Выборочные среднее и дисперсия
Пусть
для изучения генеральной совокупности
относительно количественного признака
Xизвлечена выборка объемаn.
Выборочным
средним
![]() называют среднее арифметическое значение
называют среднее арифметическое значение
признака выборочной совокупности. Если
все значения![]() признака
признака
выборки объемаnразличны,
то![]() .
.
Если
значения признака
![]() имеют
имеют
частоты![]() соответственно, причем
соответственно, причем![]() ,
,
то![]() .
.
Выборочное
среднее, найденное по данным одной
выборки, равно определенному числу. При
извлечении других выборок того же объема
выборочное среднее будет меняться от
выборки к выборке. То есть выборочное
среднее можно рассматривать как случайную
величину и говорить о его распределениях
(теоретическом и эмпирическом) и о
числовых характеристиках этого
распределения (например, о математическом
ожидании и дисперсии).
Для
охарактеризования рассеяния наблюдаемых
значений количественного признака
выборки вокруг среднего значения
![]() вводитсявыборочная дисперсия.Выборочной дисперсией
вводитсявыборочная дисперсия.Выборочной дисперсией ![]() называют среднее арифметическое
называют среднее арифметическое
квадратов отклонения наблюдаемых
значений признака от их среднего значения![]() .
.
Если все значения![]() признака
признака
выборки объемаnразличны,
то
![]() .
.
Если
значения признака
![]() имеют
имеют
частоты![]() соответственно, причем
соответственно, причем![]() ,
,
то![]() .
.
Аналогично
выборочным среднему и дисперсии
определяются генеральные среднее
и дисперсия, характеризующие
генеральную совокупность в целом. Для
расчета этих характеристик достаточно
в вышеприведенных соотношениях заменить
объем выборкиnна объем
генеральной совокупностиN.
Фундаментальное
значение для практики имеет нахождение
среднего и дисперсии признака генеральной
совокупностипо соответствующим
известнымвыборочнымпараметрам.
Можно показать, чтовыборочное
среднееявляется несмещенной
состоятельной оценкой генерального
среднего. В то же время, несмещенной
состоятельной оценкой генеральной
дисперсии оказывается не выборочная
дисперсия![]() ,
,
а так называемая “исправленная”
выборочная дисперсия, равная![]() .
.
Таким
образом, в качестве оценок генерального
среднего и дисперсии в математической
статистике принимают выборочнее среднее
и исправленную выборочную дисперсию.
Надежность и
доверительный интервал.
До
сих пор мы рассматривали точечные
оценки, т.е. такие оценки, которые
определяются одним числом. При выборке
малого
объема
точечная оценка может значительно
отличаться от оцениваемого параметра,
что приводит к грубым ошибкам. В связи
с этим при небольшом объеме выборки
пользуются интервальными оценками.
Интервальнойназывают оценку, определяющуюся двумя
числами – концами интервала. Пусть
найденная по данным выборки статистическая
характеристика![]() служит оценкой неизвестного параметра
служит оценкой неизвестного параметра![]() .
.
Очевидно,![]() тем точнее определяет параметр
тем точнее определяет параметр![]() ,
,
чем меньше абсолютная величина разности![]() .
.
Другими словами, если![]() и
и![]() ,
,
то чем меньшеd, тем
точнее оценка. Таким образом, положительное
числоdхарактеризуетточность оценки.
Статистические
методы не позволяютутверждать,
что оценка![]() удовлетворяет неравенству
удовлетворяет неравенству![]() ;
;
можно говорить лишь о вероятности, с
которой это неравенство осуществляется.
Надежностью
(доверительной вероятностью)оценки![]() по
по![]() называют вероятностьg,
называют вероятностьg,
с которой осуществляется неравенство![]() .
.
Обычно надежность оценки задается
заранее, причем в качествеgберут число, близкое к единице – как
правило 0,95; 0,99 или 0,999.
Пусть
вероятность того, что
![]() равнаg:
равнаg:![]() .
.
Заменим
неравенство
![]() равносильным ему двойным неравенством
равносильным ему двойным неравенством
![]() .
.
Это
соотношение следует понимать так:
вероятность того, что интервал
![]() заключает в себе (покрывает) неизвестный
заключает в себе (покрывает) неизвестный
параметрQ, равна![]() .
.
Таким
образом, доверительнымназывают
интервал![]() ,
,
который покрывает неизвестный параметр
с заданной надежностью![]() .
.
Величину
1 – g=aназывают уровнем значимости или
вероятностью ошибки.
Для
построения интервальной оценки параметра
необходимо знать закон его распределения
как случайной величины
Лекция
14. Доверительные интервалы для
математического ожидания и дисперсии
-
Доверительный
интервал для математического ожидания
нормального распределения при известной
дисперсии.
Пусть
количественный признак Xгенеральной совокупности распределен
нормально, причем среднее квадратическое
отклонениеsэтого
распределенияизвестно. Требуется
оценить неизвестное математическое
ожидание![]() по выборочному среднему
по выборочному среднему![]() .
