Рассмотрим вычисление квантилей для некоторых функций распределений, представленных в
MS
EXCEL
.
Понятие
Квантиля
основано на определении
Функции распределения
. Поэтому, перед изучением
Квантилей
рекомендуем освежить в памяти понятия из статьи
Функция распределения вероятности
.
Содержание статьи:
- Определение
- Квантили специальных видов
- Квантили стандартного нормального распределения
- Квантили распределения Стьюдента
- Квантили распределения ХИ-квадрат
- Квантили F-распределения
- Квантили распределения Вейбулла
- Квантили экспоненциального распределения
Сначала дадим формальное определение
квантиля,
затем приведем примеры их вычисления в MS EXCEL.
Определение
Пусть случайная величина
X
, имеет
функцию распределения
F
(
x
).
α-квантилем
(
альфа-
квантиль,
x
a
,
квантиль
порядка
α, нижний
α-
квантиль
) называют решение уравнения
x
a
=F
-1
(α), где
α
– вероятность, что случайная величина х примет значение меньшее или равное x
a
, т.е. Р(х<= x
a
)=
α.
Из определения ясно, что нахождение
квантиля
распределения является обратной операцией нахождения вероятности. Т.е. если при вычислении
функции распределения
мы находим вероятность
α,
зная x
a
, то при нахождении
квантиля
мы, наоборот, ищем
x
a
зная
α
.
Чтобы пояснить определение, используем график функции
стандартного нормального распределения
(см.
файл примера Лист Определение
):
Примечание
: О построении графиков в MS EXCEL можно прочитать статью
Основные типы диаграмм в MS EXCEL
.
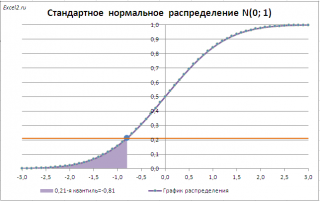
Например, с помощью графика вычислим 0,21-ю
квантиль
, т.е. такое значение случайной величины, что Р(X<=x
0,21
)=0,21.
Для этого найдем точку пересечения горизонтальной линии на уровне вероятности равной 0,21 с
функцией распределения
. Абсцисса этой точки равна -0,81. Соответственно, 0,21-я
квантиль
равна -0,81. Другими словами, вероятность того, что случайная величина, распределенная
стандартному нормальному закону,
примет значение
меньше
-0,81, равна 0,21 (21%).
Примечание
: При вычислении
квантилей
в MS EXCEL используются
обратные функции распределения
:
НОРМ.СТ.ОБР()
,
ЛОГНОРМ.ОБР()
,
ХИ2.ОБР(),
ГАММА.ОБР()
и т.д. Подробнее о распределениях, представленных в MS EXCEL, можно прочитать в статье
Распределения случайной величины в MS EXCEL
.
Точное значение
квантиля
в нашем случае можно найти с помощью формулы
=НОРМ.СТ.ОБР(0,21)
СОВЕТ
: Процедура вычисления
квантилей
имеет много общего с вычислением
процентилей
выборки
(см. статью
Процентили в MS EXCEL
).
Квантили специальных видов
Часто используются
Квантили
специальных видов:
-
процентили
x
p/100
, p=1, 2, 3, …, 99 -
квартили
x
p/4
, p=1, 2, 3 -
медиана
x
1/2
В качестве примера вычислим
медиану (0,5-квантиль)
логнормального распределения
LnN(0;1) (см.
файл примера лист Медиана
).
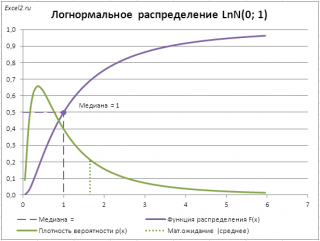
Это можно сделать с помощью формулы
=ЛОГНОРМ.ОБР(0,5; 0; 1)
Квантили стандартного нормального распределения
Необходимость в вычислении квантилей
стандартного нормального распределения
возникает при
проверке статистических гипотез
и при
построении доверительных интервалов.
Примечание
: Про
проверку статистических гипотез
см. статью
Проверка статистических гипотез в MS EXCEL
. Про
построение доверительных интервалов
см. статью
Доверительные интервалы в MS EXCEL
.
В данных задачах часто используется специальная терминология:
Нижний квантиль уровня
альфа
(
α
percentage point)
;
Верхний квантиль уровня альфа (upper
α
percentage point)
;
Двусторонние квантили уровня
альфа
.
Нижний квантиль уровня альфа
– это обычный
α-квантиль.
Чтобы пояснить название «
нижний» квантиль
, построим график
плотности вероятности
и
функцию вероятности
стандартного нормального
распределения
(см.
файл примера лист Квантили
).
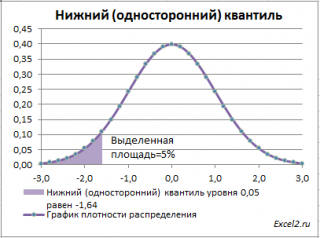
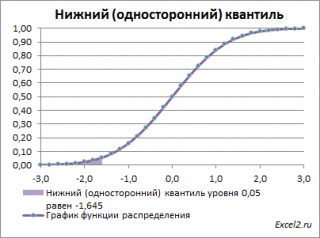
Выделенная площадь на рисунке соответствует вероятности, что случайная величина примет значение меньше
α-квантиля
. Из определения
квантиля
эта вероятность равна
α
. Из графика
функции распределения
становится понятно, откуда происходит название ”
нижний квантиль” –
выделенная область расположена в нижней части графика.
Для
α=0,05,
нижний 0,05-квантиль
стандартного нормального распределения
равен -1,645. Вычисления в MS EXCEL можно сделать по формуле:
=НОРМ.СТ.ОБР(0,05)
Однако, при
проверке гипотез
и построении
доверительных интервалов
чаще используется “верхний”
α-квантиль.
Покажем почему.
Верхним
α
–
квантилем
называют такое значение x
α
, для которого вероятность, того что случайная величина X примет значение
больше или равное
x
α
равна
альфа:
P(X>= x
α
)=
α
. Из определения понятно, что
верхний альфа
–
квантиль
любого распределения равен
нижнему (1-
α)
–
квантилю.
А для распределений, у которых
функция плотности распределения
является четной функцией,
верхний
α
–
квантиль
равен
нижнему
α
–
квантилю
со знаком минус
.
Это следует из свойства четной функции f(-x)=f(x), в силу симметричности ее относительно оси ординат.
Действительно, для
α=0,05,
верхний 0,05-квантиль
стандартного нормального распределения
равен 1,645. Т.к.
функция плотности вероятности
стандартного нормального
распределения
является четной функцией, то вычисления в MS EXCEL
верхнего квантиля
можно сделать по двум формулам:
=НОРМ.СТ.ОБР(1-0,05)
=-НОРМ.СТ.ОБР(0,05)
Почему применяют понятие
верхний
α
–
квантиль?
Только из соображения удобства, т.к. он при
α<0,5
всегда положительный (в случае
стандартного нормального
распределения
). А при проверке гипотез
α
равно
уровню значимости
, который обычно берут равным 0,05, 0,1 или 0,01. В противном случае, в процедуре
проверки гипотез
пришлось бы записывать условие отклонения
нулевой гипотезы
μ>μ
0
как Z
0
>Z
1-
α
, подразумевая, что Z
1-
α
–
обычный
квантиль
порядка
1-
α
(или как Z
0
>-Z
α
). C верхнем квантилем эта запись выглядит проще Z
0
>Z
α
.
Примечание
: Z
0
– значение
тестовой статистики
, вычисленное на основе
выборки
. Подробнее см. статью
Проверка статистических гипотез в MS EXCEL о равенстве среднего значения распределения (дисперсия известна)
.
Чтобы пояснить название «
верхний»
квантиль
, построим график
плотности вероятности
и
функцию вероятности
стандартного нормального
распределения
для
α=0,05.
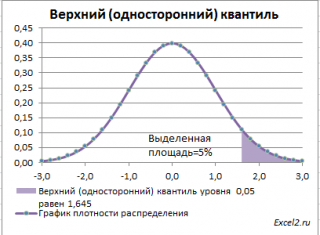
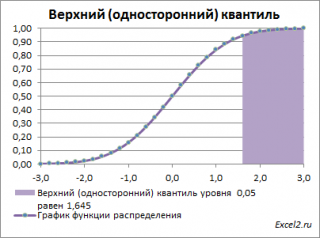
Выделенная площадь на рисунке соответствует вероятности, что случайная величина примет значение больше
верхнего 0,05-квантиля
, т.е.
больше
значения 1,645. Эта вероятность равна 0,05.
На графике
плотности вероятности
площадь выделенной области равна 0,05 (5%) от общей площади под графиком (равна 1). Из графика
функции распределения
становится понятно, откуда происходит название “верхний”
квантиль
–
выделенная область расположена в верхней части графика. Если Z
0
больше
верхнего квантиля
, т.е. попадает в выделенную область, то
нулевая гипотеза
отклоняется.
Также при
проверке двухсторонних гипотез
и построении соответствующих
доверительных интервалов
иногда используется понятие “двусторонний”
α-квантиль.
В этом случае условие отклонения
нулевой гипотезы
звучит как |Z
0
|>Z
α
/2
, где Z
α
/2
–
верхний
α/2-квантиль
. Чтобы не писать
верхний
α/2-квантиль
, для удобства используют “двусторонний”
α-квантиль.
Почему двусторонний? Как и в предыдущих случаях, построим график
плотности вероятности стандартного нормального распределения
и график
функции распределения
.
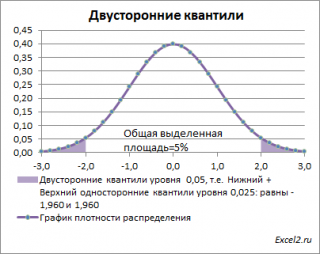
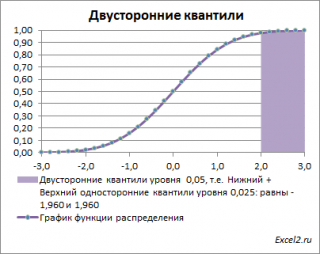
Невыделенная площадь на рисунке соответствует вероятности, что случайная величина примет значение
между
нижним квантилем уровня α
/2 и
верхним квантилем
уровня α
/2, т.е. будет между значениями -1,960 и 1,960 при α=0,05. Эта вероятность равна в нашем случае 1-(0,05/2+0,05/2)=0,95. Если Z
0
попадает в одну из выделенных областей, то
нулевая гипотеза
отклоняется.
Вычислить
двусторонний
0,05
–
квантиль
это можно с помощью формул MS EXCEL:
=НОРМ.СТ.ОБР(1-0,05/2)
или
=-НОРМ.СТ.ОБР(0,05/2)
Другими словами,
двусторонние α-квантили
задают интервал, в который рассматриваемая случайная величина попадает с заданной вероятностью α.
Квантили распределения Стьюдента
Аналогичным образом
квантили
вычисляются и для
распределения Стьюдента
. Например, вычислять
верхний
α/2-
квантиль
распределения Стьюдента с
n
-1 степенью свободы
требуется, если проводится
проверка двухсторонней гипотезы
о
среднем значении
распределения при
неизвестной
дисперсии
(
см. эту статью
).
Для
верхних квантилей
распределения Стьюдента
часто используется запись t
α/2,n-1
. Если такая запись встретилась в статье про
проверку гипотез
или про построение
доверительного интервала
, то это именно
верхний квантиль
.
Примечание
:
Функция плотности вероятности распределения Стьюдента
, как и
стандартного нормального распределения
, является четной функцией.
Чтобы вычислить в MS EXCEL
верхний
0,05/2
–
квантиль
для t-распределения с 10 степенями свободы (или тоже самое
двусторонний
0,05-квантиль
), необходимо записать формулу
=СТЬЮДЕНТ.ОБР.2Х(0,05; 10)
или
=СТЬЮДРАСПОБР(0,05; 10)
или
=СТЬЮДЕНТ.ОБР(1-0,05/2; 10)
или
=-СТЬЮДЕНТ.ОБР(0,05/2; 10)
.2X означает 2 хвоста, т.е.
двусторонний квантиль
.
Квантили распределения ХИ-квадрат
Вычислять
квантили
распределения ХИ-квадрат
с
n
-1 степенью свободы
требуется, если проводится
проверка гипотезы
о
дисперсии нормального распределения
(см. статью
Проверка статистических гипотез в MS EXCEL о дисперсии нормального распределения
).
При
проверке таких гипотез
также используются
верхние квантили.
Например, при
двухсторонней гипотезе
требуется вычислить 2
верхних
квантиля
распределения
ХИ
2
: χ
2
α/2,n-1
и
χ
2
1-
α/2,n-1
. Почему требуется вычислить два
квантиля
, не один, как при
проверке гипотез о среднем
, где используется
стандартное нормальное распределение
или
t-распределение
?
Дело в том, что в отличие от
стандартного нормального распределения
и
распределения Стьюдента
, плотность распределения
ХИ
2
не является четной (симметричной относительно оси х). У него все
квантили
больше 0, поэтому
верхний альфа-квантиль
не равен
нижнему (1-альфа)-квантилю
или по-другому:
верхний альфа-квантиль
не равен
нижнему альфа-квантилю
со знаком минус.
Чтобы вычислить
верхний
0,05/2
–
квантиль
для
ХИ
2
-распределения
с
числом степеней свободы
10, т.е.
χ
2
0,05/2,n-1
, необходимо в MS EXCEL записать формулу
=ХИ2.ОБР.ПХ(0,05/2; 10)
или
=ХИ2.ОБР(1-0,05/2; 10)
Результат равен 20,48. .ПХ означает правый хвост распределения, т.е. тот который расположен вверху на графике
функции распределения
.
Чтобы вычислить
верхний
(1-0,05/2)-
квантиль
при том же
числе степеней свободы
, т.е.
χ
2
1-0,05/2,n-1
и необходимо записать формулу
=ХИ2.ОБР.ПХ(1-0,05/2; 10)
или
=ХИ2.ОБР(0,05/2; 10)
Результат равен 3,25.
Квантили F-распределения
Вычислять
квантили
распределения Фишера
с
n
1
-1 и
n
2
-1 степенями свободы
требуется, если проводится
проверка гипотезы
о равенстве
дисперсий двух нормальных распределений
(см. статью
Двухвыборочный тест для дисперсии: F-тест в MS EXCEL
).
При
проверке таких гипотез
используются, как правило,
верхние квантили.
Например, при
двухсторонней гипотезе
требуется вычислить 2
верхних
квантиля
F
-распределения:
F
α/2,n1-1,
n
2
-1
и
F
1-α/2,n1-1,
n
2
-1
. Почему требуется вычислить два
квантиля
, не один, как при
проверке гипотез о среднем
? Причина та же, что и для распределения ХИ
2
– плотность
F-распределения
не является четной
.
Эти
квантили
нельзя выразить один через другой как для
стандартного нормального распределения
.
Верхний альфа-квантиль
F
-распределения
не равен
нижнему альфа-квантилю
со знаком минус.
Чтобы вычислить
верхний
0,05/2-квантиль
для
F
-распределения
с
числом степеней свободы
10 и 12, необходимо записать формулу
=F.ОБР.ПХ(0,05/2;10;12) =FРАСПОБР(0,05/2;10;12) =F.ОБР(1-0,05/2;10;12)
Результат равен 3,37. .ПХ означает правый хвост распределения, т.е. тот который расположен вверху на графике
функции распределения
.
Квантили распределения Вейбулла
Иногда
обратная функция распределения
может быть представлена в явном виде с помощью элементарных функций, например как для
распределения Вейбулла
. Напомним, что функция этого распределения задается следующей формулой:
![]()
После логарифмирования обеих частей выражения, выразим x через соответствующее ему значение F(x) равное P:
![]()
Примечание
: Вместо обозначения
α-квантиль
может использоваться
p
–
квантиль.
Суть от этого не меняется.
Это и есть обратная функция, которая позволяет вычислить
P
–
квантиль
(
p
–
quantile
). Для его вычисления в формуле нужно подставить известное значение вероятности P и вычислить значение х
p
(вероятность того, что случайная величина Х примет значение меньше или равное х
p
равна P).
Квантили экспоненциального распределения
Задача
:
Случайная величина имеет
экспоненциальное распределение
:
![]()
Требуется выразить
p
-квантиль
x
p
через параметр распределения λ и заданную вероятность
p
.
Примечание
: Вместо обозначения
α-квантиль
может использоваться
p-квантиль
. Суть от этого не меняется.
Решение
: Вспоминаем, что
p
-квантиль
– это такое значение x
p
случайной величины X, для которого P(X<=x
p
)=
p
. Т.е. вероятность, что случайная величина X примет значение меньше или равное x
p
равна
p
. Запишем это утверждение с помощью формулы:
![]()
По сути, мы записали
функцию вероятности экспоненциального распределения
: F(x
p
)=
p
.
Из определения
квантиля
следует, что для его нахождения нам потребуется
обратная функция распределения
.
Проинтегрировав вышеуказанное выражение, получим:
![]()
Используя это уравнение, выразим x
p
через λ и вероятность
p
.
![]()
Конечно, явно выразить
обратную функцию распределения
можно не для всех
функций распределений
.
В статье подробно показано, что такое нормальный закон распределения случайной величины и как им пользоваться при решении практически задач.
Нормальное распределение в статистике
История закона насчитывает 300 лет. Первым открывателем стал Абрахам де Муавр, который придумал аппроксимацию биномиального распределения еще 1733 году. Через много лет Карл Фридрих Гаусс (1809 г.) и Пьер-Симон Лаплас (1812 г.) вывели математические функции.
Лаплас также обнаружил замечательную закономерность и сформулировал центральную предельную теорему (ЦПТ), согласно которой сумма большого количества малых и независимых величин имеет нормальное распределение.
Нормальный закон не является фиксированным уравнением зависимости одной переменной от другой. Фиксируется только характер этой зависимости. Конкретная форма распределения задается специальными параметрами. Например, у = аx + b – это уравнение прямой. Однако где конкретно она проходит и под каким наклоном, определяется параметрами а и b. Также и с нормальным распределением. Ясно, что это функция, которая описывает тенденцию высокой концентрации значений около центра, но ее точная форма задается специальными параметрами.
Кривая нормального распределения Гаусса имеет следующий вид.

