| Нормальное распределение | |
|---|---|
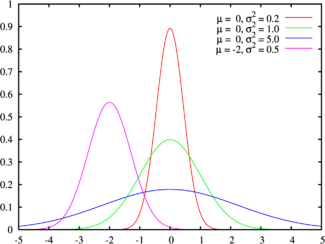 Зеленая линия соответствует стандартному нормальному распределениюПлотность вероятности |
|
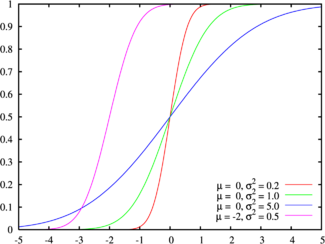 Цвета на этом графике соответствуют графику наверхуФункция распределения |
|
| Обозначение |
 |
| Параметры |
μ — коэффициент сдвига (вещественный) σ > 0 — коэффициент масштаба (вещественный, строго положительный) |
| Носитель |
 |
| Плотность вероятности |
 |
| Функция распределения |
![{frac {1}{2}}left[1+operatorname {erf} left({frac {x-mu }{sqrt {2sigma ^{2}}}}right)right]](https://wikimedia.org/api/rest_v1/media/math/render/svg/04670b14acb4ddb796469f3812ead9d9cccec275) |
| Математическое ожидание |
 |
| Медиана |
|
| Мода |
|
| Дисперсия |
 |
| Коэффициент асимметрии |
 |
| Коэффициент эксцесса |
|
| Дифференциальная энтропия |
 |
| Производящая функция моментов |
 |
| Характеристическая функция |
 |
Норма́льное распределе́ние[1][2], также называемое распределением Гаусса или Гаусса — Лапласа[3], или колоколообразная кривая — непрерывное распределение вероятностей с пиком в центре и симметричными боковыми сторонами, которое в одномерном случае задаётся функцией плотности вероятности, совпадающей с функцией Гаусса:
,
- где параметр
— среднеквадратическое отклонение,
Таким образом, одномерное нормальное распределение является двухпараметрическим семейством распределений, которое принадлежит экспоненциальному классу распределений[4]. Многомерный случай описан в статье «Многомерное нормальное распределение».
Стандартным нормальным распределением называется нормальное распределение с математическим ожиданием 

Общие сведения[править | править код]
Если величина является суммой многих случайных слабо взаимозависимых величин, каждая из которых вносит малый вклад относительно общей суммы, то центрированное и нормированное распределение такой величины при достаточно большом числе слагаемых стремится к нормальному распределению.
Это следует из центральной предельной теоремы теории вероятностей. В окружающем нас мире часто встречаются величины, значение которых определяется совокупностью многих независимых факторов. Этот факт, а также то, что распределение считалось типичным, обычным, привели к тому, что в конце XIX века стал использоваться термин «нормальное распределение». Нормальное распределение играет заметную роль во многих областях науки, например в математической статистике и статистической физике.
Случайная величина, имеющая нормальное распределение, называется нормальной, или гауссовской, случайной величиной.
Определения[править | править код]
Стандартное нормальное распределение[править | править код]
Наиболее простой случай нормального распределения — стандартное нормальное распределение — частный случай, когда

Множитель 






Гаусс называл стандартным нормальным распределение с 

Нормальное распределение с параметрами μ, σ[править | править код]
Каждое нормальное распределение — это вариант стандартного нормального распределения, область значений которого растягивается множителем



Если 





Если в экспоненте плотности вероятности раскрыть скобки и учитывать, что 

Таким образом, плотность вероятности каждого нормального распределения представляет собой экспоненту квадратичной функции:

- где

Отсюда можно выразить среднее значение как 




Обозначение[править | править код]
Плотность вероятности стандартного нормального распределения (с нулевым средним и единичной дисперсией) часто обозначается греческой буквой 

Нормальное распределение часто обозначается 


Функция распределения[править | править код]
Функция распределения стандартного нормального распределения (нормальное интегральное распределение) обычно обозначается заглавной греческой буквой 

С ней связана функция ошибок (интеграл вероятности) 
![{displaystyle [-x,x]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e23c41ff0bd6f01a0e27054c2b85819fcd08b762)

Эти интегралы не выражаются в элементарных функциях и называются специальными функциями. Многие их численные приближения известны. См. ниже.
Функции связаны, в частности, соотношением:
.
Нормальное распределение с плотностью 
![{displaystyle F(x)=Phi left({frac {x-mu }{sigma }}right)={frac {1}{2}}left[1+operatorname {erf} left({frac {x-mu }{sigma {sqrt {2}}}}right)right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6a75caa2df3861960f6c6a5ac91f0b0fa6d79504)
Можно использовать функцию 

.
График стандартной нормальной функции распределения 

Функция распределения стандартной нормальной случайной величины может быть разложена с помощью метода интегрирования по частям в ряд:
![{displaystyle Phi (x)={frac {1}{2}}+{frac {1}{sqrt {2pi }}}cdot e^{-x^{2}/2}left[x+{frac {x^{3}}{3}}+{frac {x^{5}}{3cdot 5}}+cdots +{frac {x^{2n+1}}{(2n+1)!!}}+cdots right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b755fcac449fe404b290943b01b01eab9c50440a)
где знак 
Асимптотическое разложение функции распределения для больших
Стандартное отклонение[править | править код]

Правило 68-95-99,7.
Для нормального распределения количество значений, отличающихся от среднего на число, меньшее чем одно стандартное отклонение, составляют 68,27 % выборок. В то же время количество значений, отличающиеся от среднего на два стандартных отклонения, составляют 95,45 %, а на три стандартных отклонения — 99,73 %.
Около 68 % значений из нормального распределения находятся на расстоянии не более одного стандартного отклонения σ от среднего; около 95 % значений лежат расстоянии не более двух стандартных отклонений; и 99,7 % не более трёх. Этот факт является частным случаем правила 3 сигм для нормальной выборки.
Более точно, вероятность получить нормальное число в интервале между 



