«Мороз и солнце; день чудесный…» — эти слова узнает каждый и точно назовёт их автора. Но у каждого великого поэта есть и менее известные произведения, в которых, однако, всё равно можно узнать характерный слог. Попробуете?

Мы взяли отрывки стихов своих любимых, известных любому русскому человеку, поэтов-классиков, а вам предлагаем попытаться понять, кому принадлежат эти строки. Правила просты: на первом фото отрывок и варианты ответов, на втором фото имя автора и название произведения. Начинаем 🙂
Сколько у вас попаданий, поделитесь в комментариях 😉
Теги: php, поиск, строка, подстрока, найти
В некоторых случаях возникает необходимость найти подстроку в строке, используя встроенные возможности языка программирования PHP. Чтобы решить эту задачу, можно использовать разные инструменты.

Поиск подстроки в строке с помощью strpos
В PHP есть функция под названием strpos, возвращающая позицию 1-го вхождения символа подстроки. Давайте рассмотрим небольшой пример её работы:
$mystring = 'abc'; $findme = 'a'; $pos = strpos($mystring, $findme); // Обратите внимание, что применяется ===. Применение == не даст нам верного // результата, т. к. 'a' находится в нулевой позиции. if ($pos === false) { echo "Строка '$findme' не найдена в строке '$mystring'"; } else { echo "Строка '$findme' найдена в строке '$mystring'"; echo " в позиции $pos"; }Таким образом, PHP-функция возвращает нам или порядковый номер 1-го символа подстроки в исходной строке, или false, если ничего не найдено.
Применяя эту функцию, учтите, что она может вернуть вам в качестве результата 0 — в таком случае можно говорить, что подстрока находится в самом начале нашей исходной строки. Именно поэтому следует применять троекратный знак равно, о котором упомянуто в коде ($pos === false). Это нужно для проверки успешности поиска.
Поиск подстроки в строке с помощью stripos
Эта функция является регистронезависимым аналогом strpos. Она пригодится, если захотите найти последнее вхождение подстроки. Кстати, регистронезависимый вариант есть и у неё — strripos.
Используем для поиска PHP-функцию preg_match
Данная функция позволит выполнить поиск подстроки, задействуя регулярное выражение. Напомним, что регулярное выражение представляет собой шаблон, сравниваемый со строкой. При этом под один шаблон порой подходят сразу много разных строк.
Регулярные выражения пригодятся, если надо выполнять поиск и проверку не по конкретной подстроке, а требуется обнаружить все строки, которые обладают свойствами, описанными посредством регулярных выражений. Вообще, по правде говоря, знание данной темы заметно расширит ваши возможности и облегчит работу со строками.
Выполним проверку:
$html = 'content <title>hello php!</title> content'; if (preg_match("!<title>(.*?)</title>!si", $html, $matches)){ echo $matches[1]; } else { echo "Тег не был найден"; }Остаётся добавить, что язык программирования PHP располагает богатейшим выбором функций для работы с регулярными выражениями. Это раз. Что касается нашей основной темы, то нельзя не сказать, что для работы со строками в PHP тоже есть огромное количество функций, знакомиться с которыми лучше в официальной документации.
Если же хотите прокачать свои навыки PHP-разработки под руководством практикующих экспертов, добро пожаловать на специальный курс в OTUS!

Предположим, что нам нужно найти подстроку в строке при помощи php.
Для решения этой задачи подходят разные инструменты.
Поиск подстроки с использованием функции strpos
Функция strpos возвращает позицию первого вхождения подстроки.
Пример:
$mystring = 'abc';
$findme = 'a';
$pos = strpos($mystring, $findme);
// Заметьте, что используется ===. Использование == не даст верного
// результата, так как 'a' находится в нулевой позиции.
if ($pos === false) {
echo "Строка '$findme' не найдена в строке '$mystring'";
} else {
echo "Строка '$findme' найдена в строке '$mystring'";
echo " в позиции $pos";
}
Источник: Документация по strpos
Функция возвращает либо порядковый номер первого символа подстроки в исходной строке, либо false, в случае если ничего не найдено.
При использовании этой функции, следует уделить особое внимание тому, что она может вернуть 0, в качестве результата, что говорит о нахождении подстроки в самом начале исходной строки. Поэтому нужно использовать троекратный знак равно $pos === false, для проверки успешности поиска.
Остальные “фишки” операторов сравнения описаны здесь: операторы сравнения.
Для этой функции существует регистронезависимый аналог: stripos
Еще одна функция для этой задачи: strrpos. Она находит последнее вхождение подстроки.
У нее, разумеется, тоже имеется регистронезависимый вариант: strripos
Если функция strpos не подходит для вашей цели, то найдите другой инструмент.
Для работы со строками существует также масса функций, о существовании которых необходимо знать: функции для работы со строками.
Поиск подстроки при помощи функции preg_match
Эта функция производит поиск подстроки при помощи регулярного выражения.
Регулярное выражение – это шаблон, который сравнивается со строкой. Под один шаблон может подходить сразу множество разных строк.
Они пригодятся если вам нужно производить поиск не по конкретной подстроке, а найти все строки, обладающие свойствами, описанными при помощи регулярного выражения. Знание этой темы сильно расширяет ваши возможности в работе со строками.
Пример:
$html = 'content <title>hello php!</title> content';
if (preg_match("!<title>(.*?)</title>!si", $html, $matches)){
echo $matches[1];
} else {
echo "Тег не найден";
}
Начать рекомендую с этой статьи: регулярные выражения.
