Изучаем статистику: средние значения
Один из разделов описательной статистики посвящен знакомству
с характеристиками числового набора: минимальное значение, максимальное
значение, размах, среднее арифметическое и медиана. Ученики должны научиться
определять их для набора чисел, заданного списком, таблицей или диаграммой
рассеивания.
Мы изучали этот материал в течение трех уроков. На первых
двух были введены новые понятия и решались задачи из учебного пособия (авт.
Ю.Н. Тюрин, А.А. Макаров, И.Р. Высоцкий, И.В. Ященко). Например. Найдите
наибольшее и наименьшее значение, размах, среднее значение и медиану набора
чисел: 12; 7; 25; 3; 19; 15. (Ответ: 25; 3; 22; 13,5; 13,5).
Однако естественно показать учащимся, зачем мы все это
изучаем. На третьем уроке мы решали задачи, в которых требуется выбрать
такое среднее, которое наилучшим образом отражает особенности данного набора
чисел в соответствии с их природой и требованиями задачи. В одних задачах не
сказано, какую характеристику надо искать, поэтому, чтобы ответить на вопрос
задачи, приходится примерять к поставленной задаче поочередно разные средние и
выяснять, какое подходит больше других. В этом случае ответом к задаче является
не число, а название подходящей характеристики. В других задачах присутствует
необходимость правильно интерпретировать полученные результаты, отнестись к ним
критически, попытаться найти здравое зерно даже там, где, на первый взгляд, «все
сделано неверно». И наконец, предложен и третий вид задач, в которых природа
данных накладывает определенные дополнительные требования на найденное значение
среднего: например, оно должно быть целым.
Тем самым мы не только продолжаем закреплять навык подсчета
среднего, но и демонстрируем возможности применения изученного в реальных
жизненных ситуациях. Ведь для учащихся важным фактором освоения нового является
осознание необходимости знания этого нового, то есть не только как
найти, но и зачем находить.
Данная статья состоит из двух частей. В первой дается описание наиболее
употребительных средних. Во второй части предлагается набор задач для решения в
классе и для самостоятельной работы учащихся.
Знакомимся со средними
Наибольшее и наименьшее значения
Слова «минимальный», «максимальный», «меньший», «больший»
интуитивно понятны учащимся, поэтому первые две характеристики: наибольшее
и наименьшее значения оставим без определения. Скажем, что в наборе,
упорядоченном по возрастанию, наименьшее число стоит на первом месте, а
наибольшее — на последнем.
В пособии имеются задания, в которых требуется найти
наибольшее или наименьшее значения среди чисел, указанных в таблице. К ним
добавим задания с другой формой представления данных — в виде диаграммы
рассеивания.
Задание. Имеется диаграмма 1 рассеивания, показывающая
взаимосвязь роста и веса 15 опрошенных юношей. Найти рост самого высокого и рост
самого низкого юноши (т.е. определить минимальное и максимальное значения набора
чисел, заданного диаграммой рассеивания).
Для этого будем использовать следующее: минимальный рост
соответствует абсциссе точки, расположенной левее других, а
максимальный — абсциссе крайней точки справа. Получим:
min ≈ 167 см, max ≈ 181 см.
Интересно, что остальные 13 точек участия в «обсуждении»
вообще не принимают. Их можно стереть — результат от этого не изменится (см.
диаграмму 2).
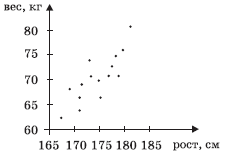
Диаграмма 1
Вторая особенность получаемого результата в том, что, в
отличие от работы с таблицей, данные, получаемые с помощью графиков и диаграмм,
являются не точными, а приближенными, то есть ответы могут отличаться.
Аналогично находим минимальное и максимальное значения веса,
как ординаты самой нижней и самой верхней точек.
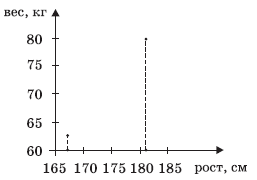
Диаграмма 2
С каким же видом представления данных удобнее работать?
Преимущество таблицы заключается в точности получаемых
результатов, но работа с ней требует концентрации внимания на протяжении
длительного времени: нельзя пропустить искомое число, а оно может попасть в
любой исследуемый столбец. И если таблица содержит не 15 чисел, а 5000, то этот
аргумент становится решающим в пользу наглядного представления данных. Оно дает
менее точные результаты, зато обработка такой информации происходит за
считанные секунды. Даже если диаграмма будет содержать 5000 точек, нас будут
интересовать только две крайние, на остальные мы даже не посмотрим.
Размах
В отличие от предыдущих понятий, размах — это
незнакомая учащимся характеристика набора. Он показывает протяженность набора
вдоль числовой оси, меру его разброса.
Определение. Размах набора чисел (R) — это
разность между наибольшим и наименьшим числом набора.
Например, в предыдущем задании размах равен: R = 181 –
167 = 14 см.
Что показывает размах значений?
Сравним диаграммы 3 и 4:
|
|
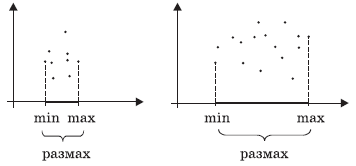
Точки, изображенные на диаграмме 3, расположены ближе друг к
другу, соответственно, и максимальное и минимальное значение отличаются друг от
друга меньше, чем на диаграмме 4. Таким образом, размах показывает, сильно ли
отличаются числа набора друг от друга.
Маленький размах показывает, что исследуемая величина
принимала практически одинаковые значения. Большой размах показывает, что
некоторая величина принимает значительно отличающиеся друг от друга значения, то
есть нестабильность. Иногда большой размах свидетельствует о наличии
грубой ошибки измерений, о том, что какое-то из чисел попало в список случайно.
