Время на прочтение
4 мин
Количество просмотров 90K
Стандартная библиотека python, начиная с версии 2.2, предоставляет множество средств для генерирования комбинаторных объектов, но в интернете мне не удалось найти ни одной статьи, которая подробно рассказывала бы о работе с ними. Поэтому я решил исправить это упущение.
Начну с того, что расскажу о комбинаторике и ее основных формулах. Если же вы уже знакомы с этим разделом математики — можете пропустить эти абзацы.
Допустим, у нас есть строка, состоящая из n разных букв и мы хотим вычислить все способы переставить эти буквы местами так, чтобы получить новую строку. На первую позицию в строке мы можем выбрать одну из n букв, имеющихся у нас, на вторую позицию одну из n-1-ой буквы и так далее. В итоге получаем произведение n (n-1)… *1 = n! количество перестановок из n элементов без повторений.
Теперь представим, что количество букв в строке ограничено. У нас есть n доступных букв и мы хотим вычислить количество способов составить из них строку длины k, где k < n, каждую букву мы можем использовать лишь единожды. Тогда на первую позицию в строке мы можем поставить одну из n букв, на вторую позицию одну из n-1 буквы и на k-ую позицию одну из n-k+1 буквы. Общее количество строк будет равно n (n — 1) (n — 2) … (n — k + 2) (n — k + 1) = n!/(n-k)! количество размещений из n по k. Если же уникальность букв не требуется, то мы получим формулу n…nn = n^k количество размещений из n по k с повторениями.
До этого мы перебирали последовательности с учетом порядка элементов, а что если порядок для нас не имеет значения. Например, у нас есть есть n разных конфет и мы хотим выбрать k из них, чтобы подарить другу, при чем k < n. Сколько существует способов выбрать k конфет из n без учета порядка? Ответ прост, в начале найдем размещение из n по k без повторений, но тогда одинаковые наборы конфет, имеющие разный порядок их следования будут повторяться. Сколько существует способов переставить k конфет? Правильно, перестановка из k элементов без повторений. Итоговый ответ: размещения из n по k делим на перестановки из k без повторений. Формула:  количество сочетаний из n по k.
количество сочетаний из n по k.
Рассмотрим случай посложнее, у нас есть n коробок каждая из которых содержит множество конфет одного вкуса, но в разных коробках вкусы разные. Сколько существует способов составить подарок другу из k конфет, при чем один и тот же вкус может встречаться любое количество раз? Так как порядок для нас значения не имеет, давайте разложим подарочные сладости следующим образом: в начале будут лежать последовательно конфеты первого вкуса, затем второго и так далее, а между конфетами разных вкусов положим спички, если конфеты какого-то вкуса отсутствуют в нашем подарке — спички, которые должны были окаймлять этот вкус слева и справа будут стоять рядом. Того у нас получится последовательность, состоящая из k конфет и n-1 спички, ибо вкусов всего n, а спички разделяют их. Теперь заметим, что по расположению спичек, мы можем восстановить исходное множество. Тогда ответом будет количество способов разместить n-1 спичку в n+k-1 ячейку без учета порядка, что равно количеству сочетаний из n+k-1 по n-1, формула:  количество сочетаний из n по k с повторениями.
количество сочетаний из n по k с повторениями.
Теперь рассмотрим несколько задач на комбинаторику, чтобы закрепить материал.
Задача 1
Есть 20 человек, сколько существует способов разбить их на пары
Решение: возьмем первого человека, сколько существует способов выбрать ему пару:  , возьмем второго человека, сколько существует способов выбрать ему пару:
, возьмем второго человека, сколько существует способов выбрать ему пару:  . Ответ: 19!!! = 654729075
. Ответ: 19!!! = 654729075
Задача 2
Есть 10 мужчин и 10 девушек, сколько существует способов разбить их на компании, состоящие из одинакового количества и мужчин и девушек, пустая компания не считается
Решение:
Cпособ 1: количество способов собрать компанию из одного мужчины и одной девушки равно произведению количества способов выбрать одну девушку и количества способов выбрать одного мужчину. Количество способов выбрать одну девушку из 10 равно сочетанию из 10 по 1 без повторений, с мужчинами аналогично, поэтому возведем в квадрат. Далее аналогично вычислим сочетания из 10 по 2, из 10 по 3 и так далее до сочетания из 10 по 10. Итоговая формула:  .
.
Способ 2: рассмотрим множество мужчин, входящих в компанию и множество девушек, не входящих в нее. По этому множеству можно однозначно восстановить компанию, а количество людей в нем всегда равно 10, так как  , k — количество мужчин в компании,
, k — количество мужчин в компании,  — количество девушек, не вошедших в нее. Количество таких множеств равно количеству сочетаний из 20 по 10, в конечном ответе мы также вычтем единицу, чтобы не учитывать пустую компанию, когда в нашем множестве 10 девушек. Итоговая формула:
— количество девушек, не вошедших в нее. Количество таких множеств равно количеству сочетаний из 20 по 10, в конечном ответе мы также вычтем единицу, чтобы не учитывать пустую компанию, когда в нашем множестве 10 девушек. Итоговая формула:  .
.
Итак, мы разобрались с теорией, теперь научимся генерировать комбинаторные объекты с помощью стандартной библиотеки python.
Работать мы будем с библиотекой itertools
from itertools import *С помощью функции permutations можно сгенерировать все перестановки для итерируемого объекта.
Пример 1
for i in permutations('abc'):
print(i, end=' ') # abc acb bac bca cab cba
print()
for i in permutations('abb'):
print(i, end=' ') # abb abb bab bba bab bba Исходя из второго вызова заметим, что одинаковые элементы, стоящие на разных позициях, считаются разными.
Пример 2
for i in permutations('abc', 2):
print(i, end=' ') # ab ac ba bc ca cb Размещение отличается от перестановки ограничением на количество доступных ячеек
Пример 3
for i in product('abc', repeat=2):
print(i, end=' ') # aa ab ac ba bb bc ca cb ccC помощью размещений с повторениями можно легко перебрать все строки фиксированной длины, состоящие из заданных символов
Пример 4
for i in combinations('abcd', 2):
print(i, end=' ') # ab ac ad bc bd cd С помощью сочетаний без повторений можно перебрать все наборы не повторяющихся букв из заданной строки, массива или другого итерируемого объекта без учета порядка
Пример 5
for i in combinations_with_replacement('abcd', 2):
print(i, end=' ') # aa ab ac ad bb bc bd cc cd dd Результат аналогичен вызову combinations, но в результат также добавлены множества с одинаковыми элементами.