График нормального распределения напоминает колокол, поэтому можно встретить название колоколообразная кривая. У графика имеется «горб» в середине и резкое снижение плотности по краям. В этом заключается суть нормального распределения. Вероятность того, что случайная величина окажется около центра гораздо выше, чем то, что она сильно отклонится от середины.

На рисунке выше изображены два участка под кривой Гаусса: синий и зеленый. Основания, т.е. интервалы, у обоих участков равны. Но заметно отличаются высоты. Синий участок удален от центра, и имеет существенно меньшую высоту, чем зеленый, который находится в самом центре распределения. Следовательно, отличаются и площади, то бишь вероятности попадания в обозначенные интервалы.
Формула нормального распределения (плотности) следующая.
![]()
Формула состоит из двух математических констант:
π – число пи 3,142;
е – основание натурального логарифма 2,718;
двух изменяемых параметров, которые задают форму конкретной кривой:
m – математическое ожидание (в различных источниках могут использоваться другие обозначения, например, µ или a);
σ2 – дисперсия;
ну и сама переменная x, для которой высчитывается плотность вероятности.
Конкретная форма нормального распределения зависит от 2-х параметров: математического ожидания (m) и дисперсии (σ2). Кратко обозначается N(m, σ2) или N(m, σ). Параметр m (матожидание) определяет центр распределения, которому соответствует максимальная высота графика. Дисперсия σ2 характеризует размах вариации, то есть «размазанность» данных.
Параметр математического ожидания смещает центр распределения вправо или влево, не влияя на саму форму кривой плотности.

А вот дисперсия определяет остроконечность кривой. Когда данные имеют малый разброс, то вся их масса концентрируется у центра. Если же у данных большой разброс, то они «размазываются» по широкому диапазону.