PHP располагает широким выбором функций по работе с регулярными выражениями.
Нашли опечатку или ошибку? Выделите её и нажмите Ctrl+Enter
Помогла ли Вам эта статья?
Поиск подстроки и смежные вопросы
Время на прочтение
13 мин
Количество просмотров 111K
Здравствуйте, уважаемое сообщество! Недавно на Хабре проскакивала неплохая обзорная статья о разных алгоритмах поиска подстроки в строке. К сожалению, там отсутствовали подробные описания каких либо из упомянутых алгоритмов. Я решил восполнить данный пробел и описать хотя бы парочку тех, которые потенциально можно запомнить. Те, кто еще помнит курс алгоритмов из института, не найдут, видимо, ничего нового для себя.
Сначала хотел бы предотвратить вопрос «на кой это надо? все уже и так написано». Да, написано. Но во-первых, полезно знать как работает используемые тобой иструменты на более низком уровне чтобы лучше понимать их ограничения, а во-вторых, есть достаточно большие смежные области, где работающей из коробочки функции strstr() окажется недостаточно. Ну и в-третьих, вам может неповезти и придется разрабатывать под мобильную платформу с неполноценным runtime, а тогда лучше знать на что подписываетесь, если решитесь самостоятельно его дополнять (чтобы убедиться, что это не сферическая проблема в вакууме, достаточно попробовать wcslen() и wcsstr() из Android NDK).
А разве просто поискать нельзя?
Дело в том, что очевидный способ, который все формулирует как «взять и поискать», является отнюдь не самым эффективным, а для такой низкоуровневой и сравнительно частовызываемой функции это немаловажно. Итак, план такой:
- Постановка задачи: здесь перечислены определения и условные обозначения.
- Решение «в лоб»: здесь будет описано, как делать не надо и почему.
- Z-функция: простейший вариант правильной реализации поиска подстроки.
- Алгоритм Кнута-Морриса-Пратта: еще один вариант правильного поиска.
- Другие задачи поиска: вкратце пробегусь по ним без подробного описания.
Постановка задачи
Канонический вариант задачи выглядит так: есть у нас строка A (текст). Необходимо проверить, есть ли в ней подстрока X (образец), и если есть, то где она начинается. То есть именно то, что делает функция strstr() в C. Дополнительно к этому можно еще попросить найти все вхождения образца. Очевидно, что задача имеет смысл только если X не длинее A.
Для простоты дальнейшего объяснения введу сразу пару понятий. Что такое строка все, наверное, понимают — это последовательность символов, возможно пустая. Символы, или буквы, принадлежат некоторому множеству, которое называют алфавитом (данный алфавит, вообще говоря, может не иметь ничего общего с алфавитом в бытовом понимании). Длина строки |A| — это, очевидно, количество символов в ней. Префикс строки A[..i] — это строка из i первых символов строки A. Суффикс строки A[j..] — это строка из |A|-j+1 последних символов. Подстроку из A будем обозначать как A[i..j], а A[i] — i-ый символ строки. Вопрос про пустые суффиксы и префиксы и т.д. не трогаем — с ними разобраться не сложно по месту. Еще есть такое понятие как сентинел — некий уникальный символ, не встречающийся в алфавите. Его обозначают значком $ и дополняют допустимый алфавит таким символом (это в теории, на практике проще применить дополнительные проверки, чем придумать такой символ, которого не могло бы оказаться во входных строках).
В выкладках будем считать символы в строке с первой позиции. Код писать традиционно проще отсчитывая от нуля. Переход от одного к другому не составляет трудностей.
Решение «в лоб»
Прямой поиск, или, как еще часто говорят, «просто взять и поискать»- это Первое решение, которое приходит в голову неискушенному программисту. Суть проста: идти по проверяемой строке A и искать в ней вхождение первого символа искомой строки X. Когда находим, делаем гипотезу, что это и есть то самое искомое вхождение. Затем остается проверять по очереди все последующие символы шаблона на совпадение с соответствующими символами строки A. Если они все совпали — значит вот оно, прямо перед нами. Но вот если какой-то из символов не совпал, то ничего не остается, как признать нашу гипотезу неверной, что возвращает нас к символу, следующему за вхождением первого символа из X.
Многие люди ошибаются в этом пункте, считая, что не надо возвращаться назад, а можно продолжать обработку строки A с текущей позиции. Почему это не так легко продемонстрировать на примере поиска X=«AAAB» в A=«AAAAB». Первая гипотеза нас приведет к четвертому символу A: “AAAAB”, где мы обнаружим несоответствие. Если не откатиться назад, то вхождение мы так и не обнаружим, хотя оно есть.
Неправильные гипотезы неизбежны, а из-за таких откатываний назад при плохом стечении обстоятельств может оказаться, что мы каждый символ в A проверили около |X| раз. То есть вычислительная сложность сложность алгоритма O(|X||A|). Так поиск фразы в параграфе может и затянуться…
Справедливости ради следует отметить, что если строки невелики, то такой алгоритм может работать быстрее «правильных» алгоритмов за счет более предсказуемого с точки зрения процессора поведения.
