Find the Wayback Machine useful?
DONATE

deviantart.com
Oct 15, 2013 21:28:20

cl.cam.ac.uk
Feb 29, 2000 18:34:39

foodnetwork.com
Oct 20, 2013 22:40:56

yahoo.com
Dec 20, 1996 15:45:10

spiegel.com
Oct 01, 2013 15:26:30

imdb.com
Oct 21, 2013 16:53:47

stackoverflow.com
Oct 14, 2013 21:22:10

ubl.com
Dec 27, 1996 20:38:47

bloomberg.com
Oct 01, 2013 23:10:45

reference.com
Oct 18, 2013 07:12:58

feedmag.com
Dec 23, 1996 10:53:17

wikihow.com
Oct 21, 2013 20:56:46

nbcnews.com
Oct 21, 2013 17:24:52

goodreads.com
Oct 21, 2013 00:42:42

obamaforillinois.com
Nov 09, 2004 04:28:06

geocities.com
Feb 22, 1997 17:47:51

amazon.com
Feb 04, 2005 00:47:33

nytimes.com
Oct 01, 2013 01:42:36

bbc.co.uk
Oct 01, 2013 00:13:32

huffingtonpost.com
Oct 21, 2013 17:11:12

reddit.com
Oct 01, 2013 03:15:39

cnet.com
Oct 21, 2013 02:07:03

whitehouse.gov
Dec 27, 1996 06:25:41

aol.com
Oct 01, 2013 05:01:31

yelp.com
Oct 19, 2013 02:44:53

etsy.com
Jun 01, 2013 01:38:52

foxnews.com
Oct 01, 2013 01:08:27

well.com
Jan 08, 1997 06:53:37

w3schools.com
Oct 19, 2013 00:55:10

buzzfeed.com
Oct 21, 2013 17:32:21

nasa.gov
Dec 31, 1996 23:58:47

mashable.com
Oct 21, 2013 02:16:14

nfl.com
Oct 21, 2013 07:39:25
![]()
Tools
Banish broken links from your blog.
Help users get where they were going.
![]()
Save Page Now
Capture a web page as it appears now for use as a trusted citation in the future.
Only available for sites that allow crawlers.
В статье мы расскажем, в каких случаях может понадобиться история сайта, как ее посмотреть. Приведем примеры основных сервисов, которые позволят заглянуть в прошлое страницы. Объясним, как посмотреть сохраненную копию страницы в поисковых систeмах и как восстановить сайт из архива.

