При работе с файлом сайта на сервере может возникнуть необходимость в определении его полного пути. Для выполнения этой задачи существует несколько способов, о них и пойдет речь далее.
Адреса файлов на серверах
Для начала предлагаю разобраться с тем, как вообще происходит получение адресов файлов. Самый распространенный способ – использование доступа к элементам при помощи протокола HTTP. В этом случае файлы выгружаются юзерами при помощи специального кодирования. В следующем отрывке кода вы наглядно видите, как происходит бинарный тип кодирования с использованием атрибута enctype:
<form action="upload" method="POST" enctype="multipart/form-data"> <input type="file" name="myfile"> <br/> <input type="submit" name="Submit"> </form>
Второй распространенный вариант – использование протокола FTP, который может работать в обоих направлениях – как для загрузки файлов, так и для их скачивания. На следующем скриншоте вы видите пример того, как отображается по FTP открытая для пользователей папка сайта с возможностью скачать любой файл.
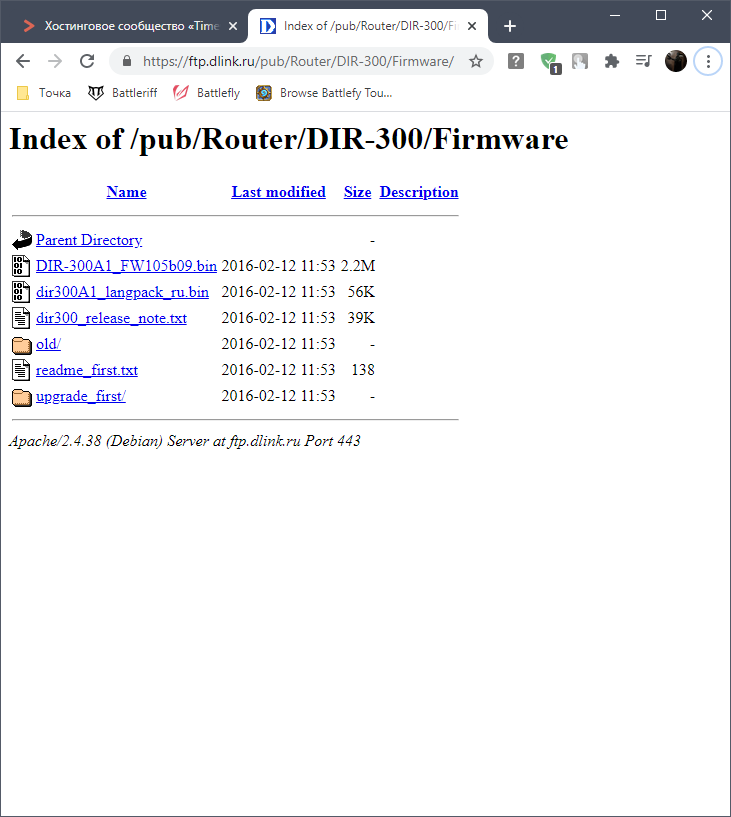
Соответственно, на этой же странице можно с легкостью получить информацию о полном пути файла.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Определение адреса файла на сервере
Разберу основные методы получения адресов файлов, хранящихся на сервере.
Консольная утилита pwd (для Linux)
Пользователи выделенного сервера или VDS с Linux могут задействовать простую консольную утилиту pwd, которая предназначена для отображения пути текущего каталога, где сейчас и выполняются все действия. Эту утилиту можно использовать и для определения адреса файла на сервере. Вывод абсолютного пути осуществляется путем ввода простой команды:

Она поддерживает дополнительные опции, позволяющие немного модернизировать результат вывода:
-L — отменяет разыменовывание символических ссылок, их отображение осуществляется без конвертирования в исходный путь.
-p — конвертирует символические ссылки в их исходные имена с отображением указываемых директорий.
Если вы задаетесь вопросом, можно ли использовать pwd в своих скриптах, то ответ на него будет «Да». В этом нет ничего сложного, а простое представление объявления утилиты выглядит как DIR=`pwd` или DIR=$(pwd).
Панели управления и FTP
При использовании услуг хостинга управление собственным веб-ресурсом происходит при помощи местной административной панели. Необходимо только знать ее устройство, чтобы быстро определить полный путь любого файла на сервере. Найдите домашнюю директорию в одном из разделов аккаунта. Путь к сайту может выглядеть примерно так: /var/www/user/data или /srv/www/hosts/mysite.com.
Конечно, есть и другие распространенные варианты представления данных путей, поэтому в случае надобности не стесняйтесь обращаться к технической поддержке хостинг-провайдера для получения соответствующей информации. Впрочем, далее остается только отыскать целевой файл в этой директории или ее подпапках, чтобы узнать путь, который и будет начинаться с адреса сайта.
Если вы арендуете виртуальный хостинг, то путь к файлу легко определить, если подключиться к серверу по FTP.
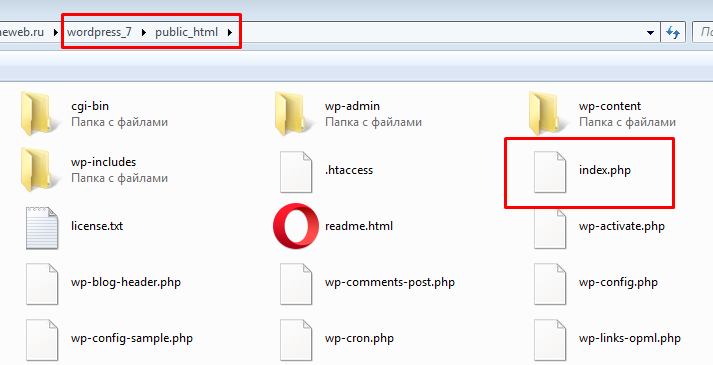
Откроем свойства файла любого файла в папке тестового сайта на WordPress и увидим его полный FTP-адрес.
Создание PHP-скрипта
Есть небольшой скрипт, который нужно сохранить в отдельном файле. Он позволяет получить абсолютный путь любого файла, а реализовывается это благодаря тому, что вся информация уже хранится под одной переменной $_SERVER. Создайте пустой файл и вставьте туда следующий код:
<?php echo 'Document root: '.$_SERVER['DOCUMENT_ROOT'].'<br>'; echo 'Полный путь к скрипту и его имя: '.$_SERVER['SCRIPT_FILENAME'].'<br>'; echo 'Имя скрипта: '.$_SERVER['SCRIPT_NAME']; ?>
Отредактируйте его под себя, после чего сохраните с любым названием и задайте тип файла .php. Используйте FTP-клиент для загрузки этого файла в корневую папку целевого сайта.
Последний этап – запуск этого скрипта. В адресной строке браузера введите адрес вашего сайта и в конце добавьте /file.php, где file замените на название файла со скриптом. На новой странице в веб-обозревателе отобразятся примерно следующие сведения:
Document root: /home/XXXXX/YYYYY Полный путь к скрипту и его имя: /home/XXXX/YYYYY/url_path.php Имя скрипта: /url_path.php
Вы можете использовать один из этих методов, когда требуется определить абсолютный путь файла.

Наверное, многие когда-нибудь задумывались, как сделать поиск на сайте? Безусловно, для крупных сайтов с большим количеством контента поиск является просто незаменимой вещью. В большинстве случаев пользователь, впервые посетив Ваш сайт в поисках чего-либо важного, не станет разбираться в навигационных панелях, выпадающих меню и прочих элементах навигации, а в спешке попытается найти что-нибудь похожее на поисковую строку. И если такой роскоши на сайте не окажется, либо он не справится с поисковым запросом, то посетитель просто закроет вкладку. Но статья не о значении поиска для сайта и не о психологии посетителей. Я расскажу, как реализовать небольшой алгоритм полнотекстового поиска, который, надеюсь, избавит начинающих разработчиков от головной боли.
У читателя может возникнуть вопрос: зачем писать все с нуля, если все уже давно написано? Да, у крупных поисковиков есть API, есть такие клевые проекты, как Sphinx и Apache Solr. Но у каждого из этих решений есть свои преимущества и недостатки. Пользуясь услугами поисковиков, типа Google и Яндекс, Вы получите множество плюшек, таких как мощный морфологический анализ, исправление опечаток и ошибок в запросе, распознавание неверной раскладки клавиатуры, однако без ложки дегтя тут не обойдется. Во первых, такой поиск не интегрируется в структуру сайта — он внешний, и Вы не сможете указать ему, какие данные наиболее важны, а какие не очень. Во вторых, содержимое сайта индексируется только с определенным интервалом, который зависит от выбранного поисковика, так что если на сайте что-нибудь обновится, придется дожидаться момента, когда эти изменения попадут в индекс и станут доступными в поиске. У Sphinx и Apache Solr дела с интеграцией и индексированием гораздо лучше, но не каждый хостинг позволит из запустить.
Ничто не мешает написать поисковый механизм самостоятельно. Предполагается, что сайт работает на PHP в связке с каким-нибудь сервером баз данных, например MySQL. Давайте сначала определимся, что требуется от поиска на сайте?
