Вместе с выбором
группировочного
признака
возникает задача определения количества
групп, на
которые следует подразделить изучаемое
явление.
Число групп зависит
от:
-
задач исследования
-
вида признака,
положенного в основу группировки -
численности
совокупности -
степени вариации
признака
Единицы анализируемой
совокупности могут быть разбиты по
одному и тому же признаку на разное
число групп. Например, при группировке
населения по возрасту с целью определения
трудовых ресурсов страны все население
делится на три группы: население моложе
трудоспособного возраста, трудоспособное
население и население старше трудоспособного
возраста. Если же анализируется
продолжительность жизни, то строится
более детальная группировка и выделяются
группы по 5 лет.
При группировке
по атрибутивному (описательному) признаку
вопрос о количестве групп решается
сравнительно просто – по количеству
градаций, видов состояния этого признака.
Например, группировка
населения по полу образует две группы,
организаций связи по федеральным округам
– 7 групп, по формам собственности – на
пять групп: государственная, муниципальная,
частная, смешанная, собственность
иностранных юридических лиц.
Если атрибутивный
(описательный) признак имеет множество
наименований (например, профессия – в
отрасли связи насчитывается несколько
десятков их наименований), то для
статистической характеристики состава
работников образуют укрупненные
группы (руководители,
специалисты, рабочие, прочие).
Такое объединение основано на изучении
сущности производственных процессов.
Характеристика
типов предприятий по их величине часто
ограничивается тремя группами: мелкие,
средние и крупные, а при изучении
рентабельности – группы нерентабельных,
рентабельных и высокорентабельных.
Группировки по
количественному признаку
очень разнообразны. При выборе числа
групп в совокупности с количественным
признаком необходимо, чтобы в каждую
группу попало достаточное количество
единиц совокупности. Только в этом
случае обобщающие характеристики каждой
группы (средние, относительные показатели)
будут устойчивыми, неслучайными,
характерными.
Сравнительно просто
образуются группы по количественным
признакам, имеющим дискретную (прерывную)
вариацию и принимающим целые значения.
Если количественный
признак изменяется в широких пределах
и имеет множество различных значений,
то каждая группа образуется в виде
интервалов.
Группировка может
быть выполнена с равными
и неравными
интервалами.
Равные
интервалы
употребляются
в тех случаях, когда признак изменяется
более или менее равномерно в ограниченных
пределах, например масса письма, посылки,
заработная плата определенной категории
работников.
Величина интервала
зависит от размаха варьирования признака
и численности изучаемой совокупности
и в случае равных интервалов может
определятся по формуле
Стерджесса.
Формула
Стерджесса
служит для
определения величины интервала:
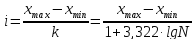
где
i
– интервал, т.е. разница между максимальным
xmax
и минимальным xmin
значениями признака в каждой группе; N
– численность единиц совокупности; k
– число групп, которое оптимально при
величине 1+3,322 lg
N.
Недостаток формулы
Стерджесса состоит в том, что её применение
дает хорошие результаты для большой
совокупности единиц и когда распределение
единиц по признаку, положенному в
основание группировки, близко к
нормальному.
Число групп можно
определить также по следующей номограмме:
|
Численность |
15..24 |
25..44 |
45..89 |
90..179 |
180..359 |
360..719 |
720..1439 |
|
Число |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
Другим способом
выполнения группировки является
использование среднего
квадратического отклонения
.
Если величина интервала равна 0,5,
то совокупность разбивается на 12 групп,
если 2/3
или,
то совокупность делится на 9 или 6 групп.
При
 ,
,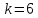 интервалы групп выглядят следующим
интервалы групп выглядят следующим
образом:
от
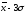 до
до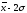
от
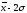 до
до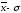
от
 до
до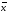
от
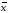 до
до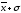
от
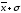 до
до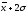
от
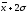 до
до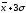
Однако при определении
групп данными методами возможно получение
пустых или малочисленных групп. Если
размах вариации признака совокупности
велик и его значения варьируют
неравномерно, то используют группировку
с неравными интервалами.
Неравные
интервалы
употребляются в тех случаях, когда
признак изменяется неравномерно. Из
неравных интервалов чаще всего
употребляются прогрессивно возрастающие
или убывающие интервалы.
Величина интервалов,
изменяющихся в арифметической прогрессии,
определяется по формуле:
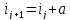 ,
,
в геометрической
прогрессии:
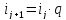
где a
– постоянная величина (положительная
для прогрессивно-возрастающих интервалов,
отрицательная – для прогрессивно-убывающих);
q
– константа – положительное число (для
прогрессивно-возрастающих интервалов
q
> 1, для прогрессивно-убывающих – q
< 1).
Например, необходимо
построить группировку предприятий
отрасли по показателю выручки от
реализации продукции, который варьирует
от 500 млн. руб. до 4000 млн. руб. в год, то
строить группировку с равными интервалами
нецелесообразно, т.к. как правило,
совокупность предприятий любой отрасли
промышленности и торговли включает
большое число малых предприятий, имеющих
небольшую выручку. С ростом выручки от
реализации продукции значительно
снижается число предприятий. Т.о.
распределение числа предприятий по
величине выручки является неравномерным.
Поэтому следует построить группировку
с неравными интервалами.
Таблица
Группировка
предприятий с неравными интервалами
|
№ группы |
Интервал |
|
I II III IV V |
500-800 800-1300 1300-2000 2000-2900 2900-4000 |
Величина каждого
последующего интервала у этой группировки
больше предыдущего на 200 млн. руб., т.е.
увеличивается в арифметической
прогрессии.
При образовании
интервалов важное значение имеет точное
обозначение границ.
Например, группы
предприятий по численности работников:
200 – 600, 600 – 1000. Такая запись предполагает,
что единица, у которой значение признака
совпадает с верхней границей интервала,
относится к следующей группе.
Обычно границы
интервалов обозначаются указанием
значений признака «от» и «до» (в нашем
примере – 200 – 599, 600 -999). Характер такого
обозначения говорит, что в группу
включаются все значения признака в
указанных границах.
После определения
группировочного признака и границ групп
строится ряд распределения.
Статистический
ряд распределения
– это упорядоченное распределение
единиц совокупности на группы по
определенному варьирующему признаку.
