В этой статье вы узнаете о последовательностях в Python и базовых операциях над ними.
Последовательность — это коллекция, элементы которого представляют собой некую последовательность.
На любой элемент последовательности можно ссылаться, используя его индекс, например, s[0] и s[1].
Индексы последовательности начинаются с 0, а не с 1. Поэтому первый элемент — s[0], а второй — s[1]. Если последовательность s состоит из n элементов, то последним элементом будет s[n-1].
В Python есть встроенные типы последовательностей: списки, байтовые массивы, строки, кортежи, диапазоны и байты. Последовательности могут быть изменяемыми и неизменяемыми.
Изменяемые: списки и байтовые массивы, неизменяемые: строки, кортежи, диапазоны и байты.
Последовательность может быть однородной или неоднородной. В однородной последовательности все элементы имеют одинаковый тип. Например, строки — это однородные последовательности, поскольку каждый элемент строки — символ — один и тот же тип.
А списки — неоднородные последовательности, потому что в них можно хранить элементы различных типов, включая целые числа, строки, объекты и т.д.
Примечание. C точки зрения хранения и операций однородные типы последовательностей более эффективны, чем неоднородные.
Последовательности и итерируемые объекты: разница
Итерируемый объект (iterable) — это коллекция объектов, в которой можно получить каждый элемент по очереди. Поэтому любая последовательность является итерируемой. Например, список — итерируемый объект.
Однако итерируемый объект может не быть последовательностью. Например, множество является итерируемым объектом, но не является последовательностью.
Примечание. Итерируемые объекты — более общий тип, чем последовательности.
Стандартные методы последовательностей
Ниже описаны некоторые встроенные в Python методы последовательностей:
1) Количество элементов последовательности
Чтобы получить количество элементов последовательности, можно использовать встроенную функцию len():
len(последовательность)
Пример
cities = ['Санкт-Петербург', 'Новосибирск', 'Москва']
print(len(cities))
Вывод
3
2) Проверка вхождения элемента в последовательность
Чтобы проверить, находится ли элемент в последовательности, можно использовать оператор in:
элемент in последовательность
Пример 1
Проверим, есть ли 'Новосибирск' в последовательности cities.
cities = ['Санкт-Петербург', 'Новосибирск', 'Москва']
print('Новосибирск' in cities)
Вывод
True
Чтобы проверить, отсутсвует ли элемент в последовательности, используется оператор not in.
Пример 2
Проверим, отсутсвует ли 'Новосибирск' в последовательности cities.
cities = ['Санкт-Петербург', 'Новосибирск', 'Москва']
print('Новосибирск' not in cities)
Вывод
False
3) Поиска индекса элемента в последовательности
Чтобы узнать индекс первого вхождения определенного элемента в последовательности, используется метод index().
последовательность.index(элемент)
Пример 1
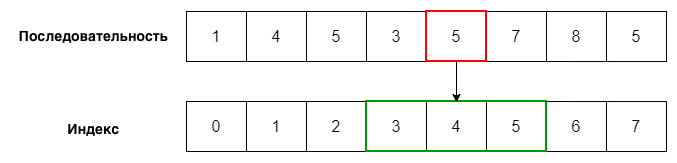
numbers = [1, 4, 5, 3, 5, 7, 8, 5]
print(numbers.index(5))
Вывод
2

Индекс первого появления числа 5 в списке numbers — 2. Если числа в последовательности нет, Python сообщит об ошибке:
numbers = [1, 4, 5, 3, 5, 7, 8, 5]
print(numbers.index(10))
Вывод
ValueError: 10 is not in list
Чтобы найти индекс вхождения элемента после определенного индекса, можно использовать метод index() в таком виде:
последовательность.index(элемент, индекс)
Пример 2
В следующем примере возвращается индекс первого вхождения числа 5 после третьего индекса:
numbers = [1, 4, 5, 3, 5, 7, 8, 5]
print(numbers.index(5, 3))Вывод
4

Чтобы найти индекс вхождения элемента между двумя определенными индексами, можно использовать метод index() в такой форме:
последовательность.index(элемент, i, j)
Поиск элемента будет осуществляться между i и j.
