Есть сайт или программа для выяснения откуда взят текст
Разрушитель
Мыслитель
(5582),
закрыт
10 лет назад
В принципе все просто, но одновременно тяжело. Имеется перепечатка учебника, однако найти его авторов не представляется возможным, во первых нет первых титульных или последних листов, а в имеющимся тексте нет сносок или отсылок, что за учебник. во вторых, строчки от туда, при забивании в яндекс/гугл не дают ничего путного. Учебник по психологии, так что схожего отсыла довольно много, а толку найти именно этот нет. ПРошу помочь, так как слышал, что есть толи сайты толи программы, защита от копирайта, мол вбиваешь текст и выдает, что за книга или учебник.
Group Дошкольников
Ученик
(108)
6 лет назад
педагог А. С. Макаренко дал определение детской игре; «Игра имеет важное значение в жизни ребенка, имеет тоже значение, какое у взрослого имеет деятельность работа, служба. Каков ребенок в игре, таким во многом он будет в работе. По этому, воспитание будущего деятеля происходит, прежде всего, в игре »…
Lana
Ученик
(192)
4 года назад
Проверяю вышеперечисленными способами (text.ru) свою авторскую статью. Выкладывала прежде всего на своем сайте, а потом уже на b17 откуда они разлились по всему интернету. Первыми показаны те сайты, которые первыми скопипостили материал и даже не те, где я сама его выкладывала и откуда он был ими взят. Мой сайт третий. Так что вопрос как найти авторский источник текста остается открытым.
Так как это влияет на продвижении в поиске моего сайта – неприятно.
Сервисы проверки скорее помогают статьям или вредят? Редакция «Текстодрома» не понаслышке знает особенности массы инструментов. Мы считаем: алгоритмы могут ошибаться, но копирайтеру и редактору не стоит ими пренебрегать — ведь все зависит от задач, стоящих перед текстом.
Помощники по улучшению качества, конечно, не панацея. Не стоит слепо следовать их требованиям в ущерб читабельности. Но если текст нужно сдать срочно, а глаз откровенно «замылился», сервисы реально помогут, указав на неудачные фразы.
Протестировали ряд инструментов для работы с текстом. А чтобы вам не было скучно, сопроводили текст анализом описания товара с сайта. Приятного путешествия по сервисам!
9 сервисов проверки на уникальность текста и один — изображений
Начнем с главного для веб-мастера критерия. Неуникальный контент не принимают 90 % заказчиков. Даже на биржах требуется от 70 % (для юридической тематики) до 80 % уникальности. Прямые заказчики обычно согласны на 90–95 %, но и 100 % — не редкость. При этом работодатель обычно имеет в виду проверку по «Текст.ру», который считается наиболее лояльным инструментом. С него и начнем.
Text.ru
Один из самых распространенных антиплагиатов, проверку по которому обычно требуют заказчики. В чем же его преимущества?
- Бесплатно. «Текст.ру» не берет оплаты и не требует обязательной регистрации. Но мы все же рекомендуем пройти эту простую процедуру: откроются некоторые функции (например, сделать результат проверки доступным для других людей и безлимитное количество прогонок в день).
- Объем статьи. Один из немногих ресурсов, который проверяет за раз до 15000 ссп: хватит на неплохой лонгрид. Если вы предпочитаете писать тексты по 20 кило (как мы), придется разбивать их на части.
- Лояльность. Хотя разработчики утверждают, что text.ru отошел от традиционных проверок по шинглам (отрывкам из 3–4 повторяющихся слов во фразе) и тем исключает возможность схитрить при рерайте, в нем вполне можно получить 100% уникальности. Сбои происходят довольно редко.
- Работает не только с уникальностью — покажет переспам, проблемы с орфографией и водностью и даже подскажет синонимы. Об этом — чуть ниже.
- Отдельная галочка — проверка по «Яндекс.Дзен».
Но есть и некоторые недостатки:
- Очереди. Буквально с лета прошлого года это стало серьезной проблемой. Текст может крутиться довольно долго (есть отметка, сколько статей перед вами в очереди, но она часто не радует: бывает и 247 проверок). Ночью ситуация обычно лучше, чем днем. Для зарегистрированных пользователей скорость немного выше, а онлайн-чат будет упорно предлагать вам купить версию PRO с возможностью мгновенно получить результат (мы не пробовали, не было необходимости).
- Ограничение для гостей. С недавнего времени можно проверить только один текст, после чего вам предложат зарегистрироваться.
- Странные сбои. Иногда Text.ru показывает 100 % даже на явно неоригинальных рерайтах. А в следующий раз он может выдать 70 % на оригинальном материале, и поднять уникальность в таком случае невероятно сложно. Мы заметили, что на строительных тематиках и сухих инструкциях Text.ru «упирается» чаще всего.
Советы по «починке» уникальности от старожилов. Исправить первое предложение в начале документа, где сервис подсвечивает плагиат. Обычно этого хватает. Только в дальнейшем «не дышите» на текст — любое измененное слово сбивает показатели. И лучше сохранить данные с помощью специальной кнопки «ссылка на проверку» или «зафиксировать уникальность» — были случаи, когда заказчик, заново проверяя статью, получал совсем другой результат.
Посмотрим на практике. Материал по стройке уже давно индексирован на сайте, поэтому «Текст.ру» должен легко распознать плагиат. После очереди для гостя в 56 человек мы видим:
Хороший результат: 0 % уникальности и единственная ссылка именно на тот источник, откуда мы взяли текст. По крайней мере, полный копипаст сайт точно отличит.
Advego. Антиплагиат онлайн
Любимый инструмент сеошников, который традиционно используют для проверки тошноты и водности. Однако в нем есть и функции антиплагиата, правда, очень урезанные.
- Требуется обязательная регистрация, иначе результаты не покажут.
- После входа в режиме пользователя откроется функция проверки до 5000 символов в день (для копирайтера с полной нагрузкой это очень мало). Все, что свыше — платно.
- Но можно скачать программу на компьютер. Доступна для Linux, macOS и классической Windows. Правда, некоторые SEO-мастера считают, что десктопная версия не настолько точная, как онлайн-сервис.
- Проверка будет довольно жесткой — после отправки текста оцениваться будут 2 критерия: «уникальность» и «рерайт». Сто процентов сложно получить даже по первому признаку, а по второму показатели еще ниже. Хорошо, что обычно заказчики все же интересуются критерием уникальности. Но имейте в виду, что требования 100 % по «Адвего» — это почти нереально, особенно для технических и юридических статей. Лучше отказать капризному заказчику.
Возьмем наш строительный текст и посмотрим реакцию «Адвего».
Заметьте, здесь тоже 0 % уникальности, но кроме основного совпадения с исходным сайтом (первый адрес в правой таблице), «Адвего» «видит» еще и незначительные совпадения на порталах «Дзена», ВК и прочих (по 1–3 %). Поэтому на ресурсе полную оригинальность набрать практически нереально: алгоритм находит даже малейшие совпадения во фразах.
Для наглядности — пример ниже. Текст, который мы проверяли первым, вообще нигде не индексирован. Однако сервис считает его уникальным на 99 % — это к слову о заказчиках, которые желают 100 % по «Адвего» (бегите от них!).
ETxt.ru
Еще один антиплагиат с неплохим по достоверности алгоритмом. Что про него нужно знать:
- проверяет гостям до 3000 знаков, после регистрации — до 5000 ссп;
- бесплатный;
- проверяет быстрее «Текст.ру», но медленнее, чем «Адвего»;
- десктопная версия без ограничений, но ее тяжело использовать из-за навязчивой капчи;
- рекомендуем все же скачать сервис, он очень удобный, но придется установить платную антикапчу.
Пока все сервисы видят неуникальный текст и правильно определяют источник. Этот нашел еще одно небольшое совпадение на другом портале (на 2 %), а это значит, что заказчиков, желающих 100 % по ETxt для инфостатей, тоже стоит опасаться. Или писать для них чистейший сторителлинг. Это не такой жесткий антиплагиат, как «Адвего», но полную оригинальность выдает нечасто.
Из забавной практики. В свое время член редакции работал на бирже, которая использовала для контроля плагиата алгоритмы ETxt.ru. Сервис несколько раз показывал 99 %, подсвечивая точку. Каким образом она оказывалась неуникальной — до сих пор загадка.
Content Watch
В бесплатной версии проверит до 3 текстов в день объемом не более 10 000 символов каждый. Регистрация не требуется. Это не самый популярный инструмент у веб-мастеров, и сейчас мы поймем почему.
По доброте душевной мы получили аж 21 % оригинальности: Content Watch нашел сайт с исходной статьей, но счел ее не полностью заимствованной. Сервис в общем быстрый, удобный и простой в использовании. Даже предлагает функцию просканировать сайт по доменному имени на предмет уникальности страниц. Но алгоритм у него явно слабее предыдущих.
