-

-
March 17 2009, 20:35

- 18+
- Cancel
как найти оригинал картинки даже по одному её фрагменту
*Это цитата сообщения
Rost :
Простая инструкция вида: “шаг за шагом” с примером.
1. Находим адрес картинки. В нашем случае это: “http://img0.liveinternet.ru/images/attach/c/0/40/403/40403940_auto.jpg”
2. Идём на сайт tineye.com
3.Загружаем картинкуадрес картинки или вставляем её адрес (слева или справа соответственно).
4. Нажимаем кнопку “Search”.
5. Получаем эту страницу
На ней видны миниатюры картинок, формат и разрешение исходных картинок, их адреса размещения, сайты вообще и прямые ссылки на страницы сайтов, где есть эти картинки.
А теперь вы знаете, как искать конкретные картинки в интернете, я скажу пару слов, зачем это нужно (если кто не понял).
Прежде всего главная “полезность” такого сервиса – поиск большой картинки по её миниатюре
(вы поняли, мои маленькие любители качественной эротической фотографии?) или даже её кусочку. Кроме того, можно найти оригинал картинки по её отфотошопленной копии и т.д.
Вещь очень и очень полезная. Рекомендую!
Поиск изображений по фрагменту
Время на прочтение
5 мин
Количество просмотров 65K

