1. Найди информационный объём следующего сообщения, если известно, что один символ кодируется одним байтом.
Кто владеет информацией, тот владеет миром.
Решение: посчитаем количество символов в сообщении, будем учитывать буквы, знаки препинания и пробелы.
Всего (43) символа. Каждый символ кодируется (1) байтом.
(I = К · i), (43 · 1) байт (= 43) байта.
Ответ: (43) байта.
2. Найди информационный объём слова из (12) символов в кодировке Unicode (каждый символ кодируется двумя байтами). Ответ дайте в битах.
Решение.
Мы знаем из условия задачи, что каждый символ кодируется двумя байтами. Найдём сколько это бит.
(2) байта (· 8 = 16) бит;
Слово состоит из (12) символов, поэтому
(16) бит (· 12) символов (= 192) бита.
Ответ: (192) бита.
3. Найди информационный вес книги, которая состоит из (700) страниц, на каждой странице (70) строк и в каждой строке (95) символов . Мощность алфавита — (256) символов. Ответ дать в Мб.
Решение: если мощность алфавита (256) символов, то информационный объём одного символа (8) бит.
Найдём количество символов в книге: (700·70·95 = 4655000) символов.
Информационный вес сообщения: (4655000·8=37240000) бит.
Ответ нужно дать в Мб, поэтому переведём биты в Мб
(37240000:8:1024:1024 = 4,44) Мб
Ответ: (4,44) Мб.
Как найти информационный объем
В курсе информатики визуальный, текстовый, графический и другие виды информации представлены в двоичном коде. Это «машинный язык» — последовательность нулей и единиц. Информационный объем позволяет сравнивать количество двоичной информации, входящей в состав разных носителей. Для примера можно рассмотреть, как вычисляются объемы текста и графики.

