж простая задача.
Зачем это нужно?
• Отсутствие некоторых релизов на дисках
В случае с видео, иногда случается так, что картину дублируют и транслируют по телевидению в какой-то стране, а на дисках не выпускают. Капперы выкладывают ТВ-рипы в файлообменные сети или BitTorrent, затем выходят DVD в другой стране, без соответствующей аудиодорожки, например, французской, и люди вынуждены либо качать DVDRip с хорошим качеством видео без французской дорожки, либо ТВ-рип с ней. Проходит время, ТВ-рип раздают все меньше и меньше людей, он удаляется с файлообменников из-за неактивности, и все — французский релиз становится скачать гораздо сложнее.
Проблему можно было бы решить, совместив аудиодорожку из ТВ-рипа с доступным видео из DVD, что не всегда так просто, как кажется. Этим никто не занялся и ТВ-версия умерла.
• Отличие контента ТВ- и DVD-версии
Например, мультсериал «Дарья» лишился почти всей музыки, которая была в ТВ-версии, из-за юридических проблем с перелицензированием. Долгое время люди, желающие посмотреть данный сериал, стояли перед выбором: либо полноценная ТВ-версия с музыкой и плохим качеством видео, либо DVD-версия с хорошим качеством, но без музыки.
• Региональные различия
Справедливы как для видео, так и для музыки. Мультсериал W.I.T.C.H. выпускался с 4 разными опенингами, только один из которых попал на DVD.
Зачастую, музыкальные альбомы, выпускаемые для рынка Японии, содержат бонусные треки, которых нет в других изданиях.
Как вы уже поняли, причин может быть множество. Где искать непопулярные и старые файлы?
Usenet
Usenet — распределенная сеть из серверов, синхронизирующих информацию между собой. Структура Usenet напоминает что-то среднее между форумами и электронной почтой: в «новостных группах» (так называются тематические категории в Usenet) сообщения имеют древовидную структуру, пользователи могут подписываться на конкретные группы, читать и писать в них. Как и в Email, у сообщений есть тема (subject), которая позволяет ориентироваться в содержании дискуссий. Сейчас используется преимущественно для обмена файлами.
История Usenet
Появившаяся в 1979 году, в до-интернетовскую эпоху сеть использовала прямые модемные соединения для передачи информации через UUCP и была инструментом преимущественно текстового общения. В свое время Usenet конкурировал с BBS, существовали специальные шлюзы в и из Fidonet. С приходом интернета, сообщения Usenet начали передаваться по TCP/IP, используя протокол NNTP, который остается относительно используемым и вне Usenet (например, можно читать огромное количество публичных списков рассылок через gmane и RSS-фиды через gwene, причем, в отличие от списков рассылок, вы всегда можете посмотреть всю историю, а не только сообщения с момента вашей подписки).

С увеличением пропускной способности линий, улучшением модемов и их протоколов, к девяностым сеть уже вовсю использовали для передачи бинарных файлов: вареза, музыки, видеофайлов. Делалось это примерно таким же образом, как и в Email: файл разбивается на небольшие части (тома), кодируется печатными символами в 7-битной кодировке с использованием Base64 или uuencode, и отправляется в ньюсгруппу. Кодирование в 7 бит добавляет около 30% накладных расходов на передачу файла. Спецификация позволяет использовать большинство символов из ASCII-таблицы, поэтому в 2001 году появляется алгоритм передачи файлов yEnc, увеличивающий файл всего на 1-2%, экранируя только символы переноса строки, NULL-байты и символ равенства (=). Им пользуются и по сей день.
Для контроля целостности и восстановления поврежденных или отсутствующих данных используется Parchive.

