Перейдя по ссылке на копию, сохраненную в кеше, можно узнать, как выглядела веб-страница, когда робот Google последний раз сканировал ее.
Важно! Если вы работаете с Search Console, используйте для отладки страницы инструмент проверки URL. Подробнее…
О ссылках на кешированные страницы
Google сохраняет резервные копии веб-страниц на случай, если они станут недоступны. Эти копии хранятся в кеше на серверах Google. Нажав на ссылку “Сохраненная копия”, вы откроете резервную копию веб-сайта.
Вы можете воспользоваться копией из кеша Google, если нужная страница загружается слишком долго или не загружается вообще.
Как получить ссылку на кешированную страницу
Совет. Если вы хотите удалить кешированную страницу из результатов поиска Google, прочитайте эту статью.
Эта информация оказалась полезной?
Как можно улучшить эту статью?
К вашим услугам кеш поисковиков, интернет-архивы и не только.

Если, открыв нужную страницу, вы видите ошибку или сообщение о том, что её больше нет, ещё не всё потеряно. Мы собрали сервисы, которые сохраняют копии общедоступных страниц и даже целых сайтов. Возможно, в одном из них вы найдёте весь пропавший контент.
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
1. Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
Есть и альтернативный способ. Введите в браузерную строку следующий URL: http://webcache.googleusercontent.com/search?q=cache:lifehacker.ru. Замените lifehacker.ru на адрес нужной страницы и нажмите Enter.
Сайт Google →
2. Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
Сайт «Яндекса» →
3. Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
Сайт Bing →
4. Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Сайт Yahoo →
Специальные архивные сервисы
Указав адрес нужной веб‑страницы в любом из этих сервисов, вы можете увидеть одну или даже несколько её архивных копий, сохранённых в разное время. Таким образом вы можете просмотреть, как менялось содержимое той или иной страницы. В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
Чтобы проверить наличие копий в одном из этих архивов, перейдите на его сайт. Введите URL нужной страницы в текстовое поле и нажмите на кнопку поиска.
1. Wayback Machine (Web Archive)
Сервис Wayback Machine, также известный как Web Archive, является частью проекта Internet Archive. Здесь хранятся копии веб‑страниц, книг, изображений, видеофайлов и другого контента, опубликованного на открытых интернет‑ресурсах. Таким образом основатели проекта хотят сберечь культурное наследие цифровой среды.
Сайт Wayback Machine →
2. Arhive.Today
Arhive.Today — аналог предыдущего сервиса. Но в его базе явно меньше ресурсов, чем у Wayback Machine. Да и отображаются сохранённые версии не всегда корректно. Зато Arhive.Today может выручить, если вдруг в Wayback Machine не окажется копий необходимой вам страницы.
Сайт Arhive.Today →
3. WebCite
Ещё один архивный сервис, но довольно нишевый. В базе WebCite преобладают научные и публицистические статьи. Если вдруг вы процитируете чей‑нибудь текст, а потом обнаружите, что первоисточник исчез, можете поискать его резервные копии на этом ресурсе.
Сайт WebCite →
Другие полезные инструменты
Каждый из этих плагинов и сервисов позволяет искать старые копии страниц в нескольких источниках.
1. CachedView
Сервис CachedView ищет копии в базе данных Wayback Machine или кеше Google — на выбор пользователя.
Сайт CachedView →
2. CachedPage
Альтернатива CachedView. Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.
Сайт CachedPage →
3. Web Archives
Это расширение для браузеров Chrome и Firefox ищет копии открытой в данный момент страницы в Wayback Machine, Google, Arhive.Today и других сервисах. Причём вы можете выполнять поиск как в одном из них, так и во всех сразу.

![]()
Читайте также 💻🔎🕸
- 3 специальных браузера для анонимного сёрфинга
- Что делать, если тормозит браузер
- Как включить режим инкогнито в разных браузерах
- 6 лучших браузеров для компьютера
- Как установить расширения в мобильный «Яндекс.Браузер» для Android
Работа с сохраненной копией страницы
Содержание:
- Зачем нужна сохраненная копия страницы и как её посмотреть
- Как посмотреть сохраненную копию в Google
- Как посмотреть сохраненную копию веб-страницы в Яндекс
- Почему сохраненной страницы может не быть
- Специализированные веб-архивы
- Wayback Machine
- Archive.Today
- Расширения для браузеров
- Cached Page
- Выводы
Чтобы пользователь нашел документ в поисковой выдаче, недостаточно добавления его на сервер. Контент должен быть проиндексирован (добавлен поисковыми роботами в индекс) поисковыми системами Яндекс и Google. Поэтому, наличие сохраненной копии — показатель что поисковый бот был на странице. Рассмотрим, что можно посмотреть и какие ошибки обнаружить с помощью сохраненной копии веб-страницы.
Роботы Яндекса и Google добавляют копии найденных веб-страниц в специальное место в облаке — кеш. При этом новая копия страницы перезаписывает старую. Поэтому в кеше отображаются свежие версии веб-страниц.
Сохраненная копия — это версия веб-страницы, которая сохранена в кэше поисковой системы. Условно это бесплатная резервная копия от поисковых систем.
На самом деле веб-страницы сохраняют:
- Поисковые системы. В них находится находится последняя проиндексированная версия страницы. Такие «снимки» используют SEO-специалисты, чтобы увидеть какие данные обнаружил на странице поисковый бот;
- Специализированные сервисы. Занимаются сохранением содержимого веб-страницы. Основная задача таких сервисов сохранить страницы в конкретный момент времени. С помощью них вы можете узнать как выглядел сайт или страница несколько лет назад.
Зачем нужна сохраненная копия страницы и как её посмотреть
На сайтах регулярно происходит добавление нового и редактирование существующего контента. Периодически изменяется его дизайн, добавляются и/или удаляются графические элементы. Это трудоемкая работа в процессе, которой могут возникнуть ошибки: потеряться контент, «съехать дизайн», удалиться блок или перестать индексироваться часть материала. Выявить, как выглядела страницы до определенного момента, поможет сохраненная копия.
Пример из практики:
Есть у нас технически сложный проект, который при заполнении объема памяти перестает, корректно работать. Если по простому, то вместо работающего сайта, мы видим ошибку базы данных.
Время от времени сайт отваливается по ночам, а утром разработчики все исправляют. И тут важный момент, сохраненные копии, позволяют понять успели ли поисковые системы проиндексировать сломанный сайт или нет. А также позволяют выявить, какие именно страницы успел переобойти бот.
Как посмотреть сохраненную копию в Google
Рассмотрим на примере страницы https://discript.ru/prodvizhenie-sajtov/kolomna/. Перед url адресом пропишите оператор «site:». В сниппете (блок информации о странице веб-сайта) результата, нажмите на иконку в виде треугольника, выберите соответствующий пункт.