Инструкция
Для вычисления информационного объема текста, из которого состоит книга, определите начальные данные. Вы должны знать количество страниц в книге, среднее количество строк текста на каждой странице и число символов с пробелами в каждой строке текста. Пусть книга содержит 150 страниц, по 40 строк на странице, по 60 символов в строке.
Найдите количество символов в книге: перемножьте данные первого шага. 150 страниц * 40 строк * 60 символов = 360 тыс. символов в книге.
Определите информационный объем книги, исходя из того, что один символ весит один байт. 360 тысяч символов * 1 байт = 360 тысяч байт.
Перейдите к более крупным единицам измерения: 1 Кб (килобайт) = 1024 байт, 1 Мб (мегабайт) = 1024 Кб. Тогда 360 тысяч байт / 1024 = 351,56 Кб или 351,56 Кб / 1024 = 0,34 Мб.
Чтобы найти информационный объем графического файла, также определите начальные данные. Пусть изображение 10×10 см получено с помощью сканера. Надо знать разрешающую способность устройства — для примера, 600 dpi — и глубину цвета. Последнее значение, так же для примера, можно взять 32 бита.
Выразите разрешающую способность сканера в точках на см. 600 dpi = 600 точек на дюйм. 1 дюйм = 2,54 см. Тогда 600 / 2,54 = 236 точек на см.
Найдите размер изображения в точках. 10 см = 10 * 236 точек на см = 2360 точек. Тогда размер картинки = 10×10 см = 2360×2360 точек.
Вычислите общее количество точек, из которых состоит изображение. 2360 * 2360 = 5569600 штук.
Рассчитайте информационный объем полученного графического файла. Для этого умножьте глубину цвета на результат восьмого шага. 32 бита * 5569600 штук = 178227200 бит.
Перейдите к более крупным единицам измерения: 1 байт = 8 бит, 1 Кб (килобайт) = 1024 байта и т.д. 178227200 бит / 8 = 22278400 байт, или 22278400 байт / 1024 = 21756 Кб, или 21756 Кб / 1024 = 21 Мб. Из-за округления результаты получаются примерными.
Источники:
- Нахождение информационного объема графического файла
- определите информационный объём
Войти на сайт
или
Забыли пароль?
Еще не зарегистрированы?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Добрый день, сегодня мы познакомимся с заданием №1 ОГЭ по информатике. Сама суть идёт из темы про кодирование информации. Когда мы пытаемся найти какое количество нужно выделить памяти у компьютера на один символ. Символ — это не только цифры (0-9) и буквы разных алфавитов, но и прочие специальные символы (знаки препинания, вопросительные, восклицательные знаки и т.д.). Пробел так же, как и любой другой символ занимает память при его использовании/наличии.
Само вычисление необходимого количества памяти происходит по формуле объёма информации:
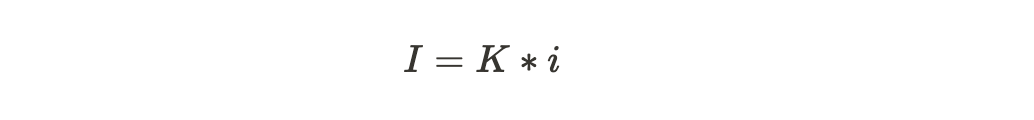
- I – объём информации (сколько весит файл/сообщение);
- K – количество символов в сообщении/в файле;
- i – количество информации (сколько памяти занимает один символ).
У этих переменных есть свои единицы измерения. Для количества символов – символы. А для объёма информации и количества информации — это бит, байт, кбайт и т.д.
Теперь, после некоторого введения в теорию мы обладаем инструментами для решения данной задачи. Осталось только определить, как применить полученные знания и каков алгоритм наших действий.
Задача №1
В кодировке КОИ-8 каждый символ кодируется 8 битами. Андрей написал текст (в нём нет лишних пробелов):
«Обь, Лена, Волга, Москва, Макензи, Амазонка — реки».
Ученик вычеркнул из списка название одной из рек. Заодно он вычеркнул лишние запятые и пробелы — два пробела не должны идти подряд. При этом размер нового предложения в данной кодировке оказался на 8 байт меньше, чем размер исходного предложения. Напишите в ответе вычеркнутое название реки.
Решение
Теперь попробуем разобрать данную задачу. У нас тут есть кодировка “КОИ-8”, которая говорит нам о том, что каждый символ весит 8 бит. А 8 бит это ровно 1 байт информации. Всё, что заключено в кавычки нас, интересует. Далее ученик вычеркнул слово (название реки) и, окружавшие его, запятую и пробел. После всех этих действий объём сообщения уменьшился на 8 байт.
Теперь мы обладаем всей полезной информацией и можем сделать некоторые выводы и суждения:
- 1 символ = 1 байту;
- удалили запятую и пробел – минус два символа, то есть 2 байта;
- 8 байт – 2 байта = 6 байт;
- 6 байт = 6 символов (в данном случае букв);
- Следовательно, необходимо найти слово (в данном случае название реки), в котором есть ровно шесть букв – Москва.
Существуют задачи, где необходимо посчитать какое количество байт будет весить файл. Попробуем разобраться с этим видом задания.
Задача №2
Статья, набранная на компьютере, содержит 20 страниц, на каждой странице 40 строк, в каждой строке 48 символов. В одном из представлений Unicode каждый символ кодируется двумя байтами. Определите информационный объём статьи в Кбайтах в этом варианте представления Unicode.
Решение
Как можем заметить тут речь идёт о файле, в котором есть 20 страниц. В каждой странице 40 строк и на каждой строке 48 символов. Исходя из этих значений найдём сколько ВСЕГО символов в файле. Также сказано что каждый символ занимает (весит) 2 байта информации. Следовательно, умножив общее количество символов на вес символа, найдём информационный объём файла (сколько он будет весить на компьютере). На словах вроде решили, теперь решим и “на бумаге”.
Для начала найдем количество символов:
После этого никто не мешает найти объем информации:
Получили достаточно большой ответ. Поскольку здесь мы умножали количество символов на байты (их вес), то и ответ получился тоже в байтах. Если бы умножали на бит, то и информационный объём тоже был бы в единицах измерения — бит. Но в самом задание сказано определить информационный объём в Кбайтах. Для этого необходимо полученное число разделить на 1024 (исходя из таблицы переводов сверху).
Вышел достаточно лаконичный ответ – 75 Кбайт.
Понравилась статья? Хочешь разбираться в информатике, программировании и уметь работать в разных программах? Тогда ставь лайк, подпишись на канал и поделись статьей с друзьями!
Читайте также:
#информатика #огэ #разбор #задания #решение #экзамен
Задачи на определение информационного объема текста
Проверяется умение оценивать количественные параметры информационных объектов.
Теоретический материал:
N = 2i , где N – мощность алфавита (количество символов в используемом
алфавите),
i – информационный объем одного символа (информационный
вес символа), бит
I = K*i, где I – информационный объем текстового документа (файла),
K – количество символов в тексте
Задача 1.

