![]() ,(20)
,(20)
где
![]() –
–
нижняя граница медианного интервала;![]() – величина медианного интервала;
– величина медианного интервала;![]() –
–
накопленная частота (или частость)
интервала, предшествующего медианному;![]() –
–
половина суммы всех частот (или частостей);![]() – частота медианного интервала.
– частота медианного интервала.
При
исчислении медианы интервального
вариационного ряда сначала находят
интервал, содержащий медиану. Для этого
используют накопленные частоты (или
частости). Медианному
интервалу соответствует первая из
накопленных частот (или частостей),
превышающая половину всего объёма
совокупности.
Пример:
процент выполнения норм выработки (х).
|
Интервалы |
xi |
mi |
Накопленные |
|
90–100 |
95 |
3 |
3 |
|
100–110 |
105 |
8 |
11 |
|
110–120 |
115 |
7 |
18 |
|
120–130 |
125 |
2 |
20 |
|
Σ |
– |
20 |
– |
Первая из накопленных
частот превышает 0,5·Σmi,
т.е. 10:
![]() 0,5·Σmi,
0,5·Σmi,
= 10.
Значит медианный
интервал (100–110):
![]() =
=
100; ![]() = 3;
= 3;
k
=
100 – 100 = 10; ![]() = 3;
= 3;
![]()
![]()
11. Мода
В математической
статистике модой
называют вариант, наиболее
часто встречающийся в данном вариационном
ряду.
Для дискретного
ряда мода
определяется по наибольшей частоте и
соответствует
варианту с наибольшей частотой.
Мода для непрерывного
(интервального с равными интервалами)
ряда исчисляется по формуле:
![]() ,(21)
,(21)
где
хМо(min) –
нижняя граница модального интервала;
mМо –
частота модального интервала;
mМо–1 –
частота интервала, предшествующего
модальному;
mМо+1
– частота интервала, последующего за
модальным;
ki
– величина модального интервала.
Может
быть: одна мода –
унимодальное распределение;
две моды –
бимодальное распределение;
три и более –
мультимодальное распределение.
Модальный интервал
определяется по набольшей частоте.
Пример:
|
Интервалы |
mi |
|
90–100 |
3 |
|
100–110 |
8 |
|
110–120 |
7 |
|
120–130 |
2 |
|
Σ |
20 |
Модальный интервал
(100–110), т.к. он имеет наибольшую частоту.
хМо(min)
= 100
k
=
10 mМо–1
= 3;
mМо
= 8; mМо+1
= 7;
![]()
Мо
≈108,3
Показатели колеблемости (вариации) признака
Такие признаки,
как заработная плата, профессия, число
членов семьи, возраст и т.д. — варьируют.
Для измерения
вариации признака математическая
статистика применяет ряд показателей.
12.
Вариационный размах (R),
или широта распределения

R
= xmax
– xmin
(22)
применялся в
формуле (8.6)
xmax
— наибольший вариант вариационного
ряда.
xmin
— наименьший вариант вариационного
ряда.
R
представляет
собой величину неустойчивую, зависящую
от случайных обстоятельств. Она
применяется в качестве приблизительной
оценки вариации.
Среднее
линейное отклонение

 невзвешенное
невзвешенное
 взвешенное
взвешенное
(23)
13
Дисперсия (средний квадрат отклонения)

 невзвешенная
невзвешенная
 взвешенная
взвешенная
(24)
У прощённая
прощённая
формула дисперсии
![]() ,
,
(25)
где
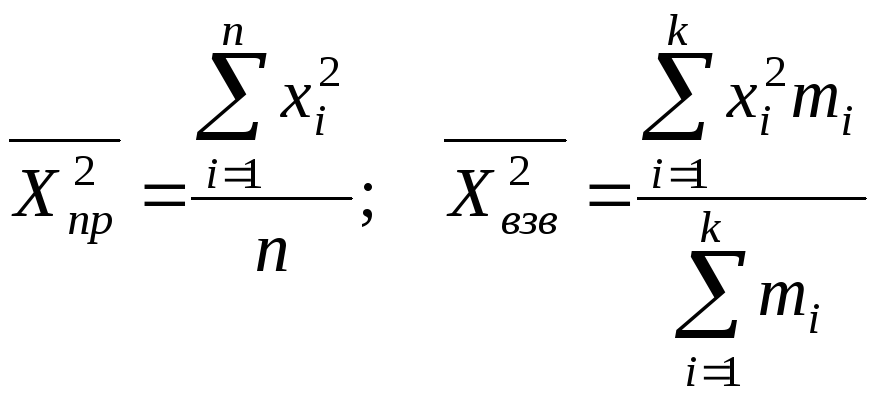
14.
Среднее квадратическое отклонение
(с.к.о.)
![]() (26)
(26)
15.
Коэффициент вариации (υ)
![]() (27)
(27)
Применяется
только для признака, принимающего только
положительные значения.
Если ν > 40%, то это
говорит о большой колеблемости признака
в изучаемой совокупности (например
большая колеблемость товарооборота в
регионе).
![]() –коэффициент
–коэффициент
осцилляции
![]() –коэффициент
–коэффициент
вариации по среднему линейному
отклонению.
16.
Свойства дисперсии
1. σ2(С)
= 0, где
С –
const.
2. Если все
значения вариантов признака Х уменьшить
на постоянную величину, то дисперсия
не изменится.
