Поиск достоверной информации при работе над научной статьей: основы фактчекинга
Во время написания научной статьи на пути автора возникает множество подводных камней. Околонаучная информация, выдаваемая за научный труд, не подтвержденные практическими опытами исследования, манипуляции фактами, а также откровенное вранье — такая информация регулярно закрадывается не только в публицистику, но и в научную среду. Использование подобной информации в исследованиях приводит к краху репутации научного сотрудника. Это, в свою очередь, влечет за собой печальные результаты: незащищенная дипломная работа, проваленная диссертация, потеря доверия и авторитета среди коллег.
Фактчекинг — это принцип работы с фактами, комплекс мер для проверки их на достоверность. В этой статье рассказываем, как проверить данные в научных публикациях, на какие ошибки можно наткнуться в научных работах, а какие ошибки может совершить сам автор во время написания статьи.
Что такое фактчекинг
Термин «фактчекинг» пришел в научный мир из журналистики и в дословном переводе звучит как «проверка фактов». Связано это понятие с информационным шумом, который не умолкает на просторах Интернета. Так же как и журналистам, научным деятелям приходится регулярно перепроверять информацию перед использованием их в своих работах.
Зачем нужен фактчекинг
В журналистике фактчекинг направлен на защиту авторских публикаций от газетных сплетен, искусственного повышения «градуса» или дезинформации. В научной среде фактчекинг направлен несколько в другое русло:
- на ликвидацию околонаучной информации, выдаваемой за достоверные факты;
- на проверку результатов исследования в условиях кризиса воспроизводимости – это, к сожалению, довольно распространенное явление, когда публикуются статьи с непроверенными результатами исследований;
- против использования искаженных данных (фактоидов);
- против манипуляции фактами, то есть намеренной расстановки фактов таким образом, чтобы подвести читателя к выгодному для автора выводу;
- против манипуляции общественным мнением, то есть желания приукрасить факты, исказить их таким образом, чтобы подтолкнуть читателей к нужному решению.
На что обратить внимание при подготовке научной статьи
Фактчекинг применяется на всех этапах подготовки исследования. В противном случае из-за критических ошибок, которые были не замечены в самом начале, автору придется заново переписывать как минимум несколько разделов.
Подготовка ссылочного материала
Прежде чем приступить к написанию самой статьи, исследователь подготавливает ключевой ссылочный материал — работы, которые он впоследствии будет использовать для написания своей статьи или диссертации. При этом необходимо обращать внимание на такие неточности, как: неверные ссылки на источники, ссылки на устаревшие документы или научные работы.
Проверка черновиков
В процессе написания материал дополняется новыми данными, которые необходимо грамотно вплести в канву научной работы. После завершения черновика необходимо еще раз проверить соответствие всех данных и результатов и обратить внимание на следующее: неполные цитаты, вырывание из контекста и вольная трактовка цитат, путаница в новых профессиональных терминах, неверное указание исторической даты в связи с переходом на григорианский календарь в 1918 году. Если вы используете названия городов или стран, обратите внимание на их актуальность.
Анализ фактов после публикации
Уже после публикации автор продолжает дополнять статью небольшими уточнениями, подтверждает или опровергает спорную информацию. Однако, если первые 2 этапа выполнены добросовестно, третий этап не всегда так уж необходим.
5 базовых правил фактчекинга
- Распознавайте чужие ошибки.
Под ошибками понимается не только подделка результатов и симуляции. Это еще и небрежность, опечатки и технические ошибки. Авторы могут неправильно написать имена, профессии, звания, научные термины. Необходимо обладать критическим мышлением, чтобы вовремя распознавать подобные ошибки и не использовать их в собственных работах. - Ищите официальные источники.
Либо используйте несколько независимых источников. Достоверность фактов и событий можно найти, прежде всего, в энциклопедиях, монографиях, узкопрофильных справочниках. Также ищите информацию на официальных сайтах деятелей и их страницах в социальных сетях.
К публикациям в научных журналах лучше относиться настороженно, и прежде чем использовать информацию оттуда, навести справки на авторитетность этого журнала и, в частности, автора статьи. - Спросите мнение всех сторон.
Если вопрос касается спорных теорий или утверждений, то будет разумно поинтересоваться у коллег из разных научных школ, которые придерживаются других точек зрения. Таким образом, автор сможет более объективно подойти к описанию подобных вопросов и не допустить грубых оплошностей. - Всегда перепроверяйте источники.
Беспристрастность и сомнение — главные союзники во время проверки информации на актуальность. Подвергайте критике информацию и ищите дополнительные доказательства описанных в источнике результатов. Довольно часто желание первым опубликовать научный труд приводит к тому, что публикуются и добавляются в научные базы данных статьи с непроверенными результатами.
Заключение
Фактчекинг — это прежде всего ответственность, заинтересованность и неравнодушие автора к своей работе. С одной стороны, интернет-коммуникации — это научные базы данных, публикации в социальных сетях, электронные библиотеки (о некоторых ресурсах мы уже рассказывали в этой статье), а общение с учеными со всего мира позволяет значительно ускорить и улучшить научную работу. Но с другой стороны, большой объем информации вовсе не означает ее качество. Большое количество неподтвержденных или вовсе антинаучных данных вынуждает современных научных деятелей уметь фильтровать информацию, анализировать и постоянно перепроверять данные.
Понравился ли Вам материал?
RCO Fact Extractor — наделенная интеллектуальными возможностями программа, предназначенная для анализа текста на русском языке. Она позволяет отыскивать описания фактов заданного типа, например относящиеся к «встречам», «договоренностям», «приобретению собственности», причем производятся их классификация и упорядочивание. Основная область применения программы — аналитические задачи, возникающие при проведении компьютерной разведки и требующие высокоточного поиска информации, в том числе автоматического подбора материала к досье на целевой объект или мониторинга определенных сторон его активности, освещаемых в СМИ. В программе Fact Extractor воплощены наиболее продвинутые технологии искусственного интеллекта, разработанные компанией «Гарант-Парк-Интернет», известной своими решениями в области компьютерной лингвистики (www.rco.ru).
Помимо Fact Extractor с графическим интерфейсом для Windows компания выпустила динамическую библиотеку для разработчиков (SDK). На ее базе и построена программа, позволяющая включать возможности анализа текста в собственные приложения, в частности обрабатывать документы в популярных текстовых форматах и из таких источников, как файловая система, база данных, оговоренные веб-сайты.
Результатом работы программы является таблица, содержащая информацию о найденных фактах, связанных с объектами мониторинга, которая может экспортироваться в файл html-формата для формирования отчета или загрузки в стороннее приложение, работающее с уже структурированными данными.
Как работать с программой?
Основные логические сущности, которыми оперирует Fact Extractor, следующие:
- факты, описания которых ищут в тексте;
- объекты мониторинга для сбора фактов;
- атрибуты объектов, к которым относятся факты;
- досье, где собирается информация обо всех найденных фактах.
Фактом называется некоторая ситуация (событие), представляющая интерес для пользователя программы. Ее описание следует искать в тексте. Каждый факт имеет свой тип — название ситуации (например, «покупка акций») — и список ролей возможных участников-фигурантов («покупатель», «продавец», «эмитент акций»). Лингвистические описания фактов требуемого типа — шаблоны для поиска в тексте — либо создаются пользователем с помощью дополнительной программы-настройщика, либо приобретаются у производителя. В стандартный пакет поставки Fact Extractor входят готовые описания для нескольких типов фактов общего характера, позволяющие выделить без детальной классификации все события, в которых участвует объект, и всех участников этих событий.

|
Рис. 1. Настройка атрибута объекта «владеет предприятиями» — объединение фактов различных типов (список в окне слева) |
К объектам мониторинга, по которым ведется сбор фактов, относятся персоны и организации. Описание объекта включает в себя целый ряд полей, значения которых задаются пользователем, например для персоны обязательные поля «Фамилия» и «Имя», желательное — «Отчество». А если есть возможность, то полезно задавать такие поля, как «Синонимы», «Контекстные синонимы», «Референтный контекст», «Эквивалентные по смыслу». Не вдаваясь в содержание этих полей, заметим, что более полное описание объекта позволяет правильно выделять большее количество упоминаний в тексте, включая полные и краткие наименования, косвенные обозначения, а также различать объекты с одинаковыми фамилиями, именами, должностями и пр.