- Поиск с учетом языковой морфологии. Независимо от падежа, окончания и
других прелестей великого и могучего языка поиск должен находить то, что нужно
пользователю. Другими словами, «яблок», «яблока», «яблоки» — это формы одного и того
же слова «яблоко», что нужно учитывать в поисковом алгоритме. Одним из способов
достижения данной цели является приведение каждого слова поискового запроса и слов
содержимого сайта к базовой форме. - Возможность указать контекст поиска. То есть, возможность самостоятельно выбрать
контент сайта, в пределах которого будет работать поисковый алгоритм, а также определить
значимость для каждого из пределов. Например, рассмотрим интернет-магазин. Предполагается,
что поисковый запрос чаще всего будет содержать название искомой продукции, поэтому поиск по
названиям товара будет иметь наивысший приоритет. В качестве следующего приоритета можно
выбрать поиск по свойствам товаров, затем поиск по описанию. - Индексирование содержимого сайта. Представьте ситуацию: одновременно около 30 человек
выполняют поисковые запросы. Сервер принимает каждое соединение, управление потоком
передается интерпретатору PHP. При каждом запросе заново инициализируется поисковый
движок, заново перерывается содержимое сайта… Сложно сказать, сколько времени и
ресурсов потребуется, чтобы обработать все эти запросы. Именно для того, чтобы не
делать одну и ту же работу по сто раз, была придумана технология индексирования.
Индексирование выполняется только при изменении или добавлении содержимого сайта,
а поиск выполняется уже по индексу, а не по содержимому. - Механизм ранжирования. Ранжирование результатов поиска — это сортировка результатов поиска, выполняемая на основе оценки значимости найденных данных. Например, в каком-нибудь блоге выполняется поисковый запрос «космос». Данное слово содержится в двух статьях: в первой 16 раз, во второй — 5 раз. Вероятнее всего, первая статья будет иметь большее значение для инициатора поиска. Также каждой разновидности содержимого сайта при индексировании задается определенный коэффициент, который будет влиять на его позиции в поисковой выдаче.
Теперь пару слов о том, что нам предстоит реализовать:
- морфологический анализатор,
- алгоритм ранжирования,
- алгоритм индексирования,
- алгоритм поиска.
В конце статьи будет показан пример реализации поиска на примере простого интернет-магазина. Тем, кому лень все это изучать и просто нужен готовый поисковик, можно смело забирать движок из репозитория GitHub FireWind.
Принцип работы
Со стороны бэкенда поиск работает так:
- содержимое сайта индексируется,
- пользователь присылает запрос,
- из запроса исключаются служебные части речи,
- получившаяся строка разбивается на массив слов, переведенных в базовую форму,
- поиск каждого слова полученного массива осуществляется в индексе,
- результаты поиска ранжируются, сортируются и отдаются пользователю.
Подготовка
Задача поставлена, теперь можно перейти к делу. Я использую Linux в качестве рабочей ОС, однако постараюсь не использовать ее экзотических возможностей, чтобы любители Windows смогли «собрать» поисковый движок по аналогии. Все, что Вам нужно — это знание основ PHP и умение обращаться с MySQL. Поехали!
Наш проект будет состоять из ядра, где будут собраны все жизненно необходимые функции, а также модуля морфологического анализа и обработки текста. Для начала создадим корневую папку проекта firewind, а в ней создадим файл core.php — он и будет ядром.
$ mkdir firewind
$ cd firewind
$ touch core.php
Теперь вооружаемся своим любимым текстовым редактором и подготавливаем каркас:
<?php
class firewind {
public $VERSION = "1.0.0";
function __construct() {
// Инициализатор //
}
}
?>
Тут мы создали основной класс, который можно будет использовать на Ваших сайтах. На этом подготовительная часть заканчивается, пора двигаться дальше.
Морфологический анализатор
Русский язык — довольно сложная штука, которая радует своим разнообразием и шокирует иностранцев конструкциями, типа «да нет, наверное». Научить машину понимать его, да и любой другой язык, — довольно непростая задача. Наиболее успешны в этом плане поисковые компании, типа Google и Яндекс, которые постоянно улучшают свои алгоритмы и держат их в секрете. Придется нам сделать что-то свое, попроще. К счастью, колесо изобретать не придется — все уже сделано за нас. Встречайте, phpMorphy — морфологический анализатор, поддерживающий русский, английский и немецкий языки. Более подробную информацию можно получить тут, однако нас интересуют только две его возможности: лемматизация, то есть получение базовой формы слова, и получение грамматической информации о слове (род, число, падеж, часть речи и т.д.).
Нужна библиотека и словарь для нее. Все это добро можно найти тут. Библиотека находится в одноименной папке «phpmorphy», словари расположены в «phpmorphy-dictionaries». Скачиваем последние версии в корневую папку проекта и распаковываем:
# Распаковываем библиотеку
$ unzip phpmorphy-0.3.7.zip
$ mv phpmorphy-0.3.7 phpmorphy
# Распаковываем словарь в phpmorphy/dicts
$ unzip morphy-0.3.x-ru_RU-withjo-utf-8.zip -d phpmorphy/dicts/
# Удаляем исходные архивы
$ rm phpmorphy-0.3.7.zip morphy-0.3.x-ru_RU-withjo-utf-8.zip
Отлично! Библиотека готова к использованию. Пришло время написать «оболочку», которая абстрагирует работу с phpMorphy. Для этого создадим еще один файл morphyus.php в корневой директории:
<?php
require_once __DIR__.'/phpmorphy/src/common.php';
class morphyus {
private $phpmorphy = null;
private $regexp_word = '/([a-zа-я0-9]+)/ui';
private $regexp_entity = '/&([a-zA-Z0-9]+);/';
function __construct() {
$directory = __DIR__.'/phpmorphy/dicts';
$language = 'ru_RU';
$options[ 'storage' ] = PHPMORPHY_STORAGE_FILE;
// Инициализация библиотеки //
$this->phpmorphy = new phpMorphy( $directory, $language, $options );
}
/**
* Разбивает текст на массив слов
*
* @param {string} content Исходный текст для выделения слов
* @param {boolean} filter Активирует фильтрацию HTML-тегов и сущностей
* @return {array} Результирующий массив
*/
public function get_words( $content, $filter=true ) {
// Фильтрация HTML-тегов и HTML-сущностей //
if ( $filter ) {
$content = strip_tags( $content );
$content = preg_replace( $this->regexp_entity, ' ', $content );
}
// Перевод в верхний регистр //
$content = mb_strtoupper( $content, 'UTF-8' );
// Замена ё на е //
$content = str_ireplace( 'Ё', 'Е', $content );
// Выделение слов из контекста //
preg_match_all( $this->regexp_word, $content, $words_src );
return $words_src[ 1 ];
}
/**
* Находит леммы слова
*
* @param {string} word Исходное слово
* @param {array|boolean} Массив возможных лемм слова, либо false
*/
public function lemmatize( $word ) {
// Получение базовой формы слова //
$lemmas = $this->phpmorphy->lemmatize( $word );
return $lemmas;
}
}
?>
Пока реализовано только два метода. get_words разбивает текст на массив слов, фильтруя при этом HTML-теги и сущности типа “ ”. Метод lemmatize возвращает массив лемм слова, либо false, если таковых не нашлось.
Механизм ранжирования на уровне морфологии
Давайте остановимся на такой единице языка, как предложение. Наиболее важной частью предложения является основа в виде подлежащего и/или сказуемого. Чаще всего подлежащее выражается существительным, а сказуемое глаголом. Второстепенные члены в основном употребляются для уточнения смысла основы. В разных предложениях одни и те же части речи порой имеют совершенно разное значение, и наиболее точно оценить это значение в контексте текста сегодня может только человек. Однако программно оценить значение какого-либо слова все-таки можно, хоть и не так точно. При этом алгоритм ранжирования должен опираться на так называемый профиль текста, который определяется его автором. Профиль представляет из себя ассоциативный массив, ключами которого являются части речи, а значениями соответственно ранг (или вес) каждой из них. Пример профиля я покажу в заключении, а пока попробуем перевести эти размышления на язык PHP, добавив еще один метод к классу morphyus:
<?php
require_once __DIR__.'/phpmorphy/src/common.php';
class morphyus {
private $phpmorphy = null;
private $regexp_word = '/([a-zа-я0-9]+)/ui';
private $regexp_entity = '/&([a-zA-Z0-9]+);/';
// ... //
/**
* Оценивает значимость слова
*
* @param {string} word Исходное слово
* @param {array} profile Профиль текста
* @return {integer} Оценка значимости от 0 до 5
*/
public function weigh( $word, $profile=false ) {
// Попытка определения части речи //
$partsOfSpeech = $this->phpmorphy->getPartOfSpeech( $word );
// Профиль по умолчанию //
if ( !$profile ) {
$profile = [
// Служебные части речи //
'ПРЕДЛ' => 0,
'СОЮЗ' => 0,
'МЕЖД' => 0,
'ВВОДН' => 0,
'ЧАСТ' => 0,
'МС' => 0,
// Наиболее значимые части речи //
'С' => 5,
'Г' => 5,
'П' => 3,
'Н' => 3,
// Остальные части речи //
'DEFAULT' => 1
];
}
// Если не удалось определить возможные части речи //
if ( !$partsOfSpeech ) {
return $profile[ 'DEFAULT' ];
}
// Определение ранга //
for ( $i = 0; $i < count( $partsOfSpeech ); $i++ ) {
if ( isset( $profile[ $partsOfSpeech[ $i ] ] ) ) {
$range[] = $profile[ $partsOfSpeech[ $i ] ];
} else {
$range[] = $profile[ 'DEFAULT' ];
}
}
return max( $range );
}
}
?>
Индексирование содержимого сайта

Как уже говорилось выше, индексирование заметно ускоряет выполнение поискового запроса, так как поисковому движку не нужно обрабатывать контент каждый раз заново — поиск выполняется по индексу. Но что же все-таки происходит при индексировании? Если по порядку, то:
- Сначала из текста формируется массив слов, и делается это с помощью метода get_words.
- Согласно профилю, из текста отбрасываются незначимые части речи.
- Значимые оцениваются по пятибальной шкале, с помощью метода weigh.