Зачем нужна информация об истории сайта в прошлом
Историю любого сайта можно посмотреть в интернете. Для этого достаточно, чтобы ресурс существовал хотя бы пару дней. Это может понадобиться в следующих случаях:
● Если необходимо купить домен, который уже был в использовании, и нужно посмотреть контент какой тематики был на нем размещен, не было ли огромного количества рекламы, исходящих ссылок и т.д.
● Нужен уникальный контент. Его можно скачать с существовавших когда-то ресурсов. Такое наполнение подойдет, например, для сайта-сателлита.
● Нужно восстановить сайт, когда нет его бэкапа.
● Нужно проанализировать конкурентов. Этот способ понадобится, чтобы посмотреть историю изменений на их сайтах, какие ошибки они допускали или, наоборот, какие «фишки» стоит позаимствовать.
● Необходимо посмотреть страницу, если она теперь недоступна напрямую.
● Интересно, как выглядел ресурс 10-20 лет назад.
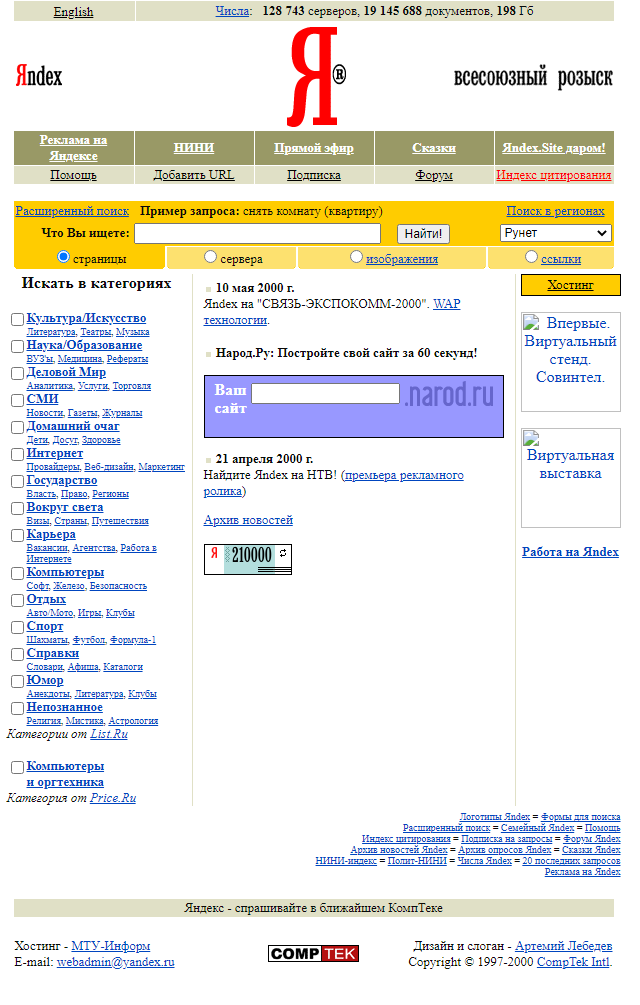
Ниже приведен пример того, как выглядела стартовая страница поисковой системы Яндекс в 2000 году:
Как посмотреть сайт в прошлом?
Есть несколько сервисов, в которых можно посмотреть, как менялось визуальное оформление страниц сайта, его структуру страниц и контент, положение в поисковой выдаче и какие изменения вносились в регистрационные данные за время существования ресурса.
Сервис Веб-архив
При его использовании сначала заходим на сайт https://web.archive.org/ и после вводим адрес страницы.
График ниже показывает количество сохранений: первое было в 1998 году.
Дни, в которые были сохранения, отмечены кружком. При клике на время во всплывающем окне, открывается сохраненная версия. Показано ниже:
Как выгрузить сайт из ВебАрхива, расскажем дальше.
Сервис Whois History
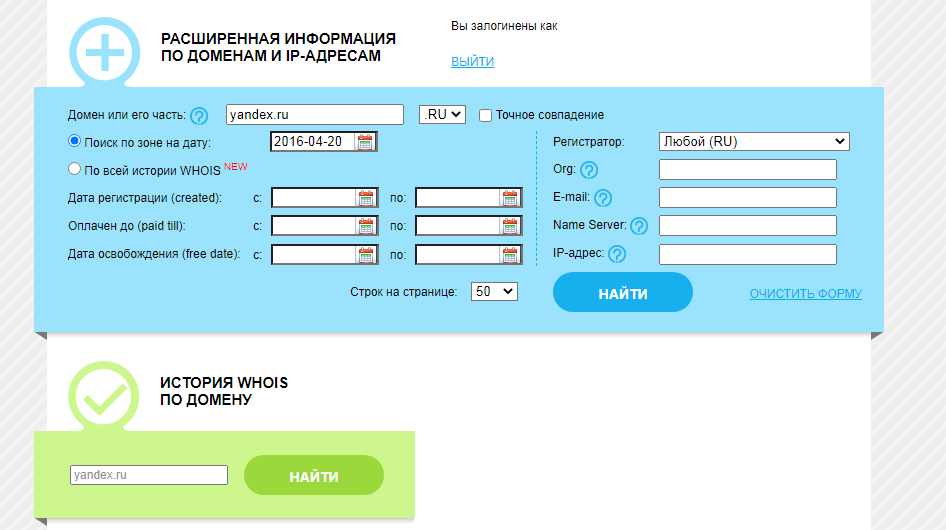
Для его использования заходим на сайт http://whoishistory.ru/и вводим данные в поиске по доменам и IP, либо по домену:
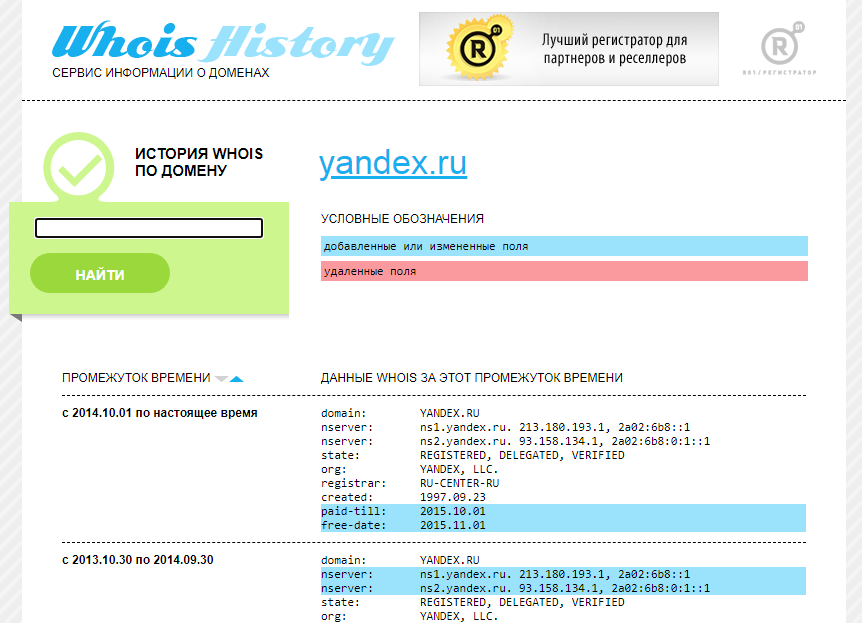
Сервис покажет информацию по данным Whois, где собраны сведения от всех регистраторов доменных имен. Посмотреть можно возраст домена, кто владелец, какие изменения вносились в регистрационные данные и т.д.
Сохраненная копия страницы в поисковых системах Яндекс и Google
Для сохранения копий страниц понадобятся дополнительные сервисы. Поисковые системы сохраняют последние версии страниц, которые были проиндексированы поисковым роботом.
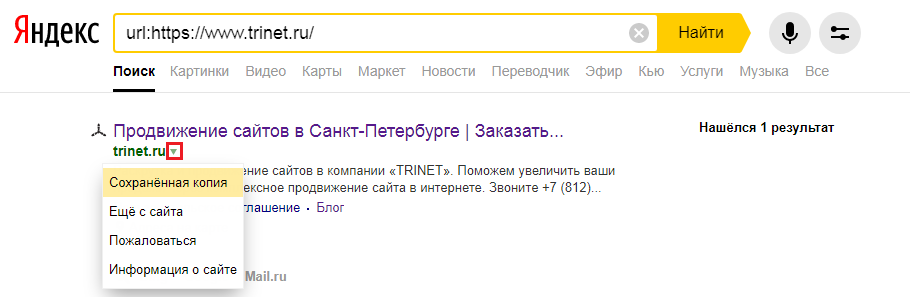
Для этого в строке поиска Яндекс вводим адрес сайта с оператором site: или url: в зависимости от того, что хотим проверить конкретную страницу или ресурс целиком. Нажимаем на стрелочку рядом с URL и выбираем «Сохраненная копия».
Откроется последняя версия страницы, которая есть у ПС. Можно посмотреть только текст, выбрав одноименную вкладку.
Посмотреть сохраненную копию конкретной страницы в Google можно с помощью оператора cache. Например, вводим cache:trinet.ru и получаем:
Вы так же можете посмотреть текстовую версию страницы.
Найти сохраненную версию страницы можно и через выдачу Google. Необходимо:
● использовать оператор site:, либо указать сразу необходимый URL
● найти страницу в выдаче
● нажать на стрелочку рядом с URL
● выбрать «Сохраненная копия»
Платформа Serpstat
С помощью этого инструмента можно посмотреть изменения видимости сайта в поисковой выдаче за год или за все время, что сайт находится в базе Serpstat.
Сервис Keys.so
Используя этот сервис можно посмотреть, сколько страниц находится в выдаче, в ТОП – 1, ТОП – 3 и т.д. Можно регулировать параметры на графике и выгружать полную статистику в Excel.
Как восстановить сайт из архива
Часто нужно не только посмотреть, как менялись страницы в прошлом, но и скачать содержимое сайта. Это легко сделать с помощью автоматических сервисов.