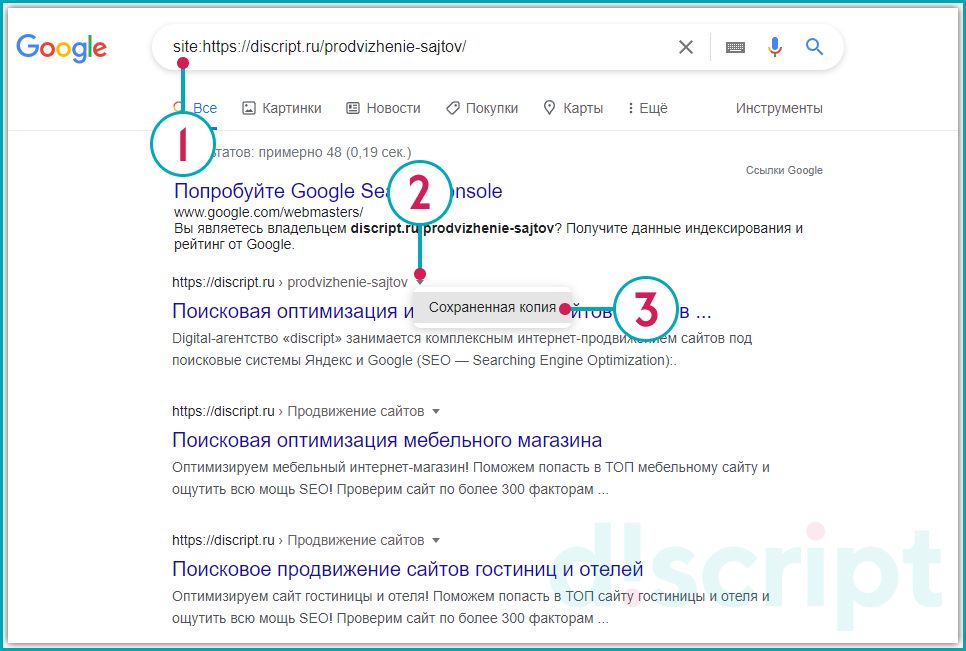
Сохраненная копия в Google
Откроется сохраненная копия веб-страницы. Google выведет окно с сообщением, что открылся «снимок» страницы.
Разберем представленную информацию:
- Дату фиксации. В данном параметре указано, когда был сделан слепок страницы. Поэтому сопоставив указанную дату с датой внесения правок, можно предположить успел ли поисковый бот обойти страницу или еще нет (Важно! данный метод не гарантирует 100% верную информацию, т.к. данные хранятся в кеше и могут отличаться в зависимости от вашего место нахождения) ;
- Полная версия. Отображается версия страница, как должен был ее увидеть пользователь.
- Текстовая версия. Позволяет просмотреть контент веб-страницы без применения стилей. Такой формат позволяет увидеть скрытые от пользователя элементы, но доступные для поисковых роботов Яндекса и Google;
- Исходный код. Выводит исходный код HTML-страницы. Это требуется для изучения тега Title и мета тегов, таких как Description. Данное представление позволяет изучить, как сверстана веб-страница, и нет ли на ней критических ошибок.
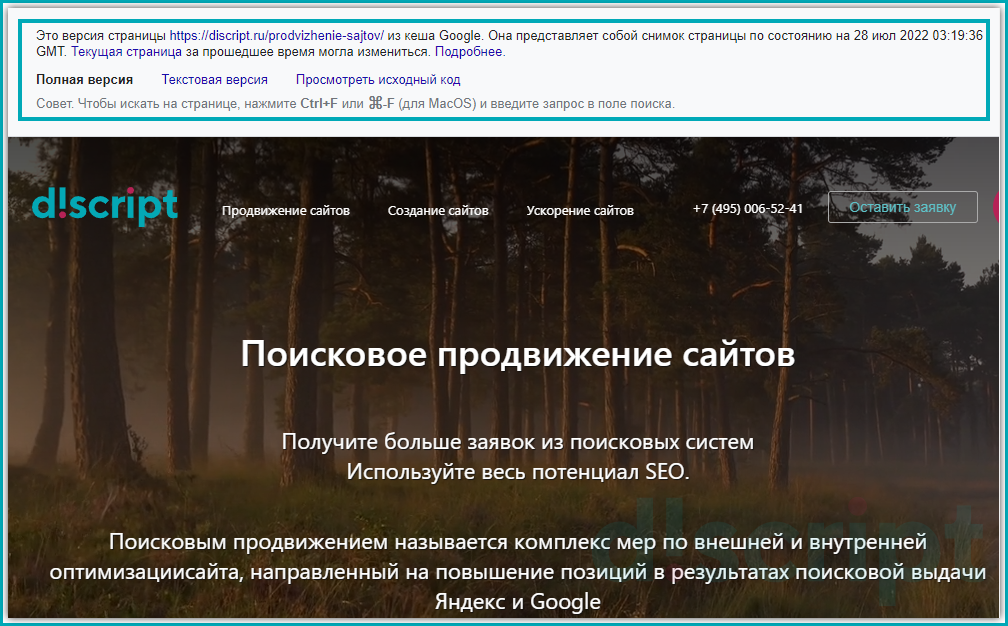
Просмотр версии страницы из кеша Google
Как посмотреть сохраненную копию веб-страницы в Яндекс
Рассмотрим на примере страницы https://discript.ru/site-development/. В строку поиска обязательно пропишите оператор «url:» перед url-адресом. нажмите на значок в виде трех горизонтальных точек, выберите «Сохраненная копия».
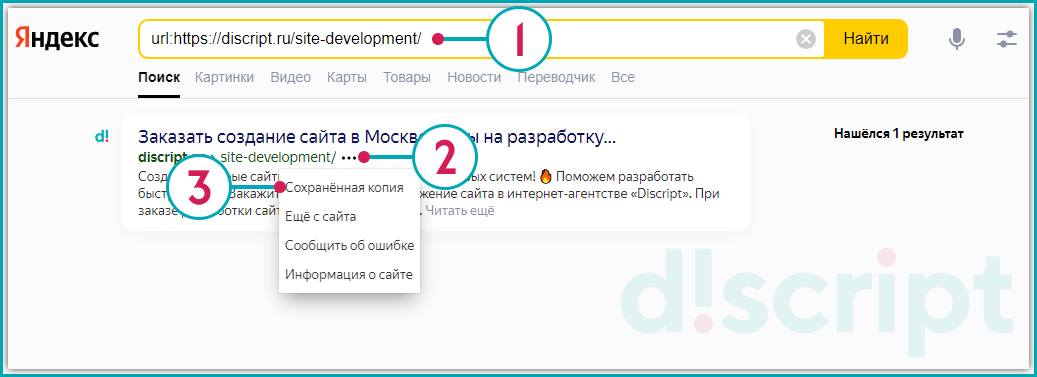
Пример поиска сохраненной страницы в Яндексе
Далее Яндекс предоставит следующие данные:
- Дата индексации. Данное значение информирует в какой момент выполнен слепок страницы.
- Полная версия страницы. Отображение страницы со всеми стилями.
- Текстовая версия страницы. Текстовая версия, аналогично позволяет изучить страницу без стилей и получить всю скрытую информацию. Часто именно при проверке текстовой копии обнаруживаются сквозные блоки текста на страницах. Т.к. при использовании стилей они скрыты.
