Мы ежедневно работаем с информацией из разных источников. При этом каждый из нас имеет некоторые интуитивные представления о том, что означает, что один источник является для нас более информативным, чем другой. Однако далеко не всегда понятно, как это правильно определить формально. Не всегда большое количество текста означает большое количество информации. Например, среди СМИ распространена практика, когда короткое сообщение из ленты информационного агентства переписывают в большую новость, но при этом не добавляют никакой «новой информации». Или другой пример: рассмотрим текстовый файл с романом Л.Н. Толстого «Война и мир» в кодировке UTF-8. Его размер — 3.2 Мб. Сколько информации содержится в этом файле? Изменится ли это количество, если файл перекодировать в другую кодировку? А если заархивировать? Сколько информации вы получите, если прочитаете этот файл? А если прочитаете его второй раз?
По мотивам открытой лекции для Computer Science центра рассказываю о том, как можно математически подойти к определению понятия “количество информации”.
В классической статье А.Н. Колмогорова “Три подхода к определению понятия количества информации” (1965) рассматривают три способа это сделать:
-
комбинаторный (информация по Хартли),
-
вероятностный (энтропия Шеннона),
-
алгоритмический (колмогоровская сложность).
Мы будем следовать этому плану.
Комбинаторный подход: информация по Хартли
Мы начнём самого простого и естественного подхода, предложенного Хартли в 1928 году.
Пусть задано некоторое конечное множество  . Количеством информации в
. Количеством информации в  будем называть
будем называть  .
.
Можно интерпретировать это определение следующим образом: нам нужно  битов для описания элемента из
битов для описания элемента из  .
.
Почему мы используем биты? Можно использовать и другие единицы измерения, например, триты или байты, но тогда нужно изменить основание логарифма на 3 или 256, соответственно. В дальшейшем все логарифмы будут по основанию 2.
Этого определения уже достаточно для того, чтобы измерить количество информации в некотором сообщении. Пусть про  стало известно, что
стало известно, что  . Теперь нам достаточно
. Теперь нам достаточно  битов для описания
битов для описания  , таким образом нам сообщили
, таким образом нам сообщили  битов информации.
битов информации.
Пример
Загадано целое число
от
 от
от  до
до  . Нам сообщили, что
. Нам сообщили, что  делится на
делится на  . Сколько информации нам сообщили?
. Сколько информации нам сообщили?Воспользуемся рассуждением выше.
![]()
(Тот факт, что некоторое сообщение может содержать нецелое количество битов, может показаться немного неожиданным.)
Можно ещё сказать, что сообщение, уменшающее пространство поиска в  раз приносит
раз приносит  битов информации. В данном примере пространство поиска уменьшилось в 1000/166 раз.
битов информации. В данном примере пространство поиска уменьшилось в 1000/166 раз.
Интересно, что одного этого определения уже достаточно для того, чтобы решать довольно нетривиальные задачи.
Применение: цена информации
Загадано целое число
 от
от  до
до  . Разрешается задавать любые вопросы на ДА/НЕТ. Если ответ на вопрос “ДА”, то мы должны заплатить рубль, если ответ “НЕТ” — два рубля. Сколько нужно заплатить для отгадывания числа
. Разрешается задавать любые вопросы на ДА/НЕТ. Если ответ на вопрос “ДА”, то мы должны заплатить рубль, если ответ “НЕТ” — два рубля. Сколько нужно заплатить для отгадывания числа Любой вопрос можно сформулировать как вопрос о принадлежности некоторому множеству, поэтому мы будем считать, что все вопросы имеют вид “ ?” для некоторого множества
?” для некоторого множества  .
.
Каким образом нужно задавать вопросы? Нам бы хотелось, чтобы вне зависимости от ответа цена за бит информации была постоянной. Другими словами, в случае ответа “НЕТ” и заплатив два рубля мы должны узнать в два больше информации, чем при ответе “ДА”. Давайте запишем это формально.
Потребуем, чтобы
![]()
Пусть  , тогда
, тогда  . Подставляем и получаем, что
. Подставляем и получаем, что
![]()
Это эквивалентно квадратному уравнению  Положительный корень этого уравнения
Положительный корень этого уравнения  . Таким образом, при любом ответе мы заплатим
. Таким образом, при любом ответе мы заплатим  рублей за бит информации, а в сумме мы заплатим примерно
рублей за бит информации, а в сумме мы заплатим примерно рублей (с точностью до округления).
рублей (с точностью до округления).
Осталось понять, как выбирать такие множества . Будем выбирать в качестве  непрерывные отрезки прямой. Пусть нам известно, что
непрерывные отрезки прямой. Пусть нам известно, что  принадлежит отрезку
принадлежит отрезку ![[a,b]](https://habrastorage.org/getpro/habr/upload_files/9a0/3e7/b69/9a03e7b69911956ef048f0e4f6496a6c.svg) (изначально это отрезок
(изначально это отрезок ![[1,n]](https://habrastorage.org/getpro/habr/upload_files/6a5/ba8/1c6/6a5ba81c6f282d08594b053eb740e8a7.svg) ). В следующего множества
). В следующего множества  возмём отрезок
возмём отрезок ![[a, a+ alphacdot(b-a)]](https://habrastorage.org/getpro/habr/upload_files/9cc/487/bdb/9cc487bdbefd53d5e81016a203868ef7.svg) , где. Тогда за каждый заплаченный рубль текущий отрезок будет уменьшаться в
, где. Тогда за каждый заплаченный рубль текущий отрезок будет уменьшаться в  раз. Когда длина отрезка станет меньше единицы, мы однозначно определим
раз. Когда длина отрезка станет меньше единицы, мы однозначно определим  . Поэтому цена отгадывания не будет превосходить
. Поэтому цена отгадывания не будет превосходить
![]()
Приведённое рассуждение доказывает только верхнюю оценку. Можно доказать и нижнюю оценку: для любого способа задавать вопросы будет такое число , для отгадывания которого придётся заплатить не менее  рублей.
рублей.
Вероятностный подход: энтропия Шеннона
Вероятностный подход, предложенный Клодом Шенноном в 1948 году, обобщает определение Хартли на случай, когда не все элементы множества являются равнозначными. Вместо множества в этом подходе мы будем рассматривать вероятностное распределение на множестве и оценивать среднее по распределению количество информации, которое содержит случайная величина.
Пусть задана случайная величина  , принимающая
, принимающая  различных значений с вероятностями
различных значений с вероятностями  . Энтропия Шеннона случайной величины
. Энтропия Шеннона случайной величины  определяется как
определяется как

(По непрерывности тут нужно доопределить  .)
.)
Энтропия Шеннона оценивает среднее количество информации (математическое ожидание), которое содержится в значениях случайной величины.
При первом взгляде на это определение, может показаться совершенно непонятно откуда оно берётся. Шеннон подошёл к этой задаче чисто математически: сформулировал требования к функции и доказал, что это единственная функция, удовлетворяющая сформулированным требованиям.
Я попробую объяснить происхождение этой формулы как обобщение информации по Хартли. Нам бы хотелось, чтобы это определение согласовывалось с определением Хартли, т.е. должны выполняться следующие “граничные условия”:
Будем искать  в виде математического ожидания количества информации, которую мы получаем от каждого возможного значения .
в виде математического ожидания количества информации, которую мы получаем от каждого возможного значения .
![]()
Как оценить, сколько информации содержится в событии  ? Пусть
? Пусть  — всё пространство элементарных исходов. Тогда событие
— всё пространство элементарных исходов. Тогда событие  соответствует множеству элементарных исходов меры
соответствует множеству элементарных исходов меры  . Если произошло событие
. Если произошло событие  , то размер множества согласованных с этим событием элементарных исходов уменьшается с
, то размер множества согласованных с этим событием элементарных исходов уменьшается с  до
до  , т.е. событие
, т.е. событие  сообщает нам
сообщает нам  битов информации. Тут мы пользуемся тем, что количество информации в сообщении, которое уменьшает размер пространство поиска в
битов информации. Тут мы пользуемся тем, что количество информации в сообщении, которое уменьшает размер пространство поиска в  раз приносит
раз приносит  битов информации.