Материалы:
Н.В. Горбачев “Сборник олимпиадных задач по математике”
Документация по python на русском
Число сочетаний можно найти используя рекурсию и, соответственно, рекуррентное соотношение. Код получается вот такой:
def C(n, k):
if k == n or k == 0:
return 1
if k != 1:
return C(n-1, k) + C(n-1, k-1)
else:
return n
print(C(int(input()), int(input())))
Но я знаю, что рекурсия штука не быстрая и не всегда надежная. Есть ли другие алгоритмы и на сколько они быстрые?
задан 16 авг 2019 в 11:36
![]()
Antivist HomeAntivist Home
751 золотой знак3 серебряных знака10 бронзовых знаков
7
Через факториал медленно и не эффективно.
В формуле n! / (k! (n - k)!), если сократить, то получится (n-k+1)(n-k+2)..n/k!
Получается такой код:
def С(n, k):
if 0 <= k <= n:
nn = 1
kk = 1
for t in xrange(1, min(k, n - k) + 1):
nn *= n
kk *= t
n -= 1
return nn // kk
else:
return 0
Также можно посмотреть библиотеку itertools:
combinations('ABCD', 2) # AB AC AD BC BD CD
![]()
nomnoms12
18.3k5 золотых знаков22 серебряных знака47 бронзовых знаков
ответ дан 16 авг 2019 в 11:47
![]()
используйте math.comb
import math
n = int(input())
k = int(input())
print(math.comb(n, k))
ответ дан 22 фев 2021 в 21:03
![]()
DanisDanis
19k5 золотых знаков20 серебряных знаков55 бронзовых знаков
Предлагаю использовать модуль itertools, там сразу реализована нужная операция. Она составляет необходимые сочетания. Подсчитать их кол-во не составит труда.
import itertools
def C(n, k):
return len(list(itertools.combinations(range(1, n), k)))
Хочу заметить, что сочетания она может составлять из чего угодно (т.е. передавать можно любой итерируемый контейнер).
ответ дан 16 авг 2019 в 11:45
![]()
V-MorV-Mor
5,1171 золотой знак13 серебряных знаков31 бронзовый знак
4
Для ТС уже неактуально, наверное, но может кому пригодится.
Треугольник Паскаля (сочетания – это биномиальные коэффициенты).
Чтобы его “нарисовать”, умножать вообще не нужно.
Быстрее уже никак.
ответ дан 12 ноя 2020 в 8:12
![]()
7
In this tutorial, you’ll learn how to use Python to get all combinations of a list. In particular, you’ll learn how to how to use the itertool.combinations method to generate a list of all combinations of values in a list.
The Quick Answer: Use itertools.combinations to Get All Combinations of a List

What Does it Mean to Get All Combinations of a List?
In your Python journey, you may encounter the need to get all combinations of the items in a list. But what does this mean?
Let’s say you have a list that looks like this: ['a', 'b', 'c'].
When you create a list of all possible combinations, you’ll end up with a list that looks like this: [(), ('a',), ('b',), ('c',), ('a', 'b'), ('a', 'c'), ('b', 'c'), ('a', 'b', 'c')]. Here we get a list of tuples that contain all possible combinations without replacement.
Now that you know what it means to get a list of all possible combinations of a list in Python, let’s see how you can get this done in Python!
Python comes built-in with a helpful library called itertools, that provides helpful functions to work with iteratable objects. One of the many functions it comes with it the combinations() function. This, as the name implies, provides ways to generate combinations of lists.
Let’s take a look at how the combinations() function works:
itertools.combinations(iterable, r)iterablerefers to the iterable for which you want to find combinations,rrefers to the length of the combinations you want to produce
Now that you know how the combinations() function works, let’s see how we can generate all possible combinations of a Python list’s items:
from itertools import combinations
sample_list = ['a', 'b', 'c']
list_combinations = list()
for n in range(len(sample_list) + 1):
list_combinations += list(combinations(sample_list, n))
print(list_combinations)
# Returns: [(), ('a',), ('b',), ('c',), ('a', 'b'), ('a', 'c'), ('b', 'c'), ('a', 'b', 'c')]Let’s break down what we’ve done here:
- We import the
combinationsfunction fromitertools - We create a sample list and an empty list to store our data in
- We then create a for-loop to loop over all possible combinations of lengths. To make this dynamic, we use the
range()function, since we may not know how long our list is at any given time. - We then create a list out of the combinations object that’s returned from passing in our sample list and our
nparameter
We can see that our list includes a blank combination as well. If we wanted to omit this, we could change our for-loop to be from range(1, len(sample_list)+1), in order to have a minimum number of elements in our combination.
In the next section, you’ll learn how to get all combinations of only unique values in a list.
Want to learn more about Python for-loops? Check out my in-depth tutorial here to learn all you need to know!
How to Get All Combinations of Unique Values of a List in Python
In this section, you’ll learn how to get all combinations of only unique values of a list in Python. Since Python lists can contain duplicate values, we’ll need to figure out how to do this.
Say we have a list that looks like this: ['a', 'b', 'c', 'c']. Instead of including duplicate combinations of c in our final list, we’ll first need to remove duplicates from our list.
Let’s see how we can do this in Python:
from itertools import combinations
sample_list = ['a', 'b', 'c', 'c']
list_combinations = list()
sample_set = set(sample_list)
for n in range(len(sample_set) + 1):
list_combinations += list(combinations(sample_set, n))
print(list_combinations)This follows the same logic as the example above. The only difference is that we have first created a set out of our list. Sets are a unique data structure in Python that require each item to be unique. Therefore, it’s a helpful way to de-duplicate our list.
We then iterate over the length of the set and the set itself, to create all possible combinations.
How to Get All Combinations with Replacement of a List in Python
In this final section, you’ll learn how to get all combinations of a list in Python with replacements. Meaning, that a single element has the potential for being picked again.