О самых популярных расскажем ниже.
Сервис Архиварикс
Сервис может восстановить как рабочие, так и не рабочие сайты. Недоступные ресурсы он скачивает из Веб-архива. Для этого нужно заполнить данные на странице https://archivarix.com/ru/restore/и нажать кнопку «Восстановить».
Для работы с полученными файлами Архиварикс предоставляет собственную систему CMS, которая совместима с любыми другими системами.
Сервис Rush Analytics
Данный сервис также восстанавливает сайты из Веб-архива. Можно задать нужную дату скачивания для любой страницы. На выходе получаем html-документ со всеми стилями, картинками и т.д.
Сервис R-tools.org
Еще один сервис, который позволяет скачивать сайты из Веб-архива. Можно скачать сайт целиком, можно отдельные страницы. Оплата происходит только за то, что скачено, поэтому выгоднее использовать данный сервис только для небольших сайтов.
Сервис Wayback Machine Download (waybackmachinedownloader.com)
С помощью него можно скачивать данные из Веб-архива. Есть демо-версия. Подходит для больших проектов. Единственный минус – сервис не русифицирован.
Сервис Mydrop.io
Этот сервис помогает найти уже освободившиеся или скоро освобождающиеся интересные домены по вашим параметрам.
Для этого необходимо применить заданные фильтры, после чего можно скачать контент этих сайтов. Сервис делает скриншоты сайтов до их удаления. Перед скачиванием можно предварительно посмотреть содержимое ресурса. Особенностью является то, что данные выгружаются не из ВебАрхива, а из собственной базы.
Плагины
Восстановить сайт из бэкапа можно автоматически с помощью плагинов для CMS. Таких инструментов множество. Например, плагины Duplicator, UpdraftPlus для системы WordPress. Все, что нужно – это иметь резервную копию, которую также можно сделать с помощью этих плагинов, если сайтом владеете вы.
Множество сервисов, предоставляющие хостинг для сайта, сохраняют бэкапы и можно восстановить предыдущую версию собственного проекта.
Заключение
Мы привели примеры основных сервисов, в которых можно посмотреть изменения сайтов и восстановить их содержимое. Список не ограничивается только этими инструментами.
Если у вас есть интересные и проверенные сервисы, о которых мы не упомянули, расскажите в комментариях. А если нужна помощь со скачиванием контента, обращайтесь к нашим специалистам.
И до встречи в следующей публикации!
Зачем нужна информация об истории сайта в прошлом
Историю любого сайта можно посмотреть в интернете. Для этого достаточно, чтобы ресурс существовал хотя бы пару дней. Это может понадобиться в следующих случаях:
- Если необходимо купить домен, который уже был в использовании, и нужно посмотреть контент какой тематики был на нем размещен, не было ли огромного количества рекламы, исходящих ссылок и т.д.
- Нужен уникальный контент. Его можно скачать с существовавших когда-то ресурсов. Такое наполнение подойдет, например, для сайта-сателлита.
- Нужно восстановить сайт, когда нет его бэкапа.
- Нужно проанализировать конкурентов. Этот способ понадобится чтобы посмотреть историю изменений на их сайтах, какие ошибки они допускали или, наоборот, какие “фишки” стоит позаимствовать.
- Необходимо посмотреть страницу, если она теперь недоступна напрямую.
- Интересно , как выглядел ресурс 10-20 лет назад.
Ниже приведен пример того, как выглядела стартовая страница поисковой системы Яндекс в 2000 году:
Как посмотреть сайт в прошлом
Есть несколько сервисов, в которых можно посмотреть, как менялось визуальное оформление страниц сайта, его структуру страниц и контент, положение в поисковой выдаче и какие изменения вносились в регистрационные данные за время существования ресурса.
Сервис Веб-архив
При его использовании сначала заходим на сайт https://web.archive.org/ и после вводим адрес страницы.