Если вычислить полусумму наименьшего и наибольшего значений
набора и обозначить ее с, а половину размаха обозначить ![]() то можно
то можно
утверждать, что все числа набора содержатся в промежутке ![]() На бытовом уровне
На бытовом уровне
размах (а точнее, полуразмах) дает информацию о точности информации: расстояние
от дома до дачи (100 ± 5) км, цена на хлеб (14 ± 2) р. и т.д.
Среднее арифметическое
Определение. Средним арифметическим нескольких чисел (![]() ) называется частное от деления суммы этих чисел на количество чисел.
) называется частное от деления суммы этих чисел на количество чисел.
Например, средним арифметическим чисел 4; 6; 11 является
число ![]()
Зачастую среднее арифметическое называют просто «средним» в
силу его наибольшей популярности. Говорят о среднем балле аттестата,
среднегодовом потреблении населением фруктов. «Потребительская корзина» для
определенного слоя граждан рассчитывается исходя из средних показателей.
Рассмотрим следующий пример. На олимпиаде по математике
предлагалось решить пять задач по 4 балла за каждую. В протоколе указана сумма
баллов каждого из восьми участников этой олимпиады:
12; 14; 14; 16; 17; 18; 19; 200.
Для ускорения подсчета имеется автоматизированная система
обработки данных, которая находит среднее арифметическое любых введенных чисел.
Какой средний балл набрали участники олимпиады?
У данного набора среднее равно 38,75. Однако такую сумму
баллов никто из участников набрать не мог. К тому же семь чисел из данных восьми
намного меньше его. Все значения этого набора, кроме крайнего правого,
достаточно кучно попадают в интервал [12; 19], а 38,75 в него не попадает. Все
это говорит о том, что полученное среднее арифметическое не только не передает
особенностей данного набора чисел, но и вообще противоречит здравому смыслу.
Значит, либо в условие, либо в решение вкралась ошибка! Посмотрим еще раз на
данные числа. Теперь, получив явно бессмысленный результат, мы сможем более
критически отнестись к условию: первые семь чисел вполне реальны, а вот
последнее… Откуда оно взялось?! Видимо, оно случайно попало в этот список:
возможно, в результате описки. Однако обнаружение ошибки в условии не избавляет
нас от необходимости довести решение до конца. Можно, конечно, посоветовать
комиссии снова переписать результаты учащихся и ввести числа из нового,
«правильного» протокола. Но где гарантия, что в нем снова не будет опечатки?
Когда все результаты более или менее кучно располагаются на
числовой оси, кроме, быть может, нескольких ненадежных значений, анализировать
результаты можно! Достаточно высокую точность полученных значений будет
гарантировать применение других средних — в частности, урезанного среднего.
Для его нахождения сначала упорядочивают набор по возрастанию, а затем
отбрасывают слева и справа равное небольшое количество чисел. При этом «выбросы»
(или ошибки наблюдений) в дальнейших вычислениях не участвуют. У полученного
«урезанного» набора обычным образом находят среднее арифметическое. Оно и
является урезанным средним исходного набора.
Вернемся к задаче. Если отбросить по одному числу с каждой
стороны, то есть числа 12 и 200, то у оставшегося набора из шести чисел среднее
равно
![]()
Это и есть урезанное среднее. Оно неплохо передает реальное
среднее количество баллов, набранных юными математиками.
Некоторая аналогия с нахождением урезанного среднего
просматривается в правилах судейства во многих видах спорта. Например, в
соревнованиях по прыжкам с трамплина технику каждого прыжка оценивают 5 судей.
Чтобы получить объективные оценки, две из них — высшую и низшую — отбрасывают, а
для трех оставшихся находят сумму. Такой подход не дает возможности судьям
повышать баллы своим соотечественникам, а спортсменам затрудняет нечестный путь
к медалям.
Медиана
Медианой числового набора является число, которое
разделяет этот набор на две одинаковые по части.
Если набор упорядочен и в нем имеется нечетное количество
чисел (2n + 1), то медиана стоит посередине этого набора, на (n +
1)-м месте. Если упорядоченный набор состоит из четного количества чисел (2n),
то медианой является любое число, находящееся между двумя числами, которые стоят
в середине (под номерами n и n + 1). Обычно берется их полусумма.
В наборе 12; 14; 14; 16; 17; 18; 19; 200 медианой является
любое число из интервала (16; 17), например, 16,5. Напомним, что урезанное
среднее равнялось 16,3. Похоже!
Перейдем к решению задач.
Вычисляем средние
1. Про отличника. У отличника Коли были отметки по математике
«5», «5», «5», «5».
И вдруг в конце четверти он получил «2». Он знает, что
учитель математики выставляет четвертную отметку как среднее всех отметок,
имеющихся у ученика, и не признает пересдач. Какое среднее было бы
предпочтительнее для Коли, если он, естественно, надеется на пятерку в четверти?
Решение. 1. Попробуем начать с такого очень
распространенного способа выставления четвертных отметок, как нахождение
среднего арифметического:
![]()
Естественно, что любой учитель округлит этот результат в
меньшую сторону и выставит итоговую отметку «4». Значит, это среднее Колю не
устраивает.
Мы видим, что один неудачный ответ на балл снизил четвертную
отметку. Ведь до этого среднее арифметическое равнялось 5.
2. Помочь Колиной мечте сбыться может другое среднее, и не
одно! Например, если в качестве среднего учитель Коли возьмет медиану или
урезанное среднее, то в четверти Коле обеспечена пятерка:
— медиана набора 2, 5, 5, 5, 5 равна 5;
— урезанное среднее набора 5, 5, 5, равно ![]()
Ответ: медиана или урезанное среднее.