Let’s see how this can be done in Python, using itertools and the combinations_with_replacement function. The function does exactly what it is described as: it gets the combinates with replacements.
from itertools import combinations_with_replacement
sample_list = ['a', 'b', 'c']
list_combinations = list()
for n in range(len(sample_list) + 1):
list_combinations += list(combinations_with_replacement(sample_list, n))
print(list_combinations)
# Returns: [(), ('a',), ('b',), ('c',), ('a', 'a'), ('a', 'b'), ('a', 'c'), ('b', 'b'), ('b', 'c'), ('c', 'c'), ('a', 'a', 'a'), ('a', 'a', 'b'), ('a', 'a', 'c'), ('a', 'b', 'b'), ('a', 'b', 'c'), ('a', 'c', 'c'), ('b', 'b', 'b'), ('b', 'b', 'c'), ('b', 'c', 'c'), ('c', 'c', 'c')]We can see here that each item has the potential for being included once, twice, or three times in a list of three items.
Conclusion
In this post, you learned how to get all combinations of a list in Python. You learned how to do this with the itertools.combinations function and the `itertools.combinations_with_replacement_ function. The functions allow you to pass in a list and get the combinations without and with replacements, respectively.
To learn more about the itertools.combinations function, check out the official documentation here.
Комбинаторика — это раздел математики, в котором изучают, сколько комбинаций, подчинённых тем или иным условиям, можно составить из данных объектов. Короче, это все о сочетаниях, перестановках, числе способов и тому подобному.
Почему важна комбинаторика? Нет, не только лишь для решения олимпиадных задач, но также комбинаторика – один из столпов теории вероятностей, которая в свою очередь служит фундаментом для машинного обучения – одно из мощнейших трендов в ПО начале 21-го века!
В встроенном в Python модуле itertools существует ряд комбинаторных функций. Это:
product()– прямое (Декартово) произведение одного или нескольких итераторов.permutations()– перестановки и размещения элементов множества.combinations()– уникальные комбинации из элементов множества.combinations_with_replacement()– комбинации с замещением (повторами, возвратами).
О каждой из них расскажу подробно. Для начала импортируем все нужные функции из модуля:
from itertools import *
Прямое произведение
Прямое, или декартово произведение двух множеств — множество, элементами которого являются все возможные упорядоченные пары элементов исходных множеств. Проще говоря мы берем из первого множества один элемент, а потом из второго выбираем элемент и составляем их в кортеж. Так вот все способы выбрать так элементы – составят декартово произведение. Пример:
>>> A = [1, 2, 3] >>> B = "123" >>> print(*product(A, B)) (1, 'a') (1, 'b') (1, 'c') (2, 'a') (2, 'b') (2, 'c') (3, 'a') (3, 'b') (3, 'c')
Примечания. Во-первых, заметьте, что элементы следуют в строгом лексографическом порядке: сначала берется нулевой элемент из первой последовательности и сочетается с каждым по очереди из второй последовательности. Во-вторых, аргументами функции могут быть любые итерируемые объекты конечной длины. Я взял для примера список и строку, причем строка автоматически разбивается на символы.
В коде произведение множеств эквивалентно вложенным циклам:
>>> print(*[(a, b) for a in A for b in B]) (1, '1') (1, '2') (1, '3') (2, '1') (2, '2') (2, '3') (3, '1') (3, '2') (3, '3')
Результат такой же, но рекомендую использовать именно библиотечную функцию, так как ее реализация, наверняка, будет лучше.
Вы можете передать в функцию больше последовательностей:
>>> print(*product([1, 2, 3])) (1,) (2,) (3,) >>> print(*product([1, 2, 3], [10, 20, 30])) (1, 10) (1, 20) (1, 30) (2, 10) (2, 20) (2, 30) (3, 10) (3, 20) (3, 30) >>> print(*product([1, 2, 3], [10, 20, 30], [100, 200, 300])) (1, 10, 100) (1, 10, 200) (1, 10, 300) (1, 20, 100) (1, 20, 200) (1, 20, 300) (1, 30, 100) (1, 30, 200) (1, 30, 300) (2, 10, 100) (2, 10, 200) (2, 10, 300) (2, 20, 100) (2, 20, 200) (2, 20, 300) (2, 30, 100) (2, 30, 200) (2, 30, 300) (3, 10, 100) (3, 10, 200) (3, 10, 300) (3, 20, 100) (3, 20, 200) (3, 20, 300) (3, 30, 100) (3, 30, 200) (3, 30, 300)
Каждый выходной элемент будет кортежем (даже в случае, если в нем только один элемент!). Также обратите внимание на то, что функция product (как и все остальные из сегодняшнего набора) возвращает не список, а особый ленивый объект. Чтобы получить все элементы, нужно преобразовать его в список функцией list:
>>> product([1, 2, 3], 'abc') <itertools.product object at 0x101aef8c0> >>> list(product([1, 2, 3], 'abc')) [(1, 'a'), (1, 'b'), (1, 'c'), (2, 'a'), (2, 'b'), (2, 'c'), (3, 'a'), (3, 'b'), (3, 'c')]
Количество элементов на выходе будет произведением длин всех последовательностей на входе:
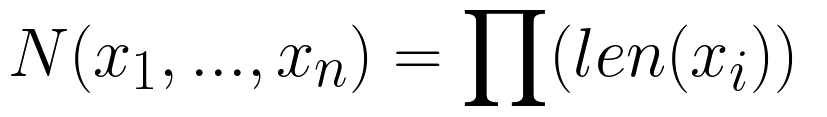
В функцию product можно передать именованный параметр repeat, который указывает сколько раз повторять цепочку вложенных циклов (по умолчанию один раз). Если repeat >= 2, то это называют декартовой степенью. То есть множество умножается на себя несколько раз. Так при repeat=2 эквивалентным кодом будет:
>>> [(a, b, a1, b1) for a in A for b in B for a1 in A for b1 in B] == list(product(A, B, repeat=2)) True
В таком случае количество элементов в результате будет вычисляться по схожей формуле с учетом того, что каждый множитель будет в степени repeat:
![]()
Перестановки
Функция permutations возвращает последовательные перестановки элементов входного множества. Первый элемент – будет исходным множеством. Второй – результат перестановки какой-то пары элементов и так далее, пока не будут перебраны все уникальные комбинации. Уникальность здесь рассматривается по позициям элементов в исходной последовательности, а не по и их значению, то есть элементы между собой алгоритмом не сравниваются. Важны только их индексы.
