Время прочтения: 2 мин.
Не так давно, при работе с проектом по сбору данных юридических лиц из Интернета, мне понадобилось извлечь информацию с сайта https://www.rusprofile.ru/. Формат Json помог быстрее и эффективнее решить эту задачу, т.к.:
- используя формат Json мы можем получить доступ к большей части информации, чем отображается на сайте,
- данные из Json будут чище чем из HTML,
- нет необходимости обрабатывать скрипт (долго по времени).
Шаг 1. Зайдем на интересующий нас сайт, и нажимаем F12, в открывшейся консоли выбираем вкладку «Сеть». Проверяем отобразившуюся информацию. Я обычно ставлю фильтр по XHR и «ответ» сервера и смотрю.
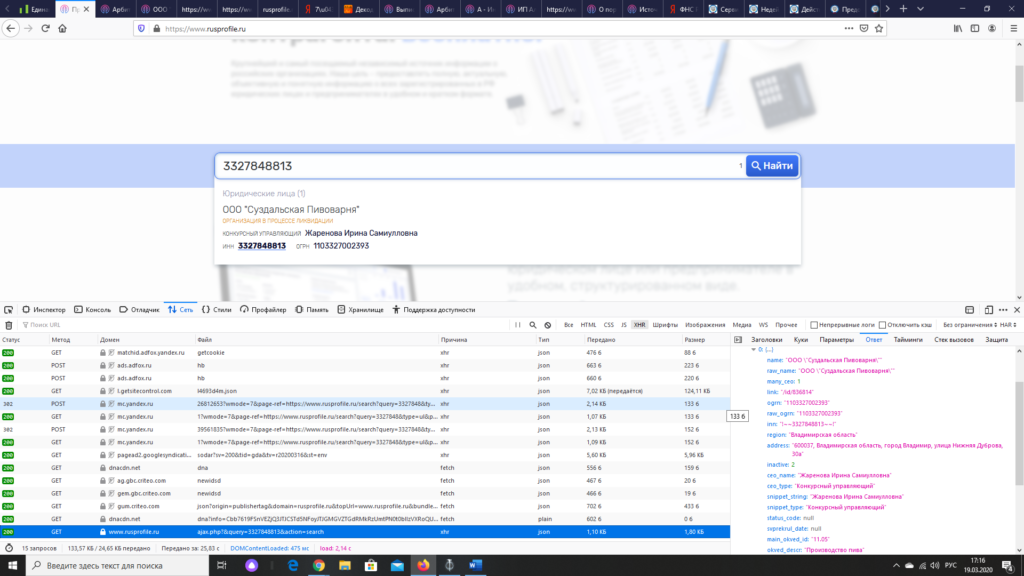
Шаг 2. Когда нашли необходимую информацию, выбираем «Заголовки» и смотрим «URL запроса:»
Получили данную ссылку:
«https://www.rusprofile.ru/ajax.php?&query=3327848813&action=search»
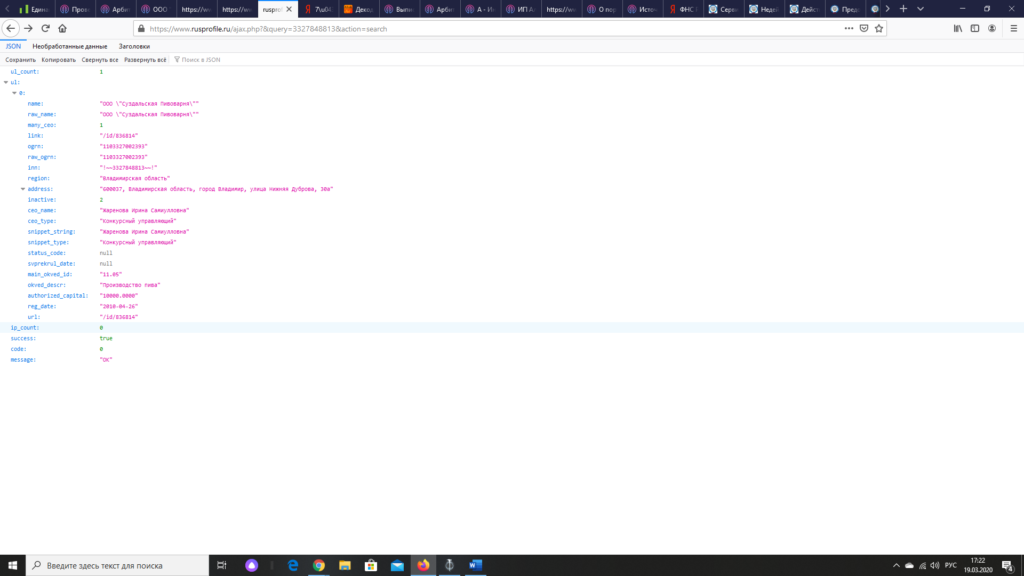
Шаг 3: Далее подставлем вместо 3327848813 любой другой интересующий нас ИНН и получаем Json.