PR-CY
Малоизвестный ресурс, который больше рассчитан на веб-мастеров. Он оценивает сайты с точки зрения посещаемости, «естественности» контента — для людей, а не машин (опираясь на закон Ципфа). Но есть и масса полезных «фишек» для копирайтеров и контент-менеджеров (см.скрин).
Нас пока интересует антиплагиат. Что обещает PR-CY гостю бесплатно? Проверять до 5000 символов (после регистрации — 10000). Кроме того, можно игнорировать сайт, который вы хотите исключить из проверки (так поступают веб-мастера, когда ищут похищенный контент).
Что мы получили в реальности? После отправки текста в окошке появилось уведомление, что без регистрации можно проверить до 1000 символов. Сами себе противоречат, но окей. Зарегистрируемся.
После регистрации текст приняли. Что интересно: сервис показывает не только количество знаков, но еще слов, предложений и даже время на его прочтение. С уникальностью все странно:
Сам по себе 1 % уникальности — логично для копипаста. Но вот источники ресурс нашел вообще «с потолка». Собственно, сайт со статьей-примером разместился на 5 месте и, по версии PR-CY, имеет 2 % совпадений. Мы считаем, что проверка здесь не пройдена в надлежащей мере.
Copywritely
Проверяет текст или сайт по URL-адресу. Без регистрации в форму можно вставить до 500 слов. Сразу после нажатия кнопки выскакивает табличка (по аналогии с «Текст.ру»). Пока идет проверка уникальности, вы можете посмотреть, сколько сервис нашел грамматических ошибок, как оценил читабельность статьи и наличие переспама. Но вот подробности можно узнать только после регистрации.
И-и-и… У нас новый антирекорд! Сервис считает, что вибропрессованная плитка абсолютно уникальна. Два балла за внимательность алгоритма.
«Антиплагиат»
Главная «страшилка» всех студентов. Сервис очень популярный, но, скорее, в проверках для будущих ученых — курсовых, дипломных и диссертаций. Дело в том, что ресурс ищет неуникальные отрывки не только в стандартных поисковых системах, но и в подключенных базах научных работ. Поэтому его используют преподаватели, чтобы поймать студентов и аспирантов, заимствующих труды более честных коллег.
Антиплагиат широко известен, поэтому сомневаться в нем не будем. Несколько моментов:
- регистрация обязательна,
- бесплатно доступны поверхностные проверки,
- по платной подписке (от 150 рублей) доступны расширенные функции, поиск заимствований и перефраза (рерайта), оценка качества экспертом.
BE1.RU
Не самый известный сервис (нам ни разу в ТЗ не попадался точно). Считается, что использует алгоритмы Яндекса. Без регистрации допускает одновременную проверку только 1000 символов, после — 10000. По идее, неуникальный отрывок также должен найти. Посмотрим.
Сайт, как видим, копипасту нашел, но вывел лишь 60 % совпадений. Так не должно быть даже при отправке неполного текста. Для сравнения прогнали тот же отрывок через «Текст.ру»:
Контраст налицо.
Copyscape
Не совсем копирайтерский инструмент — ищет копии страниц сайтов. Если ваш контент был использован кем-то еще, то появится адрес похитителя. Дублей нашего текста в сети не оказалось, поэтому взяли на пробу статью с vc.ru.
Неплохо: 7 совпадений, разные источники, в том числе «ВКонтакте» и «Яндекс.Дзен». Везде указан адрес и отрывок, совпадающий с текстом на странице. Правда, копипаст мы видим только на трех ресурсах, остальные с виду совершенно о другом. Сервис неплохой, как минимум две проверки провел бесплатно и без регистрации. После того как пользователь заведет учетную запись, станут доступны все совпадения. В режиме «гостя» сайт выдает только часть источников.
Бонус: проверка изображений TinEye
Заказчики часто требуют добавлять в статьи картинки, которые не защищены авторским правом. Где их искать и какие стоки самые популярные, мы писали в большом материале на vc. Но как проверить, не используют ли ваши оригинальные изображения другие веб-мастера?
Сервис идентифицирует загруженное изображение или фотографии из интернета через URL. Можно добавить его как расширение в Google Chrome. Как это работает? Берем первую же картинку из поисковой выдачи Google и смотрим, где еще ее видит алгоритм. Мы выбрали типичное изображение чайного набора и обнаружили, что его используют 143 сайта — как российских, так и зарубежных.
6 инструментов для семантического анализа
Для работающих с SEO-текстами копирайтеров слова «тошнота», «вода», «стоп-слова», «прямое и разбавленное вхождение» не кажутся загадкой. Типичные требования к написанию статей для веб-сайтов — не превышать определенный процент переспама (повторяющихся слов и фраз) и норму по «воде» (не несущим смысловой значимости фрагментам текста). Не менее важным является грамотное распределение и внедрение ключей. Какие популярные сервисы могут проверить эти параметры?
Bonica
Основной инструмент сеошников и незаменимый помощник для копирайтера, которому досталось ТЗ с «полотном» ключевых запросов и дополнительных слов. Часть из них и так будут по умолчанию упоминаться в тексте, поэтому проверять каждый ключ вручную — потеря времени.
Для таких статей мы рекомендуем сначала написать текст без ключей из ТЗ (кроме главных фраз). После этого нужно зайти в систему bonica.pro и распределить заданные слова по нужным окошкам. Те, которые запрещено склонять или как-то изменять, добавляете в окно «Точное вхождение». Запросы, которые разрешено использовать в разбавленном вхождении (склонять, вставлять между ними сторонние слова) — в окошко «разбавочные». Все остальное — в «дополнительные слова». Еще можно настроить другие параметры: не учитывать/учитывать ключи в заголовках, разрешить/запретить их склонение, задать «количество разбавочных слов» (по умолчанию — не более 3).
После подготовки вставьте текст во встроенный редактор — и сервис подскажет, какие запросы уже есть в статье, а каких не хватает (в скобках будет указано количество). После этого останется только вписать недостающие ключи.
Лайфхак от редакции. Иногда техническое задание бывает особенно «замороченным»: например, дополнительные слова должны упоминаться определенное количество раз. В «Бонике» можно вписать цифру в скобках после каждого запроса (в окошках «Ключевые слова»). Так намного удобнее сравнить, упомянуты ли ключи с нужной для ТЗ частотой (см. скрины 1 и 2).
Сайт бесплатный, для обычной проверки регистрация не требуется.
«Адвего» — SEO-анализ
В отличие от контроля на плагиат, семантический анализ практически не ограничен по количеству символов (до 100 тысяч за раз) и не требует регистрации. Это основной инструмент, по которому заказчики проверяют «воду» и переспам («тошноту»). Нормальными показателями по «Адвего» считаются:
- классическая тошнота — до 7 %,
- академическая тошнота — до 10 %,
- переспам по слову — до 3 % (сверять показатели в разделе «Семантическое ядро»),
- водность — не более 65 %.
Если какие-то показатели в таблице (раздел «Стилистика») вас не устроят, их можно исправить, ориентируясь на разбор по словам. На нашем примере общие показатели классической и академической тошноты в норме, но переспам по «плитка» почти на грани — 2,83 %. Несмотря на то что 3 % «тошноты» еще входят в норму, мы рекомендуем по возможности доводить этот показатель до 2 и менее процентов. Иначе термин будет «резать глаз» при прочтении.
Если вам не нравятся показатели водности, их можно уменьшить, убрав наиболее частотные предлоги или союзы (отмечены с процентами в таблице «Стоп-слова»).
Кроме семантики, сервис подсчитывает общее количество слов и символов, а также может подсветить некоторые грамматические проблемы. Но проверка орфографии — не самая его сильная сторона. Ниже мы расскажем о более эффективных онлайн-корректорах.
Текст.ру
Неплохой инструмент SEO-анализа от популярного сервиса проверки уникальности. Пользоваться можно без регистрации, количество знаков не ограничено. На выходе получите обзор, который включает:
- подсчет символов (сбп и ссп);
- общее количество слов в статье;
- параметры в процентах — заспамленность и «вода».
Нормативы у «Текст.ру» отличаются от системы подсчета «Адвего». Здесь для показателя «тошноты» нормой считается 30 % (для обычных текстов или постов), и от 30 до 60 % для информационных текстов с внедрением ключей. То есть переспам идет при показателе выше 60 %. Параметры «воды» в тексте не должны превышать 15 % (хотя именно высоким содержанием стоп-слов считается показатель от 30 %).
Минусы: нет такой наглядной таблицы, как у «Адвего». Зато он подсвечивает стоп-слова прямо в тексте — можно исправить во встроенном редакторе.
Еще одна удобная функция от Text.ru — поиск смешанных слов (из разных алфавитов). Этим способом часто пользуются нечестные копирайтеры, чтобы механически повысить уникальность, но «попасться» могут и их более честные коллеги (например, при копировании терминов из источника). Замена символов — основание для попадания сайта под фильтр при ранжировании, поэтому следить за этим параметром нужно особенно внимательно.