Число объектов остается неизменными, меняется только их порядок.
>>> print(*permutations("ABC"))
('A', 'B', 'C') ('A', 'C', 'B') ('B', 'A', 'C') ('B', 'C', 'A') ('C', 'A', 'B') ('C', 'B', 'A')
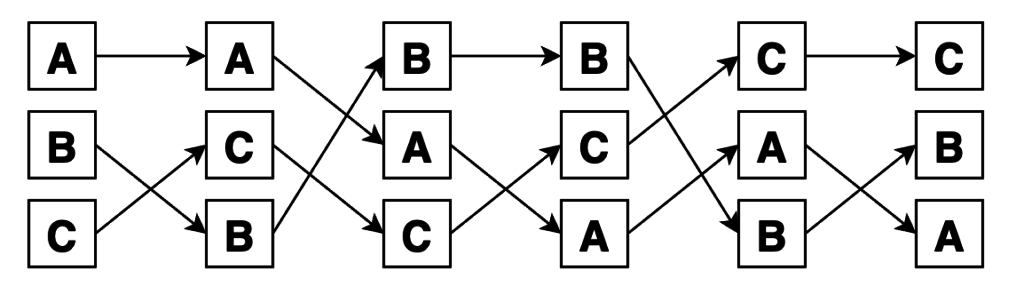
Второй параметр r отвечает за количество элементов в перестановках. По умолчанию будут выданы полные перестановки (длиной, равной длине n исходной последовательности), никакие элементы исходного множества не будут выброшены, а просто переставлены местами. Если задать 0 <= r <= n, в каждой выборке будет содержаться по r элементов. Иными словами из n входных элементов будем выбирать r объектов и переставлять всеми возможными способами между собой (то есть меняется и состав выбранных объектов, и их порядок). Получившиеся комбинации называются размещениями из n объектов по r.
Например размещения для двух элементов из коллекции из трех элементов:
>>> print(*permutations("ABC", 2))
('A', 'B') ('A', 'C') ('B', 'A') ('B', 'C') ('C', 'A') ('C', 'B')
# 2 из 4
>>> print(*permutations([1, 2, 3, 4], 2))
(1, 2) (1, 3) (1, 4) (2, 1) (2, 3) (2, 4) (3, 1) (3, 2) (3, 4) (4, 1) (4, 2) (4, 3)
Количество вариантов получится по формуле (n – длина исходной последовательности):
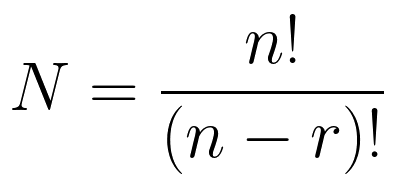
При r > n будет пустое множество, потому что невозможно из более короткой последовательности выбрать более длинную. Максимальное число вариантов – для полной перестановки равняется n! (факториал).
Размещения выглядят так. Сначала выбрали по 2 элемента из 3, а потом переставили их внутри групп всеми способами. Итого 6 вариантов:

Сочетания
combinations – функция, коротая выбирает все сочетания из входной последовательности. Пусть в ней имеется n различных объектов. Будем выбирать из них r объектов всевозможными способами (то есть меняется состав выбранных объектов, но порядок не важен). Получившиеся комбинации называются сочетаниями из n объектов по r, а их число равно:
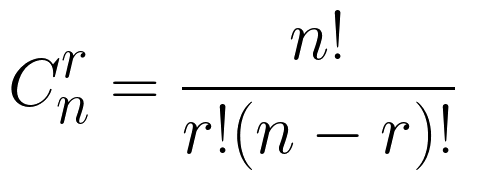
Разница сочетаний и перестановок в том, что для сочетаний нам не важен порядок, а для перестановок он важен. Пример:
>>> print(*permutations([1, 2, 3], 2)) (1, 2) (1, 3) (2, 1) (2, 3) (3, 1) (3, 2) >>> print(*combinations([1, 2, 3], 2)) (1, 2) (1, 3) (2, 3)
(1, 2) и (2, 1) – разные перестановки, но с точки зрения сочетаний – это одно и тоже, поэтому в combinations входит только один вариант из двух.
Второй параметр r – обязателен для этой функции. 0 <= r <= n. При r > n будет пустое множество.
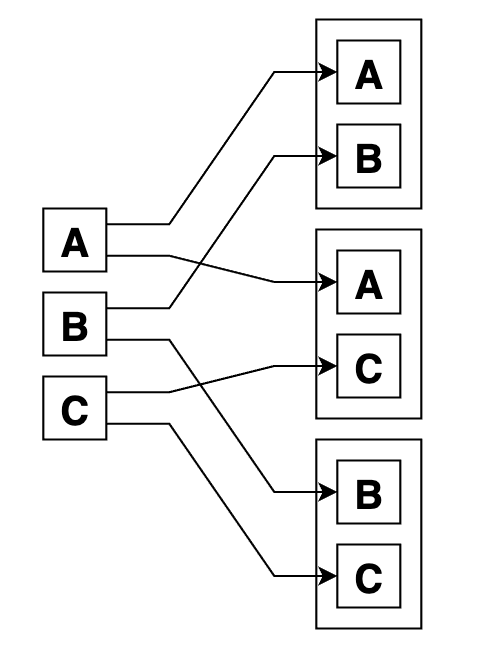
Вот графический пример сочетаний из 3 по 2. Как видно, их вдвое меньше, чем размещений из 3 по 2, так как варианты с перестановками внутри групп не учтены по определению:
Сочетания с повторами
Функция combinations_with_replacement описывает, сколькими способами можно составить комбинацию по r элементов из элементов n типов (элементы в комбинации могут повторяться, но порядок их не важен). Обратите внимание на слово «тип«, в простых сочетаниях элементы не повторялись внутри одной выборки, они были как бы конкретными экземплярами.