В своем выступлении Александр Крайнов рассказал каким способом Яндекс.Картинки кластеризировали дубликаты изображений. Другими словами, выделяли и отфильтровывали дубли картинок. Где основная идея была в том, чтобы выделить контуры изображения посредством фильтра DoG, после чего найти ключевые точки и получить их дескрипторы.
Кластеризация дубликатов сводится к поиску совпадений дескрипторов. Это и есть «цифровой формат» ключевых точек из статьи Кластеризация дубликатов в поиске по картинкам.
Но хотелось бы немного подробнее узнать, что это за дескрипторы и как производить по ним поиск.
Дескрипторы
Ключевые точки — это точки, которые в идеале не должны меняться при изменении или модификации изображения.
Дескрипторы — это, в общем виде, свертка характеристик и представление ключевых точек в формате доступном для проверки на совпадение.
Поиск эффективного выделения ключевых точек, их дескрипторов, а также методов проверки на совпадения, все еще остается на повестке дня.
Но надо с чего-то начинать, поэтому обратимся на помощь к библиотеке OpenCV.
Первое на что бросается взгляд — это дескрипторы SURF.
Которые обещают необычайную точность. Что и подтверждается после тестов.
Но есть несколько нюансов.
Дескрипторы SURF — это вектора из 128 (или 64) чисел на одну ключевую точку. Проверка на совпадение выполняется поиском ближайшей точки (или даже двух). И чем ближе точка, тем лучше.
Получается что на изображение с 1 000 ключевых точек, потребуется 128 000 чисел с плавающей точкой.
Кроме того, само обнаружение точек довольно сложная операция и требует значительное время. Что не позволяет эффективно использовать данный алгоритм на небольших устройствах. К тому же сам алгоритм закрытый и запатентован (в США).
После ознакомления с SIFT и SURF, захотелось чего-то простого в реализации с возможностью применить на небольшом сервере либо устройстве.
Перцептивные хеши
И были найдены перцептуальные или перцептивные хеши.
Задача которых в том, что бы при небольшом изменении изображения хеш также незначительно менялся.
Проверка на совпадение проводится подсчетом количества отличающихся позиций между двумя хешами. Т.е. подсчет расстояния Хэмминга. И чем меньше оно, чем меньше различающихся элементов, тем больше совпадение.
Данный метод рассчитан на поиск полных либо частичных дубликатов изображения. Т.е. при значительном изменении формата изображения либо вмешательство в контент приводит к невозможности проверки на совпадение, так как хеши будут заметно отличаться.
Другими словами перцептивные хеши не годятся для поиска полудубликатов.
Исходя из этого была предпринята попытка объединить SURF дескрипторы и перцептивные хеши с целью решить проблему поиска нечетких полудубликатов.
Метод основывается на кластеризации ключевых точек таким образом, чтобы центры кластеров совпадали на оригинальном и кропнутом изображении. А далее производилось выделение фрагмента изображения вокруг ключевой точки и получения перцептивного хеша. В результате одно изображение давало порядка 200 кроп нарезков и их хешей.
У данного метода есть два с половиной значительных недостатка:
1. низкая скорость проверки на совпадение на большом наборе хешей. Поиск по 1 млн хешей занимало 20 секунд
2. низкая скорость получения ключевых точек
3. низкая точность, множество ложных срабатываний, высокие требование к целевой базе, годится не для всех картинок, требует премодерации и т.д
Сама идея о том, что бы из изображения выделялось некоторое количество отпечатков (fingerprint), которые можно было бы просто сопоставить друг с другом, завораживала.
Поэтому было решено попытаться найти решения данным проблемам.
Низкая скорость выборки
Сложность поиска и подсчета расстояния Хэмминга на большом наборе данных является самостоятельной проблемой и требует независимого подхода.
После некоторых исследований тематики оказалось, что существует множество решений данной проблемы.
Был выбран и реализован наиболее эффективный из имеющихся алгоритм названный HEngine, который позволил в ~60 раз ускорить выборку из базы данных.
SURF и ключевые точки
Так как мы работаем уже с бинарными хешами, или отпечатками, а совпадение считаем расстоянием Хэмминга, то странно использовать такую махину как SURF и стоило бы рассмотреть другие методы получения ключевых точек и дескрипторов.
В общем виде OpenCV предоставляет два типа дескрипторов:
— Дескрипторы с плавающей точкой
— И бинарные дескрипторы
Вот бинарные дескрипторы как никакие иные подходят для нашей задачи, потому что также используют расстояние Хэмминга для проверки на совпадения.
ORB: an efficient alternative to SIFT or SURF
OpenCV уже имеет у себя отличную альтернативу SURF, которая мало того, что открытая и без лицензионных ограничений, так еще легче и работает быстрее [1].
ORB — это Oriented FAST and Rotated BRIEF — улучшенная версия и комбинация детектора ключевых точек FAST и бинарных дескрипторов BRIEF.
ORB имеет один существенный нюанс для нас — размер дескрипторов 32 байта на одну точку.
Проверка на совпадение — это сумма расстояний Хэмминга для каждого байта дескриптора (первый сравнивается с первым, второй со вторым и тд).
В нашей задаче подразумевается, что одна точка дает одно значение, а тут получается 32, которые надо еще и суммировать с соответствующими по индексу (первый с первым, второй со вторым и тд) в целевой базе данных.
Так как наш хеш это 64битное число, то требуется 32 байта дескриптора ужать в 8 байт и при этом не сильно потерять в точности.
После некоторых тестов было решено попробовать эти 32 байта представить в виде матрицы 16×16 бит. А потом эту матрицу пропустить через перцептивный хеш PHash. Результатом должно было оказаться как раз 64 битное число.
Теперь мы подошли к полному описанию концепта.
Как работает индексация
1. Получаем ключевые точки и дескрипторы ORB, выбираем количество требуемых точек на изображении.
2. Полученные дескрипторы по 32 байта представляем в виде битовой матрицы 16×16.
3. Конвертируем матрицу в 64битное число с помощью PHash.
4. Сохраняем 64битные отпечатки в MySQL.
5. Выбираем требуемое расстояние Хэмминга и запускаем демон HEngine, который будет выполнять поиск.
Как работает поиск
Выполняем идентичные шаги 1 — 3 из индексации, но только на запрашиваемом изображении.
4. Делаем запрос демону HEngine, который возвращает все хеши в заданном пределе.
5. Если требуется, отфильтровать неактуальные результаты.

Рис 1. Предел расстояния Хэмминга 7. Серые точки — это найденные ключевые точки. Зеленые — совпадающие точки. Красные — совпадающие стандартным ORB полным перебором.
А что в итоге?
В итоге удалось решить нескольких проблем:
— найти способ быстрого подсчета расстояния Хэмминга на большом наборе данных
— избавиться от большого и неудобного SURF
— увеличить скорость выделения ключевых точек и их отпечатков
— а также не потерять сильно в точности.
Что позволило находить изображения по их фрагменту, а также нечеткие полудубликаты без больших вычислительных ресурсов.

