Текущая версия страницы пока не проверялась опытными участниками и может значительно отличаться от версии, проверенной 18 февраля 2018 года; проверки требуют 12 правок.
Метод золотого сечения — метод поиска экстремума действительной функции одной переменной на заданном отрезке. В основе метода лежит принцип деления отрезка в пропорциях золотого сечения. Является одним из простейших вычислительных методов решения задач оптимизации. Впервые представлен Джеком Кифером в 1953 году.
Описание метода[править | править код]
Пусть задана унимодальная функция ![{displaystyle f(x):;[a,;b]to mathbb {R} ,;f(x)in mathrm {C} ([a,;b])}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2d5c950424ffb971c27e46842a85a952d2aafb07)



Иллюстрация выбора промежуточных точек метода золотого сечения.
, где
— пропорция золотого сечения.
Таким образом:

То есть точка ![{displaystyle [a,;x_{2}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9093ab6bd86135b5a5efefa0bc19c8cd80ff76ec)
![{displaystyle [x_{1},;b]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8ca89a3efa95fd01a5003d0d6445bcebb8840892)
Алгоритм[править | править код]
- На первой итерации заданный отрезок делится двумя симметричными относительно его центра точками и рассчитываются значения в этих точках.
- После чего тот из концов отрезка, к которому среди двух вновь поставленных точек ближе оказалась та, значение в которой максимально (для случая поиска минимума), отбрасывают.
- На следующей итерации в силу показанного выше свойства золотого сечения уже надо искать всего одну новую точку.
- Процедура продолжается до тех пор, пока не будет достигнута заданная точность.
Формализация[править | править код]
- Шаг 1. Задаются начальные границы отрезка
и точность
.
- Шаг 2. Рассчитывают начальные точки деления:
и значения в них целевой функции:
.
- Шаг 3.
Алгоритм взят из книги Мэтьюза и Финка «Численные методы. Использование MATLAB».
Реализация данного алгоритма на языке F#, в которой значения целевой функции используются повторно:
let phi = 0.5 * (1.0 + sqrt 5.0) let minimize f eps a b = let rec min_rec f eps a b fx1 fx2 = if b - a < eps then 0.5 * (a + b) else let t = (b - a) / phi let x1, x2 = b - t, a + t let fx1 = match fx1 with Some v -> v | None -> f x1 let fx2 = match fx2 with Some v -> v | None -> f x2 if fx1 >= fx2 then min_rec f eps x1 b (Some fx2) None else min_rec f eps a x2 None (Some fx1) min_rec f eps (min a b) (max a b) None None // Примеры вызова: minimize cos 1e-6 0.0 6.28 |> printfn "%.10g" // = 3.141592794; функция f вызвана 34 раза. minimize (fun x -> (x - 1.0)**2.0) 1e-6 0.0 10.0 |> printfn "%.10g" // = 1.000000145; функция f вызвана 35 раз.
Метод чисел Фибоначчи[править | править код]
В силу того, что в асимптотике 
Алгоритм[править | править код]
- Шаг 1. Задаются начальные границы отрезка
, рассчитывают начальные точки деления:
и значения в них целевой функции:
- Шаг 2.
.
- Шаг 3.
Литература[править | править код]
- Акулич И. Л. Математическое программирование в примерах и задачах: Учеб. пособие для студентов эконом. спец. вузов. — М.: Высш. шк., 1986.
- Гилл Ф., Мюррей У., Райт М. Практическая оптимизация. Пер. с англ. — М.: Мир, 1985.
- Коршунов Ю. М. Математические основы кибернетики. — М.: Энергоатомиздат, 1972.
- Максимов Ю. А., Филлиповская Е. А. Алгоритмы решения задач нелинейного программирования. — М.: МИФИ, 1982.
- Максимов Ю. А. Алгоритмы линейного и дискретного программирования. — М.: МИФИ, 1980.
- Корн Г., Корн Т. Справочник по математике для научных работников и инженеров. — М.: Наука, 1970. — С. 575—576.
- Корн Г., Корн Т. Справочник по математике для научных работников и инженеров. — М.: Наука, 1973. — С. 832 с илл..
- Джон Г. Мэтьюз, Куртис Д. Финк. Численные методы. Использование MATLAB. — 3-е издание. — М., СПб.: Вильямс, 2001. — С. 716.
См. также[править | править код]
- Золотое сечение
- Числа Фибоначчи
Метод
основан на делении текущего отрезка
[а,
b],
где
содержится искомый экстремум, на две
неравные части, подчиняющиеся правилу
золотого сечения, для определения
следующего отрезка, содержащего минимум
(максимум).
Золотое
сечение определяется по правилу:
отношение всего отрезка к большей его
части равно отношению большей части
отрезка к меньшей. Ему удовлетворяют
две точки c
и
d,
расположенные
симметрично относительно середины
отрезка.
![]()
Путем
сравнения R(c)
и
R(d)
определяют
следующий отрезок, где содержится
максимум. Если R(d)
>
R(c),
то
в качестве следующего отрезка выбирается
отрезок [с,
b],
в
противном случае – отрезок [a,
d].
Новый
отрезок снова делится на неравные части
по правилу золотого сечения. Следует
отметить, что точка d
является
и точкой золотого сечения отрезка [с,
b],
т.е.
![]()
Поэтому на каждой
следующей итерации (кроме “запуска”
метода на исходном отрезке) нужно
вычислять только одно значение критерия
оптимальности.
Существуют
аналитические формулы для расчета новой
точки на отрезке, где находится
максимальное значение R(x),
которую
нетрудно получить:
![]()
Условие
окончания поиска – величина отрезка,
содержащего максимум, меньше заданной
погрешности.
Метод
обеспечивает более быструю сходимость
к решению, чем многие другие методы, и
применим, очевидно, только для
одноэкстремальных функций.
На
рис. 3 приведены два этапа поиска максимума
функции методом золотого сечения.

