![]()
Загрузить PDF
![]()
Загрузить PDF
Среднее значение, медиана и мода — значения, которые часто используются в статистике и математике. Эти значения найти довольно легко, но их легко и перепутать. Мы расскажем, что они из себя представляют и как их найти.
-

1
Сложите все числа, которые вам даны. Допустим, вам даны числа 2, 3 и 4. Сложим их: 2 + 3 + 4 = 9.
-

2
Сосчитайте количество чисел. У нас есть три цифры.
-

3
Разделите сумму чисел на их количество. Берем 9, делим на 3. 9/3 = 3. Среднее значение в данном случае равно 3. Помните, что не всегда получается целое число.
Реклама
-

1
Запишите все числа, которые вам даны, в порядке возрастания. Например, нам даны числа: 4, 2, 8, 1, 15. Запишите их от меньшего к большему, вот так: 1, 2, 4, 8, 15.
-

2
Найдите два средних числа. Мы расскажем, как это сделать, если у вас имеется четное количество чисел, и как это сделать, если количество чисел нечетное:
- Если у вас нечетное количество чисел, вычеркните левое крайнее число, затем правое крайнее число и так далее. Один оставшийся номер и будет искомой медианой. Если вам дан ряд чисел 4, 7, 8, 11, 21, тогда 8 — медиана, так как 8 стоит посередине.
- Если у вас четное количество чисел, вычеркните по одному числу с каждой стороны, пока у вас не останется два числа посередине. Сложите их и разделите на два. Это и есть значение медианы. Если вам дан ряд чисел 1, 2, 5, 3, 7, 10, то два средних числа — это 5 и 3. Сложим 5 и 3, получим 8, разделим на два, получим 4. Это и есть медиана.
Реклама
-

1
Запишите все числа в ряд. Например, вам даны числа 2, 4, 5, 5, 4 и 5. Запишите их в порядке возрастания.
-

