Матрица смежности — один из способов представления графа в виде матрицы.
Определение[править | править код]
Матрица смежности графа 






Иногда, особенно в случае неориентированного графа, петля (ребро из 
Матрица смежности простого графа (не содержащего петель и кратных рёбер) является бинарной матрицей и содержит нули на главной диагонали.
Матрица смежности двудольного графа[править | править код]
Матрица смежности 


где 





Формально, пусть 




Если 

Примеры[править | править код]
-
Граф Матрица смежности 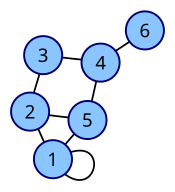

- Матрица смежности пустого графа, не содержащего ни одного ребра, состоит из одних нулей.
Свойства[править | править код]
Матрица смежности неориентированного графа симметрична, а значит обладает действительными собственными значениями и ортогональным базисом из собственных векторов. Набор её собственных значений называется спектром графа, и является основным предметом изучения спектральной теории графов.
Два графа 




.
Из этого следует, что матрицы 

Степени матрицы[править | править код]
Если 

Структура данных[править | править код]
Матрица смежности и списки смежности являются основными структурами данных, которые используются для представления графов в компьютерных программах.
Использование матрицы смежности предпочтительно только в случае неразреженных графов, с большим числом рёбер, так как она требует хранения по одному биту данных для каждого элемента. Если граф разрежён, то большая часть памяти напрасно будет тратиться на хранение нулей, зато в случае неразреженных графов матрица смежности достаточно компактно представляет граф в памяти, используя примерно 
В алгоритмах, работающих со взвешенными графами (например, в алгоритме Флойда-Уоршелла), элементы матрицы смежности вместо чисел 0 и 1, указывающих на присутствие или отсутствие ребра, часто содержат веса самих рёбер. При этом на место отсутствующих рёбер ставят некоторое специальное граничное значение (англ. sentinel), зависящее от решаемой задачи, обычно 0 или 
См. также[править | править код]
- Список рёбер
- Матрица инцидентности
Литература[править | править код]
- Кормен, Т., Лейзерсон, Ч., Ривест, Р., Штайн, К. Алгоритмы: построение и анализ = Introduction to Algorithms / Под ред. И. В. Красикова. — 2-е изд. — М.: Вильямс, 2005. — 1296 с. — ISBN 5-8459-0857-4.
Ссылки[править | править код]
- Матрица смежности графа. Код программ на Паскаль и C++
Матрица
смежности S –
это
квадратная матрица, в которой и число
строк, и число столбцов равно n –
числу вершин графа. В ячейки матрицы
смежности записываются некоторые числа
в зависимости от того, соединены
соответствующие вершины рёбрами или
нет, и от типа графа.
Матрица
смежности для неориентированного графа
Элемент
матрицы смежности sij неориентированного
графа определяется следующим образом:
–
равен единице, если вершины vi и vj смежны;
–
равен нулю, если вершины vi и vj не
смежны.
Если
на диагонали матрицы стоят 1, то это
показывает наличие петель.
|
Пример |
Пример
|


Таким
образом, матрица
смежности неориентированного
графа симметрична относительно главной
диагонали.
Матрица
смежности для ориентированного графа
Элемент
матрицы смежности sij ориентированного
графа определяется следующим образом:
–
равен единице, если из вершины vi в
вершину vj входит
дуга;
–
равен нулю, если из вершины vi в
вершину vj дуга
не входит.
Если
на диагонали матрицы стоят 1, то это
показывает наличие петель.
|
Пример
|
Пример
|

Таким
образом, матрица
смежности ориентированного
графа не симметрична.
9.4. Список ребер
|
Пример
|
9.1-9.4
|
Пример
Матрицы
|


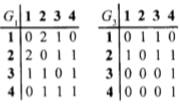

9.5. Матрица достижимости
Матрица
достижимости простого ориентированного
графа G=(V,E) — бинарная матрица замыкания
по транзитивности отношения E (оно
задаётся матрицей смежности графа).
Таким образом, в матрице достижимости
хранится информация о существовании
путей между вершинами орграфа.
Возведение
в степень матрицы смежности орграфа
показывает, за сколько шагов (величина
степени) можно достичь некой вершины.
Способы
построения матрицы достижимости:
-
Перемножение
матриц -
Алгоритм
Уоршелла -
Связанные
понятия
|
Пример Дан
Матрица Матрица Матрица Матрица Если Получим матрицу
Если
|
|||
|
Пример
|

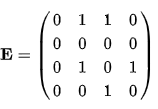

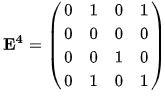
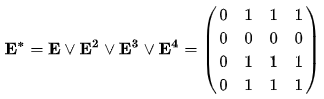


From Wikipedia, the free encyclopedia
In graph theory and computer science, an adjacency matrix is a square matrix used to represent a finite graph. The elements of the matrix indicate whether pairs of vertices are adjacent or not in the graph.
In the special case of a finite simple graph, the adjacency matrix is a (0,1)-matrix with zeros on its diagonal. If the graph is undirected (i.e. all of its edges are bidirectional), the adjacency matrix is symmetric.
The relationship between a graph and the eigenvalues and eigenvectors of its adjacency matrix is studied in spectral graph theory.
The adjacency matrix of a graph should be distinguished from its incidence matrix, a different matrix representation whose elements indicate whether vertex–edge pairs are incident or not, and its degree matrix, which contains information about the degree of each vertex.
Definition[edit]
For a simple graph with vertex set U = {u1, …, un}, the adjacency matrix is a square n × n matrix A such that its element Aij is one when there is an edge from vertex ui to vertex uj, and zero when there is no edge.[1] The diagonal elements of the matrix are all zero, since edges from a vertex to itself (loops) are not allowed in simple graphs. It is also sometimes useful in algebraic graph theory to replace the nonzero elements with algebraic variables.[2] The same concept can be extended to multigraphs and graphs with loops by storing the number of edges between each two vertices in the corresponding matrix element, and by allowing nonzero diagonal elements. Loops may be counted either once (as a single edge) or twice (as two vertex-edge incidences), as long as a consistent convention is followed. Undirected graphs often use the latter convention of counting loops twice, whereas directed graphs typically use the former convention.
Of a bipartite graph[edit]
The adjacency matrix A of a bipartite graph whose two parts have r and s vertices can be written in the form

