Расчет F-критерия Фишера онлайн
Быстрая навигация по странице:
Понятие F-критерия Фишера
F-критерий Фишера – это один из важных статистических критериев, используемых при проверке значимости как уравнения регрессии в целом, так и отдельных его коэффициентов. Для оценки статистической значимости отдельных коэффициентов уравнения множественной регрессии используют так называемые частные F-критерий Фишера. Критическое значение данного критерия при проведении анализа определяется по специальным таблицам, а также может быть определено при помощи специальных функций в различных компьютерных программах. Например, в MS Excel для этого может быть использована функция FРАСПОБР.
Размещено на www.rnz.ru
Формулы расчета F-критерия Фишера
В общем виде F-критерий Фишера рассчитывается по следующей формуле:
F = S 2 факт / S 2 ост;
где: S 2 факт – факторная дисперсия;
S 2 ост – остаточная дисперсия
Соответствующие виды дисперсий определяются по следующим формулам:
формула расчета факторной дисперсии
формула расчета остаточной дисперсии
В приведенных формулах n – это число наблюдений, m – число параметров при переменной x (то есть количество факторов в модели регрессии).
При этом необходимо обратить внимание на то, что в зависимости от типа исследуемой модели регрессии применяемая формула определения F-критерия Фишера может изменяться. Например, для расчета F-критерия Фишера для парной линейной регрессии может использоваться следующая формула:
формула расчета F-критерия Фишера для парной линейной регрессии
При использовании коэффициента детерминации расчет F-критерия Фишера для парной линейной регрессии может быть выполнен по такой формуле:
формула расчета F-критерия Фишера через коэффициент детерминации
Для парной нелинейной модели регрессии расчет F-критерия Фишера может быть осуществлен через связь с индексом детерминации по следующей формуле:
формула расчета F-критерия Фишера для парной нелинейной модели регрессии через индекс детерминации
Описания параметров n и m приведено выше.
Для уравнения множественной регрессии F-критерий Фишера рассчитывается по следующей формуле:
формула расчета F-критерия Фишера для уравнения множественной регрессии
В процессе исследования уравнения множественной регрессии кроме общего F-критерий Фишера могут быть рассчитаны частные F-критерии. В случае анализа уравнения с двумя регрессорами (переменными) вычисление частных F-критериев может быть выполнено по следующим формулам:
формула расчета частных F-критериев Фишера для уравнения множественной регрессии
Значимость F-критерия Фишера
Для определения статистической значимости рассчитанного значения F-критерия Фишера его сравнивают с критическим или табличным значением. При этом табличное значение определяется на основе числа наблюдений, степеней свободы и заданного уровня значимости следующим образом: Fтабл (a; k1; k2), где k1 = m – это количество факторов в построенной регрессионной модели, а k2 = n – m – 1 (n – число наблюдений). Для частного F-критерия k1 = 1, k2 = n – m – 1 (n – число наблюдений).
Интерпретация F – критерия Фишера для уравнения регрессии в целом следующая: в том случае, когда фактическая величина F – критерия Фишера больше табличного показателя, то уравнение регрессии в целом является статистически значимым.
Интерпретация частного F – критерия Фишера следующая: в том случае, когда рассчитанная величина частного Fxi превышает критическое значение, то дополнительное включение фактора xi в регрессионную модель статистически оправданно и коэффициент регрессии bi при соответствующем факторе xi статистически значим. Но если рассчитанная величина Fxi меньше табличного, то дополнительное включение в модель фактора xi не оправдано, т.к. данный фактор, как и коэффициент регрессии при нём является статистически незначимым.
Пример расчета F-критерия Фишера
Приведем условные примеры расчета F-критерия Фишера
Пример №1. Предположим, что исследуется регрессия с одним фактором (парная), на основе 30-ти наблюдений, в которой коэффициент детерминации составил 0,77. Тогда по приведённой выше формуле фактическое значение F-критерия Фишера составит: F = 0,77/(1-0,77)*(30-2) = 93,74. Для определения значимости его нужно сравнить с табличным значением. Предположим, что используется уровень значимости α = 0.05. Тогда критическая величины Fтабл(0,05; 1; 30-1-1) = 4,2. Так как F > Fтабл, то полученное уравнение регрессии является статистически значимым.
Пример №2. Предположим, что исследуется множественная регрессия с тремя факторами, на основе 40 наблюдений, в которой коэффициент множественной детерминации составил 0,89. Тогда по приведённой выше формуле фактическое значение F-критерия Фишера для уравнения множественной регрессии составит: F = (0,89/(1-0,89))*((40-3-1)/3) = 97,09. Для определения значимости его нужно сравнить с табличным значением. Предположим, что используется уровень значимости α = 0.05. Тогда критическая величины Fтабл(0,05; 3; 40-3-1) = 2,87. Так как F > Fтабл, то полученное уравнение множественной регрессии является статистически значимым.
Онлайн-калькулятор F-критерия Фишера
Представляем онлайн калькулятор расчета F-критерия Фишера, используя который, Вы можете самостоятельно определить значения соответствующего показателя. При заполнении приведенной формы калькулятора внимательно соблюдайте размерность полей, что позволит выполнить и точно выполнить вычисления. В приведенной форме онлайн калькулятора уже содержатся данные условного примера, чтобы пользователь мог посмотреть, как это работает и посмотреть, как правильно заполнять поля. Для определения значений соответствующих показателей по своим данным просто внесите их в соответствующие поля формы онлайн калькулятора и нажмите кнопку “Выполнить вычисления”. При заполнении формы соблюдайте размерность показателей! Дробные числа записываются с точной, а не запятой!
Калькулятор позволяет вычислить значение F-критерия Фишера на основе коэффициента детерминации (первый вариант) или на основе показателей сумм квадратов отклонений, т.е. используя элементы дисперсионного анализа. Выберите необходимый способ и выполните соответствующие вычисления. Для проверки статистической значимости используется уровень значимости α = 0.05.
Онлайн-калькулятор расчета значения F-критерия Фишера:
1-й вариант: на основе значения коэффициент (индекса) детерминации
2-й вариант: на основе сумм квадратов отклонений
Использование критерия Фишера для проверки значимости регрессионной модели
Критерий Фишера для регрессионной модели отражает, насколько хорошо эта модель объясняет общую дисперсию зависимой переменной. Расчет критерия выполняется по уравнению:

где R – коэффициент корреляции;
f1 и f2 – число степеней свободы.
Первая дробь в уравнении равна отношению объясненной дисперсии к необъясненной. Каждая из этих дисперсий делится на свою степень свободы (вторая дробь в выражении). Число степеней свободы объясненной дисперсии f1 равно количеству объясняющих переменных (например, для линейной модели вида Y=A*X+B получаем f1=1). Число степеней свободы необъясненной дисперсии f2 = N–k-1, где N-количество экспериментальных точек, k-количество объясняющих переменных (например, для модели Y=A*X+B подставляем k=1).
Для проверки значимости уравнения регрессии вычисленное значение критерия Фишера сравнивают с табличным, взятым для числа степеней свободы f1 (бóльшая дисперсия) и f2 (меньшая дисперсия) на выбранном уровне значимости (обычно 0.05). Если рассчитанный критерий Фишера выше, чем табличный, то объясненная дисперсия существенно больше, чем необъясненная, и модель является значимой.
Коэффициент корреляции и F-критерий, наряду с параметрами регрессионной модели, как правило, вычисляются в алгоритмах, реализующих метод наименьших квадратов.
Критерий Фишера и критерий Стьюдента в эконометрике
С помощью критерия Фишера оценивают качество регрессионной модели в целом и по параметрам.
Для этого выполняется сравнение полученного значения F и табличного F значения. F-критерия Фишера. F фактический определяется из отношения значений факторной и остаточной дисперсий, рассчитанных на одну степень свободы:
где n — число наблюдений;
m — число параметров при факторе х.
F табличный — это максимальное значение критерия под влиянием случайных факторов при текущих степенях свободы и уровне значимости а.
Уровень значимости а — вероятность не принять гипотезу при условии, что она верна. Как правило а принимается равной 0,05 или 0,01.
Если Fтабл > Fфакт то признается статистическая незначимость модели, ненадежность уравнения регрессии.
Таблицы по нахождению критерия Фишера и Стьюдента
Таблицы значений F-критерия Фишера и t-критерия Стьюдента Вы можете посмотреть здесь.
Табличное значение критерия Фишера вычисляют следующим образом:
- Определяют k1, которое равно количеству факторов (Х). Например, в однофакторной модели (модели парной регрессии) k1=1, в двухфакторной k=2.
- Определяют k2, которое определяется по формуле n — m — 1, где n — число наблюдений, m — количество факторов. Например, в однофакторной модели k2 = n — 2.
- На пересечении столбца k1 и строки k2 находят значение критерия Фишера
Для нахождения табличного значения критерия Стьюдента определяют число степеней свободы, которое определяется по формуле n — m — 1 и находят его значение при определенном уровне значимости (0,10, 0,05, 0,01).
Критерии Стьюдента
Для оценки статистической значимости модели по параметрам рассчитывают t-критерии Стьюдента.
Оценка значимости модели с помощью критерия Стьюдента проводится путем сравнения их значений с величиной случайной ошибки:
Случайные ошибки коэффициентов линейной регрессии и коэффициента корреляции определяются по формулам:
Сравнивая фактическое и табличное значения t-статистики и принимается или отвергается гипотеза о значимости модели по параметрам.
Зависимость между критерием Фишера и значением t-статистики Стьюдента определяется так
Как и в случае с оценкой значимости уравнения модели в целом, модель считается ненадежной если tтабл > tфакт
Видео лекциий по расчету критериев Фишера и Стьюдента
Для более подробного изучения расчетов критериев Фишера и Стьюдента советуем посмотреть это видео
Лекция 1. Критерии и Гипотезы
Лекция 2. Критерии и Гипотезы
Лекция 3. Критерии и Гипотезы
Определение доверительных интервалов
Для построения доверительного интервала определяется предельная ошибка А для обоих показателей:
Формулы для нахождения доверительных интервалов выглядят так
Прогнозное значение у определяется с помощью подстановки в
уравнение регрессии прогнозного значения х. Вычисляется средняя стандартная ошибка прогноза
и находится доверительный интервал
Задача регрессионного анализа в предмете эконометрика состоит в анализе дисперсии изучаемого показателя y:
общая сумма квадратов отклонений (TSS)
сумма квадратов отклонений, обусловленная регрессией (RSS)
остаточная сумма квадратов отклонений (ESS)
Долю дисперсии, обусловленную регрессией, в общей дисперсии показателя у характеризует коэффициент детерминации R, который должен превышать 50% (R 2 > 0,5). В контрольных по эконометрике в ВУЗах этот показатель рассчитывается всегда.
[spoiler title=”источники:”]
http://www.chem-astu.ru/science/reference/fischer.html
[/spoiler]
Критерий Фишера и Стьюдента
С помощью критерия Фишера оценивают качество регрессионной модели в целом и по параметрам.
Для этого выполняется сравнение полученного значения F и табличного F значения. F-критерия Фишера. F фактический определяется из отношения значений факторной и остаточной дисперсий, рассчитанных на одну степень свободы:

где n — число наблюдений;
m — число параметров при факторе х.
F табличный — это максимальное значение критерия под влиянием случайных факторов при текущих степенях свободы и уровне значимости а.
Уровень значимости а — вероятность не принять гипотезу при условии, что она верна. Как правило а принимается равной 0,05 или 0,01.
Если Fтабл > Fфакт то признается статистическая незначимость модели, ненадежность уравнения регрессии.
Таблицы по нахождению критерия Фишера и Стьюдента
Таблицы значений F-критерия Фишера и t-критерия Стьюдента Вы можете посмотреть здесь.
Табличное значение критерия Фишера вычисляют следующим образом:
- Определяют k1, которое равно количеству факторов (Х). Например, в однофакторной модели (модели парной регрессии) k1=1, в двухфакторной k=2.
- Определяют k2, которое определяется по формуле n — m — 1, где n — число наблюдений, m — количество факторов. Например, в однофакторной модели k2 = n — 2.
- На пересечении столбца k1 и строки k2 находят значение критерия Фишера
Для нахождения табличного значения критерия Стьюдента определяют число степеней свободы, которое определяется по формуле n — m — 1 и находят его значение при определенном уровне значимости (0,10, 0,05, 0,01).
Критерии Стьюдента
Для оценки статистической значимости модели по параметрам рассчитывают t-критерии Стьюдента.
Оценка значимости модели с помощью критерия Стьюдента проводится путем сравнения их значений с величиной случайной ошибки:

Случайные ошибки коэффициентов линейной регрессии и коэффициента корреляции определяются по формулам:

Сравнивая фактическое и табличное значения t-статистики и принимается или отвергается гипотеза о значимости модели по параметрам.
Зависимость между критерием Фишера и значением t-статистики Стьюдента определяется так

Как и в случае с оценкой значимости уравнения модели в целом, модель считается ненадежной если tтабл > tфакт
Видео лекциий по расчету критериев Фишера и Стьюдента
Для более подробного изучения расчетов критериев Фишера и Стьюдента советуем посмотреть это видео
Лекция 1. Критерии и Гипотезы
Лекция 2. Критерии и Гипотезы
Лекция 3. Критерии и Гипотезы
Определение доверительных интервалов
Для построения доверительного интервала определяется предельная ошибка А для обоих показателей:

Формулы для нахождения доверительных интервалов выглядят так

Прогнозное значение у определяется с помощью подстановки в
уравнение регрессии прогнозного значения х. Вычисляется средняя стандартная ошибка прогноза

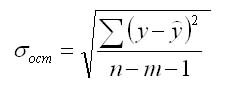
и находится доверительный интервал
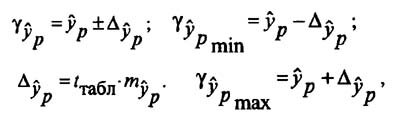
Задача регрессионного анализа в предмете эконометрика состоит в анализе дисперсии изучаемого показателя y:

 общая сумма квадратов отклонений (TSS)
общая сумма квадратов отклонений (TSS)
 сумма квадратов отклонений, обусловленная регрессией (RSS)
сумма квадратов отклонений, обусловленная регрессией (RSS)
 остаточная сумма квадратов отклонений (ESS)
остаточная сумма квадратов отклонений (ESS)
Долю дисперсии, обусловленную регрессией, в общей дисперсии показателя у характеризует коэффициент детерминации R, который должен превышать 50% (R2 > 0,5). В контрольных по эконометрике в ВУЗах этот показатель рассчитывается всегда.

Любые задачи по эконометрике решаются здесь
Текущая версия страницы пока не проверялась опытными участниками и может значительно отличаться от версии, проверенной 26 октября 2017 года; проверки требуют 8 правок.
F-тест или критерий Фишера (F-критерий, φ*-критерий) — статистический критерий, тестовая статистика которого при выполнении нулевой гипотезы имеет распределение Фишера (F-распределение).
Статистика теста так или иначе сводится к отношению выборочных дисперсий (сумм квадратов, деленных на «степени свободы»). Чтобы статистика имела распределение Фишера, необходимо, чтобы числитель и знаменатель были независимыми случайными величинами и соответствующие суммы квадратов имели распределение Хи-квадрат. Для этого требуется, чтобы данные имели нормальное распределение. Кроме того, предполагается, что дисперсия случайных величин, квадраты которых суммируются, одинакова.
Тест проводится путём сравнения значения статистики с критическим значением соответствующего распределения Фишера при заданном уровне значимости. Известно, что если 