График ниже показывает количество сохранений: первое было в 1998 году.

Дни, в которые были сохранения, отмечены кружком. При клике на время во всплывающем окне, открывается сохраненная версия. Показано ниже:

Как выгрузить сайт из ВебАрхива, расскажем дальше.
Сервис Whois History
Для его использования заходим на сайт http://whoishistory.ru/ и вводим данные в поиске по доменам и IP, либо по домену:
Сервис покажет информацию по данным Whois, где собраны сведения от всех регистраторов доменных имен. Посмотреть можно возраст домена, кто владелец, какие изменения вносились в регистрационные данные и т.д.
Сохраненная копия страницы в поисковых системах Яндекс и Google
Для сохранения копий страниц понадобятся дополнительные сервисы. Поисковые системы сохраняют последние версии страниц, которые были проиндексированы поисковым роботом.
Для этого в строке поиска Яндекс вводим адрес сайта с оператором site: или url: в зависимости от того, что хотим проверить конкретную страницу или ресурс целиком. Нажимаем на стрелочку рядом с URL и выбираем «Сохраненная копия».
Откроется последняя версия страницы, которая есть у ПС. Можно посмотреть только текст, выбрав одноименную вкладку.

Посмотреть сохраненную копию конкретной страницы в Google можно с помощью оператора cache. Например, вводим cache:trinet.ru и получаем:

Вы так же можете посмотреть текстовую версию страницы.
Найти сохраненную версию страницы можно и через выдачу Google. Необходимо:
- использовать оператор site:, либо указать сразу необходимый URL
- найти страницу в выдаче
- нажать на стрелочку рядом с URL
- выбрать «Сохраненная копия»
Платформа Serpstat
С помощью этого инструмента можно посмотреть изменения видимости сайта в поисковой выдаче за год или за все время, что сайт находится в базе Serpstat.

