Кванти́ль в математической статистике — значение, которое заданная случайная величина не превышает с фиксированной вероятностью. Если вероятность задана в процентах, то квантиль называется процентилем или перцентилем (см. ниже).
Например, фраза «90-й процентиль массы тела у новорожденных мальчиков составляет 4 кг»[1] означает, что 90 % мальчиков рождаются с весом, меньшим либо равным 4 кг, а 10 % мальчиков рождаются с весом, большим либо равным 4 кг.
Определение[править | править код]
Рассмотрим вероятностное пространство  и
и  — вероятностная мера, задающая распределение некоторой случайной величины
— вероятностная мера, задающая распределение некоторой случайной величины  . Пусть фиксировано
. Пусть фиксировано  . Тогда
. Тогда  -квантилем (или квантилем уровня ) распределения называется число
-квантилем (или квантилем уровня ) распределения называется число  , такое что
, такое что
 ,
,


В некоторых источниках (например, в англоязычной литературе)  -м
-м  -квантилем называется квантиль уровня
-квантилем называется квантиль уровня  , то есть
, то есть  -квантиль в предыдущих обозначениях.
-квантиль в предыдущих обозначениях.
Замечания[править | править код]
- Если распределение непрерывно, то -квантиль однозначно задаётся уравнением

где  — функция распределения .
— функция распределения .
- Очевидно, для непрерывных распределений справедливо следующее широко использующееся при построении доверительных интервалов равенство:

- Для эмпирического распределения -квантиль можно задать следующим способом:
- составляем вариационный ряд значений (выборка имеет объём ), а также считаем, что (это необходимо при вычислении 100 % квантили по приводимым ниже формулам);
- находим величину ;
- сравниваем и :






-
- a) если , то полагаем ;
- б) если , то полагаем ;
- в) если , то полагаем .
- a) если





Заданный таким образом -квантиль удовлетворяет приведенному выше определению.
В некоторых случаях (при большом объёме выборки и эмпирическом распределении, близком к непрерывному) вместо равенства  можно использовать приближённое сравнение
можно использовать приближённое сравнение  (это позволит, например, квантиль уровня 1/3 представлять как 0,33…333 при компьютерной обработке данных).
(это позволит, например, квантиль уровня 1/3 представлять как 0,33…333 при компьютерной обработке данных).
Медиана и квартили[править | править код]
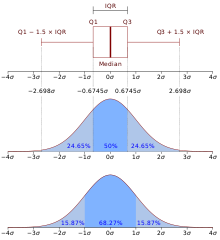
Квантили нормального распределения
- 0,25-квантиль называется первым (или нижним) кварти́лем (от лат. quarta — четверть);
- 0,5-квантиль называется медианой (от лат. mediāna — середина) или вторым кварти́лем;
- 0,75-квантиль называется третьим (или верхним) кварти́лем.
Интеркварти́льным размахом (англ. Interquartile range) называется разность между третьим и первым квартилями, то есть  . Интерквартильный размах является характеристикой разброса распределения величины и является робастным аналогом дисперсии. Вместе, медиана и интерквартильный размах могут быть использованы вместо математического ожидания и дисперсии в случае распределений с большими выбросами, либо при невозможности вычисления последних.
. Интерквартильный размах является характеристикой разброса распределения величины и является робастным аналогом дисперсии. Вместе, медиана и интерквартильный размах могут быть использованы вместо математического ожидания и дисперсии в случае распределений с большими выбросами, либо при невозможности вычисления последних.
Дециль[править | править код]
Деци́ль характеризует распределение величин совокупности, при котором девять значений дециля делят её на десять равных частей. Любая из этих десяти частей составляет 1/10 всей совокупности. Так, первый дециль отделяет 10 % наименьших величин, лежащих ниже дециля, от 90 % наибольших величин, лежащих выше дециля.
Так же, как в случае моды и медианы, у интервального вариационного ряда распределения каждый дециль (и квартиль) принадлежит определённому интервалу и имеет вполне определённое значение[2].
Процентиль[править | править код]
 -м проценти́лем называют квантиль уровня
-м проценти́лем называют квантиль уровня  . Соответственно, медиана является 50-м процентилем, а первый и третий квартиль — 25-м и 75-м процентилями соответственно.
. Соответственно, медиана является 50-м процентилем, а первый и третий квартиль — 25-м и 75-м процентилями соответственно.
В целом, понятия квантиль и процентиль взаимозаменяемы, так же, как и шкалы исчисления вероятностей — абсолютная и процентная.
Процентили также называются перцентилями или центилями.
Квантили стандартного нормального распределения[править | править код]
| Вероятность (уровень квантили), % | 99,99 | 99,90 | 99,00 | 97,72 | 97,50 | 95,00 | 90,00 | 84,13 | 50,00 |
| Квантиль (округлённый до тысячных) | 3,719 | 3,090 | 2,326 | 1,999 | 1,960 | 1,645 | 1,282 | 1,000 | 0,500 |
См. также[править | править код]
- Квантили нормального распределения
- Квантили распределения Стьюдента
- Квантили распределения хи-квадрат
- Нормальное распределение
- Доверительный интервал
- Наукометрия
Примечания[править | править код]
- ↑ Руководство участкового педиатра. — ГЭОТАР-Медиа, 2008. — С. 44. — 354 с.
- ↑ Шмойлова Р. А., Минашкин В. Г., Садовникова Н. А. Практикум по теории статистики. — 3-е изд. — М.: Финансы и статистика, 2011. — С. 130—131. — 416 с. — ISBN 9785279032969..
Ссылки[править | править код]
Материал из MachineLearning.
Перейти к: навигация, поиск
Содержание
- 1 Определение
- 2 Часто используемые квантили специальных видов
- 3 Терминология, принятая в математической статистике
- 4 Применение квантилей в задачах проверки статистических гипотез
- 5 Применение квантилей в задачах оценивания параметров
- 6 Выборочные квантили; статистическая оценка квантилей
- 7 Литература
- 8 Ссылки
–кванти́ль (или квантиль порядка ) — числовая характеристика закона распределения случайной величины; такое число, что данная случайная величина попадает левее его с вероятностью, не превосходящей .
Определение
–кванти́ль
случайной величины с функцией распределения
— это
любое число удовлетворяющее двум условиям:
-
- 1)
- 2)
- 1)
Заметим, что данные условия эквивалентны следующим:
и
Если — непрерывная строго монотонная функция, то
существует единственный квантиль
любого порядка который
однозначно определяется из уравнения
и, следовательно,
выражается через функцию, обратную к функции распределения:
Кроме указанной ситуации, когда уравнение имеет единственное решение (которое и дает соответствующий квантиль), возможны также две других:
- если указанное уравнение не имеет решений, то это означает, что существует единственная точка в которой функция распределения имеет разрыв, которая удовлетворяет данному определению и является квантилем порядка . Для этой точки выполнены соотношения: и (первое неравенство строгое, а второе может быть как строгим, так и обращаться в равенство).
- если уравнение имеет более одного решения, то все его решения образуют интервал, на котором функция распределения постоянна. В качестве квантиля порядка может быть взята любая точка этого интервала. Содержательные выводы, в которых участвует квантиль, от этого существенно не изменятся, поскольку вероятность попадания случайной величины в данный интервал равна нулю.