3. Если все
значения вариантов признака Х увеличить
в k
раз, то дисперсия увеличится в k2
раз.
4. Вычисление
дисперсии методом отсчёта от условного
нуля (методом моментов).
 (28)
(28)
17.
Частные средние и частные дисперсии
Пусть вся совокупность
разбита на l
групп. Для каждой группы вариантов
вариационного ряда можно вычислить
средние, которые называются частными
средними
и дисперсии, которые называются частными
дисперсиями или внутригрупповыми
дисперсиями.
Пусть l
групп:
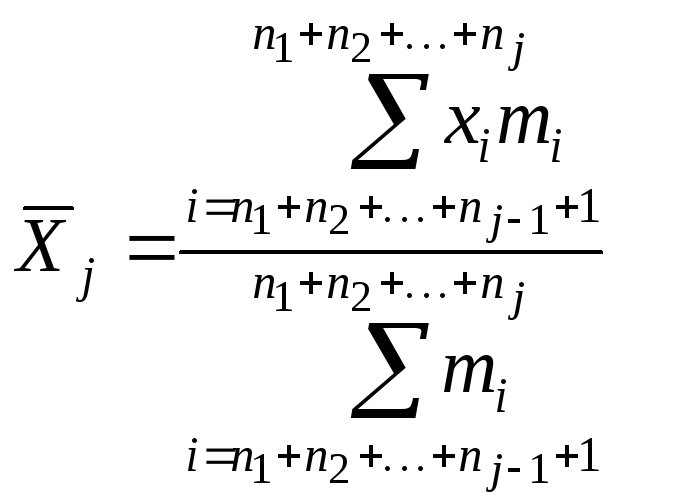 (29)
(29)
j=1,
2, …, l;
Σmi
= Nj
– объём j-ой
группы
![]() –частная средняя
–частная средняя
j-ой
группы
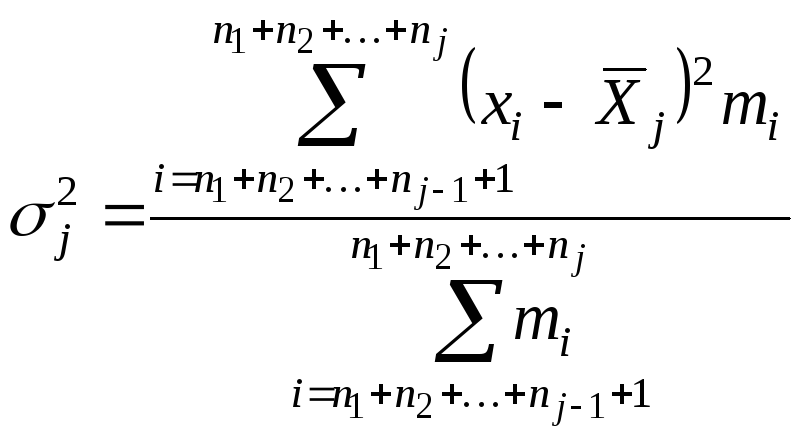 (30)
(30)
Частные средние
могут не совпадать с общей средней
![]() .
.
Убедимся в этом:
|
n1 |
n2 |
n3 |
|
x1 |
x4 |
x9 |
|
m1 |
m4 |
m9 |
Разбили на три
группы. l=3.
Группы не пересекаются
n1
+ n2
+ … + nl
= k
|
n1, |
k |
|
3 |
m1
+ m2
+ m3
= N1
– объём 1ой
группы (сумма
частот в 1ой
группе)
m4
+ m5
+ … + m8
= N2
– объём 2ой
группы
m9
+ m10
= N3
– объём 3ей
группы
![]()
Nj
– объём jтой
группы
j
= 1, 2, … , l
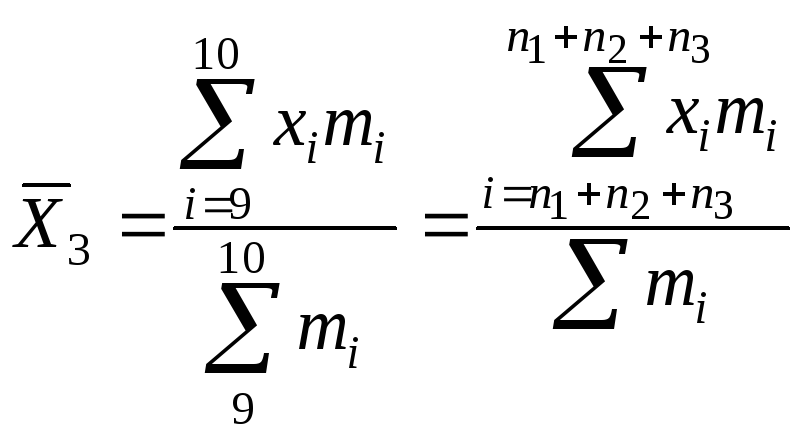
![]() или
или
![]()
i
= 3 + 5 + 1 = 8 + 1 = 9
Итак
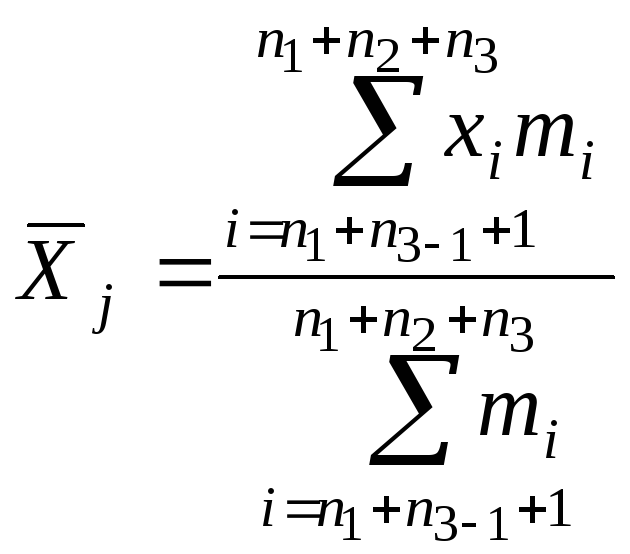 ,
,
где j
= 1, 2, …, l
Отсюда видно, как
получается формула (29).