Анализ по закону Ципфа на PR-CY
Здесь можно проконтролировать количество ключей («тошноту») и их распределение по тексту (плотность). Итоговый показатель измеряет естественность статьи в процентах, то есть насколько она комфортна для читателя. Хорошим итогом анализа считается показатель от 50 % и выше.
Можно проверить от 100 до 15 000 слов без регистрации и бесплатно. Причем анализ доступен как для отдельного текста, так и для страницы сайта (в поле добавляется ссылка).
К нашему примеру сервис оказался лоялен, оценив его естественность высокими 92 %. По Ципфу количество вхождений ключевого запроса «плитка» для pr-cy оказалось оптимальным. Напомним, что по «Адвего» показатель «тошноты» был в пределах нормы, но все же не идеальным.
Интересная опция сервиса — в таблице анализа выбранных ключевых слов в последней графе есть рекомендации по коррекции их количества (частоты). Нам предложили убрать от 1 до 2 повторов в каждом слове.
ISTIO
Еще один бесплатный SEO-анализатор. Проверяет параметры водности, классической тошноты, может определить СЯ текста и покажет по слову его употребление в процентах и релевантность к статье. Из интересных бонусов: довольно точно определяет тематику содержимого (у нас он указал «Реклама», «Недвижимость» и немного ошибся, добавив «Продукты питания»).
Нормы по параметрам в справке указаны только для «воды»: от 30 до 60 %. Разработчик предлагает варьировать этот показатель, опираясь на интуицию и тематику статьи. Сервис неплохой, но, кроме определения тематики, не дает ничего сверх того, что можно узнать на том же «Адвего».
Проверка на стоп-слова от биржи ContentMonster
Очень удобный сервис от биржи копирайтинга. Ищет именно «мусорные» слова, не несущие смысла. Причем не только указывает их процент в статье, но и подсвечивает в тексте. Без регистрации можно проверить до 10 000 символов за раз. В нашем случае сухая техническая статья была справедливо оценена в 0,75 % стоп-слов (2 штуки).
Лайфхак новичкам от редакции. Мы в свое время регистрировались на этой бирже, но не ради заказов, а чтобы ускоренно освоить азы копирайтинга. В качестве повышения квалификации работникам предлагаются учебные материалы по основным понятиям профессии: «тошнота», «вода», «ключевые слова», «уникальность», а также теги, метатеги и многое другое. После каждого блока следует тестирование — закрепление урока. Очень удобно, коротко и по сути.
Бонус: где подобрать синонимы, чтобы избежать переспама
Если показатели тошноты у вас зашкаливают, можно воспользоваться таким способом.
- Смотрите по «Адвего» слова с наибольшим процентом использования.
- Максимально их сокращаете или заменяете синонимами (в крайнем случае — местоимениями).
- Указанные выше шаги снижают академическую тошноту. Обычно показатели классической уменьшаются вместе с ней.
- Если по классической тошноте все по-прежнему печально, убирайте стоп-слова (также по наиболее повторяющимся в процентном соотношении).
Где взять синонимы для проблемных терминов? Помогут онлайн-словари. Но прежде чем перейти к ним, покажем наглядно, как работает печально известный синонимайзер и почему им лучше не пользоваться.
Обработка нашего строительного текста-примера выглядит вот так. Уникальность удалось поднять всего до 35,6 %, но статья при этом совершенно изуродована. Алгоритм механического рерайтинга действует слишком грубо. По сути, такую статью отдавать заказчику явно не стоит, хотя пару-тройку слов можно заменить на предложенные. Пользуйтесь инструментом разумно.
Подобрать синонимы по слову можно в трех онлайн-словарях.
- На «Текст.ру» — вводите слово, и из вариантов близких и дальних по значению ищете оптимальный. Словарь очень обширный, можно подобрать подходящий синоним.
- Сборник онлайн-словарей — можно вбить в строку поиска ключевое слово и в типе словарей задать словарь синонимов. Но здесь, скорее, ценна возможность определиться со значением непонятного термина. Портал предлагает массу всевозможных толкователей, включая прикладные, медицинские, технические, гуманитарные, толковые и даже жаргонные словари. Для копирайтера это бесценный ресурс, рекомендуем.
- «Синонимус» — бесплатная база синонимов. Ищет по трем вариантам: полному словарю и словарю Абрамова, а также базе, которую собирают сами пользователи, предлагая в специальном окошке свои слова. Неплохой и достаточно богатый выбор, но оценить, насколько синоним соответствует контексту, придется самостоятельно.
6 ресурсов и одно расширение для проверки стилистики
Почему мы выделили эти сервисы отдельным пунктом? Они имеют непосредственное отношение к SEO-анализу текста, так как чистят материалы от воды и стоп-слов. Но кроме этого, ресурсы дают рекомендации по общему стилю: выделяют неудачные речевые обороты, находят клише, штампы и канцеляризмы. По сути, это онлайн-редактура, которая поможет избежать ряда претензий от «живого» редактора.
Рекомендуем пользоваться сервисами для саморазвития: это помогает увидеть смысловые и стилистические несоответствия и понять, в чем ваши слабые места. Естественно, бездумно следовать указаниям искусственных алгоритмов не нужно: иногда они не соотносят свои рекомендации с общим контекстом или подачей текста.
«Тургенев.Ашманов»
Еще один главный инструмент сеошников, кроме «Боники» и «Адвего». Для работы с ним потребуется регистрация, после чего на вашем счете окажется 150 рублей: бонус на первые прогонки текстов. Одна общая проверка стоит 5 рублей. Если только по вкладке «Стилистика», то бесплатно. Но есть способы проверять статьи дешевле. Например, прогонку всего за 30 копеек можно сделать через этот сервис. Лимит — 30 тысяч символов за раз.
Основная функция — определить риск попадания сайта под фильтр из-за некачественного контента. В это понятие входит высокая концентрация ключевых запросов, повторов (тавтологий), стоп-слов, шаблонных фраз, канцеляризмов, а также удобочитаемость (сервис находит громоздкие конструкции и слишком большие предложения).
Низким считается риск до 5 баллов по «Тургеневу» (общий), выше 7 — уже проблемы. Их можно устранить прямо на сайте в редакторе. Система отмечает недочеты тремя цветами: где зеленый — проблема незначительная, желтый — лучше исправить фрагмент, красный — обязательно требуется переписать.
Наш пример балансирует на грани среднего риска (6 баллов). Для SEO-статьи и описания категории товара это нормальный показатель. «Тургенев» заметил ключевые фразы (наименование изделия), но не расценил их как запросы, а счел повторами. Из-за длинных слов и предложений он поставил дополнительные баллы по стилистике и удобочитаемости. Доступна проверка по каждому проблемному параметру, для этого нужно прогнать текст в соответствующей вкладке (внимание: каждая отдельная проверка также платная, кроме стилистики).
Совет от редакции. «Тургенев» — довольно капризный и придирчивый редактор с едкими замечаниями. Его список анти-симпатий:
- Союзы «и». Они даже вынесены отдельной графой. Старайтесь убирать сразу — уменьшите риск на балл.
- Технические и SEO-тексты. Слова типа «изделие», «изготовить», «процесс», «свойства» отмечает как канцеляризмы. Может найти запросы в прямом вхождении и начислить лишний балл.
- Ничем не завуалированный «продающий» элемент в тексте. Те самые «команда специалистов», «клиент может оценить ассортимент» и т.д. В лучшем случае сервис отметит фразы как шаблонные, в худшем — в жесткой форме опишет проблему.
На скринах выше — полезные комментарии по стилистике. Если ими воспользоваться, можно уйти от шаблонных уловок продающих текстов.
«Главред»
Онлайн-редактор от Максима Ильяхова (автора «Пиши. Сокращай») проверит, насколько текст соответствует критериям инфостиля, а также подскажет, где убрать «воду». Оценивает качество по двум параметрам: «чистота» и «читаемость».
К сервису прилагается справочник с полезными статьями. Можно скачать «Главред» как расширение для Google Документов, плагин для WordPress и еще несколько вариантов (перечислены на странице «Приложения»).
Проверка бесплатная, регистрация не требуется. В качестве оценки сервис выставляет баллы, которые обозначают количество стилистических проблем. Чем выше балл, тем больше текст отвечает инфостилю: в нем нет стоп-слов, штампов, канцеляритов и фичеризма. «Главред» особенно уделяет внимание личным местоимениям и слабым предложениям (с причастиями, деепричастиями), скобкам и страдательному залогу — из-за них можно получить низкую оценку.
Ниже на скриншотах — оценка нашего примера по чистоте (рис.1) и читаемости (рис.2).
Стремиться к 10 баллам не стоит: текст будет чересчур «высушен». Нормой по «Главреду» считается показатель от 7 и выше. Наша редакция в основном заметила нестыковки только на словах-характеристиках: иногда стандартные технические показатели принимаются за субъективную оценку. Очень полезны подробные пояснения и подсказки, которые появляются при наведении курсора на проблемный фрагмент.