В зависимости от признака, положенного
в основу образования ряда распределения,
различают атрибутивные и вариационные
ряды распределения.
Атрибутивными
называют ряды распределения, построенные
по описательным (качественным) признакам.
Вариационными
называют ряды распределения, построенные
по количественному признаку.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Дана выборка значений признака Х. Требуется:
построить статическую совокупность;
построить гистограмму частот;
найти точечные оценки генеральной средней, генеральной
дисперсии и генерального среднего квадратического отклонения;
найти доверительный интервал для неизвестного математического
ожидания;
проверить нулевую гипотезу о нормальном законе распределения
количественного признака Х генеральной совокупности.
38, 51, 57, 64, 76, 92, 89, 19, 35, 60, 22, 41, 44, 48, 60, 44, 67, 80, 86,
57, 25, 83, 73, 70, 70, 70, 64, 60, 60, 64, 57, 54, 57, 54, 32, 86, 86, 80,
76, 60, 76, 70, 70, 67, 67, 64, 64, 60, 28, 67, 41, 41, 51, 48, 44, 80, 80,
76, 73, 51, 67, 60, 32, 41, 41, 54, 57, 60, 67, 73, 73, 76, 57, 67, 73, 73,
64, 60, 54, 57.
Объем выборки n=80
Наименьшее значение признака Х
MIN:
19
Наибольшее значение
MAX:
92
Определим оптимальное число интервалов разбиения по формуле
Число интервалов:
7,00 – ПОЧЕМУ ???
Шаг интервала h=(92-19)/7=
10,43
Правило Стёрджеса — эмпирическое правило определения оптимального количества интервалов, на которые разбивается наблюдаемый диапазон изменения случайной величины при построении гистограммы плотности её распределения. Названо по имени американского статистика Герберта Стёрджеса (Herbert Arthur Sturges, 1882—1958).
Количество интервалов  определяется как:
определяется как:
 ,
,
где  — общее число наблюдений величины,
— общее число наблюдений величины,  — логарифм по основанию 2,
— логарифм по основанию 2,  — обозначает целую часть числа
— обозначает целую часть числа  .
.
Часто встречается записанным через десятичный логарифм:
- ,

Основанием для него служит оценка количества событий с разными вероятностями в схеме испытаний Бернулли длительностью в  этап. Если имеются серии испытаний с 2 альтернативными исходами с постоянной вероятностью каждого, то число видов серий, где в составе имеется
этап. Если имеются серии испытаний с 2 альтернативными исходами с постоянной вероятностью каждого, то число видов серий, где в составе имеется  исходов, принимающих первое из альтернативных значений, и, соответственно,
исходов, принимающих первое из альтернативных значений, и, соответственно,  — принимающих второе, равно: (от
— принимающих второе, равно: (от  до
до  ), а общее число серий
), а общее число серий  .
.
Если аппроксимировать значения наблюдаемой случайной величины результатами сложения случайно выпадающих в серии испытаний значений двух чисел  и
и  (например
(например  и
и  ), соответствующих исходам схемы Бернулли, то каждой серии испытаний содержащей исходов с результатом и исходов с результатом будет соответствовать сумма
), соответствующих исходам схемы Бернулли, то каждой серии испытаний содержащей исходов с результатом и исходов с результатом будет соответствовать сумма  . Количество различных значений (в рассматриваемом случае:
. Количество различных значений (в рассматриваемом случае:  , для пары
, для пары  —
—  ) будет равно количеству последовательностей с различным числом исходов . Т.о., если ставить задачу, чтобы на каждый интервал между и приходилось в среднем не меньше одного значения суммы, а значит и не меньше одной серии испытаний, моделирующей получение случайной величины, то число этапов в серии, равное числу интервалов, на которые разбивается диапазон изменения наблюдаемых значений, должно быть не больше, чем
) будет равно количеству последовательностей с различным числом исходов . Т.о., если ставить задачу, чтобы на каждый интервал между и приходилось в среднем не меньше одного значения суммы, а значит и не меньше одной серии испытаний, моделирующей получение случайной величины, то число этапов в серии, равное числу интервалов, на которые разбивается диапазон изменения наблюдаемых значений, должно быть не больше, чем 
Распределение получившихся величин (распределение Бернулли) аппроксимируется при больших нормальным распределением согласно теореме Муавра — Лапласа, что дает основания при предположении о близости распределения исследуемой величины к нормальному и, соответственно, к аппроксимируемому им биномиальному применять оценку количества интервалов разбиения соответственно количеству ожидаемых дискретных значений для распределения Бернулли, что приводит к правилу Стёрджеса.
Литература[править | править код]
- Sturges H. (1926). The choice of a class-interval. J. Amer. Statist. Assoc., 21, 65-66.
Ссылки[править | править код]
- Sturges’ rule Архивная копия от 26 января 2013 на Wayback Machine
- Авторы
- Файлы
- Литература
Дацковская М.А.
1
Колеснёв А.С.
1
Агишева Д.К.
1
Зотова С.А.
1
1 Волжский политехнический институт (филиал) Волгоградского государственного технического университета
1. Агишева Д.К., Зотова С.А., Матвеева Т.А., Светличная В.Б. Математическая статистика: учебное пособие // Успехи современного естествознания. – 2010. – № 2. – С. 122-123.
2. Булашкова М.Г., Ломакина А.Н., Чаузова Е.А., Зотова С.А. Роль математики в современном мире // Успехи современного естествознания. – 2012. – № 4. – С. 45-45.
Если признак является непрерывным или число различных значений в выборке велико, вычислять частоту каждого из них не имеет большого смысла. В этом случае составляют интервальный вариационный ряд. Весь промежуток измерения значений выборки, от минимального до максимального, разбивают на частичные интервалы (чаще одинаковой длины), т. е. производится группировка.
Число интервалов следует брать не очень большим, чтобы после группировки ряд не был громоздким, и не очень малым, чтобы не потерять особенности распределения признака.
Число интервалов может быть определено по формуле Стерджеса
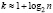 ,
,
где 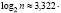 lg n, значение k подбирается целым. Однако такой способ определения числа интервалов является лишь рекомендуемым, но не является обязательным.
lg n, значение k подбирается целым. Однако такой способ определения числа интервалов является лишь рекомендуемым, но не является обязательным.