Часто используемые квантили специальных видов
Проценти́ль
Дециль
Квинтиль
Квартиль
Медиана
Терминология, принятая в математической статистике
В задачах математической статистики часто возникает необходимость отделить сверху, снизу или с обеих сторон области, вероятности попадания в которые малы. В связи с этим часто используется следующая терминология.
Нижний (односторонний) квантиль уровня — то же, что и обычный квантиль порядка :
.
Верхний (односторонний) квантиль уровня — обычный квантиль порядка :
.
Двусторонние квантили уровня — пара (нижний+верхний) односторонних квантилей уровня . Двусторонние квантили задают интервал, в который рассматриваемая случайная величина попадает с заданной вероятностью:
.
Применение квантилей в задачах проверки статистических гипотез
Часто применяемая схема решения в задаче проверки статистических гипотез имеет следующий вид. Стараются найти такую статистику , чтобы:
Если статистика с указанными свойствами существует, тогда на ее основе можно получить статистический критерий для данной задачи. Для этого необходимо с помощью соответствующих квантилей выделить область (нижнюю, верхнюю или двустороннюю), попадание в которую было бы маловероятно при нулевой гипотезе (и эта вероятность известна), однако может быть объяснено тем, что на самом деле имеет место альтернатива. Многочисленные критерии принятия решения строятся именно по такой схеме.
Если в дополнение к указанным условиям, распределение будет известно также и при альтернативе , то это еще лучше, тогда можно вычислить также вероятность ошибки II рода. Но такие ситуации в реальных задачах встречаются крайне редко, поскольку альтернатива обычно гораздо сложнее нулевой гипотезы.
Применение квантилей в задачах оценивания параметров
Рассмотрим задачу построения доверительного интервала для неизвестного числового параметра . При этом часто применяется следующая схема. Стараются найти такую случайную величину , которая зависит и от выборки, и от неизвестного параметра (и в силу этого не является статистикой), чтобы ее закон распределения был бы известен и не зависел бы от . Тогда можно для заданного уровня найти двусторонние квантили и записать следующее соотношение:
.
Далее можно попробовать разрешить неравенство, стоящее под вероятностью, относительно неизвестного параметра, и переписать его в виде:
,
чтобы величины и зависели бы только от выборки, т.е. являлись бы статистиками. Если это удается сделать, то мы построили доверительный интервал для неизвестного параметра.
Выборочные квантили; статистическая оценка квантилей
Пусть задана простая выборка , и её вариационный ряд есть
Выборочный -кванти́ль или выборочный квантиль порядка
есть статистика, равная элементу вариационного ряда с номером
(целая часть от ).
Пусть — плотность, — функция распределения случайной величины .
Тогда выборочные квантили порядка
имеют при
асимптотически k-мерное нормальное распределение с математическими ожиданиями, равными (не выборочным) квантилям
и ковариациями
Таким образом, выборочные квантили являются несмещёнными оценками обычных (не выборочных) квантилей.
Асимптотическая нормальность позволяет также записать -процентный доверительный интервал для квантиля :
Литература
- Вероятность и математическая статистика: Энциклопедия / Под ред. Ю.В.Прохорова. — М.: Большая российская энциклопедия, 2003. — 912 с.
Ссылки
- Quantile, Percentile, Decile — статьи в англоязычной Википедии.
- Квантиль — статья в русской Википедии.
Рассмотрим вычисление квантилей для некоторых функций распределений, представленных в
MS
EXCEL
.
Понятие
Квантиля
основано на определении
Функции распределения
. Поэтому, перед изучением
Квантилей
рекомендуем освежить в памяти понятия из статьи
Функция распределения вероятности
.
Содержание статьи:
- Определение
- Квантили специальных видов
- Квантили стандартного нормального распределения
- Квантили распределения Стьюдента
- Квантили распределения ХИ-квадрат
- Квантили F-распределения
- Квантили распределения Вейбулла
- Квантили экспоненциального распределения
Сначала дадим формальное определение
квантиля,
затем приведем примеры их вычисления в MS EXCEL.
Определение
Пусть случайная величина
X
, имеет
функцию распределения
F
(
x
).
α-квантилем
(
альфа-
квантиль,
x
a
,
квантиль
порядка
α, нижний
α-
квантиль
) называют решение уравнения
x
a
=F
-1
(α), где
α
– вероятность, что случайная величина х примет значение меньшее или равное x
a
, т.е. Р(х<= x
a
)=
α.
Из определения ясно, что нахождение
квантиля
распределения является обратной операцией нахождения вероятности. Т.е. если при вычислении
функции распределения
мы находим вероятность
α,
зная x
a
, то при нахождении
квантиля
мы, наоборот, ищем
x
a
зная
α
.
Чтобы пояснить определение, используем график функции
стандартного нормального распределения
(см.
файл примера Лист Определение
):
Примечание
: О построении графиков в MS EXCEL можно прочитать статью
Основные типы диаграмм в MS EXCEL
.
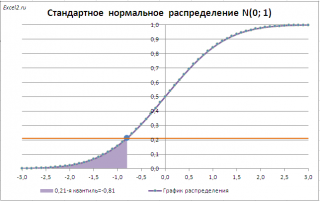
Например, с помощью графика вычислим 0,21-ю
квантиль
, т.е. такое значение случайной величины, что Р(X<=x
0,21
)=0,21.
Для этого найдем точку пересечения горизонтальной линии на уровне вероятности равной 0,21 с
функцией распределения
. Абсцисса этой точки равна -0,81. Соответственно, 0,21-я
квантиль
равна -0,81. Другими словами, вероятность того, что случайная величина, распределенная
стандартному нормальному закону,
примет значение
меньше
-0,81, равна 0,21 (21%).
Примечание
: При вычислении
квантилей
в MS EXCEL используются
обратные функции распределения
:
НОРМ.СТ.ОБР()
,
ЛОГНОРМ.ОБР()
,
ХИ2.ОБР(),
ГАММА.ОБР()
и т.д. Подробнее о распределениях, представленных в MS EXCEL, можно прочитать в статье
Распределения случайной величины в MS EXCEL
.
Точное значение
квантиля
в нашем случае можно найти с помощью формулы
=НОРМ.СТ.ОБР(0,21)
СОВЕТ
: Процедура вычисления
квантилей
имеет много общего с вычислением
процентилей
выборки
(см. статью
Процентили в MS EXCEL
).
Квантили специальных видов
Часто используются
Квантили
специальных видов:
-
процентили
x
p/100
, p=1, 2, 3, …, 99 -
квартили
x
p/4
, p=1, 2, 3 -
медиана
x
1/2
В качестве примера вычислим
медиану (0,5-квантиль)
логнормального распределения
LnN(0;1) (см.
файл примера лист Медиана
).
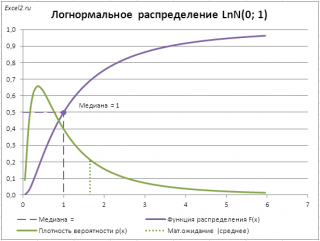
Это можно сделать с помощью формулы
=ЛОГНОРМ.ОБР(0,5; 0; 1)
Квантили стандартного нормального распределения
Необходимость в вычислении квантилей
стандартного нормального распределения
возникает при
проверке статистических гипотез
и при
построении доверительных интервалов.