На языке мешка с шарами, сочетания с повторами значит, что мы достаем шары из мешка, а потом кладем их обратно, записывая их цвета (цвет это и есть в данном случае аналог типа). Вполне может быть так, что мы достали красный шар два раза подряд, ведь после первого раза мы сунули его обратно в мешок. Пример:
>>> print(*combinations_with_replacement(['red', 'white', 'black'], 2))
('red', 'red') ('red', 'white') ('red', 'black') ('white', 'white') ('white', 'black') ('black', 'black')
Поэтому, имея возможность брать один и тот же элемент несколько раз, можно выбрать из последовательности в три элемента 4, и 5, и сколь угодно много (больше, чем было исходных типов). Например, по 4 из 2:
>>> print(*combinations_with_replacement(['red', 'black'], 4))
('red', 'red', 'red', 'red') ('red', 'red', 'red', 'black') ('red', 'red', 'black', 'black') ('red', 'black', 'black', 'black') ('black', 'black', 'black', 'black')
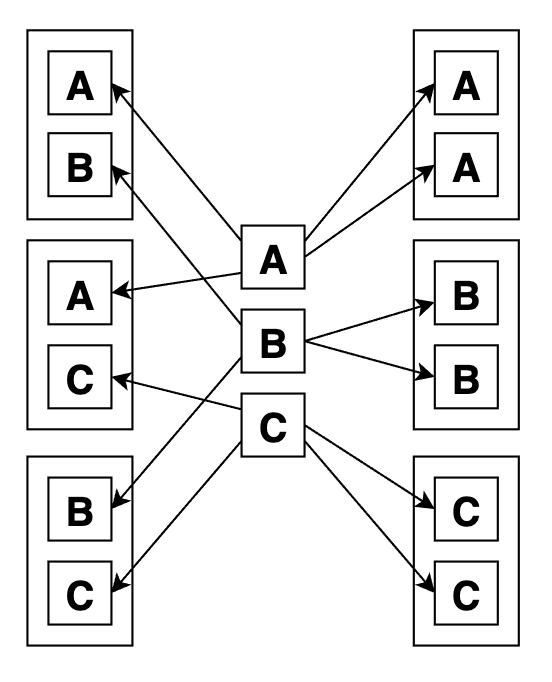
Вот графически сочетания с повторами по 2 из 3:
Формула числа элементов на выходе такова:
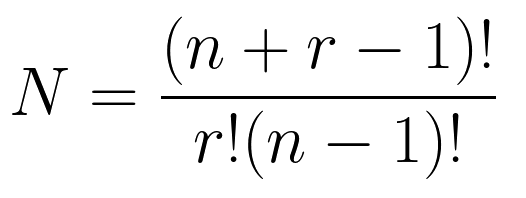
Бонус – брутфорс пароля
Как бонус предлагаю вам применение функции product() для брутфорса паролей. Сперва мы задаем набор символов, которые могут встречаться в пароле, наш алфавит, например такой:
import string # все буквы и цифры alphabet = string.digits + string.ascii_letters # 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
А потом перебираем все возможные сочетания с длинами от минимальной до максимальной. Не забываем их склеить в строку:
def brute_force(alphabet, min_len, max_len):
# функция - склеиватель последователностей символов в строку
joiner = ''.join
for cur_len in range(min_len, max_len + 1):
yield from map(joiner, product(alphabet, repeat=cur_len))
Пример применения:
# сокращенный алфавит для иллюстрации работы alphabet = '123AB' print(*brute_force(alphabet, 1, 3), sep=', ') # вывод: 1, 2, 3, A, B, 11, 12, 13, 1A, 1B, 21, 22, 23, 2A, 2B, 31, 32, 33, 3A, 3B, A1, A2, A3, AA, AB, B1, B2, B3, BA, BB, 111, 112, 113, 11A, 11B, 121, 122, 123, 12A, 12B, 131, 132, 133, 13A, 13B, 1A1, 1A2, 1A3, 1AA, 1AB, 1B1, 1B2, 1B3, 1BA, 1BB, 211, 212, 213, 21A, 21B, 221, 222, 223, 22A, 22B, 231, 232, 233, 23A, 23B, 2A1, 2A2, 2A3, 2AA, 2AB, 2B1, 2B2, 2B3, 2BA, 2BB, 311, 312, 313, 31A, 31B, 321, 322, 323, 32A, 32B, 331, 332, 333, 33A, 33B, 3A1, 3A2, 3A3, 3AA, 3AB, 3B1, 3B2, 3B3, 3BA, 3BB, A11, A12, A13, A1A, A1B, A21, A22, A23, A2A, A2B, A31, A32, A33, A3A, A3B, AA1, AA2, AA3, AAA, AAB, AB1, AB2, AB3, ABA, ABB, B11, B12, B13, B1A, B1B, B21, B22, B23, B2A, B2B, B31, B32, B33, B3A, B3B, BA1, BA2, BA3, BAA, BAB, BB1, BB2, BB3, BBA, BBB
Специально для канала @pyway. Подписывайтесь на мой канал в Телеграм @pyway 👈
9 927
Все курсы > Программирование на Питоне > Занятие 10 (часть 4)
Рассмотрим способы расчета комбинаций с помощью Питона. Помимо модуля random рассмотрим модуль itertools.
Продолжим работать в том же ноутбуке⧉
Комбинаторика в Питоне
np.random.shuffle() и np.random.permutation()
Обе эти функции перемешивают (shuffle) или переставляют (permute) элементы списка или массива. Основное отличие заключается в том, что np.random.shuffle() изменяет исходный массив, а np.random.permutation() создает «перемешанную» копию исходного массива:
|
# создадим массив и передадим его в функцию np.random.shuffle() arr = np.array([1, 2, 3, 4, 5]) # сама функция выдала None, исходный массив при этом изменился print(np.random.shuffle(arr), arr) |
|
# еще раз создадим массив arr = np.array([1, 2, 3, 4, 5]) # передав его в np.random.permutation(), # мы получим перемешанную копию и исходный массив без изменений np.random.permutation(arr), arr |
|
(array([2, 4, 3, 1, 5]), array([1, 2, 3, 4, 5])) |
Перемешивание массива можно использовать, если, например, нужно внести элемент случайности в работу с данными. Давайте создадим аналог функции train_test_split() библиотеки sklearn, которой мы пользовались для разделения выборки на обучающую и тестовую части.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
# объявим функцию, которая принимает признаки X и целевую переменную y в формате # массива Numpy или датафрейма # дополнительно пропишем размер тестовой выборки с параметром по умолчанию 0,3 # и возможностью задать точку отсчета def split_data(X, y, test_size = 0.3, random_state = None): # проверим является ли X массивом Numpy с помощью функции isinstance() if isinstance(X, np.ndarray): # если да, превратим в датафрейм X = pd.DataFrame(X) # сделаем то же самое для y if isinstance(y, np.ndarray): y = pd.DataFrame(y) # еще один способ выполнить такую проверку # if type(X). __module__ == np. __name__: # X = pd.DataFrame(X) # if type(y). __module__ == np. __name__: # y = pd.DataFrame(y) # установим точку отсчета np.random.seed(random_state) # перемешаем индексы строк датасета X, не изменяя исходный массив indices = np.random.permutation(len(X)) # определим количество строк, которые войдут в тестовую выборку # для этого умножим количество строк в X на долю тестовой выборки data_test_size = int(X.shape[0] * test_size) # начиная с этого количества (границы) будет обучающая выборка train_indices = indices[data_test_size:] # перед ним, тестовая test_indices = indices[:data_test_size] # с помощью метода .iloc() найдем в X все строки, # соответствующие индексам в переменных train_indices и test_indices X_train = X.iloc[train_indices] X_test = X.iloc[test_indices] # сделаем то же самое для y y_train = y.iloc[train_indices] y_test = y.iloc[test_indices] # выведем выборки в том порядке, в котором они выводятся в sklearn return X_train, X_test, y_train, y_test |
Подгрузим данные о пациентах с диабетом из модуля datasets библиотеки sklearn. Как это делается, мы подробно разобрали на занятии по линейной регрессии на вводном курсе.