Рис.
3. Иллюстрация метода золотого сечения:
1 – интервал, включающий в себя искомый
максимум функции после первого этапа
(первого золотого сечения в точках c
и
d);
2
–
то же, после второго этапа (новая точка
е
и
старая точка d)
Алгоритм метода золотого сечения для минимизации функции.
Начальный
этап. Выбрать
допустимую конечную длину интервала
неопределённости l
> 0. Пусть [а,
b]
– начальный интервал неопределённости.
Положить
![]()
и
![]() .
.
Вычислить R(c)
и R(d),
положить k
= 1 и перейти к основному этапу.
Основной этап.
Шаг
1. Если bk
– ak
< l,
то остановиться; точка минимума
принадлежит интервалу [аk,
bk].
В противном случае если R(ck)
> R(dk),
то перейти к шагу 2, а если R(ck)
≤ R(dk),
то к шагу 3.
Шаг
2.
Положить ak+1
= ck
и bk+1
= bk,
![]() .
.
Вычислить R(dk+1)
и перейти к шагу 4.
Шаг
3.
Положить ak+1
= ak
и bk+1
= dk,
![]() .
.
Вычислить R(ck+1)
и перейти к шагу 4.
Шаг
4.
Заменить k
на k
+
1 и перейти к шагу 1.
Пример.
Дана
функция R(x)
= D
sin(АхB
+ С), где
коэффициенты имеют следующие значения:
А
=1,0,
В = 1,0,
С
= 1,0,
D
= 1,0.
Найти максимум на интервале: [-1, 2]. Ошибка
задается по х:
ε
=0,05.
Результаты
расчетов. Для “запуска” метода
найдем две симметричные точки золотого
сечения для отрезка [-1, 2]:
x1
=0,145898, х2
=0,85410197.
Значения
критериев в этих точках соответственно
R(x1)
= 0,911080, R(x2)
=
0,960136. Следовательно, новым отрезком
является [0,145898; 2], внутри которого
находится максимальное из найденных
значений R.
Точка
золотого сечения для нового отрезка
будет x3
=0,58359214, a
R(x3)
=0,99991813.
Далее приведены только координаты
лучших точек при очередном шаге, номер
шага и значения критерия в этих точках.
х3
= 0,58359214; R3
= 0,99991813;
х4
=0,58359214; R4
= 0,99991813
х5
= 0,58359214; R5
= 0,99991813;
х6
= 0,58359214; R6
= 0,99991813
х7
= 0,58359214; R7
= 0,99991813;
х8
= 0,55920028; R8
= 0,99993277;
х9
= 0,55920028;
R9
= 0,99993277.
Всего
было проведено 10 вычислений критерия
оптимальности.
Соседние файлы в папке Системный анализ и принятие решений
- #
- #
27.02.2016389.68 Кб50Тугаринов.xmcd
From Wikipedia, the free encyclopedia

Diagram of a golden-section search. The initial triplet of x values is {x1,x2,x3}. If f(x4)=f4a, the triplet {x1,x2,x4} is chosen for the next iteration. If f(x4)=f4b, the triplet {x2,x4,x3} is chosen.
The golden-section search is a technique for finding an extremum (minimum or maximum) of a function inside a specified interval. For a strictly unimodal function with an extremum inside the interval, it will find that extremum, while for an interval containing multiple extrema (possibly including the interval boundaries), it will converge to one of them. If the only extremum on the interval is on a boundary of the interval, it will converge to that boundary point. The method operates by successively narrowing the range of values on the specified interval, which makes it relatively slow, but very robust. The technique derives its name from the fact that the algorithm maintains the function values for four points whose three interval widths are in the ratio φ:1:φ where φ is the golden ratio. These ratios are maintained for each iteration and are maximally efficient. Excepting boundary points, when searching for a minimum, the central point is always less than or equal to the outer points, assuring that a minimum is contained between the outer points. The converse is true when searching for a maximum. The algorithm is the limit of Fibonacci search (also described below) for many function evaluations. Fibonacci search and golden-section search were discovered by Kiefer (1953) (see also Avriel and Wilde (1966)).
Basic idea[edit]
The discussion here is posed in terms of searching for a minimum (searching for a maximum is similar) of a unimodal function. Unlike finding a zero, where two function evaluations with opposite sign are sufficient to bracket a root, when searching for a minimum, three values are necessary. The golden-section search is an efficient way to progressively reduce the interval locating the minimum. The key is to observe that regardless of how many points have been evaluated, the minimum lies within the interval defined by the two points adjacent to the point with the least value so far evaluated.
The diagram above illustrates a single step in the technique for finding a minimum. The functional values of 




The next step in the minimization process is to “probe” the function by evaluating it at a new value of x, namely 


Probe point selection[edit]
From the diagram above, it is seen that the new search interval will be either between 
However, there still remains the question of where 

Mathematically, to ensure that the spacing after evaluating 

However, if

Eliminating c from these two simultaneous equations yields

or

where φ is the golden ratio:

The appearance of the golden ratio in the proportional spacing of the evaluation points is how this search algorithm gets its name.
Termination condition[edit]
Any number of termination conditions may be applied, depending upon the application. The interval ΔX = X4 − X1 is a measure of the absolute error in the estimation of the minimum X and may be used to terminate the algorithm. The value of ΔX is reduced by a factor of r = φ − 1 for each iteration, so the number of iterations to reach an absolute error of ΔX is about ln(ΔX/ΔXo) / ln(r) where ΔXo is the initial value of ΔX.
Because smooth functions are flat (their first derivative is close to zero) near a minimum, attention must be paid not to expect too great an accuracy in locating the minimum. The termination condition provided in the book Numerical Recipes in C is based on testing the gaps among

where 



Algorithm[edit]
Note! The examples here describe an algorithm that is for finding the minimum of a function. For maximum, the comparison operators need to be reversed.
Iterative algorithm[edit]

Diagram of the golden section search for a minimum. The initial interval enclosed by X1 and X4 is divided into three intervals, and f[X] is evaluated at each of the four Xi. The two intervals containing the minimum of f(Xi) are then selected, and a third interval and functional value are calculated, and the process is repeated until termination conditions are met. The three interval widths are always in the ratio c:cr:c where r = φ − 1=0.619… and c = 1 − r = 0.381…, φ being the golden ratio. This choice of interval ratios is the only one that allows the ratios to be maintained during an iteration.
- Specify the function to be minimized, f(x), the interval to be searched as {X1,X4}, and their functional values F1 and F4.
- Calculate an interior point and its functional value F2. The two interval lengths are in the ratio c : r or r : c where r = φ − 1; and c = 1 − r, with φ being the golden ratio.
- Using the triplet, determine if convergence criteria are fulfilled. If they are, estimate the X at the minimum from that triplet and return.
- From the triplet, calculate the other interior point and its functional value. The three intervals will be in the ratio c:cr:c.
- The three points for the next iteration will be the one where F is a minimum, and the two points closest to it in X.
- Go to step 3
"""Python program for golden section search. This implementation does not reuse function evaluations and assumes the minimum is c or d (not on the edges at a or b)""" import math gr = (math.sqrt(5) + 1) / 2 def gss(f, a, b, tol=1e-5): """Golden-section search to find the minimum of f on [a,b] f: a strictly unimodal function on [a,b] Example: >>> f = lambda x: (x-2)**2 >>> x = gss(f, 1, 5) >>> print("%.15f" % x) 2.000009644875678 """ c = b - (b - a) / gr d = a + (b - a) / gr while abs(b - a) > tol: if f(c) < f(d): # f(c) > f(d) to find the maximum b = d else: a = c # We recompute both c and d here to avoid loss of precision which may lead to incorrect results or infinite loop c = b - (b - a) / gr d = a + (b - a) / gr return (b + a) / 2
"""Python program for golden section search. This implementation reuses function evaluations, saving 1/2 of the evaluations per iteration, and returns a bounding interval.""" import math invphi = (math.sqrt(5) - 1) / 2 # 1 / phi invphi2 = (3 - math.sqrt(5)) / 2 # 1 / phi^2 def gss(f, a, b, tol=1e-5): """Golden-section search. Given a function f with a single local minimum in the interval [a,b], gss returns a subset interval [c,d] that contains the minimum with d-c <= tol. Example: >>> f = lambda x: (x-2)**2 >>> a = 1 >>> b = 5 >>> tol = 1e-5 >>> (c,d) = gss(f, a, b, tol) >>> print(c, d) 1.9999959837979107 2.0000050911830893 """ (a, b) = (min(a, b), max(a, b)) h = b - a if h <= tol: return (a, b) # Required steps to achieve tolerance n = int(math.ceil(math.log(tol / h) / math.log(invphi))) c = a + invphi2 * h d = a + invphi * h yc = f(c) yd = f(d) for k in range(n - 1): if yc < yd: # yc > yd to find the maximum b = d d = c yd = yc h = invphi * h c = a + invphi2 * h yc = f(c) else: a = c c = d yc = yd h = invphi * h d = a + invphi * h yd = f(d) if yc < yd: return (a, d) else: return (c, b)
Recursive algorithm[edit]
public class GoldenSectionSearch { public static final double invphi = (Math.sqrt(5.0) - 1) / 2.0; public static final double invphi2 = (3 - Math.sqrt(5.0)) / 2.0; public interface Function { double of(double x); } // Returns subinterval of [a,b] containing minimum of f public static double[] gss(Function f, double a, double b, double tol) { return gss(f, a, b, tol, b - a, true, 0, 0, true, 0, 0); } private static double[] gss(Function f, double a, double b, double tol, double h, boolean noC, double c, double fc, boolean noD, double d, double fd) { if (Math.abs(h) <= tol) { return new double[] { a, b }; } if (noC) { c = a + invphi2 * h; fc = f.of(c); } if (noD) { d = a + invphi * h; fd = f.of(d); } if (fc < fd) { // fc > fd to find the maximum return gss(f, a, d, tol, h * invphi, true, 0, 0, false, c, fc); } else { return gss(f, c, b, tol, h * invphi, false, d, fd, true, 0, 0); } } public static void main(String[] args) { Function f = (x)->Math.pow(x-2, 2); double a = 1; double b = 5; double tol = 1e-5; double [] ans = gss(f, a, b, tol); System.out.println("[" + ans[0] + "," + ans[1] + "]"); // [1.9999959837979107,2.0000050911830893] } }