битов информации.
Примеры
Свойства энтропии Шеннона
Для случайной величины  , принимающей
, принимающей  значений с вероятностями
значений с вероятностями  , выполняются следующие соотношения.
, выполняются следующие соотношения.
-
.
-
распределение вырождено.
-
.
-
распределение равномерно.
 .
.
 распределение
распределение  вырождено.
вырождено. .
.
 распределение
распределение  равномерно.
равномерно.Чем распределение ближе к равномерному, тем больше энтропия Шеннона.
Энтропия пары
Понятие энтропии Шеннона можно обобщить для пары случайных величин. Аналогично это обощается для тройки, четвёрки и т.д.
Пусть совместно распределённые случайные величины  и
и  принимают значения
принимают значения  и
и  , соответственно. Энтропия пары случайных величин
, соответственно. Энтропия пары случайных величин  и
и  определяется следующим соотношением:
определяется следующим соотношением:
![H(X,Y) = sum_{i=1}^ksum_{j=1}^mPr[X = a_i, Y=b_j]cdot logfrac{1}{Pr[X = a_i, Y = b_j]}.](https://habrastorage.org/getpro/habr/upload_files/bdb/a99/dd1/bdba99dd141ec64b0456fb6ef5f765e6.svg)
Примеры
Рассмотрим эксперимент с выбрасыванием двух игральных кубиков — синего и красного.
Свойства энтропии Шеннона пары случайных величин
Для энтропии пары выполняются следующие свойства.
Условная энтропия Шеннона
Теперь давайте научимся вычислять условную энтропию одной случайной величины относительно другой.
Условная энтропия  относительно
относительно  определяется следующим соотношением:
определяется следующим соотношением:
![]()
Примеры
Рассмотрим снова примеры про два игральных кубика.
Свойства условной энтропии
Условная энтропия обладает следующими свойствами
Взаимная информация
Ещё одна информационная величина, которую мы введём в этом разделе — это взаимная информация двух случайных величин.
Информация в  о величине
о величине  (взаимная информация случайных величин
(взаимная информация случайных величин  и
и  ) определяется следующим соотношением
) определяется следующим соотношением
![]()
Примеры
И снова обратимся к примерам с двумя игральными кубиками.
Свойства взаимной информации
Выполняются следующие соотношения.
-
. Т.е. определение взаимной информации симметрично и его можно переписать так:
 . Т.е. определение взаимной информации симметрично и его можно переписать так:
. Т.е. определение взаимной информации симметрично и его можно переписать так:![]()
-
Или так:
. -
и .
-
.
-
.
 .
. и
и  .
. .
. .
.Все информационные величины, которые мы определили к этому моменту можно проиллюстрировать при помощи кругов Эйлера.
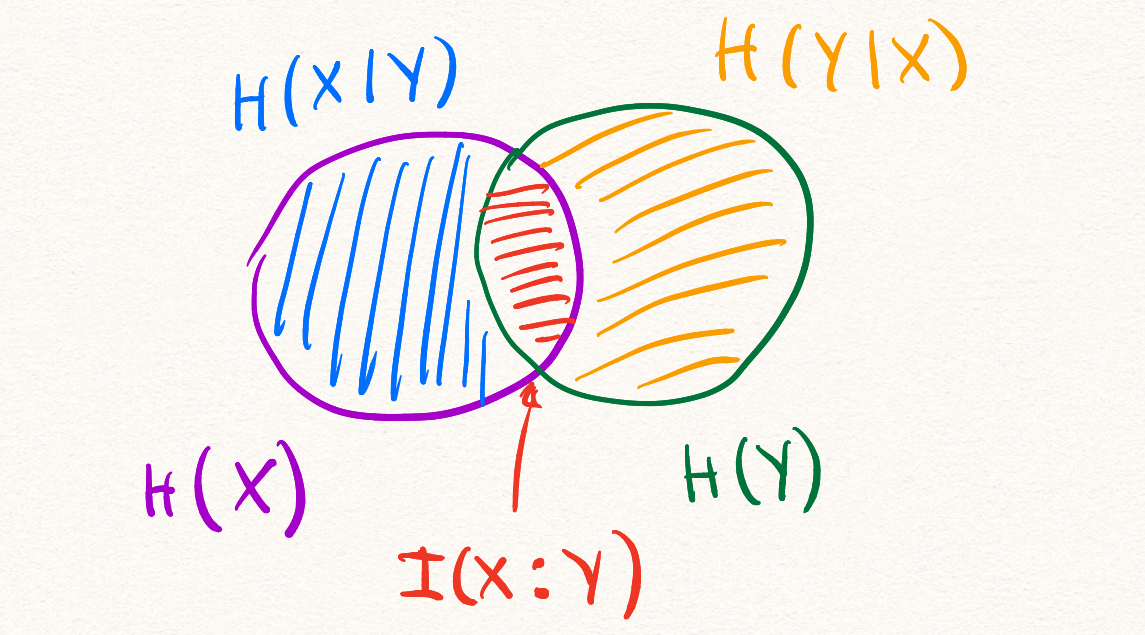
Мы пойдём дальше и рассмотрим информационную величину, зависящую от трёх случайных величин.
Пусть  ,
,  и
и  совместно распределены. Информация в
совместно распределены. Информация в  о
о  при условии
при условии  определяется следующим соотношением:
определяется следующим соотношением:
![]()
Свойства такие же как и обычной взаимной информации, нужно только добавить соответствующее условие ко всем членам.
Всё, что мы успели определить можно удобно проиллюстрировать при помощи трёх кругов Эйлера.

Из этой иллюстрации можно вывести все определения и соотношения на информационные величины.
Мы не будем продолжать дальше и рассматривать четыре случайные величины по трём причинам. Во-первых, рисовать четыре круга Эйлера со всеми возможными областями — это непросто. Во-вторых, для двух и трёх случайных величин почти все возможные соотношения можно вывести из кругов Эйлера, а для четырёх случайных величин это уже не так. И в третьих, уже для трёх случайных величин возникают неприятные эффекты, демонстрирующие, что дальше будет хуже.
Рассмотрим треугольник в пересечении всех трёх кругов  ,
,  и
и  . Этот треугольник соответствуют взаимной информации трёх случайных величин
. Этот треугольник соответствуют взаимной информации трёх случайных величин  . Проблема с этой информационной величиной заключается в том, что ей не удаётся придать какой-то “физический” смысл. Более того, в отличие от всех остальных величин на картинке
. Проблема с этой информационной величиной заключается в том, что ей не удаётся придать какой-то “физический” смысл. Более того, в отличие от всех остальных величин на картинке  может быть отрицательной!
может быть отрицательной!
Рассмотрим пример трёх случайных величин равномерно распределённых на  . Пусть
. Пусть  и
и  будут независимы, а
будут независимы, а  . Легко проверить, что
. Легко проверить, что  . При этом
. При этом  . В то же время
. В то же время  . Получается следующая картинка.
. Получается следующая картинка.

Мы знаем, что  . При этом
. При этом  . Получается, что
. Получается, что  , а
, а  , т.е. для таких случайных величин
, т.е. для таких случайных величин .
.
Применение энтропии Шеннона: кодирование
В этом разделе мы обсудим, как энтропия Шеннона возникает в теории кодирования. Будем рассматривать коды, которые кодируют каждый символ по отдельности.
Пусть задан алфавит  . Код — это отображение из
. Код — это отображение из  в
в  . Код
. Код  называется однозначно декодируемым, если любое сообщение, полученное применением
называется однозначно декодируемым, если любое сообщение, полученное применением  к символам некоторого текста, декодируется однозначно.
к символам некоторого текста, декодируется однозначно.
Код называется префиксным (prefix-free), если нет двух символов  и
и  таких, что
таких, что  является префиксом
является префиксом  .
.