Соседние файлы в папке 11-03-2014_20-15-21
- #
- #
Структурные средние – мода, медиана, квантиль, дециль
Краткая теория
Наиболее широкое применение в статистике имеют структурные
средние, к числу которых относятся мода и медиана (непараметрические средние).
Мода – величина признака (варианта), которая
встречается в ряду распределения с наибольшей частотой (весом). К моде (Мо)
прибегают для выявления величины признака, имеющей наибольшее распространение
(цена на рынке, по которой было совершено наибольшее число продаж данного
товара, номер обуви, который пользуется наибольшим спросом у покупателей и т.
д.). Мода используется только в совокупностях большой численности. В дискретном
ряду мода находится как варианта, имеющая наибольшую частоту. В интервальном
ряду сначала находится модальный интервал, то есть интервал, обладающий наибольшей частотой, а
затем – приближенное значение модальной величины признака по формуле:
– нижняя граница модального интервала
– величина модального интервала
– частота интервала, предшествующего
модальному
– частота модального интервала
– частота интервала, следующего за модальным
Квантили –
величины, разделяющие совокупность на определенной количество равных по
численности элементов частей. Самый известный квантиль – медиана, делящая совокупность на две равные части. Кроме медианы часто используются квартили, делящие ранжированный ряд на 4 равные части, децили -10 частей и перцентили – на 100
частей.
Медиана –
величина признака у единицы, находящейся в середине ранжированного
(упорядоченного) ряда. Если ряд распределения представлен конкретными
значениями признака, то медиана (Me) находится как
серединное значение признака.
Если ряд распределения дискретный, то медиана находится как
серединное значение признака (например, если число значений нечетное – 45, то
соответствует 23 значению признака в ряду
значений, расположенных в порядке возрастания, если число значений четное – 44,
то медиана соответствует полусумме 22 и 23 значений
признака).
Если ряд распределения интервальный, то первоначально
находят медианный интервал, который содержит единицу, находящуюся в середине
ранжированного ряда. Для определения этого интервала сумму частот
делят пополам и на основании последовательного накопления (суммирования)
частот интервалов, начиная с первого, находят интервал, где расположена
медиана. Значение медианы в интервальном ряду вычисляют по формуле:
– нижняя граница медианного интервала
– величина медианного интервала
– сумма
частот ряда
– сумма накопленных частот в интервалах,
предшествующих медианному
– частота медианного интервала
Квартили – это значения
признака в ранжированном ряду, выбранные таким образом, что 25% единиц
совокупности будут меньше величины
, 25% единиц будут заключены между
и
; 25% –
между
и
,
остальные 25% превосходят
. Квартили определяются по формулам,
аналогичным формуле для расчета медианы. Для интервального ряда:
Децилем
называется структурная переменная, делящая распределение на 10 равных частей по
числу единиц в совокупности. Децилей 9, а децильных
групп 10. Децили определяются по формулам, аналогичным формуле для расчета
медианы и квартилей.
В целом общая формула для расчета квантилей в интервальном
ряду такова:
– порядковый номер квантиля
– размерность квантиля (на сколько частей эти
квартили делят совокупность)
– нижняя граница квантильного
интервала
– ширина квантильного
интервала
– накопленная частота предквантильного
интервала
Для дискретного ряда номер квантиля можно
найти по формуле:
Примеры решения задач
Задача 1
(дискретный ранжированный ряд)
В
результате исследований установлен среднемесячный доход жильцов одного
подъезда:
|
1.5 |
1.8 |
2 |
2.5 |
2.8 |
2.8 |
2.8 |
3.0 |
3.6 |
3.8 |
|
3.9 |
4 |
5.8 |
5.9 |
6 |
6 |
6 |
6.8 |
7 |
7 |
Определите:
Модальный
и медианный доход, квартили и децили дохода.
Решение
Имеем уже ранжированный ряд – значения дохода жильцов распределены по возрастанию.
Мода
– наиболее часто встречающееся значение. В данном случае имеем ряд с двумя
модами.
и
Медиана
– такое значение признака, которое делит упорядоченное множество данных
пополам.
Квартили
– значения признака в ранжированном ряду, выбранные таким образом, что 25%
единиц совокупности будут меньше величины
; 25% единиц будут
заключены между
и
; 25% – между
и
; остальные 25%
превосходят
.