- Для каждого сова выполняется поиск лемм, иначе говоря базовых форм.
- Рассчитывается количество повторений каждого слова и суммарный ранг.
- Все данные записываются в объект и в виде JSON записываются в базу данных.
В результате получается объект следующего формата:
{
"range" : "<коэффициент значимости индексируемых данных>",
"words" : [
// Одно из слов //
{
"source" : "<базовая версия слова>",
"range" : "<суммарный ранг>",
"count" : "<количество повторений данного слова в тексте>",
"weight" : "<ранг на основе части речи>",
"basic" : [
// Варианты лемм слова //
]
}
]
}
Пишем инициализатор и первый метод ядра поискового движка:
<?php
require_once 'morphyus.php';
class firewind {
public $VERSION = "1.0.0";
private $morphyus;
function __construct() {
$this->morphyus = new morphyus;
}
/**
* Выполняет индексирование текста
*
* @param {string} content Текст для индексирования
* @param {integer} [range] Коэффициент значимости индексируемых данных
* @return {object} Результат индексирования
*/
public function make_index( $content, $range=1 ) {
$index = new stdClass;
$index->range = $range;
$index->words = [];
// Выделение слов из текста //
$words = $this->morphyus->get_words( $content );
foreach ( $words as $word ) {
// Оценка значимости слова //
$weight = $this->morphyus->weigh( $word );
if ( $weight > 0 ) {
// Количество слов в индексе //
$length = count( $index->words );
// Проверка существования исходного слова в индексе //
for ( $i = 0; $i < $length; $i++ ) {
if ( $index->words[ $i ]->source === $word ) {
// Исходное слово уже есть в индексе //
$index->words[ $i ]->count++;
$index->words[ $i ]->range =
$range * $index->words[ $i ]->count * $index->words[ $i ]->weight;
// Обработка следующего слова //
continue 2;
}
}
// Если исходного слова еще нет в индексе //
$lemma = $this->morphyus->lemmatize( $word );
if ( $lemma ) {
// Проверка наличия лемм в индексе //
for ( $i = 0; $i < $length; $i++ ) {
// Если у сравниваемого слова есть леммы //
if ( $index->words[ $i ]->basic ) {
$difference = count(
array_diff( $lemma, $index->words[ $i ]->basic )
);
// Если сравниваемое слово имеет менее двух отличных лемм //
if ( $difference === 0 ) {
$index->words[ $i ]->count++;
$index->words[ $i ]->range =
$range * $index->words[ $i ]->count * $index->words[ $i ]->weight;
// Обработка следующего слова //
continue 2;
}
}
}
}
// Если в индексе нет ни лемм, ни исходного слова, //
// значит пора добавить его //
$node = new stdClass;
$node->source = $word;
$node->count = 1;
$node->range = $range * $weight;
$node->weight = $weight;
$node->basic = $lemma;
$index->words[] = $node;
}
}
return $index;
}
}
?>
Теперь при добавлении или изменении данных в таблицах достаточно просто вызвать данную функцию, чтобы проиндексировать их, но это не обязательно: индексирование может быть и отложенным. Первым аргументом метода make_index является исходный текст, вторым — коэффициент значимости индексируемых данных. Ранг каждого слова, кстати, расчитывается по формуле:
<?php
$range = <коэффициент значимости> * <ранг на основе части речи> * <количество повторений>;
// В коде это выглядит так: //
$index->words[ $i ]->range = $range * $index->words[ $i ]->count * $index->words[ $i ]->weight;
?>
Хранение индексированных данных
Очевидно, что индекс нужно где-нибудь хранить, да еще и привязать к исходным данным. Наиболее подходящим местом для них будет база данных. Если индексируется содержимое файлов, то можно создать отдельную таблицу в базе данных, которая будет содержать индекс название каждого файла, а для содержимого, которое уже хранится в базе, можно добавить еще одно поле типа в структуру таблиц. Такой подход позволит разделять типы содержимого при поиске, например, названия и описание статей в случае блога.
Нерешенным остался лишь вопрос формата индексированного содержимого, ведь make_index возвращает объект, и так просто в базу данных или файл его не запишешь. Можно использовать JSON и хранить его в полях типа LONGTEXT, можно BSON или CBOR, используя тип данных LONGBLOB. Два последних формата позволяют представлять данные в более компактном виде, чем первый.
Как говорится, «хозяин — барин», так-что решать, где и как все будет храниться, Вам.
Benchmark
Давайте проверим, что у нас получилось. Я взял текст своей любимой статьи «Темная материя интернета», а именно содержимое узла #content html_format и сохранил его в отдельный файл.
<?php
require_once '../src/core.php';
$firewind = new firewind;
// Читаем исходный текст //
$source = file_get_contents( './source.html' );
// Засекаем время начала //
$begin_time = microtime( true );
echo "Indexing started: $begin_timen";
// Индексирование //
$index = $firewind->make_index( $source );
// Засекаем время конца //
$finish_time = microtime( true );
echo "Indexing finished: $finish_timen";
// Результаты //
$total_time = $finish_time - $begin_time;
echo "Total time: $total_timen";
?>
На моей машине с конфигурацией:
CPU: Intel Core i7-4510U @ 2.00GHz, 4M Cache
RAM: 2×4096 Mb
OS: Ubuntu 14.04.1 LTS, x64
PHP: 5.5.9-1ubuntu4.5
Индексирование заняло около секунды:
$ php benchmark.php
Indexing started: 1417343592.3094
Indexing finished: 1417343593.5604
Total time: 1.2510349750519
Думаю, вполне неплохой результат.
Реализация поиска
Остался последний и самый главный метод, метод поиска. В качестве первого аргумента метод принимает индекс поискового запроса, в качестве второго — индекс содержимого, в котором выполняется поиск. В результате выполнения возвращается суммарный ранг, рассчитанный на основе ранга найденных слов, либо 0, если ничего не нашлось. Это позволит сортировать поисковую выдачу.
<?php
require_once 'morphyus.php';
class firewind {
public $VERSION = "1.0.0";
private $morphyus;
// ... //
/**
* Выполняет поиск слов одного индексного объекта в другом
*
* @param {object} target Искомые данные
* @param {object} source Данные, в которых выполняется поиск
* @return {integer} Суммарный ранг на основе найденных данных
*/
public function search( $target, $index ) {
$total_range = 0;
// Перебор слов запроса //
foreach ( $target->words as $target_word ) {
// Перебор слов индекса //
foreach ( $index->words as $index_word ) {
if ( $index_word->source === $target_word->source ) {
$total_range += $index_word->range;
} else if ( $index_word->basic && $target_word->basic ) {
// Если у искомого и индексированного слов есть леммы //
$index_count = count( $index_word ->basic );
$target_count = count( $target_word ->basic );
for ( $i = 0; $i < $target_count; $i++ ) {
for ( $j = 0; $j < $index_count; $j++ ) {
if ( $index_word->basic[ $j ] === $target_word->basic[ $i ] ) {
$total_range += $index_word->range;
continue 2;
}
}
}
}
}
}
return $total_range;
}
}
?>
Все! Поисковый движок готов к использованию. Но есть одно но… На самом деле это не джин-волшебник, и просто закинув его на свой сайт Вы не получите ничего. Его нужно интегрировать, причем этот процесс во многом зависит от архитектуры Вашего сайта. Рассмотрим этот процесс на примере небольшого интернет магазина.
Реализация поиска на примере интернет-магазина
Допустим, информация о продаваемой продукции хранится в таблице production:
CREATE TABLE `production` (
`uid` INT NOT NULL AUTO_INCREMENT, -- Уникальный идентификатор
`name` VARCHAR(45) NOT NULL, -- Название продукта
`manufacturer` VARCHAR(45) NOT NULL, -- Производитель
`price` INT NOT NULL, -- Стоимость продукта
`keywords` TEXT NULL, -- Индекс ключевых слов
PRIMARY KEY ( `uid` )
);
SHOW COLUMNS FROM `production`;
+--------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-------------+------+-----+---------+-------+
| uid | int(11) | NO | PRI | NULL | |
| name | varchar(45) | NO | | NULL | |
| manufacturer | varchar(45) | NO | | NULL | |
| price | int(11) | NO | | NULL | |
| keywords | text | YES | | NULL | |
+--------------+-------------+------+-----+---------+-------+
А описание в таблице description:
CREATE TABLE `description` (
`uid` INT NOT NULL AUTO_INCREMENT, -- Уникальный идентификатор
`fid` INT NOT NULL, -- Внешний ключ для привязки описания к продукту
`description` LONGTEXT NOT NULL, -- Само описание
`index` TEXT NULL, -- Индексированное описание
PRIMARY KEY ( `uid` )
);
SHOW COLUMNS FROM `description`;
+-------------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------+----------+------+-----+---------+-------+
| uid | int(11) | NO | PRI | NULL | |
| fid | int(11) | NO | | NULL | |
| description | longtext | NO | | NULL | |
| index | text | YES | | NULL | |
+-------------+----------+------+-----+---------+-------+
Поле production.keywords будет содержать индекс ключевых слов продукта, description.index будет содержать индексированное описание. И все это будут храниться в формате JSON.