2
Найдите число, которое чаще всего встречается. В данном случае это 5. Если два числа встречаются одинаково часто, то этот ряд двухвершинный или бимодальный, а если больше — то мультимодальный.
Реклама
Советы
- Вам будет легче найти моду и медиану, если вы запишете числа в порядке возрастания.
Реклама
Об этой статье
Эту страницу просматривали 353 377 раз.
Была ли эта статья полезной?
Среднее арифметическое, размах, мода и медиана
- Алгебра
- Среднее арифметическое, размах, мода и медиана
Статистические характеристики
количество чисел
Калькулятор вычислит среднее арифметическое чисел, а также размах ряда чисел, моду ряда
чисел, медиану ряда. Для вычисления укажите количество чисел, добавьте числа и нажмите
рассчитать.
Среднее арифметическое, размах, мода и медиана
Средним арифметическим ряда чисел называется частное от деления суммы этих
чисел на число слагаемых.
Для ряда a1,a1,..,an среднее арифметическое вычисляется по
формуле:
begin{align}
& overline{a}=frac{a_1+a_2+…+a_n}{n}\
end{align}
Найдем среднее арифметическое для чисел 5,24, 6,97, 8,56, 7,32 и 6,23.
begin{align}
& overline{a}=frac{5,24+6,97+8,56+7,32+6,23}{5}=6.864\
end{align}
Размахом ряда чисел называется разность между наибольшим и наименьшим из
этих чисел.
Размах ряда 5,24, 6,97, 8,56, 7,32, 6,23 равен 8,56-5,24=3.32
Модой ряда чисел называется число, которое встречается в данном ряду чаще
других.
Ряд чисел может иметь более одной моды, а может не иметь моды совсем.
Модой ряда 32, 26, 18, 26, 15, 21, 26 является число 26, встречается 3 раза.
В ряду чисел 5,24, 6,97, 8,56, 7,32 и 6,23 моды нет.
Ряд 1, 1, 2, 2, 3 содержит 2 моды: 1 и 2.
Медианой упорядоченного ряда чисел с нечётным числом членов называется
число, записанное посередине, а медианой упорядоченного ряда чисел с чётным
числом членов называется среднее арифметическое двух чисел, записанных посередине.
Медианой произвольного ряда чисел называется медиана соответствующего упорядоченного
ряда.
Медиана ряда 4, 1, 2, 3, 3, 1 равна 2.5.
Примеры
Рассмотрим примеры нахождения среднего арифметического чисел, а также размаха, медианы и моды
ряда.
-
Среднее арифметическое чисел 30, 5, 23, 5, 28, 30
begin{align}
& overline{a}=frac{30+5+23+5+28+30}{6}=20frac{1}{6}\
end{align}Размах ряда: 30-5=25
Моды ряда: 5 и 30
Медиана ряда: 25.5
-
Среднее арифметическое чисел 40, 35, 30, 25, 30, 35
begin{align}
& overline{a}=frac{40+35+30+25+30+35}{6}=32frac{1}{2}\
end{align}Размах ряда: 40-25=15
Моды ряда: 30, 35
Медиана ряда: 32.5
-
Среднее арифметическое чисел 21, 18,5, 25,3, 18,5, 17,9
begin{align}
& overline{a}=frac{21+18,5+25,3+18,5+17,9}{5}=20,24\
end{align}Размах ряда: 25,3-17,9=7,4
Мода ряда: 18,5
Медиана ряда: 18,5
Примеры
Примеры нахождения среднего арифметического отрицательных и вещественных чисел.
-
Среднее арифметическое чисел 67,1, 68,2, 67,1, 70,4, 68,2
begin{align}
& overline{a}=frac{67,1+68,2+67,1+70,4+68,2}{5}=68,2\
end{align}Размах ряда: 70,4-67,1=3,3
Моды ряда: 67.1, 68.2
Медиана ряда: 68.2
-
Среднее арифметическое чисел 0,6, 0,8, 0,5, 0,9, 1,1
begin{align}
& overline{a}=frac{0,6+0,8+0,5+0,9+1,1}{5}=0.78\
end{align}Размах ряда: 1,1-0,5=0.6
Ряд не имеет моды
Медиана ряда: 0.8
-
Среднее арифметическое чисел -21, -33, -35, -19, -20, -22
begin{align}
& overline{a}=frac{(-21)+(-33)+(-35)+(-19)+(-20)+(-22)}{6}=-25\
end{align}Размах ряда: (-19)-(-35)=16
Ряд не имеет моды
Медиана ряда: -21,5
-
Среднее арифметическое чисел -4, -6, 0, -4, 0, 6, 8, -12
begin{align}
& overline{a}=frac{(-4)+(-6)+0+(-4)+0+6+8+(-12)}{8}=-1,5\
end{align}Размах ряда: 8-(-12)=20
Моды ряда: -4, 0
Медиана ряда: -2
-
Среднее арифметическое чисел 275, 286, 250, 290, 296, 315, 325
begin{align}
& overline{a}=frac{275+286+250+290+296+315+325}{7}=291\
end{align}Размах ряда: 325-250=75
Ряд не имеет моды
Медиана ряда: 290
-
Среднее арифметическое чисел 38, 42, 36, 45, 48, 45, 45, 42, 40, 47, 39
begin{align}
& overline{a}=frac{38+42+36+45+48+45+45+42+40+47+39}{11}=42frac{6}{11}\
end{align}Размах ряда: 48-36=12
Мода ряда: 45
Медиана ряда: 42
-
Среднее арифметическое чисел 3,8, 7,2, 6,4, 6,8, 7,2
begin{align}
& overline{a}=frac{3,8+7,2+6,4+6,8+7,2}{5}=6,28\
end{align}Размах ряда: 7,2-3,8=3,4
Мода ряда: 7,2
Медиана ряда: 6,8
-
Среднее арифметическое чисел 21,6, 37,3, 16,4, 12,6
begin{align}
& overline{a}=frac{21,6+37,3+16,4+12,6}{4}=21,025\
end{align}Размах ряда: 37,3-12,6=24,7
Мода ряда: 12,6
Медиана ряда: 17,1
Среднее значение, медиана и мода являются фундаментальными темами статистики. Вы можете легко вычислить их в Python, с использованием внешних библиотек и без них.
Эти три меры являются основными Главная тенденция. Центральная тенденция позволяет нам узнать «нормальные» или «средние» значения набора данных. Если вы только начинаете заниматься наукой о данных, это руководство для вас.
К концу этого урока вы:
- Понимание понятия среднего, медианы и моды
- Уметь создавать свои собственные функции среднего, медианы и режима в Python.
- Используйте модуль статистики Python, чтобы быстро начать использовать эти измерения.
Если вам нужна загружаемая версия следующих упражнений, не стесняйтесь проверить Репозиторий GitHub.
Давайте рассмотрим различные способы вычисления среднего значения, медианы и моды.
иметь в виду или среднее арифметическое является наиболее часто используемой мерой центральной тенденции.
Помните, что центральная тенденция является типичным значением набора данных.
Набор данных — это набор данных, поэтому набор данных в Python может быть любой из следующих встроенных структур данных:
- Списки, кортежи и наборы: коллекция объектов
- Строки: набор символов
- Словарь: набор пар ключ-значение
Примечание. Хотя в Python есть и другие структуры данных, такие как очереди или стеки, мы будем использовать только встроенные.
Мы можем вычислить среднее значение, добавив все значения набора данных и разделив результат на количество значений. Например, если у нас есть следующий список чисел:
[1, 2, 3, 4, 5, 6]