2. Про лодку. Рыбаки собираются порыбачить на озере. Но не
везде им обеспечен хороший улов. Чтобы найти рыбное место, они решили
воспользоваться лодкой с мотором. На лодке установлен мотор, который можно
регулировать по высоте, поднимая или глубже погружая его. Известно, что мотор
работает надежно и не перегревается во время работы, если опустить его как можно
ниже в глубь воды. Но тогда возникает опасность зацепить им за дно водоема.
Мотор устанавливается на желаемую высоту на берегу, в воде менять глубину
погружения нельзя. Какой информацией о глубине воды в озере надо располагать
рыбакам, чтобы не повредить мотор о дно?
Решение. Рыбаки должны узнать глубину озера вдоль
предполагаемого маршрута следования. Затем у полученного набора чисел надо найти
минимальное значение. Оно обеспечит им удачное прохождение и других,
более глубоких участков.
Ответ: минимальное значение.
3. Библиотека. Известно, что детская библиотека выдает в день
в среднем 180 книг. Сколько книг выдает библиотека в среднем за неделю? за
месяц? за год?
Решение. Под средним в данной задаче подразумевается
среднее арифметическое. Так как библиотека работает 6 дней в неделю, значит,
за неделю она выдает около 180![]() 6
6
= 1080 книг. За 26 рабочих дней месяца она выдаст 180![]() 26
26
= 4700 книг. За 12 месяцев выдача составит 4680![]() 12
12
= 56 000 книг.
Ответ: 1080 книг, около 4700 книг, около 56 000 книг.
Решая эту задачу, уместно обсудить вопрос точности полученных
результатов. Во-первых, из условия неясно, за какой период было получено
среднедневное значение. Если наблюдения велись лишь одну неделю, то к полученным
вычисленным значениям нужно относиться весьма скептически. Для получения более
точных результатов надо было проводить более длительное наблюдение, сопоставимое
по длительности с запрашиваемым периодом. А во-вторых, возможно, наблюдатели
«попали» на неделю «книжного бума», тогда результаты, распространенные на месяц
и тем более на год получатся явно завышенными. Возможна и обратная картина: нам
сообщили результаты, полученные в период летних каникул, значит, результаты
вычислений будут заниженными. Другими словами, к полученным числам нужно
относиться с большой осторожностью, если нет возможности уточнить, как было
проведено исследование, и за какой период было вычислено среднее значение 180
книг.
Этот пример показывает, что для получения достоверных
результатов исследований нужно соблюдать некоторые условия, следовать
определенным правилам, чтобы полученным выводам можно было доверять.
4. Метание молота. Спортивный клуб должен организовать
соревнования по метанию молота среди спортсменов с разной спортивной подготовкой
и разными достижениями. Для этого он должен пригласить необходимое количество
судей в сектор для метания. Судьи, с которыми сотрудничает клуб, точно отмечают
место падения молота, если находятся не далее четырех метров от него. Спортивный
клуб может запросить любую информацию о прошлых результатах приглашенных
спортсменов. Какой информацией должны располагать организаторы, чтобы пригласить
необходимое количество судей?
Решение. Надо запросить предыдущие результаты метания
молота всех участников и найти максимальный, минимальный результаты и размах.
Зная величину угла сектора для метания и максимальный результат, можно
вычислить длину дуги, вдоль которой через каждые 8 м надо расставить судей.
Количество таких рядов зависит от размаха результатов.
Если он окажется менее 8 м, то судьи могут стоять в один ряд. Если размах
окажется бóльшим, то чтобы успешно фиксировать как более далекие, так и близкие
результаты судей надо расставить в несколько рядов через каждые 8 м.
Ответ: максимальный результат, размах.
5. Отпуск на юге. Для успешной рекламы отдыха на Кипре
туристическая фирма запросила данные о погоде на острове за последние 10 лет.
Выяснилось, что за этот период было лишь 216 пасмурных или дождливых дней,
которые были равномерно распределены по запрашиваемым годам. Сколько дней в году
на острове Кипр светит солнце?
Решение. За 10 лет наблюдалось 3652 – 216 = 3436
солнечных дней. Значит, в среднем за один год — 343,6 дня. Поскольку в ответе
надо писать целое число дней, то можно округлить до целых, а можно и до
десятков: в рекламе круглые числа смотрятся лучше.
Ответ: около 340 дней.
Задачи для самостоятельного решения
1. а) Через речку хотят построить мост. Известно, что уровень
воды в реке меняется в течение года: весной при таянии снега повышается,
засушливым летом понижается. Какую характеристику уровня воды в реке надо
учитывать, чтобы построенный мост был над водой?
б) Периодически в средствах массовой информации нам сообщают
о стихийных бедствиях, в результате которых переполненные водой реки выходят из
своих берегов и даже затопляют улицы городов. Понимая возможность подобного
стихийного бедствия, не будет ли разумнее построить мост (а заодно и высокую
дамбу) как можно выше, насколько это будет технически возможно? Ведь гибель
людей несравнима ни с какими материальными затратами, позволяющими предупредить
беду.
2. За урок учительница вызывает в среднем 5 человек из класса
и каждому ставит отметку за устный ответ. Сколько отметок за устные ответы
выставит эта учительница за неделю, если она проводит в этом классе 5 уроков в
неделю? За четверть?
3. В забеге на 800 м принимали участие 19 спортсменов,
разделенных на группы, стартующие в разное время. Как судьи определили
победителя забега?
4. На зимние каникулы в одной из школ города Мурманска
учительница дала детям задание: следить за погодой и найти среднюю температуру.