Атрибут — комплексная характеристика определенной стороны объекта или его деятельности, представляющая конечный интерес для пользователя-аналитика. Экспертное суждение об атрибуте объекта будет складываться на основе фактов различного типа. Например, атрибут «политический профиль персоны» может формироваться из множества фактов типа «кого поддержал на выборах», «за что критикует власть» и т.п. В то же время один и тот же факт может интерпретироваться по-разному и отражать разные стороны объекта, т.е. относиться к нескольким его атрибутам. Поэтому каждый атрибут определяется пользователем, задающим способ объединения и интерпретации фактов.
Для каждого типа фактов указывается роль, в которой должен стоять целевой объект мониторинга, для того чтобы факт относился к данному атрибуту объекта (выбирается в группе «участники факта» в столбце «целевой»). Как видно, в атрибут дважды включен факт типа «купля-продажа акций», причем в первом случае целевой участник выступает в роли «продавца», а во втором — в роли «покупателя». Это имеет смысл при ретроспективном анализе информации, так как покупатель и продавец являлись владельцами предприятия. При анализе новостей, когда интерес представляет появление новых владельцев, целесообразно включать целевого участника только в роли «покупателя». Дополнительно в группе «участники факта» в столбце «значение» помечаются роли других участников, интересующих аналитика, которые формируют значение атрибута и отображаются на экране. В данном случае это роль «эмитента» — выпускающего акции предприятия, которым владеет покупающий или продающий их объект мониторинга. Факты с одинаковым значением группируются вместе и образуют одну запись в досье (рис. 2).
|
|
Рис. 2. Общий вид интерфейса пользователя Fact Extractor |
В итоге все найденные факты объединяются по атрибутам объектов и собираются в таблицу, называемую досье. Каждая запись досье содержит информацию об одном найденном факте или о множестве похожих: объект мониторинга и его атрибут, к которым относится факт; значение атрибута — фигурант факта, извлеченный из текста; количество упоминаний о факте в обработанных документах и др.
В окне слева — объекты и атрибуты, для удобства объединенные в логические группы. С каждым объектом можно связать свои атрибуты, перетащив их мышью. В окне справа — список найденных фактов, связанных с атрибутом «покупает» выбранной группы объектов МДМ. Атрибут настроен так, что факты сгруппированы по значению фигуранта «предмет покупки». В окне снизу приведены найденные описания факта покупки «Петровского народного банка» — шесть цитат из документов с возможностью просмотра их полного текста. Упорядочив записи досье по столбцу «значение», можно найти все факты других типов, связывающие группу МДМ и «Петровский народный банк», например заключение договоров. Упорядочив записи по столбцу «частота», можно отобрать факты, оказавшиеся в фокусе внимания журналистов.
Как работает программа?
Для поиска описаний фактов текст представляется в форме семантической сети, строящейся лингвистическим процессором — интеллектуальным ядром программы. Семантическая сеть содержит все полнозначные слова и словосочетания, упоминавшиеся в тексте: наименования предметов, персон, организаций, событий и признаков, связанные различными типами связей.
Представление текста в форме семантической сети позволяет абстрагироваться от многих его особенностей, не существенных для описания фактов. Такая сеть инвариантна к форме предложения и порядку слов с точностью до логической структуры, выбранной автором для описания ситуации, — пропозиции. Например, конструкциям «Иванов купил акции» и «об акциях, которые были куплены Ивановым», как разным способам выражения одной пропозиции, будут соответствовать одинаковые сети. В то же время пропозициям вида «Иванов становится покупателем акций» и «покупка акций — дело рук Иванова» будут соответствовать иные сети.
Шаблон факта задается множеством лингвистических описаний (ЛО), и каждое из них соответствует своему типу пропозиции и позволяет распознать целое множество семантических сетей близкой структуры. Лингвистическое описание представляет собой сеть, подобную искомой, но в ее узлах и связях с помощью логических выражений задаются условия, которым должны удовлетворять узлы и связи искомой сети. Как правило, в некоторых узлах ЛО содержатся конкретные слова и их синонимы, включаемые в описание искомой ситуации. Часть узлов, соответствующих искомым фигурантам факта, содержат не слова, а метки, обозначающие роли участников ситуации. Слова, стоящие в этих узлах и неизвестные заранее, будут выданы при нахождении факта. Для хорошего распознавания фактов обычно требуется 5—10 лингвистических описаний на каждый тип факта.
Поиск факта есть поиск в семантической сети текста подсети, изоморфной одному из ЛО. Если подсеть найдена, то факт считается установленным, после чего производятся извлечение фигурантов факта и их отнесение к заданным ролям.
Три узла, обозначенные метками BUYER, ISSUER и SELLER, представляют возможных фигурантов факта «покупка акций» в ролях «покупатель», «эмитент» и «продавец» соответственно. Наличие узла SELLER вместе с идущей к нему связью не является обязательным при поиске, так как продавец может быть и не указан в тексте, и именно пара «покупатель—эмитент» представляет интерес для факта покупки акций.
Для настройки шаблонов фактов используется модуль с графическим интерфейсом, позволяющим строить ЛО на основе типовых фраз русского языка, т.е. обучать программу на примерах. Основа ЛО — узлы и связи сети — строится программой автоматически, после чего остается лишь проставить ограничения в узлы в виде списков синонимов, указать роли искомых фигурантов факта, пометить обязательных и факультативных фигурантов. Эта процедура не требует специальных лингвистических знаний, однако предполагает хорошее владение русским языком для понимания тех способов, которыми факт может быть описан в тексте, и для учета возможных синонимов. Если вы приобретете определенную сноровку после нескольких дней работы с программой, то создание и тестирование шаблона факта, содержащего десяток ЛО, будет занимать у вас около часа.
ОБ АВТОРЕ
А. Е. Ермаков — канд. техн. наук, руководитель отдела компьютерной лингвистики ООО «Гарант-Парк-Интернет», ermakov@metric.ru
Время на прочтение
9 мин
Количество просмотров 25K
Продолжение (начало – здесь)
1.3. Поисковые системы – специализированные и не очень
В общем случае результаты поиска в первую очередь зависят от поставленной задачи и корректности запроса. Но эти результаты чаще всего, с одной стороны,
а) избыточны
и с другой стороны — б) неполны.
К счастью, и авторы и издатели, как правило, заинтересованы в том, чтобы информация о публикациях индексировалась поисковиками, но тут есть нюансы: не всегда разрешается индексация содержимого pdf-файлов, и в некоторых случаях разрешена индексация сайтов только определёнными поисковиками (например, крупнейшая отечественная электронная библиотека elibrary.ru одно время запрещала для google индексацию большинства файлов).
Кроме всего прочего, результаты запроса зависят от порядка слов и от IP-адреса, с которого осуществляется поиск.
Если говорить о поиске публикаций, то вопрос «какой поисковой системой пользоваться» имеет один ответ – Google (это если не считать специализированные библиографические поисковые системы, о них ниже).
Во-первых, google достаточно полно индексирует содержимое Сети. Во-вторых, большое количество настроек расширенного поиска (в т.ч. с использование операторов) сильно облегчают работу. В третьих, как я уже указывал, содержимое пдф-файлов googl’ом индексируется даже в том случае, когда пдф состоит из изображений и текстовый слой в файле отсутствует.

Ка известно, в гугле любят пошутить. Вот такой у меня однажды вылез результат при попытке найти книгу Pander, C. H. (1830). Beiträge zur Geognosie des Russischen Reiches. St.Petersburg, Karl Kray. 150 S.