Я рассмотрел пример получения Json с сайта www.rusprofile.ru, с
другими сайтами принцип работы такой же: иногда необходимо поменять количество
отображений на странице, перейти на следующую страницу и др.
Но бывает не все так идеально, иногда нужна просто фантазия и
перебор. Например, найти на других страницах заголовки и пытаться менять или
посмотреть в скриптах. Это уже трудозатратнее по времени, но в итоге, если поиск
успешный, то будет работать быстрее. Если данный подход не срабатывает, то используйте
selenium, а потом долго ждите пока он
отработает.
New to the JSON world and I’m trying to find out how to view a JSON object of a webpage. Will every webpage have a JSON object and if so how do I find it in order to get the data and display it on my site? I vaguely remember something about using Firebug?
Thanks,
B
asked Mar 4, 2015 at 10:00
![]()
1
Will every webpage have a JSON object
No.
Many web sites will not use any JSON; many will be completely static (HTML and CSS only).
It may only apply if there is a “Web API” (for programmatic access to content), but there are non-JSON ways to do APIs (the X in AJAX is for XML).
To determine how to access a site programmatically look at the site’s developer documentation. If there isn’t any documentation then any AJAX web debuggers (like FireBug) show may well be internal only and intended only for the site’s own implementation; other uses could well be not welcome (you could be up for violating IP).
answered Mar 4, 2015 at 10:06
![]()
RichardRichard
106k21 gold badges202 silver badges263 bronze badges
This might become a vulnerability to add sensitive JSON to your final HTML page.. JSON should be loaded like an ingredient to the soup, via Ajax for example on authenticated page. If it’s not sensitive JSON then you should load it for performance reasons once it is required… it really depends on your choice. I have built a library to handle these kind of requests for web, check it out: https://github.com/alexmano/jsMan
answered Feb 18, 2019 at 19:56
![]()
Alex MANAlex MAN
911 silver badge6 bronze badges
Как спарсить любой сайт?

Меня зовут Даниил Охлопков, и я расскажу про свой подход к написанию скриптов, извлекающих данные из интернета: с чего начать, куда смотреть и что использовать.
Написав тонну парсеров, я придумал алгоритм действий, который не только минимизирует затраченное время на разработку, но и увеличивает их живучесть, робастность, масштабируемость.
Чтобы спарсить данные с вебсайта, пробуйте подходы именно в таком порядке:
Найдите официальное API,
Найдите XHR запросы в консоли разработчика вашего браузера,
Найдите сырые JSON в html странице,
Отрендерите код страницы через автоматизацию браузера,
Если ничего не подошло — пишите парсеры HTML кода.
Совет профессионалов: не начинайте с BS4/Scrapy
BeautifulSoup4 и Scrapy — популярные инструменты парсинга HTML страниц (и не только!) для Python.
Крутые вебсайты с крутыми продактами делают тонну A/B тестов, чтобы повышать конверсии, вовлеченности и другие бизнес-метрики. Для нас это значит одно: элементы на вебстранице будут меняться и переставляться. В идеальном мире, наш написанный парсер не должен требовать доработки каждую неделю из-за изменений на сайте.