Z-функция
Одна из категорий правильных способов поиска строки сводится к вычислению в каком-то смысле корреляции двух строк. Сначала отметим, что задача сравнения начал двух строк проста и понятна: сравниваем соответствующие буквы, пока не найдем несоответствие либо какая-нибудь из строк закончится. Рассмотрим множество всех суффиксов строки A: A[|A|..] A[|A|-1..],… A[1..]. Будем сравнивать начало самой строки с каждым из ее суффиксов. Сравнение может дойти до конца суффикса, либо оборваться на каком-то символе ввиду несовпадения. Длину совпавшей части и назовем компонентой Z-функции для данного суффикса.
То есть Z-функция — это вектор длин наибольшего общего префикса строки с ее суффиксом. Ух! Отличная фраза, когда надо кого-то запутать или самоутвердиться, а чтобы понять что же это такое, лучше рассмотреть пример.
Исходная строка «ababcaba». Сравнивая каждый суффикс с самой строкой получим табличку для Z-функции:
| суффикс | строка | Z | |
|---|---|---|---|
| ababcaba | ababcaba | -> | 8 |
| babcaba | ababcaba | -> | 0 |
| abcaba | ababcaba | -> | 2 |
| bcaba | ababcaba | -> | 0 |
| caba | ababcaba | -> | 0 |
| aba | ababcaba | -> | 3 |
| ba | ababcaba | -> | 0 |
| a | ababcaba | -> | 1 |
Префикс суффикса это ничто иное, как подстрока, а Z-функция — длины подстрок, которые встречаются одновременно в начале и в середине. Рассматривая все значения компонент Z-функции, можно заметить некоторые закономерности. Во-первых, очевидно, что значение Z-функции не превышает длины строки и совпадает с ней только для «полного» суффикса A[1..] (и поэтому это значение нас не интересует — мы его будем опускать в своих рассуждениях). Во-вторых, если в строке есть некий символ в единственном экземпляре, то совпасть он может только с самим собой, и значит он делит строку на две части, а значение Z-функции нигде не может превысить длины более короткой части.
Использовать эти наблюдения предлагается следующим образом. Допустим в строке «ababcabсacab» мы хотим поискать «abca». Берем эти строчки и конкатенируем, вставляя между ними сентинел: «abca$ababcabсacab». Вектор Z-функции выглядит для такой строки так:
| a b c a $ a b a b c a b с a c a b |
| 17 0 0 1 0 2 0 4 0 0 4 0 0 1 0 2 0 |
Если отбросить значение для полного суффикса, то наличие сентинела ограничивает Zi длиной искомого фрагмента (он является меньшей половиной строки по смыслу задачи). Но вот если этот максимум и достигается, то только в позициях вхождения подстроки. В нашем примере четверками отмечены
все
позиции вхождения искомой строки (отметьте, что найденные участки расположены внахлест друг с другом, но все-равно наши рассуждения остаются верны).
Ну, значит если мы сможем быстро строить вектор Z-функции, то поиск с его помощью всех вхождений строки сводится к поиску в нем значения ее длины. Вот только если вычислять Z-функцию для каждого суффикса, то будет это явно не быстрее, чем решение «в лоб». Выручает нас то, что значение очередного элемента вектора можно узнать опираясь на предыдущие элементы.
Допустим, мы каким-то образом посчитали значения Z-функции вплоть до соответствующего i-1-ому символу. Рассмотрм некую позицию r<i, где мы уже знаем Zr.
Значит Zr символов начиная с этой позиции точно такие же, как и в начале строки. Они образуют так называемый Z-блок. Нас будет интересовать самый правый Z-блок, то-есть тот, кто заканчивается дальше всех (самый первый не в счет). В некоторых случаях самый правый блок может быть нулевой длины (когда никакой из непустых блоков не покрывает i-1, то самым правым будет i-1-ый, даже если Zi-1= 0).
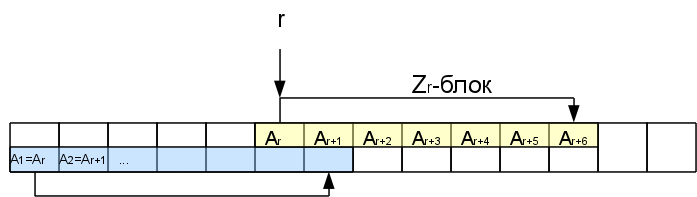
Когда мы будем рассматривать последующие символы внутри этого Z-блока, сравнивать очередной суффикс с самого начала не имеет смысла, так как часть этого суфикса уже встречалась в начале строки, а значит уже была обработана. Можно будет сразу пропускать символы аж до конца Z-блока.