.
Найдем доверительные интервалы,
покрывающие параметрaс
надежностью![]() .
.
Будем
рассматривать выборочное среднее
![]() как случайную величину
как случайную величину![]() (т.к.
(т.к.![]() меняется
меняется
от выборки к выборке) и выборочные
значения![]() – как одинаково распределенные независимые
– как одинаково распределенные независимые
случайные величины![]() (эти числа также меняются от выборки к
(эти числа также меняются от выборки к
выборке). Другими словами, математическое
ожидание каждой из этих величин равно![]() и среднее квадратическое отклонение -s. Так как случайная
и среднее квадратическое отклонение -s. Так как случайная
величинаXраспределена
нормально, то и выборочное среднее![]() также распределено нормально. Параметры
также распределено нормально. Параметры
распределения![]() равны
равны![]() .
.
Потребуем,
чтобы выполнялось соотношение
![]() ,
,
где
![]() – заданная надежность. Используем формулу
– заданная надежность. Используем формулу![]() .
.
Заменим
Xна![]() иsна
иsна![]() и получим
и получим
![]()
где
![]() .
.
Выразив из последнего равенства![]() ,
,
получим![]()
Так
как вероятность Pзадана
и равна![]() ,
,
окончательно имеем
![]() .
.
Таким
образом, с надежностью
![]() можно утверждать, что доверительный
можно утверждать, что доверительный
интервал![]() покрывает
покрывает
неизвестный параметрa,
причем точность оценки равна![]() .
.
Число
![]() определяется из равенства
определяется из равенства![]() ;
;
по таблице функции Лапласа находят
аргумент![]() ,
,
которому соответствует значение функции
Лапласа, равное![]() .
.
Отметим
два момента: 1) при возрастании объемавыборкиnчисло![]() убывает и, следовательно, точность
убывает и, следовательно, точность
оценки увеличивается, 2) увеличениенадежностиоценки![]() приводит к увеличению
приводит к увеличению![]() (так как функция Лапласа возрастающая
(так как функция Лапласа возрастающая
функция) и, следовательно, к возрастанию![]() ,
,
то естьувеличение надежностиоценки влечет за собойуменьшение
ее точности.
Если
требуется оценить математическое
ожидание с наперед заданной точностью
![]() и надежностью
и надежностью![]() ,
,
то минимальный объем выборки, который
обеспечит эту точность, находят по
формуле
![]() ,
,
следующей
из равенства
![]() .
.
-
Доверительный
интервал для математического ожидания
нормального распределения при неизвестной
дисперсии
Пусть
количественный признак Xгенеральной совокупности распределен
нормально, причем среднее квадратическое
отклонениеsэтого
распределениянеизвестно.
Требуется оценить неизвестное
математическое ожидание с помощью
доверительных интервалов.
Оказывается,
что по данным выборки можно построить
случайную величину
![]() ,
,
которая
имеет распределение Стьюдента с
![]() степенями свободы. В последнем выражении
степенями свободы. В последнем выражении
–![]() –
–
выборочное среднее,![]() – исправленное среднее квадратическое
– исправленное среднее квадратическое
отклонение,![]() – объем выборки; возможные значения
– объем выборки; возможные значения
случайной величиныTмы
будем обозначать черезt.
Плотность распределения Стьюдента
имеет вид
![]() ,
,
где
![]() некоторая постоянная, выражающаяся
некоторая постоянная, выражающаяся
через гамма – функции.
Несколько
слов о распределении Стьюдента. Пусть
![]() – независимые стандартные нормальные
– независимые стандартные нормальные
величины. Тогда случайная величина
имеет
распределение Стьюдента (В.
Госсет) с![]() степенями свободы. При росте числа
степенями свободы. При росте числа
степеней свободы распределение Стьюдента
стремится к нормальному распределению
и уже при![]() использование нормального распределения
использование нормального распределения
дает хорошие результаты.
Как
видно, распределение Стьюдента
определяется параметром n– объемом выборки (или, что то же самое
– числом степеней свободы![]() )
)
и не зависит от неизвестных параметров![]() .
.
Поскольку![]() – четная функция отt, то
– четная функция отt, то
вероятность выполнения неравенства![]()
определяется
следующим образом: .
.
Заменив
неравенство в круглых скобках двойным
неравенством, получим выражение для
искомого доверительного интервала
![]()
Итак,
с помощью распределения Стьюдента
найден доверительный интервал
![]() ,
,
покрывающий неизвестный параметрaс надежностью![]() .
.
По таблице распределения Стьюдента и
заданнымnи![]() можно найти
можно найти![]() и
и
используя найденные по выборке![]() и
и![]() ,
,
, можно определить доверительный
интервал.
Пример.
Количественный признакXгенеральной совокупности распределен
нормально. По выборке объемаn= 16 найдены генеральное среднее![]() и исправленное среднее квадратическое
и исправленное среднее квадратическое
отклонение![]() .