Плотность распределения не имеет прямого практического применения. Для расчета вероятностей нужно проинтегрировать функцию плотности.
Вероятность того, что случайная величина окажется меньше некоторого значения x, определяется функцией нормального распределения:
![]()
Используя математические свойства любого непрерывного распределения, несложно рассчитать и любые другие вероятности, так как
P(a ≤ X < b) = Ф(b) – Ф(a)
Стандартное нормальное распределение
Нормальное распределение зависит от параметров средней и дисперсии, из-за чего плохо видны его свойства. Хорошо бы иметь некоторый эталон распределения, не зависящий от масштаба данных. И он существует. Называется стандартным нормальным распределением. На самом деле это обычное нормальное нормальное распределение, только с параметрами математического ожидания 0, а дисперсией – 1, кратко записывается N(0, 1).
Любое нормальное распределение легко превращается в стандартное путем нормирования:
![]()
где z – новая переменная, которая используется вместо x;
m – математическое ожидание;
σ – стандартное отклонение.
Для выборочных данных берутся оценки:
![]()
Среднее арифметическое и дисперсия новой переменной z теперь также равны 0 и 1 соответственно. В этом легко убедиться с помощью элементарных алгебраических преобразований.
В литературе встречается название z-оценка. Это оно самое – нормированные данные. Z-оценку можно напрямую сравнивать с теоретическими вероятностями, т.к. ее масштаб совпадает с эталоном.
Посмотрим теперь, как выглядит плотность стандартного нормального распределения (для z-оценок). Напомню, что функция Гаусса имеет вид:
![]()
Подставим вместо (x-m)/σ букву z, а вместо σ – единицу, получим функцию плотности стандартного нормального распределения:
![]()
График плотности:

Центр, как и ожидалось, находится в точке 0. В этой же точке функция Гаусса достигает своего максимума, что соответствует принятию случайной величиной своего среднего значения (т.е. x-m=0). Плотность в этой точке равна 0,3989, что можно посчитать даже в уме, т.к. e0=1 и остается рассчитать только соотношение 1 на корень из 2 пи.
Таким образом, по графику хорошо видно, что значения, имеющие маленькие отклонения от средней, выпадают чаще других, а те, которые сильно отдалены от центра, встречаются значительно реже. Шкала оси абсцисс измеряется в стандартных отклонениях, что позволяет отвязаться от единиц измерения и получить универсальную структуру нормального распределения. Кривая Гаусса для нормированных данных отлично демонстрирует и другие свойства нормального распределения. Например, что оно является симметричным относительно оси ординат. В пределах ±1σ от средней арифметической сконцентрирована большая часть всех значений (прикидываем пока на глазок). В пределах ±2σ находятся большинство данных. В пределах ±3σ находятся почти все данные. Последнее свойство широко известно под названием правило трех сигм для нормального распределения.
Функция стандартного нормального распределения позволяет рассчитывать вероятности.
![]()
Понятное дело, вручную никто не считает. Все подсчитано и размещено в специальных таблицах, которые есть в конце любого учебника по статистике.
Таблица нормального распределения
Таблицы нормального распределения встречаются двух типов:
— таблица плотности;
— таблица функции (интеграла от плотности).
Таблица плотности используется редко. Тем не менее, посмотрим, как она выглядит. Допустим, нужно получить плотность для z = 1, т.е. плотность значения, отстоящего от матожидания на 1 сигму. Ниже показан кусок таблицы.

В зависимости от организации данных ищем нужное значение по названию столбца и строки. В нашем примере берем строку 1,0 и столбец 0, т.к. сотых долей нет. Искомое значение равно 0,2420 (0 перед 2420 опущен).
Функция Гаусса симметрична относительно оси ординат. Поэтому φ(z)= φ(-z), т.е. плотность для 1 тождественна плотности для -1, что отчетливо видно на рисунке.

Чтобы не тратить зря бумагу, таблицы печатают только для положительных значений.
На практике чаще используют значения функции стандартного нормального распределения, то есть вероятности для различных z.
В таких таблицах также содержатся только положительные значения. Поэтому для понимания и нахождения любых нужных вероятностей следует знать свойства стандартного нормального распределения.
Функция Ф(z) симметрична относительно своего значения 0,5 (а не оси ординат, как плотность). Отсюда справедливо равенство:
![]()
Это факт показан на картинке:

Значения функции Ф(-z) и Ф(z) делят график на 3 части. Причем верхняя и нижняя части равны (обозначены галочками). Для того, чтобы дополнить вероятность Ф(z) до 1, достаточно добавить недостающую величину Ф(-z). Получится равенство, указанное чуть выше.
Если нужно отыскать вероятность попадания в интервал (0; z), то есть вероятность отклонения от нуля в положительную сторону до некоторого количества стандартных отклонений, достаточно от значения функции стандартного нормального распределения отнять 0,5:
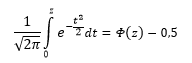
Для наглядности можно взглянуть на рисунок.

На кривой Гаусса, эта же ситуация выглядит как площадь от центра вправо до z.

Довольно часто аналитика интересует вероятность отклонения в обе стороны от нуля. А так как функция симметрична относительно центра, предыдущую формулу нужно умножить на 2:

Рисунок ниже.

Под кривой Гаусса это центральная часть, ограниченная выбранным значением –z слева и z справа.

Указанные свойства следует принять во внимание, т.к. табличные значения редко соответствуют интересующему интервалу.
Для облегчения задачи в учебниках обычно публикуют таблицы для функции вида:

Если нужна вероятность отклонения в обе стороны от нуля, то, как мы только что убедились, табличное значение для данной функции просто умножается на 2.
Теперь посмотрим на конкретные примеры. Ниже показана таблица стандартного нормального распределения. Найдем табличные значения для трех z: 1,64, 1,96 и 3.

Как понять смысл этих чисел? Начнем с z=1,64, для которого табличное значение составляет 0,4495. Проще всего пояснить смысл на рисунке.

То есть вероятность того, что стандартизованная нормально распределенная случайная величина попадет в интервал от 0 до 1,64, равна 0,4495. При решении задач обычно нужно рассчитать вероятность отклонения в обе стороны, поэтому умножим величину 0,4495 на 2 и получим примерно 0,9. Занимаемая площадь под кривой Гаусса показана ниже.

Таким образом, 90% всех нормально распределенных значений попадает в интервал ±1,64σ от средней арифметической. Я не случайно выбрал значение z=1,64, т.к. окрестность вокруг средней арифметической, занимающая 90% всей площади, иногда используется для проверки статистических гипотез и расчета доверительных интервалов. Если проверяемое значение не попадает в обозначенную область, то его наступление маловероятно (всего 10%).
Для проверки гипотез, однако, чаще используется интервал, накрывающий 95% всех значений. Половина вероятности от 0,95 – это 0,4750 (см. второе выделенное в таблице значение).

Для этой вероятности z=1,96. Т.е. в пределах почти ±2σ от средней находится 95% значений. Только 5% выпадают за эти пределы.

Еще одно интересное и часто используемое табличное значение соответствует z=3, оно равно по нашей таблице 0,4986. Умножим на 2 и получим 0,997. Значит, в рамках ±3σ от средней арифметической заключены почти все значения.

Так выглядит правило 3 сигм для нормального распределения на диаграмме.
С помощью статистических таблиц можно получить любую вероятность. Однако этот метод очень медленный, неудобный и сильно устарел. Сегодня все делается на компьютере. Далее переходим к практике расчетов в Excel.
В Excel есть несколько функций для подсчета вероятностей или обратных значений нормального распределения.

Функция НОРМ.СТ.РАСП
Функция НОРМ.СТ.РАСП предназначена для расчета плотности ϕ(z) или вероятности Φ(z) по нормированным данным (z).
=НОРМ.СТ.РАСП(z;интегральная)
z – значение стандартизованной переменной
интегральная – если 0, то рассчитывается плотность ϕ(z), если 1 – значение функции Ф(z), т.е. вероятность P(Z<z).
Рассчитаем плотность и значение функции для различных z: -3, -2, -1, 0, 1, 2, 3 (их укажем в ячейке А2).
Для расчета плотности потребуется формула =НОРМ.СТ.РАСП(A2;0). На диаграмме ниже – это красная точка.
Для расчета значения функции =НОРМ.СТ.РАСП(A2;1). На диаграмме – закрашенная площадь под нормальной кривой.

В реальности чаще приходится рассчитывать вероятность того, что случайная величина не выйдет за некоторые пределы от средней (в среднеквадратичных отклонениях, соответствующих переменной z), т.е. P(|Z|<z).

Определим, чему равна вероятность попадания случайной величины в пределы ±1z, ±2z и ±3z от нуля. Потребуется формула 2Ф(z)-1, в Excel =2*НОРМ.СТ.РАСП(A2;1)-1.

На диаграмме отлично видны основные основные свойства нормального распределения, включая правило трех сигм. Функция НОРМ.СТ.РАСП – это автоматическая таблица значений функции нормального распределения в Excel.
Может стоять и обратная задача: по имеющейся вероятности P(Z<z) найти стандартизованную величину z ,то есть квантиль стандартного нормального распределения.
Функция НОРМ.СТ.ОБР
НОРМ.СТ.ОБР рассчитывает обратное значение функции стандартного нормального распределения. Синтаксис состоит из одного параметра:
=НОРМ.СТ.ОБР(вероятность)
вероятность – это вероятность.
Данная формула используется так же часто, как и предыдущая, ведь по тем же таблицам искать приходится не только вероятности, но и квантили.

Например, при расчете доверительных интервалов задается доверительная вероятность, по которой нужно рассчитать величину z.

Учитывая то, что доверительный интервал состоит из верхней и нижней границы и то, что нормальное распределение симметрично относительно нуля, достаточно получить верхнюю границу (положительное отклонение). Нижняя граница берется с отрицательным знаком. Обозначим доверительную вероятность как γ (гамма), тогда верхняя граница доверительного интервала рассчитывается по следующей формуле.
![]()
Рассчитаем в Excel значения z (что соответствует отклонению от средней в сигмах) для нескольких вероятностей, включая те, которые наизусть знает любой статистик: 90%, 95% и 99%. В ячейке B2 укажем формулу: =НОРМ.СТ.ОБР((1+A2)/2). Меняя значение переменной (вероятности в ячейке А2) получим различные границы интервалов.