Префиксные коды являются однозначно декодируемыми. Действительно, при декодировании префиксного кода легко понять, где находятся границы кодов отдельных символов.
Теорема [Шеннон]. Для любого однозначно декодируемого кода существует префиксный код с теми же длинами кодов символов.
Таким образом для изучения однозначно декодируемых кодов достаточно рассматривать только префиксные коды.
Задача об оптимальном кодировании.
Дан текст  . Нужно найти такой код
. Нужно найти такой код  , что
, что

Пусть  . Обозначим через
. Обозначим через  частоту, с которой символ
частоту, с которой символ  встречается в
встречается в  . Тогда выражение выше можно переписать как
. Тогда выражение выше можно переписать как

Следующая теорема могла встречаться вам в курсе алгоритмов.
Теорема [Хаффман]. Код Хаффмана, построенный по  , является оптимальным префиксным кодом.
, является оптимальным префиксным кодом.
Алгоритм Хаффмана по набору частот эффективно строит оптимальный код для задачи оптимального кодирования.
Связь с энтропией
Имеют место две следующие оценки.
Теорема [Шеннон]. Для любого однозначно декодируемого кода выполняется

Теорема [Шеннон]. Для любых значений  существует префиксный код
существует префиксный код  , такой что
, такой что

Рассмотрим случайную величину  , равномерно распределённую на символах текста
, равномерно распределённую на символах текста  . Получим, что
. Получим, что  . Таким образом, эти две теоремы задают оценку на среднюю длину кода символа при оптимальном кодировании, т.е. и для кодирования Хаффмана.
. Таким образом, эти две теоремы задают оценку на среднюю длину кода символа при оптимальном кодировании, т.е. и для кодирования Хаффмана.

Следовательно, длину кода Хаффмана текста  можно оценить, как
можно оценить, как
![]()
Применение энтропии Шеннона: шифрования с закрытым ключом
Рассмотрим простейшую схему шифрования с закрытым ключом. Шифрование сообщения  с ключом шифрования
с ключом шифрования  выполняется при помощи алгоритма шифрования
выполняется при помощи алгоритма шифрования  . В результате получается шифрограмма
. В результате получается шифрограмма  . Зная
. Зная  получатель шифрограммы восстанавливает исходное сообщение
получатель шифрограммы восстанавливает исходное сообщение  :
:  .
.
Мы будем анализировать эту схему с помощью аппарата энтропии Шеннона. Пусть  и
и  являются случайными величинами. Противник не знает
являются случайными величинами. Противник не знает  и
и  , но знает
, но знает  , которая так же является случайной величиной.
, которая так же является случайной величиной.
Для совершенной схемы шифрования (perfect secrecy) выполняются следующие соотношения:
-
, т.е. шифрограмма однозначно определяется по ключу и сообщению.
-
, т.е. исходное сообщение однозначно восстанавливается по шифрограмме и ключу.
-
, т.е. в отсутствие ключа из шифрограммы нельзя получить никакой информации о пересылаемом сообщении.
 , т.е. шифрограмма однозначно определяется по ключу и сообщению.
, т.е. шифрограмма однозначно определяется по ключу и сообщению. , т.е. исходное сообщение однозначно восстанавливается по шифрограмме и ключу.
, т.е. исходное сообщение однозначно восстанавливается по шифрограмме и ключу. , т.е. в отсутствие ключа из шифрограммы нельзя получить никакой информации о пересылаемом сообщении.
, т.е. в отсутствие ключа из шифрограммы нельзя получить никакой информации о пересылаемом сообщении.Теорема [Шеннон].  , даже если условие
, даже если условие  нарушается (т.е. алгоритм
нарушается (т.е. алгоритм  использует случайные биты).
использует случайные биты).
Эта теорема утверждает, что для совершенной схемы шифрования длина ключа должна быть не менее длины сообщения. Другими словами, если вы хотите зашифровать и передать своему знакомому файл размера 1Гб, то для этого вы заранее должны встретиться и обменяться закрытым ключом размера не менее 1Гб. И конечно, этот ключ можно использовать только однажды. Таким образом, самая оптимальная совершенная схема шифрования — это “одноразовый блокнот”, в котором длина ключа совпадает с длиной сообщения.
Если же вы используете ключ, который короче пересылаемого сообщения, то шифрограмма раскрывает некоторую информацию о зашифрованном сообщении. Причём количество этой информации можно оценить, как разницу между энтропией сообщения и энтропией ключа. Если вы используете пароль из 10 символов при пересылке файла размера 1Гб, то вы разглашаете примерно 1Гб – 10 байт.
Это всё звучит очень печально, но не всё так плохо. Мы ведь никак не учитываем вычислительную мощь противника, т.е. мы не ограничиваем количество времени, которое противнику потребуется на выделение этой информации.
Современная криптография строится на предположении об ограниченности вычислительных возможностей противника. Тут есть свои проблемы, а именно отсутствие математического доказательства криптографической стойкости (все доказательства строятся на различных предположениях), так что может оказаться, что вся эта криптография бесполезна (подробнее можно почитать в статье о мирах Рассела Импальяццо, которая переведена на хабре), но это уже совсем другая история.
Доказательство. Нарисуем картинку для трёх случайных величин и отметим то, что нам известно.

-
.
-
, следовательно , а значит .
-
(по свойству взаимной информации), следовательно , а значит .
-
. Таким образом,
 , следовательно
, следовательно  , а значит
, а значит  .
. (по свойству взаимной информации), следовательно
(по свойству взаимной информации), следовательно  , а значит
, а значит  .
. . Таким образом,
. Таким образом,![]()
В доказательстве мы действительно не воспользовались тем, что .
Алгоритмический подход: колмогоровская сложность
Подход Шеннона хорош для случайных величин, но если мы попробуем применить его к текстам, то выходит, что количество информации в тексте зависит только от частот символов, но не зависит от их порядка. При таком подходе получается, что в “Войне и мире” и в тексте, который получается сортировкой всех знаков в “Войне и мире”, содержится одинаковое количество информации. Колмогоров предложил подход, позволяющий измерять количество информации в конкретных объектах (строках), а не в случайных величинах.
Внимание. До этого момента я старался следить за математической строгостью формулировок. Для того, чтобы двигаться дальше в том же ключе, мне потребовалось бы предположить, что читатель неплохо знаком с математической логикой и теорией вычислимости. Я пойду более простым путём и просто буду махать руками, заметая под ковёр некоторые подробности. Однако, все утверждения и рассуждения дальше можно математически строго сформулировать и доказать.
Нам потребуется зафиксировать способ описания битовой строки. Чтобы не углубляться в рассуждения про машины Тьюринга, мы будем описывать строки на языках программирования. Нужно только сделать оговорку, что программы на этих языках будут запускаться на компьютере с неограниченным объёмом оперативной памяти (иначе мы получили бы более слабую вычислительную модель, чем машина Тьюринга).
Сложностью  строки
строки  относительно языка программирования
относительно языка программирования  называется длина кратчайшей программы, которая выводит
называется длина кратчайшей программы, которая выводит  .
.
Таким образом сложность “Войны и мира” относительноя языка Python — это длина кратчайшей программы на Python, которая печатает текст “Войны и мира”. Естественным образом сложность отсортированной версии “Войны и мира” относительно языка Python получится значительно меньше, т.к. её можно предварительно закодировать при помощи RLE.
Сравнение языков программирования
Дальше нам потребуется научиться любимой забаве всех программистов — сравнению языков программирования.
Будем говорить, что язык  не хуже языка программирования
не хуже языка программирования  и обозначать
и обозначать  , если существует константа
, если существует константа  такая, что для для всех
такая, что для для всех  выполняется
выполняется 
Исходя из этого определения получается, что язык Python не хуже (!) этого вашего Haskell! И я это докажу. В качестве константы  мы возьмём длину реализации интепретатора Haskell на Python. Таким образом, любая программа на Haskell переделывается в программу на Python просто дописыванием к ней интерпретатора Haskell на Python.