.
Требуется оценить неизвестное
математическое ожидание при помощи
доверительного интервала с надежностью
0,95.
Решение.
Найдем![]() по таблице распределения Стьюдента,
по таблице распределения Стьюдента,
используя значения![]() .
.
Этот параметр оказывается равным 2,13.
Найдем границы доверительного интервала:
![]()
![]()
То
есть с надежностью 0,95 неизвестный
параметр aзаключен в
доверительном интервале![]()
Можно показать,
что при возрастании объема выборки nраспределение Стьюдента стремится к
нормальному. Поэтому практически приn> 30 можно вместо него
пользоваться нормальным распределением.
Прималыхnэто
приводит к значительным ошибкам.
3.
Доверительный интервал для оценки
среднего квадратического отклонения
s
нормального распределения
Пусть
количественный признак Xгенеральной совокупности распределен
нормально и требуется оценить неизвестное
генеральное среднее квадратическое
отклонениеsпо
исправленному выборочному среднему
квадратическому отклонениюs.
Найдем доверительные интервалы,
покрывающие параметрsс заданной надежностью![]() .
.
Потребуем,
чтобы выполнялось соотношение
![]() или
или
![]()
Преобразуем
двойное неравенство
![]() в равносильное неравенство
в равносильное неравенство![]() и обозначимd/s=q. Имеем
и обозначимd/s=q. Имеем![]() (A)
(A)
и
необходимо найти q. С этой
целью введем в рассмотрение случайную
величину![]()
Оказывается,
величина
![]() распределена по закону
распределена по закону![]() сn– 1 степенями свободы.
сn– 1 степенями свободы.
Несколько
слов о распределении хи-квадрат. Если
![]() – независимые стандартные нормальные
– независимые стандартные нормальные
величины, то говорят, что случайная
величина![]()
имеет
распределение хи-квадратс![]() степенями свободы.
степенями свободы.
Плотность
распределения cимеет
вид

Это
распределение не зависит от оцениваемого
параметра s, а зависит
только от объема выборкиn.
Преобразуем
неравенство (A) так, чтобы
оно приняло вид![]() .
.
Вероятность этого неравенства равна
заданной вероятности![]() ,
,
т.е. .
.
Предполагая,
что q< 1, перепишем (A)
в виде
![]()
![]() ,
,
далее, умножим все
члены неравенства на
![]() :
:
![]()
![]() или
или![]() .
.
Вероятность того,
что это неравенство, а также равносильное
ему неравенство (A) будет
справедливо, равна
 .
.
Из этого уравнения
можно по заданным
![]() найти
найти![]() ,
,
используя имеющиеся расчетные таблицы.
Вычислив по выборке![]() и найдя по таблице
и найдя по таблице![]() ,
,
получим искомый интервал (A1),
покрывающийsс
заданной надежностью![]() .
.
Пример.
Количественный признакXгенеральной совокупности распределен
нормально. По выборке объемаn= 25 найдено исправленное среднее
квадратическое отклонениеs= 0.8. Найти доверительный интервал,
покрывающий генеральное среднее
квадратическое отклонениеsс надежностью 0,95.
Решение.
По заданным![]() по таблице находим значениеq= 0.32. Искомый доверительный интервал
по таблице находим значениеq= 0.32. Искомый доверительный интервал
есть
![]() .
.
Мы предполагали,
что q< 1. Если это не так,
то мы придем к соотношениям
![]() ,
,
и значение q>1 может быть найдено из уравнения
![]()
Лекция
14. Доверительные интервалы для
математического ожидания и дисперсии
-
Доверительный
интервал для математического ожидания
нормального распределения при известной
дисперсии.
Пусть
количественный признак Xгенеральной совокупности распределен
нормально, причем среднее квадратическое
отклонениеsэтого
распределенияизвестно. Требуется
оценить неизвестное математическое
ожидание![]() по выборочному среднему
по выборочному среднему![]() .
.
Найдем доверительные интервалы,
покрывающие параметрaс
надежностью![]() .
.
Будем
рассматривать выборочное среднее
![]() как случайную величину
как случайную величину![]() (т.к.
(т.к.![]() меняется
меняется
от выборки к выборке) и выборочные
значения![]() – как одинаково распределенные независимые
– как одинаково распределенные независимые
случайные величины![]() (эти числа также меняются от выборки к
(эти числа также меняются от выборки к
выборке). Другими словами, математическое
ожидание каждой из этих величин равно![]() и среднее квадратическое отклонение -s. Так как случайная
и среднее квадратическое отклонение -s. Так как случайная
величинаXраспределена
нормально, то и выборочное среднее![]() также распределено нормально. Параметры
также распределено нормально. Параметры
распределения![]() равны
равны![]() .
.
Потребуем,
чтобы выполнялось соотношение
![]() ,
,
где
![]() – заданная надежность. Используем формулу
– заданная надежность. Используем формулу![]() .
