Критерий фишера таблица как пользоваться пример?
kafedra meis
23 октября 2018 · 15,8 K
Образование Высшее – закончил в 2000г ВГАСУ. Слушаю рок, панк, рок как русский так и… · 23 окт 2018
Для определения критерия Фишера сначала нужно определиться какая таблица нам нужна, то есть нужно знать уровень значимости (0.1, 0.05 или 0.01).
Зная уровень значимости, выбираем Таблицу значений F-критерия Фишера при уровне значимости (здесь уровень значимости, например, 0.05).
Затем определяем k1 (равно количеству факторов). Например, в однофакторной модели k1=1, а в четыхфакторной k1=4.
После нам нужно определить k2 по формуле: k2=n-m-1, где n – число наблюдений, m – количество факторов. Например для четырехфакторной модели k2 = n – 5.
И в заключении, когда известны k1 и k2, на пересечении столбца k1 и строки k2 находится значение критерия Фишера.
Для нашего примера (четырехфакторная модель, пусть будет при 10 измерениях, при уровне значимости 0.05) на пересечении k1 = 4 и k2 = 10 – 5 = 5 в Таблице значений F-критериев Фишера при уровне значимости 0.05 находится значение 4.53. Это и есть нужное нам значение критерия Фишера для заданных условий.
13,4 K
А если k1 = 15 и этого значения нет в таблице?
Комментировать ответ…Комментировать…
Критерий
Фишера позволяет
сравнивать величины выборочных
дисперсий двух независимых выборок.
Для вычисления Fэмп нужно
найти отношение дисперсий двух выборок,
причем так, чтобы большая по величине
дисперсия находилась бы в числителе, а
меньшая – в знаменателе. Формула
вычисления критерия Фишера такова:
 (8)
(8)
где ![]() –
–
дисперсии первой и второй выборки
соответственно.
Так
как, согласно условию критерия, величина
числителя должна быть больше или равна
величине знаменателя, то значение
Fэмп всегда
будет больше или равно единице.
Число
степеней свободы определяется также
просто:
k1=nl –
1 для
первой выборки (т.е. для той выборки,
величина дисперсии которой больше)
и k2=n2 –
1 для
второй выборки.
В
Приложении 1 критические значения
критерия Фишера находятся по
величинам k1 (верхняя
строчка таблицы) и k2 (левый
столбец таблицы).
Если tэмп>tкрит,
то нулевая гипотеза принимается, в
противном случае принимается
альтернативная.
Пример
3. В
двух третьих классах проводилось
тестирование умственного развития по
тесту ТУРМШ десяти учащихся.[3] Полученные
значения величин средних достоверно
не различались, однако психолога
интересует вопрос — есть ли различия
в степени однородности показателей
умственного развития между классами.
Решение.
Для критерия Фишера необходимо сравнить
дисперсии тестовых оценок в обоих
классах. Результаты тестирования
представлены в таблице:
Таблица
3.
|
№№ учащихся |
Первый |
Второй |
|
1 |
90 |
41 |
|
2 |
29 |
49 |
|
3 |
39 |
56 |
|
4 |
79 |
64 |
|
5 |
88 |
72 |
|
6 |
53 |
65 |
|
7 |
34 |
63 |
|
8 |
40 |
87 |
|
9 |
75 |
77 |
|
10 |
79 |
62 |
|
Суммы |
606 |
636 |
|
Среднее |
60,6 |
63,6 |
Рассчитав
дисперсии для переменных X и Y, получаем:
sx2=572,83; sy2=174,04
Тогда
по формуле (8) для расчета по F критерию
Фишера находим:
![]()
По
таблице из Приложения 1 для F критерия
при степенях свободы в обоих случаях
равных k=10
– 1 = 9 находим Fкрит=3,18
(<3.29), следовательно, в терминах
статистических гипотез можно утверждать,
что Н0 (гипотеза
о сходстве) может быть отвергнута на
уровне 5%, а принимается в этом случае
гипотеза Н1.
Иcследователь
может утверждать, что по степени
однородности такого показателя, как
умственное развитие, имеется различие
между выборками из двух классов.
6.2 Непараметрические критерии
Сравнивая
на глазок (по процентным соотношениям)
результаты до и после какого-либо
воздействия, исследователь приходит к
заключению, что если наблюдаются
различия, то имеет место различие в
сравниваемых выборках. Подобный подход
категорически неприемлем, так как для
процентов нельзя определить уровень
достоверности в различиях. Проценты,
взятые сами по себе, не дают возможности
делать статистически достоверные
выводы. Чтобы доказать эффективность
какого-либо воздействия, необходимо
выявить статистически значимую тенденцию
в смещении (сдвиге) показателей. Для
решения подобных задач исследователь
может использовать ряд критериев
различия. Ниже будет рассмотрены
непараметрические критерии: критерий
знаков и критерий хи-квадрат.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Критерий Фишера и Стьюдента
С помощью критерия Фишера оценивают качество регрессионной модели в целом и по параметрам.
Для этого выполняется сравнение полученного значения F и табличного F значения. F-критерия Фишера. F фактический определяется из отношения значений факторной и остаточной дисперсий, рассчитанных на одну степень свободы:

где n — число наблюдений;
m — число параметров при факторе х.
F табличный — это максимальное значение критерия под влиянием случайных факторов при текущих степенях свободы и уровне значимости а.
Уровень значимости а — вероятность не принять гипотезу при условии, что она верна. Как правило а принимается равной 0,05 или 0,01.
Если Fтабл > Fфакт то признается статистическая незначимость модели, ненадежность уравнения регрессии.
Таблицы по нахождению критерия Фишера и Стьюдента
Таблицы значений F-критерия Фишера и t-критерия Стьюдента Вы можете посмотреть здесь.
Табличное значение критерия Фишера вычисляют следующим образом:
- Определяют k1, которое равно количеству факторов (Х). Например, в однофакторной модели (модели парной регрессии) k1=1, в двухфакторной k=2.
- Определяют k2, которое определяется по формуле n — m — 1, где n — число наблюдений, m — количество факторов. Например, в однофакторной модели k2 = n — 2.
- На пересечении столбца k1 и строки k2 находят значение критерия Фишера
Для нахождения табличного значения критерия Стьюдента определяют число степеней свободы, которое определяется по формуле n — m — 1 и находят его значение при определенном уровне значимости (0,10, 0,05, 0,01).
Критерии Стьюдента
Для оценки статистической значимости модели по параметрам рассчитывают t-критерии Стьюдента.
Оценка значимости модели с помощью критерия Стьюдента проводится путем сравнения их значений с величиной случайной ошибки:

Случайные ошибки коэффициентов линейной регрессии и коэффициента корреляции определяются по формулам:

Сравнивая фактическое и табличное значения t-статистики и принимается или отвергается гипотеза о значимости модели по параметрам.
Зависимость между критерием Фишера и значением t-статистики Стьюдента определяется так

Как и в случае с оценкой значимости уравнения модели в целом, модель считается ненадежной если tтабл > tфакт
Видео лекциий по расчету критериев Фишера и Стьюдента
Для более подробного изучения расчетов критериев Фишера и Стьюдента советуем посмотреть это видео
Лекция 1. Критерии и Гипотезы
Лекция 2. Критерии и Гипотезы
Лекция 3. Критерии и Гипотезы
Определение доверительных интервалов
Для построения доверительного интервала определяется предельная ошибка А для обоих показателей:

Формулы для нахождения доверительных интервалов выглядят так

Прогнозное значение у определяется с помощью подстановки в
уравнение регрессии прогнозного значения х. Вычисляется средняя стандартная ошибка прогноза

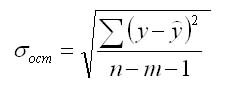
и находится доверительный интервал
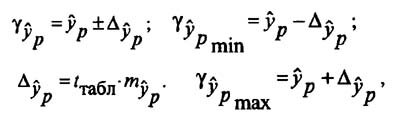
Задача регрессионного анализа в предмете эконометрика состоит в анализе дисперсии изучаемого показателя y:

 общая сумма квадратов отклонений (TSS)
общая сумма квадратов отклонений (TSS)
 сумма квадратов отклонений, обусловленная регрессией (RSS)
сумма квадратов отклонений, обусловленная регрессией (RSS)
 остаточная сумма квадратов отклонений (ESS)
остаточная сумма квадратов отклонений (ESS)
Долю дисперсии, обусловленную регрессией, в общей дисперсии показателя у характеризует коэффициент детерминации R, который должен превышать 50% (R2 > 0,5). В контрольных по эконометрике в ВУЗах этот показатель рассчитывается всегда.