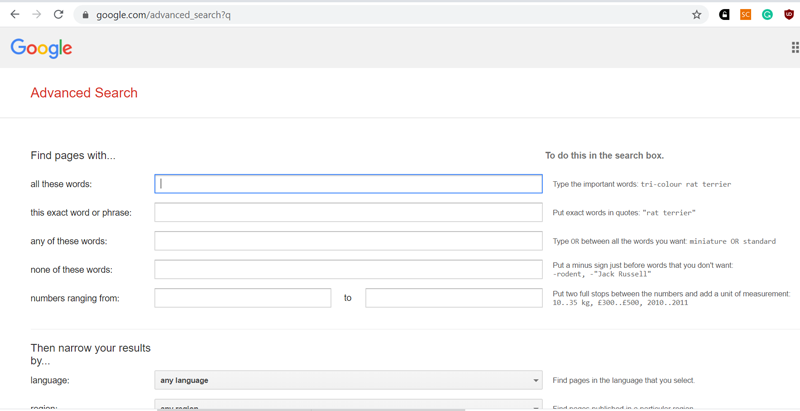
Настройки расширенного поиска google. На Яндексе, к сожалению, большая часть настроек расширенного поиска из имевшихся ранее давно сгинула, остались мелочи типа поиска по расширению файла (только вместо гугловского filetype: используется оператор mime: )
Для поиска публикаций наиболее полезными являются расширенные настройки и операторы, позволяющие ограничивать поиск файлами определённого формата (например, pdf c помощью filetype:pdf ), определёнными сайтами / доменами. Например, если мне понадобится посмотреть, на каких китайских сайтах выложены публикации в формате pdf, где упоминаются аммониты, то поможет вот такой запрос: ammonites filetype:pdf site:cn. Ну а “+” и “-” используются для указания обязательных или нежелательных терминов. К примеру, при поиски информации по головоногим моллюскам — аммонитам обычно не нужны сведения об одноимённом взрывчатом веществе или племени, некогда обитавшем на Ближнем Востоке и регулярно упоминающемся в Библии. Соответственно, запрос можно подкорректировать таким образом: аммониты filetype:pdf -взрывчатка -Библия
Если ищется какая-то конкретная публикация, то желательно часть её названия или всё название взять в кавычки.
Ещё немаловажно, что у гугла есть два отдельных проекта, имеющих прямое отношение к поиску публикаций:
1) Google books – это фактически отдельная поисковая система, индексирующая содержимое огромного количества книг, журналов, сборников и других изданий. При этом существенная часть публикаций доступна для скачивания в виде пдф (как правило, это старые издания, от начала ХХ века и старше); в зависимости от IP список доступных для скачивания изданий может существенно различаться, максимально число работ доступно пользователям из США.
Довольно много публикаций доступно для просмотра целиком или частично. Такие работы можно скачать с помощью специальных программ типа EDS Google Book downloader или плагинов (таких как Greasemonkey для Mozilla в сочетании с программой для автоматической загрузки файлов, например Download Master).
И, наконец, немалую пользу можно получить даже от той информации, которая присутствует в публикациях, которые вообще недоступны для просмотра в каком-либо виде кроме фрагментов в несколько строк (snippet view). С такими публикациями, правда, есть две основные сложности:
а) можно, конечно, попробовать поискать такие работы где-то ещё, но вероятность того что с ними можно будет ознакомиться только в библиотеке довольно велика.
б) в названиях источников (особенно тех, которые исходно даны не латиницей) путаницы очень и очень много, и отображаемая информация обычно неполна.
Тем не менее информация, содержащаяся в таких фрагментах может быть очень важной и практически не находимой другими способами
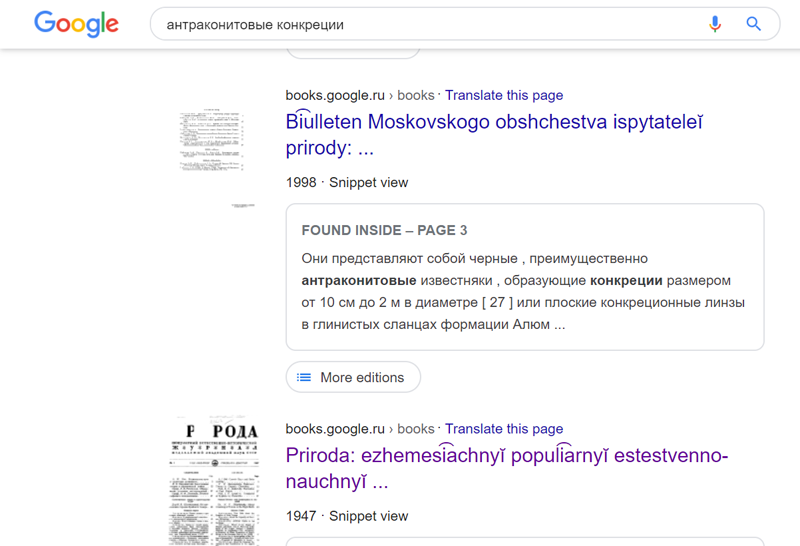
Так выглядит типичный вариант выдачи на google books в формате snippet view: как правило, отсутствует часть нужной библиографической информации (номер выпуска для журнала, иногда — важные части названия издания). Хорошо, если у журнала выходит 2 номера в год. А если 20? А если название указано с ошибкой?
2) Google Scholar (в русскоязычном варианте Академия Google ). Это библиографическая поисковая система, которая неплохо ищет как сами статьи, так и ссылки на них, заодно позволяя сразу скопировать названия публикаций, отформатированные согласно популярным типам цитирования (APA, Harvard, ГОСТ и т.д.). К числу удобств данной системы стоит отнести то, что индексируются не только сайты издателей, но и специализированные социальные сети и самые разные сайты, где нередко безвозмездно выкладываются научные работы, и все ссылки на полнотекстовые версии группируются в единый кластер. Тем не менее, Google Scholar индексирует не все публикации – это легко проверить с помощью идентичного поискового запроса «ключевые слова» filetype:pdf в Google и Google Scholar. Особенно это ярко это различие проявляется с редко встречающимися ключевыми словами.
Ну а наиболее полезная функция google scholar – это возможность подписки на самые разные оповещения (об этом подробнее — в продолжении данного поста)
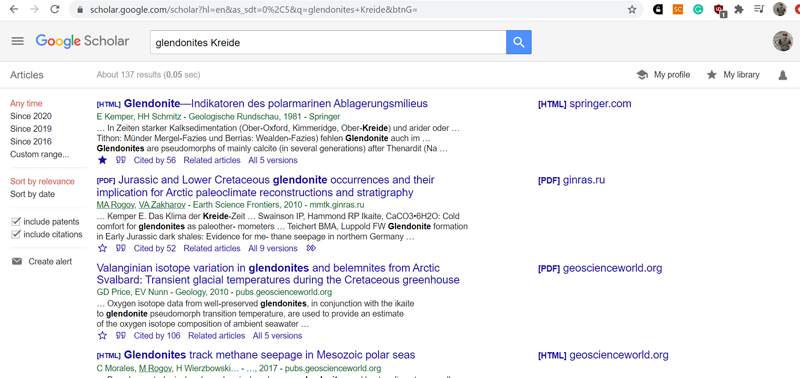
Выдача поиска по ключевым словам на google scholar. Обратите внимание на варианты сортировки, возможности выбора временного диапазона и кластеры статей.
Библиографические поисковые системы (БПС), ориентированные на работу с публикациями, сейчас весьма разнообразны и многочисленны. Кроме перечисленных выше проектов Google можно отметить следующие сайты, которые могут рассматриваться как БПС:
1) сайты, индексирующие огромное количество публикаций по всему миру. В первую очередь это Scopus и Web of Science, доступные по подписке (в случае со Scopus доступ также предоставляется рецензентам Elsevier’овских журналов), а также крупнейший сайт, присваивающий DOI публикациям (CrossRef) или агрегатор информации о публикациях, грантах, исследователях и т.д. Dimensions.
Все они кроме Dimensions позволяют искать информацию по ограниченному массиву данных – это преимущественно название / ключевые слова / резюме. В худшую сторону тут выделяется CrossRef – там поиск идёт только по названию, причём со строгой привязкой к форме слова. Правда, в CrossRef существенно больше проиндексировано русскоязычных публикаций, чем в других БПС из этого пункта, и плюс к тому это наиболее удобный способ решить задачу типа «у меня есть название публикации, надо найти её DOI» (все DOI так не найти – это не единственный регистратор цифровых идентификаторов к публикациям, есть ещё DataCite, например – но универсального сервиса для решения такой задачи, как ни странно, просто нет).