.
Заменим
Xна![]() иsна
иsна![]() и получим
и получим
![]()
где
![]() .
.
Выразив из последнего равенства![]() ,
,
получим![]()
Так
как вероятность Pзадана
и равна![]() ,
,
окончательно имеем
![]() .
.
Таким
образом, с надежностью
![]() можно утверждать, что доверительный
можно утверждать, что доверительный
интервал![]() покрывает
покрывает
неизвестный параметрa,
причем точность оценки равна![]() .
.
Число
![]() определяется из равенства
определяется из равенства![]() ;
;
по таблице функции Лапласа находят
аргумент![]() ,
,
которому соответствует значение функции
Лапласа, равное![]() .
.
Отметим
два момента: 1) при возрастании объемавыборкиnчисло![]() убывает и, следовательно, точность
убывает и, следовательно, точность
оценки увеличивается, 2) увеличениенадежностиоценки![]() приводит к увеличению
приводит к увеличению![]() (так как функция Лапласа возрастающая
(так как функция Лапласа возрастающая
функция) и, следовательно, к возрастанию![]() ,
,
то естьувеличение надежностиоценки влечет за собойуменьшение
ее точности.
Если
требуется оценить математическое
ожидание с наперед заданной точностью
![]() и надежностью
и надежностью![]() ,
,
то минимальный объем выборки, который
обеспечит эту точность, находят по
формуле
![]() ,
,
следующей
из равенства
![]() .
.
-
Доверительный
интервал для математического ожидания
нормального распределения при неизвестной
дисперсии
Пусть
количественный признак Xгенеральной совокупности распределен
нормально, причем среднее квадратическое
отклонениеsэтого
распределениянеизвестно.
Требуется оценить неизвестное
математическое ожидание с помощью
доверительных интервалов.
Оказывается,
что по данным выборки можно построить
случайную величину
![]() ,
,
которая
имеет распределение Стьюдента с
![]() степенями свободы. В последнем выражении
степенями свободы. В последнем выражении
–![]() –
–
выборочное среднее,![]() – исправленное среднее квадратическое
– исправленное среднее квадратическое
отклонение,![]() – объем выборки; возможные значения
– объем выборки; возможные значения
случайной величиныTмы
будем обозначать черезt.
Плотность распределения Стьюдента
имеет вид
![]() ,
,
где
![]() некоторая постоянная, выражающаяся
некоторая постоянная, выражающаяся
через гамма – функции.
Несколько
слов о распределении Стьюдента. Пусть
![]() – независимые стандартные нормальные
– независимые стандартные нормальные
величины. Тогда случайная величина
имеет
распределение Стьюдента (В.
Госсет) с![]() степенями свободы. При росте числа
степенями свободы. При росте числа
степеней свободы распределение Стьюдента
стремится к нормальному распределению
и уже при![]() использование нормального распределения
использование нормального распределения
дает хорошие результаты.
Как
видно, распределение Стьюдента
определяется параметром n– объемом выборки (или, что то же самое
– числом степеней свободы![]() )
)
и не зависит от неизвестных параметров![]() .
.
Поскольку![]() – четная функция отt, то
– четная функция отt, то
вероятность выполнения неравенства![]()
определяется
следующим образом: .
.
Заменив
неравенство в круглых скобках двойным
неравенством, получим выражение для
искомого доверительного интервала
![]()
Итак,
с помощью распределения Стьюдента
найден доверительный интервал
![]() ,
,
покрывающий неизвестный параметрaс надежностью![]() .
.
По таблице распределения Стьюдента и
заданнымnи![]() можно найти
можно найти![]() и
и
используя найденные по выборке![]() и
и![]() ,
,
, можно определить доверительный
интервал.
Пример.
Количественный признакXгенеральной совокупности распределен
нормально. По выборке объемаn= 16 найдены генеральное среднее![]() и исправленное среднее квадратическое
и исправленное среднее квадратическое
отклонение![]() .
.
Требуется оценить неизвестное
математическое ожидание при помощи
доверительного интервала с надежностью
0,95.
Решение.
Найдем![]() по таблице распределения Стьюдента,
по таблице распределения Стьюдента,
используя значения![]() .
.
Этот параметр оказывается равным 2,13.
Найдем границы доверительного интервала:
![]()
![]()
То
есть с надежностью 0,95 неизвестный
параметр aзаключен в
доверительном интервале![]()
Можно показать,
что при возрастании объема выборки nраспределение Стьюдента стремится к
нормальному. Поэтому практически приn> 30 можно вместо него
пользоваться нормальным распределением.
Прималыхnэто
приводит к значительным ошибкам.
3.
Доверительный интервал для оценки
среднего квадратического отклонения
s
нормального распределения
Пусть
количественный признак Xгенеральной совокупности распределен
нормально и требуется оценить неизвестное
генеральное среднее квадратическое
отклонениеsпо
исправленному выборочному среднему
квадратическому отклонениюs.