where B is an r × s matrix, and 0r,r and 0s,s represent the r × r and s × s zero matrices. In this case, the smaller matrix B uniquely represents the graph, and the remaining parts of A can be discarded as redundant. B is sometimes called the biadjacency matrix.
Formally, let G = (U, V, E) be a bipartite graph with parts U = {u1, …, ur}, V = {v1, …, vs} and edges E. The biadjacency matrix is the r × s 0–1 matrix B in which bi,j = 1 if and only if (ui, vj) ∈ E.
If G is a bipartite multigraph or weighted graph, then the elements bi,j are taken to be the number of edges between the vertices or the weight of the edge (ui, vj), respectively.
Variations[edit]
An (a, b, c)-adjacency matrix A of a simple graph has Ai,j = a if (i, j) is an edge, b if it is not, and c on the diagonal. The Seidel adjacency matrix is a (−1, 1, 0)-adjacency matrix. This matrix is used in studying strongly regular graphs and two-graphs.[3]
The distance matrix has in position (i, j) the distance between vertices vi and vj. The distance is the length of a shortest path connecting the vertices. Unless lengths of edges are explicitly provided, the length of a path is the number of edges in it. The distance matrix resembles a high power of the adjacency matrix, but instead of telling only whether or not two vertices are connected (i.e., the connection matrix, which contains boolean values), it gives the exact distance between them.
Examples[edit]
Undirected graphs[edit]
The convention followed here (for undirected graphs) is that each edge adds 1 to the appropriate cell in the matrix, and each loop adds 2.[4] This allows the degree of a vertex to be easily found by taking the sum of the values in either its respective row or column in the adjacency matrix.
| Labeled graph | Adjacency matrix |
|---|---|
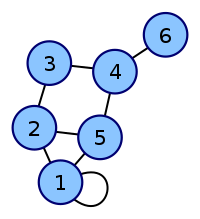
|

Coordinates are 1–6. |

Nauru graph |

Coordinates are 0–23. |
Directed graphs[edit]
The adjacency matrix of a directed graph can be asymmetric. One can define the adjacency matrix of a directed graph either such that
- a non-zero element Aij indicates an edge from i to j or
- it indicates an edge from j to i.
The former definition is commonly used in graph theory and social network analysis (e.g., sociology, political science, economics, psychology).[5] The latter is more common in other applied sciences (e.g., dynamical systems, physics, network science) where A is sometimes used to describe linear dynamics on graphs.[6]
Using the first definition, the in-degrees of a vertex can be computed by summing the entries of the corresponding column and the out-degree of vertex by summing the entries of the corresponding row. When using the second definition, the in-degree of a vertex is given by the corresponding row sum and the out-degree is given by the corresponding column sum.
| Labeled graph | Adjacency matrix |
|---|---|
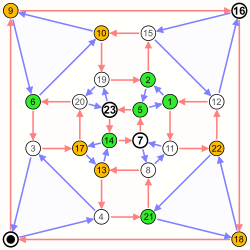
Directed Cayley graph of S4 |

Coordinates are 0–23. |
Trivial graphs[edit]
The adjacency matrix of a complete graph contains all ones except along the diagonal where there are only zeros. The adjacency matrix of an empty graph is a zero matrix.
Properties[edit]
Spectrum[edit]
The adjacency matrix of an undirected simple graph is symmetric, and therefore has a complete set of real eigenvalues and an orthogonal eigenvector basis. The set of eigenvalues of a graph is the spectrum of the graph.[7] It is common to denote the eigenvalues by 
The greatest eigenvalue 


For d-regular graphs, d is the first eigenvalue of A for the vector v = (1, …, 1) (it is easy to check that it is an eigenvalue and it is the maximum because of the above bound). The multiplicity of this eigenvalue is the number of connected components of G, in particular 


The difference 



Isomorphism and invariants[edit]
Suppose two directed or undirected graphs G1 and G2 with adjacency matrices A1 and A2 are given. G1 and G2 are isomorphic if and only if there exists a permutation matrix P such that

