Поиск подстроки и смежные вопросы
Время на прочтение
13 мин
Количество просмотров 111K
Здравствуйте, уважаемое сообщество! Недавно на Хабре проскакивала неплохая обзорная статья о разных алгоритмах поиска подстроки в строке. К сожалению, там отсутствовали подробные описания каких либо из упомянутых алгоритмов. Я решил восполнить данный пробел и описать хотя бы парочку тех, которые потенциально можно запомнить. Те, кто еще помнит курс алгоритмов из института, не найдут, видимо, ничего нового для себя.
Сначала хотел бы предотвратить вопрос «на кой это надо? все уже и так написано». Да, написано. Но во-первых, полезно знать как работает используемые тобой иструменты на более низком уровне чтобы лучше понимать их ограничения, а во-вторых, есть достаточно большие смежные области, где работающей из коробочки функции strstr() окажется недостаточно. Ну и в-третьих, вам может неповезти и придется разрабатывать под мобильную платформу с неполноценным runtime, а тогда лучше знать на что подписываетесь, если решитесь самостоятельно его дополнять (чтобы убедиться, что это не сферическая проблема в вакууме, достаточно попробовать wcslen() и wcsstr() из Android NDK).
А разве просто поискать нельзя?
Дело в том, что очевидный способ, который все формулирует как «взять и поискать», является отнюдь не самым эффективным, а для такой низкоуровневой и сравнительно частовызываемой функции это немаловажно. Итак, план такой:
- Постановка задачи: здесь перечислены определения и условные обозначения.
- Решение «в лоб»: здесь будет описано, как делать не надо и почему.
- Z-функция: простейший вариант правильной реализации поиска подстроки.
- Алгоритм Кнута-Морриса-Пратта: еще один вариант правильного поиска.
- Другие задачи поиска: вкратце пробегусь по ним без подробного описания.
Постановка задачи
Канонический вариант задачи выглядит так: есть у нас строка A (текст). Необходимо проверить, есть ли в ней подстрока X (образец), и если есть, то где она начинается. То есть именно то, что делает функция strstr() в C. Дополнительно к этому можно еще попросить найти все вхождения образца. Очевидно, что задача имеет смысл только если X не длинее A.
Для простоты дальнейшего объяснения введу сразу пару понятий. Что такое строка все, наверное, понимают — это последовательность символов, возможно пустая. Символы, или буквы, принадлежат некоторому множеству, которое называют алфавитом (данный алфавит, вообще говоря, может не иметь ничего общего с алфавитом в бытовом понимании). Длина строки |A| — это, очевидно, количество символов в ней. Префикс строки A[..i] — это строка из i первых символов строки A. Суффикс строки A[j..] — это строка из |A|-j+1 последних символов. Подстроку из A будем обозначать как A[i..j], а A[i] — i-ый символ строки. Вопрос про пустые суффиксы и префиксы и т.д. не трогаем — с ними разобраться не сложно по месту. Еще есть такое понятие как сентинел — некий уникальный символ, не встречающийся в алфавите. Его обозначают значком $ и дополняют допустимый алфавит таким символом (это в теории, на практике проще применить дополнительные проверки, чем придумать такой символ, которого не могло бы оказаться во входных строках).
В выкладках будем считать символы в строке с первой позиции. Код писать традиционно проще отсчитывая от нуля. Переход от одного к другому не составляет трудностей.
Решение «в лоб»
Прямой поиск, или, как еще часто говорят, «просто взять и поискать»- это Первое решение, которое приходит в голову неискушенному программисту. Суть проста: идти по проверяемой строке A и искать в ней вхождение первого символа искомой строки X. Когда находим, делаем гипотезу, что это и есть то самое искомое вхождение. Затем остается проверять по очереди все последующие символы шаблона на совпадение с соответствующими символами строки A. Если они все совпали — значит вот оно, прямо перед нами. Но вот если какой-то из символов не совпал, то ничего не остается, как признать нашу гипотезу неверной, что возвращает нас к символу, следующему за вхождением первого символа из X.
Многие люди ошибаются в этом пункте, считая, что не надо возвращаться назад, а можно продолжать обработку строки A с текущей позиции. Почему это не так легко продемонстрировать на примере поиска X=«AAAB» в A=«AAAAB». Первая гипотеза нас приведет к четвертому символу A: “AAAAB”, где мы обнаружим несоответствие. Если не откатиться назад, то вхождение мы так и не обнаружим, хотя оно есть.
Неправильные гипотезы неизбежны, а из-за таких откатываний назад при плохом стечении обстоятельств может оказаться, что мы каждый символ в A проверили около |X| раз. То есть вычислительная сложность сложность алгоритма O(|X||A|). Так поиск фразы в параграфе может и затянуться…
Справедливости ради следует отметить, что если строки невелики, то такой алгоритм может работать быстрее «правильных» алгоритмов за счет более предсказуемого с точки зрения процессора поведения.
Z-функция
Одна из категорий правильных способов поиска строки сводится к вычислению в каком-то смысле корреляции двух строк. Сначала отметим, что задача сравнения начал двух строк проста и понятна: сравниваем соответствующие буквы, пока не найдем несоответствие либо какая-нибудь из строк закончится. Рассмотрим множество всех суффиксов строки A: A[|A|..] A[|A|-1..],… A[1..]. Будем сравнивать начало самой строки с каждым из ее суффиксов. Сравнение может дойти до конца суффикса, либо оборваться на каком-то символе ввиду несовпадения. Длину совпавшей части и назовем компонентой Z-функции для данного суффикса.
То есть Z-функция — это вектор длин наибольшего общего префикса строки с ее суффиксом. Ух! Отличная фраза, когда надо кого-то запутать или самоутвердиться, а чтобы понять что же это такое, лучше рассмотреть пример.
Исходная строка «ababcaba». Сравнивая каждый суффикс с самой строкой получим табличку для Z-функции:
| суффикс | строка | Z | |
|---|---|---|---|
| ababcaba | ababcaba | -> | 8 |
| babcaba | ababcaba | -> | 0 |
| abcaba | ababcaba | -> | 2 |
| bcaba | ababcaba | -> | 0 |
| caba | ababcaba | -> | 0 |
| aba | ababcaba | -> | 3 |
| ba | ababcaba | -> | 0 |
| a | ababcaba | -> | 1 |
Префикс суффикса это ничто иное, как подстрока, а Z-функция — длины подстрок, которые встречаются одновременно в начале и в середине. Рассматривая все значения компонент Z-функции, можно заметить некоторые закономерности. Во-первых, очевидно, что значение Z-функции не превышает длины строки и совпадает с ней только для «полного» суффикса A[1..] (и поэтому это значение нас не интересует — мы его будем опускать в своих рассуждениях). Во-вторых, если в строке есть некий символ в единственном экземпляре, то совпасть он может только с самим собой, и значит он делит строку на две части, а значение Z-функции нигде не может превысить длины более короткой части.
Использовать эти наблюдения предлагается следующим образом. Допустим в строке «ababcabсacab» мы хотим поискать «abca». Берем эти строчки и конкатенируем, вставляя между ними сентинел: «abca$ababcabсacab». Вектор Z-функции выглядит для такой строки так:
| a b c a $ a b a b c a b с a c a b |
| 17 0 0 1 0 2 0 4 0 0 4 0 0 1 0 2 0 |
Если отбросить значение для полного суффикса, то наличие сентинела ограничивает Zi длиной искомого фрагмента (он является меньшей половиной строки по смыслу задачи). Но вот если этот максимум и достигается, то только в позициях вхождения подстроки. В нашем примере четверками отмечены
все
позиции вхождения искомой строки (отметьте, что найденные участки расположены внахлест друг с другом, но все-равно наши рассуждения остаются верны).
Ну, значит если мы сможем быстро строить вектор Z-функции, то поиск с его помощью всех вхождений строки сводится к поиску в нем значения ее длины. Вот только если вычислять Z-функцию для каждого суффикса, то будет это явно не быстрее, чем решение «в лоб». Выручает нас то, что значение очередного элемента вектора можно узнать опираясь на предыдущие элементы.
Допустим, мы каким-то образом посчитали значения Z-функции вплоть до соответствующего i-1-ому символу. Рассмотрм некую позицию r<i, где мы уже знаем Zr.
Значит Zr символов начиная с этой позиции точно такие же, как и в начале строки. Они образуют так называемый Z-блок. Нас будет интересовать самый правый Z-блок, то-есть тот, кто заканчивается дальше всех (самый первый не в счет). В некоторых случаях самый правый блок может быть нулевой длины (когда никакой из непустых блоков не покрывает i-1, то самым правым будет i-1-ый, даже если Zi-1= 0).
