К вашим услугам кеш поисковиков, интернет-архивы и не только.

Если, открыв нужную страницу, вы видите ошибку или сообщение о том, что её больше нет, ещё не всё потеряно. Мы собрали сервисы, которые сохраняют копии общедоступных страниц и даже целых сайтов. Возможно, в одном из них вы найдёте весь пропавший контент.
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
1. Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
Есть и альтернативный способ. Введите в браузерную строку следующий URL: http://webcache.googleusercontent.com/search?q=cache:lifehacker.ru. Замените lifehacker.ru на адрес нужной страницы и нажмите Enter.
Сайт Google →
2. Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
Сайт «Яндекса» →
3. Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
Сайт Bing →
4. Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Сайт Yahoo →
Специальные архивные сервисы
Указав адрес нужной веб‑страницы в любом из этих сервисов, вы можете увидеть одну или даже несколько её архивных копий, сохранённых в разное время. Таким образом вы можете просмотреть, как менялось содержимое той или иной страницы. В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
Чтобы проверить наличие копий в одном из этих архивов, перейдите на его сайт. Введите URL нужной страницы в текстовое поле и нажмите на кнопку поиска.
1. Wayback Machine (Web Archive)
Сервис Wayback Machine, также известный как Web Archive, является частью проекта Internet Archive. Здесь хранятся копии веб‑страниц, книг, изображений, видеофайлов и другого контента, опубликованного на открытых интернет‑ресурсах. Таким образом основатели проекта хотят сберечь культурное наследие цифровой среды.
Сайт Wayback Machine →
2. Arhive.Today
Arhive.Today — аналог предыдущего сервиса. Но в его базе явно меньше ресурсов, чем у Wayback Machine. Да и отображаются сохранённые версии не всегда корректно. Зато Arhive.Today может выручить, если вдруг в Wayback Machine не окажется копий необходимой вам страницы.
Сайт Arhive.Today →
3. WebCite
Ещё один архивный сервис, но довольно нишевый. В базе WebCite преобладают научные и публицистические статьи. Если вдруг вы процитируете чей‑нибудь текст, а потом обнаружите, что первоисточник исчез, можете поискать его резервные копии на этом ресурсе.
Сайт WebCite →
Другие полезные инструменты
Каждый из этих плагинов и сервисов позволяет искать старые копии страниц в нескольких источниках.
1. CachedView
Сервис CachedView ищет копии в базе данных Wayback Machine или кеше Google — на выбор пользователя.
Сайт CachedView →
2. CachedPage
Альтернатива CachedView. Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.
Сайт CachedPage →
3. Web Archives
Это расширение для браузеров Chrome и Firefox ищет копии открытой в данный момент страницы в Wayback Machine, Google, Arhive.Today и других сервисах. Причём вы можете выполнять поиск как в одном из них, так и во всех сразу.

![]()
Читайте также 💻🔎🕸
- 3 специальных браузера для анонимного сёрфинга
- Что делать, если тормозит браузер
- Как включить режим инкогнито в разных браузерах
- 6 лучших браузеров для компьютера
- Как установить расширения в мобильный «Яндекс.Браузер» для Android
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:https://www.iphones.ru/
Где https://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета

Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет

К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
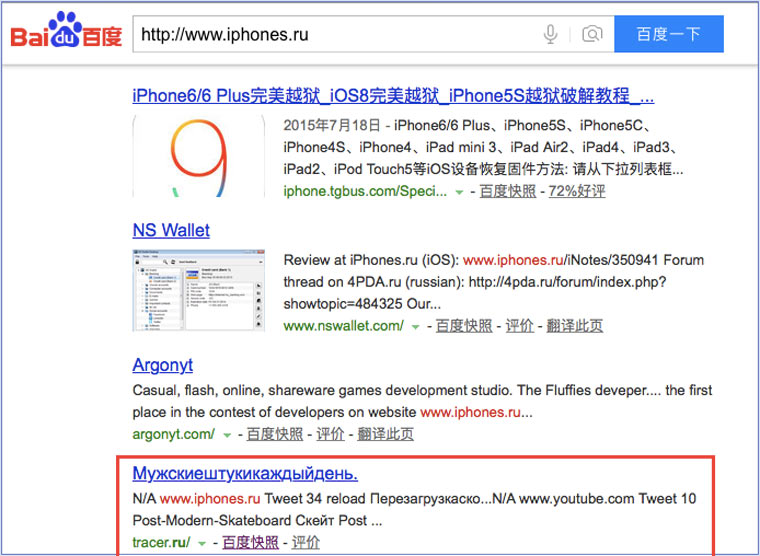
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
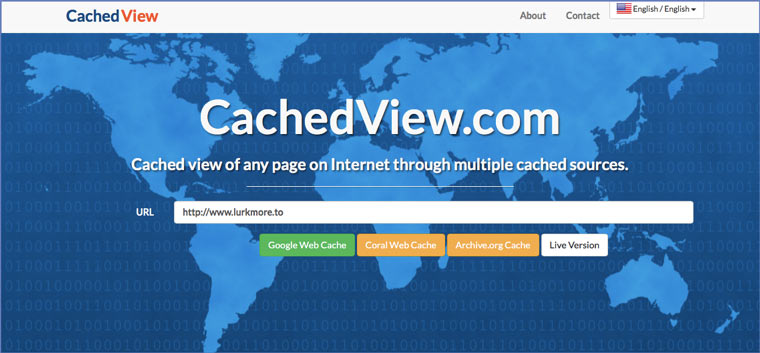
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
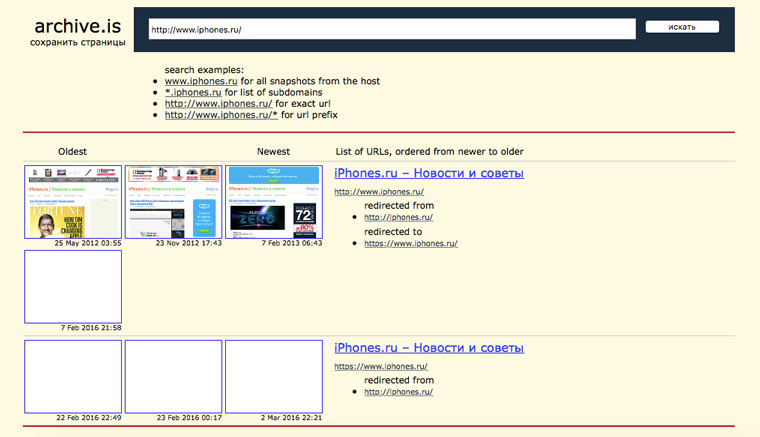
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari.
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
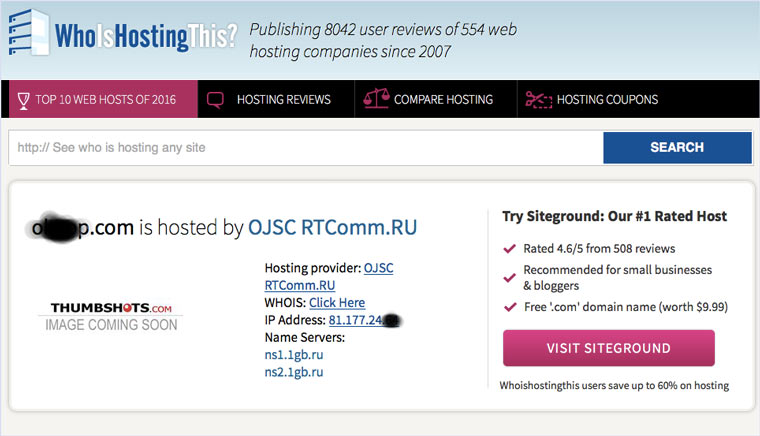
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:

Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
О других методах поиска читайте в статье 12 способов найти владельца сайта и узнать про него все.
А о сборе информации про людей читайте в статьях 9 сервисов для поиска информации в соцсетях и 15 фишек для сбора информации о человеке в интернете.