In particular, A1 and A2 are similar and therefore have the same minimal polynomial, characteristic polynomial, eigenvalues, determinant and trace. These can therefore serve as isomorphism invariants of graphs. However, two graphs may possess the same set of eigenvalues but not be isomorphic.[9] Such linear operators are said to be isospectral.
Matrix powers[edit]
If A is the adjacency matrix of the directed or undirected graph G, then the matrix An (i.e., the matrix product of n copies of A) has an interesting interpretation: the element (i, j) gives the number of (directed or undirected) walks of length n from vertex i to vertex j. If n is the smallest nonnegative integer, such that for some i, j, the element (i, j) of An is positive, then n is the distance between vertex i and vertex j. A great example of how this is useful is in counting the number of triangles in an undirected graph G, which is exactly the trace of A3 divided by 6. We divide by 6 to compensate for the overcounting of each triangle (3! = 6 times). The adjacency matrix can be used to determine whether or not the graph is connected.
Data structures[edit]
The adjacency matrix may be used as a data structure for the representation of graphs in computer programs for manipulating graphs. The main alternative data structure, also in use for this application, is the adjacency list.[10][11]
The space needed to represent an adjacency matrix and the time needed to perform operations on them is dependent on the matrix representation chosen for the underlying matrix. Sparse matrix representations only store non-zero matrix entries and implicitly represent the zero entries. They can, for example, be used to represent sparse graphs without incurring the space overhead from storing the many zero entries in the adjacency matrix of the sparse graph. In the following section the adjacency matrix is assumed to be represented by an array data structure so that zero and non-zero entries are all directly represented in storage.
Because each entry in the adjacency matrix requires only one bit, it can be represented in a very compact way, occupying only |V |2 / 8 bytes to represent a directed graph, or (by using a packed triangular format and only storing the lower triangular part of the matrix) approximately |V |2 / 16 bytes to represent an undirected graph. Although slightly more succinct representations are possible, this method gets close to the information-theoretic lower bound for the minimum number of bits needed to represent all n-vertex graphs.[12] For storing graphs in text files, fewer bits per byte can be used to ensure that all bytes are text characters, for instance by using a Base64 representation.[13] Besides avoiding wasted space, this compactness encourages locality of reference.
However, for a large sparse graph, adjacency lists require less storage space, because they do not waste any space representing edges that are not present.[11][14]
An alternative form of adjacency matrix (which, however, requires a larger amount of space) replaces the numbers in each element of the matrix with pointers to edge objects (when edges are present) or null pointers (when there is no edge).[14] It is also possible to store edge weights directly in the elements of an adjacency matrix.[11]
Besides the space tradeoff, the different data structures also facilitate different operations. Finding all vertices adjacent to a given vertex in an adjacency list is as simple as reading the list, and takes time proportional to the number of neighbors. With an adjacency matrix, an entire row must instead be scanned, which takes a larger amount of time, proportional to the number of vertices in the whole graph. On the other hand, testing whether there is an edge between two given vertices can be determined at once with an adjacency matrix, while requiring time proportional to the minimum degree of the two vertices with the adjacency list.[11][14]
See also[edit]
- Laplacian matrix
- Self-similarity matrix
References[edit]
- ^ Biggs, Norman (1993), Algebraic Graph Theory, Cambridge Mathematical Library (2nd ed.), Cambridge University Press, Definition 2.1, p. 7.
- ^ Harary, Frank (1962), “The determinant of the adjacency matrix of a graph”, SIAM Review, 4 (3): 202–210, Bibcode:1962SIAMR…4..202H, doi:10.1137/1004057, MR 0144330.
- ^ Seidel, J. J. (1968). “Strongly Regular Graphs with (−1, 1, 0) Adjacency Matrix Having Eigenvalue 3”. Lin. Alg. Appl. 1 (2): 281–298. doi:10.1016/0024-3795(68)90008-6.
- ^ Shum, Kenneth; Blake, Ian (2003-12-18). “Expander graphs and codes”. Volume 68 of DIMACS series in discrete mathematics and theoretical computer science. Algebraic Coding Theory and Information Theory: DIMACS Workshop, Algebraic Coding Theory and Information Theory. American Mathematical Society. p. 63. ISBN 9780821871102.
- ^
Borgatti, Steve; Everett, Martin; Johnson, Jeffrey (2018), Analyzing Social Networks (2nd ed.), SAGE, p. 20 - ^
Newman, Mark (2018), Networks (2nd ed.), Oxford University Press, p. 110 - ^ Biggs (1993), Chapter 2 (“The spectrum of a graph”), pp. 7–13.
- ^ Brouwer, Andries E.; Haemers, Willem H. (2012), “1.3.6 Bipartite graphs”, Spectra of Graphs, Universitext, New York: Springer, pp. 6–7, doi:10.1007/978-1-4614-1939-6, ISBN 978-1-4614-1938-9, MR 2882891
- ^ Godsil, Chris; Royle, Gordon Algebraic Graph Theory, Springer (2001), ISBN 0-387-95241-1, p.164
- ^ Goodrich & Tamassia (2015), p. 361: “There are two data structures that people often use to represent graphs, the adjacency list and the adjacency matrix.”
- ^ a b c d Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2001), “Section 22.1: Representations of graphs”, Introduction to Algorithms (Second ed.), MIT Press and McGraw-Hill, pp. 527–531, ISBN 0-262-03293-7.
- ^ Turán, György (1984), “On the succinct representation of graphs”, Discrete Applied Mathematics, 8 (3): 289–294, doi:10.1016/0166-218X(84)90126-4, MR 0749658.