Дицили делят ряд на 10 равных частей:
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Задача 2
(интервальный ряд)
Для
определения среднего размера вклада в кредитном учреждении были получены
следующие данные:
| Размер вклада, тыс.р. | до 10.0 | 10.0-16.0 | 16.0-22.0 | 22.0-28.0 | 28.0-34.0 | Свыше 34.0 |
|
Удельный вес вкладов, % |
5.0 | 8.0 | 15.0 | 22.0 | 30.0 | 20.0 |
Рассчитайте
структурные средние (моду, медиану,
квартили).
Решение
Вычислим моду размера вклада:
Мода – варианта, которой соответствует наибольшая частота.
Мода вычисляется по формуле:
–
начало модального интервала
–
величина интервала
–
частота модального интервала
–
частота интервала, предшествующего модальному
–
частота интервала, следующего за модальным
Таким образом, наибольшее
количество вкладов имеют размер 30,7 тыс.р.
Медиана – варианта, находящаяся в середине ряда распределения.
Расчет медианы производится по формуле:
-начало
(нижняя граница) медианного интервала
-величина интервала
-сумма всех частот ряда
-частота медианного интервала
-сумма накопленных частот вариантов до
медианного
Таким образом, половина вкладов имеет размер до 28 тыс.р.,
другая половина – более 28 тыс.р.
Вычислим квартили:
Таким
образом 25% вкладов меньше 20,8 тыс.р., 25% вкладов
лежат в интервале от 20,8 тыс.р. до 28 тыс.р., 25% лежат в интервале от 28 тыс.р.
до 33 тыс.р., 25% больше величины в 33 тыс.р.
Задача 3
Постройте
графики для вариационного ряда. На графике покажите моду, медиану, среднюю, квартили.
| Возраст детей (лет) | Число детей (доли) |
| 0-3 | 0.15 |
| 3-6 | 0.2 |
| 6-9 | 0.4 |
| 9-12 | 0.2 |
| 12-15 | 0.05 |
Решение
Вычислим
среднюю
: Для этого просуммируем
произведения середин интервалов и соответствующих частот, и полученную сумму
разделим на сумму частот.
Вычисление моды интервального ряда на графике
Построим
гистограмму.
Мода определяется по
гистограмме распределения. Для этого выбирается самый высокий прямоугольник,
который в данном случае является модальным. Затем правую вершину модального
прямоугольника соединяют с правым верхним углом предыдущего прямоугольника. А
левую вершину модального прямоугольника – с левым верхним углом последующего
прямоугольника. Далее из точки их пересечения опускают перпендикуляр на ось
абсцисс.
Абсцисса точки пересечения
этих прямых и будет модой распределения
Гистограмма
По
гистограмме получаем, что
Вычисление медианы и квартилей интервального ряда на графике
Построим
кумулятивную кривую частот (график накопленных частот)
Кумулятивная кривая частот
На получившимся графике
накопленных частот из последней получившейся точки (в нашем примере) проведем
линию перпендикулярную к оси
она так же
является максимальной высотой. Поделим ее на 4 части. Через полученные точки
строим параллельную оси
линии которая должна пересекать высоту к оси
и кумуляту. От
места пересечения кумуляты опускаем перпендикуляры. Получившиеся точки есть квартили
и медиана (квартиль при
).
Вывод к задаче
Таким образом
средний возраст детей 6,9 лет. Наибольшее количество детей имеют возраст 7,5
лет. Четверть детей младше 4,5 лет, а самая старшая четверть детей старше 9,1
лет. Половина детей имеет возраст менее 7,3 лет, другая половина – более 7,3
лет.
Интервальный вариационный ряд и его характеристики
- Построение интервального вариационного ряда по данным эксперимента
- Гистограмма и полигон относительных частот, кумулята и эмпирическая функция распределения
- Выборочная средняя, мода и медиана. Симметрия ряда
- Выборочная дисперсия и СКО
- Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
- Алгоритм исследования интервального вариационного ряда
- Примеры
п.1. Построение интервального вариационного ряда по данным эксперимента
Интервальный вариационный ряд – это ряд распределения, в котором однородные группы составлены по признаку, меняющемуся непрерывно или принимающему слишком много значений.
Общий вид интервального вариационного ряда
| Интервалы, (left.left[a_{i-1},a_iright.right)) | (left.left[a_{0},a_1right.right)) | (left.left[a_{1},a_2right.right)) | … | (left.left[a_{k-1},a_kright.right)) |
| Частоты, (f_i) | (f_1) | (f_2) | … | (f_k) |
Здесь k – число интервалов, на которые разбивается ряд.
Размах вариации – это длина интервала, в пределах которой изменяется исследуемый признак: $$ F=x_{max}-x_{min} $$
Правило Стерджеса
Эмпирическое правило определения оптимального количества интервалов k, на которые следует разбить ряд из N чисел: $$ k=1+lfloorlog_2 Nrfloor $$ или, через десятичный логарифм: $$ k=1+lfloor 3,322cdotlg Nrfloor $$
Скобка (lfloor rfloor) означает целую часть (округление вниз до целого числа).
Шаг интервального ряда – это отношение размаха вариации к количеству интервалов, округленное вверх до определенной точности: $$ h=leftlceilfrac Rkrightrceil $$
Скобка (lceil rceil) означает округление вверх, в данном случае не обязательно до целого числа.
