Текущая версия страницы пока не проверялась опытными участниками и может значительно отличаться от версии, проверенной 22 апреля 2022 года; проверки требуют 2 правки.

Коэффициент детерминации (
Определение и формула[править | править код]
Истинный коэффициент детерминации модели зависимости случайной величины y от факторов x определяется следующим образом:
![{displaystyle R^{2}=1-{frac {D[y|x]}{D[y]}}=1-{frac {sigma ^{2}}{sigma _{y}^{2}}},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f2ffe2a841ddede9113884ebe73c6633c7479174)
где ![{displaystyle D[y]=sigma _{y}^{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d4c8def4c310c71c31a430bc67518ca6223b6550)
![{displaystyle D[y|x]=sigma ^{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3d7ca94ae9436533484c22aa26df4363d00dd658)
В данном определении используются истинные параметры, характеризующие распределение случайных величин. Если использовать выборочную оценку значений соответствующих дисперсий, то получим формулу для выборочного коэффициента детерминации (который обычно и подразумевается под коэффициентом детерминации):

где 



В случае линейной регрессии с константой 


Необходимо подчеркнуть, что эта формула справедлива только для модели с константой, в общем случае необходимо использовать предыдущую формулу[источник не указан 390 дней].
Интерпретация[править | править код]
- Коэффициент детерминации для модели с константой принимает значения от 0 до 1. Чем ближе значение коэффициента к 1, тем сильнее зависимость. При оценке регрессионных моделей это интерпретируется как соответствие модели данным. Для приемлемых моделей предполагается, что коэффициент детерминации должен быть хотя бы не меньше 50 % (в этом случае коэффициент множественной корреляции превышает по модулю 70 %). Модели с коэффициентом детерминации выше 80 % можно признать достаточно хорошими (коэффициент корреляции превышает 90 %). Значение коэффициента детерминации 1 означает функциональную зависимость между переменными.
- При отсутствии статистической связи между объясняемой переменной и факторами, статистика
для линейной регрессии имеет асимптотическое распределение
, где
— количество факторов модели (см. тест множителей Лагранжа). В случае линейной регрессии с нормально распределёнными случайными ошибками статистика
имеет точное (для выборок любого объёма) распределение Фишера
(см. F-тест). Информация о распределении этих величин позволяет проверить статистическую значимость регрессионной модели исходя из значения коэффициента детерминации. Фактически в этих тестах проверяется гипотеза о равенстве истинного коэффициента детерминации нулю.
- Коэффициент детерминации не может быть отрицательным, данный вывод исходит из свойств коэффициента детерминации. Однако скорректированный коэффициент детерминации вполне может принимать отрицательные значения.
Недостаток R2 и альтернативные показатели[править | править код]
Основная проблема применения (выборочного)
Скорректированный (adjusted) R2[править | править код]
Для того, чтобы была возможность сравнивать модели с разным числом факторов так, чтобы число регрессоров (факторов) не влияло на статистику

который даёт штраф за дополнительно включённые факторы, где n — количество наблюдений, а k — количество параметров.
Данный показатель всегда меньше единицы, но теоретически может быть и меньше нуля (только при очень маленьком значении обычного коэффициента детерминации и большом количестве факторов). Поэтому теряется интерпретация показателя как «доли». Тем не менее, применение показателя в сравнении вполне обоснованно.
Для моделей с одинаковой зависимой переменной и одинаковым объёмом выборки сравнение моделей с помощью скорректированного коэффициента детерминации эквивалентно их сравнению с помощью остаточной дисперсии 

Информационные критерии[править | править код]
AIC — информационный критерий Акаике — применяется исключительно для сравнения моделей. Чем меньше значение, тем лучше. Часто используется для сравнения моделей временных рядов с разным количеством лагов. 
BIC или SC — байесовский информационный критерий Шварца — используется и интерпретируется аналогично AIC. 
R2-обобщённый (extended)[править | править код]
В случае отсутствия в линейной множественной МНК регрессии константы свойства коэффициента детерминации могут нарушаться для конкретной реализации. Поэтому модели регрессии со свободным членом и без него нельзя сравнивать по критерию 
Для случая регрессии без свободного члена:

где X — матрица nxk значений факторов, 


История[править | править код]
Основой коэффициента детерминации является регрессионный анализ и коэффициент корреляции. Британский натуралист сэр Фрэнсис Гальтон (1822—1911) основал регрессионный анализ в 1870-х годах. Он, как и его двоюродный брат Чарльз Дарвин, был внуком Эразма Дарвина. Гальтон был известен своей сильной страстью к сбору данных любого рода. Например, он собрал данные о семенах сладкого горошка чина. Сравнивая диаметры семян, он построил то, что сегодня широко известно как корреляционная диаграмма. Связь, обнаруженную им в этой деятельности, он сначала окрестил «реверсией» (разворотом); однако позже он выбрал название «регрессия». Анализируя семена, он обнаружил явление регрессии к центру, согласно которому — после крайне неудачного изменения, последующее изменение снова приближается к среднему: средний диаметр потомства более крупных семян был меньше среднего диаметра семян родителей (изменения разворачиваются). В своих корреляционных диаграммах он нарисовал линию тренда, для которой он использовал коэффициент корреляции в качестве наклона.[1]
Термин «дисперсия» был введен статистиком Рональдом Фишером (1890—1962) в его статье 1918 года под названием «Корреляция между родственниками на основе предположения о менделевском наследовании» (The Correlation between Relatives on the Supposition of Mendelian Inheritance)[2]. Фишер был одним из самых выдающихся статистиков 20-го века и известен своим вкладом в эволюционную теорию. F-критерий, тесно связанный с коэффициентом детерминации, также назван в его честь. Карл Пирсон (1857—1936), основатель биометрики, предоставил формально-математическое обоснование коэффициента корреляции, квадратом которого является коэффициент детерминации.[3]
Коэффициент детерминации подвергся резкой критике в последующие годы. Это произошло потому, что у него есть свойство, что чем больше количество независимых переменных, тем большим он становится. И это не зависит от того, вносят ли дополнительные «объясняющие переменные» вклад в «объяснительную силу». Чтобы учесть это обстоятельство, эконометрик Анри Тейл (1924—2000) в 1961 году предложил скорректированный коэффициент детерминации[4] (Adjusted coefficient of determination (англ.)), который учитывает потерю степени свободы, связанную с ростом количества объясняющих переменных. Скорректированный коэффициент детерминации изменяется за счет штрафа, который накладывается на модель при увеличении числа переменных. Однако немецкий учёный Хорст Ринне подверг критике данный подход[5] за недостаточное штрафование за потерю степени свободы по мере увеличения числа объясняющих переменных.
Замечание[править | править код]
Высокие значения коэффициента детерминации, вообще говоря, не свидетельствуют о наличии причинно-следственной зависимости между переменными (так же как и в случае обычного коэффициента корреляции). Например, если объясняемая переменная и факторы, на самом деле не связанные с объясняемой переменой, имеют возрастающую динамику, то коэффициент детерминации будет достаточно высок. Поэтому логическая и смысловая адекватность модели имеют первостепенную важность. Кроме того, необходимо использовать критерии для всестороннего анализа качества модели.
См. также[править | править код]
- Коэффициент корреляции
- Корреляция
- Мультиколлинеарность
- Дисперсия случайной величины
- Метод группового учёта аргументов
- Регрессионный анализ
Примечания[править | править код]
- ↑ Franka Miriam Brückler: Geschichte der Mathematik kompakt: Das Wichtigste aus Analysis, Wahrscheinlichkeitstheorie, angewandter Mathematik, Topologie und Mengenlehre. Springer-Verlag, 2017, ISBN 978-3-662-55573-6, S. 116. (нем.)
- ↑ Ronald Aylmer Fisher: The correlation between relatives on the supposition of Mendelian inheritance. In: Trans. Roy. Soc. Edinb. 52, 1918, S. 399—433. (англ.)
- ↑ Franka Miriam Brückler: Geschichte der Mathematik kompakt: Das Wichtigste aus Analysis, Wahrscheinlichkeitstheorie, angewandter Mathematik, Topologie und Mengenlehre. Springer-Verlag, 2017, ISBN 978-3-662-55573-6, S. 117. (нем.)
- ↑ Henri Theil: Economic Forecasts and Policy. Amsterdam 1961, S. 213. (англ.)
- ↑ Horst Rinne: Ökonometrie: Grundlagen der Makroökonometrie. Vahlen, 2004. (нем.)
Литература[править | править код]
- Бахрушин В. Е. Методы оценивания характеристик нелинейных статистических связей // Системные технологии. — 2011. — № 2(73). — С. 9—14.[1]
- Магнус Я.Р., Катышев П.К., Пересецкий А.А. Эконометрика. Начальный курс.. — 6,7,8-е изд., доп. и перераб.. — Москва: Дело. — Т. “”. — 576 с. — ISBN 5-7749-0055-X.
- Ершов Э.Б. Распространение коэффициента детерминации на общий случай линейной регрессии, оцениваемой с помощью различных версий метода наименьших квадратов (рус., англ.) // ЦЭМИ РАН Экономика и математические методы. — Москва: ЦЭМИ РАН, 2002. — Т. 38, вып. 3. — С. 107—120.
- Айвазян С.А., Мхитарян В.С. Прикладная статистика. Основы эконометрики (в 2-х т.). — ??. — Москва: Юнити-Дана (проект TASIS), 2001. — Т. “1,2”. — 1088 с. — ISBN 5-238-00304-8.
- Ершов Э.Б. Выбор регрессии максимизирующий несмещённую оценку коэффициента детерминации (рус., англ.) // Айвазян С.А. Прикладная эконометрика. — Москва: Маркет ДС, 2008. — Т. 12, вып. 4. — С. 71—83.
Ссылки[править | править код]
- Глоссарий статистических терминов (недоступная ссылка с 13-05-2013 [3656 дней] — история)
What Is the Coefficient of Determination?
The coefficient of determination is a statistical measurement that examines how differences in one variable can be explained by the difference in a second variable when predicting the outcome of a given event. In other words, this coefficient, more commonly known as r-squared (or r2), assesses how strong the linear relationship is between two variables and is heavily relied on by investors when conducting trend analysis.
This coefficient generally answers the following question: If a stock is listed on an index and experiences price movements, what percentage of its price movement is attributed to the index’s price movement?
Key Takeaways
- The coefficient of determination is a complex idea centered on statistical analysis of data and financial modeling.
- The coefficient of determination is used to explain the relationship between an independent and dependent variable.
- The coefficient of determination is commonly called r-squared (or r2) for the statistical value it represents.
- This measure is represented as a value between 0.0 and 1.0, where a value of 1.0 indicates a perfect correlation. Thus, it is a reliable model for future forecasts, while a value of 0.0 suggests that asset prices are not a function of dependency on the index.
R-Squared
Understanding the Coefficient of Determination
The coefficient of determination is a measurement used to explain how much the variability of one factor is caused by its relationship to another factor. This correlation is represented as a value between 0.0 and 1.0 (0% to 100%).
A value of 1.0 indicates a 100% price correlation and is thus a reliable model for future forecasts. A value of 0.0 suggests that the model shows that prices are not a function of dependency on the index.
So, a value of 0.20 suggests that 20% of an asset’s price movement can be explained by the index, while a value of 0.50 indicates that 50% of its price movement can be explained by it, and so on.
The coefficient of determination is the square of the correlation coefficient, also known as “r” in statistics. The value “r” can result in a negative number, but because r-squared is the result of “r” multiplied by itself (or squared), r2 cannot result in a negative number—regardless of what is found on the internet—the square of a negative number is always a positive value.
Calculating the Coefficient of Determination
To calculate the coefficient of determination. This is done by creating a scatter plot of the data and a trend line.
For instance, if you were to plot the closing prices for the S&P 500 and Apple stock (Apple is listed on the S&P 500) for trading days from Dec. 21, 2022, to Jan. 20, 2023, you’d collect the prices as shown in the table below.
| S&P Daily Close | APPL Daily Close | |
|---|---|---|
| Jan. 20 | $3,972.61 | $137.87 |
| 19 | $3,898.85 | $135.27 |
| 18 | $3,928.86 | $135.21 |
| 17 | $3,990.97 | $135.94 |
| 13 | $3,999.09 | $134.76 |
| 12 | $3,983.17 | $133.41 |
| 11 | $3,969.61 | $133.49 |
| 10 | $3,919.25 | $130.73 |
| 9 | $3,892.09 | $130.15 |
| 6 | $3,895.08 | $129.62 |
| 5 | $3,808.10 | $125.02 |
| 4 | $3,852.97 | $126.36 |
| 3 | $3,824.14 | $125.07 |
| Dec. 30 | $3,839.50 | $139.93 |
| 29 | $3,849.28 | $129.61 |
| 28 | $3,783.22 | $126.04 |
| 27 | $3,829.25 | $130.03 |
| 23 | $3,844.82 | $131.86 |
| 22 | $3,822.39 | $132.23 |
| 21 | $3,878.44 | $135.45 |
Then, you’d create a scatter plot. On a graph, how well the data fits the regression model is called the goodness of fit, which measures the distance between a trend line and all of the data points that are scattered throughout the diagram.
Spreadsheets
Most spreadsheets use the same formula to calculate the r2 of a dataset. So, if the data reside in columns A and B on your sheet:
= RSQ ( A1 : A10 , B1 : B10 )
Using this formula and highlighting the corresponding cells for the S&P 500 and Apple prices, you get an r2 of 0.347, suggesting that the two prices are less correlated than if the r2 was between 0.5 and 1.0.
Manual Calculation
Calculating the coefficient of determination by hand involves several steps. First, you gather the data as in the previous table. Second, you need to calculate all the values you need, as shown in this table, where:
- x= S&P 500 daily close
- y = APPL daily close
| x | x2 | y | y2 | xy | |
|---|---|---|---|---|---|
| Jan. 20 | $3,972.61 | $15,781,630.21 | $137.87 | $19,008.14 | $547,703.74 |
| 19 | $3,898.85 | $15,201,031.32 | $135.27 | $18,297.97 | $527,397.44 |
| 18 | $3,928.86 | $15,435,940.90 | $135.21 | $18,281.74 | $531,221.16 |
| 17 | $3,990.97 | $15,927,841.54 | $135.94 | $18,479.68 | $542,532.46 |
| 13 | $3,999.09 | $15,992,720.83 | $134.76 | $18,160.26 | $538,917.37 |
| 12 | $3,983.17 | $15,865,643.25 | $133.41 | $17,798.23 | $531,394.71 |
| 11 | $3,969.61 | $15,757,803.55 | $133.49 | $17,819.58 | $529,903.24 |
| 10 | $3,919.25 | $15,360,520.56 | $130.73 | $17,090.33 | $512,363.55 |
| 9 | $3,892.09 | $15,148,364.57 | $130.15 | $16,939.02 | $506,555.51 |
| 6 | $3,895.08 | $15,171,648.21 | $129.62 | $16,801.34 | $504,880.27 |
| 5 | $3,808.10 | $14,501,625.61 | $125.02 | $15,630.00 | $476,088.66 |
| 4 | $3,852.97 | $14,845,377.82 | $126.36 | $15,966.85 | $486,861.29 |
| 3 | $3,824.14 | $14,624,046.74 | $125.07 | $15,642.50 | $478,285.19 |
| Dec. 30 | $3,839.50 | $14,741,760.25 | $139.93 | $19,580.40 | $537,261.24 |
| 29 | $3,849.28 | $14,816,956.52 | $129.61 | $16,798.75 | $498,905.18 |
| 28 | $3,783.22 | $14,312,753.57 | $126.04 | $15,886.08 | $476,837.05 |
| 27 | $3,829.25 | $14,663,155.56 | $130.03 | $16,907.80 | $497,917.38 |
| 23 | $3,844.82 | $14,782,640.83 | $131.86 | $17,387.06 | $506,977.97 |
| 22 | $3,822.39 | $14,610,665.31 | $132.23 | $17,484.77 | $505,434.63 |
| 21 | $3,878.44 | $15,042,296.83 | $135.45 | $18,346.70 | $525,334.70 |
| Sum (Σ) | $77,781.69 | $302,584,424.00 | $2,638.05 | $348,307.23 | $10,262,772.73 |
Next, use this formula and substitute the values for each row of the table, where n equals the number of samples taken, in this case, 20:
r
2
=
(
n
(
∑
x
y
)
−
(
∑
x
)
(
∑
y
)
[
n
∑
x
2
−
(
∑
x
)
2
]
×
[
n
∑
y
2
−
(
∑
y
)
2
]
)
2
begin{aligned}&r ^ 2 = Big ( frac {n ( sum xy) – ( sum x )( sum y ) }{ sqrt { [ n sum x ^ 2 – ( sum x ) ^ 2 ] } times sqrt { [ n sum y ^ 2 – ( sum y ) ^ 2 ] } } Big ) ^ 2 \end{aligned}
r2=([n∑x2−(∑x)2]×[n∑y2−(∑y)2]n(∑xy)−(∑x)(∑y))2
Where √ represents the square root of the product in the brackets that follow it.
r
2
=
(
20
(
10
,
262
,
772.73
)
−
(
77
,
781.69
)
(
2
,
638.05
)
[
20
(
302
,
584
,
424
)
−
(
77
,
781.69
)
2
]
×
[
20
(
348
,
307.23
)
−
(
2
,
638.05
)
2
]
)
2
begin{aligned}&r ^ 2 = Big ( tiny { frac {20 ( 10,262,772.73) – ( 77,781.69 )( 2,638.05 ) }{ sqrt { [ 20 ( 302,584,424 ) – ( 77,781.69 ) ^ 2 ] } times sqrt { [ 20 ( 348,307.23 ) – ( 2,638.05 ) ^ 2 ] } } } Big ) ^ 2 \end{aligned}
r2=([20(302,584,424)−(77,781.69)2]×[20(348,307.23)−(2,638.05)2]20(10,262,772.73)−(77,781.69)(2,638.05))2
So you now have:
1.