Длина интервала находится по формуле
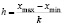 .
.
За начало первого частичного интервала, как правило (но не обязательно), выбирается точка
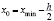 .
.
В первую строку таблицы интервального ряда вписывают частичные промежутки 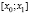 ,
, 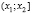 , …,
, …, 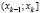 , имеющие одинаковую длину h, при этом весь интервал
, имеющие одинаковую длину h, при этом весь интервал 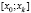 должен полностью покрывать все имеющиеся значения признака, т. е.
должен полностью покрывать все имеющиеся значения признака, т. е. 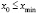 ,
, 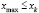 .
.
Во второй строке вписывают количество наблюдений 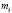 (
(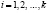 ), попавших в каждый интервал.
), попавших в каждый интервал.
Рассмотрим пример составления интервального вариационного ряда.
В таблице 1 приведена выборка результатов измерения роста 105 студентов (юношей). Измерения проводились с точностью до 1 см.
Требуется составить интервальный вариационный ряд.
Очевидно, что рост юношей есть случайная непрерывная величина. Найдём количество интервалов при
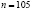 :
: 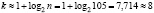 .
.
Т. к. 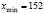 ,
, 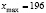 , то длина частичного интервала находится по формуле:
, то длина частичного интервала находится по формуле:
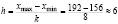 .
.
Примем 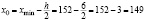 .
.
Исходные данные разбиваем на 8 интервалов: 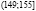 ,
, 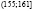 ,
, 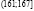 , (167;173],
, (167;173], 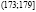 ,
, 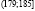 ,
, 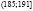 ,
, 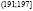 .
.
Подсчитав число студентов 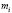 , попавших в каждый из полученных промежутков, получим интервальный вариационный ряд (табл. 2). Здесь
, попавших в каждый из полученных промежутков, получим интервальный вариационный ряд (табл. 2). Здесь
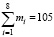 .
.
Таблица 1
|
155 |
170 |
185 |
180 |
188 |
152 |
173 |
178 |
178 |
168 |
185 |
172 |
170 |
183 |
175 |
|
173 |
170 |
183 |
175 |
180 |
175 |
193 |
178 |
183 |
180 |
197 |
178 |
181 |
187 |
168 |
|
174 |
179 |
184 |
183 |
178 |
180 |
178 |
163 |
166 |
178 |
175 |
182 |
190 |
167 |
170 |
|
178 |
183 |
170 |
178 |
181 |
173 |
168 |
185 |
175 |
170 |
155 |
169 |
186 |
179 |
189 |
|
156 |
174 |
179 |
179 |
169 |
186 |
174 |
171 |
184 |
175 |
193 |
178 |
184 |
180 |
196 |
|
175 |
181 |
188 |
168 |
179 |
178 |
183 |
184 |
178 |
181 |
177 |
163 |
166 |
178 |
175 |
|
183 |
190 |
167 |
170 |
178 |
183 |
170 |
178 |
182 |
173 |
168 |
186 |
176 |
171 |
188 |
Таблица 2
|
Рост, |
149-155 |
155-161 |
161-167 |
167-173 |
173-179 |
179-185 |
185-191 |
191-197 |
|
Частота, |
3 |
1 |
6 |
22 |
33 |
26 |
10 |
4 |
Библиографическая ссылка
Дацковская М.А., Колеснёв А.С., Агишева Д.К., Зотова С.А. ИНТЕРВАЛЬНЫЙ ВАРИАЦИОННЫЙ РЯД // Международный студенческий научный вестник. – 2015. – № 3-4.
;
URL: https://eduherald.ru/ru/article/view?id=14154 (дата обращения: 21.05.2023).
Предлагаем вашему вниманию журналы, издающиеся в издательстве «Академия Естествознания»
(Высокий импакт-фактор РИНЦ, тематика журналов охватывает все научные направления)
Варианты для выполнения работы
I. Установление закономерностей, которым подчинены массовые случайные явления, основано на изучении методами теории вероятностей статистических данных — результатов наблюдений.
Почти все встречающиеся в жизни величины (урожайность сельскохозяйственных растений, продуктивности скота, производительность труда и заработная плата рабочих, объем производства продукции и т.д.) принимают неодинаковые значения у различных членов совокупности. Поэтому возникает необходимость в изучении их изменяемости. Это изучение начинается с проведения соответствующих наблюдений, обследований.
В результате наблюдений получают сведения о численной величине изучаемого признака у каждого члена данной совокупности.
Пример. Имеются данные о размере прибыли 100 коммерческих банков. Прибыль, млн. рублей.
| 30,2 | 51,9 | 43,1 | 58,9 | 34,1 | 55,2 | 47,9 | 43,7 | 53,2 | 34,9 |
| 47,8 | 65,7 | 37,8 | 68,6 | 48,4 | 67,5 | 27,3 | 66,1 | 52,0 | 55,6 |
| 54,1 | 26,9 | 53,6 | 42,5 | 59,3 | 44,8 | 52,8 | 42,3 | 55,9 | 48,1 |
| 44,5 | 69,8 | 47,3 | 35,6 | 70,1 | 39,5 | 70,3 | 33,7 | 51,8 | 56,1 |
| 28,4 | 48,7 | 41,9 | 58,1 | 20,4 | 56,3 | 46,5 | 41,8 | 59,5 | 38,1 |
| 41,4 | 70,4 | 31,4 | 52,5 | 45,2 | 52,3 | 40,2 | 60,4 | 27,6 | 57,4 |
| 29,3 | 53,8 | 46,3 | 40,1 | 50,3 | 48,9 | 35,8 | 61,7 | 49,2 | 45,8 |
| 45,3 | 71,5 | 35,1 | 57,8 | 28,1 | 57,6 | 49,6 | 45,5 | 36,2 | 63,2 |
| 61,9 | 25,1 | 65,1 | 49,7 | 62,1 | 46,1 | 39,9 | 62,4 | 50,1 | 33,1 |
| 33,3 | 49,8 | 39,8 | 45,9 | 37,3 | 78,0 | 64,9 | 28,8 | 62,5 | 58,7 |
Из данной таблицы видно, что интересующий нас признак (прибыль банков) меняется от одного члена совокупности к другому, варьирует. Варьирование есть изменяемость признака у отдельных членов совокупности.