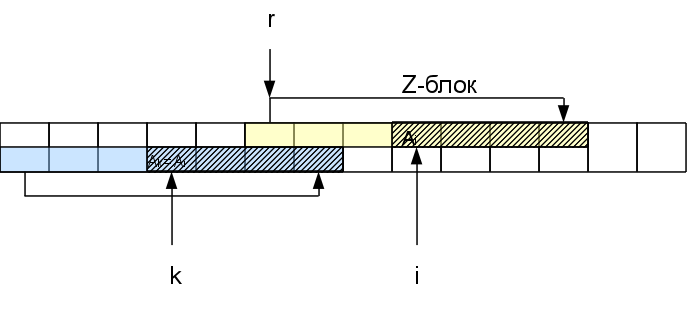
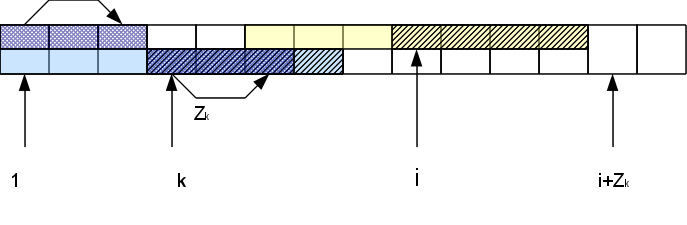
А именно, если мы рассматриваем i-й символ, находящийся в Zr-блоке, то есть соответствующий символ в начале строки на позиции k=i-r+1. Функция Zk нам уже известна. Если она меньше, чем оставшееся до конца Z-блока расстояние Zr-(i-r), то сразу можем быть уверены, что вся область совпадения для этого символа лежит внутри r-того Z-блока и значит результат будет тот же, что и в начале строки: Zi=Zk. Если же Zk >= Zr-(i-r), то Zi тоже больше или равна Zr-(i-r). Чтобы узнать насколько именно она больше, нам надо будет проверять следующие за Z-блоком символы. При этом в случае совпадения h этих символов с соответствующими им в начале строки, Zi увеличивается на h: Zi=Zk + h. В результате у нас может появиться новый самый правый Z-блок (если h>0).
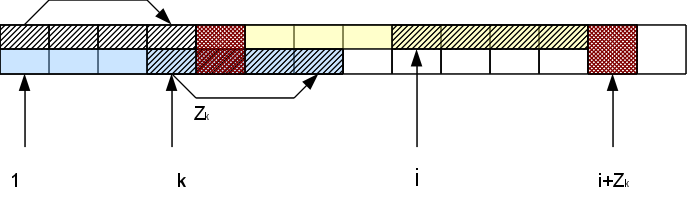
Таким образом, сравнивать символы нам приходится только правее самого правого Z-блока, причем за счет успешных сравнений блок «продвигается» правее, а неуспешные сообщают, что вычисление для данной позиции окончено. Это обеспечивает нам построение всего вектора Z-функции за линейное по длине строки время.
Применив этот алгоритм для поиска подстроки получим сложность по времени O(|A|+|X|), что значительно лучше, чем произведение, которое было в первом варианте. Правда, нам пришлось хранить вектор для Z-функции, на что уйдет дополнительной памяти порядка O(|A|+|X|). На самом деле, если не нужно находить все вхождения, а достаточно только одного, то можно обойтись и O(|X|) памяти, так как длина Z-блока все-равно не может быть больше чем |X|, кроме этого можно не продолжать обработку строки после обнаружения первого вхождения.
Напоследок, пример функции, вычисляющей Z-функцию. Просто модельный вариант без каких либо хитростей.
void z_preprocess(vector<int> & Z, const string & str)
{
const size_t len = str.size();
Z.clear();
Z.resize(len);
if (0 == len)
return;
Z[0] = len;
for (size_t curr = 1, left = 0, right = 1; curr < len; ++curr)
{
if (curr >= right)
{
size_t off = 0;
while ( curr + off < len && str[curr + off] == str[off] )
++off;
Z[curr] = off;
right = curr + Z[curr];
left = curr;
}
else
{
const size_t equiv = curr - left;
if (Z[equiv] < right - curr)
Z[curr] = Z[equiv];
else
{
size_t off = 0;
while ( right + off < len && str[right - curr + off] == str[right + off] )
++off;
Z[curr] = right - curr + off;
right += off;
left = curr;
}
}
}
}
Алгоритм Кнута-Морриса-Пратта (КМП)
Не смотря на логическую простоту предыдущего метода, более популярным является другой алгоритм, который в некотором смысле обратный Z-функции — алгоритм Кнута-Морриса-Пратта (КМП). Введем понятие префикс-функции. Префикс-функция для i-ой позиции — это длина максимального префикса строки, который короче i и который совпадает с суффиксом префикса длины i. Если определение Z-функции не сразило оппонента наповал, то уж этим комбо вам точно удастся поставить его на место 🙂 А на человеческом языке это выглядит так: берем каждый возможный префикс строки и смотрим самое длинное совпадение начала с концом префикса (не учитывая тривиальное совпадение самого с собой). Вот пример для «ababcaba»:
| префикс | префикс | p |
|---|---|---|
| a | a | 0 |
| ab | ab | 0 |
| aba | aba | 1 |
| abab | abab | 2 |
| ababc | ababc | 0 |
| ababca | ababca | 1 |
| ababcab | ababcab | 2 |
| ababcaba | ababcaba | 3 |
Опять же наблюдаем ряд свойств префикс-функции. Во-первых, значения ограничены сверху своим номером, что следует прямо из определения — длина префикса должна быть больше префикс-функции. Во-вторых, уникальный символ точно так же делит строку на две части и ограничивает максимальное значение префикс-функции длиной меньшей из частей — потому что все, что длиннее, будет содержать уникальный, ничему другому не равный символ.
Отсюда получается интересующий нас вывод. Допустим, мы таки достигли в каком-то элементе этого теоретического потолка. Это значит, что здесь закончился такой префикс, что начальная часть совпадает с конечной и одна из них представляет «полную» половинку. Понятно, что в префиксе полная половинка обязана быть спереди, а значит при таком допущении это должна быть более короткая половинка, максимума же мы достигаем на более длинной половинке.