(
20
×
10
,
262
,
772.73
)
−
(
77
,
781.69
×
2
,
638.05
)
=
63
,
467.32
2.
(
(
20
×
302
,
584
,
424
)
−
(
77
,
781.69
)
2
=
1
,
697
,
180.74
=
1
,
302.76
3.
(
(
20
×
10
,
262
,
772.73
)
−
(
2
,
638.05
)
2
=
6
,
836.85
=
82.69
begin{aligned}&1. tiny { ( 20 times 10,262,772.73 ) – ( 77,781.69 times 2,638.05 ) = 63,467.32 } \&2. tiny { (sqrt { ( 20 times 302,584,424 ) – ( 77,781.69 ) ^ 2 } = sqrt { 1,697,180.74 } = 1,302.76 } \&3. tiny { (sqrt { ( 20 times 10,262,772.73 ) – ( 2,638.05 ) ^ 2 } = sqrt { 6,836.85 } = 82.69 }\end{aligned}
1.(20×10,262,772.73)−(77,781.69×2,638.05)=63,467.322.((20×302,584,424)−(77,781.69)2=1,697,180.74=1,302.763.((20×10,262,772.73)−(2,638.05)2=6,836.85=82.69
Then, multiply steps two and three, divide step one by the result, and square it:
(
63
,
467.32
1
,
302.76
×
82.69
)
2
=
0.347
begin{aligned}&Big ( frac { 63,467.32 }{ 1,302.76 times 82.69 } Big ) ^ 2 = 0.347end{aligned}
(1,302.76×82.6963,467.32)2=0.347
You can see how this can become very tedious with lots of room for error, especially, if you’re using more than a few weeks of trading data.
Interpreting the Coefficient of Determination
Once you have the coefficient of determination, you use it to evaluate how closely the price movements of the asset you’re evaluating correspond to the price movements of an index or benchmark. In the Apple and S&P 500 example, the coefficient of determination for the period was 0.347.
Because 1.0 demonstrates a high correlation and 0.0 shows no correlation, 0.357 shows that Apple stock price movements are somewhat correlated to the index.
Apple is listed on many indexes, so you can calculate the r2 to determine if it corresponds to any other indexes’ price movements.
One aspect to consider is that r-squared doesn’t tell analysts whether the coefficient of determination value is intrinsically good or bad. It is their discretion to evaluate the meaning of this correlation and how it may be applied in future trend analyses.
How Do You Interpret a Coefficient of Determination?
The coefficient of determination shows how correlated one dependent and one independent variable are. Also called r2 (r-squared), the value should be between 0.0 and 1.0. The closer to 0.0, the less correlated the dependent value is. The closer to 1.0, the more correlated the value is.
What Does R-Squared Tell You in Regression?
It tells you whether there is a dependency between two values and how much dependency one value has on the other.
What If the Coefficient of Determination Is Greater Than 1?
The coefficient of determination cannot be more than one because the formula always results in a number between 0.0 and 1.0. If it is greater or less than these numbers, something is not correct.
The Bottom Line
The coefficient of determination is a ratio that shows how dependent one variable is on another variable. Investors use it to determine how correlated an asset’s price movements are with its listed index.
When an asset’s r2 is closer to zero, it does not demonstrate dependency on the index; if its r2 is closer to 1.0, it is more dependent on the price moves the index makes.
Материал из MachineLearning.
Перейти к: навигация, поиск
Коэффициент детерминации ( – R-квадрат) — это доля дисперсии зависимой переменной, объясняемая рассматриваемой моделью. Более точно — это единица минус доля необъяснённой дисперсии (дисперсии случайной ошибки модели, или условной по признакам дисперсии зависимой переменной) в дисперсии зависимой переменной. В случае линейной зависимости
является квадратом так называемого множественного коэффициента корреляции между зависимой переменной и объясняющими переменными. В частности, для модели линейной регрессии с одним признаком
коэффициент детерминации равен квадрату обычного коэффициента корреляции между
и
.
Содержание
- 1 Определение и формула
- 2 Интерпретация
- 3 Недостатки и альтернативные показатели
- 3.1 Скорректированный (adjusted)
- 3.2 Обобщённый (extended)
- 3.3 Ссылки
Определение и формула
Истинный коэффициент детерминации модели зависимости случайной величины от признаков
определяется следующим образом:
где — условная (по признакам
) дисперсия зависимой переменной (дисперсия случайной ошибки модели).
В данном определении используются истинные параметры, характеризующие распределение случайных величин. Если использовать выборочную оценку значений соответствующих дисперсий, то получим формулу для выборочного коэффициента детерминации (который обычно и подразумевается под коэффициентом детерминации):
где
— сумма квадратов регрессионных остатков,
— общая дисперсия,
— соответственно, фактические и расчетные значения объясняемой переменной,
— выборочное вреднее.
В случае линейной регрессии с константой , где
— объяснённая сумма квадратов, поэтому получаем более простое определение в этом случае. Коэффициент детерминации — это доля объяснённой дисперсии в общей:
.
Необходимо подчеркнуть, что эта формула справедлива только для модели с константой, в общем случае необходимо использовать предыдущую формулу.
Интерпретация
- Коэффициент детерминации для модели с константой принимает значения от 0 до 1. Чем ближе значение коэффициента к 1, тем сильнее зависимость. При оценке регрессионных моделей это интерпретируется как соответствие модели данным. Для приемлемых моделей предполагается, что коэффициент детерминации должен быть хотя бы не меньше 50% (в этом случае коэффициент множественной корреляции превышает по модулю 70%). Модели с коэффициентом детерминации выше 80% можно признать достаточно хорошими (коэффициент корреляции превышает 90%). Равенство коэффициента детерминации единице означает, что объясняемая переменная в точности описывается рассматриваемой моделью.
- При отсутствии статистической связи между объясняемой переменной и признаками статистика
для линейной регрессии имеет асимптотическое распределение
, где
— число признаков в модели. В случае линейной регрессии с независимыми одинаково распределёнными нормальными случайными ошибками статистика
имеет точное (для выборок любого объёма) распределение Фишера
. Информация о распределении этих величин позволяет проверить статистическую значимость регрессионной модели исходя из значения коэффициента детерминации. Фактически в этих тестах проверяется гипотеза о равенстве истинного коэффициента детерминации нулю.
Недостатки 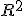 и альтернативные показатели
и альтернативные показатели
Основная проблема применения (выборочного) заключается в том, что его значение увеличивается (не уменьшается) от добавления в модель новых переменных, даже если эти переменные никакого отношения к объясняемой переменной не имеют. Поэтому сравнение моделей с разным количеством признаков с помощью коэффициента детерминации, вообще говоря, некорректно. Для этих целей можно использовать альтернативные показатели.
Скорректированный (adjusted)
Для того, чтобы была возможность сравнивать модели с разным числом признаков так, чтобы число регрессоров (признаков) не влияло на статистику обычно используется скорректированный коэффициент детерминации, в котором используются несмещённые оценки дисперсий:
который даёт штраф за дополнительно включённые признаки, где — количество наблюдений, а
— количество параметров.
Данный показатель всегда меньше единицы, но теоретически может быть и меньше нуля (только при очень маленьком значении обычного коэффициента детерминации и большом количестве признаков), поэтому интерпретировать его как долю объясняемой дисперсии уже нельзя. Тем не менее, применение показателя в сравнении вполне обоснованно.
Для моделей с одинаковой зависимой переменной и одинаковым объемом выборки сравнение моделей с помощью скорректированного коэффициента детерминации эквивалентно их сравнению с помощью остаточной дисперсии или стандартной ошибки модели
.
Обобщённый (extended)
В случае отсутствия в линейной множественной МНК регрессии константы свойства коэффициента детерминации могут нарушаться для конкретной реализации. Поэтому модели регрессии со свободным членом и без него нельзя сравнивать по критерию . Эта проблема решается с помощью построения обобщённого коэффициента детерминации
, который совпадает с исходным для случая МНК регрессии со свободным членом. Суть этого метода заключается рассмотрении проекции единичного вектора на плоскость объясняющих переменных.
Для случая регрессии без свободного члена:
где — матрица
значений признаков,
— проектор на плоскость
,
,
— единичный вектор
.
При некоторой модификации также подходит для сравнения между собой регрессионных моделей, построенных с помощью: МНК, обобщённого метода наименьших квадратов (ОМНК), условного метода наименьших квадратов (УМНК), обобщённо-условного метода наименьших квадратов (ОУМНК).
Ссылки
- Rules for Cheaters: How to Get a High R squared
- Wikipedia
- Emmanuelle Rieuf: Beginners Guide to Regression Analysis and Plot Interpretations, December 7, 2016.
Для того чтобы модель линейной регрессии можно было применять на практике необходимо сначала оценить её качество. Для этих целей предложен ряд показателей, каждый из которых предназначен для использования в различных ситуациях и имеет свои особенности применения (линейные и нелинейные, устойчивые к аномалиям, абсолютные и относительные, и т.д.). Корректный выбор меры для оценки качества модели является одним из важных факторов успеха в решении задач анализа данных.
- Среднеквадратичная ошибка (Mean Squared Error)
- Корень из среднеквадратичной ошибки (Root Mean Squared Error)
- Среднеквадратичная ошибка в процентах (Mean Squared Percentage Error)
- Cредняя абсолютная ошибка (Mean Absolute Error)
- Средняя абсолютная процентная ошибка (Mean Absolute Percentage Error)
- Cимметричная средняя абсолютная процентная ошибка (Symmetric Mean Absolute Percentage Error)
- Средняя абсолютная масштабированная ошибка (Mean absolute scaled error)
- Средняя относительная ошибка (Mean Relative Error)
- Среднеквадратичная логарифмическая ошибка (Root Mean Squared Logarithmic Error
- R-квадрат
- Скорректированный R-квадрат
- Сравнение метрик
«Хорошая» аналитическая модель должна удовлетворять двум, зачастую противоречивым, требованиям — как можно лучше соответствовать данным и при этом быть удобной для интерпретации пользователем. Действительно, повышение соответствия модели данным как правило связано с её усложнением (в случае регрессии — увеличением числа входных переменных модели). А чем сложнее модель, тем ниже её интерпретируемость.
Поэтому при выборе между простой и сложной моделью последняя должна значимо увеличивать соответствие модели данным чтобы оправдать рост сложности и соответствующее снижение интерпретируемости. Если это условие не выполняется, то следует выбрать более простую модель.
Таким образом, чтобы оценить, насколько повышение сложности модели значимо увеличивает её точность, необходимо использовать аппарат оценки качества регрессионных моделей. Он включает в себя следующие меры:
- Среднеквадратичная ошибка (MSE).
- Корень из среднеквадратичной ошибки (RMSE).
- Среднеквадратичная ошибка в процентах (MSPE).
- Средняя абсолютная ошибка (MAE).
- Средняя абсолютная ошибка в процентах (MAPE).
- Cимметричная средняя абсолютная процентная ошибка (SMAPE).
- Средняя абсолютная масштабированная ошибка (MASE)
- Средняя относительная ошибка (MRE).
- Среднеквадратичная логарифмическая ошибка (RMSLE).
- Коэффициент детерминации R-квадрат.
- Скорректированный коэффициент детеминации.
Прежде чем перейти к изучению метрик качества, введём некоторые базовые понятия, которые нам в этом помогут. Для этого рассмотрим рисунок.
Рисунок 1. Линейная регрессия
Наклонная прямая представляет собой линию регрессии с переменной, на которой расположены точки, соответствующие предсказанным значениям выходной переменной widehat{y} (кружки синего цвета). Оранжевые кружки представляют фактические (наблюдаемые) значения y . Расстояния между ними и линией регрессии — это ошибка предсказания модели y-widehat{y} (невязка, остатки). Именно с её использованием вычисляются все приведённые в статье меры качества.
Горизонтальная линия представляет собой модель простого среднего, где коэффициент при независимой переменной x равен нулю, и остаётся только свободный член b, который становится равным среднему арифметическому фактических значений выходной переменной, т.е. b=overline{y}. Очевидно, что такая модель для любого значения входной переменной будет выдавать одно и то же значение выходной — overline{y}.
В линейной регрессии такая модель рассматривается как «бесполезная», хуже которой работает только «случайный угадыватель». Однако, она используется для оценки, насколько дисперсия фактических значений y относительно линии среднего, больше, чем относительно линии регрессии с переменной, т.е. насколько модель с переменной лучше «бесполезной».
MSE
Среднеквадратичная ошибка (Mean Squared Error) применяется в случаях, когда требуется подчеркнуть большие ошибки и выбрать модель, которая дает меньше именно больших ошибок. Большие значения ошибок становятся заметнее за счет квадратичной зависимости.
Действительно, допустим модель допустила на двух примерах ошибки 5 и 10. В абсолютном выражении они отличаются в два раза, но если их возвести в квадрат, получив 25 и 100 соответственно, то отличие будет уже в четыре раза. Таким образом модель, которая обеспечивает меньшее значение MSE допускает меньше именно больших ошибок.
MSE рассчитывается по формуле:
MSE=frac{1}{n}sumlimits_{i=1}^{n}(y_{i}-widehat{y}_{i})^{2},
где n — количество наблюдений по которым строится модель и количество прогнозов, y_{i} — фактические значение зависимой переменной для i-го наблюдения, widehat{y}_{i} — значение зависимой переменной, предсказанное моделью.
Таким образом, можно сделать вывод, что MSE настроена на отражение влияния именно больших ошибок на качество модели.
Недостатком использования MSE является то, что если на одном или нескольких неудачных примерах, возможно, содержащих аномальные значения будет допущена значительная ошибка, то возведение в квадрат приведёт к ложному выводу, что вся модель работает плохо. С другой стороны, если модель даст небольшие ошибки на большом числе примеров, то может возникнуть обратный эффект — недооценка слабости модели.
RMSE
Корень из среднеквадратичной ошибки (Root Mean Squared Error) вычисляется просто как квадратный корень из MSE:
RMSE=sqrt{frac{1}{n}sumlimits_{i=1}^{n}(y_{i}-widehat{y_{i}})^{2}}
MSE и RMSE могут минимизироваться с помощью одного и того же функционала, поскольку квадратный корень является неубывающей функцией. Например, если у нас есть два набора результатов работы модели, A и B, и MSE для A больше, чем MSE для B, то мы можем быть уверены, что RMSE для A больше RMSE для B. Справедливо и обратное: если MSE(A)<MSE(B), то и RMSE(A)<RMSE(B).