 (30 голосов, общий рейтинг: 4.80 из 5)
(30 голосов, общий рейтинг: 4.80 из 5)
🤓 Хочешь больше? Подпишись на наш Telegram.
![]()
iPhones.ru
Сервисы и трюки, с которыми найдётся ВСЁ. Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход. Всё, что попадает в интернет,…
- Google,
- полезный в быту софт,
- хаки
![]()
Посмотреть удалённую страницу можно посмотреть в Гугле и в Яндексе. Как это сделать?
К примеру, на этой странице НАТО опубликовали якобы “спутниковые” снимки, которые должны были подтвердить, что бронетехника РФ находится на территории Украины. Когда выяснилось, что эти снимки были взяты американской разведкой из социальных сетей (позор разведке США!), они решили быстренько удалить страничку.
Теперь (02.09.2014) эта страничка выглядит вот так.

Обидно, да? Но это не страшно. Дело в том, что Гугл даёт прекрасную возможность “вытащить страничку из кэша“. Любая страница сохранена в кэше поисковой системы. Достать её оттуда можно следующим образом:
- зайдите на страницу поисковой системы гугл
- в поле поиска задайте “info:”. Скопируйте ссылку удалённой страницы и вставьте её после двоеточия
- теперь внизу страницы с результатами поиска Вы видите предложения “показать сохранённую в Гугле версию страницы”. Кликните на это предложение и – вуаля! – перед вами удалённая страничка, её последняя сохранённая версия.
Искать удалённую страницу в кэше Яндекса можно подобным образом, только с помощью оператора “url:” и ссылки на удалённую страницу. Внизу под результатом поиска нажмите на “зелёный” адрес URL, а затем на ссылку “копия”, которая появится рядом.
Вот так выглядит “спасённая” из кэша Гугла страница с фотографиями-подделками из соцсетей, предоставленных США в качестве “доказательства” присутствия войск РФ на Украине.
Учтите, что по истечении определённого времени страничка удаляется из кэша и становится полностью недоступной.

Бывает просматривая ленту дзен, или гугл новости, или другой какой агрегатор новостей, при переходе на понравившееся превью страница оказывается удалённой. Мы попросту лицезрим страницу 404, оформленную часто как то необычно.
Конечно, если у вас по какой либо причине просто заблокирован какойто сайт, то прочитать его содержимое поможет любой веб прокси, к примеру https://whoer.net/webproxy, или же можете сделать свой собственный прочитав мою запись в дзене.
А если страница была удалена, то на помощь нам придут поисковые системы, яндекс и гугл.
Достаём информацию из кеша поисковых систем
Ничего сложного здесь нет, думаю многие пользователи при поиске какой либо информации в поисковике, замечали напротив каждого сайта в результатах поиска, маленькую стрелочку, нажав на которую мы найдём заветное меню «Сохранённая копия».
Догадливый пользователь уже понял как посмотреть удалённую страницу. Нам нужно скопировать ссылку на удалённую страницу, вставить в поле поиска и нажать «Найти», далее просматриваем при помощи «Сохранённая копия».
Конечно, данный способ сработает только если поисковики успели проиндексировать удалённую страницу, в современном интернете делают это они достаточно быстро, так, что шансы достаточно высокие.
Если страница удалена достаточно давно
Бывает так, что сайт уже не доступен, либо страница на нём удалена очень давно – год и более. В таком случае поисковики могут такую страницу полностью исключить из своей базы, и у нас остаётся последняя надежда – вебархив.
Многие знают, многие слышали, а некоторые не знают – веб архив, это сайт, который собирает по мере своих возможностей копии всех сайтов когда либо существовавших в сети интернет.
И так
Заходим на сайт https://web.archive.org/, в поле «Enter a URL or words related to a site’s home page» вставляем ссылку на нужную страницу и жмакаем «Enter». Перед нами должно предстать поле с датами (как календарь).
С верху временная шкала по годам, чёрные палочки показывают в каком году были сохранены копии сайта, нажимаем на них, и в поле с календарём ищем цифры обведённые бирюзовым (на мой взгляд) цветом
жмакаем их по очереди и ищем нашу страницу в более менее хорошем состоянии, и черпаем из неё нужную информацию.
—————————————————–
зы Последнее время я часто пишу в дзен, и хотелось бы знать нравится вам то, как я и про что пишу. Яндекс обещает сделать комментирование для записей, но эта возможность будет не у всех авторов, а только у популярных, поэтому если вам нужна такая возможность на моём канале дзен, чтобы писать ваши пожелания и жалобы, не забывайте подписывать на канал и ставить “лайки”, спасибо.
Как посмотреть кэшированную копию в Яндексе: основные способы
Перед тем как открыть сохраненную копию сайта в Яндексе, выберите удобный способ — с помощью сервисов (Page Promoter в Firefox или RDS bar в Google Chrome) или вручную. Плагины — это удобно, но они могут давать сбой, поэтому стоит освоить и ручной метод просмотра.
Способ № 1 — плагины
Расширения для браузеров, плагины и различные онлайн-сервисы позволяют быстро открывать кэш сайтов. Один из самых популярных на сегодня сервисов — это RDS bar. Плагин отличается интуитивным пользовательским интерфейсом и позволяет посмотреть последние изменения страницы, отсканированной роботами. Но если нужная страница еще не проиндексировалась, то и плагин ничего не покажет.