import math invphi = (math.sqrt(5) - 1) / 2 # 1 / phi invphi2 = (3 - math.sqrt(5)) / 2 # 1 / phi^2 def gssrec(f, a, b, tol=1e-5, h=None, c=None, d=None, fc=None, fd=None): """Golden-section search, recursive. Given a function f with a single local minimum in the interval [a,b], gss returns a subset interval [c,d] that contains the minimum with d-c <= tol. Example: >>> f = lambda x: (x-2)**2 >>> a = 1 >>> b = 5 >>> tol = 1e-5 >>> (c,d) = gssrec(f, a, b, tol) >>> print (c, d) 1.9999959837979107 2.0000050911830893 """ (a, b) = (min(a, b), max(a, b)) if h is None: h = b - a if h <= tol: return (a, b) if c is None: c = a + invphi2 * h if d is None: d = a + invphi * h if fc is None: fc = f(c) if fd is None: fd = f(d) if fc < fd: # fc > fd to find the maximum return gssrec(f, a, d, tol, h * invphi, c=None, fc=None, d=c, fd=fc) else: return gssrec(f, c, b, tol, h * invphi, c=d, fc=fd, d=None, fd=None)
Fibonacci search[edit]
A very similar algorithm can also be used to find the extremum (minimum or maximum) of a sequence of values that has a single local minimum or local maximum. In order to approximate the probe positions of golden section search while probing only integer sequence indices, the variant of the algorithm for this case typically maintains a bracketing of the solution in which the length of the bracketed interval is a Fibonacci number. For this reason, the sequence variant of golden section search is often called Fibonacci search.
Fibonacci search was first devised by Kiefer (1953) as a minimax search for the maximum (minimum) of a unimodal function in an interval.
See also[edit]
- Ternary search
- Brent’s method
- Binary search
References[edit]
- Kiefer, J. (1953), “Sequential minimax search for a maximum”, Proceedings of the American Mathematical Society, 4 (3): 502–506, doi:10.2307/2032161, JSTOR 2032161, MR 0055639
- Avriel, Mordecai; Wilde, Douglass J. (1966), “Optimality proof for the symmetric Fibonacci search technique”, Fibonacci Quarterly, 4: 265–269, MR 0208812
- Press, WH; Teukolsky, SA; Vetterling, WT; Flannery, BP (2007), “Section 10.2. Golden Section Search in One Dimension”, Numerical Recipes: The Art of Scientific Computing (3rd ed.), New York: Cambridge University Press, ISBN 978-0-521-88068-8
Метод золотого сечения также является последовательным методом минимизации. Опираясь на свойства золотого сечения отрезка, этот метод использует найденные значения F(X) более рационально, чем метод деления отрезка пополам, что позволяет переходить к очередному отрезку, содержащему точку Х* после вычисления одного, а не двух значений F(X).
Метод основан на делении текущего отрезка [A; B], где содержится искомый экстремум, на две неравные части, подчиняющиеся правилу золотого сечения, для определения следующего отрезка, содержащего максимум.
Правило золотого сечения: Отношение всего Отрезка к большей его части равно отношению большей части отРезка к меньшей. Ему удовлетворяют две точки с и D, располоЖенные симметрично относительно середины отрезка:
![]()
Путем сравнения F(с) И F(D) Определяют следующий отрезок, где содержится максимум. Если F(D) > F(с), то в качестве следующего отрезка выбирается отрезок [с, B], в противном случае — отрезок [а, D].
Новый отрезок снова делится на неравные части по правилу золотого сечения. Следует отметить, что точка D является и точкой золотого сечения отрезка [с, B], Т. е.
![]()
Поэтому на каждой следующей итерации (кроме “запуска” метода на исходном отрезке) нужно вычислять только одно значение критерия оптимальности.
Существуют аналитические формулы для расчета новой точки на отрезке, где находится максимальное значение F(X).
Золотое сечение отрезка [A; B] осуществляется двумя точками:
![]() (3)
(3)
Причем Х1 есть вторая точка золотого сечения отрезка [A; X2], а Х2 – первая точка золотого сечения отрезка [X1; B].
Зная одну из точек золотого сечения отрезка [A; B], другую можно найти по одной из формул
X1 = A + B – X2, X2 = A + B – X1. (4)
Пусть F(X) Q[A; B] и требуется найти точку минимума Х* функции F(X) на [A; B]. Построим последовательности {An}, {Bn}, {![]() }, N = 1, 2, …, следующим образом:
}, N = 1, 2, …, следующим образом:
 (5)
(5)
Первая и вторая точки золотого сечения (3) отрезка [An-1; Bn-1].
Для определения чисел An, Bn, ![]() По найденным An-1, Bn-1,
По найденным An-1, Bn-1, ![]() Необходимо выполнить следующие операции:
Необходимо выполнить следующие операции:
1) найти одну из точек золотого сечения отрезка [An-1; Bn-1] по известной другой точке ![]() , используя формулы (4) или (3);
, используя формулы (4) или (3);
2) вычислить значение F(X) во вновь найденной точке золотого сечения;
3) сравнить значения ![]() и
и ![]() и найти An, bn, Xn по формулам (5).
и найти An, bn, Xn по формулам (5).
Таким образом, на каждом шаге определения An, Bn и ![]() , N=2, 3, …, требуется вычисление одного значения F(X). Положив
, N=2, 3, …, требуется вычисление одного значения F(X). Положив ![]() , найдем точку минимума Х* с точностью N:
, найдем точку минимума Х* с точностью N:
 (6)
(6)
Откуда следует, что число шагов N метода золотого сечения, обеспечивающее заданную точность нахождения точки Х*, должно удовлетворять неравенству:
 (7)
(7)
Либо можно принять другое условие окончания поиска — величина отрезка, содержащего максимум, меньше заданной погрешности.
Метод золотого сечения обеспечивает более быструю сходимость к решению, чем многие другие методы, и применим, очевидно, только для одноэкстремальных функций, т. е. функций, содержащих один экстремум того типа, который ищется в задаче.