С точностью до 12 значащих цифр значения для 
 |
 |
 |
 |
OEIS |
|---|---|---|---|---|
| 1 | 0,682689492137 | 0,317310507863 |
3,15148718753 |
A178647 |
| 2 | 0,954499736104 | 0,045500263896 |
21,9778945080 |
A110894 |
| 3 | 0,997300203937 | 0,002699796063 |
370,398347345 |
A270712 |
| 4 | 0,999936657516 | 0,000063342484 |
15787.1927673 |
|
| 5 | 0,999999426697 | 0,000000573303 |
1744277,89362 |
|
| 6 | 0,999999998027 | 0,000000001973 |
506797345,897 |
Свойства[править | править код]
Моменты[править | править код]
Моментами и абсолютными моментами случайной величины 



Если 
![{displaystyle mathbb {E} left[X^{p}right]={begin{cases}0&p=2n+1,\sigma ^{p},left(p-1right)!!&p=2n.end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c39f9a1d5eadfbc872b3cd41f8135576e3123bc4)
Здесь 



Центральные абсолютные моменты для неотрицательных целых
![{displaystyle mathbb {E} left[left|Xright|^{p}right]=sigma ^{p},left(p-1right)!!cdot left.{begin{cases}{sqrt {frac {2}{pi }}}&p=2n+1,\1&p=2n.end{cases}}right}=sigma ^{p}cdot {frac {2^{frac {p}{2}}Gamma left({frac {p+1}{2}}right)}{sqrt {pi }}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c45215d47f1e0fc958abfae9a8d7137995cf90a8)
Последняя формула справедлива также для произвольных 
Преобразование Фурье и характеристическая функция[править | править код]
Преобразование Фурье нормальной плотности вероятности 

- где
есть мнимая единица.
Если математическое ожидание 
В теории вероятности, преобразование Фурье плотности распределения действительной случайной величины 



Бесконечная делимость[править | править код]
Нормальное распределение является бесконечно делимым.
Если случайные величины 








Отсюда вытекает, что нормальная случайная величина представима как сумма произвольного числа независимых нормальных случайных величин.
Максимальная энтропия[править | править код]
Нормальное распределение имеет максимальную дифференциальную энтропию среди всех непрерывных распределений, дисперсия которых не превышает заданную величину[11][12].
Правило трёх сигм для гауссовской случайной величины[править | править код]

График плотности вероятности нормального распределения и процент попадания случайной величины на отрезки, равные среднеквадратическому отклонению.
Правило трёх сигм (

- где
— математическое ожидание и параметр нормальной случайной величины.
Более точно — приблизительно с вероятностью 0,9973 значение нормально распределённой случайной величины лежит в указанном интервале.
Моделирование нормальных псевдослучайных величин[править | править код]
При компьютерном моделировании, особенно при применении метода Монте-Карло, желательно использовать величины, распределенные по нормальному закону. Многие алгоритмы дают стандартные нормальные величины, так как нормальную величину 

- где Z — стандартная нормальная величина.
Алгоритмы также используют различные преобразования равномерных величин.
Простейшие приближённые методы моделирования основываются на центральной предельной теореме. Если сложить достаточно большое количество независимых одинаково распределённых величин с конечной дисперсией, то сумма будет иметь распределение, близкое к нормальному. Например, если сложить 100 независимых стандартно равномерно распределённых случайных величин, то распределение суммы будет приближённо нормальным.
Для программного генерирования нормально распределённых псевдослучайных величин предпочтительнее использовать преобразование Бокса — Мюллера. Оно позволяет генерировать одну нормально распределённую величину на базе одной равномерно распределённой.
Также существует алгоритм Зиккурат, который работает даже быстрее преобразования Бокса — Мюллера. Тем не менее, сложнее в реализации, но его применение оправдано в случаях, когда требуется генерирование очень большого числа неравномерно распределённых случайных чисел.
Нормальное распределение в природе и приложениях[править | править код]
Нормальное распределение часто встречается в природе. Например, следующие случайные величины хорошо моделируются нормальным распределением:
- отклонение при стрельбе;
- погрешности измерений (однако погрешности некоторых измерительных приборов имеют иное распределение);
- некоторые характеристики живых организмов в популяции.
Такое широкое распространение этого распределения связано с тем, что оно является бесконечно делимым непрерывным распределением с конечной дисперсией. Поэтому к нему в пределе приближаются некоторые другие, например биномиальное и пуассоновское. Этим распределением моделируются многие недетерминированные физические процессы[13].
Многомерное нормальное распределение используется при исследовании многомерных случайных величин (случайных векторов). Одним из многочисленных примеров таких приложений является исследование параметров личности человека в психологии и психиатрии.
Связь с другими распределениями[править | править код]
![{displaystyle t={frac {{overline {X}}-mu }{S/{sqrt {n}}}}={frac {{frac {1}{n}}(X_{1}+cdots +X_{n})-mu }{sqrt {{frac {1}{n(n-1)}}left[(X_{1}-{overline {X}})^{2}+cdots +(X_{n}-{overline {X}})^{2}right]}}}sim t_{n-1}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/36ff0d3c79a0504e8f259ef99192b825357914d7)

- Отношение квадратов двух стандартных нормальных случайных величин имеет распределение Фишера со степенями свободы

