-

1
-

2
Row-reduce to reduced row-echelon form (RREF).[2]
For large matrices, you can usually use a calculator. Recognize that row-reduction here does not change the augment of the matrix because the augment is 0.Advertisement
-

3
Write out the RREF matrix in equation form.[3]
-

4
Reparameterize the free variables and solve.[4]
-

5
Rewrite the solution as a linear combination of vectors.[5]
The weights will be the free variables. Because they can be anything, you can write the solution as a span.

Advertisement
Add New Question
-
Question
How do you find the basis for the column space of a matrix?

Alphabet
Community Answer
Row reduce the matrix and pick the columns that have pivot points. Let us use the matrix A: 1 3 5, 5 6 7, 10 12 14. If we now reduce it, we get the following matrix: 1 0 -1, 0 1 2, 0 0 0. The first two columns have pivot positions, but the last column does not. So we go back to the original matrix A and the first two columns of the original matrix A form the basis of the column space.
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
-
The dimension of the null space comes up in the rank theorem, which posits that the rank of a matrix is the difference between the dimension of the null space and the number of columns.

Thanks for submitting a tip for review!
Advertisement
References
About This Article
Thanks to all authors for creating a page that has been read 147,402 times.
Did this article help you?
Ядро линейного отображения — это такое линейное подпространство области определения отображения, каждый элемент которого отображается в нулевой вектор [1][2]. А именно: если задано линейное отображение 




Свойства[править | править код]

Ядро и образ отображения
L.
Ядро отображения L — это линейное подпространство области определения V[4].
В линейном отображении

Из этого следует, что образ L изоморфен факторпространству пространства V по ядру:

В случае, когда V конечномерно, из этого следует теорема о ранге и дефекте[en]:

где под рангом мы понимаем размерность образа отображения L, а под дефектом — размерность ядра отображения L[5].
Если V является предгильбертовым пространством, факторпространство 

Приложение к модулям[править | править код]
Понятие ядра также имеет смысл для гомоморфизмов модулей, которые являются обобщениями векторных пространств, где скаляры — элементы кольца, а не поля. Область определения отображения — это модуль с ядром, образующий подмодуль. Здесь концепции ранга и размерности ядра не обязательны.
В функциональном анализе[править | править код]
Если 


Представление в виде матричного умножения[править | править код]
Рассмотрим линейное отображение, представленное матрицей 






Ядро этого линейного отображения — это множество решений уравнения 

Матричное уравнение эквивалентно однородной системе линейных уравнений:

Тогда ядро матрицы
Свойства подпространства[править | править код]
Ядро 

.
- Если
и
, то
. Это следует из свойства дистрибутивности матричного умножения.
- Если
является скаляром
, то
, поскольку
.
Пространство строк матрицы[править | править код]
Произведение 

Здесь 
Пространство строк, или кообраз матрицы
Размерность пространства строк матрицы
[5]
Левое нуль-пространство (коядро)[править | править код]
Левое нуль-пространство или коядро матрицы 


и левое нуль-пространство матрицы
Неоднородные системы линейных уравнений[править | править код]
Ядро играет также большую роль при решении неоднородных систем линейных уравнений:

Пусть векторы 

Таким образом, разность любых двух решений системы 
Отсюда следует, что любое решение уравнения 

Геометрически это означает, что множество решений уравнения
Иллюстрация[править | править код]
Ниже приведена простая иллюстрация вычисления ядра матрицы (см. Вычисление методом Гаусса ниже для метода, более подходящего для более сложных вычислений). Иллюстрация затрагивает также пространства строк и их связь с ядром.
Рассмотрим матрицу

Ядро этой матрицы состоит из всех векторов 

что можно выразить в виде однородной системы линейных уравнений относительно 



Те же самые равенства можно выписать в матричном виде:
![{displaystyle left[{begin{array}{ccc|c}2&3&5&0\-4&2&3&0end{array}}right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5714ae9767da1d68a8826f59d3f1df192764c1a7)
С помощью метода Гаусса матрица может быть сведена к:
![{displaystyle left[{begin{array}{ccc|c}1&0&1/16&0\0&1&13/8&0end{array}}right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3dd8ba9c851e7adfab7845d89e0f4620e56be52d)
Преобразование матрицы в уравнения даёт:

Элементы ядра можно выразить в параметрическом виде следующим образом:

Поскольку

Ядро матрицы 
Следующие скалярные произведения равны нулю:

что показывает, что вектора ядра матрицы
Линейная оболочка этих двух (линейно независимых) вектор-строк — это плоскость, ортогональная вектору 
Поскольку ранг матрицы
Примеры[править | править код]
-
,
- то ядром оператора L является множество решений системы

-
- Тогда ядро of L состоит из всех функций
, для которых
.

-
- Тогда ядро of D состоит из всех функций в
, производная которых равна нулю, то есть из всех постоянных функций.

-
- Тогда ядром оператора s будет одномерное подпространство, состоящее из всех векторов
.