Примечание
: Про
проверку статистических гипотез
см. статью
Проверка статистических гипотез в MS EXCEL
. Про
построение доверительных интервалов
см. статью
Доверительные интервалы в MS EXCEL
.
В данных задачах часто используется специальная терминология:
Нижний квантиль уровня
альфа
(
α
percentage point)
;
Верхний квантиль уровня альфа (upper
α
percentage point)
;
Двусторонние квантили уровня
альфа
.
Нижний квантиль уровня альфа
– это обычный
α-квантиль.
Чтобы пояснить название «
нижний» квантиль
, построим график
плотности вероятности
и
функцию вероятности
стандартного нормального
распределения
(см.
файл примера лист Квантили
).
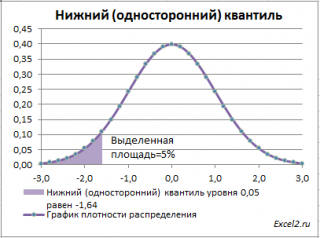
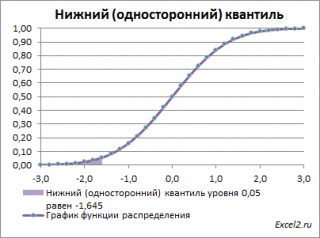
Выделенная площадь на рисунке соответствует вероятности, что случайная величина примет значение меньше
α-квантиля
. Из определения
квантиля
эта вероятность равна
α
. Из графика
функции распределения
становится понятно, откуда происходит название ”
нижний квантиль” –
выделенная область расположена в нижней части графика.
Для
α=0,05,
нижний 0,05-квантиль
стандартного нормального распределения
равен -1,645. Вычисления в MS EXCEL можно сделать по формуле:
=НОРМ.СТ.ОБР(0,05)
Однако, при
проверке гипотез
и построении
доверительных интервалов
чаще используется “верхний”
α-квантиль.
Покажем почему.
Верхним
α
–
квантилем
называют такое значение x
α
, для которого вероятность, того что случайная величина X примет значение
больше или равное
x
α
равна
альфа:
P(X>= x
α
)=
α
. Из определения понятно, что
верхний альфа
–
квантиль
любого распределения равен
нижнему (1-
α)
–
квантилю.
А для распределений, у которых
функция плотности распределения
является четной функцией,
верхний
α
–
квантиль
равен
нижнему
α
–
квантилю
со знаком минус
.
Это следует из свойства четной функции f(-x)=f(x), в силу симметричности ее относительно оси ординат.
Действительно, для
α=0,05,
верхний 0,05-квантиль
стандартного нормального распределения
равен 1,645. Т.к.
функция плотности вероятности
стандартного нормального
распределения
является четной функцией, то вычисления в MS EXCEL
верхнего квантиля
можно сделать по двум формулам:
=НОРМ.СТ.ОБР(1-0,05)
=-НОРМ.СТ.ОБР(0,05)
Почему применяют понятие
верхний
α
–
квантиль?
Только из соображения удобства, т.к. он при
α<0,5
всегда положительный (в случае
стандартного нормального
распределения
). А при проверке гипотез
α
равно
уровню значимости
, который обычно берут равным 0,05, 0,1 или 0,01. В противном случае, в процедуре
проверки гипотез
пришлось бы записывать условие отклонения
нулевой гипотезы
μ>μ
0
как Z
0
>Z
1-
α
, подразумевая, что Z
1-
α
–
обычный
квантиль
порядка
1-
α
(или как Z
0
>-Z
α
). C верхнем квантилем эта запись выглядит проще Z
0
>Z
α
.
Примечание
: Z
0
– значение
тестовой статистики
, вычисленное на основе
выборки
. Подробнее см. статью
Проверка статистических гипотез в MS EXCEL о равенстве среднего значения распределения (дисперсия известна)
.
Чтобы пояснить название «
верхний»
квантиль
, построим график
плотности вероятности
и
функцию вероятности
стандартного нормального
распределения
для
α=0,05.
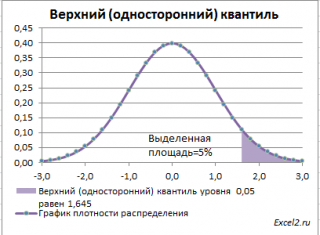
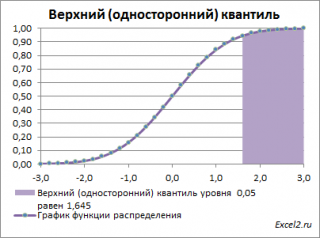
Выделенная площадь на рисунке соответствует вероятности, что случайная величина примет значение больше
верхнего 0,05-квантиля
, т.е.
больше
значения 1,645. Эта вероятность равна 0,05.
На графике
плотности вероятности
площадь выделенной области равна 0,05 (5%) от общей площади под графиком (равна 1). Из графика
функции распределения
становится понятно, откуда происходит название “верхний”
квантиль
–
выделенная область расположена в верхней части графика. Если Z
0
больше
верхнего квантиля
, т.е. попадает в выделенную область, то
нулевая гипотеза
отклоняется.
Также при
проверке двухсторонних гипотез
и построении соответствующих
доверительных интервалов
иногда используется понятие “двусторонний”
α-квантиль.
В этом случае условие отклонения
нулевой гипотезы
звучит как |Z
0
|>Z
α
/2
, где Z
α
/2
–
верхний
α/2-квантиль
. Чтобы не писать
верхний
α/2-квантиль
, для удобства используют “двусторонний”
α-квантиль.
Почему двусторонний? Как и в предыдущих случаях, построим график
плотности вероятности стандартного нормального распределения
и график
функции распределения
.
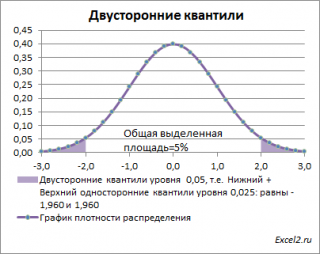
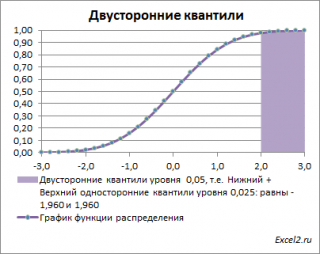
Невыделенная площадь на рисунке соответствует вероятности, что случайная величина примет значение
между
нижним квантилем уровня α
/2 и
верхним квантилем
уровня α
/2, т.е. будет между значениями -1,960 и 1,960 при α=0,05. Эта вероятность равна в нашем случае 1-(0,05/2+0,05/2)=0,95. Если Z
0
попадает в одну из выделенных областей, то
нулевая гипотеза
отклоняется.
Вычислить
двусторонний
0,05
–
квантиль
это можно с помощью формул MS EXCEL:
=НОРМ.СТ.ОБР(1-0,05/2)
или
=-НОРМ.СТ.ОБР(0,05/2)
Другими словами,
двусторонние α-квантили
задают интервал, в который рассматриваемая случайная величина попадает с заданной вероятностью α.
