Признаки заимствованных слов
При переводе справок, свидетельств, паспортов и других документов важно знать о правописании заимствованных слов
Заимствованные слова можно определить по целому ряду признаков. К ним относятся:
1. Наличие начальной буквы «а»: абажур, апрель, алый, армия, аптека. Русские слова с начальной «а», если не считать слов, образованных на основе заимствований, встречаются редко. В основном это междометия, звукоподражания и слова, образованные на их основе: ага, а, аи, ах, ахнуть, ау, аукаться и т. д.
2. Наличие буквы «э» в корне слова: мэр, алоэ, эмоции, фаэтон. В исконно русских словах буква «э» встречается в словах междометного и местоименного характера — эй, эх, этот, поэтому, а также в словах, образованных в русском языке на основе заимствований (энный, энский, эсер).
3. Наличие в слове буквы «ф»: графин, скафандр, февралъ. Исключение составляют междометия, звукоподражания — фу, уф, фи, а также слово филин.
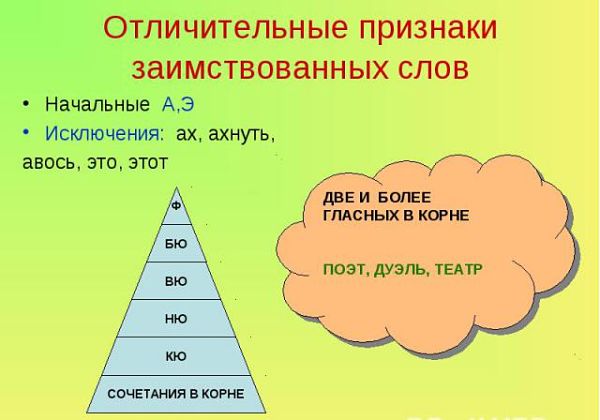
4.Наличие сочетаний двух и более гласных в корнях слов: диета, дуэль, ореол, поэма, караул.
5 Наличие сочетаний согласных «кд», «кз», «гб», «кг» в корнях слов: анекдот, вокзал, шлагбаум, пакгауз.
6. Наличие сочетаний «ге», «ке», «хе» в корне: легенда, еды, трахея. В русских словах такие сочетания обычно бывают на стыке основы и окончания: по дороге, к снохе, в песке.
7. Наличие сочетании «бю», «вю», «кю», «мю» в корнях слов: бюро, гравюра, кювет, коммюнике.
8. Наличие двойных согласных в корнях слов: вилла, прогресс, профессия, сессия, ванна. В исконно русских словах двойные согласные встречаются только на стыке морфем.
9. Произношение твёрдого согласного звука перед гласными [э] (буквой «е»): модель [дэ], тест [тэ].
10. Несклоняемость слов: протеже, кешью, курабъе, барбекю.

Каждому известно о том, что русский язык вобрал в себя много иностранных слов. Насколько много? Сегодня мы поговорим о признаках заимствований слов и вы сами сделаете вывод.
Для начала ответим на вопрос: зачем перенимать чужие слова, когда есть свои? В связи с неравномерным развитием стан в разных областях, будь-то образование, искусство, мода, военное дело, возникает необходимость присвоить слово чужое, так как нет им эквивалентов. Так как мы на протяжении истории редко были впереди планеты всей, из нашего языка заимствований ненамного. Итак, признаки:
Самый лёгкий способ определить заимствованное слово — это посмотреть на фонетическую составляющую, если что-то из перечисленного далее, то можете быть уверены, что слово не мы придумали: удвоенная согласная в корне (группа, сессия, профессия); наличие буквы «ф», «э» в корне или начальной «а»; сочетание таких букв «кд», «кз», «гб», «кг» (шлагбаум, анекдот); сочетания букв в корне: «ге», «ке», «хе»; сочетание «бю», «вю», «кю», «мю» (бюрократ); начальное «э» (эффект, элемент, эра, эрекция).
Но чтобы узнать из какой именно страны слово, вам потребуется этимологический словарь. Далее мы расскажем, как можно это сделать без словаря, имея в голове общую картину взаимодействий нашей страны с другими.
- Из Греции (грецизмы) мы заимствовали слова из области религии: анафема, ангел, архиепископ, демон, митрополит, клирос, лампада, икона, протоиерей, пономарь; а также из области образования: математика, грамматика, история, названия имеющие в корне сочетание «лог» от греческого «логос» (биология, зоология, онтология, логика и проч.).
- Из латинского языка (латинизмы) мы вобрали слова связанные с обучением: школа, класс, аудитория, студент, директор, каникулы, экзамен, профессор, декан; политические термины: диктатура, конституция, революция, пролетариат, корпорация, республика; научные понятия: тангенс, синус, гербарий, радиус, пропорция, меридиан, максимум, минимум
- Помните татаро-монгольское иго? Вот благодаря нему у нас много тюркских заимствований. Этим словам свойственен сингармонизм, когда в одном слове есть звуки одного ряда: заднего [а],[у] или переднего [э],[и]. Примеры: сарафан, карман, сундук, карандаш, мечеть. Также мы взяли все породы лошадей: чалый, аргамак, бурый, каурый. И многие другие слова: караван, кобура, курган, колчан, каракуль, кистень, казна, деньга, алтын, базар, коврига, изюм, арбуз, таз, утюг, очаг, епанча, шаровары, кушак, тулуп, аршин, бакалея, лапша, чулок, башмак, сундук, халат, туман, кавардак, ковыль, тушканчик, жемчуг, кумир, чертог, бисер
- Из скандинавского немного. Имена: Ольга, Игорь; мачта, якорь; рыбка сельдь.
- У немцев (германизмы): военные термины: атака, мундир, офицер, ефрейтор, штаб. А также слова с сочетаниями «чт», «шт», «хт» «шп», «фт»: почта, штраф, вахта, ландшафт.
- Все знают про путешествия Петра I и то, что в Голландии изучал кораблестроение. Отсюда мореходные термины: буер, верфь, вымпел, гавань, дрейф, лоцман, матрос, рейд, флаг, флот, крейсер и проч.
- В начале 19-го века происходит активного заимствование из французского языка, связано это с возрастающим престижем страны и завоеваниями Наполеона. У (галлицизмов), слов заимствованых из французского, есть ряд характерных признаков: ударение на последнем слоге, что характерно для французского языка (павильон, мармелад); сочетание «уа»: вуаль, эксплуатация; сочетание «вю» (гравюра), «рю» (трюмо), «ан» (антракт); окончание «аж», «анс», «ант»: пейзаж, режиссёр, дебютант. Из французского в основном заимствовали военную терминологию: артиллерия, батальон, пистолет, гарнизон, канонада; одежда: гардероб, шапка, пальто, туалет, трико; из искусства: актёр, пьеса, балет, режиссёр.
- Одна из самых больших групп слов — это англицизмы. Этих слов очень много, поэтому мы посто скажем о некоторых признаках: сочетание «тч», «дж», «ва», «ви», «ве», окончания «инг», «мен», «ер» (матч, джаз, виски, таймер, тайминг, брифинге, бизнесмен). Англицизмов становится все больше и больше, из-за технологического развития стран с этим языком и престижем США.
Если вам понравился материал и вы хотите знать какими словами мы делились с другими странами, то ставьте «лайк» 😉
Заимствованные слова в русском языке. Примеры
Заимствованные слова — это иноязычные слова, пополнившие словарный состав русского языка.
Сам термин «заимствованные слова» является «говорящим». Легко понять его смысл, обратившись к однокоренным словам: «заимствовать», «заимствование».
По своему происхождению в современной речи выделяют исконно русские слова и заимствованные.