Вычисления по методу Гаусса[править | править код]
Базис ядра матрицы можно вычислить с помощью метода Гаусса.
Для этой цели, если дана ![{displaystyle left[{begin{array}{c}A\hline Eend{array}}right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8f978cac52a35a542f8d6a1ed29debb8ff2e6d1c)


Если вычислим ступенчатый по столбцам вид матрицы методом Гаусса (или любым другим подходящим методом), мы получим матрицу ![{displaystyle left[{begin{array}{c}B\hline Cend{array}}right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/23eb3e77c6f0f5d0f7b6beb321e501a19ba5190c)


Фактически вычисление может быть остановлено, как только матрица принимает ступенчатый по столбцам вид — остальное вычисление состоит из изменения базиса векторного пространства, образованного столбцами, верхняя часть которых равна нулю.
Например, представим, что
![{displaystyle A=left[{begin{array}{cccccc}1&0&-3&0&2&-8\0&1&5&0&-1&4\0&0&0&1&7&-9\0&0&0&0&0&0end{array}},right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0972372a6a55ce6f1e89d59cd4c80db78f07eb0f)
Тогда
![{displaystyle left[{begin{array}{c}A\hline Eend{array}}right]=left[{begin{array}{cccccc}1&0&-3&0&2&-8\0&1&5&0&-1&4\0&0&0&1&7&-9\0&0&0&0&0&0\hline 1&0&0&0&0&0\0&1&0&0&0&0\0&0&1&0&0&0\0&0&0&1&0&0\0&0&0&0&1&0\0&0&0&0&0&1end{array}}right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/952ce567a3c13d72611dfb429290701721434f5c)
Если привести верхнюю часть с помощью операций над столбцами к ступенчатому виду, получим
![{displaystyle left[{begin{array}{c}B\hline Cend{array}}right]=left[{begin{array}{cccccc}1&0&0&0&0&0\0&1&0&0&0&0\0&0&1&0&0&0\0&0&0&0&0&0\hline 1&0&0&3&-2&8\0&1&0&-5&1&-4\0&0&0&1&0&0\0&0&1&0&-7&9\0&0&0&0&1&0\0&0&0&0&0&1end{array}}right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d12b3c06e06f4ea602e52aa23819eccc250e6ba4)
Последние три столбца матрицы
![{displaystyle left[!!{begin{array}{r}3\-5\1\0\0\0end{array}}right],;left[!!{begin{array}{r}-2\1\0\-7\1\0end{array}}right],;left[!!{begin{array}{r}8\-4\0\9\0\1end{array}}right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4475f0a687bbd8ed7c618b63795b4b4898daa755)
являются базисом ядра матрицы
Доказательство, что метод вычисляет ядро: поскольку операции над столбцами соответствуют умножению справа на обратимую матрицу, из факта, что ![{displaystyle left[{begin{array}{c}A\hline Eend{array}}right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/16e875ad15a4391fb44e2e2e89a1e294502b27f2)
![{displaystyle left[{begin{array}{c}B\hline Cend{array}}right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a442c9b2ce18d358183bd22f68108996ffed4240)

![{displaystyle left[{begin{array}{c}A\hline Eend{array}}right]P=left[{begin{array}{c}B\hline Cend{array}}right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7281682377713bd63d90c3906686b919db93094c)












Численные вычисления[править | править код]
Задача вычисления ядра на компьютере зависит от природы коэффициентов.
Точные коэффициенты[править | править код]
Если коэффициенты матрицы заданы как точные числа, ступенчатый вид матрицы может быть вычислен алгоритмом Барейса, который более эффективен, чем метод Гаусса. Ещё более эффективно использование сравнения по модулю и китайской теоремы об остатках, которые сводят задачу к нескольким аналогичным задачам над конечными полями (что сокращает издержки, порождённые нелинейной вычислительной сложностью целочисленного умножения).
Для коэффициентов из конечного поля метод Гаусса работает хорошо, но для больших матриц, которые случаются в криптографии и при вычислении базиса Грёбнера, известны более эффективные алгоритмы, которые имеют почти ту же вычислительную сложность, но работают быстрее и более подходят для современных компьютерных устройств.
Вычисления с плавающей точкой[править | править код]
Для матриц, элементами которых служат числа с плавающей запятой, задача вычисления ядра имеет смысл только для матриц, число строк которых равно её рангу — ввиду ошибок округления[en] матрицы с плавающими значениями почти всегда имеют полный ранг, даже когда они являются аппроксимацией матрицы много меньшего ранга. Даже для матрицы полного ранга можно вычислить её ядро только тогда, когда она хорошо обусловлена, то есть имеет низкое число обусловленности[6].
И для хорошо обусловленной матрицы полного ранга метод Гаусса не ведёт себя корректно: ошибки округления слишком велики для получения значимого результата. Так как вычисление ядра матрицы является специальным случаем решения однородной системы линейных уравнений, ядро может быть вычислено любым алгоритмом, предназначенным для решения однородных систем. Передовым программным обеспечением для этих целей является библиотека Lapack.
См. также[править | править код]
- Ядро (алгебра)
- Нуль функции
- Пространство столбцов
- Пространство функций[en]
- Альтернатива Фредгольма
Примечания[править | править код]
- ↑ The Definitive Glossary of Higher Mathematical Jargon — Null. Math Vault (1 августа 2019). Дата обращения: 9 декабря 2019.
- ↑ Weisstein, Eric W. Kernel. mathworld.wolfram.com. Дата обращения: 9 декабря 2019.
- ↑ Kernel (Nullspace) | Brilliant Math & Science Wiki. brilliant.org. Дата обращения: 9 декабря 2019.
- ↑ Линейная алгебра в том виде, как обсуждается в этой статье, является хорошо проработанной математической дисциплиной, для которой можно найти много книг. Почти весь материал статьи можно найти в лекциях Лея (Lay, 2005), Мейера (Meyer, 2001) и Стренга.
- ↑ 1 2 Weisstein, Eric W. Rank-Nullity Theorem. mathworld.wolfram.com. Дата обращения: 9 декабря 2019.
- ↑ Archived copy. Дата обращения: 14 апреля 2015. Архивировано 29 августа 2017 года.
Литература[править | править код]
- Sheldon Jay Axler. Linear Algebra Done Right. — 2nd. — Springer-Verlag, 1997. — ISBN 0-387-98259-0.
- Гилберт Стренг. Линейная алгебра и её применение. — Москва: «Мир», 1980.
- David C. Lay. Linear Algebra and Its Applications. — 3rd. — Addison Wesley, 2005. — ISBN 978-0-321-28713-7.
- Carl D. Meyer. Matrix Analysis and Applied Linear Algebra. — Society for Industrial and Applied Mathematics (SIAM), 2001. — ISBN 978-0-89871-454-8.
- David Poole. Linear Algebra: A Modern Introduction. — 2nd. — Brooks/Cole, 2006. — ISBN 0-534-99845-3.
- Howard Anton. Elementary Linear Algebra (Applications Version). — 9th. — Wiley International, 2005.
- Steven J. Leon. Linear Algebra With Applications. — 7th. — Pearson Prentice Hall, 2006.
- Serge Lang. Linear Algebra. — Springer, 1987. — ISBN 9780387964126.
- Lloyd N. Trefethen, David III Bau. Numerical Linear Algebra. — SIAM, 1997. — ISBN 978-0-89871-361-9.
Ссылки[править | править код]
- Hazewinkel, Michiel, ed. (2001), Kernel of a matrix, Encyclopedia of Mathematics, Springer, ISBN 978-1-55608-010-4
- Khan Academy, Introduction to the Null Space of a Matrix
Линейная алгебра для исследователей данных
Время на прочтение
5 мин
Количество просмотров 14K