Доверительный интервал для 95% равен 1,96, то есть почти 2 среднеквадратичных отклонения. Отсюда легко даже в уме оценить возможный разброс нормальной случайной величины. В общем, доверительным вероятностям 90%, 95% и 99% соответствуют доверительные интервалы ±1,64, ±1,96 и ±2,58 σ.
В целом функции НОРМ.СТ.РАСП и НОРМ.СТ.ОБР позволяют произвести любой расчет, связанный с нормальным распределением. Но, чтобы облегчить и уменьшить количество действий, в Excel есть несколько других функций. Например, для расчета доверительных интервалов средней можно использовать ДОВЕРИТ.НОРМ. Для проверки статистической гипотезы о средней арифметической есть формула Z.ТЕСТ.
Рассмотрим еще пару полезных формул с примерами.
Функция НОРМ.РАСП
Функция НОРМ.РАСП отличается от НОРМ.СТ.РАСП лишь тем, что ее используют для обработки данных любого масштаба, а не только нормированных. Параметры нормального распределения указываются в синтаксисе.
=НОРМ.РАСП(x;среднее;стандартное_откл;интегральная)
x – значение (или ссылка на ячейку), для которого рассчитывается плотность или значение функции нормального распределения
среднее – математическое ожидание, используемое в качестве первого параметра модели нормального распределения
стандартное_откл – среднеквадратичное отклонение – второй параметр модели
интегральная – если 0, то рассчитывается плотность, если 1 – то значение функции, т.е. P(X<x).
Например, плотность для значения 15, которое извлекли из нормальной выборки с матожиданием 10, стандартным отклонением 3, рассчитывается так:

Если последний параметр поставить 1, то получим вероятность того, что нормальная случайная величина окажется меньше 15 при заданных параметрах распределения. Таким образом, вероятности можно рассчитывать напрямую по исходным данным.
Функция НОРМ.ОБР
Это квантиль нормального распределения, т.е. значение обратной функции. Синтаксис следующий.
=НОРМ.ОБР(вероятность;среднее;стандартное_откл)
вероятность – вероятность
среднее – матожидание
стандартное_откл – среднеквадратичное отклонение
Назначение то же, что и у НОРМ.СТ.ОБР, только функция работает с данными любого масштаба.
Пример показан в ролике в конце статьи.
Моделирование нормального распределения
Для некоторых задач требуется генерация нормальных случайных чисел. Готовой функции для этого нет. Однако В Excel есть две функции, которые возвращают случайные числа: СЛУЧМЕЖДУ и СЛЧИС. Первая выдает случайные равномерно распределенные целые числа в указанных пределах. Вторая функция генерирует равномерно распределенные случайные числа между 0 и 1. Чтобы сделать искусственную выборку с любым заданным распределением, нужна функция СЛЧИС.
Допустим, для проведения эксперимента необходимо получить выборку из нормально распределенной генеральной совокупности с матожиданием 10 и стандартным отклонением 3. Для одного случайного значения напишем формулу в Excel.
=НОРМ.ОБР(СЛЧИС();10;3)
Протянем ее на необходимое количество ячеек и нормальная выборка готова.
Для моделирования стандартизованных данных следует воспользоваться НОРМ.СТ.ОБР.
Процесс преобразования равномерных чисел в нормальные можно показать на следующей диаграмме. От равномерных вероятностей, которые генерируются формулой СЛЧИС, проведены горизонтальные линии до графика функции нормального распределения. Затем от точек пересечения вероятностей с графиком опущены проекции на горизонтальную ось.