Любые задачи по эконометрике решаются здесь
Текущая версия страницы пока не проверялась опытными участниками и может значительно отличаться от версии, проверенной 26 октября 2017 года; проверки требуют 8 правок.
F-тест или критерий Фишера (F-критерий, φ*-критерий) — статистический критерий, тестовая статистика которого при выполнении нулевой гипотезы имеет распределение Фишера (F-распределение).
Статистика теста так или иначе сводится к отношению выборочных дисперсий (сумм квадратов, деленных на «степени свободы»). Чтобы статистика имела распределение Фишера, необходимо, чтобы числитель и знаменатель были независимыми случайными величинами и соответствующие суммы квадратов имели распределение Хи-квадрат. Для этого требуется, чтобы данные имели нормальное распределение. Кроме того, предполагается, что дисперсия случайных величин, квадраты которых суммируются, одинакова.
Тест проводится путём сравнения значения статистики с критическим значением соответствующего распределения Фишера при заданном уровне значимости. Известно, что если  , то
, то  . Кроме того, квантили распределения Фишера обладают свойством
. Кроме того, квантили распределения Фишера обладают свойством  . Поэтому обычно на практике в числителе участвует потенциально большая величина, в знаменателе — меньшая и сравнение осуществляется с «правой» квантилью распределения. Тем не менее тест может быть и двусторонним, и односторонним. В первом случае при уровне значимости
. Поэтому обычно на практике в числителе участвует потенциально большая величина, в знаменателе — меньшая и сравнение осуществляется с «правой» квантилью распределения. Тем не менее тест может быть и двусторонним, и односторонним. В первом случае при уровне значимости  используется квантиль
используется квантиль  , а при одностороннем тесте —
, а при одностороннем тесте —  [1].
[1].
Более удобный способ проверки гипотез — с помощью p-значения  — вероятностью того, что случайная величина с данным распределением Фишера превысит данное значение статистики. Если (для двустороннего теста —
— вероятностью того, что случайная величина с данным распределением Фишера превысит данное значение статистики. Если (для двустороннего теста —  )) меньше уровня значимости , то нулевая гипотеза отвергается, в противном случае принимается.
)) меньше уровня значимости , то нулевая гипотеза отвергается, в противном случае принимается.
Примеры F-тестов[править | править код]
F-тест на равенство дисперсий[править | править код]
Две выборки[править | править код]
Пусть имеются две выборки объёмом m и n соответственно случайных величин X и Y, имеющих нормальное распределение. Необходимо проверить равенство их дисперсий. Статистика теста

где  — выборочная дисперсия.
— выборочная дисперсия.
Если статистика больше критического значения, соответствующего выбранному уровню значимости, то дисперсии случайных величин признаются не одинаковыми.
Несколько выборок[править | править код]
Пусть выборка объёмом N случайной величины X разделена на k групп с количеством наблюдений  в i-ой группе.
в i-ой группе.
Межгрупповая («объяснённая») дисперсия: 
Внутригрупповая («необъяснённая») дисперсия: 

Данный тест можно свести к тестированию значимости регрессии переменной X на фиктивные переменные-индикаторы групп. Если статистика превышает критическое значение, то гипотеза о равенстве средних в выборках отвергается, в противном случае средние можно считать одинаковыми.
Проверка ограничений на параметры регрессии[править | править код]
Статистика теста для проверки линейных ограничений на параметры классической нормальной линейной регрессии определяется по формуле:

где  -количество ограничений, n-объём выборки, k-количество параметров модели, RSS-сумма квадратов остатков модели,
-количество ограничений, n-объём выборки, k-количество параметров модели, RSS-сумма квадратов остатков модели,  -коэффициент детерминации, индексы S и L относятся соответственно к короткой и длинной модели (модели с ограничениями и модели без ограничений).
-коэффициент детерминации, индексы S и L относятся соответственно к короткой и длинной модели (модели с ограничениями и модели без ограничений).
Замечание[править | править код]
Описанный выше F-тест является точным в случае нормального распределения случайных ошибок модели. Однако F-тест можно применить и в более общем случае. В этом случае он является асимптотическим. Соответствующую F-статистику можно рассчитать на основе статистик других асимптотических тестов — теста Вальда (W), теста множителей Лагранжа(LM) и теста отношения правдоподобия (LR) — следующим образом:

Все эти статистики асимптотически имеют распределение F(q, n-k), несмотря на то, что их значения на малых выборках могут различаться.
Проверка значимости линейной регрессии[править | править код]
Данный тест очень важен в регрессионном анализе и по существу является частным случаем проверки ограничений. В данном случае нулевая гипотеза — об одновременном равенстве нулю всех коэффициентов при факторах регрессионной модели (то есть всего ограничений k-1). В данном случае короткая модель — это просто константа в качестве фактора, то есть коэффициент детерминации короткой модели равен нулю. Статистика теста равна:

Соответственно, если значение этой статистики больше критического значения при данном уровне значимости, то нулевая гипотеза отвергается, что означает статистическую значимость регрессии. В противном случае модель признается незначимой.
Пример[править | править код]
Пусть оценивается линейная регрессия доли расходов на питание в общей сумме расходов на константу, логарифм совокупных расходов, количество взрослых членов семьи и количество детей до 11 лет. То есть всего в модели 4 оцениваемых параметра (k=4). Пусть по результатам оценки регрессии получен коэффициент детерминации  . По вышеприведенной формуле рассчитаем значение F-статистики в случае, если регрессия оценена по данным 34 наблюдений и по данным 64 наблюдений:
. По вышеприведенной формуле рассчитаем значение F-статистики в случае, если регрессия оценена по данным 34 наблюдений и по данным 64 наблюдений:


Критическое значение статистики при 1 % уровне значимости (в Excel функция FРАСПОБР) в первом случае равно  , а во втором случае
, а во втором случае  . В обоих случаях регрессия признается значимой при заданном уровне значимости. В первом случае P-значение равно 0,1 %, а во втором — 0,00005 %. Таким образом, во втором случае уверенность в значимости регрессии существенно выше (существенно меньше вероятность ошибки в случае признания модели значимой).
. В обоих случаях регрессия признается значимой при заданном уровне значимости. В первом случае P-значение равно 0,1 %, а во втором — 0,00005 %. Таким образом, во втором случае уверенность в значимости регрессии существенно выше (существенно меньше вероятность ошибки в случае признания модели значимой).
Проверка гетероскедастичности[править | править код]
См. Тест Голдфелда-Куандта
См. также[править | править код]
- Проверка статистических гипотез
- Статистический критерий
- Тест Вальда
- Тест отношения правдоподобия
- Тест множителей Лагранжа
- Тест Голдфелда-Куандта
Примечания[править | править код]
- ↑ F-Test for Equality of Two Variances (англ.). NIST. Дата обращения: 29 марта 2017. Архивировано 9 марта 2017 года.
Критерий Фишера используют в качестве проверке равенства (однородности) дисперсий двух выборок, в том числе проверки значимости модели регрессии.
Критерий Фишера находится по формуле:
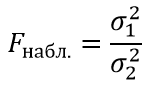
при σ1>σ2
σ1 – большая дисперсия выборки;
σ2 – меньшая дисперсия выборки.
Формула критерий Фишера для оценки значимости уравнения регрессии:
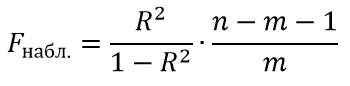
При Fнабл<Fкр нулевая гипотеза принимается.
Число степеней свободы исправленных дисперсий находятся по формулам:
для первой выборки
f1=n1−1
для второй выборки
f2=n2−1
Fкр (α, f1, f2) определяется по таблице
Пример
Дана выборка успеваемости по двум группам.
| № п/п | X | Y |
| 1 | 34 | 45 |
| 2 | 44 | 68 |
| 3 | 97 | 76 |
| 4 | 62 | 56 |
| 5 | 39 | 78 |
| 6 | 73 | 64 |
| 7 | 42 | 84 |
| 8 | 95 | 54 |
| 9 | 35 | 81 |
| 10 | 37 | 79 |
| 11 | 45 | 41 |
| 12 | 43 | 47 |
| 13 | 73 | 79 |
| 14 | 53 | 32 |
| 15 | 32 | 44 |
Требуется определить различия в оценках между двумя группами при α = 0.05.
Решение
Вычислим дисперсию по X и по Y
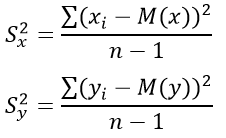
| № п/п | X | Y | D(X) | D(Y) |
| 1 | 34 | 45 | 42,684 | 31,609 |
| 2 | 44 | 68 | 10,24 | 4,1798 |
| 3 | 97 | 76 | 209,28 | 22,195 |
| 4 | 62 | 56 | 7,84 | 3,8242 |
| 5 | 39 | 78 | 23,684 | 28,92 |
| 6 | 73 | 64 | 41,818 | 0,5057 |
| 7 | 42 | 84 | 14,951 | 54,432 |
| 8 | 95 | 54 | 190,44 | 6,876 |
| 9 | 35 | 81 | 38,44 | 40,676 |
| 10 | 37 | 79 | 30,618 | 32,617 |
| 11 | 45 | 41 | 8,2178 | 48,38 |
| 12 | 43 | 47 | 12,484 | 24,558 |
| 13 | 73 | 79 | 41,818 | 32,617 |
| 14 | 53 | 32 | 0,04 | 99,113 |
| 15 | 32 | 44 | 51,84 | 35,469 |
| Сумма | 804 | 928 | 724,4 | 465,97 |
| Среднее | 53,6 | 61,867 |
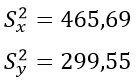
По критерию Фишера находим Fэмп.
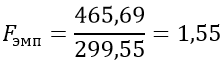
k1=15 — 1 = 14,
k2=15 — 1 = 14
По таблице критерия Фишера находим критическое значение
Fкрит=2.49, следовательно, 2.49>1.55, Fкрит>Fэмп
Отсюда, различия в оценках между двумя выборками групп присутствует, принимаем гипотезу.
![]() 20582
20582