До 2008 года крупнейшие Usenet-провайдеры хранили бинарные файлы около 100-150 дней с момента их загрузки (так называемый retention time, срок хранения файлов). С 2008 года самые крупные провайдеры вообще перестали что-либо удалять, и на текущий момент можно без проблем скачать файлы восьмилетней давности, а провайдеры поменьше выставили retention time в 1000+ дней, что тоже немало. К этому моменту текстовое общение в Usenet сошло на нет и сеть использовалась преимущественно для хранения и передачи файлов.
Начиная где-то с середины 2011 года за сетью начали следить правообладатели, из-за чего Usenet-провайдерам пришлось удалять файлы, что сильно повлияло на целостность релизов. Некоторые провайдеры сделали автоматизированные системы удаления файлов, чтобы правообладатели могли удалять загрузки самостоятельно. Дабы предотвратить или хотя бы замедлить обнаружение файлов правообладателями, энтузиасты начинают загружать файлы с обфусцированными именами, в архивах под паролями, и добавляют их в каталоги систем индексации релизов (indexers), доступ к которым, как правило, осуществляется либо за деньги, либо по приглашениям. Обычными способами ни найти, ни скачать такие релизы не удастся.
В современной России о Usenet почти никому не известно, хотя рунет зарождался именно с него, по протоколу UUCP, и был одним из двух рабочих каналов для связи с Западом во время путча 1991 года (второй — FIDO). Сейчас Usenet наиболее популярен в странах, законы которых позволяют штрафовать пользователей за скачивание или раздачу контента, защищенного авторским правом, например, в Германии. В отличие от BitTorrent, узнать IP-адресы пользователей Usenet сторонней организации невозможно.
Подключение к Usenet
Полноценно пользоваться сетью бесплатно, скорее всего, не получится: либо столкнетесь с низким временем хранения файлов (10-30 дней), либо с низкой скоростью, либо получите доступ только к текстовым группам. Придется купить доступ у какого-нибудь провайдера или их реселлеров. Большинство провайдеров имеют два типа тарифов: месячный абонемент без ограничений по количеству скачанного (unlimited) и пакет трафика без ограничения по времени (block). Если вы собираетесь качать файлы из сети пару раз в месяц, block-доступа вам хватит надолго.
Крупнейшими провайдерами являются Altopia, Giganews, Eweka, NewsHosting, Astraweb.
Теперь нужно каким-то образом получить nzb-файл с метаинформацией, это что-то вроде .torrent-файла. Если у вас его нет, нужно воспользоваться поисковиком-индексатором.
Индексаторы
Общедоступные индексаторы завалены спамом с вирусами и ищут, как правило, плохо, но, тем не менее, подходят для поиска устаревших файлов, загруженных около 5 и более лет назад.
Вот некоторые из них:
- binsearch.info
- binzb.com
- nzbindex.com
- nzbsearch.net
- nzbking.com
Бесплатные индексаторы, требующие регистрацию, больше подходят для файлов посвежее. Они хорошо каталогизированы, релизы имеют не только название, но и описание с картинкой.
- nzbfinder.ws
- nzbid.org
- nzbnoob.com
- nzb.ag
- nzbfriends.com
- usenet-crawler.com
- drunkenslug.com
- nzbgeek.info
Последние два особенно рекомендую, в них можно найти множество обфусцированных релизов.
Существуют и узконаправленные сайты. Например, индексатор аниме anizb и музыки albumsindex.
Скачивание с Usenet
Давайте попробуем скачать фильм The FP 2011 года, достаточно неизвестный и непопулярный, BDRip’а которого в 1080p так просто найти мне не удалось. Для этого вам нужно найти nzb-файл и импортировать его в программу для закачки, например, NZBGet или SABnzbd, предварительно ее установив.
Заходим на nzbking.com, выполняем поиск по «the.fp.2011».

Видим в индексе файл, у которого доступна только одна часть из 3867. Такой файл не скачать, поэтому индексатор отображает этот параметр красным цветом.

Файлы, защищенные паролем, как правило, являются просто фейками.

На второй странице обнаруживается DVDRip, с адекватным размером, в архиве без пароля — хороший знак.

На третьей странице находим BDRip и несколько DVDRip’ов, похожих на настоящие (судя по размеру файла и дате загрузки).
Выбираем файлы, которые хотим скачать, нажимаем кнопку «Download NZB», скачиваем .nzb-файл и импортируем его в NZBGet или SABnzbd, предварительно вписав данные своего Usenet-аккаунта в настройки программы. Начинается скачивание со скоростью канала моего провайдера.

По окончанию скачивания, NZBGet автоматически распакует архивы и удалит их. Файл размером 6.74 ГБ, загруженный 4.5 года назад, скачался за 15 минут!
IRC / DCC / XDCC
Internet Relay Chat — протокол текстового общения, до сих пор пользующийся популярностью у разработчиков свободного ПО, администраторов торрент-трекеров, анимешников и авторов ботнетов из-за своей простоты. Появившийся в 1989 году, IRC стал стандартом групповых чатов в интернете на долгие годы, и начинает терять популярность только к середине 2000-х, с приходом ICQ и Jabber. В IRC существует возможность передачи файлов — DCC, на основе которой в 1994 году был написан первый бот для автоматического распространения доступных боту файлов — Xabi DCC (отсюда и название — XDCC).
На сегодняшний день существуют как отдельные каналы, так и целые серверы, посвященные файлообмену через XDCC. Почти у любой мало-мальски серьезной аниме релиз-группы, у которой даже может не быть веб-сайта, есть свой бот, с которого можно скачать все релизы группы независимо от их возраста. Популярность XDCC обусловлена функциональностью скриптов, легкостью их настройки и администрирования: выкладывающему релиз достаточно загрузить каким-либо образом файл на сервер с ботом, например по FTP, а бот сам добавит его в индекс, оповестит пользователей на канале о появлении нового файла, автоматически отправит его пользователям, подписавшимся на обновления этого бота (например, если это новый эпизод сериала).
В специальных IRC-сетях распространяют варез, свежие и не очень фильмы, музыку, игры, книги. XDCC не наделен вниманием правообладателей, поэтому у ботов можно найти множество вещей, которые сложно найти в других местах.
Индексаторы
Многие (но не все) XDCC-боты индексируются специальными скриптами, предоставляющими веб-интерфейс для эффективного поиска файлов.
Общие индексаторы контента:
- ixirc.com
- xdcc.eu
- sunxdcc.com
- cr4wl.ga
Индексаторы аниме:
- news.kae.re
- nibl.co.uk
- intel.haruhichan.com
Скачивание из IRC
Вам потребуется IRC-клиент, подойдет практически любой (подавляющее большинство клиентов поддерживает DCC). Подключаемся к интересующему вас серверу из списка, заходим на канал. Крупнейшие серверы с книгами:
- irc.undernet.org, канал #bookz
- irc.irchighway.net, канал #ebooks
Варезом:
- irc.criten.net, канал #elitewarez
- irc.infatech.net, канал #elitewarez
- irc.scenep2p.net, канал #the.source
Фильмами:
- irc.abjects.net, канал #moviegods
- irc.abjects.net, канал #beast-xdcc
Мультфильмами и аниме:
- irc.rizon.net, канал #news
- irc.xertion.org, канал #cartoon-world
Все версии ботов принимают команду !find или @find для поиска файлов, после чего отправляют результаты личным сообщением. Для популярных запросов на каналах с большим количеством ботов вас буквально заспамит ответами, поэтому, если канал поддерживает команду @search, лучше воспользоваться ей — специальный индексатор канала отправит вам результаты одним файлом через DCC.
Попробуем скачать «How Music Got Free» («Как музыка стала свободной» по-русски) — замечательная книга об истории музыкальной индустрии, технологиях обмена музыкой и человеке, который почти в одиночку стащил 2000 альбомов и выложил их в сеть.