Найдем доверительные интервалы,
покрывающие параметрsс заданной надежностью![]() .
.
Потребуем,
чтобы выполнялось соотношение
![]() или
или
![]()
Преобразуем
двойное неравенство
![]() в равносильное неравенство
в равносильное неравенство![]() и обозначимd/s=q. Имеем
и обозначимd/s=q. Имеем![]() (A)
(A)
и
необходимо найти q. С этой
целью введем в рассмотрение случайную
величину![]()
Оказывается,
величина
![]() распределена по закону
распределена по закону![]() сn– 1 степенями свободы.
сn– 1 степенями свободы.
Несколько
слов о распределении хи-квадрат. Если
![]() – независимые стандартные нормальные
– независимые стандартные нормальные
величины, то говорят, что случайная
величина![]()
имеет
распределение хи-квадратс![]() степенями свободы.
степенями свободы.
Плотность
распределения cимеет
вид

Это
распределение не зависит от оцениваемого
параметра s, а зависит
только от объема выборкиn.
Преобразуем
неравенство (A) так, чтобы
оно приняло вид![]() .
.
Вероятность этого неравенства равна
заданной вероятности![]() ,
,
т.е. .
.
Предполагая,
что q< 1, перепишем (A)
в виде
![]()
![]() ,
,
далее, умножим все
члены неравенства на
![]() :
:
![]()
![]() или
или![]() .
.
Вероятность того,
что это неравенство, а также равносильное
ему неравенство (A) будет
справедливо, равна
 .
.
Из этого уравнения
можно по заданным
![]() найти
найти![]() ,
,
используя имеющиеся расчетные таблицы.
Вычислив по выборке![]() и найдя по таблице
и найдя по таблице![]() ,
,
получим искомый интервал (A1),
покрывающийsс
заданной надежностью![]() .
.
Пример.
Количественный признакXгенеральной совокупности распределен
нормально. По выборке объемаn= 25 найдено исправленное среднее
квадратическое отклонениеs= 0.8. Найти доверительный интервал,
покрывающий генеральное среднее
квадратическое отклонениеsс надежностью 0,95.
Решение.
По заданным![]() по таблице находим значениеq= 0.32. Искомый доверительный интервал
по таблице находим значениеq= 0.32. Искомый доверительный интервал
есть
![]() .
.
Мы предполагали,
что q< 1. Если это не так,
то мы придем к соотношениям
![]() ,
,
и значение q>1 может быть найдено из уравнения
![]()
Лекция
15. Проверка статистических гипотез.
Нулевая и альтернативная гипотезы,
статистический критерий. Ошибки первого
и второго рода. Этапы проверки
статистической гипотезы. Критерий
согласия Пирсона о виде распределения.
На прошлой
лекции мы рассматривали задачу построения
доверительных интервалов для неизвестных
параметров генеральной совокупности.
Сегодня мы продолжим изучение основных
задач математической статистики и
перейдем к вопросупроверки
статистических гипотез.
Проверка
статистических гипотез представляет
собой важнейший этап процесса принятия
решения в управленческой деятельности,
позволяя проводить подготовительный
этап предстоящих действий с учетом
реальных характеристик процесса
производства, контроля качества
продукции, коммерческой деятельности,
и т.п.
Как известно,
закон распределенияопределяет
количественные характеристики генеральной
совокупности.
Если закон
распределения неизвестен, но есть
основания предположить, что он имеет
определенный вид (например, А), то
выдвигают гипотезу: генеральная
совокупность распределена по закону
А. В этой гипотезе речь идето виде
предполагаемого распределения.
Часто закон
распределения известен, но неизвестны
его параметры. Если есть основания
предположить, что неизвестный параметр![]() равен определенному значению
равен определенному значению![]() ,
,
то может выдвигаться гипотеза![]() .
.
В этой гипотезе речь идет опредполагаемой
величине параметраизвестного
распределения.
Возможны и другие
гипотезы: о равенстве параметров двух
или нескольких распределений, о
независимости выборок и т. д.
Приведем несколько
задач, которые могут быть решены с
помощью проверки статистических гипотез.
1. Используется
два метода измерения одной и той же
величины. Первый метод дает оценки
![]() этой величины, второй –
этой величины, второй –![]() .
.
Требуется определить, обеспечивают ли
оба методаодинаковую точность
измерений.
2. Контроль точности
работы некоторой производственной
системы. Получаемые характеристики
выпускаемой продукции характеризуются
некоторым разбросом (дисперсией). Обычно
величина этого разброса не должна
превышать некоторого заранее заданного
уровня. Требуется определить, обеспечивает
ли система (например, линия сборки или
отдельный станок) заданную точность.
Итак, статистической
называют гипотезу о виде неизвестного
распределения или о параметрах известных
распределений. Примеры статистических
гипотез: генеральная совокупность
распределена по закону Пуассона;
дисперсии двух нормальных распределений
равны между собой.
