Как получить из данных полезную информацию, которая приведет к максимально сильному воздействию?
Следующие 3 метода помогут вам достичь этого.
1. Выявляйте выбросы и аномалии
Ищите данные, которые отклоняются от нормы.
Это могут быть внезапные изменения в большую или меньшую сторону по сравнению с прошлым периодом или с целевым значением.
Пример:
Определение городов, продуктов, продавцов, которые либо показывают результаты больше ожидаемых, либо отстают на значительную величину.
2. Определяйте причины и взаимосвязи
Это означает поиск реальных причин отклонений в ваших данных.
Пример:
Вы обнаружили резкое падение продаж за вчерашний день. Вы ищете реальные причины такого падения и выясняете, что оно связано с пользователями, использующими браузер chrome. У данных пользователей по сравнению с предыдущим периодом наблюдалось падение на последнем шаге воронки – на шаге оформления заказа. Копнув глубже, вы находите причину – она была в неработающей кнопке “Оформить заказ”.
Типы визуализаций, которые можно использовать для достижения этой цели
Комбинированная диаграмма с накоплением (Stacked bar chart)
Более всего комбинированная диаграмма полезна при сравнении категорий.
“Маленькие” или решатчатые диаграммы (Small multiples, or trellising)
Разбивают визуальный элемент на несколько версий самого себя. Это позволяет легко сравнивать данные.
Кумулятивные линейные графики (cumulative line graph)
Такая диаграмма используется для визуализации вклада каждой составляющей в общий результат.
Боксплот или “ящик с усами” (box and whisker plot)
Диаграмма “ящик с усами” показывает распределение данных по квартилям, выделяя их выбросы. В полях могут быть линии, протянутые вертикально под названием “усы”. Эти линии указывают на отклонение за пределами верхнего и нижнего квартилей, и любая точка за пределами этих линий (усов) считается выбросом.
Диаграмма рассеяния (scatter plot)
Диаграммы рассеяния используются для демонстрации наличия или отсутствия корреляции между двумя переменными.
Тепловые таблицы (heat table)
Графическое представление данных, где индивидуальные значения в таблице отображаются при помощи цвета.
И другие…
3. Преобразуйте, сегментируйте и группируйте данные
Когда вы изменяете представление своих данных, вы даете возможность себе находить новые идеи.
Например, переведите числовые значения в текст или наоборот.
Или используйте методы кластеризации.
Кластерный анализ — это статистический метод обработки данных. Он работает путем организации элементов в группы или кластеры на основе того, насколько тесно они связаны.
Используйте инструменты для анализа данных:
- Tableau
- Power BI
- Библиотеки Python (Pandas, Numpy)
- R
Подписывайтесь на мой Telegram-канал Аналитика и Growth mind-set, там я рассказываю о своей работе продуктовым аналитиком и делюсь полезными материалами по аналитике.
Аналитические дашборды не помогают принимать решения, или Где на самом деле брать инсайты из данных
Время на прочтение
4 мин
Количество просмотров 5.6K
Привет! Меня зовут Ольга Татаринова, я руковожу отделом аналитики в Agima.ai. Один из самых частых запросов, с которым к нам приходят клиенты, такой: «Сделайте нам дашборд c бизнес-KPI. Мы хотим найти какие-то инсайты в наших данных, чтобы понять точки роста». Проблема с такой постановкой задачи в том, что дашборды хорошо помогают следить за бизнес-kpi. Но напрямую мешают находить инсайты в данных.
Есть такой старый анекдот.
Полицейский подходит на улице к человеку, который ползает под фонарём.
— Что вы тут делаете? — спрашивает полицейский.
— Ключи ищу, — отвечает человек.Они вдвоём какое-то время безуспешно ищут ключи, и наконец полицейский спрашивает:
— А вы уверены, что вы их именно тут потеряли?
— Нет, — говорит человек. — Я их в парке потерял!
— А почему же здесь ищете?
— А здесь светлее!
Феномен поиска под фонарем того, что потеряно в другом месте, известен как «эффект уличного освещения» (или эффект поиска пьяницы), и он на удивление распространён. Люди склонны искать ответы там, где информация легкодоступна, а не там, где на самом деле есть ответы.
В случае с анализом данных этот эффект работает так: бизнес-пользователи смотрят на дашборд и видят, что, например, средний чек заказа на прошлой неделе упал. И задают совершенно правильный вопрос: «А почему средний чек упал?»
Но, скорее всего, нет ни одного дашборда, который мог бы ответить на вопрос «почему упал средний чек?». Ответ на него можно найти только исследуя полный набор доступных данных, не ограниченный дашбордами.
Но из-за «эффекта уличного освещения» бизнес-пользователи зачастую:
-
просматривают все доступные дашборды в поисках ответа, почему (и не получают его);
-
ставят задачу аналитикам «добавить ещё фильтры на дашборд», ждут задачу неделю, перебирают все фильтры и не получают ответа;
-
собирают менеджмент-митинг и поручают аналитикам «сделать уже дашборд, на котором будет всё понятно», и кончено, никогда его не получают (но получают дашборд на 17 экранов графиков, который запутывает окончательно).
В итоге настоящие причины того, почему упал средний чек заказа, ускользают, а решение, что же делать с упавшим средним чеком, принимаются интуитивно.
Поэтому я не очень люблю проектировать дашборды, зато очень люблю проектировать наборы данных, которые могут самостоятельно исследовать бизнес-пользователи. Такой подход называется аналитикой самообслуживания (или Self-service аналитикой).
На всех проектах для заказчиков мы обязательно готовим данные для использования в режиме самообслуживания. За пять лет практики мы поняли, как сделать Self-service-подход проще для бизнес-пользователей.