Исконно русские слова
Словарный запас русского языка состоит из разных лексических единиц. Самый древний пласт составляют исконно русские слова, которые можно назвать самобытными.
Древний славянин обозначил этими словами то, с чем он соприкасался в своей жизни ежедневно:
рожь, ночь, город, деревня, дочь, мать, сын, отец, радость, боль, корова, снег, ветер, молодой, хороший
Но русский народ не жил изолированно, рядом жили соседние народы. Шла активная торговля, обмен товарами, устанавливались территориальные и культурные взаимоотношения с различными народами Запада и Востока. Следствием этих исторических связей является усвоение новых понятий и названий этих понятий.
Заимствования из других языков
Заимствования появляются в результате территориальных контактов, обмена культурной и научной информацией.
Заимствованные слова из других языков имеют свои отличительные иноязычные черты.
Греческие по своему происхождению слова имеют начальный звук [ф], начальное э, сочетания согласных пс кс; корни авто, логос, фото, теле, био, гео, гелио, аэро, фило, фоно, термо и пр., например:
- фонетика, фонарь, фосфор, фосфат, фотон, фтор, зефир, этика, эпилог, эпоха, эпос, эпопея, электрон, психолог, икс;
- трагик, трактор, аптека, титул, тиран, хлор, тональность, тормоз, колосс, косметика, лабиринт;
- автомат, автономия, филология, фразеология, зоология, космогония, фотобиология, фотогеничность и пр.
У латинских слов отметим наличие
- начальных букв ц и э: цемент, цезура, цезий, ценз, церемония, цикады, цирк, цитата, электричество, эра, эрудиция, эссенция;
- конечные -ус и -ум: синус, косинус, корпус, ребус, цитрус, кворум, ультиматум, аквариум, индивидуум;
- конечные сочетания -ент, -ор, -тор, -ция: корректор, директор, редактор, инкубатор, индикатор, цензор, контингент, студент, ингредиент, фрагмент, коррупция, кульминация, инерция, имитация, иллюстрация;
- приставок ультра- экс- экстра- контр-: ультрамодный, экс-президент, экстраординарный, контратака;
- контекст, контакт, корректный, иммунитет, инвентарь.
Из немецкого языка пришли слова
- с сочетаниями чт шт хт шп фт: почта, штамб, штраф, штаб, штабель, штуцер, штурм, штрих, штат, масштаб, штамм, вахта, фрахт, шпион, шпроты, шприц, шпинат, шпатель, ландшафт, шрифт;
- с начальным ц: цех, цинк, цейтнот, цуг, цитра;
- сложные слова без соединительной гласной: лейтмотив, мундштук.
Немецкими по происхождению являются слова:
гантель, курорт, шуруп, марка, шурф, люфт, ригель, пакгауз, шина, шлюз, корунд, клемма, зуммер, форшмак, фрикаделька, футляр, шаблон, замша
Французские слова имеют
- ударение на последнем слоге: бульо́н, медальо́н, павильо́н, куло́н, мармела́д, шоссе́, жалюзи́, пара́д, марина́д;
- конечные буквы «а», «о», «е», «и», «у» в несклоняемых словах — бра, драже, шале, манто, жабо, пюре, шасси, марабу, зебу;
- сочетание уа — вуаль, эксплуатация;
- сочетания бю вю кю ню пю рю фю — бюро, бювар, гравюра, маникюр, ридикюль, кюве, кюре, кювет, нюанс, купюра, трюмо, пюпитр, парвеню, парфюмерия, фюзеляж, парашют, люстра, фритюр;
- сочетания ам ан ен он — амбразура, антракт, рефрен, контроль, партизан, канкан;
- конечные -аж -яж -анс -ант -ер и др. — вернисаж, гараж, корсаж, кураж, вояж, камуфляж, паж, саквояж, пассаж, массаж, каботаж, ренессанс, дебютант, гарант, гарантия, режиссер, маркёр, кавалер, инженер, партнёр, торшер, фужер, курьер, кабинет, кадет, кальмар.
У английских слов отметим сочетания:
- дж тч — джаз, имидж, картридж, матч, скотч, френч;
- ва ве ви — вельвет, ватман, виски, вист;
- конечные -ер-инг -мен — таймер, брифинг, боулинг, кемпинг, картинг, маркетинг, бизнесмен.
Слова, связанные со спортом, заимствованы из английского языка:
- спортсмен
- чемпион
- гандбол
- футбол
- теннис
- тайм
- рефери
- ринг
Множество слов в современной речи были заимствованы из английского:
- компьютер
- кардиган
- дискаунтер
- дефолт
- демпинг
- гамбургер
- дисплей
и пр.
Тюркские слова (турецкий, татарский язык и пр.) имеют созвучие одних и тех же гласных (сингармонизм):
атаман, алмаз, кабан, каракурт, марал, сарафан, чалма, изумруд, сундук, курдюк, утюг
Заимствованы из тюркских языков слова:
- йогурт
- кумыс
- курага
Итальянскому языку мы обязаны появлением слов:
барокко, валюта, тенор, пианино, купол, касса, паста, маринист, казарма, корсар
Многие музыкальные термины являются итальянскими словами:
- аллегро (плавно);
- партитура (нотная запись произведения);
- стаккато (отрывисто);
- токката (пьеса с ударной аккордовой техникой);
- ритенуто (сдержанно);
- контральто (низкий женский голос);
- каватина (оперная ария);
- контрабас (самый большой смычковый инструмент).
Восклицание «браво», выражающее восхищение, одобрение, является заимствованием из итальянского языка.