мы возьмём длину реализации интепретатора Haskell на Python. Таким образом, любая программа на Haskell переделывается в программу на Python просто дописыванием к ней интерпретатора Haskell на Python.
Соломонов и Колмогоров пошли дальше и доказали существования оптимального языка программирования.
Теорема [Соломонова-Колмогорова]. Существует способ описания (язык программирования)  такой, что для любого другого способа описания
такой, что для любого другого способа описания  выполняется
выполняется  .
.
И да, некоторые уже наверное догадались, что — это JavaScript. Или любой другой Тьюринг полный язык программирования.
Это приводит нас к следующему определению, предложенному Колмогоровым в 1965 году.
Колмогоровской сложностью строки  будем называть её сложность относительно оптимального способа описания и будем обозначать
будем называть её сложность относительно оптимального способа описания и будем обозначать  .
.
Важно понимать, что при разных выборах оптимального языка программирования колмогоровская сложность будет отличаться, но только на константу. Для любых двух оптимальных языков программирования  и
и  выполняется
выполняется  и
и  , т.е. существует такая константа
, т.е. существует такая константа  , что
, что  Это объясняет, почему в этой науке аддитивные константы принято игнорировать.
Это объясняет, почему в этой науке аддитивные константы принято игнорировать.
При этом для конкретной строки и конкретного выбора колмогоровская сложность определена однозначно.
Свойства колмогоровской сложности
Начнём с простых свойств. Колмогоровская сложность обладает следующими свойствами.
Первое свойство выполняется потому, что мы всегда можем зашить строку в саму программу. Второе свойство верно, т.к. из программы, выводящей строку  , легко сделать программу, которая выводит эту строку дважды.
, легко сделать программу, которая выводит эту строку дважды.
Примеры
Несжимаемые строки
Важнейшее свойство колмогоровской сложности заключается в существовании сложных (несжимаемых строк). Проверьте себя и попробуйте объяснить, почему не бывает идеальных архиваторов, которые умели бы сжимать любые файлы хотя бы на 1 байт, и при этом позволяли бы однозначно разархивировать результат.
В терминах колмогоровской сложности это можно сформулировать так.
Вопрос. Существует ли такая длина строки
 , что для любой строки
, что для любой строки  колмогоровская сложность
колмогоровская сложность  меньше
меньше  ?
?Следующая теорема даёт отрицательный ответ на этот вопрос.
Теорема. Для любого  существует
существует  такой, что
такой, что  .
.
Доказательство. Битовых строк длины  всего
всего  . Число строк сложности меньше
. Число строк сложности меньше  не превосходит число программ длины меньше
не превосходит число программ длины меньше  , т.е. таких программ не больше чем
, т.е. таких программ не больше чем
![]()
Таким образом, для какой-то строки гарантированно не хватит программы.
Верна и более сильная теорема.
Теорема. Существует  такое, что для
такое, что для  слов длины
слов длины  верно
верно
![]()
Другими словами, почти все строки длины  имеют почти максимальную сложность.
имеют почти максимальную сложность.
Колмогоровская сложность: вычислимость
В этом разделе мы поговорим про вычислимость колмогоровской сложности. Я не буду давать формально определение вычислимости, а буду опираться на интуитивные предствления читателей.
Теорема. Не существует программы, которая по двоичной записи числа  выводит строку
выводит строку  , такую что
, такую что  .
.
Эта теорема говорит о том, что не существует программы-генератора, которая умела бы генерировать сложные строки по запросу.
Доказательство. Проведём доказетельство от противного. Пусть такая программа  существует и
существует и  . Тогда с одной стороны сложность
. Тогда с одной стороны сложность  не меньше
не меньше  , а с другой стороны мы можем описать
, а с другой стороны мы можем описать  при помощи
при помощи  битов и кода программы
битов и кода программы .
.
![]()
Это приводит нас к противоречию, т.к. при достаточно больших значениях  неизбежно станет больше, чем
неизбежно станет больше, чем  .
.
Как следствие мы получаем невычислимость колмогоровской сложности.
Следствие. Отображение  не является вычислимым.
не является вычислимым.
Опять же, предположим, что это нет так и существует программа  , которая по строку вычисляет её колмогоровскую сложность. Тогда на основе программы
, которая по строку вычисляет её колмогоровскую сложность. Тогда на основе программы  можно реализовать программу
можно реализовать программу  из теоремы выше: она будет перебирать все строки длины не более
из теоремы выше: она будет перебирать все строки длины не более  и находить лексикографически первую, для которой сложность будет не меньше
и находить лексикографически первую, для которой сложность будет не меньше  . А мы уже доказали, что такой программы не существует.
. А мы уже доказали, что такой программы не существует.
Связь с энтропией Шеннона
Теорема. Пусть  длины
длины  содержит
содержит  единиц и
единиц и  нулей, тогда
нулей, тогда

Я надеюсь, что вы уже узнали энтропию Шеннона для случайной величины с двумя значениями с вероятностями  и
и  .
.
Для колмогоровской сложности можно проделать весь путь, который мы проделали для энтропии Шеннона: определить условную колмогоровскую сложность, сложность пары строк, взаимную информацию и условную взаимную информацию и т.д. При этом формулы будут повторять формулы для энтропии Шеннона с точностью до  . Однако это тема для отдельной статьи.
. Однако это тема для отдельной статьи.
Применение колмогоровской сложности: бесконечность множества простых чисел
Начнём с довольно игрушечного применения. С помощью колмогоровской сложности мы докажем следующую теорему, знакомую нам со школы.
Теорема. Простых чисел бесконечно много.
Очевидно, что для доказательства этой теоремы никакая колмогоровская сложность не нужна. Однако на этом примере я смогу продемонстрировать основные идеи применения колмогоровской сложности в более сложных ситуациях.
Доказательство. Проведём доказательство от обратного. Пусть существует всего  простых чисел:
простых чисел:  . Тогда любое натуральное
. Тогда любое натуральное  раскладывается на степени простых:
раскладывается на степени простых:
![]()
т.е. определяется набором степеней  . Каждое
. Каждое  , т.е. задаётся
, т.е. задаётся  битами. Поэтому любое
битами. Поэтому любое  можно задать при помощи
можно задать при помощи  битов (помним, что
битов (помним, что  — это константа).
— это константа).
Теперь воспользуемся теоремой о существовании несжимаемых строк. Как следствие, мы можем заключить, что существуют  -битовые числа
-битовые числа  сложности не менее
сложности не менее  (можно взять сложную строку и приписать в начало единицу). Получается, что сложное число можно задать при помощи небольшого числа битов.
(можно взять сложную строку и приписать в начало единицу). Получается, что сложное число можно задать при помощи небольшого числа битов.
![]()
Противоречие.
Применение колмогоровской сложности: алгоритмическая случайность
Колмогоровская сложность позволяет решить следующую проблему из классической теории вероятностей.
Пусть в лаборатории живёт обезьянка, которую научили печатать на печатной машинке так, что каждую кнопку она нажимает с одинаковой вероятность. Вам предлагается посмотреть на лист печатного текста и сказать, верите ли вы, что его напечатала эта обезьянка. Вы смотрите на лист и видите, что это первая страница “Гамлета” Шекспира. Поверите ли вы? Очевидно, что нет. Хорошо, а если это не Шекспир, а, скажем, текст детектива Дарьи Донцовой? Скорей всего тоже не поверите. А если просто какой-то набор русских слов? Опять же, очень сомневаюсь, что вы поверите.
Внимание, вопрос. А как объяснить, почему вы не верите? Давайте для простоты считать, что на странице помещается 2000 знаков и всего на машинке есть 80 знаков. Вы можете резонно заметить, что вероятность того, что обезьянка случайным образом породила текст “Гамлета” порядка  , что астрономически мало. Это верно.
, что астрономически мало. Это верно.
Теперь предположим, что вам показали текст, который вас устроил (он с вашей точки зрения будет похож на “случайный”). Но ведь вероятность его появления тоже будет порядка . Как же вы определяете, что один текст выглядит “случайным”, а другой — не выглядит?