История[править | править код]
Впервые нормальное распределение как предел биномиального распределения при 
См. также[править | править код]
- Аддитивный белый гауссовский шум
- Логнормальное распределение
- Равномерное распределение
- Центральная предельная теорема
- Двумерное нормальное распределение
- Многомерное нормальное распределение
- Распределение хи-квадрат
- Статистический критерий
- Частотное распределение
Примечания[править | править код]
- ↑ Вентцель Е. С. Теория вероятностей. — 10-е изд., стереотипное.. — М.: Academia, 2005. — 576 с. — ISBN 5-7695-2311-5.
- ↑ Ширяев А. Н. Вероятность. — М.: Наука, 1980.
- ↑ 1 2 Математический энциклопедический словарь. — М.: Советская энциклопедия, 1988. — С. 139—140.
- ↑ Wasserman L. All of Statistics. — New York, NY: Springer, 2004. — С. 142. — 433 с. — ISBN 978-1-4419-2322-6.
- ↑ Доказательство см. Гауссов интеграл
- ↑ Halperin, Hartley & Hoel, 1965, item 7.
- ↑ McPherson (1990)
- ↑ Wolfram|Alpha: Computational Knowledge Engine. Wolframalpha.com. Дата обращения: 3 марта 2017.
- ↑ Bryc (1995, p. 23)
- ↑ Bryc (1995, p. 24)
- ↑ Cover, Thomas M.; Thomas, Joy A. Elements of Information Theory. — John Wiley and Sons, 2006. — С. 254.
- ↑ Park, Sung Y.; Bera, Anil K. Maximum Entropy Autoregressive Conditional Heteroskedasticity Model (англ.) // Journal of Econometrics (англ.) (рус. : journal. — Elsevier, 2009. — P. 219—230. Архивировано 7 марта 2016 года.
- ↑ Талеб Н. Н. Чёрный лебедь. Под знаком непредсказуемости = The Black Swan: The Impact of the Highly Improbable. — КоЛибри, 2012. — 525 с. — ISBN 978-5-389-00573-0.
- ↑ Королюк, 1985, с. 135.
- ↑ Галкин В. М., Ерофеева Л. Н., Лещева С. В. Оценки параметра распределения Коши // Труды Нижегородского государственного технического университета им. Р. Е. Алексеева. — 2014. — № 2(104). — С. 314—319. — УДК 513.015.2(G).
- ↑ Lukacs, Eugene. A Characterization of the Normal Distribution (англ.) // The Annals of Mathematical Statistics (англ.) (рус. : journal. — 1942. — Vol. 13, no. 1. — P. 91—3. — ISSN 0003-4851. — doi:10.1214/aoms/1177731647. — JSTOR 2236166.
- ↑ Lehmann, E. L.ruen. Testing Statistical Hypotheses. — 2nd. — Springer (англ.) (рус., 1997. — С. 199. — ISBN 978-0-387-94919-2.
- ↑ The doctrine of chances; or, a method of calculating the probability of events in play, L., 1718, 1738, 1756; L., 1967 (репродуцир. изд.); Miscellanea analytica de scriebus et quadraturis, L., 1730.
Литература[править | править код]
- Королюк В. С., Портенко Н. И., Скороход А. В., Турбин А. Ф. Справочник по теории вероятностей и математической статистике. — М.: Наука, 1985. — 640 с.
- Halperin, Max; Hartley, Herman O.; Hoel, Paul G. Recommended Standards for Statistical Symbols and Notation. COPSS Committee on Symbols and Notation (англ.) // The American Statistician (англ.) (рус. : journal. — 1965. — Vol. 19, no. 3. — P. 12—14. — doi:10.2307/2681417. — JSTOR 2681417.
- McPherson, Glen. Statistics in Scientific Investigation: Its Basis, Application and Interpretation (англ.). — Springer-Verlag, 1990. — ISBN 978-0-387-97137-7.
- Bryc, Wlodzimierz. The Normal Distribution: Characterizations with Applications (англ.). — Springer-Verlag, 1995. — ISBN 978-0-387-97990-8.
Ссылки[править | править код]
- Таблица значений функции стандартного нормального распределения
- Онлайн расчёт вероятности нормального распределения
Макеты страниц
Изучение различных явлений показывает, что многие случайные величины, например, такие, как погрешности при измерениях, боковое отклонение и отклонение по дальности точки попадания от некоторого центра при стрельбе, величина износа деталей во многих механизмах и т. д., имеют плотность распределения вероятности, выражающуюся формулой


Рис. 429.
В этом случае говорят, что случайная величина подчинена нормальному закону распределения (это распределение также называют законом Гаусса). Кривая нормального распределения изображена на рис. 429. Таблица значений функции (1) при  помещена в конце книги (см. табл. 2). Аналогичная кривая подробно исследована в § 9 гл. V т. I.
помещена в конце книги (см. табл. 2). Аналогичная кривая подробно исследована в § 9 гл. V т. I.
Покажем сначала, что плотность распределения (1) удовлетворяет основному соотношению (5) § 12:

Действительно, вводя обозначение

можем написать

так как

Определим математическое ожидание случайной величины с нормальным законом распределения (1). По формуле (1) § 14 имеем

Сделав замену переменной

получаем

Следовательно,

Первый интегралсправа равен  Вычислим второй интеграл:
Вычислим второй интеграл:

Итак,

Значение параметра а в формуле (1) равно математическому ожиданию рассматриваемой случайной величины. Точка  является центром распределения вероятностей, или центром рассеивания. При
является центром распределения вероятностей, или центром рассеивания. При  функция
функция  имеет наибольшее значение, поэтому значение
имеет наибольшее значение, поэтому значение  а является модой случайной величины.
а является модой случайной величины.

Рис. 430.
Так как кривая (1) симметрична относительно прямой  то
то

т. е. значение  является медианой нормального распределения. Если в формуле (1) положим
является медианой нормального распределения. Если в формуле (1) положим  , то получим
, то получим