|
# импортируем данные о пациентах с диабетом from sklearn.datasets import load_diabetes # помещаем их в переменную data data = load_diabetes() # создаем два датафрейма X = pd.DataFrame(data.data, columns = data.feature_names) y = pd.DataFrame(data.target, columns = [‘target’]) # для проверки работы функции можно также создать массивы Numpy # X = data.data # y = data.target |
Вызовем созданную функцию и проверим ее работу.
|
X_train, X_test, y_train, y_test = split_data(X, y, random_state = 42) |
Теперь проверим, правильно ли записались данные в созданные выше переменные и расположены ли в них строки в случайном порядке.


Похоже, что все работает как надо.
Модуль itertools
Рассмотренные выше функции не позволяют вывести все возможные комбинации элементов. Для этого есть модуль itertools.
Перестановки
Напомню, что перестановка (permutation) в комбинаторике позволяет узнать, сколькими способами можно разместить элементы множества в определенном порядке.
Перестановки без замены
Вначале возьмем те случаи, когда один элемент может повторяться только один раз. В этом случае мы говорим о перестановках без замены (permutations without replacement). Они бывают двух видов: без повторений и с повторениями.
Перестановки без повторений
Рассмотрим простой пример. У нас есть три элемента A, B и C. Сколькими способами можно переставить эти объекты так, чтобы порядок элементов не повторялся?
Так как элементы в исходном множестве не повторяются, то такая перестановка называется перестановкой без повторения (permutation without repetition).
Очевидно, на первое место мы можем поставить любой из трех элементов, на второе только оставшиеся два, на третьем месте окажется только один элемент. Получается 3 x 2 x 1 = 6. Такой расчет не что иное, как факториал числа три (3!).
$$ P(n) = n! rightarrow P(3) = 3! = 6 $$
На Питоне мы можем вычислить факториал нужного нам числа через функцию factorial() модуля math.
|
# импортируем модуль math import math # передадим функции factorial() число 3 math.factorial(3) |
Кроме того, мы можем воспользоваться функцией permutations() модуля itertools. В этом случае мы можем вывести все возможные перестановки элементов множества.
|
# импортируем модуль itertools import itertools # создадим строку из букв A, B, C x = ‘ABC’ # помимо строки можно использовать и список # x = [‘A’, ‘B’, ‘C’] # и передадим ее в функцию permutations() # так как функция возвращает объект itertools.permutations, # для вывода результата используем функцию list() list(itertools.permutations(x)) |
|
[(‘A’, ‘B’, ‘C’), (‘A’, ‘C’, ‘B’), (‘B’, ‘A’, ‘C’), (‘B’, ‘C’, ‘A’), (‘C’, ‘A’, ‘B’), (‘C’, ‘B’, ‘A’)] |
Если все же нас интересуют не сами перестановки, а их количество, можно воспользоваться функцией len().
|
len(list(itertools.permutations(x))) |
Размещения
Приведем чуть более сложный пример. Предположим, в соревнованиях учавствуют шесть команд (n = 6), и нам нужно узнать, сколькими способами эти команды могут занять первое, второе и третье призовые места. Просто вычислить факториал мы уже не можем, нам нужно уменьшить общее число вариантов на то количество перестановок, которое не будет реализовано, потому что мест всего три (r = 3).
Такой тип перестановок называют размещением (partial permulation). Приведем формулу.
$$ P(n, r) = frac{n!}{(n-r)!} rightarrow P(6, 3) = frac{6!}{(6-3)!} = 120 $$
На Питоне мы можем применить ту же функцию permutations(), передав ей через параметр r размер выборки (количество мест).
|
# теперь элементов исходного множества шесть x = ‘ABCDEF’ # чтобы узнать, сколькими способами их можно разместить на трех местах, # передадим параметр r = 3 и выведем первые пять элементов list(itertools.permutations(x, r = 3))[:5] |
|
[(‘A’, ‘B’, ‘C’), (‘A’, ‘B’, ‘D’), (‘A’, ‘B’, ‘E’), (‘A’, ‘B’, ‘F’), (‘A’, ‘C’, ‘B’)] |
Посмотрим на общее количество перестановок.
|
# как и в предыдущем случае, воспользуемся функцией len() len(list(itertools.permutations(x, r = 3))) |
Дополнительно замечу, что в случае если выборка r также велика, как и множество n (первый пример), то формулу размещения можно записать как
$$ P(n, n) = frac{n!}{(n-n)!} $$
В знаменателе получается 0!, и для того чтобы избежать деления на ноль, принято считать, что факториал нуля равен единице (0! = 1).
Перестановки с повторениями
Давайте дополнительно усложним задачу и рассчитаем количество перестановок букв в слове «молоко». В данном случае мы не можем воспользоваться факториалом, потому что буква «о» повторяется трижды, и соответственно мы можем разместить ее 3! способами. Как следствие, для получения правильного ответа нам нужно разделить количество перестановок на шесть (3! = 6).