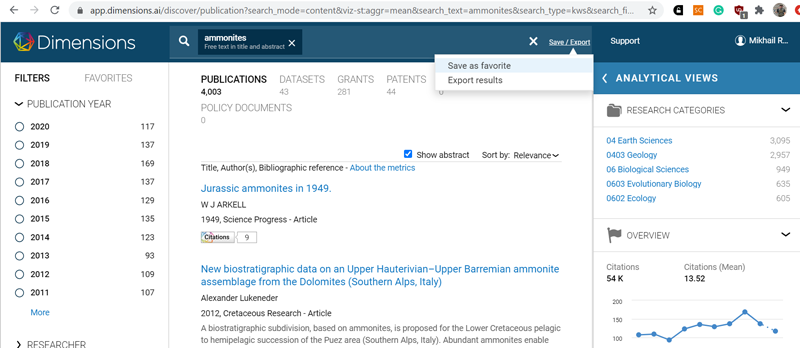
Простой поиск в Dimensions
Dimensions – совсем недавно появившийся очень интересный проект, в первую очередь благодаря множеству самых разнообразных настроек, широкому охвату публикаций (индексируются только публикации с DOI, их пока немного меньше чем есть на CrossRef) и полнотекстовому поиску. Вернее, тут можно выбирать разные опции поиска (полнотекстовый / по резюме / по названию и ключевым словам). Результаты можно сортировать самыми разнообразными способами (дата / релевантность / число ссылок / число альтметрик), и ограничивать по разным параметрам (источник / автор / годы / тематика и многое другое ). У Dimensions есть разные версии (включая платную и корпоративную), здесь рассматривается только бесплатный вариант (с другими пока не доводилось иметь дело). Отдельно можно искать информацию как по публикациям, так и по базам данных и грантам (последняя опция доступна только по подписке).
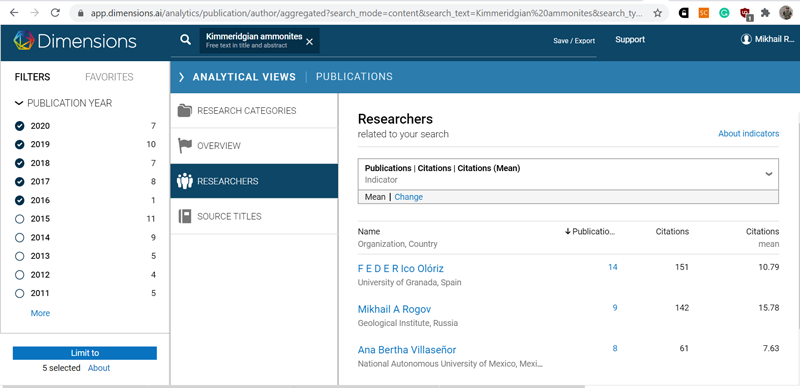
Во вкладке Analytical view можно посмотреть, например, кто или в каких журналах публиковался по интересующей нас тематике в то или иное время (в данном случае — с 2016 по 2020 годы). Ну а нажав на фамилию автора, можно посмотреть с кем вместе он публиковался, в каких журналах и т.д.
Дополнительные опции предлагаются во вкладке Analytical view. Они позволяют легко понять, кто сейчас или в любом выбранном временном диапазоне занимается той или иной тематикой, в какие журналы эти люди пишут статьи и с какими соавторами. Это удобный способ для поиска потенциальных соавторов и рецензентов, особенно для тех, кто только начал заниматься какой-либо тематикой и не очень хорошо себе представляет что с ней в мировом масштабе делается. Для тех исследователей, у которых в статьях имеется ORCID, в профиле приводится и этот идентификатор, и Scopus author ID, а также (при наличии) цепляющийся к ним «автоматом» ResearcherID / профиль на Publons. Повторюсь – Dimensions это крайне полезный проект, причём интуитивно понятный. Можно просто тыкать на все кнопки подряд и залезать во все вкладки.
2) также в качестве специализированных БПС можно рассматривать сайты крупнейших международных издателей (Elsevier, Wiley, Springer, Taylor & Francis и т.д.) и распространителей (Ingentaconnect, GeoscienceWorld) научных изданий. Впрочем, ограничение результатов поиска тем или иным издателем или распространителем на пользу, как правило, не идёт и скорее может быть полезно для того, чтобы кратко ознакомиться с той или иной темой.
3) в какой-то мере функции БПС выполняют научные социальные сети (Academia.edu, ResearchGate ), а также «гибрид» социальный сети и библиографического менеджера Mendeley (доступна как оффлайн-версия в виде программы, так и её онлайн-вариант; сейчас, после покупки Mendeley компанией Elsevier там доступны многие опции Scopus). Впрочем, содержимое научных социальных сетей хорошо индексируется googl’ом, и тут разве что есть смысл регулярно просматривать ленту обновлений в поисках чего-нибудь совсем нового.
4) в отдельную категорию БПС можно выделить региональные или специализированные сайты, где в основном имеются данные о публикациях, изданных в какой-либо стране или нескольких странах (например, Национальная электронная библиотека elibrary.ru в России, Национальный институт информатики в Японии, Национальная библиотека Франции ), а также специализированные сайты, посвящённые каким-то конкретным научным направлениям (например, BiodiversityHeritageLibrary (BHL))
Характерной особенностью таких порталов является то, что они крайне неохотно дают индексировать своё содержимое сторонним поисковикам, так что если нужно найти что-то французское или японское – надёжнее заглянуть на соответствующие сайты и поискать там.
До недавнего времени на сайте Национальной библиотеки Франции весь интерфейс был франкоязычный, пока они туда в конце концов не приделали сначала англоязычную версию сайта, а затем и автоматический перевод по IP
Отдельно следует сказать про BHL. Это крайне полезный проект для всех исследователей, которые так или иначе связаны с изучением современных или ископаемых организмов. Данную библиотеку отличает широкий охват источников (включая разные редкости) и наличие специальных поисковых инструментов (таких как поиск по таксону во вкладке Advanced search – если кто-то собирает материалы по той или иной группе животных и растений, это очень хороший способ быстро найти публикации по теме). Из недостатков BHL можно отметить то, что нередко текстовый слой может быть распознан неверно (с ошибочно выбранным языком), а также чудовищное качество иллюстраций по умолчанию (качество плохого размытого .djvu ).
Поскольку для таксономических исследований качество изображений обычно имеет большое значение, то здесь наиболее правильным подходом является скачивание нужной публикации в формате jp2, а потом – обработка файлов (сначала переформатирование в обычный jpg / tiff, потом обработка ScanTailor и OCR). Кстати, все публикации с BHL размещаются на archive.org, и иногда удобнее проводить полнотекстовый поиск именно по archive.org (это может быть актуально в случае поиска каких-либо редкостей – тут может попасться кое-что интересное, в том числе загруженное пользователями.