Рис 2. Сладкое к пятнице
Учитывая то, что в зависимости от настроек, описанный алгоритм через бинарные дескрипторы ORB выдает около 1 000 хешей на картинку.
На базу в 1 000 изображений получается 1 000 000 хешей в базе. Поиск и кластеризация всех дубликатов занимает полторы минуты. Включает в себя полный перебор и поиск совпадающих хешей.
Ссылки
[1] Ethan Rublee, Vincent Rabaud, Kurt Konolige, Gary R. Bradski: ORB: An efficient alternative to SIFT or SURF. ICCV 2011: 2564-2571.
[2] en.wikipedia.org/wiki/SURF
[3] ru.wikipedia.org/wiki/Расстояние_Хэмминга
[4] phash.org
[5] habrahabr.ru/post/143667 Кластеризация дубликатов в Яндекс.Картинках
[6] habrahabr.ru/post/211264 HEngine — алгоритм поиска хешей в пределах заданного расстояния Хэмминга на большом наборе данных
[7] github.com/valbok/img.chk Мой прототип поиска по фрагментам
Как найти похожую картинку, фотографию, изображение в интернет
12.07.2019
Допустим у Вас есть какое-то изображение (рисунок, картинка, фотография), и Вы хотите найти такое же (дубликат) или похожее в интернет. Это можно сделать при помощи специальных инструментов поисковиков Google и Яндекс, сервиса TinEye, а также потрясающего браузерного расширения PhotoTracker Lite, который объединяет все эти способы. Рассмотрим каждый из них.
Поиск по фото в Гугл
Тут всё очень просто. Переходим по ссылке https://www.google.ru/imghp и кликаем по иконке фотоаппарата:

Дальше выбираем один из вариантов поиска:
- Указываем ссылку на изображение в интернете
- Загружаем файл с компьютера
На открывшейся страничке кликаем по ссылке «Все размеры»:

В итоге получаем полный список похожих картинок по изображению, которое было выбрано в качестве образца:

Есть еще один хороший способ, работающий в браузере Chrome. Находясь на страничке с интересующей Вас картинкой, подведите к ней курсор мыши, кликните правой клавишей и в открывшейся подсказке выберите пункт «Найти картинку (Google)»:

Вы сразу переместитесь на страницу с результатами поиска!
Статья по теме: Поисковые сервисы Google, о которых Вы не знали!
Поиск по картинкам в Яндекс
У Яндекса всё не менее просто чем у Гугла 🙂 Переходите по ссылке https://yandex.by/images/ и нажимайте значок фотоаппарата в верхнем правом углу:

Укажите адрес картинки в сети интернет либо загрузите её с компьютера (можно простым перетаскиванием в специальную области в верхней части окна браузера):
![]()
Результат поиска выглядит таким образом:
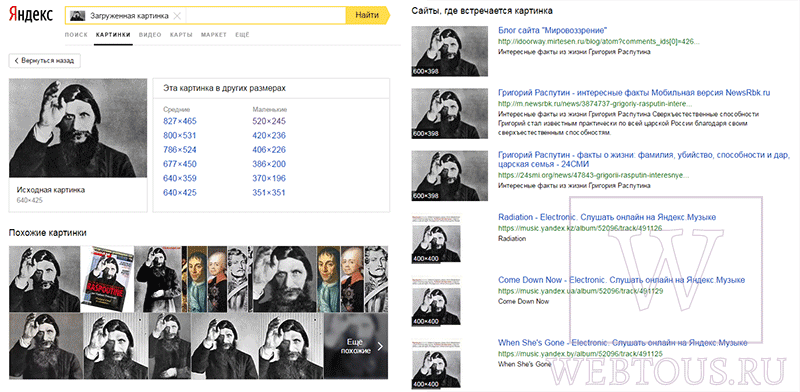
Вы мгновенно получаете доступ к следующей информации:
- Какие в сети есть размеры изображения, которое Вы загрузили в качестве образца для поиска
- Список сайтов, на которых оно встречается
- Похожие картинки (модифицированы на основе исходной либо по которым алгоритм принял решение об их смысловом сходстве)
Поиск похожих картинок в тинай
Многие наверняка уже слышали об онлайн сервисе TinEye, который русскоязычные пользователи часто называют Тинай. Он разработан экспертами в сфере машинного обучения и распознавания объектов. Как следствие всего этого, тинай отлично подходит не только для поиска похожих картинок и фотографий, но их составляющих.
Проиндексированная база изображений TinEye составляет более 10 миллиардов позиций, и является крупнейших во всем Интернет. «Здесь найдется всё» — это фраза как нельзя лучше характеризует сервис.

Переходите по ссылке https://www.tineye.com/, и, как и в случае Яндекс и Google, загрузите файл-образец для поиска либо ссылку на него в интернет.