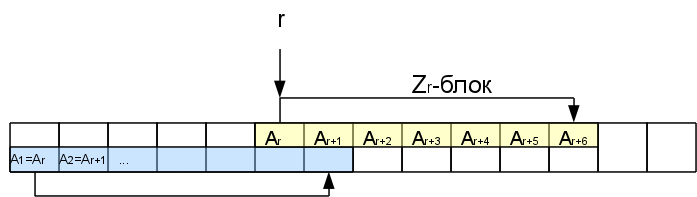
Когда мы будем рассматривать последующие символы внутри этого Z-блока, сравнивать очередной суффикс с самого начала не имеет смысла, так как часть этого суфикса уже встречалась в начале строки, а значит уже была обработана. Можно будет сразу пропускать символы аж до конца Z-блока.
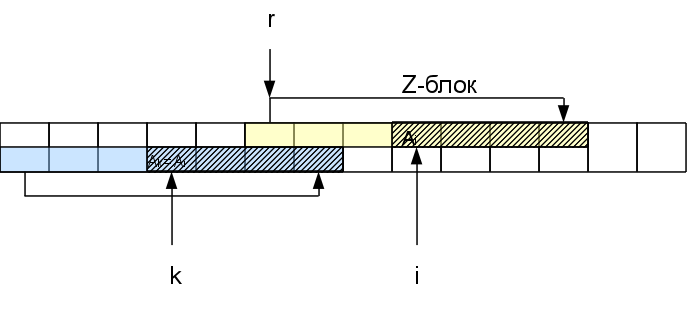
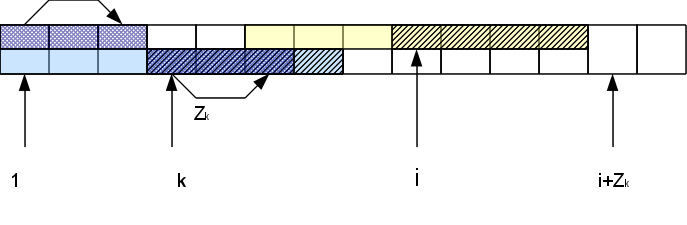
А именно, если мы рассматриваем i-й символ, находящийся в Zr-блоке, то есть соответствующий символ в начале строки на позиции k=i-r+1. Функция Zk нам уже известна. Если она меньше, чем оставшееся до конца Z-блока расстояние Zr-(i-r), то сразу можем быть уверены, что вся область совпадения для этого символа лежит внутри r-того Z-блока и значит результат будет тот же, что и в начале строки: Zi=Zk. Если же Zk >= Zr-(i-r), то Zi тоже больше или равна Zr-(i-r). Чтобы узнать насколько именно она больше, нам надо будет проверять следующие за Z-блоком символы. При этом в случае совпадения h этих символов с соответствующими им в начале строки, Zi увеличивается на h: Zi=Zk + h. В результате у нас может появиться новый самый правый Z-блок (если h>0).
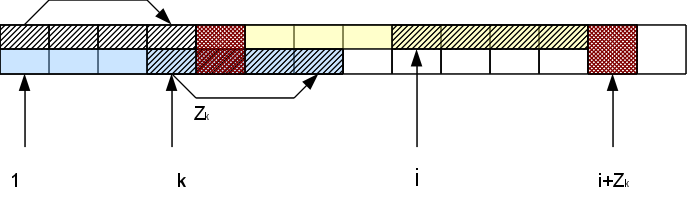
Таким образом, сравнивать символы нам приходится только правее самого правого Z-блока, причем за счет успешных сравнений блок «продвигается» правее, а неуспешные сообщают, что вычисление для данной позиции окончено. Это обеспечивает нам построение всего вектора Z-функции за линейное по длине строки время.
Применив этот алгоритм для поиска подстроки получим сложность по времени O(|A|+|X|), что значительно лучше, чем произведение, которое было в первом варианте. Правда, нам пришлось хранить вектор для Z-функции, на что уйдет дополнительной памяти порядка O(|A|+|X|). На самом деле, если не нужно находить все вхождения, а достаточно только одного, то можно обойтись и O(|X|) памяти, так как длина Z-блока все-равно не может быть больше чем |X|, кроме этого можно не продолжать обработку строки после обнаружения первого вхождения.
Напоследок, пример функции, вычисляющей Z-функцию. Просто модельный вариант без каких либо хитростей.
void z_preprocess(vector<int> & Z, const string & str)
{
const size_t len = str.size();
Z.clear();
Z.resize(len);
if (0 == len)
return;
Z[0] = len;
for (size_t curr = 1, left = 0, right = 1; curr < len; ++curr)
{
if (curr >= right)
{
size_t off = 0;
while ( curr + off < len && str[curr + off] == str[off] )
++off;
Z[curr] = off;
right = curr + Z[curr];
left = curr;
}
else
{
const size_t equiv = curr - left;
if (Z[equiv] < right - curr)
Z[curr] = Z[equiv];
else
{
size_t off = 0;
while ( right + off < len && str[right - curr + off] == str[right + off] )
++off;
Z[curr] = right - curr + off;
right += off;
left = curr;
}
}
}
}
Алгоритм Кнута-Морриса-Пратта (КМП)
Не смотря на логическую простоту предыдущего метода, более популярным является другой алгоритм, который в некотором смысле обратный Z-функции — алгоритм Кнута-Морриса-Пратта (КМП). Введем понятие префикс-функции. Префикс-функция для i-ой позиции — это длина максимального префикса строки, который короче i и который совпадает с суффиксом префикса длины i. Если определение Z-функции не сразило оппонента наповал, то уж этим комбо вам точно удастся поставить его на место 🙂 А на человеческом языке это выглядит так: берем каждый возможный префикс строки и смотрим самое длинное совпадение начала с концом префикса (не учитывая тривиальное совпадение самого с собой). Вот пример для «ababcaba»:
| префикс | префикс | p |
|---|---|---|
| a | a | 0 |
| ab | ab | 0 |
| aba | aba | 1 |
| abab | abab | 2 |
| ababc | ababc | 0 |
| ababca | ababca | 1 |
| ababcab | ababcab | 2 |
| ababcaba | ababcaba | 3 |
Опять же наблюдаем ряд свойств префикс-функции. Во-первых, значения ограничены сверху своим номером, что следует прямо из определения — длина префикса должна быть больше префикс-функции. Во-вторых, уникальный символ точно так же делит строку на две части и ограничивает максимальное значение префикс-функции длиной меньшей из частей — потому что все, что длиннее, будет содержать уникальный, ничему другому не равный символ.
Отсюда получается интересующий нас вывод. Допустим, мы таки достигли в каком-то элементе этого теоретического потолка. Это значит, что здесь закончился такой префикс, что начальная часть совпадает с конечной и одна из них представляет «полную» половинку. Понятно, что в префиксе полная половинка обязана быть спереди, а значит при таком допущении это должна быть более короткая половинка, максимума же мы достигаем на более длинной половинке.
Таким образом, если мы, как и в предыдущей части, конкатенируем искомую строчку с той, в которой ищем, через сентинел, то точка вхождения длины искомой подстроки в компоненту префикс-функции будет соответствовать месту окончания вхождения. Возьмем наш пример: в строке «ababcabсacab» мы ищем «abca». Конкатенированный вариант «abca$ababcabсacab». Префикс-функция выглядит так:
| a b c a $ a b a b c a b с a c a b |
| 0 0 0 1 0 1 2 1 2 3 4 2 3 4 0 1 2 |
Снова мы нашли все вхождения подстроки одним махом — они оканчиваются на позициях четверок. Осталось понять как же эффективно посчитать эту префикс-функцию. Идея алгоритма незначительно отличается от идеи построения Z-функции.

Самое первое значение префикс-функции, очевидно, 0. Пусть мы посчитали префикс-функцию до i-ой позиции включительно. Рассмотрим i+1-ый символ. Если значение префикс-функции в i-й позиции Pi, то значит префикс A[..Pi] совпадает с подстрокой A[i-Pi+1..i]. Если символ A[Pi+1] совпадет с A[i+1], то можем спокойно записать, что Pi+1=Pi+1. Но вот если нет, то значение может быть либо меньше, либо такое же. Конечно, при Pi=0 сильно некуда уменьшаться, так что в этом случае Pi+1=0. Допустим, что Pi>0. Тогда есть в строке префикс A[..Pi], который эквивалентен подстроке A[i-Pi+1..i]. Искомая префикс-функция формируется в пределах этих эквивалентных участков плюс обрабатываемый символ, а значит нам можно забыть о всей строке после префикса и оставить только данный префикс и i+1-ый символ — ситуация будет идентичной.