Соответствующая кривая симметрична относительно оси Оу. Функция f(x) есть плотность нормального распределения случайной величины с центром распределения вероятностей, совпадающим с началом координат (рис. 430). Числовые характеристики
случайных величин с законами распределения (1) и (4), определяющие характер рассеивания значений случайной величины относительно центра рассеивания, определяются формой кривой, которая не зависит от величины а, и поэтому совпадают. Величина а определяет величину сдвига кривой (1) вправо (при а > 0) или влево (при а < 0). Для некоторого сокращения письма мы будем проводить/многие дальнейшие рассуждения применительно к плотности распределения, определяемой формулой (4).
-
Нормальное распределение, его математическое ожидание, дисперсия.
Случайная
величина ![]() называется
называется
распределенной по нормальному закону,
если ее плотность вероятности имеет
вид:
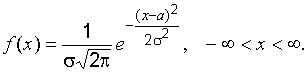
Здесь ![]() математическое
математическое
ожидание, ![]() дисперсия,
дисперсия, ![]() среднее
среднее
квадратическое отклонение. Как и
ранее, 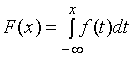 ,
,
однако, этот интеграл вычисляется
численными методами. Чтобы упростить
эту процедуру, пользуются преобразованием
случайной величины ![]() и
и
правилом сохранения элемента вероятности ![]() ,
,
где ![]() плотность
плотность
распределения вероятности случайной
величины ![]() :
:
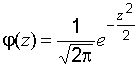 .
.
Как
видим, индивидуальные числовые
характеристики распределения
(математическое ожидание и дисперсия)
в последнее выражение не входят, т.е.
вышеуказанным преобразованием нормальная
случайная величина ![]() приведена
приведена
к нормальной стандартной случайной
величине ![]() с
с
параметрами 0 (математическое ожидание)
и 1 (дисперсия). Дифференциальная и
интегральная функции стандартного
нормального распределения табулированы
(имеются таблицы), что существенно
облегчает вычисления. Интегральная
функция распределения обозначается ![]() ,
,
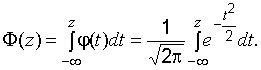
Часто
используют функцию Лапласа:
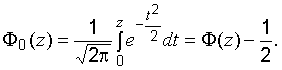
Очевидны
следующие свойства:
![]()
![]()
где ![]() .
.
Пример.
Нормальная
случайная величина ![]() задана
задана
математическим ожиданием ![]() и
и
средним квадратическим отклонением ![]() .
.
Записать соответствующую дифференциальную
функцию, схематично изобразить ее
график, вычислить вероятность попадания
случайной величины ![]() в
в
интервал ![]()
Решение:
Записать дифференциальную функцию
нормальной случайной величины ![]() с
с
заданными значениями математического
ожидания и дисперсии значит в общее
выражение для дифференциальной функции
нормальной случайной величины подставить
заданные ![]() и
и ![]() .
.
Например, если ![]() ,
,
то получим
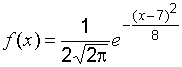 .
.
При
изображении этой функции на схематичном
графике следует учесть, что эта функция
имеет максимум при ![]() ,
,
симметрична относительно ![]() (это
(это
видно непосредственно из приведенной
выше формулы) и стремится к нулю при ![]() .
.
Однако правило![]() (вероятность
(вероятность
того, что случайная величина примет
значение, по модулю отличающееся от
математического ожидания на ![]() или
или
более, пренебрежимо мала – составляет
всего около 0,0027) позволяет нам закончить
правую ветвь в точке ![]() а
а
левую – в точке ![]() Высота
Высота
максимума в точке ![]() составит
составит 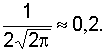 Дополнительно
Дополнительно
надо учесть, что перегибы ветвей будут
иметь место в точках ![]()
Вероятность
попадания случайной величины ![]() в
в
интервал ![]() вычислим
вычислим
так:
![]()
При
этом следует воспользоваться таблицами
функции стандартного нормального
распределения ![]() или
или
функции Лапласа ![]() .
.
36. Нормальная кривая.
Центральная
предельная теорема. Если
случайная величина Х представляет собой
сумму очень большого числа взаимно
независимых случайных величин, влияние
каждой из которых на всю сумму ничтожно
мало, то Х имеет распределение, близкое
к нормальному.
Говорят,
что случайная величина Х распределена
по нормальному
закону с
параметрами а и ![]() ,
,
если плотность распределения вероятностей
имеет вид:
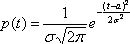 ,
,
–¥<t<¥.
Вероятностный
смысл параметров а и ![]() таков: а –
таков: а –
математическое ожидание случайной
величины Х, s –
среднее квадратическое отклонение
величины.
Иногда
такой закон распределения
называют Гауссовским. График плотности
нормального распределения называют
нормальной кривой (кривой Гаусса). На
рисунке изображены нормальные кривые
с параметрами а=1
и ![]() ,
, ![]() ,
, ![]() .
.
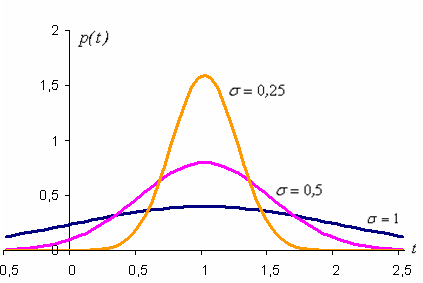
Из
рисунка видно, что положение пика кривых
определяется параметром а=1,
а параметр s (среднее квадратическое отклонение)
характеризует форму нормальной кривой.
При увеличении s уменьшается
максимум кривой распределения, сама
кривая становится более пологой,
растягиваясь вдоль оси абсцисс. И,
наоборот, при уменьшении s возрастает
максимум кривой распределения, сама
кривая становится более «островершинной».
Площадь, ограниченная любой нормальной
кривой и осью абсцисс, равна единице.
Параметр а(математическое
ожидание величины) определяет положение
максимума на оси абсцисс, не влияя на
форму кривой. На рисeyrt
ниже показаны нормальные кривые с
одинаковым средним квадратическим отклонением ![]() и
и
разными математическими
ожиданиями а=–1, а=0, а=1.
![]()
![]()
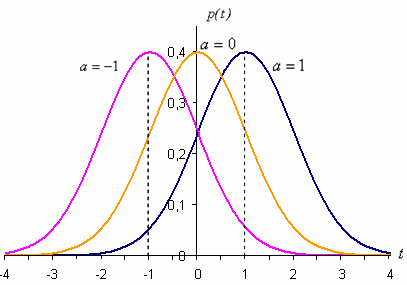
Нормальное
распределение с параметрами а=0
и ![]() называется нормированным.
называется нормированным.
-
Вероятность
попадания в заданный интервал нормальной
случайной величины.
Вероятность
того, что Х примет значение, принадлежащее
интервалу (α,β)
P(α<X<β)=Ф((β-a)/σ)-Ф((α-a)/σ),
где
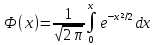
– функция Лапласа.
-
Ф(-∞)=0
-
Ф(+∞)=1
-
Ф(-х)=1-Ф(х)
P(mx-l<x<mx+l)=Ф(l/σ)-Ф(-l/σ)=2Ф(l/σ)-1
38.
Вычисление вероятности заданного
отклонения.
Часто
требуется вычислить вероятность того,
что отклонение нормально распределенной
случайной величины Х по
абсолютной величине меньше заданного
положительного числа d, т.
е. требуется найти вероятность
осуществления неравенства |x —а|<d.
Заменим
это неравенство равносильным ему двойным
неравенством
![]()
Тогда
получим:
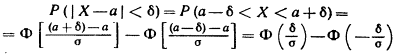
Приняв
во внимание равенство:
![]()
(функция
Лапласа—нечетная), окончательно имеем
![]() Вероятность
Вероятность
заданного отклонения равна
![]()
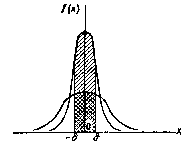
На
рисунке наглядно показано, что если две
случайные величины нормально распределены
и а = 0,
то вероятность принять значение,
принадлежащее интервалу (-d,d),больше
у той величины, которая имеет меньшее
значение d. Этот
факт полностью соответствует вероятностному
смыслу параметра s .
Пример.
Случайная величина Х распределена
нормально. Математическое ожидание и
среднее квадратическое
отклонение Х соответственно
равны 20 и 10. Найти вероятность того, что
отклонение по абсолютной величине будет
меньше трех.
Решение: Воспользуемся
формулой
![]()
По
условию ,
![]()
тогда
![]()
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Нормальное распределение
Время на прочтение
7 мин
Количество просмотров 35K
Автор статьи: Виктория Ляликова
Нормальный закон распределения или закон Гаусса играет важную роль в статистике и занимает особое положение среди других законов. Вспомним как выглядит нормальное распределение