Колмогоровская сложность позволяет дать формальный ответ на этот вопрос. Если у текста отстутствует короткое описание (т.е. в нём нет каких-то закономерностей, которые можно было бы использовать для сжатия), то такую строку можно назвать случайной. И как мы увидели выше почти все строки имеют большую колмогоровскую сложность. Поэтому, когда вы видите строку с закономерностями, т.е. маленькой колмогоровской сложности, то это соответствует очень редкому событию. В противоположность наблюдению строки без закономерностей. Вероятность увидеть строку без закономерностей близка к 1.
Это обобщается на случай бесконечных последовательностей. Пусть  . Как определить понятие случайной последовательности?
. Как определить понятие случайной последовательности?
(неформальное определение)
Последовательность случайна по Мартину–Лёфу, если каждый её префикс является несжимаемым.
Оказывается, что это очень хорошее определение случайных последовательностей, т.к. оно обладает ожидаемыми свойствами.
Свойства случайных последовательностей
-
Почти все последовательности являются случайными по Мартину–Лёфу, а мера неслучайных равна
. -
Всякая случайная по Мартину-Лёфу последовательность невычислима.
-
Если
случайная по Мартин-Лёфу, то
 .
. случайная по Мартин-Лёфу, то
случайная по Мартин-Лёфу, то
Заключение
Если вам интересно изучить эту тему подробнее, то я рекомендую обратиться к следующим источникам.
-
Верещагин Н.К., Щепин Е.В. Информация, кодирование и предсказание. МЦНМО. (нет в свободном доступе, но pdf продаётся за копейки)
-
В.А. Успенский, А.Х. Шень, Н.К. Верещагин. Колмогоровская сложность и алгоритмическая случайность.
-
Курс “Введение в теорию информации” А.Е. Ромащенко в Computer Science клубе.
Если вам интересны подобные материалы, подписывайтесь в соцсетях на CS клуб и CS центр, а так же на наши каналы на youtube: CS клуб, CS центр.
Информатика
7 класс
Урок № 6
Единицы измерения информации
Перечень вопросов, рассматриваемых в теме:
- Алфавитный подход к измерению информации.
- Наименьшая единица измерения информации.
- Информационный вес одного символа алфавита и информационный объём всего сообщения.
- Единицы измерения информации.
- Задачи по теме урока.
Тезаурус:
Каждый символ информационного сообщения несёт фиксированное количество информации.
Единицей измерения количества информации является бит – это наименьшаяединица.
1 байт = 8 бит
1 Кб (килобайт) = 1024 байта= 210байтов
1 Мб (мегабайт) = 1024 Кб = 210Кб
1 Гб (гигабайт) = 1024 Мб = 210 Мб
1 Тб (терабайт) =1024 Гб = 210 Гб
Формулы, которые используются при решении типовых задач:
Информационный вес символа алфавита и мощность алфавита связаны между собой соотношением: N = 2i.
Информационный объём сообщения определяется по формуле:
I = К · i,
I – объём информации в сообщении;
К – количество символов в сообщении;
i – информационный вес одного символа.
Основная литература:
- Босова Л. Л. Информатика: 7 класс. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2017. – 226 с.
Дополнительная литература:
- Босова Л. Л. Информатика: 7–9 классы. Методическое пособие. // Босова Л. Л., Босова А. Ю., Анатольев А. В., Аквилянов Н.А. – М.: БИНОМ, 2019. – 512 с.
- Босова Л. Л. Информатика. Рабочая тетрадь для 7 класса. Ч 1. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2019. – 160 с.
- Босова Л. Л. Информатика. Рабочая тетрадь для 7 класса. Ч 2. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2019. – 160 с.
- Гейн А. Г. Информатика: 7 класс. // Гейн А. Г., Юнерман Н. А., Гейн А.А. – М.: Просвещение, 2012. – 198 с.
Теоретический материал для самостоятельного изучения.
Любое сообщение несёт некоторое количество информации. Как же его измерить?
Одним из способов измерения информации является алфавитный подход, который говорит о том, что каждый символ любого сообщения имеет определённый информационный вес, то есть несёт фиксированное количество информации.
Сегодня на уроке мы узнаем, чему равен информационный вес одного символа и научимся определять информационный объём сообщения.
Что же такое символ в компьютере? Символом в компьютере является любая буква, цифра, знак препинания, специальный символ и прочее, что можно ввести с помощью клавиатуры. Но компьютер не понимает человеческий язык, он каждый символ кодирует. Вся информация в компьютере представляется в виде нулей и единичек. И вот эти нули и единички называются битом.
Информационный вес символа двоичного алфавита принят за минимальную единицу измерения информации и называется один бит.
Алфавит любого понятного нам языка можно заменить двоичным алфавитом. При этом мощность исходного алфавита связана с разрядностью двоичного кода соотношением: N = 2i.
Эту формулу можно применять для вычисления информационного веса одного символа любого произвольного алфавита.
Рассмотрим пример:
Алфавит древнего племени содержит 16 символов. Определите информационный вес одного символа этого алфавита.
Составим краткую запись условия задачи и решим её:
Дано:
N=16, i = ?
Решение:
N = 2i
16 = 2i, 24 = 2i, т. е. i = 4
Ответ: i = 4 бита.
Информационный вес одного символа этого алфавита составляет 4 бита.
Сообщение состоит из множества символов, каждый из которых имеет свой информационный вес. Поэтому, чтобы вычислить объём информации всего сообщения, нужно количество символов, имеющихся в сообщении, умножить на информационный вес одного символа.
Математически это произведение записывается так: I = К · i.
Например: сообщение, записанное буквами 32-символьного алфавита, содержит 180 символов. Какое количество информации оно несёт?
Дано:
N = 32,
K = 180,
I= ?
Решение:
I = К · i,
N = 2i
32 = 2i, 25 = 2 i, т.о. i = 5,
I = 180 · 5 = 900 бит.
Ответ: I = 900 бит.
Итак, информационный вес всего сообщения равен 900 бит.
В алфавитном подходе не учитывается содержание самого сообщения. Чтобы вычислить объём содержания в сообщении, нужно знать количество символов в сообщении, информационный вес одного символа и мощность алфавита. То есть, чтобы определить информационный вес сообщения: «сегодня хорошая погода», нужно сосчитать количество символов в этом сообщении и умножить это число на восемь.
I = 23 · 8 = 184 бита.
Значит, сообщение весит 184 бита.
Как и в математике, в информатике тоже есть кратные единицы измерения информации. Так, величина равная восьми битам, называется байтом.
Бит и байт – это мелкие единицы измерения. На практике для измерения информационных объёмов используют более крупные единицы: килобайт, мегабайт, гигабайт и другие.
1 байт = 8 бит
1 Кб (килобайт) = 1024 байта= 210байтов
1 Мб (мегабайт) = 1024 Кб = 210Кб
1 Гб (гигабайт) = 1024 Мб = 210 Мб
1 Тб (терабайт) =1024 Гб = 210 Гб
Итак, сегодня мы узнали, что собой представляет алфавитный подход к измерению информации, выяснили, в каких единицах измеряется информация и научились определять информационный вес одного символа и информационный объём сообщения.
Материал для углубленного изучения темы.
Как текстовая информация выглядит в памяти компьютера.
Набирая текст на клавиатуре, мы видим привычные для нас знаки (цифры, буквы и т.д.). В оперативную память компьютера они попадают только в виде двоичного кода. Двоичный код каждого символа, выглядит восьмизначным числом, например 00111111. Теперь возникает вопрос, какой именно восьмизначный двоичный код поставить в соответствие каждому символу?
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код ‑ просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.Таблица для кодировки – это «шпаргалка», в которой указаны символы алфавита в соответствии порядковому номеру. Для разных типов компьютеров используются различные таблицы кодировки.
Таблица ASCII (или Аски), стала международным стандартом для персональных компьютеров. Она имеет две части.