Вариационным рядом называется последовательность вариант, записанных в возрастающем порядке и соответствующих им частот.
Число, показывающее, сколько раз повторяется в данной совокупности каждое значение признака, называется частотой.
Составим ранжированный вариационный ряд (выпишем варианты в порядке возрастания):
| 20,4 | 25,1 | 26,9 | 27,3 | 27,6 | 28,1 | 28,4 | 28,8 | 29,3 | 30,2 |
| 31,4 | 33,1 | 33,3 | 33,7 | 34,1 | 34,9 | 35,1 | 35,6 | 35,8 | 36,2 |
| 37,3 | 37,8 | 38,1 | 39,5 | 39,8 | 39,9 | 40,1 | 40,2 | 41,4 | 41,8 |
| 41,9 | 42,3 | 42,5 | 43,1 | 43,7 | 44,5 | 44,8 | 45,2 | 45,3 | 45,5 |
| 45,8 | 45,9 | 46,1 | 46,3 | 46,5 | 47,3 | 47,8 | 47,9 | 48,1 | 48,4 |
| 48,7 | 48,9 | 49,2 | 49,6 | 49,7 | 49,8 | 50,1 | 50,3 | 51,8 | 51,9 |
| 52,0 | 52,3 | 52,5 | 52,8 | 53,2 | 53,6 | 53,8 | 54,1 | 55,2 | 55,6 |
| 55,9 | 56,1 | 56,3 | 57,4 | 57,6 | 57,8 | 58,1 | 58,7 | 58,9 | 59,3 |
| 59,5 | 60,4 | 61,7 | 61,9 | 62,1 | 62,4 | 62,5 | 63,2 | 64,9 | 65,1 |
| 65,7 | 66,1 | 67,5 | 68,6 | 69,8 | 70,1 | 70,3 | 70,4 | 71,5 | 78,0 |
В нашем случае каждое значение признака (варианта вариационного ряда) повторилось только один раз, т.е. значение частоты для всех вариант равно единице. Перейдем к интервальному вариационному ряду, так как интересующий нас признак принимает дробные, практически не повторяющиеся значения.
Для этого необходимо определить число интервалов (классов) и длину интервала (классного промежутка), после чего произвести разноску, т.е. подсчитать для каждого интервала число вариант, попавших в него.
Количество классов устанавливают в зависимости от степени точности, с которой ведется обработка, и количества объектов в выборке. Считается удобным при объеме выборки (n) в пределах от 30 до 60 вариант распределять их на 6-7 классов, при n от 60 до 100 вариант — на 7-8 классов, при n от 100 и более вариант — на 9-17 классов.
Нужное количество групп также может быть ориентировочно вычислено по формуле Стерджесса:
![[k=1+3,322lgn]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-827d2afc3c23ef764fe96a262dc05464_l3.png "Rendered by QuickLaTeX.com")
где  — число групп (классов, интервалов) ряда распределения; n — объем выборки.
— число групп (классов, интервалов) ряда распределения; n — объем выборки.
Можно также использовать выражение:
![[k=sqrt{n}.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-c751034bcfa1dc301e6aa8cc4c208523_l3.png "Rendered by QuickLaTeX.com")
При  они дают примерно одинаковые результаты.
они дают примерно одинаковые результаты.
В рассматриваемом примере о размере прибыли коммерческих банков, n=100. Применяя формулу Стерджесса, получим:
![[k=1+3,322lg100=1+3,322cdot 2=7,644approx 8.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-c58a320e33430cf4c7533ebf191c3ab5_l3.png "Rendered by QuickLaTeX.com")
Однако  Таким образом, число интервалов может быть равно 8, 9, 10 и т.д.
Таким образом, число интервалов может быть равно 8, 9, 10 и т.д.
Нахождение нужного количества групп и их размеров часто бывает взаимообусловлено. Для того, чтобы как-то определиться с числом интервалов, найдем размах вариации — разность между наибольшей и наименьшей вариантой:
![[R=x_{max}-x_{min}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-aafc593639af68dbf52da085dd4d8c8c_l3.png "Rendered by QuickLaTeX.com")
где  — размах вариации,
— размах вариации,
 — наибольшее значение варьирующего признака,
— наибольшее значение варьирующего признака,
 — наименьшее значение варьирующего признака.
— наименьшее значение варьирующего признака.
Найдем размах вариации для рассматриваемой задачи:
![[R=78,0-20,4=57,6]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-56080b6ec34bbf2f588d137e9eaf87cb_l3.png "Rendered by QuickLaTeX.com")
Для того, чтобы найти длину интервала (величину классового промежутка) необходимо разделить размах вариации на число классов и полученную величину округлить таким образом, чтобы было удобно производить сначала разноску, а затем и различные вычисления. Рекомендую округлять до единиц, до которых округлены варианты в исходной таблице, в нашем случае до десятых.
![[happrox frac{R}{k}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-3e0b8eaa452c3f09d2f7f8090a3d7e36_l3.png "Rendered by QuickLaTeX.com")
Согласно формуле получаем
![[happrox frac{57,6}{8}=7,2]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-243ada79cae79e51927cddc6d6d38988_l3.png "Rendered by QuickLaTeX.com")
Теперь необходимо определиться с началом первого интервала. Для этого можно использовать формулу:
![[x_1approx x_{min}-frac{h}{2}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-5a6eab01e8fb5fc5d82b10533b954fc7_l3.png "Rendered by QuickLaTeX.com")
![[x_1approx 20,4-frac{7,2}{2}=16,8.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-f9ce5df5c222c16a62501fec5810487b_l3.png "Rendered by QuickLaTeX.com")
Замечание. За начало первого интервала можно принять некоторое значение, несколько меньшее или само значение . Далее в табличном виде я покажу оба варианта.
Прибавив к началу первого интервала (нижней границе) шаг, получим верхнюю границу первого интервала и одновременно нижнюю границу второго интервала. Выполняя последовательно указанные действия, будем находить границы последующих интервалов до тех пор, пока не будет получено или перекрыто .