Квантили распределения Стьюдента
Аналогичным образом
квантили
вычисляются и для
распределения Стьюдента
. Например, вычислять
верхний
α/2-
квантиль
распределения Стьюдента с
n
-1 степенью свободы
требуется, если проводится
проверка двухсторонней гипотезы
о
среднем значении
распределения при
неизвестной
дисперсии
(
см. эту статью
).
Для
верхних квантилей
распределения Стьюдента
часто используется запись t
α/2,n-1
. Если такая запись встретилась в статье про
проверку гипотез
или про построение
доверительного интервала
, то это именно
верхний квантиль
.
Примечание
:
Функция плотности вероятности распределения Стьюдента
, как и
стандартного нормального распределения
, является четной функцией.
Чтобы вычислить в MS EXCEL
верхний
0,05/2
–
квантиль
для t-распределения с 10 степенями свободы (или тоже самое
двусторонний
0,05-квантиль
), необходимо записать формулу
=СТЬЮДЕНТ.ОБР.2Х(0,05; 10)
или
=СТЬЮДРАСПОБР(0,05; 10)
или
=СТЬЮДЕНТ.ОБР(1-0,05/2; 10)
или
=-СТЬЮДЕНТ.ОБР(0,05/2; 10)
.2X означает 2 хвоста, т.е.
двусторонний квантиль
.
Квантили распределения ХИ-квадрат
Вычислять
квантили
распределения ХИ-квадрат
с
n
-1 степенью свободы
требуется, если проводится
проверка гипотезы
о
дисперсии нормального распределения
(см. статью
Проверка статистических гипотез в MS EXCEL о дисперсии нормального распределения
).
При
проверке таких гипотез
также используются
верхние квантили.
Например, при
двухсторонней гипотезе
требуется вычислить 2
верхних
квантиля
распределения
ХИ
2
: χ
2
α/2,n-1
и
χ
2
1-
α/2,n-1
. Почему требуется вычислить два
квантиля
, не один, как при
проверке гипотез о среднем
, где используется
стандартное нормальное распределение
или
t-распределение
?
Дело в том, что в отличие от
стандартного нормального распределения
и
распределения Стьюдента
, плотность распределения
ХИ
2
не является четной (симметричной относительно оси х). У него все
квантили
больше 0, поэтому
верхний альфа-квантиль
не равен
нижнему (1-альфа)-квантилю
или по-другому:
верхний альфа-квантиль
не равен
нижнему альфа-квантилю
со знаком минус.
Чтобы вычислить
верхний
0,05/2
–
квантиль
для
ХИ
2
-распределения
с
числом степеней свободы
10, т.е.
χ
2
0,05/2,n-1
, необходимо в MS EXCEL записать формулу
=ХИ2.ОБР.ПХ(0,05/2; 10)
или
=ХИ2.ОБР(1-0,05/2; 10)
Результат равен 20,48. .ПХ означает правый хвост распределения, т.е. тот который расположен вверху на графике
функции распределения
.
Чтобы вычислить
верхний
(1-0,05/2)-
квантиль
при том же
числе степеней свободы
, т.е.
χ
2
1-0,05/2,n-1
и необходимо записать формулу
=ХИ2.ОБР.ПХ(1-0,05/2; 10)
или
=ХИ2.ОБР(0,05/2; 10)
Результат равен 3,25.
Квантили F-распределения
Вычислять
квантили
распределения Фишера
с
n
1
-1 и
n
2
-1 степенями свободы
требуется, если проводится
проверка гипотезы
о равенстве
дисперсий двух нормальных распределений
(см. статью
Двухвыборочный тест для дисперсии: F-тест в MS EXCEL
).
При
проверке таких гипотез
используются, как правило,
верхние квантили.
Например, при
двухсторонней гипотезе
требуется вычислить 2
верхних
квантиля
F
-распределения:
F
α/2,n1-1,
n
2
-1
и
F
1-α/2,n1-1,
n
2
-1
. Почему требуется вычислить два
квантиля
, не один, как при
проверке гипотез о среднем
? Причина та же, что и для распределения ХИ
2
– плотность
F-распределения
не является четной
.
Эти
квантили
нельзя выразить один через другой как для
стандартного нормального распределения
.
Верхний альфа-квантиль
F
-распределения
не равен
нижнему альфа-квантилю
со знаком минус.
Чтобы вычислить
верхний
0,05/2-квантиль
для
F
-распределения
с
числом степеней свободы
10 и 12, необходимо записать формулу
=F.ОБР.ПХ(0,05/2;10;12) =FРАСПОБР(0,05/2;10;12) =F.ОБР(1-0,05/2;10;12)
Результат равен 3,37. .ПХ означает правый хвост распределения, т.е. тот который расположен вверху на графике
функции распределения
.
Квантили распределения Вейбулла
Иногда
обратная функция распределения
может быть представлена в явном виде с помощью элементарных функций, например как для
распределения Вейбулла
. Напомним, что функция этого распределения задается следующей формулой:
![]()
После логарифмирования обеих частей выражения, выразим x через соответствующее ему значение F(x) равное P:
![]()
Примечание
: Вместо обозначения
α-квантиль
может использоваться
p
–
квантиль.
Суть от этого не меняется.
Это и есть обратная функция, которая позволяет вычислить
P
–
квантиль
(
p
–
quantile
). Для его вычисления в формуле нужно подставить известное значение вероятности P и вычислить значение х
p
(вероятность того, что случайная величина Х примет значение меньше или равное х
p
равна P).
Квантили экспоненциального распределения
Задача
:
Случайная величина имеет
экспоненциальное распределение
:
![]()
Требуется выразить
p
-квантиль
x
p
через параметр распределения λ и заданную вероятность
p
.
Примечание
: Вместо обозначения
α-квантиль
может использоваться
p-квантиль
. Суть от этого не меняется.
Решение
: Вспоминаем, что
p
-квантиль
– это такое значение x
p
случайной величины X, для которого P(X<=x
p
)=
p
. Т.е. вероятность, что случайная величина X примет значение меньше или равное x
p
равна
p
. Запишем это утверждение с помощью формулы:
![]()
По сути, мы записали
функцию вероятности экспоненциального распределения
: F(x
p
)=
p
.
Из определения
квантиля
следует, что для его нахождения нам потребуется
обратная функция распределения
.
Проинтегрировав вышеуказанное выражение, получим:
![]()
Используя это уравнение, выразим x
p
через λ и вероятность
p
.
![]()
Конечно, явно выразить
обратную функцию распределения
можно не для всех
функций распределений
.
В примерах в данной статье данные генерятся при каждой загрузке страницы. Если Вы хотите посмотреть пример с другими значениями –
обновите страницу .
Параметры дискретного закона распределения
В статье описано как найти среднее значение и стандартное отклонение. Вы узнаете, что такое квантиль и каких он бывает видов, а также,
как построить доверительный интервал.
Математическое описание
Смотря на закон распределения, мы можем понять, какова вероятность того или иного события,
можем сказать, какова вероятность, что произойдёт группа событий, а в этой статье мы рассмотрим, как наши выводы “на глаз” перевести
в математически обоснованное утверждение.