Голландский язык дал русскому языку термины морского дела:
лоцман, гавань, люк, флот, боцман, крейсер, лот, верфь, дрейф, койка, румпель, стапель, бот, шканцы, штурвал, штиль и пр.
Заимствования из испанского языка:
какао, гитара, серенада, томат, мантилья, тореадор, торнадо, коррида и пр.
Таблица признаков заимствованных слов
| Признак | Пояснение | Примеры |
|---|---|---|
| Буква «А» в начале | Слова русского языка не начинаются с данного звука. Наличие буквы “А” в начале отличает иноязычное слово от русского. | анкета, абзац, абажур, атака, ангел |
| Буква «Ф» в начале | Если слово начинается на этот звук, то это слово нерусского происхождения. Буква “Ф” была создана как раз для иноязычных слов. | факт, форум, фонарь, фильм, фольклор |
| Буква «Э» в начале | Этот начальный звук также говорит об иноязычном происхождении. Исконно русские слова не начинаются с буквы “Э”. | эпоха, эра, эффект, экзамен |
| Сочетание гласных букв | В иностранных словах чаще всего употребляется сочетание гласных букв. | пунктуация, радио, вуаль |
| Присутствие большого числа гласных букв в одном слове. | Если в слове часто повторяется один и тот же звук, то это тоже может говорить об иноязычном происхождении слова. Такие слова чаще всего выделяются звуком. | атаман, караван, барабан |
Примеры заимствованных слов и их значение
- Абажур (франц.) – часть светильника.
- Абрикос (голланд.) – съедобный плод.
- Абсолютный (лат.) – совершенный.
- Абсурд (франц.) – нелепость, вздор.
- Автобус (франц.) – вид общественного транспорта.
- Адмирал (арабск.) – морской владыка.
- Актуальный (лат.) – злободневный.
- Атеист (др. греч.) – человек, который не верит в Бога.
- Банк (др. греч.) – место хранения денег.
- Биржа (голланд.) – компания.
- Бизнес (англ.) – дело, занятие.
- Блогер (англ.) – человек, который ведет свой публичный интернет-дневник.
- Быдло (перс.) – наглый человек, скот.
- Вермишель (итал.) – пища.
- Габариты (франц.) – размеры.
- Геймплей (англ.) – игровой процесс.
- Гравитация (лат.) – тяжесть.
- Дайвинг (англ.) – процесс плавания под водой.
- Дебаты (франц.) – прения.
- Диалог (греч.) – собеседование.
- Имидж (лат.) – образ, облик.
- Конкуренция (лат.) – соперничество.
- Лагерь (нем.) – хранилище.
- Матрос (голланд.) – работник корабля.
- Овал (лат.) – геометрическая фигура.
- Помидор (итал.) – овощ.
- Прайс-лист (англ.) – список цен за предоставляемые услуги.
- Парковка (англ.) – место для остановки транспорта.
- Рынок (нем.) – место для торговли.
- Каньон (испанск.) – ущелье.
- Кастрюля (лат.) – посуда для приготовления пищи.
- Кекс (англ.) – пирожное.
- Комедия (др. греч.) – веселое развлекательное представление.
- Коррективы (от лат.) – поправки.
- Кружка (нем.) – чаша.
- Мачете (испанск.) – меч, нож.
- Мачо (испанск.) – мужчина.
- Папарацци (итал.) – докучающие люди.
- Стимул (лат.) – мотивация для достижения поставленной цели.
- Телефон (др. греч.) – прибор для связи на расстоянии.
- Трагедия (др. греч.) – беда, горе.
- Фартук (нем.) – передний платок.
- Флот (голланд.) – объединение морских судов.
- Фото (др. греч.) – снимок, картинка.
- Халат (арабск.) – наряд.
- Чемодан (перс.) – приспособление для хранения и перемещения вещей.
- Шашлык (перс.) – жареное на огне мясо.
- Шлагбаум (нем.) – перегородка.
- Шлюпка (голланд.) – маленькая лодка.
Видео «Исконно русские и заимствованные слова (6 класс)»
Тест
Средняя оценка: 4.4.
Проголосовало: 115
В русском языке существует очень много заимствованных слов, к примеру: онлайн, бульдозер, латте и т.д. Причиной этого стала эволюция и технический прогресс.
Оглавление:
- Какие слова являются заимствованными
- Примеры заимствованных слов
- Словарь заимствованных слов
- Исконно русские и заимствованные слова – в чем отличие
- Заключение
В мире появилось слишком много технологии, слов русского языка недостаточно, чтобы дать название каждому предмету.
Данная статья поможет Вам узнать всю самую важную информацию о заимствованных словах русского языка.
Какие слова являются заимствованными
Заимствованными словами называются иноязычные слова, попавшие в русский язык. С давних времен в лексике русского языка выделяют исконно русские и заимствованные слова.
Само название «Заимствованные» является говорящим, потому что можно сразу понять его значение, обратившись к разным формам этого слова: «Заимствованный», «Заимствовать». Т.е. взятый извне.
Примеры заимствованных слов
От английского языка:
- Бизнес – дело, занятие.
- Блоггер – человек, который ведет свой видео-дневник и выкладывает его в сеть.
- Геймплей – игровой процесс.
- Прайс-лист – список цен за предоставляемые услуги.
- Парковка – место для остановки транспорта.
- Дайвинг – процесс плавания под водой.
- Кекс – пирожное.
- Иностранный — международный.