Таким образом, если мы, как и в предыдущей части, конкатенируем искомую строчку с той, в которой ищем, через сентинел, то точка вхождения длины искомой подстроки в компоненту префикс-функции будет соответствовать месту окончания вхождения. Возьмем наш пример: в строке «ababcabсacab» мы ищем «abca». Конкатенированный вариант «abca$ababcabсacab». Префикс-функция выглядит так:
| a b c a $ a b a b c a b с a c a b |
| 0 0 0 1 0 1 2 1 2 3 4 2 3 4 0 1 2 |
Снова мы нашли все вхождения подстроки одним махом — они оканчиваются на позициях четверок. Осталось понять как же эффективно посчитать эту префикс-функцию. Идея алгоритма незначительно отличается от идеи построения Z-функции.

Самое первое значение префикс-функции, очевидно, 0. Пусть мы посчитали префикс-функцию до i-ой позиции включительно. Рассмотрим i+1-ый символ. Если значение префикс-функции в i-й позиции Pi, то значит префикс A[..Pi] совпадает с подстрокой A[i-Pi+1..i]. Если символ A[Pi+1] совпадет с A[i+1], то можем спокойно записать, что Pi+1=Pi+1. Но вот если нет, то значение может быть либо меньше, либо такое же. Конечно, при Pi=0 сильно некуда уменьшаться, так что в этом случае Pi+1=0. Допустим, что Pi>0. Тогда есть в строке префикс A[..Pi], который эквивалентен подстроке A[i-Pi+1..i]. Искомая префикс-функция формируется в пределах этих эквивалентных участков плюс обрабатываемый символ, а значит нам можно забыть о всей строке после префикса и оставить только данный префикс и i+1-ый символ — ситуация будет идентичной.
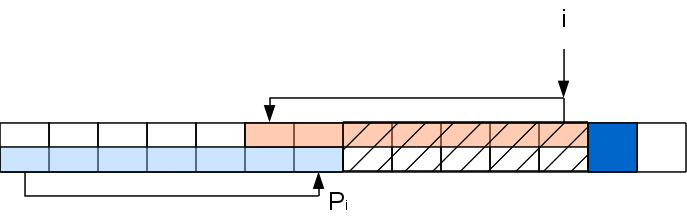
Задача на данном шаге свелась к задаче для строки с вырезанной серединкой: A[..Pi]A[i+1], которую можно решать рекурсивно таким же способом (хотя хвостовая рекурсия и не рекурсия вовсе, а цикл). То есть если A[PPi+1] совпадет с A[i+1], то Pi+1=PPi+1, а иначе снова выкидываем из рассмотрения часть строки и т.д. Повторяем процедуру пока не найдем совпадение либо не дойдем до 0.
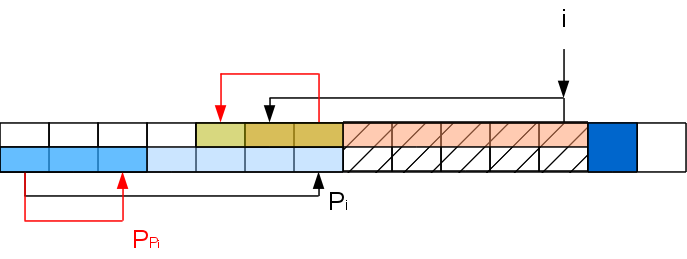
Повторение этих операций должно насторожить — казалось бы получается два вложенных цикла. Но это не так. Дело в том, что вложенный цикл длиной в k итераций уменьшает префикс-функцию в i+1-й позиции хотя бы на k-1, а для того, чтобы нарастить префикс-функцию до такого значения, нужно хотя бы k-1 раз успешно сопоставить буквы, обработав k-1 символов. То есть длина цикла соответствует промежутку между выполнением таких циклов и поэтому сложность алгоритма по прежнему линейна по длине обрабатываемой строки. С памятью тут такая-же ситуация, как и с Z-функцией — линейная по длине строки, но есть способ сэкономить. Кроме этого есть удобный факт, что символы обрабатываются последовательно, то есть мы не обязаны обрабатывать всю строку, если первое вхождение мы уже получили.
Ну и для примера фрагмент кода:
void calc_prefix_function(vector<int> & prefix_func, const string & str)
{
const size_t str_length = str.size();
prefix_func.clear();
prefix_func.resize(str_length);
if (0 == str_length)
return;
prefix_func[0] = 0;
for (size_t current = 1; current < str_length; ++current)
{
size_t matched_prefix = current - 1;
size_t candidate = prefix_func[matched_prefix];
while (candidate != 0 && str[current] != str[candidate])
{
matched_prefix = prefix_func[matched_prefix] - 1;
candidate = prefix_func[matched_prefix];
}
if (candidate == 0)
prefix_func[current] = str[current] == str[0] ? 1 : 0;
else
prefix_func[current] = candidate + 1;
}
}
Не смотря на то, что алгоритм более замысловат, реализация его даже проще, чем для Z-функции.
Другие задачи поиска
Дальше пойдет просто много букв о том, что этим задачи поиска строк не ограничиваются и что есть другие задачи и другие способы решения, так что если кому не интересно, то дальше можно не читать. Эта информация просто для ознакомления, чтобы в случае необходимости хотя бы осознавать, что «все уже украдено до нас» и не переизобретать велосипед.