Вот пример функции добавления нового продукта:
<?php
require_once 'firewind/core.php';
$firewind = new firewind;
$connection = new mysqli( 'host', 'user', 'password', 'database' );
if ( $connection->connect_error ) {
die( 'Cannot connect to database.' );
}
$connection->set_charset( 'UTF8' );
function add_product( $name, $manufacturer, $price, $description, $keywords ) {
global $firewind, $connection;
// Индексирование описания продукта //
$description_index = $firewind->make_index( $description );
$description_index = json_encode( $description_index );
// Индексирование ключевых слов //
$keywords_index = $firewind->make_index( $keywords, 2 );
$keywords_index = json_encode( $keywords_index );
// Подготовка запросов //
$production_query = $connection->prepare(
"INSERT INTO `production` ( `name`, `manufacturer`, `price`, `keywords` )
VALUES ( ?, ?, ?, ? )"
);
$description_query = $connection->prepare(
"INSERT INTO `description` ( `fid`, `description`, `index` )
VALUES ( LAST_INSERT_ID(), ?, ? )"
);
if ( !$production_query || !$description_query ) {
die( "Cannot prepare requests!n" );
}
if (
// Биндинг параметров //
$production_query -> bind_param( 'ssis', $name, $manufacturer, $price, $keywords_index ) &&
$description_query -> bind_param( 'ss', $description, $description_index ) &&
// Выполнение запросов //
$production_query -> execute() &&
$description_query -> execute()
) {
// Если запросы выполнились успешно //
echo( "Product successfully added!n" );
// Завершение запросов //
$production_query -> close();
$description_query -> close();
return true;
} else {
die( "An error occurred while executing query...n" );
}
}
?>
Здесь поисковый механизм был интегрирован в функцию добавления нового продукта магазина. А теперь обработчик поисковых запросов:
<?php
require_once '../src/core.php';
$firewind = new firewind;
$connection = new mysqli( 'host', 'user', 'password', 'database' );
if ( $connection->connect_error ) {
die( 'Cannot connect to database.' );
}
$connection->set_charset( 'UTF8' );
// Поисковый запрос //
$query = isset( $_GET[ 'query' ] ) ? trim( $_GET[ 'query' ] ) : false;
if ( $query ) {
// Обработка поискового запроса //
$query_index = $firewind->make_index( $query );
// Получение данных //
$production = $connection->query("
SELECT p.`uid`, p.`name`, p.`keywords`, d.`index`
FROM `production` p, `description` d
WHERE p.`uid` = d.`uid`
");
if ( !$production ) {
die( "Cannot get production info.n" );
}
// Выполнение поиска //
while ( $product = $production->fetch_assoc() ) {
// Распаковка индекса //
$keywords = json_decode( $product[ 'keywords' ] );
$index = json_decode( $product[ 'index' ] );
$range = $firewind->search( $query_index, $keywords );
$range += $firewind->search( $query_index, $index );
if ( $range > 0 ) {
$result[ $product[ 'uid' ] ] = $range;
}
}
// Если что-нибудь нашлось //
if ( isset( $result ) ) {
// Сортировка по убыванию //
arsort( $result );
// Вывод результатов //
$i = 1;
foreach ( $result as $uid => $range ) {
printf(
"#%d. Found product with id %d and range %d.n",
$i++,
$uid,
$range
);
}
} else {
echo( "Sorry, no results found.n" );
}
} else {
echo( "Query cannot be empty. Try again.n" );
}
?>
Данный сценарий принимает поисковый запрос в виде GET-параметра query и выполняет поиск. В результате выводятся найденные продукты магазина.
Заключение
В статье был описан один из вариантов реализации поиска для сайта. Это самая первая его версия, поэтому буду только рад узнать Ваши замечания, мнения и пожелания. Присоединяйтесь к моему проекту на Github: https://github.com/axilirator/firewind. В планах добавить туда еще кучу всяких возможностей, вроде кэширования поисковых запросов, подсказок при вводе поискового запроса и алгоритма побуквенного сравнения, который поможет бороться с опечатками.
Всем спасибо за внимание, ну и с днем информационной безопасности!
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Какой поиск для сайта предпочитаете Вы?
23.2%
Своя реализация
174
12.27%
Не использую поиск для сайта
92
Проголосовали 750 пользователей.
Воздержались 287 пользователей.
Если Вам необходимо быстро найти нужный файл сайта на хостинге, Вы можете через файловый менеджер в панели ISPmanager воспользоваться поиском.
Для этого Вам надо в панели управления перейти в раздел «Менеджер файлов» и нажать на кнопку «Поиск».

В открывшемся окне можно настроить параметры поиска файлов.
- «Каталог», по которому будет происходить поиск.
- «Маска имени» предназначена для того, чтобы упростить поиск файлов, отобрав файлы с похожими символами в названии. «*» — набор символов, «?» — один символ.
- Если убрать галочку «Искать в подкаталогах», то поиск будет происходить только в каталоге, указанном в соответствующем поле.
- Поставив галочку «Искать по содержимому», откроются дополнительные поля:
- «Маска содержимого», то же самое, что маска имени, только отбор происходит по содержимому файла. Например, регулярное выражение может начинаться с символа «^»(для обозначения начала строки) и заканчиваться символом «$» (для обозначения конца строки).
- «Выбрать кодировку» содержимого файла.
Нажимаем кнопку «ОК».

Далее откроется окно «Результаты поиска файлов», где отобразится список файлов и папок совпадающих с Вашим запросом.

Купить недорогой хостинг Вы можете на нашем хостинге.
Для начала работы в терминале Linux не нужно быть гуру администрирования — достаточно знать список базовых команд для навигации и работы с файлами и папками.
- Навигация
- Поиск
- Работа с папками
- Работа с файлами
- Переименование, перемещение и копирование
Навигация
После подключения к серверу вы оказываетесь в домашней папке пользователя. Чтобы узнать точный путь к вашему текущему местонахождению, воспользуйтесь командой:
pwd
Она выведет текущую рабочую директорию (print working directory).
Если вам нужно перейти в другую папку, для этого используется команда cd (change directory) с указанием пути к нужной вам папке:
cd /home
Говоря о навигации, нельзя не упомянуть сокращения для обозначения некоторых директорий:
| / | корневая папка сервера |
| . |
текущая директория, в которой вы сейчас находитесь. Например, чтобы найти файл с именем find . -name hello.txt |
| .. |
директория, расположенная на уровень выше текущей. Если вы находитесь в папке cd .. |
| ~ |
домашняя папка текущего пользователя. Например, запустить скрипт sh ~/some-script.sh |
| – |
предыдущая посещённая директория. Представим, что вы перешли в папку cd - |
Для навигации с помощью команды cd есть два формата указания пути к нужной папке: абсолютный и относительный.
Абсолютный путь — это полный путь от корневой папки сервера «/». Например, вот такой:
/var/www/data/username/data/www/example.com/
Также к абсолютным относятся пути, в которых используется ~ — указание на домашнюю папку текущего пользователя. Например, при доступе к файлу ~/.bash_profile он всегда будет открываться из одного и того же места: вместо ~ будет использоваться значение переменной окружения $HOME, которое не меняется.
Относительный путь — это неполный путь. Он указывается относительно какого-то объекта: например, текущей рабочей директории. То есть в начале отсутствует символ корневой папки «/».
./docs/files/file.txt file.txt
Представим, что мы сейчас работаем с файлами в папке /var/www/data/username. Нам нужно отредактировать содержимое в директории на уровень выше — /var/www/data. Чтобы управлять данными в этой папке, нам не обязательно постоянно указывать полный путь к ним — можно работать с относительным, начиная его с «../».
Также относительные пути используются, когда нужно выполнить операцию над файлом или папкой в директории, в которой мы сейчас работаем. Для выполнения команды достаточно указать имя файла или папки — система поймёт, что мы имеем в виду файл из текущего каталога.
Чтобы отобразить список содержимого папки, можно использовать команду ls (list). Если дополнить её ключами -al, она покажет типы данных, разрешения и скрытые файлы. Следующий пример покажет названия файлов и папок текущей рабочей папки:
ls
А этот выведет в терминал подробный список содержимого папки /etc:
ls -al /etc
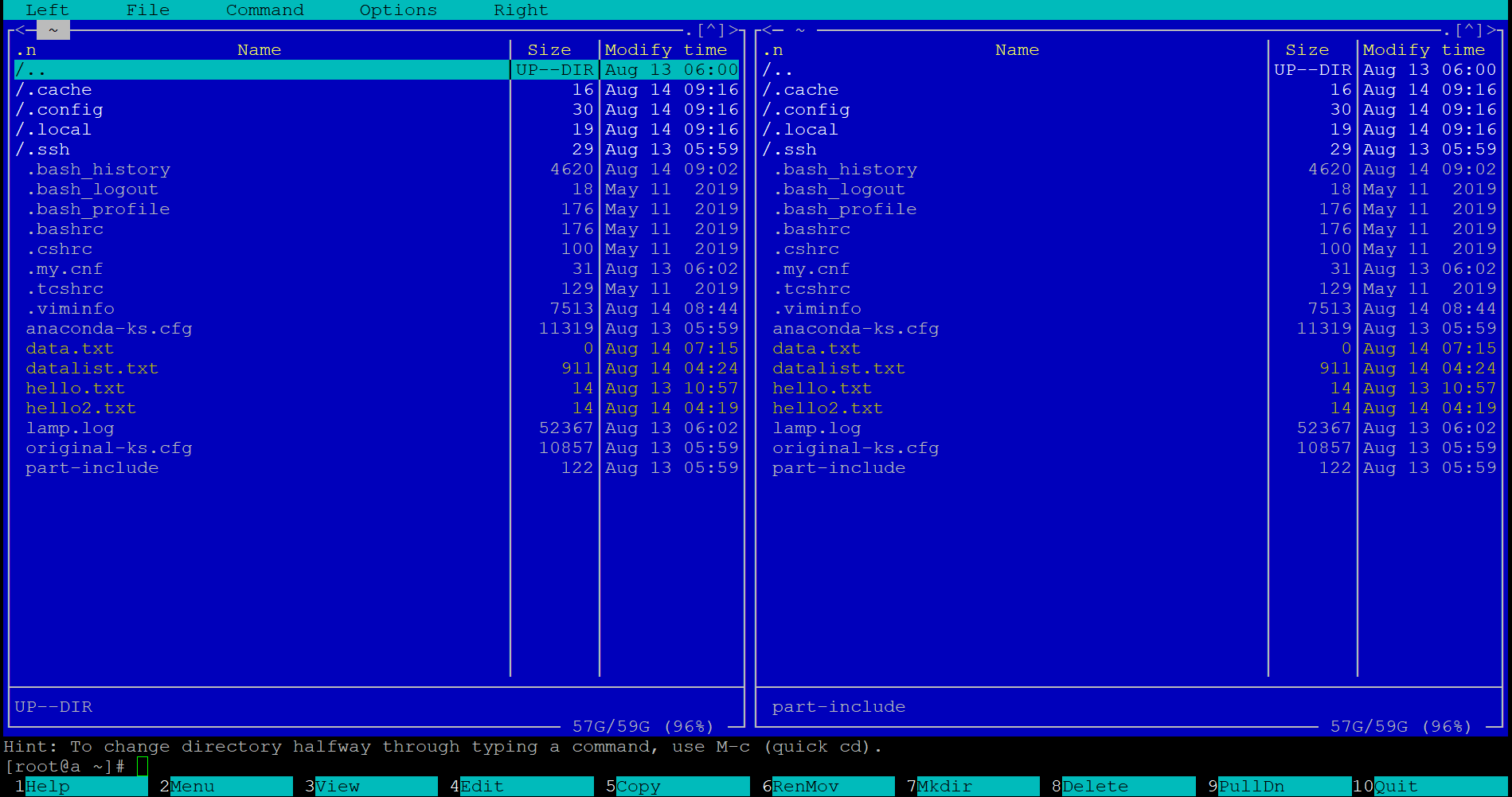
Чтобы немного упростить себе жизнь, можно использовать консольные файловые менеджеры, например, mc.