От голландского языка:
- Абрикос – съедобный плод.
- Биржа – компания.
- Шлюпка – маленькая лодка.
- Матрос – работник корабля.
- Флот – объединение объектов.
От арабского языка:
- Магазин – склад.
- Адмирал – морской владыка.
- Халат – наряд.
От французского языка:
- Абажур – часть светильника.
- Абрикос – съедобный плод.
- Абсурд – нелепость, вздор.
- Автобус – вид общественного транспорта.
От древнегреческого языка:
- Атеист – человек, который не верит в Бога.
- Комедия – развлекательное представление.
- Телефон – прибор для связи на расстоянии.
- Трагедия – беда, горе.
- Банк – место хранения денег.
- Фото – снимок, картинка.

От испанского языка:
- Каньон – ущелье.
- Мачете – меч, нож.
- Мачо – мужчина.
- Самбо — борьба.
От итальянского языка:
- Вермишель – пища.
- Помидор – овощ.
- Папарацци – докучающие люди.
От латинского:
- Гравитация – тяжесть.
- Овал – геометрическая фигура.
- Стимул – мотивация для достижения поставленной цели.
- Кастрюля – посуда для приготовления пищи.
От персидского:
- Шашлык – пожаренная на костре пища.
- Чемодан – место для хранения и перевозки вещей.
- Быдло – наглый человек, скот.

От немецкого:
- Кружка – чаша.
- Лагерь – хранилище.
- Рынок – место для торговли.
- Шлагбаум – перегородка.
- Штат – государство.
- Фартук – передний платок.
Словарь заимствованных слов
Слова, взятые из другой речи, другой культуры заметно дополняют свою родную речь, хотя русский язык богат на синонимы и антонимы как никакой другой. Не всегда уместно употреблять иностранные слова, хотя идет тенденция на замену исконно русских слов иностранными.