Крайне важное определение: математическое ожидание – это площадь под графиком распределения. Если мы говорим о дискретном распределении –
это сумма событий умноженных на соответсвующие вероятности, также известно как момент:
(2) E(X) = Σ(pi•Xi) E – от английского слова Expected (ожидание)
Для математического ожидания справедливы равенства:(3) E(X + Y) = E(X) + E(Y)
(4) E(X•Y) = E(X) • E(Y)
Момент степени k:
(5) νk = E(Xk)
Центральный момент степени k:
(6) μk = E[X – E(X)]k
Среднее значение
Среднее значение (μ) закона распределения – это математическое ожидание случайной величины
(случайная величина – это событие), например, сколько в среднем посетителей заходит в магазин в час:
| Кол-во посетителей | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| Количество наблюдений | 110 | 47 | 106 | 11 | 47 | 21 | 58 |
| Таблица 1. Количество посетителей в час |
График 1. Количество посетителей в час
Чтобы найти среднее значение всех результатов необходимо сложить всё вместе и разделить на количество результатов:
μ = (110 • 0 + 47 • 1 + 106 • 2 + 11 • 3 + 47 • 4 + 21 • 5 + 58 • 6) / 400 = 933/400 = 2.33
То же самое мы можем проделать используя формулу 2:
μ = M(X) = Σ(Xi•pi) = 0 • 0.28 + 1 • 0.12 + 2 • 0.27 + 3 • 0.03 + 4 • 0.12 + 5 • 0.05 + 6 • 0.15 = 2.33 Момент первой степени, формула (5)
Собственно, формула 2 представляет собой среднее арифметическое всех значений
Итог: в среднем, 2.33 посетителя в час
| Количество посетителей | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| Вероятность (%) | 27.5 | 11.8 | 26.5 | 2.8 | 11.8 | 5.3 | 14.5 |
| Таблица 2. Закон распределения количества посетителей |
Отклонение от среднего
Посмотрите на это распределение, можно предположить, что в среднем случайная величина равна 100±5, поскольку
кажется, что таких значений несравнимо больше чем тех, что меньше 95 или больше 105:
График 2. График функции вероятности. Распределение ≈ 100±5
Среднее значение по формуле (2): μ = 99.95, но как посчитать, насколько далеко все значения находятся от среднего? Вам должна быть
знакома запись 100±5. Что бы получить это значение ±, нам необходимо определить диапазон значений вокруг среднего. И мы могли бы
использовать в качестве меры удалённости “разность” между средним и случайными величинами:
(7) xi – μ
но сумма таких расстояний, а следовательно и любое производное от этого числа, будет равно нулю, поэтому в качестве меры выбрали квадрат разниц
между величинами и средним значением:
(8) (xi – μ)2
Соответственно, среднее значение удалённости – это математическое ожидание квадратов удалённости:
(9) σ2 = E[(X – E(X))2]
Поскольку вероятности любой удалённости равносильны – вероятность каждого из них – 1/n, откуда:
(10) σ2 = E[(X – E(X))2] = ∑[(Xi – μ)2]/n
Она же формула центрального момента (6) второй степени
σ возведена в квадрат, поскольку вместо расстояний мы взяли квадрат расстояний. σ2 называется дисперсией. Корень из дисперсии
называется средним квадратическим отклонением, или среднеквадратическим отклоненим, и его используют в качестве меры разброса:
(11) μ±σ
(12) σ = √(σ2) = √[∑[(Xi – μ)2]/n]
Возвращаясь к примеру, посчитаем среднеквадратическое отклонение для графика 2:
σ = √(∑(x-μ)2/n) = √{[(90 – 99.95)2 + (91 – 99.95)2 + (92 – 99.95)2 + (93 – 99.95)2 + (94 – 99.95)2 + (95 – 99.95)2 + (96 – 99.95)2 + (97 – 99.95)2 + (98 – 99.95)2 + (99 – 99.95)2 + (100 – 99.95)2 + (101 – 99.95)2 + (102 – 99.95)2 + (103 – 99.95)2 + (104 – 99.95)2 + (105 – 99.95)2 + (106 – 99.95)2 + (107 – 99.95)2 + (108 – 99.95)2 + (109 – 99.95)2 + (110 – 99.95)2]/21} = 6.06
Итак, для графика 2 мы получили:
X = 99.95±6.06 ≈ 100±6 , что немного отличается от полученного “на глаз”
Квантиль
График 3. Функция распределения. Медиана
График 4. Функция распределения. 4-квантиль или квартиль
График 5. Функция распределения. 0.34-квантиль
Для анализа функции распределения ввели понятие квантиль. Квантиль – это случайная величина при заданном уровне вероятности, т.е.:
квантиль для уровня вероятности 50% – это случайная величина на графике плотности вероятности, которая имеет вероятность 50%.
На примере с графиком 3, квантиль уровня 0.5 = 99 (ближайшее значение, поскольку распределение дискретно и события со значением 99.3 просто не существует)
- 2-квантиль – медиана
- 4-квантиль – квартиль
- 10-квантиль – дециль
- 100-квантиль – перцентиль
То есть, если мы говорим о дециле (10-квантиле), то это означает, что мы разбили график на 10 частей, что соответствует девяти линяям,
и для каждого дециля нашли значение случайной величины.
Также, используется обозначение x-квантиль, где х – дробное число, например, 0.34-квантиль, такая запись означает значение случайной величины при
p = 0.34.
Для дискретного распределения квантиль необходимо выбирать следующим образом: квантиль гарантирует вероятность, поэтому, если рассчитанный
квантиль не совпадает с одним и значений, необходимо выбирать меньшее значение.
Построение интервалов
Квантили используют для построения доверительных интервалов, которые необходимы для исследования статистики не одного конкретного события (например,
интерес – случайное число = 98), а для группы событий (например, интерес – случайное число между 96 и 99). Доверительный интервал бывает двух видов:
односторонний и двусторонний. Параметр доверительного интервала – уровень доверия. Уровень доверия означает процент событий, которые можно считать успешными.
Двусторонний доверительный интервал
Двусторонний доверительный интервал строится следующим образом: мы задаёмся уровнем значимости, например, 10%, и выделяем область на графике так, что 90% всех
событий попадут в эту область. Поскольку интервал двусторонний, то мы отсекаем по 5% с каждой стороны, т.е. мы ищем 5й перцентиль, 95й перцентиль и значения
случайной величины между ними будут являться доверительной областью, значения за пределами доверительной области называются “критическая область”
График 6. Плотность вероятности
График 7. Функция распределения с 5 и 95 перцентилями. Цветом выделен доверительный интервал с уровнем доверия 0.9
График 8. Функция вероятности и двусторонний доверительный интервал с уровнем доверия 90%
Доверительный интервал
Левосторонний и правосторонний доверительные интервалы строятся аналогично двустороннему: для левостороннего интервала мы находим перцентиль уровня
[‘один’ минус ‘уровень значимости’]. Таким образом, для построения доверительного левостороннего интервала уровня значимости 4% нам необходимо найти четвёртый перцентиль
и всё, что справа – доверительный интервал, всё что слева – критическая область.