Приходим к выводу, что не надо извлекать данные из HTML тегов раньше времени: разметка страницы может сильно поменяться, а CSS-селекторы и XPath могут не помочь. Используйте другие методы, о которых ниже. ⬇️
Используйте официальный API
Ого? Это не очевидно ? Конечно, очевидно! Но сколько раз было: сидите пилите парсер сайта, а потом БАЦ — нашли поддержку древней RSS-ленты, обширный sitemap.xml или другие интерфейсы для разработчиков. Становится обидно, что поленились и потратили время не туда. Даже если API платный, иногда дешевле договориться с владельцами сайта, чем тратить время на разработку и поддержку.
Sitemap.xml — список страниц сайта, которые точно нужно проиндексировать гуглу. Полезно, если нужно найти все объекты на сайте. Пример: http://techcrunch.com/sitemap.xml
RSS-лента — API, который выдает вам последние посты или новости с сайта. Было раньше популярно, сейчас все реже, но где-то еще есть! Пример: https://habr.com/ru/rss/hubs/all/
Поищите XHR запросы в консоли разработчика

Кабина моего самолета
Все современные вебсайты (но не в дарк вебе, лол) используют Javascript, чтобы догружать данные с бекенда. Это позволяет сайтам открываться плавно и скачивать контент постепенно после получения структуры страницы (HTML, скелетон страницы).

Обычно, эти данные запрашиваются джаваскриптом через простые GET/POST запросы. А значит, можно подсмотреть эти запросы, их параметры и заголовки — а потом повторить их у себя в коде! Это делается через консоль разработчика вашего браузера (developer tools).
В итоге, даже не имея официального API, можно воспользоваться красивым и удобным закрытым API. ☺️
Даже если фронт поменяется полностью, этот API с большой вероятностью будет работать. Да, добавятся новые поля, да, возможно, некоторые данные уберут из выдачи. Но структура ответа останется, а значит, ваш парсер почти не изменится.
Алгорим действий такой:
Открывайте вебстраницу, которую хотите спарсить
Правой кнопкой -> Inspect (или открыть dev tools как на скрине выше)
Открывайте вкладку Network и кликайте на фильтр XHR запросов
Обновляйте страницу, чтобы в логах стали появляться запросы
Найдите запрос, который запрашивает данные, которые вам нужны
Копируйте запрос как cURL и переносите его в свой язык программирования для дальнейшей автоматизации.
Вы заметите, что иногда эти XHR запросы включают в себя огромные строки — токены, куки, сессии, которые генерируются фронтендом или бекендом. Не тратьте время на ревёрс фронта, чтобы научить свой парсер генерировать их тоже.
Вместо этого попробуйте просто скопипастить и захардкодить их в своем парсере: очень часто эти строчки валидны 7-30 дней, что может быть окей для ваших задач, а иногда и вообще несколько лет. Или поищите другие XHR запросы, в ответе которых бекенд присылает эти строчки на фронт (обычно это происходит в момент логина на сайт). Если не получилось и без куки/сессий никак, — советую переходить на автоматизацию браузера (Selenium, Puppeteer, Splash — Headless browsers) — об этом ниже.
Поищите JSON в HTML коде страницы
Как было удобно с XHR запросами, да? Ощущение, что ты используешь официальное API. Приходит много данных, ты все сохраняешь в базу. Ты счастлив. Ты бог парсинга.
Но тут надо парсить другой сайт, а там нет нужных GET/POST запросов! Ну вот нет и все. И ты думаешь: неужели расчехлять XPath/CSS-selectors? ♀️ Нет! ♂️
Чтобы страница хорошо проиндексировалась поисковиками, необходимо, чтобы в HTML коде уже содержалась вся полезная информация: поисковики не рендерят Javascript, довольствуясь только HTML. А значит, где-то в коде должны быть все данные.
Современные SSR-движки (server-side-rendering) оставляют внизу страницы JSON со всеми данные, добавленный бекендом при генерации страницы. Стоп, это же и есть ответ API, который нам нужен!
Вот несколько примеров, где такой клад может быть зарыт (не баньте, плиз):
 Красивый JSON на главной странице Habr.com. Почти официальный API! Надеюсь, меня не забанят.
