Вычислим среднее значение выборки и математическое ожидание случайной величины в MS EXCEL.
Выборочное среднее
Среднее выборки
или
выборочное среднее
(sample average, mean) представляет собой
среднее
арифметическое
всех значений
выборки
.
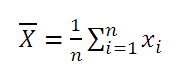
В MS EXCEL для вычисления
среднего выборки
можно использовать функцию
СРЗНАЧ()
. В качестве аргументов функции нужно указать ссылку на диапазон, содержащий значения
выборки
.
Выборочное среднее
является «хорошей» (несмещенной и эффективной) точечной оценкой
математического ожидания
случайной величины (см.
ниже
), т.е.
среднего значения
исходного распределения, из которого взята
выборка
.
Примечание
: О вычислении
доверительных интервалов
при оценке
математического ожидания
можно прочитать, например, в статье
Доверительный интервал для оценки среднего (дисперсия известна) в MS EXCEL
.
Некоторые свойства
среднего арифметического
:
-
Сумма всех отклонений от
среднего значения
равна 0:
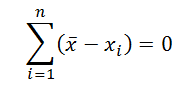
-
Если к каждому из значений x
i
прибавить одну и туже константу
с
, то
среднее арифметическое
увеличится на такую же константу; -
Если каждое из значений x
i
умножить на одну и туже константу
с
, то
среднее арифметическое
умножится на такую же константу.
Математическое ожидание
Среднее значение
можно вычислить не только для выборки, но для случайной величины, если известно ее
распределение
. В этом случае
среднее значение
имеет специальное название –
Математическое ожидание.
Математическое ожидание
характеризует «центральное» или среднее значение случайной величины.
Примечание
: В англоязычной литературе имеется множество терминов для обозначения
математического ожидания
: expectation, mathematical expectation, EV (Expected Value), average, mean value, mean, E[X] или first moment M[X].
Если случайная величина имеет
дискретное распределение
, то
математическое ожидание
вычисляется по формуле:
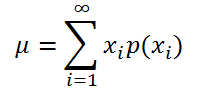
где x
i
– значение, которое может принимать случайная величина, а р(x
i
) – вероятность, что случайная величина примет это значение.
Если случайная величина имеет
непрерывное распределение
, то
математическое ожидание
вычисляется по формуле:
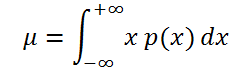
где р(x) –
плотность вероятности
(именно
плотность вероятности
, а не вероятность, как в дискретном случае).
Для каждого распределения, из представленных в MS EXCEL,
Математическое ожидание
можно вычислить аналитически, как функцию от параметров распределения (см. соответствующие
статьи про распределения
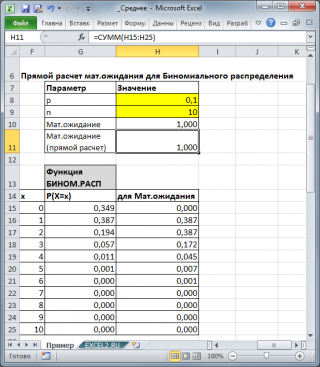
). Например, для
Биномиального распределения
среднее значение
равно произведению его параметров: n*p (см.
файл примера
).
Свойства математического ожидания
E[a*X]=a*E[X], где а – const
E[X+a]=E[X]+a
E[a]=a
E[E[X]]=E[X] – т.к. величина E[X] – является const
E[X+Y]=E[X]+E[Y] – работает даже для случайных величин не являющихся независимыми.
СОВЕТ
: Про другие показатели распределения –
Дисперсию
и
Стандартное отклонение,
можно прочитать в статье
Дисперсия и стандартное отклонение в MS EXCEL
.

1 .
.
Выборочная оценка математического
ожидания – выборочное среднее![]()
в Excel
вычисляется с помощью
функция СРЗНАЧ,
при этом
реализуется формула
 .
.
2 .
.
Оценка дисперсии – несмещенная
(исправленная) выборочная дисперсия![]() может быть получена с помощью функцииДИСП.
может быть получена с помощью функцииДИСП.
В Excel
реализована формула
 .
.
3.
Несмещенное выборочное средние
квадратические отклонения (стандартное
отклонение)
![]() вычисляется
вычисляется
с помощью функции
СТАНДОТКЛОН.
Вычисления
в Excel
выполнены по формуле
 .
.
4 .
.
Выборочная (смещенная) оценка дисперсии

вычисляется с помощью
функция ДИСПР.
Результат
вычисления выборочных оценок
![]() ,
,
![]() ,
,
![]() и
и![]()
показан на рис.1.

… … … …
… … …

Рис.
1. Фрагмент листа Excel
с исходными данными и выборочными
оценками параметров.
2. Описательная статистика.
Выполните
процедуру Описательная
статистика.
В
главном меню Excel
выбрать: Данные
→ Анализ данных → Описательная статистика
→ ОК.
В
появившемся окне Описательная
статистика
ввести:
Входной
интервал –
100 случайных чисел в ячейках $A$3:
$A$102;
Группирование
– по столбцам;
Выходной
интервал –
адрес ячейки, с которой начинается
таблица Описательная
статистика – например,
$D$8;
Итоговая
статистика
– поставить галочку. ОК.
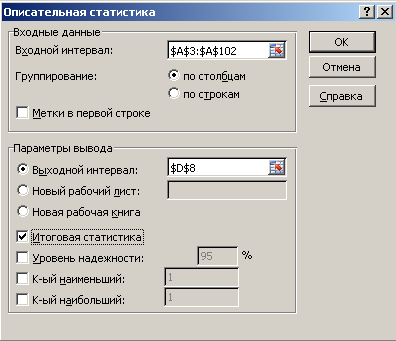
Рис.
2. Диалоговое окно Описательная
статистика
с заполненными полями ввода.
На
листе Excel
появится таблица – Столбец
1. В
таблице даются все необходимые параметры,
кроме моды Mo(X).

Рис.
3. Таблица Описательная
статистика
Таблица содержит
описательные статистики, в частности:
Среднее
– оценка математического ожидания
![]() ;
;
Стандартное
отклонение
– оценка среднего квадратического
отклонения![]() ;
;
Дисперсия
– выборочная исправленная дисперсия
![]() ;
;
Эксцесс
и Асимметричность
– оценки эксцесса и асимметрии;
Медиана
– оценка
медианы;
Мода
– оценка
моды, #Н/Д – нет данных (наиболее часто
встречающееся значение случайной
величины в выборке).
Приблизительное
равенство нулю оценок эксцесса и
асимметрии, и приблизительное равенство
оценки среднего оценке медианы дает
предварительное основание выбрать в
качестве основной гипотезы H0
распределения элементов генеральной
совокупности – нормальный закон.
Интервал
– размах выборки;
Минимум
– минимальное значение случайной
величины в выборке ![]() ;
;
Максимум
– максимальное значение случайной
величины в выборке ![]() .
.
Результаты
процедуры Описательная
статистика
потребуются в дальнейшем при построении
теоретического закона распределения.
3. Построение гистограммы
В
главном меню Excel
выбрать Данные
→ Анализ данных → Гистограмма → ОК.
Далее
необходимо заполнить поля ввода в
диалоговом окне Гистограмма.
Входной
интервал:
100 случайных чисел в ячейках $A$3:
$A$102;
Интервал
карманов:
не
заполнять;
Выходной
интервал:
адрес ячейки, с которой начинается вывод
результатов процедуры Гистограмма;
Вывод
графика –
поставьте галочку.
Если
поле ввода Интервал
карманов не
заполняется, то процедура вычисляет
число интервалов группировки k
и границы интервалов автоматически по
формуле.
![]() ,
,
где,
скобки
![]() означают – округление до целой части
означают – округление до целой части
числа в меньшую сторону.
В
рассматриваемом варианте n
= 100,
следовательно, k
= 11.
Действительно:

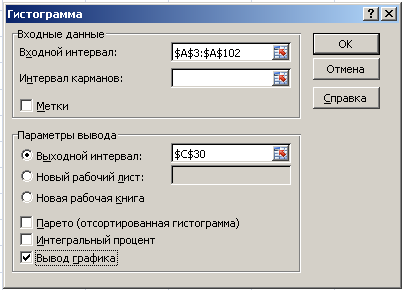
Рис.
4. Диалоговое окно Гистограмма.
В
результате выполнения процедуры
Гистограмма
появляется таблица, содержащая границы
xi
интервалов
группировки (столбец – Карман)
и частоту попадания случайных величин
выборки mi
в i–ый
интервал (столбец
–
Частота).
Справа от таблицы
– график гистограммы.
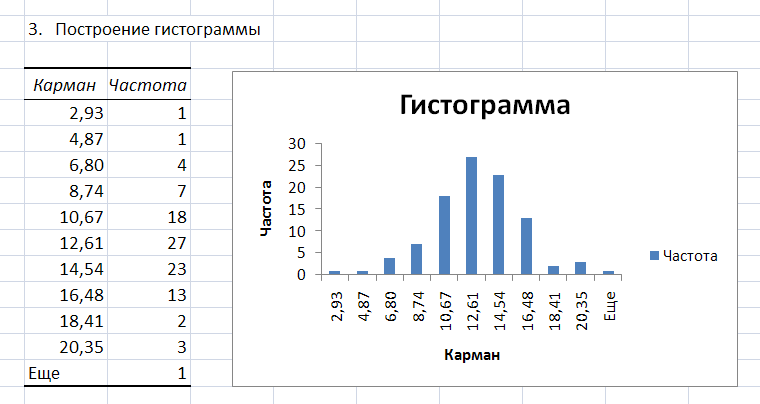
Рис.
5. Фрагмент листа Excel
с результатами процедуры Гистограмма.
По
виду гистограммы можно предположить
(принять гипотезу) о том, что выборка
случайных чисел подчиняется нормальному
закону распределения.
Далее,
для того чтобы убедиться в правильности
выбранной гипотезы (по крайней мере
визуально) надо, первое – построить
график гипотетического нормального
закона распределения, выбрав в качестве
параметров (математического ожидания
и среднего квадратического отклонении)
их оценки (среднее и стандартное
отклонение), и совместить график
гипотетического распределения с графиком
гистограммы.
И,
второе – используя критерий согласия
Пирсона установить справедливость
выбранной гипотезы.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Не все явления измеряются в количественной шкале типа 1, 2, 3 … 100500 … Не всегда явление может принимать бесконечное или большое количество различных состояний. Например, пол у человека может быть либо М, либо Ж. Стрелок либо попадает в цель, либо не попадает. Голосовать можно либо «За», либо «Против» и т.д. и т.п. Другими словами, такие данные отражают состояние альтернативного признака – либо «да» (событие наступило), либо «нет» (событие не наступило). Наступившее событие (положительный исход) еще называют «успехом».
Эксперименты с такими данными называются схемой Бернулли, в честь известного швейцарского математика, который установил, что при большом количестве испытаний соотношение положительных исходов и общего количества испытаний стремится к вероятности наступления этого события.
Переменная альтернативного признака
Для того, чтобы в анализе задействовать математический аппарат, результаты подобных наблюдений следует записать в числовом виде. Для этого положительному исходу присваивают число 1, отрицательному – 0. Другими словами, мы имеем дело с переменной, которая может принимать только два значения: 0 или 1.
Какую пользу отсюда можно извлечь? Вообще-то не меньшую, чем от обычных данных. Так, легко подсчитать количество положительных исходов – достаточно просуммировать все значения, т.е. все 1 (успехи). Можно пойти далее, но для этого потребуется ввести парочку обозначений.
Первым делом нужно отметить, что положительные исходы (которые равны 1) имеют некоторую вероятность появления. Например, выпадение орла при подбрасывании монеты равно ½ или 0,5. Такая вероятность традиционно обозначается латинской буквой p. Следовательно, вероятность наступления альтернативного события равна 1 — p, которую еще обозначают через q, то есть q = 1 – p. Указанные обозначения можно наглядно систематизировать в виде таблички распределения переменной X.