Среднее значение будет 3,5, потому что сумма списка равна 21, а его длина равна 6. Двадцать один разделить на шесть равно 3,5. Вы можете выполнить этот расчет с помощью следующего расчета:
(1 + 2 + 3 + 4 + 5 + 6) / 6 = 21
В этом уроке мы будем использовать игроков баскетбольной команды в качестве примера данных.
Создание пользовательской функции среднего
Начнем с расчета среднего (среднего) возраста игроков баскетбольной команды. Название команды будет «Pythonic Machines».
pythonic_machine_ages = [19, 22, 34, 26, 32, 30, 24, 24]
def mean(dataset):
return sum(dataset) / len(dataset)
print(mean(pythonic_machine_ages))
Разбираем этот код:
- «pythonic_machine_ages» — это список возрастов баскетболистов.
- Мы определяем функцию mean(), которая возвращает сумму данного набора данных, деленную на его длину.
- Функция sum() возвращает общую сумму (по иронии судьбы) значений итерируемого объекта, в данном случае списка. Попробуйте передать набор данных в качестве аргумента, он вернет 211
- Функция len() возвращает длину итерации, если вы передадите ей набор данных, вы получите 8
- Мы передаем возраст баскетбольной команды в функцию mean() и печатаем результат.
Если вы проверите вывод, вы получите:
26.375 # Because 211 / 8 = 26.375
Этот результат представляет собой средний возраст игроков баскетбольной команды. Обратите внимание, что число не появляется в наборе данных, но точно описывает возраст большинства игроков.
Использование mean() из статистического модуля Python
Вычисление показателей центральной тенденции является обычной операцией для большинства разработчиков. Это потому что Статистика Python модуль предоставляет различные функции для их расчета, а также другие основные темы статистики.
Поскольку это часть Стандартная библиотека Python вам не нужно будет устанавливать какой-либо внешний пакет с PIP.
Вот как вы используете этот модуль:
from statistics import mean pythonic_machine_ages = [19, 22, 34, 26, 32, 30, 24, 24] print(mean(pythonic_machine_ages))
В приведенном выше коде вам просто нужно импортировать функцию mean() из модуля статистики и передать ей набор данных в качестве аргумента. Это вернет тот же результат, что и пользовательская функция, которую мы определили в предыдущем разделе:
26.375
Теперь у вас есть кристально ясное понятие среднего, давайте продолжим измерение медианы.
Нахождение медианы в Python
медиана является средним значением отсортированного набора данных. Он используется — опять же — для предоставления «типичного» значения определенного Население.
В программировании мы можем определить медиану как значение, которое разделяет последовательность на две части — нижнюю половину и верхнюю половину.
Чтобы вычислить медиану, сначала нам нужно отсортировать набор данных. Мы могли бы сделать это с помощью алгоритмов сортировки или с помощью встроенной функции sorted(). Второй шаг — определить, является ли длина набора данных четной или нечетной. В зависимости от этого некоторые из следующих процессов:
- Нечетный: медиана — это среднее значение набора данных.
- Четное: медиана представляет собой сумму двух средних значений, деленную на два.
Продолжая работу с набором данных нашей баскетбольной команды, давайте рассчитаем средний рост игроков в сантиметрах:
[181, 187, 196, 196, 198, 203, 207, 211, 215] # Since the dataset is odd, we select the middle value median = 198
Как видите, поскольку длина набора данных нечетная, мы можем взять среднее значение в качестве медианы. Однако что произойдет, если игрок только что вышел на пенсию?
Нам нужно будет вычислить медиану, взяв два средних значения набора данных.
[181, 187, 196, 198, 203, 207, 211, 215] # We select the two middle values, and divide them by 2 median = (198 + 203) / 2 median = 200.5
Создание пользовательской медианной функции
Давайте реализуем описанную выше концепцию в функции Python.
Помните три шага, которые нам нужно выполнить, чтобы получить медиану набора данных:
- Сортировка набора данных: мы можем сделать это с помощью функции sorted()
- Определите, является ли он нечетным или четным: мы можем сделать это, получив длину набора данных и используя оператор по модулю (%)
- Верните медиану на основе каждого случая:
- Нечетный: вернуть среднее значение
- Даже: возвращает среднее значение двух средних значений.
Это приведет к следующей функции:
pythonic_machines_heights = [181, 187, 196, 196, 198, 203, 207, 211, 215]
after_retirement = [181, 187, 196, 198, 203, 207, 211, 215]
def median(dataset):
data = sorted(dataset)
index = len(data) // 2
# If the dataset is odd
if len(dataset) % 2 != 0:
return data[index]
# If the dataset is even
return (data[index - 1] + data[index]) / 2
Печать результата наших наборов данных:
print(median(pythonic_machines_heights)) print(median(after_retirement))
Выход:
198 200.5
Обратите внимание, как мы создаем переменную данных, которая указывает на отсортированную базу данных в начале функции. Хотя приведенные выше списки отсортированы, мы хотим создать повторно используемую функцию, поэтому набор данных будет сортироваться при каждом вызове функции.
Индекс сохраняет среднее значение — или верхне-среднее значение — набора данных с помощью оператора целочисленного деления. Например, если бы мы передавали список «pythonic_machine_heights», он имел бы значение 4.
Помните, что в Python индексы последовательности начинаются с нуля, потому что мы можем вернуть средний индекс списка с целочисленным делением.
Затем мы проверяем, является ли длина набора данных нечетной, сравнивая результат операции по модулю с любым значением, отличным от нуля. Если условие истинно, мы возвращаем средний элемент, например, со списком «pythonic_machine_heights»:
>>> pythonic_machine_heights[4] # 198
С другой стороны, если набор данных четный, мы возвращаем сумму средних значений, деленную на два. Обратите внимание, что данные[index -1] дает нам нижнюю среднюю точку набора данных, а данные[index] дает нам верхнюю среднюю точку.