Красивый JSON на главной странице Habr.com. Почти официальный API! Надеюсь, меня не забанят. 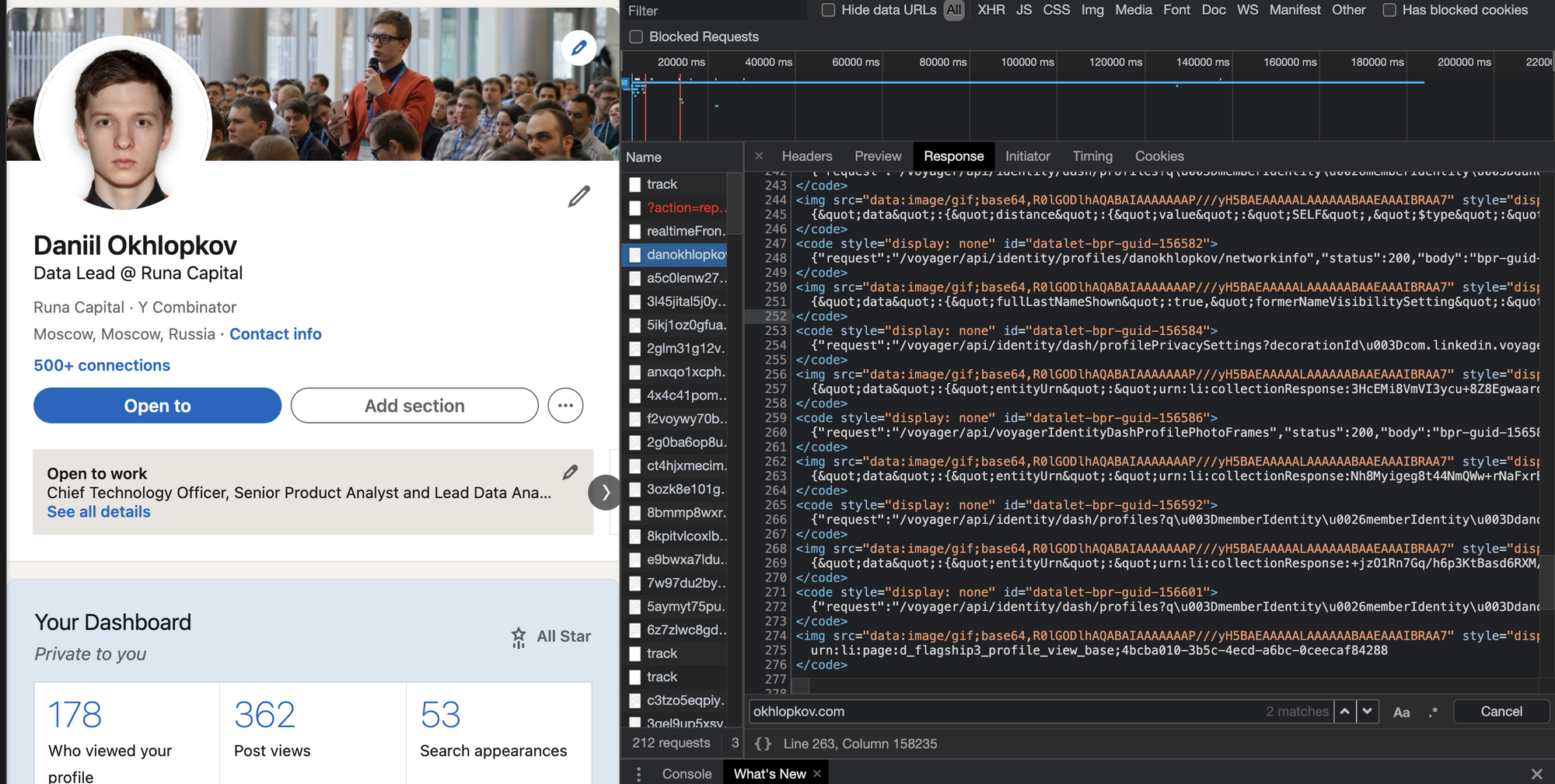 И наш любимый (у парсеров) Linkedin!
И наш любимый (у парсеров) Linkedin!
Алгоритм действий такой:
В dev tools берете самый первый запрос, где браузер запрашивает HTML страницу (не код текущий уже отрендеренной страницы, а именно ответ GET запроса).
Внизу ищите длинную длинную строчку с данными.