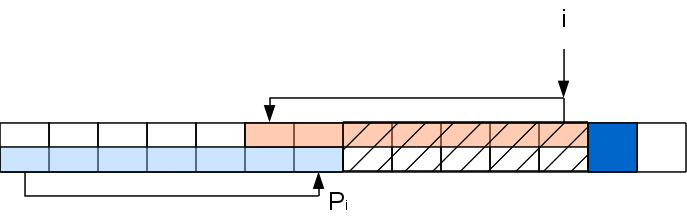
Задача на данном шаге свелась к задаче для строки с вырезанной серединкой: A[..Pi]A[i+1], которую можно решать рекурсивно таким же способом (хотя хвостовая рекурсия и не рекурсия вовсе, а цикл). То есть если A[PPi+1] совпадет с A[i+1], то Pi+1=PPi+1, а иначе снова выкидываем из рассмотрения часть строки и т.д. Повторяем процедуру пока не найдем совпадение либо не дойдем до 0.
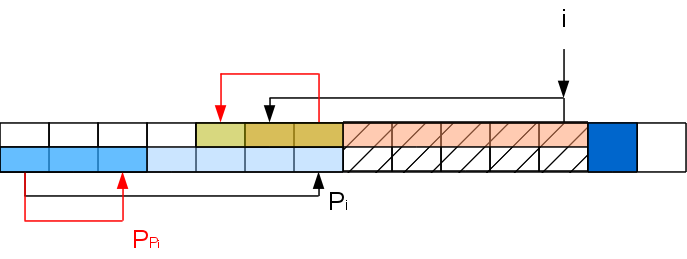
Повторение этих операций должно насторожить — казалось бы получается два вложенных цикла. Но это не так. Дело в том, что вложенный цикл длиной в k итераций уменьшает префикс-функцию в i+1-й позиции хотя бы на k-1, а для того, чтобы нарастить префикс-функцию до такого значения, нужно хотя бы k-1 раз успешно сопоставить буквы, обработав k-1 символов. То есть длина цикла соответствует промежутку между выполнением таких циклов и поэтому сложность алгоритма по прежнему линейна по длине обрабатываемой строки. С памятью тут такая-же ситуация, как и с Z-функцией — линейная по длине строки, но есть способ сэкономить. Кроме этого есть удобный факт, что символы обрабатываются последовательно, то есть мы не обязаны обрабатывать всю строку, если первое вхождение мы уже получили.
Ну и для примера фрагмент кода:
void calc_prefix_function(vector<int> & prefix_func, const string & str)
{
const size_t str_length = str.size();
prefix_func.clear();
prefix_func.resize(str_length);
if (0 == str_length)
return;
prefix_func[0] = 0;
for (size_t current = 1; current < str_length; ++current)
{
size_t matched_prefix = current - 1;
size_t candidate = prefix_func[matched_prefix];
while (candidate != 0 && str[current] != str[candidate])
{
matched_prefix = prefix_func[matched_prefix] - 1;
candidate = prefix_func[matched_prefix];
}
if (candidate == 0)
prefix_func[current] = str[current] == str[0] ? 1 : 0;
else
prefix_func[current] = candidate + 1;
}
}
Не смотря на то, что алгоритм более замысловат, реализация его даже проще, чем для Z-функции.
Другие задачи поиска
Дальше пойдет просто много букв о том, что этим задачи поиска строк не ограничиваются и что есть другие задачи и другие способы решения, так что если кому не интересно, то дальше можно не читать. Эта информация просто для ознакомления, чтобы в случае необходимости хотя бы осознавать, что «все уже украдено до нас» и не переизобретать велосипед.
Хоть вышеописанные алгоритмы и гарантируют линейное время выполнения, звание «алгоритма по умолчанию» получил алгоритм Бойера-Мура. В среднем он тоже дает линейное время, но еще и имеет лучше константу при этой линейной функции, но это в среднем. Бывают «плохие» данные, на которых он оказываются не лучше простейшего сравнения «в лоб» (ну прямо как с qsort). Он на редкость запутан и рассматривать его не будем — все-равно не упомнить. Есть еще ряд экзотических алгоритмов, которые ориентированы на обработку текстов на естественном языке и опираются в своих оптимизациях на статистические свойства слов языка.
Ну ладно, есть у нас алгоритм, который так или иначе за O(|X|+|A|) ищет подстроку в строке. А теперь представим, что мы пишем движок для гостевой книги. Есть у нас список запрещенных матерных слов (понятно, что так не поможет, но задача просто для примера). Мы собираемся фильтровать сообщения. Будем каждое из запрещенных слов искать в сообщении и… на это у нас уйдет O(|X1|+|X2|+…+|Xn|+n|A|). Как-то так себе, особенно если словарь «могучих выражений» «великого и могучего» очень «могуч». Для этого случая есть способ так предобработать словарь искомых строк, что поиск будет занимать только O(|X1|+|X2|+…+|Xn|+|A|), а это может быть существенно меньше, особенно если сообщения длинные.
Такая предобработка сводится к построению бора (trie) из словаря: дерево начинается в некотором фиктивном корне, узлы соответствует буквам слов в словаре, глубина узла дерева соответствует номеру буквы в слове. Узлы, в которых заканчивается слово из словаря называются терминальными и помечены неким образом (красным цветом на рисунке).
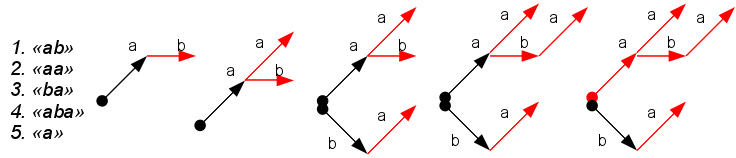
Полученное дерево является аналогом префикс-функции алгоритма КМП. С его помощью можно найти все вхождения всех слов словаря в фразе. Надо идти по дереву, проверяя наличие очередного символа в виде узла дерева, попутно отмечая встречающиеся терминальные вершины — это вхождения слов. Если соответствующего узла в дереве нет, то как и в КМП, происходит откат выше по дереву по специальным ссылкам. Данный алгоритм носит название алгоритма Ахо-Корасика. Такую же схему можно применять для поиска во время ввода и предсказания следующего символа в электронных словарях.
В данном примере построение бора несложно: просто добавляем в бор слова по очереди (нюансы только с дополнительными ссылками для «откатов»). Есть ряд оптимизаций, направленный на сокращение использования памяти этим деревом (т.н. сжатие бора — пропуск участков без ветвлений). На практике эти оптимизации чуть ли не обязательны. Недостатком данного алгоритма является его алфавитозависимость: время на обработку узла и занимаемая память зависят от количества потенциально возможных детей, которое равно размеру алфавита. Для больших алфавитов это серьезная проблема (представляете себе набор символов юникода?). Подробнее про это все можно почитать в этом хабратопике или воспользовавшись гуглояндексом — благо инфы по этомоу вопросу много.
Теперь посмотрим на другую задачу. Если в предыдущей мы знали заранее, что мы должны будем найти в поступающих потом данных, то здесь с точностью до наоборот: нам заранее выдали строчку, в которой будут искать, но что будут искать — неизвестно, а искать будут много. Типичный пример — поисковик. Документ, в котором ищется слово, известен заранее, а вот слова, которые там ищут, сыпятся на ходу. Вопрос, опять же, как вместо O(|X1|+|X2|+…+|Xn|+n|A|) получить O(|X1|+|X2|+…+|Xn|+|A|)?
Предлагается построить бор, в котором будут все возможные суффиксы имеющейся строки. Тогда поиск шаблона сведется к проверки наличия пути в дереве, соответствующего искомому шаблону. Если строить такой бор перебором всех суффиксов, то эта процедура может занять O(|A|2) времени, да и по памяти много. Но, к счастью, существуют алгоритмы, которые позволяют построить такое дерево сразу в сжатом виде — суффиксное дерево, причем сделать это за O(|A|). Недавно на Хабре была по этому поводу статья, так что интересующиеся могут прочитать про алгоритм Укконена там.