Сервис специально указывает: его проверка не подходит для художественных текстов. Поэтому мы рекомендуем править статью исходя из ее цели. Если это информационный текст или карточка товара, к ряду советов сервиса (особенно по штампам, местоимениям и построению предложений) прислушаться нужно. Если вы пишете в блог или социальные сети, редактируйте только самые важные моменты.
«Свежий взгляд»
Полезный онлайн-сервис поиска тавтологий от Петра Панды. Еще один гуру из мира копирайтинга создал сразу несколько ресурсов, которые помогают улучшать тексты коллег.
Ценность «Свежего взгляда» — разные формы проверки. Кроме явных тавтологий, сервис видит повторения предлогов и даже созвучий (если слова, близкие по смыслу или звучанию, находятся слишком близко друг к другу).
Можно выставить условия проверки: по длине контекста, области поиска тавтологий, порогу срабатывания и коэффициенту частотности. Мы добавили в окошко наш пример, оставили настройки по умолчанию (мягкая проверка) и нажали «Обработать».
Чем ярче выделены слова, тем критичнее повторы по мнению ресурса. Если навести мышкой на подсвеченное слово, появляется пара, которая оценена как повтор. Сервис действительно работает на созвучиях: у нас он выделил слова «своим — свойствам», «водопоглощение — менее», «плотность — прочность».
Думаем, такой функционал подойдет авторам сценариев для видеороликов, где важно соблюсти благозвучность и легкость прочтения текста.
Существует еще один «Свежий взгляд» — расширение для Google Docs от Дмитрия Кирсанова. Тоже ищет паронимы и случайные созвучия (незаметную на первый взгляд тавтологию). Автор сам отмечает недостатки своего сервиса: медленная работа и сброс после 6 минут проверки.
«Хемингуэй» — для англоязычных текстов
Ищет слова и предложения в английских текстах, которые делают их слишком сложными для восприятия:
- длинные или нечитабельные конструкции (выделяет желтым или красным);
- длинные слова (выделит, если можно заменить коротким вариантом);
- деепричастия;
- страдательный залог.
Для примера мы взяли текст средней сложности для школьников 9 класса с онлайн-сайта. Обратите внимание, что уровень читаемости сервисом определен очень хорошо:
К сожалению, программа не воспринимает русские тексты. Но может пригодиться для переводчиков и копирайтеров, работающих на английском языке.
Анализаторы читабельности и посыла текста
Еще два стилистических редактора онлайн, которые настроены на определение читабельности текста и его целевой аудитории.
«Простым языком». Проект может определить, насколько сложной получилась ваша статья. Дает оценку читаемости (просто / сложно), уровень в баллах (чем ниже цифра, тем проще воспринимать статью) и определяет аудиторию (возраст, уровень образования). Еще сервис подскажет, почему счел текст сложным для восприятия: обычно причина в длинных и сложных словах.
Наш пример — описание строительного товара с профессиональными терминами и специфическими характеристиками, рассчитанное на специалистов. Поэтому аудиторию для него «Простым языком» определил как взрослую (студенты-выпускники). Если вы пишете статьи для массового читателя (инфосайты), блогов и соцсетей, проследите, чтобы сервис определил ваш текст как простой для восприятия (аудитория — школьники средних классов).
«Анализ писем» — оригинальный ресурс, который определяет настроение текста. В описании сервиса специальная пометка: «Не подходит для специализированных писем, но точно характеризует послания личного характера». Основываясь на звуках речи, преобладающих в тексте, анализатор определяет настроение автора и степень открытости письма (чем больше синих полос в результате, тем менее замкнутым кажется отправитель).
Кому пригодится: идеально для копирайтеров и маркетологов, работающих с email-рассылками. Это один из сложнейших вариантов работы с клиентами — чтобы погрузить читателя в воронку продаж, важно идеально соблюсти доверительный стиль письма и приятный настрой. Программа видит типичные рекламные уловки и называет такие тексты неискренними. Сравните 2 скриншота ниже: перевод рекламной рассылки от Tiffany и набор шаблонных фраз, собранных с описаний товаров на маркетплейсах.
7 сервисов проверки орфографии
Если программы проверки стилистики — своего рода редактор в вашем компьютере, то сервисы проверки орфографии — типичный корректор. Проверяют они именно грамматику (написание слов, пунктуация), но некоторые ресурсы могут указать и на лексические недочеты. Все варианты в подборке бесплатные, кроме «Орфограммки». И начнем мы именно с нее.
«Орфограммка»
Пожалуй, самый развитый онлайн-корректор, который вычищает ошибки по максимуму. Особенно хороша проверка пунктуации: если правописание более-менее контролируют Word и Google Документы, то с запятыми у многих сервисов проблема.
Из полезного:
- все рекомендации подкрепляет правилами (выносит их в правое окно);
- видит лексические ошибки и проблемы в согласовании;
- хорошо видит опечатки, которые пропустила автопроверка в документе;
- кроме вкладки «Грамотность», есть разделы «Качество» и «Красота», где текст можно прогнать по SEO-параметрам и стилистике.
Небольшие недочеты:
- Очень любит букву «ё», которую в веб-статьях никто не использует. Поэтому приходится продираться через советы изменить «е» на «ё».
- Перестраховывается. Алгоритм не может оценить общий посыл текста, поэтому на всякий случай указывает и на вероятные ошибки (с пометкой «проверьте контекст»). Но так как одновременно сервис выдает и правило, можно самостоятельно решить, подходит оно под ваш случай или нет.
«Орфограммка» платная, стоимость зависит от выбранного пакета услуг. Можно покупать подписку по объему (за знаки) или по времени (за месяц и более использования). При выборе лучше исходить из того, как часто и насколько регулярно вы планируете пользоваться ресурсом. Для новичков дается пробный тест системы: бесплатная проверка до 6000 символов однократно.
«Яндекс.Спеллер»
Бесплатный вариант проверки (аналог Word, только онлайн). Из плюсов: не отмечает незнакомые ему термины как ошибку, обширный словарный запас, понимает три языка (русский, английский и украинский).
Из минусов: замечает не все недочеты (опечатки и верстку). Для теста сделали лишний пробел в тексте — программа не обратила на него внимания. Кроме того, не нашел опечатку, которую увидела «Орфограммка»: лишнюю точку с запятой в списке характеристик («влагонепроницаемость; водопоглощение»). Но с явными ошибками сервис справляется неплохо.
Languagetool
Онлайн-корректор, который может проверить орфографию и стилистику на 27 языках. Есть бесплатная версия и платный премиум-аккаунт. Они отличаются количеством символов, которые можно проверить за раз (20 000 или 40 000), и дополнительными функциями проверки для иностранных языков.
Видит незнакомые слова и тавтологии в нашем примере. При проверке на пунктуацию (специально убрали часть запятых) ошибок не нашел:
«Орфограф»
Сервис от студии Артемия Лебедева. Можно проверить текст или веб-страницу на выбор. По сравнению с описанными ранее это простейший алгоритм: он просто выделяет незнакомые слова желтым цветом. Подсказок не дается: автору придется самостоятельно разбираться, есть ли в выделенном фрагменте ошибка.
Мы специально изменили пунктуацию на неправильную в некоторых частях текста — ее сервис не проверяет.
«ОРФО.Онлайн»
Проверяет тексты по нескольким параметрам: орфография, грамматика и пунктуация, стилистика. Для проверки требует регистрацию (можно через аккаунт «Тургенева»). Бесплатная прогонка ограничена: проверяет 5000 символов и только на орфографические ошибки.
Grammarly (английский корректор)
Бесплатное расширение Google Chrome для проверки английских текстов. Можно набирать письмо прямо во встроенном редакторе — ИИ подскажет, где допущена ошибка (орфографическая или пунктуационная). Судя по презентации разработчиков, обещают, что сервис подберет и более подходящие по смыслу слова.
Текст.ру
Кроме уникальности и SEO-анализа, универсальный ресурс проверяет и орфографию. «Текст.ру» подсвечивает проблемные слова и дает рекомендации по исправлению. Возможности этого онлайн-корректора слабоваты: в основном он просто не распознает узкоспециальные термины, зато дает подсказки по пунктуации. Еще одна полезная функция (см. скрин) — обнаружение повторов пробела. Мы пользуемся орфо-проверкой сервиса исключительно для поиска этой проблемы.
Бонус: помощь в правописании склонений и цифр прописью
Два полезных сервиса, которые помогут в затруднительных ситуациях.
«БезБукв» — просклоняет любое слово. Не требует регистрации или скачивания программы. Вбиваете в строку сложное слово в онлайн-режиме и получаете табличку склонения по падежам и числам.
«Сумма прописью» — онлайн-калькулятор. Помогает рассчитать налог в любой валюте (с учетом размера налога по странам), процент от выбранной суммы и даже количество дней между заданными датами. Нас интересует автоматический перевод суммы в числовом эквиваленте в буквенный. Удобно для тех, кто затрудняется при написании чисел прописью.