Способ № 2 — вручную
Самый простой и эффективный «механический» способ просмотра. Что нужно сделать:
- Найти в поисковике нужную страницу — по запросу или вбив в поисковую строку адрес сайта.
- В результате поиска в сниппете нажать на маленькую стрелочку.

- В выпавшем окошке нажать «Сохраненная копия».

- Нажать и посетить сайт с данными, сохраненными с последнего визита робота на страницу.


Просмотр в кеше браузера
Посмотреть профиль социальной сети, который был удален можно и через кеш браузера. Он сохраняет копии всех сайтов, на которые заходил пользователь, чтобы уменьшить время загрузки. Если перед удалением страничка была посещена и кеш после этого не чистился, ее можно просмотреть. Для каждого браузера есть свой способ попасть в кеш:
- Хром: набрать и перейти chrome://cache;
- Опера: набрать и перейти opera://cache;
- Мозила: набрать в поисковой строке и перейти about:cache.
Браузер перекинет на страницу с кэшем, который отображается в виде ссылок. Там можно найти с помощью поиска нужную ссылку и посмотреть, как выглядела страница Вконтакте раньше.
Почему страницы может не быть?
Иногда во время поиска при нажатии на стрелочку сниппета нужного пункта может и не быть. Это происходит по ряду причин:
- Сбой в работе поисковика. В Яндексе даже не скрывают, что нет никаких гарантий на наличие и показ копий — система может просто не сохранять страницы по какой-либо причине.
- Второй вариант: html-кодировка документа содержит мета-тег «robots» со значением «noarchive», что означает запрет на кэширование. Чтобы не рисковать из-за этого трафиком, стоит внимательно настроить соответствующие блоки и очистить ненужные значения.
Нет копии: чем это грозит?
С точки зрения продвижения — опасность нулевая. А вот сами причины, из-за которых невозможно сохранение, могут быть вредны, нужно разбираться именно в них.
Эксперты уверены, что проблема с копиями может обернуться трудностями при работе с биржами ссылок. Так, на некоторых известных биржах строго контролируют, есть ли в Яндексе копия, проверяя параметр No Index Cache (NIC).
Используем поиск Google
Если в Яндексе копия уже изменена и не открывается в виде до изменений, можно попробовать поискать ту же информацию в другой поисковой системе. Есть вероятность что другой поисковик не успел внести изменения.
Чтобы найти удаленную страницу при помощи другого поисковика необходимо:
- Зайти на удаленный аккаунт Вконтакте и скопировать адрес.
- Вставить скопированный элемент в поисковую систему, например, Гугл.

- Навести курсор на выпадающее меню и выбрать сохраненную копию.