Плохо в суффиксном дереве, как обычно, две вещи: то, что это дерево, и то, что узлы дерева алфавитозависимы. От этих недостатков избавлен суффиксный массив. Суть суффиксного массива заключается в том, что если все суффиксы строки отсортировать, то поиск подстроки сведется к поиску группы расположенных рядом суффиксов по первой букве искомого образца и дальнейшего уточнения диапазона по последующим. При этом сами суффиксы в отсортированном виде хранить незачем, достаточно хранить позиции, в которых они начинаются в исходных данных. Правда, временные зависимости у данной структуры несколько хуже: единичный поиск будет обходиться O(|X| + log|A|) если подумать и сделать все аккуратно, и O(|X|log|A|) если не заморачиваться. Для сравнения в дереве для фиксированного алфавита O(|X|). Но зато то, что это массив, а не дерево, может улучшить ситуацию с кэшированием памяти и облегчить задачу предсказателю переходов процессора. Строится суффиксный массив за линейное время с помощью алгоритма Kärkkäinen-Sanders (уж извините, но плохо представляю как это должно звучать на русском). Нынче это один из самых популярных методов индексирования строк.
Вопросов приближенного поиска строк и анализа степени похожести мы тут касаться не будем совсем — слишком большая область для того, чтобы запихнуть в эту статью. Просто упомяну, что там люди зря хлеб не ели и придумали много всяких подходов, поэтому если столкнетесь с подобной задачей — найдите и почитайте. Весьма возможно такая задача уже решена.
Спасибо тем, кто читал! А тем, кто дочитал досюда, спасибо особенное!
UPD: Добавил ссылку на содержательную статью про бор (он же луч, он же префиксное дерево, он же нагруженное дерево, он же trie).
Операции со строками
Последнее обновление: 05.01.2022
Объединение строк
Конкатенация строк или объединение может производиться как с помощью операции +, так и с помощью метода Concat:
string s1 = "hello"; string s2 = "world"; string s3 = s1 + " " + s2; // результат: строка "hello world" string s4 = string.Concat(s3, "!!!"); // результат: строка "hello world!!!" Console.WriteLine(s4);
Метод Concat является статическим методом класса string, принимающим в качестве параметров две строки. Также имеются другие версии
метода, принимающие другое количество параметров.
Для объединения строк также может использоваться метод Join:
string s5 = "apple";
string s6 = "a day";
string s7 = "keeps";
string s8 = "a doctor";
string s9 = "away";
string[] values = new string[] { s5, s6, s7, s8, s9 };
string s10 = string.Join(" ", values);
Console.WriteLine(s10); // apple a day keeps a doctor away
Метод Join также является статическим. Использованная выше версия метода получает два параметра: строку-разделитель (в данном случае пробел) и
массив строк, которые будут соединяться и разделяться разделителем.
Сравнение строк
Для сравнения строк применяется статический метод Compare:
string s1 = "hello";
string s2 = "world";
int result = string.Compare(s1, s2);
if (result<0)
{
Console.WriteLine("Строка s1 перед строкой s2");
}
else if (result > 0)
{
Console.WriteLine("Строка s1 стоит после строки s2");
}
else
{
Console.WriteLine("Строки s1 и s2 идентичны");
}
// результатом будет "Строка s1 перед строкой s2"
Данная версия метода Compare принимает две строки и возвращает число. Если первая строка по алфавиту стоит выше второй, то возвращается число меньше нуля.
В противном случае возвращается число больше нуля. И третий случай – если строки равны, то возвращается число 0.
В данном случае так как символ h по алфавиту стоит выше символа w, то и первая строка будет стоять выше.
Поиск в строке
С помощью метода IndexOf мы можем определить индекс первого вхождения отдельного символа или подстроки в строке:
string s1 = "hello world"; char ch = 'o'; int indexOfChar = s1.IndexOf(ch); // равно 4 Console.WriteLine(indexOfChar); string substring = "wor"; int indexOfSubstring = s1.IndexOf(substring); // равно 6 Console.WriteLine(indexOfSubstring);
Подобным образом действует метод LastIndexOf, только находит индекс последнего вхождения символа или подстроки в строку.
Еще одна группа методов позволяет узнать начинается или заканчивается ли строка на определенную подстроку. Для этого предназначены методы
StartsWith и EndsWith. Например, в массиве строк хранится список файлов, и нам надо вывести все файлы с
расширением exe:
var files = new string[]
{
"myapp.exe",
"forest.jpg",
"main.exe",
"book.pdf",
"river.png"
};
for (int i = 0; i < files.Length; i++)
{
if (files[i].EndsWith(".exe"))
Console.WriteLine(files[i]);
}
Разделение строк
С помощью функции Split мы можем разделить строку на массив подстрок. В качестве параметра функция Split
принимает массив символов или строк, которые и будут служить разделителями. Например, подсчитаем количество слов в сроке,
разделив ее по пробельным символам:
string text = "И поэтому все так произошло";
string[] words = text.Split(new char[] { ' ' });
foreach (string s in words)
{
Console.WriteLine(s);
}
Это не лучший способ разделения по пробелам, так как во входной строке у нас могло бы быть несколько подряд идущих пробелов и в итоговый массив
также бы попадали пробелы, поэтому лучше использовать другую версию метода:
string[] words = text.Split(new char[] { ' ' }, StringSplitOptions.RemoveEmptyEntries);
Второй параметр StringSplitOptions.RemoveEmptyEntries говорит, что надо удалить все пустые подстроки.
Обрезка строки
Для обрезки начальных или концевых символов используется функция Trim:
string text = " hello world ";
text = text.Trim(); // результат "hello world"
text = text.Trim(new char[] { 'd', 'h' }); // результат "ello worl"
Функция Trim без параметров обрезает начальные и конечные пробелы и возвращает обрезанную строку. Чтобы явным образом указать, какие
начальные и конечные символы следует обрезать, мы можем передать в функцию массив этих символов.
Эта функция имеет частичные аналоги: функция TrimStart обрезает начальные символы, а функция TrimEnd обрезает конечные символы.
Обрезать определенную часть строки позволяет функция Substring:
string text = "Хороший день"; // обрезаем начиная с третьего символа text = text.Substring(2); // результат "роший день" Console.WriteLine(text); // обрезаем сначала до последних двух символов text = text.Substring(0, text.Length - 2); // результат "роший де" Console.WriteLine(text);
Функция Substring также возвращает обрезанную строку. В качестве параметра первая использованная версия применяет индекс, начиная с
которого надо обрезать строку. Вторая версия применяет два параметра – индекс начала обрезки и длину вырезаемой части строки.
Вставка
Для вставки одной строки в другую применяется функция Insert:
string text = "Хороший день"; string substring = "замечательный "; text = text.Insert(8, substring); Console.WriteLine(text); // Хороший замечательный день
Первым параметром в функции Insert является индекс, по которому надо вставлять подстроку, а второй параметр – собственно подстрока.
Удаление строк
Удалить часть строки помогает метод Remove:
string text = "Хороший день"; // индекс последнего символа int ind = text.Length - 1; // вырезаем последний символ text = text.Remove(ind); Console.WriteLine(text); // Хороший ден // вырезаем первые два символа text = text.Remove(0, 2); Console.WriteLine(text); // роший ден
Первая версия метода Remove принимает индекс в строке, начиная с которого надо удалить все символы. Вторая версия принимает еще один параметр – сколько
символов надо удалить.
Замена
Чтобы заменить один символ или подстроку на другую, применяется метод Replace:
string text = "хороший день";
text = text.Replace("хороший", "плохой");
Console.WriteLine(text); // плохой день
text = text.Replace("о", "");
Console.WriteLine(text); // плхй день
Во втором случае применения функции Replace строка из одного символа “о” заменяется на пустую строку, то есть фактически удаляется из текста.
Подобным способом легко удалять какой-то определенный текст в строках.
Смена регистра
Для приведения строки к верхнему и нижнему регистру используются соответственно функции ToUpper() и
ToLower():
string hello = "Hello world!"; Console.WriteLine(hello.ToLower()); // hello world! Console.WriteLine(hello.ToUpper()); // HELLO WORLD!
Текстовые переменные str в Питоне
Строковый тип str в Python используют для работы с любыми текстовыми данными. Python автоматически определяет тип str по кавычкам – одинарным или двойным:
>>> stroka = 'Python'
>>> type(stroka)
<class 'str'>
>>> stroka2 = "code"
>>> type(stroka2)
<class 'str'>
Для решения многих задач строковую переменную нужно объявить заранее, до начала исполнения основной части программы. Создать пустую переменную str просто:
stroka = ''
Или:
stroka2 = ""
Если в самой строке нужно использовать кавычки – например, для названия книги – то один вид кавычек используют для строки, второй – для выделения названия:
>>> print("'Самоучитель Python' - возможно, лучший справочник по Питону.")
'Самоучитель Python' - возможно, лучший справочник по Питону.
>>> print('"Самоучитель Python" - возможно, лучший справочник по Питону.')
"Самоучитель Python" - возможно, лучший справочник по Питону.