Таким образом, верхняя граница одного интервала одновременно является нижней границей другого интервала. Чтобы не возникало сомнений, в какой интервал отнести варианту, попавшую на границу, условимся относить ее к верхнему интервалу.
Составим теперь рабочую таблицу для построения интервального вариационного ряда и произведем подсчет частот вариант, попавших в тот или иной интервал.
Как и обещал покажу две таблицы построения ряда:
1. Отсчет ведем от , т.е. нижняя граница первого интервала совпадает с .
|
Группы банков по размеру прибыли (границы интервалов) |
Количество банков, принадлежащих данной группе (частоты, |
Накопленные частоты,
|
| 20,4 — 27,6 | 4 | 4 |
| 27,6 — 34,8 | 11 | 15 |
| 34,8 — 42 | 16 | 31 |
| 42 — 49,2 | 21 | 52 |
| 49,2 — 56,4 | 21 | 73 |
| 56,4 — 63,6 | 15 | 88 |
| 63,6 — 70,8 | 10 | 98 |
| 70,8 — 78 | 2 | 100 |

2. Начало первого интервала определяем с помощью формулы:  .
.
|
Группы банков по размеру прибыли (границы интервалов) |
Количество банков, принадлежащих данной группе (частоты, |
Накопленные частоты,
|
| 16,8 — 24 | 1 | 1 |
| 24 — 31,2 | 9 | 10 |
| 31,2 — 38,4 | 13 | 23 |
| 38,4 — 45,6 | 17 | 40 |
| 45,6 — 52,8 | 23 | 63 |
| 52,8 — 60 | 18 | 81 |
| 60 — 67,2 | 11 | 92 |
| 67,2 — 74,4 | 7 | 99 |
| 74,4 — 81,6 | 1 | 100 |
Как мы видим в 1-м случае у нас получилось восемь интервалов, что полностью совпадает с результатом, который нам дала формула Стерджесса. Во втором случае у нас получилось девять интервалов, так как при поиске начала первого интервала пользовались специальной формулой.
Для дальнейшего исследования я буду пользоваться результатами второй таблицы, так как там ярко выражен модальный интервал (одна мода) и медиана практически точно попадает на середину вариационного ряда.
Мы получили интервальный вариационный ряд — упорядоченную совокупность интервалов варьирования значений случайной величины с соответствующими частотами попаданий в каждый из них значений величины.
II. Графическая интерпретация вариационных рядов.
| № п/п |
Границы интервалов,
|
Середины интервалов,
|
Частоты интервалов,
|
Относительные частоты
|
Плотность относит. частоты
|
Плотность частоты
|
| 1 | 16,8 — 24 | 20,4 | 1 | 0,01 | 0,001 | 0,139 |
| 2 | 24 — 31,2 | 27,6 | 9 | 0,09 | 0,013 | 1,250 |
| 3 | 31,2 — 38,4 | 34,8 | 13 | 0,13 | 0,018 | 1,806 |
| 4 | 38,4 — 45,6 | 42 | 17 | 0,17 | 0,024 | 2,361 |
| 5 | 45,6 — 52,8 | 49,2 | 23 | 0,23 | 0,032 | 3,194 |
| 6 | 52,8 — 60 | 56,4 | 18 | 0,18 | 0,025 | 2,500 |
| 7 | 60 — 67,2 | 63,6 | 11 | 0,11 | 0,015 | 1,528 |
| 8 | 67,2 — 74,4 | 70,8 | 7 | 0,07 | 0,010 | 0,972 |
| 9 | 74,4 — 81,6 | 78 | 1 | 0,01 | 0,001 | 0,139 |
 |
 |





Строим графики:





Далее найдем моду вариационного ряда:
![[M_o(X)=x_{M_o}+hfrac{(n_2-n_1)}{(n_2-n_1)+(n_2-n_3)}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-5618d73a38aaff5a278596c8af7758c8_l3.png "Rendered by QuickLaTeX.com")
где
 — начало модального интервала;
— начало модального интервала;
 — длина частичного интервала (шаг);
— длина частичного интервала (шаг);
 — частота предмодального интервала;
— частота предмодального интервала;
 — частота модального интервала;
— частота модального интервала;
 — частота послемодального интервала.
— частота послемодального интервала.
Определим модальный интервал — интервал, имеющий наибольшую частоту. Из таблицы видно, что модальным является интервал (45,6 — 52,8).
![[M_o(X)=45,6+7,2frac{(23-17)}{(23-17)+(23-18)}=]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-473f77b88c7bd6de3e31bd12541d8833_l3.png "Rendered by QuickLaTeX.com")
![[=45,6+7,2cdot frac{6}{6+5}=45,6+3,93=49,5]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-9122e42dfec05a0505617226d32d75df_l3.png "Rendered by QuickLaTeX.com")
Медиана
Для интервального ряда медиана находится по формуле:
![[M_e(X)=x_{M_e}+hfrac{0,5n-S_{M_{e}-1}}{n_{M_e}}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-c464daab40bab9748a191e3a00b95831_l3.png "Rendered by QuickLaTeX.com")
где
 — начало медианного интервала;
— начало медианного интервала;
— длина частичного интервала (шаг);
 — объем совокупности;
— объем совокупности;
 — накопленная частота интервала, предшествующая медианному;
— накопленная частота интервала, предшествующая медианному;
 — частота медианного интервала.
— частота медианного интервала.
Определим медианный интервал — интервал, в котором впервые накопленная частота превышает половину объема выборки.Так как объем выборки n=100, то n/2=50. По таблице найдем интервал, где впервые накопленные частоты превысят это значение. Таким является интервал (45,6 — 52,8).
Получаем,
![[M_e(X)=45,6+7,2frac{0,5cdot 100-40}{23}approx 48,7.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-d820d343bc16acd48af9d431995a7222_l3.png "Rendered by QuickLaTeX.com")
III. Расчет сводных характеристик выборки.
Для определения  составим расчетную таблицу. Для начала определимся с ложным нулем С. В качестве ложного нуля можно принять любую варианту. Максимальная простота вычислений достигается, если выбрать в качестве ложного нуля варианту, которая расположена примерно в середине вариационного ряда (часто такая варианта имеет наибольшую частоту).