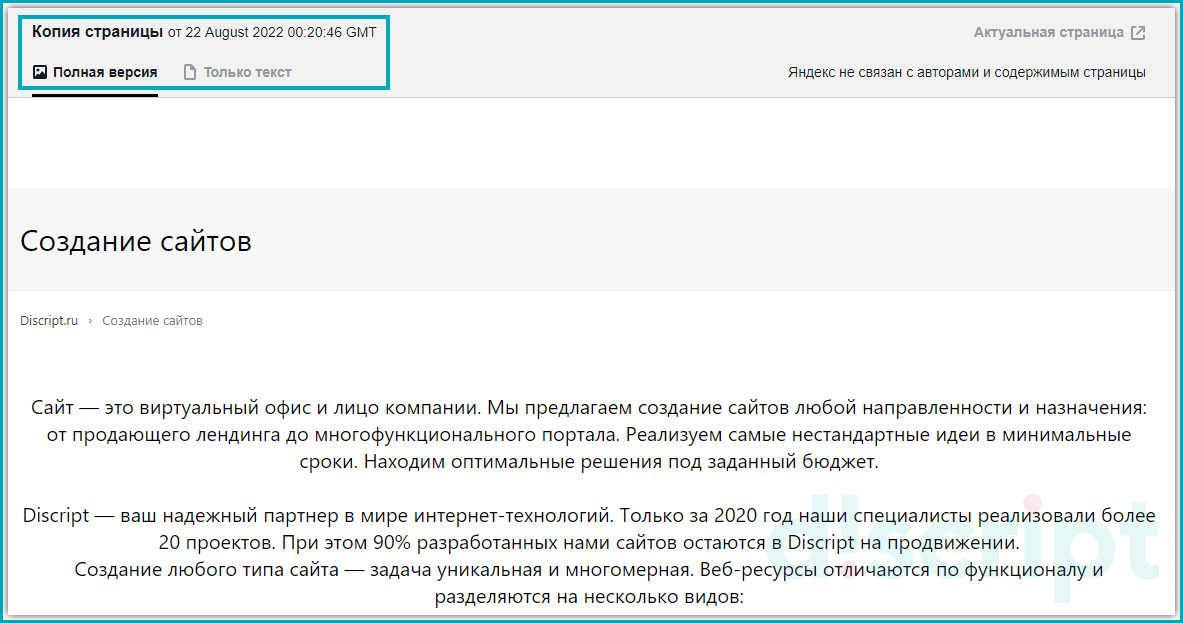
Предоставление данных о копии страницы в Яндексе
Почему сохраненной страницы может не быть
Это происходит в результате:
- Сбой работы поисковых систем. Разработчики Яндекса даже говорят, что нет стопроцентной гарантии, что страница сохранится. Конкретная причина не указывается.
- HTML-код содержит мета тег мета-тег «robots» со значением «noarchive», что означает запрет на кэширование (локальное сохранение данных для получения быстрого доступа к странице при следующих запросах).
Что предпринять если в ПС нет сохраненной копии, а посмотреть содержимое нужно? Попробуйте изучить специализированные площадки и расширения.
Рассмотренными выше способами можно посмотреть:
- Мобильную версию веб-сайта. Пропишите url мобильной версии в Яндексе или Google. Из выдачи перейдите на нее далее, как в примере рассмотренном выше.
- Адаптивную версию. Перейдя в сохраненную копию (так же как в примере выше). Открываем инструменты разработчика. Клавиша F12 в обозревателе. Или нажать ПКМ на пустом месте страницы, выбрать «Посмотреть код». Переходим в раздел мобильное отображение и перезагружаем веб-страницу.
Специализированные веб-архивы
Выше мы обсуждали, что существуют сервисы, задачи которых сохранять в истории страницы сайтов. Сейчас рассмотрим их подробнее и расскажем, как с ними работать.
И начнем с самого популярного и известно.
Wayback Machine
Сервис Wayback Machine — бесплатным онлайн-архивом, задача которого является сохранить и архивировать информацию размещенную в открытых интернет‑ресурсах. Wayback Machine является частью некоммерческого проекта Интернет Архива. На его серверах хранятся копии веб-сайтов, книг, аудио, фото, видео.
Чтобы открыть копию страницы перейдите на https://archive.org/, далее откроется поисковая форма, куда пропишите URL страницы. Нажмите кнопку «GO».

Онлайн-архив Wayback Machine
Сервис отобразит имеющиеся в архиве снимки.
Далее выберите в календаре нужную дату и откройте страницы. Результатом вывода будет открытие страницы, которую зафиксировали роботы за выбранную дату.
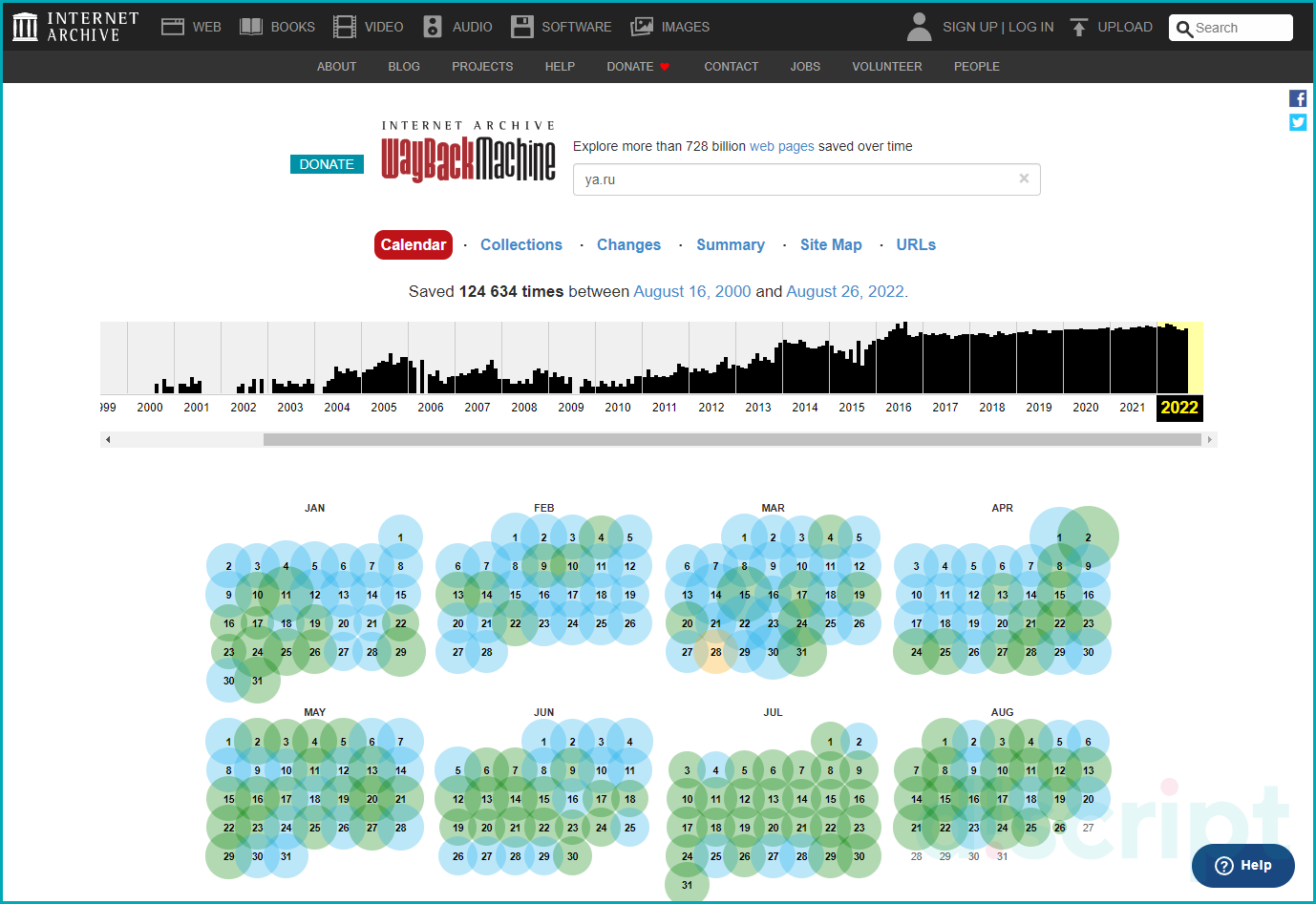
Календарь Wayback Machine
Кроме просмотра снимков страниц, сервис поможет:
- Проанализировать robots.txt. Сервис будет сканировать веб-сайты вне зависимости от настроек robots.txt;
- Узнать данные о домене. Актуально перед покупкой. Уточните какая информация размещалась на нем. Если вы купите «заспамленный» или домен под «санкциями» (например была размещена информация для взрослых) новый контент будет плохо ранжироваться. Если же ранее на нем размещалась информация, которая подходит по тематике и качеству для вашего будущего ресурса, тогда вы сможете использовать ее на этом же домене.