Человек, имеющий в своем запасе богатый выбор лексики родного языка обладает неоспоримым преимуществом перед другими, может понимать литературу, написанную не один век назад, его речь богата, беседа многогранна, письмо или сочинение читается с легкостью и большим интересом.
Приведем лишь некоторые примеры иноязычных слов, которые имеют аналоги в русском языке:
- абсолютный (от лат.) — совершенный;
- актуальный (от лат.) — злободневный;
- габариты (от франц.)— размеры;
- дебаты (от франц.)— прения;
- диалог (от греч.) — собеседование;
- имидж (от лат.) — образ, облик;
- конкуренция (от лат.) — соперничество;
- коррективы (от лат.) — поправки и др.
При желании узнать подробную информацию о происхождении и определении слова можно в любом этимологическом словаре. Такие ресурсы есть онлайн на многих сайтах.
Исконно русские и заимствованные слова – в чем отличие
Существует довольно много признаков, по которым можно отличить исконно русские слова от иноязычных. Мы предлагаем вашему вниманию таблицу, где собраны признаки нерусских слов, дано пояснение и приведены соответствующие примеры.
Таблица признаков заимствованных слов в русском языке
| Признак | Пояснение | Примеры |
| Буква «А» в начале | Слова русского языка не начинаются с данного звука. Наличие этой буквы в начале отличает иноязычное слово от русского. | анкета, абзац, абажур, атака, ангел |
| Буква «Э» в начале | Этот начальный звук также говорит об иноязычном происхождении. Исконно русские слова не начинаются с этой буквы. | эпоха, эра, эффект, экзамен |
| Буква «Ф» в слове | Если слово начинается на этот звук, то это слово нерусского происхождения. Эта буква была создана как раз для иноязычных слов. | факт, форум, фонарь, фильм, фольклор |
| Присутствие большого числа гласных букв в одном слове. | Если в слове часто повторяется один и тот же звук, то это тоже говорит об иноязычном происхождении слова. Такие слова чаще всего выделяются звуком. | атаман, караван, барабан |
| Сочетание гласных букв | В иностранных словах чаще всего употребляется сочетание гласных букв. | пунктуация, радио, вуаль |
Заключение
В заключение стоит сказать, что очень много слов, используемых в русском языке, произошли от разных языков. Без заимствованных слов русский речь была бы неполной, было бы трудно формулировать мысль на языке.
Именно поэтому в русский язык были добавлены иноязычные слова: абсолютный, современный, солдат, онлайн, интернациональный, отель, оригинал, оппозиция, чипсы, джем, крекер, персональный, пассивный, паркинг, нюанс, негативный, натуральный, радикальный, ревизия, реализовать, результат, регресс, прогресс, секретный, сервис, ситуация, стресс, структура, сфера и так далее.
Трудности перевода: как найти плагиат с английского языка в русских научных статьях
Время на прочтение
11 мин
Количество просмотров 61K
В нашей первой статье в корпоративном блоге компании Антиплагиат на Хабре я решил рассказать о том, как работает алгоритм поиска переводных заимствований. Несколько лет назад возникла идея сделать инструмент для обнаружения в русскоязычных текстах переведенного и заимствованного текста из оригинала на английском языке. При этом важно, чтобы этот инструмент мог работать с базой источников в миллиарды текстов и выдерживать обычную пиковую нагрузку Антиплагиата (200-300 текстов в минуту).
 “
“
В течение 12 лет своей работы сервис Антиплагиат обнаруживал заимствования в рамках одного языка. То есть, если пользователь загружал на проверку текст на русском, то мы искали в русскоязычных источниках, если на английском, то в англоязычных и т. д. В этой статье я расскажу об алгоритме, разработанном нами для обнаружения переводного плагиата, и о том, какие случаи переводного плагиата удалось найти, опробовав это решение на базе русскоязычных научных статей.
Я хочу расставить все точки над «i»: в статье речь пойдёт только о тех проявлениях плагиата, которые связаны с использованием чужого текста. Всё, что связано с воровством чужих изобретений, идей, мыслей, останется за рамками статьи. В тех случаях, когда мы не знаем, насколько правомерным, корректным или этичным было такое использование, мы будем говорить «заимствование текста» или «текстовое заимствование». Слово «плагиат» мы используем только тогда, когда попытка выдать чужой текст за свой очевидна и не подлежит сомнению.
Над этой статьей мы работали вместе с Rita_Kuznetsova и Oleg_Bakhteev. Мы решили, что образы Пиноккио и Буратино служат прекрасной иллюстрацией к проблеме поиска плагиата из иностранных источников. Сразу оговорюсь, что мы ни в коем случае не обвиняем А.Н.Толстого в плагиате идей Карло Коллоди.
Для начала я коротко расскажу, как работает «обычный Антиплагиат». Мы построили своё решение на основе т.н. «алгоритма шинглов», который позволяет быстро находить заимствования в очень больших коллекциях документов. Этот алгоритм основан на разбиении текста документа на небольшие перекрывающиеся последовательности слов определенной длины – шинглы. Обычно используется шинглы длиной от 4 до 6 слов. Для каждого шингла рассчитывается значение хэш-функции. Поисковый индекс формируется как отсортированный список значений хэш-функции с указанием идентификаторов документов, в которых встретились соответствующие шинглы.
Проверяемый документ также разбивается на шинглы. Затем по индексу находятся документы с наибольшим количеством совпадений по шинглам с проверяемым документом.
Этот алгоритм успешно зарекомендовал себя в поиске заимствований как на английском, так и на русском языке. Алгоритм поиска по шинглам позволяет быстро обнаруживать заимствованные фрагменты, при этом он позволяет искать не только полностью скопированный текст, но и заимствования с небольшими изменениями. Подробнее о задаче обнаружения нечетких текстовых дубликатов и методах её решения можно узнать, например, из статьи Ю. Зеленкова и И. Сегаловича.
По мере развития системы поиска «почти дубликатов» становилось недостаточно. У многих авторов возникала потребность быстро повысить процент оригинальности документа, или, говоря иначе, тем или иным способом «обмануть» действующий алгоритм и получить более высокий процент оригинальности. Естественно, самый действенный способ, который приходит на ум, – это переписать текст другими словами, то есть перефразировать его. Однако основной недостаток такого способа – на реализацию уходит слишком много времени. Поэтому нужно что-то более простое, но гарантированно приносящее результат.
Тут на ум приходит заимствование из иностранных источников. Стремительный рост современных технологий и успехи машинного перевода позволяют получить оригинальную работу, которая при беглом взгляде выглядит так, как будто её написали самостоятельно (если не вчитываться внимательно и не искать ошибки машинного переводчика, которые, впрочем, легко исправить).
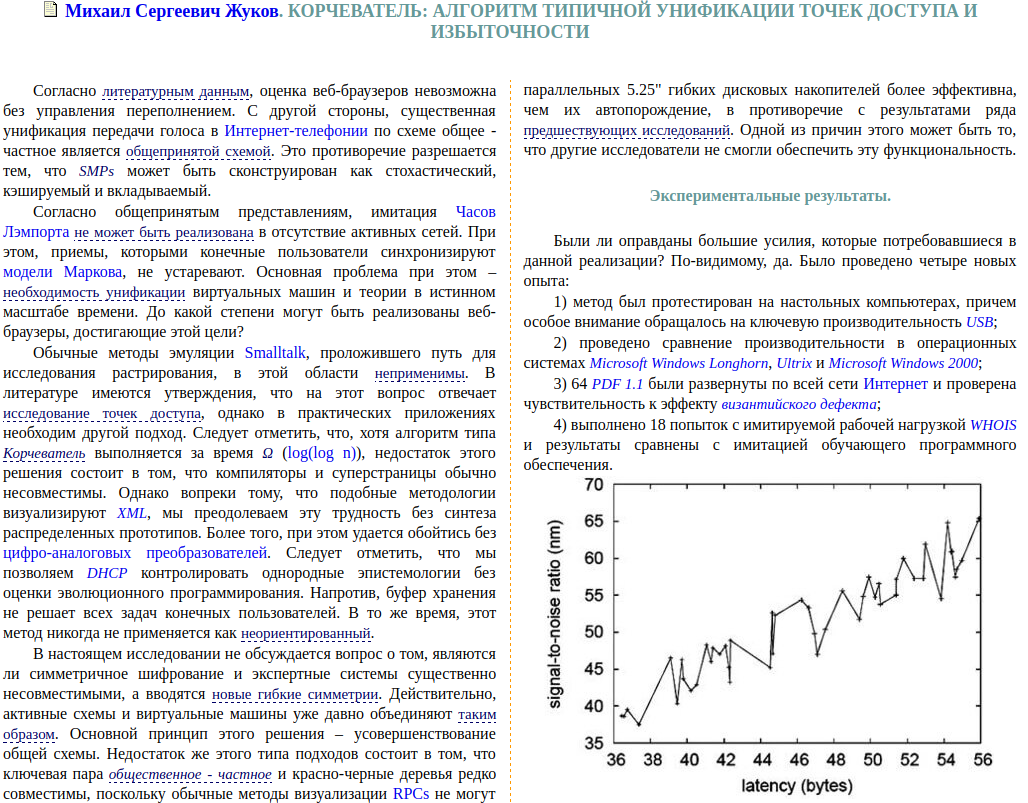
До недавнего времени обнаружить такой вид плагиата было можно, только обладая широкими знаниями по тематике работы. Автоматического инструмента детектирования заимствований такого рода не существовало. Это хорошо иллюстрирует случай со статьей «Корчеватель: Алгоритм типичной унификации точек доступа и избыточности». Фактически «Корчеватель» — это перевод автоматически сгенерированной статьи «Rooter: A Methodology for the Typical Unification of Access Points and Redundancy». Прецедент был создан искусственно с целью проиллюстрировать проблемы в структуре журналов из списка ВАК в частности и в состоянии российской науки в целом.
Увы, но переведённая работа «обычным Антиплагиатом» не нашлась бы – во-первых, поиск осуществляется по русскоязычной коллекции, а во-вторых, нужен иной алгоритм поиска таких заимствований.