Мы получили перечень возможных значений и их вероятности. Можно рассчитать математическое ожидание и дисперсию. Матожидание – это сумма произведений всех возможных значений на соответствующие им вероятности:
![]()
Вычислим матожидание, используя обозначения в таблицы выше.
![]()
Получается, что математическое ожидание альтернативного признака равно вероятности этого события – p.
Теперь определим, что такое дисперсия альтернативного признака. Дисперсия – есть средний квадрат отклонений от математического ожидания. Общая формула (для дискретных данных) имеет вид:
![]()
Отсюда дисперсия альтернативного признака:

Нетрудно заметить, что эта дисперсия имеет максимум 0,25 (при p=0,5).
Стандартное отклонение – корень из дисперсии:
![]()
Максимальное значение не превышает 0,5.
Как видно, и математическое ожидание, и дисперсия альтернативного признака имеют очень компактный вид.
Биномиальное распределение случайной величины
Рассмотрим ситуацию под другим углом. Действительно, кому интересно, что среднее выпадение орлов при одном бросании равно 0,5? Это даже невозможно представить. Интересней поставить вопрос о числе выпадения орлов при заданном количестве бросков.
Другими словами, исследователя часто интересует вероятность наступления некоторого числа успешных событий. Это может быть количество бракованных изделий в проверяемой партии (1- бракованная, 0 — годная) или количество выздоровлений (1 – здоров, 0 – больной) и т.д. Количество таких «успехов» будет равно сумме всех значений переменной X, т.е. количеству единичных исходов.
![]()
Случайная величина B называется биномиальной и принимает значения от 0 до n (при B = 0 – все детали годные, при B = n – все детали бракованные). Предполагается, что все значения x независимы между собой. Рассмотрим основные характеристики биномиальной переменной, то есть установим ее математическое ожидание, дисперсию и распределение.
Матожидание биномиальной переменной получить очень легко. Математическое ожидание суммы величин есть сумма математических ожиданий каждой складываемой величины, а оно у всех одинаковое, поэтому:
![]()
Например, математическое ожидание количества выпавших орлов при 100 подбрасываниях равно 100 × 0,5 = 50.
Теперь выведем формулу дисперсии биномиальной переменной. Дисперсия суммы независимых случайных величин есть сумма дисперсий. Отсюда
![]()
Стандартное отклонение, соответственно
![]()
Для 100 подбрасываний монеты стандартное отклонение количества орлов равно
![]()
И, наконец, рассмотрим распределение биномиальной величины, т.е. вероятности того, что случайная величина B будет принимать различные значения k, где 0≤ k ≤n. Для монеты эта задача может звучать так: какова вероятность выпадения 40 орлов при 100 бросках?
Чтобы понять метод расчета, представим, что монета подбрасывается всего 4 раза. Каждый раз может выпасть любая из сторон. Мы задаемся вопросом: какова вероятность выпадения 2 орлов из 4 бросков. Каждый бросок независим друг от друга. Значит, вероятность выпадения какой-либо комбинации будет равна произведению вероятностей заданного исхода для каждого отдельного броска. Пусть О – это орел, Р – решка. Тогда, к примеру, одна из устраивающих нас комбинаций может выглядеть как ООРР, то есть:

Вероятность такой комбинации равняется произведению двух вероятностей выпадения орла и еще двух вероятностей не выпадения орла (обратное событие, рассчитываемое как 1 — p), т.е. 0,5×0,5×(1-0,5)×(1-0,5)=0,0625. Такова вероятность одной из устраивающих нас комбинации. Но вопрос ведь стоял об общем количестве орлов, а не о каком-то определенном порядке. Тогда нужно сложить вероятности всех комбинаций, в которых присутствует ровно 2 орла. Ясно, все они одинаковы (от перемены мест множителей произведение не меняется). Поэтому нужно вычислить их количество, а затем умножить на вероятность любой такой комбинации. Подсчитаем все варианты сочетаний из 4 бросков по 2 орла: РРОО, РОРО, РООР, ОРРО, ОРОР, ООРР. Всего 6 вариантов.

Следовательно, искомая вероятность выпадения 2 орлов после 4 бросков равна 6×0,0625=0,375.
Однако подсчет подобным образом утомителен. Уже для 10 монет методом перебора получить общее количество вариантов будет очень трудно. Поэтому умные люди давно изобрели формулу, с помощью которой рассчитывают количество различных сочетаний из n элементов по k, где n – общее количество элементов, k – количество элементов, варианты расположения которых и подсчитываются. Формула сочетания из n элементов по k такова:
![]()
Подобные вещи проходят в разделе комбинаторики. Всех желающих подтянуть знания отправляю туда. Отсюда, кстати, и название биномиального распределения (формула выше является коэффициентом в разложении бинома Ньютона).
Формулу для определения вероятности легко обобщить на любое количество n и k. В итоге формула биномиального распределения имеет следующий вид.
![]()
Количество подходящих под условие комбинаций умножить на вероятность одной из них.
Для практического использования достаточно просто знать формулу биномиального распределения. А можно даже и не знать – ниже показано, как определить вероятность с помощью Excel. Но лучше все-таки знать.
Рассчитаем по этой формуле вероятность выпадения 40 орлов при 100 бросках:
![]()
Или всего 1,08%. Для сравнения вероятность наступления математического ожидания этого эксперимента, то есть 50 орлов, равна 7,96%. Максимальная вероятность биномиальной величины принадлежит значению, соответствующему математическому ожиданию.
Расчет вероятностей биномиального распределения в Excel
Если использовать только бумагу и калькулятор, то расчеты по формуле биномиального распределения, несмотря на отсутствие интегралов, даются довольно тяжело. К примеру значение 100! – имеет более 150 знаков. Раньше, да и сейчас тоже, для вычисления подобных величин использовали приближенные формулы. В настоящий момент целесообразно использовать специальное ПО, типа MS Excel. Таким образом, любой пользователь (даже гуманитарий по образованию) вполне может вычислить вероятность значения биномиально распределенной случайной величины.
Для закрепления материала задействуем Excel пока в качестве обычного калькулятора, т.е. произведем поэтапное вычисление по формуле биномиального распределения. Рассчитаем, например, вероятность выпадения 50 орлов. Ниже приведена картинка с этапами вычислений и конечным результатом.

Как видно, промежуточные результаты имеют такой масштаб, что не помещаются в ячейку, хотя везде и используются простые функции типа: ФАКТР (вычисление факториала), СТЕПЕНЬ (возведение числа в степень), а также операторы умножения и деления. Более того, этот расчет довольно громоздок, во всяком случаен не является компактным, т.к. задействовано много ячеек. Да и разобраться с ходу трудновато.
В общем в Excel предусмотрена готовая функция для вычисления вероятностей биномиального распределения. Функция называется БИНОМ.РАСП.

Синтаксис функции состоит из 4 аргументов:

Поля имеют следующие назначения:
Число успехов – количество успешных испытаний. У нас их 50.
Число испытаний – количество бросков: 100 раз.
Вероятность успеха – вероятность выпадения орла при одном подбрасывании 0,5.
Интегральная – указывается либо 1, либо 0. Если 0, то рассчитается вероятность P(B=k); если 1, то рассчитается функция биномиального распределения, т.е. сумма всех вероятностей от B=0 до B=k включительно.
Нажимаем ОК и получаем тот же результат, что и выше, только все рассчиталось одной функцией.

Очень удобно. Эксперимента ради вместо последнего параметра 0 поставим 1. Получим 0,5398. Это значит, что при 100 подкидываниях монеты вероятность выпадения орлов в количестве от 0 до 50 равна почти 54%. А поначалу то казалось, что должно быть 50%. В общем, расчеты производятся легко и быстро.
Настоящий аналитик должен понимать, как ведет себя функция (каково ее распределение), поэтому произведем расчет вероятностей для всех значений от 0 до 100. То есть зададимся вопросом: какова вероятность, что не выпадет ни одного орла, что выпадет 1 орел, 2, 3, 50, 90 или 100. Расчет приведен в следующей картинке. Синяя линия – само биномиальное распределение, красная точка – вероятность для конкретного числа успехов k.