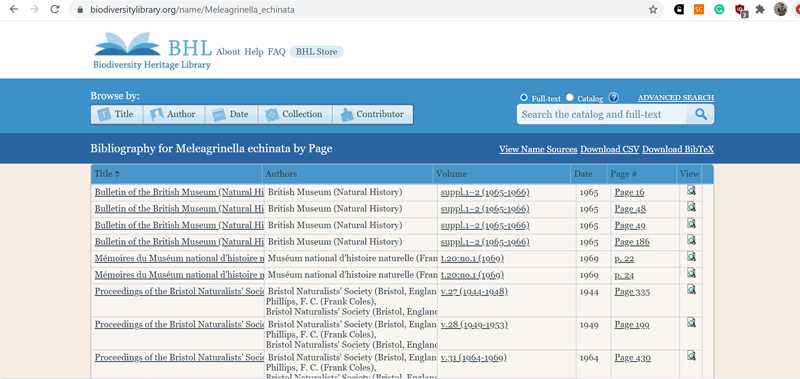
Пример выдачи при поиске по таксону на BHL
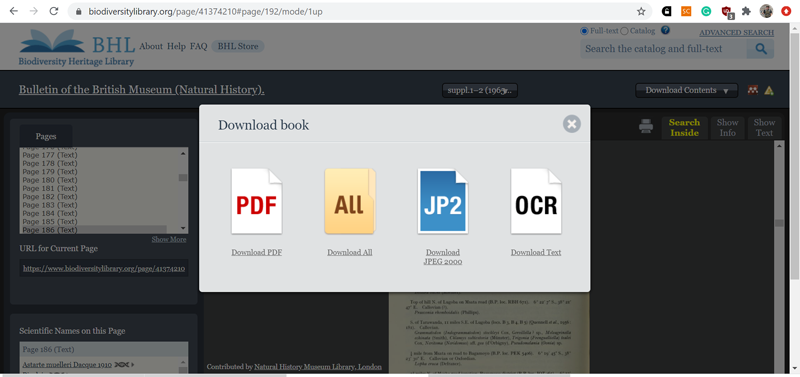
Если нужен качественный пдф — лучше сохранить файл способом «Download Content — Download book — Download JPEG 2000», а потом обработать
И, конечно, в случае необходимости найти русскоязычные публикации не обойтись без поиска в elibrary в сочетании с cyberleninka. Хотя в elibrary охват источников намного больше, регулярно встречается ситуация, когда в elibrary за ту или иную статью предлагают заплатить – а на сайте Киберленинки та же статья лежит в отрытом доступе.
Несмотря на ряд недостатков, заложенных в elibrary, кажется, с рождения (отсутствие возможности скачать даже работу открытого доступа без ввода логина / пароля; отсутствие англоязычной версии и опции подписки на те или иные обновления) поиск там достаточно приличный. Но если есть необходимость регулярно отслеживать информацию по русскоязычным журналам, стоит сделать также отдельный каталог ссылок на сайты необходимых изданий – на elibrary не угадаешь, когда и почему они могут вдруг закрыть доступ к тем или иным изданиям. И ещё один момент – в том случае, когда журнал отсутствует в открытом доступе и распространяется только за деньги как через elibrary, так и через сайт издательства, то на сайте издательства статьи могут быть дешевле (такова ситуация, например, с журналом «Нефтяное хозяйство»).
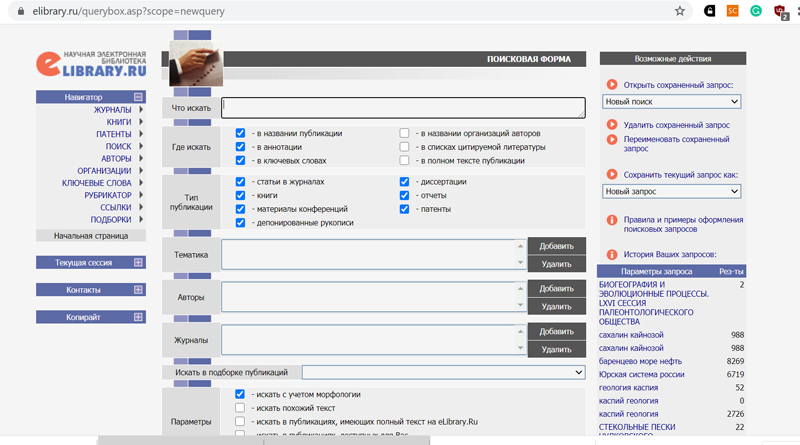
Настройки расширенного поиска на elibrary (на заглавной странице сайта — слева сверху ссылка «расширенный поиск»). Здесь же сохраняется история предыдущих поисковых запросов
5) в качестве БПС можно рассматривать и крупнейшие «пиратские» проекты, обеспечивающие свободный доступ к научным публикациям – SciHub и LibGen, поскольку на них в том или ином виде реализована возможность поиска по названию публикации или ключевым словам.
И если sci-hub может быть скорее использован в качестве удобного дополнения к поиску на Dimensions, то на LibGen регулярно появляются редкие монографии, которых в других местах нет – они сканируются энтузиастами и размещаются на ЛибГене в частном порядке.
И напоследок отдельно стоит сказать про поиск диссертаций. Хотя многие диссертации (как современные российские, так и иногда достаточно старые зарубежные) выложены в Интернете в открытом доступе и индексируются поисковиками, для получения информации о свежих диссертациях, которые только планируется защитить, имеет смысл заглядывать на сайт ВАКа. Там сейчас диссертации можно искать по специальностям, ключевым словам, дате защиты и другим параметрам (при этом отдельно поиск ведётся по ВАКовским диссертациям, а отдельно – по тем, которые защищаются на советах организаций, обладающих правом самостоятельного присуждения степеней). Но есть нюанс – если у вас установлен uBlock Origin, то он блокирует поиск по данному сайту.
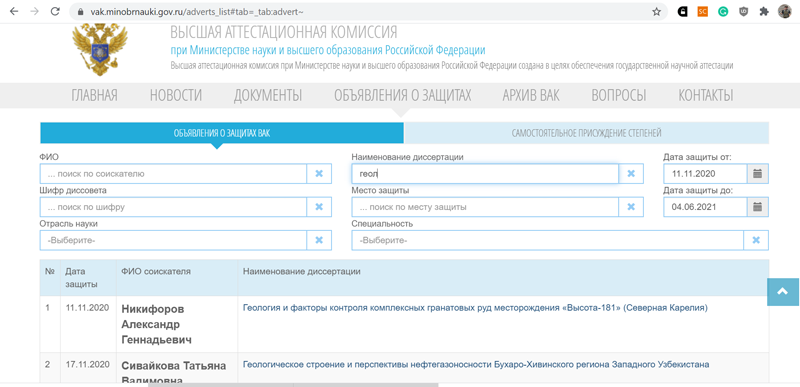
Пример поиска по сайту ВАК
Продолжение: часть 3
Мы в редакции постоянно чекаем информацию, и на практике это не так просто. Нужно научиться отличать факты от фейков и фактоидов — недостоверных данных, которые подают как истину. Издания допускают неточности случайно или специально дезинформируют аудиторию, чтобы привлечь к себе внимание или манипулировать сознанием читателей. А нам при подготовке материалов важно сохранить объективность и передать клиенту качественный текст, которому будут доверять читатели.
Провести фактчекинг — проверить, насколько данные и утверждения в статье соответствуют действительности. Раньше фактчекинг использовали журналисты, чтобы отличать фейковые новости от реальных. Теперь проверять факты нужно всем, кто производит контент — маркетологам, SMM-специалистам, копирайтерам, редакторам.
Зачем проверять факты
Начнем с глобального:
Недостоверные факты влияют на жизнь людей. Сомнительные медицинские советы вредят здоровью. А фейковые новости могут привести к печальным последствиям, например, убыткам. Так, в 2013 году хакеры разместили в официальном Twitter информагентства Associated Press твит о нападении на Белый дом и ранении президента, которым в то время был Барак Обама. Биржевой индекс Dow Jones просел на 150 пунктов, а акции компаний потеряли $130 млрд стоимости.
Большинство СМИ и ресурсов в интернете не имеют такого влияния, но фактчекать материалы все равно придется — потому что:
Непроверенная информация вредит самой площадке, где ее размещают. Во-первых, государство негативно относится к распространению фейковых новостей. По закону всем, кто распространяет информацию, которая вредит чьей-либо жизни, здоровью или безопасности, общественному порядку или работе важных объектов, грозит штраф или блокировка.
Во-вторых, неправильные даты, названия и цитаты в тексте могут испортить репутацию компании или медиа, подорвать доверие читателей.
Один из примеров — кейс Тинькофф Журнала. У издания есть рубрика — дневник трат, где герои разных профессий рассказывают, как они живут, сколько тратят и откладывают. В 2020 году редакция опубликовала дневник управляющего отделом качества в диджитал-агентстве с доходом в 950 000 ₽. Читатели усомнились: указанный возраст героя — 25 лет, а в публикации практически нет подробностей о работе. Вскоре выяснилось, что персонаж не имеет отношения к описанной должности, ведет сомнительный образ жизни, а публикация в популярном издании нужна для пиара.