где a -математическое ожидание, ![]() – среднее квадратическое отклонение.
– среднее квадратическое отклонение.
Тестирование данных на нормальность является достаточно частым этапом первичного анализа данных, так как большое количество статистических методов использует тот факт, что данные распределены нормально. Если выборка не подчиняется нормальному закону, тогда предположении о параметрических статистических тестах нарушаются, и должны использоваться непараметрические методы статистики
Нормальное распределение естественным образом возникает практически везде, где речь идет об измерении с ошибками. Например, координаты точки попадания снаряда, рост, вес человека имеют нормальный закон распределения. Более того, центральная предельная теорема вообще утверждает, что сумма большого числа слагаемых сходится к нормальной случайной величине, не зависимо от того, какое было исходное распределение у выборки. Таким образом, данная теорема устанавливает условия, при которых возникает нормальное распределение и нарушение которых ведет к распределению, отличному от нормального.
Можно выделить следующие этапы проверки выборочных значений на нормальность
-
Подсчет основных характеристик выборки. Выборочное среднее, медиана, коэффициенты асимметрии и эксцесса.
-
Графический. К этому методу относится построение гистограммы и график квантиль-квантиль или кратко QQ
-
Статистические методы. Данные методы вычисляют статистику по данным и определяют, какая вероятность того, что данные получены из нормального распределения
При нормальном распределении, которое симметрично, значения медианы и выборочного среднего будут одинаковы, значения эксцесса равно 3, а асимметрии равно нулю. Однако ситуация, когда все указанные выборочные характеристики равны именно таким значениям, практически не встречается. Поэтому после этапа подсчета выборочных характеристик можно переходить к графическому представлению выборочных данных.
Гистограмма позволяет представить выборочные данные в графическом виде – в виде столбчатой диаграммы, где данные делятся на заранее определенное количество групп. Вид гистограммы дает наглядное представление функции плотности вероятности некоторой случайной величины, построенной по выборке.
График QQ (квантиль-квантиль) является графиком вероятностей, который представляет собой графический метод сравнения двух распределений путем построения их квантилей. QQ график сравнивает наборы данных теоретических и выборочных (эмпирических) распределений. Если два сравниваемых распределения подобны, тогда точки на графике QQ будут приблизительно лежать на линии y=x. Основным шагом в построении графика QQ является расчет или оценка квантилей.
Существует множество статистических тестов, которые можно использовать для проверки выборочных значений на нормальность. Каждый тест использует разные предположения и рассматривает разные аспекты данных.
Чтобы применять статистические критерии сформулируем задачу. Выдвигаются две гипотезы H0 и H1, которые утверждают
H0 – Выборка подчиняется нормальному закону распределения
H1 – Выборка не подчиняется нормальному распределению
Установи уровень значимости alpha=0,05.
Теперь задача состоит в том, чтобы на основании какого-то критерия отвергнуть или принять основную нулевую гипотезу при уровне значимости
Критерий Шапиро-Уилка
Критерий Шапиро-Уилка основан на отношении оптимальной линейной несмещенной оценки дисперсии к ее обычной оценке методом максимального правдоподобия. Статистика критерия имеет вид

Числитель является квадратом оценки среднеквадратического отклонения Ллойда. Коэффициенты ![]() и критические
и критические ![]() значения статистики являются табулированными значениями. Если
значения статистики являются табулированными значениями. Если ![]() , то нулевая гипотеза нормальности распределения отклоняется на уровне значимости
, то нулевая гипотеза нормальности распределения отклоняется на уровне значимости ![]() .
.
В Python функция ![]() содержится в библиотеке scipy.stats и возвращает как статистику, рассчитанную тестом, так и значение p. В Python можно использовать выборку до 5000 элементов. Интерпретация вывода осуществляется следующим образом
содержится в библиотеке scipy.stats и возвращает как статистику, рассчитанную тестом, так и значение p. В Python можно использовать выборку до 5000 элементов. Интерпретация вывода осуществляется следующим образом
Если значение ![]() , тогда принимается гипотеза H0, в противном случае, т.е. если,
, тогда принимается гипотеза H0, в противном случае, т.е. если, ![]() , тогда принимается гипотеза H1, т.е. что выборка не подчиняется нормальному закону.
, тогда принимается гипотеза H1, т.е. что выборка не подчиняется нормальному закону.
Критерий Д’Агостино
В данном критерии в качестве статистики для проверки нормальности распределения используется отношение оценки Даутона для стандартного отклонения к выборочному стандартному отклонению, оцененному методом максимального правдоподобия

В качестве статистики критерия Д’Агостино используется величина
![]()
значение которой рассчитывается на основе центральной предельной теоремы, которая утверждает, что при ![]()
![limlimits_{x to infty}Pbigg(frac{D-M[D]}{sqrt{D[D]}}{<x}bigg)=Phi(x)](https://habrastorage.org/getpro/habr/upload_files/942/0a9/b3a/9420a9b3a29c728265cf3734143c97bd.svg)
где![]() стандартная нормальная случайная величина.
стандартная нормальная случайная величина.