Наряду с выдвинутой
гипотезой всегда рассматривают и
противоречащую ей гипотезу. Если
выдвинутая гипотеза будет отвергнута,
то принимается противоречащая гипотеза.
Нулевой (основной)
называют выдвинутую гипотезу![]() .
.
Альтернативной
(конкурирующей) называют
гипотезу![]() ,
,
которая противоречит нулевой. Например,
если нулевая гипотеза состоит в
предположении, что математическое
ожидание нормального распределения
равно 5, то альтернативная гипотеза,
например, может состоять в предположении,
что![]() .
.
Кратко это записывают так:![]() .
.
Простойназывают гипотезу, содержащую только
одно предположение. Например, если![]() – параметр показательного распределения,
– параметр показательного распределения,
то гипотеза![]() – простая.Сложной называют
– простая.Сложной называют
гипотезу, состоящую из конечного или
бесконечного числа простых гипотез.
Например, сложная гипотеза![]() состоит из бесконечного множества
состоит из бесконечного множества
простых гипотез вида![]() ,
,
где![]() – любое число, большее 3.
– любое число, большее 3.
Выдвинутая гипотеза
может быть правильной или неправильной,
поэтому возникает необходимость ее
проверки. Так как проверку производят
статистическими методами, то ее называют
статистической. В итогестатистической проверки гипотезыв двух случаях может быть принято
неправильное решение, т.е. могут быть
допущены ошибки двух родов.
Ошибка первого
рода состоит в том, что будетотвергнута правильнаягипотеза.
Ошибка второго рода состоит
в том, что будетпринята неправильнаягипотеза. Следует отметить, что последствия
ошибок могут оказаться различными. Если
отвергнуто правильное решение “продолжать
строительство жилого дома”, то эта
ошибка первого рода повлечет материальный
ущерб; если же принято неправильное
решение “продолжать строительство”
несмотря на опасность обвала дома, то
эта ошибка второго рода может привести
к многочисленным жертвам. Иногда,
наоборот, ошибка первого рода влечет
более тяжелые последствия.
Естественно,
правильное решение может быть принято
также в двух случаях, когда принимается
правильнаягипотеза илиотвергается
невернаягипотеза.
Вероятность
совершения ошибки первого роданазываютуровнем значимостии
обозначают![]() .
.
Чаще всего уровень значимости принимают
равным 0,05 или 0,01. Если, например, принят
уровень значимости 0,05, то это означает,
что в пяти случаях из ста имеется риск
допустить ошибку первого рода (отвергнуть
правильную гипотезу).
Макеты страниц
Так как задача оценки среднего значения случайной величины по существу идентична с задачей оценки среднего значения стационарного в широком смысле вероятностного процесса, то мы будем рассматривать одновременно обе эти задачи. Пусть х — действительная случайная величина с конечным средним значением  и конечной дисперсией
и конечной дисперсией  , а
, а  — выборочные функции стационарного в широком смысле действительного вероятностного процесса, имеющая те же конечные средние значения
— выборочные функции стационарного в широком смысле действительного вероятностного процесса, имеющая те же конечные средние значения  и дисперсию
и дисперсию  Предположим теперь, что мы выполнили N измерений случайной величины или выборочной функции вероятностного процесса. Пусть, далее,
Предположим теперь, что мы выполнили N измерений случайной величины или выборочной функции вероятностного процесса. Пусть, далее,  где
где  есть значение
есть значение  выборки случайной величины, пусть
выборки случайной величины, пусть  — значение выборочной функции в момент
— значение выборочной функции в момент  и пусть
и пусть  случайная величина, описывающая возможные значения, которые может принимать
случайная величина, описывающая возможные значения, которые может принимать  или
или  Заметим, что
Заметим, что  имеет те же статистические свойства, что и х или
имеет те же статистические свойства, что и х или  . В частности, для всех
. В частности, для всех 

В § 4.1 мы указали, что среднее значение случайной величины является обобщением понятия арифметического среднего выборочной функции. Имея это в виду, рассмотрим выборочное среднее  , определяемое как арифметическое среднее N случайных величин
, определяемое как арифметическое среднее N случайных величин 

в качестве статистики, которая будет использована для оценки искомого среднего. Математическое ожидание выборочного среднего равно

т. е. математическое ожидание выборочного среднего равно среднему значению изучаемой случайной величины (или вероятностного процесса). Статистику, для которой ее математическое ожидание равно оцениваемой величине, называют несмещенной оценкой; выборочное среднее представляет собой, таким образом, несмещенную оценку для среднего значения.
Как найти математическое ожидание?
Математическое ожидание случайной величины $X$ (обозначается $M(X)$ или реже $E(X)$) характеризует среднее значение случайной величины (дискретной или непрерывной). Мат. ожидание – это первый начальный момент заданной СВ.