Хоть вышеописанные алгоритмы и гарантируют линейное время выполнения, звание «алгоритма по умолчанию» получил алгоритм Бойера-Мура. В среднем он тоже дает линейное время, но еще и имеет лучше константу при этой линейной функции, но это в среднем. Бывают «плохие» данные, на которых он оказываются не лучше простейшего сравнения «в лоб» (ну прямо как с qsort). Он на редкость запутан и рассматривать его не будем — все-равно не упомнить. Есть еще ряд экзотических алгоритмов, которые ориентированы на обработку текстов на естественном языке и опираются в своих оптимизациях на статистические свойства слов языка.
Ну ладно, есть у нас алгоритм, который так или иначе за O(|X|+|A|) ищет подстроку в строке. А теперь представим, что мы пишем движок для гостевой книги. Есть у нас список запрещенных матерных слов (понятно, что так не поможет, но задача просто для примера). Мы собираемся фильтровать сообщения. Будем каждое из запрещенных слов искать в сообщении и… на это у нас уйдет O(|X1|+|X2|+…+|Xn|+n|A|). Как-то так себе, особенно если словарь «могучих выражений» «великого и могучего» очень «могуч». Для этого случая есть способ так предобработать словарь искомых строк, что поиск будет занимать только O(|X1|+|X2|+…+|Xn|+|A|), а это может быть существенно меньше, особенно если сообщения длинные.
Такая предобработка сводится к построению бора (trie) из словаря: дерево начинается в некотором фиктивном корне, узлы соответствует буквам слов в словаре, глубина узла дерева соответствует номеру буквы в слове. Узлы, в которых заканчивается слово из словаря называются терминальными и помечены неким образом (красным цветом на рисунке).
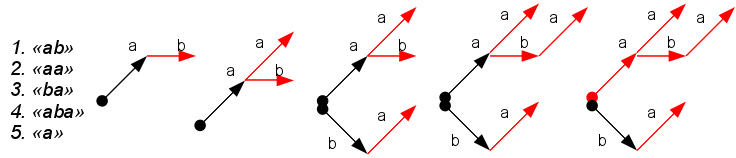
Полученное дерево является аналогом префикс-функции алгоритма КМП. С его помощью можно найти все вхождения всех слов словаря в фразе. Надо идти по дереву, проверяя наличие очередного символа в виде узла дерева, попутно отмечая встречающиеся терминальные вершины — это вхождения слов. Если соответствующего узла в дереве нет, то как и в КМП, происходит откат выше по дереву по специальным ссылкам. Данный алгоритм носит название алгоритма Ахо-Корасика. Такую же схему можно применять для поиска во время ввода и предсказания следующего символа в электронных словарях.
В данном примере построение бора несложно: просто добавляем в бор слова по очереди (нюансы только с дополнительными ссылками для «откатов»). Есть ряд оптимизаций, направленный на сокращение использования памяти этим деревом (т.н. сжатие бора — пропуск участков без ветвлений). На практике эти оптимизации чуть ли не обязательны. Недостатком данного алгоритма является его алфавитозависимость: время на обработку узла и занимаемая память зависят от количества потенциально возможных детей, которое равно размеру алфавита. Для больших алфавитов это серьезная проблема (представляете себе набор символов юникода?). Подробнее про это все можно почитать в этом хабратопике или воспользовавшись гуглояндексом — благо инфы по этомоу вопросу много.
Теперь посмотрим на другую задачу. Если в предыдущей мы знали заранее, что мы должны будем найти в поступающих потом данных, то здесь с точностью до наоборот: нам заранее выдали строчку, в которой будут искать, но что будут искать — неизвестно, а искать будут много. Типичный пример — поисковик. Документ, в котором ищется слово, известен заранее, а вот слова, которые там ищут, сыпятся на ходу. Вопрос, опять же, как вместо O(|X1|+|X2|+…+|Xn|+n|A|) получить O(|X1|+|X2|+…+|Xn|+|A|)?
Предлагается построить бор, в котором будут все возможные суффиксы имеющейся строки. Тогда поиск шаблона сведется к проверки наличия пути в дереве, соответствующего искомому шаблону. Если строить такой бор перебором всех суффиксов, то эта процедура может занять O(|A|2) времени, да и по памяти много. Но, к счастью, существуют алгоритмы, которые позволяют построить такое дерево сразу в сжатом виде — суффиксное дерево, причем сделать это за O(|A|). Недавно на Хабре была по этому поводу статья, так что интересующиеся могут прочитать про алгоритм Укконена там.
Плохо в суффиксном дереве, как обычно, две вещи: то, что это дерево, и то, что узлы дерева алфавитозависимы. От этих недостатков избавлен суффиксный массив. Суть суффиксного массива заключается в том, что если все суффиксы строки отсортировать, то поиск подстроки сведется к поиску группы расположенных рядом суффиксов по первой букве искомого образца и дальнейшего уточнения диапазона по последующим. При этом сами суффиксы в отсортированном виде хранить незачем, достаточно хранить позиции, в которых они начинаются в исходных данных. Правда, временные зависимости у данной структуры несколько хуже: единичный поиск будет обходиться O(|X| + log|A|) если подумать и сделать все аккуратно, и O(|X|log|A|) если не заморачиваться. Для сравнения в дереве для фиксированного алфавита O(|X|). Но зато то, что это массив, а не дерево, может улучшить ситуацию с кэшированием памяти и облегчить задачу предсказателю переходов процессора. Строится суффиксный массив за линейное время с помощью алгоритма Kärkkäinen-Sanders (уж извините, но плохо представляю как это должно звучать на русском). Нынче это один из самых популярных методов индексирования строк.