- Найти в архивных копиях пропавшую информацию.
- Если, например, на веб-сайте наблюдается спад трафика, откройте сохраненную версия сайта до момента уменьшения посещаемости. Проанализируйте, какие были сделаны изменения, чтобы разобраться в причине падения посещаемости.
Archive.Today
Archive.Today — бесплатный некоммерческий севрис сохраняющий веб-страницы в оналйн режиме. Особенность — сохраняет не только статические страницы, но и генерируемые Веб 2.0-проектами страницы. Например, карты Google.
Основное отличие от Wayback Machine, что Archive.Today сохраняет веб-страницы только по запросу пользователей. При этом сервер полностью сохраняет:
- HTML-страницы,
- CSS файлы,
- JS файлы,
- PDF,
- аудио файлы,
- пр.
Важно, помнить, что Archive.Today игнорирует файл robots.txt поэтому в нем можно сохранить страницы недоступные для Wayback Machine.
Обратите внимание, общий в Размер заархивированной страницы со всеми изображениями не должен превышать 50 МБ.
У Archive.Today есть собственное приложение для браузера Mozilla Firefox. Ссылка на ПО https://addons.mozilla.org/en-US/firefox/addon/archive-page/
Для начала работы с Archive.Today перейдите по адресу: https://archive.md/. Чтобы получить результат укажите в форму интересующий URL-адрес.
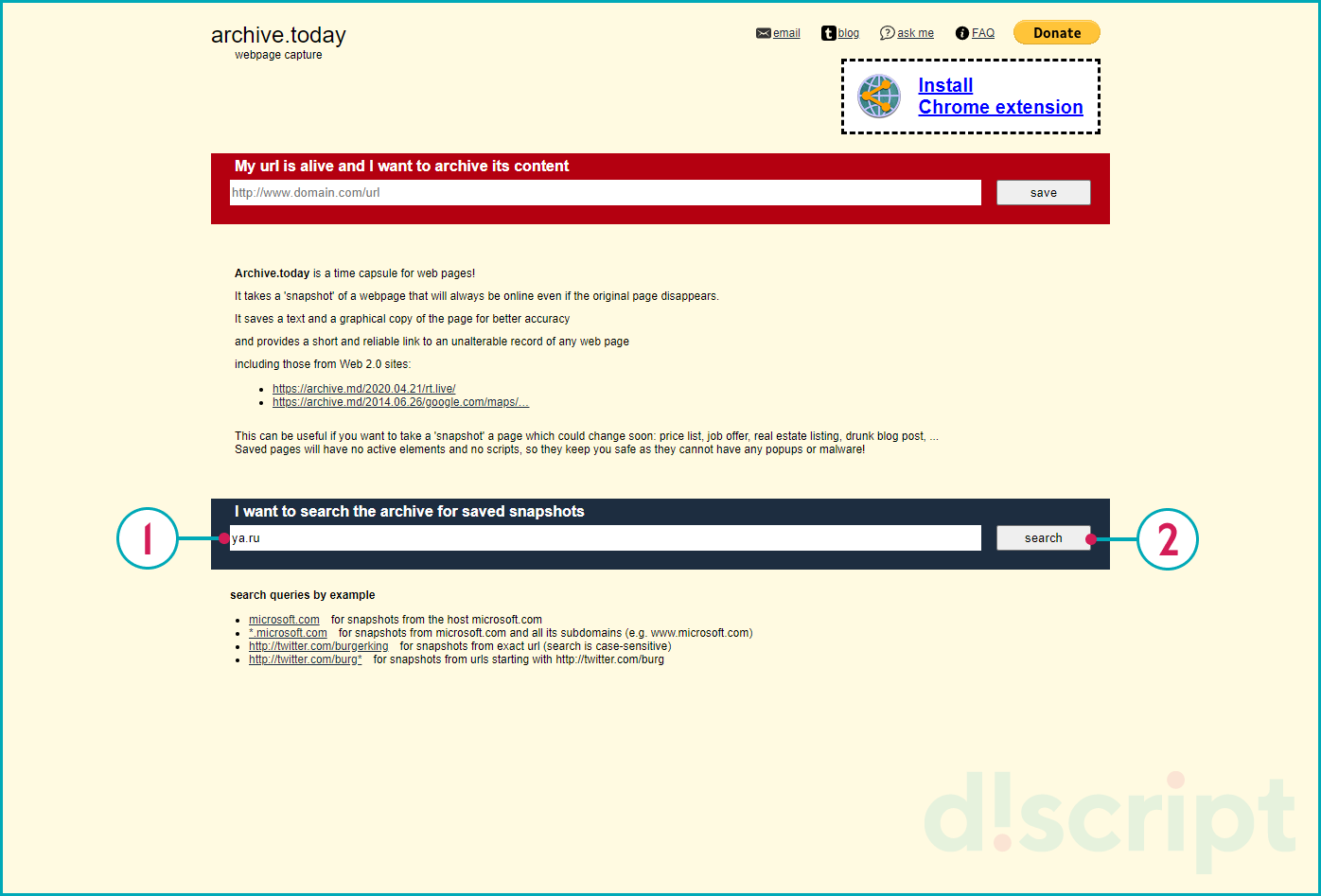
Сервис Archive.Today
Откроется страница с сохраненными снимками и информацией о дате создания копии.