«Наша [Ирвинга Капланского и Пола Халмоша] общая философия в отношении линейной алгебры такова: мы думаем в безбазисных терминах, пишем в безбазисных терминах, но когда доходит до серьезного дела, мы запираемся в офисе и вовсю считаем с помощью матриц».
Ирвинг Капланский
Для многих начинающих исследователей данных линейная алгебра становится камнем преткновения на пути к достижению мастерства в выбранной ими профессии.

В этой статье я попытался собрать основы линейной алгебры, необходимые в повседневной работе специалистам по машинному обучению и анализу данных.
Произведения векторов
Для двух векторов x, y ∈ ℝⁿ их скалярным или внутренним произведением xᵀy
называется следующее вещественное число:

Как можно видеть, скалярное произведение является особым частным случаем произведения матриц. Также заметим, что всегда справедливо тождество
.
![]()
Для двух векторов x ∈ ℝᵐ, y ∈ ℝⁿ (не обязательно одной размерности) также можно определить внешнее произведение xyᵀ ∈ ℝᵐˣⁿ. Это матрица, значения элементов которой определяются следующим образом: (xyᵀ)ᵢⱼ = xᵢyⱼ, то есть

След
Следом квадратной матрицы A ∈ ℝⁿˣⁿ, обозначаемым tr(A) (или просто trA), называют сумму элементов на ее главной диагонали:

След обладает следующими свойствами:
-
Для любой матрицы A ∈ ℝⁿˣⁿ: trA = trAᵀ.
-
Для любых матриц A,B ∈ ℝⁿˣⁿ: tr(A + B) = trA + trB.
-
Для любой матрицы A ∈ ℝⁿˣⁿ и любого числа t ∈ ℝ: tr(tA) = t trA.
-
Для любых матриц A,B, таких, что их произведение AB является квадратной матрицей: trAB = trBA.
-
Для любых матриц A,B,C, таких, что их произведение ABC является квадратной матрицей: trABC = trBCA = trCAB (и так далее — данное свойство справедливо для любого числа матриц).

Нормы
Норму ∥x∥ вектора x можно неформально определить как меру «длины» вектора. Например, часто используется евклидова норма, или норма l₂:

Заметим, что ‖x‖₂²=xᵀx.
Более формальное определение таково: нормой называется любая функция f : ℝn → ℝ, удовлетворяющая четырем условиям:
-
Для всех векторов x ∈ ℝⁿ: f(x) ≥ 0 (неотрицательность).
-
f(x) = 0 тогда и только тогда, когда x = 0 (положительная определенность).
-
Для любых вектора x ∈ ℝⁿ и числа t ∈ ℝ: f(tx) = |t|f(x) (однородность).
-
Для любых векторов x, y ∈ ℝⁿ: f(x + y) ≤ f(x) + f(y) (неравенство треугольника)
Другими примерами норм являются норма l₁
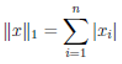
и норма l∞
![]()
Все три представленные выше нормы являются примерами норм семейства lp, параметризуемых вещественным числом p ≥ 1 и определяемых как

Нормы также могут быть определены для матриц, например норма Фробениуса:

Линейная независимость и ранг
Множество векторов {x₁, x₂, …, xₙ} ⊂ ℝₘ называют линейно независимым, если никакой из этих векторов не может быть представлен в виде линейной комбинации других векторов этого множества. Если же такое представление какого-либо из векторов множества возможно, эти векторы называют линейно зависимыми. То есть, если выполняется равенство

для некоторых скалярных значений α₁,…, αₙ-₁ ∈ ℝ, то мы говорим, что векторы x₁, …, xₙ линейно зависимы; в противном случае они линейно независимы. Например, векторы