Если нашли — повторяете у себя в парсере этот GET запрос страницы (без рендеринга headless браузерами). Просто requests.get .
Вырезаете JSON из HTML любыми костылямии (я использую html.find(«=
Отрендерите JS через Headless Browsers
Если XHR запросы требуют актуальных tokens, sessions, cookies. Если вы нарываетесь на защиту Cloudflare. Если вам обязательно нужно логиниться на сайте. Если вы просто решили рендерить все, что движется загружается, чтобы минимизировать вероятность бана. Во всех случаях — добро пожаловать в мир автоматизации браузеров!
Если коротко, то есть инструменты, которые позволяют управлять браузером: открывать страницы, вводить текст, скроллить, кликать. Конечно же, это все было сделано для того, чтобы автоматизировать тесты веб интерфейса. I’m something of a web QA myself.
После того, как вы открыли страницу, чуть подождали (пока JS сделает все свои 100500 запросов), можно смотреть на HTML страницу опять и поискать там тот заветный JSON со всеми данными.
Selenoid — open-source remote Selenium cluster
Для масштабируемости и простоты, я советую использовать удалённые браузерные кластеры (remote Selenium grid).
Недавно я нашел офигенный опенсорсный микросервис Selenoid, который по факту позволяет вам запускать браузеры не у себя на компе, а на удаленном сервере, подключаясь к нему по API. Несмотря на то, что Support team у них состоит из токсичных разработчиков, их микросервис довольно просто развернуть (советую это делать под VPN, так как по умолчанию никакой authentication в сервис не встроено). Я запускаю их сервис через DigitalOcean 1-Click apps: 1 клик — и у вас уже создался сервер, на котором настроен и запущен кластер Headless браузеров, готовых запускать джаваскрипт!
Вот так я подключаюсь к Selenoid из своего кода: по факту нужно просто указать адрес запущенного Selenoid, но я еще зачем-то передаю кучу параметров бразеру, вдруг вы тоже захотите. На выходе этой функции у меня обычный Selenium driver, который я использую также, как если бы я запускал браузер локально (через файлик chromedriver).
Заметьте фложок enableVNC . Верно, вы сможете смотреть видосик с тем, что происходит на удалённом браузере. Всегда приятно наблюдать, как ваш скрипт самостоятельно логинится в Linkedin: он такой молодой, но уже хочет познакомиться с крутыми разработчиками.
Парсите HTML теги
Если случилось чудо и у сайта нет ни официального API, ни вкусных XHR запросов, ни жирного JSON внизу HTML, если рендеринг браузерами вам тоже не помог, то остается последний, самый нудный и неблагодарный метод. Да, это взять и начать парсить HTML разметку страницы. То есть, например, из <a href=»https://okhlopkov.com»>Cool website</a> достать ссылку. Это можно делать как простыми регулярными выражениями, так и через более умные инструменты (в питоне это BeautifulSoup4 и Scrapy) и фильтры (XPath, CSS-selectors).
Мой единственный совет: постараться минимизировать число фильтров и условий, чтобы меньше переобучаться на текущей структуре HTML страницы, которая может измениться в следующем A/B тесте.

Даниил Охлопков — Data Lead @ Runa Capital
Подписывайтесь на мой Телеграм канал, где я рассказываю свои истории из парсинга и сливаю датасеты.
Надеюсь, что-то из этого было полезно! Я считаю, что в парсинге важно, с чего ты начинаешь. С чего начать — я рассказал, а дальше ваш ход
Время прочтения: 2 мин.
Не так давно, при работе с проектом по сбору данных юридических лиц из Интернета, мне понадобилось извлечь информацию с сайта https://www.rusprofile.ru/. Формат Json помог быстрее и эффективнее решить эту задачу, т.к.:
- используя формат Json мы можем получить доступ к большей части информации, чем отображается на сайте,
- данные из Json будут чище чем из HTML,
- нет необходимости обрабатывать скрипт (долго по времени).
Шаг 1. Зайдем на интересующий нас сайт, и нажимаем F12, в открывшейся консоли выбираем вкладку «Сеть». Проверяем отобразившуюся информацию. Я обычно ставлю фильтр по XHR и «ответ» сервера и смотрю.