История быстро распространилась за пределы Т—Ж — о ней написали разные паблики и телеграм-каналы. Журнал дневник не удалил, но оставил к тексту примечание:

Конечно, такой факап не может разрушить репутацию Тинькофф Журнала, который годами выпускает крутые материалы. Но это пример, как непроверенные факты вызывают гнев аудитории и серьезный общественный резонанс.
Поисковые системы Яндекс и Google заинтересованы в том, чтобы дать исчерпывающий ответ на запрос пользователя, поэтому:
Низкое качество контента сказывается на видимости страницы. Алгоритмы поисковиков умеют оценивать экспертность и авторитетность текста. А значит они продвигают качественный контент и банят сомнительный.
Что точно стоит проверить
Чтобы прокачать навык фактчекинга, подвергать сомнению нужно всё. Вот список, на что важно обратить внимание в первую очередь.
✔Имена, профессии, должности, звания
В чем подвох. Проверяйте всё, что связано с людьми — не только формальности, но и другие детали — пол, внешность. Например, важно убедиться, что Е.И. Самчук — бабушка главного героя, а не дедушка. Лучше уточнить факты у самого героя либо проверить, что о нем говорят авторитетные источники.
✔Названия, деятельность и статус компаний
В чем подвох. Промахнуться здесь легко, достаточно запутаться в аббревиатурах или назвать дилера дистрибьютором.
У нас факапы тоже случаются. Однажды ручное переписывание и корявый первоисточник привели к тому, что вместо бренда Elettrica в тексте появилась Elletrica. Так вместо статьи о кофеварках вышел текст про кран-манипулятор. Мы потом все поправили, но осадочек остался.
Перепроверяйте контактные данные, особенно, если взяли их не у представителя компании, а из открытого источника — телефон может поменяться, а офис — переехать.
✔Числа
В чем подвох. Ошибки в датах, времени события, возрасте героев лидируют по количеству опечаток. Чтобы не краснеть, сравните разные источники.
Другой возможный факап — недостоверная статистика. Проверяйте, на что ссылается текст, и оставляйте ссылку на исследование.
✔Документы
В чем подвох. У законов и разных актов длинные и сложные названия, они быстро устаревают, появляются поправки. Обращайте внимание и на статус документа — возможно, речь не о законе, а о проекте или акте на стадии рассмотрения.
В работе с законами вообще много нюансов. Например, госзакупки регулируются двумя законами — 44-ФЗ и 223-ФЗ. У них много отличий, и они называются по-разному, но если не разобраться, то легко перепутать — а это серьезная фактическая ошибка.
✔Термины, профессиональный сленг
В чем подвох. Проверяйте значение незнакомых слов в словаре и контекст, в котором их употребляют. Особенно это важно для статей, чья аудитория — профи в сфере. Потерять их доверие очень легко.
✔Цитаты
В чем подвох. Выдержка должна быть дословной, иначе смысл фразы искажается. Нужно проверить и контекст — нередко вырванные цитаты приобретают другой смысл. Например, один из вариантов известного выражения «цель оправдывает средства» — «если цель — спасение души, то цель оправдывает средства». Согласитесь, смысл у полной цитаты отличается.
Как провести фактчекинг
Выберите источник
Не все каналы информации заслуживают доверия. Ищите первоисточник, откуда появилась информация.
Участники и свидетели событий
Они могут предоставить информацию «из первых рук». Это не значит просто довериться случайному человеку. Нужно определить:
- имеет ли он доступ к информации;
- достаточно ли его мнения для освещения темы;
- насколько он объективен, не преследует ли свои цели;
- согласен ли он указать себя в качестве источника.
Когда нужен текст для бизнеса, где необходимо глубоко разобраться с продуктом — мы обращаемся за вводными к клиенту. Сотрудники компании глубоко погружены в работу, поэтому могут прояснить детали, которые не найдешь в открытом доступе. Если тема специфическая, ищем экспертов или снова обращаемся к клиенту.
Закон
При работе с законами и нормативно-правовыми актами правильно выбирайте ресурс. Иначе можно натолкнуться на устаревшую редакцию документа и плакал тогда фактчекинг.
Законы со всеми изменениями смотрим на платформах Гарант и Консультант. Они бесплатные, правда с ограничениями.
А на сайте Госдумы можно отследить, на каком этапе документ — он уже опубликован и вступил в силу или только проходит согласование.
Стадии рассмотрения проекта отмечены на шкале, ниже — их расшифровка с подтверждающими документами
Когда нужно проверить, как закон работает на практике, например, какие штрафы назначают по определенной статье, ищите судебные дела в сервисе Судакт. Это большая база с делами разных судов — арбитражных, общей юрисдикции, мировых. Можно искать практику по тексту документа: вбить название компании-участника, либо выбрать статью, по которой вынесено решение или приговор.
В поиске правильно определите тип суда. На примере этого скрина выдача покажет все решения по статье 15 ГК РФ о возмещении убытков.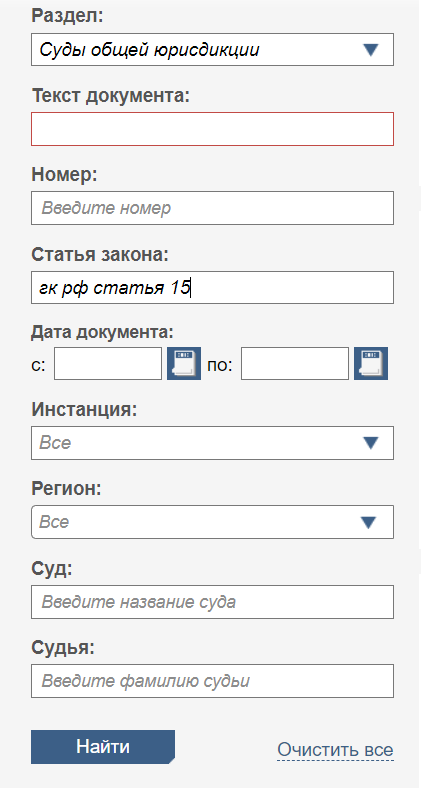
Другой достоверный источник — публикации на официальных порталах ведомств — ФНС, Минфин, Пенсионный фонд, Госуслуги. Но обращайте внимание на дату публикации — старые материалы лучше перепроверьте по законам.
Статистика
Правила, если нужно фактчекнуть статистические данные:
✔Опирайтесь на официальную статистику или информацию от крупных агентств — у них больше возможностей провести полноценное исследование.
✔Выбирайте свежую статистику, информация быстро устаревает.
✔Не полагайтесь на исследования, где мало данных или опрошено недостаточное количество респондентов — выводы по ним могут быть неточными и даже ошибочными.
✔Проверьте, как собирали и оценивали данные: лучше отказаться от исследований, которые опираются на личный опыт, либо не раскрывают, как проводили аналитику.
✔Ссылайтесь на первоисточник, а не на ресурс, который эту статистику перепечатал.
Мы указываем требования по фактчекингу и оформлению ссылок в нашей редполитике
Случай из нашей практики: автор рассказывает о пользе блога для корпоративных клиентов и добавляет в текст такую цитату — «По данным HubSpot, компании, у которых есть блог, привлекают на 126% больше лидов, чем их „безбложные“ конкуренты».
Мы проверяем источник, и он вполне подходит. HubSpot — крупная компания, которая производит CRM, они знают, какие каналы приводят лидов, поэтому им можно доверять. С количеством опрошенных и методами исследования тоже все хорошо. Но радоваться рано: дата публикации статистики — 2010 год. С тех пор в интернет-пространстве все поменялось, поэтому такие данные нельзя считать достоверными.
Где лучше искать информацию
Официальную статистику в России публикуют на сайте Росстата. Опросы и общественные мнения анализируют исследовательские центры — государственные и негосударственные. Самые известные — ВЦИОМ и Левада-центр.
Еще статистикой занимаются частные компании и специальные агентства, которые проводят исследования на разные тематики на заказ для бизнеса или других целей. Например, маркетинговые исследования регулярно публикуют компания Mediascope и медиахолдинг РБК.