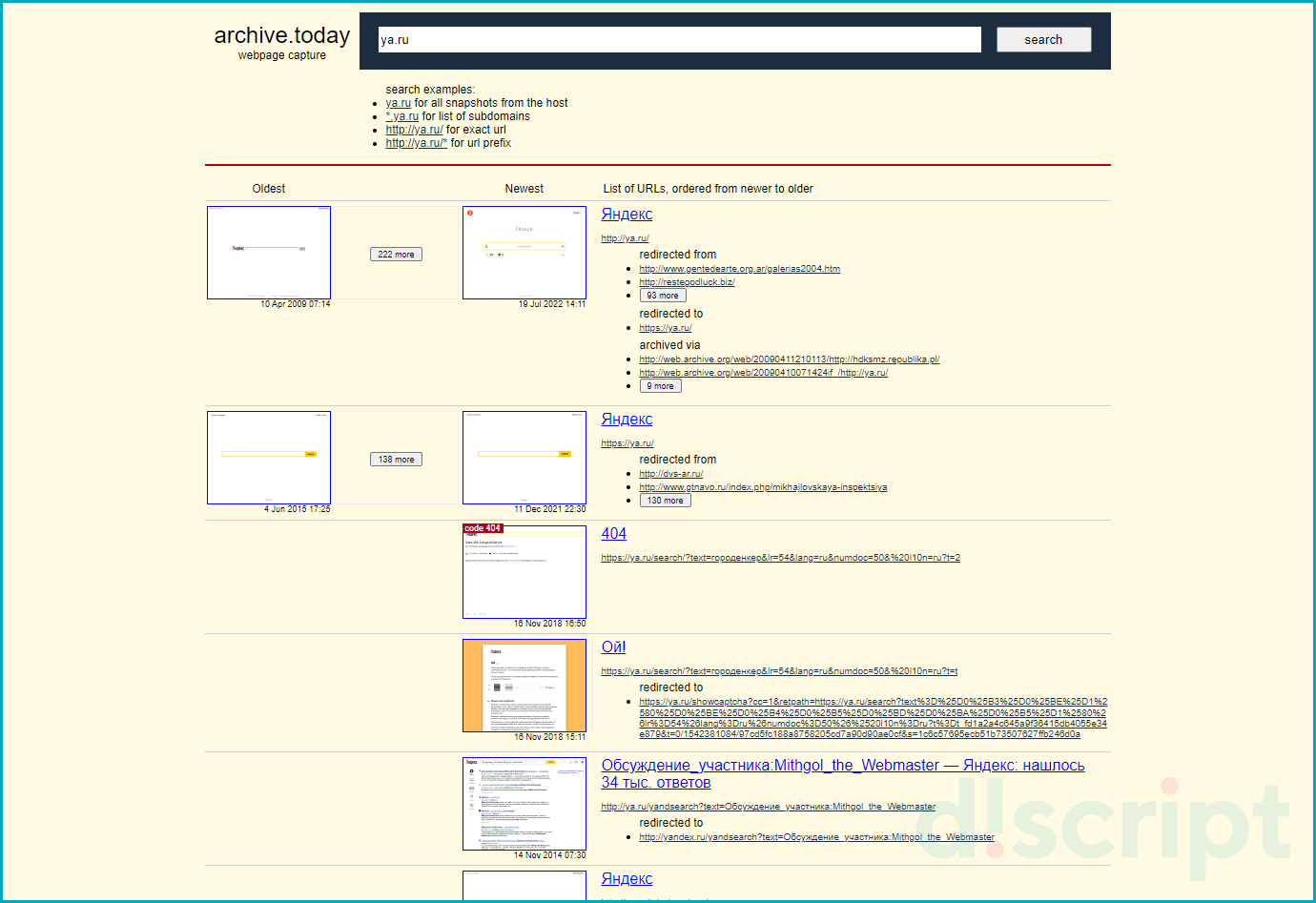
Страница с сохраненными снимками в сервисе Archive.Today
Вы можете скачать сохраненную копию виде архива. И восстановить версию страницы у себе на сервере.
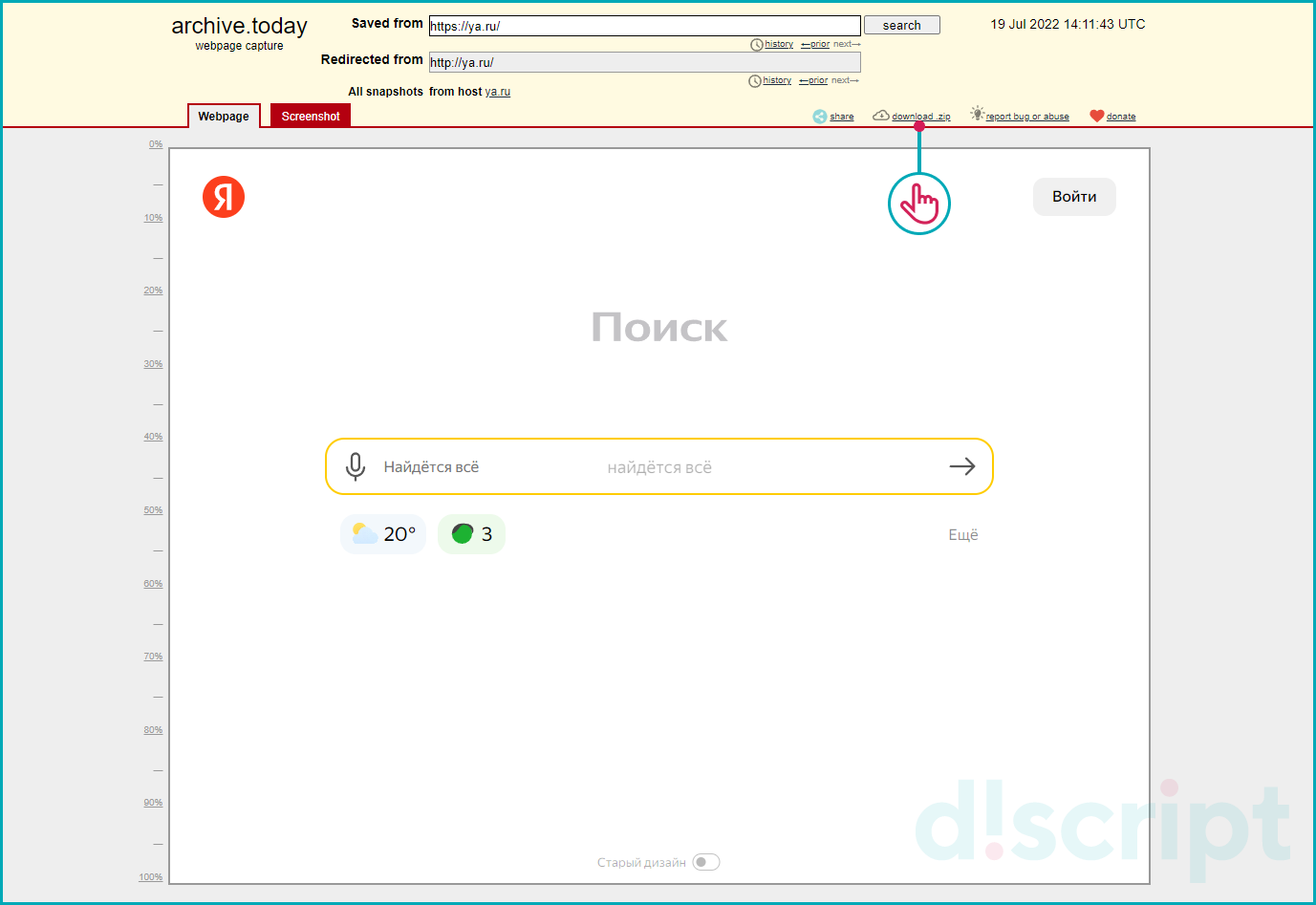
Сохранение страницы в сервисе Archive.Today
Расширения для браузеров
Существуют, плагины для браузеров, позволяющие создавать и просматривать сохраненные версии страниц.
Например, расширение Web Cache Viewer позволяет:
- Загружать веб-страницу из локального кэша на компьютере;
- Автоматически находить страницу при помощи сервиса Wayback Machine.
Перейдя по ссылке, рассмотренной, выше, нажмите кнопку «Установить».
Сервис Web Cache Viewer
После инсталляции расширения в браузере, нажмите правой кнопкой мыши пустом месте страницы для просмотра версии из Google или Wayback Machine.