Математическое ожидание относят к так называемым характеристикам положения распределения (к которым также принадлежат мода и медиана). Эта характеристика описывает некое усредненное положение случайной величины на числовой оси. Скажем, если матожидание случайной величины – срока службы лампы, равно 100 часов, то считается, что значения срока службы сосредоточены (с обеих сторон) от этого значения (с тем или иным разбросом, о котором уже говорит дисперсия).
Нужна помощь? Решаем теорию вероятностей на отлично
Полезная страница? Сохрани или расскажи друзьям
Формула среднего случайной величины
Математическое ожидание дискретной случайной величины Х вычисляется как сумма произведений значений $x_i$ , которые принимает СВ Х, на соответствующие вероятности $p_i$:
$$
M(X)=sum_{i=1}^{n}{x_i cdot p_i}.
$$
Для непрерывной случайной величины (заданной плотностью вероятностей $f(x)$), формула вычисления математического ожидания Х выглядит следующим образом:
$$
M(X)=int_{-infty}^{+infty} f(x) cdot x dx.
$$
Пример нахождения математического ожидания
Рассмотрим простые примеры, показывающие как найти M(X) по формулам, введеным выше.
Пример 1. Вычислить математическое ожидание дискретной случайной величины Х, заданной рядом:
$$
x_i quad -1 quad 2 quad 5 quad 10 quad 20 \
p_i quad 0.1 quad 0.2 quad 0.3 quad 0.3 quad 0.1
$$
Используем формулу для м.о. дискретной случайной величины:
$$
M(X)=sum_{i=1}^{n}{x_i cdot p_i}.
$$
Получаем:
$$
M(X)=sum_{i=1}^{n}{x_i cdot p_i} =-1cdot 0.1 + 2 cdot 0.2 +5cdot 0.3 +10cdot 0.3+20cdot 0.1=6.8.
$$
Вот в этом примере 2 описано также нахождение дисперсии Х.
Пример 2. Найти математическое ожидание для величины Х, распределенной непрерывно с плотностью $f(x)=12(x^2-x^3)$ при $x in(0,1)$ и $f(x)=0$ в остальных точках.
Используем для нахождения мат. ожидания формулу:
$$
M(X)=int_{-infty}^{+infty} f(x) cdot x dx.
$$
Подставляем из условия плотность вероятности и вычисляем значение интеграла:
$$
M(X)=int_{-infty}^{+infty} f(x) cdot x dx = int_{0}^{1} 12(x^2-x^3) cdot x dx = int_{0}^{1} 12(x^3-x^4) dx = \
=left.(3x^4-frac{12}{5}x^5) right|_0^1=3-frac{12}{5} = frac{3}{5}=0.6.
$$
Другие задачи с решениями по ТВ
Подробно решим ваши задачи по теории вероятностей
Вычисление математического ожидания онлайн
Как найти математическое ожидание онлайн для произвольной дискретной случайной величины? Используйте калькулятор ниже.
- Введите число значений случайной величины К.
- Появится форма ввода для значений $x_i$ и соответствующих вероятностей $p_i$ (десятичные дроби вводятся с разделителем точкой, например: -10.3 или 0.5). Введите нужные значения (проверьте, что сумма вероятностей равна 1, то есть закон распределения корректный).
- Нажмите на кнопку “Вычислить”.
- Калькулятор покажет вычисленное математическое ожидание $M(X)$.
Видео. Полезные ссылки
Видеоролики: что такое среднее (математическое ожидание)
Если вам нужно более подробное объяснение того, что такое мат.ожидание, как она вычисляется и какими свойствами обладает, рекомендую два видео (для дискретной и непрерывной случайной величины соответственно).
Полезная страница? Сохрани или расскажи друзьям
Полезные ссылки
А теперь узнайте о том, как находить дисперсию или проверьте онлайн-калькулятор для вычисления математического ожидания, дисперсии и среднего квадратического отклонения дискретной случайной величины.
Что еще может пригодиться? Например, для изучения основ теории вероятностей – онлайн учебник по терверу. Для закрепления материала – еще примеры решений по теории вероятностей.
А если у вас есть задачи, которые надо срочно сделать, а времени нет? Можете поискать готовые решения в решебнике или заказать в МатБюро:
Во-первых, что такое “выборочное математическое ожидание”? Есть выборочное среднее. Это, разумеется, не то же самое, что выборочная дисперсия и не то же самое, что математическое ожидание.
Математическое ожидание и дисперсия — это величины, характеризующие случайную величину. Эти понятия имеют смысл, когда известно, какому закону распределения подчинена случайная величина (т. е. известна функция распределения) .
Математическое ожидание — это мера среднего значения (это, однако, отнюдь не значит, что она лежит в середине интервала, где случайная величина распределена, или же является наиболее вероятным значением, принимаемым случайной величиной, хоть и существуют распределения, для которых справедливо обратное) .
Дисперсия — это мера разброса случайной величины, т. е. её отклонение от мат. ожидания.