Более удобный способ проверки гипотез — с помощью p-значения 

Примеры F-тестов[править | править код]
F-тест на равенство дисперсий[править | править код]
Две выборки[править | править код]
Пусть имеются две выборки объёмом m и n соответственно случайных величин X и Y, имеющих нормальное распределение. Необходимо проверить равенство их дисперсий. Статистика теста

где 
Если статистика больше критического значения, соответствующего выбранному уровню значимости, то дисперсии случайных величин признаются не одинаковыми.
Несколько выборок[править | править код]
Пусть выборка объёмом N случайной величины X разделена на k групп с количеством наблюдений 
Межгрупповая («объяснённая») дисперсия: 
Внутригрупповая («необъяснённая») дисперсия: 

Данный тест можно свести к тестированию значимости регрессии переменной X на фиктивные переменные-индикаторы групп. Если статистика превышает критическое значение, то гипотеза о равенстве средних в выборках отвергается, в противном случае средние можно считать одинаковыми.
Проверка ограничений на параметры регрессии[править | править код]
Статистика теста для проверки линейных ограничений на параметры классической нормальной линейной регрессии определяется по формуле:

где 

Замечание[править | править код]
Описанный выше F-тест является точным в случае нормального распределения случайных ошибок модели. Однако F-тест можно применить и в более общем случае. В этом случае он является асимптотическим. Соответствующую F-статистику можно рассчитать на основе статистик других асимптотических тестов — теста Вальда (W), теста множителей Лагранжа(LM) и теста отношения правдоподобия (LR) — следующим образом:
Все эти статистики асимптотически имеют распределение F(q, n-k), несмотря на то, что их значения на малых выборках могут различаться.

Проверка значимости линейной регрессии[править | править код]
Данный тест очень важен в регрессионном анализе и по существу является частным случаем проверки ограничений. В данном случае нулевая гипотеза — об одновременном равенстве нулю всех коэффициентов при факторах регрессионной модели (то есть всего ограничений k-1). В данном случае короткая модель — это просто константа в качестве фактора, то есть коэффициент детерминации короткой модели равен нулю. Статистика теста равна:

Соответственно, если значение этой статистики больше критического значения при данном уровне значимости, то нулевая гипотеза отвергается, что означает статистическую значимость регрессии. В противном случае модель признается незначимой.
Пример[править | править код]
Пусть оценивается линейная регрессия доли расходов на питание в общей сумме расходов на константу, логарифм совокупных расходов, количество взрослых членов семьи и количество детей до 11 лет. То есть всего в модели 4 оцениваемых параметра (k=4). Пусть по результатам оценки регрессии получен коэффициент детерминации 


Критическое значение статистики при 1 % уровне значимости (в Excel функция FРАСПОБР) в первом случае равно 