Кто-то может спросить, а не похоже ли биномиальное распределение на… Да, очень похоже. Еще Муавр (в 1733 г.) говорил, что биномиальное распределение при больших выборках приближается к нормальному закону (не знаю, как это тогда называлось), но его никто не слушал. Только Гаусс, а затем и Лаплас через 60-70 лет вновь открыли и тщательно изучили нормальной закон распределения. На графике выше отлично видно, что максимальная вероятность приходится на математическое ожидание, а по мере отклонения от него, резко снижается. Также, как и у нормального закона.
Биномиальное распределение имеет большое практическое значение, встречается довольно часто. С помощью Excel расчеты проводятся легко и быстро.
Поделиться в социальных сетях:
Формула математическое ожидания в MS Excel – расчет по шагам
Среднее выборки или выборочное среднее (sample average, mean) представляет собой среднее арифметическое всех значений выборки.
В MS EXCEL для вычисления среднего выборки можно использовать функцию СРЗНАЧ() . В качестве аргументов функции нужно указать ссылку на диапазон, содержащий значения выборки.
Выборочное среднее является «хорошей» (несмещенной и эффективной) точечной оценкой математического ожидания случайной величины (см. ниже), т.е. среднего значения исходного распределения, из которого взята выборка.
Примечание: О вычислении доверительных интервалов при оценке математического ожидания можно прочитать, например, в статье Доверительный интервал для оценки среднего (дисперсия известна) в MS EXCEL.
Некоторые свойства среднего арифметического:
- Сумма всех отклонений от среднего значения равна 0:
- Если к каждому из значений xi прибавить одну и туже константу с, то среднее арифметическое увеличится на такую же константу;
- Если каждое из значений xi умножить на одну и туже константу с, то среднее арифметическое умножится на такую же константу.
Математическое ожидание
Среднее значение можно вычислить не только для выборки, но для случайной величины, если известно ее распределение. В этом случае среднее значение имеет специальное название – Математическое ожидание. Математическое ожидание характеризует «центральное» или среднее значение случайной величины.
Примечание: В англоязычной литературе имеется множество терминов для обозначения математического ожидания: expectation, mathematical expectation, EV (Expected Value), average, mean value, mean, E[X] или first moment M[X].
Если случайная величина имеет дискретное распределение, то математическое ожидание вычисляется по формуле:
где xi – значение, которое может принимать случайная величина, а р(xi) – вероятность, что случайная величина примет это значение.
Если случайная величина имеет непрерывное распределение, то математическое ожидание вычисляется по формуле:
где р(x) – плотность вероятности (именно плотность вероятности, а не вероятность, как в дискретном случае).
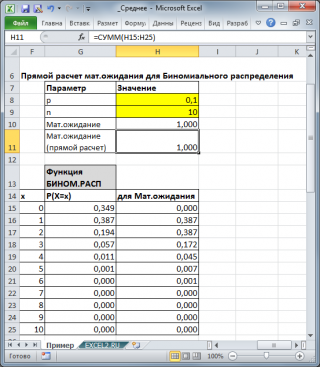
Для каждого распределения, из представленных в MS EXCEL, Математическое ожидание можно вычислить аналитически, как функцию от параметров распределения (см. соответствующие статьи про распределения). Например, для Биномиального распределения среднее значение равно произведению его параметров: n*p (см. файл примера ).
Функция СРОТКЛ в Excel используется для анализа числового ряда, передаваемого в качестве аргумента, и возвращает число, соответствующее среднему значению, рассчитанному для модулей отклонений относительно среднего арифметического для исследуемого ряда.
Примеры методов анализа числовых рядов в Excel
Смысл данной функции становится предельно ясен после рассмотрения примера. Допустим, на протяжении суток каждые 3 часа фиксировались показатели температуры воздуха. Был получен следующий ряд значений: 16, 14, 17, 21, 25, 26, 22, 18. С помощью функции СРЗНАЧ можно определить среднее значение температуры – 19,88 (округлим до 20).
Для определения отклонения каждого значения от среднего необходимо вычесть из него полученное среднее значение. Например, для первого замера температуры это будет равно 16-20=-4. Получаем ряд значений: -4, -6, -3, 1, 5, 6, 2, -2. Поскольку СРОТКЛ по определению работает с модулями отклонений, итоговый ряд значений имеет вид: 4, 6, 3, 1, 5, 6, 2, 2. Теперь нужно получить среднее значение для данного ряда с помощью функции СРЗНАЧ – примерно 3,63. Именно таков алгоритм работы рассматриваемой функции.
Таким образом, значение, вычисляемое функцией СРОТКЛ, можно рассчитать с помощью формулы массива без использования этой функции. Допустим, перечисленные результаты замеров температур записаны в столбец (ячейки A1:A8). Тогда для определения среднего значения отклонений можно использовать формулу =СРЗНАЧ(ABS(A1:A8-СРЗНАЧ(A1:A8))). Однако, рассматриваемая функция значительно упрощает расчеты.
Пример 1. Имеются два ряда значений, представляющих собой результаты наблюдений одного и того же физического явления, сделанные в ходе двух различных экспериментов. Определить, среднее отклонение от среднего значения результатов для какого эксперимента является максимальным?
Вид таблицы данных:
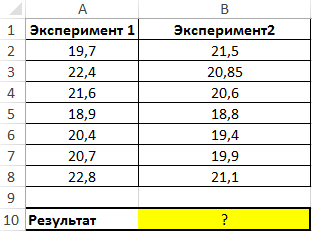
Используем следующую формулу:
Сравниваем результаты, возвращаемые функцией СРОТКЛ для первого и второго ряда чисел с использованием функции ЕСЛИ, возвращаем соответствующий результат.
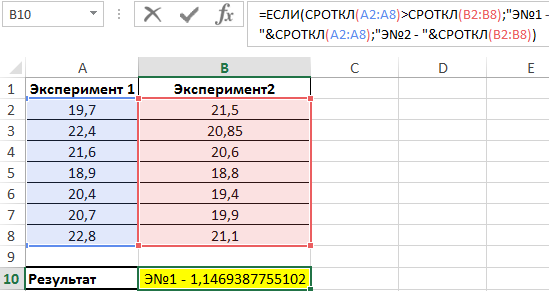
В результате мы получили среднее отклонение от среднего значения. Это весьма интересная функция для технического анализа финансовых рынков, прогнозов курсов валют и даже позволяет повысить шансы выигрышей в лотереях.
Формула расчета линейного коэффициента вариации в Excel
Пример 2. Студенты сдали экзамены по различным предметам. Определить число студентов, которые удовлетворяют следующему критерию успеваемости – линейный коэффициент вариации оценок не превышает 15%.
Вид таблицы данных:
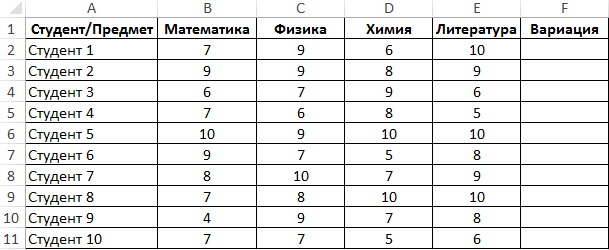
Линейный коэффициент вариации определяется как отношение среднего отклонения к среднему значению. Для расчета используем следующую формулу:
Растянем ее вниз по столбцу и получим следующие значения:
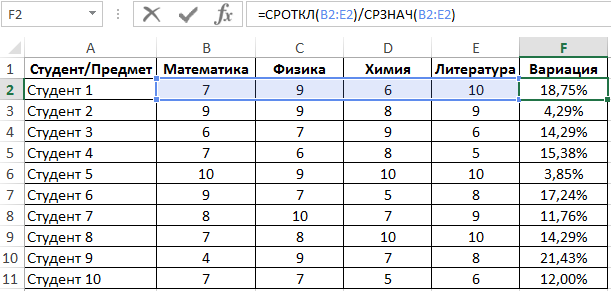
Для определения числа неуспешных студентов по указанному критерию используем функцию:
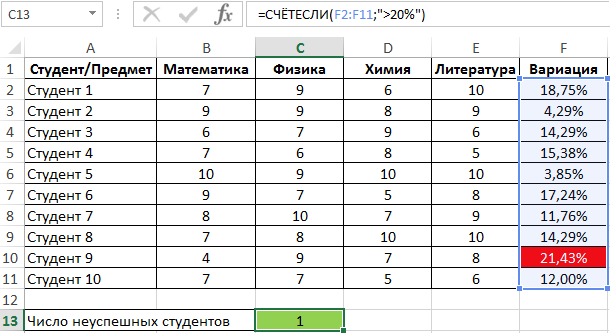
Правила использования функции СРОТКЛ в Excel
Функция имеет следующий синтаксис:
=СРОТКЛ( число1 ;[число2];. )
- число1 – обязательный, принимает числовое значение, характеризующее первый член ряда значений, для которых необходимо определить среднее отклонение от среднего;
- [число2];… – необязательный, принимает второе и последующие значения из исследуемого числового ряда.
- При использовании функции СРОТКЛ удобнее задавать первый аргумент в виде ссылки на диапазон ячеек, например =СРОТКЛ(A1:A8) вместо перечисления (=СРОТКЛ(A1;A2:A3…;A8)).
- В качестве аргумента функции может быть передана константа массива, например =СРОТКЛ(<2;5;4;7;10>).
- Для получения достоверного результата необходимо привести все значения ряда к единой системе измерения величин. Например, если часть длин указана в мм, а остальные – в см, результат расчетов будет некорректен. Необходимо преобразовать все значения в мм или см соответственно.
- Если в качестве аргументов функции переданы нечисловые данные, которые не могут быть преобразованы к числам, функция вернет код ошибки #ЧИСЛО!. Если хотя бы одно значение из ряда является числовым, функция выполнит расчет, не возвращая код ошибки.
- Не преобразуемые к числам текстовые строки и пустые ячейки не учитываются в расчете. Если ячейка содержит значение 0 (нуль), оно будет учтено.
- Логические данные автоматически преобразуются к числовым: ИСТИНА – 1, ЛОЖЬ – 0 соответственно.
1. Вычислить математическое ожидание:
1) Пуск > Все программы > Microsoft Office > Microsoft Excel
2) Так как функция математического ожидания это т оже самое, что и функция среднего арифметического, то: в пустой ячейке вводим «=», далее нажимаем fx, выбираем функцию СРЗНАЧ, выделяем числовые данные нашей исходной таблицы.
2. Вычислить дисперсию:
Вводим =, далее – fx, “Статистические” – “ДИСП”, выделить числовые данные нашей исходной таблицы.
3. Среднее квадратичесое отклонение (не смещённое):
Вводим =, далее – fx, “Статистические” – “СТАНДТОТКЛОН”, выделить числовые данные нашей исходной таблицы.
4. Среднее квадратическое отклонение (смещённое):
Вводим =, далее – fx, “Статистические” – “СТАНДТОТКЛОН”, выделить числовые данные нашей исходной таблицы.
Вывод: Microsoft Excel является одной из самых удобных компьютерных программ, с помощью которых можно высчитать статические данные. В этом я убедился, когда высчитывал вышеуказанные данные.
Среднее выборки или выборочное среднее (sample average, mean) представляет собой среднее арифметическое всех значений выборки .
В MS EXCEL для вычисления среднего выборки можно использовать функцию СРЗНАЧ() . В качестве аргументов функции нужно указать ссылку на диапазон, содержащий значения выборки .
Выборочное среднее является «хорошей» (несмещенной и эффективной) точечной оценкой математического ожидания случайной величины (см. ниже ), т.е. среднего значения исходного распределения, из которого взята выборка .
Примечание : О вычислении доверительных интервалов при оценке математического ожидания можно прочитать, например, в статье Доверительный интервал для оценки среднего (дисперсия известна) в MS EXCEL .
Некоторые свойства среднего арифметического :
- Сумма всех отклонений от среднего значения равна 0:
- Если к каждому из значений x i прибавить одну и туже константу с , то среднее арифметическое увеличится на такую же константу;
- Если каждое из значений x i умножить на одну и туже константу с , то среднее арифметическое умножится на такую же константу.
Математическое ожидание
Среднее значение можно вычислить не только для выборки, но для случайной величины, если известно ее распределение . В этом случае среднее значение имеет специальное название — Математическое ожидание. Математическое ожидание характеризует «центральное» или среднее значение случайной величины.
Примечание : В англоязычной литературе имеется множество терминов для обозначения математического ожидания : expectation, mathematical expectation, EV (Expected Value), average, mean value, mean, E[X] или first moment M[X].
Если случайная величина имеет дискретное распределение , то математическое ожидание вычисляется по формуле:
где x i – значение, которое может принимать случайная величина, а р(x i ) – вероятность, что случайная величина примет это значение.
Если случайная величина имеет непрерывное распределение , то математическое ожидание вычисляется по формуле:
где р(x) – плотность вероятности (именно плотность вероятности , а не вероятность, как в дискретном случае).
Для каждого распределения, из представленных в MS EXCEL, Математическое ожидание можно вычислить аналитически, как функцию от параметров распределения (см. соответствующие статьи про распределения ). Например, для Биномиального распределения среднее значение равно произведению его параметров: n*p (см. файл примера ).
Свойства математического ожидания
E[a*X]=a*E[X], где а — const
E[E[X]]=E[X] — т.к. величина E[X] — является const
E[X+Y]=E[X]+E[Y] — работает даже для случайных величин не являющихся независимыми.
СОВЕТ : Про другие показатели распределения — Дисперсию и Стандартное отклонение, можно прочитать в статье Дисперсия и стандартное отклонение в MS EXCEL .