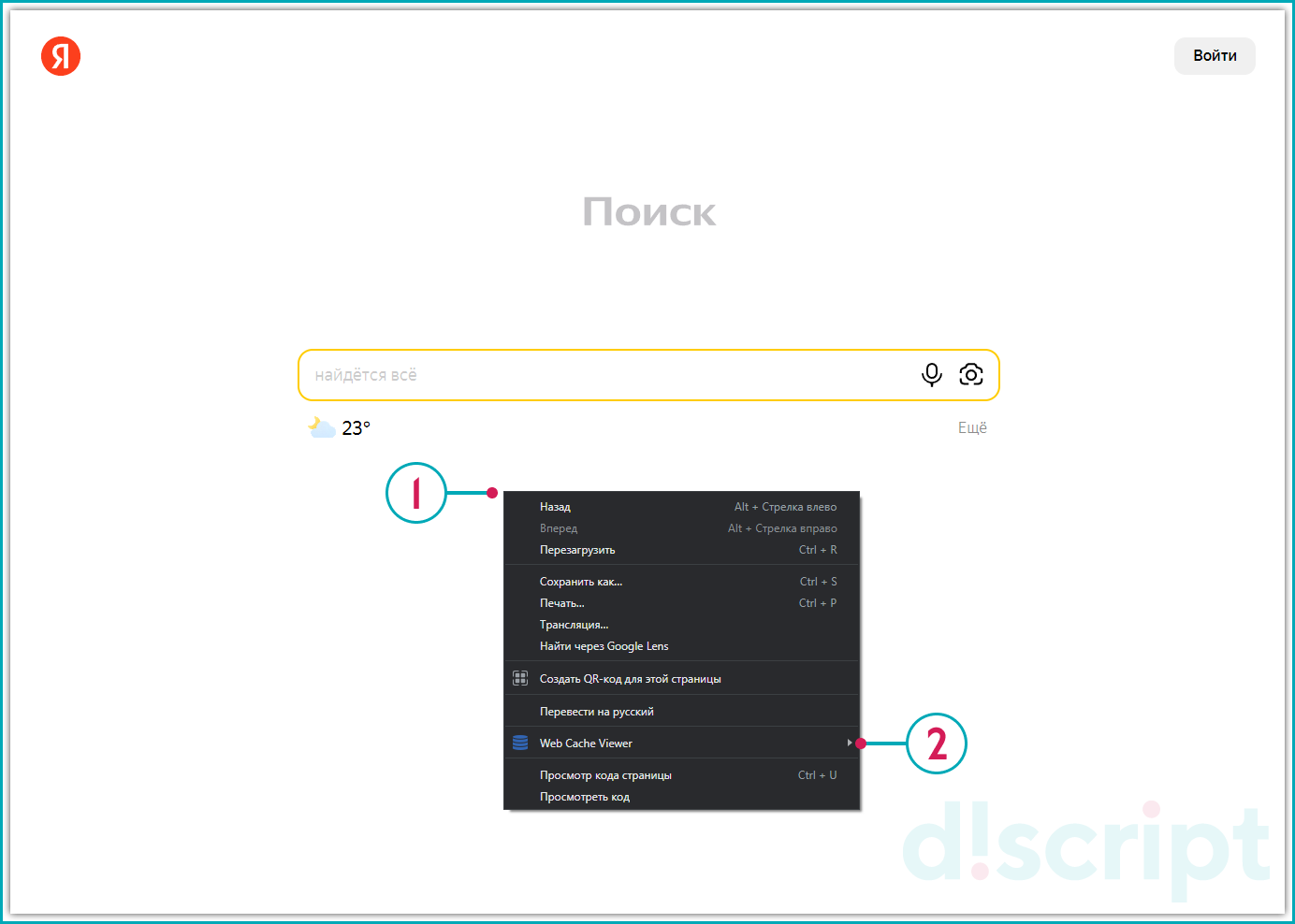
Просмотр версии из Google или Wayback Machine
Для пользователей Firefox существует аналогичное дополнение со схожим функционалом Web Archives.
Cached Page
Веб-сайт Cached Page ищет копии веб-страниц в поиске Google, Интернет Архиве, WebSite. Используйте площадку, если описанные выше способы не помогли найти сохраненную копию веб-сайта.
Пропишите название сайта в специальную форму. Для поиска нажмите одну из трех кнопок. Сервис предложит произвести поиск веб-страницы в:
- Веб-кэш Google;
- Интернет Архив;
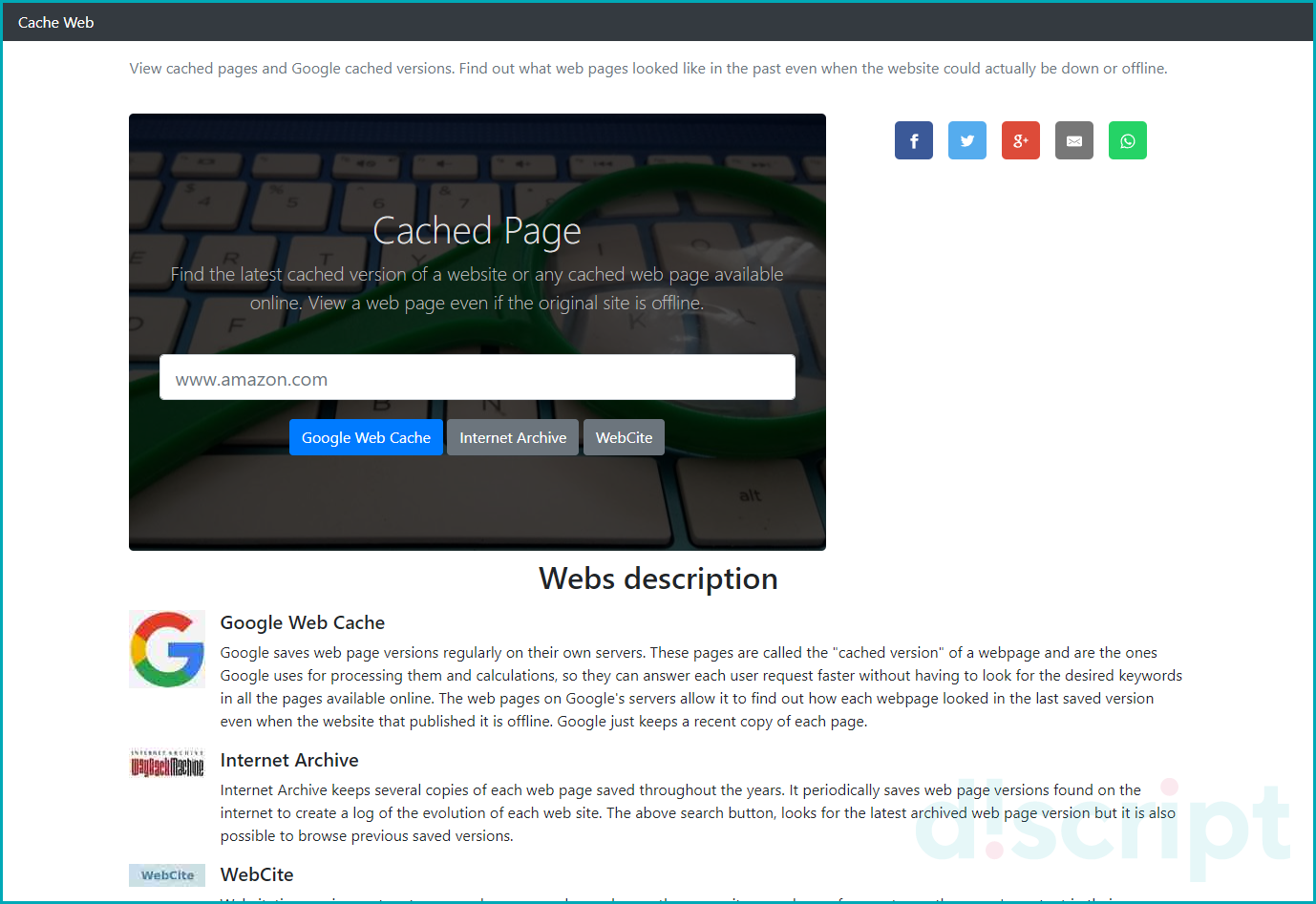
Поиск в сервисе Cached Page
Например, прописав в форму адрес https://discript.ru/prodvizhenie-sajtov/lyubercy/, и нажав кнопку «Архив Интернета», произойдет переход на страницу сервиса Wayback Machine. Если страница сохранена в БД сервиса, она отобразится на странице.