Пример 3
numbers = [1, 4, 5, 3, 5, 7, 8, 5]
print(numbers.index(5, 3, 5))
Вывод
4
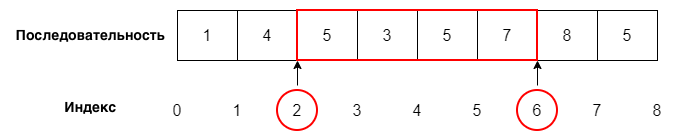
4) Слайсинг последовательности
Чтобы получить срез от индекса i до индекса j (не включая его), используйте следующий синтаксис:
последовательность[i:j]
Пример 1
numbers = [1, 4, 5, 3, 5, 7, 8, 5]
print(numbers[2:6])
Вывод
[5, 3, 5, 7]
Когда вы «слайсите» последовательность, представляйте, что индексы последовательности располагаются между двумя элементами, как показано на рисунке:
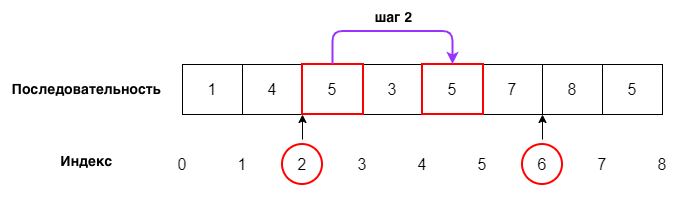
Расширенный слайсинг позволяет получить срез последовательности от индекса i до j (не включая его) с шагом k:
последовательность[i:j:k]
Пример 2
numbers = [1, 4, 5, 3, 5, 7, 8, 5]
print(numbers[2:6:2])
Вывод
[5, 5]
5) Получение максимального и минимального значений из последовательности
Если задан порядок между элементами в последовательности, можно использовать встроенные функции min() и max() для нахождения минимального и максимального элементов:
numbers = [1, 4, 5, 3, 5, 7, 8, 5]
print(min(numbers)) # Вывод: 1
print(max(numbers)) # Вывод: 8
6) Объединение (конкатенация) последовательностей
Чтобы объединить две последовательности в одну, используется оператор +:
последовательность3 = последовательность1 + последовательность2
Пример
east = ['Владивосток', 'Якутск']
west = ['Санкт-Петербург', 'Москва']
cities = east + west
print(cities)Вывод
['Владивосток', 'Якутск', 'Санкт-Петербург', 'Москва']
Неизменяемые последовательно объединять безопасно. В следующем примере мы доблавяем один элемент к списку west. И это не влияет на последовательность cities:
west.append('Благовещенск')
print(west)
print(cities)Вывод
['Владивосток', 'Якутск', 'Благовещенск']
['Владивосток', 'Якутск', 'Санкт-Петербург', 'Москва']
Однако когда вы работаете с изменяемыми последовательностями, стоит быть внимательными. . В следующем примере показано, как объединить список самого с собой.
city = [['Санкт-Петербург', 900_000]]
cities = city + city
print(cities)Вывод
[[‘Санкт-Петербург’, 1000000], [‘Санкт-Петербург’, 1000000]]
Поскольку список является изменяемой последовательностью, адреса памяти первого и второго элементов из списка citites одинаковы:
print(id(cities[0]) == id(cities[1])) # Вывод: TrueКроме того, при изменении значения из исходного списка изменяется и объединенный список:
city[0][1] = 1_000_000
print(cities)Соберем все вместе:
city = [['Санкт-Петербург', 900_000]]
cities = city + city
print(cities)
print(id(cities[0]) == id(cities[1])) # Вывод: True
city[0][1] = 1_000_000
print(cities)Вывод
[['Санкт-Петербург', 900000], ['Санкт-Петербург', 900000]]
True
[['Санкт-Петербург', 1000000], ['Санкт-Петербург', 1000000]]7) Повторение последовательности
Чтобы повторить последовательность несколько раз, используется оператор умножения *.
В следующем примере строка повторяется 3 раза:
s = 'ха'
print(s*3)
Вывод
хахаха
К примеру у нас есть список x = [1, 4, 6, 4, 6, 7, 8], как найти индекс числа 7?