Дополнительные ресурсы проверок
Сравнение текстов
Чаще всего используются для поиска правок редактора, корректора или заказчика (если вы пишете статьи в Word без возможности просмотра изменений как в Google Docs). Иногда бывает и так, что на сайте залитого исходника просто нет, а проверить сходство текстов необходимо (например, вы пишете рерайт с другого текста или нужно найти совпадение в каких-то документах).
Сравнить статьи можно с помощью двух онлайн-сервисов:
Сравнение текстов онлайн. Простой алгоритм: в два окошка вставляете ваши тексты. Цветом будут выделены различия: желтые — то, что есть в первом тексте, зеленые — во втором. Общие участки остаются с белым фоном.
Инструмент от Петра Панды. Тоже цветом выделяет общие фрагменты и уникальные отрывки статей. Но, кроме подсвеченных участков, определяет результат в процентах и считает количество отличающихся символов. Можно вставить сами тексты в окошко или загрузить их в виде документов.
«Хронометр»
Удобно для специалистов, которые пишут сценарии или тексты на озвучку. Оценивает время, которое в среднем тратится на прочтение текста. Инструмент подходит и для веб-мастеров и контент-менеджеров. Замечали, что на некоторых сайтах в начале статей пишутся: «Время прочтения — N минут»? Пользователю удобно знать заранее, сколько времени он потратит на изучение материала.
На бесплатном ресурсе можно обозначить требуемый хронометраж и проверить, насколько результат совпадает с заданным временем.
Верстка и раскладка
В редакционной политике обычно прописаны правила верстки. Они типично требуют отделять абзацы, ставить правильные длинные тире и кавычки-елочки.
С грамотным типографическим оформлением текста помогут два текста.
«Типограф». Еще один инструмент от дизайнера Артемия Лебедева. Готовит тексты для публикации, в том числе выравнивает, заменяет неправильно проставленные символы, избавляется от разрыва.
Примечание. Сервис исправляет текст с помощью html-кодов. Результат предназначен для заливки контент-мастером на сайт с помощью вставки «Текст» (для WordPress).
До автоматической верстки:
После:
А так выглядит этот фрагмент в админке WordPress в окошке «Текст» (вставлять отрывок нужно именно туда) и при переходе в раздел «Визуально»:
Типографская раскладка Ильи Бирмана. Арт-директор студии «Бюро Горбунова» придумал инструмент для ввода специальных символов, которых нет на обычной клавиатуре (те же длинные тире, кавычки). Раскладка бесплатная, ее можно скачать и установить на Windows, следуя инструкциям на сайте.
Чтобы вставить нужный символ, используется комбинация с удерживанием клавиши Alt (см. скриншот).
Заключение
Многие сервисы действительно облегчают работу мастеров по текстам; некоторые (например, «Главред», «КонтентМонстр») содержат справочную информацию, крайне полезную для начинающих. Но часть инструментов не оправдала ожиданий.
Так роботы-алгоритмы все-таки портят тексты или улучшают? Вопрос риторический: все зависит от автора и задач, стоящих перед текстом. Если воспринимать онлайн-помощники как инструмент поиска стилистических и иных ошибок, можно по-настоящему усилить вашу статью. Главное — не забывать, что ИИ тоже ошибается.
Пользуйтесь с удовольствием. Хороших вам заказов, ну а найти их можно у нас на Telegram-канале.
Онлайн проверка на плагиат – бесплатно, быстро, и без регистрации!
Тщательный анализ текста и поиск копий в Интернете.
Специально разработанный алгоритм проверит ваш текст на уникальность и сразу скажет результат.
Наш сервис умеет определять рерайт и другие способы уникализации текста.
Ваши последние проверки
Для доступа к истории проверок нужно войти в систему
Новости сервиса
О проверке текста на уникальность
При проверке текста на уникальность система онлайн проверки на плагиат найдет в Интернете страницы, содержащие его полные или частичные копии.
Содержимое этих страниц будет сравниваться с указанным текстом для выявления совпадений.
На основе найденных совпадений будет подсчитана общая уникальность текста в процентах, а также уникальность относительно каждой найденной страницы с совпадениями.
Вы сможете посмотреть, какие части текста были найдены на каждой из проанализированных страниц.
Если Вы знаете, что указанный текст размещён на каком-то сайте и не хотите учитывать его при подсчёте общей уникальности, введите адрес в поле “Игнорировать сайт”.
Достаточно ввести домен.
Бесплатная версия
- Текст длиной до 10.000 символов
- До 3 проверок в день
- Использовать любые средства автоматического доступа к сервису запрещено
Закончился лимит? Хотите проверить тексты вдвое больше? Берите подписку!
Автоматическая регулярная проверка сайта
Попробуйте нашу автоматическую регулярную проверку – добавьте страницы сайта на защиту, и мы будем мониторить их уникальность и отправлять вам отчеты на почту!
Пожалуйста, сообщайте об ошибках, оставляйте отзывы и предложения.
Обратите внимание, на нашем сайте можно проверить уникальность контента сайта.
-
Главная
-
Новости
- Апгрейд инструмента проверка уникальности — первоисточник и неуникальные фрагменты
Апгрейд инструмента проверка уникальности — первоисточник и неуникальные фрагменты
09 Января 2017
Россия, Москва, посленовогодний постапокалипсис, 9 января 2017 года.
Команда проекта прокачала инструмент «Проверка текста на уникальность». Теперь с его помощью можно численно определять сайты-первоисточники по фрагменту текста (рекомендуется) или URL и выгружать для рерайта/анализа неуникальные фрагменты текста.
Как это работает?
Достаточно просто:
- Вводите текст, скажем, с вашего сайта.
- Система определяет список сайтов/URL на которых найден данный текст (его фрагменты).
- Выводит список первоисточников (сайтов, который являются автором контента по мнению поисковой системы Яндекс).
- Рядом с каждым URL указывается процент фрагментов текста, по которым он признан первоисточником.
- Дополнительно: выводится список неуникальных фрагментов (полезен в том случае, если вы проверяете текст, который нигде не был размещен, скажем, только написан после ТЗ на копирайтинг).
- Всё данные можно выгрузить в CSV.
Пара иллюстраций
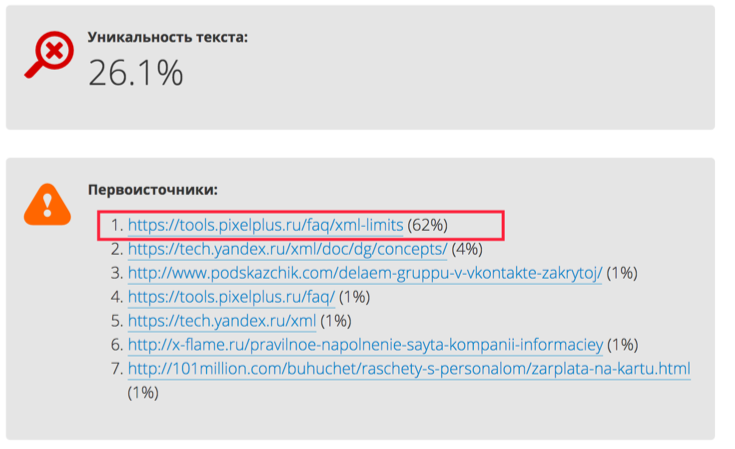
1. Взят текст со страницы. По факту — текст неуникальный, он уже проиндексирован поисковой системой. Но мы хотим понять, является ли наш сайт первоисточником по нему или конкуренты, которые украли текст, смогли присвоить его (частая история)?
Проверяем — выдыхаем. Лишь по 9% фрагментов текста наш URL не выдается как первоисточник в Яндексе. Не страшно:
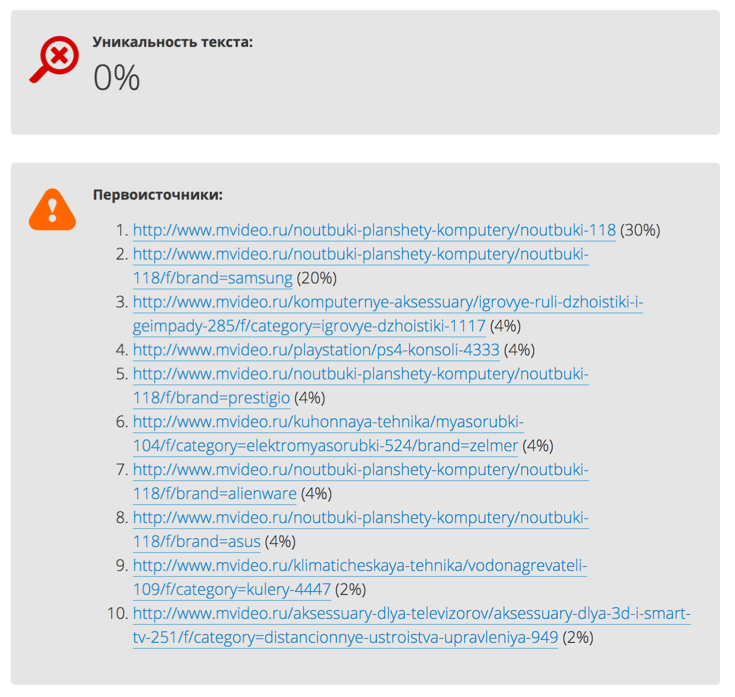
2. Взят текст из рубрики каталога. По факту, авторство/уникальность текста внутри домена — «размазана» по нескольким страницам. Не самый хороший признак. Но, других доменов среди первоисточник нет — хорошо.