Проверка гетероскедастичности[править | править код]
См. Тест Голдфелда-Куандта
См. также[править | править код]
- Проверка статистических гипотез
- Статистический критерий
- Тест Вальда
- Тест отношения правдоподобия
- Тест множителей Лагранжа
- Тест Голдфелда-Куандта
Примечания[править | править код]
- ↑ F-Test for Equality of Two Variances (англ.). NIST. Дата обращения: 29 марта 2017. Архивировано 9 марта 2017 года.
Критерий
Фишера позволяет сравнивать величины
выборочных дисперсий двух рядов
наблюдений. Для вычисления
![]() нужно
нужно
найти отношение дисперсий двух выборок,
причем так, чтобы большая по величине
дисперсия находилась бы в числителе, а
меньшая знаменателе. Формула вычисления
по критерию Фишера F такова:![]()
Где
![]()
и
![]()
Поскольку,
согласно условию критерия, величина
числителя должна быть больше или равна
величине знаменателя, то значение
![]() всегда
всегда
будет больше или равно единице, т.е.![]() .
.
Число степеней свободы определяется
также просто:![]() для
для
первой (т.е. для той выборки, величина
дисперсии которой больше) и![]() для
для
второй выборки. В таблице 18 Приложения
6 критические значения критерия Фишера![]() находятся
находятся
по величинам![]() (верхняя
(верхняя
строчка таблицы) и![]() (левый
(левый
столбец таблицы).
Пример:
В двух третьих классах проводилось
тестирование умственного развития по
тесту ТУРМШ десяти учащихся. Полученные
значения величин средних достоверно
не различались, однако психолога
интересует вопрос – есть ли различия в
степени однородности показателей
умственного развития между классами.
Для
критерия Фишера необходимо сравнить
дисперсии тестовых оценок в обоих
классах. Результаты тестирования
представлены в табл. 11.
Таблица
11
|
№ учащихся |
Первый класс X |
Второй класс Y |
|
1 |
90 |
41 |
|
2 |
29 |
49 |
|
3 |
39 |
56 |
|
4 |
79 |
64 |
|
5 |
88 |
72 |
|
6 |
53 |
65 |
|
7 |
34 |
63 |
|
8 |
40 |
87 |
|
9 |
75 |
77 |
|
10 |
79 |
62 |
|
Суммы |
606 |
636 |
|
Среднее |
60,6 |
63,6 |
Как
видно из табл. 11, величины средних в
обеих группах практически совпадают
между собой 60,6
![]() 63,
63,
6 и величина t – критерия Стьюдента
оказалась равной 0, 347 и незначимой.
Рассчитав
дисперсии для переменных X и Y, получаем
![]()
![]()
Тогда,
по формуле для расчета по F – критерию
Фишера находим:
![]()
По
табл. 18 приложения 6 для F – критерия при
степенях свободы в обоих случаях равных
df![]() = 10 – 1 = 9 находим
= 10 – 1 = 9 находим![]() :
:
3,18
для P
![]() 0,05
0,05
5,35
для P
![]() 0,01
0,01
Строим
“ось значимости”:

Таким
образом, полученная величина
![]() попала
попала
в зону неопределенности. В терминах
статистических гипотез можно утверждать,
что Н![]() (гипотеза о сходстве) может быть отвергнута
(гипотеза о сходстве) может быть отвергнута
на уровне 5%, а принимается в этом случае
гипотеза Н![]() .
.
Психолог может утверждать, что по степени
однородности такого показателя, как
умственное развитие, имеется различие
между выборками из двух классов.
Для
применения критерия F Фишера необходимо
соблюдать следующие условия:
1.
Измерение может быть проведено в шкале
интервалов и отношений.
2.
Сравниваемые выборки должны быть
распределены по нормальному закону.
8.6. Корреляционный анализ
Корреляцией
называют зависимость между двумя
переменными величинами.
Переменная
– это любая величина, которая может быть
измерена и чье количественное выражение
может варьировать.
При
изучении корреляций стараются установить,
существует ли какая-то связь между двумя
показателями в одной выборке (например,
между ростом и весом детей или между
уровнем IQ и школьной успеваемостью)
либо между двумя различными выборками
(например, при сравнении пар близнецов),
и если эта связь существует, то увеличение
одного показателя сопровождается
возрастанием (положительная корреляция)
или уменьшением (отрицательная корреляция)
другого.
Коэффициент
корреляции
– это величина, которая может варьировать
в пределах от +1 до -1. В случае полной
положительной корреляции этот коэффициент
равен +1, а при полной отрицательной -1.
В
случаи, если коэффициент корреляции
равен 0, обе переменные полностью
независимы друг от друга.
В
гуманитарных науках корреляция считается
сильной, если ее коэффициент выше 0,60;
если же он превышает 0,90, то корреляция
считается очень сильной.
Можно
выделить несколько видов корреляционного
анализа: линейный, ранговый, парный и
множественный. Мы рассмотрим два вида
корреляционного анализа – линейный и
ранговый.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