Считаем количество символов в заданном тексте (перед и после тире – пробел, после знаков препинания, кроме последнего – пробел, пробел – это тоже символ). В результате получаем – 52 символа в тексте.
Дано:
i = 16 бит
K = 52
I – ?
Решение:
I = K*i
I = 52*16бит = 832бит (такой ответ есть – 2)
Ответ: 2
Задача 2.

Дано:
K = 16*35*64 – количество символов в статье
i = 8 бит
I – ?
Решение: Чтобы перевести ответ в Кбайты нужно разделить результат на 8 и на 1024 (8=23, 1024=210)
I=16*35*64*8 бит= =35Кбайт Ответ: 4
=35Кбайт Ответ: 4
Задача 3.

Пусть x – это количество строк на каждой странице, тогда K=10*x*64 – количество символов в тексте рассказа.
Дано:
I = 15 Кбайт
K =10*x*64
i = 2 байта
x – ?
Решение:
Переведем информационный объем текста из Кбайт в байты.
I = 15 Кбайт = 15*1024 байт (не перемножаем)
Подставим все данные в формулу для измерения количества информации в тексте.
I = K*i
15*1024 = 10*x*64*2
Выразим из полученного выражения x
x =  – количество строк на каждой странице – 4
– количество строк на каждой странице – 4
Ответ: 4
Задачи для самостоятельного решения:
Задача 1.

Задача 2.

Задача 3.

Задача 4.

Задача 5.

Задача 6.

Задача 7.