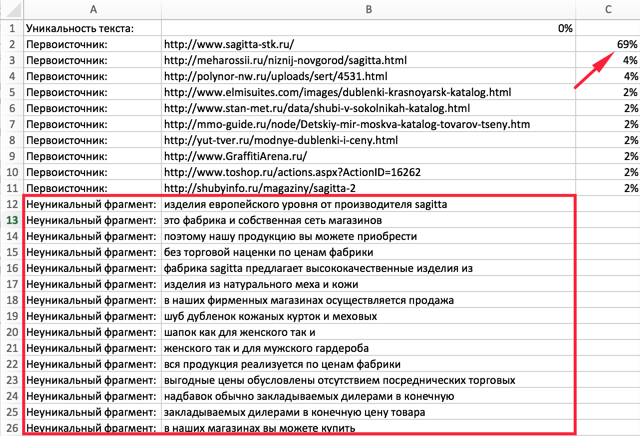
3. Бывает, что текст был впервые размещён на одном сайте, но, потом он стал неуникальным и авторство потерялось. Это уже фирменная беда. Теперь её можно быстро диагностировать с помощью бесплатного инструмента «Пиксель Тулс».
Выгрузка в CSV и исключение доменов из анализа
При привычке — можно выгрузить данные анализа уникальности в CSV, а также исключить с помощью настроек несколько доменов из анализа.
Проверяйте уникальность и определяйте первоисточник правильно!
По оценкам 30 пользователей
Задайте вопрос или оставьте комментарий
Другие новости
Время на прочтение
9 мин
Количество просмотров 25K
Продолжение (начало – здесь)
1.3. Поисковые системы – специализированные и не очень
В общем случае результаты поиска в первую очередь зависят от поставленной задачи и корректности запроса. Но эти результаты чаще всего, с одной стороны,
а) избыточны
и с другой стороны — б) неполны.
К счастью, и авторы и издатели, как правило, заинтересованы в том, чтобы информация о публикациях индексировалась поисковиками, но тут есть нюансы: не всегда разрешается индексация содержимого pdf-файлов, и в некоторых случаях разрешена индексация сайтов только определёнными поисковиками (например, крупнейшая отечественная электронная библиотека elibrary.ru одно время запрещала для google индексацию большинства файлов).
Кроме всего прочего, результаты запроса зависят от порядка слов и от IP-адреса, с которого осуществляется поиск.
Если говорить о поиске публикаций, то вопрос «какой поисковой системой пользоваться» имеет один ответ – Google (это если не считать специализированные библиографические поисковые системы, о них ниже).
Во-первых, google достаточно полно индексирует содержимое Сети. Во-вторых, большое количество настроек расширенного поиска (в т.ч. с использование операторов) сильно облегчают работу. В третьих, как я уже указывал, содержимое пдф-файлов googl’ом индексируется даже в том случае, когда пдф состоит из изображений и текстовый слой в файле отсутствует.

Ка известно, в гугле любят пошутить. Вот такой у меня однажды вылез результат при попытке найти книгу Pander, C. H. (1830). Beiträge zur Geognosie des Russischen Reiches. St.Petersburg, Karl Kray. 150 S.
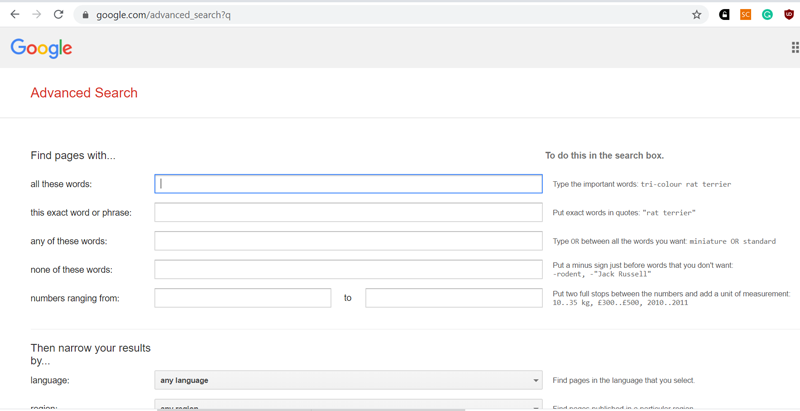
Настройки расширенного поиска google. На Яндексе, к сожалению, большая часть настроек расширенного поиска из имевшихся ранее давно сгинула, остались мелочи типа поиска по расширению файла (только вместо гугловского filetype: используется оператор mime: )
Для поиска публикаций наиболее полезными являются расширенные настройки и операторы, позволяющие ограничивать поиск файлами определённого формата (например, pdf c помощью filetype:pdf ), определёнными сайтами / доменами. Например, если мне понадобится посмотреть, на каких китайских сайтах выложены публикации в формате pdf, где упоминаются аммониты, то поможет вот такой запрос: ammonites filetype:pdf site:cn. Ну а “+” и “-” используются для указания обязательных или нежелательных терминов. К примеру, при поиски информации по головоногим моллюскам — аммонитам обычно не нужны сведения об одноимённом взрывчатом веществе или племени, некогда обитавшем на Ближнем Востоке и регулярно упоминающемся в Библии. Соответственно, запрос можно подкорректировать таким образом: аммониты filetype:pdf -взрывчатка -Библия
Если ищется какая-то конкретная публикация, то желательно часть её названия или всё название взять в кавычки.
Ещё немаловажно, что у гугла есть два отдельных проекта, имеющих прямое отношение к поиску публикаций:
1) Google books – это фактически отдельная поисковая система, индексирующая содержимое огромного количества книг, журналов, сборников и других изданий. При этом существенная часть публикаций доступна для скачивания в виде пдф (как правило, это старые издания, от начала ХХ века и старше); в зависимости от IP список доступных для скачивания изданий может существенно различаться, максимально число работ доступно пользователям из США.
Довольно много публикаций доступно для просмотра целиком или частично. Такие работы можно скачать с помощью специальных программ типа EDS Google Book downloader или плагинов (таких как Greasemonkey для Mozilla в сочетании с программой для автоматической загрузки файлов, например Download Master).
И, наконец, немалую пользу можно получить даже от той информации, которая присутствует в публикациях, которые вообще недоступны для просмотра в каком-либо виде кроме фрагментов в несколько строк (snippet view). С такими публикациями, правда, есть две основные сложности:
а) можно, конечно, попробовать поискать такие работы где-то ещё, но вероятность того что с ними можно будет ознакомиться только в библиотеке довольно велика.
б) в названиях источников (особенно тех, которые исходно даны не латиницей) путаницы очень и очень много, и отображаемая информация обычно неполна.
Тем не менее информация, содержащаяся в таких фрагментах может быть очень важной и практически не находимой другими способами
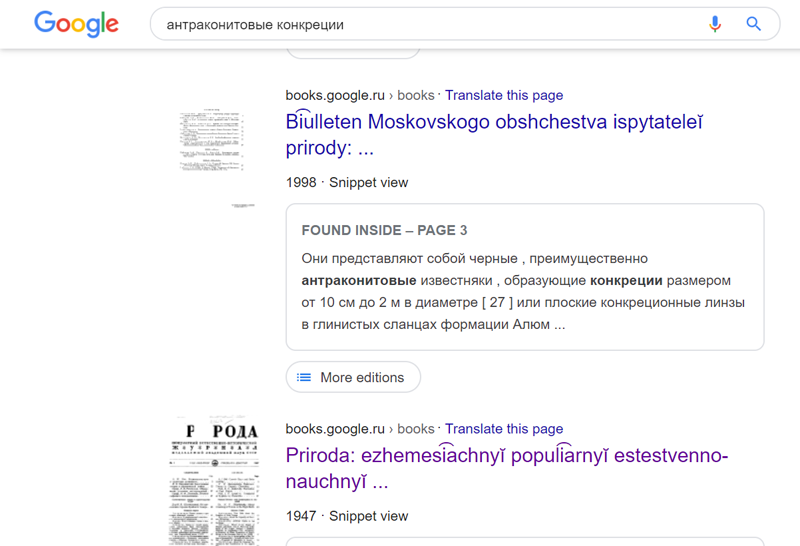
Так выглядит типичный вариант выдачи на google books в формате snippet view: как правило, отсутствует часть нужной библиографической информации (номер выпуска для журнала, иногда — важные части названия издания). Хорошо, если у журнала выходит 2 номера в год. А если 20? А если название указано с ошибкой?