Использование median() из статистического модуля Python
Этот способ намного проще, потому что мы используем уже существующую функцию из модуля статистики.
Лично для меня, если бы что-то уже было определено, я бы использовал это из-за принципа DRY — Don’t Repeat Yourself (в данном случае — не повторять чужой код).
Вы можете вычислить медиану предыдущих наборов данных с помощью следующего кода:
from statistics import median pythonic_machines_heights = [181, 187, 196, 196, 198, 203, 207, 211, 215] after_retirement = [181, 187, 196, 198, 203, 207, 211, 215] print(median(pythonic_machines_heights)) print(median(after_retirement))
Выход:
198 200.5
Вычисление режима в Python
Режим является наиболее часто встречающимся значением в наборе данных. Мы можем думать об этом как о «популярной» группе школы, которая может представлять собой стандарт для всех учащихся.
Примером режима могут быть ежедневные продажи в магазине техники. Режим этого набора данных будет самым продаваемым продуктом за определенный день.
['laptop', 'desktop', 'smartphone', 'laptop', 'laptop', 'headphones']
Как вы понимаете, режим приведенного выше набора данных — «ноутбук», потому что это наиболее часто встречающееся значение в списке.
Преимущество режима в том, что набор данных не должен быть числовым. Например, мы можем работать со строками.
Проанализируем продажи другого дня:
['mouse', 'camera', 'headphones', 'usb', 'headphones', 'mouse']
Приведенный выше набор данных имеет два режима: «мышь» и «наушники», потому что оба имеют частоту, равную двум. Это означает, что это мультимодальный набор данных.
Что, если мы не сможем найти моду в наборе данных, как показано ниже?
['usb', 'camera', 'smartphone', 'laptop', 'TV']
Это называется равномерное распределениепо сути, это означает, что в наборе данных нет моды.
Теперь, когда вы быстро разобрались с концепцией режима, давайте посчитаем его в Python.
Создание функции пользовательского режима
Мы можем думать о частоте значения как о паре ключ-значение, другими словами, как о словаре Python.
Повторяя аналогию с баскетболом, мы можем использовать два набора данных для работы: количество очков за игру и спонсорство кроссовок некоторых игроков.
Чтобы сначала найти моду, нам нужно создать словарь частот с каждым из значений, присутствующих в наборе данных, затем получить максимальную частоту и вернуть все элементы с этой частотой.
Переведем это в код:
points_per_game = [3, 15, 23, 42, 30, 10, 10, 12]
sponsorship = ['nike', 'adidas', 'nike', 'jordan',
'jordan', 'rebook', 'under-armour', 'adidas']
def mode(dataset):
frequency = {}
for value in dataset:
frequency[value] = frequency.get(value, 0) + 1
most_frequent = max(frequency.values())
modes = [key for key, value in frequency.items()
if value == most_frequent]
return modes
Проверка результата с передачей двух списков в качестве аргументов:
print(mode(points_per_game)) print(mode(sponsorship))
Выход:
[10] ['nike', 'adidas', 'jordan']
Как видите, первый оператор печати дал нам один режим, а второй вернул несколько режимов.
Объяснение более глубокого кода выше:
- Объявляем частотный словарь
- Мы перебираем набор данных, чтобы создать гистограмма — статистический термин для набора счетчиков (или частот) —
- Если ключ найден в словаре, то он добавляет единицу к значению
- Если он не найден, мы создаем пару ключ-значение со значением один
- Переменная most_frequent хранит, по иронии судьбы, самое большое значение (не ключ) частотного словаря.
- Мы возвращаем переменную режимов, которая состоит из всех ключей в частотном словаре с наибольшей частотой.
Обратите внимание, как важно именовать переменные для написания читаемого кода.
Использование режима() и мультимода() из статистического модуля Python
И снова модуль статистики предоставляет нам быстрый способ выполнения основных операций со статистикой.
Мы можем использовать две функции: Режим() а также многомодовый().
from statistics import mode, multimode
points_per_game = [3, 15, 23, 42, 30, 10, 10, 12]
sponsorship = ['nike', 'adidas', 'nike', 'jordan',
'jordan', 'rebook', 'under-armour', 'adidas']
Приведенный выше код импортирует обе функции и определяет наборы данных, с которыми мы работали.
Вот небольшое отличие: функция mode() возвращает первый обнаруженный режим, а multimode() возвращает список с наиболее часто встречающимися значениями в наборе данных.
Следовательно, мы можем сказать, что пользовательская функция, которую мы определили, на самом деле является функцией multimode().
print(mode(points_per_game)) print(mode(sponsorship))
Выход:
10 nike
Примечание. В Python 3.8 и более поздних версиях функция mode() возвращает первый найденный режим. Если у вас более старая версия, вы получите СтатистикаОшибка.
Использование функции multimode():
print(multimode(points_per_game)) print(multimode(sponsorship))
Выход:
[10] ['nike', 'adidas', 'jordan']
Подводить итоги
Поздравляем! Если вы дочитали до этого момента, вы научились вычислять среднее значение, медиану и моду, основные измерения центральной тенденции.
Хотя вы можете определить свои пользовательские функции для поиска среднего значения, медианы и моды, рекомендуется использовать модуль статистики, так как он является частью стандартной библиотеки, и вам не нужно ничего устанавливать, чтобы начать его использовать.
Затем прочитайте дружественное введение в анализ данных в Python.
Расчет моды
Теперь посмотрим, как рассчитать моду. Мода – это то значение в анализируемой совокупности данных, которое встречается чаще других, поэтому нужно посмотреть на частоты значений и отыскать максимальное из них. Например, в наборе данных 3, 4, 6, 7, 3, 5, 3, 4 модой будет значение 3 – повторяется чаще остальных. Это в дискретном ряду, и здесь все просто. Если данных много, то моду легче всего найти с помощью соответствующей гистограммы. Бывает так, что совокупность данных имеет бимодальное распределение.