- ^ McKay, Brendan, Description of graph6 and sparse6 encodings, archived from the original on 2001-04-30, retrieved 2012-02-10.
- ^ a b c Goodrich, Michael T.; Tamassia, Roberto (2015), Algorithm Design and Applications, Wiley, p. 363.
External links[edit]
- Weisstein, Eric W. “Adjacency matrix”. MathWorld.
- Fluffschack — an educational Java web start game demonstrating the relationship between adjacency matrices and graphs.
- Open Data Structures – Section 12.1 – AdjacencyMatrix: Representing a Graph by a Matrix, Pat Morin
- Café math : Adjacency Matrices of Graphs : Application of the adjacency matrices to the computation generating series of walks.
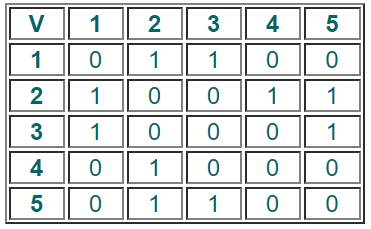
Определение 1. Пусть G – неориентированный граф. Пусть Mc – квадратная матрица, строки и столбцы которой обозначены вершинами неориентированного графа G. Элемент i-ой строки и j-гo столбца матрицы Mc, обозначаемый cij, равен единице, если имеется ребро из i-ой вершины в j-ую вершину, и равен нулю в противном случае. Матрица Mc называется матрицей смежности графа G.
Заметим, что для сокращения записи обозначения строк и столбцов в матрицах смежности можно опускать, но рекомендуется их оставлять особенно в матрицах больших размерностей.
Говоря о свойствах матрицы смежности неориентированного графа, необходимо отметить, что она не только квадратная, но и всегда симметрична относительно главной диагонали.
Для демонстрации примеров введём следующие графы (см. два рис. ниже).
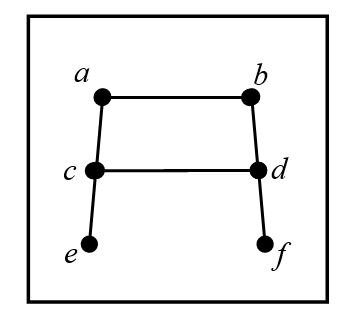
Этот неориентированный граф G1 состоит из множества вершин V(G1), содержащего 6 элементов, и множества рёбер E(G1), содержащего 6 элементов: V(G1) = {a, b, c, d, e, f}, E(G1) = {{a, b}, {a, c}, {b, d}, {c, d}, {с, e}, {d, f}}.
Неориентированный граф G2 состоит из множества вершин V(G2), содержащего 6 элементов, и множества рёбер E(G2), содержащего 5 элементов: V(G2) = {a, b, c, d, e, f}, E(G2) = {{a, c}, {b, e}, {c, d}, {d, e}, {d, f}}.
Пример 1. Для неориентированных графов G1 и G2, показанных на рис. выше, определим матрицы смежности.
Неориентированный граф G1 состоит из 6 вершин, поэтому его матрица смежности имеет размерность 6 на 6:
Неориентированный граф G2 также состоит из 6 вершин, поэтому его матрица смежности также имеет размерность 6 на 6:
Определение 2. Пусть G – неориентированный граф. Списком вершин (списком смежности) неориентированного графа называется таблица, в первом столбце которой указаны вершины графа, во втором столбце – соответствующие им смежные вершины. Таким образом, можно считать, что список вершин получен из матрицы смежности неориентированного графа путём замены единиц в каждой строке (столбце) на обозначение соответствующей строки (столбца), а нули отброшены.
Пример 2. Для неориентированных графов G1 и G2, показанных на рис. выше, определим списки вершин. Неориентированный граф G1 состоит из 6 вершин, поэтому список вершин будет состоять из 6 строк (см. табл. далее).
Неориентированный граф G2 также состоит из 6 вершин, поэтому его список вершин также будет состоять из 6 строк (табл. ниже).
Определение 3. Пусть G – неориентированный граф. Списочной структурой (списком смежности) неориентированного графа называется массив указателей на списки смежных вершин, другими словами, каждый элемент списка смежности представляется структурой с двумя полями: номером вершины и указателем на смежные вершины.
Пример 3. Для неориентированных графов G1и G2, показанных на рис. выше, изобразим списочную структуру. Неориентированный граф G1 состоит из 6 вершин, поэтому списочная структура (см. рис. далее) будет состоять из 6 строк. Введём обозначение вершин графа G1 таким образом, чтобы каждой вершине присвоить номер: вершине a присвоим номер 1, вершине b – 2, вершине с – 3, вершине d – 4, вершине e – 5, вершине f – 6.
Неориентированный граф G2 также состоит из 6 вершин, поэтому его списочная структура (см. рис. ниже) также будет состоять из 6 строк (более того, также введём номерное обозначение: вершине a присвоим номер 1, вершине b – 2, вершине с – 3, вершине d – 4, вершине e – 5, вершине f – 6).
Определение 4. Пусть G – неориентированный граф. Пусть Mи − матрица, строки которой обозначены вершинами графа, а столбцы – рёбрами графа. Будем считать, что вершины и рёбра неориентированного графа пронумерованы. Элемент i-ой строки и j-гo столбца матрицы Mи, обозначаемый Mij, равен единице, если i-ая вершина инцидентна j-ому ребру, и равен нулю в противном случае. Построенная таким образом матрица Mи называется матрицей инцидентности графа G.
Замечание. Поскольку каждая единица в строке матрицы инцидентности представляет инцидентность этой вершины соответствующему ребру, то степень каждой вершины графа равна сумме элементов строки матрицы инцидентности, а в каждом столбце имеются две единицы, так как каждое ребро инцидентно двум вершинам.
Заметим также, что если имеется неориентированный граф с петлями, то это сразу можно определить по виду матрицы инцидентности: соответствующий столбец содержит только одну единицу. При этом заметим, что в матрице инцидентности для неориентированного графа с петлями сумма элементов строки, соответствующей некоторой вершине, не представляет собой степень вершины, если в ней имеются петли.
Пример 4. Для неориентированных графов G1 и G2, показанных на рис. выше, определим матрицы инцидентности. Неориентированный граф G1 состоит из 6 вершин и 6 рёбер, поэтому его матрица инцидентности имеет размерность 6 на 6:
Неориентированный граф G2 состоит из 6 вершин и 5 рёбер, поэтому его матрица инцидентности имеет размерность 6 на 5:
Определение 5. Пусть G – неориентированный граф. Списком рёбер (списком инцидентности) неориентированного графа называется таблица, в первой строке которой указаны рёбра графа, во второй строке – инцидентные этим рёбрам вершины. Таким образом, можно считать, что список рёбер получен из матрицы инцидентности путём замены единиц в каждом столбце на обозначение соответствующих вершин, а нули отброшены.