линейно зависимы, так как x₃ = −2xₙ + x₂.
Столбцовым рангом матрицы A ∈ ℝᵐˣⁿ называют число элементов в максимальном подмножестве ее столбцов, являющемся линейно независимым. Упрощая, говорят, что столбцовый ранг — это число линейно независимых столбцов A. Аналогично строчным рангом матрицы является число ее строк, составляющих максимальное линейно независимое множество.
Оказывается (здесь мы не будем это доказывать), что для любой матрицы A ∈ ℝᵐˣⁿ столбцовый ранг равен строчному, поэтому оба этих числа называют просто рангом A и обозначают rank(A) или rk(A); встречаются также обозначения rang(A), rg(A) и просто r(A). Вот некоторые основные свойства ранга:
-
Для любой матрицы A ∈ ℝᵐˣⁿ: rank(A) ≤ min(m,n). Если rank(A) = min(m,n), то A называют матрицей полного ранга.
-
Для любой матрицы A ∈ ℝᵐˣⁿ: rank(A) = rank(Aᵀ).
-
Для любых матриц A ∈ ℝᵐˣⁿ, B ∈ ℝn×p: rank(AB) ≤ min(rank(A),rank(B)).
-
Для любых матриц A,B ∈ ℝᵐˣⁿ: rank(A + B) ≤ rank(A) + rank(B).
Ортогональные матрицы
Два вектора x, y ∈ ℝⁿ называются ортогональными, если xᵀy = 0. Вектор x ∈ ℝⁿ называется нормированным, если ||x||₂ = 1. Квадратная м
атрица U ∈ ℝⁿˣⁿ называется ортогональной, если все ее столбцы ортогональны друг другу и нормированы (в этом случае столбцы называют ортонормированными). Заметим, что понятие ортогональности имеет разный смысл для векторов и матриц.
Непосредственно из определений ортогональности и нормированности следует, что
![]()
Другими словами, результатом транспонирования ортогональной матрицы является матрица, обратная исходной. Заметим, что если U не является квадратной матрицей (U ∈ ℝᵐˣⁿ, n < m), но ее столбцы являются ортонормированными, то UᵀU = I, но UUᵀ ≠ I. Поэтому, говоря об ортогональных матрицах, мы будем по умолчанию подразумевать квадратные матрицы.
Еще одно удобное свойство ортогональных матриц состоит в том, что умножение вектора на ортогональную матрицу не меняет его евклидову норму, то есть
![]()
для любых вектора x ∈ ℝⁿ и ортогональной матрицы U ∈ ℝⁿˣⁿ.

Область значений и нуль-пространство матрицы
Линейной оболочкой множества векторов {x₁, x₂, …, xₙ} является множество всех векторов, которые могут быть представлены в виде линейной комбинации векторов {x₁, …, xₙ}, то есть
![]()
Областью значений R(A) (или пространством столбцов) матрицы A ∈ ℝᵐˣⁿ называется линейная оболочка ее столбцов. Другими словами,
![]()
Нуль-пространством, или ядром матрицы A ∈ ℝᵐˣⁿ (обозначаемым N(A) или ker A), называют множество всех векторов, которые при умножении на A обращаются в нуль, то есть
![]()
Квадратичные формы и положительно полуопределенные матрицы
Для квадратной матрицы A ∈ ℝⁿˣⁿ и вектора x ∈ ℝⁿ квадратичной формой называется скалярное значение xᵀ Ax. Распишем это выражение подробно:
![]()
Заметим, что
![]()
-
Симметричная матрица A ∈ 𝕊ⁿ называется положительно определенной, если для всех ненулевых векторов x ∈ ℝⁿ справедливо неравенство xᵀAx > 0. Обычно это обозначается как

(или просто A > 0), а множество всех положительно определенных матриц часто обозначают
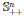
.
-
Симметричная матрица A ∈ 𝕊ⁿ называется положительно полуопределенной, если для всех векторов справедливо неравенство xᵀ Ax ≥ 0. Это записывается как
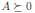
(или просто A ≥ 0), а множество всех положительно полуопределенных матриц часто обозначают

.
-
Аналогично симметричная матрица A ∈ 𝕊ⁿ называется отрицательно определенной

-
, если для всех ненулевых векторов x ∈ ℝⁿ справедливо неравенство xᵀAx < 0.
-
Далее, симметричная матрица A ∈ 𝕊ⁿ называется отрицательно полуопределенной (
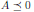
), если для всех ненулевых векторов x ∈ ℝⁿ справедливо неравенство xᵀAx ≤ 0.
-
Наконец, симметричная матрица A ∈ 𝕊ⁿ называется неопределенной, если она не является ни положительно полуопределенной, ни отрицательно полуопределенной, то есть если существуют векторы x₁, x₂ ∈ ℝⁿ такие, что

и

.
Собственные значения и собственные векторы
Для квадратной матрицы A ∈ ℝⁿˣⁿ комплексное значение λ ∈ ℂ и вектор x ∈ ℂⁿ будут соответственно являться собственным значением и собственным вектором, если выполняется равенство
![]()
На интуитивном уровне это определение означает, что при умножении на матрицу A вектор x сохраняет направление, но масштабируется с коэффициентом λ. Заметим, что для любого собственного вектора x ∈ ℂⁿ и скалярного значения с ∈ ℂ справедливо равенство A(cx) = cAx = cλx = λ(cx). Таким образом, cx тоже является собственным вектором. Поэтому, говоря о собственном векторе, соответствующем собственному значению λ, мы обычно имеем в виду нормализованный вектор с длиной 1 (при таком определении все равно сохраняется некоторая неоднозначность, так как собственными векторами будут как x, так и –x, но тут уж ничего не поделаешь).
Перевод статьи был подготовлен в преддверии старта курса “Математика для Data Science”. Также приглашаем всех желающих посетить бесплатный демоурок, в рамках которого рассмотрим понятие линейного пространства на примерах, поговорим о линейных отображениях, их роли в анализе данных и порешаем задачи.
-
ЗАПИСАТЬСЯ НА ДЕМОУРОК
![]()
SCILAB: Библиотеки
Глава 1. Библиотека линейной алгебры
Содержание главы:
•Введение
•Краткий русско-английский словарь основных терминов линейной алгебры
•Как найти обратную матрицу?
•Как найти псевдообратную матрицу?
•Как найти сингулярное разложение матрицы?
•Как найти собственные значения матрицы?
•Как определить норму матрицы?
•Как определить модуль матрицы?
•Как определить детерминант (определитель) матрицы?
•Как извлечь из матрицы диагональные элементы?
•Как определить ранг матрицы?
•Как найти ядро (нуль-пространство) матрицы?
•Солвер для решения линейных уравнений
Введение
Линейная алгебра, как никакая другая ветвь математики самым тесным образом переплелась с многочисленными приложениями и является важным инструментом в решении многих прикладных задач. Хотя в пакете Scilab выделена отдельная алгебраическая библиотека, команды, относящиеся к линейной алгебре разбросаны и по другим библиотекам и разделам. Поэтому в этом пособии будут представлены наиболее важные (по нашему мнению) команды, относящиеся к предмету матричных вычислений и связанных с ним задач. Здесь же будут для удобства приведены и некоторые элементарные команды, не входящие непосредственно в библиотеку линейной алгебры, но необходимые для работы с матрицами.
Доступ в алгебраическую и другие основные библиотеки является стандартным и, поэтому при вызове команд оттуда указывать имя библиотеки не требуется.
1