Бот присылает результат поиска в виде ZIP-архива с текстовым файлом:

Отправляем боту запрос на скачивание файла:

…и принимаем его!

Конечно, не обязательно искать напрямую на канале. Если вы нашли нужный файл через индексатор, можете сразу запросить его у бота командой, которую вам сгенерирует сайт.
DC++
Direct Connect-сеть представляет собой клиент-серверную архитектуру, где все коммуникации, кроме непосредственно обмена файлами, происходят через сервер. В DC++ есть возможность расшаривания файлов и директорий, поиск файлов с учетом их типа (видео, аудио, архивы, документы, образы дисков), ссылки на файлы, независящие от имени файла и, конечно же, чат, из-за чего DC++-хабы были очень популярны в локальных сетях интернет-провайдеров РФ. Сибирский провайдер GoodLine рекламировал свой внутрисетевой хаб на уличных рекламных щитах, писал ПО для упрощения файлообмена и даже встраивал его в свои Set-top box, чтобы клиенты могли смотреть новинки кинематографа прямо с телевизора. На хабе сидело более 100000 человек — больше, чем в любом другом хабе в мире.

Из-за того, что пользователю достаточно указать путь к файлам, к которым он хочет открыть публичный доступ, в DC++ можно найти жуткое, малоизвестное старьё, которое, по мнению пользователя с этим файлом, уж точно никому не сдалось, но он его все равно расшарил, так, на всякий случай.

3 человека раздают видеоурок 11-летней давности, который ни одному вменяемому человеку смотреть не захочется, поверьте.
Скачивание из DC++
Вам потребуется какой-нибудь DC-клиент. Под Windows рекомендую FlylinkDC++ (который, к тому же, поддерживает BitTorrent), под Linux — EiskaltDC++ и AirDC++ Web. Далее нужно подключиться к популярным хабам, лучше сразу к десятку. Список хабов есть в самих программах, но можно воспользоваться специальной страницей и скопировать адреса оттуда.
Настоятельно рекомендую включить «активный» режим, пробросить порты, ввести ваш внешний IP-адрес в настройках программы и удостовериться, что к вам возможны подключения извне, иначе, в «пассивном» режиме у вас будут ограничения на количество результатов поиска, вы не сможете качать файлы с других пользователей в «пассивном» режиме.

Поиск и скачивание файлов интуитивно понятно: вводите название, опционально выбираете тип контента и фильтр по размеру, нажимаете кнопку поиска, кликаете два раза по результату, файл начинает скачиваться. Также можно посмотреть все файлы пользователя (и, например, скачать папку с найденным файлом целиком), нажав правой кнопкой по конкретному результату и выбрав соответствующий пункт меню.