Ежедневно в течение десяти дней в 15 часов Наташа записывала показания
термометра:
–13, –10, –15, 11, –9, –9, –11, –12, –10, –11.
А затем вычислила среднее арифметическое и получила –8,9.
а) Действительно ли в период наблюдений температура
колебалась вблизи этого числа?
б) Почему большинство значений (9 из 10) меньше найденного
среднего?
в) Как исправить ответ, если он неверный (заново повторить
наблюдение, естественно, нельзя)?
5. Имеются данные об успеваемости по химии 8 «А» и 8 «Б» : о
количестве учащихся, получивших ту или иную четвертную отметку. Данные занесены
в таблице:
|
Отметка
|
8 «А»
|
8 «Б»
|
|
5 |
6 чел. |
4 чел. |
|
4 |
12 чел. |
10 чел. |
|
3 |
6 чел. |
5 чел. |
Какой класс в среднем имеет лучшие результаты?
6. Лучший нападающий баскетбольной команды «Луч» за восемь
прошедших матчей принес своей команде 61 очко. Сколько в среднем очков добавлял
своей команде этот игрок за каждую игру?
Подводя итог сказанному, хочется отметить, что решение задач,
приведенных в этой статье, было встречено учениками с большим интересом. В их
глазах просматривалось и удивление: оказывается школьные знания имеют прямое
отношение к реальной жизни. Длинные формулировки задач не только не мешали
воспринимать задачу, а напротив, учащиеся успевали глубже погрузиться в
ситуацию, пропустить ее через себя. Сюжеты не были надуманными, они
согласовывались с имеющимся у детей жизненным опытом, поэтому даже слабо
подготовленные ученики на этих уроках проявляли необычную для них активность.
Решение некоторых задач проходило в форме жаркой, но доброжелательной дискуссии,
и доказать свою правоту могла только та сторона, которая аргументированно
отстаивала свою позицию, опираясь на строгие математические факты и здравый
смысл!
Решения и ответы
1. а) Максимальное значение уровня воды в реке.
б) Все зависит от массы обстоятельств: географического
положения реки, «поведения» реки в прошлом и др. Конечно, раз в 100–150 лет даже
на самой «мирной» реке может быть катастрофический паводок. Однако стоит ли
строить очень высокий мост через каждую речку, ожидая ужасного, но
маловероятного катаклизма?
2. Около 25 отметок; около 200 отметок.
3. Победитель затратил на преодоление дистанции минимальное
время.
4. а) Нет, в период наблюдений температура колебалась в
промежутке [–15; –9], которому найденное среднее не принадлежит;
б) потому что имеется число 11, которое существенно
отличается от всех остальных и поэтому меняет среднее в большую сторону;
в) найти урезанное среднее данного набора:
–9, –9, –10, –10, –11, –11, –12, –13, –15,
11. Оно приближенно равно 11,4.
5. 8 «А».
6. Около 8 очков.
Багишова О.
 Ящичковые диаграммы из эксперимента Майкельсона – Морли, показывающие максимумы и минимумы выборки
Ящичковые диаграммы из эксперимента Майкельсона – Морли, показывающие максимумы и минимумы выборки
В статистике, максимум выборки и минимум выборки, также называется наибольшее наблюдение и наименьшее наблюдение, являются значениями наибольшего и наименьшего элементов выборки. Это базовая сводная статистика, используемая в описательной статистике, такой как пятизначная сводка и семизначная сводка Боули и связанные прямоугольная диаграмма.
Минимальное и максимальное значение – это первая и последняя статистика порядка (часто обозначается X (1) и X (n) соответственно для размера выборки n).
Если в выборке есть выбросы, они обязательно включают в себя максимум выборки или минимум выборки, или и то, и другое, в зависимости от того, являются ли они чрезвычайно высокими или низкими. Однако максимум и минимум выборки не обязательно должны быть выбросами, если они не слишком далеки от других наблюдений.
Содержание
- 1 Устойчивость
- 2 Производная статистика
- 3 Приложения
- 3.1 Гладкий максимум
- 3.2 Итоговая статистика
- 3.3 Интервал прогноза
- 3.4 Оценка
- 3.4.1 Равномерное распределение
- 3.5 Тестирование нормальности
- 3.6 Теория экстремальных значений
- 4 См. также
Устойчивость
Максимум и минимум выборки являются наименее надежными статистическими данными : они максимально чувствителен к выбросам.
Это может быть либо преимуществом, либо недостатком: если экстремальные значения реальны (а не ошибки измерения) и имеют реальные последствия, как в приложениях теории экстремальных значений, таких как строительство дамб или финансовых убытков, тогда важны выбросы (отраженные в экстремумах выборки). С другой стороны, если выбросы мало или совсем не влияют на фактические результаты, то использование ненадежной статистики, такой как экстремумы выборки, просто затуманивает статистику, и следует использовать надежные альтернативы, такие как другие квантили : 10-й и 90-й процентили (первый и последний дециль ) являются более надежными альтернативами.
Производная статистика
Помимо того, что они являются компонентом каждой статистики, в которой используются все элементы выборки, экстремумы выборки являются важными частями диапазона, мера дисперсия и средний диапазон, мера местоположения. Они также осознают максимальное абсолютное отклонение : одна из них является самой удаленной точкой от любой заданной точки, в частности, мера центра, такая как медиана или среднее значение.
Приложения
Максимум сглаживания
Для набора выборок функция максимума негладкая и, следовательно, недифференцируемая. Для задач оптимизации, возникающих в статистике, часто требуется аппроксимация гладкой функцией, близкой к максимуму набора.