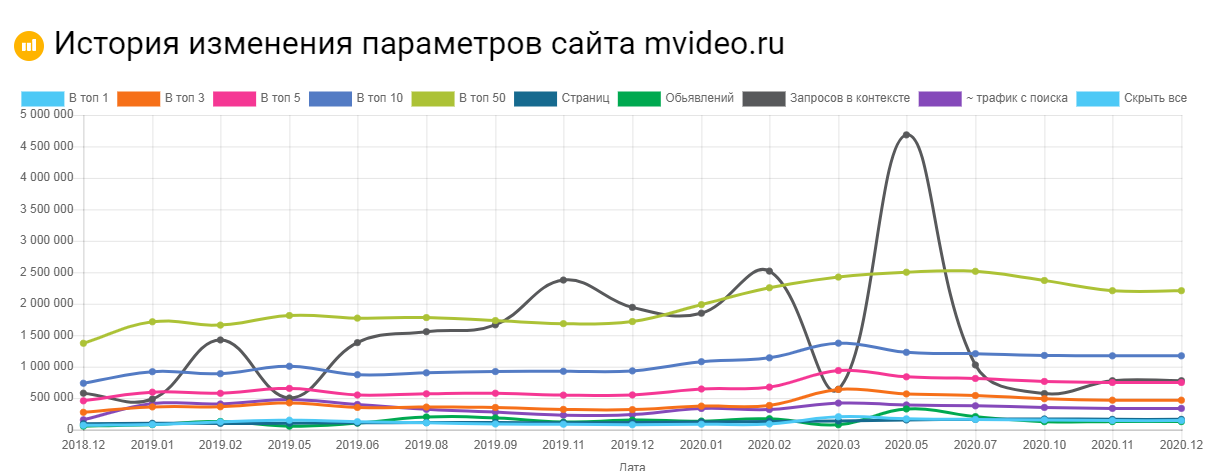
Сервис Keys.so
Используя этот сервис можно посмотреть, сколько страниц находится в выдаче, в ТОП – 1, ТОП – 3 и т.д. Можно регулировать параметры на графике и выгружать полную статистику в Excel.
Как восстановить сайт из архива
Часто нужно не только посмотреть, как менялись страницы в прошлом, но и скачать содержимое сайта. Это легко сделать с помощью автоматических сервисов.
О самых популярных расскажем ниже.
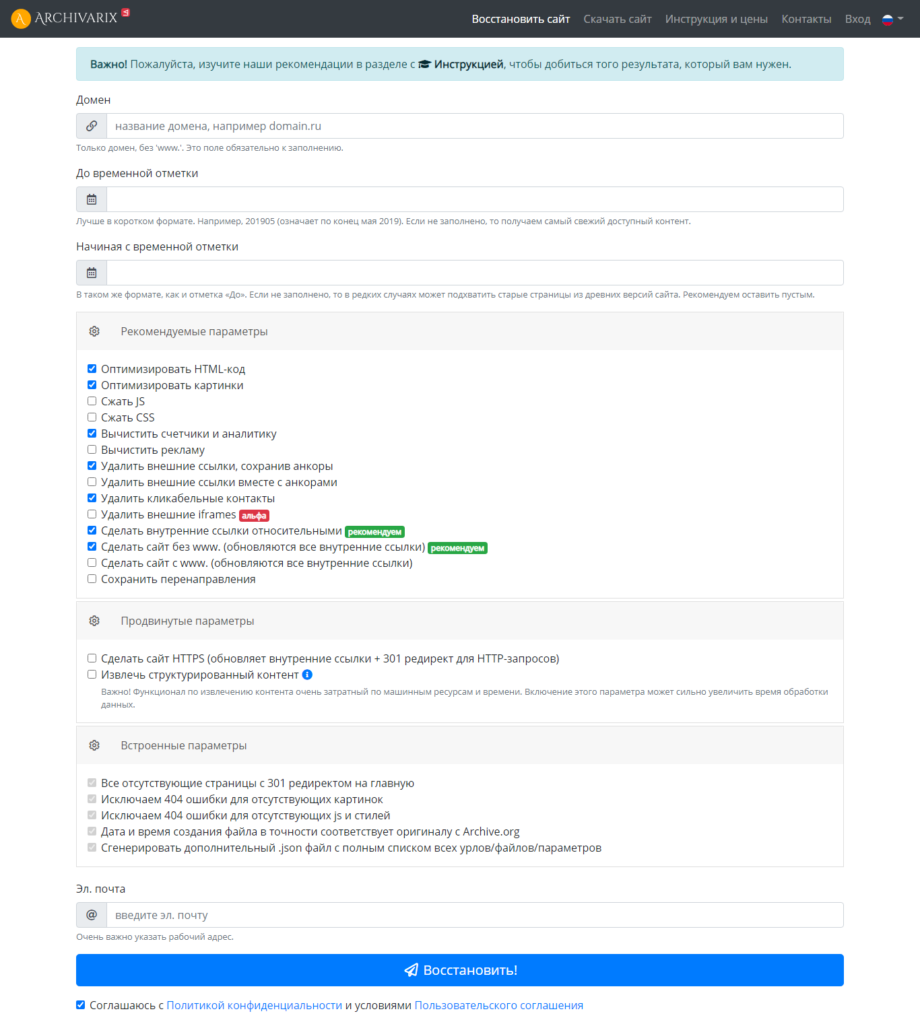
Сервис Архиварикс
Сервис может восстановить как рабочие, так и не рабочие сайты. Недоступные ресурсы он скачивает из Веб-архива. Для этого нужно заполнить данные на странице https://archivarix.com/ru/restore/ и нажать кнопку «Восстановить».
Для работы с полученными файлами Архиварикс предоставляет собственную систему CMS, которая совместима с любыми другими системами.
Сервис Rush Analytics
Данный сервис также восстанавливает сайты из Веб-архива. Можно задать нужную дату скачивания для любой страницы. На выходе получаем html-документ со всеми стилями, картинками и т.д.
Ссылка на сервис https://www.rush-analytics.ru/land/skachivanie-kopiy-saytov-iz-wayback-machine
Сервис R-tools.org
Еще один сервис, который позволяет скачивать сайты из Веб-архива. Можно скачать сайт целиком, можно отдельные страницы. Оплата происходит только за то, что скачено, поэтому выгоднее использовать данный сервис только для небольших сайтов.
Сервис Wayback Machine Download (waybackmachinedownloader.com)
С помощью него можно скачивать данные из Веб-архива. Есть демо-версия. Подходит для больших проектов. Единственный минус – сервис не русифицирован.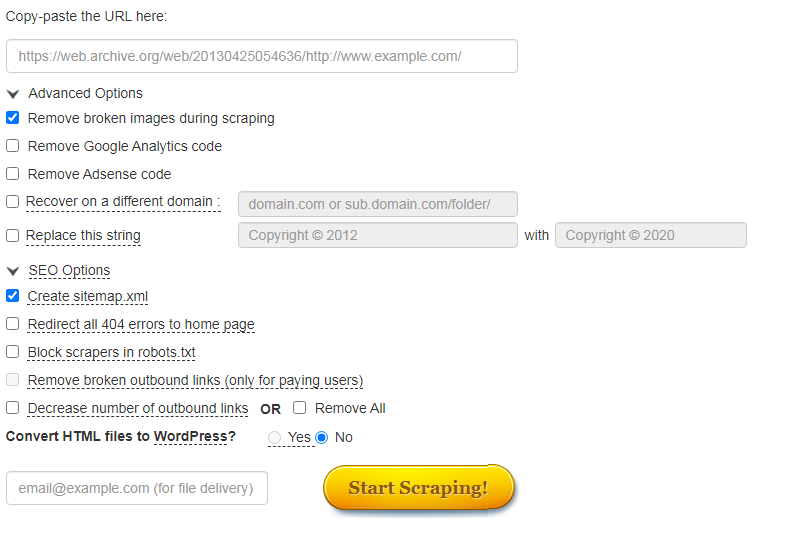
Сервис Mydrop.io
Этот сервис помогает найти уже освободившиеся или скоро освобождающиеся интересные домены по вашим параметрам.
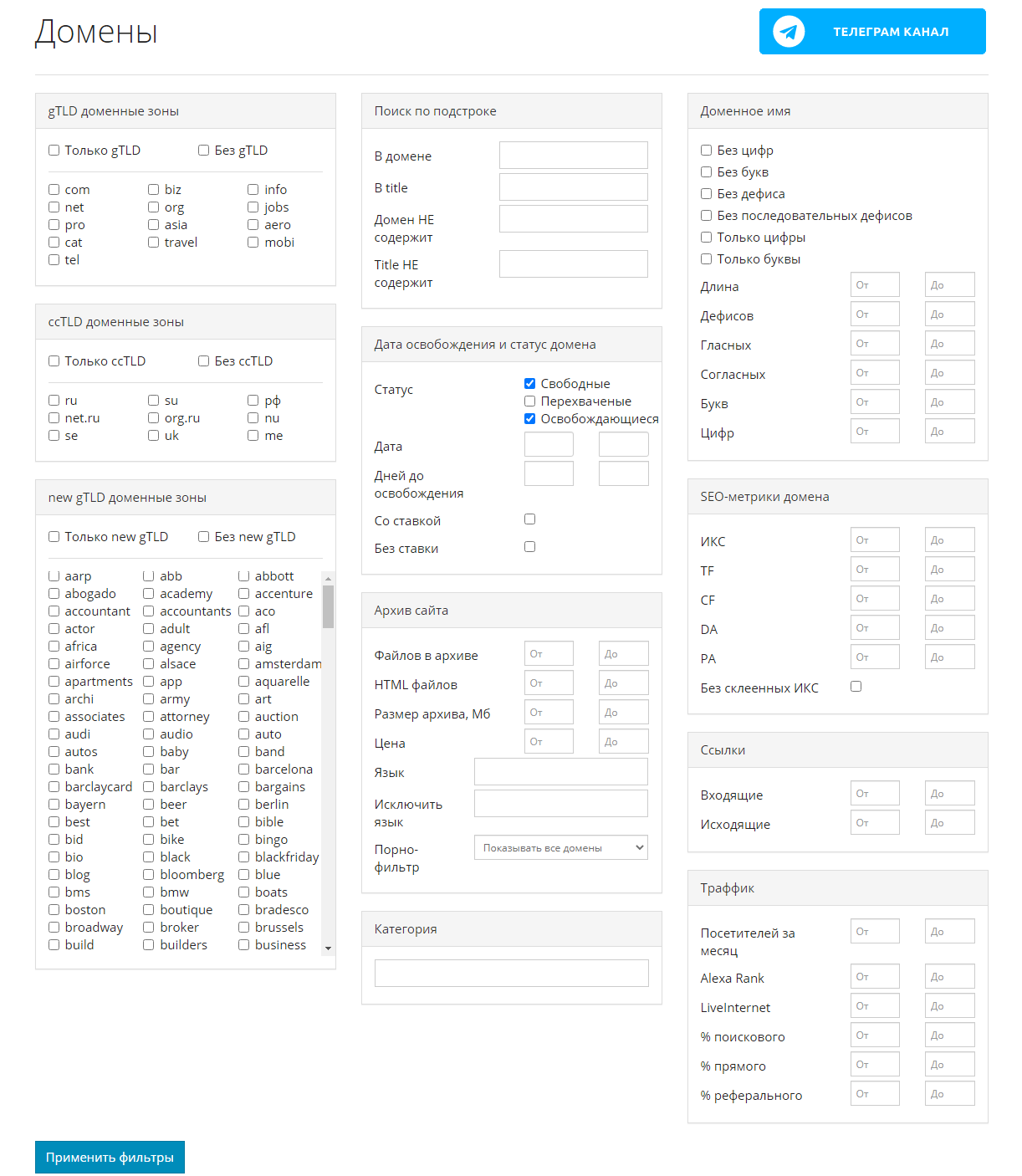
Для этого необходимо применить заданные фильтры, после чего можно скачать контент этих сайтов. Сервис делает скриншоты сайтов до их удаления. Перед скачиванием можно предварительно посмотреть содержимое ресурса. Особенностью является то, что данные выгружаются не из ВебАрхива, а из собственной базы.
Плагины
Восстановить сайт из бэкапа можно автоматически с помощью плагинов для CMS. Таких инструментов множество. Например, плагины Duplicator, UpdraftPlus для системы WordPress. Все, что нужно – это иметь резервную копию, которую также можно сделать с помощью этих плагинов, если сайтом владеете вы.
Множество сервисов, предоставляющие хостинг для сайта, сохраняют бэкапы и можно восстановить предыдущую версию собственного проекта.
Заключение
Мы привели примеры основных сервисов, в которых можно посмотреть изменения сайтов и восстановить их содержимое. Список не ограничивается только этими инструментами.
Если у вас есть интересные и проверенные сервисы, о которых мы не упомянули, расскажите в комментариях. А если нужна помощь со скачиванием контента или комплексные услуги по продвижению и созданию сайтов, обращайтесь к нашим специалистам.
И до встречи в следующей публикации!
К вашим услугам кеш поисковиков, интернет-архивы и не только.