График 9. Левосторонний доверительный интервал с уровнем значимости 4%. Заливкой выделен доверительный интервал
График 10. Правосторонний доверительный интервал с уровнем значимости 4%. Заливкой выделен доверительный интервал
Итого
Среднее значение – математическое ожидание случайной величины, находится по формуле:
μ = E(X) = Σ(pi•Xi)
Среднеквадратичное отклонение – математическое ожидание удалённости значений от среднего, находится по формуле:
σ = √(σ2) = √[∑[(Xi – μ)2]/n]
n-квантиль – разделение функции распределения на n равных отрезков, основные типы квантилей:
- 2-квантиль – медиана
- 4-квантиль – квартили
- 10-квантиль – децили
- 100-квантиль – перцентили
Доверительный интервал уровня α – участок функции вероятности, содержащий α всех возможных значений. Двусторонний доверительный
интервал строится отсечением (1-α)/2 справа и слева. Левосторонний и правосторонний доверительные интервалы строятся отсечением
области (1-α) слева и справа соответственно.
Построить ряд распределения
Предположим, мы имеем 100 значений и все разные, например: масса тела Сомалийских пиратов.
Такой набор данных обрабатывать неудобно, мы даже не можем представить их на обычном графике.
Поэтому нам необходимо категоризировать имеющиеся данные и для этого мы делаем следующее:
Запишем наши данные в таблицу:
| 79 | 112 | 78 | 97 | 89 | 65 | 107 | 66 | 63 | 93 |
| 61 | 94 | 79 | 123 | 118 | 102 | 117 | 114 | 113 | 110 |
| 82 | 101 | 95 | 82 | 101 | 83 | 81 | 73 | 56 | 82 |
| 67 | 114 | 68 | 70 | 108 | 86 | 76 | 104 | 70 | 94 |
| 68 | 95 | 69 | 79 | 98 | 112 | 61 | 73 | 77 | 58 |
| 79 | 67 | 81 | 103 | 101 | 72 | 76 | 89 | 61 | 98 |
| 60 | 81 | 111 | 111 | 99 | 57 | 58 | 65 | 102 | 91 |
| 117 | 98 | 105 | 80 | 76 | 113 | 115 | 65 | 62 | 101 |
| 85 | 93 | 59 | 76 | 66 | 83 | 90 | 76 | 74 | 80 |
| 109 | 68 | 122 | 113 | 80 | 68 | 54 | 95 | 83 | 73 |
| Таблица 3. Вес сомалийских пиратов |
Данные разобьём на группы, для начала предлагаю разбить на восемь интервалов:
Узнаём максимальное и минимальное значения, вычитаем их друг из друга и делим на количество
интервалов – получили отрезки:
Максимальное значение: 123
Минимальное значение: 54
Разница: 123 – 54 = 69
Длина интервала: 69 / 8 = 8.63
Теперь посчитаем количество пиратов (весов, я имею ввиду) в каждом интервале:
| # | Интервал | Количество элементов |
|---|---|---|
| 1. | 54 – 62.63 | 11 |
| 2. | 62.63 – 71.26 | 15 |
| 3. | 71.26 – 79.89 | 16 |
| 4. | 79.89 – 88.52 | 14 |
| 5. | 88.52 – 97.15 | 12 |
| 6. | 97.15 – 105.78 | 13 |
| 7. | 105.78 – 114.41 | 13 |
| 8. | 114.41 – 123.04 | 6 |
| Таблица 4. Количество элементов в интервалах |
Вуа-ля, наше распределение на графике:
График 11. Ряд распределения массы тела сомалийских пиратов
Бонус
Интервалы лучше брать целыми числами, поэтому, если с выбранным количеством интервалов
размер выходит нецелым, то можно раздвинуть диапазон значений, пример:
Значение интервала равно 8.63, число не является целым, поэтому
отодвигаем верхнюю границу:
Остаток от деления: [(123 – 54) / 8] = 5
Подвинуть на: 3
Новый диапазон: [54;126]
Диапазон можно двигать как вверх, так и вниз, но лучше в обе стороны.
Совет
Принято делить распределение на 7-8 интервалов, но в каждой конкретной ситуации
Вы можете выбрать отличное количество интервалов, впрочем, как и сделать их
различной длины.
Список параметров
Итак, вот список основных параметров дискретного закона распределения:
| Название | Символ | Формула |
|---|---|---|
| Математическое ожидание (среднее) | E(X) | Σ(pi•Xi) |
| Центральный момент (среднеквадратичное отклонение) |
σx | σ = √(σ2) = √[∑[(Xi – μ)2]/n] |
| Длина интервала | R | max(x) – min(x) |
| Мода | mo | max P(x = mo) |
| 1й квантиль | – | F(x) = 0.25 |
| Медиана | me | F(x) = 0.5 |
| Дециль | – | F(x) = 0.1 |
| Таблица 5. Основные параметры дискретного закона распределения |
Шаблон гистограммы в OpenOffice Calc
Файл histogram_mock.ods содержит шаблон
построения гистограммы.
Вам понравилась статья?
/
Просмотров: 15 962
Содержание
- Доверительный интервал для оценки дисперсии в EXCEL
- Задача
- Функция распределения и плотность вероятности в EXCEL
- Генеральная совокупность и случайная величина
- Функция распределения
- Непрерывные распределения и плотность вероятности
- Вычисление плотности вероятности с использованием функций MS EXCEL
- Вычисление вероятностей с использованием функций MS EXCEL
- Обратная функция распределения (Inverse Distribution Function)
Доверительный интервал для оценки дисперсии в EXCEL
history 27 ноября 2016 г.
Построим доверительный интервал для оценки дисперсии случайной величины, распределенной по нормальному закону, в MS EXCEL .
Построение доверительного интервала для оценки среднего приведено в статье Доверительный интервал для оценки среднего (дисперсия известна) в MS EXCEL . Процедура построения доверительного интервала для оценки дисперсии имеет много общего с процедурой для оценки среднего , поэтому в этой статье она изложена менее подробно, чем в указанной статье.
Формулировка задачи. Предположим, что из генеральной совокупности имеющей нормальное распределение с неизвестным средним значением μ и неизвестной дисперсией σ 2 взята выборка размера n. Необходимо на основании этой выборки оценить дисперсию распределения и построить доверительный интервал .
Примечание : Построение доверительного интервала для оценки среднего относительно нечувствительно к отклонению генеральной совокупности от нормального закона . А вот при построении доверительного интервала для оценки дисперсии требование нормальности является строгим.
СОВЕТ : Для построения Доверительного интервала нам потребуется знание следующих понятий:
В качестве точечной оценкой дисперсии распределения, из которого взята выборка , используют Дисперсию выборки s 2 .
Также, перед процедурой проверки гипотезы , исследователь устанавливает требуемый уровень значимости – это допустимая для данной задачи ошибка первого рода , т.е. вероятность отклонить нулевую гипотезу , когда она верна ( уровень значимости обозначают буквой α (альфа) и чаще всего выбирают равным 0,1; 0,05 или 0,01)
В статье про ХИ2-распределение показано, что выборочное распределение статистики y=(n-1) s 2 /σ 2 , имеет ХИ2-распределение с n-1 степенью свободы.