A сглаженный максимум, например,
- g (x 1, x 2,…, x n) = log (exp (x 1) + exp (x 2) +… + exp (x n))
– хорошее приближение к максимуму выборки.
Сводная статистика
Максимум и минимум выборки представляют собой базовую сводную статистику, показывающую самые экстремальные наблюдения, и используются в сводке из пяти цифр и версия семизначной сводки и связанная с ним прямоугольная диаграмма .
Интервал прогнозирования
Максимум и минимум выборки обеспечивают непараметрический интервал прогнозирования : в выборке из генеральной совокупности или, в более общем смысле, заменяемой последовательности случайных величин, каждое наблюдение с равной вероятностью будет максимумом или минимумом.
Таким образом, если есть образец {X 1,…, X n}, { displaystyle {X_ {1}, dots, X_ {n} },}





Например, если n = 19, то [m, M] дает интервал прогноза 18/20 = 90% – 90% времени, 20-е наблюдение попадает между наименьшим и наибольшим наблюдением, которое наблюдалось до сих пор. Аналогично, n = 39 дает 95% интервал прогнозирования, а n = 199 дает 99% интервал прогнозирования.
Оценка
Из-за их чувствительности к выбросам экстремумы выборки нельзя надежно использовать в качестве оценок, если данные не чистые – надежные альтернативы включают первый и последний децили.
Тем не менее, с чистыми данными или в теоретических условиях они могут иногда оказаться очень хорошими оценками, особенно для платикуртических распределений, где для небольших наборов данных средний диапазон является самый эффективный оценщик.
Однако они неэффективны для оценки местоположения для мезокуртических распределений, таких как нормальное распределение и лептокуртических распределений.
Равномерное распределение
Для выборки без замены из равномерного распределения с одной или двумя неизвестными конечными точками (поэтому 1, 2,…, N { displaystyle 1, 2, dots, N}

Если неизвестна только верхняя конечная точка, максимум выборки является смещенной оценкой для максимума совокупности, но несмещенной оценкой k + 1 км – 1 { displaystyle { frac {k + 1} {k}} m-1}
Если обе конечные точки неизвестны, то диапазон выборки является смещенной оценкой для диапазона генеральной совокупности, но поправка на максимум выше дает оценку UMVU.
Если обе конечные точки неизвестны, то средний диапазон является несмещенной (и, следовательно, UMVU) оценкой средней точки интервала (здесь эквивалентно медианы, среднего или среднего значения совокупности спектр).
Причина, по которой экстремумы выборки являются достаточной статистикой, заключается в том, что условное распределение неэкстремальных выборок – это просто распределение для равномерного интервала между максимумом и минимумом выборки – как только конечные точки фиксированы, значения внутренние точки не добавляют дополнительной информации.
Тестирование нормальности
 Выборочные экстремумы можно использовать для тестирования нормальности, поскольку события за пределами диапазона 3σ очень редки.
Выборочные экстремумы можно использовать для тестирования нормальности, поскольку события за пределами диапазона 3σ очень редки.
Выборочные экстремумы можно использовать для простого тест нормальности, в частности эксцесса: вычисляется t-статистика максимума и минимума выборки (вычитается среднее значение выборки и делится на стандартное отклонение выборки ), и если они необычно велики для размера выборки (согласно правилу трех сигм и таблице в нем, или, точнее, t-распределение Стьюдента ), то эксцесс распределения выборки значительно отклоняется от нормального распределения.
Например, ежедневный процесс должен ожидать событие 3σ один раз в год (календарных дней; раз в полтора года в рабочие дни), тогда как событие 4σ происходит в среднем каждые 40 лет календарных дней, 60 лет рабочих дней (один раз в жизни), события 5σ происходят каждые 5000 лет (один раз в зарегистрированной истории), а события 6σ происходят каждые 1,5 миллиона лет (практически никогда). Таким образом, если экстремумы выборки находятся на 6 сигмах от среднего, у одного имеется значительный отказ от нормальности.
Кроме того, этот тест очень прост в использовании без использования статистики.
Эти тесты на нормальность могут применяться, например, если кто-то сталкивается с риском эксцесса.
Теория экстремальных значений
 События могут выходить за рамки любых ранее наблюдаемых, так как в Лиссабонском землетрясении 1755 года.
События могут выходить за рамки любых ранее наблюдаемых, так как в Лиссабонском землетрясении 1755 года.
Выборочные экстремумы играют две основные роли в теории экстремальных значений :
- во-первых, они дают нижнюю границу экстремальных событий – события могут быть как минимум такими экстремальными и для выборки этого размера;
- во-вторых, они иногда могут использоваться в оценках вероятности более экстремальных событий.
Однако следует соблюдать осторожность при использовании экстремумов выборки в качестве руководства: в распределениях с тяжелыми хвостами или для нестационарных процессов экстремальные события могут быть значительно более экстремальными, чем любое ранее наблюдаемое событие.. Это подробно описано в теории черного лебедя.
См. Также
 Математический портал
Математический портал
- Максимумы и минимумы
В статистика, то максимум выборки и минимум образца, также называется самое большое наблюдение и наименьшее наблюдение, являются значениями наибольшего и наименьшего элементов образец. Они основные сводные статистические данные, используется в описательная статистика такой как пятизначное резюме и Семизначное резюме Боули и связанные коробчатый сюжет.
Минимальное и максимальное значение – это первое и последнее статистика заказов (часто обозначается Икс(1) и Икс(п) соответственно, для размера выборки п).
Если в образце выбросы, они обязательно включают максимум выборки или минимум выборки, или оба, в зависимости от того, являются они чрезвычайно высокими или низкими. Однако максимум и минимум выборки не обязательно должны быть выбросами, если они не слишком далеки от других наблюдений.