Краткий русско-английский словарь основных терминов линейной алгебры
|
Вырожденность |
singularity |
|
Детерминант (определитель) |
determinant |
|
Единичная матрица |
identity matrix |
|
Модуль матрицы |
absolute value, magnitude |
|
Норма матрицы |
matrix norm |
|
Обратная матрица |
inverse of matrix |
|
Псевдообратный |
pseudoinverse |
|
Пучок матриц |
pensil matrix |
|
Размерность |
dimension |
|
Ранг матрицы |
rank of a matrix |
|
Разреженная матрица |
sparse matrix |
|
Собственные значения матрицы |
eigenvalues of matrices |
|
Сингулярное разложение |
singular value decomposition (SVD) |
Ядро (нуль-пространство) матрицы kernel, nullspace
Как найти обратную матрицу(inverse of matrix)?
Способ 1.
С помощью команды inv. Синтаксис
inv(X)
Параметры
X : действительная или комплексная квадратная матрица, полиномиальная матрица или рациональная матрица.
Для полиномиальной матрицы команда даст тот же результат, что и invr.
В результате преобразования inv(X)*X, будет иметь вид единичной матрицы (то есть диагональные элементы =1, а остальные элементы =0). Обратная матрица находится методом LU-факторизации, используя библиотеку LAPACK.
Пример 1.
a=[1 2 3;2 2 3; 5 -1 2] b=inv(a)
Результат:
|
b = |
1. |
-8.327E-17 |
! |
|
! – 1. |
|||
|
! – 1.5714286 |
1.8571429 |
– .4285714 |
! |
|
! 1.7142857 |
– 1.5714286 |
.2857143 |
! |
c=a*b
2
Результат: c =
|
! |
1. |
0. |
1.110E-16 ! |
|
|
! – 8.882E-16 |
1. |
0. |
! |
|
|
! |
4.441E-16 |
– 8.882E-16 |
1. |
! |
То есть практически получили единичную матрицу.
Пример 2.
Получение обратной матрицы для матрицы, заданной в алгебраической (символьной форме).
r=[poly([1 2 3],”x”,”c”),1;poly([1 -2],”x”,”c”),2]
Результат : r =
|
! 1 + 2x + 3x2 |
1 ! |
||
|
! |
! |
||
|
! 1 – 2x |
2 ! |
||
|
inv(r) |
|||
|
Результат: |
|||
|
ans = |
2 |
– 1 |
! |
|
! |
|||
|
! ———— |
————— ! |
||
|
! 1 + 6x + 6x2 |
1 + 6x + 6x2 |
! |
|
|
! |
1 + 2x + 3x2 |
! |
|
|
! – 1 + 2x |
! |
||
|
! ———— |
————— ! |
||
|
! 1 + 6x + 6x2 |
1 + 6x + 6x2 |
! |
Замечание: Если обращаемая матрица вырожденна (singular) или почти вырожденна (определитель матрицы равен или близок к нулю) (например, a=[1 2 3;11 22 33; 110 220 330]), то в результате выполнения команды b=inv(a) получим сообщение:
!–error 19 singular matrix
Способ 2.
Для обращения матриц в алгебраических виде существует специальная команда invr. Синтаксис
F = invr(H)
Параметры
H : полиномиальная или рациональная матрица
F : полиномиальная или рациональная матрица
В результате работы команды вычисляется F=H-1 с помощью алгоритма Леверье
(Leverrier).
Способ 3.
Для полиномиальных матриц с помощью команды coffg. Параметры
Fs : квадратная полиномиальная матрица.
Команда coffg вычисляет Fs-1 методом ко-факторов (co-factors method). В результате выполнения команды будут получены два числа, полностью характеризующие обратную матрицу:
Ns = числитель (является полиномиальной матрицей) и d = общий знаменатель.
Матрица, обратная данной матрице Fs, будет вычисляться по формуле Ns/d.
3

Замечание: Для больших матриц результат может оказаться неудовлетворительным.
Пример.
r=[poly([1 2 3],”x”,”c”),1;poly([1 -2],”x”,”c”),2] r =
|
!1 + 2x |
+ 3x2 |
1! |
|
! |
! |
|
|
!1 – 2x |
2! |
[a,d]=coffg(r)
Результат:
d =
1 + 6x + 6x2
|
a = |
– 1 |
! |
|
|
! |
2 |
||
|
! |
! |
||
|
!- 1 + 2x |
1 + 2x + 3x2 ! |
Матрица, s=a/d будет обратной к матрице r.
Как найти псевдообратную (pseudoinverse) матрицу?
С помощью команды псевдоинверсии pinv.
Синтаксис
pinv(A,[tol])
Параматры
A : действительная или комплексная матрица tol : действительное число
Команда вычисляет такую матрицу X той же размерности, что и A’, чтобы выполнялось условие:
A*X*A = A, X*A*X = X и оба A*X и X*A были Эрмитовы (Hermitian) .
Вычисление базируется на методе сингулярного разложения SVD (Singular Value Decomposition) и все сингулярные значения меньшие, чем допуск (tolerance) очищаются до нуля. Этот допуск является необязательным параметром команды pinv.
Пример.
A=rand(5,2)*rand(2,4);
norm(A*pinv(A)*A-A,1) // определяется норма матрицы
С помощью команды norm мы определили, с какой погрешностью была произведена псевдоинверсия.
Как найти сингулярное разложение матрицы?
С помощью команды svd (=singular value decomposition).
Синтаксис
s=svd(X)
[U,S,V]=svd(X) [U,S,V]=svd(X,0) (obsolete)
4