На рис. 18 приведены два этапа поиска максимума функции методом золотого сечения: 1 – интервал, включающий в себя искомый максимум функции после первого этапа (первого золотого сечения в точках C и D); 2 – то же, после второго этапа (новая точка E и старая точка D).
Пример 17. Найти минимальное значение F* и точку минимума Х* функции ![]() На отрезке [1.5; 2]. Точку Х* Найти с точностью =0,05.
На отрезке [1.5; 2]. Точку Х* Найти с точностью =0,05.
Решение. Вычисления проведем по формулам (5) представив результаты в табл. 12.
Таблица 12
|
N |
n |
An |
Bn |
X1(n) |
X2(n) |
F(x1(n)) |
F(x2(n)) |
Примечание |
|
1 |
0,309 |
1,500 |
2,000 |
1,691 |
1,809 |
-92,049 |
–91,814 |
|
|
2 |
0,191 |
1,500 |
1,809 |
1,618 |
1,691 |
-91,464 |
–92,049 |
|
|
3 |
0,118 |
1,618 |
1,809 |
1,691 |
1,736 |
-92,049 |
–92,138 |
|
|
4 |
0,073 |
1,691 |
1,809 |
1,736 |
1,764 |
-92,138 |
–92,084 |
|
|
5 |
0,045 |
1,736 |
-92,138 |
|
Первоначальные значения Х1 И х2 находим по формулам (3), а значения точности по формуле (6).
Из таблицы получаем ![]()
Заметим, что если воспользоваться формулой (7), то необходимое число шагов N можно определить заранее. В нашем случае N 4,79, т. е. N = 5, и отпадает необходимость во втором столбце табл. 12.
Пример 18. Найти точку минимума Х*И минимум F* функции F(X)=X2+3X(Lnx-1) на отрезке [0.5; 1] С точностью =0,05.
Решение. Вычисления представим в табл. 13.
Таблица 13
|
N |
n |
An |
Bn |
Х1(n) |
X2(n) |
F(x1(n)) |
F(x2(n)) |
Примечание |
|
1 |
0,309 |
0,5 |
1 |
0,691 |
0,809 |
-2,362 |
-2,287 |
|
|
2 |
0,191 |
0,5 |
0,809 |
0,618 |
0,691 |
-2,364 |
-2,362 |
|
|
3 |
0,118 |
0,5 |
0,691 |
0,573 |
0,618 |
-2,348 |
-2,364 |
|
|
4 |
0,073 |
0,573 |
0,691 |
0,618 |
0,646 |
-2,364 |
-2,368 |
|
|
5 |
0,045 |
0,646 |
-2,368 |
|
Следовательно, Х* ![]() 0,646, и F*
0,646, и F* ![]() F (0,646) = -2,368.
F (0,646) = -2,368.
| < Предыдущая | Следующая > |
|---|
Решение нелинейных уравнений метод золотого сечения
1. МЕТОДЫ ОДНОМЕРНОЙ ОПТИМИЗАЦИИ
При построении процесса оптимизации стараются сократить объем вычислений и время поиска. Этого достигают обычно путем сокращения количества вычислений значений целевой функции f ( x ). Одним из наиболее эффективных методов, в которых при ограниченном количестве вычислений f ( x ) достигается наилучшая точность, является метод золотого сечения.
Если известно, что функция f ( x ) унимодальная на отрезке [ a , b ], то положение точки минимума можно уточнить, вычислив f ( x ) в двух внутренних точках отрезка. При этом возможны две ситуации:
Минимум реализуется на отрезке [ a , x 2 ] .
Минимум реализуется на отрезке [ x 1 , b ] .
В методе золотого сечения каждая из точек x 1 и x 2 делит исходный интервал на две части так, что отношение целого к большей части равно отношении большей части к меньшей, т.е. равно так называемому “золотому отношению”. Это соответствует следующему простому геометрическому представлению:
Итак, длины отрезков [ a , x 1 ] и [ x 2 , b ] одинаковы и составляют 0,382 от длины ( a , b ) . Значениям f ( x 1 ) и f ( x 2 ) определяется новей интервал ( a , x 2 ) или ( x 1 , b ) , в котором локализован минимум. Найденный интервал снова делится двумя точками в том же отношении, причем одна из новых точек деления сов падает с уже использованной на предыдущем шаге.
Взаимное расположение точек первых трех вычислений можно показать следующим образом:
Таким образом, длина интервала неопределенности на каждом шаге сжимается с коэффициентом 0,618. На первом шаге необходимы два вычисления функции, на каждом последующем – одно.
Длина интервала неопределенности после S вычислений значений f ( x ) составляет:
Алгоритм метода золотого сечения для минимизации функции f ( x ) складывается из следующих этапов:
- Вычисляется значение функции f ( x1 ) , где x1 = a +0,382( b – a ) .
- Вычисляется значение функции f ( x2 ) , где x1 = b +0,382( b – a ) .
- Определяется новый интервал (a,x2) или (x1,b), в котором локализован минимум.
- Внутри полученного интервала находится новая точка ( x1 в случае 1) или ( x2 в случае 2), отстоящая от его конца на расстоянии, составляющем 0,382 от его длины. В этой точке рассчитывается значение f ( x ). Затем вычисления повторяются, начиная с пункта 3, до тех пор, пока величина интервала неопределенности станет меньше или равна ε, где ε – заданное сколь угодно малое положительное число.
Блок-схема алгоритма поиска минимума функции f ( x ) методом золотого сечения.
Используя метод золотого сечения, минимизировать функцию f (х)= x 2 +2х на интервале (-3,5). Алина конечного интервала неопределенности не должна превосходить 0,2.
Программирование на C, C# и Java
Уроки программирования, алгоритмы, статьи, исходники, примеры программ и полезные советы
ОСТОРОЖНО МОШЕННИКИ! В последнее время в социальных сетях участились случаи предложения помощи в написании программ от лиц, прикрывающихся сайтом vscode.ru. Мы никогда не пишем первыми и не размещаем никакие материалы в посторонних группах ВК. Для связи с нами используйте исключительно эти контакты: vscoderu@yandex.ru, https://vk.com/vscode
Метод золотого сечения на Java
В статье речь пойдет о методе золотого сечения и, соответственно, о нахождении с помощью этого метода экстремума функции на заданном отрезке. Для реализации алгоритма будет использован язык Java.