Следовательно, сравнение моделей с помощью RMSE даст такой же результат, что и для MSE. Однако с MSE работать несколько проще, поэтому она более популярна у аналитиков. Кроме этого, имеется небольшая разница между этими двумя ошибками при оптимизации с использованием градиента:
frac{partial RMSE}{partial widehat{y}_{i}}=frac{1}{2sqrt{MSE}}frac{partial MSE}{partial widehat{y}_{i}}
Это означает, что перемещение по градиенту MSE эквивалентно перемещению по градиенту RMSE, но с другой скоростью, и скорость зависит от самой оценки MSE. Таким образом, хотя RMSE и MSE близки с точки зрения оценки моделей, они не являются взаимозаменяемыми при использовании градиента для оптимизации.
Влияние каждой ошибки на RMSE пропорционально величине квадрата ошибки. Поэтому большие ошибки оказывают непропорционально большое влияние на RMSE. Следовательно, RMSE можно считать чувствительной к аномальным значениям.
MSPE
Среднеквадратичная ошибка в процентах (Mean Squared Percentage Error) представляет собой относительную ошибку, где разность между наблюдаемым и фактическим значениями делится на наблюдаемое значение и выражается в процентах:
MSPE=frac{100}{n}sumlimits_{i=1}^{n}left ( frac{y_{i}-widehat{y}_{i}}{y_{i}} right )^{2}
Проблемой при использовании MSPE является то, что, если наблюдаемое значение выходной переменной равно 0, значение ошибки становится неопределённым.
MSPE можно рассматривать как взвешенную версию MSE, где вес обратно пропорционален квадрату наблюдаемого значения. Таким образом, при возрастании наблюдаемых значений ошибка имеет тенденцию уменьшаться.
MAE
Cредняя абсолютная ошибка (Mean Absolute Error) вычисляется следующим образом:
MAE=frac{1}{n}sumlimits_{i=1}^{n}left | y_{i}-widehat{y}_{i} right |
Т.е. MAE рассчитывается как среднее абсолютных разностей между наблюдаемым и предсказанным значениями. В отличие от MSE и RMSE она является линейной оценкой, а это значит, что все ошибки в среднем взвешены одинаково. Например, разница между 0 и 10 будет вдвое больше разницы между 0 и 5. Для MSE и RMSE, как отмечено выше, это не так.
Поэтому MAE широко используется, например, в финансовой сфере, где ошибка в 10 долларов должна интерпретироваться как в два раза худшая, чем ошибка в 5 долларов.
MAPE
Средняя абсолютная процентная ошибка (Mean Absolute Percentage Error) вычисляется следующим образом:
MAPE=frac{100}{n}sumlimits_{i=1}^{n}frac{left | y_{i}-widehat{y_{i}} right |}{left | y_{i} right |}
Эта ошибка не имеет размерности и очень проста в интерпретации. Её можно выражать как в долях, так и в процентах. Если получилось, например, что MAPE=11.4, то это говорит о том, что ошибка составила 11.4% от фактического значения.
SMAPE
Cимметричная средняя абсолютная процентная ошибка (Symmetric Mean Absolute Percentage Error) — это мера точности, основанная на процентных (или относительных) ошибках. Обычно определяется следующим образом:
SMAPE=frac{100}{n}sumlimits_{i=1}^{n}frac{left | y_{i}-widehat{y_{i}} right |}{(left | y_{i} right |+left | widehat{y}_{i} right |)/2}
Т.е. абсолютная разность между наблюдаемым и предсказанным значениями делится на полусумму их модулей. В отличие от обычной MAPE, симметричная имеет ограничение на диапазон значений. В приведённой формуле он составляет от 0 до 200%. Однако, поскольку диапазон от 0 до 100% гораздо удобнее интерпретировать, часто используют формулу, где отсутствует деление знаменателя на 2.
Одной из возможных проблем SMAPE является неполная симметрия, поскольку в разных диапазонах ошибка вычисляется неодинаково. Это иллюстрируется следующим примером: если y_{i}=100 и widehat{y}_{i}=110, то SMAPE=4.76, а если y_{i}=100 и widehat{y}_{i}=90, то SMAPE=5.26.
Ограничение SMAPE заключается в том, что, если наблюдаемое или предсказанное значение равно 0, ошибка резко возрастет до верхнего предела (200% или 100%).
MASE
Средняя абсолютная масштабированная ошибка (Mean absolute scaled error) — это показатель, который позволяет сравнивать две модели. Если поместить MAE для новой модели в числитель, а MAE для исходной модели в знаменатель, то полученное отношение и будет равно MASE. Если значение MASE меньше 1, то новая модель работает лучше, если MASE равно 1, то модели работают одинаково, а если значение MASE больше 1, то исходная модель работает лучше, чем новая модель. Формула для расчета MASE имеет вид:
MASE=frac{MAE_{i}}{MAE_{j}}
MASE симметрична и устойчива к выбросам.
MRE
Средняя относительная ошибка (Mean Relative Error) вычисляется по формуле:
MRE=frac{1}{n}sumlimits_{i=1}^{n}frac{left | y_{i}-widehat{y}_{i}right |}{left | y_{i} right |}
Несложно увидеть, что данная мера показывает величину абсолютной ошибки относительно фактического значения выходной переменной (поэтому иногда эту ошибку называют также средней относительной абсолютной ошибкой, MRAE). Действительно, если значение абсолютной ошибки, скажем, равно 10, то сложно сказать много это или мало. Например, относительно значения выходной переменной, равного 20, это составляет 50%, что достаточно много. Однако относительно значения выходной переменной, равного 100, это будет уже 10%, что является вполне нормальным результатом.
Очевидно, что при вычислении MRE нельзя применять наблюдения, в которых y_{i}=0.
Таким образом, MRE позволяет более адекватно оценить величину ошибки, чем абсолютные ошибки. Кроме этого она является безразмерной величиной, что упрощает интерпретацию.
RMSLE
Среднеквадратичная логарифмическая ошибка (Root Mean Squared Logarithmic Error) представляет собой RMSE, вычисленную в логарифмическом масштабе:
RMSLE=sqrt{frac{1}{n}sumlimits_{i=1}^{n}(log(widehat{y}_{i}+1)-log{(y_{i}+1}))^{2}}
Константы, равные 1, добавляемые в скобках, необходимы чтобы не допустить обращения в 0 выражения под логарифмом, поскольку логарифм нуля не существует.
Известно, что логарифмирование приводит к сжатию исходного диапазона изменения значений переменной. Поэтому применение RMSLE целесообразно, если предсказанное и фактическое значения выходной переменной различаются на порядок и больше.
R-квадрат
Перечисленные выше ошибки не так просто интерпретировать. Действительно, просто зная значение средней абсолютной ошибки, скажем, равное 10, мы сразу не можем сказать хорошая это ошибка или плохая, и что нужно сделать чтобы улучшить модель.
В этой связи представляет интерес использование для оценки качества регрессионной модели не значения ошибок, а величину показывающую, насколько данная модель работает лучше, чем модель, в которой присутствует только константа, а входные переменные отсутствуют или коэффициенты регрессии при них равны нулю.
Именно такой мерой и является коэффициент детерминации (Coefficient of determination), который показывает долю дисперсии зависимой переменной, объяснённой с помощью регрессионной модели. Наиболее общей формулой для вычисления коэффициента детерминации является следующая:
R^{2}=1-frac{sumlimits_{i=1}^{n}(widehat{y}_{i}-y_{i})^{2}}{sumlimits_{i=1}^{n}({overline{y}}_{i}-y_{i})^{2}}
Практически, в числителе данного выражения стоит среднеквадратическая ошибка оцениваемой модели, а в знаменателе — модели, в которой присутствует только константа.
Главным преимуществом коэффициента детерминации перед мерами, основанными на ошибках, является его инвариантность к масштабу данных. Кроме того, он всегда изменяется в диапазоне от −∞ до 1. При этом значения близкие к 1 указывают на высокую степень соответствия модели данным. Очевидно, что это имеет место, когда отношение в формуле стремится к 0, т.е. ошибка модели с переменными намного меньше ошибки модели с константой. R^{2}=0 показывает, что между независимой и зависимой переменными модели имеет место функциональная зависимость.
Когда значение коэффициента близко к 0 (т.е. ошибка модели с переменными примерно равна ошибке модели только с константой), это указывает на низкое соответствие модели данным, когда модель с переменными работает не лучше модели с константой.
Кроме этого, бывают ситуации, когда коэффициент R^{2} принимает отрицательные значения (обычно небольшие). Это произойдёт, если ошибка модели среднего становится меньше ошибки модели с переменной. В этом случае оказывается, что добавление в модель с константой некоторой переменной только ухудшает её (т.е. регрессионная модель с переменной работает хуже, чем предсказание с помощью простой средней).
На практике используют следующую шкалу оценок. Модель, для которой R^{2}>0.5, является удовлетворительной. Если R^{2}>0.8, то модель рассматривается как очень хорошая. Значения, меньшие 0.5 говорят о том, что модель плохая.
Скорректированный R-квадрат
Основной проблемой при использовании коэффициента детерминации является то, что он увеличивается (или, по крайней мере, не уменьшается) при добавлении в модель новых переменных, даже если эти переменные никак не связаны с зависимой переменной.
В связи с этим возникают две проблемы. Первая заключается в том, что не все переменные, добавляемые в модель, могут значимо увеличивать её точность, но при этом всегда увеличивают её сложность. Вторая проблема — с помощью коэффициента детерминации нельзя сравнивать модели с разным числом переменных. Чтобы преодолеть эти проблемы используют альтернативные показатели, одним из которых является скорректированный коэффициент детерминации (Adjasted coefficient of determinftion).
Скорректированный коэффициент детерминации даёт возможность сравнивать модели с разным числом переменных так, чтобы их число не влияло на статистику R^{2}, и накладывает штраф за дополнительно включённые в модель переменные. Вычисляется по формуле:
R_{adj}^{2}=1-frac{sumlimits_{i=1}^{n}(widehat{y}_{i}-y_{i})^{2}/(n-k)}{sumlimits_{i=1}^{n}({overline{y}}_{i}-y_{i})^{2}/(n-1)}
где n — число наблюдений, на основе которых строится модель, k — количество переменных в модели.
Скорректированный коэффициент детерминации всегда меньше единицы, но теоретически может принимать значения и меньше нуля только при очень малом значении обычного коэффициента детерминации и большом количестве переменных модели.
Сравнение метрик
Резюмируем преимущества и недостатки каждой приведённой метрики в следующей таблице:
| Мера | Сильные стороны | Слабые стороны |
|---|---|---|
| MSE | Позволяет подчеркнуть большие отклонения, простота вычисления. | Имеет тенденцию занижать качество модели, чувствительна к выбросам. Сложность интерпретации из-за квадратичной зависимости. |
| RMSE | Простота интерпретации, поскольку измеряется в тех же единицах, что и целевая переменная. | Имеет тенденцию занижать качество модели, чувствительна к выбросам. |
| MSPE | Нечувствительна к выбросам. Хорошо интерпретируема, поскольку имеет линейный характер. | Поскольку вклад всех ошибок отдельных наблюдений взвешивается одинаково, не позволяет подчёркивать большие и малые ошибки. |
| MAPE | Является безразмерной величиной, поэтому её интерпретация не зависит от предметной области. | Нельзя использовать для наблюдений, в которых значения выходной переменной равны нулю. |
| SMAPE | Позволяет корректно работать с предсказанными значениями независимо от того больше они фактического, или меньше. | Приближение к нулю фактического или предсказанного значения приводит к резкому росту ошибки, поскольку в знаменателе присутствует как фактическое, так и предсказанное значения. |
| MASE | Не зависит от масштаба данных, является симметричной: положительные и отрицательные отклонения от фактического значения учитываются одинаково. Устойчива к выбросам. Позволяет сравнивать модели. | Сложность интерпретации. |
| MRE | Позволяет оценить величину ошибки относительно значения целевой переменной. | Неприменима для наблюдений с нулевым значением выходной переменной. |
| RMSLE | Логарифмирование позволяет сделать величину ошибки более устойчивой, когда разность между фактическим и предсказанным значениями различается на порядок и выше | Может быть затруднена интерпретация из-за нелинейности. |
| R-квадрат | Универсальность, простота интерпретации. | Возрастает даже при включении в модель бесполезных переменных. Плохо работает когда входные переменные зависимы. |
| R-квадрат скорр. | Корректно отражает вклад каждой переменной в модель. | Плохо работает, когда входные переменные зависимы. |
В данной статье рассмотрены наиболее популярные меры качества регрессионных моделей, которые часто используются в различных аналитических приложениях. Эти меры имеют свои особенности применения, знание которых позволит обоснованно выбирать и корректно применять их на практике.
Однако в литературе можно встретить и другие меры качества моделей регрессии, которые предлагаются различными авторами для решения конкретных задач анализа данных.
Другие материалы по теме:
Отбор переменных в моделях линейной регрессии
Репрезентативность выборочных данных
Логистическая регрессия и ROC-анализ — математический аппарат
Пример нахождения коэффициента детерминации
Коэффициент детерминации рассчитывается для оценки качества подбора уравнения регрессии. Для приемлемых моделей предполагается, что коэффициент детерминации должен быть хотя бы не меньше 50%. Модели с коэффициентом детерминации выше 80% можно признать достаточно хорошими. Значение коэффициента детерминации R 2 = 1 означает функциональную зависимость между переменными.
Для линейной зависимости коэффициент детерминации равен квадрату коэффициента корреляции rxy: R 2 = rxy 2 .
2 “>Рассчитать свое значение
Например, значение R 2 = 0.83, означает, что в 83% случаев изменения х приводят к изменению y . Другими словами, точность подбора уравнения регрессии – высокая.
В общем случае, коэффициент детерминации находится по формуле: 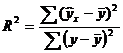 или
или 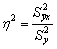
В этой формуле указаны дисперсии: 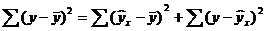 ,
,
где ∑(y- y ) 2 – общая сумма квадратов отклонений;
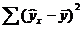 – сумма квадратов отклонений, обусловленная регрессией («объясненная» или «факторная»);
– сумма квадратов отклонений, обусловленная регрессией («объясненная» или «факторная»); 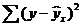 – остаточная сумма квадратов отклонений.
– остаточная сумма квадратов отклонений.
В случае нелинейной регрессии коэффициент детерминации рассчитывается через этот калькулятор. При множественной регрессии, коэффициент детемрминации можно найти через сервис Множественная регрессия
Пример . Дано:
- доля денежных доходов, направленных на прирост сбережений во вкладах, займах, сертификатах и в покупку валюты, в общей сумме среднедушевого денежного дохода, % (Y)
- среднемесячная начисленная заработная плата, тыс. руб. (X)
Следует выполнить: 1. построить поле корреляции и сформировать гипотезу о возможной форме и направлении связи; 2. рассчитать параметры уравнений линейной и A1; 3. выполнить расчет прогнозного значения результата, предполагая, что прогнозные значения факторов составят B2 % от их среднего уровня; 4. оценить тесноту связи с помощью показателей корреляции и детерминации, проанализировать их значения; 5. Дать с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом; 6. Оценить с помощью средней ошибки аппроксимации качество уравнений; 7. Оценить надежность уравнений в целом через F-критерий Фишера для уровня значимости а = 0,05. По значениям характеристик, рассчитанных в пп. 5,6 и данном пункте, выберете лучшее уравнение регрессии и дайте его обоснование.
- Решение онлайн
- Видео решение
Уравнение имеет вид y = ax + b
1. Параметры уравнения регрессии.
Средние значения
Связь между признаком Y фактором X сильная и прямая.
Уравнение регрессии
Коэффициент детерминации для линейной регрессии равен квадрату коэффициента корреляции.