Среднее арифметическое в Excel
Среднее арифметическое значение — самый известный статистический показатель. В этой заметке рассмотрим его смысл, формулы расчета и свойства.
Средняя арифметическая как оценка математического ожидания
Теория вероятностей занимается изучением случайных величин. Для этого строятся различные характеристики, описывающие их поведение. Одной из основных характеристик случайной величины является математическое ожидание, являющееся своего рода центром, вокруг которого группируются остальные значения.
Формула матожидания имеет следующий вид:
![]()
где M(X) – математическое ожидание
xi – это случайные величины
То есть, математическое ожидание случайной величины — это взвешенная сумма значений случайной величины, где веса равны соответствующим вероятностям.
Математическое ожидание суммы выпавших очков при бросании двух игральных костей равно 7. Это легко подсчитать, зная вероятности. А как рассчитать матожидание, если вероятности не известны? Есть только результат наблюдений. В дело вступает статистика, которая позволяет получить приблизительное значение матожидания по фактическим данным наблюдений.
Математическая статистика предоставляет несколько вариантов оценки математического ожидания. Основное среди них – среднее арифметическое.
Среднее арифметическое значение рассчитывается по формуле, которая известна любому школьнику.
![]()
где xi – значения переменной,
n – количество значений.
Среднее арифметическое – это соотношение суммы значений некоторого показателя с количеством таких значений (наблюдений).
Свойства средней арифметической (математического ожидания)
Теперь рассмотрим свойства средней арифметической, которые часто используются при алгебраических манипуляциях. Правильней будет вновь вернутся к термину математического ожидания, т.к. именно его свойства приводят в учебниках.
Матожидание в русскоязычной литературе обычно обозначают как M(X), в иностранных учебниках можно увидеть E(X). Встречается обозначение греческой буквой μ (читается «мю»). Для удобства предлагаю вариант M(X).
Итак, свойство 1. Если имеются переменные X, Y, Z, то математическое ожидание их суммы равно сумме их математических ожиданий.
M(X+Y+Z) = M(X) + M(Y) + M(Z)
Допустим, среднее время, затрачиваемое на мойку автомобиля M(X) равно 20 минут, а на подкачку колес M(Y) – 5 минут. Тогда общее среднее арифметическое время на мойку и подкачку составит M(X+Y) = M(X) + M(Y) = 20 + 5 = 25 минут.
Свойство 2. Если переменную (т.е. каждое значение переменной) умножить на постоянную величину (a), то математическое ожидание такой величины равно произведению матожидания переменной и этой константы.
К примеру, среднее время мойки одной машины M(X) 20 минут. Тогда среднее время мойки двух машин составит M(aX) = aM(X) = 2*20 = 40 минут.
Свойство 3. Математическое ожидание постоянной величины (а) есть сама эта величина (а).
Если установленная стоимость мойки легкового автомобиля равна 100 рублей, то средняя стоимость мойки нескольких автомобилей также равна 100 рублей.
Свойство 4. Математическое ожидание произведения независимых случайных величин равно произведению их математических ожиданий.
Автомойка за день в среднем обслуживает 50 автомобилей (X). Средний чек – 100 рублей (Y). Тогда средняя выручка автомойки в день M(XY) равна произведению среднего количества M(X) на средний тариф M(Y), т.е. 50*100 = 500 рублей.
Формула среднего значения в Excel
Среднее арифметическое чисел в Excel рассчитывают с помощью функции СРЗНАЧ. Выглядит примерно так.
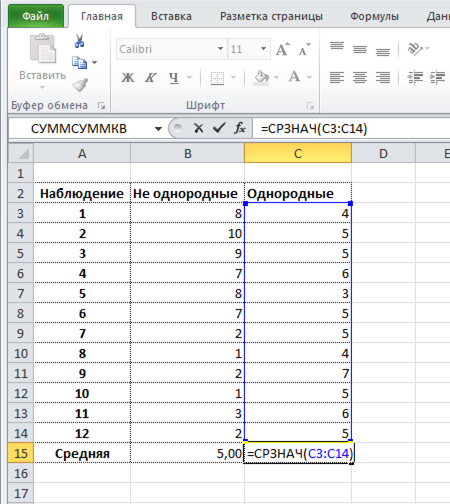
У этой формулы есть замечательное свойство. Если в диапазоне, по которому рассчитывается формула, присутствуют пустые ячейки (не нулевые, а именно пустые), то они исключается из расчета.
Вызвать функцию можно разными способами. Например, воспользоваться командой автосуммы во вкладке Главная:
После вызова формулы нужно указать диапазон данных, по которому рассчитывается среднее значение.
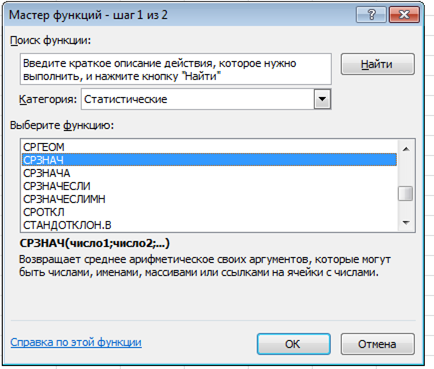
Есть и стандартный способ для всех функций. Нужно нажать на кнопку fx в начале строки формул. Затем либо с помощью поиска, либо просто по списку выбрать функцию СРЗНАЧ (в категории «Статистические»).
Средняя арифметическая взвешенная
Рассмотрим следующую простую задачу. Между пунктами А и Б расстояние S, которые автомобиль проехал со скоростью 50 км/ч. В обратную сторону – со скоростью 100 км/ч.
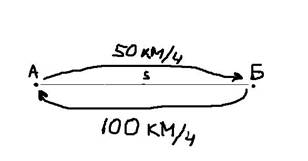
Какова была средняя скорость движения из А в Б и обратно? Большинство людей ответят 75 км/ч (среднее из 50 и 100) и это неправильный ответ. Средняя скорость – это все пройденное расстояние, деленное на все потраченное время. В нашем случае все расстояние – это S + S = 2*S (туда и обратно), все время складывается из времени из А в Б и из Б в А. Зная скорость и расстояние, время найти элементарно. Исходная формула для нахождения средней скорости имеет вид:
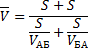
Теперь преобразуем формулу до удобного вида.
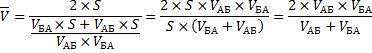
![]()
Правильный ответ: средняя скорость автомобиля составила 66,7 км/ч.
Средняя скорость – это на самом деле среднее расстояние в единицу времени. Поэтому для расчета средней скорости (среднего расстояния в единицу времени) используется средняя арифметическая взвешенная по следующей формуле.
![]()
где x – анализируемый показатель; f – вес.
Аналогичным образом по формуле средневзвешенной средней рассчитывается средняя цена (средняя стоимость на единицу продукции), средний процент и т.д. То есть если средняя считается по другим усредненным значениям, нужно применить среднюю взвешенную, а не простую.
Формула средневзвешенного значение в Excel
Обычная функция среднего значения в Excel СРЗНАЧ, к сожалению, считает только среднюю простую. Готовой формулы для среднего взвешенного значения в Excel нет. Однако расчет несложно сделать подручными средствами.
Самый понятный вариант создать дополнительный столбец. Выглядит примерно так.
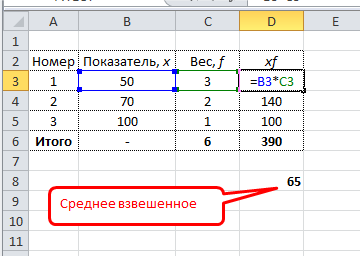
Имеется возможность сократить количество расчетов. Есть функция СУММПРОИЗВ. С ее помощью можно рассчитать числитель одним действием. Разделить на сумму весов можно в этой же ячейке. Вся формула для расчета среднего взвешенного значения в Excel выглядит так:
Интерпретация средней взвешенной такая же, как и у средней простой. Средняя простая – это частный случай взвешенной, когда все веса равны 1.
Физический смысл средней арифметической
Представим, что имеется спица, на которой в разных местах нанизаны грузики различной массы.
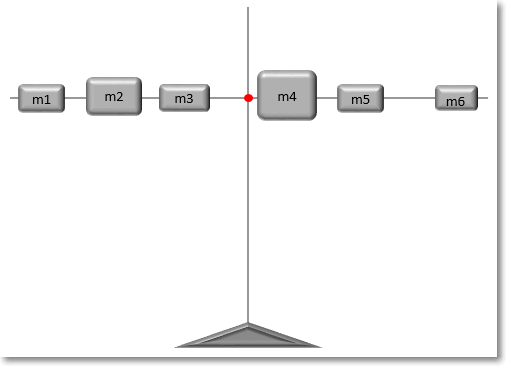
Как отыскать центр тяжести? Центр тяжести – это такая точка, за которую можно ухватиться, и спица при этом останется в горизонтальном положении и не будет переворачиваться под действием силы тяжести. Она должна быть в центре всех масс, чтобы силы слева равнялись силам справа. Для нахождения точки равновесия следует рассчитать среднее арифметическое взвешенное расстояний от начала спицы до каждого грузика. Весами будут являться массы грузиков (mi), что в прямом смысле слова соответствует понятию веса. Таким образом, среднее арифметическое расстояние – это центр равновесия системы, когда силы с одной стороны точки уравновешивают силы с другой стороны.
И последнее. В русском языке так сложилось, что под словом «средний» обычно понимают именно среднее арифметическое. То есть моду и медиану как-то не принято называть средним значением. А вот на английском языке слово «средний» (average) может трактоваться и как среднее арифметическое (mean), и как мода (mode), и как медиана (median). Так что при чтении иностранной литературы следует быть бдительным.
Среднее выборки или выборочное среднее (sample average, mean) представляет собой среднее арифметическое всех значений выборки .
В MS EXCEL для вычисления среднего выборки можно использовать функцию СРЗНАЧ() . В качестве аргументов функции нужно указать ссылку на диапазон, содержащий значения выборки .
Выборочное среднее является «хорошей» (несмещенной и эффективной) точечной оценкой математического ожидания случайной величины (см. ниже ), т.е. среднего значения исходного распределения, из которого взята выборка .
Примечание : О вычислении доверительных интервалов при оценке математического ожидания можно прочитать, например, в статье Доверительный интервал для оценки среднего (дисперсия известна) в MS EXCEL .
Некоторые свойства среднего арифметического :
- Сумма всех отклонений от среднего значения равна 0:
- Если к каждому из значений x i прибавить одну и туже константу с , то среднее арифметическое увеличится на такую же константу;
- Если каждое из значений x i умножить на одну и туже константу с , то среднее арифметическое умножится на такую же константу.
Математическое ожидание
Среднее значение можно вычислить не только для выборки, но для случайной величины, если известно ее распределение . В этом случае среднее значение имеет специальное название — Математическое ожидание. Математическое ожидание характеризует «центральное» или среднее значение случайной величины.
Примечание : В англоязычной литературе имеется множество терминов для обозначения математического ожидания : expectation, mathematical expectation, EV (Expected Value), average, mean value, mean, E[X] или first moment M[X].
Если случайная величина имеет дискретное распределение , то математическое ожидание вычисляется по формуле:
где x i – значение, которое может принимать случайная величина, а р(x i ) – вероятность, что случайная величина примет это значение.
Если случайная величина имеет непрерывное распределение , то математическое ожидание вычисляется по формуле:
где р(x) – плотность вероятности (именно плотность вероятности , а не вероятность, как в дискретном случае).
Для каждого распределения, из представленных в MS EXCEL, Математическое ожидание можно вычислить аналитически, как функцию от параметров распределения (см. соответствующие статьи про распределения ). Например, для Биномиального распределения среднее значение равно произведению его параметров: n*p (см. файл примера ).
Свойства математического ожидания
E[a*X]=a*E[X], где а — const
E[E[X]]=E[X] — т.к. величина E[X] — является const
E[X+Y]=E[X]+E[Y] — работает даже для случайных величин не являющихся независимыми.
СОВЕТ : Про другие показатели распределения — Дисперсию и Стандартное отклонение, можно прочитать в статье Дисперсия и стандартное отклонение в MS EXCEL .
Основные статистики в EXCEL
События, характеризующие данные, могут носить случайный характер и появляться с разной вероятностью.
Вероятность события p есть отношение числа благоприятных исходов m к числу всех возможных исходов n этогособытия: p=m/n. Например, вероятность появления туза в наугад выбранной карте из колоды в 52 карты равна 4/52=0.0769, так как m=4, а n=52.
Если известно соответствие между появлениями (величинами) x1, x2, …, xn случайного события (переменной) X и соответствующими вероятностями их реализации p1, p2, …, pn, то говорят, что известен закон распределения случайной величины F(x). Большинство встречающихся на практике распределений вероятностей реализовано в Excel.
Распределения вероятностей имеют числовые характеристики.
Функции Excel для вычисления числовых характеристик распределения вероятностей. Они входят в группу Статистические. При вычислении функций в качестве случайных величин используйте следующие значения:

Математическое ожидание случайной величины (среднее арифметическое), характеризующее центр распределения вероятностей, вычисляется функцией СРЗНАЧ. СРЗНАЧ(A1:A7) = 9.
Дисперсия, характеризует разброс случайной величины относительно центра распределения вероятностей и вычисляется функцией ДИСПР. ДИСПР(A1:A7) = 4.857.
Среднеквадратичное отклонение есть квадратный корень из дисперсии, характеризует разброс случайной величины в единицах случайной величины и вычисляется функцией СТАНДОТКЛОНП. СТАНДОТКЛОНП(A1:A7) = 2.203893.
Квантиль случайной величины с законом распределения F(x) есть значение случайной величины x при заданной вероятности p., т.е. есть решение уравнения F(x)=p. Медиана есть квантиль с вероятностью p=0.5.
Excel, вместо квантилей содержит функции вычисления х для определенных уровней р: квартили (кварта – четверть), децили (дециль – десятая часть), персентили (персент – процент). Различают нижний квартиль с вероятностью p=0.25 и верхний квартиль с вероятностью p=0.75. Децили это квантили с вероятностью 0.1, 0.2, …, 0.9.
Функцию КВАРТИЛЬ используют, чтобы разбить данные на группы. В качестве второго аргумента указывают уровень (четверть), для которого нужно вернуть решение: 0 – минимальное значение распределения, 1 – первый, нижний квартиль, 2 – медиана, 3 – третий, верхний квартиль, 4 – максимальное значение. Например, КВАРТИЛЬ(A1:A7;3) = 10, т.е. 75% всех значений меньше 10, КВАРТИЛЬ(A1:A7;2) = 9.
Функция ПЕРСЕНТИЛЬ вычисляет квантиль указанного уровня вероятности и используется для определения порога приемлемости значений. В качестве второго аргумента указывают уровень 0.1, 0.2, …, 0.9. ПЕРСЕНТИЛЬ(A1:A7;0,9) = 11.8, т.е. 90% всех значений меньше 11.8.
Excel содержит инструмент Ранг и персентиль, который на основе набора данных формирует выходную таблицу, содержащую порядковый и процентный ранги для каждого значения в наборе данных. См. справку по F1. Ниже приведен пример установки надстройки Пактет анализа
Распределения вероятностей, реализованные в Excel.
Каждый закон распределения описывает процессы разной вероятностной природы и характеризуется специфическими параметрами:
— равномерное распределение – n случайных чисел выпадает с одной и той же вероятностью p=1/n; характеризуется нижней и верхней границей; примером является появление чисел 1, 2, …, 6 при бросании игральной кости (p=1/6);
— биномиальное распределение моделирует взаимосвязь числа успешных испытаний m и вероятностей успеха каждого испытания p при общем количестве испытаний n — функции БИНОМРАСП и КРИТБИНОМ;
— нормальное (гауссово) распределение описывает процессы, в которых на результат воздействует большое число независимых случайных факторов, среди которых нет сильно выделяющихся – функции НОРМРАСП, НОРМСТРАСП, НОРМОБР, НОРМСТОБР и НОРМАЛИЗАЦИЯ;
— распределение Пуассона, предсказывает число случайных событий на определенном отрезке времени или на определенном пространстве, позволяет аппроксимировать биномиальное распределение – функция ПУАССОН;
— экспоненциальное (показательное) распределение, моделирует временные задержки между событиями, описывает процессы в задачах массового обслуживания и в задачах с «временем жизни» — ЭКСПРАСП;
— распределение хи-квадрат, связано с нормальным, возвращает одностороннюю вероятность распределения и используется для сравнения предполагаемых и наблюдаемых значений – функция ХИ2РАСП;
— распределение Стьюдента, связано с нормальным, возвращает вероятность для t-распределения Стьюдента и используется для проверки гипотез при малом объеме выборки – функция СТЬЮДРАСП;
— F-распределение (Фишера), связано с нормальным и может быть использовано в F-тесте, который сравнивает степени разброса двух множеств данных – fраспобр;
— гамма-распределение используется для изучения случайных величин, имеющих асимметричное распределение, в теории очередей – функция ГАММАРАСП;
— а также другие распределения – функции БЕТАРАСП, ВЕЙБУЛЛ, ОТРБИНОМРАСП, ГИПЕРГЕОМЕТ, ЛОГНОРМРАСП и др.
Биномиальное распределениехарактеризуется числом успешных испытаний m, вероятностью успеха каждого испытания p и общим количеством испытаний n. Классическим примером использования биномиального распределения является выборочный контроль качества больших партий товара, изделий в торговле, на производстве, когда сплошная проверка невозможна. Из партии выбирают n образцов и регистрируют число бракованных m. Бракованными могут быть 1, 2, … , n образцов, но вероятности реального числа бракованных будут различными. Если контрольная вероятность брака ниже допустимой вероятности, то можно гарантировать достаточное качество всей партии.
В Excel функция БИНОМРАСП вычисляет вероятность отдельного значения распределения по заданным m, n и р, а функция КРИТБИНОМ – случайное число по заданной вероятности. Обычно функция КРИТБИНОМ используется для определения наибольшего допустимого числа брака.
В качестве примера построим график плотности вероятности биномиального распределения для n=10 (1, 2, …, 10) и p=0.2. Введите исходные данные, как показано на рисунке:
Далее в ячейку В4 введите статистическую функцию БИНОМРАСП и заполните ее параметры как показано на рисунке:
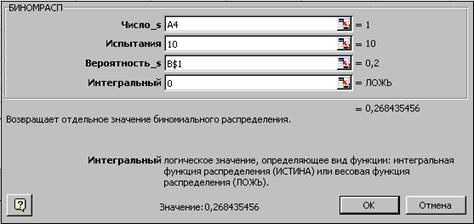
Здесь параметр Число_s есть число успешных испытаний m, Испытания – число независимых испытаний n, Вероятность_s – вероятность успеха каждого испытания p. Параметр Интегральный равен 0, если требуется получить плотность распределения (вероятность для значения m), и равен 1, если требуется получить вероятность с накоплением (вероятность того, что число успешных испытаний не меньше значения аргумента Число_s).
Формулу из В4 размножьте в ячейки В5:В13. Ниже показан результат:

В колонке В вычислены вероятности успешных испытаний m=1, 2, …, 10. Теперь по диапазону В4:В13 постройте график или гистограмму биномиальной функции плотности распределения – результат на рисунке. Поэкспериментируйте, изменяя значение вероятности в ячейке В1: 0.3, 0.4, 0.8, проследите за изменениями формы графика.
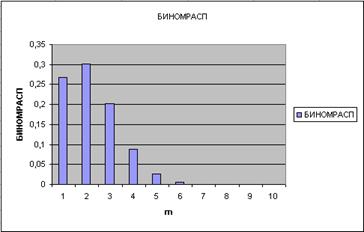
Для иллюстрации функции КРИТБИНОМ используем предыдущий пример – необходимо найти число m, для которого вероятность интегрального распределения больше или равна 0.75. Вызовите функцию КРИТБИНОМ и заполните параметры. Вы должны получить значение 3. Это означает, что при вероятности интегрального распределения >= 0.75 будет не менее трех (m>=3) успешных испытаний.

Нормальное распределениехарактеризуется средним арифметическим (математическим ожиданием) m и стандартным (среднеквадратичным) отклонением r. Дисперсия равна r 2 . Краткое обозначение распределения N(m,r 2 ). График нормального распределения симметричен относительно центра распределения (точки m), чем меньше r, тем больше вероятность появления случайной величины. В пределы [m-r,m+r] нормально распределенная случайная величина попадает с вероятностью 0,683 в пределы [m-2r,m+2r] — с вероятностью 0,955 и т.д.
При m=0 и r=1 нормальное распределение называется стандартным или нормированным – N(0,1).
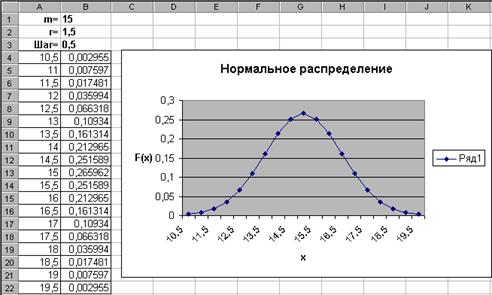
Нормальное распределение имеет очень широкий круг приложений. В качестве примера построим график плотности вероятностей нормального распределения при m=15 и r=1,5 в диапазоне [m-3r,m+3r] c шагом 0,5. Результат показан на рисунке.
Выполните следующие действия:
— в ячейку А4 введите формулу =B1-3*B2, в ячейку А5 формулу =A4+B$3 и размножьте ее по ячейку А22;
— в ячейку В4 введите функцию НОРМРАСП из группы Статистические – параметры заполните как на рисунке;
— размножьте формулу из ячейки В4 по ячейку В22 и по диапазону В4:В22 постройте график; на 2-ом шаге мастера диаграмм в закладке Ряд введите подписи к оси х из диапазона А4:А22.
Формула математическое ожидания в MS Excel – расчет по шагам
Среднее выборки или выборочное среднее (sample average, mean) представляет собой среднее арифметическое всех значений выборки.
В MS EXCEL для вычисления среднего выборки можно использовать функцию СРЗНАЧ() . В качестве аргументов функции нужно указать ссылку на диапазон, содержащий значения выборки.
Выборочное среднее является «хорошей» (несмещенной и эффективной) точечной оценкой математического ожидания случайной величины (см. ниже), т.е. среднего значения исходного распределения, из которого взята выборка.
Примечание: О вычислении доверительных интервалов при оценке математического ожидания можно прочитать, например, в статье Доверительный интервал для оценки среднего (дисперсия известна) в MS EXCEL.
Некоторые свойства среднего арифметического:
- Сумма всех отклонений от среднего значения равна 0:
- Если к каждому из значений xi прибавить одну и туже константу с, то среднее арифметическое увеличится на такую же константу;
- Если каждое из значений xi умножить на одну и туже константу с, то среднее арифметическое умножится на такую же константу.
Математическое ожидание
Среднее значение можно вычислить не только для выборки, но для случайной величины, если известно ее распределение. В этом случае среднее значение имеет специальное название – Математическое ожидание. Математическое ожидание характеризует «центральное» или среднее значение случайной величины.
Примечание: В англоязычной литературе имеется множество терминов для обозначения математического ожидания: expectation, mathematical expectation, EV (Expected Value), average, mean value, mean, E[X] или first moment M[X].
Если случайная величина имеет дискретное распределение, то математическое ожидание вычисляется по формуле:
где xi – значение, которое может принимать случайная величина, а р(xi) – вероятность, что случайная величина примет это значение.
Если случайная величина имеет непрерывное распределение, то математическое ожидание вычисляется по формуле:
где р(x) – плотность вероятности (именно плотность вероятности, а не вероятность, как в дискретном случае).
Для каждого распределения, из представленных в MS EXCEL, Математическое ожидание можно вычислить аналитически, как функцию от параметров распределения (см. соответствующие статьи про распределения). Например, для Биномиального распределения среднее значение равно произведению его параметров: n*p (см. файл примера ).
Функция СРОТКЛ в Excel используется для анализа числового ряда, передаваемого в качестве аргумента, и возвращает число, соответствующее среднему значению, рассчитанному для модулей отклонений относительно среднего арифметического для исследуемого ряда.
Примеры методов анализа числовых рядов в Excel
Смысл данной функции становится предельно ясен после рассмотрения примера. Допустим, на протяжении суток каждые 3 часа фиксировались показатели температуры воздуха. Был получен следующий ряд значений: 16, 14, 17, 21, 25, 26, 22, 18. С помощью функции СРЗНАЧ можно определить среднее значение температуры – 19,88 (округлим до 20).
Для определения отклонения каждого значения от среднего необходимо вычесть из него полученное среднее значение. Например, для первого замера температуры это будет равно 16-20=-4. Получаем ряд значений: -4, -6, -3, 1, 5, 6, 2, -2. Поскольку СРОТКЛ по определению работает с модулями отклонений, итоговый ряд значений имеет вид: 4, 6, 3, 1, 5, 6, 2, 2. Теперь нужно получить среднее значение для данного ряда с помощью функции СРЗНАЧ – примерно 3,63. Именно таков алгоритм работы рассматриваемой функции.
Таким образом, значение, вычисляемое функцией СРОТКЛ, можно рассчитать с помощью формулы массива без использования этой функции. Допустим, перечисленные результаты замеров температур записаны в столбец (ячейки A1:A8). Тогда для определения среднего значения отклонений можно использовать формулу =СРЗНАЧ(ABS(A1:A8-СРЗНАЧ(A1:A8))). Однако, рассматриваемая функция значительно упрощает расчеты.
Пример 1. Имеются два ряда значений, представляющих собой результаты наблюдений одного и того же физического явления, сделанные в ходе двух различных экспериментов. Определить, среднее отклонение от среднего значения результатов для какого эксперимента является максимальным?
Вид таблицы данных:
Используем следующую формулу:
Сравниваем результаты, возвращаемые функцией СРОТКЛ для первого и второго ряда чисел с использованием функции ЕСЛИ, возвращаем соответствующий результат.
В результате мы получили среднее отклонение от среднего значения. Это весьма интересная функция для технического анализа финансовых рынков, прогнозов курсов валют и даже позволяет повысить шансы выигрышей в лотереях.
Формула расчета линейного коэффициента вариации в Excel
Пример 2. Студенты сдали экзамены по различным предметам. Определить число студентов, которые удовлетворяют следующему критерию успеваемости – линейный коэффициент вариации оценок не превышает 15%.
Вид таблицы данных:
Линейный коэффициент вариации определяется как отношение среднего отклонения к среднему значению. Для расчета используем следующую формулу:
Растянем ее вниз по столбцу и получим следующие значения:
Для определения числа неуспешных студентов по указанному критерию используем функцию:
Правила использования функции СРОТКЛ в Excel
Функция имеет следующий синтаксис:
=СРОТКЛ( число1 ;[число2];. )
- число1 – обязательный, принимает числовое значение, характеризующее первый член ряда значений, для которых необходимо определить среднее отклонение от среднего;
- [число2];… – необязательный, принимает второе и последующие значения из исследуемого числового ряда.
- При использовании функции СРОТКЛ удобнее задавать первый аргумент в виде ссылки на диапазон ячеек, например =СРОТКЛ(A1:A8) вместо перечисления (=СРОТКЛ(A1;A2:A3…;A8)).
- В качестве аргумента функции может быть передана константа массива, например =СРОТКЛ(<2;5;4;7;10>).
- Для получения достоверного результата необходимо привести все значения ряда к единой системе измерения величин. Например, если часть длин указана в мм, а остальные – в см, результат расчетов будет некорректен. Необходимо преобразовать все значения в мм или см соответственно.
- Если в качестве аргументов функции переданы нечисловые данные, которые не могут быть преобразованы к числам, функция вернет код ошибки #ЧИСЛО!. Если хотя бы одно значение из ряда является числовым, функция выполнит расчет, не возвращая код ошибки.
- Не преобразуемые к числам текстовые строки и пустые ячейки не учитываются в расчете. Если ячейка содержит значение 0 (нуль), оно будет учтено.
- Логические данные автоматически преобразуются к числовым: ИСТИНА – 1, ЛОЖЬ – 0 соответственно.
1. Вычислить математическое ожидание:
1) Пуск > Все программы > Microsoft Office > Microsoft Excel
2) Так как функция математического ожидания это т оже самое, что и функция среднего арифметического, то: в пустой ячейке вводим «=», далее нажимаем fx, выбираем функцию СРЗНАЧ, выделяем числовые данные нашей исходной таблицы.
2. Вычислить дисперсию:
Вводим =, далее – fx, “Статистические” – “ДИСП”, выделить числовые данные нашей исходной таблицы.
3. Среднее квадратичесое отклонение (не смещённое):
Вводим =, далее – fx, “Статистические” – “СТАНДТОТКЛОН”, выделить числовые данные нашей исходной таблицы.
4. Среднее квадратическое отклонение (смещённое):
Вводим =, далее – fx, “Статистические” – “СТАНДТОТКЛОН”, выделить числовые данные нашей исходной таблицы.
Вывод: Microsoft Excel является одной из самых удобных компьютерных программ, с помощью которых можно высчитать статические данные. В этом я убедился, когда высчитывал вышеуказанные данные.
Как посчитать математическое ожидание в excel
Проверка статистической гипотезы позволяет сделать строгий вывод о характеристиках генеральной совокупности на основе выборочных данных. Гипотезы бывают разные. Одна из них – это гипотеза о средней (математическом ожидании). Суть ее в том, чтобы на основе только имеющейся выборки сделать корректное заключение о том, где может или не может находится генеральная средняя (точную правду мы никогда не узнаем, но можем сузить круг поиска).
Распределение Стьюдента
Общий подход в проверке гипотез описан здесь, поэтому сразу к делу. Предположим для начала, что выборка извлечена из нормальной совокупности случайных величин X с генеральной средней μ и дисперсией σ 2 . Средняя арифметическая из этой выборки, очевидно, сама является случайной величиной. Если извлечь много таких выборок и посчитать по ним средние, то они также будут иметь нормальное распределение с математическим ожиданием μ и дисперсией
Тогда случайная величина
имеет стандартное нормальное распределение со всеми вытекающими отсюда последствиями. Например, с вероятностью 95% ее значение не выйдет за пределы ±1,96.
Однако такой подход будет корректным, если известна генеральная дисперсия. В реальности, как правило, она не известна. Вместо нее берут оценку – несмещенную выборочную дисперсию:
Возникает вопрос: будет ли генеральная средняя c вероятностью 95% находиться в пределах ±1,96sx̅. Другими словами, являются ли распределения случайных величин
Впервые этот вопрос был поставлен (и решен) одним химиком, который трудился на пивной фабрике Гиннесса в г. Дублин (Ирландия). Химика звали Уильям Сили Госсет и он брал пробы пива для проведения химического анализа. В какой-то момент, видимо, Уильяма стали терзать смутные сомнения на счет распределения средних. Оно получалось немного более размазанным, чем должно быть у нормального распределения.
Собрав математическое обоснование и рассчитав значения функции обнаруженного им распределения, химик из Дублина Уильям Госсет написал заметку, которая была опубликована в мартовском выпуске 1908 года журнала «Биометрика» (главред – Карл Пирсон). Гиннесс строго-настрого запретил выдавать секреты пивоварения, и Госсет подписался псевдонимом Стьюдент.
Несмотря на то что, К. Пирсон уже изобрел распределение Хи-квадрат, все-таки всеобщее представление о нормальности еще доминировало. Никто не собирался думать, что распределение выборочных оценок может быть не нормальным. Поэтому статья У. Госсета осталась практически не замеченной и забытой. И только Рональд Фишер по достоинству оценил открытие Госсета. Фишер использовал новое распределение в своих работах и дал ему название t-распределение Стьюдента. Критерий для проверки гипотез, соответственно, стал t-критерием Стьюдента. Так произошла «революция» в статистике, которая шагнула в эру анализа выборочных данных. Это был краткий экскурс в историю.
Посмотрим, что же мог увидеть У. Госсет. Сгенерируем 20 тысяч нормальных выборок из 6-ти наблюдений со средней (X̅) 50 и среднеквадратичным отклонением (σ) 10. Затем нормируем выборочные средние, используя генеральную дисперсию:
Получившиеся 20 тысяч средних сгруппируем в интервалы длинной 0,1 и подсчитаем частоты. Изобразим на диаграмме фактическое (Norm) и теоретическое (ENorm) распределение частот выборочных средних.

Точки (наблюдаемые частоты) практически совпадают с линией (теоретическими частотами). Оно и понятно, ведь данные взяты из одной и то же генеральной совокупности, а отличия – это лишь ошибки выборки.
Проведем новый эксперимент. Нормируем средние, используя выборочную дисперсию.
Снова подсчитаем частоты и нанесем их на диаграмму в виде точек, оставив для сравнения линию стандартного нормального распределения. Обозначим эмпирическое частоты средних, скажем, через букву t.

Видно, что распределения на этот раз не очень-то и совпадают. Близки, да, но не одинаковы. Хвосты стали более «тяжелыми».
У Госсета-Стьюдента не было последней версии MS Excel, но именно этот эффект он и заметил. Почему так получается? Объяснение заключается в том, что случайная величина
зависит не только от ошибки выборки (числителя), но и от стандартной ошибки средней (знаменателя), которая также является случайной величиной.
Давайте немного разберемся, какое распределение должно быть у такой случайной величины. Вначале придется кое-что вспомнить (или узнать) из математической статистики. Есть такая теорема Фишера, которая гласит, что в выборке из нормального распределения:
1. средняя X̅ и выборочная дисперсия s 2 являются независимыми величинами;
2. соотношение выборочной и генеральной дисперсии, умноженное на количество степеней свободы, имеет распределение χ 2 (хи-квадрат) с таким же количеством степеней свободы, т.е.
где k – количество степеней свободы (на английском degrees of freedom (d.f.))
Вернемся к распределению средней. Разделим числитель и знаменатель выражения
Числитель – это стандартная нормальная случайная величина (обозначим ξ (кси)). Знаменатель выразим из теоремы Фишера.
Тогда исходное выражение примет вид
Это и есть t-критерий Стьюдента в общем виде (стьюдентово отношение). Вывести функцию его распределения можно уже непосредственно, т.к. распределения обеих случайных величин в данном выражении известны. Оставим это удовольствие математикам.
Функция t-распределения Стьюдента имеет довольно сложную для понимания формулу, поэтому не имеет смысла ее разбирать. Вероятности и квантили t-критерия приведены в специальных таблицах распределения Стьюдента и забиты в функции разных ПО вроде Excel.
Итак, вооружившись новыми знаниями, вы сможете понять официальное определение распределения Стьюдента.
Случайной величиной, подчиняющейся распределению Стьюдента с k степенями свободы, называется отношение независимых случайных величин
где ξ распределена по стандартному нормальному закону, а χ 2 k подчиняется распределению χ 2 c k степенями свободы.
Таким образом, формула критерия Стьюдента для средней арифметической
есть частный случай стьюдентова отношения
Из формулы и определения следует, что распределение т-критерия Стьюдента зависит лишь от количества степеней свободы.
При k > 30 t-критерий практически не отличается от стандартного нормального распределения.
В отличие от хи-квадрат, t-критерий может быть одно- и двусторонним. Обычно пользуются двусторонним, предполагая, что отклонение может происходить в обе стороны от средней. Но если условие задачи допускает отклонение только в одну сторону, то разумно применять односторонний критерий. От этого немного увеличивается мощность критерия.
Условия применения t-критерия Стьюдента
Несмотря на то, что открытие Стьюдента в свое время совершило переворот в статистике, t-критерий все же довольно сильно ограничен в возможностях применения, т.к. сам по себе происходит из предположения о нормальном распределении исходных данных. Если данные не являются нормальными (что обычно и бывает), то и t-критерий уже не будет иметь распределения Стьюдента. Однако в силу действия центральной предельной теоремы средняя даже у ненормальных данных быстро приобретает колоколообразную форму распределения.
Рассмотрим, для примера, данные, имеющие выраженный скос вправо, как у распределения хи-квадрат с 5-ю степенями свободы.