Типичные проблемы данных при Self-service-подходе
1. В Self-service-режиме доступны только данные веб-аналитики.
Самый частый пример данных, доступных для самостоятельного изучения бизнес-пользователями, это данные веб-аналитики. Зачастую продакт-менеджеры и другие бизнес-пользователи умеют следить за метриками в Google Analytics или Amplitude. Но если смотреть только в события веб-аналитики, то можно пропустить важные вещи, которые нельзя залогировать в качестве веб-событий.
Например, продакт-менеджер может оптимизировать конверсию в заказ на сайте, но упускать тот факт, что каждый заказ с сайта в конечном итоге приносит компании убыток из-за плохих процессов в логистике и на складах.
2. В Self-service доступны только самые очевидные данные.
Зачастую ответ на вопрос о том, почему упал средний чек, лежит в маргинальных датасетах, которые относятся, например, к складам, работе логистики и даже погодным условиям. Этих данных часто не оказывается в Self-service-слое, и истинные причины явлений пропускают при анализе.
При проектировании Self-service-слоя мы стараемся найти все известные датасеты, в том числе маргинальные, и подготовить их для самостоятельной работы пользователей. При таком подходе пользователи как минимум знают, что определенные данные доступны и находятся от них в одном клике.
3. Много точек входа в Self-service, непонятно, с чего начинать исследование данных
При проектировании аналитических витрин первое, что хочется сделать, это собрать отдельную таблицу под каждое понятие предметной области (например, USERS, ORDERS, SUBSCRIPTIONS и т. п.). Отношения между этими таблицами довольно быстро становятся сложными, и приходится возвращаться к SQL или обращаться за помощью к аналитикам.
Сейчас мы стараемся свести весь Self-service к одной витрине, которую мы называем таймлайн, за который «зацеплены» все остальные таблицы (пользователи, заказы, подписки и т. п.). Это обеспечивает бизнес-пользователям одну точку входа во все данные, что сильно упрощает начало работы.
4. «Технический шум» в данных.
В любом наборе данных всегда много частичного дублирования информации и технических колонок, например, ключи партицирования, метаинформация. Часть атрибутов дублируется в нескольких таблицах.
Такой «технический шум» отвлекает внимание и мешает исследовать данные.
В Self-service-слое должны оставаться только понятные и значимые атрибуты данных.
5. Отсутствие документации.
Чтобы бизнес-пользователи могли работать с Self-service-слоем, каждый атрибут, вынесенный в Self-service, должен быть:
-
уникально поименован;
-
задокументирован и описан в терминах, понятных бизнес-пользователям.
Поскольку на документацию никогда не остается времени, мы перешли к Document-first-подходу. То есть сначала моделируем и документируем те атрибуты, которые должны оказаться в Self-service-слое, а только затем приступаем к их реализации. Мы описывали этот подход в предыдущей публикации.
Выводы
Подводя итог всему вышесказанному, хочу сформулировать несколько тезисов:
-
В компаниях сейчас много данных, но зачастую мало инсайтов. Отсутствие инсайтов во многом обусловлено «эффектом уличного освещения»: все ищут инсайты там, где светлее (на дашбордах), а не там, где они на самом деле есть (в полном наборе данных).
-
Полные наборы данных в BI-системах сейчас доступны только «элите»: аналитикам и Data-scientist’ам. И недоступны людям, которые должны принимать бизнес-решения на основе данных: продакт-менеджерам, маркетологам, финансистам. Зачастую люди, принимающие конкретные проектные решения, не знают, какие данные доступны в принципе и поэтому принимают бизнес-решения интуитивно.
-
Основной задачей аналитиков должна стать не «подготовка отчетов по запросу бизнеса», а подготовка такой среды, в которой бизнес самостоятельно мог бы получать ответы на свои вопросы.
-
Инсайт нельзя сгенерировать по заказу, но возможно сделать такую среду, которая приводит к возникновению инсайтов. Если вложиться в то, чтобы сделать данные доступными бизнес-пользователям, то качество инсайтов из данных, а следовательно и качество решений, которые принимаются в компании, ощутимо вырастет.

В наши дни компании имеют доступ к огромным массивам данных, но порой даже самые опытные аналитики не могут разглядеть в таком обилии информации по-настоящему важные сведения. Главная задача современных data-специалистов состоит в том, чтобы отвечать на вопросы руководителей высшего звена, принимающих основные бизнес-решения. Аналитические сервисы сами по себе не способны извлекать из данных ценные инсайты, и потому им приходится брать на себя роль неких «переводчиков» между деловым и технологическим мирами.
В большинстве случаев эти вопросы касаются очень значимых аспектов бизнеса, но в то же время формулируются они весьма расплывчато:
- Проверим эту новую функцию на наших «лучших» клиентах?
- Как мы улучшим «клиентский опыт»?
- Мы провели множество маркетинговых кампаний; что сработало?
Как применить это на «лучших» клиентах?
Возьмем пример с «лучшими» клиентами. Что значит это словосочетание? С точки зрения аналитики, вам нужно разобраться с ним в первую очередь, так как оно может иметь самые разные значения.
Скажем, если дело касается пользователей ритейл-сервиса, оно может означать следующее:
- Часто покупающие клиенты: Выражается в таких метриках, как количество транзакций за последние 12 месяцев, общее количество транзакций, среднее число дней между транзакциями, количество визитов и т. д.
- Большие «транжиры»: Выражается в таких метриках, как средний чек, средняя сумма на клиента за последние 4 года, пожизненная ценность и т. д.