Воспользуемся этим свойством и построим двухсторонний доверительный интервал для оценки дисперсии :
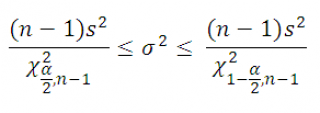 где χ 2 α/2,n-1 – верхний α/2-квантиль распределения ХИ-квадрат с n -1 степенью свободы ( такое значение случайной величины χ 2 n-1 , что P ( χ 2 n-1 >= χ 2 α/2,n-1 )=α/2) . Чтобы найти этот квантиль в MS EXCEL используйте формулу =ХИ2.ОБР.ПХ(α; n-1) . χ 2 1-α/2,n-1 – верхний 1-α/2-квантиль , который равен нижнему α/2- квантилю. Чтобы найти этот квантиль в MS EXCEL используйте формулу =ХИ2.ОБР(α; n-1) .
где χ 2 α/2,n-1 – верхний α/2-квантиль распределения ХИ-квадрат с n -1 степенью свободы ( такое значение случайной величины χ 2 n-1 , что P ( χ 2 n-1 >= χ 2 α/2,n-1 )=α/2) . Чтобы найти этот квантиль в MS EXCEL используйте формулу =ХИ2.ОБР.ПХ(α; n-1) . χ 2 1-α/2,n-1 – верхний 1-α/2-квантиль , который равен нижнему α/2- квантилю. Чтобы найти этот квантиль в MS EXCEL используйте формулу =ХИ2.ОБР(α; n-1) .
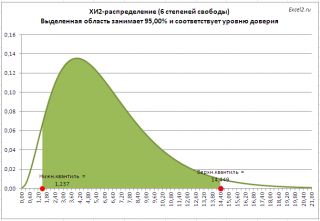
Примечание : В файле примера на листе Квантили показан расчет квантилей для распределения ХИ2 . На рисунке выделена область соответствующая уровню доверия 95%, которая ограничена верхним и нижним квантилем . Обратите внимание, что в отличие от нормального и t-распределения распределение ХИ2 несимметрично, поэтому для двустороннего доверительного интервала потребуется вычислить два квантиля , значения которых будут отличаться.
Примечание : Доверительный интервал для стандартного отклонения может быть получен путем извлечения квадратного корня из вышеуказанного выражения.
В файле примера на листе 2х сторонний создана форма для расчета и построения двухстороннего доверительного интервала .
Для построения односторонних доверительных интервалов используйте нижеследующие выражения:
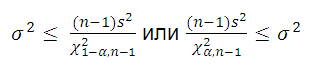
Задача
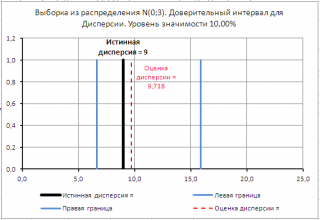
В следующей задаче найдем верхний односторонний доверительный интервал для дисперсии .
Автоматический аппарат заполняет емкости с растворителем. Предполагается, что объемы налитой жидкости в емкостях распределены по нормальному закону . Если разброс значений объемов будет слишком велик, то значительная часть емкостей будет существенно переполнена или не заполнена. Для оценки дисперсии в качестве выборки взято 20 наполненных жидкостью емкостей. На основе выборки была вычислена дисперсия выборки s 2 , которая составила 0,0153 (литров 2 ). Принято решение оценить верхний уровень дисперсии с уровнем доверия 95%.
Для решения задачи воспользуемся выражением
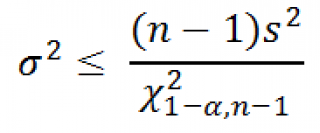
Сначала найдем верхний (1-α)-квантиль (или равный ему нижний α-квантиль ) ХИ2-распределения с n-1 степенью свободы при у ровне значимости α равном 1-0,95=0,05. Это можно сделать в MS EXCEL по формулам: =ХИ2.ОБР.ПХ(1-0,05; 20-1) или =ХИ2.ОБР(0,05; 20-1)
В результате получим верхний доверительный интервал для дисперсии: σ 2 файле примера на листе 1 сторонний .
СОВЕТ : О построении других доверительных интервалов см. статью Доверительные интервалы в MS EXCEL .
Источник
Функция распределения и плотность вероятности в EXCEL
history 13 октября 2016 г.
Даны определения Функции распределения случайной величины и Плотности вероятности непрерывной случайной величины. Эти понятия активно используются в статьях о статистике сайта ]]> www.excel2.ru ]]> . Рассмотрены примеры вычисления Функции распределения и Плотности вероятности с помощью функций MS EXCEL .
Введем базовые понятия статистики, без которых невозможно объяснить более сложные понятия.
Генеральная совокупность и случайная величина
Пусть у нас имеется генеральная совокупность (population) из N объектов, каждому из которых присуще определенное значение некоторой числовой характеристики Х.
Примером генеральной совокупности (ГС) может служить совокупность весов однотипных деталей, которые производятся станком.
Поскольку в математической статистике, любой вывод делается только на основании характеристики Х (абстрагируясь от самих объектов), то с этой точки зрения генеральная совокупность представляет собой N чисел, среди которых, в общем случае, могут быть и одинаковые.
В нашем примере, ГС — это просто числовой массив значений весов деталей. Х – вес одной из деталей.
Если из заданной ГС мы выбираем случайным образом один объект, имеющей характеристику Х, то величина Х является случайной величиной . По определению, любая случайная величина имеет функцию распределения , которая обычно обозначается F(x).
Функция распределения
Функцией распределения вероятностей случайной величины Х называют функцию F(x), значение которой в точке х равно вероятности события X файл примера ):
В справке MS EXCEL Функцию распределения называют Интегральной функцией распределения ( Cumulative Distribution Function , CDF ).
Приведем некоторые свойства Функции распределения:
- Функция распределения F(x) изменяется в интервале [0;1], т.к. ее значения равны вероятностям соответствующих событий (по определению вероятность может быть в пределах от 0 до 1);
- Функция распределения – неубывающая функция;
- Вероятность того, что случайная величина приняла значение из некоторого диапазона [x1;x2): P(x 1 Примечание : В MS EXCEL имеется несколько функций, позволяющих вычислить вероятности дискретных случайных величин. Перечень этих функций приведен в статье Распределения случайной величины в MS EXCEL .
Непрерывные распределения и плотность вероятности
В случае непрерывного распределения случайная величина может принимать любые значения из интервала, в котором она определена. Т.к. количество таких значений бесконечно велико, то мы не можем, как в случае дискретной величины, сопоставить каждому значению случайной величины ненулевую вероятность (т.е. вероятность попадания в любую точку (заданную до опыта) для непрерывной случайной величины равна нулю). Т.к. в противном случае сумма вероятностей всех возможных значений случайной величины будет равна бесконечности, а не 1. Выходом из этой ситуации является введение так называемой функции плотности распределения p(x) . Чтобы найти вероятность того, что непрерывная случайная величина Х примет значение, заключенное в интервале (а; b), необходимо найти приращение функции распределения на этом интервале:
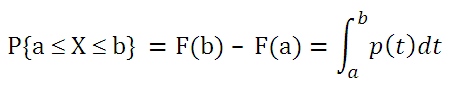
Как видно из формулы выше плотность распределения р(х) представляет собой производную функции распределения F(x), т.е. р(х) = F’(x).