Вопросов приближенного поиска строк и анализа степени похожести мы тут касаться не будем совсем — слишком большая область для того, чтобы запихнуть в эту статью. Просто упомяну, что там люди зря хлеб не ели и придумали много всяких подходов, поэтому если столкнетесь с подобной задачей — найдите и почитайте. Весьма возможно такая задача уже решена.
Спасибо тем, кто читал! А тем, кто дочитал досюда, спасибо особенное!
UPD: Добавил ссылку на содержательную статью про бор (он же луч, он же префиксное дерево, он же нагруженное дерево, он же trie).
Казалось бы, никогда еще не было так просто найти информацию о каком-либо объекте, как сегодня. В интернете появляется все больше сервисов для идентификации контента: например, распознавание музыки через Shazam, поиск изображений через «Яндекс», проверка текстов на антиплагиат и так далее. Инструментарий становится более точным и простым в использовании. На практике, в поисках правообладателя цифрового контента можно не всегда прийти к положительным результатам, так как пока нет единой базы для всех создаваемых творческих объектов. Как узнать, кому принадлежат права на произведение, рассказываем в статье.
Объекты авторского права
Практически все, что создается умом человека, является интеллектуальной собственностью и охраняется законодательством. К объектам авторского права относятся произведения науки, литературы и искусства (ст. 1259 ГК РФ), а именно:
-
литературные произведения
-
драматические и музыкально-драматические произведения, сценарные произведения
-
хореографические произведения и пантомимы
-
музыкальные произведения с текстом или без текста
-
аудиовизуальные произведения
-
произведения живописи, скульптуры, графики, дизайна, графические рассказы, комиксы и другие произведения изобразительного искусства
-
произведения декоративно-прикладного и сценографического искусства
-
произведения архитектуры, градостроительства и садово-паркового искусства
-
фотографические произведения
-
а также программы для ЭВМ и так далее
Авторские права возникают в момент создания произведения, когда оно выражается в какой-либо форме, например, на бумаге или в виде электронного файла. Также для охраноспособности произведение должно обладать творческой составляющей. Обычная новостная заметка не будет охраняться (подп.4 п.6 ст. 1259 ГК РФ). Но если дополнить ее интервью и репортажем с оригинальным описанием происходящих событий, то она может стать объектом авторского права.
Итак, произведение охраняется авторским правом — что это значит? Это означает, что только автор или правообладатель может использовать свою работу или давать согласие на ее использование. Без разрешения просто так воспользоваться понравившимся произведением нельзя. Перед этим следует узнать, кому принадлежат права на песню, исполнение, мелодию, изображение, шрифт и любой другой объект авторского права. Затем, например, получить лицензию на объект или письменное разрешение на его использование.
Но найти правообладателя не всегда просто, поскольку исключительное авторское право может передаваться другим лицам. Например, музыкант мог создать саундтрек к фильму и передать на него полный объем прав через договор об отчуждении исключительного права: правообладателем саундтрека станет другое лицо, физическое или юридическое, к примеру, киностудия. Также исключительное право могло перейти к наследникам или даже от наследника к новому правообладателю.
В России процедура регистрации авторских прав не предусмотрена для произведений науки, литературы и искусства, поэтому единого реестра, в котором можно было бы получить информацию обо всех правообладателях, пока не существует. Тогда как найти правообладателя?
Способы определения правообладателей
Если необходимо найти правообладателя, можно начать с самого простого: искать в поисковой системе «Яндекс» или Google с запросом «название произведения + правообладатель» и изучить предложенные ссылки. Когда нужно узнать автора текста или цитаты, можно скопировать отрывок из одного-двух предложений, поместить в кавычки и начать поиск.
Для тех, кто хочет получить информацию об изображении, в «Яндекс» и Google предусмотрена удобная функция поиска по картинкам: в поисковой строке можно загрузить изображение или ссылку на него, и сервис выдаст похожие изображения, которые также могут привести к источнику или подробной информации о правообладателе. Даже если автор предоставил лицензию на свою работу по открытой лицензии Creative Commons, поиск по картинке приведет на сайт фотостока, где будет указана информация об изображении.
Как еще узнать, кому принадлежат авторские права? Некоторые авторы и правообладатели уведомляют пользователей о том, что их работа защищена, и ставят рядом с произведением знак охраны авторского права ©, а также уведомление об авторстве, например, «название произведения © 2022 имя правообладателя. Все права защищены».
В России действуют несколько организаций по управлению правами на коллективной основе, с которыми сотрудничают авторы и правообладатели. Например, если необходимо найти правообладателя фонограммы или аудиовизуального произведения, можно перейти на сайт Российского Союза Правообладателей, где опубликован реестр с произведениями: при введении названия в выдаче появляется название работы, информация об авторе и соавторах, их творческих ролях, а также имена наследников или правообладателей.
На сайте Российского Авторского Общества доступен реестр как российских правообладателей, так и зарубежных. Достаточно ввести название произведения или имя автора, и в выдаче появятся возможные подходящие варианты.
Для двух объектов авторского права предусмотрена добровольная процедура государственной регистрации в Роспатенте — программы для ЭВМ и базы данных. После регистрации произведения информация об объекте и его правообладателе попадает в общедоступный реестр Роспатента, через который можно узнать точную информацию о владельце программного обеспечения.