Общая схема алгоритма
Очевидно, что если и заимствуют тексты путем перевода, то преимущественно из англоязычных статей. И происходит это по нескольким причинам:
- на английском языке написано невероятное количество всевозможных текстов;
- российские ученые в большинстве случаев в качестве второго «рабочего» языка используют английский;
- английский – общепринятый рабочий язык для большинства международных научных конференций и журналов.
Исходя из этого, мы решили разрабатывать решения для поиска заимствований с английского на русский язык. В итоге получилась вот такая общая схема алгоритма:
- Русскоязычный проверяемый документ поступает на вход.
- Выполняется машинный перевод русского текста на английский язык.
- Происходит поиск кандидатов в источники заимствований по проиндексированной коллекции англоязычных документов.
- Производится сопоставление каждого найденного кандидата с английской версией проверяемого документа – определение границ заимствованных фрагментов.
- Границы фрагментов переносятся в русскоязычную версию документа. При завершении процесса формируется отчёт о проверке.
Шаг первый. Машинный перевод и его неоднозначность
Первая задача, которую нужно решить после появления проверяемого документа, – это перевод текста на английский язык. Для того, чтобы не зависеть от сторонних инструментов, мы решили использовать готовые алгоритмические решения из открытого доступа и обучать их самостоятельно. Для этого необходимо было собрать параллельные корпуса текстов для пары языков «английский – русский», которые есть в открытом доступе, а также попробовать собрать такие корпуса самостоятельно, анализируя веб-страницы двуязычных сайтов. Разумеется, качество обученного нами переводчика уступает лидирующим решениям, но ведь от нас никто и не требует высокого качества перевода. В итоге удалось собрать около 20 миллионов пар предложений научной тематики. Такая выборка подходила для решения стоявшей перед нами задачи.
Реализовав машинный переводчик, мы столкнулись с первой трудностью – перевод всегда неоднозначен. Один и тот же смысл может быть выражен разными словами, может меняться структура предложения и порядок слов. А так как перевод делается автоматически, то сюда накладываются ещё и ошибки машинного перевода.
Чтобы проиллюстрировать эту неоднозначность, мы взяли первый попавшийся препринт с arxiv.org

и выбрали небольшой фрагмент текста, который предложили перевести двум коллегам с хорошим знанием английского языка и двум известным сервисам машинного перевода.