составим расчетную таблицу. Для начала определимся с ложным нулем С. В качестве ложного нуля можно принять любую варианту. Максимальная простота вычислений достигается, если выбрать в качестве ложного нуля варианту, которая расположена примерно в середине вариационного ряда (часто такая варианта имеет наибольшую частоту).
Варианте, которая принята в качестве ложного нуля, соответствует условная варианта, равная нулю. В нашем случае С=49,2.
Равноотстоящими называют варианты, которые образуют арифметическую прогрессию с разностью h.
Условными называют варианты, определяемые равенством:
![[U_i=frac{(x_i-C)}{h}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-c6c24a440a025414d18ebe8781aa22b6_l3.png "Rendered by QuickLaTeX.com")
Произведем расчет условных вариант согласно формуле:
![[U_1=frac{20,4-49,2}{7,2}=-4]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-159a490fe276ae2b2a6081e4f9647090_l3.png "Rendered by QuickLaTeX.com")
![[U_2=frac{27,6-49,2}{7,2}=-3]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-a3e4e66d8520f3a12aa6519c36e69ba1_l3.png "Rendered by QuickLaTeX.com")
![[U_3=frac{34,8-49,2}{7,2}=-2]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-187afa35d11ed679a257edd766e3a0f1_l3.png "Rendered by QuickLaTeX.com")
![[U_4=frac{42-49,2}{7,2}=-1]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-929695d78c47d35b023c9dc2d11f5a3f_l3.png "Rendered by QuickLaTeX.com")
![[U_5=frac{49,2-49,2}{7,2}=0]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-aa956af961d374361e948bd16a3e1317_l3.png "Rendered by QuickLaTeX.com")
![[U_6=frac{56,4-49,2}{7,2}=1]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-fb490f3a7e06599bee2c19bcc67e4b9f_l3.png "Rendered by QuickLaTeX.com")
![[U_7=frac{63,6-49,2}{7,2}=2]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-8a98b7a3d0f9e4d9733242a9bf102866_l3.png "Rendered by QuickLaTeX.com")
![[U_8=frac{70,8-49,2}{7,2}=3]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-e9d062cda3a1324da90f6286b5542af0_l3.png "Rendered by QuickLaTeX.com")
![[U_9=frac{78-49,2}{7,2}=4]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-aa53c7e67e340a81ca72c0b720d8ca36_l3.png "Rendered by QuickLaTeX.com")
| N п/п |
Середины интервалов,
|
Частоты интервалов,
|
Условные варианты,
|
Произведения частот и условных вариант,
|
Произведения частот и условных вариант,
|
Произведения частот и условных вариант,
|
Произведения частот и условных вариант,
|
Произведения частот и условных вариант,
|
Произведения частот и условных вариант,
|
| 1 | 20,4 | 1 | -4 | -4 | 16 | -64 | 256 | 9 | 81 |
| 2 | 27,6 | 9 | -3 | -27 | 81 | -243 | 729 | 36 | 144 |
| 3 | 34,8 | 13 | -2 | -26 | 52 | -104 | 208 | 13 | 13 |
| 4 | 42 | 17 | -1 | -17 | 17 | -17 | 17 | 0 | 0 |
| 5 | 49,2 | 23 | 0 | 0 | 0 | 0 | 0 | 23 | 23 |
| 6 | 56,4 | 18 | 1 | 18 | 18 | 18 | 18 | 72 | 288 |
| 7 | 63,6 | 11 | 2 | 22 | 44 | 88 | 176 | 99 | 891 |
| 8 | 70,8 | 7 | 3 | 21 | 63 | 189 | 567 | 112 | 1792 |
| 9 | 78 | 1 | 4 | 4 | 16 | 64 | 256 | 25 | 625 |
|
 |
 |
 |
 |
 |
 |








Контроль:
![[sum n_i U_i^2 + 2sum n_iU_i+n=sum n_i{(U_i+1)}^2]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-bfe916445efb3e33681b87967ff3ee72_l3.png "Rendered by QuickLaTeX.com")
![[sum n_i U_i^2 + 2sum n_iU_i+n=307+2cdot (-9)+100=389]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-c979f642509fc9a23d3107e2a82fc723_l3.png "Rendered by QuickLaTeX.com")
![[sum n_i{(U_i+1)}^2=389]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-6b54236fb1d63f048c9dbec240de42d5_l3.png "Rendered by QuickLaTeX.com")
Контроль:
![[sum n_i U_i^4 + 4sum n_iU_i^3+6sum n_iU_i^2+4sum n_iU_i+n=sum n_i{(U_i+1)}^4]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-f07f4af98630f4642b04e2030e849232_l3.png "Rendered by QuickLaTeX.com")
![[sum n_i U_i^4 + 4sum n_iU_i^3+6sum n_iU_i^2+4sum n_iU_i+n=]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-fb86aec2d3151a542084e9e4805ecb1f_l3.png "Rendered by QuickLaTeX.com")
![[=2227+4cdot (-69)+6 cdot 307+4cdot (-9)+100=3857]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-81abf9514098d32eca4d80dbef425404_l3.png "Rendered by QuickLaTeX.com")
![[sum n_i{(U_i+1)}^4=3857]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-08ea4071bdd89be8534b6573048c6226_l3.png "Rendered by QuickLaTeX.com")
Равенство выполнено, следовательно вычисления произведены верно.