R 2 = 0.91 2 = 0.83, т.е. в 83% случаев изменения х приводят к изменению y. Другими словами – точность подбора уравнения регрессии – высокая
| x | y | x 2 | y 2 | x ∙ y | y(x) | (y-y cp ) 2 | (y-y(x)) 2 | (x-x p ) 2 |
| 15.1 | 255 | 228.01 | 65025 | 3850.5 | 505.26 | 527451.17 | 62630.22 | 420.25 |
| 17 | 261 | 289 | 68121 | 4437 | 549.38 | 518772.07 | 83161.41 | 345.96 |
| 12 | 293 | 144 | 85849 | 3516 | 433.28 | 473699.53 | 19678.51 | 556.96 |
| 10 | 310 | 100 | 96100 | 3100 | 386.84 | 450587.75 | 5904.58 | 655.36 |
| 74 | 1425 | 5476 | 2030625 | 105450 | 1872.88 | 196906.67 | 200600 | 1474.56 |
| 83 | 1985 | 6889 | 3940225 | 164755 | 2081.86 | 1007497.33 | 9381.6 | 2246.76 |
| 85 | 2549 | 7225 | 6497401 | 216665 | 2128.3 | 2457813.93 | 176990.6 | 2440.36 |
| 81 | 2012 | 6561 | 4048144 | 162972 | 2035.42 | 1062428.38 | 548.49 | 2061.16 |
| 22 | 1562 | 484 | 2439844 | 34364 | 665.47 | 337260.88 | 803758.38 | 184.96 |
| 10 | 386 | 100 | 148996 | 3860 | 386.84 | 354332.48 | 0.71 | 655.36 |
| 4 | 383 | 16 | 146689 | 1532 | 247.52 | 357913.03 | 18353.53 | 998.56 |
| 14.1 | 354.1 | 198.81 | 125386.81 | 4992.81 | 482.04 | 393327.58 | 16368.87 | 462.25 |
| 427.2 | 11775.1 | 27710.82 | 19692405.81 | 709494.31 | 11775.1 | 8137990.81 | 1397376.9 | 12502.5 |
2. Оценка параметров уравнения регрессии
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл
Tтабл (n-m-1;a) = (10;0.05) = 1.812
Поскольку Tнабл > Tтабл , то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически – значим
Анализ точности определения оценок коэффициентов регрессии
S a = 3.3432
Доверительные интервалы для зависимой переменной
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X = 1
(-557.64;913.38)
Проверка гипотез относительно коэффициентов линейного уравнения регрессии
1) t-статистика
Статистическая значимость коэффициента регрессии a подтверждается (6.95>1.812).
Статистическая значимость коэффициента регрессии b не подтверждается (0.96 Fkp, то коэффициент детерминации статистически значим
Расчет коэффициента детерминации в Microsoft Excel

Одним из показателей, описывающих качество построенной модели в статистике, является коэффициент детерминации (R^2), который ещё называют величиной достоверности аппроксимации. С его помощью можно определить уровень точности прогноза. Давайте узнаем, как можно произвести расчет данного показателя с помощью различных инструментов программы Excel.
Вычисление коэффициента детерминации
В зависимости от уровня коэффициента детерминации, принято разделять модели на три группы:
- 0,8 – 1 — модель хорошего качества;
- 0,5 – 0,8 — модель приемлемого качества;
- 0 – 0,5 — модель плохого качества.
В последнем случае качество модели говорит о невозможности её использования для прогноза.
Выбор способа вычисления указанного значения в Excel зависит от того, является ли регрессия линейной или нет. В первом случае можно использовать функцию КВПИРСОН, а во втором придется воспользоваться специальным инструментом из пакета анализа.
Способ 1: вычисление коэффициента детерминации при линейной функции
Прежде всего, выясним, как найти коэффициент детерминации при линейной функции. В этом случае данный показатель будет равняться квадрату коэффициента корреляции. Произведем его расчет с помощью встроенной функции Excel на примере конкретной таблицы, которая приведена ниже.
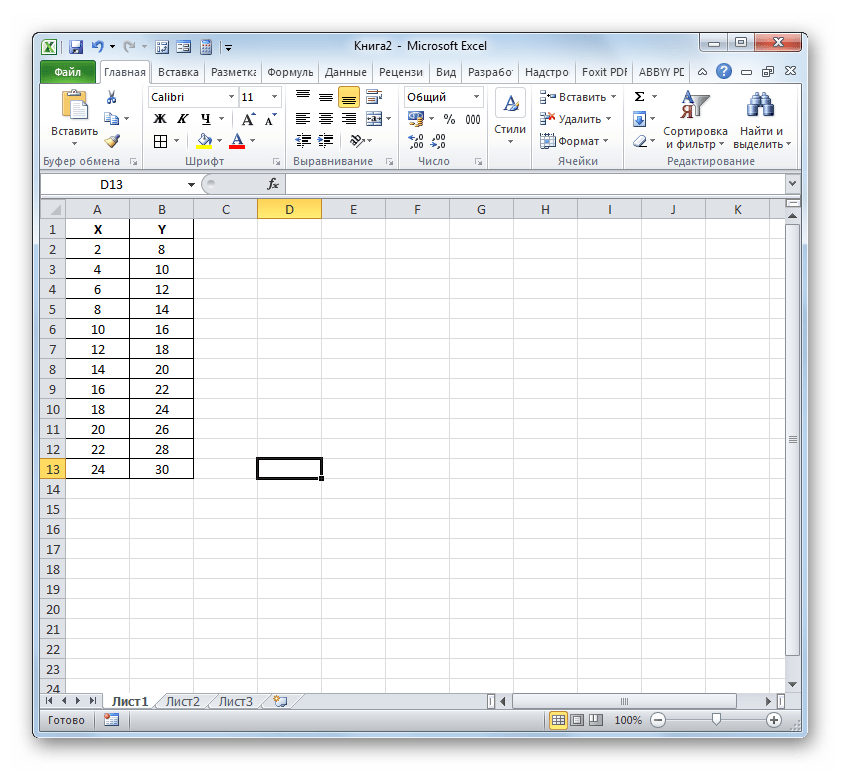
- Выделяем ячейку, где будет произведен вывод коэффициента детерминации после его расчета, и щелкаем по пиктограмме «Вставить функцию».
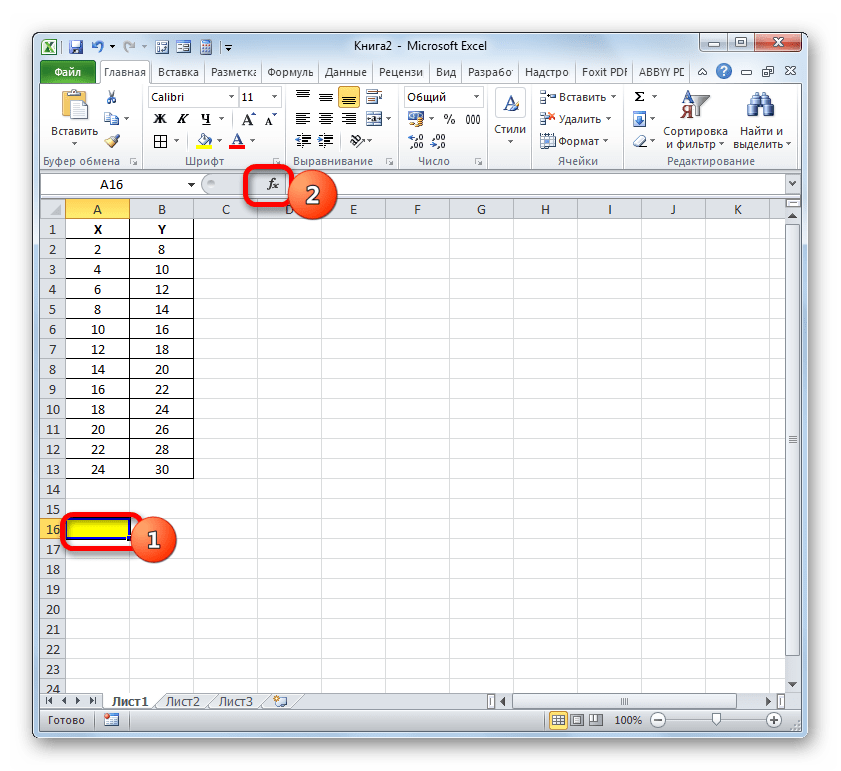
Запускается Мастер функций. Перемещаемся в его категорию «Статистические» и отмечаем наименование «КВПИРСОН». Далее клацаем по кнопке «OK».
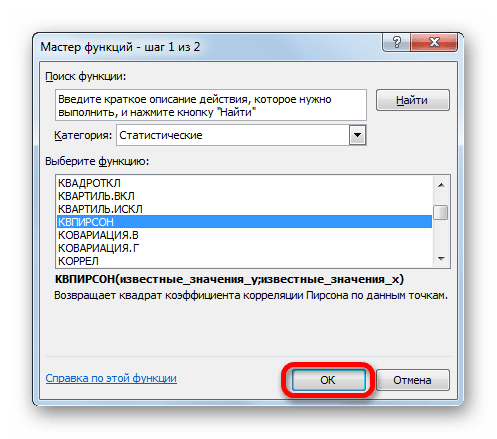
Происходит запуск окна аргументов функции КВПИРСОН. Данный оператор из статистической группы предназначен для вычисления квадрата коэффициента корреляции функции Пирсона, то есть, линейной функции. А как мы помним, при линейной функции коэффициент детерминации как раз равен квадрату коэффициента корреляции.
Синтаксис этого оператора такой:
Таким образом, функция имеет два оператора, один из которых представляет собой перечень значений функции, а второй – аргументов. Операторы могут быть представлены, как непосредственно в виде значений, перечисленных через точку с запятой (;), так и в виде ссылок на диапазоны, где они расположены. Именно последний вариант и будет использован нами в данном примере.
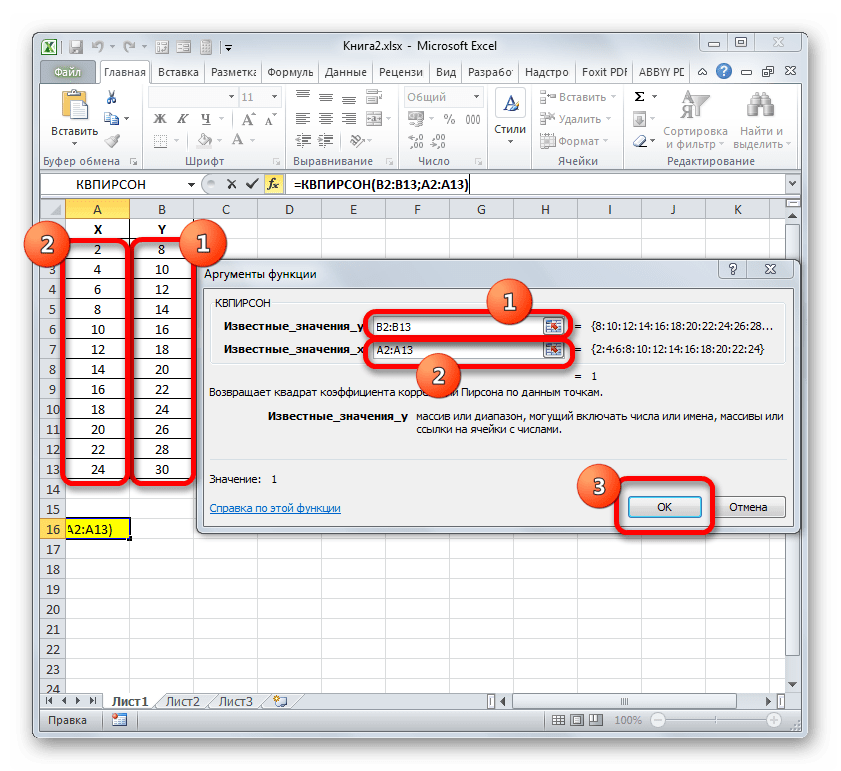
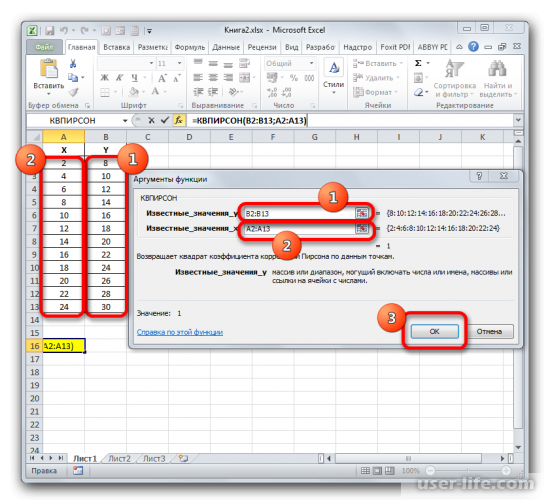
Устанавливаем курсор в поле «Известные значения y». Выполняем зажим левой кнопки мышки и производим выделение содержимого столбца «Y» таблицы. Как видим, адрес указанного массива данных тут же отображается в окне.
Аналогичным образом заполняем поле «Известные значения x». Ставим курсор в данное поле, но на этот раз выделяем значения столбца «X».
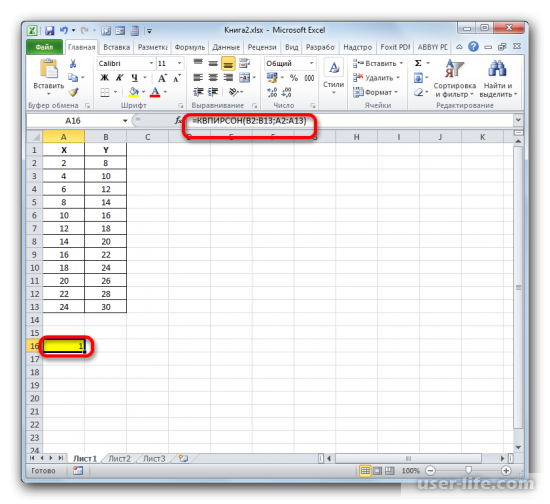
После того, как все данные были отображены в окне аргументов КВПИРСОН, клацаем по кнопке «OK», расположенной в самом его низу.
Способ 2: вычисление коэффициента детерминации в нелинейных функциях
Но указанный выше вариант расчета искомого значения можно применять только к линейным функциям. Что же делать, чтобы произвести его расчет в нелинейной функции? В Экселе имеется и такая возможность. Её можно осуществить с помощью инструмента «Регрессия», который является составной частью пакета «Анализ данных».
-
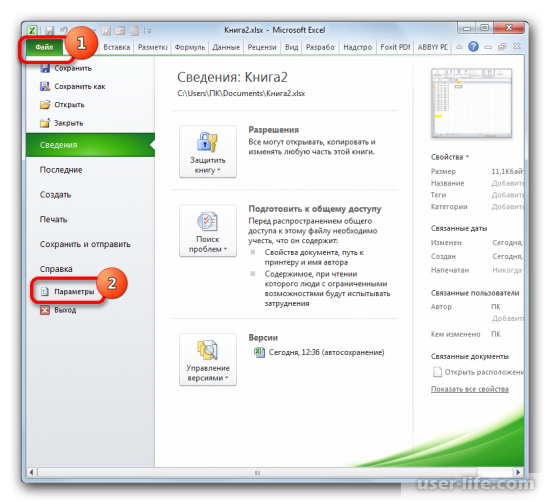
Но прежде, чем воспользоваться указанным инструментом, следует активировать сам «Пакет анализа», который по умолчанию в Экселе отключен. Перемещаемся во вкладку «Файл», а затем переходим по пункту «Параметры».