Правообладателей фотографий, негативов, графики, а также кино и видеопродукции также можно искать через сайт Министерства культуры РФ, на котором есть Государственный каталог Музейного фонда Российской Федерации, а также Реестр прокатных удостоверений фильмов. При поиске правообладателя кинофильма открывается информация о режиссерах, студиях-производителях, годах производства. В этом реестре можно найти сведения обо всех прокатных удостоверениях и правообладателях кинофильмов, которые распространяются в России.
Для поиска правообладателя контента можно воспользоваться цифровой платформой IPEX: на ней музыканты, фотографы, иллюстраторы, видеографы, копирайтеры, писатели и многие другие творцы размещают свои работы для дальнейшей продажи.
На IPEX предусмотрен поиск по правообладателям, для удобства доступна сортировка по алфавиту. При нажатии на правообладателя открывается список со всеми его работами, а при выборе отдельного произведения можно увидеть подробную информацию по объекту. Например, при открытии музыкальной композиции доступны имена изготовителя, автора музыки и текста, исполнителя, а также информация о том, кому принадлежат права на объект.
Через IPEX можно связаться с правообладателем произведения и заключить с ним сделку по приобретению прав на объект на его условиях, или же предложить свои условия. Стороны могут заключить лицензионный договор, предусматривающий ограниченное использование произведения, например, для рекламного проекта, а также договор об отчуждении исключительного права, при котором покупателю переходит полностью исключительное права: он может делать с произведение все, что захочет.
Некоторые авторы, преимущественно статей, идентифицировали свои работы с помощью DOI, что тоже могло упростить поиск правообладателя. Что это такое?
DOI, или Digital Object Identifier — это цифровой идентификатор объектов интеллектуальной собственности, преимущественно используемый для идентификации статей и документов в интернете. Он был разработан Международным фондом DOI. Многие агентства регистрируют этот идентификатор, но именно некоммерческая организация Crossref предлагает самый широкий инструментарий для поддержки научного контента, в том числе регистрируя DOI. Организация стремится сделать так, чтобы результаты научных исследований можно было легко искать и цитировать другими авторами.
К примеру, автор прочитал научную статью и ему понравился небольшой отрывок из него: он может быть помечен номером DOI и выходить в библиографическом списке. Нажимая на идентификатор DOI, можно быстрее найти документ по конкретной цитате, перейдя на сайт, откуда можно легально воспользоваться статьей, например, путем цитирования. Чтобы найти статью по идентификатору DOI, можете превратить любой DOI, начинающийся с 10, в URL-адрес, добавив http://doi.org/ перед DOI. Например, 10.3352/jeehp.2013.10.3, получается https://doi.org/10.3352/jeehp.2013.10.3.
Доказательство авторства
Автор является автором произведения просто в силу его создания, для возникновения авторских прав не нужно соблюдения каких-либо формальностей. Первоначально ему принадлежит исключительное право на творение, позволяющее как-либо распоряжаться созданным произведением. Поэтому, когда его работу используют без разрешения, он вправе заявить о нарушении исключительного права. Но зачастую в спорных ситуациях автору нужно подтвердить авторство на свое произведение, предоставив доказательства — что это может быть?
-
Свидетельство о регистрации в Роспатенте — подходит для программного обеспечения, которое можно зарегистрировать в качестве литературного произведения.
-
Исходник произведения: например, для «перестраховки» фотографам лучше снимать в формате RAW, чтобы сохранить исходную версию изображения. Если кто-то использует снимок без разрешения, у нарушителя вряд ли будет иметься копия снимка в самом высоком разрешении, а у автора он будет.
-
Различные договоры: заключение лицензионного договора, договора авторского заказа, соглашения между соавторами, договора об отчуждении исключительного права может также подтвердить авторство.
-
Нотариальное заявление — авторы обращаются к нотариусу, чтобы заверить экземпляр произведения, засвидетельствовать дату его предъявления и сведения о лице, которое его предоставило.
-
Заказное письмо — можно отправить самому себе оригинал произведения по почте. На письме будет проставлен почтовый штемпель с информацией о дате отправки, а также автор получает уникальный трек-номер для отслеживания письма. Но полученный конверт нельзя открывать до тех пор, пока не возникнет спорная ситуация.
-
Свидетельство о депонировании — один из самых актуальных документов, подтверждающих авторство, который можно предъявить в суде для защиты исключительного права. Для того, чтобы получить такое свидетельство, необходимо зарегистрироваться на сайте n’RIS, затем пройти процедуру депонирования. Автору нужно перевести произведение в электронный формат и загрузить в защищенную ячейку — в ходе процедуры информация от транзакции попадает в распределенный блокчейн-реестр IPChain, поэтому данные о произведении и транзакции изменить невозможно. Доступа к ячейке нет ни у кого, кроме автора. За автором закрепляется временной приоритет, подтверждающий факт владения конкретным произведением в определенные дату и время. Это будет подтверждаться свидетельством, номер которого можно указывать при обнародовании работы.
Пока что не придумали автоматическую цифровую идентификацию контента: если правообладатель хочет заявить о своем авторстве, он должен предпринимать самостоятельные шаги, например, ставить рядом с материалами знак охраны авторского права. А желающим использовать чужой контент — самостоятельно искать правообладателя с помощью различных инструментов. Несмотря на это, найти правообладателя объекта авторских и смежных прав все же можно, главное иметь время и желание на поиск.