Использование одного и того же вида кавычек внутри и снаружи строки вызовет ошибку:
>>> print(""Самоучитель Python" - возможно, лучший справочник по Питону.")
File "<pyshell>", line 1
print(""Самоучитель Python" - возможно, лучший справочник по Питону.")
^
SyntaxError: invalid syntax
Кроме двойных " и одинарных кавычек ', в Python используются и тройные ''' – в них заключают текст, состоящий из нескольких строк, или программный код:
>>> print('''В тройные кавычки заключают многострочный текст.
Программный код также можно выделить тройными кавычками.''')
В тройные кавычки заключают многострочный текст.
Программный код также можно выделить тройными кавычками.
Длина строки len в Python
Для определения длины строки используется встроенная функция len(). Она подсчитывает общее количество символов в строке, включая пробелы:
>>> stroka = 'python'
>>> print(len(stroka))
6
>>> stroka1 = ' '
>>> print(len(stroka1))
1
Преобразование других типов данных в строку
Целые и вещественные числа преобразуются в строки одинаково:
>>> number1 = 55
>>> number2 = 55.5
>>> stroka1 = str(number1)
>>> stroka2 = str(number2)
>>> print(type(stroka1))
<class 'str'>
>>> print(type(stroka2))
<class 'str'>
Решение многих задач значительно упрощается, если работать с числами в строковом формате. Особенно это касается заданий, где нужно разделять числа на разряды – сотни, десятки и единицы.
Сложение и умножение строк
Как уже упоминалось в предыдущей главе, строки можно складывать – эта операция также известна как конкатенация:
>>> str1 = 'Python'
>>> str2 = ' - '
>>> str3 = 'самый гибкий язык программирования'
>>> print(str1 + str2 + str3)
Python - самый гибкий язык программирования
При необходимости строку можно умножить на целое число – эта операция называется репликацией:
>>> stroka = '*** '
>>> print(stroka * 5)
*** *** *** *** ***
Подстроки
Подстрокой называется фрагмент определенной строки. Например, ‘abra’ является подстрокой ‘abrakadabra’. Чтобы определить, входит ли какая-то определенная подстрока в строку, используют оператор in:
>>> stroka = 'abrakadabra'
>>> print('abra' in stroka)
True
>>> print('zebra' in stroka)
False
Для обращения к определенному символу строки используют индекс – порядковый номер элемента. Python поддерживает два типа индексации – положительную, при которой отсчет элементов начинается с 0 и с начала строки, и отрицательную, при которой отсчет начинается с -1 и с конца:
| Положительные индексы | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| Пример строки | P | r | o | g | l | i | b |
| Отрицательные индексы | -7 | -6 | -5 | -4 | -3 | -2 | -1 |
Чтобы получить определенный элемент строки, нужно указать его индекс в квадратных скобках:
>>> stroka = 'программирование'
>>> print(stroka[7])
м
>>> print(stroka[-1])
е
Срезы строк в Python
Индексы позволяют работать с отдельными элементами строк. Для работы с подстроками используют срезы, в которых задается нужный диапазон:
>>> stroka = 'программирование'
>>> print(stroka[7:10])
мир
Диапазон среза [a:b] начинается с первого указанного элемента а включительно, и заканчивается на последнем, не включая b в результат:
>>> stroka = 'программa'
>>> print(stroka[3:8])
грамм
Если не указать первый элемент диапазона [:b], срез будет выполнен с начала строки до позиции второго элемента b:
>>> stroka = 'программa'
>>> print(stroka[:4])
прог
В случае отсутствия второго элемента [a:] срез будет сделан с позиции первого символа и до конца строки:
>>> stroka = 'программa'
>>> print(stroka[3:])
граммa
Если не указана ни стартовая, ни финальная позиция среза, он будет равен исходной строке:
>>> stroka = 'позиции не заданы'
>>> print(stroka[:])
позиции не заданы
Шаг среза
Помимо диапазона, можно задавать шаг среза. В приведенном ниже примере выбирается символ из стартовой позиции среза, а затем каждая 3-я буква из диапазона:
>>> stroka = 'Python лучше всего подходит для новичков.'
>>> print(stroka[1:15:3])
yoлшв
Шаг может быть отрицательным – в этом случае символы будут выбираться, начиная с конца строки:
>>> stroka = 'это пример отрицательного шага'
>>> print(stroka[-1:-15:-4])
а нт
Срез [::-1] может оказаться очень полезным при решении задач, связанных с палиндромами:
>>> stroka = 'А роза упала на лапу Азора'
>>> print(stroka[::-1])
арозА упал ан алапу азор А
Замена символа в строке
Строки в Python относятся к неизменяемым типам данных. По этой причине попытка замены символа по индексу обречена на провал:
>>> stroka = 'mall'
>>> stroka[0] = 'b'
Traceback (most recent call last):
File "<pyshell>", line 1, in <module>
TypeError: 'str' object does not support item assignment
Но заменить любой символ все-таки можно – для этого придется воспользоваться срезами и конкатенацией. Результатом станет новая строка:
>>> stroka = 'mall'
>>> stroka = 'b' + stroka[1:]
>>> print(stroka)
ball
Более простой способ «замены» символа или подстроки – использование метода replace(), который мы рассмотрим ниже.
Полезные методы строк
Python предоставляет множество методов для работы с текстовыми данными. Все методы можно сгруппировать в четыре категории:
- Преобразование строк.
- Оценка и классификация строк.
- Конвертация регистра.
- Поиск, подсчет и замена символов.
Рассмотрим эти методы подробнее.
Преобразование строк
Три самых используемых метода из этой группы – join(), split() и partition(). Метод join() незаменим, если нужно преобразовать список или кортеж в строку:
>>> spisok = ['Я', 'изучаю', 'Python']
>>> stroka = ' '.join(spisok)
>>> print(stroka)
Я изучаю Python
При объединении списка или кортежа в строку можно использовать любые разделители:
>>> kort = ('Я', 'изучаю', 'Django')
>>> stroka = '***'.join(kort)
>>> print(stroka)
Я***изучаю***Django
Метод split() используется для обратной манипуляции – преобразования строки в список:
>>> text = 'это пример текста для преобразования в список'
>>> spisok = text.split()
>>> print(spisok)
['это', 'пример', 'текста', 'для', 'преобразования', 'в', 'список']
По умолчанию split() разбивает строку по пробелам. Но можно указать любой другой символ – и на практике это часто требуется:
>>> text = 'цвет: синий; вес: 1 кг; размер: 30х30х50; материал: картон'
>>> spisok = text.split(';')
>>> print(spisok)
['цвет: синий', ' вес: 1 кг', ' размер: 30х30х50', ' материал: картон']
Метод partition() поможет преобразовать строку в кортеж:
>>> text = 'Python - простой и понятный язык'
>>> kort = text.partition('и')
>>> print(kort)
('Python - простой ', 'и', ' понятный язык')
В отличие от split(), partition() учитывает только первое вхождение элемента-разделителя (и добавляет его в итоговый кортеж).
Оценка и классификация строк
В Python много встроенных методов для оценки и классификации текстовых данных. Некоторые из этих методов работают только со строками, в то время как другие универсальны. К последним относятся, например, функции min() и max():
>>> text = '12345'
>>> print(min(text))
1
>>> print(max(text))
5
В Python есть специальные методы для определения типа символов. Например, isalnum() оценивает, состоит ли строка из букв и цифр, либо в ней есть какие-то другие символы:
>>> text = 'abracadabra123456'
>>> print(text.isalnum())
True
>>> text1 = 'a*b$ra cadabra'
>>> print(text1.isalnum())
False
Метод isalpha() поможет определить, состоит ли строка только из букв, или включает специальные символы, пробелы и цифры:
>>> text = 'программирование'
>>> print(text.isalpha())
True
>>> text2 = 'password123'
>>> print(text2.isalpha())
False
С помощью метода isdigit() можно определить, входят ли в строку только цифры, или там есть и другие символы:
>>> text = '1234567890'
>>> print(text.isdigit())
True
>>> text2 = '123456789o'
>>> print(text2.isdigit())
False
Поскольку вещественные числа содержат точку, а отрицательные – знак минуса, выявить их этим методом не получится:
>>> text = '5.55'
>>> print(text.isdigit())
False
>>> text1 = '-5'
>>> print(text1.isdigit())
False
Если нужно определить наличие в строке дробей или римских цифр, подойдет метод isnumeric():
>>> text = '½⅓¼⅕⅙'
>>> print(text.isdigit())
False
>>> print(text.isnumeric())
True
Методы islower() и isupper() определяют регистр, в котором находятся буквы. Эти методы игнорируют небуквенные символы:
>>> text = 'abracadabra'
>>> print(text.islower())
True
>>> text2 = 'Python bytes'
>>> print(text2.islower())
False
>>> text3 = 'PYTHON'
>>> print(text3.isupper())
True
Метод isspace() определяет, состоит ли анализируемая строка из одних пробелов, или содержит что-нибудь еще:
>>> stroka = ' '
>>> print(stroka.isspace())
True
>>> stroka2 = ' a '
>>> print(stroka2.isspace())
False
Конвертация регистра
Как уже говорилось выше, строки относятся к неизменяемым типам данных, поэтому результатом любых манипуляций, связанных с преобразованием регистра или удалением (заменой) символов будет новая строка.