Сохраненную копию можно просмотреть, если оригинальную удалили не так давно. Если пользователь удалил профиль, например, год назад, то осуществить просмотр таким способом не представляется возможным.
Как посмотреть кеш в Google
Существует несколько способов найти удаленные страницы сайтов. Самый простой – воспользоваться стандартным поиском Google и придерживаться следующего алгоритма действий:
- В поисковой строке вводим адрес сайта, с которого нужно восстановить информацию.
- В выдаче находим нужную ссылку, а под ней – маленькую стрелку зеленого цвета.
- При нажатии на стрелку появляется меню, в котором нужно выбрать графу «Сохраненная копия».
- Система автоматически переходит в архив сайтов и открывает нужные страницы.
Если для работы в Интернете вы используете Google Chrome, вам подойдет еще один простой способ, как посмотреть удаленную страницу в кеше. Для этого достаточно перед адресом сайта ввести слово «cache» и поставить двоеточие. На примере сайта htmlbook.ru это будет выглядеть так: «cache:htmlbook.ru» и далее адрес конкретной страницы, которая вам нужна.
Если по каким-то причинам перечисленные методы не подошли, найти кеш страницы можно и таким способом:
- Открываем новую вкладку в браузере и в адресную строку вставляем текст «webcache.googleusercontent.com/search?q=cache:» (кавычки убираем).
- После двоеточия без пробела вставляем адрес сайта или страницы, которую хотим найти в памяти Google.
- Переходим по ссылке и получаем доступ к последней сохраненной версии.
Обратите внимание! Кеш сайта – это преимущественно текстовая информация. Если на странице были размещены изображения, которые владелец удалил, восстановить их может быть не так просто, как непосредственно статью.
Просмотр кеша страницы
Поисковые системы постоянно сохраняют копии посещенных сайтов. И если аккаунт Вконтакте был стерт недавно, то есть шанс что система не посетила его и не сохранила недавние изменения.
Посмотреть профиль можно следующим образом:
- Заходим на удаленный аккаунт Вконтакте и копируем его адрес.
- Вставляем скопированный элемент в поисковую строку.

- Возле каждого результата выдачи есть стрелочка с выпадающим меню. В нем необходимо выбрать строку «Сохраненная копия». И поисковик перенаправит на сохраненную копию аккаунт со всеми удаленными данными.