Теперь создадим 20 тысяч выборок и будет наблюдать, как меняется распределение средних в зависимости от их объема.
Отличие довольно заметно в малых выборках до 15-20-ти наблюдений. Но дальше оно стремительно исчезает. Таким образом, ненормальность распределения – это, конечно, нехорошо, но некритично.
Больше всего t-критерий «боится» выбросов, т.е. аномальных отклонений. Возьмем 20 тыс. нормальных выборок по 15 наблюдений и в часть из них добавим по одному случайном выбросу.

Картина получается нерадостная. Фактические частоты средних сильно отличаются от теоретических. Использование t-распределения в такой ситуации становится весьма рискованной затеей.
Итак, в не очень малых выборках (от 15-ти наблюдений) t-критерий относительно устойчив к ненормальному распределению исходных данных. А вот выбросы в данных сильно искажают распределение t-критерия, что, в свою очередь, может привести к ошибкам статистического вывода, поэтому от аномальных наблюдений следует избавиться. Часто из выборки удаляют все значения, выходящие за пределы ±2 стандартных отклонения от средней.
Пример проверки гипотезы о математическом ожидании с помощью t- критерия Стьюдента в MS Excel
В Excel есть несколько функций, связанных с t-распределением. Рассмотрим их.
СТЬЮДЕНТ.РАСП – «классическое» левостороннее t-распределение Стьюдента. На вход подается значение t-критерия, количество степеней свободы и опция (0 или 1), определяющая, что нужно рассчитать: плотность или значение функции. На выходе получаем, соответственно, плотность или вероятность того, что случайная величина окажется меньше указанного в аргументе t-критерия, т.е. левосторонний p-value.
СТЬЮДЕНТ.РАСП.2Х – двухсторонне распределение. В качестве аргумента подается абсолютное значение (по модулю) t-критерия и количество степеней свободы. На выходе получаем вероятность получить такое или еще больше значение t-критерия (по модулю), т.е. фактический уровень значимости (p-value).
СТЬЮДЕНТ.РАСП.ПХ – правостороннее t-распределение. Так, 1-СТЬЮДЕНТ.РАСП(2;5;1) = СТЬЮДЕНТ.РАСП.ПХ(2;5) = 0,05097. Если t-критерий положительный, то полученная вероятность – это p-value.
СТЬЮДЕНТ.ОБР.2Х – обратное значение для двухстороннего распределения Стьюдента, т.е. значение t-критерия (по модулю). Также на вход подается уровень значимости α. Только на этот раз отсчет ведется с двух сторон одновременно, поэтому вероятность распределяется на два хвоста. Так, СТЬЮДЕНТ.ОБР(1-0,025;5) = СТЬЮДЕНТ.ОБР.2Х(0,05;5) = 2,57058
СТЬЮДЕНТ.ТЕСТ – функция для проверки гипотезы о равенстве математических ожиданий в двух выборках. Заменяет кучу расчетов, т.к. достаточно указать лишь два диапазона с данными и еще пару параметров. На выходе получим p-value.
ДОВЕРИТ.СТЬЮДЕНТ – расчет доверительного интервала средней с учетом t-распределения.
Рассмотрим такой учебный пример. На предприятии фасуют цемент в мешки по 50кг. В силу случайности в отдельно взятом мешке допускается некоторое отклонение от ожидаемой массы, но генеральная средняя должна оставаться 50кг. В отделе контроля качества случайным образом взвесили 9 мешков и получили следующие результаты: средняя масса (X̅) составила 50,3кг, среднеквадратичное отклонение (s) – 0,5кг.
Согласуется ли полученный результат с нулевой гипотезой о том, что генеральная средняя равна 50кг? Другими словами, можно ли получить такой результат по чистой случайности, если оборудование работает исправно и выдает среднее наполнение 50 кг? Если гипотеза не будет отклонена, то полученное различие вписывается в диапазон случайных колебаний, если же гипотеза будет отклонена, то, скорее всего, в настройках аппарата, заполняющего мешки, произошел сбой. Требуется его проверка и настройка.
Краткое условие в обще принятых обозначениях выглядит так.
Есть основания предположить, что распределение заполняемости мешков подчиняются нормальному распределению (или не сильно от него отличается). Значит, для проверки гипотезы о математическом ожидании можно использовать t-критерий Стьюдента. Случайные отклонения могут происходить в любую сторону, значит нужен двусторонний t-критерий.
Вначале применим допотопные средства: ручной расчет t-критерия и сравнение его с критическим табличным значением. Расчетный t-критерий:
Теперь определим, выходит ли полученное число за критический уровень при уровне значимости α = 0,05. Воспользуемся таблицей для критерия Стьюдента (есть в любом учебнике по статистике).

Сравниваем фактическое (1,8) и табличное значение (2.306). Расчетный критерий оказался меньше табличного. Следовательно, имеющиеся данные не противоречат гипотезе H0 о том, что генеральная средняя равна 50 кг (но и не доказывают ее). Это все, что мы можем узнать, используя таблицы. Можно, конечно, еще p-value попробовать найти, но он будет приближенным. А, как правило, именно p-value используется для проверки гипотез. Поэтому далее переходим в Excel.
Готовой функции для расчета t-критерия в Excel нет. Но это и не страшно, ведь формула t-критерия Стьюдента довольно проста и ее можно легко соорудить прямо в ячейке Excel.

Получили те же 1,8. Найдем вначале критическое значение. Альфа берем 0,05, критерий двусторонний. Нужна функция обратного значения t-распределения для двухсторонней гипотезы СТЬЮДЕНТ.ОБР.2Х.

Полученное значение отсекает критическую область. Наблюдаемый t-критерий в нее не попадает, поэтому гипотеза не отклоняется.
Однако это тот же способ проверки гипотезы с помощью табличного значения. Более информативно будет рассчитать p-value, т.е. вероятность получить наблюдаемое или еще большее отклонение от средней 50кг, если эта гипотеза верна. Потребуется функция распределения Стьюдента для двухсторонней гипотезы СТЬЮДЕНТ.РАСП.2Х.

P-value равен 0,1096, что больше допустимого уровня значимости 0,05 – гипотезу не отклоняем. Но теперь можно судить о степени доказательства. P-value оказался довольно близок к тому уровню, когда гипотеза отклоняется, а это наводит на разные мысли. Например, что выборка оказалась слишком мала для обнаружения значимого отклонения.
Пусть через некоторое время отдел контроля снова решил проверить, как выдерживается стандарт заполняемости мешков. На этот раз для большей надежности было отобрано не 9, а 25 мешков. Интуитивно понятно, что разброс средней уменьшится, а, значит, и шансов найти сбой в системе становится больше.
Допустим, были получены те же значения средней и стандартного отклонения по выборке, что и в первый раз (50,3 и 0,5 соответственно). Рассчитаем t-критерий.
Критическое значение для 24-х степеней свободы и α = 0,05 составляет 2,064. На картинке ниже видно, что t-критерий попадает в область отклонения гипотезы.

Можно сделать вывод о том, что с доверительной вероятностью более 95% генеральная средняя отличается от 50кг. Для большей убедительности посмотрим на p-value (последняя строка в таблице). Вероятность получить среднюю с таким или еще большим отклонением от 50, если гипотеза верна, составляет 0,0062, или 0,62%, что при однократном измерении практически невозможно. В общем, гипотезу отклоняем, как маловероятную.
Расчет доверительного интервала для математического ожидания с помощью t-распределения Стьюдента в Excel
С проверкой гипотез тесно связан еще один статистический метод – расчет доверительных интервалов. Если в полученный интервал попадает значение, соответствующее нулевой гипотезе, то это равносильно тому, что нулевая гипотеза не отклоняется. В противном случае, гипотеза отклоняется с соответствующей доверительной вероятностью. В некоторых случаях аналитики вообще не проверяют гипотез в классическом виде, а рассчитывают только доверительные интервалы. Такой подход позволяет извлечь еще больше полезной информации.
Рассчитаем доверительные интервалы для средней при 9 и 25 наблюдениях. Для этого воспользуемся функцией Excel ДОВЕРИТ.СТЬЮДЕНТ. Здесь, как ни странно, все довольно просто. В аргументах функции нужно указать только уровень значимости α, стандартное отклонение по выборке и размер выборки. На выходе получим полуширину доверительного интервала, то есть значение которое нужно отложить по обе стороны от средней. Проведя расчеты и нарисовав наглядную диаграмму, получим следующее.

Как видно, при выборке в 9 наблюдений значение 50 попадает в доверительный интервал (гипотеза не отклоняется), а при 25-ти наблюдениях не попадает (гипотеза отклоняется). При этом в эксперименте с 25-ю мешками можно утверждать, что с вероятностью 97,5% генеральная средняя превышает 50,1 кг (нижняя граница доверительного интервала равна 50,094кг). А это довольно ценная информация.
Таким образом, мы решили одну и ту же задачу тремя способами:
1. Древним подходом, сравнивая расчетное и табличное значение t-критерия
2. Более современным, рассчитав p-value, добавив степень уверенности при отклонении гипотезы.
3. Еще более информативным, рассчитав доверительный интервал и получив минимальное значение генеральной средней.
Важно помнить, что t-критерий относится к параметрическим методам, т.к. основан на нормальном распределении (у него два параметра: среднее и дисперсия). Поэтому для его успешного применения важна хотя бы приблизительная нормальность исходных данных и отсутствие выбросов.
Напоследок предлагаю видеоролик о том, как рассчитать критерий Стьюдента и проверить гипотезу о генеральной средней в Excel.
Иногда просят объяснить, как делаются такие наглядные диаграммы с распределением. Ниже можно скачать файл, где проводились расчеты для этой статьи.
Рассмотрим равномерное непрерывное распределение. Вычислим математическое ожидание и дисперсию. Сгенерируем случайные значения с помощью функции MS EXCEL СЛЧИС() и надстройки Пакет Анализа, произведем оценку среднего значения и стандартного отклонения.