Если нужного вам файла не нашлось, имеет смысл периодически повторять поиск. Некоторые люди запускают DC-клиент только тогда, когда им нужно что-то скачать, и вам нужно поймать момент, чтобы найти файл у таких пользователей.
Из-за ограничений протокла NMDC, одновременный поиск нескольких файлов затруднен, результаты одного поискового запроса могут перемешиваться и отображаться в соседних окнах поиска, поэтому лучше не искать несколько файлов одновременно. У хабов, работающих по протоколу ADC, таких ограничений нет, но и таких хабов удручающе мало (их URI начинается с adc://, а не с dchub://).
Индексаторы
Поиск внутри программы может найти только файлы пользователей, находящихся в DC-сети на момент поиска, поэтому индексаторы очень полезны для нахождения и скачивания файлов с редко запускающих программу людей.
Насколько мне известно, полноценный индексатор DC++ есть только один — spacelib.dlinkddns.com (и его второй адрес dcpoisk.no-ip.org). Поиск основан на движке Sphinx и учитывает морфологию (в том числе и русского языка). Поисковик генерирует magnet-ссылки для результатов поиска, которые можно поставить на закачку в клиенте.
Иногда он подолгу недоступен, например, в прошлый раз он не работал два месяца подряд.
eDonkey2000 (ed2k), Kad
ed2k — протокол децентрализованной передачи файлов, требующий сервер-хаб для нахождения пользователей и соединения с ними. Был протоколом №1 для передачи файлов среди всех слоев населения, до закрытия самого популярного сервера Razorback 2 в 2006 году и роста популярности BitTorrent.
eDonkey2000 выжил. Этому поспособствовал протокол полностью децентрализованного обмена Kad, который был внедрен в сторонние клиенты незадолго до закрытия Razorback 2 и главного сервера оригинальной программы, уступающей в функциональности и скорости альтернативным реализациям.
В ed2k можно найти примерно то же самое, что и в DC++ — старые файлы, ТВ-шоу на разных языках, разнообразную музыку, игры, варез, старые книги по программированию, математике, биологии. Новинки, разумеется, тоже в наличии. Хоть протокол и поддерживает чаты и просмотр всех файлов пользователя в открытом доступе, эти функции по умолчанию отключены, и, скорее всего, вам не удастся пообщаться с интересующими вас людьми через программу.
Скачивание в eDonkey2000 / Kad
Как вы уже догадались, потребуется ed2k-клиент. Хороший выбор для Linux — aMule, для Windows, наверное, eMule, хоть он и не обновлялся с 2011 (Обновление: появилась официальная версия eMule от сообщества, доступная для скачивания на официальном сайте, она обновляется). Крайне рекомендую пробросить порты, чтобы иметь возможность скачивать с пользователей за NAT (LowID).
Процесс поиска и скачивания файлов очень похож на таковой в DC++ — вводим поисковой запрос, получаем результаты поиска с пользователей, находящихся онлайн, кликаем на файлы для начала скачивания.
Файл отобразится в результатах даже в том случае, у пользователей, находящихся онлайн, есть только его части, но не файл целиком.
Попробуем найти малоизвестный документальный фильм 2009 года We Live In Public — картину, повествующую о событиях 90-х, которые частично предсказали современный интернет. Часть времени в фильме уделяется сайту pseudo.com — сервису аудио- и видеотрансляций, основанном в 1993 году.
Вводим поисковую фразу, получаем результаты:

Кликаем, начинается скачивание:

Загрузка файла может растянуться на недели и месяцы. По какой-то причине, многие пользователи сети имеют отвратительное интернет-соединение, да еще и появляются раз в неделю на пару часов, а то и меньше.
Soulseek
Soulseek — централизованная сеть обмена музыкальным файлами по принципу P2P, созданная в 2000 году одним из разработчиков Napster. Долгое время была популярна среди слушателей и авторов IDM и прочей электронной музыки, и по сей день сеть развивается и остается хорошим местом для поиска аудиофайлов. Есть групповые и приватные чаты, возможность раздачи файлов только друзьям, удобный поиск музыки с указанием битрейта и других характеристик аудиофайлов. Некоторые поисковые запросы цензурируются.
Существует официальный кроссплатформенный проприетарный клиент SoulseekQt и два развивающихся неофициальных: Nicotine+ и Museek+.
BitTorrent DHT
Все популярные клиенты BitTorrent могут искать пиров и обмениваться торрент-файлами через распределенную хеш-таблицу (DHT). Этим пользуются не только компании, отслеживающие раздающих файл пользователей, по договору с правообладателями контента, но и индексаторы, которые пытаются получить torrent-файл с infohash из DHT-запроса и сохранить его в своей базе. Индексаторы могут найти нигде не опубликованный или просто редкий торрент по названию директории или файла, а также различные дубликаты интересующего вас торрента с потенциальными сидерами.
Ранее самым популярным индексатором был ныне неработающий btdigg, на смену ему, с некоторым запозданием, пришли следующие сайты:
- bitsnoop.com
- godht.com
- btdb.in
- digbt.org
- btdb.in
- btkitty.bid
- kikibt.net
- btdig.com (не имеет отношения к оригинальному btdigg, хоть и страница в wikipedia говорит об обратном)
К сожалению, подобные сервисы не живут долго: два моих любимых, fastbot и BTKitty.red, не открывались на момент написания статьи.
Файлообменники и FTP-серверы
Почти в каждом регионе существуют свои местные файлообменники, пользующиеся популярностью у конкретной языковой группы. Например, на uloz.to можно найти много чешского и словацкого контента, zone-telechargement.ws подойдет любителям французского языка, а chomikuj.pl для поляков.
Индексаторы FTP-серверов нечасто находят нужные файлы, но попытаться стоит:
- mmnt.net
- searchftps.net
- filemare.com
- ftpsearch.lostclus.kiev.ua
- filewatcher.com
- krasfs.ru
- ftplike.com
Поисковики по популярным файлообменникам тоже существуют, но не всегда эффективны:
- filediva.com
- rapid-search-engine.com
- alluc.ee
До совсем недавнего времени большое количество контента можно было найти на ex.ua, но увы.
Как искать
Не всегда достаточно искать файлы только по названию материала, так можно упустить сценические релизы.
Рели́зная гру́ппа — сообщество людей-энтузиастов, объединенных идеей свободы информации. Выпускает электронные копии CD или DVD с фильмами, музыкой, программами и играми для компьютеров и игровых приставок, руководствуясь правилами релизов и соревнуясь со своими коллегами-конкурентами в скорости и качестве выпуска таких копий (релизов). Сообщество релизных групп, объединенных одной темой (музыка определенного жанра, кинофильмы или варез), называется сценой.
https://ru.wikipedia.org/wiki/Релизная_группа
Сценические релизы очень часто содержат сокращенные или намеренно испорченные имена архивов, которые нельзя найти обычным поиском по имени файла. Чтобы узнать настоящее имя, нужно поискать его в специальных индексаторах сцен-релизов: layer13.net, pre.corrupt-net.org и predb.me.
Попробуем узнать сценическое название архивов с релизом We Live In Public от PUZZLE на Layer13:

NFO-файл называется «puzzle-wlip.nfo». Названия архивов практически всегда, в 99% случаев совпадают с названием NFO, поэтому попробуем поискать это название в Usenet-индексаторе:

Ура, теперь мы можем скачать DVD фильма!
Обычные поисковые системы вроде Google не всегда будут вам помощниками. Во-первых, Google следует букве закона и удаляет (скрывает) результаты с сайтов, о которых сообщают ему правообладатели в рамках DMCA, во-вторых, поиск контента с названием из спецсимволов затруднен: проблемно найти что-либо о W.I.T.C.H., вам постоянно подсовывают информацию о Witch, The Witch или Blair Witch. Я предпочитаю пользоваться DuckDuckGo, Bing и метапоисковиком SearX — через них можно найти материалы, недоступные в Google.
Если вас интересует релиз на конкретном языке, уместней узнать локализованное название и совершать поиск по нему. Получить подобную информацию можно на Wikipedia, IMDb и других подобных сайтах.
Для аниме есть anidb, хранящий информацию о релизах групп на разных языках. Карточка группы, как правило, содержит ссылку на сайт или IRC-канал, где можно пообщаться с ее членами и скачать файлы через XDCC.

Помимо источника, разрешения видео, языков аудиодорожек и субтитров, на anidb есть TTH-хеш для DC++ и ed2k-ссылка для каждого файла.
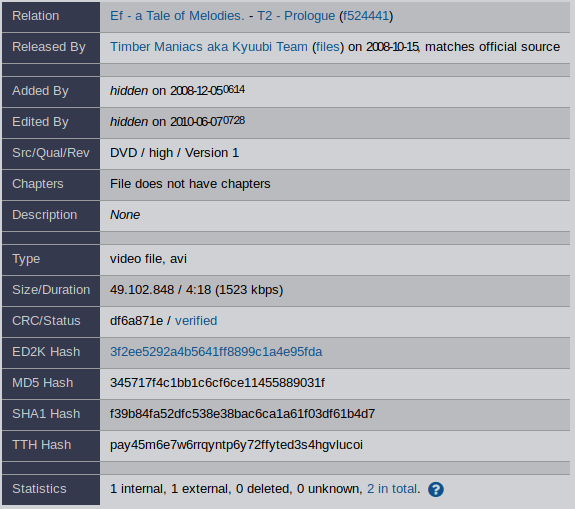
Заключение
Примерно так я ищу нужные мне файлы. В посте намеренно не упомянуты очевидные вещи, вроде покупки дисков с Amazon или Ebay и поиска по популярным открытым и закрытым Torrent-трекерам. Все способы применимы для медиаконтента из Европы и США, мне никогда не приходилось искать, например, арабский и индийский контент, поэтому не могу сказать, насколько они эффективны.
Скрытый текст
А еще Usenet можно использовать для дешевого хранения резервных копий: шифруем файлы, покупаем доступ в Usenet за $10, загружаем файлы, через 4 года опять покупаем доступ и скачиваем их за еще одни $10. В отличие от облаков, в Usenet не нужно оплачивать хранение файлов. Но без фанатизма, а то удалят.
Как найти информацию в интернете?
Анонимный вопрос
21 апреля 2018 · 18,4 K
Engineer – programmer ⚡⚡ Разбираюсь в компьютерах, технике, электронике, интернете и… · 12 нояб 2018 ·
Любую информацию в интернете можно найти с помощью адресной строки или поисковой строки. С поисковой все просто: открываете одну из поисковых систем, в поисковую строку вводите запрос и обрабатываете результат поиска. К основным “поисковикам” относятся следующие:
- Яндекс
- Rambler
- Yahoo
- Bing
- Поиск@Mail.Ru
- Nigma
С адресной строкой посложнее: требуется ввести запрос в формате адреса сайта в интернете, т.е. ввести его имя на латинице и домен. У каждой страны свой домен: в России — ru, в Беларуси — by, в Украине — ua. Например, требуется найти “Как разброкировать iPhone?”. В адресную строку следует ввести адрес сайта, который соответствует вашей задаче, к примеру, “razblokirivkaiphone(точка)ru или (точка) ua. Не факт, что сайт с таким именем существует, поэтому следует перебрать много вариантов с названием сайта и его доменом.
8,2 K
Комментировать ответ…Комментировать…
Грамотно пользуйтесь поисковыми сервисами и сможете найти в интернете ну почти всё. Не вводите в поисковой запрос слишком короткую фразу, пусть это будет как минимум два ключевых слова. Слишком длинный запрос тоже не следует вводить. Также пользуйтесь расширенным поиском, в котором вы отсечете всю ненужную информацию и, возможно, найдете именно то, что искали. Не… Читать далее
3,2 K
есть вопрос. как сделать сортировку англоязычный сайтов, имеющих на сайтах странички на русском языке?
Комментировать ответ…Комментировать…
Уже два десятка лет, работая в СМИ, я наблюдаю один и тот же феномен. А именно: одни журналисты совершенно не настроены осваивать новые технологии, и, похоже, до сих пор ностальгируют по печатающим машинкам.
А другие, наоборот, осваивают новые технологии с космической скоростью, опережая самых отъявленных техногиков. Этот текст – для второй категории.
Все мы привыкли для поиска необходимой нам информации использовать самую популярную в мире поисковую систему – Google. Ежедневно на сайтах Google, доступных примерно на 200 языках, регистрируются миллиарды поисковых запросов – не случайно основной сайт Google.com считается самым популярным интернет-ресурсом. Также довольно часто используется «Яндекс» и Bing.
Однако нужно признать: поисковая система Google рассчитана на массового потребителя, на того, кому в 99% случаев с лихвой хватает первых трех страниц поисковой выдачи. Но журналисты – это как раз те люди, которым бывает необходимо найти что-то не слишком распространенное, глубоко покопаться в вопросе. Однако даже самая совершенная поисковая система не способна одинаково хорошо искать в блогах и в научных статьях, в цифровых изображениях и кулинарных рецептах. Именно по этой причине существует множество не слишком известных поисковых систем, которые специализируются на каком-либо «узком» поиске, либо умеют искать там, где обычно не ищут традиционные поисковики. Ведь универсальные поисковые системы просто «не видят», например, уже не существующие веб-страницы, либо старые версии страниц, контент в социальных сетях, страницы, которые преднамеренно закрыты для «веб-пауков» и т.д.