Без диаграммы очень трудно понять, что в данных не один, а два центра. К примеру, на президентских выборах предпочтения сельских и городских жителей могут отличаться. Поэтому распределение доли отданных голосов за конкретного кандидата может быть «двугорбым». Первый «горб» – выбор городского населения, второй – сельского.
Немного сложнее с интервальными данными, когда вместо конкретных значений имеются интервалы. В этом случае говорят о модальном интервале (при анализе доходов населения, например), то есть интервале, частота которого максимальна относительно других интервалов. Однако и здесь можно отыскать конкретное модальное значение, хотя оно будет условным и примерным, так как нет точных исходных данных. Представим, что есть следующая таблица с распределением цен.

Для наглядности изобразим соответствующую диаграмму.

Требуется найти модальное значение цены.
Вначале нужно определить модальный интервал, который соответствует интервалу с наибольшей частотой. Найти его так же легко, как и моду в дискретном ряду. В нашем примере это третий интервал с ценой от 301 до 400 руб. На графике – самый высокий столбец. Теперь нужно определить конкретное значение цены, которое соответствует максимальному количеству. Точно и по факту сделать это невозможно, так как нет индивидуальных значений частот для каждой цены. Поэтому делается допущение о том, что интервалы выше и ниже модального в зависимости от своей частоты имеют разные вес и как бы перетягивают моду в свою сторону. Если частота интервала следующего за модальным больше, чем частота интервала перед модальным, то мода будет правее середины модального интервала и наоборот. Давайте еще раз посмотрим на рисунок, чтобы понять формулу, которую я напишу чуть ниже.