![]()
insolor
45.6k15 золотых знаков54 серебряных знака94 бронзовых знака
задан 7 дек 2022 в 19:00
1
Если вас интересует именно list, вам нужна функция index:
print([1, 2, 3, 4, 5, 6, 7].index(7))
ответ дан 7 дек 2022 в 19:04
![]()
DuracellDuracell
1,9913 золотых знака16 серебряных знаков33 бронзовых знака
Если нужных чисел в списке несколько, можно их индексы найти так:
x = [1, 4, 6, 4, 6, 7, 8, 7, 9]
indexes = [i for i,d in enumerate(x) if d == 7]
print(indexes)
[5, 7]
ответ дан 7 дек 2022 в 20:06
![]()
Алексей РАлексей Р
7,0972 золотых знака4 серебряных знака16 бронзовых знаков
Думаю, что решения с методом index вам поможет решить задачу, но хотелось бы подметить несколько важных моментов. Метод index работает за O(n). Что не самый плохой результат, но всё же не идеальный. Для более эффективного поиска элемента в списке можно применить, так называемый “бинарный поиск”.
Wiki
Его худшая асимптотика – O(log n), что намного лучше, чем у index. Но для корректной работы бинарного поиска необходимо, чтобы список был отсортирован. Т.е. если в вашей задаче дан заведомо отсортированный список, то стоит обратить внимание на бинарный поиск.
В python есть стандартная библиотека, реализующая бинарный поиск – bisect.
Доки
ответ дан 7 дек 2022 в 21:08
Ret7020Ret7020
4512 серебряных знака9 бронзовых знаков
Изучая программирование на Python, вы практически в самом начале знакомитесь со списками и различными операциями, которые можете выполнять над ними. В этой статье мы бы хотели рассказать об одной из таких операций над списками.
Представьте, что у вас есть список, состоящий из каких-то элементов, и вам нужно определить индекс элемента со значением x. Сегодня мы рассмотрим, как узнать индекс определенного элемента списка в Python.
Но сначала давайте убедимся, что все понимают, что представляет из себя список.
Список в Python — это встроенный тип данных, который позволяет нам хранить множество различных значений, таких как числа, строки, объекты datetime и так далее.
Важно отметить, что списки упорядочены. Это означает, что последовательность, в которой мы храним значения, важна.
Индексирование списка начинаются с нуля и заканчивается на длине списка минус один. Для получения более подробной информации о списках вы можете обратиться к статье «Списки в Python: полное руководство для начинающих».
Итак, давайте посмотрим на пример списка:
fruits = ["apple", "orange","grapes","guava"] print(type(fruits)) print(fruits[0]) print(fruits[1]) print(fruits[2]) # Результат: # <class 'list'> # apple # orange # grapes
Мы создали список из 4 элементов. Первый элемент в списке имеет нулевой индекс, второй элемент — индекс 1, третий элемент — индекс 2, а последний — 3.
Для списка получившихся фруктов fruits допустимыми индексами являются 0, 1, 2 и 3. При этом длина списка равна 4 (в списке 4 элемента). Индекс последнего элемента равен длине списка (4) минус один, то есть как раз 3.
[python_ad_block]
Как определить индекс элемента списка в Python
Итак, как же определить индекс элемента в Python? Давайте представим, что у нас есть элемент списка и нам нужно узнать индекс или позицию этого элемента. Сделать это можно следующим образом:
print(fruits.index('orange'))
# 1
print(fruits.index('guava'))
# 3
print(fruits.index('banana'))
# А здесь выскочит ValueError, потому что в списке нет значения banana
Списки Python предоставляют нам метод index(), с помощью которого можно получить индекс первого вхождения элемента в список, как это показано выше.
Познакомиться с другими методами списков можно в статье «Методы списков Python».
Мы также можем заметить, что метод index() вызовет ошибку VauleError, если мы попытаемся определить индекс элемента, которого нет в исходном списке.
Для получения более подробной информации о методе index() загляните в официальную документацию.
Базовый синтаксис метода index() выглядит так:
list_var.index(item),
где list_var — это исходный список, item — искомый элемент.