-
Ubuntu и Debian:
apt -y install mc
-
CentOS:
yum -y install mc
Его особенность — примитивный графический интерфейс. Он позволяет быстро ориентироваться в структуре каталогов, перемещаться между ними, создавать новые директории. Интерфейс разбит на два окна, между которыми вы можете перемещать файлы и папки. Помимо прочего, в нём можно работать и с помощью мыши — перемещаться двойным кликом по папкам, использовать кнопки в нижней части панели.
Поиск
С помощью команды find можно найти на сервере папку или файл по набору условий. Структура команды проста:
find [где искать] [как искать] [что искать]
Например, мы знаем название файла hello.txt, но не знаем, где именно на сервере он лежит. Найти его поможет конструкция:
find / -name "hello.txt"
/указывает, что искать надо, начиная с корневой папки сервера. Если вам известно, где может лежать искомый файл, можно задать путь точнее.-nameуказывает, что искать надо строго по имени."hello.txt"— имя файла, который нам нужно найти. Если известна только часть имени, можно указать сокращённый вариант:"hello*","*.txt"
Кроме -name, команда find имеет множество опций, которые позволяют уточнить условия поиска подробнее. Вот список наиболее полезных параметров:
|
|
Позволяет указать тип искомых данных: |
|
|
Позволяет вывести файлы с определённым уровнем доступа. Например, – |
|
|
Отображает только пустые файлы или папки |
|
|
Позволяет искать данные среди файлов, принадлежащих конкретному пользователю: |
|
|
Позволяет искать данные среди файлов, принадлежащих определённой группе пользователей: |
|
|
Позволяет задать условие относительно времени изменения файлов:
|
|
|
Позволяет задать условие относительно времени последнего доступа к файлу, аналогично |
|
|
Позволяет уточнить размер (или диапазон размера) искомых файлов |
|
|
Позволяет применить к найденным файлам команду |
Больше информации о возможностях find можно узнать в файлах документации:
man find
Из встроенных инструментов поиска можно также отметить утилиту whereis. Она предназначена для поиска бинарных и системных файлов и директорий служб. Следующий пример выведет список всех файлов и папок, имеющих прямое отношение к php:
whereis php
Работа с папками
Для создания новых директорий используется команда mkdir с указанием пути до создаваемой папки. Пример ниже создаст папку /new в существующей директории /home/user:
mkdir /home/user/new
Если нужно создать сразу несколько вложенных папок, можно использовать параметр -p. В таком случае все несуществующие директории, указанные в пути, будут созданы автоматически. Представим, что нам нужно создать вложенные папки docs/photos/2020-08-17 в текущей директории — это будет выглядеть так:
mkdir -p docs/photos/2020-08-17
Если нужно создать несколько папок за раз, можно просто перечислить их через пробел:
mkdir docs pictures games
Удалить папку можно с помощью команды rmdir с указанием пути. Папка будет удалена только в случае, если она пуста (можно использовать параметр --ignore-fail-on-non-empty, чтобы удалить папку в любом случае). Для удаления нескольких вложенных папок можно аналогично использовать параметр -p. Пример ниже удалит папку /photos и все каталоги внутри неё:
rmdir -p docs/photos
Для удаления есть более эффективный инструмент, rm, про который расскажем ниже.
Работа с файлами
Создание
В терминале есть несколько способов создания новых файлов.
Самый простой, одновременно создающий и файл, и недостающие папки — команда touch. Достаточно передать ей полный путь к файлу. Для примера создадим в папке docs папку copies, а внутри неё — файл copies-list.txt:
touch docs/copies/copies-list.txt
Несуществующая папка copies создастся автоматически.
Если нужно создать сразу несколько файлов, можно просто перечислить их через пробел:
touch file1.txt file2.txt file3.txt
Ещё один способ создания новых файлов — вызвать какой-нибудь консольный текстовый редактор с указанием полного пути к файлу. Однако все папки придётся создать заранее. Тогда редактор автоматически создаст файл и откроет его для редактирования. Если не сохранить файл в редакторе, даже пустой, он не будет создан. Команда ниже добавит новый файл с помощью редактора vi:
vi new-file.txt
Для сохранения и выхода из файла в vi нужно нажать клавишу Esc, ввести сочетание :wq и нажать Enter. Для выхода без сохранения нужно также нажать Esc, ввести сочетание :q! и нажать Enter.
Ещё пара способов создания пустых файлов:
cat > new-file.txt echo > new-file.txt
Редактирование
Для редактирования файлов используются консольные текстовые редакторы. Самые известные — vi и nano. В некоторых дистрибутивах vi заменён на vim (vi improved, улучшенный vi) или vim.tiny
Редактор vi будет доступен вам по умолчанию на большинстве Linux-систем.

А теперь к делу. Vi (более известен как Vim) — старый, очень гибкий и при этом не очень простой в плане управления редактор. Собственно, так он и попал в популярные программистские и админские шуточки.
Запуск редактора без аргументов откроет его в режиме справки:
vi
Чтобы закрыть Vim (без сохранения), введите сочетание :q!
Если указать редактору путь к файлу, он откроет его для редактирования. Если файл не существовал, он будет создан:
vi new-file.txt
При первом входе Vim открывает файл в режиме просмотра. Он не позволяет редактировать его содержимое, но можно вводить командные последовательности, перемещаться по тексту, выполнять поиск и пр.
Чтобы начать ввод, нужно перейти в режим редактирования с помощью клавиши I. Чтобы вернуться в режим просмотра, нажмите Esc.
Перемещение по тексту выполняется с клавиатуры:
- перемещение в начало текста: Esc + дважды G
- перемещение в конец текста: Shift + G
- перемещение по строке горизонтально: стрелки ← →
- перемещение по строкам вертикально: стрелки ↑ ↓
- отображение номеров строк: Esc, введите
:set number, нажмите Enter - перемещение по номерам строк: Esc, введите
:номер строки, нажмите Enter
Для выхода с сохранением файла нажмите Esc и введите :wq!
Текстовый редактор vim — краткое руководство
Более современной и удобной альтернативой Vim считается редактор nano. Современные дистрибутивы включают его по умолчанию, но на ранних версиях устанавливать придётся вручную:
-
Ubuntu и Debian:
apt -y install nano
-
CentOS:
yum -y install nano
Вызов nano без аргументов откроет пустой редактор. Можно начать ввод (при сохранении вам будет предложено указать имя и сохранить файл) или вызвать режим помощи со списком доступных команд с помощью сочетания Ctrl+G.
Для сохранения файла нажмите Ctrl+O — редактор предложит ввести имя файла: введите имя и нажмите Enter. Если файл существовал, и имя изменять не требуется, просто нажмите Enter.
Для выхода из редактора нажмите Ctrl+X.
Чтение
Бывает, что нам нужно получить какую-то информацию из файла без необходимости редактировать его. В таком случае необязательно использовать текстовый редактор — есть более простые инструменты.