В этой таблице латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений. Это правило соблюдается и в других таблицах кодировки и называется принципом последовательного кодирования алфавитов. Благодаря этому понятие «алфавитный порядок» сохраняется и в машинном представлении символьной информации. Для русского алфавита принцип последовательного кодирования соблюдается не всегда.
Запишем, например, внутреннее представление слова «file». В памяти компьютера оно займет 4 байта со следующим содержанием:
01100110 01101001 01101100 01100101.
А теперь попробуем решить обратную задачу. Какое слово записано следующим двоичным кодом:
01100100 01101001 01110011 01101011?
В таблице 2 приведен один из вариантов второй половины кодовой таблицы АSСII, который называется альтернативной кодировкой. Видно, что в ней для букв русского алфавита соблюдается принцип последовательного кодирования.

Вывод: все тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные для нас буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в форме двоичного кода.
Из памяти же компьютера текст может быть выведен на экран или на печать в символьной форме.
Сейчас используют целых пять систем кодировок русского алфавита (КОИ8-Р, Windows, MS-DOS, Macintosh и ISO). Из-за количества систем кодировок и отсутствия одного стандарта, очень часто возникают недоразумения с переносом русского текста в компьютерный его вид. Поэтому, всегда нужно уточнять, какая система кодирования установлена на компьютере.
Разбор решения заданий тренировочного модуля
№1. Определите информационный вес символа в сообщении, если мощность алфавита равна 32?
Варианты ответов:
3
5
7
9
Решение:
Информационный вес символа алфавита и мощность алфавита связаны между собой соотношением: N = 2i.
32 = 2i, 32 – это 25, следовательно, i =5 битов.
Ответ: 5 битов.
№2. Выразите в килобайтах 216 байтов.
Решение:
216 можно представить как 26 · 210.
26 = 64, а 210 байт – это 1 Кб. Значит, 64 · 1 = 64 Кб.
Ответ: 64 Кб.
№3. Тип задания: выделение цветом
8х = 32 Кб, найдите х.
Варианты ответов:
3
4
5
6
Решение:
8 можно представить как 23. А 32 Кб переведём в биты.
Получаем 23х=32 · 1024 ·8.
Или 23х = 25 · 210 · 23.
23х = 218.
3х = 18, значит, х=6.
Ответ: 6.

Все мы привыкли к тому, что все вокруг можно измерить. Мы можем определить массу посылки, длину стола, скорость движения автомобиля. Но как определить количество информации, содержащееся в сообщении? Ответ на вопрос в статье.
Итак, давайте для начала выберем сообщение. Пусть это будет «Принтер — устройство вывода информации.«. Наша задача — определить, сколько информации содержится в данном сообщении. Иными словами — сколько памяти потребуется для его хранения.
Определение количества информации в сообщении
Для решения задачи нам нужно определить, сколько информации несет один символ сообщения, а потом умножить это значение на количество символов. И если количество символов мы можем посчитать, то вес символа нужно вычислить. Для этого посчитаем количество различных символов в сообщении. Напомню, что знаки препинания, пробел — это тоже символы. Кроме того, если в сообщении встречается одна и та же строчная и прописная буква — мы считаем их как два различных символа. Приступим.
В слове Принтер 6 различных символов (р встречается дважды и считается один раз), далее 7-й символ пробел и девятый — тире. Так как пробел уже был, то после тире мы его не считаем. В слове устройство 10 символов, но различных — 7, так как буквы с, т и о повторяются. Кроме того буквы т и р уже была в слове Принтер. Так что получается, что в слове устройство 5 различных символов. Считая таким образом дальше мы получим, что в сообщении 20 различных символов.
Далее вспомним формулу, которую называют главной формулой информатики:
2i=N
Подставив в нее вместо N количество различных символов, мы узнаем, сколько информации несет один символ в битах. В нашем случае формула будет выглядеть так:
2i=20
Вспомним степени двойки и поймем, что i находится в диапазоне от 4 до 5 (так как 24=16, а 25=32). А так как бит — минимальная единица измерения информации и дробным быть не может, то мы округляем i в большую сторону до 5. Иначе, если принять, что i=4, мы смогли бы закодировать только 24=16 символов, а у нас их 20. Поэтому получаем, что i=5, то есть каждый символ в нашем сообщении несет 5 бит информации.
Осталось посчитать сколько символов в нашем сообщении. Но теперь мы будем считать все символы, не важно повторяются они или нет. Получим, что сообщение состоит из 39 символов. А так как каждый символ — это 5 бит информации, то, умножив 5 на 39 мы получим:
5 бит x 39 символов = 195 бит
Это и есть ответ на вопрос задачи — в сообщении 195 бит информации. И, подводя итог, можно написать алгоритм нахождения объема информации в сообщении:
- посчитать количество различных символов.
- подставив это значение в формулу 2i=N найти вес одного символа (округлив в большую сторону)
- посчитать общее количество символов и умножить это число на вес одного символа.
Автор:
Здравствуйте! С вами Елена TeachYOU, и сегодня мы разберем задачи 11 из ЕГЭ по информатике. Задачи несложные, но почему-то у многих учеников с ними возникают проблемы.
Что такое равномерное кодирование
Для того, чтобы работать с какими-то объектами с помощью компьютера, необходимо их закодировать. Так как подавляющее большинство современных ЭВМ использует двоичную логику, разумно кодировать объекты с использованием двоичного кодирования.
Двоичное кодирование можно разделить на равномерное (когда кодовые слова, или коды, имеют одинаковую длину), и неравномерное (когда длина кодовых слов разная). Тема неравномерного кодирования поднимается в 4 задании ЕГЭ, можете посмотреть материал по нему в этой статье. Там разобраны примеры с разными вариантами кодирования. Если вам все еще непонятно, чем равномерное кодирование отличается от неравномерного, то перед тем, как читать материал по 11 заданию дальше, советую сначала просмотреть материал по ссылке выше.
Перевод битов в байты и далее
Прежде чем двигаться дальше, напомню правила перевода между единицами измерения информации. Основное:
- 1 байт = 8 бит
- 1 Кбайт = 1024 байт = 2^10 байт = 2^13 бит
- 1 Мбайт = 1024 Кбайт = 2^10 Кбайт = 2^23 бит
1. Сначала переводим 5 Мбайт в Кбайты, домножая на 1024: 5 Мбайт = 5 * 1024 Кбайт.
2. Затем переводим Кбайты в байты домножением на 1024: 5 * 1024 Кбайт = 5 * 1024 * 1024 байт.
3. Для перевода в биты домножаем на 8: 5 * 1024 * 1024 байт = 5 * 1024 * 1024 * 4 бит.
Переведем 24576 бит в килобайты:
1. Делим на 8, чтобы перевести в байты: 24576 / 8 = 3072 (байт).
2. Делим на 1024, чтобы перейти к Кбайтам: 3072 / 1024 = 3 (Кбайт).
Что нужно знать про равномерное двоичное кодирование
Кодирование равномерное => все кодовые слова имеют одинаковую, минимально возможную, длину. Кодирование двоичное => кодовые слова состоят только из 0 и 1.
Сколько объектов можно закодировать, используя кодовые слова имеют длины i ?
Например, буква А может кодироваться кодовым словом 01101. В нем пять знаков (0 или 1). Говорят, что кодовое слово 01101 состоит из пяти бит. Бит – это ячейка, принимающая значение 0 или 1 (тире или точка, вкл или выкл и пр.).
Тогда кодовое слово 0110 состоит из 4 бит, слово 110011 – из 6 бит и т.д.
Посмотрим, сколько разных кодовых слов можно составить, если брать кодовые слова определенной длины (здесь нам поможет теория по теме “Комбинаторика” для 8 номера).
- Кодовые слова длины 1 – это 0 и 1. Их два (каждое занимает 1 бит).
- Кодовые слова длины 2 – это 00, 01, 10 и 11. Их четыре (каждое занимает 2 бит).