В таком случае мы говорим про перестановки с повторениями (permutations with repetitions).
$$ frac{6!}{3!} = 120 $$
В целом, если какой-то из элементов повторяется, то общее число перестановок нужно разделить на произведение факториалов повторяющихся элементов (правильнее сказать на произведение факториалов повторяемости каждого элемента, однако факториал неповторяющихся элементов равен 1! = 1, поэтому ими можно пренебречь).
$$ frac{P(n, r)}{n_1! cdot n_2! cdot … cdot n_r!}, text{где } n_1! + n_2! + … + n_r! = n $$
Для расчета перестановок с повторениями напишем собственную функцию.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
# импортируем необходимые библиотеки import itertools import numpy as np import math # объявим функцию permutations_w_repetition(), которая будет принимать два параметра # x – строка, список или массив Numpy # r – количество мест в перестановке, по умолчанию равно количеству элементов в x def permutations_w_repetition(x, r = len(x)): # если передается строка, if isinstance(x, str): # превращаем ее в список x = list(x) # в числителе рассчитаем количество перестановок без повторений numerator = len(list(itertools.permutations(x, r = r))) # для того чтобы рассчитать знаменатель найдем, # сколько раз повторяется каждый из элементов _, counts = np.unique(x, return_counts = True) # объявим переменную для знаменателя denominator = 1 # и в цикле будем помещать туда произведение факториалов # повторяющихся элементов for c in counts: # для этого проверим повторяется ли элемент if c > 1: # и если да, умножим знаменатель на факториал повторяющегося элемента denominator *= math.factorial(c) # разделим числитель на знаменатель # деление дает тип float, поэтому используем функцию int(), # чтобы результат был целым числом return int(numerator/denominator) |
Рассчитаем количество перестановок с повторениями букв в слове «молоко».
|
# создадим строку со словом “молоко” x = ‘МОЛОКО’ # вызовем функцию permutations_w_repetition(x) |
Перестановки с заменой
Перестановки с заменой (permutations with replacement), когда элементы могут использоваться более одного раза, есть не что иное, как прямое или декартово произведение множества само на себя.
Вначале рассмотрим суть декартова произведения.
Декартово произведение (Cartesian product) двух множеств предполагает, что мы создаем все возможные упорядоченные пары исходных множеств.
В частности, если у нас есть одно множество A с элементами {1, 2, 3} и множество B с элементами {x, y}, то их произведением A x B будут все возможные упорядоченные комбинации этих элементов.

При умножении множества само на себя один раз мы говорим про квадрат Декарта (Cartesian square). В частности, если умножить множество действительных чисел R само на себя (R x R), то получится координатная плоскость или декартова система координат (Cartesian plane).

Замечу, что множество можно умножить само на себя много раз, в этом случае говорят про декартову степень (Cartesian power).
Так вот, перестановка с заменой и есть декартова степень исходного множества.
Например, представим, что в кафе есть два сорта мороженого, ванильное и клубничное, и мы можем заказать любые два шарика. В частности, два шарика ванильного или два шарика клубничного. Тогда возможные варианты заказа можно представить следующим образом.

При этом так как это перестановки и порядок имеет значение, (клубника, ваниль) и (ваниль, клубника) это разные блюда.
В модуле itertools для такой операции есть функция product().
|
# посмотрим, сколькими способами можно выбрать два сорта мороженого list(itertools.product([‘Ваниль’, ‘Клубника’], repeat = 2)) |
|
[(‘Ваниль’, ‘Ваниль’), (‘Ваниль’, ‘Клубника’), (‘Клубника’, ‘Ваниль’), (‘Клубника’, ‘Клубника’)] |
В целом формула прямого произведения выглядит как nr. Например, если во множестве четыре элемента, то поставить два элемента из этих четырех можно шестнадцатью способами (42 = 16).
|
# посмотрим на способы переставить с заменой два элемента из четырех list(itertools.product(‘ABCD’, repeat = 2)) |
|
[(‘A’, ‘A’), (‘A’, ‘B’), (‘A’, ‘C’), (‘A’, ‘D’), (‘B’, ‘A’), (‘B’, ‘B’), (‘B’, ‘C’), (‘B’, ‘D’), (‘C’, ‘A’), (‘C’, ‘B’), (‘C’, ‘C’), (‘C’, ‘D’), (‘D’, ‘A’), (‘D’, ‘B’), (‘D’, ‘C’), (‘D’, ‘D’)] |
Убедимся, что таких способов 16.
|
len(list(itertools.product(‘ABCD’, repeat = 2))) |
В данном случае мы умножаем множество само на себя два раза.

Замечу, что если умножать множество на себя три раза, то графически понадобился бы куб. Резюмируем все изученные способы перестановок на схеме ниже.

Сочетания
Сочетания без повторений
В отличие от перестановок при расчете сочетаний (combinations) порядок значения не имеет. Например, представьте, что в парном теннисе из пяти кандидатов нам нужно собрать команду из двух человек.
По сравнению с похожей задачей с призовыми местами, нам не важно кто будет первым, а кто вторым и если считать через перестановки, то получится так
$$ P(5, 2) = frac{5!}{(5-2)!} = 20 $$
Для наглядности посмотрим на эти комбинации с помощью Питона.
|
# возьмем пять элементов x = ‘ABCDE’ # и найдем способ переставить два элемента из этих пяти list(itertools.permutations(x, r = 2)) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
[(‘A’, ‘B’), (‘A’, ‘C’), (‘A’, ‘D’), (‘A’, ‘E’), (‘B’, ‘A’), (‘B’, ‘C’), (‘B’, ‘D’), (‘B’, ‘E’), (‘C’, ‘A’), (‘C’, ‘B’), (‘C’, ‘D’), (‘C’, ‘E’), (‘D’, ‘A’), (‘D’, ‘B’), (‘D’, ‘C’), (‘D’, ‘E’), (‘E’, ‘A’), (‘E’, ‘B’), (‘E’, ‘C’), (‘E’, ‘D’)] |
Однако обратите внимание, некоторые комбинации, если не учитывать порядок, повторяются (например, AB и BA). Поэтому сочетаний (то есть перестановок без учета порядка) меньше. Причем меньше на количество перестановок каждого типа, то есть r!. В данном случае перестановок каждого типа два, то есть 2! = 2.