[U,S,V]=svd(X,”e”)
[U,S,V,rk]=svd(X [,tol])
Параметры
X : действительная или комплексная матрица
s : действительный вектор (сингулярные значения)
S : действительная диагональная матрица (сингулярные значения)
U, V : ортогональная или унитарная квадратная матрица (сингулярные вектора). tol : действительное число. Играет роль допуска.
Команда svd вычисляет три матрицы (X, S и V), обладающие следующими свойствами: матрица S диагональна и имеет ту же размерность, что и матрица X. Ее диагональные элементы неотрицательны и расположены в порядке убывания;
матрицы U и V унитарны и выполняется условие: X = U*S*V’ или производится разложение “экономичного размера”.
Если матрица X имеет размер m на n и m > n, то вычисляются только первые n столбцов матрицы U, а матрица S будет иметь размер n на n.
В случае синтаксиса s=svd(X), возвращает вектор s, содержащий сингулярные значения. Конструкция [U,S,V,rk]=svd(X [,tol]) возвращает дополнительный параметр rk, числовое значение ранга матрицы X, то есть число сингулярных значений, больших чем значение допуска tol.
Значение tol по умолчанию совпадает с рангом матрицы.
Пример.
X=rand(4,2)*rand(2,4)
svd(X)
sqrt(spec(X*X’))
Как найти собственные значения матрицы?
С помощью команды spec.
Подробно смотрите с помощью help spec.
Как определить норму матрицы?
С помощью команды norm.
Матричные нормы часто требуются при анализе матричных алгоритмов. Например, программа решения системы уравнений может давать некачественный результат, если матрица коэффициентов “почти вырожденная”. Для количественной характеристики близости к вырожденности нам нужно уметь измерять расстояния в пространстве матриц. Такую возможность предоставляют матричные нормы.
Синтаксис команды norm.
[y]=norm(x [,flag])
Параметры
x : действительный или комплексный вектор или матрица (тип full или sparse) flag : строка (тип нормы) (значение по умолчанию =2)
5

Для матриц:
norm(x) : эквивалентно norm(x,2) и является наибольшим сингулярным значением x
(max(svd(x))).
norm(x,1) : наибольшая сумма по столбцу, то есть maxi(sum(abs(x),’r’))).
norm(x,’inf’),norm(x,%inf) : бесконечная норма (infinity norm) x. Является наибольшая суммой по строке: maxi(sum((x),’c’)).
norm(x,’fro’) : Норма Фробениуса (Frobenius). Вычисляется по формуле sqrt(sum(diag(x’*x))).
Для векторов эта команда определяет p-нормы. norm(v,p) : l_p норма (sum(v(i)p))(1/p) .
norm(v) : равна =norm(v,2), то есть норма при p=2. norm(v,’inf’) : max(abs(v(i))).
Замечание:
Наиболее важными являются нормы при p=1, 2, infinity.
norm(v,1) является суммой модулей всех элементов вектора. norm(v,1)=|x(1)|+|x(2)|+…+|x(n)|
norm(v,2) является квадратным корнем из суммы квадратов всех элементов вектора norm(v,2)=(|x(1)|2+|x(2)|2+…+|x(n)|2)1/2
norm(v,’inf’) равна модулю максимального элемента вектора по модулю
Пример. v=[1,2,3];
norm(v,1) // Результат: 6=1+2+3
norm(v,’inf’) // Результат: значение максимального элемента =3 A=[1,2;3,4]
norm(A,1) // Результат =6. Это максимальная из сумм элементов по столбцам
(2+4)
Как определить модуль матрицы?
С помощью команды abs.
Синтаксис
t=abs(x)
Параметры
x : действительный или комплексный вектор или матрица t : действительный вектор или матрица
Команда возвращает модуль всех элементов x.
Если значения x комплексны, то команда abs(x) возвращает комплексный модуль всех элементов x.
Пример 1.
a=[1.1 -2.2 3;4.4 -5.4 0]
6

Результат: a=
! 1.1 – 2.2 3. ! ! 4.4 – 5.4 0. ! t=abs(a)
Результат:
|
! |
1.1 |
2.2 |
3. |
! |
|
! |
4.4 |
5.4 |
0. |
! |
Пример 2.
x=[1,%i,2;-1,-%i,1+%i] //%i – мнимая единица
Результат: x =
|
! 1. |
i |
2. |
! |
|
! – 1. |
– i |
1. |
+ i ! |
|
t=abs(x) |
Результат: ans =
|
! |
1. |
1. |
2. |
! |
|
! |
1. |
1. |
1.4142136 ! |
Как определить детерминант (определитель) матрицы?
Способ 1.
С помощью команды det.
Замечание: Матрица должна быть квадратной.
Синтаксис команды det det(X) [e,m]=det(X)
Параметры
X : действительная или комплексная квадратная матрица, полиномиальная или рациональная матрица
m : действительное или комплексное число, детерминант основанный на мантиссе 10. e : целое число, степень числа
Представление детерминанта в виде двух чисел способствует повышению точности в численных вычислениях.
det(X)= m*10e
Для полиномиальных матриц команда det(X) эквивалентна команде determ(X). Для рациональных матриц команда det(X) эквивалентна команде detr(X).
Пример 1. x=poly(0,’x’); a=[x,1+x;2-x,5]
Результат:
|
a= |
1 |
+ x! |
|
!x |
||
|
! |
5 |
! |
|
!2 – x |
! |
D=det(a)
Результат:
D =- 2 + 4x^2 + x
7