- Кодовые слова длины 3 я перечислять не буду. Их количество равно 2*2*2 = 2^3 = 8 (если непонятно, загляните в материал по комбинаторике). Каждое кодовое слово занимает 3 бита.
- ….
- Кодовые слова длины i – их 2^i. Каждое занимает i бит.
Получается, что, если для кодирования мы выберем кодовые слова длины i (i-битные), то сможем закодировать 2^i объектов.
Если в сообщении используется N символов, сколько бит нужно для кодирования каждого символа?
Количество i-битных кодовых слов равно 2^i.
Похоже, что, нужно подобрать такое i, чтобы N = 2^i.
Но на практике не всегда число N является степенью двойки. Поэтому для кодирования N объектов нужно взять такое минимальное i, чтобы выполнялось условие N <= 2^i.
Например:
- N = 14: 14 <= 16 = 2^4. Получается, что при кодировании 14 объектов с использованием равномерного двоичного кодирования на каждый объект будет приходиться 4 бита.
- N = 250: 250 <= 256 = 2^8 => 8 бит на объект.
- N = 2050: 2050 <= 4096 = 2^12 => 12 бит на объект.
Рассмотрим задачи 11 из ЕГЭ
Задача 1 (номер 1964 с компегэ)
При регистрации в компьютерной системе каждому объекту сопоставляется идентификатор, состоящий из 15 символов и содержащий только символы из 8-символьного набора: А, В, C, D, Е, F, G, H. В базе данных для хранения сведений о каждом объекте отведено одинаковое и минимально возможное целое число байт. При этом используют посимвольное кодирование идентификаторов, все символы кодируют одинаковым и минимально возможным количеством бит. Кроме собственно идентификатора, для каждого объекта в системе хранятся дополнительные сведения, для чего отведено 24 байта на один объект.
Определите объём памяти (в байтах), необходимый для хранения сведений о 20 объектах. В ответе запишите только целое число – количество байт.
Из задачи следует, что нужно сохранить данные о 20 объектах. Для каждого из них хранится идентификатор (его информационный вес нужно вычислить) и дополнительные сведения (известны, 24 байта на один объект).
Начнем с вычисления количества байт, которое занимает один идентификатор.
Длина идентификатора 15 символов, а мощность алфавита равна восьми. Вспоминаем основную формулу информатики: N = 2^i, где N – количество кодируемых равномерным кодированием объектов, i – количество бит, которое приходится на один объект. N = 8 (нужно закодировать все символы из набора, поэтому N = мощности алфавита). Из 8 = 2^i находим i=3 бита. Каждый символ кодируется 3 битами, а идентификатор состоит из 15 символов. Получается, на один идентификатор приходится 15 * 3 = 45 бит = 5,625 байт.
Обращаем внимание, что в задаче говорится, что для хранения сведений о каждом объекте отведено одинаковое и минимально возможное целое число байт. Необходимо округлить 5,625 байт до целого значения. Но в большую или меньшую сторону?
Если округлим в меньшую, то получим 5 байт = 40 бит. Но для хранения идентификатора нужно 45 бит! 45 бит не помещаются в “коробочку” из 5 байт. Значит, нужно округлять в большую. Итого, на идентификатор приходится 6 байт.
Для вычисления информационного объема, необходимого для хранения сведений об одном объекте, найдем сумму байт, приходящихся на идентификатор и на дополнительные сведения:
6 + 24 = 30 (байт) – на 1 объект.
Вычислим объем информации для хранения сведений о 20 объектах:
30 (байт) * 20 (объектов) = 600 (байт).
Задача 2 (номер 212 с компегэ)
Для регистрации на сайте необходимо продумать пароль, состоящий из 9 символов. Он может содержать десятичные цифры, строчные или заглавные буквы латинского алфавита (алфавит содержит 26 букв) и символы из перечисленных: «.», «$», «#», «@», «%», «&». В базе данных для хранения сведения о каждом пользователе отведено одинаковое и минимальное возможное целое число байт. При этом используют посимвольное кодирование паролей, все символы кодируют одинаковым и минимально возможным количеством бит. Кроме собственного пароля, для каждого пользователя в системе хранятся дополнительные сведения, для чего выделено целое число байт одинаковое для каждого пользователя. Для хранения сведений о двадцати пользователях потребовалось 500 байт. Сколько байт выделено для хранения дополнительных сведений об одном пользователе. В ответе запишите только целое число – количество байт.
Сайт хранит данные о 20 пользователях. Они занимают 500 байт. Для каждого пользователя хранятся пароль (его информационный объем нужно вычислить) и дополнительные сведения (эту величину нужно найти и взять в качестве ответа).
Начнем с поиска количества байт, приходящихся на одного пользователя:
500 (байт) / 20 (польз.) = 25 (байт на 1 польз.)
Разберемся с паролем. Мощность алфавита символов, которые используются для его записи:
N = 10 (цифр) + 26 (строчных букв) + 26 (заглавных букв) + 6 (символов «.», «$», «#», «@», «%», «&») = 68 (символов).
Сколькими битами можно закодировать каждый из 78 символов при использовании равномерного кодирования?
68 <= 2^i, i = 7 (бит).
Тогда пароль занимает
7 (бит) * 9 (символов) = 63 (бит) = 8 (байт).
Для одного пользователя хранится пароль (8 байт) и доп. сведения. Всего на пользователя приходится 25 байт. Тогда доп. сведения занимают
25 – 8 = 17 (байт).
Задача 3 (номер 463 с компегэ)
Очень люблю эту задачу авторства Евгения Джобса за нацеленность на понимание темы
Автомобильный номер состоит из одиннадцати букв русского алфавита A, B,C, E, H, K, M, O, P, T, X и десятичных цифр от 0 до 9. Каждый номер состоит из двух букв, затем идет 3 цифры и еще одна буква. Например, АВ901С.
В системе каждый такой номер кодируется посимвольно, при этом каждая буква и каждая цифра кодируются одинаковым минимально возможным количеством бит.
Укажите, сколько бит на один номер можно сэкономить, если кодировать с помощью одинакового минимально возможного количества бит каждую из трех групп – первые две буквы, три цифры и последняя буква.
В этой задаче есть “до” и “после”.
“До”: каждая буква и каждая цифра кодируются отдельно.
“После”: кодируются отдельно первые две буквы, три цифры и последняя буква.
Разберемся, сколько бит занимал автомобильный номер при выборе способа кодирования “до”.
- Буквы: N = 11 <= 16 = 2^4 => i = 4.
- Цифры: N = 10 <= 16 = 2^4 => i = 4.
- Весь номер состоит их трех цифр и трех букв, это 3 (буквы) * 4 (бита) + 3 (цифры) * 4 (бита) = 24 (бит на один номер)
Как кодируем номер “после”?
- Первые две буквы. Букв 11. Количество пар букв (АА, АВ, … , ХХ) равно 11*11 = 121. Нашли объекты – это пары букв. Их количество N = 121 <= 128 = 2^7 => i=7 бит. Раньше каждую букву мы кодировали 4 битами и две буквы занимали 8 бит. А теперь 7. Э – экономия!
- Три цифры. Цифр 10. Количество троек цифр (000, 001, … , 999) равно 10*10*10 = 1000. В этом случае кодируемые объекты – это тройки цифр. N = 1000 <= 1024 = 2^10 => i = 10 бит. “До” каждую цифру кодировали 4 битами, три цифры занимали 12 бит. А сейчас 10. И здесь сэкономили.
- Последняя буква. N = 11 <= 16 = 2^4 => i=4. Тут ничего не изменилось: “до” кодировали объекты-буквы и здесь поступили так же.
- Количество бит на номер “после”: 7 + 10 + 4 = 21 (бит).
Итого сэкономили 24 – 21 = 3 (бита).
Какие еще задачи посмотреть, чтобы закрепить материал?
Сайт kompege.ru покорил мое сердце, и теперь я считаю себя его амбассадором)
Если вы только знакомитесь с 11 номерами, решайте любые задачи (на сайте компегэ их можно отсортировать по сложности, начните с простых).