Ресурсов, откуда можно взять факты, много. Мы рекомендуем пользоваться книгой о поиске фактуры Светланы Дучак — там есть информация почти по всем достоверным типам источников.
Авторитетный источник
Медиа, экспертные блоги — им тоже можно доверять, но осторожно: придется научиться отличать авторитетные источники от сомнительных.
Надежные источники:
✔имеют сложившуюся репутацию;
✔указывают авторов и экспертов материалов;
✔используют в материалах конкретику, которую легко проверить — числа, даты, имена, события;
✔дают ссылки на источники, откуда взяли информацию.
Что можно использовать для фактчекинга:
| новостей | научных публикаций | медицинских статей |
| информационные агентства и пресс-центры ТАСС, РИА Новости, Интерфакс, Лента, РБК | электронные библиотеки eLIBRARY.RU и КиберЛенинка | MedSpecial — публикуют о том, что уже доказано научными фактами |
| авторитетные СМИ — N+1, Т—Ж, Forbes | портал Российской государственной библиотеки | MadMedMedia — медиа о доказательной медицине, ориентируются на исследования, науку и доказанные факты |
| Википедия (лучше англоязычная) со ссылками на источники | ||
| Google Scholar — поисковая система с текстами рецензируемых научных издательств | ||
| сайт ВШЭ |
Не проверяйте факты по текстам анонимов на неизвестных сайтах. За такие статьи никто не отвечает, а значит их достоверность под вопросом. Настораживает, если в тексте много эмоций или у площадки, где разместили публикацию, есть определенная цель или позиция — это часто искажает факты. Много скажет оформление: проблемы с версткой, скачущие строки, неработающие ссылки — один из признаков недостоверной информации. Авторитетные издания следят за качеством публикации.
Какие источники выбирать, зависит от темы: у медицины свои авторитеты, у сферы финансов — свои. Но ошибаются все, поэтому лучше все-таки опираться на собственные выводы — найти первоисточник, документ или закон и перепроверить текст.
Найдите эксперта
Эксперт поможет разобраться в сложной или специализированной теме и поделится фактурой из личного опыта.
Как-то мы готовили статью по банковским вкладам, ориентируясь на открытые источники, в том числе и страницы с предложениями банков. В тексте говорили, что банки не любят малый бизнес и не хотят предлагать им выгодные условия по вкладам. Материалы проверял эксперт по налогообложению, который часто консультирует предпринимателей:

Он рассказал, что банки как раз наоборот часто поддерживают установку государства и привел примеры, на какие плюшки могут рассчитывать МСП.
Где искать экспертов:
Запросить у клиентов. Эксперты заказчика хорошо погружены в продукт или услугу и могут проконсультировать по ним.
В интернете: тематические сайты, телеграм-каналы и группы. Обычно специалисты, развивающие собственный бренд, соглашаются работать за рекламу — упоминание в тексте.
В окружении. Спросить знакомых или написать пост в социальной сети.
Когда в статье указывают имя эксперта, ответственность за факты переходят к нему. Но фактчекинг по-прежнему остается задачей автора и редактора, поэтому нужно понять, что эксперт действительно компетентный. Сперва мы проверяем профильное образование и спрашиваем про опыт работы. Лучше, чтобы было и то, и другое. Если у эксперта есть диплом, но нет практики, скорее всего, он не сможет разобраться в таких темах, где нужно следить за изменениями — праве, медицине, финансах.
Еще смотрим, что человек постит в соцсетях или личном блоге. Бывает, что спец позиционирует себя как медик, но постит что-то сомнительное — странные народные рецепты или советует только гомеопатию. Обычно у экспертов с опытом есть определенная репутация — они могут поделиться кейсами, отзывами о работе или предоставить рекомендации, публикации.
Если вы пишете книгу или готовите материал на узкоспециализированную тему, где невозможно самому хорошо проверить факты, понадобится научный консультант. Это фактчекер для экспертов: он проверяет, насколько актуальны экспертные комментарии и источники, на которые ссылаются.
Какие сервисы для фактчекинга использовать
Есть специальные ресурсы, где подтверждают и публикуют опровержения информации, помогают проверить факты. Известные русскоязычные сервисы для фактчекинга:
- Проверено — некоммерческий проект, разоблачающий фейки. Можно прислать на проверку свою историю.
- Злая проверочная — телеграм-канал с разбором и опровержением фейков в медиа.
- Война с фейками — проект с несколькими телеграм-каналами, разоблачающими фальшивые новости в актуальной повестке.
- FactCheck.kz — казахстанский ресурс для проверки достоеверности любой информации, обновляется регулярно.
Свой сервис для фактчекинга есть у Google — Fact Check Explorer. Это аналог поисковой системы, где ищут информацию по ключевым словам или фразам.
В выдаче по запросу появляется только проверенные данные с оценкой фактографа — например, «скорее правда», «не факт», «фейк»
Для фактчекинга англоязычных новостей подойдут Snopes, EU vs Disinfo.
Другие сервисы для проверки данных:
- Who is — узнаете, кто и когда создал сайт.
- Tineye.com, Google Image search, RevEye Chrome extension — найдете первоисточник картинки.
- Forensically — увеличите масштаб и рассмотрите мелкие детали и водяные знаки на изображениях.
- YouTube Data Viewer — определите точное время загрузки видео и проанализируете метаданные в видео.
Основные правила
- Проверяйте в тексте всё. Особенно внимательно относитесь к именам, должностям, названиям, любым числам, документам, цитатам и терминам.
- Ищите первоисточник. Опрашивайте очевидцев, сверяйте информацию с законами, официальными документами и статистикой.
- Выбирайте авторитетные медиа — издания с хорошей репутацией, которые указывают авторов материалов, ссылки на исследования и факты. И порталы, которые помогают проверить фейки — медиа Проверено, телеграм-канал Злая проверочная, Google Fact Check Explorer, FactCheck.kz.
- Рассматривайте противоположные мнения. Всегда лучше использовать несколько источников — так материал получится непредвзятым и более достоверным.
- Работайте с экспертами. Попросите его контакты у компании-заказчика, ищите в тематических пабликах, сервисах по поиску экспертов или в своем окружении.
![]()
Больше мяса, больше фактов – вот что хотят заказчики статей от копирайтера. Вода не нужна никому. Но где их брать, эти самые факты?
Давайте подкину несколько источников, где копаюсь сама. Только тссс! Тихонько репост себе сделали, и никому не рассказывайте.
Что может быть фактом?
Кстати, да. Что может быть фактом в статье, который подтверждает ту мысль, которую вы хотите донести?
— кейс (заказчика или чужой). Обычно в кейсах описывают не только подход к делу – в конце можно найти интересную статистику. Иногда даже оформленную в виде инфографики. Можно взять – только с указанием ссылки на источник (если чужое).
— результаты исследований. Всякие разные компании проводят разные никому не нужные интересные исследования и публикуют отчеты о них в сети. Это не просто факты – это убойные факты, которые можно вплести в статью (опять же, со ссылкой на источник).
— мнение эксперта по теме. Если эксперт известный и уважаемый – каждое его слово может восприниматься как факт.
— различная статистика по теме.
— собственный опыт. Если вам есть чем его подтвердить, конечно, чтобы не выглядело как ваши домыслы. Для вас то, что вы на своей шкуре испытали – самый очевидный факт (правда, объективный).
Любые цифры, результаты экспериментов и исследований, которые можно привязать к теме вашей статьи, которые подтверждают высказанные вами мысли – все это факты. Их не просто можно, их нужно использовать в своих статьях. Тогда ваши материалы будут выглядеть серьезнее, что ли, но более правдивыми и четкими уж точно.

Где все это брать?
1. Сайты конкурентов
Самая первая мысль, которая приходит в голову копирайтеру, когда он начинает работать над статьей: «А пойду-ка я погуглю». Нагугливает обычно он несколько сайтов конкурентов и копается в их статьях по теме: о чем они писали, как, какие данные использовали.
Легкий путь, но опасный: далеко не все что пишут другие – правда. Даже, скорее всего, наоборот – на сайтах конкурентов может быть много выдумок. Потому не стоит, совсем не стоит слепо рерайтить чужие материалы.