- Последние клиенты: Выражается в количестве дней с момента последней покупки.
Разумеется, большинству аналитиков хотелось бы, чтобы руководство их компании структурировало свои вопросы более конкретно, но «переводить» обыкновенные предложения в понятные для машин показатели должны именно они.
Разные специалисты могут вкладывать в слово «лучшие» совершенно разные значения. Так, маркетологов программ лояльности может заботить лишь фактор частоты транзакций, с учетом ценности потребителя как вторичной метрики.
Но если вы углубитесь и учтете здесь еще и элемент «непрерывности» — как в компаниях, работающих по модели регулярных абонентских платежей — слово «лучшие» также будет трактоваться иначе. Теперь вам придется думать о длительности отношений с клиентом, наряду с транзакциями и фактором лояльности:
- Срок пребывания в статусе клиента: Выражается в таких метриках, как количество месяцев с момента первой транзакции или регистрации.
- Взаимодействия: Количество обращений в службу поддержки, решений проблем, жалоб или переходов на другой тарифный план.
- Другие действия: Такие, как аннулирование аккаунта, просрочка платежа или реактивация.
Например, для авиакомпаний слово «лучшие» может иметь разные значения в каждом рейсе. В их случае рассмотрению могут подлежать следующие данные:
- Количество миль по программе
- Общее количество миль (lifetime mileage)
- Класс/код билета
- Стоимость билета на рейс/величина скидки
- Частота полетов (число перелетов за последние 12 месяцев, среднее количество дней между перелетами/бронированием)
- Второстепенные покупки и платные обновления
Зачем такие подробности? Аналитики должны быть готовы к любым типам бизнес-задач и ситуаций, с которыми они могут столкнуться.
Как улучшить «клиентский опыт»?
«Клиентский опыт» также можно разбить на несколько переменных, чтобы предоставить людям, принимающим решения, разные опции. Из чего состоит опыт клиента и что вам нужно понять обо всем его пути? Сегодня, когда мы можем отслеживать каждый клик, слово и просмотр, вы должны учитывать эти критерии, чтобы получать ответы максимально быстро.
По сути, вам нужно акцентировать внимание на таких аспектах «клиентского опыта»:
- Интересующий продукт: Почему клиент с вами связался? Начните с классификации проблем и обозначения соответствующих продуктов и категорий. Уровень сложности проблем также стоит пометить.
- Количество действий и реакций: Выражается количеством контактов/входящих звонков на клиента, количеством исходящих звонков, чатов и т. д.
- Решение: Каков был фактический результат? Проблема решена или нет? Удовлетворительно или нет?
- Как много времени все это отняло: Выражается в минутах между изначальным обращением и решением, среднем количестве минут между действиями, средней продолжительности взаимодействий и т. д. Говоря в общем, чем быстрее все это происходит — тем лучше для вас.
При таком подходе хороший клиентский опыт можно измерить более объективно.
Какая кампания сработала?
Теперь перейдем к третьему вопросу, который касается эффективности тех или иных маркетинговых кампаний. Аналитические консультанты часто сталкиваются с подобными задачами и утверждают, что вся сложность здесь заключается не в самом процессе, а в плохой структуризации данных. Чтобы понять, что сработало, вы должны определить, что это значит? Прежде всего, уясните для себя, каков был желаемый результат?
- Открытия и клики: Традиционные метрики в digital-аналитике
- Конверсия: Теперь вам нужно покопаться в транзакционных данных и согласовать их с соответствующими кампаниями и каналами
- Продление: Если речь идет о B2B-сегменте
- Улучшение имиджа бренда: Это сложное и субъективное понятие, поэтому оно также нуждается в дополнительном пояснении
Затем вы должны учесть все факторы, которые могут повлиять на ваш результат:
- Канал: «Маст хев» в омниканальном мире.
- Источник: Где вы взяли контактное имя клиента?
- Критерии выбора: Как вы выбирали имя для контакта? По какой переменной? Если вы использовали продвинутую аналитику, то для какого сегмента, модели и групп моделей?
- Тип/Название/Цель кампании: Например, ежегодное продвижение продукта, рождественское предложение.
- Продукт: Какой продукт был основным в ходе кампании?
- Оффер: В чем заключалась наживка? Скидка в денежном эквиваленте или в %? Бесплатная доставка? Возможность получить вторую покупку бесплатно? Дисконт на ограниченный период?
- Креативные элементы: Например, контент, типы изображений, тип и размер шрифта и другие графические элементы.
- День/время падения: Время суток на момент падения кампании, день недели, время года и т. д.
- Волна: Если кампания включала несколько волн.
- Особенности сплит-тестирования: В какой среде проводилось исследование (контролируемой или нет).
Безусловно, здесь перечислены лишь некоторые предположения. Ваша компания может руководствоваться другим набором параметров. Старайтесь не зацикливаться на каком-то конкретном элементе, а получать как можно больше «грязных» и «чистых» данных. Если вы действительно хотите узнать, «что сработало» в ваших маркетинговых кампаниях, такая разбивка вам попросту необходима.
Вместо заключения
Когда дело касается data-майнинга, вы должны четко понимать, откуда именно стоит начинать поиск инсайтов, ведь в конечном счете это определяет качество всей вашей последующей бизнес-аналитики. Сталкиваясь со сложными неоднозначными задачами и вопросами, всегда разбивайте их на более мелкие и ощутимые элементы. Это позволит вам работать с данными эффективнее, даже если вы ничего не смыслите в аналитике.
Делайте бизнес на основе данных!