Алгоритм построения интервального ряда
На входе: все значения признака (left{x_jright}, j=overline{1,N})
Шаг 1. Найти размах вариации (R=x_{max}-x_{min})
Шаг 2. Найти оптимальное количество интервалов (k=1+lfloorlog_2 Nrfloor)
Шаг 3. Найти шаг интервального ряда (h=leftlceilfrac{R}{k}rightrceil)
Шаг 4. Найти узлы ряда: $$ a_0=x_{min}, a_i=1_0+ih, i=overline{1,k} $$ Шаг 5. Найти частоты (f_i) – число попаданий значений признака в каждый из интервалов (left.left[a_{i-1},a_iright.right)).
На выходе: интервальный ряд с интервалами (left.left[a_{i-1},a_iright.right)) и частотами (f_i, i=overline{1,k})
Заметим, что поскольку шаг h находится с округлением вверх, последний узел (a_kgeq x_{max}).
Например:
Проведено 100 измерений роста учеников старших классов.
Минимальный рост составляет 142 см, максимальный – 197 см.
Найдем узлы для построения соответствующего интервального ряда.
По условию: (N=100, x_{min}=142 см, x_{max}=197 см).
Размах вариации: (R=197-142=55) (см)
Оптимальное число интервалов: (k=1+lfloor 3,322cdotlg 100rfloor=1+lfloor 6,644rfloor=1+6=7)
Шаг интервального ряда: (h=lceilfrac{55}{5}rceil=lceil 7,85rceil=8) (см)
Получаем узлы ряда: $$ a_0=x_{min}=142, a_i=142+icdot 8, i=overline{1,7} $$
| (left.left[a_{i-1},a_iright.right)) cм | (left.left[142;150right.right)) | (left.left[150;158right.right)) | (left.left[158;166right.right)) | (left.left[166;174right.right)) | (left.left[174;182right.right)) | (left.left[182;190right.right)) | (left[190;198right]) |
п.2. Гистограмма и полигон относительных частот, кумулята и эмпирическая функция распределения
Относительная частота интервала (left.left[a_{i-1},a_iright.right)) – это отношение частоты (f_i) к общему количеству исходов: $$ w_i=frac{f_i}{N}, i=overline{1,k} $$
Гистограмма относительных частот интервального ряда – это фигура, состоящая из прямоугольников, ширина которых равна шагу ряда, а высота – относительным частотам каждого из интервалов.
Площадь гистограммы равна 1 (с точностью до округлений), и она является эмпирическим законом распределения исследуемого признака.
Полигон относительных частот интервального ряда – это ломаная, соединяющая точки ((x_i,w_i)), где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Накопленные относительные частоты – это суммы: $$ S_1=w_1, S_i=S_{i-1}+w_i, i=overline{2,k} $$ Ступенчатая кривая (F(x)), состоящая из прямоугольников, ширина которых равна шагу ряда, а высота – накопленным относительным частотам, является эмпирической функцией распределения исследуемого признака.
Кумулята – это ломаная, которая соединяет точки ((x_i,S_i)), где (x_i) – середины интервалов.
Например:
Продолжим анализ распределения учеников по росту.
Выше мы уже нашли узлы интервалов. Пусть, после распределения всех 100 измерений по этим интервалам, мы получили следующий интервальный ряд:
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| (left.left[a_{i-1},a_iright.right)) cм | (left.left[142;150right.right)) | (left.left[150;158right.right)) | (left.left[158;166right.right)) | (left.left[166;174right.right)) | (left.left[174;182right.right)) | (left.left[182;190right.right)) | (left[190;198right]) |
| (f_i) | 4 | 7 | 11 | 34 | 33 | 8 | 3 |
Найдем середины интервалов, относительные частоты и накопленные относительные частоты:
| (x_i) | 146 | 154 | 162 | 170 | 178 | 186 | 194 |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 |
| (S_i) | 0,04 | 0,11 | 0,22 | 0,56 | 0,89 | 0,97 | 1 |
Построим гистограмму и полигон:

Построим кумуляту и эмпирическую функцию распределения: 

Эмпирическая функция распределения (относительно середин интервалов): $$ F(x)= begin{cases} 0, xleq 146\ 0,04, 146lt xleq 154\ 0,11, 154lt xleq 162\ 0,22, 162lt xleq 170\ 0,56, 170lt xleq 178\ 0,89, 178lt xleq 186\ 0,97, 186lt xleq 194\ 1, xgt 194 end{cases} $$
п.3. Выборочная средняя, мода и медиана. Симметрия ряда
Выборочная средняя интервального вариационного ряда определяется как средняя взвешенная по частотам: $$ X_{cp}=frac{x_1f_1+x_2f_2+…+x_kf_k}{N}=frac1Nsum_{i=1}^k x_if_i $$ где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Или, через относительные частоты: $$ X_{cp}=sum_{i=1}^k x_iw_i $$
Модальным интервалом называют интервал с максимальной частотой: $$ f_m=max f_i $$ Мода интервального вариационного ряда определяется по формуле: $$ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h $$ где
(h) – шаг интервального ряда;
(x_o) – нижняя граница модального интервала;
(f_m,f_{m-1},f_{m+1}) – соответственно, частоты модального интервала, интервала слева от модального и интервала справа.
Медианным интервалом называют первый интервал слева, на котором кумулята превысила значение 0,5. Медиана интервального вариационного ряда определяется по формуле: $$ M_e=x_o+frac{0,5-S_{me-1}}{w_{me}}h $$ где
(h) – шаг интервального ряда;
(x_o) – нижняя граница медианного интервала;
(S_{me-1}) накопленная относительная частота для интервала слева от медианного;
(w_{me}) относительная частота медианного интервала.