Надежность
Максимум и минимум выборки – это наименее надежная статистика: они максимально чувствительны к выбросам.
Это может быть либо преимуществом, либо недостатком: если экстремальные значения реальны (а не ошибки измерения) и имеют реальные последствия, как в приложениях теория экстремальных ценностей например, строительство дамб или финансовые потери, тогда важны выбросы (как показано в экстремумах выборки). С другой стороны, если выбросы имеют незначительное влияние или не влияют на фактические результаты, то использование ненадежных статистических данных, таких как экстремумы выборки, просто затуманивает статистику, и следует использовать надежные альтернативы, например другие квантили: 10-е и 90-е процентили (в общем и целом дециль ) являются более надежными альтернативами.
Полученная статистика
Помимо того, что они являются компонентом каждой статистики, которая использует все элементы выборки, экстремумы выборки являются важными частями ассортимент, мера дисперсии и средний диапазон, мера местоположения. Они также осознают максимальное абсолютное отклонение: один из них – самый дальний точка от любой заданной точки, особенно меры центра, такие как медиана или среднее значение.
Приложения
Гладкий максимум
Для набора образцов функция максимума негладкая и, следовательно, недифференцируемая. Для задач оптимизации, возникающих в статистике, часто требуется аппроксимация гладкой функцией, близкой к максимуму набора.
А гладкий максимум, Например,
- г(Икс1, Икс2, …, Иксп) = журнал (ехр (Икс1) + ехр (Икс2) +… + Exp (Иксп) )
является хорошим приближением к максимуму выборки.
Сводные статистические данные
Максимум и минимум выборки являются основными сводные статистические данные, показывающие самые экстремальные наблюдения, и используются в пятизначное резюме и версия семизначное резюме и связанные коробчатый сюжет.
Интервал прогноза
Максимум и минимум выборки обеспечивают непараметрическое интервал прогноза: в выборке из совокупности или, в более общем смысле, заменяемая последовательность случайных величин, каждое наблюдение с равной вероятностью будет максимальным или минимальным.
Таким образом, если у вас есть образец
Например, если п = 19, тогда [м,M] дает интервал предсказания 18/20 = 90% – 90% времени, 20-е наблюдение попадает между наименьшим и наибольшим наблюдением, которое наблюдалось до сих пор. Точно так же п = 39 дает 95% интервал прогноза, а п = 199 дает интервал прогноза 99%.
Предварительный расчет
Из-за их чувствительности к выбросам экстремумы выборки нельзя надежно использовать в качестве оценщики если данные не чистые – надежные альтернативы включают первый и последний децили.
Тем не менее, с чистыми данными или в теоретических условиях они иногда могут оказаться очень хорошими оценками, особенно для Platykurtic распределения, где для небольших данных устанавливает средний диапазон наиболее эффективный оценщик.
Они неэффективны для оценки местоположения мезокуртических распределений, таких как нормальное распределение, и лептокуртические распределения, однако.
Равномерное распределение
Для отбора проб без замены из равномерное распределение с одной или двумя неизвестными конечными точками (так
Если неизвестна только верхняя конечная точка, максимум выборки является смещенной оценкой для максимума совокупности, но несмещенная оценка
Если обе конечные точки неизвестны, то диапазон выборки является смещенной оценкой для диапазона популяции, но корректировка максимума выше дает оценку UMVU.
Если обе конечные точки неизвестны, то средний диапазон является несмещенной (и, следовательно, UMVU) оценкой середины интервала (здесь эквивалентно медианы, среднего или среднего значения совокупности).
Причина, по которой экстремумы выборки являются достаточной статистикой, заключается в том, что условное распределение неэкстремальных выборок – это просто распределение для равномерного интервала между максимумом и минимумом выборки – после того, как конечные точки зафиксированы, значения внутренних точек не добавляют никакой дополнительной информации .
Тестирование нормальности
Примеры экстремумов можно использовать для проверка нормальности, поскольку события за пределами диапазона 3σ очень редки.
Экстремумы выборки можно использовать для простого тест на нормальность, в частности, эксцесса: вычисляется t-статистика максимума и минимума выборки (вычитает выборочное среднее и делится на стандартное отклонение выборки ), и если они необычно велики для размера выборки (согласно правило трех сигм и таблица в нем, а точнее Распределение Стьюдента ), то эксцесс выборочного распределения значительно отличается от нормального распределения.
Например, ежедневный процесс должен ожидать событие 3σ один раз в год (календарных дней; раз в полтора года в рабочие дни), в то время как событие 4σ происходит в среднем каждые 40 лет календарных дней, 60 лет рабочих дней ( один раз в жизни), события 5σ происходят каждые 5000 лет (один раз в зарегистрированной истории), а события 6σ происходят каждые 1,5 миллиона лет (практически никогда). Таким образом, если экстремумы выборки находятся на 6 сигмах от среднего, один имеет существенное нарушение нормальности.
Кроме того, этот тест очень прост в использовании без привлечения статистики.
Эти тесты на нормальность могут применяться, если кто-то сталкивается с риск эксцесса, например.
Теория экстремальных ценностей
Экстремумы выборки играют две основные роли в теория экстремальных ценностей:
- во-первых, они дают нижнюю границу экстремальных событий – события могут быть как минимум такими экстремальными и для выборки такого размера;
- во-вторых, их иногда можно использовать для оценки вероятности более экстремальных событий.
Однако следует соблюдать осторожность при использовании экстремумов выборки в качестве руководства: распределения с тяжелыми хвостами или для нестационарный процессов, экстремальные события могут быть значительно более экстремальными, чем любое ранее наблюдаемое событие. Это подробно описано в теория черного лебедя.