2) Google Scholar (в русскоязычном варианте Академия Google ). Это библиографическая поисковая система, которая неплохо ищет как сами статьи, так и ссылки на них, заодно позволяя сразу скопировать названия публикаций, отформатированные согласно популярным типам цитирования (APA, Harvard, ГОСТ и т.д.). К числу удобств данной системы стоит отнести то, что индексируются не только сайты издателей, но и специализированные социальные сети и самые разные сайты, где нередко безвозмездно выкладываются научные работы, и все ссылки на полнотекстовые версии группируются в единый кластер. Тем не менее, Google Scholar индексирует не все публикации – это легко проверить с помощью идентичного поискового запроса «ключевые слова» filetype:pdf в Google и Google Scholar. Особенно это ярко это различие проявляется с редко встречающимися ключевыми словами.
Ну а наиболее полезная функция google scholar – это возможность подписки на самые разные оповещения (об этом подробнее — в продолжении данного поста)
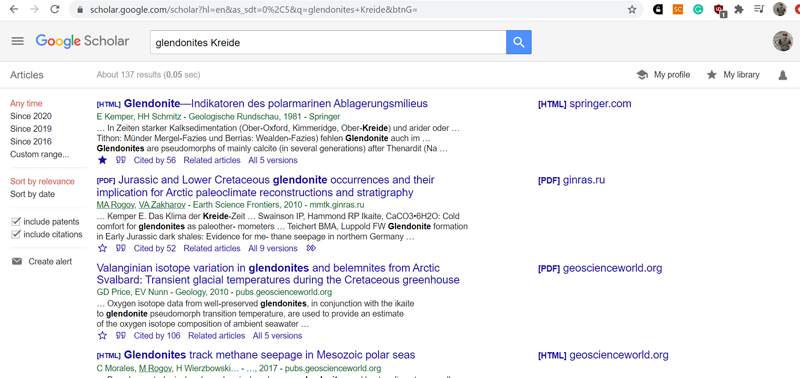
Выдача поиска по ключевым словам на google scholar. Обратите внимание на варианты сортировки, возможности выбора временного диапазона и кластеры статей.
Библиографические поисковые системы (БПС), ориентированные на работу с публикациями, сейчас весьма разнообразны и многочисленны. Кроме перечисленных выше проектов Google можно отметить следующие сайты, которые могут рассматриваться как БПС:
1) сайты, индексирующие огромное количество публикаций по всему миру. В первую очередь это Scopus и Web of Science, доступные по подписке (в случае со Scopus доступ также предоставляется рецензентам Elsevier’овских журналов), а также крупнейший сайт, присваивающий DOI публикациям (CrossRef) или агрегатор информации о публикациях, грантах, исследователях и т.д. Dimensions.
Все они кроме Dimensions позволяют искать информацию по ограниченному массиву данных – это преимущественно название / ключевые слова / резюме. В худшую сторону тут выделяется CrossRef – там поиск идёт только по названию, причём со строгой привязкой к форме слова. Правда, в CrossRef существенно больше проиндексировано русскоязычных публикаций, чем в других БПС из этого пункта, и плюс к тому это наиболее удобный способ решить задачу типа «у меня есть название публикации, надо найти её DOI» (все DOI так не найти – это не единственный регистратор цифровых идентификаторов к публикациям, есть ещё DataCite, например – но универсального сервиса для решения такой задачи, как ни странно, просто нет).
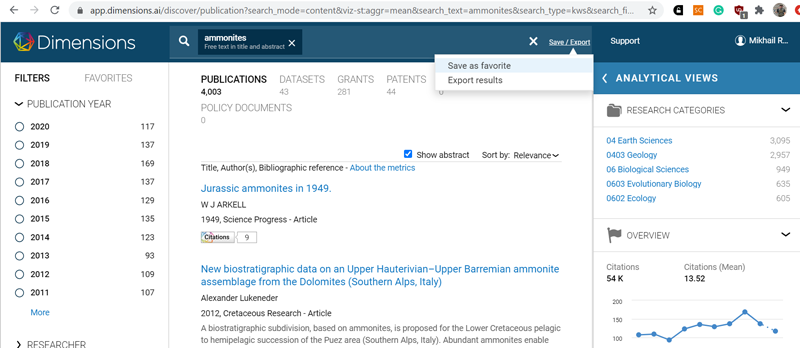
Простой поиск в Dimensions
Dimensions – совсем недавно появившийся очень интересный проект, в первую очередь благодаря множеству самых разнообразных настроек, широкому охвату публикаций (индексируются только публикации с DOI, их пока немного меньше чем есть на CrossRef) и полнотекстовому поиску. Вернее, тут можно выбирать разные опции поиска (полнотекстовый / по резюме / по названию и ключевым словам). Результаты можно сортировать самыми разнообразными способами (дата / релевантность / число ссылок / число альтметрик), и ограничивать по разным параметрам (источник / автор / годы / тематика и многое другое ). У Dimensions есть разные версии (включая платную и корпоративную), здесь рассматривается только бесплатный вариант (с другими пока не доводилось иметь дело). Отдельно можно искать информацию как по публикациям, так и по базам данных и грантам (последняя опция доступна только по подписке).
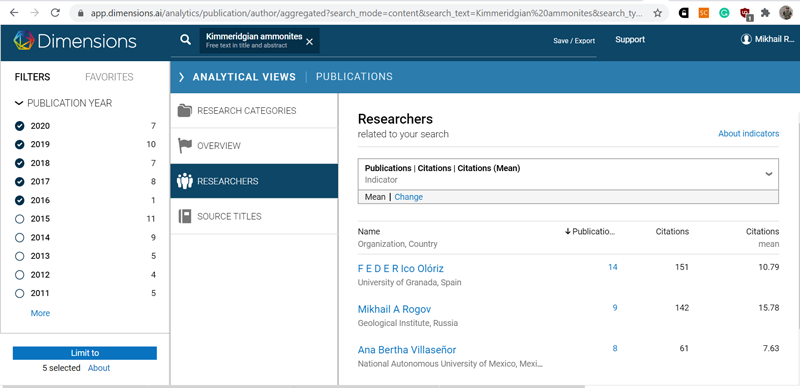
Во вкладке Analytical view можно посмотреть, например, кто или в каких журналах публиковался по интересующей нас тематике в то или иное время (в данном случае — с 2016 по 2020 годы). Ну а нажав на фамилию автора, можно посмотреть с кем вместе он публиковался, в каких журналах и т.д.
Дополнительные опции предлагаются во вкладке Analytical view. Они позволяют легко понять, кто сейчас или в любом выбранном временном диапазоне занимается той или иной тематикой, в какие журналы эти люди пишут статьи и с какими соавторами. Это удобный способ для поиска потенциальных соавторов и рецензентов, особенно для тех, кто только начал заниматься какой-либо тематикой и не очень хорошо себе представляет что с ней в мировом масштабе делается. Для тех исследователей, у которых в статьях имеется ORCID, в профиле приводится и этот идентификатор, и Scopus author ID, а также (при наличии) цепляющийся к ним «автоматом» ResearcherID / профиль на Publons. Повторюсь – Dimensions это крайне полезный проект, причём интуитивно понятный. Можно просто тыкать на все кнопки подряд и залезать во все вкладки.
2) также в качестве специализированных БПС можно рассматривать сайты крупнейших международных издателей (Elsevier, Wiley, Springer, Taylor & Francis и т.д.) и распространителей (Ingentaconnect, GeoscienceWorld) научных изданий. Впрочем, ограничение результатов поиска тем или иным издателем или распространителем на пользу, как правило, не идёт и скорее может быть полезно для того, чтобы кратко ознакомиться с той или иной темой.
3) в какой-то мере функции БПС выполняют научные социальные сети (Academia.edu, ResearchGate ), а также «гибрид» социальный сети и библиографического менеджера Mendeley (доступна как оффлайн-версия в виде программы, так и её онлайн-вариант; сейчас, после покупки Mendeley компанией Elsevier там доступны многие опции Scopus). Впрочем, содержимое научных социальных сетей хорошо индексируется googl’ом, и тут разве что есть смысл регулярно просматривать ленту обновлений в поисках чего-нибудь совсем нового.
4) в отдельную категорию БПС можно выделить региональные или специализированные сайты, где в основном имеются данные о публикациях, изданных в какой-либо стране или нескольких странах (например, Национальная электронная библиотека elibrary.ru в России, Национальный институт информатики в Японии, Национальная библиотека Франции ), а также специализированные сайты, посвящённые каким-то конкретным научным направлениям (например, BiodiversityHeritageLibrary (BHL))
Характерной особенностью таких порталов является то, что они крайне неохотно дают индексировать своё содержимое сторонним поисковикам, так что если нужно найти что-то французское или японское – надёжнее заглянуть на соответствующие сайты и поискать там.