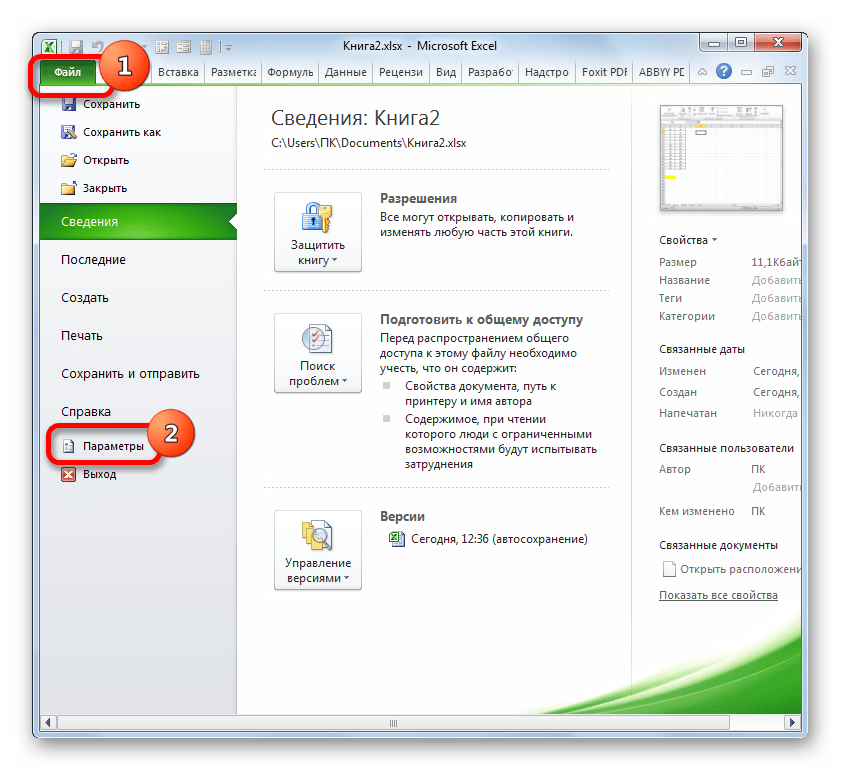
В открывшемся окне производим перемещение в раздел «Надстройки» при помощи навигации по левому вертикальному меню. В нижней части правой области окна располагается поле «Управление». Из списка доступных там подразделов выбираем наименование «Надстройки Excel…», а затем щелкаем по кнопке «Перейти…», расположенной справа от поля.
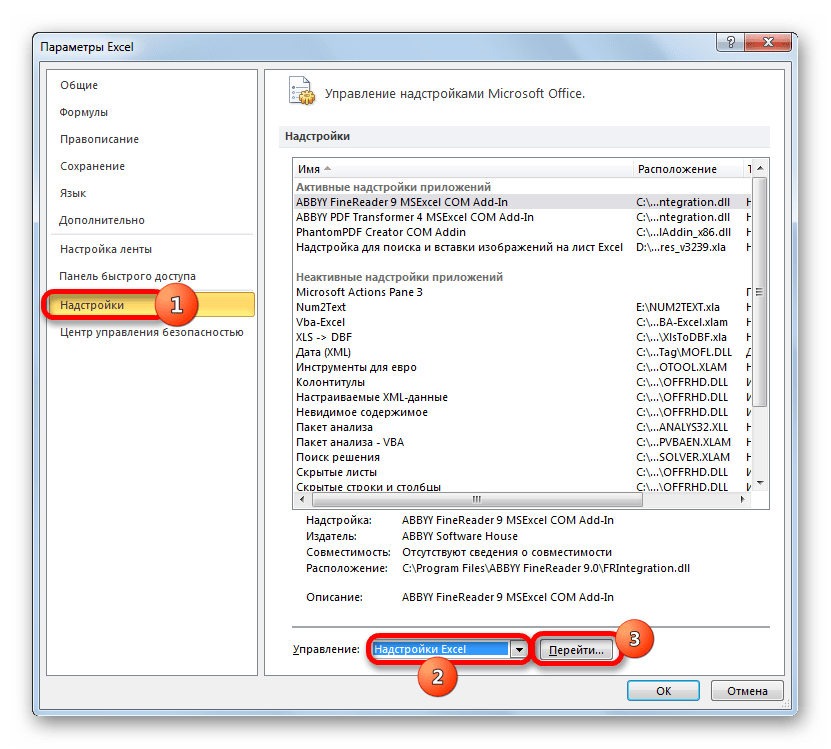
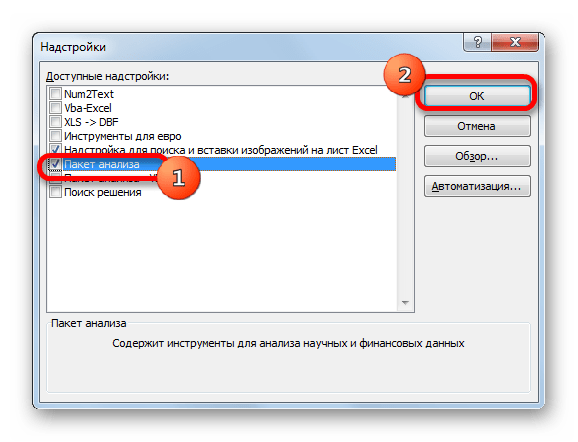
Производится запуск окна надстроек. В центральной его части расположен список доступных надстроек. Устанавливаем флажок около позиции «Пакет анализа». Вслед за этим требуется щелкнуть по кнопке «OK» в правой части интерфейса окна.
Пакет инструментов «Анализ данных» в текущем экземпляре Excel будет активирован. Доступ к нему располагается на ленте во вкладке «Данные». Перемещаемся в указанную вкладку и клацаем по кнопке «Анализ данных» в группе настроек «Анализ».
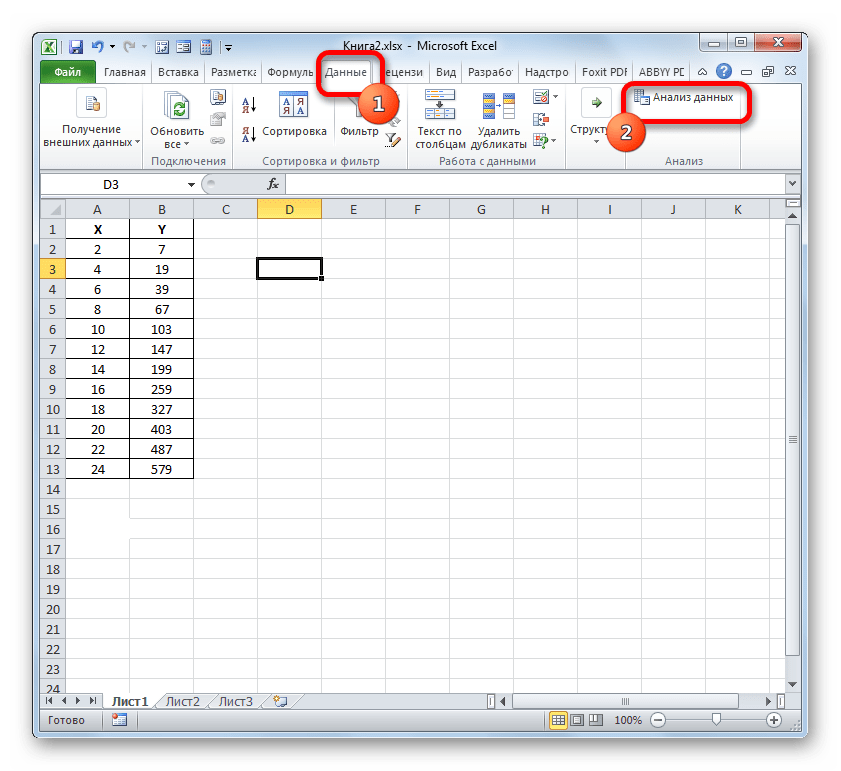
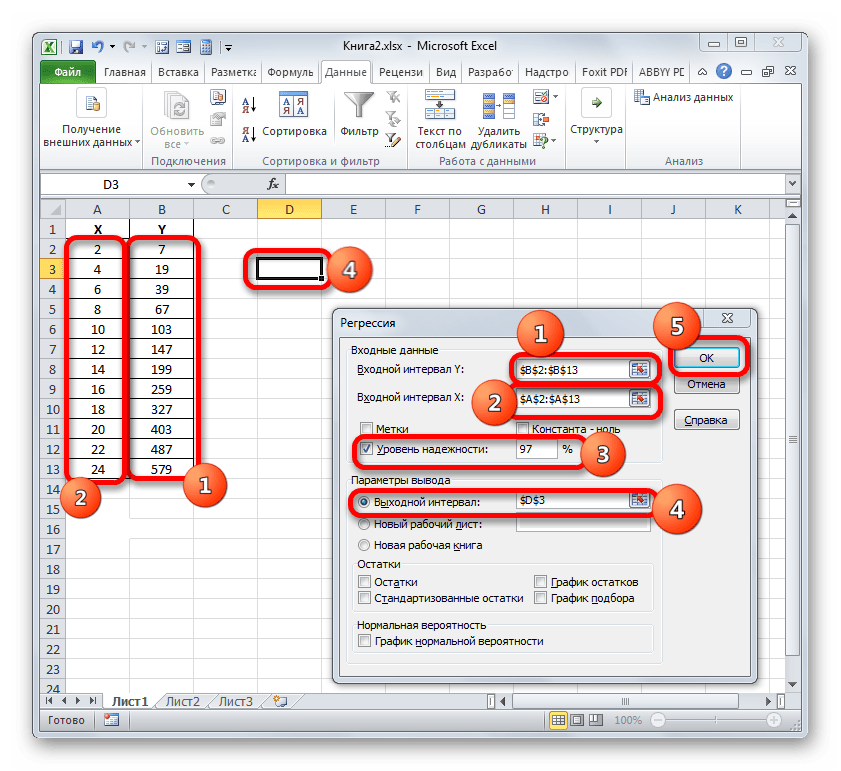
Активируется окошко «Анализ данных» со списком профильных инструментов обработки информации. Выделяем из этого перечня пункт «Регрессия» и клацаем по кнопке «OK».
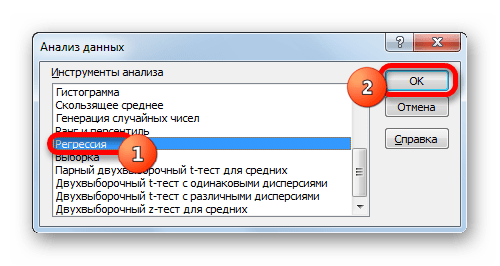
Затем открывается окно инструмента «Регрессия». Первый блок настроек – «Входные данные». Тут в двух полях нужно указать адреса диапазонов, где находятся значения аргумента и функции. Ставим курсор в поле «Входной интервал Y» и выделяем на листе содержимое колонки «Y». После того, как адрес массива отобразился в окне «Регрессия», ставим курсор в поле «Входной интервал Y» и точно таким же образом выделяем ячейки столбца «X».
Около параметров «Метка» и «Константа-ноль» флажки не ставим. Флажок можно установить около параметра «Уровень надежности» и в поле напротив указать желаемую величину соответствующего показателя (по умолчанию 95%).
В группе «Параметры вывода» нужно указать, в какой области будет отображаться результат вычисления. Существует три варианта:
- Область на текущем листе;
- Другой лист;
- Другая книга (новый файл).
Остановим свой выбор на первом варианте, чтобы исходные данные и результат размещались на одном рабочем листе. Ставим переключатель около параметра «Выходной интервал». В поле напротив данного пункта ставим курсор. Щелкаем левой кнопкой мыши по пустому элементу на листе, который призван стать левой верхней ячейкой таблицы вывода итогов расчета. Адрес данного элемента должен высветиться в поле окна «Регрессия».
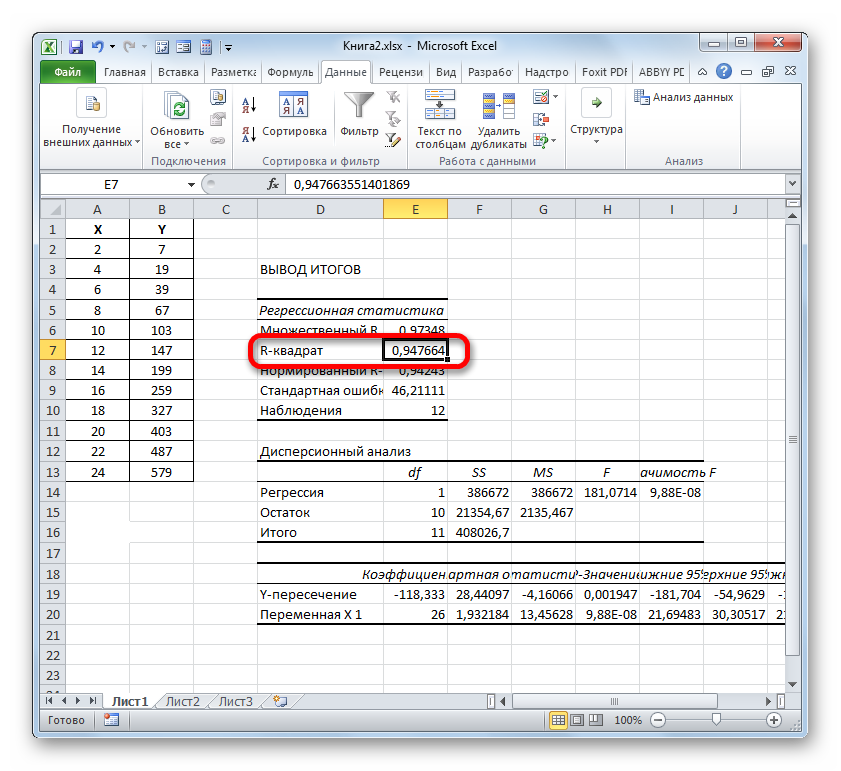
Группы параметров «Остатки» и «Нормальная вероятность» игнорируем, так как для решения поставленной задачи они не важны. После этого клацаем по кнопке «OK», которая размещена в правом верхнем углу окна «Регрессия».
Способ 3: коэффициент детерминации для линии тренда
Кроме указанных выше вариантов, коэффициент детерминации можно отобразить непосредственно для линии тренда в графике, построенном на листе Excel. Выясним, как это можно сделать на конкретном примере.
-
Мы имеем график, построенный на основе таблицы аргументов и значений функции, которая была использована для предыдущего примера. Произведем построение к нему линии тренда. Кликаем по любому месту области построения, на которой размещен график, левой кнопкой мыши. При этом на ленте появляется дополнительный набор вкладок – «Работа с диаграммами». Переходим во вкладку «Макет». Клацаем по кнопке «Линия тренда», которая размещена в блоке инструментов «Анализ». Появляется меню с выбором типа линии тренда. Останавливаем выбор на том типе, который соответствует конкретной задаче. Давайте для нашего примера выберем вариант «Экспоненциальное приближение».
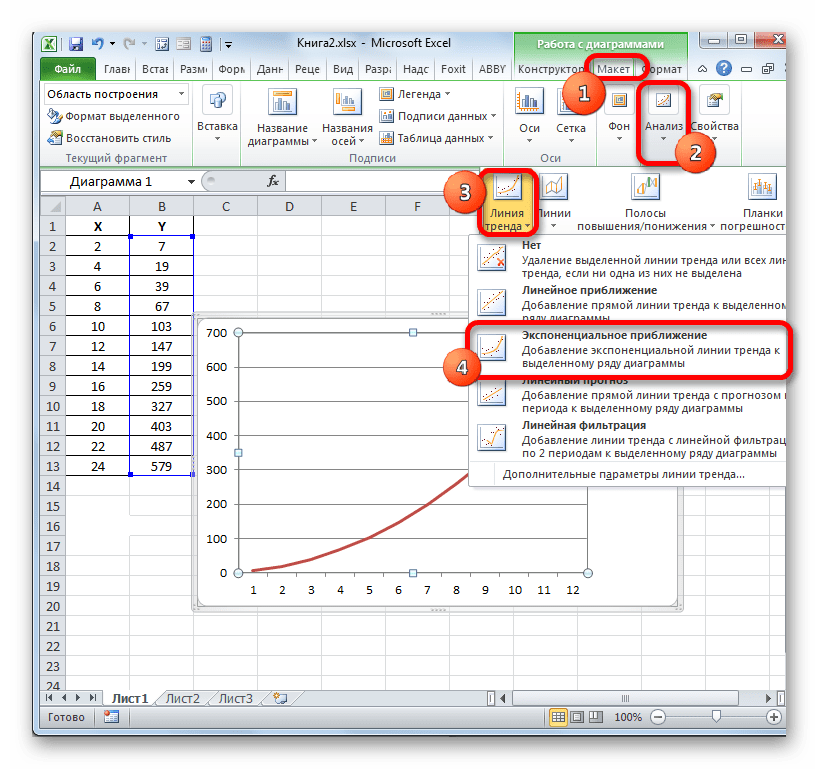
Эксель строит прямо на плоскости построения графика линию тренда в виде дополнительной черной кривой.