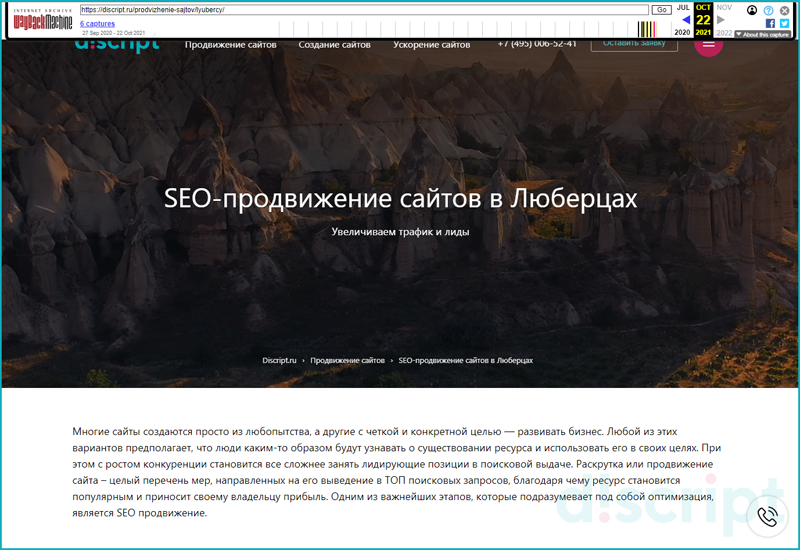
Отображение страницы в сервисе Wayback Machine
Выводы
Работая с сохраненными копиями страниц, можно выявить достаточного много полезных нюансов.
Сохраненные копии позволяют:
- Узнать, поисковый бот успел ли обойти вашу страницу после внесенных правок.
- Как бот воспринимает информацию со страницы. Все ли учитывает или остались места, которые ПС не видят.
- Выявить, какие элементы пропали и когда.
- Выявить, какие страницы успел обойти поисковый бот, после того, как сайт перестал быть доступным.
- Создать копии страниц.
- Восстановить копию сайта, когда забыли оплатить домен.
Сохраненная копия веб-страницы поможет определить, какая версия документа проиндексирована поисковыми роботами и участвует в ранжировании. Поэтому наличие «снимка» страницы в Яндексе и Google говорит об успешной проведенной индексации.
Другие статьи
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:https://www.iphones.ru/
Где https://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета

Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет

К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
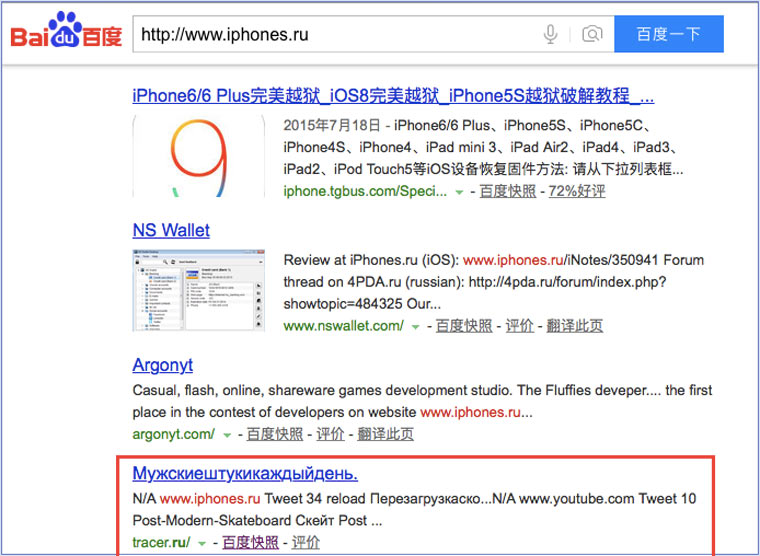
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
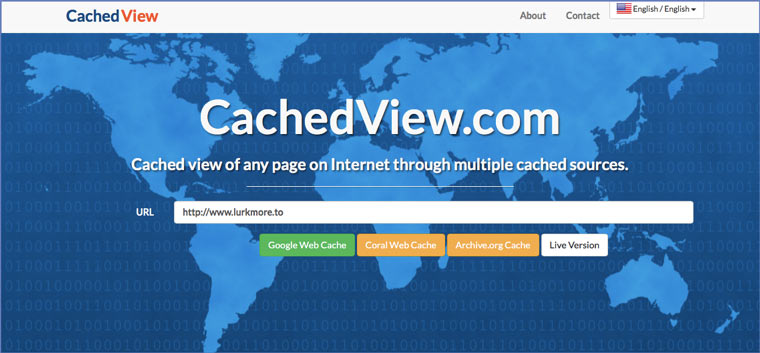
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
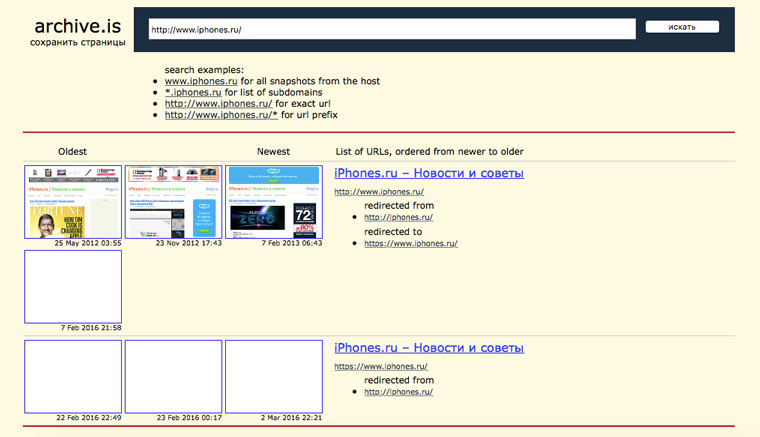
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari.
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
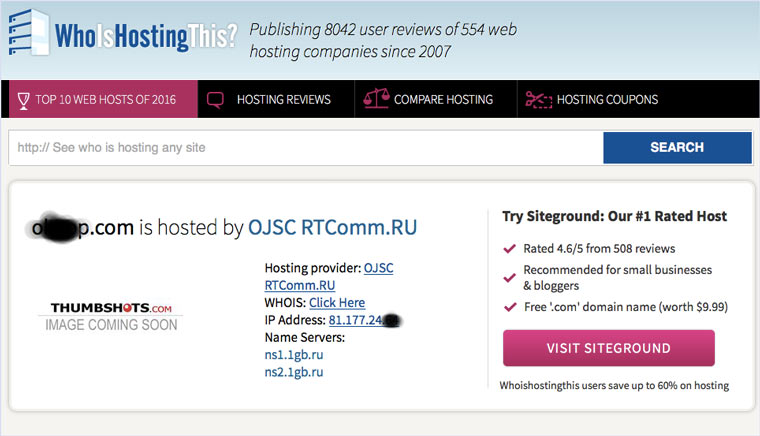
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:

Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
О других методах поиска читайте в статье 12 способов найти владельца сайта и узнать про него все.