На выходе получаются значения с характерной концентрацией около центра. Вот так обратный прогон через функцию нормального распределения превращает равномерные числа в нормальные. Excel позволяет за несколько секунд воспроизвести любое количество выборок любого размера.
Как обычно, прилагаю ролик, где все вышеописанное показывается в действии.
Скачать файл с примером.
Поделиться в социальных сетях:
Excel for Microsoft 365 Excel for Microsoft 365 for Mac Excel for the web Excel 2021 Excel 2021 for Mac Excel 2019 Excel 2019 for Mac Excel 2016 Excel 2016 for Mac Excel 2013 Excel 2010 Excel 2007 Excel for Mac 2011 Excel Starter 2010 More…Less
Returns the quartile of a data set. Quartiles often are used in sales and survey data to divide populations into groups. For example, you can use QUARTILE to find the top 25 percent of incomes in a population.
Important: This function has been replaced with one or more new functions that may provide improved accuracy and whose names better reflect their usage. Although this function is still available for backward compatibility, you should consider using the new functions from now on, because this function may not be available in future versions of Excel.
For more information about the new functions, see QUARTILE.EXC function and QUARTILE.INC function.
Syntax
QUARTILE(array,quart)
The QUARTILE function syntax has the following arguments:
-
Array Required. The array or cell range of numeric values for which you want the quartile value.
-
Quart Required. Indicates which value to return.
|
If quart equals |
QUARTILE returns |
|---|---|
|
0 |
Minimum value |
|
1 |
First quartile (25th percentile) |
|
2 |
Median value (50th percentile) |
|
3 |
Third quartile (75th percentile) |
|
4 |
Maximum value |
Remarks
-
If array is empty, QUARTILE returns the #NUM! error value.
-
If quart is not an integer, it is truncated.
-
If quart < 0 or if quart > 4, QUARTILE returns the #NUM! error value.
-
MIN, MEDIAN, and MAX return the same value as QUARTILE when quart is equal to 0 (zero), 2, and 4, respectively.
Example
Copy the example data in the following table, and paste it in cell A1 of a new Excel worksheet. For formulas to show results, select them, press F2, and then press Enter. If you need to, you can adjust the column widths to see all the data.
|
Data |
||
|---|---|---|
|
1 |
||
|
2 |
||
|
4 |
||
|
7 |
||
|
8 |
||
|
9 |
||
|
10 |
||
|
12 |
||
|
Formula |
Description (Result) |
R |
|
=QUARTILE(A2:A9,1) |
First quartile (25th percentile) of the data above (3.5) |
3.5 |
Need more help?
Want more options?
Explore subscription benefits, browse training courses, learn how to secure your device, and more.
Communities help you ask and answer questions, give feedback, and hear from experts with rich knowledge.
В статье проведена оценка показателей надежности безотказной работы системы. На примере показан расчет основных показателей средствами Excel.
Ключевые слова:
безотказная работа, доверительный интервал, испытания, нормальный закон распределения, число отказов.
Определение показателей надёжности необходимо для формулирования требования по надежности к проектируемым устройствам или системам. Показатель надежности — это количественная характеристика одного или нескольких свойств, составляющих надежность объекта [1].
Поскольку отказы и сбои элементов являются случайными событиями, то теория вероятностей и математическая статистика являются основным аппаратом, используемым при исследовании надежности, а сами характеристики надежности должны выбираться из числа показателей, принятых в теории вероятностей [2, с.
13].
Количественные характеристики надежности при нормальном законе распределения отказов могут быть определены из следующих выражений:
(1)
P(t)=
(2)
λ(
)=
(3),
где
нормированная и центрированная функция Лапласа.
Произведем расчет параметров надежности испытаний, проведенных в течение 100 часов на 100 деталях, 34 из которых вышли из строя.
Для построения статистического ряда время испытаний разбивают на интервалы (разряды) и подсчитывают частоту, интенсивность и вероятность отказов, используя выражения (1), (2) и (3). Определяют доверительные интервалы математического ожидания и среднеквадратичного отклонения при нормальном законе распределения отказов и заданном коэффициенте доверия [3, с. 60].
Результаты вычислений представлены в таблице Excel (Таблица 1).
Таблица 1
Результаты расчета основных показателей испытаний
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10 |
20 |
30 |
40 |
50 |
60 |
70 |
80 |
90 |
100 |
|
|
5 |
3 |
5 |
2 |
2 |
3 |
3 |
3 |
5 |
3 |
|
|
0,935 |
0,917 |
0,896 |
0,870 |
0,841 |
0,805 |
0,767 |
0,725 |
0,680 |
0,633 |
|
|
0,983 |
0,986 |
0,988 |
0,990 |
0,991 |
0,992 |
0,993 |
0,993 |
0,994 |
0,994 |
|
λн(t) |
1,050 |
1,074 |
1,102 |
1,137 |
1,178 |
1,232 |
1,294 |
1,369 |
1,460 |
1,570 |
|
|
0,064 |
0,082 |
0,103 |
0,129 |
0,158 |
0,194 |
0,232 |
0,274 |
0,319 |
0,366 |
|
|
0,014 |
0,002 |
0,026 |
0,020 |
0,011 |
0,005 |
0,002 |
0,014 |
0,009 |
0,026 |
|
|
0,085065269 |
|||||||||
Листинг фрагмента программы расчета показателей при нормальном законе распределения:
‘Вычислим 43 строку таблицы(45)=============================Рн(t)
СтрокаТаблицы = 45
‘a=(t-Tср)/Сигма
СтолбецТаблицы = 4
For n = СтолбецТаблицы To (КоличествоСтолбцовТаблицы + СтолбецТаблицы — 1)
a = Abs(Sheets(«ОсновнаяТаблица»). Cells(3, n).Value — Tcp) / Сигма
Cells(3, n).Value — Tcp) / Сигма
‘b=Фо
СтрокаТаблФункцЛапласа = 2
While Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа, 1).Value <> «»
СтрокаТаблФункцЛапласа = СтрокаТаблФункцЛапласа + 1
Wend
If a <= Sheets(«Таблица функции Лапласа»).Cells(2, 1).Value Then
ф0 = Sheets(«Таблица функции Лапласа»).Cells(2, 2).Value
GoTo далее
End If
If a >= Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа — 1, 1).Value Then
ф0 = Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа — 1, 2).Value
GoTo далее
End If
СтрокаТаблФункцЛапласа = 2
While Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа, 1).Value <> «»
If Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа, 1).Value = a Then
ф0 = Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа, 2).Value
GoTo далее3
End If
If a < Sheets(«Таблица функции Лапласа»). Cells(СтрокаТаблФункцЛапласа, 1).Value And a > Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа — 1, 1).Value Then
Cells(СтрокаТаблФункцЛапласа, 1).Value And a > Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа — 1, 1).Value Then
If Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа, 1).Value — a < a — Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа — 1, 1).Value Then
ф0 = Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа, 2).Value
Else
ф0 = Sheets(«Таблица функции Лапласа»).Cells(СтрокаТаблФункцЛапласа — 1, 2).Value
End If
GoTo далее3
End If
СтрокаТаблФункцЛапласа = СтрокаТаблФункцЛапласа + 1
Wend
далее3:
Sheets(«ОсновнаяТаблица»).Cells(СтрокаТаблицы, n).Value = 0.5 + ф0
Next
‘Вычислим 44 строку таблицы(46)=============================fн(t)
СтрокаТаблицы = 46
СтолбецТаблицы = 4
Pi = Application.WorksheetFunction.Pi
For n = СтолбецТаблицы To (КоличествоСтолбцовТаблицы + СтолбецТаблицы — 1)
Sheets(«ОсновнаяТаблица»). 2)))
2)))
Next
‘Заполним 45 строку таблицы(47)=============================Лямбда н(t)
СтрокаТаблицы = 47
СтолбецТаблицы = 4
For n = СтолбецТаблицы To (КоличествоСтолбцовТаблицы + СтолбецТаблицы — 1)
Sheets(«ОсновнаяТаблица»).Cells(СтрокаТаблицы, n).Value = Sheets(«ОсновнаяТаблица»).Cells(46, n).Value / Sheets(«ОсновнаяТаблица»).Cells(45, n).Value
Next
Для определения доверительного интервала для математического ожидания по таблице квантилей распределения Стьюдента находят квантиль вероятности. Используя выражения (4) и (5) проводят расчеты
(4)
(5)
‘Заполним 30 строку таблицы(32)=============================Tср min
СтрокаТаблицы = 32
СтолбецТаблицы = 4
For n = СтолбецТаблицы To (КоличествоСтолбцовТаблицы + СтолбецТаблицы — 1)
Next
СтепеньСвободыПриНормРаспред = КоличествоСтолбцовТаблицы + 1 — 2
Sheets(«ОсновнаяТаблица»).Cells(СтрокаТаблицы, 4). Value = Tcp — Sheets(«ОсновнаяТаблица»).Cells(31, 4).Value * Сигма / Sqr(СтепеньСвободыПриНормРаспред)
Value = Tcp — Sheets(«ОсновнаяТаблица»).Cells(31, 4).Value * Сигма / Sqr(СтепеньСвободыПриНормРаспред)
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаТаблицы, 4), Cells(СтрокаТаблицы, n — 1)).MergeCells = True
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаТаблицы, 4), Cells(СтрокаТаблицы, n — 1)).HorizontalAlignment = xlCenter
‘Заполним 31 строку таблицы(33)=============================Tср max