На рисунке отчетливо видно, что соотношение высоты столбцов, расположенных слева и справа от модального определяет близость моды к левому или правому краю модального интервала. Задача по расчету модального значения состоит в том, чтобы найти точку пересечения линий, соединяющих модальный столбец с соседними (как показано на рисунке пунктирными линиями) и нахождении соответствующего значения признака (в нашем примере цены). Зная основы геометрии (7-й класс), по данному рисунку нетрудно вывести формулу расчета моды в интервальном ряду.
Формула моды имеет следующий вид.

Где Мо – мода,
x – значение начала модального интервала,
h – размер модального интервала,
fМо – частота модального интервала,
fМо-1 – частота интервала, находящего перед модальным,
fМо1 – частота интервала, находящего после модального.
Второе слагаемое формулы моды соответствует длине красной линии на рисунке выше.
Рассчитаем моду для нашего примера.

Таким образом, мода интервального ряда представляет собой сумму, состоящую из значения начального уровня модального интервала и отрезка, который определяется соотношением частот ближайших интервалов от модального.
Видео
Мода и медиана
Модой называют элемент, который встречается в выборке чаще других.
Рассмотрим следующую выборку: шестеро спортсменов, а также время в секундах за которое они пробегают 100 метров

Элемент 14 встречается в выборке чаще других, поэтому элемент 14 назовем модой.
Рассмотрим еще одну выборку. Тех же спортсменов, а также смартфоны, которые им принадлежат

Элемент iphone встречается в выборке чаще других, значит элемент iphone является модой. Говоря простым языком, носить iphone модно.
Конечно элементы выборки в этот раз выражены не числами, а другими объектами (смартфонами), но для общего представления о моде этот пример вполне приемлем.
Рассмотрим следующую выборку: семеро спортсменов, а также их рост в сантиметрах:

Упорядочим данные в таблице так, чтобы рост спортсменов шел по возрастанию. Другими словами, построим спортсменов по росту:

Выпишем рост спортсменов отдельно:
180, 182, 183, 184, 185, 188, 190
В получившейся выборке 7 элементов. Посередине этой выборки располагается элемент 184. Слева и справа от него по три элемента. Такой элемент как 184 называют медианой упорядоченной выборки.
Медианой упорядоченной выборки называют элемент, располагающийся посередине.
Отметим, что данное определение справедливо в случае, если количество элементов упорядоченной выборки является нечётным.
В рассмотренном выше примере, количество элементов упорядоченной выборки было нечётным. Это позволило нам быстро указать медиану

Но возможны случаи, когда количество элементов выборки чётно.
К примеру, рассмотрим выборку в которой не семеро спортсменов, а шестеро:

Построим этих шестерых спортсменов по росту:

Выпишем рост спортсменов отдельно:
180, 182, 184, 186, 188, 190
В данной выборке не получается указать элемент, который находился бы посередине. Если указать элемент 184 как медиану, то слева от этого элемента будут располагаться два элемента, а справа — три. Если как медиану указать элемент 186, то слева от этого элемента будут располагаться три элемента, а справа — два.
В таких случаях для определения медианы выборки, нужно взять два элемента выборки, находящихся посередине и найти их среднее арифметическое. Полученный результат будет являться медианой.
Вернемся к нашим спортсменам. В упорядоченной выборке 180, 182, 184, 186, 188, 190 посередине располагаются элементы 184 и 186

Найдем среднее арифметическое элементов 184 и 186

Элемент 185 является медианой выборки, несмотря на то, что этот элемент не является членом исходной и упорядоченной выборки. Спортсмена с ростом 185 нет среди остальных спортсменов. Рост в 185 см используется в данном случае для статистики, чтобы можно было сказать о том, что срединный рост спортсменов составляет 185 см.
Поэтому более точное определение медианы зависит от количества элементов в выборке.
Если количество элементов упорядоченной выборки нечётно, то медианой выборки называют элемент, располагающийся посередине.
Если количество элементов упорядоченной выборки чётно, то медианой выборки называют среднее арифметическое двух чисел, располагающихся посередине этой выборки.
Медиана и среднее арифметическое по сути являются «близкими родственниками», поскольку и то и другое используют для определения среднего значения. Например, для предыдущей упорядоченной выборки 180, 182, 184, 186, 188, 190 мы определили медиану, равную 185. Этот же результат можно получить путем определения среднего арифметического элементов 180, 182, 184, 186, 188, 190

Но медиана в некоторых случаях отражает более реальную ситуацию. Например, рассмотрим следующий пример:
Было подсчитано количество имеющихся очков у каждого спортсмена. В результате получилась следующая выборка:
0, 1, 1, 1, 2, 1, 2, 3, 5, 4, 5, 0, 1, 6, 1
Определим среднее арифметическое для данной выборки — получим значение 2,2