А о сборе информации про людей читайте в статьях 9 сервисов для поиска информации в соцсетях и 15 фишек для сбора информации о человеке в интернете.

 (30 голосов, общий рейтинг: 4.80 из 5)
(30 голосов, общий рейтинг: 4.80 из 5)
🤓 Хочешь больше? Подпишись на наш Telegram.
![]()
iPhones.ru
Сервисы и трюки, с которыми найдётся ВСЁ. Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход. Всё, что попадает в интернет,…
- Google,
- полезный в быту софт,
- хаки
![]()
В статье мы расскажем, в каких случаях может понадобиться история сайта, как ее посмотреть. Приведем примеры основных сервисов, которые позволят заглянуть в прошлое страницы. Объясним, как посмотреть сохраненную копию страницы в поисковых систeмах и как восстановить сайт из архива.

Зачем нужна информация об истории сайта в прошлом
Историю любого сайта можно посмотреть в интернете. Для этого достаточно, чтобы ресурс существовал хотя бы пару дней. Это может понадобиться в следующих случаях:
● Если необходимо купить домен, который уже был в использовании, и нужно посмотреть контент какой тематики был на нем размещен, не было ли огромного количества рекламы, исходящих ссылок и т.д.
● Нужен уникальный контент. Его можно скачать с существовавших когда-то ресурсов. Такое наполнение подойдет, например, для сайта-сателлита.
● Нужно восстановить сайт, когда нет его бэкапа.
● Нужно проанализировать конкурентов. Этот способ понадобится, чтобы посмотреть историю изменений на их сайтах, какие ошибки они допускали или, наоборот, какие «фишки» стоит позаимствовать.
● Необходимо посмотреть страницу, если она теперь недоступна напрямую.
● Интересно, как выглядел ресурс 10-20 лет назад.
Ниже приведен пример того, как выглядела стартовая страница поисковой системы Яндекс в 2000 году:
Как посмотреть сайт в прошлом?
Есть несколько сервисов, в которых можно посмотреть, как менялось визуальное оформление страниц сайта, его структуру страниц и контент, положение в поисковой выдаче и какие изменения вносились в регистрационные данные за время существования ресурса.
Сервис Веб-архив
При его использовании сначала заходим на сайт https://web.archive.org/ и после вводим адрес страницы.
График ниже показывает количество сохранений: первое было в 1998 году.
Дни, в которые были сохранения, отмечены кружком. При клике на время во всплывающем окне, открывается сохраненная версия. Показано ниже:
Как выгрузить сайт из ВебАрхива, расскажем дальше.
Сервис Whois History
Для его использования заходим на сайт http://whoishistory.ru/и вводим данные в поиске по доменам и IP, либо по домену:
Сервис покажет информацию по данным Whois, где собраны сведения от всех регистраторов доменных имен. Посмотреть можно возраст домена, кто владелец, какие изменения вносились в регистрационные данные и т.д.
Сохраненная копия страницы в поисковых системах Яндекс и Google
Для сохранения копий страниц понадобятся дополнительные сервисы. Поисковые системы сохраняют последние версии страниц, которые были проиндексированы поисковым роботом.
Для этого в строке поиска Яндекс вводим адрес сайта с оператором site: или url: в зависимости от того, что хотим проверить конкретную страницу или ресурс целиком. Нажимаем на стрелочку рядом с URL и выбираем «Сохраненная копия».
Откроется последняя версия страницы, которая есть у ПС. Можно посмотреть только текст, выбрав одноименную вкладку.
Посмотреть сохраненную копию конкретной страницы в Google можно с помощью оператора cache. Например, вводим cache:trinet.ru и получаем:
Вы так же можете посмотреть текстовую версию страницы.
Найти сохраненную версию страницы можно и через выдачу Google. Необходимо:
● использовать оператор site:, либо указать сразу необходимый URL
● найти страницу в выдаче
● нажать на стрелочку рядом с URL
● выбрать «Сохраненная копия»
Платформа Serpstat
С помощью этого инструмента можно посмотреть изменения видимости сайта в поисковой выдаче за год или за все время, что сайт находится в базе Serpstat.
Сервис Keys.so
Используя этот сервис можно посмотреть, сколько страниц находится в выдаче, в ТОП – 1, ТОП – 3 и т.д. Можно регулировать параметры на графике и выгружать полную статистику в Excel.
Как восстановить сайт из архива
Часто нужно не только посмотреть, как менялись страницы в прошлом, но и скачать содержимое сайта. Это легко сделать с помощью автоматических сервисов.
О самых популярных расскажем ниже.
Сервис Архиварикс
Сервис может восстановить как рабочие, так и не рабочие сайты. Недоступные ресурсы он скачивает из Веб-архива. Для этого нужно заполнить данные на странице https://archivarix.com/ru/restore/и нажать кнопку «Восстановить».
Для работы с полученными файлами Архиварикс предоставляет собственную систему CMS, которая совместима с любыми другими системами.
Сервис Rush Analytics
Данный сервис также восстанавливает сайты из Веб-архива. Можно задать нужную дату скачивания для любой страницы. На выходе получаем html-документ со всеми стилями, картинками и т.д.
Сервис R-tools.org
Еще один сервис, который позволяет скачивать сайты из Веб-архива. Можно скачать сайт целиком, можно отдельные страницы. Оплата происходит только за то, что скачено, поэтому выгоднее использовать данный сервис только для небольших сайтов.
Сервис Wayback Machine Download (waybackmachinedownloader.com)
С помощью него можно скачивать данные из Веб-архива. Есть демо-версия. Подходит для больших проектов. Единственный минус – сервис не русифицирован.
Сервис Mydrop.io
Этот сервис помогает найти уже освободившиеся или скоро освобождающиеся интересные домены по вашим параметрам.
Для этого необходимо применить заданные фильтры, после чего можно скачать контент этих сайтов. Сервис делает скриншоты сайтов до их удаления. Перед скачиванием можно предварительно посмотреть содержимое ресурса. Особенностью является то, что данные выгружаются не из ВебАрхива, а из собственной базы.
Плагины
Восстановить сайт из бэкапа можно автоматически с помощью плагинов для CMS. Таких инструментов множество. Например, плагины Duplicator, UpdraftPlus для системы WordPress. Все, что нужно – это иметь резервную копию, которую также можно сделать с помощью этих плагинов, если сайтом владеете вы.
Множество сервисов, предоставляющие хостинг для сайта, сохраняют бэкапы и можно восстановить предыдущую версию собственного проекта.
Заключение
Мы привели примеры основных сервисов, в которых можно посмотреть изменения сайтов и восстановить их содержимое. Список не ограничивается только этими инструментами.
Если у вас есть интересные и проверенные сервисы, о которых мы не упомянули, расскажите в комментариях. А если нужна помощь со скачиванием контента, обращайтесь к нашим специалистам.
И до встречи в следующей публикации!