Вычислим условные моменты 1-го, 2-го, 3-го и 4-го порядков:
![[M_1^{*}=frac{sum n_iU_i}{n}=frac{-9}{100}=-0,09;]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-20762ac62aef7ff58d3d5a21f72d97fc_l3.png "Rendered by QuickLaTeX.com")
![[M_2^{*}=frac{sum n_iU_i^2}{n}=frac{307}{100}=3,07;]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-49fc1f9b0b295a1fc1aa27f267380093_l3.png "Rendered by QuickLaTeX.com")
![[M_3^{*}=frac{sum n_iU_i^3}{n}=frac{-69}{100}=-0,69;]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-dd8d7a50c08c5c1dd7b8a871e2493bde_l3.png "Rendered by QuickLaTeX.com")
![[M_4^{*}=frac{sum n_iU_i^4}{n}=frac{2227}{100}=22,27.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-8513720d7a2df45aaa7d99686e4d4436_l3.png "Rendered by QuickLaTeX.com")
Найдем выборочные среднюю, дисперсию и среднее квадратическое отклонение :
![[x_{B}=M_1^{*}cdot h+C=-0,09cdot 7,2+49,2=48,552;]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-01563ec6dda7fdedaa93513c74ff997e_l3.png "Rendered by QuickLaTeX.com")
![[D_{B}=(M_2^{*}-{(M_1^{*})}^2)h^2=(3,07-{(-0,09)}^2){7,2}^2approx 158,73.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-db67c404df7fbd10fcba1803dc1d9aef_l3.png "Rendered by QuickLaTeX.com")
![[sigma_{B}=sqrt{D_B}=sqrt{158,73}=12,6.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-d8d05199c63db71062b09ee4969f6df5_l3.png "Rendered by QuickLaTeX.com")
Также для оценки отклонения эмпирического распределения от нормального используют такие характеристики, как асимметрия и эксцесс.
Асимметрией теоретического распределения называют отношение центрального момента третьего порядка к кубу среднего квадратического отклонения:
![[a_s=frac{m_3}{sigma_B^3}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-b4a9bc811679794242a602b480953ec6_l3.png "Rendered by QuickLaTeX.com")
Асимметрия положительна, если «длинная часть» кривой распределения расположена справа от математического ожидания; асимметрия отрицательна, если «длинная часть» кривой расположена слева от математического ожидания. Практически определяют знак асимметрии по расположению кривой распределения относительно моды (точки максимума дифференциальной функции): если «длинная часть» кривой расположена правее моды, то асимметрия положительна, если слева — отрицательна.
Эксцесс эмпирического распределения определяется равенством:
![[e_k=frac{m_4}{sigma_B^4}-3]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-ebd36893c40d9e5760b22c5515404887_l3.png "Rendered by QuickLaTeX.com")
где  — центральный эмпирический момент четвертого порядка.
— центральный эмпирический момент четвертого порядка.
Для нормального распределения эксцесс равен нулю. Поэтому если эксцесс некоторого распределения отличен от нуля, то кривая этого распределения отличается от нормальной кривой: если эксцесс положительный, то кривая имеет более высокую и «острую» вершину, чем нормальная кривая; если эксцесс отрицательный, то сравниваемая кривая имеет более низкую и «плоскую» вершину, чем нормальная кривая. При этом предполагается, что нормальное и теоретическое распределения имеют одинаковые математические ожидания и дисперсии.
Вычисляем центральные эмпирические моменты третьего и четвертого порядков:
![[m_3=(M_3^*-3M_1^*M_2^*+2{(M_1^*)}^3)cdot h^3=51,3;]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-35fa469c4f36b2aae7705925a013be5e_l3.png "Rendered by QuickLaTeX.com")
![[m_4=(M_4^*-4M_3^*M_1^*+6M_2^*{(M_1^*)}^2-3{(M_1^*)}^4)cdot h^4=59580,97;]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-f687774454962c3d0e3377e6df0573e8_l3.png "Rendered by QuickLaTeX.com")
Найдем асимметрию и эксцесс:
![[a_s=frac{51,3}{{12,6}^3}=0,026]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-3ea65f54fb9839acecf06e17f7a04d64_l3.png "Rendered by QuickLaTeX.com")
![[e_k=frac{59580,97}{{12,6}^4}-3=-0,635]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-0ed5e864eda55df96619480c0a06a254_l3.png "Rendered by QuickLaTeX.com")
IV. Проверка гипотезы о нормальном распределении генеральной совокупности. Критерий согласия Пирсона.
Проверим генеральную совокупность значений размера прибыли банков по критерию Пирсона 
Правило. Для того, чтобы при заданном уровне значимости проверить нулевую гипотезу  : генеральная совокупность распределена нормально, надо сначала вычислить теоретические частоты, а затем наблюдаемое значение критерия:
: генеральная совокупность распределена нормально, надо сначала вычислить теоретические частоты, а затем наблюдаемое значение критерия:
![[chi^2_{nabl}=sum frac{ {(n_i-n_i^{'})}^2}{n_i^{'}}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-43685ed67e69272b6c950828a97acd89_l3.png "Rendered by QuickLaTeX.com")
и по таблице критических точек распределения , по заданному уровню значимости  и числу степеней свободы
и числу степеней свободы  найти критическую точку
найти критическую точку  , где s — количество интервалов.
, где s — количество интервалов.
Если  — нет оснований отвергнуть нулевую гипотезу.
— нет оснований отвергнуть нулевую гипотезу.
Если  — нулевую гипотезу отвергают.
— нулевую гипотезу отвергают.
Найдем теоретические частоты  , для этого составим следующую таблицу.
, для этого составим следующую таблицу.
|
Середины интервалов,
|
Частоты интервалов,
|
Произведем расчет,
|
Произведем расчет,
|
Значения функции Гаусса,
|
Произведем расчет,
|
Теоретические частоты,
|
| 20,4 | 1 | -28,152 | -2,23 | 0,0332 | 57 | 2 |
| 27,6 | 9 | -20,952 | -1,66 | 0,1006 | 57 | 6 |
| 34,8 | 13 | -13,752 | -1,09 | 0,2203 | 57 | 13 |
| 42 | 17 | -6,552 | -0,52 | 0,3485 | 57 | 20 |
| 49,2 | 23 | 0,648 | 0,05 | 0,3984 | 57 | 23 |
| 56,4 | 18 | 7,848 | 0,62 | 0,3292 | 57 | 19 |
| 63,6 | 11 | 15,048 | 1,19 | 0,1965 | 57 | 11 |
| 70,8 | 7 | 22,248 | 1,77 | 0,0833 | 57 | 5 |
| 78 | 1 | 29,448 | 2,34 | 0,0258 | 57 | 1 |
 |
 |





Вычислим  , для чего составим расчетную таблицу.