Что можно взять? Можно потянуть у них ссылки на источники, откуда они сами брали статистику. Факты, ссылки на исследования. Хорошенько изучить эти первоисточники. Хорошенько подумать, подходит ли это все нам. Если да – можно забрать к себе в текст. Главное – чтобы ваш текст потом не был похож на их как две капли воды. А чтобы он был еще и сильнее, достовернее, полнее – позаимствованные у них источники нужно усилить еще и другими. То есть, взяли что-то у конкурентов – не нужно думать, что поисковая работа окончена. Это только начало.
2. Зарубежные источники
Наш народ любит ссылаться на заграничные сайты. У них там прогресс идет впереди нашего – не поспоришь. У них все самое свежее, которое потом доходит до нас спустя полгода-год, переведенное и перерайченное. Особенно, что касается ИТ.
Ссылаться на заграничные источники – это круто. Это типа как «вот смотри, я даже инглиш шпрехаю и даже их исследования изучаю, я такой, да… впереди планеты всей».
Добавляем крутизны в свой текст. Ищем исследования и кейсы на заграничных сайтах. Для этого не так и много нужно: ввести запрос на английском по своей теме, добавив туда что-то типа «case study», «research» (и то это не всегда обязательно). Ну и знать английский хотя бы на уровне «читать читаю, и даже что-то понимаю».
Например, не так давно я искала для статьи статистику о мобильном и десктопном трафике. Нашлось легко:
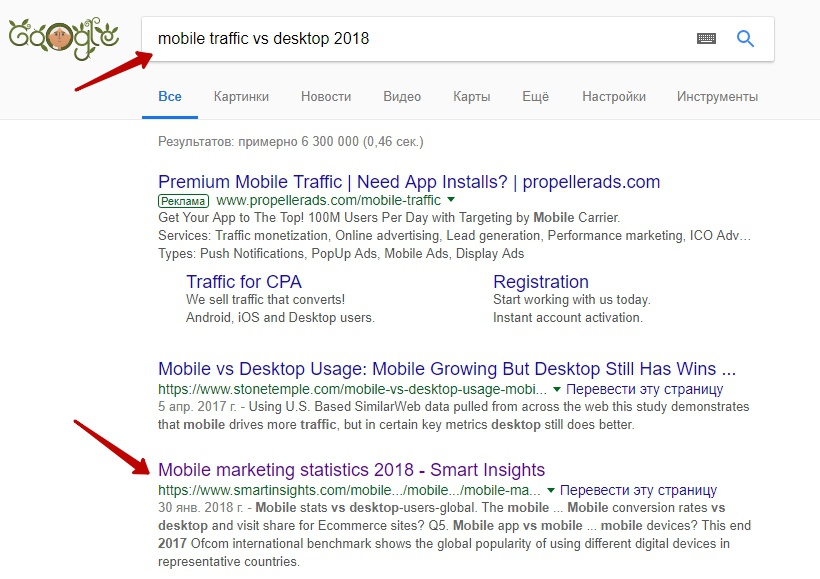
На той странице я нашла все необходимое – с графиками, таблицами, схемами.
Осталось взять нужную информацию и дать ссылку на источник.
Маленький лайфхак: подобные сайты рекомендую добавлять в закладки. Если нужно будет поискать материал для других статей – у вас будет небольшая база ресурсов, где такое есть. А то спустя время будете гадать, где вы что видели, и как тот сайт найти.
3. Эксперты
Экспертное мнение в статье – это хорошо. Их словам верят, потому как говорит человек с именем и опытом. Его слова – это тоже факт. Если экспертов несколько – круто вдвойне. Осталось только найти таких людей и попросить их ответить на ваш вопрос или дать комментарий по теме.
Где таких искать?
— в соцсети. Тут многие продвигают свой личный бренд. Если вы работаете в одной нише – то у вас уже должно быть в загашнике несколько таких товарищей (точнее, вы должны уже были подписаться на странички таких людей). Если еще нет – рекомендую начать искать и подписываться. Тем более они все друг с другом тусуются, и через одного можно найти еще двух-трех как минимум. Еще можно прочесать крупные тематические сообщества.
— через поиск в Google. Здесь вы найдете сайты таких людей. Пишете через обратную связь (или на почту) свой вопрос и ждете ответа.
Я искала по-разному. Сразу двумя способами. Всегда находила, и всегда отвечали. Особенно если скажешь, что дашь со статьи ссылку на их сайт. Для них ведь это тоже пиар, и для SEO полезно.
Не забывайте об элементарной вежливости и не надоедайте. И кстати, рассчитывайте время: если сдавать статью завтра утром, а тут вы вспомнили об экспертах – ничего у вас не выйдет. Готовьтесь недельки за две. Известные люди заняты, и могут отвечать очень долго.
Кстати, для вас полезно тоже – мало какой эксперт не поделится у себя на страничке потом вашей статьей со словами: вот у меня взяли очередное интервью/спросили совета. А с его странички вы уже получаете дополнительный трафик на свою статью. Профит.
4. Книги
Когда мы учились в колледже/университете/академии (нужное подчеркнуть), то все данные для рефератов, исследований, курсовых работ брали из книг. Почему-то в работе своей мы редко обращаемся к такому элементарному источнику знаний. А зря.
Пришлось мне писать статью на тему воспитания. Вот тут-то мне и пригодились книги, которые покупала, будучи студенткой. Цитаты из книг здорово дополнили мои мысли.
В сети можно найти много книг в электронном варианте. Пользуйтесь. А если есть дома подходящая литература – почему бы и не взять какую-то умную мысль оттуда?
5. Википедия
Самый элементарный источник фактов. Только почему-то мы часто о нем забываем. На что обращайте внимание – чтобы статья была уже проверена опытными участниками электронной энциклопедии. А то иногда и там можно найти данные, мало имеющие связь с действительностью.
6. Взять у клиента
Об этом тоже мало кто думает. Просто спросите своего клиента, нет ли у него кейсов, статистики, каких-то интересных данных по теме. На моей практике было такое: написала статью, а мне клиент – а давайте вот еще это добавим, мы тут исследование проводили… Почему раньше не сказали? «А вы не спрашивали».
Вот спрашивайте. Каждый раз у своих клиентов – нет ли у них каких-то цифр, данных, которые можно использовать в статье. Нет – значит нет. Если есть – это сильный козырь. Одно дело написать статью, основанную на чужих исследованиях. Другое – показать, что наша компания тоже не лыком шита. Мы тут тоже исследуем и тестируем.
7. Собственный опыт
Если вы сами проводили какие-то испытания, и у вас есть данные об этом – напишите. Почему нет? Ваш собственный опыт – это тоже факт, возможно, немного субъективный. Но если вписать в статью свой мини-кейс – это сделает ее интереснее и ценнее в глазах читателя – как минимум.
Вот даже в этой статье я уже несколько раз рассказывала о том, что и как делала сама. И вы же мне верите, правда? Но я и не вру, если что, рассказываю факты из собственного опыта.
8. ВЦИОМ и т.п.
Вот здесь можно почерпнуть данные из социологических опросов. Весьма достоверные и конкретные. Причем на разные темы, нужно только хорошо поискать. Это будет факт, против которого не попрешь. Вообще.
Пригодится тем, кто пишет о финансах, политике и других остросоциальных темах.
Где брать факты разобрались. Хочу дать напоследок несколько советов:
— никогда ни под каким предлогом не забывайте дать ссылку на источник. Если это инфографика или картинка с водяным знаком – поставьте под ней ссылку, откуда вы это сперли. Иначе могут быть проблемы – сами знаете.
— не берите старые факты и данные, которым больше двух-трех лет. Особенно если тема касается ИТ. Тут уже данные за полгода устаревают другой раз безнадежно.
— когда приступаете к работе над статьей, сначала ищите именно факты, и выписывайте их на отдельный лист. Так будет проще писать – вам останется только «нарастить» мясо на этот скелет и сделать правильные выводы – вот и статья готова.
— если никаких исследований не нашли – не выдумывайте их сами. Нет – значит, нет, а врать не надо.
Успехов вам и убойных статей!