Критические значения являются табулированными значениями. Гипотеза нормальности принимается, если значение статистики лежит в интервале критических значений. Данный критерий показывает хорошую мощность против большого спектра альтернатив, по мощности немного уступая критерию Шапиро-Уилка.
В Python функция normaltest() также содержится в библиотеке scipy.stats и возвращает статистику теста и значение p. Интерпретация результата аналогична результатам в критерии Шапиро-Уилка.
Критерий согласия![]() – Пирсона
– Пирсона
Данный критерий является одним из наиболее распространенных критериев проверки гипотез о виде закона распределения и позволяет проверить значимость расхождения эмпирических (наблюдаемых) и теоретических (ожидаемых) частот. Таким образом, данный критерий позволяет проверить гипотезу о принадлежности наблюдаемой выборки некоторому теоретическому закону. Можно сказать, что критерий является универсальным, так как позволяет проверить принадлежность выборочных значений практическому любому закону распределения.
Для решения задачи используется статистика ![]() – Пирсона
– Пирсона

где![]() – эмпирические частоты (подсчитывается число элементов выборки, попавших в интервал),
– эмпирические частоты (подсчитывается число элементов выборки, попавших в интервал), ![]() – теоретические частоты. Подсчитывается критическое значение
– теоретические частоты. Подсчитывается критическое значение ![]() . Если
. Если ![]() , отклоняется гипотеза о принадлежности выборки нормальному распределению и принимается, если
, отклоняется гипотеза о принадлежности выборки нормальному распределению и принимается, если ![]() .
.
Теперь перейдем к практической части. Для демонстрации функций будем использовать Dataset, взятый с сайта kaggle.com по прогнозированию инсульта по 11 клиническим характеристикам.
Загружаем необходимые библиотеки
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as npЗагружаем датасет
data_healthcares = pd.read_csv('E:/vika/healthcare-dataset-stroke-data.csv')
Набор состоит из 5110 строк и 12 столбцов.
Посмотрим на основные характеристики, каждого признака.data_healthcares.describe()

Из данных характеристик можно увидеть, что есть пропущенные значения в показателях индекс массы тела. Посчитаем количество пропущенных значений.