Расположение выборочной средней, моды и медианы в зависимости от симметрии ряда аналогично их расположению в дискретном ряду (см. §65 данного справочника).
Например:
Для распределения учеников по росту получаем:
| (x_i) | 146 | 154 | 162 | 170 | 178 | 186 | 194 | ∑ |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 | 1 |
| (x_iw_i) | 5,84 | 10,78 | 17,82 | 57,80 | 58,74 | 14,88 | 5,82 | 171,68 |
$$ X_{cp}=sum_{i=1}^k x_iw_i=171,68approx 171,7 text{(см)} $$ На гистограмме (или полигоне) относительных частот максимальная частота приходится на 4й интервал [166;174). Это модальный интервал.
Данные для расчета моды: begin{gather*} x_o=166, f_m=34, f_{m-1}=11, f_{m+1}=33, h=8\ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h=\ =166+frac{34-11}{(34-11)+(34-33)}cdot 8approx 173,7 text{(см)} end{gather*} На кумуляте значение 0,5 пересекается на 4м интервале. Это – медианный интервал.
Данные для расчета медианы: begin{gather*} x_o=166, w_m=0,34, S_{me-1}=0,22, h=8\ \ M_e=x_o+frac{0,5-S_{me-1}}{w_me}h=166+frac{0,5-0,22}{0,34}cdot 8approx 172,6 text{(см)} end{gather*} begin{gather*} \ X_{cp}=171,7; M_o=173,7; M_e=172,6\ X_{cp}lt M_elt M_o end{gather*} Ряд асимметричный с левосторонней асимметрией.
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|}=frac{2,0}{0,9}approx 2,2lt 3), т.е. распределение умеренно асимметрично.
п.4. Выборочная дисперсия и СКО
Выборочная дисперсия интервального вариационного ряда определяется как средняя взвешенная для квадрата отклонения от средней: begin{gather*} D=frac1Nsum_{i=1}^k(x_i-X_{cp})^2 f_i=frac1Nsum_{i=1}^k x_i^2 f_i-X_{cp}^2 end{gather*} где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Или, через относительные частоты: $$ D=sum_{i=1}^k(x_i-X_{cp})^2 w_i=sum_{i=1}^k x_i^2 w_i-X_{cp}^2 $$
Выборочное среднее квадратичное отклонение (СКО) определяется как корень квадратный из выборочной дисперсии: $$ sigma=sqrt{D} $$
Например:
Для распределения учеников по росту получаем:
| $x_i$ | 146 | 154 | 162 | 170 | 178 | 186 | 194 | ∑ |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 | 1 |
| (x_iw_i) | 5,84 | 10,78 | 17,82 | 57,80 | 58,74 | 14,88 | 5,82 | 171,68 |
| (x_i^2w_i) – результат | 852,64 | 1660,12 | 2886,84 | 9826 | 10455,72 | 2767,68 | 1129,08 | 29578,08 |
$$ D=sum_{i=1}^k x_i^2 w_i-X_{cp}^2=29578,08-171,7^2approx 104,1 $$ $$ sigma=sqrt{D}approx 10,2 $$
п.5. Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
Исправленная выборочная дисперсия интервального вариационного ряда определяется как: begin{gather*} S^2=frac{N}{N-1}D end{gather*}
Стандартное отклонение выборки определяется как корень квадратный из исправленной выборочной дисперсии: $$ s=sqrt{S^2} $$
Коэффициент вариации это отношение стандартного отклонения выборки к выборочной средней, выраженное в процентах: $$ V=frac{s}{X_{cp}}cdot 100text{%} $$
Подробней о том, почему и когда нужно «исправлять» дисперсию, и для чего использовать коэффициент вариации – см. §65 данного справочника.
Например:
Для распределения учеников по росту получаем: begin{gather*} S^2=frac{100}{99}cdot 104,1approx 105,1\ sapprox 10,3 end{gather*} Коэффициент вариации: $$ V=frac{10,3}{171,7}cdot 100text{%}approx 6,0text{%}lt 33text{%} $$ Выборка однородна. Найденное значение среднего роста (X_{cp})=171,7 см можно распространить на всю генеральную совокупность (старшеклассников из других школ).
п.6. Алгоритм исследования интервального вариационного ряда
На входе: все значения признака (left{x_jright}, j=overline{1,N})
Шаг 1. Построить интервальный ряд с интервалами (left.right[a_{i-1}, a_ileft.right)) и частотами (f_i, i=overline{1,k}) (см. алгоритм выше).
Шаг 2. Составить расчетную таблицу. Найти (x_i,w_i,S_i,x_iw_i,x_i^2w_i)
Шаг 3. Построить гистограмму (и/или полигон) относительных частот, эмпирическую функцию распределения (и/или кумуляту). Записать эмпирическую функцию распределения.
Шаг 4. Найти выборочную среднюю, моду и медиану. Проанализировать симметрию распределения.
Шаг 5. Найти выборочную дисперсию и СКО.
Шаг 6. Найти исправленную выборочную дисперсию, стандартное отклонение и коэффициент вариации. Сделать вывод об однородности выборки.
п.7. Примеры
Пример 1. При изучении возраста пользователей коворкинга выбрали 30 человек.