Метод золотого сечения — это итеративный метод поиска экстремумов (минимума или максимума) функции одной переменной на заданном отрезке [a; b]. Метод золотого сечения был продемонстрирован в 1953 году Джеком Кифером. В его основе лежит принцип деления отрезка в пропорции золотого сечения.
Теоретические сведения
Пусть задана функция f(x) и отрезок [a; b], на котором требуется найти экстремум. Рассматриваемый отрезок делится в оба направления точками x1 и x2 в отношении золотого сечения. То есть:
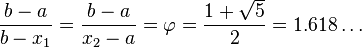
φ — это пропорция золотого сечения.
Следовательно координаты x1 и x2 находятся по формулам:
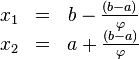
Таким образом точки x1 и x2 делят отрезки [a; x2] и [x1; b] соответственно в пропорции золотого сечения. Это свойство далее будет использоваться для построения итеративного процесса вычисления экстремума функции.
Описание алгоритма
- Задаются начальные параметры: границы отрезка [a; b] и точность вычислений ε.
- Рассчитываются координаты точек деления:
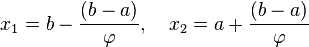 . Затем вычисляется значение функции f(x) в этих точках:
. Затем вычисляется значение функции f(x) в этих точках: 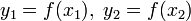 . ЕСЛИ
. ЕСЛИ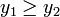 (случай поиска минимума функции. Для поиска точки максимума изменить неравенство на
(случай поиска минимума функции. Для поиска точки максимума изменить неравенство на 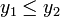 ), ТО
), ТО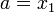 . ИНАЧЕ
. ИНАЧЕ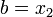 .
. - ЕСЛИ требуемая точность достигнута:
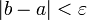 , ТО
, ТО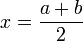 и конец алгоритма. ИНАЧЕ возврат к шагу 2.
и конец алгоритма. ИНАЧЕ возврат к шагу 2.
Реализация алгоритма
Напишем программу, реализующую приведенный выше алгоритм метода золотого сечения. Также приведем пример поиска экстремума для конкретной функции. Разработку будем вести на языке программирования JAVA.
Класс GoldenSection, позволяющий выполнить поиск экстремума функции на отрезке [a; b] с точностью ε, содержит (по порядку): определение константы пропорции золотого сечения φ, метод, вычисляющий значение целевой функции f(x), метод, выполняющий поиск минимума функции и метод, выполняющий поиск максимума функции.
Численные методы: решение нелинейных уравнений
Задачи решения уравнений постоянно возникают на практике, например, в экономике, развивая бизнес, вы хотите узнать, когда прибыль достигнет определенного значения, в медицине при исследовании действия лекарственных препаратов, важно знать, когда концентрация вещества достигнет заданного уровня и т.д.
В задачах оптимизации часто необходимо определять точки, в которых производная функции обращается в 0, что является необходимым условием локального экстремума.
В статистике при построении оценок методом наименьших квадратов или методом максимального правдоподобия также приходится решать нелинейные уравнения и системы уравнений.
Итак, возникает целый класс задач, связанных с нахождением решений нелинейных уравнений, например, уравнения или уравнения и т.д.
В простейшем случае у нас имеется функция , заданная на отрезке ( a , b ) и принимающая определенные значения.
Каждому значению x из этого отрезка мы можем сопоставить число , это и есть функциональная зависимость, ключевое понятие математики.
Нам нужно найти такое значение при котором такие называются корнями функции
Визуально нам нужно определить точку пересечения графика функции с осью абсцисс.
Метод деления пополам
Простейшим методом нахождения корней уравнения является метод деления пополам или дихотомия.
Этот метод является интуитивно ясным и каждый действовал бы при решении задачи подобным образом.
Алгоритм состоит в следующем.
Предположим, мы нашли две точки и , такие что и имеют разные знаки, тогда между этими точками находится хотя бы один корень функции .
Поделим отрезок пополам и введем среднюю точку .
Тогда либо , либо .
Оставим ту половину отрезка, для которой значения на концах имеют разные знаки. Теперь этот отрезок снова делим пополам и оставляем ту его часть, на границах которой функция имеет разные знаки, и так далее, достижения требуемой точности.
Очевидно, постепенно мы сузим область, где находится корень функции, а, следовательно, с определенной степенью точности определим его.
Заметьте, описанный алгоритм применим для любой непрерывной функции.
К достоинствам метода деления пополам следует отнести его высокую надежность и простоту.
Недостатком метода является тот факт, что прежде чем начать его применение, необходимо найти две точки, значения функции в которых имеют разные знаки. Очевидно, что метод неприменим для корней четной кратности и также не может быть обобщен на случай комплексных корней и на системы уравнений.
Порядок сходимости метода линейный, на каждом шаге точность возрастает вдвое, чем больше сделано итераций, тем точнее определен корень.
Метод Ньютона: теоретические основы
Классический метод Ньютона или касательных заключается в том, что если — некоторое приближение к корню уравнения , то следующее приближение определяется как корень касательной к функции , проведенной в точке .
Уравнение касательной к функции в точке имеет вид:
В уравнении касательной положим и .
Тогда алгоритм последовательных вычислений в методе Ньютона состоит в следующем:
Сходимость метода касательных квадратичная, порядок сходимости равен 2.
Таким образом, сходимость метода касательных Ньютона очень быстрая.