СтрокаТаблицы = 33
СтолбецТаблицы = 4
For n = СтолбецТаблицы To (КоличествоСтолбцовТаблицы + СтолбецТаблицы — 1)
Next
Sheets(«ОсновнаяТаблица»).Cells(СтрокаТаблицы, 4).Value = Tcp + Sheets(«ОсновнаяТаблица»).Cells(31, 4).Value * Сигма / Sqr(СтепеньСвободыПриНормРаспред)
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаТаблицы, 4), Cells(СтрокаТаблицы, n — 1)).MergeCells = True
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаТаблицы, 4), Cells(СтрокаТаблицы, n — 1)).HorizontalAlignment = xlCenter
|
Тср, min = |
79,29380755 ч. |
|
Тср, max = |
172,43129 ч. |
Для определения доверительного интервала для среднеквадратичного отклонения по таблице квантилей χ
2
– квадрат распределения определяют квантили для заданных вероятностей
P
1
и
P
2
.
|
(0,05) = |
3,32511 |
|
(0,95) = |
16,919 |
‘Заполним 32 строку таблицы(34)=============================X1(0,05)
СтрокаОсновнойТаблицы = 34
СтрокаТаблКвантили = 4
ВходнаяСтрочнаяВеличина = СтепеньСвободыПриНормРаспред
While Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили, 1).Value <> «»
СтрокаТаблКвантили = СтрокаТаблКвантили + 1
Wend
If ВходнаяСтрочнаяВеличина <= Sheets(«Квантили распределения хи»). Cells(4, 1).Value Then
Cells(4, 1).Value Then
СтрокаТабл = 4
GoTo СледующийПоиск10
End If
If ВходнаяСтрочнаяВеличина >= Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили — 1, 1).Value Then
СтрокаТабл = СтрокаТаблКвантили — 1
GoTo СледующийПоиск10
End If
СтрокаТаблКвантили = 4
While Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили, 1).Value <> «»
If Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили, 1).Value = ВходнаяСтрочнаяВеличина Then
СтрокаТабл = СтрокаТаблКвантили
GoTo СледующийПоиск10
End If
If ВходнаяСтрочнаяВеличина < Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили, 1).Value And ВходнаяСтрочнаяВеличина > Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили — 1, 1).Value Then
If Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили, 1).Value — ВходнаяСтрочнаяВеличина < ВходнаяСтрочнаяВеличина — Sheets(«Квантили распределения хи»). Cells(СтрокаТаблКвантили — 1, 1).Value Then
Cells(СтрокаТаблКвантили — 1, 1).Value Then
СтрокаТабл = СтрокаТаблКвантили
Else
СтрокаТабл = СтрокаТаблКвантили — 1
End If
GoTo СледующийПоиск10
End If
СтрокаТаблКвантили = СтрокаТаблКвантили + 1
Wend
СледующийПоиск10:
СтолбецТаблКвантили = 2
ВходнаяВертикальнаяВеличина = 0.05
While Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили).Value <> «»
СтолбецТаблКвантили = СтолбецТаблКвантили + 1
Wend
If ВходнаяВертикальнаяВеличина <= Sheets(«Квантили распределения хи»).Cells(3, 2).Value Then
СтолбецТабл = 2
GoTo СледующийПоиск11
End If
If ВходнаяВертикальнаяВеличина >= Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили — 1).Value Then
СтолбецТабл = СтолбецТаблКвантили — 1
GoTo СледующийПоиск11
End If
СледующийПоиск11:
СтолбецТаблКвантили = 11
While Sheets(«Квантили распределения хи»). Cells(3, СтолбецТаблКвантили).Value <> «»
Cells(3, СтолбецТаблКвантили).Value <> «»
If Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили).Value = ВходнаяВертикальнаяВеличина Then
СтолбецТабл = СтолбецТаблКвантили
GoTo СледующийПоиск12
End If
If ВходнаяСтрочнаяВеличина < Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили).Value And ВходнаяВертикальнаяВеличина > Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили — 1).Value Then
If Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили).Value — ВходнаяВертикальнаяВеличина < ВходнаяВертикальнаяВеличина — Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили — 1).Value Then
СтолбецТабл = СтолбецТаблКвантили
Else
СтолбецТабл = СтолбецТаблКвантили — 1
End If
GoTo СледующийПоиск12
End If
СтолбецТаблКвантили = СтолбецТаблКвантили + 1
Wend
СледующийПоиск12:
x1 = Sheets(«Квантили распределения хи»).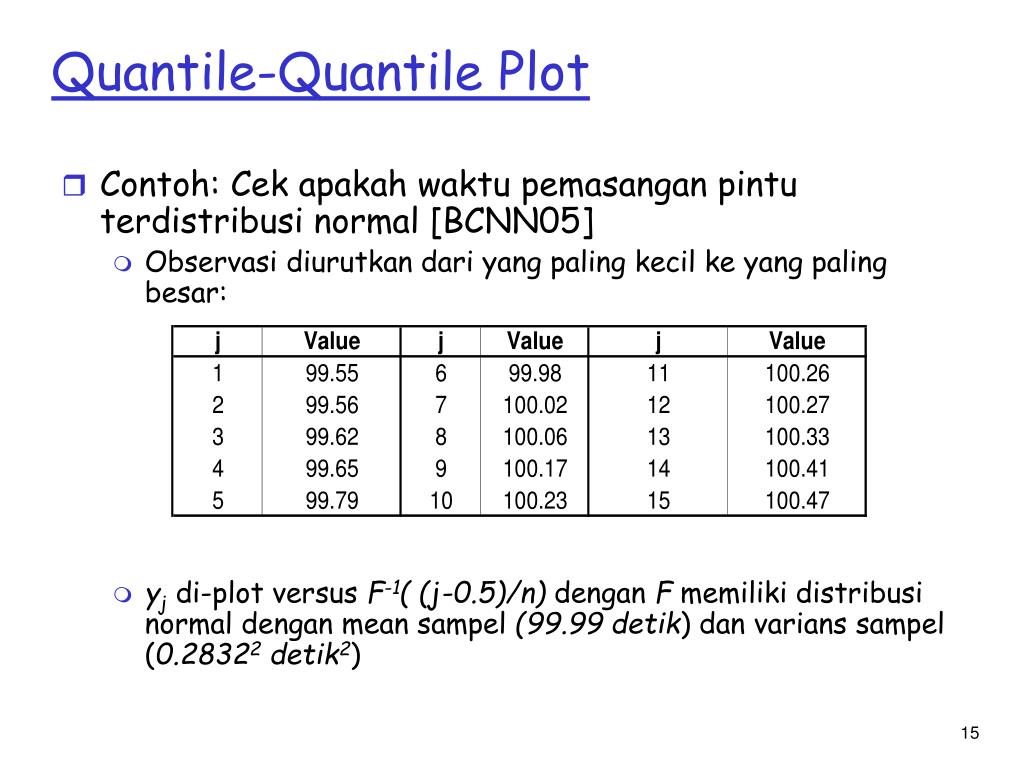 Cells(СтрокаТабл, СтолбецТабл).Value
Cells(СтрокаТабл, СтолбецТабл).Value
Sheets(«ОсновнаяТаблица»).Cells(СтрокаОсновнойТаблицы, 4).Value = x1
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаОсновнойТаблицы, 4), Cells(СтрокаОсновнойТаблицы, n — 1)).MergeCells = True
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаОсновнойТаблицы, 4), Cells(СтрокаОсновнойТаблицы, n — 1)).HorizontalAlignment = xlCenter
‘Заполним 33 строку таблицы(35)=============================X2(0,95)
СтрокаОсновнойТаблицы = 35
СтрокаТаблКвантили = 4
ВходнаяСтрочнаяВеличина = СтепеньСвободыПриНормРаспред
While Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили, 1).Value <> «»
СтрокаТаблКвантили = СтрокаТаблКвантили + 1
Wend
If ВходнаяСтрочнаяВеличина <= Sheets(«Квантили распределения хи»).Cells(4, 1).Value Then
СтрокаТабл = 4
GoTo СледующийПоиск13
End If
If ВходнаяСтрочнаяВеличина >= Sheets(«Квантили распределения хи»). Cells(СтрокаТаблКвантили — 1, 1).Value Then
Cells(СтрокаТаблКвантили — 1, 1).Value Then
СтрокаТабл = СтрокаТаблКвантили — 1
GoTo СледующийПоиск13
End If
СтрокаТаблКвантили = 4
While Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили, 1).Value <> «»
If Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили, 1).Value = ВходнаяСтрочнаяВеличина Then
СтрокаТабл = СтрокаТаблКвантили
GoTo СледующийПоиск13
End If
If ВходнаяСтрочнаяВеличина < Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили, 1).Value And ВходнаяСтрочнаяВеличина > Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили — 1, 1).Value Then
If Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили, 1).Value — ВходнаяСтрочнаяВеличина < ВходнаяСтрочнаяВеличина — Sheets(«Квантили распределения хи»).Cells(СтрокаТаблКвантили — 1, 1).Value Then
СтрокаТабл = СтрокаТаблКвантили
Else
СтрокаТабл = СтрокаТаблКвантили — 1
End If
GoTo СледующийПоиск13
End If
СтрокаТаблКвантили = СтрокаТаблКвантили + 1
Wend
СледующийПоиск13:
СтолбецТаблКвантили = 2
ВходнаяВертикальнаяВеличина = 0. 95
95
While Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили).Value <> «»
СтолбецТаблКвантили = СтолбецТаблКвантили + 1
Wend
If ВходнаяВертикальнаяВеличина <= Sheets(«Квантили распределения хи»).Cells(3, 2).Value Then
СтолбецТабл = 2
GoTo СледующийПоиск14
End If
If ВходнаяВертикальнаяВеличина >= Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили — 1).Value Then
СтолбецТабл = СтолбецТаблКвантили — 1
GoTo СледующийПоиск14
End If
СледующийПоиск14:
СтолбецТаблКвантили = 2
While Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили).Value <> «»
If Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили).Value = ВходнаяВертикальнаяВеличина Then
СтолбецТабл = СтолбецТаблКвантили
GoTo СледующийПоиск15
End If
If ВходнаяСтрочнаяВеличина < Sheets(«Квантили распределения хи»).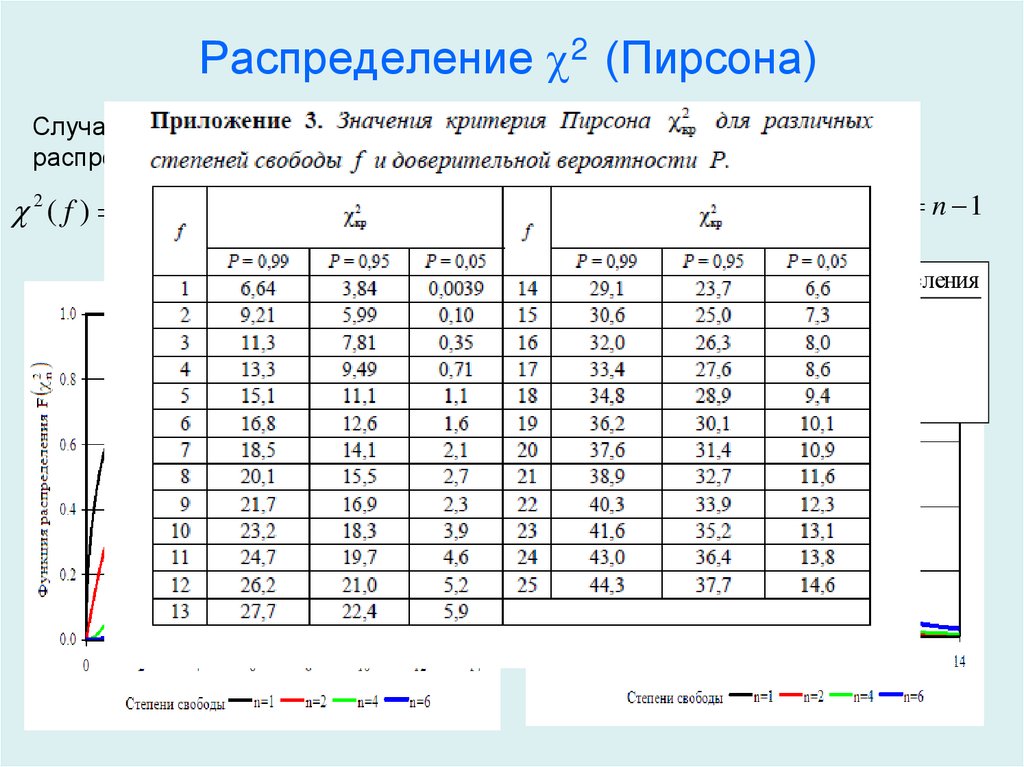 Cells(3, СтолбецТаблКвантили).Value And ВходнаяВертикальнаяВеличина > Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили — 1).Value Then
Cells(3, СтолбецТаблКвантили).Value And ВходнаяВертикальнаяВеличина > Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили — 1).Value Then
If Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили).Value — ВходнаяВертикальнаяВеличина < ВходнаяВертикальнаяВеличина — Sheets(«Квантили распределения хи»).Cells(3, СтолбецТаблКвантили — 1).Value Then
СтолбецТабл = СтолбецТаблКвантили
Else
СтолбецТабл = СтолбецТаблКвантили — 1
End If
GoTo СледующийПоиск15
End If
СтолбецТаблКвантили = СтолбецТаблКвантили + 1
Wend
СледующийПоиск15:
x1 = Sheets(«Квантили распределения хи»).Cells(СтрокаТабл, СтолбецТабл).Value
Sheets(«ОсновнаяТаблица»).Cells(СтрокаОсновнойТаблицы, 4).Value = x1
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаОсновнойТаблицы, 4), Cells(СтрокаОсновнойТаблицы, n — 1)).MergeCells = True
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаОсновнойТаблицы, 4), Cells(СтрокаОсновнойТаблицы, n — 1)). HorizontalAlignment = xlCenter
HorizontalAlignment = xlCenter
Получим минимальное σ
min
и максимальное σ
max
значения среднеквадратического отклонения:
(6)
(7)
‘Заполним 34 строку таблицы(36)=============================Сигма min
СтрокаТаблицы = 36
СтолбецТаблицы = 4
For n = СтолбецТаблицы To (КоличествоСтолбцовТаблицы + СтолбецТаблицы — 1)
Next
Sheets(«ОсновнаяТаблица»).Cells(СтрокаТаблицы, 4).Value = Сигма * Sqr((СтепеньСвободыПриНормРаспред — 1) / Sheets(«ОсновнаяТаблица»).Cells(35, 4).Value)
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаТаблицы, 4), Cells(СтрокаТаблицы, n — 1)).MergeCells = True
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаТаблицы, 4), Cells(СтрокаТаблицы, n — 1)).HorizontalAlignment = xlCenter
‘Заполним 35 строку таблицы(37)=============================Сигма max
СтрокаТаблицы = 37