Выборочное среднее и выборочная дисперсия — это оценки, соответственно, математического ожидания и дисперсии, основанные на выборке.
Например, монета подбрасывается 6 раз. Число выпавших “гербов” имеет биномиальный закон распределения, математическое ожидание можем вычислить по формуле Mx=0,5*6=3, а дисперсию по формуле 0,5(1-0,5)*6=1,5.
Другой пример, приводится измерение размеров некоторой детали, изготавливаемой заводом, в результате будем иметь выборку (которая будет подчинена нормальному закону распределения) , на основании которой можно вычислить выборочное среднее (как среднее арифметическое размеров) и выборочную дисперсию.
Точные определения можно посмотреть здесь:
http://ru.wikipedia.org/wiki/Выборочное_среднее
http://ru.wikipedia.org/wiki/Математическое_ожидание
http://ru.wikipedia.org/wiki/Выборочная_дисперсия
http://ru.wikipedia.org/wiki/Дисперсия_случайной_величины
По поводу добавленного рисунка.
Видимо, имеется выборочное среднее.
Если ui — частота, что скорее всего, то выборочное среднее будет равно:
Сумма (xi*ui)/n=(2*16+5*12+7*8+10*14)(16+12+8+14)=(32+60+56+140)/50=288/50=5,76.
Вычислим среднее значение выборки и математическое ожидание случайной величины в MS EXCEL.
Выборочное среднее
Среднее выборки
или
выборочное среднее
(sample average, mean) представляет собой
среднее
арифметическое
всех значений
выборки
.
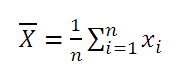
В MS EXCEL для вычисления
среднего выборки
можно использовать функцию
СРЗНАЧ()
. В качестве аргументов функции нужно указать ссылку на диапазон, содержащий значения
выборки
.
Выборочное среднее
является «хорошей» (несмещенной и эффективной) точечной оценкой
математического ожидания
случайной величины (см.
ниже
), т.е.
среднего значения
исходного распределения, из которого взята
выборка
.
Примечание
: О вычислении
доверительных интервалов
при оценке
математического ожидания
можно прочитать, например, в статье
Доверительный интервал для оценки среднего (дисперсия известна) в MS EXCEL
.
Некоторые свойства
среднего арифметического
:
-
Сумма всех отклонений от
среднего значения
равна 0:
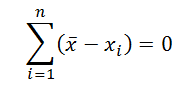
-
Если к каждому из значений x
i
прибавить одну и туже константу
с
, то
среднее арифметическое
увеличится на такую же константу; -
Если каждое из значений x
i
умножить на одну и туже константу
с
, то
среднее арифметическое
умножится на такую же константу.
Математическое ожидание
Среднее значение
можно вычислить не только для выборки, но для случайной величины, если известно ее
распределение
. В этом случае
среднее значение
имеет специальное название –
Математическое ожидание.
Математическое ожидание
характеризует «центральное» или среднее значение случайной величины.
Примечание
: В англоязычной литературе имеется множество терминов для обозначения
математического ожидания
: expectation, mathematical expectation, EV (Expected Value), average, mean value, mean, E[X] или first moment M[X].
Если случайная величина имеет
дискретное распределение
, то
математическое ожидание
вычисляется по формуле:
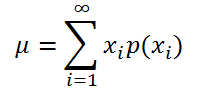
где x
i
– значение, которое может принимать случайная величина, а р(x
i
) – вероятность, что случайная величина примет это значение.
Если случайная величина имеет
непрерывное распределение
, то
математическое ожидание
вычисляется по формуле:
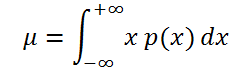
где р(x) –
плотность вероятности
(именно
плотность вероятности
, а не вероятность, как в дискретном случае).
Для каждого распределения, из представленных в MS EXCEL,
Математическое ожидание
можно вычислить аналитически, как функцию от параметров распределения (см. соответствующие
статьи про распределения
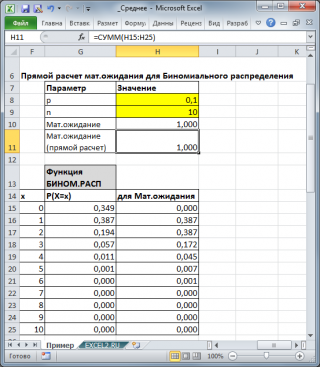
). Например, для
Биномиального распределения
среднее значение
равно произведению его параметров: n*p (см.
файл примера
).
Свойства математического ожидания
E[a*X]=a*E[X], где а – const
E[X+a]=E[X]+a
E[a]=a
E[E[X]]=E[X] – т.к. величина E[X] – является const
E[X+Y]=E[X]+E[Y] – работает даже для случайных величин не являющихся независимыми.
СОВЕТ
: Про другие показатели распределения –
Дисперсию
и
Стандартное отклонение,
можно прочитать в статье
Дисперсия и стандартное отклонение в MS EXCEL
.