Если, открыв нужную страницу, вы видите ошибку или сообщение о том, что её больше нет, ещё не всё потеряно. Мы собрали сервисы, которые сохраняют копии общедоступных страниц и даже целых сайтов. Возможно, в одном из них вы найдёте весь пропавший контент.
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
1. Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
Есть и альтернативный способ. Введите в браузерную строку следующий URL: http://webcache.googleusercontent.com/search?q=cache:lifehacker.ru. Замените lifehacker.ru на адрес нужной страницы и нажмите Enter.
Сайт Google →
2. Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
Сайт «Яндекса» →
3. Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
Сайт Bing →
4. Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Сайт Yahoo →
Специальные архивные сервисы
Указав адрес нужной веб‑страницы в любом из этих сервисов, вы можете увидеть одну или даже несколько её архивных копий, сохранённых в разное время. Таким образом вы можете просмотреть, как менялось содержимое той или иной страницы. В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
Чтобы проверить наличие копий в одном из этих архивов, перейдите на его сайт. Введите URL нужной страницы в текстовое поле и нажмите на кнопку поиска.
1. Wayback Machine (Web Archive)
Сервис Wayback Machine, также известный как Web Archive, является частью проекта Internet Archive. Здесь хранятся копии веб‑страниц, книг, изображений, видеофайлов и другого контента, опубликованного на открытых интернет‑ресурсах. Таким образом основатели проекта хотят сберечь культурное наследие цифровой среды.
Сайт Wayback Machine →
2. Arhive.Today
Arhive.Today — аналог предыдущего сервиса. Но в его базе явно меньше ресурсов, чем у Wayback Machine. Да и отображаются сохранённые версии не всегда корректно. Зато Arhive.Today может выручить, если вдруг в Wayback Machine не окажется копий необходимой вам страницы.
Сайт Arhive.Today →
3. WebCite
Ещё один архивный сервис, но довольно нишевый. В базе WebCite преобладают научные и публицистические статьи. Если вдруг вы процитируете чей‑нибудь текст, а потом обнаружите, что первоисточник исчез, можете поискать его резервные копии на этом ресурсе.
Сайт WebCite →
Другие полезные инструменты
Каждый из этих плагинов и сервисов позволяет искать старые копии страниц в нескольких источниках.
1. CachedView
Сервис CachedView ищет копии в базе данных Wayback Machine или кеше Google — на выбор пользователя.
Сайт CachedView →
2. CachedPage
Альтернатива CachedView. Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.
Сайт CachedPage →
3. Web Archives
Это расширение для браузеров Chrome и Firefox ищет копии открытой в данный момент страницы в Wayback Machine, Google, Arhive.Today и других сервисах. Причём вы можете выполнять поиск как в одном из них, так и во всех сразу.