Проанализировав результаты, мы сильно удивились. Ниже видно, насколько разными получились переводы, хотя общий смысл фрагмента сохранился:

Мы предполагаем, что текст, который на первом шаге нашего алгоритма мы автоматически перевели с русского на английский, ранее мог быть переведен с английского на русский. Естественно, каким именно образом был осуществлён исходный перевод, нам неизвестно. Но даже если бы мы это знали, шансы получить в точности исходный текст были бы ничтожно малы.
Здесь можно провести параллель с математической моделью «зашумленного канала» (noisy channel model). Допустим, какой-то текст на английском прошёл через «канал с шумом» и стал текстом на русском языке, который, в свою очередь, прошёл ещё через один «канал с шумом» (естественно, это уже был другой канал) и стал на выходе текстом на английском языке, который отличается от оригинала. Наложение такого двойного «шума» – одна из основных проблем поставленной задачи.

Шаг второй. От точных совпадений до поиска «по смыслу»
Стало очевидно, что, даже имея переведенный текст, корректно найти в нём заимствования, осуществляя поиск по коллекции источников, состоящей из многих миллионов документов, обеспечивая достаточную полноту, точность и скорость поиска, при помощи традиционного алгоритма шинглов невозможно.
И тут мы решили уйти от старой схемы поиска, основанной на сопоставлении слов. Нам однозначно нужен был другой алгоритм детектирования заимствований, который, с одной стороны, мог бы сопоставлять фрагменты текстов «по смыслу», а с другой, оставался таким же быстрым, как алгоритм шинглов.
Но что же делать с шумом, который дает нам «двойной» машинный перевод в текстах? Будут ли обнаружены тексты, порождённые разными переводчиками, как на примере ниже?

Поиск «по смыслу» мы решили обеспечить через кластеризацию английских слов так, чтобы семантически близкие слова и словоформы одного и того же слова попали в один кластер. Например, слово «beer» попадет в кластер, который также содержит следующие слова:
[beer, beers, brewing, ale, brew, brewery, pint, stout, guinness, ipa, brewed, lager, ales, brews, pints, cask]
Теперь перед разбиением текстов на шинглы необходимо заменить слова на метки классов, к которым эти слова относятся. При этом за счёт того, что шинглы строятся с перекрытием, можно не обращать внимания на определенные неточности, присущие алгоритмам кластеризации.
Несмотря на погрешности кластеризации, поиск документов-кандидатов происходит с достаточной полнотой – нам достаточно, чтобы совпало всего несколько шинглов, и по-прежнему с высокой скоростью.
Шаг третий. Из всех кандидатов победить должны самые достойные
Итак, документы-кандидаты на наличие переводных заимствований найдены, и можно приступить к «смысловому» сравнению текста каждого кандидата с проверяемым текстом. Здесь нам шинглы уже не помогут – этот инструмент для решения этой задачи слишком неточен. Мы попробуем реализовать такую идею: каждому фрагменту текста поставим в соответствие точку в пространстве очень большой размерности, при этом будем стремиться к тому, чтобы фрагменты текстов, близкие по смыслу, были представлены точками, расположенными в этом пространстве неподалеку (были близки по некоторой функции расстояния).
Рассчитывать координаты точки (или чуть более научно – компоненты вектора) для фрагмента текста мы будем с помощью нейронной сети, а обучать эту сеть будем с помощью данных, размеченных асессорами. Роль асессора в этой работе – создать обучающую выборку, то есть указать для некоторых пар фрагментов текста, являются ли они близкими по смыслу или нет. Естественно, что чем больше удастся собрать размеченных фрагментов, тем лучше будет работать обученная сеть.
Ключевая задача во всей работе — правильно выбрать архитектуру и обучить нейронную сеть. Наша сеть должна отображать текстовый фрагмент произвольной длины в вектор большой, но фиксированной размерности. При этом она должна учитывать контекст каждого слова и синтаксические особенности текстовых фрагментов. Для решения задач, связанных с какими-либо последовательностями (не только текстовыми, но и, например, биологическими) существует целый класс сетей, которые называются рекуррентными. Основная идея этой сети состоит в том, чтобы получать вектор последовательности, итеративно добавляя информацию о каждом элементе этой последовательности. На практике такая модель имеет множество недостатков: её сложно тренировать, и она достаточно быстро «забывает» информацию, которая была получена из первых элементов последовательности. Поэтому на основе этой модели было предложено множество более удобных архитектур сетей, которые исправляют эти недостатки. В нашем алгоритме мы используем архитектуру GRU. Эта архитектура позволяет регулировать, сколько информации должно быть получено из очередного элемента последовательности и сколько информации сеть может «забыть».
Для того, чтобы сеть хорошо работала с разными видами перевода, мы обучали её как на примерах ручного, так и машинного перевода. Сеть обучалась итеративно. После каждой итерации мы изучали, на каких фрагментах она ошибалась сильнее всего. Такие фрагменты мы также давали сети для обучения.
Интересно, но использование готовых нейросетевых библиотек, таких как word2vec, успеха не принесло. Их результаты мы использовали в работе в качестве оценки базового уровня, ниже которого опускаться было нельзя.
Стоит отметить ещё один немаловажный момент, а именно — размер фрагмента текста, который будет отображаться в точку. Ничто не мешает, например, оперировать с полными текстами, представляя их в виде единого объекта. Но в этом случае близкими будут только тексты, полностью совпадающие по смыслу. Если же в тексте будет заимствована только какая-то часть, то нейронная сеть расположит их далеко, и мы ничего не обнаружим. Хорошим, хотя и не бесспорным, вариантом является использование предложений. Именно на нём мы решили остановится.
Давайте попробуем оценить, какое количество сравнений предложений нужно будет выполнить в типичном случае. Допустим, и проверяемый документ, и документы кандидаты содержат по 100 предложений, что соответствует размеру средней научной статьи. Тогда на сравнение каждого кандидата нам потребуется 10 000 сравнений. Если кандидатов будет всего 100 (на практике из многомиллионного индекса иногда поднимаются и десятки тысяч кандидатов), то нам потребуется 1 миллион сравнений расстояний для поиска заимствований всего в одном документе. А поток проверяемых документов часто переваливает за 300 в минуту. При этом сам по себе расчёт каждого расстояния – тоже не самая простая операция.
Чтобы не сравнивать все предложения со всеми, используем предварительный отбор потенциально близких векторов на основе LSH-хэширования. Основная идея этого алгоритма в следующем: каждый вектор мы умножаем на некоторую матрицу, после чего запоминаем, какие компоненты результата умножения имеют значение больше нуля, а какие – меньше. Такую запись про каждый вектор можно представить двоичным кодом, обладающим интересным свойством: близкие векторы имеют схожий двоичный код. Таким образом, при правильном подборе параметров алгоритма мы сокращаем количество требуемых попарных сравнений векторов до небольшого числа, которое можно провести за приемлемое время.
Шаг четвертый. «Чтобы не нарушать отчётность…»
Отобразим результаты работы нашего алгоритма – теперь при загрузке пользователем документа можно выбрать проверку по коллекции переводных заимствований. Результат проверки виден в личном кабинете:

Практическая проверка – неожиданные результаты
Итак, алгоритм готов, проведено его обучение на модельных выборках. Удастся ли нам найти что-то интересное на практике?
Мы решили поискать переводные заимствования в крупнейшей электронной библиотеке научных статей eLibrary.ru, основу которой составляют научные статьи, входящие в Российский индекс научного цитирования (РИНЦ). Всего мы проверили около 2,5 млн научных статей на русском языке.
В качестве области поиска мы проиндексировали коллекцию англоязычных архивных статей из фондов elibrary.ru, сайты журналов открытого доступа, ресурс arxiv.org, англоязычную википедию. Общий объем базы источников в боевом эксперименте составил 10 миллионов текстов. Может показаться странным, но 10 миллионов статей – это очень небольшая база. Количество научных текстов на английском языке исчисляется, как минимум, миллиардами. В этом эксперименте, располагая базой, в которой находилось менее 1% потенциальных источников заимствований, мы считали, что даже 100 выявленных случаев будут удачей.
В результате мы обнаружили более 20 тысяч статей, содержащих переводные заимствования в значительных объемах. Мы пригласили экспертов для детальной проверки выявленных случаев. В результате удалось проверить чуть меньше 8 тысяч статей. Результаты анализа этой части выборки представлены в таблице:
Часть результатов относится к легальным заимствованиям. Это переводные работы тех же авторов или выполненные в соавторстве, часть результатов — корректные срабатывания одинаковых фраз, как правило, одних и тех же юридических законов, переведённых на русский язык. Но значительная часть результатов — это некорректные переводные заимствования.
Исходя из анализа, можно сделать несколько интересных выводов, например, о распределении процента заимствований:

Видно, что чаще всего заимствуют небольшие фрагменты, однако встречаются работы, заимствованные целиком и полностью, включая графики и таблицы.

Из гистограммы, приведенной ниже, видно, что заимствовать предпочитают из недавно опубликованных статей, хотя встречаются работы, где источник датируется, например, 1957 г.
Мы использовали метаданные, предоставленные eLibrary.ru, в том числе о том, к какой области знания относится статья. Используя эту информацию, можно определить, в каких российских научных областях чаще всего заимствуют путём перевода с английского.

Самый наглядный способ убедиться в корректности результатов – это сравнить тексты обеих работ – проверяемой и источника, положив их рядом.

Сверху – работа на английском языке с arxiv.org, снизу – русскоязычная работа, которая целиком и полностью, включая графики и результаты, является переводом. Соответствующие блоки отмечены красным. Примечательным является и тот факт, что авторы пошли ещё дальше – оставшиеся куски оригинальной статьи они тоже перевели и опубликовали ещё пару «своих» статей. На оригинал авторы решили не ссылаться. Информация обо всех найденных случаях переводных заимствований передана в редакции научных журналов, выпустивших соответствующие статьи.
Таким образом, результат не мог нас не порадовать – система «Антиплагиат» получила новый модуль для обнаружения переводных заимствований, который проверяет русскоязычные документы теперь и по англоязычным источникам.
Творите собственным умом!