Шаг 2. Когда нашли необходимую информацию, выбираем «Заголовки» и смотрим «URL запроса:»
Получили данную ссылку: «https://www.rusprofile.ru/ajax.php?&query=3327848813&action=search»
Шаг 3: Далее подставлем вместо 3327848813 любой другой интересующий нас ИНН и получаем Json.
Я рассмотрел пример получения Json с сайта www.rusprofile.ru, с другими сайтами принцип работы такой же: иногда необходимо поменять количество отображений на странице, перейти на следующую страницу и др.
Но бывает не все так идеально, иногда нужна просто фантазия и перебор. Например, найти на других страницах заголовки и пытаться менять или посмотреть в скриптах. Это уже трудозатратнее по времени, но в итоге, если поиск успешный, то будет работать быстрее. Если данный подход не срабатывает, то используйте selenium, а потом долго ждите пока он отработает.
Посмотреть файл JSON в браузере
Это не вопрос программирования, но нужно ваше мнение в нескольких словах.
Когда мы нажимаем URL JSON в Браузере, он просит нас сохранить файл. Почему это происходит? Есть ли способ просмотреть его на самой странице? Есть ли дополнение для просмотра JSON-файла в браузере?
11 ответов
В Chrome используйте JSONView или Firefox использует JSONView
Для файлов JSON Закладок Firefox используйте этот превосходный Bookmarklet:
Если вы не хотите устанавливать расширения, вы можете просто добавить к этому URL view-source: , например, view-source:http://content.dimestore.com/prod/survey_data/4535/4535.json . Обычно это работает в Firefox и Chrome (однако все равно будет предлагать загрузить файл, если присутствует заголовок Content-Disposition: attachment ).
Что ж, я искал просмотр json-файла в WebBrowser в моем приложении для настольного компьютера, когда я пробовал в IE все еще ту же проблему, IE также предлагал загрузить файл. К счастью, после долгих поисков я нашел решение для этого.
Вам необходимо: Открыть Блокнот и вставить следующее:
После этого вы можете просмотреть файл JSON в IE, и вы получите удовольствие от рабочего стола WebBrowser 🙂
В Chrome используйте JSONView для просмотра отформатированного JSON.
Чтобы просмотреть «локальные» файлы * .json: — после установки Вы должны открыть опцию «Расширения» в меню «Окно». — Установите флажок «Разрешить доступ к URL-адресам файлов» — обратите внимание, что сохранение выполняется автоматически (т.е. явное сохранение не требуется)
Снова откройте файл * .json, и он должен быть отформатирован.
Щелкните правой кнопкой мыши файл JSON, выберите «Открыть» и перейдите к программе, которую хотите открыть (блокнот). Последовательное открытие автоматически с помощью блокнота.
Я бы также рекомендовал использовать Notepad ++ с расширением json-view. Вы получите расширение здесь: https://sourceforge.net/projects/nppjsonviewer/ Установите и перезапустите Notepad ++. Затем откройте json-файл в Блокноте и перейдите в «Расширения -> Json-Viewer -> Форматировать JSON». Тогда у вас будет иерархическое представление json.
Вы также можете использовать один из онлайн-зрителей (http://jsonviewer.stack.hu/, https://jsoneditoronline.org/ ), что выглядит неплохо, но я бы не рекомендовал это, если ваши данные чувствительны в Условия конфиденциальности.
Попробуйте этот URL
У меня Content-Type моих CGI-файлов для JSON-печати установлен на text/javascript .
Прекрасно работает как для отображения в браузере (например, Firefox), так и для обработки в скрипте.
Конечно, в этом случае нет подсветки синтаксиса.
Firefox 44 включает встроенную программу просмотра JSON (без надстроек требуется). По умолчанию эта функция отключена, поэтому включите devtools.jsonview.enabled : Как отключить новый JSON Viewer / Reader в Firefox Developer Edition?
Если есть заголовок ответа Content-Disposition: attachment , Firefox попросит вас сохранить файл, даже если у вас установлен JSONView для форматирования JSON.