По материалам: targetmarketingmag.com, Изображение: wollis
29-08-2017
Нам иногда кажется что процессы, нас окружающие, хаотичны, однако это далеко не всегда так, и в случайных событиях можно находить определенные паттерны поведения процесса, собирая данные этого процесса и анализируя их. Сложные бизнес-задачи порой кажутся неразрешимыми, но, собирая данные бизнес-процессов, обработав и визуализировав их можно находить ценные инсайты, постепенно приводящие к решению таких задач в том или ином виде. Поиск инсайтов в хаосе данных фактически стал профессией в современном мире.
В этой статье я хочу рассказать про то как можно увидеть определенные паттерны в событиях, на первый взгляд кажущимися хаотичными. Собрав небольшое количество данных, после и подготовки и визуализации можно не найти каких-либо интересных результатов поведения исследуемых систем. Но чем шире становится выборка, по мере увеличения набора данных, визуализация может приобретать заметные поведенческие особенности системы, которые можно описать словами, и которые дадут вам некоторое понимание работы системы. C другой стороны, когда у вам очень много данных, отображение всех событий сразу тоже может не дать понимания, поэтому данные придется агрегировать. Для иллюстрации такого примера в этой статье рассмотрим футбольные пасы.
Футбол, наверное, самый популярный спорт в мире. Я не увлекаюсь футболом, но мне всегда было интересно посмотреть базовые паттерны этой игры, исследуя большое количество данных в разных матчах. То есть, интересно было построить некую усредненную картину футбола. Надо отметить, что для футбола есть свои правила игры, поэтому паттерны игры должны существовать.
Попробуйте мысленно разделить все футбольное поле на квадратные метры и прикинуть в каких направлениях и на какие дистанции пасуют игроки, а также из каких зон поля производится больше всего пасов. Понятно, что прикинуть можно, но на сколько верная картина у вас получится — непонятно. Поэтому дальше мы будем находить, преобразовывать и работать в Tableau с данными футбольных пасов.
Один раз я случайно наткнулся на 2 статьи:
— Football Winds Map
— Advanced sports visualization with Python, Matplotlib and Seaborn
В статьях рассматривался анализ и визуализация событий футбольных матчей, и в первой статье была приведена интересная аналогия футбольных пасов с ветром и сделана карта «футбольного ветра».
Вообще, описание хаотичных, на первых взгляд, систем известными физическими уравнениями для газа или жидкости практикуется, например, в анализе транспортных потоков, где транспортные потоки описываются уравнениями Навье-Стокса для Ньютоновской жидкости (Статья Traffic Management Model). Поэтому визуализация футбольных пасов в виде карты ветров тоже достаточно интересна, и мне интересно стало сделать что-то подобное в Tableau.
1. Сбор и преобразование данных
Данные о действиях на поле во время матчей собраны StatsBomb – часть из них есть в открытом доступе на GitHub. Данные представлены в виде 890 JSON файлов, каждый файл содержит данные одного матча. Данные содержат информацию о следующих лигах/кубках:
— Champion League 1999
— 2019 — FA Women’s Super League 2018
— 2020 — FIFA World Cup 2018
— La Liga 2004 — 2020
— NWSL 2018
— Premier League 2003 — 2004
— Women’s World Cup 2019
Tableau может читать JSON, но не 890 файлов сразу, поэтому далее преобразуем все 890 JSON файлов в 1 CSV файл. Предварительно нужно скачать zip архив с GitHub и распаковать все 890 файлов в локальную директорию. Скрипт ниже читает все JSON файлы в указанной папке на локальном компьютере и преобразует каждый файл в CSV файл.
import json
import pandas as pd
from pandas.io.json import json_normalize
import os
#set working directory
path="C:DocsTableauSportsVizSundayFoolball 2018open-data-masterdatamatches"
for filename in os.listdir(path):
if filename.endswith(".json"):
bb=os.path.join(path, filename)
print(bb)
with open(bb, encoding="utf8") as data_file:
data = json.load(data_file)
df = json_normalize(data, sep="_")
a = df.to_csv(path + filename + '.csv', encoding="utf8", index=None)
df1 = pd.read_csv(path + filename + '.csv')
df1.to_csv(path + filename + '.csv', index=False)
continue
else:
continue
После завершения работы этого скрипта вы получите 890 .csv файлов в указанной в скрипте директории. Далее склеим все файлы в 1 .csv. Следующий скрипт делает UNION всех файлов в указанной папке и сохраняет их как один CSV файл:
import os
import glob
import pandas as pd
#set working directory
os.chdir('C:/Docs/Tableau/SportsVizSunday/Foolball 2018/open-data-master/data')
#find all csv files in the folder
#use glob pattern matching -> extension = 'csv'
#save result in list -> all_filenames
extension = 'csv'
all_filenames = [i for i in glob.glob('*.{}'.format(extension))]
#print(all_filenames)
#combine all files in the list
combined_csv = pd.concat([pd.read_csv(f) for f in all_filenames ])
#export to csv
combined_csv.to_csv( "combined_ccs.csv", index=False, encoding='utf-8-sig')
Теперь у нас есть один общий CSV файл, содержащий информацию о событиях в каждом из 890 матчей. Дальнейшую очистку данных и удаление ненужных полей я сделал в Tableau Prep. В данных осталась только информация о пасах. Координаты точек пасов в конечном датасете определяются точками начала и конца паса на декартовой системе координат, и их можно отобразить на футбольном поле. Для различных футбольных матчей размеры поля могут отличаться; в исходных данных такие отклонения были компенсированы так, чтобы каждый матч можно было отобразить на поле со следующими координатами:
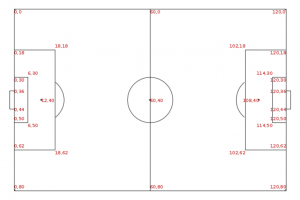
В самом датасете данные всех координат игровых событий подготовлены так, как будто для любой команды правая сторона поля — это сторона противника.