Получили следующий набор данных:
18,38,28,29,26,38,34,22,28,30,22,23,35,33,27,24,30,32,28,25,29,26,31,24,29,27,32,24,29,29
Постройте интервальный ряд и исследуйте его.
1) Построим интервальный ряд. В наборе данных: $$ x_{min}=18, x_{max}=38, N=30 $$ Размах вариации: (R=38-18=20)
Оптимальное число интервалов: (k=1+lfloorlog_2 30rfloor=1+4=5)
Шаг интервального ряда: (h=lceilfrac{20}{5}rceil=4)
Получаем узлы ряда: $$ a_0=x_{min}=18, a_i=18+icdot 4, i=overline{1,5} $$
| (left.left[a_{i-1},a_iright.right)) лет | (left.left[18;22right.right)) | (left.left[22;26right.right)) | (left.left[26;30right.right)) | (left.left[30;34right.right)) | (left.left[34;38right.right)) |
Считаем частоты для каждого интервала. Получаем интервальный ряд:
| (left.left[a_{i-1},a_iright.right)) лет | (left.left[18;22right.right)) | (left.left[22;26right.right)) | (left.left[26;30right.right)) | (left.left[30;34right.right)) | (left.left[34;38right.right)) |
| (f_i) | 1 | 7 | 12 | 6 | 4 |
2) Составляем расчетную таблицу:
| (x_i) | 20 | 24 | 28 | 32 | 36 | ∑ |
| (f_i) | 1 | 7 | 12 | 6 | 4 | 30 |
| (w_i) | 0,033 | 0,233 | 0,4 | 0,2 | 0,133 | 1 |
| (S_i) | 0,033 | 0,267 | 0,667 | 0,867 | 1 | – |
| (x_iw_i) | 0,667 | 5,6 | 11,2 | 6,4 | 4,8 | 28,67 |
| (x_i^2w_i) | 13,333 | 134,4 | 313,6 | 204,8 | 172,8 | 838,93 |
3) Строим полигон и кумуляту

Эмпирическая функция распределения: $$ F(x)= begin{cases} 0, xleq 20\ 0,033, 20lt xleq 24\ 0,267, 24lt xleq 28\ 0,667, 28lt xleq 32\ 0,867, 32lt xleq 36\ 1, xgt 36 end{cases} $$ 4) Находим выборочную среднюю, моду и медиану $$ X_{cp}=sum_{i=1}^k x_iw_iapprox 28,7 text{(лет)} $$ На полигоне модальным является 3й интервал (самая высокая точка).
Данные для расчета моды: begin{gather*} x_0=26, f_m=12, f_{m-1}=7, f_{m+1}=6, h=4\ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h=\ =26+frac{12-7}{(12-7)+(12-6)}cdot 4approx 27,8 text{(лет)} end{gather*}
На кумуляте медианным является 3й интервал (преодолевает уровень 0,5).
Данные для расчета медианы: begin{gather*} x_0=26, w_m=0,4, S_{me-1}=0,267, h=4\ M_e=x_o+frac{0,5-S_{me-1}}{w_{me}}h=26+frac{0,5-0,4}{0,267}cdot 4approx 28,3 text{(лет)} end{gather*} Получаем: begin{gather*} X_{cp}=28,7; M_o=27,8; M_e=28,6\ X_{cp}gt M_egt M_0 end{gather*} Ряд асимметричный с правосторонней асимметрией.
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|} =frac{0,9}{0,1}=9gt 3), т.е. распределение сильно асимметрично.
5) Находим выборочную дисперсию и СКО: begin{gather*} D=sum_{i=1}^k x_i^2w_i-X_{cp}^2=838,93-28,7^2approx 17,2\ sigma=sqrt{D}approx 4,1 end{gather*}
6) Исправленная выборочная дисперсия: $$ S^2=frac{N}{N-1}D=frac{30}{29}cdot 17,2approx 17,7 $$ Стандартное отклонение (s=sqrt{S^2}approx 4,2)
Коэффициент вариации: (V=frac{4,2}{28,7}cdot 100text{%}approx 14,7text{%}lt 33text{%})
Выборка однородна. Найденное значение среднего возраста (X_{cp}=28,7) лет можно распространить на всю генеральную совокупность (пользователей коворкинга).
8.4. МОДА и МЕДИАНА (структурные средние)
Мода и медиана наиболее часто используемые в экономической практике структурные средние.
Мода – это величина признака (варианта), который наиболее часто встречается в данной совокупности, т.e. это варианта, имеющая наибольшую частоту.
В дискретном ряду мода определяется в соответствии с определением, т.е. это одна из вариант признака, которая в ряду распределения имеет наибольшую частоту.
Для интервального ряда моду находим по формуле (8.16), сначала по наибольшей частоте определив модальный интервал:

(8.16 – формула Моды)
где хо – начальная (нижняя) граница модального интервала;
h – величина интервала;
fМо – частота модального интервала;
fМо-1 – частота интервала, предшествующая модальному;
fМо+1– частота интервала следующая за модальным.
Медианой называется такое значение признака, которое приходится на середину ранжированного ряда, т.е. в ранжированном ряду распределения одна половина ряда имеет значение признака больше медианы, другая – меньше медианы.
В дискретном ряду медиана находится непосредственно по накопленной частоте, соответствующей номеру медианы.