На открывшейся страничке Вы получите точные данные о том, сколько раз картинка встречается в интернет, и ссылки на странички, где она была найдена.
PhotoTracker Lite – поиск 4в1
Расширение для браузера PhotoTracker Lite (работает в Google Chrome, Opera с версии 36, Яндекс.Браузере, Vivaldi) позволяет в один клик искать похожие фото не только в указанных выше источниках, но и по базе поисковика Bing (Bing Images)!
Скриншот интерфейса расширения:
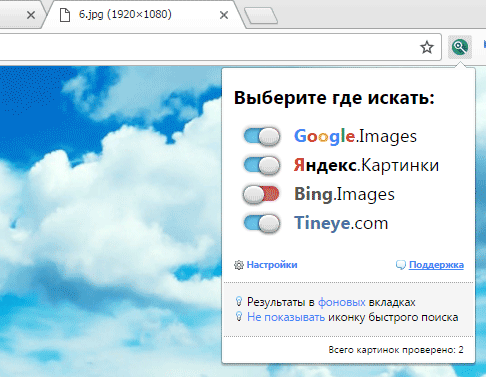
В настройках приложения укажите источники поиска, после чего кликайте правой кнопкой мыши на любое изображение в браузере и выбирайте опцию «Искать это изображение» PhotoTracker Lite:
![]()
Есть еще один способ поиска в один клик. По умолчанию в настройках приложения активирован пункт «Показывать иконку быстрого поиска». Когда Вы наводите на какое-то фото или картинку, всплывает круглая зеленая иконка, нажатие на которую запускает поиск похожих изображений – в новых вкладках автоматически откроются результаты поиска по Гугл, Яндекс, Тинай и Бинг.

Расширение создано нашим соотечественником, который по роду увлечений тесно связан с фотографией. Первоначально он создал этот инструмент, чтобы быстро находить свои фото на чужих сайтах.
Когда это может понадобиться
- Вы являетесь фотографом, выкладываете свои фото в интернет и хотите посмотреть на каких сайтах они используются и где возможно нарушаются Ваши авторские права.
- Вы являетесь блогером или копирайтером, пишите статьи и хотите подобрать к своему материалу «незаезженное» изображение.
- А вдруг кто-то использует Ваше фото из профиля Вконтакте или Фейсбук в качестве аватарки на форуме или фальшивой учетной записи в какой-либо социальной сети? А ведь такое более чем возможно!
- Вы нашли фотографию знакомого актера и хотите вспомнить как его зовут.
На самом деле, случаев, когда может пригодиться поиск по фотографии, огромное множество. Можно еще привести и такой пример…
Как найти оригинал заданного изображения
Например, у Вас есть какая-то фотография, возможно кадрированная, пожатая, либо отфотошопленная, а Вы хотите найти её оригинал, или вариант в лучшем качестве. Как это сделать? Проводите поиск в Яндекс и Гугл, как описано выше, либо средствами PhotoTracker Lite и получаете список всех найденных изображений. Далее руководствуетесь следующим:
- Оригинальное изображение, как правило имеет больший размер и лучшее качество по сравнению с измененной копией, полученной в результате кадрирования. Конечно можно в фотошопе выставить картинке любой размер, но при его увеличении относительно оригинала, всегда будут наблюдаться артефакты. Их можно легко заметить даже при беглом визуальном осмотре.
Статья в тему: Как изменить размер картинки без потери в качестве.
- Оригинальные фотографии часто имеют водяные знаки, обозначающие авторство снимка (фамилия, адрес сайта, название компании и пр.). Конечно водяной знак может добавить кто угодно на абсолютно на любое изображение, но в этом случае можно поискать образец фото на сайте или по фамилии автора, наверняка он где-то выкладывает своё портфолио онлайн.
- И наконец, совсем простой признак. Если Ваш образец фото черно-белый (сепия и пр.), а Вы нашли такую же, но полноцветную фотографию, то у Вас явно не оригинал. Добавить цветность ч/б фотографии гораздо более сложнее, чем перевести цветную фотографию в черно-белую 🙂
Уважаемые читатели, порекомендуйте данный материал своим друзьям в социальных сетях, а также задавайте свои вопросы в комментариях и делитесь своим мнением!
Похожие публикации:
- 3 способа изменить шрифт в Telegram
- Можно ли включить плагины NPAPI в браузере Хром?
- Что делать, если Хром не хочет обновляться до свежей версии?
- Как раз и навсегда поставить обновления Windows 10 под полный контроль
- Как решить проблему нечеткого размытого шрифта в новых версиях Google Chrome
Понравилось? Поделитесь с друзьями!