Запомните этот замечательный факт!
Без всяких изменений метод обобщается на комплексный случай.
Если корень является корнем второй кратности и выше, то порядок сходимости падает и становится линейным.
Упражнение 1. Найти с помощью метода касательных решение уравнения на отрезке (0, 2).
Упражнение 2. Найти с помощью метода касательных решение уравнения на отрезке (1, 3).
К недостаткам метода Ньютона следует отнести его локальность, поскольку он гарантированно сходится при произвольном стартовом приближении только, если везде выполнено условие , в противной ситуации сходимость есть лишь в некоторой окрестности корня.
Недостатком метода Ньютона является необходимость вычисления производных на каждом шаге.
Визуализация метода Ньютона
Метод Ньютона (метод касательных) применяется в том случае, если уравнение f(x) = 0 имеет корень , и выполняются условия:
1) функция y= f(x) определена и непрерывна при ;
2) f(a)·f(b) 0. Таким образом, выбирается точка с абсциссой x0, в которой касательная к кривой y=f(x) на отрезке [a;b] пересекает ось Ox. За точку x0 сначала удобно выбирать один из концов отрезка.
Рассмотрим метод Ньютона на конкретном примере.
Пусть нам дана возрастающая функция y = f(x) =x 2 -2, непрерывная на отрезке (0;2), и имеющая f ‘(x) = 2x > 0 и f ”(x) = 2 > 0.
Уравнение касательной в общем виде имеет представление:
В нашем случае: y-y0=2x0·(x-x0). В качестве точки x0 выбираем точку B1(b; f(b)) = (2,2). Проводим касательную к функции y = f(x) в точке B1, и обозначаем точку пересечения касательной и оси Ox точкой x1. Получаем уравнение первой касательной:y-2=2·2(x-2), y=4x-6.
Точка пересечения касательной и оси Ox: x1 =
Рисунок 2. Результат первой итерации
Затем находим точку пересечения функции y=f(x) и перпендикуляра, проведенного к оси Ox через точку x1, получаем точку В2 =(1.5; 0.25). Снова проводим касательную к функции y = f(x) в точке В2, и обозначаем точку пересечения касательной и оси Ox точкой x2.
Точка пересечения касательной и оси Ox: x2 = .
Рисунок 3. Вторая итерация метода Ньютона
Затем находим точку пересечения функции y=f(x) и перпендикуляра, проведенного к оси Ox через точку x2, получаем точку В3 и так далее.
В3 = ()
Рисунок 4. Третий шаг метода касательных
Первое приближение корня определяется по формуле:
= 1.5.
Второе приближение корня определяется по формуле:
=
Третье приближение корня определяется по формуле:
Таким образом, i-ое приближение корня определяется по формуле:
Вычисления ведутся до тех пор, пока не будет достигнуто совпадение десятичных знаков, которые необходимы в ответе, или заданной точности e – до выполнения неравенства |xi–xi-1|
using namespace std;
float f(double x) //возвращает значение функции f(x) = x^2-2
float df(float x) //возвращает значение производной
float d2f(float x) // значение второй производной
int _tmain(int argc, _TCHAR* argv[])
int exit = 0, i=0;//переменные для выхода и цикла
double x0,xn;// вычисляемые приближения для корня
double a, b, eps;// границы отрезка и необходимая точность
cin>>a>>b; // вводим границы отрезка, на котором будем искать корень
cin>>eps; // вводим нужную точность вычислений
if (a > b) // если пользователь перепутал границы отрезка, меняем их местами
if (f(a)*f(b)>0) // если знаки функции на краях отрезка одинаковые, то здесь нет корня
cout 0) x0 = a; // для выбора начальной точки проверяем f(x0)*d2f(x0)>0 ?
xn = x0-f(x0)/df(x0); // считаем первое приближение
cout eps) // пока не достигнем необходимой точности, будет продолжать вычислять
xn = x0-f(x0)/df(x0); // непосредственно формула Ньютона
> while (exit!=1); // пока пользователь не ввел exit = 1
Посмотрим, как это работает. Нажмем на зеленый треугольник в верхнем левом углу экрана, или же клавишу F5.
Если происходит ошибка компиляции «Ошибка error LNK1123: сбой при преобразовании в COFF: файл недопустим или поврежден», то это лечится либо установкой первого Service pack 1, либо в настройках проекта Свойства -> Компоновщик отключаем инкрементную компоновку.
Рис. 4. Решение ошибки компиляции проекта
Мы будем искать корни у функции f(x) = x2-2.
Сначала проверим работу приложения на «неправильных» входных данных. На отрезке [3; 5] нет корней, наша программа должна выдать сообщение об ошибке.
У нас появилось окно приложения:
Рис. 5. Ввод входных данных
Введем границы отрезка 3 и 5, и точность 0.05. Программа, как и надо, выдала сообщение об ошибке, что на данном отрезке корней нет.
Рис. 6. Ошибка «На этом отрезке корней нет!»
Выходить мы пока не собираемся, так что на сообщение «Exit?» вводим «0».
Теперь проверим работу приложения на корректных входных данных. Введем отрезок [0; 2] и точность 0.0001.
Рис. 7. Вычисление корня с необходимой точностью
Как мы видим, необходимая точность была достигнута уже на 4-ой итерации.
Чтобы выйти из приложения, введем «Exit?» => 1.
Метод секущих
Чтобы избежать вычисления производной, метод Ньютона можно упростить, заменив производную на приближенное значение, вычисленное по двум предыдущим точкам:
/
Итерационный процесс имеет вид:
где .
Это двухшаговый итерационный процесс, поскольку использует для нахождения последующего приближения два предыдущих.
Порядок сходимости метода секущих ниже, чем у метода касательных и равен в случае однократного корня .
Эта замечательная величина называется золотым сечением:
Убедимся в этом, считая для удобства, что .
Таким образом, с точностью до бесконечно малых более высокого порядка