Пример 2. s=[1,2.3;-4,5.2] [e,m]=det(s) D=det(s)
Результат:
D=14.4 m = 1.44 e = 1.
Мы проверили, что det(s)=m*10e.
Способ 2.
С помощью команды detr. Синтаксис
d=detr(h)
Параметры
h : полиномиальная или рациональная квадратная матрица Метод вычислений основан на алгоритме Леверрье(Leverrier).
Способ 3.
С помощью команды determ(X). Эта команда специально служит для вычисления детерминанта полиномиальных (то есть представленных в символьном виде) матриц. Вычисление с помощью этой команды детерминанта матриц, заданных численно, недопустимо.
Синтаксис res=determ(W [,k])
Параметры
W : действительная квадратная полиномиальная матрица
k : целое число, служащее верхней границей в представлении детерминанта матрицы W в виде полинома.
Детерминант вычисляется с помощью метода FFT.
Пример. s=poly(0,’s’);
w=[s, 1+s^2;s-2, s+4]
|
w = |
s |
1 + s2! |
|
! |
||
|
! |
! |
|
|
! – 2 + s |
4 + s ! |
determ(w)
Результат:
ans =
2 + 3s + 3s2 – s3 determ(w,2)
Результат: ans =
5 + 2s
Замечание: Команда determ с незаданным параметром k даст тот же результат, что и команда det(w).
8

Как извлечь из матрицы диагональные элементы?
С помошью команды diag. Синтаксис
[y]=diag(vm, [k])
Параметры
vm : вектор или матрица (полная или разреженная)
k : целое число. По умолчанию принимает значение “0”, то есть действие команд diag(vm) и diag(vm,0) эквивалентно.
y : вектор или матрица
Для матрицы vm команда diag(vm,k) возвращает вектор или матрицу из элементов, стоящих по k -той диагонали матрицы. Команда diag(vm) возвращает вектор из элементов главной диагонали и эквивалентна команде diag(vm,0). Значения k>0 соответствуют диагоналям, лежащим выше главной диагонали матрицы, а k<0 соответственно ниже.
Пример.
A=[1,2;3,4] A =
!1. 2. !
!3. 4. !
d_1=diag(A) // Главная диагональ
Результат: d_1 =
!1. !
!4. ! diag(A,1)
Результат: ans =2 diag(A,-1)
Результат: ans =4
Замечание: Для создания диагональной линейной системы используйте команду sysdiag.
Как определить ранг матрицы?
С помощью команды rank.
Синтаксис
[i]=rank(X)
[i]=rank(X,tol)
Параметры
X : действительная или комплексная матрица tol : неотрицательное действительное число
Вспомним определение:
Рангом матрицы называется наивысший порядок отличного от нуля минора этой матрицы. Фактически рангом матрицы является максимальным числом линейно независимых строк матрицы. Понятие ранга является важным при решении системы линейных уравнений.
Необязательный параметр tol лимитирует точность вычислений.
9

Пример.
a=[1 2 3; -6 3 -2;10 20 30;49 -2 5]
Результат: a =
! 1. 2. 3. !
!-6. 3. -2. !
!10. 20. 30. !
!49. -2. 5. !
t=rank(a)
Результат: t =
3.
Как найти ядро (нуль-пространство) матрицы?
С помощью команды kernel.
Вспомним определение ядра (нуль-пространством) матрицы:
Ядро матрицы А – это множество векторов х таких, произведение матрицы А на которые равно нулевому вектору. Поиск ядра матрицы А эквивалентен решению системы линейных однородных уравнений.
Ядром матрицы A являются все решения уравнения AW=0.
Синтаксис команды kernel
W=kernel(A [,tol,[,flag])
Параметры
A : действительная или комплексная матрица. В случае, если матрица представлена в разреженном виде (тип sparse), то только действительная A.
flag : строка, имеющая значение ‘svd’ (по умолчанию) или ‘qr’ tol : действительное число
W : полная матрицы
Команда kernel возвращает ортономальный базис нуль-пространства матрицы A. W=kernel(A) возвращает ядро матрицы A. Если матрица W будет непустой, будет выполняться:
A*W=0 .
Параметры flag и tol являются необязательными: flag = ‘qr’ или ‘svd’ (по умолчанию принимает значение ‘svd’). Указывают на используемый алгоритм вычисления.
tol = параметр допуска. В качестве значения tol по умолчанию принимается величина порядка %eps(~2.220E-16).
Пример.
A=[2 -3 5 7;4 -6 2 3;2 -3 -11 -15]
|
A = |
– 3. |
5. |
7. |
! |
||
|
! 2. |
||||||
|
! |
4. |
– |
6. |
2. |
3. |
! |
|
! |
2. |
– |
3. |
– 11. |
– 15. |
! |
W=kernel(A)
10
Соседние файлы в папке scilab_manual
- #
- #
- #
- #
- #
- #
- #
Нулевое пространство
Сначала посмотрите на определение. A – это матрица размера m × n, а x – вектор-столбец. Если существует набор векторов N, выполняйте следующие условия:

Говорит, что N является нулевым пространством A.
Значение нулевого пространства
Из определения видно, что пустое пространство – это множество всех решений уравнения Ax = 0:

Нулевое пространство A связано с решением уравнения Ax = 0, а точнее, с пространством, образованным решением.Уравнение, равное нулевому вектору, также является значением «нуля» в нулевом пространстве. Поскольку x ∈ Rn, нулевое пространство также связано с решением x, поэтому пространство, образованное x, также находится в Rn, то является ли оно подпространством Rn?
Во-первых, вектор 0 – это набор решений уравнения. Предполагая, что v1 и v2 также являются решениями уравнения, теперь давайте посмотрим на завершение добавления:

V1, v2 удовлетворяют аддитивному замыканию. Наконец, проверьте замыкание умножения, C – произвольная константа:

V также удовлетворяет замкнутости умножения, поэтому нулевое пространство также является подпространством Rn. Поскольку нулевое пространство является подпространством, это подпространство должно включать нулевой вектор.Когда Ax = b, b ≠ 0, поскольку нет решения с нулевым значением, A не должно иметь нулевого пространства.
Найдите нулевое пространство
Мы уже знаем значение нулевого пространства, как найти нулевое пространство?
Сначала посмотрите на пример:

Пример относительно прост. Помимо всех нулевых решений, существует несколько наборов решений системы уравнений. В частности, если C – любая константа, то:

В пространстве R3 N (A) – прямая линия, проходящая через начало координат.
Вот еще один немного более сложный пример:

Нужно только решить систему уравнений, один из способов – преобразовать A в простейшую ступенчатую матрицу:

Чтобы облегчить решение, наша цель – сделать систему уравнений как можно меньше, чтобы мы могли еще больше упростить:

Преобразуйте простейшую ступенчатую матрицу строки в систему уравнений:

Два уравнения, четыре неизвестных, система уравнений имеет бесчисленное множество решений, является ли нулевое пространство A целым R4 или другими подпространствами R4? Прежде чем ответить на этот вопрос, нам необходимо дополнительно преобразовать уравнения:

X3, x4 могут быть любыми действительными числами, a и b линейно независимы, поэтому нулевое пространство A – это пространство, образованное a и b:

В частности, нулевое пространство A – это плоскость, проходящая через начало координат в пространстве R4, и, конечно же, это также подпространство в R4.
Нулевое пространство не имеет ничего общего с линейностью
Обратим внимание на природу A в Ax = 0. Am × n состоит из n векторов-столбцов:

Если A линейно независима, это означает, что система уравнений имеет только одно полностью нулевое решение, или, другими словами, множество решений этого уравнения является нулевым пространством A, и это нулевое пространство содержит только нулевые векторы. На этом этапе A должно быть упрощено до единичной матрицы:

Вывод состоит в том, что если и только если вектор-столбец A является линейно независимым, нулевое пространство A является нулевым вектором. В это время A должна быть квадратной матрицей, а простейшая ступенчатая матрица строк A является единичной матрицей. .
Колонка
Если A – матрица размера m × n, то пространство столбцов матрицы A – это пространство, образованное всеми векторами-столбцами в A. Пространство столбцов A представлено C (A):

C (A), очевидно, является подпространством в Rm.
Значение пространства столбца
Сначала вызовите матрицу:

Три вектора не могут образовывать все пространство R4, они могут образовывать только подпространство R4. Так в чем же смысл пространства столбцов? По-прежнему необходимо объединить уравнения.Нулевое пространство связано с решением Ax = 0; пространство столбцов связано с тем, в Ax = b, какой тип b может заставить уравнение иметь решение. Для любого b уравнение не всегда имеет решение, например следующее:

Четыре уравнения, три неизвестных, система уравнений может не иметь решения. С точки зрения векторного пространства три вектора не могут заполнить все четырехмерное пространство, поэтому должно быть много b, которые не являются линейными комбинациями этих трех векторов. В то же время эта система уравнений может быть разрешимой.Какой тип b может сделать систему уравнений разрешимой? Простой способ – сначала написать x, а затем вычесть b согласно b = Ax:

Можно видеть, что b является линейной комбинацией A, поэтому b должен находиться в пространстве столбцов A, а Ax = b имеет решение; и наоборот, если b не находится в пространстве столбцов A, это означает, что Ax = b не имеет решения, которое имеет значение.
В приведенном выше примере третий вектор-столбец A может быть представлен линейной комбинацией первых двух, поэтому пространство столбцов A является двумерным подпространством R4:

пример
Что такое подпространства в R3?

Сначала посмотрите на подпространство. Подпространство включает в себя нулевые векторы. Линейная комбинация всех векторов в подпространстве все еще находится в подпространстве.
1. Здесь описывается, что взаимосвязь между компонентами вектора является линейной, что может быть преобразовано в уравнение:

<A1, a2, a3> – это пустое пространство <1,1, -1>, а пустое пространство – это подпространство R3.
2. Три компонента больше не являются линейными, что означает, что 80% не является подпространством, и вы можете перечислить несколько векторов по желанию. Когда a1 = 1, a2 = 1, a3 = a1 a2 = 1, <a1, a2, a3> = <1, 1, 1>, поскольку подпространство закрыто для логарифмического умножения, поэтому <2, 2, 2> будет также Оно должно быть в подпространстве, но в это время a3 ≠ a1a2, поэтому условие вопроса 2 не может составлять подпространство.
3. Сначала упростите выражение:

<A1, a2, a3> – это линейная комбинация <1, 0, -1> и <1, 0, 1>, которая является подпространством.
4. Давайте сначала упростим выражение:

Обратите внимание, что второй компонент равен 1. Это фиксированное значение, которое не может образовывать нулевой вектор.Условие вопроса 4 не может образовывать подпространство.
Автор: Я 8-битный
Источник:http://www.cnblogs.com/bigmonkey
Эта статья посвящена изучению, исследованию и распространению информации. Если вам нужно перепечатать, свяжитесь со мной и укажите автора и источник. Она не предназначена для коммерческого использования! Чтобы
Отсканируйте QR-код, чтобы подписаться на общедоступную учетную запись «Я 8-значный»