Равномерно распределенная на отрезке [a; b] случайная величина имеет плотность распределения (вероятности) :
Функция распределения определяется следующим образом:

Равномерное непрерывное распределение (англ. Continuous uniform d istribution или Rectangular distribution ) часто встречается на практике.
Пример1. Например, известно, что гейзер извергается каждые 50 минут. Найти вероятность, того что турист увидит извержение, если будет ждать у гейзера 20 минут. В соответствии с вышеуказанными формулами вероятность увидеть извержение в течение времени наблюдения равна 20/50=0,4, т.е. 40%.
Пример2. Симметричный волчок после раскручивания падает набок. Вертикальная ось волчка после падения указывает на определенный угол от 0 до 360 градусов. Найти вероятность, того что ось волчка укажет на сектор от 90 до 180 градусов. Вероятность равна (180-90)/(360-0)=0,25.

В файле примера приведены графики плотности распределения вероятности и интегральной функции распределения .
Математическое ожидание и дисперсия
Математическое ожидание для равномерного непрерывного распределения вычисляется по формуле =(a+b)/2.
Генерация случайных чисел
Случайные числа, имеющие равномерное непрерывное распределение на отрезке [0; 1), можно сгенерировать с помощью функции MS EXCEL СЛЧИС() . В функции нельзя задать нижнюю и верхнюю границу интервала, но записав формулу =СЛЧИС()*(b-a)+a можно сгенерировать равномерно распределенные числа на любом интервале [a; b).
Примечание : Чтобы сгенерировать случайные числа, имеющие равномерное дискретное распределение , воспользуйтесь функцией СЛУЧМЕЖДУ() .
Сгенерировать случайные числа, извлеченные из непрерывного равномерного распределения, можно также с помощью надстройки Пакет анализа .
Сгенерируем массив из 50 чисел из диапазона [3,3; 7,5). Для этого в окне Генерация случайных чисел установим следующие параметры (см. файл примера лист Генерация ):

Как видно из рисунка выше, в поле Случайное рассеивание установлен необязательный параметр равный 2. Параметр Случайное рассеивание может принимать значение от 1 до 32767. Если установить этот параметр, то MS EXCEL будет каждый раз генерировать один и тот же массив чисел, соответствующий этот значению. Этот подход удобен для генерации одинаковых массивов, например, на различных компьютерах.
Оценка среднего и стандартного отклонения
Нижнюю и верхнюю границу интервала возьмем [3,3; 7,5) и разместим их в ячейках B4:B5 . Сгенерируем 50 чисел ( выборку ) и поместим их в диапазоне С14:С63 .
Математическое ожидание этого распределения =(B4+B5)/2 и равно 5,4. Стандартное отклонение распределения равно =КОРЕНЬ(((B5-B4)^2)/12)=1,21
Чтобы оценить математическое ожидание воспользуемся значениями выборки =СУММ(C14:C63)/СЧЁТ(C14:C63) .
Оценить стандартное отклонение можно с помощью формулы =СТАНДОТКЛОН.В(C14:C63) в MS EXCEL 2010 или =СТАНДОТКЛОН(C14:C63) для более ранних версий.
Чтобы оценить дисперсию используйте формулу =ДИСП.В(C14:C63) в MS EXCEL 2010 или =ДИСП(C14:C63) для более ранних версий. Также можно использовать формулу =СТАНДОТКЛОН.В(C14:C63)^2 .
СОВЕТ : О других распределениях MS EXCEL можно прочитать в статье Распределения случайной величины в MS EXCEL .
Среднее выборки или выборочное среднее (sample average, mean) представляет собой среднее арифметическое всех значений выборки .

В MS EXCEL для вычисления среднего выборки можно использовать функцию СРЗНАЧ() . В качестве аргументов функции нужно указать ссылку на диапазон, содержащий значения выборки .
Выборочное среднее является «хорошей» (несмещенной и эффективной) точечной оценкой математического ожидания случайной величины (см. ниже ), т.е. среднего значения исходного распределения, из которого взята выборка .
Примечание : О вычислении доверительных интервалов при оценке математического ожидания можно прочитать, например, в статье Доверительный интервал для оценки среднего (дисперсия известна) в MS EXCEL .
Некоторые свойства среднего арифметического :
- Сумма всех отклонений от среднего значения равна 0:

- Если к каждому из значений x i прибавить одну и туже константу с , то среднее арифметическое увеличится на такую же константу;
- Если каждое из значений x i умножить на одну и туже константу с , то среднее арифметическое умножится на такую же константу.
Математическое ожидание
Среднее значение можно вычислить не только для выборки, но для случайной величины, если известно ее распределение . В этом случае среднее значение имеет специальное название — Математическое ожидание. Математическое ожидание характеризует «центральное» или среднее значение случайной величины.
Примечание : В англоязычной литературе имеется множество терминов для обозначения математического ожидания : expectation, mathematical expectation, EV (Expected Value), average, mean value, mean, E[X] или first moment M[X].
Если случайная величина имеет дискретное распределение , то математическое ожидание вычисляется по формуле:

где x i – значение, которое может принимать случайная величина, а р(x i ) – вероятность, что случайная величина примет это значение.
Если случайная величина имеет непрерывное распределение , то математическое ожидание вычисляется по формуле:

где р(x) – плотность вероятности (именно плотность вероятности , а не вероятность, как в дискретном случае).
Для каждого распределения, из представленных в MS EXCEL, Математическое ожидание можно вычислить аналитически, как функцию от параметров распределения (см. соответствующие статьи про распределения ). Например, для Биномиального распределения среднее значение равно произведению его параметров: n*p (см. файл примера ).

Свойства математического ожидания
E[a*X]=a*E[X], где а — const
E[E[X]]=E[X] — т.к. величина E[X] — является const
E[X+Y]=E[X]+E[Y] — работает даже для случайных величин не являющихся независимыми.
СОВЕТ : Про другие показатели распределения — Дисперсию и Стандартное отклонение, можно прочитать в статье Дисперсия и стандартное отклонение в MS EXCEL .
Среднее выборки или выборочное среднее (sample average, mean) представляет собой среднее арифметическое всех значений выборки.
В MS EXCEL для вычисления среднего выборки можно использовать функцию СРЗНАЧ() . В качестве аргументов функции нужно указать ссылку на диапазон, содержащий значения выборки.
Выборочное среднее является «хорошей» (несмещенной и эффективной) точечной оценкой математического ожидания случайной величины (см. ниже), т.е. среднего значения исходного распределения, из которого взята выборка.
Примечание: О вычислении доверительных интервалов при оценке математического ожидания можно прочитать, например, в статье Доверительный интервал для оценки среднего (дисперсия известна) в MS EXCEL.
Некоторые свойства среднего арифметического:
- Сумма всех отклонений от среднего значения равна 0:
- Если к каждому из значений xi прибавить одну и туже константу с, то среднее арифметическое увеличится на такую же константу;
- Если каждое из значений xi умножить на одну и туже константу с, то среднее арифметическое умножится на такую же константу.
Математическое ожидание
Примечание: В англоязычной литературе имеется множество терминов для обозначения математического ожидания: expectation, mathematical expectation, EV (Expected Value), average, mean value, mean, E[X] или first moment M[X].
Если случайная величина имеет дискретное распределение, то математическое ожидание вычисляется по формуле:
где xi – значение, которое может принимать случайная величина, а р(xi) – вероятность, что случайная величина примет это значение.
Если случайная величина имеет непрерывное распределение, то математическое ожидание вычисляется по формуле:
где р(x) – плотность вероятности (именно плотность вероятности, а не вероятность, как в дискретном случае).
Для каждого распределения, из представленных в MS EXCEL, Математическое ожидание можно вычислить аналитически, как функцию от параметров распределения (см. соответствующие статьи про распределения). Например, для Биномиального распределения среднее значение равно произведению его параметров: n*p (см. файл примера ).
Функция СРОТКЛ в Excel используется для анализа числового ряда, передаваемого в качестве аргумента, и возвращает число, соответствующее среднему значению, рассчитанному для модулей отклонений относительно среднего арифметического для исследуемого ряда.
Примеры методов анализа числовых рядов в Excel
Смысл данной функции становится предельно ясен после рассмотрения примера. Допустим, на протяжении суток каждые 3 часа фиксировались показатели температуры воздуха. Был получен следующий ряд значений: 16, 14, 17, 21, 25, 26, 22, 18. С помощью функции СРЗНАЧ можно определить среднее значение температуры – 19,88 (округлим до 20). Для определения отклонения каждого значения от среднего необходимо вычесть из него полученное среднее значение. Например, для первого замера температуры это будет равно 16-20=-4. Получаем ряд значений: -4, -6, -3, 1, 5, 6, 2, -2. Поскольку СРОТКЛ по определению работает с модулями отклонений, итоговый ряд значений имеет вид: 4, 6, 3, 1, 5, 6, 2, 2. Теперь нужно получить среднее значение для данного ряда с помощью функции СРЗНАЧ – примерно 3,63. Именно таков алгоритм работы рассматриваемой функции.
Пример 1. Имеются два ряда значений, представляющих собой результаты наблюдений одного и того же физического явления, сделанные в ходе двух различных экспериментов. Определить, среднее отклонение от среднего значения результатов для какого эксперимента является максимальным?
Вид таблицы данных:

Используем следующую формулу:
Сравниваем результаты, возвращаемые функцией СРОТКЛ для первого и второго ряда чисел с использованием функции ЕСЛИ, возвращаем соответствующий результат.

В результате мы получили среднее отклонение от среднего значения. Это весьма интересная функция для технического анализа финансовых рынков, прогнозов курсов валют и даже позволяет повысить шансы выигрышей в лотереях.
Формула расчета линейного коэффициента вариации в Excel
Пример 2. Студенты сдали экзамены по различным предметам. Определить число студентов, которые удовлетворяют следующему критерию успеваемости – линейный коэффициент вариации оценок не превышает 15%.
Вид таблицы данных:

Линейный коэффициент вариации определяется как отношение среднего отклонения к среднему значению. Для расчета используем следующую формулу:
Растянем ее вниз по столбцу и получим следующие значения:

Для определения числа неуспешных студентов по указанному критерию используем функцию:

Правила использования функции СРОТКЛ в Excel
Функция имеет следующий синтаксис:
=СРОТКЛ( число1 ;[число2];. )
Название работы: Расчет математического ожидания, среднего квадратического отклонения, дисперсии, с помощью программы Microsoft Excel
Категория: Лабораторная работа
Предметная область: Информатика, кибернетика и программирование
Описание: Так как функция математического ожидания это т оже самое что и функция среднего арифметического то: в пустой ячейке вводим = далее нажимаем fx выбираем функцию СРЗНАЧ выделяем числовые данные нашей исходной таблицы. Вычислить дисперсию: Вводим = далее fx Статистические ДИСП выделить числовые данные.
Дата добавления: 2014-02-08
Размер файла: 33.5 KB
Работу скачали: 269 чел.
Национальный Технический Университет Украины
„Киевский Политехнический Институт”
Факультет социологии и права
Лабораторная работа №2
Математические методы социологических исследований
„ Расчет математического ожидания, среднего квадратического отклонения, дисперсии, с помощью программы Microsoft Excel”
студент 2 курса
1. Вычислить математическое ожидание:
1) Пуск > Все программы > Microsoft Office > Microsoft Excel
2) Так как функция математического ожидания это т оже самое, что и функция среднего арифметического, то: в пустой ячейке вводим «=», далее нажимаем fx, выбираем функцию СРЗНАЧ, выделяем числовые данные нашей исходной таблицы.
2. Вычислить дисперсию:
3. Среднее квадратичесое отклонение (не смещённое):
4. Среднее квадратическое отклонение (смещённое):
Вывод: Microsoft Excel является одной из самых удобных компьютерных программ, с помощью которых можно высчитать статические данные. В этом я убедился, когда высчитывал вышеуказанные данные.