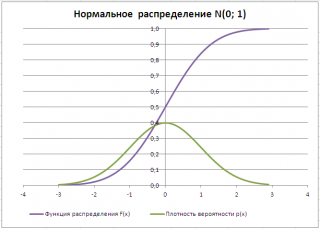
Типичный график функции плотности распределения для непрерывной случайно величины приведен на картинке ниже (зеленая кривая):
Примечание : В MS EXCEL имеется несколько функций, позволяющих вычислить вероятности непрерывных случайных величин. Перечень этих функций приведен в статье Распределения случайной величины в MS EXCEL .
В литературе Функция плотности распределения непрерывной случайной величины может называться: Плотность вероятности, Плотность распределения, англ. Probability Density Function (PDF) .
Чтобы все усложнить, термин Распределение (в литературе на английском языке — Probability Distribution Function или просто Distribution ) в зависимости от контекста может относиться как Интегральной функции распределения, так и кее Плотности распределения.
Из определения функции плотности распределения следует, что p(х)>=0. Следовательно, плотность вероятности для непрерывной величины может быть, в отличие от Функции распределения, больше 1. Например, для непрерывной равномерной величины , распределенной на интервале [0; 0,5] плотность вероятности равна 1/(0,5-0)=2. А для экспоненциального распределения с параметром лямбда =5, значение плотности вероятности в точке х=0,05 равно 3,894. Но, при этом можно убедиться, что вероятность на любом интервале будет, как обычно, от 0 до 1.
Напомним, что плотность распределения является производной от функции распределения , т.е. «скоростью» ее изменения: p(x)=(F(x2)-F(x1))/Dx при Dx стремящемся к 0, где Dx=x2-x1. Т.е. тот факт, что плотность распределения >1 означает лишь, что функция распределения растет достаточно быстро (это очевидно на примере экспоненциального распределения ).
Примечание : Площадь, целиком заключенная под всей кривой, изображающей плотность распределения , равна 1.
Примечание : Напомним, что функцию распределения F(x) называют в функциях MS EXCEL интегральной функцией распределения . Этот термин присутствует в параметрах функций, например в НОРМ.РАСП (x; среднее; стандартное_откл; интегральная ). Если функция MS EXCEL должна вернуть Функцию распределения, то параметр интегральная , д.б. установлен ИСТИНА. Если требуется вычислить плотность вероятности , то параметр интегральная , д.б. ЛОЖЬ.
Примечание : Для дискретного распределения вероятность случайной величине принять некое значение также часто называется плотностью вероятности (англ. probability mass function (pmf)). В справке MS EXCEL плотность вероятности может называть даже «функция вероятностной меры» (см. функцию БИНОМ.РАСП() ).
Вычисление плотности вероятности с использованием функций MS EXCEL
Понятно, что чтобы вычислить плотность вероятности для определенного значения случайной величины, нужно знать ее распределение.
Найдем плотность вероятности для стандартного нормального распределения N(0;1) при x=2. Для этого необходимо записать формулу =НОРМ.СТ.РАСП(2;ЛОЖЬ) =0,054 или =НОРМ.РАСП(2;0;1;ЛОЖЬ) .
Напомним, что вероятность того, что непрерывная случайная величина примет конкретное значение x равна 0. Для непрерывной случайной величины Х можно вычислить только вероятность события, что Х примет значение, заключенное в интервале (а; b).
Вычисление вероятностей с использованием функций MS EXCEL
1) Найдем вероятность, что случайная величина, распределенная по стандартному нормальному распределению (см. картинку выше), приняла положительное значение. Согласно свойству Функции распределения вероятность равна F(+∞)-F(0)=1-0,5=0,5.
В MS EXCEL для нахождения этой вероятности используйте формулу =НОРМ.СТ.РАСП(9,999E+307;ИСТИНА) -НОРМ.СТ.РАСП(0;ИСТИНА) =1-0,5. Вместо +∞ в формулу введено значение 9,999E+307= 9,999*10^307, которое является максимальным числом, которое можно ввести в ячейку MS EXCEL (так сказать, наиболее близкое к +∞).
2) Найдем вероятность, что случайная величина, распределенная по стандартному нормальному распределению , приняла отрицательное значение. Согласно определения Функции распределения, вероятность равна F(0)=0,5.
В MS EXCEL для нахождения этой вероятности используйте формулу =НОРМ.СТ.РАСП(0;ИСТИНА) =0,5.
3) Найдем вероятность того, что случайная величина, распределенная по стандартному нормальному распределению , примет значение, заключенное в интервале (0; 1). Вероятность равна F(1)-F(0), т.е. из вероятности выбрать Х из интервала (-∞;1) нужно вычесть вероятность выбрать Х из интервала (-∞;0). В MS EXCEL используйте формулу =НОРМ.СТ.РАСП(1;ИСТИНА) — НОРМ.СТ.РАСП(0;ИСТИНА) .
Все расчеты, приведенные выше, относятся к случайной величине, распределенной по стандартному нормальному закону N(0;1). Понятно, что значения вероятностей зависят от конкретного распределения. В статье Распределения случайной величины в MS EXCEL приведены распределения, для которых в MS EXCEL имеются соответствующие функции, позволяющие вычислить вероятности.
Обратная функция распределения (Inverse Distribution Function)
Вспомним задачу из предыдущего раздела: Найдем вероятность, что случайная величина, распределенная по стандартному нормальному распределению, приняла отрицательное значение.
Вероятность этого события равна 0,5.
Теперь решим обратную задачу: определим х, для которого вероятность, того что случайная величина Х примет значение =НОРМ.СТ.ОБР(0,5) =0.
Однозначно вычислить значение случайной величины позволяет свойство монотонности функции распределения.
Обратите внимание, что для вычисления обратной функции мы использовали именно функцию распределения , а не плотность распределения . Поэтому, в аргументах функции НОРМ.СТ.ОБР() отсутствует параметр интегральная , который подразумевается. Подробнее про функцию НОРМ.СТ.ОБР() см. статью про нормальное распределение .
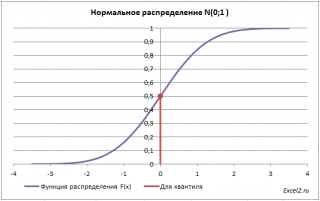
Обратная функция распределения вычисляет квантили распределения , которые используются, например, при построении доверительных интервалов . Т.е. в нашем случае число 0 является 0,5-квантилем нормального распределения . В файле примера можно вычислить и другой квантиль этого распределения. Например, 0,8-квантиль равен 0,84.
В англоязычной литературе обратная функция распределения часто называется как Percent Point Function (PPF).
Примечание : При вычислении квантилей в MS EXCEL используются функции: НОРМ.СТ.ОБР() , ЛОГНОРМ.ОБР() , ХИ2.ОБР(), ГАММА.ОБР() и т.д. Подробнее о распределениях, представленных в MS EXCEL, можно прочитать в статье Распределения случайной величины в MS EXCEL .
Источник