Из всех методов, связанных с конвертацией регистра, наиболее часто используются на практике два – lower() и upper(). Они преобразуют все символы в нижний и верхний регистр соответственно:
>>> text = 'этот текст надо написать заглавными буквами'
>>> print(text.upper())
ЭТОТ ТЕКСТ НАДО НАПИСАТЬ ЗАГЛАВНЫМИ БУКВАМИ
>>> text = 'зДесь ВСе букВы рАзныЕ, а НУжнЫ проПИСНыЕ'
>>> print(text.lower())
здесь все буквы разные, а нужны прописные
Иногда требуется преобразовать текст так, чтобы с заглавной буквы начиналось только первое слово предложения:
>>> text = 'предложение должно начинаться с ЗАГЛАВНОЙ буквы.'
>>> print(text.capitalize())
Предложение должно начинаться с заглавной буквы.
Методы swapcase() и title() используются реже. Первый заменяет исходный регистр на противоположный, а второй – начинает каждое слово с заглавной буквы:
>>> text = 'пРИМЕР иСПОЛЬЗОВАНИЯ swapcase'
>>> print(text.swapcase())
Пример Использования SWAPCASE
>>> text2 = 'тот случай, когда нужен метод title'
>>> print(text2.title())
Тот Случай, Когда Нужен Метод Title
Поиск, подсчет и замена символов
Методы find() и rfind() возвращают индекс стартовой позиции искомой подстроки. Оба метода учитывают только первое вхождение подстроки. Разница между ними заключается в том, что find() ищет первое вхождение подстроки с начала текста, а rfind() – с конца:
>>> text = 'пример текста, в котором нужно найти текстовую подстроку'
>>> print(text.find('текст'))
7
>>> print(text.rfind('текст'))
37
Такие же результаты можно получить при использовании методов index() и rindex() – правда, придется предусмотреть обработку ошибок, если искомая подстрока не будет обнаружена:
>>> text = 'Съешь еще этих мягких французских булок!'
>>> print(text.index('еще'))
6
>>> print(text.rindex('чаю'))
Traceback (most recent call last):
File "<pyshell>", line 1, in <module>
ValueError: substring not found
Если нужно определить, начинается ли строка с определенной подстроки, поможет метод startswith():
>>> text = 'Жила-была курочка Ряба'
>>> print(text.startswith('Жила'))
True
Чтобы проверить, заканчивается ли строка на нужное окончание, используют endswith():
>>> text = 'В конце всех ждал хэппи-енд'
>>> print(text.endswith('енд'))
True
Для подсчета числа вхождений определенного символа или подстроки применяют метод count() – он помогает подсчитать как общее число вхождений в тексте, так и вхождения в указанном диапазоне:
>>> text = 'Съешь еще этих мягких французских булок, да выпей же чаю!'
>>> print(text.count('е'))
5
>>> print(text.count('е', 5, 25))
2
Методы strip(), lstrip() и rstrip() предназначены для удаления пробелов. Метод strip() удаляет пробелы в начале и конце строки, lstrip() – только слева, rstrip() – только справа:
>>> text = ' здесь есть пробелы и слева, и справа '
>>> print('***', text.strip(), '***')
*** здесь есть пробелы и слева, и справа ***
>>> print('***', text.lstrip(), '***')
*** здесь есть пробелы и слева, и справа ***
>>> print('***', text.rstrip(), '***')
*** здесь есть пробелы и слева, и справа ***
Метод replace() используют для замены символов или подстрок. Можно указать нужное количество замен, а сам символ можно заменить на пустую подстроку – проще говоря, удалить:
>>> text = 'В этой строчке нужно заменить только одну "ч"'
>>> print(text.replace('ч', '', 1))
В этой строке нужно заменить только одну "ч"
Стоит заметить, что метод replace() подходит лишь для самых простых вариантов замены и удаления подстрок. В более сложных случаях необходимо использование регулярных выражений, которые мы будем изучать позже.
Практика
Задание 1
Напишите программу, которая получает на вход строку и выводит:
- количество символов, содержащихся в тексте;
- True или False в зависимости от того, являются ли все символы буквами и цифрами.
Решение:
text = input()
print(len(text))
print(text.isalpha())
Задание 2
Напишите программу, которая получает на вход слово и выводит True, если слово является палиндромом, или False в противном случае. Примечание: для сравнения в Python используется оператор ==.
Решение:
text = input().lower()
print(text == text[::-1])
Задание 3
Напишите программу, которая получает строку с именем, отчеством и фамилией, написанными в произвольном регистре, и выводит данные в правильном формате. Например, строка алеКСандр СЕРГЕЕВИЧ ПушкиН должна быть преобразована в Александр Сергеевич Пушкин.
Решение:
text = input()
print(text.title())
Задание 4
Имеется строка 12361573928167047230472012. Напишите программу, которая преобразует строку в текст один236один573928один670472304720один2.
Решение:
text = '12361573928167047230472012'
print(text.replace('1', 'один'))
Задание 5
Напишите программу, которая последовательно получает на вход имя, отчество, фамилию и должность сотрудника, а затем преобразует имя и отчество в инициалы, добавляя должность после запятой.
Пример ввода:
Алексей
Константинович
Романов
бухгалтер
Вывод:
А. К. Романов, бухгалтер
Решение:
first_name, patronymic, last_name, position = input(), input(), input(), input()
print(first_name[0] + '.', patronymic[0] + '.', last_name + ',', position)
Задание 6
Напишите программу, которая получает на вход строку текста и букву, а затем определяет, встречается ли данная буква (в любом регистре) в тексте. В качестве ответа программа должна выводить True или False.
Пример ввода:
ЗонтИК
к
Вывод:
True
Решение:
text = input().lower()
letter = input()
print(letter in text)
Задание 7
Напишите программу, которая определяет, является ли введенная пользователем буква гласной. В качестве ответа программы выводит True или False, буквы могут быть как в верхнем, так и в нижнем регистре.
Решение:
vowels = 'аиеёоуыэюя'
letter = input().lower()
print(letter in vowels)
Задание 8
Напишите программу, которая принимает на вход строку текста и подстроку, а затем выводит индексы первого вхождения подстроки с начала и с конца строки (без учета регистра).
Пример ввода:
Шесть шустрых мышат в камышах шуршат
ша
Вывод:
16 33
Решение:
text, letter = input().lower(), input()
print(text.find(letter), text.rfind(letter))
Задание 9
Напишите программу для подсчета количества пробелов и непробельных символов в введенной пользователем строке.
Пример ввода:
В роще, травы шевеля, мы нащиплем щавеля
Вывод:
Количество пробелов: 6, количество других символов: 34
Решение:
text = input()
nospace = text.replace(' ', '')
print(f"Количество пробелов: {text.count(' ')}, количество других символов: {len(nospace)}")
Задание 10
Напишите программу, которая принимает строку и две подстроки start и end, а затем определяет, начинается ли строка с фрагмента start, и заканчивается ли подстрокой end. Регистр не учитывать.
Пример ввода:
Программирование на Python - лучшее хобби
про
про
Вывод:
True
False
Решение:
text, start, end = input().lower(), input(), input()
print(text.startswith(start))
print(text.endswith(end))
Подведем итоги
В этой части мы рассмотрели самые популярные методы работы со строками – они пригодятся для решения тренировочных задач и в разработке реальных проектов. В следующей статье будем разбирать методы работы со списками.
***
📖 Содержание самоучителя
- Особенности, сферы применения, установка, онлайн IDE
- Все, что нужно для изучения Python с нуля – книги, сайты, каналы и курсы
- Типы данных: преобразование и базовые операции
- Методы работы со строками
- Методы работы со списками и списковыми включениями
- Методы работы со словарями и генераторами словарей
- Методы работы с кортежами
- Методы работы со множествами
- Особенности цикла for
- Условный цикл while
- Функции с позиционными и именованными аргументами
- Анонимные функции
- Рекурсивные функции
- Функции высшего порядка, замыкания и декораторы
- Методы работы с файлами и файловой системой
- Регулярные выражения
- Основы скрапинга и парсинга
- Основы ООП: инкапсуляция и наследование
- Основы ООП – абстракция и полиморфизм
- Графический интерфейс на Tkinter
***
Материалы по теме
- ТОП-15 трюков в Python 3, делающих код понятнее и быстрее

В этой статье поговорим про строки в Python, особенности поиска, а также о том, как искать подстроку или символ в строке.