Если бы нам необходимо было делать модель для прогноза, то пропущенные значения bmi являются достаточно большой проблемой, в которой возникает вопрос как их восстановить. Поэтому будем предполагать, что значения столбца bmi (индекс массы тела) подчиняются нормальному закону распределения (предварительно был построен график распределения, поэтому сделано такое предположение). Но так как, на данный момент, у нас нет необходимости в построении модели для прогноза, то удалим все пропущенные значения
new_data=data_healthcares.dropna()
Теперь можем приступать к проверке выборочных значений показателя bmi на нормальность. Вычислим основные выборочные характеристики
|
Выборочная характеристика |
Код в python |
Значение характеристики |
|
Выборочное среднее |
new_data.bmi.mean() |
28,89 |
|
Выборочная медиана |
new_data.bmi.median() |
28,1 |
|
Выборочная мода |
new_data.bmi.mode() |
28,7 |
|
Выборочное среднеквадратическое отклонение |
new_data.bmi.std() |
7.854066729680458 |
|
Выборочный коэффициент асиметрии |
new_data.bmi.skew() |
1.0553402052962928 |
|
Выборочный эксцесс |
new_data.bmi.kurtosis() |
3.362659165623678 |
После вычислений основных характеристик мы видим, что выборочное среднее и медиана можно сказать принимают одинаковые значения и коэффициент эксцесса равен 3. Но, к сожалению коэффициент асимметрии равен 1, что вводить нас в некоторое замешательство, т.е. мы уже можем предположить, что значения bmi не подчиняются нормальному закону. Продолжим исследования, перейдем к построению графиков.
Строим гистограмму
fig = plt.figure
fig,ax= plt.subplots(figsize=(7,7))
sns.distplot(new_data.bmi,color='red',label='bmi',ax=ax)
plt.show()
Гистограмма достаточно хорошо напоминает нормальное распределение, кроме конечно, небольшого выброса справа, но смотрим дальше. Тут скорее, можно предположить, что значения bmi подчиняются распределению ![]() .
.
Строим QQ график. В python есть отличная функция qqplot(), содержащаяся в библиотеке statsmodel, которая позволяет строить как раз такие графики.
from statsmodels.graphics.gofplots import qqplot
from matplotlib import pyplot
qqplot(new_data.bmi, line=’s’)
Pyplot.show
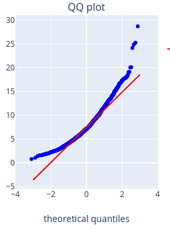
Что имеем из графика QQ? Наши выборочные значений имеют хвосты слева и справа, и также в правом верхнем углу значения становятся разреженными.
На основе данных графика можно сделать вывод, что значения bmi не подчиняются нормальному закону распределения. Рядом приведен пример QQ графика распределения хи-квадрат с 8 степенями свободы из выборки в 1000 значений.
Для примера построим график QQ для выборки из нормального распределения с такими же показателями стандартного отклонения и среднего, как у bmi.
std=new_data.bmi.std() # вычисляем отклонение
mean=new_data.bmi.mean() #вычисляем среднее
Z=np.random.randn(4909)*std+mean # моделируем нормальное распределение
qqplot(Z,line='s') # строим график
pyplot.show()
Продолжим исследования. Перейдем к статистическим критериям. Будем использовать критерий Шапиро-Уилка и Д’Агостино, чтобы окончательно принять или опровергнуть предположение о нормальном распределении. Для использования критериев подключим библиотеки
from scipy.stats import shapiro
from scipy.stats import normaltest
shapiro(new_data.bmi)
ShapiroResult(statistic=0.9535483717918396, pvalue=6.623218133972133e-37)
Normaltest(new_data.bmi)
NormaltestResult(statistic=1021.1795052962864, pvalue=1.793444363882936e-222)После применения двух тестов мы имеем, что значение p-value намного меньше заданного критического значения alpha , значит выборочные значения не принадлежат нормальному закону.
Конечно, мы рассмотрели не все тесты на нормальности, которые существуют. Какие можно дать рекомендации по проверке выборочных значений на нормальность. Лучше использовать все возможные варианты, если они уместны.
На этом все. Еще хочу порекомендовать бесплатный вебинар, который 15 июня пройдет на платформе OTUS в рамках запуска курса Математика для Data Science. На вебинаре расскажут про несколько часто используемых подходов в анализе данных, а также разберут, какие математические идеи работают у них под капотом и почему эти подходы вообще работают так, как нам нужно. Регистрация на вебинар доступна по этой ссылке.
Нормальным называют распределение вероятностей непрерывной случайной величины
, плотность которого имеет вид:
где
–
математическое ожидание,
–
среднее квадратическое отклонение
.
Вероятность того, что
примет
значение, принадлежащее интервалу
:
где
– функция Лапласа:
Вероятность того, что абсолютная
величина отклонения меньше положительного числа
:
В частности, при
справедливо
равенство:
Асимметрия, эксцесс,
мода и медиана нормального распределения соответственно равны:
, где
Правило трех сигм
Преобразуем формулу:
Положив
. В итоге получим
если
, и, следовательно,
, то
то есть вероятность того, что
отклонение по абсолютной величине будет меньше утроенного среднего квадратического отклонение, равна 0,9973.
Другими словами, вероятность того,
что абсолютная величина отклонения превысит утроенное среднее квадратическое отклонение, очень мала, а именно равна
0,0027. Это означает, что лишь в 0,27% случаев так может произойти. Такие
события исходя из принципа невозможности маловероятных
событий можно считать практически невозможными. В этом и состоит
сущность правила трех сигм: если случайная величина распределена нормально, то
абсолютная величина ее отклонения от математического ожидания не превосходит
утроенного среднего квадратического отклонения.
На практике правило трех сигм
применяют так: если распределение изучаемой случайной величины неизвестно, но
условие, указанное в приведенном правиле, выполняется, то есть основание
предполагать, что изучаемая величина распределена нормально; в противном случае
она не распределена нормально.
Смежные темы решебника:
- Таблица значений функции Лапласа
- Непрерывная случайная величина
- Показательный закон распределения случайной величины
- Равномерный закон распределения случайной величины
Пример 2
Ошибка
высотометра распределена нормально с математическим ожиданием 20 мм и средним
квадратичным отклонением 10 мм.
а) Найти
вероятность того, что отклонение ошибки от среднего ее значения не превзойдет 5
мм по абсолютной величине.
б) Какова
вероятность, что из 4 измерений два попадут в указанный интервал, а 2 – не
превысят 15 мм?
в)
Сформулируйте правило трех сигм для данной случайной величины и изобразите
схематично функции плотности вероятностей и распределения.
Решение
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
а) Вероятность того, что случайная величина, распределенная по
нормальному закону, отклонится от среднего не более чем на величину
:
В нашем
случае получаем:
б) Найдем
вероятность того, что отклонение ошибки от среднего значения не превзойдет 15
мм:
Пусть событие
– ошибки 2
измерений не превзойдут 5 мм и ошибки 2 измерений не превзойдут 0,8664 мм
– ошибка не
превзошла 5 мм;
– ошибка не
превзошла 15 мм
в)
Для заданной нормальной величины получаем следующее правило трех сигм:
Ошибка высотометра будет лежать в интервале:
Функция плотности вероятностей:
График плотности распределения нормально распределенной случайной величины
Функция распределения:
График функции
распределения нормально распределенной случайной величины
Задача 1
Среднее
количество осадков за июнь 19 см. Среднеквадратическое отклонение количества
осадков 5 см. Предполагая, что количество осадков нормально-распределенная
случайная величина найти вероятность того, что будет не менее 13 см осадков.
Какой уровень превзойдет количество осадков с вероятностью 0,95?
Задача 2
Найти
закон распределения среднего арифметического девяти измерений нормальной
случайной величины с параметрами m=1.0 σ=3.0. Чему равна вероятность того, что
модуль разности между средним арифметическим и математическим ожиданием