- 1. Структура проекта для разбора JSON
- 2. JSONParser.pro
- 3. widget.h
- 4. widget.cpp
- 5. Итог
- 6. Видеоурок
В процессе написания программы
EColor
появилась задача, в которой было необходимо каким-то образом уведомлять пользователя о том, что вышла новая версия программы. Решением этой задачи стало наличие
JSON
файла на сайте. С помощью
QNetworkAccessManager
получаем
JSON
файл и производим его разбор, благодаря классам библиотеки
Qt
:
QJsonDocument, QJsonObject, QJsonArray.
В случае с программой
EColor
на сайте содержится
JSON
файл с названием программы, полной версией в строковом варианте и тремя объектами с Мажорной частью версии, Минорной и Патч-версией. При разборе файла производится сравнение текущей версии программы с той, которая находится на сайте. В случае, если на сайте выложена более свежая версия, то программа сообщает об этом пользователю.
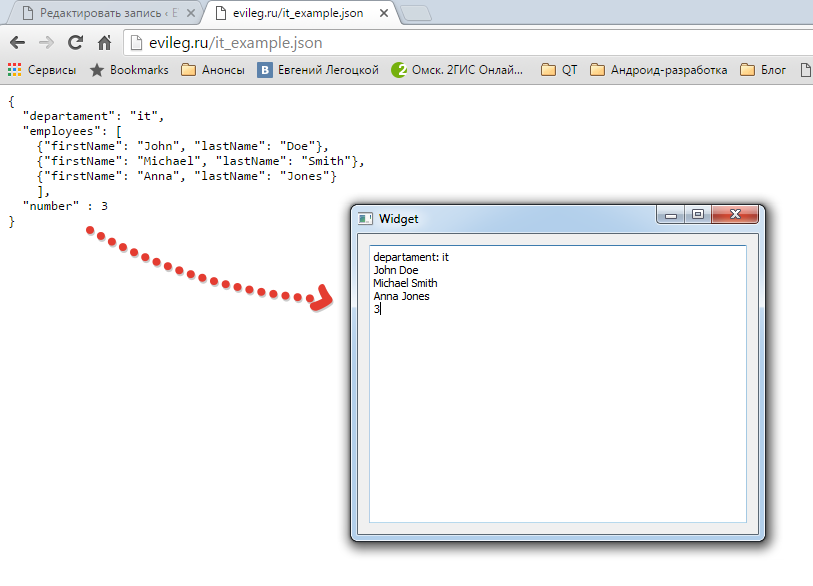
Например, по адресу
http://www.evileg.ru/it_example.json
на сайте располагается
JSON
файл со следующим содержанием:
{ "departament": "it", "employees": [ {"firstName": "John", "lastName": "Doe"}, {"fisrtName": "Michael", "lastName": "Smith"}, {"firstName": "Anna", "lastName": "Jones"} ], "number" : 3 }В корневом объекте файла располагается три объекта, второй из которых является массивом. Первый объект – это строковое свойство
“departament”
, которое содержит название отдела. Второй объект – это массив с именами и фамилиями сотрудников. А третий объект – это число сотрудников типа
Integer
.Структура проекта для разбора JSON
JSONParser.pro
– профайл проекта;
main.cpp
– основной файл исходных кодов проекта;
widget.h
– заголовочный файл окна приложения, в котором содержится поле
QTextEdit,
в которое будет помещен результат парсинга файла;
widget.cpp
– файл исходных кодов с
QNetworkAccessManager.
widget.ui
– файл интерфейса программы.
JSONParser.pro
Не забываем подключить в профайле проекта модуль
network
, чтобы была возможность работать с классом
QNetworkAccessManager.
#------------------------------------------------- # # Project created by QtCreator 2016-01-02T13:12:55 # #------------------------------------------------- QT += core gui network greaterThan(QT_MAJOR_VERSION, 4): QT += widgets TARGET = JSONParser TEMPLATE = app SOURCES += main.cpp widget.cpp HEADERS += widget.h FORMS += widget.uiwidget.h
Подключаем класс
QNetworkAccessManager
, также в заголовочном файле объявленСЛОТ
onResult(QNetworkReply *reply)
, в котором будет разбираться
JSON
файл при получении ответа от сайта с содержимым файла.#ifndef WIDGET_H #define WIDGET_H #include <QWidget> #include <QNetworkAccessManager> namespace Ui { class Widget; } class Widget : public QWidget { Q_OBJECT public: explicit Widget(QWidget *parent = 0); ~Widget(); private slots: // Обработчик данных полученных от объекта QNetworkAccessManager void onResult(QNetworkReply *reply); private: Ui::Widget *ui; QNetworkAccessManager *networkManager; }; #endif // WIDGET_Hwidget.cpp
Процесс заключается в том, чтобы создать объект
QJsonDocument
и записать в него содержимое ответа
QNetworkReply.