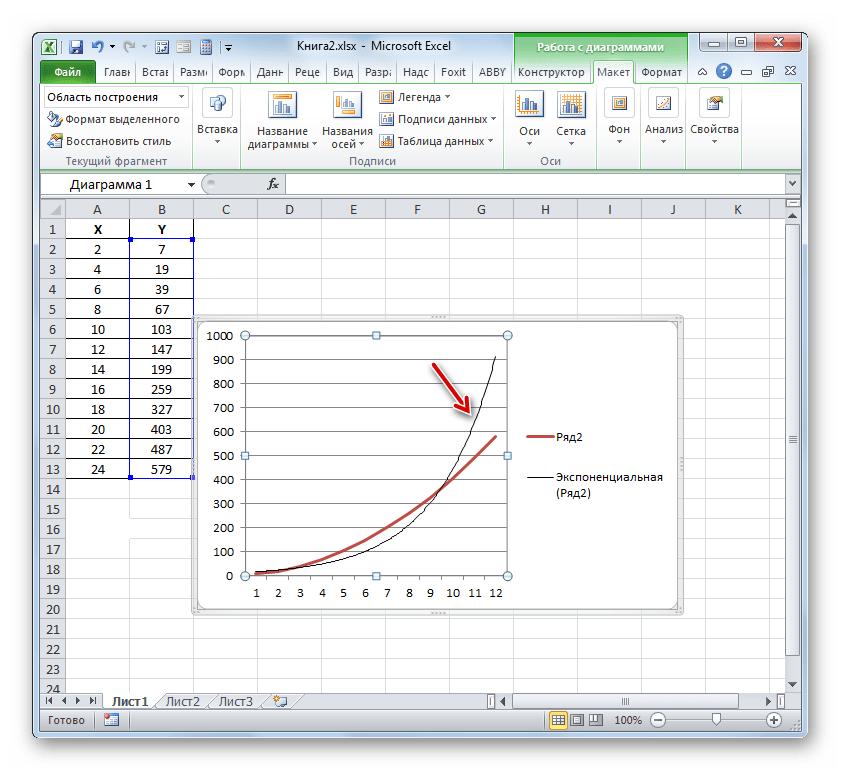
Теперь нашей задачей является отобразить собственно коэффициент детерминации. Кликаем правой кнопкой мыши по линии тренда. Активируется контекстное меню. Останавливаем выбор в нем на пункте «Формат линии тренда…».
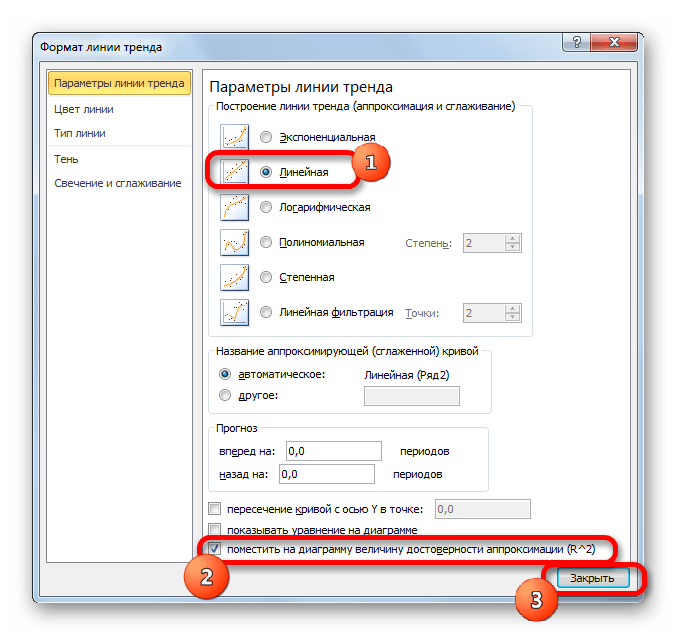
Для выполнения перехода в окно формата линии тренда можно выполнить альтернативное действие. Выделяем линию тренда кликом по ней левой кнопки мыши. Перемещаемся во вкладку «Макет». Клацаем по кнопке «Линия тренда» в блоке «Анализ». В открывшемся списке клацаем по самому последнему пункту перечня действий – «Дополнительные параметры линии тренда…».
После любого из двух вышеуказанных действий запускается окошко формата, в котором можно произвести дополнительные настройки. В частности, для выполнения нашей задачи необходимо установить флажок напротив пункта «Поместить на диаграмму величину достоверности аппроксимации (R^2)». Он размещен в самом низу окна. То есть, таким образом мы включаем отображение коэффициента детерминации на области построения. Затем не забываем нажать на кнопку «Закрыть» внизу текущего окна.
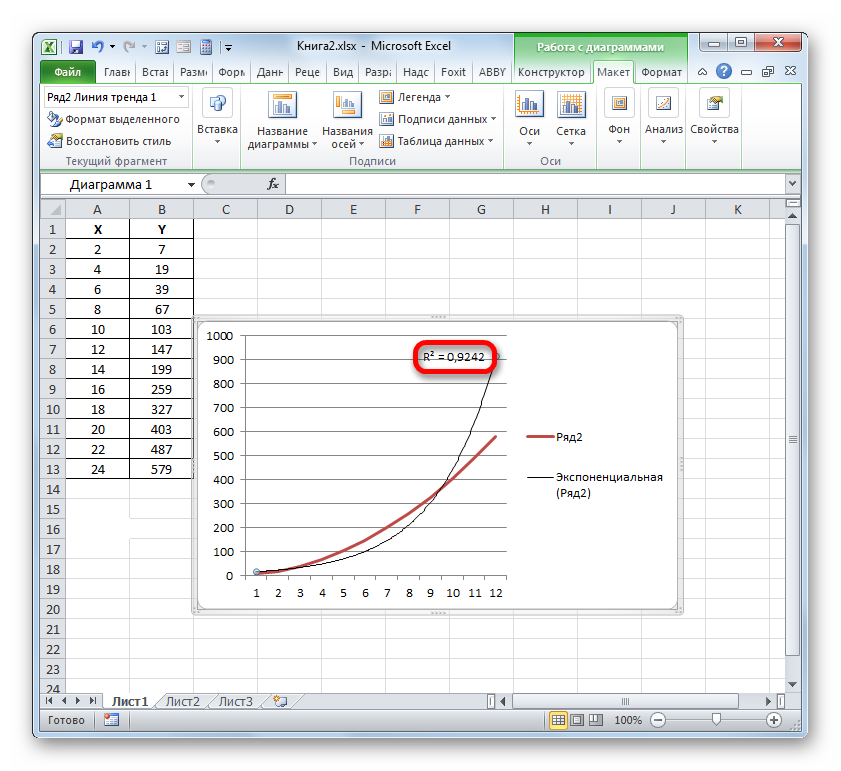
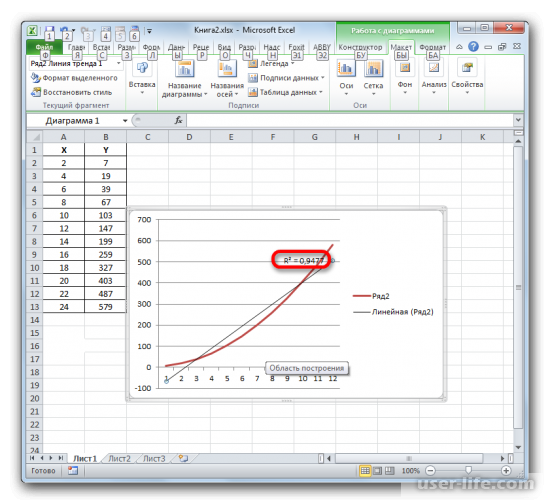
Значение достоверности аппроксимации, то есть, величина коэффициента детерминации, будет отображено на листе в области построения. В данном случае эта величина, как видим, равна 0,9242, что характеризует аппроксимацию, как модель хорошего качества.
Абсолютно точно таким образом можно устанавливать показ коэффициента детерминации для любого другого типа линии тренда. Можно менять тип линии тренда, произведя переход через кнопку на ленте или контекстное меню в окно её параметров, как было показано выше. Затем уже в самом окне в группе «Построение линии тренда» можно переключиться на другой тип. Не забываем при этом контролировать, чтобы около пункта «Поместить на диаграмму величину достоверности аппроксимации» был установлен флажок. Завершив вышеуказанные действия, щелкаем по кнопке «Закрыть» в нижнем правом углу окна.
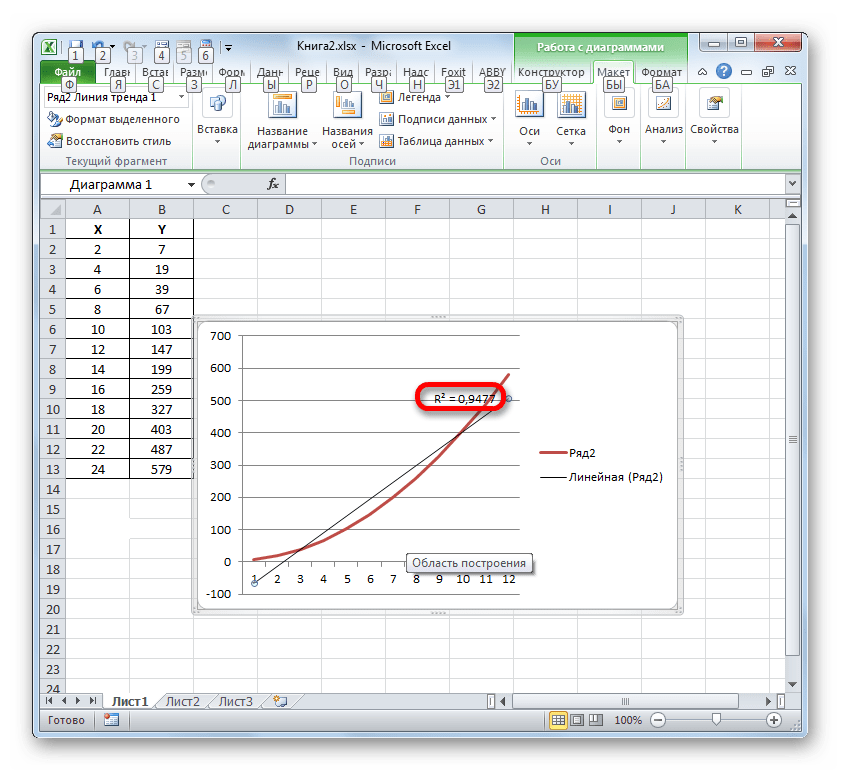
При линейном типе линия тренда уже имеет значение достоверности аппроксимации равное 0,9477, что характеризует эту модель, как ещё более достоверную, чем рассматриваемую нами ранее линию тренда экспоненциального типа.
Таким образом, переключаясь между разными типами линии тренда и сравнивая их значения достоверности аппроксимации (коэффициент детерминации), можно найти тот вариант, модель которого наиболее точно описывает представленный график. Вариант с самым высоким показателем коэффициента детерминации будет наиболее достоверным. На его основе можно строить самый точный прогноз.
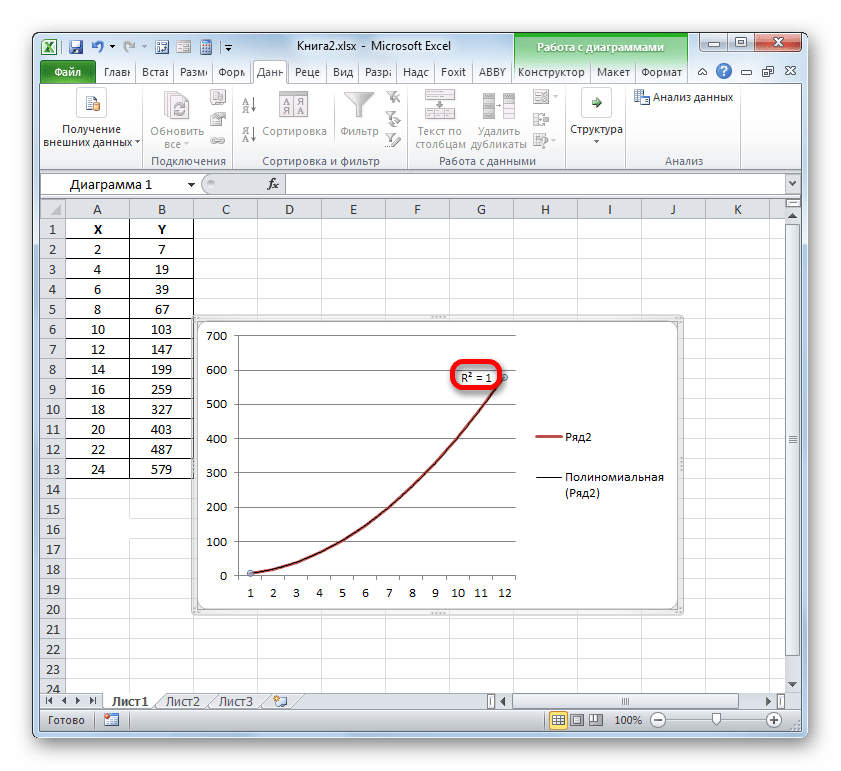
Например, для нашего случая опытным путем удалось установить, что самый высокий уровень достоверности имеет полиномиальный тип линии тренда второй степени. Коэффициент детерминации в данном случае равен 1. Это говорит о том, что указанная модель абсолютно достоверная, что означает полное исключение погрешностей.
Но, в то же время, это совсем не значит, что для другого графика тоже наиболее достоверным окажется именно этот тип линии тренда. Оптимальный выбор типа линии тренда зависит от типа функции, на основании которой был построен график. Если пользователь не обладает достаточным объемом знаний, чтобы «на глаз» прикинуть наиболее качественный вариант, то единственным выходом определения лучшего прогноза является как раз сравнение коэффициентов детерминации, как было показано на примере выше.
В Экселе существуют два основных варианта вычисления коэффициента детерминации: использование оператора КВПИРСОН и применение инструмента «Регрессия» из пакета инструментов «Анализ данных». При этом первый из этих вариантов предназначен для использования только в процессе обработки линейной функции, а другой вариант можно использовать практически во всех ситуациях. Кроме того, существует возможность отображения коэффициента детерминации для линии трендов графиков в качестве величины достоверности аппроксимации. С помощью данного показателя имеется возможность определить тип линии тренда, который располагает самым высоким уровнем достоверности для конкретной функции.
Помимо этой статьи, на сайте еще 12698 инструкций.
Добавьте сайт Lumpics.ru в закладки (CTRL+D) и мы точно еще пригодимся вам.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Коэффициент детерминации в excel
Коэффициент детерминации рассчитывается для оценки качества подбора уравнения регрессии. Для приемлемых моделей предполагается, что коэффициент детерминации должен быть хотя бы не меньше 50%. Модели с коэффициентом детерминации выше 80% можно признать достаточно хорошими. Значение коэффициента детерминации R 2 = 1 означает функциональную зависимость между переменными.
Для линейной зависимости коэффициент детерминации равен квадрату коэффициента корреляции rxy: R 2 = rxy 2 .
2 «>Рассчитать свое значение
Например, значение R 2 = 0.83, означает, что в 83% случаев изменения х приводят к изменению y . Другими словами, точность подбора уравнения регрессии — высокая.
В общем случае, коэффициент детерминации находится по формуле: или
В этой формуле указаны дисперсии:
,
где ∑(y- y ) — общая сумма квадратов отклонений;
— сумма квадратов отклонений, обусловленная регрессией («объясненная» или «факторная»);
— остаточная сумма квадратов отклонений.