Мы также можем указать подсписок для поиска, и синтаксис для этого будет выглядеть следующим образом:
list_var.index(item, start_index_of_sublist, end_index_of_sublist)
Здесь добавляются два аргумента: start_index_of_sublist и end_index_of_sublist. Тут всё просто. start_index_of_sublist обозначает, с какого элемента списка мы хотим начать поиск, а end_index_of_sublist, соответственно, на каком элементе (не включительно) мы хотим закончить.
Чтобы проиллюстрировать это для лучшего понимания, давайте рассмотрим следующий пример.
Предположим, у нас есть список book_shelf_genres, где индекс означает номер полки (индексация начинается с нуля). У нас много полок, среди них есть и полки с учебниками по математике.
Мы хотим узнать, где стоят учебники по математике, но не вообще, а после четвертой полки. Для этого напишем следующую программу:
book_shelf_genres = ["Fiction", "Math", "Non-fiction", "History", "Math", "Coding", "Cooking", "Math"]
print(book_shelf_genres.index("Math"))
# Результат:
# 1
Здесь мы видим проблему. Использование просто метода index() без дополнительных аргументов выдаст первое вхождение элемента в список, но мы хотим знать индекс значения «Math» после полки 4.
Для этого мы используем метод index() и указываем подсписок для поиска. Подсписок начинается с индекса 5 до конца списка book_shelf_genres, как это показано во фрагменте кода ниже:
print(book_shelf_genres.index("Math", 5))
# Результат:
# 7
Обратите внимание, что указывать конечный индекс подсписка необязательно.
Чтобы вывести индекс элемента «Math» после полки номер 1 и перед полкой номер 5, мы просто напишем следующее:
print(book_shelf_genres.index("Math", 2, 5))
# Результат:
# 4
Как найти индексы всех вхождений элемента в списке
А что, если искомое значение встречается в списке несколько раз и мы хотим узнать индексы всех этих элементов? Метод index() выдаст нам индекс только первого вхождения.
В этом случае мы можем использовать генератор списков:
book_shelf_genres = ["Fiction", "Math", "Non-fiction", "History", "Math", "Coding",
"Cooking", "Math"]
indices = [i for i in range(0, len(book_shelf_genres)) if book_shelf_genres[i]=="Math"]
print(indices)
# Результат:
# [1, 4, 7]
В этом фрагменте кода мы перебираем индексы списка в цикле for и при помощи range(). Далее мы проверяем значение элемента под каждым индексом на равенство «Math«. Если значение элемента — «Math«, мы сохраняем значение индекса в списке.
Все это делается при помощи генератора списка, который позволяет нам перебирать список и выполнять некоторые операции с его элементами. В нашем случае мы принимаем решения на основе значения элемента списка, а в итоге создаем новый список.
Подробнее про генераторы списков можно почитать в статье «Генераторы списков в Python для начинающих».
Благодаря генератору мы получили все номера полок, на которых стоят книги по математике.
Как найти индекс элемента в списке списков
Теперь представьте ситуацию, что у вас есть вложенный список, то есть список, состоящий из других списков. И ваша задача — определить индекс искомого элемента для каждого из подсписков. Сделать это можно следующим образом:
programming_languages = [["C","C++","Java"],
["Python","Rust","R"],
["JavaScript","Prolog","Python"]]
indices = [(i, x.index("Python")) for i, x in enumerate(programming_languages) if "Python" in x]
print(indices)
# Результат:
# [(1, 0), (2, 2)]
Здесь мы используем генератор списков и метод index(), чтобы найти индексы элементов со значением «Python» в каждом из имеющихся подсписков. Что же делает этот код?
Мы передаем список programming_languages методу enumerate(), который просматривает каждый элемент в списке и возвращает кортеж, содержащий индекс и значение элемента списка.
Каждый элемент в списке programming_languages также является списком. Оператор in проверяет, присутствует ли элемент «Python» в этом списке. Если да — мы сохраняем индекс подсписка и индекс элемента «Python» внутри подсписка в виде кортежа.
Результатом программы, как вы можете видеть, является список кортежей. Первый элемент кортежа — индекс подсписка, а второй — индекс искомого элемента в этом подсписке.
Таким образом, (1,0) означает, что подсписок с индексом 1 списка programming_languages имеет элемент «Python», который расположен по индексу 0. То есть, говоря простыми словами, второй подсписок содержит искомый элемент и этот элемент стоит на первом месте. Не забываем, что в Python индексация идет с нуля.