Web.archive.org найти и восстановить удалённый сайт

Приветствую вас, любознательные читатели блога seo-ap.ru! Недавно я рассказывал, что такое Википедия. Это виртуальная энциклопедия, которая завоевала всенародную любовь. Невзирая на то, что она постоянно подвергается критике со стороны ученых мужей
Одно то, что этот проект вот уже не один десяток лет «пашет» на пользу всего прогрессивного человечества, питает его полезной информацией на безвозмездной основе, заслуживает большого уважения и длинных дифирамбов.
Но в сети есть еще один некоммерческий проект, не менее грандиозный – web.archive.org. Он создан, чтобы надежно хранить сайты, печатные материалы, аудио и видеопродукцию. Все, чем сегодня наполнен интернет. И то, что было во всемирной паутине много лет назад. Разве такое возможно?
Да. Более того, сайты архивируются не в виде мертвых скриншотов. Они реально работают! На веб-страницах имеются все картинки, ссылки, сохраняется стилевое оформление CSS. Сайты в веб-архиве имеют еще и сотни копий. Они накопились за все время, пока сайты еще функционировали, и содержат всю их эволюцию, от рождения и до последнего вздоха.
Какую пользу веб-архив сайтов может дать лично вам?
Вы можете отправиться в путешествие по страничкам сайта вашей юности, поностальгировать. Проследить, как изменялся и развивался не только ваш, но и любой другой сайт в интернете. К примеру, материалы для своих статей о поисковой системе Апорт, которая уже приказала долго жить, я брал как раз в этом веб-архиве сайтов, в его потаенных закромах. И все скриншоты, наглядно показывающие хронологию главной страницы всеми любимого Яндекса, взяты оттуда же.
Следующий сюрприз. Допустим, вы добавили в закладку сайт, а в нем страница не открывается. Тогда вы обращаетесь к Гуглу или Яндексу, пытаясь извлечь страницу из кеша (изучите информацию о том, как эффективнее искать что-либо в Google – пригодится!). Но если к вашему ресурсу уже давно нет доступа, мертвые ссылки оживить поможет только archive.org. Хотя и там этот ресурс может отсутствовать. Почему? Об этом напишу чуть далее по тексту.
Если звезды сошлись так, что вы не сделали резервную копию своего сайта (бэкап), то вы сможете восстановить его из web archive. И это будет единственный способ решить проблему. При этом можно убрать из ссылок все привязки к web.archive.org, они могут стать прямыми для вашего сайта. Более подробно о ссылках и привязках читайте ниже.
И еще одно полезное свойство веб-архива сайтов. Он дает доступ к поиску готовых уникальных текстов. Если написание статей – не ваше призвание, то здесь вы найдете их целые залежи, настоящие Клондайк и Эльдорадо, вместе взятые! Но чтобы ими разжиться, кое-какие телодвижения совершить все же придется.
Мертвые сайты с их внутренним наполнением недоступны в действующей сети интернета. Но вы можете зайти в веб-архив, отыскать нужные вам тексты и вытащить их с того света. А затем прогнать через проверку на уникальность и опубликовать на своих страницах. Никто не обвинит вас в воровстве (плагиате) и нарушении авторских прав в копирайтинге. Однако этот увлекательный поиск некоторым может показаться долгим и тернистым.
Webarchive появился в интернете, страшно сказать – в далеком 1996 году! Еще в прошлом веке. На то время задача, стоящая перед разработчиками проекта, казалась архисложной, как говорил вождь мирового пролетариата. Несмотря на то, что интернет тогда еще не вошел в полную силу, сайтов было в сотни и тысячи раз меньше. И архивировались они гораздо реже. Как говорится, миссия невыполнима. Но мало-помалу, постепенно увеличивая вместимость своих «сусеков» и «кладовых», сервис успешно копировал и резервировал сайты.
Уже в следующем, 1997 году Webarchive поместил в базу сам себя. Посмотрите, как выглядела его главная страница более двадцати лет назад:
- Сейчас вся информация веб-архива занимает дисковое пространство объемом в 1015 Тбайт. Это гигантское число носит название квадриллион. Чтобы вам было легче его представить – примерно столько муравьев живет во всех муравейниках нашей планеты. Сервис Web.archive.org имеет официальный статус библиотеки. У него зеркала во многих центрах хранения и обработки данных.
- Если считать только архивы разных интернет-страниц, то их количество уже приближается к ста миллиардам. В это число входят все копии, которые были хоть однажды сняты и сохранены.
- Wayback Machine (обратная машина). Это архив страниц интернета. Он находится на главной странице сайта и доступен каждому. Здесь же хранятся телевизионные архивы, аудиоматериалы, отсканированные книги:
Просмотр сайта в Web.arhive
Но в данном случае нас интересуют возможности Wayback Machine. В строку формы, которая там имеется, можно вставить URL (адрес вашего сайта или отдельной страницы) или домен сайта, который вам нужен. Перед этим разберитесь с тем, что представляют собой домен и URL , чем они отличаются друг от друга. И тогда вы окажетесь на странице с календариком:
Здесь я вижу, что мой блог в первый раз был за архивирован в марте 2015 г. Ровно через пять дней после того, как я зарегистрировал (купил) свое доменное имя seo-ap.ru. Много воды утекло с той памятной даты. За все это время архивное копирование сайта выполнялось 100 раз, и каждую копию можно посмотреть и пощупать, переходя со страницы на страницу (все ссылки работают).
Как открыть мертвые ссылки? Для этого сайт должен находиться в archive.org
Смотрим на календарь. Цифры в голубых кружочках обозначают даты создания так называемых слепков – веб-архивов сайта. Разумеется, в процессе снятия копии не будут учитываться изменения, которые производились на ресурсе после того, как запущено архивирование. А время его проведения Webarchive устанавливает в соответствии с собственными таймерами и заложенными программами.
Поэтому не всегда имеет смысл использовать веб-архив в качестве способа открытия сайтов, недоступных лишь временно. В Яндексе можно тоже просмотреть их архивы:
Онлайн сервис Веб-архив
Ежедневно в Интернете происходят изменения. Страницы удаляются, создаются новые. И есть сервисы которые регистрируют и сохраняют подобные изменения. Веб-архив занимается этим, и с помощью него можно увидеть удаленные страницы Вконтакте. Чтобы это сделать необходимо воспользоваться инструкцией:
- Зайти на сайт Веб-архива.
- Вставить ссылку на удаленный аккаунт в поиск сайта.
- Ниже поиска появится календарь с отмеченными датами.

- Нажимая на отмеченные даты можно узнать, что именно изменялось на странице и просмотреть.

Семейное положение Вконтакте – как установить, скрыть или полностью убрать со страницы