Смотрите также
- Максимумы и минимумы
Мода и медиана
Модой ряда чисел называется число, наиболее часто встречающееся в данном ряду.
Обратимся снова к нашему примеру со сборной по футболу:
Чему в данном примере равна мода? Какое число наиболее часто встречается в этой выборке?
Все верно, это число ( displaystyle 181), так как два игрока имеют рост ( displaystyle 181) см; рост же остальных игроков не повторяется.
Тут все должно быть ясно и понятно, да и слово знакомое, правда?
Перейдем к медиане, ты ее должен знать из курса геометрии. Но мне не сложно напомнить, что в геометрии медиана (в переводе с латинского- «средняя») — отрезок внутри треугольника, соединяющий вершину треугольника с серединой противоположной стороны.
Ключевое слово – СЕРЕДИНА. Если ты знал это определение, то тебе легко будет запомнить, что такое медиана в статистике.
Медианой ряда чисел с нечетным числом членов называется число, которое окажется посередине, если этот ряд упорядочить (проранжировать, т.е. расположить значения в порядке убывания или возрастания).
Медианой ряда чисел с четным числом членов называется среднее арифметическое двух чисел, записанных посередине, если этот ряд упорядочить.
Ну что, вернемся к нашей выборке футболистов?
Ты заметил в определении медианы важный момент, который нам еще здесь не встречался? Конечно, «если этот ряд упорядочить»!
Для того, чтобы в ряду чисел был порядок, можно расположить значения роста футболистов как в порядке убывания, так и в порядке возрастания. Мне удобней выстроить этот ряд в порядке возрастания (от самого маленького к самому большому).
Вот, что у меня получилось:
Так, ряд упорядочили, какой еще есть важный момент в определении медианы? Правильно, четное и нечетное количество членов в выборке.
Заметил, что для четного и нечетного количества даже определения отличаются? Да, ты прав, не заметить – сложно. А раз так, то нам надо определиться, четное у нас количество игроков в нашей выборке или нечетное?
Все верно – игроков ( displaystyle 11), значит, количество нечетное! Теперь можем применять к нашей выборке менее заковыристое определение медианы для нечетного количества членов в выборке.
Ищем число, которое оказалось посередине в нашем упорядоченном ряду:
Ну вот, чисел у нас ( displaystyle 11), значит, по краям остается по пять чисел, а рост ( displaystyle 183) см будет медианой в нашей выборке.
Не так уж и сложно, правда?
Частота и относительная частота
Частота представляет собой число повторений, сколько раз за какой-то период происходило некоторое событие, проявлялось определенное свойство объекта либо наблюдаемый параметр достигал данной величины.
То есть частота определяет то, как часто повторяется та или иная величина в выборке.
Разберемся на нашем примере с футболистами. Перед нами вот такой вот упорядоченный ряд:
![]()
Частота – это число повторений какой-либо величины параметра. В нашем случае, это можно считать вот так. Сколько игроков имеет рост ( 176)?
Все верно, один игрок. Таким образом, частота встречи игрока с ростом ( 176) в нашей выборке равна ( 1).
Сколько игроков имеет рост ( 178)? Да, опять же один игрок. Частота встречи игрока с ростом ( 178) в нашей выборке равна ( 1).
Задавая такие вопросы и отвечая на них, можно составить вот такую табличку:
Ну вот, все довольно просто. Помни, что сумма частот должна равняться количеству элементов в выборке (объему выборки).
То есть в нашем примере: ( 1+1+1+2+1+1+1+1+1+1=11)
Перейдем к следующей характеристике – относительная частота.
Относительная частота – это отношение частоты к общему числу данных в ряду. Как правило, относительная частота выражается в процентах.
Обратимся опять к нашему примеру с футболистами. Частоты для каждого значения мы рассчитали, общее количество данных в ряду мы тоже знаем ( left( n=11 right)) .
Рассчитываем относительную частоту для каждого значения роста и получаем вот такую табличку:
А теперь сам составь таблицы частот и относительных частот для примера с 9-классниками, решающими задачи.
В статистике , то образец максимальной и образец минимум, также называют крупнейшим наблюдение и наименьшее наблюдение, являются значения наибольшего и наименьшего элементов выборки . Они являются основными сводными статистическими данными , используемыми в описательных статистиках , такие как резюме пяти чисел и резюме семизначных Боулей в и соответствующей коробке участок .
Минимальное и максимальное значение – это статистика первого и последнего порядка (часто обозначаются как X (1) и X ( n ) соответственно, для размера выборки n ).
Если в выборке есть выбросы , они обязательно включают максимум или минимум выборки, или оба, в зависимости от того, являются ли они чрезвычайно высокими или низкими. Однако максимум и минимум выборки не обязательно должны быть выбросами, если они не слишком далеки от других наблюдений.
Надежность
Максимум и минимум выборки являются наименее надежной статистикой : они максимально чувствительны к выбросам.
Это может быть либо преимуществом, либо недостатком: если экстремальные значения реальны (а не ошибки измерения) и имеют реальные последствия, как в приложениях теории экстремальных значений, таких как строительство дамб или финансовые потери, то выбросы (как отражено в экстремумах выборки) важные. С другой стороны, если выбросы мало или не влияют на фактические результаты, то использование ненадежной статистики, такой как экстремумы выборки, просто затуманивает статистику, и следует использовать надежные альтернативы, такие как другие квантили : 10-й и 90-й процентили ( первый и последний дециль ) являются более надежными альтернативами.