превысит 0,5?
Указание:
воспользоваться таблицами нормального распределения (функции Лапласа).
Задача 3
Отклонение
напряжения в сети переменного тока описывается нормальным законом
распределения. Дисперсия составляет 20 В. Какова вероятность при изменении
выйти за пределы требуемых 10% (22 В).
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Задача 4
Автомат
штампует детали. Контролируется длина детали Х, которая распределена нормально
с математическим ожиданием (проектная длинна), равная 50 мм. Фактическая длина
изготовленных деталей не менее 32 и не более 68 мм. Найти вероятность того, что
длина наудачу взятой детали: а) больше 55 мм; б) меньше 40 мм.
Задача 5
Случайная
величина X распределена нормально с математическим ожиданием a=10и средним
квадратическим отклонением σ=5. Найти
интервал, симметричный относительно математического ожидания, в котором с
вероятностью 0,9973 попадает величина Х в результате испытания.
Задача 6
Заданы
математическое ожидание ax=19 и среднее квадратическое отклонение σ=4
нормально распределенной случайной величины X. Найти: 1) вероятность
того, что X примет значение, принадлежащее интервалу (α=15;
β=19); 2) вероятность того, что абсолютная величина отклонения значения
величины от математического ожидания окажется меньше δ=18.
Задача 7
Диаметр
выпускаемой детали – случайная величина, распределенная по нормальному закону с
математическим ожиданием и дисперсией, равными соответственно 10 см и 0,16 см2.
Найти вероятность того, что две взятые наудачу детали имеют отклонение от
математического ожидания по абсолютной величине не более 0,16 см.
Задача 8
Ошибка
прогноза температуры воздуха есть случайная величина с m=0,σ=2℃. Найти вероятность
того, что в течение недели ошибка прогноза трижды превысит по абсолютной
величине 4℃.
Задача 9
Непрерывная
случайная величина X распределена по нормальному
закону: X∈N(a,σ).
а) Написать
плотность распределения вероятностей и функцию распределения.
б) Найти
вероятность того, что в результате испытания случайная величина примет значение
из интервала (α,β).
в) Определить
приближенно минимальное и максимальное значения случайной величины X.
г) Найти
интервал, симметричный относительно математического ожидания a, в котором с
вероятностью 0,98 будут заключены значения X.
a=5; σ=1.3;
α=4; β=6
Задача 10
Производится измерение вала без
систематических ошибок. Случайные ошибки измерения X
подчинены нормальному закону с σx=10. Найти вероятность того, что измерение будет
произведено с ошибкой, превышающей по абсолютной величине 15 мм.
Задача 11
Высота
стебля озимой пшеницы – случайная величина, распределенная по нормальному закону
с параметрами a = 75 см, σ = 1 см. Найти вероятность того, что высота стебля:
а) окажется от 72 до 80 см; б) отклонится от среднего не более чем на 0,5 см.
Задача 12
Деталь,
изготовленная автоматом, считается годной, если отклонение контролируемого
размера от номинала не превышает 10 мм. Точность изготовления деталей
характеризуется средним квадратическим отклонением, при данной технологии
равным 5 мм.
а)
Считая, что отклонение размера детали от номинала есть нормально распределенная
случайная величина, найти долю годных деталей, изготовляемых автоматом.
б) Какой
должна быть точность изготовления, чтобы процент годных деталей повысился до
98?
в)
Написать выражение для функции плотности вероятности и распределения случайной
величины.
Задача 13
Диаметр
детали, изготовленной цехом, является случайной величиной, распределенной по
нормальному закону. Дисперсия ее равна 0,0001 см, а математическое ожидание –
2,5 см. Найдите границы, симметричные относительно математического ожидания, в
которых с вероятностью 0,9973 заключен диаметр наудачу взятой детали. Какова
вероятность того, что в серии из 1000 испытаний размер диаметра двух деталей
выйдет за найденные границы?
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Задача 14
Предприятие
производит детали, размер которых распределен по нормальному закону с
математическим ожиданием 20 см и стандартным отклонением 2 см. Деталь будет
забракована, если ее размер отклонится от среднего (математического ожидания)
более, чем на 2 стандартных отклонения. Наугад выбрали две детали. Какова вероятность
того, что хотя бы одна из них будет забракована?
Задача 15
Диаметры
деталей распределены по нормальному закону. Среднее значение диаметра равно d=14 мм
, среднее квадратическое
отклонение σ=2 мм
. Найти вероятность того,
что диаметр наудачу взятой детали будет больше α=15 мм и не меньше β=19 мм; вероятность того, что диаметр детали
отклонится от стандартной длины не более, чем на Δ=1,5 мм.
Задача 16
В
электропечи установлена термопара, показывающая температуру с некоторой
ошибкой, распределенной по нормальному закону с нулевым математическим
ожиданием и средним квадратическим отклонением σ=10℃. В момент когда термопара
покажет температуру не ниже 600℃, печь автоматически отключается. Найти
вероятность того, что печь отключается при температуре не превышающей 540℃ (то
есть ошибка будет не меньше 30℃).
Задача 17
Длина
детали представляет собой нормальную случайную величину с математическим
ожиданием 40 мм и среднеквадратическим отклонением 3 мм. Найти:
а)
Вероятность того, что длина взятой наугад детали будет больше 34 мм и меньше 43
мм;
б)
Вероятность того, что длина взятой наугад детали отклонится от ее
математического ожидания не более, чем на 1,5 мм.
Задача 18
Случайное
отклонение размера детали от номинала распределены нормально. Математическое
ожидание размера детали равно 200 мм, среднее квадратическое отклонение равно
0,25 мм, стандартами считаются детали, размер которых заключен между 199,5 мм и
200,5 мм. Из-за нарушения технологии точность изготовления деталей уменьшилась
и характеризуется средним квадратическим отклонением 0,4 мм. На сколько
повысился процент бракованных деталей?
Задача 19
Случайная
величина X~N(1,22). Найти P{2
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Задача 20
Заряд пороха для охотничьего ружья
должен составлять 2,3 г. Заряд отвешивается на весах, имеющих ошибку
взвешивания, распределенную по нормальному закону со средним квадратическим
отклонением, равным 0,2 г. Определить вероятность повреждения ружья, если максимально
допустимый вес заряда составляет 2,8 г.
Задача 21
Заряд
охотничьего пороха отвешивается на весах, имеющих среднеквадратическую ошибку
взвешивания 150 мг. Номинальный вес порохового заряда 2,3 г. Определить
вероятность повреждения ружья, если максимально допустимый вес порохового
заряда 2,5 г.
Задача 21
Найти
вероятность попадания снарядов в интервал (α1=10.7; α2=11.2).
Если случайная величина X распределена по
нормальному закону с параметрами m=11;
σ=0.2.
Задача 22
Плотность
вероятности распределения случайной величины имеет вид
Найти
вероятность того, что из 3 независимых случайных величин, распределенных по
данному закону, 3 окажутся на интервале (-∞;5).
Задача 23
Непрерывная
случайная величина имеет нормальное распределение. Её математическое ожидание
равно 12, среднее квадратичное отклонение равно 2. Найти вероятность того, что
в результате испытания случайная величина примет значение в интервале (8,14)
Задача 24
Вероятность
попадания нормально распределенной случайной величины с математическим
ожиданием m=4 в интервал (3;5) равна 0,6. Найти дисперсию данной случайной
величины.
Задача 25
В
нормально распределенной совокупности 17% значений случайной величины X
меньше 13% и 47% значений случайной величины X
больше 19%. Найти параметры этой совокупности.
Задача 26
Студенты
мужского пола образовательного учреждения были обследованы на предмет
физических характеристик и обнаружили, что средний рост составляет 182 см, со
стандартным отклонением 6 см. Предполагая нормальное распределение для роста,
найдите вероятность того, что конкретный студент-мужчина имеет рост более 185
см.