Итак, чем мы можем воспользоваться?
1. Ответить на вопрос
Можно искать что-то по ключевым словам или фразам, а можно задать вопрос на естественном человеческом языке. Именно на такие вопросы отвечает Answers.com – поисковая система, позволяющая найти ответы на огромное количество вопросов. Результат поиска – это не набор ссылок, а статьи с Википедии, Оксфордовского университета и других авторитетных ресурсов. Вот только спрашивать придется на чистом английском языке.
2. Найти то, чего уже нет
Сегодня практически каждый продвинутый интернетчик умеет пользоваться кэшем Google или «Яндекса», когда у него возникает необходимость просмотреть (и/или представить в качестве доказательства) недавно удаленную либо измененную страницу в ее первоначальном виде. Ну или увидеть ее такой, какой она была в определенный момент времени. Однако есть определенная проблема: такой кэш доступен для поисковой выдачи только сравнительно короткое время. Это понятно: задача поискового робота – выдавать наиболее актуальную версию интернет-ресурса.
Однако иногда бывает нужно увидеть какой-то сайт так, как он выглядел, скажем, несколько лет назад. Для этого созданы специальные поисковые средства – такие, скажем, как веб-сервис Wayback Machine. Его работу поддерживает некоммерческая организация «Архив Интернета», которая с 1997 года собирает копии веб-страниц и размещаемый в Сети мультимедийный контент. Все эти копии, сохраненные на множестве серверов, бесплатно доступны для всех желающих. Wayback Machine позволяет отыскать не только старую версию ныне существующего сайта, но и те веб-страницы, которые давно не существуют – речь о закрытых сайтах. К сегодняшнему дню «Архив Интернета» собрал уже более 366 млрд страниц, так что найти требуемое можно с очень большой вероятностью.
3. Ищем картинку
Сегодня подавляющее большинство пользователей, которым нужно отыскать какое-то фото или иной графический файл, используют для этой цели Google Images. Но все-таки самый-большой-поисковик-в-мире «заточен» под текстовый поиск, а поиск картинок для него – только один из дополнительных сервисов.
Так что, если вы не смогли отыскать требуемое при помощи Google Images, имеет смысл использовать что-то специализированное. Например, сервис Picsearch. По заявлению его создателей, их детище на сегодняшний день проиндексировало уже более трех с половиной миллиардов цифровых картинок.
В числе преимуществ Picsearch – как многоязычный пользовательский интерфейс, так и полноценный многоязычный поиск, а также ряд очень практичных фильтров, например, возможность поиска только черно-белых или цветных изображений, картинок с преобладанием какого-то конкретного цвета, поиск «обоев» для рабочего стола, а также лиц или анимированных изображений.
Достойной альтернативой Google Images также может стать поисковая система Everystockphoto. С одной стороны, она намного меньше по размеру – содержит «всего» порядка 25 млн картинок, хранящихся на онлайновых фотосайтах, включая Flickr, Fotolia и Wikimedia Commons. Однако, как говорят специалисты, результаты ее работы по-настоящему впечатляют. Большинство из найденных снимков можно использовать бесплатно, правда, при условии, что будет указано имя фотографа или правообладателя.
Особняком стоит сервис поиска по содержимому картинок Picollator.ru. Когда вы вводите запрос в большинстве поисковиков, предлагающих поиск графических файлов, вы получаете результаты исходя из того, какой текст встречается на странице, а также на названиях файлов. Picollator работает принципиально иначе, идентифицируя то, что изображено на картинках. Понятно, что в этом случае поисковый запрос должен формулироваться не в виде слова или словосочетания, а быть картинкой.
То есть для поиска следует загрузить на сервер фотографию или указать ссылку на сайт, куда она уже загружена. В поисковой выдаче будут собраны эскизы изображений, похожих на загруженное фото. Правда, этот сервис работает только с фотографиями людей, причем хорошего качества.
4. Не только найти, но и подсчитать
К сожалению, слишком многие журналисты – особенно выходцы с журфака – «не дружат» с цифрами. Многие даже не видят разницы между процентами и процентными пунктами, из-за чего статьи по экономике порой превращаются в абракадабру. Помочь им может один из самых известных «альтернативных» поисковиков – WolframAlpha.