Как искать индекс элемента, которого, возможно, нет в списке
Бывает, нужно получить индекс элемента, но мы не уверены, есть ли он в списке.
Если попытаться получить индекс элемента, которого нет в списке, метод index() вызовет ошибку ValueError. При отсутствии обработки исключений ValueError вызовет аварийное завершение программы. Такой исход явно не является хорошим и с ним нужно что-то сделать.
Вот два способа, с помощью которых мы можем избежать такой ситуации:
books = ["Cracking the Coding Interview", "Clean Code", "The Pragmatic Programmer"]
ind = books.index("The Pragmatic Programmer") if "The Pragmatic Programmer" in books else -1
print(ind)
# Результат:
# 2
Один из способов — проверить с помощью оператора in, есть ли элемент в списке. Оператор in имеет следующий синтаксис:
var in iterable
Итерируемый объект — iterable — может быть списком, кортежем, множеством, строкой или словарем. Если var существует как элемент в iterable, оператор in возвращает значение True. В противном случае он возвращает False.
Это идеально подходит для решения нашей проблемы. Мы просто проверим, есть ли элемент в списке, и вызовем метод index() только если элемент существует. Это гарантирует, что метод index() не вызовет нам ошибку ValueError.
Но если мы не хотим тратить время на проверку наличия элемента в списке (это особенно актуально для больших списков), мы можем обработать ValueError следующим образом:
books = ["Cracking the Coding Interview", "Clean Code", "The Pragmatic Programmer"]
try:
ind = books.index("Design Patterns")
except ValueError:
ind = -1
print(ind)
# Результат:
# -1
Здесь мы применили конструкцию try-except для обработки ошибок. Программа попытается выполнить блок, стоящий после слова try. Если это приведет к ошибке ValueError, то она выполнит блок после ключевого слова except. Подробнее про обработку исключений с помощью try-except можно почитать в статье «Обрабатываем исключения в Python: try и except».
Заключение
Итак, мы разобрали как определить индекс элемента списка в Python. Теперь вы знаете, как это сделать с помощью метода index() и генератора списков.
Мы также разобрали, как использовать метод index() для вложенных списков и как найти каждое вхождение элемента в списке. Кроме того, мы рассмотрели ситуацию, когда нужно найти индекс элемента, которого, возможно, нет в списке.
Мы надеемся, что данная статья была для вас полезной. Успехов в написании кода!
Больше 50 задач по Python c решением и дискуссией между подписчиками можно посмотреть тут
Перевод статьи «Python Index – How to Find the Index of an Element in a List».

Привет! Есть задача:
Дано число n.
Дана непустая последовательность целых чисел, оканчивающаяся числом -10. Определить порядковый номер первого числа, которое больше заданного числа n.
У меня следующее решение:
| Python | ||
|
Но в данном случае считаются все значения, которые меньше n. То есть, если n == 10, а последовательность = 1 2 3 4 12 45 1 2 -10, то с = 6, хотя, по факту, ответ должен быть 5. Не понимаю, как ограничить подсчет до первого значения, которое больше.
Чтобы определить номер элемента (индекс) в массиве (списке) Python, зная его значение, вы можете использовать метод index(). Например, предположим, у вас есть список чисел или строк, и вы хотите найти индекс определенного значения:
my_list = [10, 20, 30, 40, 50]# Значение, индекс которого вы хотите найти
value_to_find = 30# Используйте метод index() для поиска индекса значения
index = my_list.index(value_to_find)# Выведите результат
print(f"Индекс значения {value_to_find} в списке: {index}")
Этот код найдет индекс значения 30 в списке my_list и выведет результат. В случае, если значение не найдено в списке, метод index() вызовет исключение ValueError. Вы можете обработать это исключение, чтобы избежать ошибок в вашей программе:
my_list = [10, 20, 30, 40, 50]
value_to_find = 60try:
index = my_list.index(value_to_find)
print(f"Индекс значения {value_to_find} в списке: {index}")
except ValueError:
print(f"Значение {value_to_find} не найдено в списке.")
В этом примере, если значение не найдено, код выведет сообщение об ошибке, но не прервет выполнение программы.