2. Оценка данных при помощи Tableau
Tableau идеально подходит для быстрого анализа (поиск инсайтов в данных), поэтому попробуем просто отобразить все пасы при помощи линий и оценить их количество, Подключим полученный CSV файл к Tableau и отобразим точки начал и концов пасов. Точки начала:
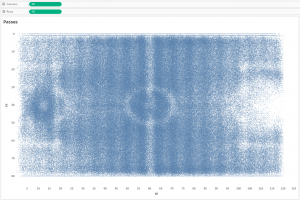
Точки конца:
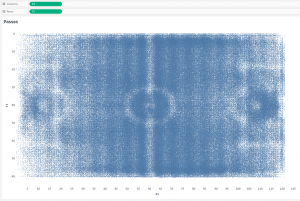
Получились картинки из которых ничего непонятно, поскольку количество точек на каждой немногим меньше 900 000 штук, а это почти миллион. Для построения линий пасов сделаем UNION в Tableau:
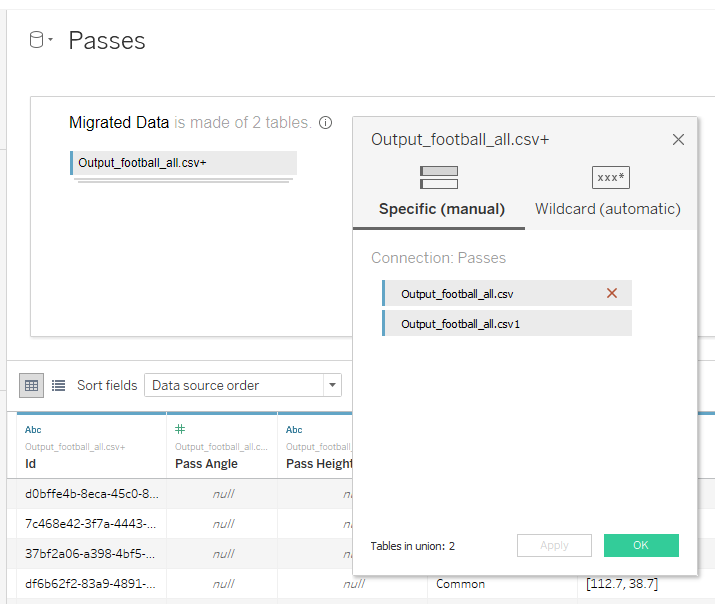
Таблица Output_football_all.csv будет отвечать за координаты начала пасов, а Output_football_all.csv1 будет отрисовывать координаты концов пасов. Если соединить все точки, то есть, каждый пас представить линией, получим на уровне прозрачности 1% следующее:
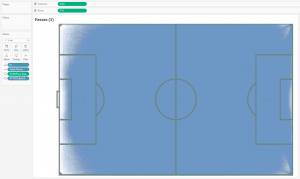
Id в грануляции здесь – это идентификатор паса. То есть Tableau на минимальном уровне прозрачности рисует около 890 000 линий, и все они сливаются в один синий прямоугольник — это нам тоже ничего не дает. Но мы можем понять что в одном матче, в среднем, проводится примерно 1000 пасов, то есть, каждая команда выполняет около 500 пасов. Это примерно соответствует официальной футбольной статистике.
Вычисления XXX и YYY выглядят следующим образом:
XXX
CASE RIGHT([Table Name],1)
WHEN ‘1’ THEN [X0] ELSE [X1]
END
YYY
CASE RIGHT([Table Name],1)
WHEN ‘1’ THEN [Y0]
ELSE [Y1]
END
3. Агрегация данных
Эта картина нам ни о чем не говорит, потому что здесь около 890 000 линий, и все они накладываются друг на друга. Поэтому следующим шагом я решил сгруппировать линии по началу старта, округлив X0 и Y0:
X0
ROUND(FLOAT(MID(SPLIT([Location],’,’,1),2,10)))
Y0
ROUND(FLOAT(SPLIT(SPLIT([Location],’,’,2),’]’,1)))
Если расположить округленные координаты на футбольном поле, получим следующее:
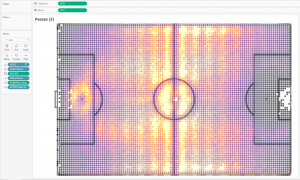
То есть, футбольное поле было разделено на квадраты примерно метр на метр, и все координаты пасов в пределах каждого квадратного метра были стянуты в одну точку. Вычисление COUNT в цвете здесь определяет количество пасов в каждой точке:
COUNT { FIXED [X0],[Y0]: SUM(1)} / 2
То есть, вычислениями с округлениями мы разбили футбольное поле на квадраты со стороной 1 метр (примерно), и далее будем визуализировать пасы из каждого квадрата. 2 в знаменателе нам нужно для того, чтобы вернуть верное кол-во пасов, поскольку данные были увеличены в 2 раза операцией UNION. Для каждого такого квадрата усредним координаты конца паса:
XXX
CASE RIGHT([Table Name],1)
WHEN ‘1’ THEN [X0]
ELSE { FIXED [X0], [Y0], [Table Name]: AVG([X1])}
END
YYY
CASE RIGHT([Table Name],1)
WHEN ‘1’ THEN [Y0]
ELSE { FIXED [X0], [Y0], [Table Name]: AVG([Y1])}
END
То есть, усредняя координаты конца паса, мы все пасы с одного квадратного метра заменяем только одной линией — это сильно уменьшает общее количество линий на визуализации. Так мы избавляемся от проблемы перекрытия большим количеством линий друг друга. Получается такая картина:
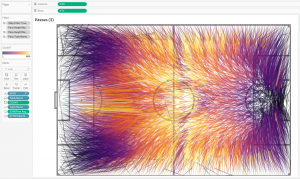
Направления пасов показываем добавлением Table Name в Size, получая утолщение линии в конце паса. Так создается ощущение летящего мяча.