Пример 5. Для неориентированных графов G1 и G2 , показанных на рис. выше, определим списки рёбер.
Неориентированный граф G1 состоит из шести рёбер, поэтому список рёбер будет состоять из шести столбцов (см. табл. далее).
Неориентированный граф G2 состоит из пяти рёбер, поэтому его список рёбер будет состоять из пяти столбцов (см. табл. далее).
Определение 6. Пусть G – неориентированный граф. Пусть MK– квадратная матрица, строки и столбцы которой обозначены вершинами неориентированного графа G. Элементы матрицы MK, обозначаемые kij, расположенные на главной диагонали, т.е. элементы i-ой строки и i-гo столбца, равны степени i-ой вершины, элементы i-ой строки и j-гo столбца (при i не равном j) равны -1, если имеется ребро из i-ой вершины в j-ую вершину, и равен нулю в противном случае. Матрица MK называется матрицей Кирхгофа неориентированного графа G.
Замечание. Матрица Кирхгофа неориентированного графа G связана с его матрицей смежности следующей зависимостью: MK = D – Mс, где D представляет собой матрицу, диагональные элементы которой равны степеням соответствующих вершин, остальные элементы нулевые.
Пример 6. Для неориентированных графов G1и G2, показанных на рис. выше, определим матрицы Кирхгофа.
Неориентированный граф G1 состоит из шести вершин, поэтому его матрица Кирхгофа имеет размерность 6 на 6.
На диагонали матрицы Кирхгофа располагаем числа, соответствующие степеням вершин графа: вершине a инцидентно 2 ребра, вершине b – 2 ребра, c – 3, d – 3, e – 1, f – 1.
Далее матрица заполняется в соответствии со смежностью вершин: вершины a и c – смежные – в соответствующие клетки матрицы ставим «-1», смежные вершины в графе a и b, c и d, d и f, b и d, e и c.
Матрица Кирхгофа неориентированного графа G1 имеет вид:
Проверим выполнимость замечания о связи матрицы Кирхгофа и матрицы смежности следующими вычислениями:
Как видно из выражений выше, левая и правая часть совпадают, следовательно, показана связь между матрицами смежности и Кирхгофа.
Неориентированный граф G2 также состоит из шести вершин, поэтому его матрица Кирхгофа также имеет размерность 6 на 6.
На диагонали матрицы Кирхгофа располагаем числа, соответствующие степеням вершин графа: вершине a инцидентно 1 ребро, вершине b – 1 ребро, c – 2, d – 3, e – 2, f – 1.
Далее матрица заполняется в соответствии со смежностью вершин: вершины a и c – смежные – в соответствующие клетки матрицы ставим «-1», смежные вершины в графе c и d, d и e, b и e, d и f.
Матрица Кирхгофа неориентированного графа G2 имеет следующий вид:
В качестве Упражнения предлагается записать все выше определённые способы задания неориентированных графов для следующих вариантов графов.
В чем особенности представления графа матрицей смежности
Содержание:
-
Матрица смежности для графов
- В чем особенности представления
- Списки смежности и списки ребер, плюсы и минусы
- Классификация графов
- Способы представления графа, алгоритмы обхода
- Как построить граф по матрице смежности
Матрица смежности для графов
Матрица смежности графа является квадратной матрицей с элементами, каждый из которых имеет одно из двух значений: 0 или 1.
Простой пример матрицы смежности изображен на рисунке.
Данная матрица является двоичной квадратной, то есть количество строк в единичном случае соответствует количеству столбцов, а также строки и столбы имеют значения либо 1, либо 0. Первая строка и первый столбец, не состоящие в матрице, а записанные для легкости восприятия, содержат номера, на пересечении которых расположен каждый из элементов, и они определяют индексное значение последних. Достаточно просто выполнить построение матрицы данного типа, зная соответствующий ей граф.
Осторожно! Если преподаватель обнаружит плагиат в работе, не избежать крупных проблем (вплоть до отчисления). Если нет возможности написать самому, закажите тут.
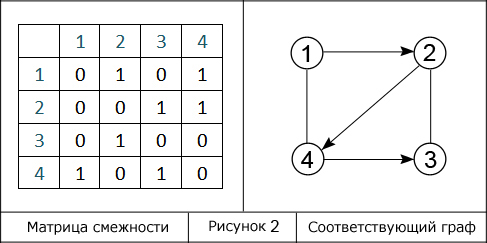
В левой стороне на рисунке представлена аналогичная матрица смежности с размерностью 4х4. Числа, выделенные синим цветом, допустимо рассматривать в виде вершин смешанного графа, записанного в правой стороне – того, представлением которого является матрица.
Отобразить граф можно путем вычисления по матрице смежности числа его вершин и применения специального правила. В том случае, когда из одной вершины в другую проход свободен, то есть имеется ребро, в ячейку записывают 1, в противном случае – 0. Таким образом:
если из i в j существует ребро, то (A[i][j]:=1), в противном случае (A[i][j]:=0.)
Заметим, что для элементов, расположенных на главной диагонали, характерно нулевое значение. Это является следствием отсутствия у графа петель. Однако, в информатике нет ограничений для записи некоторых или всех элементов на главной диагонали в виде единиц.
В чем особенности представления
В программе матрицу смежности задают с помощью обычного двумерного массива. Его размерность соответствует n x n, где n является числом вершин графа.
В том случае, когда граф неизвестен заранее, а определен пользователем, необходимо вводить двумерный массив вручную. Это объясняется условиями работы конкретного языка программирования. При необходимости предоставления графа в виде матрицы смежности требуется (O(|V|^{2})) памяти, так как ее размер соответствует квадрату числа всех вершин.
Если количество ребер графа в сравнении с числом вершин является небольшим, значения многих элементов матрицы смежности будут соответствовать нулю. Таким образом, применение рассматриваемой методики нецелесообразно, в связи с наличием для подобных графов наиболее эффективных способов представления.
Списки смежности и списки ребер, плюсы и минусы
Относительно памяти, списки смежности менее требовательны по сравнению с матрицами смежности. Объем памяти для их хранения составляет (O(|V|+|E|)). Такой перечень целесообразно представить как таблицу с двумя столбцами и строками в количестве, не превышающем число вершин в графе. Для примера можно рассмотреть граф смешанного типа:
В данном случае, граф состоит из 6 вершин (|V|) и 5 ребер (|E|). Из последних 2 ребра являются направленными и 3 ненаправленными. При этом из каждой вершины выходит, как минимум одно ребро в другую вершину. Таким образом, список смежности рассматриваемого графа содержит |V| строк.
В i строке и 1 столбце указана вершина выхода, а в i строке и 2 столбце – вершина входа. Например, из вершины 5 выходят два ребра, входящие в вершины 1 и 4.
В процессе программной реализации списка смежности число вершин и ребер задают с помощью клавиатуры. Можно установить лимиты, то есть задать пару констант, одна из которых определяет максимально допустимое число вершин (Vmax), другая – ребер (Emax). Затем следует использовать три одномерных целочисленных массива:
- terminal[1..Emax] – для хранения вершин, содержащих ребра;
- next [1..Emax] – включает указатели на элементы массива terminal;
- head[1..Vmax] – состоит из указателей на начало подсписков, то есть такие вершины, записанные в массив terminal, с которых начинается процесс перечисления всех вершин, смежных одной i-ой вершине.
Примечание
Допустимым действием является выделение в программе двух ключевых частей. К ним относят ввод ребер для дальнейшего добавления их в список смежности и вывод полученного списка смежности на экран.
В первую очередь выполняют запрос на ввод суммы вершин (n) и ребер (m) графа (данная информация должна быть у пользователя). Следующим шагом является запуск цикла ввода ребер, то есть смежных вершин. Условие в этом цикле нужно для того, чтобы узнать, какое введено ребро.
Если введено направленное ребро, то функция add вызывается 1 раз, иначе – 2, тем самым внося сведения, что есть ребро как из вершины v в вершину u, так и из u в v. По окончанию формирования списка смежности происходит его отображение программой на экране.
Вывод на экран осуществляется:
- по циклу от 1 до n, где n – является количеством вершин;
- согласно вложенному в него циклу, который прекращает свою работу тогда, когда указатель на следующий элемент для i-ой вершины отсутствует, то есть все смежные ей вершины уже выведены.
Функция add производит добавление ребер в изначально пустой список смежности:
(Add(v, u))
(k:=k+1)
(terminal[k]:=u)
(next[k]:=head[v])
(head[v]:=k)
Действия реализуются, согласно алгоритму с формальными параметрами, вспомогательной переменной k и тремя одномерными целочисленными массивами:
- значение переменной k увеличивается на 1;
- в k-ый элемент массива terminal добавляют конечную для какого-либо ребра вершина (u);
- в строке №3 для k-ого элемента массива next определяется адрес следующего элемента массива terminal;
- массив head заполняют указателями на стартовые элементы, которые являются началом подсписка (строки в таблице) смежных вершин с некоторой i-ой вершиной.
В ячейке, где пересекаются i-ая строка и 2-ой столбец, могут быть записи нескольких элементов в соответствии с несколькими смежными вершинами. Можно обозначить каждую строку из списка смежности его подсписком. В результате выведенный список смежности будет включать элементы подсписков, отсортированные в обратном порядке. Обычно порядок вывода смежных вершин (в подсписках) не имеет принципиального значения.
Список со строками, содержащими запись двух смежных вершин и вес ребра, которое их соединяет, называют списком ребер графа. В качестве примера можно рассмотреть связный граф G=(V, E). Множество ребер E следует сгруппировать следующим образом:
- d – подмножество, включающее только неориентированные ребра графа G;
- k – подмножество, включающее только ориентированные ребра графа G.
Допустим, какая-либо величина p равна количеству всех ребер, которые включены в подмножество d, а s – то же самое относительно k. Тогда для графа G высотой списка ребер будет являться величина:
s+p*2
Таким образом, число строк из списка ребер в любом случае должно соответствовать величине, определенной по итогам сложения ориентированных ребер с неориентированными, умноженными на 2. Рассматриваемый способ представления графа предполагает хранение в каждой строке пары смежных вершин, а неориентированное ребро, которое соединяет вершины v и u, идет как из v в u, так и из u в v.
Например, имеется некий граф смешанного типа с 5 вершинами и 4 ребрами, каждому из которых соответствует определенное целое значение (для наглядности оно составлено из номеров вершин):
Граф содержит 3 направленных ребра и 1 ненаправленное. Путем подстановки значений в формулу можно определить высоту списка ребер: 3+1*2=5
На рисунке изображен список ребер для рассматриваемого графа. Таблица в размерах составляет n×3, где n= s+p*2=3+1*2=5. Элементы в первом столбце расположены по возрастанию, во втором – порядок расположения элементов определен первым, а в третьем – зависит от двух предыдущих.
Список ребер реализуется программой. Процесс схож с операциями при реализации списка смежностей. В первую очередь организуют ввод данных, которые с помощью особой функции распределяются среди массивов. Затем происходит вывод полученного списка смежности на экран. В связи с необходимостью в использовании дополнительного массива, функция добавления ребер организована по-другому.
Максимально допустимое число вершин в графе определено с помощью константы Vmax, а количество ребер – Emax. Вторая константа инициализируется формулой Vmax*(Vmax-1)/2, вычисляющей количество ребер в полном графе при известном числе вершин.
Далее, в программах описываются 5 массивов:
- terminal – массив вершин, включающий ребра;
- weight – массив весов ребер;
- head[i]=k – для хранения i-ой вершины номер k-ого элемента массивов terminal и weight, где terminal[k] – является первой вершиной, смежной с i-ой, а weight[k] – вес инцидентного ей ребра;
- last[i]=k – для хранения i-ой вершины номер k-ого элемента массивов terminal и weight, где terminal[k] – является последней вершиной, смежной с i-ой, а weight[k] – вес инцидентного ей ребра;
- point[i]=k – хранит для i-ой вершины номер k-ого элемента массивов terminal и weight, где terminal[k] – следующая вершина, смежная с i-ой, а weight[k] – вес инцидентного ей ребра.