В случае нелинейной регрессии коэффициент детерминации рассчитывается через этот калькулятор. При множественной регрессии, коэффициент детемрминации можно найти через сервис Множественная регрессия
- доля денежных доходов, направленных на прирост сбережений во вкладах, займах, сертификатах и в покупку валюты, в общей сумме среднедушевого денежного дохода, % (Y)
- среднемесячная начисленная заработная плата, тыс. руб. (X)
Следует выполнить: 1. построить поле корреляции и сформировать гипотезу о возможной форме и направлении связи; 2. рассчитать параметры уравнений линейной и A1; 3. выполнить расчет прогнозного значения результата, предполагая, что прогнозные значения факторов составят B2 % от их среднего уровня; 4. оценить тесноту связи с помощью показателей корреляции и детерминации, проанализировать их значения; 5. Дать с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом; 6. Оценить с помощью средней ошибки аппроксимации качество уравнений; 7. Оценить надежность уравнений в целом через F-критерий Фишера для уровня значимости а = 0,05. По значениям характеристик, рассчитанных в пп. 5,6 и данном пункте, выберете лучшее уравнение регрессии и дайте его обоснование.
Уравнение имеет вид y = ax + b
1. Параметры уравнения регрессии.
Средние значения
Связь между признаком Y фактором X сильная и прямая.
Уравнение регрессии
По таблице Стьюдента находим Tтабл
Tтабл (n-m-1;a) = (10;0.05) = 1.812
Поскольку Tнабл > Tтабл , то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически — значим
Анализ точности определения оценок коэффициентов регрессии
S a = 3.3432
Доверительные интервалы для зависимой переменной
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X = 1
(-557.64;913.38)
Проверка гипотез относительно коэффициентов линейного уравнения регрессии
1) t-статистика
Статистическая значимость коэффициента регрессии a подтверждается
Статистическая значимость коэффициента регрессии b не подтверждается
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(a — t a S a; a + t aS a)
(17.1616;29.2772)
(b — t b S b; b + t bS b)
(-136.4585;445.7528)
Fkp = 4.96
Поскольку F > Fkp, то коэффициент детерминации статистически значим
Коэффициент детерминации в Excel (Эксель)
Для статистических моделей во многих случаях необходимо определить точность прогноза. Это производится с помощью специальных расчётов в Microsoft Excel, а использоваться будет коэффициент детерминации. Он обозначается как R^2.
Статистические модели можно разделить на качественные уровни в зависимости от коэффициента. От 0.8 до 1 относятся модели хорошего качества, модели достаточного качества имеют уровень от 0.5 до 0.8, а плохое качество имеет диапазон от 0 до 0.5.
Способ определения точности с помощью функции КВПИРСОН
В линейной функции коэффициент детерминации будет равен квадрату корреляционного коэффициента. Рассчитать его можно с помощью специальной функции. Для начала создадим таблицу с данными.
Потом нужно выбрать место, где будет показан результат расчёта и нажимаем на кнопку вставки функции.

После этого откроется специальное окно. Категорию нужно выбрать «Статистические» и выбираем КВПИРСОН. Эта функция позволяет определить коэффициент корреляции касательно функции Пирсона, соответственно квадратное значение коэффициента корреляции = коэффициенту детерминации.
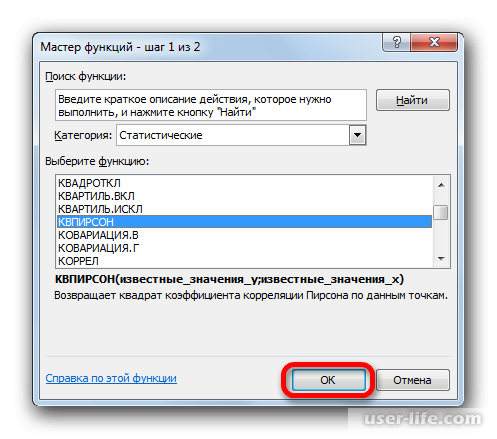
После подтверждения действия, появится окно в котором нужно в полях выставить «Известные значения Х» и «Известные значения Y». Нажимаем мышкой поле «Известные значения Y» и в рабочем окне выделяем данные столбца Y. Аналогичное действие делаем и с другим полем выбирая данные уже с таблицы Х.
Как результат этих действий будет показано значение коэффициента детерминации в ячейке, которая ранее была выбрана для отображения результата.
Определение коэффициента детерминации если функция не является линейной.
Если функция нелинейная, то инструментарий Excel также позволяет рассчитать коэффициент с помощью инструмента «Регрессия». Его можно найти в пакете анализа данных. Но для начала нужно активировать этот пакет, перейдя в раздел «Файл» и в списке открыть «Параметры».
После этого можно увидеть новое окно, в котором нужно в меню выбрать «Надстройки», а в специальном поле по управлению надстройками выбираем «Надстройки Excel» и переходим к ним.
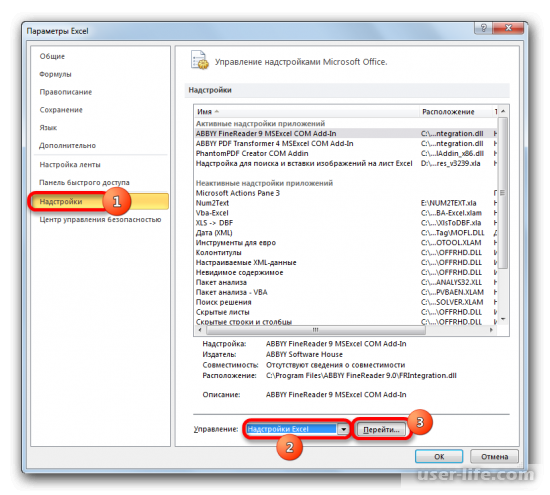
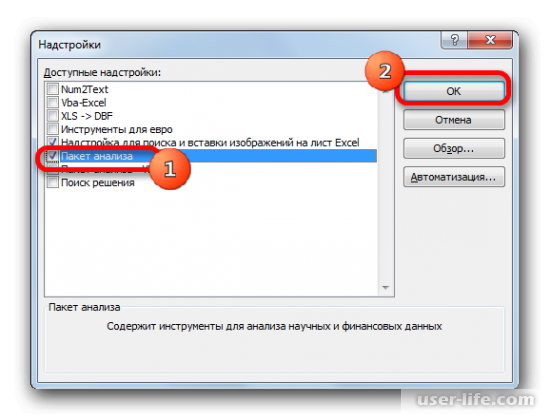
После перехода в надстройки Excel появится новое окно. В нём можно увидеть доступные для пользователя надстройки. Ставим галочку возле «Пакет анализа» и подтверждаем действие.
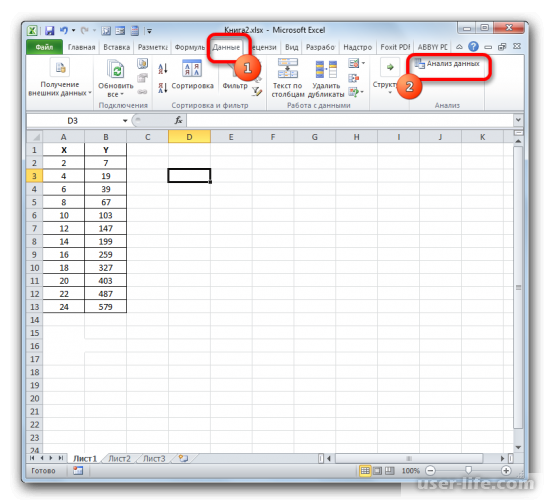
Найти его можно в разделе «Данные», после перехода в который нажимаем на «Анализ данных» в правой части экрана.
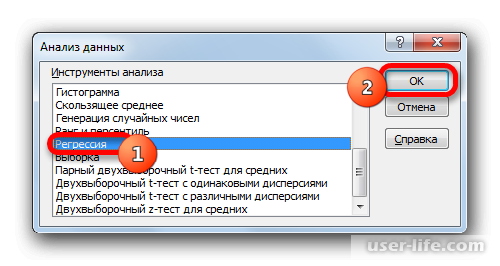
После его открытия, в списке выбираем «Регрессия»и подтверждаем действие.
После этого появится новое окно в котором можно производить настройки. Входные данные позволяют настроить значение интервалов Х и Y, достаточно выделить соответствующие ячейки аргументов другого аргумента. В поле уровня надежности можно выставить нужный показатель. Параметры вывода позволяют задать где будет показан результат. Если к примеру выбрать показ на текущем листе, то для начала нужно выбрать пункт «Выходной интервал» — и нажать на области основного окна где будет в будущем отображаться результат и координаты ячейки будут показаны соответствующем поле. В конце подтверждаем действие.
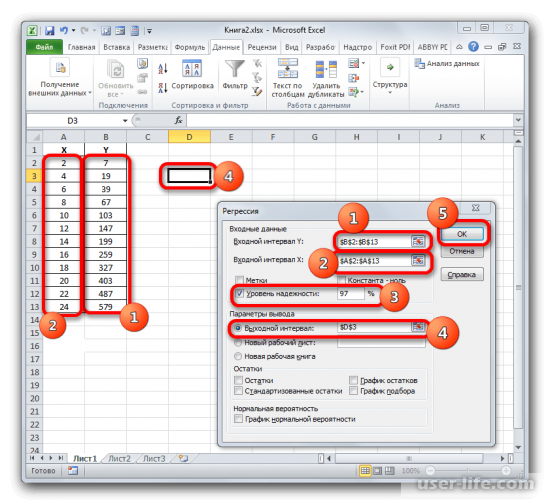
В рабочем окне появится результат. Так как мы вычисляем коэффициент детерминации, то в итогах нам нужен R-коэффициент. Если посмотреть на значение, то можно увидеть что оно относится к наилучшему качеству.
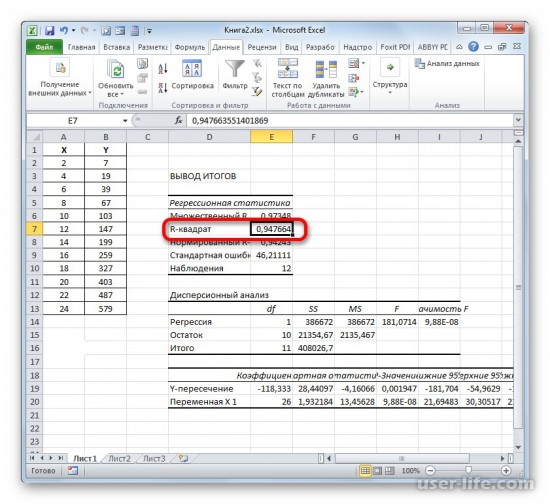
Способ определения коэффициента детерминации для линии тренда
Имея созданную таблицу с соответствующими значение, создаем график. Чтобы провести на нём линию тренда надо нажать на график, а именно на область где строится линия. Сверху в панели инструментов выбрать раздел «Макет», а в нём выбрать «Линия тренда». После этого в контексте данного примера в списке выбираем «Экспоненциальное приближение».
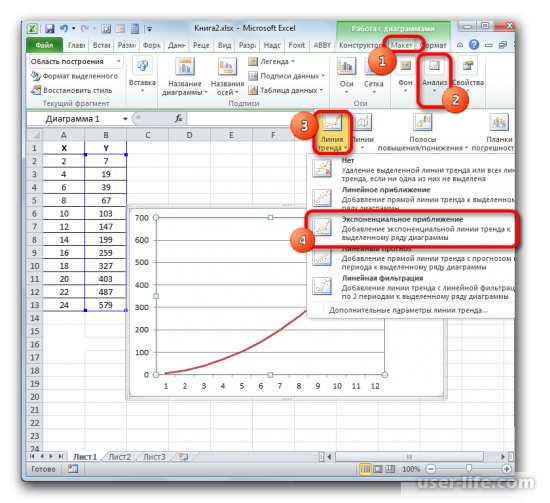
Линия тренда будет отображена на графике как кривая с черным цветом.
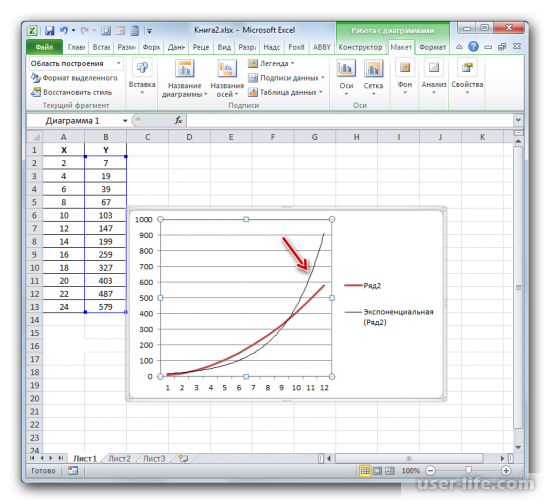
Для того чтобы показать коэффициент детерминации, нужно по черной кривой нажать правой кнопкой мыши и выбрать в списке «Формат линии тренда».
После этого появится новое окно. В нём нужно отметить флажком и выбрать нужное действие (показано на скриншоте). Благодаря этому коэффициент будет отображен на графике. После того как это было сделано, закрываем окно.
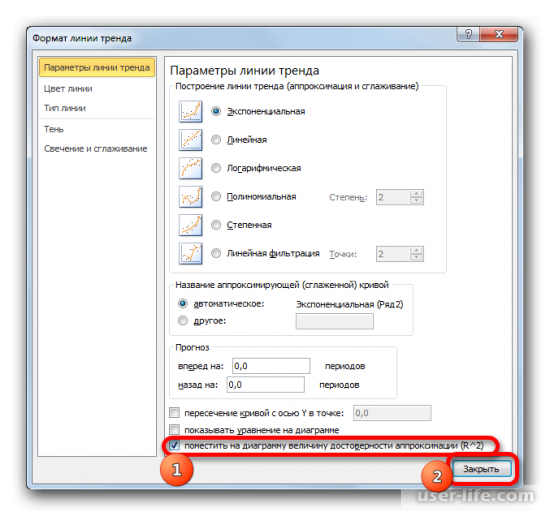
После закрытия окна формата линии тренда в рабочем окне можно увидеть значение коэффициента детерминации.
Если пользователю нужен другой типаж линии тренда, то в окне «Формат линии тренда» можно выбрать его. Не забыв задать его ранее при создании линии тренда в разделе «Макет» или в контекстном меню. Также не забываем ставить флажок для функции R^2.
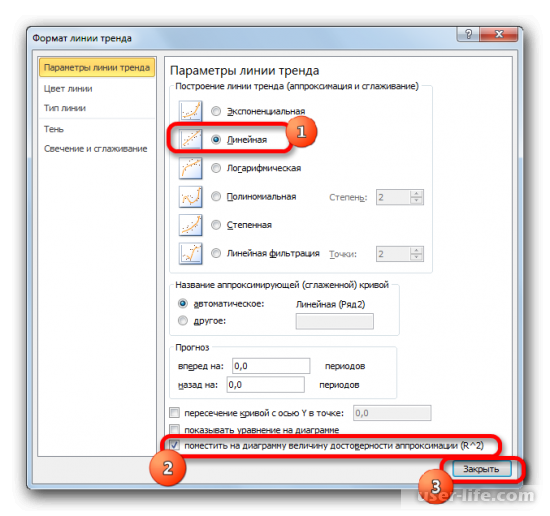
Как результат можно увидеть изменение линии тренда и число достоверности.
После просмотра разных вариаций линий тренда, пользователь может определить наиболее подходящую для себя так как показатель достоверности может меняться в зависимости от выбора линии. Максимальный коэффициент это единица, что означает максимальную достоверность, однако не всегда можно достигнуть этого значения.
Так было рассмотрено несколько способов по нахождению коэффициента детерминации. Пользователь может выбрать наиболее оптимальный для своих целей.
Алгоритм вычисления коэффициента выборочной детерминации в MS-Excel Текст научной статьи по специальности « Математика»
CC BY
Аннотация научной статьи по математике, автор научной работы — Красильников Дмитрий Евгеньевич
Рассматривается коэффициент выборочной детерминации как критерий однородности выборок в социально-экономических исследованиях. Приводится геометрическое доказательство закона разложения дисперсии , предлагается алгоритм вычисления коэффициента выборочной детерминации в MS-Excel, рассматривается случай, когда закон разложения дисперсии не выполняется, показана связь между коэффициентом выборочной детерминации и эмпирическим корреляционным отношением .