И конечный виз в Tableau:

В этом визе специально низкое количество пасов отмечается черным цветом, чтобы на темном фоне такие линии, как несущественные, были практически не видны. Если поменять палитру, усилив линии с низким количеством пасов, то получим:
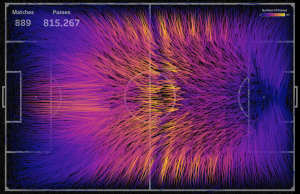
Поиск инсайтов в данных можно делать визуально, используя интерактивные возможности Tableau: фильтруя данные, разделяя команды на группы и т.д. Интересно построить динамическую картину пасов, начиная с одного матча, и на каждом следующем шаге добавляя пасы другого матча. Такая динамическая картина как раз показывает переход от кажущегося хаоса на малом количестве данных к упорядочению линий на большом количестве данных:
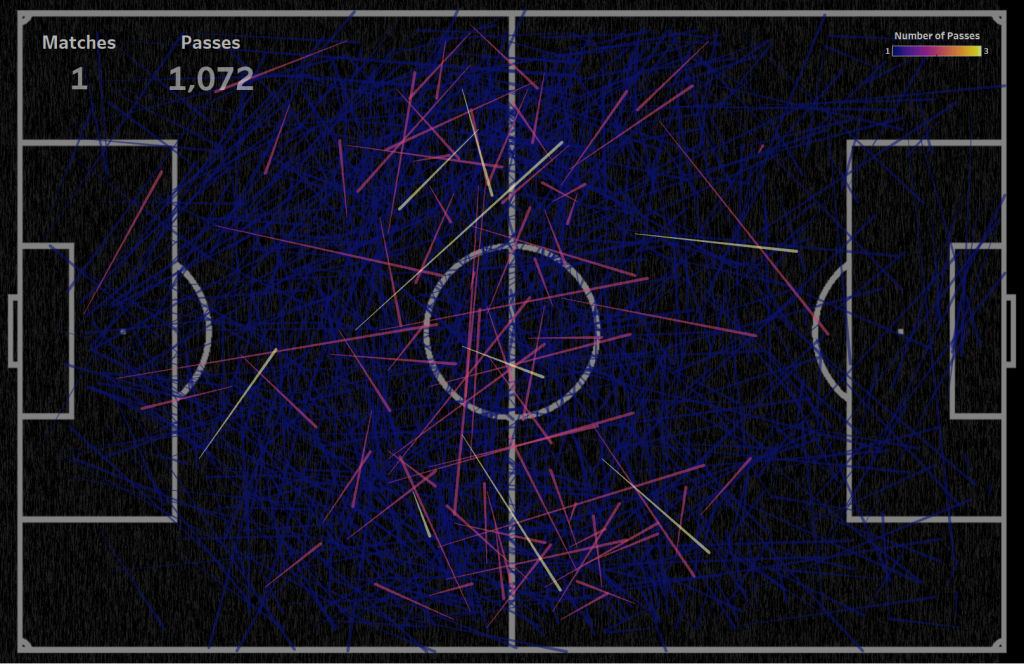
В этом видео из визуализации были убраны данные о пасах вратаря, угловые и сбрасывания, чтобы оставить только пасы игроков в процессе игры, определяющие картину атаки. Сравните визуализацию данных одного матча, где не наблюдается закономерности в пасах и создается ощущение случайных данных, и визуализацию данных пасов в 889 матчах, где есть четкая симметричная картина атаки.
Про то как создавать такого рода видео я писал в статье «Создание видео при помощи Tableau и программных роботов«.