Сергей Сандаков, 42 года.
С 2011 г. пишу обзоры полезных онлайн сервисов и сайтов, программ для ПК.
Интересуюсь всем, что происходит в Интернет, и с удовольствием рассказываю об этом своим читателям.
Перевод публикуется с сокращениями, автор оригинальной
статьи Anusha Saive.
Вы можете легко вывести свой проект или маркетинговую кампанию на новый уровень с помощью правильных изображений. Если знать, как использовать правильные фильтры для сортировки и ключевые слова, нетрудно получить изображение для любой цели.
Далеко не каждая
поисковая система предоставит вам лучшие изображения. Приступим к
рассмотрению.
1. TinEye
TinEye – инструмент для поиска похожих на
оригинал изображений, требующий, чтобы вы либо ввели URL, либо загрузили картинку, чтобы узнать, откуда она появилась. Эта поисковая система проста в
использовании и отличается дружественным интерфейсом.
Можно также использовать расширение браузера TinEye для быстрого поиска: нажмите правой кнопкой мыши на любое изображение и найдите его.
2. Google Images
Никто не опережает Google Images,
когда дело доходит до поиска изображений. Все, что вам нужно сделать – ввести ключевое слово и нажать «Enter». Для более
детального поиска предлагаются определенные фильтры, предоставляющие широкий
выбор связанных изображений. Этот удобный инструмент дает именно то, что вам
необходимо.
Вы можете выбрать из
большого списка фильтров, представляющих изображения в виде клипарта,
мультфильма, иллюстраций и т. д. Фильтрация позволяет выбрать цвет,
размер, тематику и другую подобную информацию. Чтобы воспользоваться этим
инструментом, найдите значок камеры в поле поиска и нажмите на него.
3. Yahoo Image Search
Yahoo Image Search – еще один удобный вариант для поиска изображений. Он похож на Google Images и дает отличные результаты. В этом продукте
фильтры менее сложны, но удобно расположены и находятся на виду.
4. Picsearch
Если хотите получить более разнообразные результаты по введенному ключевому слову, попробуйте Picsearch.
Эта поисковая система не показывает массу конкретных
результатов, как некоторые другие поисковики, но демонстрирует связанные
изображения по ключевому слову.
Расширенные опции поиска позволяют фильтровать
результаты по размеру, разрешению картинки, заднему фону и т. д.

5. Bing Image Search
Bing IS является лучшей альтернативой Google Images,
поскольку выдает довольно похожие результаты. С точки зрения макета он также
довольно близок к сервису Google и обладает невероятными функциями для поиска людей,
используя параметры лица, головы и плеч.
Доступны многочисленные опции поиска и фильтры.
6. Flickr
Flickr работает несколько
иначе. Это своего рода платформа, где фотографы-любители и профессионалы делятся изображениями. В случае, если вы
находитесь на Flickr для поиска картинок на маркетинговую, брендовую или
коммерческую тематику, обязательно изучите лицензию.
7. Pinterest Visual Search Tool
Pinterest давно всем знаком и многие жить без него не
могут из-за некоторых особенностей инструмента. Одна из них – встроенный
визуальный поиск. Чтобы получить доступ к этой платформе, вам нужно войти в
свою учетку, нажать на любой появившийся в ленте пин,
а затем щелкнуть по значку в правом нижнем углу, связанному с закрепленными в
системе изображениями.
Эта поисковая машина
имеет обширную базу данных и дает лучшие результаты,
соответствующие искомому изображению.
8. Getty Images
Getty
Images выполняет поиск по ключевым словам и по
изображению. Для поиска по ключевым словам существует
несколько вариантов с функциями автоматического предложения. Ресурс предлагает набор фильтров, гарантирующих, что вы получите именно то, что
ищете.
Сервис предоставляет
изображения в двух вариантах: творческие и редакционные, а также видео. Вам
придется заплатить за лицензию, чтобы использовать любую фотографию (ее можно купить в пакетах или поштучно с фиксированной ценой).