![]()
Читайте также 💻🔎🕸
- 3 специальных браузера для анонимного сёрфинга
- Что делать, если тормозит браузер
- Как включить режим инкогнито в разных браузерах
- 6 лучших браузеров для компьютера
- Как установить расширения в мобильный «Яндекс.Браузер» для Android
Раньше история человечества фиксировалась на картинах, в книгах, письмах и газетах. Эти носители хранятся в картинных галереях, крупных библиотеках и исторических архивах. Сейчас значимые события обязательно появляются на сайтах, видеохостингах и в социальных сетях. Но сайты, как и книги, не вечны. Их удаляют, как только они становятся не нужны. Для сохранения этих данных есть веб-архив. Он доступен всем пользователям в любое время.
Что такое веб-архив и как им пользоваться
Веб-архив (web archive) – это бесплатная электронная библиотека, где вместо книг хранятся сайты. Сервис периодически делает снимки (снэпшоты) веб-ресурсов и сохраняет их. То есть вы всегда сможете увидеть, как выглядел сайт в момент, когда была сделана копия.
Как работает веб-архив? У каждого сайта могут быть сотни сохраненных копий. Частота снимков зависит от популярности веб-ресурса: у страниц с многотысячным трафиком копии могут делаться ежедневно или даже пару раз в день.
Есть несколько веб-архивов, например, archive.md (также он размещен на адресах archive.ph и archive.today), но самым популярным и удобным считается Wayback Machine. Сервис был создан в 1996 году Брюстером Кейлом. И создавался с целью сохранить историю развития интернета. А с 1999 года Wayback Machine стал фиксировать также аудио, видео, иллюстрации и ПО. За почти 30 лет он успел собрать 737 миллиардов страниц, поэтому далее мы будем рассматривать именно этот веб-архив.
Для чего нужен архив сайтов
- Для восстановления своего сайта. Никто не застрахован от поломки веб-ресурса. Конечно, лучше настраивать автоматическое резервное копирование. Но если его у вас его всё-таки нет, не беда. Найдите ближайшую версию сайта в веб-архиве и восстановите ее. Восстановить можно как вручную, так и с помощью дополнительных программ.
- Для анализа конкурентов. Ваши конкуренты могут тестировать лучшее расположение кнопок и баннеров, менять меню и цветовую гамму сайта. Всю историю изменений вы можете проследить в веб-архиве и сделать выводы для развития своего проекта.
- Поиск информации с удаленного веб-ресурса. Некоторые проекты закрываются, сайты удаляются и, возможно, ценная информация теряется. Поисковик может долго давать вам ссылку на уже нерабочий сайт. Но как узнать, что там было? Просто зайдите в веб-архив.
- Проанализировать историю домена перед покупкой. Покупая дроп-домен, вы рискуете приобрести веб-адрес с плохой историей: сайт на этом домене мог в лучшем случае быть непопулярным, а в худшем на нем распространялся недобросовестный контент, вследствие чего веб-адрес попал в черный список. Если у домена плохая история, проекту его нового владельца не поздоровится.
- Для проведения интересного расследования или погружения в приятную ностальгию. Веб-архив ― это современный кладезь знаний. В нем можно найти много интересного, проследить, как развивались крупные компании и какие интересные проекты реализовывались, на заре эры интернета.
- Поиск интересного контента для рерайта. Если сайт не выглядел современно, как сейчас, это не значит, что над его контентом не работали талантливые люди. Вы можете вдохновиться или даже взять информацию со старых страниц и опубликовать её на своем сайте. Но об этом мы поговорим позже.
Как посмотреть страницу в веб-архиве
Чтобы проследить историю конкретного сайта, вам нужно знать только его домен.
- Перейдите на сайт Wayback Machine.
- Введите адрес сайта или конкретной страницы.
-
Нажмите BROWSE HISTORY:

-
Перед вами появится временная шкала и календарь. Вы можете заметить, что разные даты имеют разный цвет:
✅ голубой ― при архивации не возникло проблем,
✅ зелёный ― был настроен редирект,
✅ оранжевый ― при архивации произошла ошибка на стороне клиента,
✅ красный ― проблемы на стороне сервера.Чаще всего нужны даты, которые находятся в голубых или зеленых кружках.
- Выберите необходимый год, месяц и дату. Теперь вы можете увидеть прошлые версии сайта. Вперед к изучению!

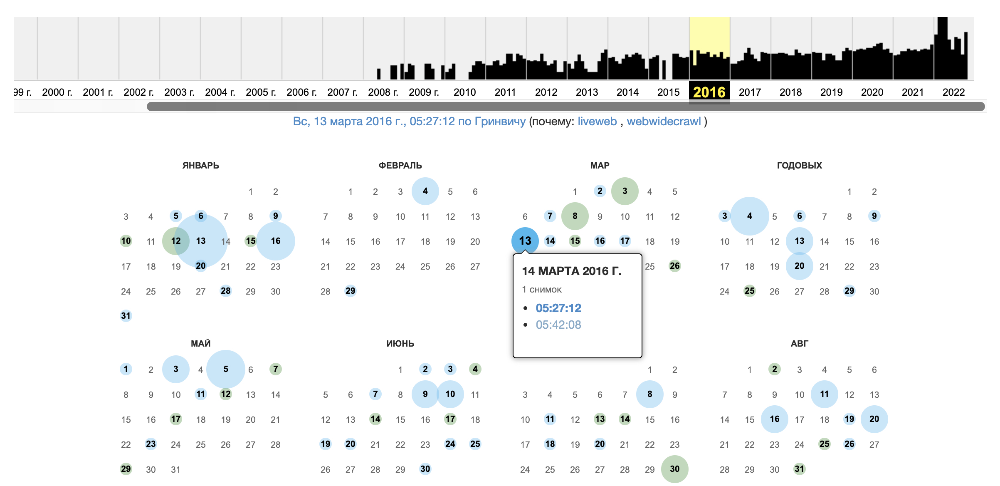

Вот так выглядел наш сайт в марте 2016 года
Если вы не знаете конкретный URL сайта, в поиск можно вбить ключевое слово, название компании или бренда. Архив выдаст вам все подходящие варианты, которые найдет у себя в хранилище.
С чем вы можете столкнуться
Во-первых, в некоторых версиях сайта может не быть картинок и элементов дизайна. К сожалению, тут ничего не поделаешь. В этой ситуации можно попробовать посмотреть другой снимок.
Во-вторых, сайт может вообще отсутствовать. Это происходит в случае, если:
- владелец веб-ресурса потребовал удалить копии его контента,
- снимки сайта удалили, так как проект нарушал закон о защите интеллектуальной собственности,
- создатели сайта ограничили доступ роботам веб-архива.
Как самостоятельно добавить версию сайта
Хотите, чтобы ваш сайт точно сохранился в архиве и копий было много?Возьмите дело в свои руки и добавьте копию сайта самостоятельно.
Для этого:
- В правом нижнем углу найдите поле Save Page Now.
- Введите в поле домен сайта и нажмите Save page:

Это актуально для небольших сайтов с маленьким трафиком, так как копии таких ресурсов делаются редко.
Как удалить копии сайта и запретить дальнейшее сохранение в веб-архив
Может случиться и обратная ситуация, когда владелец сайта не хочет, чтобы его сайт попал в веб-архив. Такое сделать тоже нетрудно. Для этого вам нужно ограничить веб-архиву доступ в robots.txt. Файл находится в корневой папке сайта. В robots.txt нужно добавить код:
User-agent: ia_archiverDisallow: /User-agent: ia_archiver-web.archive.orgDisallow: /
После вписанных в файл настроек существующие версии сайта удалятся из архива, а новые перестанут создаваться до тех пор, пока домен зарегистрирован и в robots.txt указаны настройки. Если регистрация домена закончится и он не будет продлен, старые версии сайта вернутся в веб-архив. То есть удалить историю сайта одним движением навсегда не получится.
Как восстановить сайт из веб-архива
Восстановление сайта можно сделать двумя способами:
- с использованием программ-помощников.
- вручную.
Хотим предостеречь! Веб-архив действительно может помочь в критической ситуации, но он ни в коем случае не заменит бэкапы. С какими проблемами вы можете столкнуться:
- Не все страницы сохраняются. Веб-архив не делает полную копию сайта. В основном 50-70%. Самые непопулярные страницы, скорее всего, будут потеряны. Однако, если никакой альтернативы нет, это лучше, чем ничего.
- Код может быть замусорен. Часто веб-архив добавляет свои строки кода, что влияет на чистоту написанного сайта. После восстановления код, скорее всего, придется чистить.
- Могут измениться URL страниц.
Способ 1. С использованием программ
Сейчас уже есть много программ, которые помогут скачать сайт из веб-архива. Вам останется только поместить файлы веб-сервиса на хостинг. Примеры программ:
✅ Archivarix,
✅ Wayback machine downloader,
✅ Rush Analytics,
✅ RoboTools.
Несмотря на то что сервисы платные, стоят они недорого. Также они могут почистить код и привести скачанные данные в приемлемый вид. Учитывая стоимость работ программиста, это действительно дешевле.
Способ 2. Вручную
- Перейдите на сервер или компьютер, куда нужно скачать копию сайта. Установите Ruby (если нет): sudo apt install ruby
- Теперь установим утилиту для скачивания сайта: sudo gem install wayback_machine_downloader
Дальнейшие действия зависят от того, какая версия сайта вам нужна. Если вам нужна самая последняя версия сайта, введите команду:
wayback_machine_downloader http://site.com
Где http://site.com ― URL нужного сайта.
Если вас интересует конкретная версия сайта:
- Перейдите в веб-архив и выберите нужную версию сайта.
- Скопируйте из URL, который появится при загрузке выбранной версии, только цифры, которые идут после web/:
https://web.archive.org/web/20220322041638/https://2domains.ru/ - Вернитесь на сервер/компьютер, куда хотите скачать копию сайта, и введите:

wayback_machine_downloader http://example.com –from 20220322041638
или
wayback_machine_downloader http://example.com –to 20220322041638
Где 20220322041638 ― номер версии, который вы скопировали из веб-архива.
Чем отличаются команды:
✅ –from ― скачивает файлы только с указанной даты или более поздней версии;
✅ –to ― скачивает файлы только с указанной даты или более ранней версии.
Другие параметры для скачивания можно прочитать здесь. Например, при вводе параметра –exclude можно скачать файлы конкретного типа (pdf, .jpg, .txt).
Теперь ждите, когда скачаются все файлы сайта, и можете переносить их на хостинг. Скачивание файлов может занять как несколько часов, так и несколько дней. Время скачивания зависит от размера сайта.
Теперь нужно просмотреть файлы и привести все в порядок. Как мы уже говорили, у полученного из веб-архива HTML-кода может быть много ненужных строк.
Можно ли использовать уникальный контент из старых материалов
Люди работают над продвижением сайтов. Наполняют их контентом: ведут блоги, делятся советами и лайфхаками, делают расследования и создают продающие тексты. Однако проекты заканчиваются, нередко компании удаляют свои сайты, блогеры перестают вести странички и т. д. Можно ли пользоваться всем этим полезным контентом в своих целях? Конечно, да. Мы не будем рассуждать об этической составляющей этого действия. С точки зрения закона и со стороны поисковых систем никаких претензий не будет.
Через некоторое время удаленные сайты перестают индексироваться поисковыми системами, то есть, если вы перезальете текст с нерабочей страницы к себе на веб-ресурс, система будет считать его уникальным.
Главное, чтобы кто-то другой не сделал также с выбранной вами статьей. Вполне возможно, что вы ни один такой умный искатель контента. Поэтому, как только вы нашли подходящий текст, обязательно проверьте его на уникальность. Сделать это можно, например, на text.ru или content-watch.ru.
Проверить, свободен ли домен, можно в Whois или посмотреть среди освободившихся доменов.
Где хранится история интернета? Теперь вы знаете ответ. Вперед за удивительными и интересными открытиями!