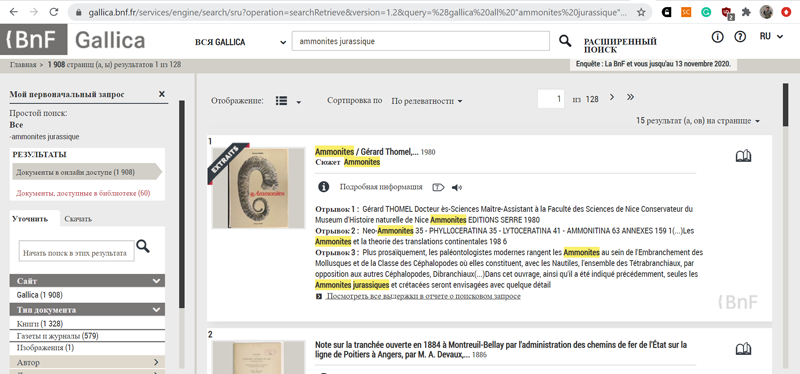
До недавнего времени на сайте Национальной библиотеки Франции весь интерфейс был франкоязычный, пока они туда в конце концов не приделали сначала англоязычную версию сайта, а затем и автоматический перевод по IP
Отдельно следует сказать про BHL. Это крайне полезный проект для всех исследователей, которые так или иначе связаны с изучением современных или ископаемых организмов. Данную библиотеку отличает широкий охват источников (включая разные редкости) и наличие специальных поисковых инструментов (таких как поиск по таксону во вкладке Advanced search – если кто-то собирает материалы по той или иной группе животных и растений, это очень хороший способ быстро найти публикации по теме). Из недостатков BHL можно отметить то, что нередко текстовый слой может быть распознан неверно (с ошибочно выбранным языком), а также чудовищное качество иллюстраций по умолчанию (качество плохого размытого .djvu ).
Поскольку для таксономических исследований качество изображений обычно имеет большое значение, то здесь наиболее правильным подходом является скачивание нужной публикации в формате jp2, а потом – обработка файлов (сначала переформатирование в обычный jpg / tiff, потом обработка ScanTailor и OCR). Кстати, все публикации с BHL размещаются на archive.org, и иногда удобнее проводить полнотекстовый поиск именно по archive.org (это может быть актуально в случае поиска каких-либо редкостей – тут может попасться кое-что интересное, в том числе загруженное пользователями.
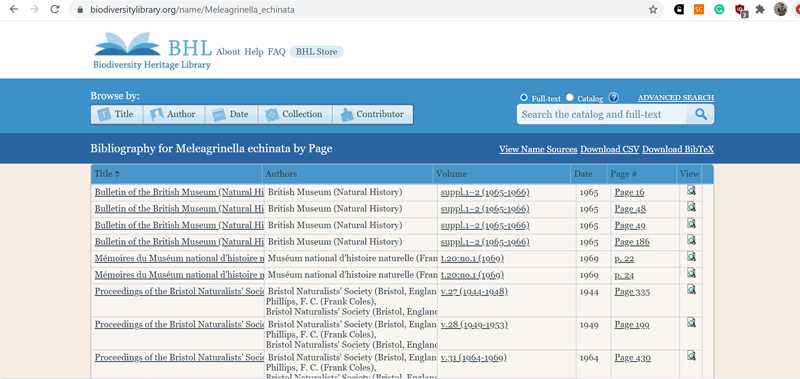
Пример выдачи при поиске по таксону на BHL
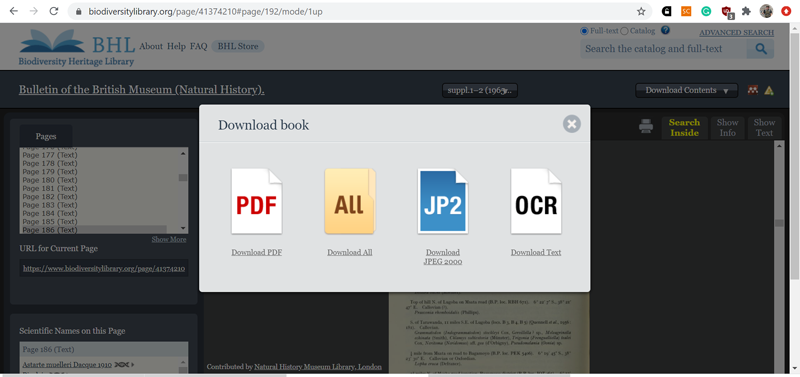
Если нужен качественный пдф — лучше сохранить файл способом «Download Content — Download book — Download JPEG 2000», а потом обработать
И, конечно, в случае необходимости найти русскоязычные публикации не обойтись без поиска в elibrary в сочетании с cyberleninka. Хотя в elibrary охват источников намного больше, регулярно встречается ситуация, когда в elibrary за ту или иную статью предлагают заплатить – а на сайте Киберленинки та же статья лежит в отрытом доступе.
Несмотря на ряд недостатков, заложенных в elibrary, кажется, с рождения (отсутствие возможности скачать даже работу открытого доступа без ввода логина / пароля; отсутствие англоязычной версии и опции подписки на те или иные обновления) поиск там достаточно приличный. Но если есть необходимость регулярно отслеживать информацию по русскоязычным журналам, стоит сделать также отдельный каталог ссылок на сайты необходимых изданий – на elibrary не угадаешь, когда и почему они могут вдруг закрыть доступ к тем или иным изданиям. И ещё один момент – в том случае, когда журнал отсутствует в открытом доступе и распространяется только за деньги как через elibrary, так и через сайт издательства, то на сайте издательства статьи могут быть дешевле (такова ситуация, например, с журналом «Нефтяное хозяйство»).
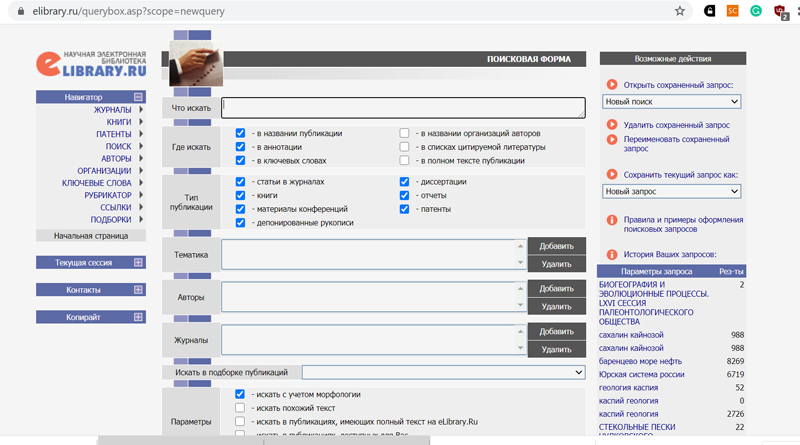
Настройки расширенного поиска на elibrary (на заглавной странице сайта — слева сверху ссылка «расширенный поиск»). Здесь же сохраняется история предыдущих поисковых запросов
5) в качестве БПС можно рассматривать и крупнейшие «пиратские» проекты, обеспечивающие свободный доступ к научным публикациям – SciHub и LibGen, поскольку на них в том или ином виде реализована возможность поиска по названию публикации или ключевым словам.
И если sci-hub может быть скорее использован в качестве удобного дополнения к поиску на Dimensions, то на LibGen регулярно появляются редкие монографии, которых в других местах нет – они сканируются энтузиастами и размещаются на ЛибГене в частном порядке.
И напоследок отдельно стоит сказать про поиск диссертаций. Хотя многие диссертации (как современные российские, так и иногда достаточно старые зарубежные) выложены в Интернете в открытом доступе и индексируются поисковиками, для получения информации о свежих диссертациях, которые только планируется защитить, имеет смысл заглядывать на сайт ВАКа. Там сейчас диссертации можно искать по специальностям, ключевым словам, дате защиты и другим параметрам (при этом отдельно поиск ведётся по ВАКовским диссертациям, а отдельно – по тем, которые защищаются на советах организаций, обладающих правом самостоятельного присуждения степеней). Но есть нюанс – если у вас установлен uBlock Origin, то он блокирует поиск по данному сайту.
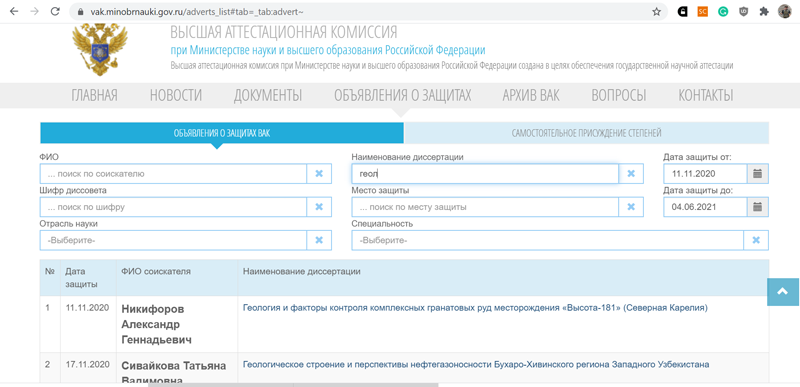
Пример поиска по сайту ВАК
Продолжение: часть 3