|
int(len(list(itertools.permutations(x, r = 2)))/math.factorial(2)) |
Выведем формулу.
$$ C(n, r) = frac{n!}{(n-r)! r!} rightarrow C(5, 2) = frac{5!}{(5-2)! 2!} = 10 $$
В Питоне для сочетаний есть удобная функция combinations().
|
list(itertools.combinations(x, 2)) |
|
[(‘A’, ‘B’), (‘A’, ‘C’), (‘A’, ‘D’), (‘A’, ‘E’), (‘B’, ‘C’), (‘B’, ‘D’), (‘B’, ‘E’), (‘C’, ‘D’), (‘C’, ‘E’), (‘D’, ‘E’)] |
|
len(list(itertools.combinations(x, 2))) |
Сочетания с повторениями
Если допустить повторение элементов, сочетаний станет больше.
|
list(itertools.combinations_with_replacement(‘AB’, 2)) |
|
[(‘A’, ‘A’), (‘A’, ‘B’), (‘B’, ‘B’)] |
В целом количество сочетаний с повторениями (combinations with repetitions или иногда with replacement) вычисляется по следующей формуле.
$$ C(n, r)_{rep} = frac{(n+r-1)!}{(n-r)! r!} $$
В нашем случае,
$$ C(2, 2)_{rep} = frac{(2+2-1)!}{(2-2)! 2!} = frac{3!}{2!} = 3 $$
Биномиальные коэффициенты
Давайте вернемся к биномиальному распределению и его функции вероятности. Напомню, что во втором примере мы три раза подбрасывали монету (n = 3), вероятность выпадения орла составляла 0,7 (p = 0,7), а найти мы должны были выпадение двух орлов (k = 2).
$$ P(X = k) = C(n, k) p^k (1-p)^{n-k} $$
$$ P(X = 2) = C(3, 2) times 0,7^2 times (1-0,7)^{3-2} = 3 times 0,7^2 times 0,3^1 = 0,441 $$
Первая часть этой формулы и есть количество сочетаний при выпадении двух орлов в трех бросках. Для того чтобы вывести дерево вероятностей мы можем воспользоваться декартовой степенью множества {решка, орел} или {H, T}.
|
# трижды умножим множество {H, T} само на себя list(itertools.product(‘HT’, repeat = 3)) |
|
[(‘H’, ‘H’, ‘H’), (‘H’, ‘H’, ‘T’), (‘H’, ‘T’, ‘H’), (‘H’, ‘T’, ‘T’), (‘T’, ‘H’, ‘H’), (‘T’, ‘H’, ‘T’), (‘T’, ‘T’, ‘H’), (‘T’, ‘T’, ‘T’)] |
Само же количество сочетаний рассчитаем через функцию combinations().
|
# посмотрим, в скольких комбинациях выпадет две решки при трех бросках comb = len(list(itertools.combinations(‘ABC’, 2))) comb |
Полный расчет на Питоне будет выглядеть вот так.
|
round(comb * (0.7 ** 2 * (1 – 0.7)** (3 – 2)), 3) |
Конечно же этот результат гораздо проще получить через библиотеку scipy.
|
binom.pmf(k = 2, n = 3, p = 0.7).round(3) |
Подведем итог
По большому счету мы затронули три важные темы:
- Моделирование и исследование случайных процессов с помощью модуля random;
- Распределения (дискретные и непрерывные) случайных величин; и
- Комбинаторику на Питоне.
Пройденный материал поможет как в дальнейшем изучении теории, так и в построении более качественных моделей машинного обучения.
Вопросы для закрепления
Вопрос. Чем теоретическая вероятность отличается от эмпирической?
Посмотреть правильный ответ
Ответ: теоретическая вероятность — это соотношение благоприятствующих событию исходов ко всем возможным исходам испытания, эту вероятность мы можем рассчитать; эмпирическая вероятность — соотношение наступления события к общему числу испытаний, которое мы наблюдаем в результате эксперимента
Вопрос. Чем отличается функция вероятности (probability mass function, pmf) от плотности вероятности (probability density function, pdf)?
Посмотреть правильный ответ
Ответ: функция вероятности задает распределение дискретной случайной величины (discrete random variable), а плотность вероятности описывает распределение непрерывной величины (discrete random variable)
Вопрос. Чем сочетания отличаются от перестановок?
Посмотреть правильный ответ
Ответ: при расчете количества перестановок мы учитываем порядок, в котором располагаются элементы, при расчете количества сочетаний порядок не важен.
В конце ноутбука приведены дополнительные упражнения⧉.
На следующем занятии мы немного отдохнем от математики и рассмотрим объектно-ориентированный подход к программированию.
Ответы на вопросы
Вопрос. Подскажите, а зачем повторно импортировать Numpy, itertools и math перед объявлением собственной функции permutations_w_repetition()? Ведь вы уже импортировали их перед этим.
Ответ. Я повторно импортировал необходимые библиотеки на случай использования функции в других проектах. Предположим, вы захотите использовать эту функцию в своей работе и поместите ее в отдельный файл. Для того чтобы код сработал, вам сначала понадобится импортировать эти три библиотеки.
Дополнительно замечу, что Руководство по написанию кода на Питоне (Python Enhancement Proposal или PEP 8) рекомендует⧉ делать импорт необходимых библиотек и модулей «после комментариев к модулю и строк документации, и перед объявлением констант», а не внутри функций или классов. Подробнее об этом мы поговорим через одно занятие.
Вопрос. Скажите, а чем матожидание отличается от среднего значения?
Ответ. Матожидание (expected value) — это то среднее значение, которое мы предполагаем/ожидаем получить с учетом известного нам типа распределения. Например, зная, что случайная величина следует биномиальному распределению с параметрами n = 3 и p = 0,7, мы ожидаем наблюдать среднее значение np = 3 x 0,7 = 2,1. В частности, с помощью функции scipy.stats.binom.stats() мы рассчитываем именно матожидание распределения.
Собрав же фактические данные (мы для этого использовали модуль random и функцию np.random.binomial()), мы можем посмотреть насколько среднее (mean value) этих данных согласуется с математическим ожиданием. При достаточно большом количестве экспериментов среднее должно стремиться к математическому ожиданию.
Привел пример в конце ноутбука⧉.