9. Яндекс
Яндекс позволяет искать изображения с помощью широкого
спектра фильтров и параметров сортировки по формату, ориентации,
размеру и т. д. Также доступен еще один
инструмент поиска, называемый «Похожие изображения».
10. Shutterstock
Ищете бюджетный вариант с хорошим ассортиментом? Shutterstock – то что нужно. Он отобрал пальму первенства у Getty Images с помощью огромной
библиотеки изображений.
Ресурс позволяет
выполнять поиск изображений любым удобным для вас способом. Ежемесячные и
годовые тарифные планы предполагают варианты с предоплатой или с оплатой после покупки.
11. The New York Public Library Digital Collections
Последний, но не худший
источник. Если вам нужны изображения с высоким разрешением, относящиеся к
исторической эпохе, картам, книгам, бухгалтерской тематике, фотографии и т. д.,
не забудьте поискать в The New York Public Library! Огромный архив изображений – общественное достояние.
Этот инструмент поиска
исторических изображений позволяет уточнить условия, выбрав
результат в зависимости от жанра, коллекции, места, темы, издателя и т.д.
Дополнительные материалы:
- 10 лучших альтернатив YouTube, которые стоит попробовать в 2021 году
Источники
- https://www.fossmint.com/image-search-engines/
В статье рассматривается способ решения задачи поиска изображений по фрагменту. Представленное решение позволяет быстро и эффективно находить похожие ключевые точки изображений. В работе используется алгоритм ORB.
ORB – бесплатная, быстрая и эффективная альтернатива алгоритмам обнаружения ключевых точек SIFT и SURF. Алгоритм не патентован, а значит, его использование в любых проектах не ограничивается. Входит в состав opencv.
Для задачи поиска изображений по фрагменту на Python необходимы библиотеки numpy и opencv.
Загрузка изображений и перевод в монохром:
query_img = cv2.imread(‘query.jpg’)
original_img = cv2.imread(‘original.jpg’) query_img_bw = cv2.cvtColor(query_img, cv2.IMREAD_GRAYSCALE)
original_img_bw = cv2.cvtColor(original_img, cv2.IMREAD_GRAYSCALE)
Поиск ключевых точек и дескрипторов:
orb = cv2.ORB_create()
queryKP, queryDes = orb.detectAndCompute(query_img_bw,None)
trainKP, trainDes = orb.detectAndCompute(original_img_bw,None)
Сравнение дескрипторов ключевых точек и сортировка результатов по расстоянию Хамминга:
matcher = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = matcher.match(queryDes,trainDes)
matches = sorted(matches, key = lambda x:x.distance)
matches будет содержать массивы объектов – результатов сравнения дескрипторов. Для каждого такого массива атрибут distance будет содержать значение расстояния Хэмминга.
Иллюстрация сравнения:
final_img = cv2.drawMatches(query_img, queryKP,
original_img, trainKP, matches[:20],None)
final_img = cv2.resize(final_img, (1000,650))
Отображение результата, отрисованы и сопоставлены первые 20 ключевых точек:
cv2.imshow(“Matches”, final_img)
cv2.waitKey()
Для поиска исходного изображения фрагмента среди множества изображений предлагается:
-
Создать список с результатами сравнения для каждого изображения,
-
Отсортировать результаты сравнения (то есть, каждый элемент списка) по расстоянию Хэмминга,
-
Для каждого элемента списка брать сумму его первых пяти (или больше, но эмпирическим путём было установлено, что для большинства случаев достаточно пяти) расстояний Хэмминга. Элемент с наименьшей суммой и будет результатом сравнения с искомым изображением.
При искажении изображения, в зависимости от способа искажения, качество работы алгоритма может сильно пострадать, например:
Результат работы алгоритма с искажением изображения для поиска (поворот)
Результат работы алгоритма с искажением изображения для поиска (наклон, вращение)
Результат работы алгоритма с искажением изображения для поиска (наклон, вращение) и обрезкой исходного изображения
Результат работы алгоритма с искажением исходного изображения (уменьшение разрешения до 30% от начального)
Результат работы алгоритма с искажением изображения для поиска (повышение яркости)
Результат работы алгоритма с искажением изображения для поиска (повышение яркости) и обрезкой исходного изображения
Как видно из примеров, наибольшее влияние на работу алгоритма оказывает обращение цветов изображения. Почему это происходит? Так как алгоритм работает с монохромными изображениями, ключевые точки содержат в себе пиксели определённой яркости. И, если цвета обращены, то, в том же месте изображения, где ранее была ключевая точка, будут пиксели с другими характеристиками.
Также стоит отметить, что, даже при условии уменьшения количества совпадений ключевых точек при искажении искомого изображения, расстояние Хэмминга найденных верно совпадающих точек будет минимальным, что позволит успешно применять алгоритм даже при наклонах и/или поворотах изображения, применяя метод, описанный выше.
Таким образом, алгоритм хорошо работает в задаче поиска дубликатов изображений и поиске исходных изображений для фрагмента, особенно, при малых искажениях, однако, в ходе тестирования было обнаружено, что эффективность алгоритма в задаче поиска объектов на изображении достаточно низкая, так как разные изображения одного объекта могут содержать разные ключевые точки.