СтолбецТаблицы = 4
For n = СтолбецТаблицы To (КоличествоСтолбцовТаблицы + СтолбецТаблицы — 1)
Next
СтепеньСвободыПриНормРаспред = КоличествоСтолбцовТаблицы + 1 — 2
Sheets(«ОсновнаяТаблица»). Cells(СтрокаТаблицы, 4).Value = Сигма * Sqr((СтепеньСвободыПриНормРаспред — 1) / Sheets(«ОсновнаяТаблица»).Cells(34, 4).Value)
Cells(СтрокаТаблицы, 4).Value = Сигма * Sqr((СтепеньСвободыПриНормРаспред — 1) / Sheets(«ОсновнаяТаблица»).Cells(34, 4).Value)
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаТаблицы, 4), Cells(СтрокаТаблицы, n — 1)).MergeCells = True
Sheets(«ОсновнаяТаблица»).Range(Cells(СтрокаТаблицы, 4), Cells(СтрокаТаблицы, n — 1)).HorizontalAlignment = xlCenter
Число разрядов, на которые следует группировать статистический ряд, не должно быть слишком большим (тогда ряд распределения становится невыразительным, и часто в нем обнаруживают незакономерные колебания), с другой стороны, оно не должен быть слишком малым (свойства распределения при этом описываются статистическим рядом слишком грубо).
Литература:
-
ГОСТ 27.
 002-89 Надежность в технике (ССНТ). Основные понятия. Термины и определения.
002-89 Надежность в технике (ССНТ). Основные понятия. Термины и определения.
- Федотов, А. В. Основы теории надежности и технической диагностики: конспект лекций / А. В. Федотов, Н. Г. Скабкин. – Омск : Изд-во ОмГТУ, 2010 – 64 с.
- Коваленко, В. Н. Надежность устройств железнодорожной автоматики, телемеханики : учеб. пособие / В. Н. Коваленко. – Екатеринбург : Изд-во УрГУПС, 2013. – 87 с.
Основные термины (генерируются автоматически): Таблица функции, строка таблицы, доверительный интервал, Сигма, математическое ожидание, распределение отказов, среднеквадратичное отклонение, статистический ряд, таблица, теория вероятностей.
КОРРЕЛЯЦИОННЫЙ И РЕГРЕССИОННЫЙ АНАЛИЗ В EXCEL
1. ОПРЕДЕЛЕНИЕ КОЭФФИЦИЕНТА ПАРНОЙ
КОРРЕЛЯЦИИ В ПРОГРАММЕ EXCEL
t-статистика=0,99*(КОРЕНЬ(20-2)/КОРЕНЬ(1-0,99*0,99))=29,7745296027549
Коэффициент корреляции=0,991477169252612
Распределение Стьюдента=2,10092204024104
Расчетное значение t-статистики больше квантиля распределения Стьюдента, следовательно величина коэффициента корреляции является значимой.
2. ПОСТРОЕНИЕ РЕГРЕССИОННОЙ МОДЕЛИ СВЯЗИ
МЕЖДУ ДВУМЯ ВЕЛИЧИНАМИ
1-ый способ
| a1= 0,5014 | a0= 2,5326 |
| Se1= 0,0155 | Se0= 0,7075 |
| R2= 0,9830 | Se= 0,5561 |
| Se= 0,5561 | n-k-1= 18 |
| QR= 322,4250 | Qe= 5,5670 |
Для проверки адекватности
модели нашли квантиль распределения Фишера Ff. с помощью функции FРАСПОБР
FРАСПОБР=4,4139
Проверили адекватность
построенной модели, используя расчетный уровень значимости (P):
2,18499711496499E-17
2 –й способ
|
а=2,532579627 |
|
в=0,50139175 |
Для данного примера
уравнение модели имеет вид:Y=2,53+0,5X
Проверка адекватности модели выполняется по расчетному уровню значимости P,
указанному в столбце Значимость F.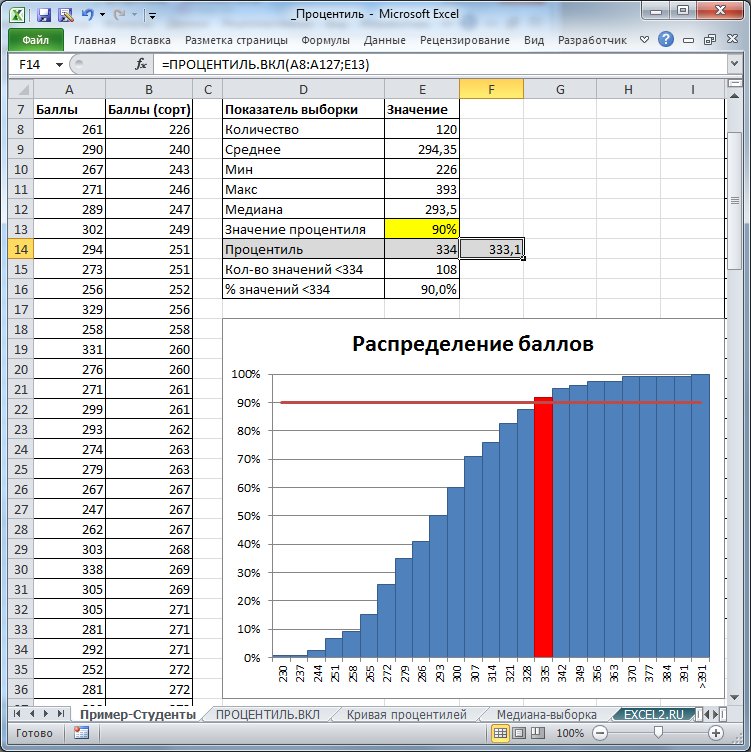 Если
Если
расчетный уровень значимости меньше заданного уровня значимости α =0,05, то модель адекватна.
Проверка статистической значимости коэффициентов модели выполняется по расчетным
уровням значимости P, указанным в столбце P-значение. Если расчетный уровень значимости меньше заданного
уровня значимости α =0,05, то соответствующий
коэффициент модели статистически значим.
Множественный R – коэффициент корреляции. Чем ближе его величина к 1, тем более
тесная связь между изучаемыми показателями. Для данного примера R= 0,99. Это позволяет сделать
вывод, что качество земли – один из основных факторов, от которого зависит
урожайность зерновых культур.
R-квадрат – коэффициент
детерминации. Он получается возведением в квадрат коэффициента корреляции –
R2=0,98. Он
показывает, что урожайность зерновых культур на 98% зависит от качества почвы,
а на долю других факторов приходится 0,02%.
3-ий способ (графический)
Расчет квантилей или процентилей в Excel
В этом руководстве показано, как вычислять квантили или процентили, связанные с доверительными интервалами, в Excel с помощью программного обеспечения XLSTAT.
Квантиль и процентили
XLSTAT имеет полный инструмент для вычисления квантилей или процентилей, их доверительного интервала и графического представления.
Квантили являются важными статистическими показателями, их легко понять. Квантиль 0,5 — это значение, при котором половина выборки находится ниже, а другая половина — выше. Его еще называют средним. Квантиль называется процентилем, если он основан на шкале от 0 до 100. 0,95-квантиль эквивалентен 95-процентилю и таков, что 95 % выборки ниже его значения, а 5 % выше.
Набор данных для создания квантиля
Набор данных был получен от [Lewis T. and Taylor L.R. (1967). Введение в экспериментальную экологию, Нью-Йорк: Academic Press, Inc. Это касается 237 детей, описанных по полу и росту в сантиметрах (1 см = 0,4 дюйма).
Настройка расчета определенного квантиля
После открытия XLSTAT выберите XLSTAT / Description / Quantiles , или нажмите на соответствующую кнопку панели инструментов «Описание» (см. ниже).
ниже).
После нажатия кнопки появится диалоговое окно Quantile . Выберите данные на листе Excel.
В нашем случае; переменная — это «Высота». Данные должны быть количественными .
Поскольку для переменных был выбран заголовок столбца, необходимо активировать опцию Метки переменных .
Мы выбираем метод оценки по умолчанию ( средневзвешенное значение при x(Np) ) и оба типа доверительных интервалов с доверительной вероятностью 95 % .
Подробную информацию о статистических методах можно найти в справке XLSTAT.
Во вкладке диаграммы выбираем все диаграммы и нас интересует 67-процентиль (две трети детей меньше, а одна треть выше).
Вычисления начинаются после того, как вы нажмете на ОК . Затем будут отображены результаты.
Интерпретация результатов генерации квантилей
В первой таблице показаны некоторые описательные статистические данные о переменной высоты. Во второй таблице отображаются квантили и связанные с ними доверительные интервалы для различных часто используемых значений. Например, медиана 159,9 см. 95-процентиль показывает, что 95% детей меньше 174,98 см.
Во второй таблице отображаются квантили и связанные с ними доверительные интервалы для различных часто используемых значений. Например, медиана 159,9 см. 95-процентиль показывает, что 95% детей меньше 174,98 см.
Затем отображается значение 67-процентиля. Две трети детей меньше 164,58 см.
Первый график (см. ниже) позволяет нам визуализировать эмпирическую кумулятивную функцию распределения со значением 67-го процентиля.
Вторая и третья диаграммы представляют собой коробчатую диаграмму и диаграмму рассеяния. 67-процентиль отображается синей линией.
Вы также можете использовать подвыборки, например пол можно использовать в качестве групповой переменной. Веса, связанные с наблюдениями, также могут быть включены.
Была ли эта статья полезной?
- Да
- №
Квантиль (квартиль, дециль и процентиль): расчет вручную + Microsoft
Квантиль — важная статистическая концепция, позволяющая разделить данные на равные группы. Они часто используются для выявления и анализа шаблонов данных и проведения значимых сравнений между различными наборами данных. В этом кратком руководстве мы рассмотрим основы квантилей и более подробно рассмотрим некоторые из наиболее распространенных типов: квартили, децили и процентили.
Они часто используются для выявления и анализа шаблонов данных и проведения значимых сравнений между различными наборами данных. В этом кратком руководстве мы рассмотрим основы квантилей и более подробно рассмотрим некоторые из наиболее распространенных типов: квартили, децили и процентили.
Квантиль
Квантиль — это мера, указывающая значение, ниже которого падает определенная доля наблюдений в группе наблюдений. Квантиль используется в статистике для разделения группы наблюдений на группы одинакового размера. Например, квантиль 0,25 — это значение, ниже которого падают 25% наблюдений; квантиль 0,50 — это значение, ниже которого падает 50%, и так далее. Другим родственным измерением является медиана, которая совпадает с квантилем 0,50, поскольку 50% данных находятся ниже медианы.
Какие общие квантили существуют?
Некоторые распространенные квантили включают:
1. Квартиль
Квартиль — это тип квантиля, который делит группу наблюдений на четыре группы одинакового размера. Например, в группе наблюдений первый квартиль (Q1) — это значение, ниже которого опускаются первые 25 % наблюдений, второй квартиль (Q2, также известный как медиана) — это значение, ниже которого средние 50 % наблюдений падают, а третий квартиль (Q3) — это значение, ниже которого падают последние 25% наблюдений.