Но сначала давайте вспомним основные методы для обработки строк в Python:
• isalpha(str): если строка в Python включает в себя лишь алфавитные символы, возвращается True;
• islower(str): True возвращается, если строка включает лишь символы в нижнем регистре;
• isupper(str): True, если символы строки в Python находятся в верхнем регистре;
• startswith(str): True, когда строка начинается с подстроки str;
• isdigit(str): True, когда каждый символ строки — цифра;
• endswith(str): True, когда строка в Python заканчивается на подстроку str;
• upper(): строка переводится в верхний регистр;
• lower(): строка переводится в нижний регистр;
• title(): для перевода начальных символов всех слов в строке в верхний регистр;
• capitalize(): для перевода первой буквы самого первого слова строки в верхний регистр;
• lstrip(): из строки в Python удаляются начальные пробелы;
• rstrip(): из строки в Python удаляются конечные пробелы;
• strip(): из строки в Python удаляются и начальные, и конечные пробелы;
• rjust(width): когда длина строки меньше, чем параметр width, слева добавляются пробелы, строка выравнивается по правому краю;
• ljust(width): когда длина строки в Python меньше, чем параметр width, справа от неё добавляются пробелы для дополнения значения width, при этом происходит выравнивание строки по левому краю;
• find(str[, start [, end]): происходит возвращение индекса подстроки в строку в Python. В том случае, если подстрока не найдена, выполняется возвращение числа -1;
• center(width): когда длина строки в Python меньше, чем параметр width, слева и справа добавляются пробелы (равномерно) для дополнения значения width, причём происходит выравнивание строки по центру;
• split([delimeter[, num]]): строку в Python разбиваем на подстроки в зависимости от разделителя;
• replace(old, new[, num]): в строке одна подстрока меняется на другую;
• join(strs): строки объединяются в одну строку, между ними вставляется определённый разделитель.
Обрабатываем строку в Python
Представим, что ожидается ввод числа с клавиатуры. Перед преобразованием введенной нами строки в число можно легко проверить, введено ли действительно число. Если это так, выполнится операция преобразования. Для обработки строки используем такой метод в Python, как isnumeric():
string = input("Введите какое-нибудь число: ") if string.isnumeric(): number = int(string) print(number)Следующий пример позволяет удалять пробелы в конце и начале строки:
string = " привет мир! " string = string.strip() print(string) # привет мир!Так можно дополнить строку пробелами и выполнить выравнивание:
print("iPhone 7:", "52000".rjust(10)) print("Huawei P10:", "36000".rjust(10))В консоли Python будет выведено следующее:
iPhone 7: 52000 Huawei P10: 36000Поиск подстроки в строке
Чтобы в Python выполнить поиск в строке, используют метод find(). Он имеет три формы и возвращает индекс 1-го вхождения подстроки в строку:
• find(str): поиск подстроки str производится с начала строки и до её конца;
• find(str, start): с помощью параметра start задаётся начальный индекс, и именно с него и выполняется поиск;
• find(str, start, end): посредством параметра end задаётся конечный индекс, поиск выполняется до него.
Когда подстрока не найдена, метод возвращает -1:
welcome = "Hello world! Goodbye world!" index = welcome.find("wor") print(index) # 6 # ищем с десятого индекса index = welcome.find("wor",10) print(index) # 21 # ищем с 10-го по 15-й индекс index = welcome.find("wor",10,15) print(index) # -1Замена в строке
Чтобы в Python заменить в строке одну подстроку на другую, применяют метод replace():
• replace(old, new): подстрока old заменяется на new;
• replace(old, new, num): параметр num показывает, сколько вхождений подстроки old требуется заменить на new.Пример замены в строке в Python:
phone = "+1-234-567-89-10" # дефисы меняются на пробелы edited_phone = phone.replace("-", " ") print(edited_phone) # +1 234 567 89 10 # дефисы удаляются edited_phone = phone.replace("-", "") print(edited_phone) # +12345678910 # меняется только первый дефис edited_phone = phone.replace("-", "", 1) print(edited_phone) # +1234-567-89-10Разделение на подстроки в Python
Для разделения в Python используется метод split(). В зависимости от разделителя он разбивает строку на перечень подстрок. В роли разделителя в данном случае может быть любой символ либо последовательность символов. Этот метод имеет следующие формы:
• split(): в роли разделителя применяется такой символ, как пробел;
• split(delimeter): в роли разделителя применяется delimeter;
• split(delimeter, num): параметром num указывается, какое количество вхождений delimeter применяется для разделения. При этом оставшаяся часть строки добавляется в перечень без разделения на подстроки.Соединение строк в Python
Рассматривая простейшие операции со строками, мы увидели, как объединяются строки через операцию сложения. Однако есть и другая возможность для соединения строк — метод join():, объединяющий списки строк. В качестве разделителя используется текущая строка, у которой вызывается этот метод:
words = ["Let", "me", "speak", "from", "my", "heart", "in", "English"] # символ разделителя - пробел sentence = " ".join(words) print(sentence) # Let me speak from my heart in English # символ разделителя - вертикальная черта sentence = " | ".join(words) print(sentence) # Let | me | speak | from | my | heart | in | EnglishА если вместо списка в метод join передать простую строку, разделитель будет вставляться уже между символами:
word = "hello" joined_word = "|".join(word) print(joined_word) # h|e|l|l|o

Поиск подстроки в строке
Задача поиска подстроки одна из достаточно распространённых в информатике. Строкой называют последовательность символов (в произвольном порядке) взятых из заданного алфавита. Так например, алфавитом могут быть цифры {0, 1} из которых можно составлять неограниченную по длине цепочку символов, например, 0110100110 или 0. Понятие алфавита и другие раскрываются в теории формальных языков.
В рамках этой статьи рассмотрены задачи нахождения одной строки в другой. Результатом поиска могут быть как простой ответ «да / нет» на вопрос «содержит ли данная строка представленный образец», так и информация о точном месте начала (или начал, если их несколько) совпадения подстроки с образцом. Назовём образцом искомую строку, а подстрокой — массив  для индексов
для индексов  таких что
таких что  , где
, где  — длина строки, а
— длина строки, а  — сама строка. Также введём образец как
— сама строка. Также введём образец как  .
.
Простой (наивный) поиск
Суть алгоритма простого поиска состоит в последовательном переборе с последующим сравнением символов строки и образца. Для этого достаточно выполнить следующий алгоритм:
for i = 0 to S.length do:
for j = 0 to P.length do:
if S[i + j] != P[j] then break
end for
if j == P.length then return i
end for
return -1
Переменная i отвечает за сдвиг образца на один символ на каждой итерации. Внутренний цикл проверяет совпадение символа строки с индексом i + j и символа образца с индексом j. Если символы не совпадают, тогда внутренний цикл прекращает работу. Оговоримся, что если алгоритм отрабатывает все итерации, то переменная цикла будет равна значению правой границы указанного как N. В таком случае, если длина образца и переменной равны, то это будет означать, что внутренний цикл не нашёл разных символов, а значит подстрока найдена, а индексом начала подстроки является переменная i. В противном случае внешний цикл продолжает работу.
Здесь намеренно не приводится ограничений на правую границу внешнего цикла, т.к. сути алгоритма это не меняет. В общем легко посчитать, что сложность такого поиска будет  , где — длина строки , а
, где — длина строки , а  — образца .
— образца .
Алгоритм Рабина — Карпа
Этот алгоритм старается уменьшить количество проверок во внутреннем цикле простого поиска за счёт использования хэш-функции.
Понятие хэш-функции
Хэш-функция в данном случае преобразовывает исходную строку в числовое значение. Само преобразование называется хэшированием и в общем может выполняться не только для строк, но и для произвольного массива данных, а выходным значением является битовый массив заданной длины. Рассмотрим эти определения на простых примерах, где задано множество  чисел для которых нужно посчитать хэш-функцию в множество
чисел для которых нужно посчитать хэш-функцию в множество  . Тогда нам нужна функция
. Тогда нам нужна функция  , значение которой будет принадлежать множеству .
, значение которой будет принадлежать множеству .