В случае интервального вариационного ряда медиану определяют по формуле:
 (8.17 – формула Медианы)
(8.17 – формула Медианы)
где хо – нижняя граница медианного интервала;
NМе– порядковый номер медианы (Σf/2);
S Me-1 – накопленная частота до медианного интервала;
fМе – частота медианного интервала.
Пример вычисления Моды.
Рассчитаем моду и медиану по данным табл. 8.4.
Таблица 8.4 – Распределение семей города N по размеру среднедушевого дохода в январе 2018 г. руб.(цифры условные)
| Группы семей по размеру дохода, руб. | Число
семей |
Накоп-
ленные частоты |
в % к итогу |
| До 5000 | 600 | 600 | 6 |
| 5000-6000 | 700 | 1300
(600+700) |
13 |
| 6000-7000 | 1700 (fМо-1) | 3000 (S Me-1 )
(1300+1700) |
30 |
| 7000-8000
(хо) |
2500
(fМо) (fМе) |
5500 (S Me) | 55 |
| 8000-9000 | 2200 (fМо+1) | 7700 | 77 |
| 9000-10000 | 1500 | 9200 | 92 |
| Свыше 10000 | 800 | 10000 | 100 |
| Итого | 10000 | – | – |
Пример вычисления Моды. Найдем моду по формуле (8.16) см. обозначения в таблице, а h = 8000-7000=1000, т.е. получаем:

Пример вычисления Моды
Пример вычисления Медианы интервального вариационного ряда. Рассчитаем медиану по формуле (8.17):
1) сначала находим порядковый номер медианы: NМе = Σfi/2= 5000.
2) по накопленным частотам в соответствии с номером медианы определяем, что 5000 находится в интервале (7000 – 8000), далее значение медианы определим по формуле (8.17):

Пример вычисления Медианы
Вывод: по моде – наиболее часто встречается среднедушевой доход в размере 7730 руб., по медиане – что половина семей города имеет среднедушевой доход ниже 7800 руб., остальные семьи – более 7800 руб.
Пример .СРЕДНИЙ, МЕДИАННЫЙ И МОДАЛЬНЫЙ УРОВЕНЬ ДЕНЕЖНЫХ ДОХОДОВ НАСЕЛЕНИЯ ЦЕЛОМ ПО РОССИИ И ПО СУБЪЕКТАМ РОССИЙСКОЙ ФЕДЕРАЦИИ ЗА 2013 год см. по ссылке. Источник: оценка на основании данных выборочного обследования бюджетов домашних хозяйств и макроэкономического показателя денежных доходов населения
Соотношение моды, медианы и средней арифметической указывает на характер распределения признака в совокупности, позволяет оценить его асимметрию.
Если Мо<Ме<Х – имеет место правосторонняя асимметрия.
При Х<Ме<Мо следует сделать вывод о левосторонней асимметрии ряда.
Средние величины (арифметическая, гармоническая, геометрическая, квадратическая) см. по ссылке
Оценка статьи:
![]() Загрузка…
Загрузка…
Определение моды и медианы
По данным таблицы рассчитаем моду и медиану
|
Интервалы |
Диапазон по продолжительности жизни |
Число стран (частота), f |
Накопленная частота, f |
|
1 |
60,8 — 63,53 |
6 |
6 |
|
2 |
63,53 – 66,25 |
13 |
19 |
|
3 |
66,25 – 68,98 |
12 |
31 |
|
4 |
68,98 – 71,70 |
18 |
49 |
|
5 |
71,70 — 74,43 |
37 |
86 |
|
6 |
74,43 — 77,15 |
22 |
108 |
|
7 |
77,15 — 79,88 |
27 |
135 |
|
8 |
79,88 — 82,60 |
15 |
150 |
Определение моды
Интервал, имеющий наибольшую частоту, будет являться модальным, а конкретное (дискретное) значение моды будет находиться внутри него. Рассчитать конкретное, значение моды в интервальном ряду можно по следующей формуле:

где: ХМо — нижняя граница модального интервала,
i — длина модального интервала,
fMo — частота модального интервала,
fMo-1 — частота, соответствующая предшествующему интервалу,
fMo+1 — частота, соответствующая последующему интервалу.
Самая большая частота, 37 стран, соответствует варианту 71,70 — 74,43. Этот интервал является модальным.

Определение медианы
Медиана применяется для количественной характеристики структуры и равна такому варианту, который делит ранжированную совокупность на две равные части. У одной половины совокупности признаки не больше медианы (меньше или равны), у второй — не меньше медианы (больше или равны).
Если рассматриваемый ряд интервальный, то накопленные частоты покажут нам медианный интервал. Конкретное значение медианы рассчитывается по формуле:

i — длина медианного интервала,
сумма f — сумма частот ряда (объем совокупности),
f’Me-1 — накопленная частота в интервале, предшествующем медианному,
fMe — частота медианного интервала.
Для нахождения медианного интервала нужно знать половину частот, то есть 150 : 2 = 75. В столбце «накопленные частоты» выбираем 5 интервал, так как в 4 интервале частот накопилось еще 49 стран — меньше половины. С помощью формулы найдем конкретное значение медианы, оно принадлежит медианному интервалу 71,70 — 74,43.

Разница между 74,14 и 73,61 говорит об умеренном асимметричном распределении
Заказать задачи по статистике Вы можете на странице http://univer-nn.ru/zadachi-po-statistike-primeri/