, для чего составим расчетную таблицу.
 |
 |
 |
 |
 |
 |
 |
 |
| 1 | 1 | 2 | -1 | 1 | 0,5 | 1 | 0,5 |
| 2 | 9 | 6 | 3 | 9 | 1,5 | 81 | 13,5 |
| 3 | 13 | 13 | 0 | 0 | 0 | 169 | 13 |
| 4 | 17 | 20 | -3 | 9 | 0,45 | 289 | 14,45 |
| 5 | 23 | 23 | 0 | 0 | 0 | 529 | 23 |
| 6 | 18 | 19 | -1 | 1 | 0,05 | 324 | 17,05 |
| 7 | 11 | 11 | 0 | 0 | 0 | 121 | 11 |
| 8 | 7 | 5 | 2 | 4 | 0,8 | 49 | 9,8 |
| 9 | 1 | 1 | 0 | 0 | 0 | 1 | 1 |
 |
100 | 100 |
Наблюдаемое значение критерия,
|
103,30 |

Контроль:
![[sumfrac{n_i^2}{n_i^{'}}-n=sum frac{{(n_i-n_i^{'})}^2}{n_i^'}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-6c32fcc2a5c6b3b4b603ae3d99533b4a_l3.png "Rendered by QuickLaTeX.com")
![[sumfrac{n_i^2}{n_i'}-n=103,3-100=3,3]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-a9fda2a1f7cb2dccff4e36db3eca149a_l3.png "Rendered by QuickLaTeX.com")
![[sum frac{{(n_i-n_i')}^2}{n_i'}=3,3]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-008fc9e192109f46116930043ed491f9_l3.png "Rendered by QuickLaTeX.com")
Вычисления произведены правильно.
Найдем число степеней свободы, учитывая, что число групп выборки (число различных вариант) s=9;
![[k=s-3=9-3=6.]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-591c6b21dce56f5cf0fa9cd47789d7b6_l3.png "Rendered by QuickLaTeX.com")
По таблице критических точек распределения по уровню значимости  и числу степеней свободы k=6 находим
и числу степеней свободы k=6 находим 
Так как — нет оснований отвергнуть нулевую гипотезу. Другими словами, расхождение эмпирических и теоретических частот незначительное. Следовательно, данные наблюдений согласуются с гипотезой о нормальном распределении генеральной совокупности.
На рисунке построены нормальная (теоретическая) кривая по теоретическим частотам (зеленый график) и полигон наблюдаемых частот (коричневый график). Сравнение графиков наглядно показывает, что построенная теоретическая кривая удовлетворительно отражает данные наблюдений.

V. Интервальные оценки.
Интервальной называют оценку, которая определяется двумя числами — концами интервала, покрывающего оцениваемый параметр.
Доверительным называют интервал, который с заданной надежностью  покрывает заданный параметр.
покрывает заданный параметр.
Интервальной оценкой (с надежностью ) математического ожидания (а) нормально распределенного количественного признака Х по выборочной средней  при известном среднем квадратическом отклонении
при известном среднем квадратическом отклонении  генеральной совокупности служит доверительный интервал
генеральной совокупности служит доверительный интервал
![[x_B-frac{tsigma}{sqrt{n}}<a<x_B+frac{tsigma}{sqrt{n}},]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-9750e199194b01ecfa06ba1601feab7d_l3.png "Rendered by QuickLaTeX.com")
где  — точность оценки, n — объем выборки, t — значение аргумента функции Лапласа
— точность оценки, n — объем выборки, t — значение аргумента функции Лапласа  (см. приложение 2), при котором
(см. приложение 2), при котором  ;
;
при неизвестном среднем квадратическом отклонении (и объеме выборки n<30)
![[x_B-frac{t_{gamma}cdot S}{sqrt{n}}<a<x_B+frac{t_{gamma}cdot S}{sqrt{n}},]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-d9ee32ae620adb447d86d28cba84e871_l3.png "Rendered by QuickLaTeX.com")
![[S=sqrt{frac{n}{n-1}D_B}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-dfe89e1cead729b251b9981b9eac134b_l3.png "Rendered by QuickLaTeX.com")
где S — исправленное выборочное среднее квадратическое отклонение,  находят по таблице приложения по заданным n и .
находят по таблице приложения по заданным n и .
В нашем примере среднее квадратическое отклонение известно,  . А также
. А также  , ,
, ,  . Поэтому для поиска доверительного интервала используем первую формулу:
. Поэтому для поиска доверительного интервала используем первую формулу:
![[x_B-frac{tsigma}{sqrt{n}}<a<x_B+frac{tsigma}{sqrt{n}}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-600f869b70725152f297f8ba0a2459fa_l3.png "Rendered by QuickLaTeX.com")
Все величины, кроме t, известны. Найдем t из соотношения  По таблице приложения находим t=1,96. Подставив t=1,96, , , в формулу, окончательно получим искомый доверительный интервал:
По таблице приложения находим t=1,96. Подставив t=1,96, , , в формулу, окончательно получим искомый доверительный интервал:
![[48,55-frac{1,96cdot 12,6}{10}<a<48,55+frac{1,96cdot 12,6}{10}]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-18be4f2ab8257c8e7f50af9fdc1766fa_l3.png "Rendered by QuickLaTeX.com")
![[48,55-2,47<a<48,55+2,47]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-268428dac12802b423e852d51d9dd03d_l3.png "Rendered by QuickLaTeX.com")
![[46,08<a<51,02]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-45b72334d0171fd5dd4329bd36b155b3_l3.png "Rendered by QuickLaTeX.com")
Интервальной оценкой (с надежностью ) среднего квадратического отклонения нормально распределенного количественного признака Х по «исправленному» выборочному среднему квадратическому отклонению S служит доверительный интервал
 (при q<1), (*)
(при q<1), (*)
 (при q>1),
(при q>1),
где q — находят по таблице приложения по заданным n и .
По данным и n=100 по таблице приложения 4 найдем q=0,143. Так как q<1, то, подставив  в соотношение (*), получим доверительный интервал:
в соотношение (*), получим доверительный интервал:
![[12,66(1-0,143)<sigma<12,66(1+0,143)]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-a4a65a9250ea6393a930f1b29215644f_l3.png "Rendered by QuickLaTeX.com")
![[10,85<sigma<14,47]](https://ischanow.com/wp-content/ql-cache/quicklatex.com-f3d033cb268eca08d52ccfbe86fecd99_l3.png "Rendered by QuickLaTeX.com")