Для пасов одного матча вообще непонятно что происходит на поле, практически невозможно выделить приоритетные направления пасов:
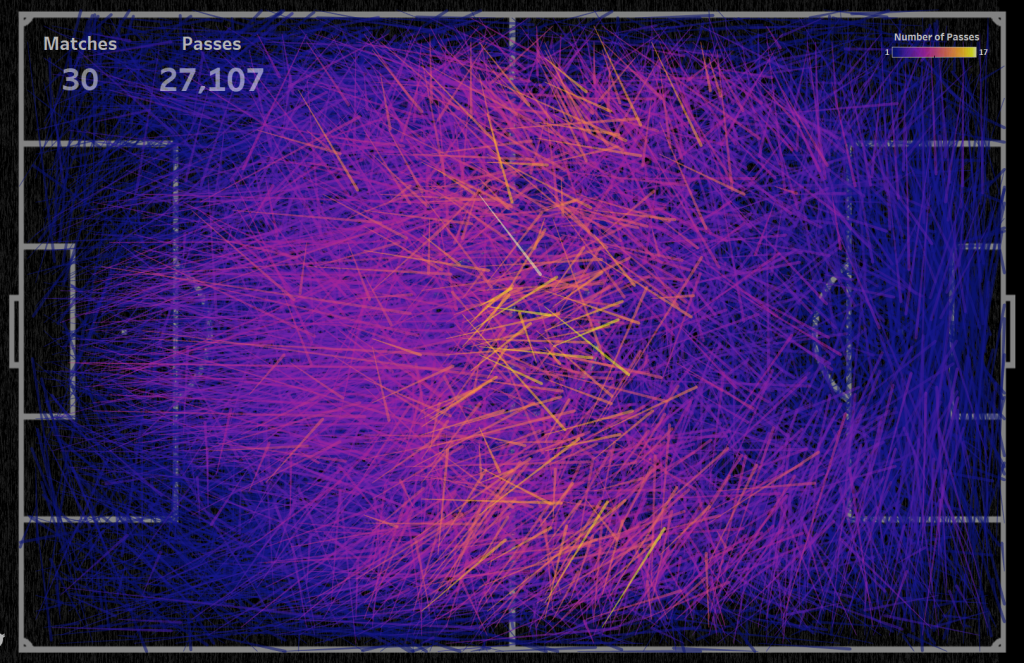
Для 30 матчей полупрозрачные линии закрывают разметку в центре поле, но можно выделить некоторые участки, где наиболее часто производятся пасы:
Для 889 матчей можно видеть приоритетные направления пасов на каждом участке поля:
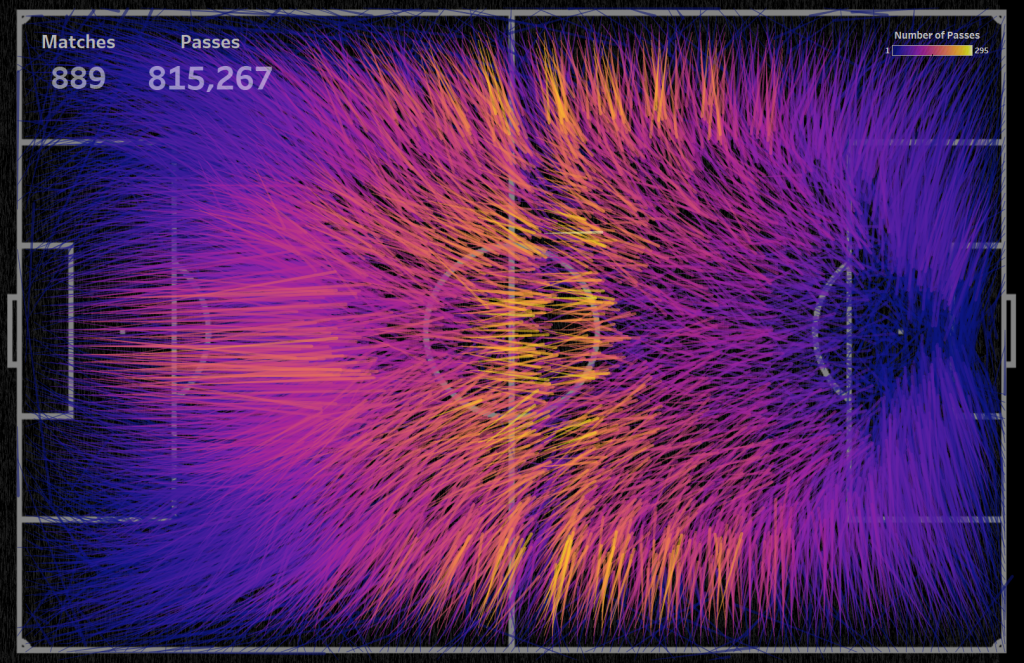
Надо отметить что после 300 матчей картина сильно не меняется.
Заключение
Данные, которые мы визуализировали, включают информацию о пасах в различных видах соревнований, игры различных лиг, женский и мужской футбол. Мы получили общую усредненную картину, которая может дать понимание того, как в футболе проходит атака. На сайте Reddit в сообществе r/dataisbeautiful этот виз прокомментировали 600 раз, виз собрал более 35000 upvotes, каждый нашел свои инсайты в этой визуализации. Поиск инсайтов в данных особенно хорошо работает с интерактивными возможностями визуализации где каждый может найти что-то своё.
Целью визуализации не являлся точный анализ футбольных матчей — в этой визуализации из хаоса цифр была создана упорядоченная и логичная картина, которая сама по себе является достаточно красивой визуализацией. Также приведенный пример показывает насколько сильно меняется картина пасов от одного матча до данных нескольких сотен матчей, то есть, мы можем видеть переход от казалось бы хаотичной системы к упорядоченной.
Также выше мы могли убедиться, что небольшое количество данных и слишком большое количество точек не работают на визуализации, а работает некоторое среднее количество.
Все больше компаний нанимают продуктовых аналитиков. Бизнесы часто выдвигают разные требования, но сходятся в одном: ключевая компетенция product analyst — искать и находить инсайты для развития продукта.
Разбираемся вместе с Богданой Юрык, лекторкой курса Product Analysis и Product Analyst Lead в SQUAD, как найти инсайты в данных.
#1. Изучите ваш продукт
Да, начинать нужно не с данных, а с продукта. Например, вы работаете над сервисом аренды электросамокатов. Для начала установите приложение и запишите ваши первые впечатления от его настройки — они очень важны. Разберитесь, как работает сервис, какие шаги нужно сделать, чтобы найти ценность продукта и почувствовать aha-момент. Выйдите на улицу, покатайтесь на электросамокатах — ваших и конкурентов, сравните их. Спросите себя, были ли у вас трудности, что вам понравилось. Пройдите путь пользователя (customer journey), будьте им.
Приберегите мастерство и критический подход для следующих этапов, здесь вам понадобятся мышление новичка и живой интерес к продукту.
#2. Определите инструменты
Вам нужно определиться с минимальным набором инструментов для обработки данных и визуализации.