Например, у нас есть множество целых чисел от 0 до 1 000 000 и ограничение на значение хэш-функции в 10 битов. 10 битов это  доступных значений функции. Существуют различные способы написать такую функцию, например:
доступных значений функции. Существуют различные способы написать такую функцию, например:
- методом деления, когда входное число делится на количество доступных значений хэш-функции, а результатом является остаток от такого деления:
 ;
;
- метод середины квадрата умножает входное число само на себя, а из его середины берутся необходимое количество знаков;
- метод умножения имеет вид
![hash(k)=left[rleftlfloor {frac {A}{w}}*krightrfloor right]](data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%20166%2024'%3E%3C/svg%3E "Rendered by QuickLaTeX.com") , где
, где  — количество символов представимых машинным словом (для 32-битной системы это будет
— количество символов представимых машинным словом (для 32-битной системы это будет  ), а
), а  — взаимно простое число к .
— взаимно простое число к .
 ;
;
![hash(k)=left[rleftlfloor {frac {A}{w}}*krightrfloor right]](https://markoutte.me/wp-content/ql-cache/quicklatex.com-155e08ed1018d42acf5683e5389254c0_l3.svg "Rendered by QuickLaTeX.com") , где
, где  — количество символов представимых машинным словом (для 32-битной системы это будет
— количество символов представимых машинным словом (для 32-битной системы это будет  ), а
), а  — взаимно простое число к
— взаимно простое число к При любой функции могут случаться коллизии. Коллизиями называется ситуация, когда разные элементы множества отображаются в один элемент множества . Например, для примера в методе деления такое происходит при  . Если коллизии не случаются, то такое хэширование называют идеальным хэшированием.
. Если коллизии не случаются, то такое хэширование называют идеальным хэшированием.
Также существуют хэш-таблицы, которые являются ещё одним способом создания словаря (англ. map). Они используют разные стратегии для разрешения коллизий при сохранении пары ключ-значения в таблицу, например, метод цепочек или метод открытой адресации.
Для работы алгоритма необходимо написать хэш-функцию для заданной строки. Если пронумеровать символы алфавита из которых состоит строка, то можно написать тривиальный скользящий хэш, представляющий из себя сумму индексов каждого символа. Например, когда задан алфавит {A, B, C, D}, а символы имеют индексы от 1 до 4, то для строки ACDDAB будем иметь, что 1 + 3 + 4 + 4 + 1 + 2 = 15.
При сдвиге образца на один символ значение хэш-функции для подстроки будет меняться как «минус предыдущий элемент, плюс следующий». Заранее посчитав значение хэш-функции для образца и пользуясь предложенной хэш-функцией при сдвиге образца, мы каждый раз сравниваем сами значения получаемых хэш-функций. Если они совпадают, то нам нужно уже проверить строки посимвольно и, если они полностью совпали, то ответ получен (сравнивать необходимо из-за возможности коллизий):
PH = hash(P)
SH = hash(S(0, P.length))
for i = 0 to S.length do
if PH == SH and S(i, i + P.length) == P then
return i
end if
SH = SH - S[i] + S[i + P.length]
end for
return -1
В общем случае без использования скользящего хэша необходимо на каждой итерации считать хэш от подстроки и скорость работы напрямую зависит от того, насколько быстро этот хэш можно посчитать.
Алгоритм Бойера — Мура
Идея этого алгоритма заключается в том, что строки можно сравнивать с конца. Это позволит пропускать не 1 символ как в наивном алгоритме, но зачастую сразу всю строку. Это возможно, поскольку в тот момент, когда обнаруживается несовпадающий символ между строкой и образцом, то образец необходимо сдвинуть вправо на столько символов, чтобы несовпадающий символ строки теперь совпал с символом образца. Если такого символа в образце нет, то строка сдвигается полностью.
Рассмотрим пример:
ровкдткотор кот********
Начиная проверку с конца к началу определяем, что не совпадают символы «в» и «т». Сдвиг, величина шага которого зависит от таблицы, описанную позже, в этом случае будет равен 3:
ровкдткотор ***кот*****
Снова проверяем сконца: после совпадения «т» в обеих строках не совпадают «д» и «о». Снова сдвигаем, шаг в этом случае равен 3:
ровкдткотор ******кот**
В данном примере все символы совпадают, поэтому алгоритм останавливается. Теперь определим, каким образом определяется величина шага для каждого символа. Поскольку суть алгоритма в том, чтобы при несовпадении символа мы двигали образец вправо до тех пор, пока этот символ не совпадёт с символом образца:
персональные данные данные************* -> не совпал "н" (не совпал в первом символе, индекс 5), сдвигаем на 5 - 3 = 2 (3 по таблице) **данные*********** -> не совпал "л", сдвигаем на 6, т.к. символа нет в таблице ********данные***** -> не совпал "д" (не совпал в первом символе индекс 5), сдвигаем на 5 - 0 = 5 (0 по таблице) *************данные -> совпали
Для составления таблицы используется следующее правило: значение для символа равно максимальному индексу этого элемента в образце (исключая последний символ, для него и всех других значение равно количеству символов в образце). Так для строки «данные» это будет:
Тогда величина сдвига при сравнении справа налево и при не совпадении символа на j-ой позиции, где сам символ ![c = S[j]](https://markoutte.me/wp-content/ql-cache/quicklatex.com-0064004376a203033343923bd1d74191_l3.svg "Rendered by QuickLaTeX.com") , будет равна
, будет равна ![i = j - Table[c]](https://markoutte.me/wp-content/ql-cache/quicklatex.com-4af27acbb6f0193dad130be4a3d1abf5_l3.svg "Rendered by QuickLaTeX.com") . Приведём алгоритм с приведённой эвристикой, называемой эвристикой стоп-символа:
. Приведём алгоритм с приведённой эвристикой, называемой эвристикой стоп-символа:
table = create map
for i = 0 to P.length - 1 do
table[P[i]] = i
end for
for i = 0 to S.length do #NEXT
for j = P.length - 1 down to 0 do
if P[j] != S[j + i] then
step = j - table[S[j + i]]
i = i + step
go to #NEXT
end if
end for
return i
end for
return -1
Эффективность поиска в таком алгоритме достигает 
Алгоритм Кнута — Морриса — Пратта
Последний из рассматриваемых алгоритмов и являющимся самым эффективным, т.к. работает за линейное время. Основой алгоритма является определение префикс-функции. Префикс-функция  вычисляет длину наибольшего собственного (т.е. не равного самой подстроке) префикса совпадающего с суффиксом этой подстроки. Так, для строки
вычисляет длину наибольшего собственного (т.е. не равного самой подстроке) префикса совпадающего с суффиксом этой подстроки. Так, для строки котокот префикс «кот» совпадает с суффиксом и длина его равна 3.
Наивный алгоритм подсчёта префикс-функции для произвольной строки при всех значениях  (при этом
(при этом  ) занимает квадратичное время. Для более эффективного расчёта нужно отметить, что при добавлении нового символа подстроки
) занимает квадратичное время. Для более эффективного расчёта нужно отметить, что при добавлении нового символа подстроки  при
при  у нас может получится, что
у нас может получится, что ![S[i + 1] = S[k + 1]](https://markoutte.me/wp-content/ql-cache/quicklatex.com-da3605f389862dca88c1262e5512b745_l3.svg "Rendered by QuickLaTeX.com") , т.е. увеличенный суффикс совпадает с префиксом. Это означает, что в этом случае можно сказать, что
, т.е. увеличенный суффикс совпадает с префиксом. Это означает, что в этом случае можно сказать, что  . Если они не совпадают, то мы пробуем посмотреть на меньший суффикс. Поскольку
. Если они не совпадают, то мы пробуем посмотреть на меньший суффикс. Поскольку  к этому моменту уже подсчитано и мы знаем для него префикс, то полагаем, что
к этому моменту уже подсчитано и мы знаем для него префикс, то полагаем, что  и снова проверяем условие . Если в какой-то момент
и снова проверяем условие . Если в какой-то момент  , то полагаем, что
, то полагаем, что  .
.
Таким образом задача сводится к заполнению таблицы вида:
Для решения задачи поиска подстроки достаточно склеить образец и строку с помощью символа, который не входит в алфавит, напр.: P + ‘#’ + S, после чего начать считать префикс-функцию. Как только значение функции будет равно длине образца, то это будет означать, что подстрока найдена:
C = P + '#' + S
PI = create array with C.length
for i = 1 to C.length do
j = PI[i - 1]
while j > 0 and C[j] != C[i] do
j = PI[j - 1]
end while
if C[j] == C[i] then
PI[i] = j + 1
end if
if PI[i] == P.length then return TRUE
end for
return FALSE