По сути, это «энциклопедическая» поисковая система, задача которой – давать ответы на действительно сложные вопросы в таких областях, как математика, физика, медицина, статистика, история, лингвистика и прочие области науки. По сути, WolframAlpha – это в большей степени колоссальная база данных, часть которой преобразована в вычислительные алгоритмы. Именно благодаря им пользователь поисковика может получить обстоятельные сведения о том, сколько граммов белков и калорий содержится в чашке какао, какова ожидаемая средняя продолжительность жизни в США, Франции и Австралии в следующем году или как решается алгебраическое уравнение.
Впрочем, чтобы полноценно использовать WolframAlpha, нужно хорошо владеть английским языком. Другие языки система, к сожалению, не поддерживает.
5. И снова наука
Научный мир всегда был в некоторой степени закрыт для непосвященных. Конечно, не отгораживается от широкой публики стальной стеной, но чтобы читать научные публикации, копаться в специфических базах данных и смотреть результаты экспериментов пользователям Сети обычно нужно пройти регистрацию и получить специальный доступ. То есть обычные поисковики эту информацию не индексируют – для них практически все научные статьи относятся к категории так называемого «глубокого Веба» (Deep Web).
Так что если вам действительно нужно покопаться в научной информации, непонятной большинству непосвященных, – используйте специализированную поисковую систему. Такую, как поисковик CompletePlanet, имеющий доступ более чем к 70.000 научных баз данных и узконаправленных поисковых систем.
6. Ищу человека!
Обычный поисковик вполне можно использовать только для поиска информации о какой-то знаменитости. Если вам нужна информация совсем не о публичной персоне, то шансы отыскать какие-либо данные резко падают. И тогда нужно использовать специализированную поисковую систему.
Самая известная из таких систем – поисковик Pipl. Она проводит поиск данных о людях в целом ряде публичных реестров, онлайновых баз данных, служб и социальных сетей. Большое преимущество сервиса Pipl – то, что он работает и с кириллицей, так что он достаточно эффективен и с русскоязычными фамилиями.
Альтернатива – российский сервис SpravkaRU.NET. Он может отыскать адрес и домашний телефон жителя не только России, но и Украины, Беларуси, Казахстана, Латвии и Молдовы. По сути, это большой электронный телефонный справочник крупных городов постсоветских стран, хотя далеко не полный. Однако, в отличие от многих подобных сервисов, SpravkaRU.NET содержит вполне актуальные базы. Так что если у вас есть хоть какая-то информация о родственниках или примерном месте проживания объекта вашего интереса, то это наверняка поможет его найти. Замечу, что сервис часто не работает.
Самый простой способ кого-то отыскать – использовать поисковик «Яндекс.Люди». Проверено: сильно много информации вы не получите, но самого человека разыщете почти наверняка.
7. Поиск по блогам
За последние полтора десятилетия блоги стали не просто общественно культурным явлением, но и просто бездонным источником самой разнообразной информации. Далеко не всегда достоверной и корректно поданной, но нередко все же очень интересной. Специализированный поиск по русскоязычным блогам – сервис «Яндекс.Блоги». Без особых наворотов, просто работающий поиск.
8. Держать свой поиск в секрете
Одна из выдающихся разработок 2010-х годов – анонимный поисковик DuckDuckGo. Это Это поисковая система с открытым исходным кодом, основанная в сентябре 2008 года. В своем пользовательском соглашении DDG особо подчеркивает конфиденциальность предоставляемых пользователями данных, отказ от записи и хранения пользовательской информации и от слежки за пользователями.
В технологическом плане DuckDuckGo отличается от универсальных поисковиков тем, что не использует «пузырь фильтров» (Filter bubble), то есть не учитывает прошлые запросы пользователя для определения того, какая информация ему наиболее интересна. DuckDuckGo по умолчанию использует работу между клиентом и сервером по протоколу HTTPS, работая по алгоритму шифрования RC4 с ключом 128 бит. Также DDG Поисковик не использует cookies и не хранит данные об IP-адресах пользователей, не предлагает залогиниться и по умолчанию шифрует передаваемые данные.
Хранящий анонимность поисковик – детище программиста Гэбриела Вайнберга. Он создал DDG в 2008 году, с самого начала решив, что тот не будет хранить данные пользователей, так как они содержат слишком много личной информации. «Если вы спросите людей о важности приватности их поиска, они ответят, что это очень важно, но при этом практически никто не пытается сделать свои поисковые запросы анонимными, – писал Вайнберг в своем блоге. – Google хранит не только поисковые запросы пользователей, но и IP-адреса, с которых они обращались. То, что Google обязательно должен хранить всю эту информацию, – миф. Почти все деньги, которые они получают, основаны на том, что пользователь набирает в строке поиска».