По результатам ввода числа вершин (n) и ребер (m) графа будет запущен цикл, каждый этап которого сопровождается вводом пользователем с клавиатуры пары смежных вершин и веса ребра, расположенного между ними. Если ребро ориентированное, функция записи в список ребер (Add) вызывается единожды, при неориентированном ребре – дважды. Суммарное количество вызовов функции определяется по формуле:
s+(p*2)
где s – является ориентированными ребрами графа
p – неориентированные ребра
По итогам формирования списка ребер следует умножить на 2 переменную m. Это связано с тем, что при чисто неориентированном графе высота списка составляет:
0+(m*2)
Завершающим этапом является отображение на экране результирующей конструкции. В связи с тем, что на номер первой вершины, смежной с i-ой вершиной, указывает элемент head[i], каждая новая итерация внешнего цикла начинается с взятия этого номера (k=head[i]). Внутренний цикл прекращает реализацию в том случае, когда отсутствует смежная с i-ой вершины (k станет равной нулю), а внешний – по окончанию вывода списка ребер.
Ключевые действия, включая добавление ребра, удаление ребра, проверку наличия ребра от вершины i до вершины j, отличаются высокой эффективностью и являются операциями с постоянным временем. В том случае, когда граф плотный, а количество ребер большое, матрица смежности представляет собой наиболее целесообразное решение. Даже когда граф и матрица смежности разрежены, можно представить ее с помощью структур данных для разреженной матрицы.
Главное достоинство методики заключается в применении матриц. Благодаря передовым разработкам в сфере аппаратного обеспечения, представляется возможным реализовывать даже дорогостоящие матричные операции на графическом процессоре (GPU). В процессе выполнения операций со смежной матрицей можно получить ценные данные о природе графа и том, как связаны его вершины.
К минусам матрицы смежности можно отнести риски возникновения недостатка объема памяти по причине наличия требований к пространству матрицы смежности VxV. Однако, зачастую графы не обладают чрезмерно большим числом соединений, что является основным поводом выбрать списки смежности для решения распространенных задач.
С другой стороны, несмотря на простоту базовых операций, существуют такие операции, как inEdges и outEdges, которые отличаются дороговизной при использовании для представления матрицы смежности.
Классификация графов
Ярким примером графа является схема метро или некий другой маршрут. Программисты знакомы с компьютерной сетью, которая также представляет собой граф. Общим в этих примерах является наличие точек, соединенных линиями.
В случае компьютерной сети точками являются отдельные серверы, а линиями – разные типы электрических сигналов. В метрополитене точки можно принять за станции, а линии – за туннели, проложенные между станциями. Согласно теории графов, точки представляют собой вершины или узлы, а линии – ребра или дуги.
Граф является совокупностью вершин, которые соединены ребрами.
В математике преимущественно рассматривают не содержание, а структуру вещей, отделяя ее от всего остального. Данный прием позволяет определять какие-либо объекты, как графы. В случае компьютерной сети можно отметить наличие определенной топологии и возможности условного представления в виде некоторого количества компьютеров и соединительных путей. На рисунке изображена полносвязная топология:
Фактически такая топология является графом. Пять компьютеров представляют собой вершины, а соединения или пути передачи сигналов являются ребрами. Ели выполнить замену компьютеров на вершины, то в результате получится математический объект или граф с 10 ребрами и 5 вершинами. Нумерацию вершин допустимо выполнять произвольно.
В рассматриваемом примере не используются петли, то есть такие ребра, которые выходят из вершины и сразу же водят в нее. В теории графов существует ряд обозначений:
- G=(V, E), здесь G – граф, V – его вершины, E – ребра;
- |V| – порядок (число вершин);
- |E| – размер графа (число рёбер).
Применительно к рисунку:
|V|=5, |E|=10.
Классификация графов:
- связные, в которых между какой-либо парой вершин расположено от одного и более путей;
- несвязные – хотя бы с одной вершиной, не связанной с другими.
В том случае, когда из любой вершины доступна другая вершина, граф является неориентированным и связным. При невыполнении данного условия для связного графа, его называет ориентированным или орграфом.
Примечание
Степень вершины определяется числом ребер, которые соединяют ее с другими вершинами.
В сумме все степени графа соответствуют удвоенному количеству всех его ребер. К примеру, на рисунке изображен граф со суммой степеней, равной 20:
Орграф отличается от неориентированного графа возможностью перемещаться из вершины h в вершину s без промежуточных вершин лишь тогда, когда ребро выходит из h и входит в s, но не наоборот. Форма записи ориентированного графа:
G=(V, A)
где V – является вершинами, A – определяет направленные ребра.
К третьему типу относят смешанные графы. Такие графы включают направленные и ненаправленные ребра. Формальная запись смешанного графа:
G=(V, E, A)
Источник: kvodo.ru
На рисунке изображен граф с направленными [(e, a), (e, c), (a, b), (c, a), (d, b)] и ненаправленными [(e, d), (e, b), (d, c)…] дугами. Предположим, что имеются два графа:
Данные графы эквиваленты друг другу, так как без изменений в структуре одного графа можно построить второй. Такие графы являются изоморфными, то есть обладают следующим свойством: какая-либо вершина с определенным числом ребер в одном графе имеет тождественную вершину в другом. На приведенном выше рисунке изображена пара изоморфных графов.
В случае, когда каждое ребро графа соответствует некоторому значению в виде веса ребра, граф является взвешенным. При решении задач можно встретить примеры, когда за вес принимают длину, цену маршрута и другие виды измерений. При графическом изображении графа принято указывать весовые значения около ребер.