Полученная статистика
В дополнение к тому, что они являются компонентом каждой статистики, которая использует все элементы выборки, экстремумы выборки являются важными частями диапазона , мерой дисперсии и средним диапазоном , мерой местоположения. Они также осознают максимальное абсолютное отклонение : одна из них является самой удаленной точкой от любой заданной точки, в частности, мера центра, такая как медиана или среднее значение.
Приложения
Гладкий максимум
Для набора образцов функция максимума негладкая и, следовательно, недифференцируемая. Для задач оптимизации, возникающих в статистике, часто требуется аппроксимация гладкой функцией, близкой к максимуму набора.
Гладкой максимум , например,
- g ( x 1 , x 2 ,…, x n ) = log (exp ( x 1 ) + exp ( x 2 ) +… + exp ( x n ))
является хорошим приближением к максимуму выборки.
Сводные статистические данные
Максимум и минимум выборки представляют собой базовую сводную статистику , показывающую наиболее экстремальные наблюдения, и используются в сводке с пятью числами, версии сводки с семью номерами и связанной с ними прямоугольной диаграмме .
Интервал прогноза
Максимум и минимум выборки обеспечивают непараметрический интервал прогнозирования : в выборке из генеральной совокупности или, в более общем смысле, в заменяемой последовательности случайных величин каждое наблюдение с равной вероятностью будет максимумом или минимумом.
Таким образом, если у одного есть выборка, и один выбирает другое наблюдение, то это имеет вероятность быть наибольшим значением, наблюдаемым до сих пор, вероятность быть наименьшим значением, наблюдаемым до сих пор, и, следовательно, другой раз, находится между максимумом выборки и минимумом выборки. из
Таким образом, обозначая образца максимум и минимум на М и м, Это дает интервал предсказания [ т , М ].
Например, если n = 19, то [ m , M ] дает интервал прогноза 18/20 = 90% – 90% времени, 20-е наблюдение попадает между наименьшим и наибольшим наблюдением, которое наблюдалось до сих пор. Аналогично, n = 39 дает 95% интервал прогнозирования, а n = 199 дает 99% интервал прогнозирования.
Оценка
Из-за их чувствительности к выбросам экстремумы выборки не могут надежно использоваться в качестве оценок, если данные не являются чистыми – надежные альтернативы включают первый и последний децили .
Однако с чистыми данными или в теоретической обстановке они иногда могут оказаться очень хорошими оценками, особенно для платикуртических распределений, где для небольших наборов данных средний диапазон является наиболее эффективным средством оценки.
Однако они не являются эффективными оценками местоположения для мезокуртических распределений, таких как нормальное распределение и лептокуртические распределения.
Равномерное распределение
Для выборки без замены из равномерного распределения с одной или двумя неизвестными конечными точками (то есть с N неизвестными или с M и N неизвестными), максимум выборки или, соответственно, максимум выборки и минимум выборки являются достаточными и полной статистикой для неизвестного конечные точки; таким образом, несмещенная оценка, полученная из них, будет оценкой UMVU .
Если неизвестна только верхняя конечная точка, максимум выборки является смещенной оценкой для максимума совокупности, но несмещенная оценка (где m – максимум выборки, а k – размер выборки) является оценщиком UMVU; см. проблему с немецкими танками .
Если обе конечные точки неизвестны, то диапазон выборки является смещенной оценкой для диапазона популяции, но корректировка максимума выше дает оценку UMVU.
Если обе конечные точки неизвестны, то средний диапазон представляет собой несмещенную (и, следовательно, UMVU) оценку средней точки интервала (здесь эквивалентно медианы, среднего или среднего значения для популяции).
Причина, по которой экстремумы выборки являются достаточной статистикой, заключается в том, что условное распределение неэкстремальных выборок – это просто распределение для равномерного интервала между максимумом и минимумом выборки – после того, как конечные точки зафиксированы, значения внутренних точек не добавляют никакой дополнительной информации .
Тестирование нормальности
Экстремумы выборки можно использовать для проверки нормальности , поскольку события за пределами диапазона 3σ очень редки.
Экстремумы выборки могут использоваться для простого теста нормальности , в частности эксцесса: вычисляется t-статистика максимума и минимума выборки (вычитается среднее значение выборки и делится на стандартное отклонение выборки ), и если они необычно велики для выборки размера (в соответствии с правилом трех сигм и таблицей в нем, или, точнее , t-распределением Стьюдента ), то эксцесс выборочного распределения значительно отличается от нормального распределения.
Например, ежедневный процесс должен ожидать событие 3σ один раз в год (календарных дней; раз в полтора года в рабочие дни), в то время как событие 4σ происходит в среднем каждые 40 лет календарных дней, 60 лет рабочих дней ( один раз в жизни), события 5σ происходят каждые 5000 лет (один раз в зарегистрированной истории), а события 6σ происходят каждые 1,5 миллиона лет (практически никогда). Таким образом, если экстремумы выборки находятся на 6 сигмах от среднего, это означает существенное нарушение нормальности.
Кроме того, этот тест очень прост в использовании без привлечения статистики.
Эти тесты на нормальность могут применяться, например, при наличии риска эксцесса .
Теория экстремальных ценностей
Выборочные экстремумы играют две основные роли в теории экстремальных значений :
- во-первых, они дают нижнюю границу экстремальных событий – события могут быть по крайней мере такими экстремальными и для этой выборки;
- во-вторых, их иногда можно использовать для оценки вероятности более экстремальных событий.
Однако следует проявлять осторожность при использовании экстремумов выборки в качестве руководства: в распределениях с тяжелыми хвостами или для нестационарных процессов экстремальные события могут быть значительно более экстремальными, чем любое ранее наблюдаемое событие. Это разработано в теории черного лебедя .
Смотрите также
- Максимумы и минимумы