Я проанализировала вакансии и требования к дата- и продуктовым аналитикам на портале dou.ua и сайтах 5 tech-гигантов (GAFAM). Вот ключевые направления работы и инструменты:
- Работа с базами данных SQL (PostgreSQL, PL/SQL, MySQL) иNoSQL
- Обработка и анализ данных в R или Python
- Визуализация данных (Tableau, Power BI)
#3. Займитесь сбором и логированием данных
Работа с данными начинается с проверки того, какие логи (ивенты) пишутся в базу. Например, компания может собирать:
- техническую информацию о работе и производительности продукта (приложение, сайт, физический продукт)
- продуктовые ивенты, которые отслеживают поведение пользователя, как он взаимодействует с продуктом
- финансовые данные, которые включают расходы (например, на рекламу) и платежи от клиентов, их банковскую информацию
Затем мы смотрим, все ли нужные опции записаны и за какое время их можно обработать исходя из бизнес-запроса и возможностей базы.
Для отслеживания продуктовых ивентов вы можете использовать внутреннюю базу данных и/или внешнюю систему (например, Mixpanel или Amplitude). Если нужный ивент есть, переходите к следующему пункту, если нет — пропишите логику ивента и начните трекинг. Это может быть регистрация или настройка приложения, для этого вы пропишете, что может сделать пользователь, кликнув на кнопку, — какие опции или страницы регистрации выбрать.
#4. Определите цель анализа
У каждого исследования должна быть цель. Чтобы ее определить, ответьте на главные вопросы:
- Что вы исследуете?
- Какие данные нужны и за какой период?
- Какова целевая аудитория?
- Какую проблему хотите решить с помощью аналитики?
Например, у вас уже есть регулярные отчеты — и там вы увидели, что на прошлой неделе был пик по установкам приложения, а общая конверсия в регистрации снизилась.
Это значит, что вы исследуете изменение метрики. Нужно взять логи приложения по новым пользователям за последние несколько недель. Проблема здесь — исследование резкого спада конверсии в регистрации.
Если возникли сложности с определением проблемы — попросите помощи у продуктового менеджера.
#5. Сформулируйте гипотезы
Не начинайте проверять все подряд, постарайтесь структурировать ваш подход.
Причины для изменения метрики можно разделить на две большие группы:
- Внутренние: ошибки работы приложения, новая версия аппки не оттестирована, новый функционал, который блокирует действия, ошибки логирования, непонятный UX
- Внешние: вышли PR-кампании, сезонность, действия конкурентов, изменения в работе адвертайзеров, реферов или платформ, погодные или социальные условия в конкретном регионе.
В зависимости от возможных причин и снижения метрики (резкого или продолжительного), сформулируйте гипотезы.
#6. Проверьте корректность данных
Чтобы подключиться к базе данных, вам понадобится SQL. Проверьте, пишутся ли все необходимые данные. Чтобы лучше понять, какие ивенты и как пишутся, проделайте нужные шаги в продукте (зарегистрируйтесь, пройдите онбординг или протестируйте новый функционал), а потом отследите логи, которые вы нагенерили в базе.
#7. Сформируйте рабочие дата-сорсы и очистите данные
Если вы работаете с большой базой данных и подключиться к ней напрямую невозможно или нецелесообразно, подготовьте рабочие таблицы, используя SQL, Python или R. Исключите ненужные сегменты (платформы или регионы), ограничьте временной период, проверьте, нет ли пустых значений, некорректно записанных данных, неожиданных экстремумов.
#8. Проанализируйте метрики
Анализ метрик всегда зависит от исследуемой проблемы и от того, к какому этапу продукта или жизненного пути пользователя она относится.
В нашем примере нужно определить, почему и какие пользователи не проходят регистрацию. Для этого делаем анализ каждого шага при регистрации (заполнение личных данных, ввод и подтверждение банковской карты, подтверждение личности с помощью sms/email) и считаем конверсию переходов на каждый этап и затраченное время на их прохождение. Возможно, вы увидите резкое снижение или долгое прохождение какого-то из этапов. Если нужно, делим на сегменты по регионам, платформам, рекламным каналам.
Продуктовый анализ — это о проверке гипотез.
#9. Сделайте понятные визуализации посчитанных метрик
Определитесь, что вы хотите сказать визуализацией. Нужна история. Графики только помогают рассказать ее. Не усложняйте визуализацию, уберите все лишнее, выберите цветовую гамму, расставьте акценты. Вот пример хорошей визуализации продаж по разным регионам, выполненной в Tableau:
- Есть акценты на большие цифры
- Используется только 4 основных цвета
- Есть важные разрезы по регионам и категориям продукта
- Все графики подписаны и есть дополнения
- Легко переходить между уровнями агрегации данных
- Легко фильтровать
#10. Читайте отзывы пользователей и говорите с ними
Узнайте, какие проблемы они решают с помощью вашего продукта, почему выбирают его и чего им не хватает. Ищите ответ на вопрос «Почему?» в качественных исследованиях, чтобы подтвердить количественный анализ.
#11. Всегда делайте выводы и делитесь ими
Вы можете включить их в отчет или презентацию перед командой. Люди не всегда могут быстро понять графики и таблицы — помогите им, написав ключевые мысли.
Для хорошего продуктового анализа мало выучить метрики и статистики, нужно знать инструменты, с помощью которых вы вытянете данные и визуализируете их. Да, когда продуктовый аналитик знает, умеет и совмещает навыки из многих областей, глубоко понимает продукт и его пользователей, это дает классные инсайты и рост бизнеса. Хорошая новость — понимание продукта, а также умение рассказывать истории, которые хранят данные, приходит с опытом. Не бойтесь пробовать.