Сперва DuckDuckGo был малоизвестен: еще в начале июня 2013 года он обрабатывал только 1,7 млн запросов в день. Но затем случился скандал: в США была обнародована информация о программе PRISM – с ее помощью АНБ США получало доступ к серверам компаний, включая владельцев крупнейших в мире поисковых систем – Google, Microsoft и Yahoo. Вскоре после этого число ежедневных запросов к DuckDuckGo превысило 3 млн в день и продолжило быстро расти.
9. Хранить тайны
УаСу – поисковик, работающий по технологии Р2Р (peer-to-peer). Хранение поискового индекса и обработка запросов производятся не на центральном сервере, а в распределенной сети пиров Fгeewoгld. Присоединиться к сети может любой желающий, достаточно просто установить соответствующее ПО. Здесь царит полная анонимность: распределенная сеть и открытый код гарантируют УаСу устойчивость и защищают его от попыток цензуры.
Поисковая система Ixquick также делает приоритетом анонимность и безопасность пользователей. lxquick, как и DuckDuckGo, не сохраняет информацию ни о запросах пользователей, ни о них самих.
10. «Прошерстить» форумы и блоги
Omgili – поисковая система, специально созданная, чтобы индексировать форумы по всевозможным тематикам, а также тематические блоги. Используя этот поисковик можно будет быстрее найти уже опубликованные вопросы и получить на них ответы.
11. Найти звуки в Сети
Ресурс FindSounds.com специально создан для пользователей, которым требуется искать звуковые файлы разных форматов – wav, mp3, aiff, au. В базе данных ресурса есть самые разнообразные звуки – крики животных, скрежет машин, звон, стук, сирены, жужжание насекомых, грохот взрывов и стрельбы, всплеск воды и т.д. Звуковые файлы можно искать по разным критериям, например, по размеру, наличию двух или одного каналов звучания (стерео/моно), частоте дискретизации и разрядности звучания. В результатах поиска отображаются не только ссылки на найденные файлы, но и их основные характеристики, а также показывается график амплитуды звука, по которой можно судить о характере звучания данного семпла. Поисковик может пригодиться, например тем, кто создает интерактивную web-графику и желает внести разнообразие на сайт, сопроводив нажатие элементов навигации страниц различными звуками.
12. Ищем dll-файлы
Думаю, всякому доводилось хотя бы раз столкнуться с проблемой отсутствия в операционной системе какой-то библиотеки dll. В результате программы или игры отказываются запускаться, а на экран выводится сообщение «Couldn’t find *****.dll». Отсутствие нужного файла может быть вызвано некорректным удалением ранее установленного приложения, случайным повреждением файла и т.д. Кроме того, разработчик мог просто не включить в дистрибутив своего продукта эту библиотеку.
Исправить ситуацию очень просто – достаточно найти в интернете недостающий файл, загрузить его и скопировать в каталог программы, которая отказывается запускаться, либо в папку ..WINDOWSsystem32… Найти и скачать отсутствующий файл можно легко и быстро с помощью поисковика Alldll.net.
Это поисковая база данных по наиболее популярным библиотекам dll. Файлы рассортированы по алфавиту, присутствует функция поиска. Искомый файл можно отыскать, даже если известно только приблизительное название библиотеки.
13. Поиск медицинской информации
Сайт Medpoisk.ru – универсальный поисковик, который предназначен для поиска исключительно на медицинских сайтах. Использует движок поиска от Google. Это практичный инструмент не только для врачей, но и для каждого, кому нужен ответ на любой вопрос из области медицины. Как лечить ту или иную болезнь, какие противопоказания у того или иного лекарства, к какому врачу обратиться. Также в поисковик включена биржа труда для медицинских работников.
14. Космос – наше все
Астрономический поисковый сервис Astronet.ru специализируется на поиск информации по сайтам, тематика которых имеет отношение к астрономии и исследованию космоса. Всего в базе данных поисковой системы около пятисот сайтов астрономической тематики – сайты обсерваторий, любительские странички, библиотеки научной литературы и тому подобное.
Помимо функции поиска, на сайте есть масса других полезных сервисов, среди которых, например, англо-русско-английский астрономический словарь, биографический справочник с подробными сведениями обо всех ученых, внесших вклад в развитие астрономии, глоссарий астрономических терминов. Есть также удобная карта звездного неба, которая генерирует положение созвездий, в зависимости от широты и долготы точки наблюдения, а также времени суток.
Безусловно, это лишь небольшая часть альтернативных поисковых сервисов. Причем со временем одни из них прекращают работу, но появляются новые. Лучшие умы создают все более совершенные алгоритмы отбора результатов интернет-поиска. Впрочем, если научиться умело оперировать синтаксисом поискового запроса, то и Google, Yandex, Yahoo! и другие поисковые системы «общего назначения» могут выдавать результаты не хуже, чем это делают альтернативные поисковики.