Для более продвинутых настоятельно советую прорешать задачи из списка ниже, так как в каждой есть свои тонкости.
Номера 11: 4468, 4323, 2119, 5433.
И традиционно – успехов!
Набор символов знаковой системы (алфавит) можно рассматривать как различные возможные состояния (события).
Тогда, если считать, что появление символов в сообщении равновероятно, количество возможных событийN можно вычислить как N=2i
Количество информации в сообщении I можно подсчитать умножив количество символов K на информационный вес одного символа i
Итак, мы имеем формулы, необходимые для определения количества информации в алфавитном подходе:
Если к этим задачам добавить задачи на соотношение величин, записанных в разных единицах измерения, с использованием представления величин в виде степеней двойки мы получим 9 типов задач.
Рассмотрим задачи на все типы. Договоримся, что при переходе от одних единиц измерения информации к другим будем строить цепочку значений. Тогда уменьшается вероятность вычислительной ошибки.
Задача 1. Получено сообщение, информационный объем которого равен 32 битам. чему равен этот объем в байтах?
Решение: В одном байте 8 бит. 32:8=4
Ответ: 4 байта.
Задача 2. Объем информацинного сообщения 12582912 битов выразить в килобайтах и мегабайтах.
Решение: Поскольку 1Кбайт=1024 байт=1024*8 бит, то 12582912:(1024*8)=1536 Кбайт и
поскольку 1Мбайт=1024 Кбайт, то 1536:1024=1,5 Мбайт
Ответ:1536Кбайт и 1,5Мбайт.
Задача 3. Компьютер имеет оперативную память 512 Мб. Количество соответствующих этой величине бит больше:
1) 10 000 000 000бит 2) 8 000 000 000бит 3) 6 000 000 000бит 4) 4 000 000 000бит Решение: 512*1024*1024*8 бит=4294967296 бит.
Ответ: 4.
Задача 4. Определить количество битов в двух мегабайтах, используя для чисел только степени 2.
Решение: Поскольку 1байт=8битам=23битам, а 1Мбайт=210Кбайт=220байт=223бит. Отсюда, 2Мбайт=224бит.
Ответ: 224бит.
Задача 5. Сколько мегабайт информации содержит сообщение объемом 223бит?
Решение: Поскольку 1байт=8битам=23битам, то
223бит=223*223*23бит=210210байт=210Кбайт=1Мбайт.
Ответ: 1Мбайт
Задача 6. Один символ алфавита “весит” 4 бита. Сколько символов в этом алфавите?
Решение:
Дано:
| i=4 | По формуле N=2i находим N=24, N=16 |
| Найти: N – ? |
Ответ: 16
Задача 7. Каждый символ алфавита записан с помощью 8 цифр двоичного кода. Сколько символов в этом алфавите?
Решение:
Дано:
| i=8 | По формуле N=2i находим N=28, N=256 |
| Найти:N – ? |
Ответ: 256
Задача 8. Алфавит русского языка иногда оценивают в 32 буквы. Каков информационный вес одной буквы такого сокращенного русского алфавита?
Решение:
Дано:
| N=32 | По формуле N=2i находим 32=2i, 25=2i,i=5 |
| Найти: i– ? |
Ответ: 5
Задача 9. Алфавит состоит из 100 символов. Какое количество информации несет один символ этого алфавита?
Решение:
Дано:
| N=100 | По формуле N=2i находим 32=2i, 25=2i,i=5 |
| Найти: i– ? |
Ответ: 5
Задача 10. У племени “чичевоков” в алфавите 24 буквы и 8 цифр. Знаков препинания и арифметических знаков нет. Какое минимальное количество двоичных разрядов им необходимо для кодирования всех символов? Учтите, что слова надо отделять друг от друга!
Решение:
Дано:
| N=24+8=32 | По формуле N=2i находим 32=2i, 25=2i,i=5 |
| Найти: i– ? |
Ответ: 5
Задача 11. Книга, набранная с помощью компьютера, содержит 150 страниц. На каждой странице — 40 строк, в каждой строке — 60 символов. Каков объем информации в книге? Ответ дайте в килобайтах и мегабайтах
Решение:
Дано:
| K=360000 | Определим количество символов в книге 150*40*60=360000. Один символ занимает один байт. По формуле I=K*iнаходим I=360000байт 360000:1024=351Кбайт=0,4Мбайт |
| Найти: I– ? |
Ответ: 351Кбайт или 0,4Мбайт
Задача 12. Информационный объем текста книги, набранной на компьютере с использованием кодировки Unicode, — 128 килобайт. Определить количество символов в тексте книги.
Решение:
Дано:
| I=128Кбайт,i=2байт | В кодировке Unicode один символ занимает 2 байта. Из формулыI=K*i выразимK=I/i,K=128*1024:2=65536 |
| Найти: K– ? |
Ответ: 65536
Задача 13.Информационное сообщение объемом 1,5 Кб содержит 3072 символа. Определить информационный вес одного символа использованного алфавита
Решение:
Дано:
| I=1,5Кбайт,K=3072 | Из формулы I=K*i выразимi=I/K,i=1,5*1024*8:3072=4 |
| Найти: i– ? |
Ответ: 4
Задача 14.Сообщение, записанное буквами из 64-символьного алфавита, содержит 20 символов. Какой объем информации оно несет?
Решение:
Дано:
| N=64, K=20 | По формуле N=2i находим 64=2i, 26=2i,i=6. По формуле I=K*i I=20*6=120 |
| Найти: I– ? |
Ответ: 120бит
Задача 15. Сколько символов содержит сообщение, записанное с помощью 16-символьного алфавита, если его объем составил 1/16 часть мегабайта?
Решение:
Дано:
| N=16, I=1/16 Мбайт | По формуле N=2i находим 16=2i, 24=2i,i=4. Из формулы I=K*i выразим K=I/i, K=(1/16)*1024*1024*8/4=131072 |
| Найти: K– ? |
Ответ: 131072
Задача 16. Объем сообщения, содержащего 2048 символов,составил 1/512 часть мегабайта. Каков размер алфавита, с помощью которого записано сообщение?
Решение:
Дано:
| K=2048,I=1/512 Мбайт | Из формулы I=K*i выразим i=I/K, i=(1/512)*1024*1024*8/2048=8. По формулеN=2iнаходим N=28=256 |
| Найти: N– ? |
Ответ: 256
Задачи для самостоятельного решения:
- Каждый символ алфавита записывается с помощью 4 цифр двоичного кода. Сколько символов в этом алфавите?
- Алфавит для записи сообщений состоит из 32 символов, каков информационный вес одного символа? Не забудьте указать единицу измерения.
- Информационный объем текста, набранного на компьюте¬ре с использованием кодировки Unicode (каждый символ кодируется 16 битами), — 4 Кб. Определить количество символов в тексте.
- Объем информационного сообщения составляет 8192 бита. Выразить его в килобайтах.
- Сколько бит информации содержит сообщение объемом 4 Мб? Ответ дать в степенях 2.
- Сообщение, записанное буквами из 256-символьного ал¬фавита, содержит 256 символов. Какой объем информации оно несет в килобайтах?
- Сколько существует различных звуковых сигналов, состоящих из последовательностей коротких и длинных звонков. Длина каждого сигнала — 6 звонков.
- Метеорологическая станция ведет наблюдение за влажностью воздуха. Результатом одного измерения является целое число от 20 до 100%, которое записывается при помощи минимально возможного количества бит. Станция сделала 80 измерений. Определите информационный объем результатом наблюдений.
- Скорость передачи данных через ADSL-соединение равна 512000 бит/с. Через данное соединение передают файл размером 1500 Кб. Определите время передачи файла в секундах.
- Определите скорость работы модема, если за 256 с он может передать растровое изображение размером 640х480 пикселей. На каждый пиксель приходится 3 байта. А если в палитре 16 миллионов цветов?
Тема определения количества информации на основе алфавитного подхода используется в заданиях А1, А2, А3, А13, В5 контрольно-измерительных материалов ЕГЭ.