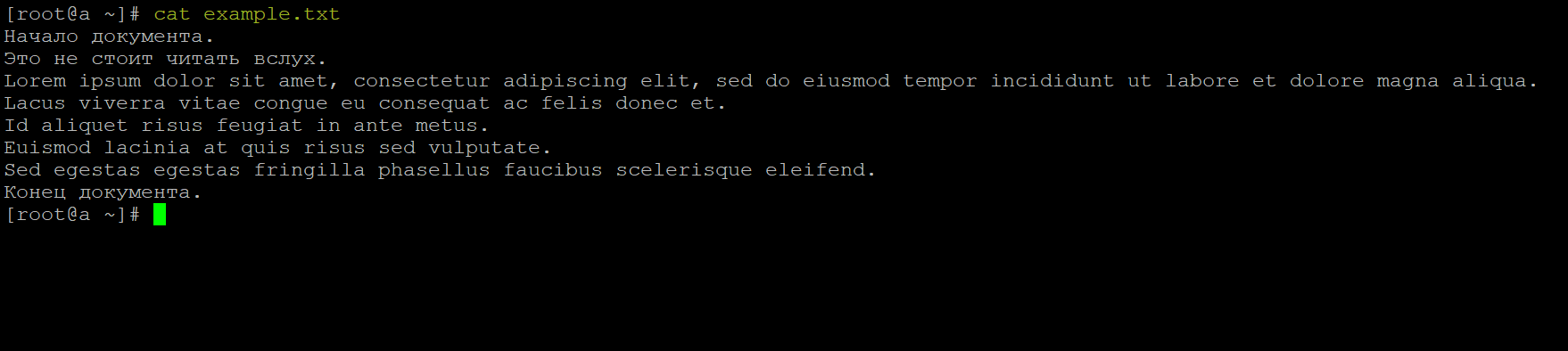
Команда cat позволяет вывести в терминал всё содержимое файла, который указан в качестве аргумента:
cat example.txt
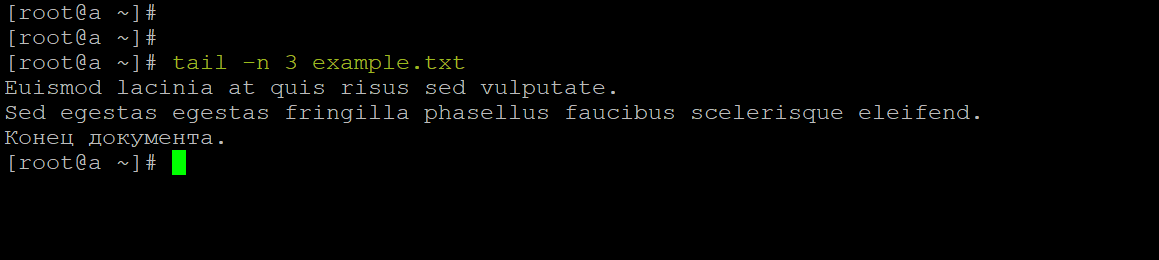
Однако, если мы заведомо знаем, что в файле большой объём информации, нет смысла выводить его целиком. Например, команды head и tail могут вывести часть содержимого с начала или конца файла соответственно. Если добавить к ним ключ -n, можно уточнить, сколько строк текста нужно вывести:
head -n 3 example.txt

tail -n 3 example.txt
Помимо прочего, команда tail очень удобна для чтения логов с ключом -f. В таком режиме она открывает файл в режиме ожидания и выводит все добавляемые данные. Пригодится для тестирования или дебаггинга.
Иногда нам всё-таки нужно полностью просмотреть файл. При этом читать его вывод в терминале неудобно. На такие случаи есть команда less — она открывает файл (или переданный в неё вывод другой команды) в режиме чтения:
less example.com
В режиме чтения less можно перемещаться, искать текст и многое другое. Все командные последовательности и горячие клавиши можно вывести с помощью параметра --help:
less --help
Для выхода из режима чтения введите q и нажмите Enter.
Удаление
Для удаления файлов используется команда rm. Она крайне опасна — неправильное применение грозит удалением всего содержимого сервера. Поэтому, как говорится, семь раз отмерь, один раз отрежь: категорически важно перепроверять путь, который вы указываете для удаления.
Самая простая версия rm удалит файл с предварительным подтверждением — для этого потребуется ввести y и нажать Enter:
rm new-file.txt
Для полного же уничтожения всего и вся к команде добавляются параметры -rf. Первый отвечает за рекурсивное удаление данных (т.е. удаление вложенных файлов и папок), второй позволяет отключить подтверждение при удалении. Например, следующая команда удалит папку photos, размещённую в папке docs, и всё её содержимое:
rm -rf docs/photos
Для шуток над неопытными администраторами им под тем или иным предлогом предлагают выполнить команду rm -rf [/] (без квадратных скобок). Она удаляет всё содержимое сервера от корня. Результат — все данные безвозвратно теряются, а сервер перестаёт работать.
Скачивание и загрузка
Для передачи файлов на сервер и с сервера есть много способов. Самые простые — использование wget, curl или scp.
-
wgetпозволяет скачивать данные на сервер. Он поддерживает HTTP, HTTPS и FTP протоколы.wget [как скачать] [откуда скачать]
Скачать файл по ссылке в вашу текущую рабочую директорию можно с помощью команды:
wget https://ru.wordpress.org/latest-ru_RU.tar.gz
С помощью параметра
-Pможно указать путь, куда нужно сохранить скачиваемый файл:wget -P /var/www/example.com https://ru.wordpress.org/latest-ru_RU.tar.gz
Полный список параметров
wgetможно посмотреть в справочной информации:man wget
-
curlиспользуется как для скачивания файлов на ваш сервер, так и для передачи данных с него на другие серверы / хранилища. Он универсальнееwgetблагодаря огромному количеству поддерживаемых протоколов: FTP, HTTP, HTTPS, IMAP, POP3, SCP, SFTP, SMB, SMTP, Telnet и др.curl [как скачать] [откуда скачать / куда загрузить]
В современных дистрибутивах
curlустановлен по умолчанию. При необходимости установить его вручную можно следующим образом:- Ubuntu и Debian:
apt -y install curl - CentOS:
yum -y install curl
Для работы с
curlнужно знать название и расположение файлов, которые необходимо скачать/загрузить. Например, так будет выглядеть команда на скачивание файла по ссылке:curl -O https://ru.wordpress.org/latest-ru_RU.tar.gzВ примере мы скачиваем архив
latest-ru_RU.tar.gzпо ссылке и сохраняем его в текущую рабочую директорию с таким же именем — за это отвечает ключ-O. Если использовать опцию-o, можно задать своё имя (wp.tar.gz) для сохраняемого файла:curl -o wp.tar.gz https://ru.wordpress.org/latest-ru_RU.tar.gzЕсли нам нужно загрузить файл c нашего сервера на другой, используется следующая конструкция:
curl -T filename.txt https://example.com/downloads/filename.txt
Здесь файл
filename.txtиз текущей рабочей директории загружается на сайтexample.comв папкуdownloads/и сохраняется с именемfilename.txt. Пример подразумевает, что у нас есть права на запись в указанный каталог.Остальные возможности
curlможно узнать в справочной информации:man curl
- Ubuntu и Debian:
-
Утилита
scpпозволяет копировать файлы между двумя серверами, используя протокол SSH.scp [где взять файлы] [куда их загрузить]
Например, для передачи файла
filename.txtс нашего сервера на удалённый сервер1.2.3.4в папкуnew-documentsпользователяusernameможно использовать следующую команду:scp ~/documents/filename.txt username@1.2.3.4:/home/username/new-documents
В процессе система запросит у нас пароль пользователя
usernameдля подключения к удалённому серверу. После авторизации файл будет скопирован на целевой сервер в указанную папку.Чтобы скачать файл с удалённого сервера, достаточно немного видоизменить нашу команду:
scp username@1.2.3.4:/home/username/documents/filename.txt ~/new-documents/
Здесь мы в качестве источника для получения копии файла указали удалённый сервер, а в качестве цели для загрузки копии — папку на текущем сервере.
С помощью
scpаналогичным образом можно копировать данные между двумя удалёнными серверами:scp username1@1.2.3.4:/home/username1/documents/filename.txt username2@2.3.4.5:/home/username2/new-documents
Запуск исполняемых bash-скриптов
Чтобы запустить скрипт script.sh на сервере, нужно выполнить два шага:
-
Настроить права на запуск файла для пользователей:
chmod +x ./script.sh
-
Запустить скрипт. Если вы находитесь в той же директории, где лежит скрипт, достаточно вызвать его по имени:
./script.sh
В некоторых случаях нужно использовать команду
shлибо указать путь к исполняемому файлу командной оболочки:sh ./script.sh
либо
/bin/bash ./script.sh
Если вы находитесь в другой директории, для запуска нужно указать полный путь к скрипту.
Чтобы иметь возможность запускать скрипт из любого места на сервере одной простой командой, можно создать для него алиас — короткую команду (псевдоним), которая будет ассоциироваться системой с полным вызовом скрипта.
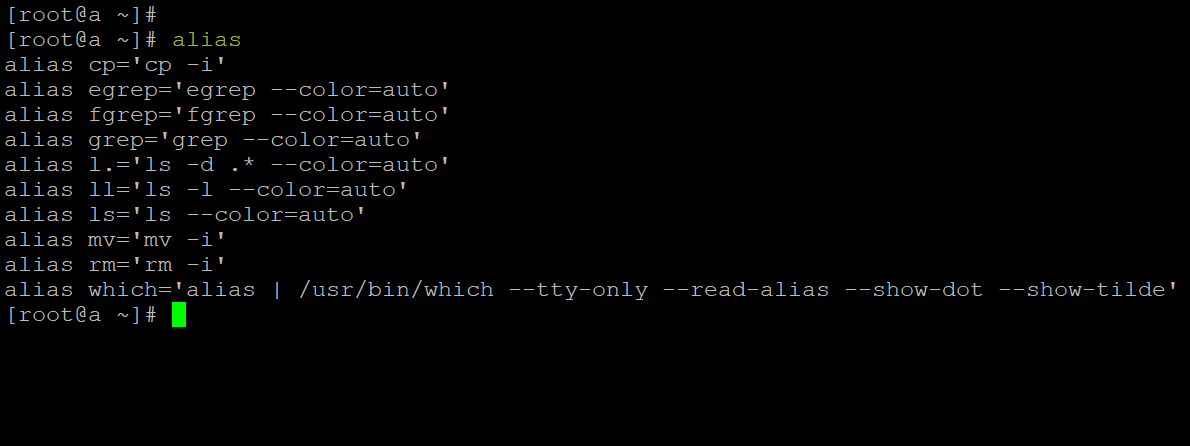
Весь список существующих алиасов системы можно вывести с помощью команды alias:
Создать свой постоянный алиас можно с помощью файла .bashrc, размещённого в домашнем каталоге вашего пользователя. Нужно открыть его для редактирования:
vi ~/.bashrc
В соответствующем разделе нужно добавить ваш алиас в следующем формате:
alias [короткая команда]='[исходная команда]'
Например, если нам потребуется создать псевдоним для скрипта выше, настройки будут выглядеть так:
alias myScript='sh /путь/к/скрипту/script.sh'
Чтобы после добавления алиас сразу стал доступен, предварительно нужно обновить командную оболочку:
source ~/.bashrc
После этого вы сможете вызывать ваш скрипт с помощью короткой команды.