После чего забираем из документа корневой объект
root
, который будет содержать все три свойства. После этого забираем по названиям свойств их значения. Из второго свойства
“employes”
забираем массив с именами и фамилиями сотрудников отдела. Все данные помещаем в поле ui->textEdit.#include "widget.h" #include "ui_widget.h" #include <QJsonDocument> #include <QJsonObject> #include <QJsonArray> #include <QUrlQuery> #include <QNetworkReply> #include <QUrl> Widget::Widget(QWidget *parent) : QWidget(parent), ui(new Ui::Widget) { ui->setupUi(this); networkManager = new QNetworkAccessManager(); // Подключаем networkManager к обработчику ответа connect(networkManager, &QNetworkAccessManager::finished, this, &Widget::onResult); // Получаем данные, а именно JSON файл с сайта по определённому url networkManager->get(QNetworkRequest(QUrl("http://www.evileg.ru/it_example.json"))); } Widget::~Widget() { delete ui; } void Widget::onResult(QNetworkReply *reply) { // Если ошибки отсутсвуют if(!reply->error()){ // То создаём объект Json Document, считав в него все данные из ответа QJsonDocument document = QJsonDocument::fromJson(reply->readAll()); // Забираем из документа корневой объект QJsonObject root = document.object(); /* Находим объект "departament", который располагается самым первым в корневом объекте. * С помощью метода keys() получаем список всех объектов и по первому индексу * забираем название объекта, по которому получим его значение * */ ui->textEdit->append(root.keys().at(0) + ": " + root.value(root.keys().at(0)).toString()); // Второе значение пропишем строкой QJsonValue jv = root.value("employees"); // Если значение является массивом, ... if(jv.isArray()){ // ... то забираем массив из данного свойства QJsonArray ja = jv.toArray(); // Перебирая все элементы массива ... for(int i = 0; i < ja.count(); i++){ QJsonObject subtree = ja.at(i).toObject(); // Забираем значения свойств имени и фамилии добавляя их в textEdit ui->textEdit->append(subtree.value("firstName").toString() + " " + subtree.value("lastName").toString()); } } // В конце забираем свойство количества сотрудников отдела и также выводим в textEdit ui->textEdit->append(QString::number(root.value("number").toInt())); } reply->deleteLater(); }Итог
В результате работы данного программного кода получится следующий результат, который показан на ниже следующем изображении. Также работу приложения Вы можете увидеть на в видеоуроке.
Видеоурок
- Remove From My Forums
-
Вопрос
-
Коллеги, требуется помощь или совет, всю голову сломал, хотя вроде ничего сложного нет.
Мне нужно вытащить JSON файл сайта.
Никак не получается это сделать.
Я использую командлетInvoke-WebRequest -Uri $SITE -Method post -ContentType "application/json"
Правильно ли я понимаю, для того чтобы забрать JSON файл сайта, мне нужно в команду, добавить запрос,
ну например , который будет выбирать JSON.$zapros=@"{"startDate":"2019.01.20","endDate":"2019.03.20","idUser":"77777", }"@Invoke-WebRequest -Uri $SITE -Method post -ContentType "application/json" -body $zaprosМне кажется, что я что то путаю. Как дать команде понять, что мне нужно закачать файл JSON? Может кто направит? Спасибо!
Ответы
-
Вы уверены что сайт умеет возвращать JSON?
Если это чей то сайт то спросите владельца.
Если это ваш сайт то проверьте и измените его код.
This posting is provided “AS IS” with no warranties, and confers no rights.
-
Помечено в качестве ответа
27 марта 2019 г. 9:33
-
Помечено в качестве ответа