Похожие темы научных работ по математике , автор научной работы — Красильников Дмитрий Евгеньевич
Текст научной работы на тему «Алгоритм вычисления коэффициента выборочной детерминации в MS-Excel»
Д. Е. Красильников
АЛГОРИТМ ВЫЧИСЛЕНИЯ КОЭФФИЦИЕНТА ВЫБОРОЧНОЙ ДЕТЕРМИНАЦИИ
Нижегородский почтамт. Отделение почтовой связи №24
Рассматривается коэффициент выборочной детерминации как критерий однородности выборок в социально-экономических исследованиях. Приводится геометрическое доказательство закона разложения дисперсии, предлагается алгоритм вычисления коэффициента выборочной детерминации в MS-Excel, рассматривается случай, когда закон разложения дисперсии не выполняется, показана связь между коэффициентом выборочной детерминации и эмпирическим корреляционным отношением.
Ключевые слова: коэффициент выборочной детерминации, закон разложения дисперсии, MS-Excel, критерий однородности выборок, дисперсионный анализ, эмпирическое корреляционное отношение.
При проведении социологических, психологических, экономических и маркетинговых исследований почти всегда встает вопрос о репрезентативности исследуемой выборки. Под репрезентативностью выборки, чаще всего, понимается ее однородность. При этом в современной литературе по соответствующим дисциплинам не дается универсальный метод проверки гипотезы об однородности. Как правило, для такой проверки используют так называемый ¿-критерий, F-критерий или критерий «Хи-квадрат» (см., например, [1]), которые базируются на сравнении средних величин со значением функции Стьюдента, Фишера или Хи -квадрат. Однако эти критерии слабо чувствительны к социально-экономическим данным ввиду небольшого разброса значений таких данных, а применение указанных функций недостаточно обосновано, так как эти критерии были разработаны для биологических, а не социально-экономических исследований.
Другим распространенным подходом к оценке репрезентативности является обоснованность выборки с позиций той или иной задачи. Например, при изучении спроса на автомобили стоимостью от миллиона рублей выборка, сделанная из лиц с доходом 8-10 тыс. руб. , будет всегда нерепрезентативной.
Тем не менее, в Советском Союзе была разработана специальная статистика (функция от выборочной совокупности), позволяющая оценить однородность любой выборки при условии ее стратификации — коэффициент выборочной детерминации (^2выб). Его не следует путать с коэффициентом детерминации (R2 ), который характеризует качество аппроксимации с помощью линейной функции и не имеет отношения к выборочному методу.
Данная статистика основана на разложении дисперсии на межгрупповую и внутриг-рупповую. Это разложение также используется в дисперсионном анализе. «Первоначально (1918 г.) дисперсионный анализ был разработан английским математиком-статистиком Р.А. Фишером для обработки результатов агрономических опытов по выявлению условий получения максимального урожая различных сортов сельскохозяйственных культур. Сам термин «дисперсионный анализ» Фишер употребил позднее [2, с. 392].
Чтобы понять, на чем основано разложение дисперсии, рассмотрим так называемый «прямоугольный выборочный план», используемый в однофакторном дисперсионном анализе (табл. 1).
Этот план представляет собой таблицу, в которой каждый столбец является выборкой с n элементами. Всего делается m таких выборок. В литературе эти столбцы часто называют факторами, группами или стратами, а само расположение элементов выборок — стратификацией.
© Красильников Д. Е., 2016.
В этой статье при обозначении элемента таблицы символом у, первый индекс указывает номер строки, а второй — номер столбца, в соответствии с правилом обозначения элементов матриц, принятым в Советском Союзе. Замечу, что в английской традиции принята обратная запись, то есть сначала пишут столбец, а затем строку, а в современной российской литературе встречаются оба варианта.
Очевидно, что общее число элементов в таблице N есть
Прямоугольный выборочный план
1 у11 у12 уЦ у 1т
2 у21 у22 у 2 i у 2т
1 у,1 у 2 у, у гт
п уп1 уп 2 у п] у пт
Среднее у1 у 2 у, у т
По каждому столбцу вычисляется среднее арифметическое у. (внутригрупповая средняя), которое заносится в последнюю строку таблицы,
Матрица парных коэффициентов корреляции
Матрица парных коэффициентов корреляции представляет собой матрицу, элементами которой являются парные коэффициенты корреляции. Например, для трех переменных эта матрица имеет вид:
| — | y | x1 | x2 | x3 |
| y | 1 | ryx1 | ryx2 | ryx3 |
| x1 | rx1y | 1 | rx1x2 | rx1x3 |
| x2 | rx2y | rx2x1 | 1 | rx2x3 |
| x3 | rx3y | rx3x1 | rx3x2 | 1 |
Вставьте в поле матрицу парных коэффициентов.
Пример . По данным 154 сельскохозяйственных предприятий Кемеровской области 2003 г. изучить эффективность производства зерновых (табл. 13).
- Определите факторы, формирующие рентабельность зерновых в сельскохозяйственных предприятий в 2003 г.
- Постройте матрицу парных коэффициентов корреляции. Установите, какие факторы мультиколлинеарны.
- Постройте уравнение регрессии, характеризующее зависимость рентабельности зерновых от всех факторов.
- Оцените значимость полученного уравнения регрессии. Какие факторы значимо воздействуют на формирование рентабельности зерновых в этой модели?
- Оцените значение рентабельности производства зерновых в сельскохозяйственном предприятии № 3.
Решение получаем с помощью калькулятора Уравнение множественной регрессии :
Матрица X T
Умножаем матрицы, (X T X)
| 22 | 19.76 | 27.81 | 13.19 |
| 19.76 | 23.78 | 22.45 | 15.73 |
| 27.81 | 22.45 | 42.09 | 14.96 |
| 13.19 | 15.73 | 14.96 | 10.45 |
В матрице, (X T X) число 22, лежащее на пересечении 1-й строки и 1-го столбца, получено как сумма произведений элементов 1-й строки матрицы X T и 1-го столбца матрицы X
Умножаем матрицы, (X T Y)
Находим определитель det(X T X) T = 34.35
Находим обратную матрицу (X T X) -1
| 0.6821 | 0.3795 | -0.2934 | -1.0118 |
| 0.3795 | 9.4402 | -0.133 | -14.4949 |
| -0.2934 | -0.133 | 0.1746 | 0.3204 |
| -1.0118 | -14.4949 | 0.3204 | 22.7272 |
Вектор оценок коэффициентов регрессии равен
s = (X T X) -1 X T Y =
| 0.1565 |
| 0.3375 |
| 0.0043 |
| 0.2986 |
Уравнение регрессии (оценка уравнения регрессии): Y = 0.1565 + 0.3375X 1+ 0.0043X 2+ 0.2986X 3
Матрица парных коэффициентов корреляции
Для y и x2
Уравнение имеет вид y = ax + b
Средние значения
Для y и x3
Уравнение имеет вид y = ax + b
Средние значения
Для x1 и x2
Уравнение имеет вид y = ax + b
Средние значения
Для x1 и x3
Уравнение имеет вид y = ax + b
Средние значения
Для x2 и x3
Уравнение имеет вид y = ax + b
Средние значения
Оценка среднеквадратичного отклонения равна
Частные коэффициент эластичности E1 2 = 0.62 2 = 0.38, т.е. в 38.0855 % случаев изменения х приводят к изменению y. Другими словами — точность подбора уравнения регрессии — средняя
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл
Tтабл(n-m-1;a) = (18;0.05) = 1.734
Поскольку Tнабл > Tтабл , то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически — значим
Интервальная оценка для коэффициента корреляции (доверительный интервал)
Доверительный интервал для коэффициента корреляции
r(0.3882;0.846)
5. Проверка гипотез относительно коэффициентов уравнения регрессии (проверка значимости параметров множественного уравнения регрессии).
1) t-статистика
Статистическая значимость коэффициента регрессии b0не подтверждается
Статистическая значимость коэффициента регрессии b1не подтверждается
Статистическая значимость коэффициента регрессии b2не подтверждается
Статистическая значимость коэффициента регрессии b3не подтверждается
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(bi— t iS i; bi+ t iS i)
b 0: (-0.7348;1.0478)
b 1: (-2.9781;3.6531)
b 2: (-0.4466;0.4553)
b 3: (-4.8459;5.4431)
Алгоритм вычисления коэффициента выборочной детерминации в MS-Excel Текст научной статьи по специальности « Математика»
CC BY
Аннотация научной статьи по математике, автор научной работы — Красильников Дмитрий Евгеньевич
Рассматривается коэффициент выборочной детерминации как критерий однородности выборок в социально-экономических исследованиях. Приводится геометрическое доказательство закона разложения дисперсии , предлагается алгоритм вычисления коэффициента выборочной детерминации в MS-Excel, рассматривается случай, когда закон разложения дисперсии не выполняется, показана связь между коэффициентом выборочной детерминации и эмпирическим корреляционным отношением .
Похожие темы научных работ по математике , автор научной работы — Красильников Дмитрий Евгеньевич
Текст научной работы на тему «Алгоритм вычисления коэффициента выборочной детерминации в MS-Excel»
Д. Е. Красильников
АЛГОРИТМ ВЫЧИСЛЕНИЯ КОЭФФИЦИЕНТА ВЫБОРОЧНОЙ ДЕТЕРМИНАЦИИ
Нижегородский почтамт. Отделение почтовой связи №24
Рассматривается коэффициент выборочной детерминации как критерий однородности выборок в социально-экономических исследованиях. Приводится геометрическое доказательство закона разложения дисперсии, предлагается алгоритм вычисления коэффициента выборочной детерминации в MS-Excel, рассматривается случай, когда закон разложения дисперсии не выполняется, показана связь между коэффициентом выборочной детерминации и эмпирическим корреляционным отношением.
Ключевые слова: коэффициент выборочной детерминации, закон разложения дисперсии, MS-Excel, критерий однородности выборок, дисперсионный анализ, эмпирическое корреляционное отношение.
При проведении социологических, психологических, экономических и маркетинговых исследований почти всегда встает вопрос о репрезентативности исследуемой выборки. Под репрезентативностью выборки, чаще всего, понимается ее однородность. При этом в современной литературе по соответствующим дисциплинам не дается универсальный метод проверки гипотезы об однородности. Как правило, для такой проверки используют так называемый ¿-критерий, F-критерий или критерий «Хи-квадрат» (см., например, [1]), которые базируются на сравнении средних величин со значением функции Стьюдента, Фишера или Хи -квадрат. Однако эти критерии слабо чувствительны к социально-экономическим данным ввиду небольшого разброса значений таких данных, а применение указанных функций недостаточно обосновано, так как эти критерии были разработаны для биологических, а не социально-экономических исследований.
Другим распространенным подходом к оценке репрезентативности является обоснованность выборки с позиций той или иной задачи. Например, при изучении спроса на автомобили стоимостью от миллиона рублей выборка, сделанная из лиц с доходом 8-10 тыс. руб. , будет всегда нерепрезентативной.
Тем не менее, в Советском Союзе была разработана специальная статистика (функция от выборочной совокупности), позволяющая оценить однородность любой выборки при условии ее стратификации — коэффициент выборочной детерминации (^2выб). Его не следует путать с коэффициентом детерминации (R2 ), который характеризует качество аппроксимации с помощью линейной функции и не имеет отношения к выборочному методу.
Данная статистика основана на разложении дисперсии на межгрупповую и внутриг-рупповую. Это разложение также используется в дисперсионном анализе. «Первоначально (1918 г.) дисперсионный анализ был разработан английским математиком-статистиком Р.А. Фишером для обработки результатов агрономических опытов по выявлению условий получения максимального урожая различных сортов сельскохозяйственных культур. Сам термин «дисперсионный анализ» Фишер употребил позднее [2, с. 392].
Чтобы понять, на чем основано разложение дисперсии, рассмотрим так называемый «прямоугольный выборочный план», используемый в однофакторном дисперсионном анализе (табл. 1).
Этот план представляет собой таблицу, в которой каждый столбец является выборкой с n элементами. Всего делается m таких выборок. В литературе эти столбцы часто называют факторами, группами или стратами, а само расположение элементов выборок — стратификацией.
© Красильников Д. Е., 2016.
В этой статье при обозначении элемента таблицы символом у, первый индекс указывает номер строки, а второй — номер столбца, в соответствии с правилом обозначения элементов матриц, принятым в Советском Союзе. Замечу, что в английской традиции принята обратная запись, то есть сначала пишут столбец, а затем строку, а в современной российской литературе встречаются оба варианта.
Очевидно, что общее число элементов в таблице N есть
Прямоугольный выборочный план
1 у11 у12 уЦ у 1т
2 у21 у22 у 2 i у 2т
1 у,1 у 2 у, у гт
п уп1 уп 2 у п] у пт
Среднее у1 у 2 у, у т
По каждому столбцу вычисляется среднее арифметическое у. (внутригрупповая средняя), которое заносится в последнюю строку таблицы,
Построение функции тренда в Excel. Быстрый прогноз без учета сезонности
Глядя на любой набор данных распределенных во времени (динамический ряд), мы можем визуально определить падения и подъемы показателей, которые он содержит. Закономерность подъемов и падений называется трендом, который может говорить о том, увеличиваются или уменьшаются наши данные.
Пожалуй, цикл статей о прогнозировании я начну с самого простого — построении функции тренда. Для примера возьмем данные о продажах и построим модель, которая опишет зависимость продаж от времени.
Базовые понятия
Думаю, еще со школы все знакомы с линейной функцией, она как раз и лежит в основе тренда:
Y — это объем продаж, та переменная, которую мы будем объяснять временем и от которого она зависит, то есть Y(t);
t — номер периода (порядковый номер месяца), который объясняет план продаж Y;
a0 — это нулевой коэффициент регрессии, который показывает значение Y(t), при отсутствии влияния объясняющего фактора (t=0);
a1 — коэффициент регрессии, который показывает, на сколько исследуемый показатель продаж Y зависит от влияющего фактора t;
E — случайные возмущения, которые отражают влияния других неучтенных в модели факторов, кроме времени t.
Построение модели
Итак, мы знаем объем продаж за прошедшие 9 месяцев. Вот, что из себя представляет наша табличка:
Следующее, что мы должны сделать — это определить коэффициенты a0 и a1 для прогнозирования объема продаж за 10-ый месяц.
Определение коэффициентов модели
Строим график. По горизонтали видим отложенные месяцы, по вертикали объем продаж:
В Google Sheets выбираем Редактор диаграмм -> Дополнительные и ставим галочку возле Линии тренда. В настройках выбираем Ярлык — Уравнение и Показать R^2.
Если вы делаете все в MS Excel, то правой кнопкой мыши кликаем на график и в выпадающем меню выбираем «Добавить линию тренда».
По умолчанию строится линейная функция. Справа выбираем «Показывать уравнение на диаграмме» и «Величину достоверности аппроксимации R^2».
Вот, что получилось:
На графике мы видим уравнение функции:
y = 4856*x + 105104
Она описывает объем продаж в зависимости от номера месяца, на который мы хотим эти продажи спрогнозировать. Рядом видим коэффициент детерминации R^2, который говорит о качестве модели и на сколько хорошо она описывает наши продажи (Y). Чем ближе к 1, тем лучше.
У меня R^2 = 0,75. Это средний показатель, он говорит о том, что в модели не учтены какие-то другие значимые факторы помимо времени t, например, это может быть сезонность.
Прогнозируем
Чтобы рассчитать продажи за 10-ый месяц, подставляем в функцию тренда 10 вместо x. То есть,
y = 4856*10 + 105104
Получаем 153664 продажи в следующем месяце. Если добавим новую точку на график, то сразу видим, что R^2 улучшился.
Таким образом вы можете спрогнозировать данные на несколько месяцев вперед, но без учета других факторов ваш прогноз будет лежать на линии тренда и будет не таким информативным как хотелось бы. К тому же, долгосрочный прогноз, сделанный таким способом будет очень приблизительным.
Повысить точность модели можно добавлением сезонности к функции тренда, что мы и сделаем в следующей статье.
[spoiler title=”источники:”]
http://lumpics.ru/coefficient-of-determination-in-excel/
http://fobosworld.ru/koeffitsient-determinatsii-v-excel/
[/spoiler]