Отбрасывая остаточный член, получаем рекуррентное соотношение, решение которого естественно искать в виде .
После подстановки имеем: и
Для сходимости необходимо, чтобы было положительным, поэтому .
Поскольку знание производной не требуется, то при том же объёме вычислений в методе секущих (несмотря на меньший порядок сходимости) можно добиться большей точности, чем в методе касательных.
Отметим, что вблизи корня приходится делить на малое число, и это приводит к потере точности (особенно в случае кратных корней), поэтому, выбрав относительно малое , выполняют вычисления до выполнения и продолжают их пока модуль разности соседних приближений убывает.
Как только начнется рост, вычисления прекращают и последнюю итерацию не используют.
Такая процедура определения момента окончания итераций называется приемом Гарвика.
Метод парабол
Рассмотрим трехшаговый метод, в котором приближение определяется по трем предыдущим точкам , и .
Для этого заменим, аналогично методу секущих, функцию интерполяционной параболой проходящей через точки , и .
В форме Ньютона она имеет вид:
Точка определяется как тот из корней этого полинома, который ближе по модулю к точке .
Порядок сходимости метода парабол выше, чем у метода секущих, но ниже, чем у метода Ньютона.
Важным отличием от ранее рассмотренных методов, является то обстоятельство, что даже если вещественна при вещественных и стартовые приближения выбраны вещественными, метод парабол может привести к комплексному корню исходной задачи.
Этот метод очень удобен для поиска корней многочленов высокой степени.
Метод простых итераций
Задачу нахождения решений уравнений можно формулировать как задачу нахождения корней: , или как задачу нахождения неподвижной точки.
Пусть и — сжатие: (в частности, тот факт, что — сжатие, как легко видеть, означает, что).
По теореме Банаха существует и единственна неподвижная точка
Она может быть найдена как предел простой итерационной процедуры
где начальное приближение — произвольная точка промежутка .
Если функция дифференцируема, то удобным критерием сжатия является число . Действительно, по теореме Лагранжа
Таким образом, если производная меньше единицы, то является сжатием.
Условие существенно, ибо если, например, на [0,1] , то неподвижная точка отсутствует, хотя производная равна нулю. Скорость сходимости зависит от величины . Чем меньше , тем быстрее сходимость.
Рассмотрим уравнение: .
Если в качестве взять функцию , то соответствующая итерационная процедура будет иметь вид: . Как нетрудно убедиться, метод итераций в данном случае расходится при любой начальной точке , не совпадающей с собственно неподвижной точкой .
Однако можно в качестве можно взять, например, функцию . Соответствующая итерационная процедура имеет вид: .
Эти итерации сходятся к неподвижной точке для любого начального приближения :
Действительно, в первом случае , т.е. для выполнения условия необходимо чтобы , но тогда . Таким образом, отображение сжатием не является.
Рассмотрим , неподвижная точка та же самая, ситуация другая. Здесь, хотя формально производная может быть довольно большой (при малых ж), однако уже на следующем шаге она будет меньше 1.
т.е. такой итерационный процесс всегда сходится.
Метод Ньютона представляет собой частный случай метода простых итераций.
Здесь нетрудно убедиться, что при существует окрестность корня, в которой .
то если корень кратности , то в его окрестности и, следовательно,.
Если — простой корень, то сходимость метода касательных квадратичная (то есть порядок сходимости равен 2).
Поскольку , то
Таким образом, сходимость метода Ньютона очень быстрая.
Нахождение всех корней уравнения
Недостатком почти всех итерационных методов нахождения корней является то, что они при однократном применении позволяют найти лишь один корень функции, к тому же, мы не знаем какой именно.
Чтобы найти другие корни, можно было бы брать новые стартовые точки и применять метод вновь, но нет гарантии, что при этом итерации сойдутся к новому корню, а не к уже найденному, если вообще сойдутся.
Для поиска других корней используется метод удаления корней.
Пусть — корень функции , рассмотрим функцию. Точка будет являться корнем функции на единицу меньшей кратности, чем, при этом все остальные корни у функций и совпадают с учетом кратности.
Применяя тот или иной метод нахождения корней к функции , мы найдем новый корень (который может в случае кратных корней и совпадать с ). Далее можно рассмотреть функцию и искать корни у неё.
Повторяя указанную процедуру, можно найти все корни с учетом кратности.
Заметим, что когда мы производим деление на тот или иной корень , то в действительности мы делим лишь на найденное приближение , и, тем самым, несколько сдвигаем корни вспомогательной функции относительно истинных корней функции . Это может привести к значительным погрешностям, если процедура отделения применялась уже достаточное число раз.
Чтобы избежать этого, с помощью вспомогательных функций вычисляются лишь первые итерации, а окончательные проводятся по исходной функции , используя в качестве стартового приближения, последнюю итерацию, полученную по вспомогательной функции.
Мы рассмотрели решение уравнений только в одномерном случае, нахождение решений многомерных уравнений существенно более трудная задача.
[spoiler title=”источники:”]
http://statistica.ru/branches-maths/chislennye-metody-resheniya-uravneniy/
[/spoiler]