По данному значению можно сказать, что в среднем у спортсменов 2,2 очка
Теперь определим медиану для этой же выборки. Упорядочим элементы выборки и укажем элемент, находящийся посередине:
0, 0, 1, 1, 1, 1, 1, 1, 2, 2, 3, 4, 5, 5, 6
В данном примере медиана лучше отражает реальную ситуацию, поскольку половина спортсменов имеет не более одного очка.
Среднее арифметическое
Понятие среднего значения часто используется в повседневной жизни.
Примеры:
- средняя зарплата жителей страны;
- средний балл учащихся;
- средняя скорость движения;
- средняя производительность труда.
Речь идет о среднем арифметическом — результате деления суммы элементов выборки на их количество.
Среднее арифметическое — это результат деления суммы элементов выборки на их количество.

Вернемся к нашему примеру

Узнаем сколько в среднем мы тратили в каждом из шести дней:

Теория для решения данных задач. Формулы для расчета моды и медианы
Модой в статистике называется величины признака (варианта), которая чаще всего встречается в данной совокупности.
Медианой в статистике называется варианта, которая находится в середине вариационного ряда. Медиана делит ряд пополам. Обозначают медиану символом.
Распределительные средние – мода и медиана, их сущность и способы исчисления.
Данные показатели относятся к группе распределительных средних и используются для формирования обобщающей характеристики величины варьирующего признака.
Мода  – это наиболее часто встречающееся значение варьирующего признака в вариационном ряду. Модой распределения называется такая величина изучаемого признака, которая в данной совокупности встречается наиболее часто, т.е. один из вариантов признака повторяется чаще, чем все другие. Для дискретного ряда (ряд, в котором значение варьирующего признака представлены отдельными числовыми показателями) модой является значение варьирующего признака обладающего наибольшей частотой. Для интервального ряда сначала определяется модальный интервал (т.е. содержащий моду), в случае интервального распределения с равными интервалами определяется по наибольшей частоте; с неравными интервалами – по наибольшей плотности, а определение моды требует проведения расчетов на основе следующих формул:
– это наиболее часто встречающееся значение варьирующего признака в вариационном ряду. Модой распределения называется такая величина изучаемого признака, которая в данной совокупности встречается наиболее часто, т.е. один из вариантов признака повторяется чаще, чем все другие. Для дискретного ряда (ряд, в котором значение варьирующего признака представлены отдельными числовыми показателями) модой является значение варьирующего признака обладающего наибольшей частотой. Для интервального ряда сначала определяется модальный интервал (т.е. содержащий моду), в случае интервального распределения с равными интервалами определяется по наибольшей частоте; с неравными интервалами – по наибольшей плотности, а определение моды требует проведения расчетов на основе следующих формул:

где: — нижняя граница модального интервала;
— нижняя граница модального интервала;
 — величина модального интервала;
— величина модального интервала;
 — частота модального интервала;
— частота модального интервала;
 — частота интервала, предшествующего модальному;
— частота интервала, предшествующего модальному;
 — частота интервала, следующего за модальным;
— частота интервала, следующего за модальным;
Медиана (Ме) — это значение варьирующего признака, приходящееся на середину ряда, расположенного в порядке возрастания или убывания числовых значений признака, т.е. величина изучаемого признака, которая находится в середине упорядоченного вариационного ряда. Главное свойство медианы в том, что сумма абсолютных отклонений значений признака от медианы меньше, чем от любой другой величины:

Для определения медианы в дискретном ряду при наличии частот, сначала исчисляется полусумма частот, а затем определяется какое значение варьирующего признака ей соответствует. При исчислении медианы интервального ряда сначала определяются медианы интервалов, а затем определяется какое значение варьирующего признака соответствует данной частоте. Для определения величины медианы используется формула:

где: — нижняя граница медианного интервала;
— нижняя граница медианного интервала;
 — величина медианного интервала;
— величина медианного интервала;
 — накопленная частота интервала, предшествующего медианному;
— накопленная частота интервала, предшествующего медианному;
 — частота медианного интервала;
— частота медианного интервала;
Медианный интервал не обязательно совпадает с модальным.
Моду и медиану в интервальном ряду распределения можно определить графически. Мода определяется по гистограмме распределения. Для этого выбирается самый высокий прямоугольник, который в данном случае является модальным. Затем правую вершину модального прямоугольника соединяют с правым верхним углом предыдущего прямоугольника. А левую вершину модального прямоугольника – с левым верхним углом последующего прямоугольника. Далее из точки их пересечения опускают перпендикуляр на ось абсцисс.
Теги
Мода
и медиана –
особого рода средние, которые используются
для изучения структуры вариационного
ряда. Их иногда называют структурными
средними, в отличие от рассмотренных
ранее степенных средних.
Мода
– это величина признака (варианта),
которая чаще всего встречается в данной
совокупности, т.е. имеет наибольшую
частоту.
Мода
имеет большое практическое применение
и в ряде случаев только мода может дать
характеристику общественных явлений.
Медиана
– это варианта, которая находится в
середине упорядоченного вариационного
ряда.
Медиана
показывает количественную границу
значения варьирующего признака, которой
достигла половина единиц совокупности.
Применение медианы наряду со средней
или вместо нее целесообразно при наличии
в вариационном ряду открытых интервалов,
т.к. для вычисления медианы не требуется
условное установление границ отрытых
интервалов, и поэтому отсутствие сведений
о них не влияет на точность вычисления
медианы.
Медиану
применяют также тогда, когда показатели,
которые нужно использовать в качестве
весов, неизвестны. Медиану применяют
вместо средней арифметической при
статистических методах контроля качества
продукции. Сумма абсолютных отклонений
варианты от медианы меньше, чем от любого
другого числа.
Рассмотрим
расчет моды и медианы в дискретном
вариационном ряду:
|
Стаж, |
Число |
Накопленные |
|
1 |
2 |
2 |
|
3 |
4 |
6 |
|
4 |
5 |
(11) |
|
8 |
4 |
15 |
|
10 |
1 |
16 |
|
ИТОГО: |
16 |
– |
Определить моду и медиану.
Мода
Мо =
4 года, так как этому значению соответствует
наибольшая частота f
= 5.
Т.е.
наибольшее число рабочих имеют стаж 4
года.
Для
того, чтобы вычислить медиану, найдем
предварительно половину суммы частот.
Если сумма частот является числом
нечетным, то мы сначала прибавляем к
этой сумме единицу, а затем делим пополам:
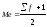
Ме=16/2=8
Медианой
будет восьмая по счету варианта.
Для
того, чтобы найти, какая варианта будет
восьмой по номеру, будем накапливать
частоты до тех пор, пока не получим сумму
частот, равную или превышающую половину
суммы всех частот. Соответствующая
варианта и будет медианой.
Ме
= 4 года.
Т.е.
половина рабочих имеет стаж меньше
четырех лет, половина больше.
Если
сумма накопленных частот против одной
варианты равна половине сумме частот,
то медиана определяется как средняя
арифметическая этой варианты и
последующей.
Вычисление
моды и медианы в интервальном вариационном
ряду
Мода
в интервальном вариационном ряду
вычисляется по формуле
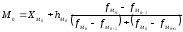
где ХМ0
– начальная
граница модального интервала,
hм0
– величина модального интервала,
fм0,
fм0-1,
fм0+1
– частота
соответственно модального интервала,
предшествующего модальному и последующего.
Модальным
называется такой интервал, которому
соответствует наибольшая частота.
Пример
1
|
Группы |
Число |
Накопленные |
|
1 |
2 |
3 |
|
До |
4 |
4 |
|
2-4 |
23 |
27 |
|
4-6 |
20 |
47 |
|
6-8 |
35 |
82 |
|
8-10 |
11 |
93 |
|
свыше |
7 |
100 |
|
ИТОГО: |
100 |
– |
Определить
моду и медиану.
Решение.
Модальный
интервал [6-8], т.к. ему соответствует
наибольшая частота f
= 35. Тогда:
Хм0=6,
fм0=35
hм0=2,
fм0-1=20
fм0+1=11

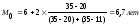
Вывод:
Наибольшее число рабочих имеет стаж
примерно 6,7 лет.
Для
интервального ряда Ме вычисляется по
следующей формуле:

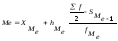
где Хме
–
нижняя граница медиального интервала,
hме
– величина медиального интервала,
![]() –
–
половина суммы частот,
fме
– частота медианного интервала,
Sме-1
–сумма
накопленных частот интервала,
предшествующего медианному.
Медианный
интервал – такой интервал, которому
соответствует кумулятивная частота,
равная или превышающая половину суммы
частот.
Определим
медиану для нашего примера.
Найдем:
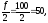
т.к
82>50, то медианный интервал [6-8].
Тогда:
Хме
=6, fме
=35,
hме
=2, Sме-1=47,
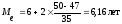
Вывод: Половина рабочих имеет стаж
меньше 6,16 лет, а половина имеет стаж
больше, чем 6,16 лет.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