Скрипт можно добавить в расписание планировщика cron, чтобы он запускался регулярно.
Как настроить cron по ssh
Переименование, перемещение и копирование файлов и папок
Скопировать файл в терминале можно с помощью команды:
cp [что копируем] [куда копируем]
C её помощью можно, к примеру, создать копию конфигурационного файла, который вы хотите изменить. Здесь мы создаём копию конфигурационного файла nginx.conf
cp nginx.conf nginx.conf.copy
Папки копируются аналогично. При необходимости скопировать каталог со всем содержимым (рекурсивно) можно добавить к команде ключ -r:
cp -r /docs /files
Здесь мы создаём копию папки docs со всем её содержимым с именем files.
Переместить или переименовать файл также просто:
mv [что переместить/переименовать] [куда переместить/как назвать]
Например, следующая команда переместит файл file.txt в папку new:
mv file.txt docs/new
Переименовать файл не сложнее:
mv /docs/new/file.txt /docs/new/todolist.txt
В этом примере файл file.txt переименовывается в todolist.txt
Аналогично можно перемещать и переименовывать директории.
Теперь, когда вы можете перемещаться по серверу и работать с файлами и папками, самое время познакомиться с файловой структурой Linux-систем.
Структура каталогов Linux

В работе системного администратора, нередко возникает необходимость посмотреть логи сервера (Server Logs), с какими задачами работал сервер в конкретное время, какие действия совершали пользователи. Причины возникновения этой необходимости могут быть разные:
- Сбой в работе сервера;
- Выявление неблагонамеренных действий;
- Анализ рабочих процессов.
Всю необходимую информацию можно получить в логи сервера (Server Logs), то есть файлах, в которые вносятся записи о различных процессах, действиях пользователей, и т.п. Но, для этого необходимо понимать, где хранятся эти данные, а главное, как с ними работать.
Что такое логи сервера?
Собственно говоря, само слово «логи сервера», является банальной транслитерацией, от словосочетания «server log», которое переводится как «журнал сервера».
Существуют следующие типы логов:
- Ошибки – записи, фиксирующие различные сбои в работе сервера, или при обращении к конкретным функциям или задачам. С их помощью можно быстро ликвидировать разные баги и сбои;
- Доступ – записи, которые фиксируют точные дату и время подключения конкретного пользователя, каким образом он попал на сайт, и т.д. Позволяют проводить аналитическую работу, а также находить уязвимые места, в тех случаях, когда ресурс пытались взломать;
- Прочее – записи с данными о работе разных компонентов сервера, например, почты.
Разумеется, если вы не наблюдаете никаких проблем, или подозрительных моментов, связанных с работой сервера, то нет никакой необходимости в частом просмотре логов. Тем не менее, специалисты рекомендуют выборочно изучать их, хотя бы раз в год.
С другой стороны, если уже произошло какое-то ЧП, например, сайт резко начал выдавать большое количество ошибок, подвергся спам-атаке, или стремительно возросла нагрузка на сервер, то изучение логов, позволит быстро понять в чем проблема и устранить её.
Тем не менее, для большинства рядовых пользователей записи в log-файлах, представляют собой просто странный набор символов. А значит, нужно понять, как правильно их читать.
Как правильно читать логи сервера?

В данном примере, мы разберем два типа записей, касающихся логов доступа и ошибок, поскольку именно к ним чаще всего обращаются, при возникновении каких-то проблем.
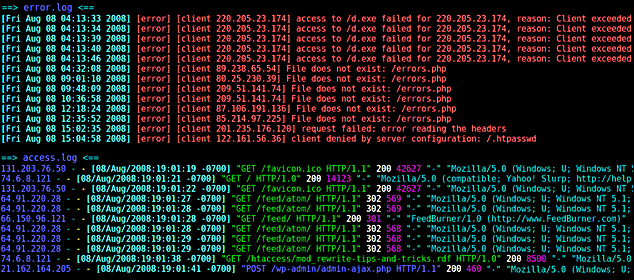
Итак, запись лога доступа, из файла access.log:
mysite.biz 25.34.94.132 — — [21/Nov/2017:03:21:08 +0200] «GET /blog/2/ HTTP/1.0» 200 18432 «-» «Unknow Bot (http://www.unknow.com/bot; [email protected])»
Что она обозначает:
- mysite.biz – домен сайта, которым вы интересуетесь;
- 34.94.132 – IP-адрес, который использовал пользователь при заходе на сайт;
- [21/Nov/2017:03:21:08 +0200] – дата, точное время и часовой пояс пользователя;
- GET – запрос, который отправляется для получения данных. В том случае, если пользователь передает данные, запрос будет «POST»;
- /blog/2/ — относительный адрес страницы, к которой был обращен запрос;
- HTTP/1.0 – используемый протокол;
- 200 – код ответа на запрос;
- 18432 – количество данных, переданных по запросу, в байтах;
- Unknow Bot (http://www.unknow.com/bot; [email protected]) – данные о роботе, или реальном человеке, который зашел на сайт. В том случае, если это человек, будет отображена ОС, тип устройства и т.д. В конкретном примере на сайт зашел робот-парсер, принадлежащий ресурсу unknow.com.
Таким образом, мы узнали, что с IP-адреса 25.34.94.132, двадцать первого ноября, 2017-го года, в три часа, двадцать одну минуту и восемь секунд, на наш сайт заходил бот, принадлежащий другому веб-ресурсу. Он отправил запрос на получение данных, и получил 18432 байт информации.
Теперь можно заблокировать доступ для ботов от этого сайта, либо от всех, кто пользуется этим IP, разумеется, если в этом есть необходимость.
Логи ошибок, можно посмотреть в файле с говорящим именем – error.log. Они выглядят следующим образом:
[Sat Oct 1 18:23:28.719615 2019] [:error] [pid 10706] [client 44.248.44.22:35877]
PHP Notice: Undefined variable: moduleclass_sfx in
/var/data/www/mysite.biz/modules/contacts/default.php on line 13
Что здесь написано?
- Дата, время и тип ошибки, а также IP-адрес, который использовал посетитель;
- Тип события, в данном случае – «PHP Notice» (уведомление), а также уточнение, что в данном случае, мы имеем дело с неизвестной переменной;
- Местоположение файла с уведомлением, а также строка, на которой оно находится.
Если говорить просто, то в данном случае мы имеем сообщение о том, что первого октября, в 18:23, 2019-го года, произошла ошибка, связанная с модулем контактов.
Разумеется, даже после расшифровки, полученные данные не так просто проанализировать. Именно поэтому, для удобной обработки данных из логов сервера, используется различное программное обеспечение. К таким программам относятся: Awstats, Webtrends, WebAlyzer, и многие другие.
Сегодня существует множество платных и бесплатных вариантов программ, для обработки и анализа лог-файлов.
Логи серверов на Windows
У логов серверов на Windows, изначально более удобный и структурированный вывод информации, в виде простой и понятной таблицы.
Существует несколько уровней событий:
- Подробности;
- Сведения;
- Предупреждение;
- Ошибка;
- Критический.
Также есть возможность быстрой фильтрации и сортировки записей, в зависимости от того, какие данные вы хотите получить.
Логи SQL сервера
На сегодняшний день, базы данных SQL, являются наиболее распространенным способом работы с большими объемами информации. В первую очередь, логи sql сервера, стоит изучить, если вы не уверены в том, что какие-то процессы были успешно завершены. Этими процессами могут быть:
- Резервное копирование;
- Восстановление данных;
- Массовые изменения;
- Различные скрипты, и программы для обработки данных.
Для того, чтобы просмотреть записи в логах, можно использовать SQL Server Management Studio, либо другой, удобный вам редактор текстов. Записи распределены по журналам следующих типов:
- Сбор данных;
- Database Mail;
- SQL Сервер;
- События Windows;
- Журнал заданий;
- Коллекция аудита;
- SQL Сервер, агент.
Для того, чтобы получить доступ к журналам, необходимо иметь права «securityadmin».
Как включить или выключить запись логов сервера?
Для того, чтобы осуществить эту операцию, нужно зайти в административную панель вашего хостера. Как правило, в основном меню есть раздел «Журнал», или «Логи», в котором можно включить или выключить запись данных о предоставленном доступе, ошибках, и т.п.
Где находятся логи сервера?
Расположение журналов, зависит в первую очередь от используемой вами операционной системы.
Логи серверов с CentOS, или Fedora, хранятся в дирректории «/var/log/».
Названия файлов:
- Журнал ошибок – «error.log»;
- Журнал nginx – «nginx»;
- Журнал доступов – «log»;
- Основной журнал – «syslog»;
- Журнал загрузки системы – «dmesg».