Например, в группе наблюдений первый квартиль (Q1) — это значение, ниже которого опускаются первые 25 % наблюдений, второй квартиль (Q2, также известный как медиана) — это значение, ниже которого средние 50 % наблюдений падают, а третий квартиль (Q3) — это значение, ниже которого падают последние 25% наблюдений.
2. Дециль
Дециль – это мера, которая делит группу наблюдений на десять групп одинакового размера. Например, в группе наблюдений первый дециль (D1) — это значение, ниже которого попадают первые 10% наблюдений, второй дециль (D2) — это значение, ниже которого попадают первые 20% наблюдений, и скоро. 9-й дециль (D9) — это значение, ниже которого опускаются последние 10% наблюдений.
3. Процентиль
Процентиль — это мера, указывающая значение, ниже которого находится определенный процент наблюдений в группе наблюдений. Например, в группе наблюдений 20-й процентиль (P20) — это значение, ниже которого опускаются первые 20% наблюдений, 50-й процентиль (P50) — это значение, ниже которого опускаются средние 50% наблюдений, и 95-й процентиль (P95) — это значение, ниже которого падают последние 95% наблюдений.
50-й процентиль также является медианой, вторым квартилем и 5-м децилем.
Процентиль: Расчет вручную / Microsoft Excel
Процентиль — это мера, используемая в статистике для указания значения, ниже которого находится определенный процент наблюдений в группе наблюдений.
Чтобы найти местоположение определенного процентиля, такие программы, как Minitab, Python, R и Excel, используют следующие шаги:
- Расположите наблюдения в порядке возрастания.
- Используйте формулу для определения положения процентиля, чтобы вычислить положение, в котором будет располагаться значение процентиля, используя желаемое значение процентиля и общее количество наблюдений в качестве входных данных. Существует два подхода: EXC (Exclusive) и INC (Inclusive). Процентное положение в подходе EXC определяется формулой (K(N+1)), а положение в подходе INC определяется формулой (K(N-1)+1).
- Если местоположение процентиля является целым числом, значение в этой позиции в упорядоченном списке наблюдений является значением процентиля.
- Если местоположение процентиля не является целым числом, значение процентиля рассчитывается путем вычисления значения на пропорциональной основе между этими двумя числами.
Чтобы найти 65-й процентиль в группе из 8 наблюдений, вы должны сначала расположить наблюдения в порядке возрастания: 8, 9, 12, 22, 23, 33, 55, 61.
Затем вы должны использовать формулу для местоположения процентиля, чтобы вычислить положение, в котором будет расположен 65-й процентиль:
Для ПРОЦЕНТИЛЬ.ИСКЛ рассчитанный ранг равен (K(N+1)).
Расположение в процентиле (с использованием эксклюзивного подхода) = (left(frac{65}{100}right)(8+1)) = 5,85
Поскольку положение в процентиле не является целым числом, 65-й процентиль будет между 5-м пунктом (номер 23) и 6-м пунктом (номер 33) на пропорциональной основе. Это будет (23+0,85(33-23) = 31,5).
Для PERCENTILE.INC (и PERCENTILE) рассчитанный ранг равен (K(N-1)+1).
Расположение в процентах (с использованием инклюзивного подхода) = ((65/100) (8-1)+1) = 5,55
Поскольку местоположение процентиля не является целым числом, 65-й процентиль будет почти посередине между 5-м элементом (число 23) и 6-м элементом (число 33). Пропорционально получится (23+0,55(33-23)) = 28,5.
Пропорционально получится (23+0,55(33-23)) = 28,5.
Квартиль: пример расчета вручную
Квартиль — это статистическое значение, которое делит набор данных на четыре равные части или четверти. Первый квартиль, также известный как нижний квартиль или Q1, — это значение, которое отделяет самые низкие 25 % данных от остальных. Второй квартиль, также известный как медиана или Q2, представляет собой значение, которое отделяет самые низкие 50% данных от самых высоких 50% данных. Третий квартиль, также известный как верхний квартиль или Q3, — это значение, которое отделяет самые высокие 25% данных от остальных.
Например, если у нас есть следующие числа: 14, 9, 10, 11, 11 и 6, мы можем разделить данные на четыре равные группы, найдя первый, второй и третий квартили.
Чтобы найти квартили набора данных, нам сначала нужно расположить данные в порядке возрастания следующим образом: 6, 9, 10, 11, 11, 14.
Затем нам нужно найти медиану, или Q2, которая является средним значением в наборе данных.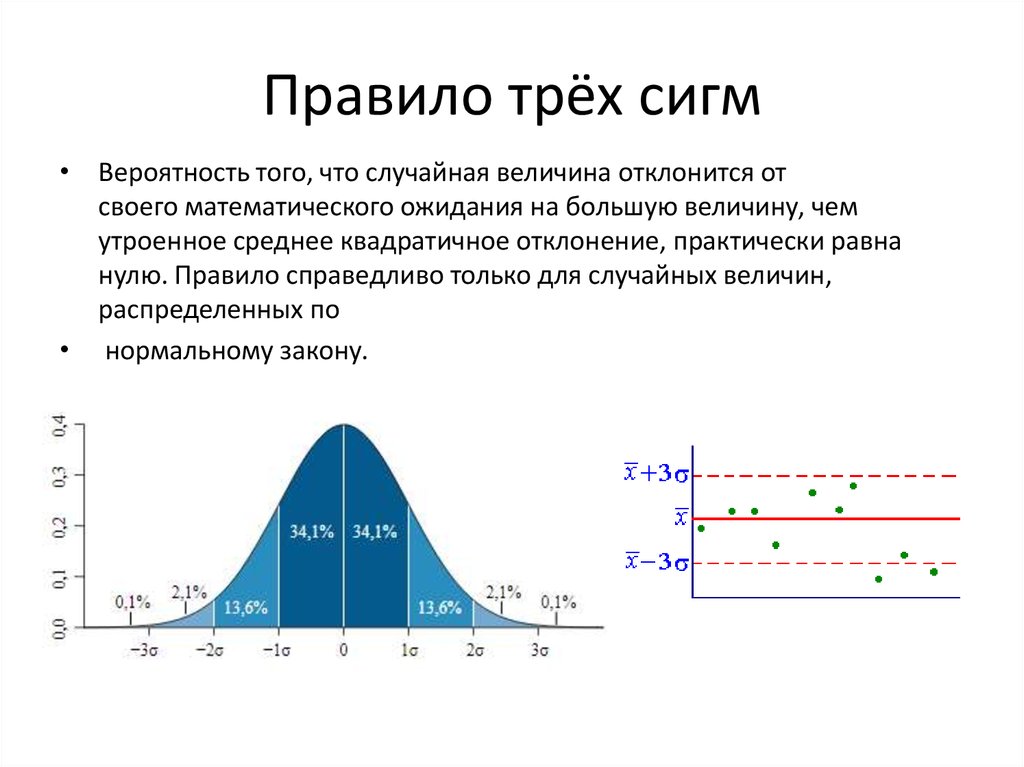 В этом случае в наборе данных шесть чисел, поэтому медиана — это среднее значение третьего и четвертого значений, равное 10,5.
В этом случае в наборе данных шесть чисел, поэтому медиана — это среднее значение третьего и четвертого значений, равное 10,5.
Чтобы найти нижний квартиль или Q1, мы берем медиану значений ниже медианы. В данном случае это будет медиана 9. Чтобы найти верхнюю квартиль или Q3, мы берем медиану значений выше медианы. В данном случае это будет медиана 11, 11 и 14, что равно 11.
Таким образом, для этого набора данных квартили: эти числа расчета квартиля не совпадают с расчетом Excel?
Квартиль Использование Excel:
Для расчета квартилей такие программы, как Microsoft Excel и Minitab, используют метод процентилей, как объяснялось ранее. Q1 рассчитывается как 25-й процентиль, Q2 — как 50-й и Q3 — как 75-й процентиль. Это приводит к тому, что значение квартиля иногда отличается от значения, рассчитанного с использованием обычного ручного метода расчета.
Возьмем тот же пример, который мы использовали ранее в ручном расчете для расчета первого квартиля (Q1).
Чтобы найти квартили набора данных, нам сначала нужно расположить данные в порядке возрастания следующим образом: 6, 9, 10, 11, 11, 14.
Вы можете использовать функцию КВАРТИЛЬ.ИСКЛ или КВАРТИЛЬ.ВКЛ. найти квартили набора чисел в Excel.
Quartile.Exc
Для QUARTILE.EXC расчетный ранг равен K*(N+1). Чтобы рассчитать положение Q1 (или 25-го процентиля), подставим в эту формулу соответствующие значения.
Местоположение 1-го квартиля (с использованием эксклюзивного подхода) = (25/100) * (6+1) = 1,75
Поскольку положение процентиля не является целым числом, 1-й квартиль будет между 1-м элементом (номер 6) и 2-м элементом (номер 9) на пропорциональной основе. Получится (6 + (9-6)*0,75) = 8,25.
Использование Minitab: Если вы используете Minitab для расчета Q1, это значение (8,25), которое вы получите в описательной статистике. Minitab использует метод EXC для расчета процентилей и квартилей.
Квартиль.Вкл
Для КВАРТИЛЬ.
I am interested in the definition of quartile that is usually used when you’re in basic statistics. I have a Stat 101 type book and it just gives an intuitive definition. “About one quarter of the data falls on or below the first quartile…” But, it gives an example where it calculates Q1, Q2, and Q3 for the set of data
5, 7, 9, 10, 11, 13, 14, 15, 16, 17, 18, 18, 20, 21, 37
Since there are 15 pieces of data, it chooses 15 as the median, Q2. It then splits up the remaining data into two halves, 5 through 14, and 16 through 37. These each contain 7 pieces of data and they find the median of each of these sets, 10 and 18, as Q1 and Q3, respectively. This is how I would calculate it myself.
I looked at Wikipedia’s article and it gives 2 methods. One agrees with the above, and one says you could also include the median 15 in both sets (but you wouldn’t include the median if it was the average of the two middle numbers in the case of an even number of data points). This all makes sense to me.
But, then I checked Excel to see how Excel calculates it. I am using Excel 2010, which has 3 different functions. Quartile was available in 2007 and previous versions. It seems they want you to stop using this in 2010 but it’s still available. Quartile.Inc is new but agrees exactly with Quartile as far as I can tell. And, there is Quartile.Exc as well. Both of the last 2 are new in 2010 I believe. This time, I just tried using the integers 1, 2, 3, …, 10. I’m expecting Excel to give median of 5.5, Q1 of 3, and Q3 of 8. The method from the statistics book, as well as both methods on Wikipedia would give these answers, since the median is the average of the middle two numbers. Excel gives
quartile number, Quartile.Inc, Quartile.Exc
1, 3.25, 2.75
2, 5.5, 5.5
3, 7.75, 8.25
Neither of these agree with what I have previously talked about.
The descriptions in the help file for Excel are:
Quartile.Inc – Returns the quartile of a data set, based on percentile values from 0..1, inclusive.
Quartile.Exc – Returns the quartile of the data set, based on percentile values from 0..1, exclusive.
Can any one help me understand this definition Excel is using?