Путь – последовательность вершин, каждая из которых связана с последующей с помощью ребра.
При совпадении первой и последней вершины путь называют циклом. Длина пути равна количеству составляющих его ребер. К примеру, на рисунке путь является последовательностью [(e), (a), (b), (c)]. Этот путь представляет собой подграф, так как к нему применимо определение последнего, а именно: граф G’=(V’, E’) является подграфом графа G=(V, E), только тогда когда V’ и E’ принадлежат V, E.
Способы представления графа, алгоритмы обхода
Граф, как и другие распространенные типы математических объектов, можно представить на компьютере, то есть сохранить в его памяти. Наиболее известные способы интерпретации графов:
- матрица смежности;
- матрица инцидентности;
- список смежности;
- список ребер.
Первые два метода заключаются в хранении графа в виде двумерного массива или матрицы. Размеры этих массивов определяются числом вершин и/или ребер в определенном графе. Таким образом, размер матрицы смежности – n×n (где n – число вершин), а матрицы инцидентности – n×m (n – число вершин, m – число ребер в графе).
В процессе решения многих задач с применением графов требуется обходить все вершины и ребра, то есть дуги. Обойти граф – значит, пройти все его вершины точно по одному разу. Алгоритмы обхода:
- в глубину;
- в ширину.
Реализация алгоритма обхода заключается в последовательном посещении вершин и исследовании ребер. Не посещенную вершину называют новой. После посещения вершину считают открытой до момента исследования всех инцидентных ей ребер. По итогу манипуляций вершина становится закрытой.
Обход в глубину выполняют, согласно следующим правилам:
- при нахождении в вершине х следует перемещаться в какую-либо другую вершину, не посещенную ранее, с одновременным запоминанием первой дуги;
- в том случае, когда невозможно переместиться в ранее не посещенную вершину из вершины х, требуется вернуться в вершину z, из которой впервые удалось попасть в х, и продолжить обход в глубину из вершины z.
Примечание
Поиск в ширину отличается тем, что за активную принимается такая открытая вершина, которая была посещена последней. В том случае, когда выполняется обход в глубину, чем позднее будет посещена вершина, тем раньше она будет использована.
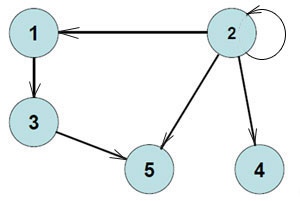
В качестве примера можно рассмотреть неориентированный граф, изображенный на рисунке:
Обход следует начинать со стартовой вершины 1. Она является активной и единственной, которая открыта. Другие вершины: 2,3,4,5,6 – новые. Вершина 1 обладает тремя инцидентными ребрами – 1–2, 1–4 и 1–6. Можно начать с ребра 1–2. В результате его прохождения открывается вершина 2. Она обладает одним инцидентным ребром 2–1, которое просмотрено. Вершина 2 была просмотрена, в результате чего она преобразуется в закрытую.
Затем по ребру 2–1 можно вернуться в вершину 1. По ребру 1– 4 легко попасть в вершину 4, которая становится открытой. Вершина 4 обладает четырьмя инцидентными ребрами: 4–1, 4–3, 4–5, 4–6. Таким образом, ребро 4–1 просмотрено.
Далее следует рассмотреть ребро 4–3. С его помощью удобно попасть в вершину 3, которая в результате становится открытой. Вершина 3 обладает одним инцидентным ребром 3–4. Данная вершина просмотрена. В результате вершина 3 закрыта, а по ребру 3–4 можно вернуться в вершину 4. Затем следует рассмотреть ребро 4 – 5.
Вершина 5 обладает двумя инцидентными ей ребрами: просмотренным (4–5) и ребром 5–6, по которому можно попасть в вершину 6. Вершина 6 обладает тремя инцидентными ей ребрами: просмотренным 6–5, 6–1 и 6–4. С помощью ребра 6–1 можно попасть в просмотренную вершину 1. По ребру 6–4 просто попасть в просмотренную вершину 4. В результате все вершины графа просмотрены. Порядок посещения вершин: 1, 2, 4, 3, 5, 6.
Основной особенностью и отличием поиска в ширину является выбор в виде активной вершины – такой, которая посещалась раньше, чем остальные. Таким образом, можно сформулировать ключевое свойство обхода в ширину: чем ближе вершина к старту, тем раньше она будет посещена.
Вершина используется путем просмотра одновременно всех вершин, которые ранее не были просмотрены и являются смежными с рассматриваемой вершиной. В результате поиск реализуют по всем вероятным направлением сразу. В первую очередь посещается вершина А, далее смежные с ней вершины, удаленные от А на 1.
Затем посещаются вершины, которые расположены на расстоянии 2 от А, и так далее. Чем ближе вершина к стартовой вершине, тем раньше она будет посещена. Поиск в ширину направлен на определение наиболее короткого из возможных путей.
В качестве примера можно рассмотреть неориентированный граф, изображенный на рисунке:
Обход следует начать со стартовой вершины 1, которая является просмотренной. Вершины 2, 4, 6 и стартовая вершина – смежные. Данные вершины можно отметить, как просмотренные, и поместить в очередь. При рассмотрении вершины 2 можно заметить, что она не обладает смежными вершинами.
Затем нужно рассмотреть вершину 4 с двумя смежными вершинами 3 и 5. Их можно поместить в очередь и отметить, как просмотренные. В результате просмотрены все вершины графа. Порядок посещения вершин: 1, 2, 4, 6, 3, 5.
Как построить граф по матрице смежности
Данная методика отличается удобством, что позволяет представлять плотные графы с количеством ребер (|E|), которое приблизительно соответствует числу вершин в квадрате (|V|2). В процессе требуется заполнить матрицу размером |V| x |V| следующим образом:
A[i][j] = 1 (Если существует ребро из i в j)
A[i][j] = 0 (Иначе)
Метод допустим к применению в случае ориентированных и неориентированных графов. Во втором варианте матрица A имеет вид симметричной, то есть A[i][j] == A[j][i]. Это объясняется тем, что при существовании ребра между i и j, оно является и ребром из i в j, и ребром из j в i. С помощью данного свойства сокращают практически вдвое объем требуемой памяти, в связи с тем, что элементы хранятся лишь в верхней части матрицы, над главной диагональю.