Логи ошибок, связанных с работой MySQL, находятся в директории «/var/lib/mysql/», в файле «$hostname.err».
Для операционных систем Debian и Ubuntu, логи сервера располагаются в папке «/var/log/», в файлах:
- Nginx — журнал nginx;
- /mysql/error.log – журнал ошибок для баз данных MySQL;
- Syslog – основной журнал;
- Dmesg – загрузка системы, драйвера;
- Apache2 – журнал веб-сервера Apache.
Как видите, у всех ОС, основанных на Linux, логи сервера, как правило имеют одинаковые названия, и директории.
С логами для Windows server, дело обстоит несколько иначе. Если нужно просмотреть журналы, необходимо войти в систему, нажать клавиши «Win» и «R», после чего откроется окно просмотра событий, где есть возможность подобрать интересующие нас логи.
Если вы хотите посмотреть логи PowerShell, то необходимо открыть программу и ввести команду: «Get-EventLog -Logname ‘System’».
Все данные будут выведены в виде удобной таблицы.
Пример работы с логами сервера
Представьте себе, что вы внезапно обнаружили существенное увеличение нагрузки на ваш сервер, связанное с внешними воздействиями. Сервисы аналитики начинают регистрировать рекорды посещаемости, и можно было бы радоваться, но видно, что эти «пользователи» не совершают действий, которых от них ждут, неважно что это – изучение контента, или покупки на сайте.
Можно потратить много времени на выяснения причины, а можно просто посмотреть логи доступа и проверить, с каких IP, и кто заходил на ваш сайт, в выбранные промежуток времени. Вполне вероятно, что вы обнаружите большое количество переходов с нескольких IP-адресов, которые делались автоматически, то есть ваш сайт попал под DDoS-атаку.
В этом случае, можно заблокировать доступ к сайту с выбранных IP, и в дальнейшем расширять этот список, при необходимости.
Вывод
На сегодняшний день, log-файлы сервера, являются крайне удобным инструментом, который позволяет отслеживать работу сайта, выявлять баги и ошибки, злонамеренных пользователей, противодействовать DDoS-атакам.
Для того, чтобы правильно работать с логами сервера, необходимо знать их расположение, иметь возможность изучить нужные файлы, а также понимать разные типы записей. В большинстве панелей управления, пользователю сразу предоставляется возможность включать и выключать запись логов. К тому же есть возможность скачивать или просматривать журналы.
Кроме того, сегодня можно найти ряд программного обеспечения, и они позволяют взаимодействовать с информацией из журналов через удобный графический интерфейс, с большой скоростью расшифровывать её и выводить в простом виде.
У систем, основанных на Linux, как правило примерно одинаковое расположение файлов с логами, что существенно упрощает работу с ними.
У Windows Server, есть свой собственный графический интерфейс для чтения логов, который весьма удобен, и позволяет быстро получить необходимую информацию.
”FAQ
Какие виды логов сервера существуют?
Существует несколько видов логов сервера, которые могут быть полезны при обнаружении проблем и улучшении производительности вашего сервера.
Системные логи – это логи, которые ведутся самой операционной системой и хранят информацию о событиях, происходящих в системе. Они могут включать в себя ошибки, предупреждения, информационные сообщения и другую полезную информацию.
Важная информация:
Системные логи могут быть использованы для обнаружения проблем в работе сервера и операционной системы.
Информация в системных логах может помочь в анализе причин отказов и сбоев на сервере.
Хранение системных логов может потребовать дополнительной памяти и ресурсов сервера.
Логи веб-сервера – это логи, которые создаются веб-сервером и содержат информацию о запросах клиентов, ответах сервера и других событиях, связанных с работой веб-сервера.
Важная информация:
Логи веб-сервера могут быть использованы для анализа производительности и оптимизации веб-сайта.
Информация в логах веб-сервера может помочь в обнаружении атак и уязвимостей безопасности.
Хранение логов веб-сервера может занимать большой объем дискового пространства.
Логи приложений – это логи, которые создаются приложениями, установленными на сервере, и содержат информацию о работе приложений.
Важная информация:
Логи приложений могут помочь в обнаружении ошибок и проблем в работе приложений.
Информация в логах приложений может быть полезна для анализа производительности приложений и оптимизации их работы.
Хранение логов приложений может занимать много места на диске, поэтому их необходимо регулярно очищать.
Где можно найти файлы логов сервера?
Файлы логов сервера находятся на самом сервере и могут быть найдены в разных местах, в зависимости от операционной системы и типа сервера.
В операционной системе Linux файлы логов обычно находятся в директории /var/log. В этой директории находятся различные поддиректории, которые содержат различные логи, такие как системные логи (syslog), логи веб-сервера (apache, nginx), логи баз данных (mysql, postgresql) и т.д.
Важная информация:
Для доступа к файлам логов необходимы права администратора.
Файлы логов могут быть сохранены в различных форматах, включая текстовые файлы и бинарные файлы.
Некоторые серверные приложения и сервисы могут хранить свои логи в других местах, поэтому необходимо проверять документацию для каждого приложения.
В операционной системе Windows файлы логов могут находиться в различных местах, в зависимости от конфигурации системы. Некоторые из распространенных мест для логов включают директории C:WindowsSystem32LogFiles и C:inetpublogsLogFiles.
Важная информация:
Для доступа к файлам логов также необходимы права администратора.
Файлы логов могут быть сохранены в различных форматах, включая текстовые файлы и бинарные файлы.
Некоторые серверные приложения и сервисы могут хранить свои логи в других местах, поэтому необходимо проверять документацию для каждого приложения.
Как просмотреть файлы логов сервера?
Чтение файлов логов сервера может помочь в анализе производительности и обнаружении проблем на сервере. Способы просмотра файлов логов зависят от операционной системы и типа сервера.
В Linux можно использовать команду less для просмотра содержимого файлов логов. Например, чтобы просмотреть содержимое файла syslog, нужно ввести команду less /var/log/syslog.
Важная информация:
Команда less позволяет просматривать содержимое файлов логов постранично.
Для поиска конкретных фрагментов в файле логов можно использовать команду grep.
В Windows можно использовать инструмент Event Viewer для просмотра логов системы. Event Viewer позволяет просматривать системные логи, логи приложений и логи безопасности.
Важная информация:
Для доступа к Event Viewer необходимо иметь права администратора.
В Event Viewer можно настроить фильтры для отображения только нужной информации из логов.
Как использовать логи сервера для анализа производительности?
Анализ логов сервера может помочь в выявлении проблем с производительностью и оптимизации работы сервера. Вот несколько способов использования логов сервера для анализа производительности:
Анализ времени ответа сервера. Логи веб-сервера содержат информацию о времени ответа сервера на запросы от клиентов. Анализ этих логов может помочь выявить проблемы с производительностью сервера, такие как медленное выполнение запросов или долгое время загрузки страниц.
Важная информация:
Для анализа времени ответа сервера нужно обратить внимание на значения, указанные в логах, такие как время ответа сервера и время загрузки страницы.
Для оптимизации времени ответа сервера можно использовать различные методы, такие как кэширование данных, оптимизация запросов и настройка сервера.
Анализ ошибок сервера. Логи сервера могут содержать информацию о возникающих ошибках, таких как ошибки базы данных, ошибки в коде приложения и т.д. Анализ этих логов может помочь выявить проблемы с производительностью сервера и исправить ошибки.
Важная информация:
Для анализа ошибок сервера нужно обратить внимание на сообщения об ошибках, указанные в логах.
Для исправления ошибок можно использовать различные методы, такие как обновление приложения, настройка сервера или исправление кода.
Анализ использования ресурсов сервера. Логи сервера могут содержать информацию о загрузке процессора, использовании памяти и других ресурсах сервера. Анализ этих логов может помочь выявить проблемы с производительностью сервера и оптимизировать его работу.
Важная информация:
Для анализа использования ресурсов сервера нужно обратить внимание на значения, указанные в логах, такие как процент загрузки процессора и использование памяти.
Для оптимизации использования ресурсов сервера можно использовать различные методы, такие как настройка сервера и уменьшение нагрузки на сервер.
Как обезопасить логи сервера?
Логи сервера содержат важную информацию о работе сервера и могут быть использованы злоумышленниками для получения доступа к системе. Вот несколько способов обезопасить логи сервера:
Шифрование логов. Логи сервера могут быть зашифрованы для защиты от несанкционированного доступа.
Важная информация:
Для шифрования логов можно использовать различные методы, такие как использование шифрования на уровне файловой системы или шифрование на уровне приложения.
Ограничение доступа к логам. Доступ к логам сервера должен быть ограничен только для авторизованных пользователей.
Важная информация:
Для ограничения доступа к логам можно использовать различные методы, такие как настройка прав доступа на уровне файловой системы или использование специальных программ для мониторинга доступа к файлам.
Удаление устаревших логов. Устаревшие логи сервера должны быть удалены, чтобы предотвратить их использование злоумышленниками.
Важная информация:
Для удаления устаревших логов можно использовать различные методы, такие как настройка автоматического удаления или ручное удаление логов через определенный период времени.
Мониторинг логов. Логи сервера должны быть мониторингом для выявления несанкционированного доступа и других проблем с безопасностью.
Важная информация:
Для мониторинга логов можно использовать различные программы и инструменты, такие как системы мониторинга событий и программы для анализа логов.
Защита логов от удаления. Логи сервера должны быть защищены от удаления злоумышленниками.
Важная информация:
Для защиты логов от удаления можно использовать различные методы, такие как использование систем резервного копирования или использование специальных программ для мониторинга изменений в файловой системе.
![]() Загрузка…
Загрузка…