Задачи взяты с сайта fipi.ru из открытого банка заданий (с.1-7)
Информатика
7 класс
Урок № 6
Единицы измерения информации
Перечень вопросов, рассматриваемых в теме:
- Алфавитный подход к измерению информации.
- Наименьшая единица измерения информации.
- Информационный вес одного символа алфавита и информационный объём всего сообщения.
- Единицы измерения информации.
- Задачи по теме урока.
Тезаурус:
Каждый символ информационного сообщения несёт фиксированное количество информации.
Единицей измерения количества информации является бит – это наименьшаяединица.
1 байт = 8 бит
1 Кб (килобайт) = 1024 байта= 210байтов
1 Мб (мегабайт) = 1024 Кб = 210Кб
1 Гб (гигабайт) = 1024 Мб = 210 Мб
1 Тб (терабайт) =1024 Гб = 210 Гб
Формулы, которые используются при решении типовых задач:
Информационный вес символа алфавита и мощность алфавита связаны между собой соотношением: N = 2i.
Информационный объём сообщения определяется по формуле:
I = К · i,
I – объём информации в сообщении;
К – количество символов в сообщении;
i – информационный вес одного символа.
Основная литература:
- Босова Л. Л. Информатика: 7 класс. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2017. – 226 с.
Дополнительная литература:
- Босова Л. Л. Информатика: 7–9 классы. Методическое пособие. // Босова Л. Л., Босова А. Ю., Анатольев А. В., Аквилянов Н.А. – М.: БИНОМ, 2019. – 512 с.
- Босова Л. Л. Информатика. Рабочая тетрадь для 7 класса. Ч 1. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2019. – 160 с.
- Босова Л. Л. Информатика. Рабочая тетрадь для 7 класса. Ч 2. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2019. – 160 с.
- Гейн А. Г. Информатика: 7 класс. // Гейн А. Г., Юнерман Н. А., Гейн А.А. – М.: Просвещение, 2012. – 198 с.
Теоретический материал для самостоятельного изучения.
Любое сообщение несёт некоторое количество информации. Как же его измерить?
Одним из способов измерения информации является алфавитный подход, который говорит о том, что каждый символ любого сообщения имеет определённый информационный вес, то есть несёт фиксированное количество информации.
Сегодня на уроке мы узнаем, чему равен информационный вес одного символа и научимся определять информационный объём сообщения.
Что же такое символ в компьютере? Символом в компьютере является любая буква, цифра, знак препинания, специальный символ и прочее, что можно ввести с помощью клавиатуры. Но компьютер не понимает человеческий язык, он каждый символ кодирует. Вся информация в компьютере представляется в виде нулей и единичек. И вот эти нули и единички называются битом.
Информационный вес символа двоичного алфавита принят за минимальную единицу измерения информации и называется один бит.
Алфавит любого понятного нам языка можно заменить двоичным алфавитом. При этом мощность исходного алфавита связана с разрядностью двоичного кода соотношением: N = 2i.
Эту формулу можно применять для вычисления информационного веса одного символа любого произвольного алфавита.
Рассмотрим пример:
Алфавит древнего племени содержит 16 символов. Определите информационный вес одного символа этого алфавита.
Составим краткую запись условия задачи и решим её:
Дано:
N=16, i = ?
Решение:
N = 2i
16 = 2i, 24 = 2i, т. е. i = 4
Ответ: i = 4 бита.
Информационный вес одного символа этого алфавита составляет 4 бита.
Сообщение состоит из множества символов, каждый из которых имеет свой информационный вес. Поэтому, чтобы вычислить объём информации всего сообщения, нужно количество символов, имеющихся в сообщении, умножить на информационный вес одного символа.
Математически это произведение записывается так: I = К · i.
Например: сообщение, записанное буквами 32-символьного алфавита, содержит 180 символов. Какое количество информации оно несёт?
Дано:
N = 32,
K = 180,
I= ?
Решение:
I = К · i,
N = 2i
32 = 2i, 25 = 2 i, т.о. i = 5,
I = 180 · 5 = 900 бит.
Ответ: I = 900 бит.
Итак, информационный вес всего сообщения равен 900 бит.
В алфавитном подходе не учитывается содержание самого сообщения. Чтобы вычислить объём содержания в сообщении, нужно знать количество символов в сообщении, информационный вес одного символа и мощность алфавита. То есть, чтобы определить информационный вес сообщения: «сегодня хорошая погода», нужно сосчитать количество символов в этом сообщении и умножить это число на восемь.
I = 23 · 8 = 184 бита.
Значит, сообщение весит 184 бита.
Как и в математике, в информатике тоже есть кратные единицы измерения информации. Так, величина равная восьми битам, называется байтом.
Бит и байт – это мелкие единицы измерения. На практике для измерения информационных объёмов используют более крупные единицы: килобайт, мегабайт, гигабайт и другие.
1 байт = 8 бит
1 Кб (килобайт) = 1024 байта= 210байтов
1 Мб (мегабайт) = 1024 Кб = 210Кб
1 Гб (гигабайт) = 1024 Мб = 210 Мб
1 Тб (терабайт) =1024 Гб = 210 Гб
Итак, сегодня мы узнали, что собой представляет алфавитный подход к измерению информации, выяснили, в каких единицах измеряется информация и научились определять информационный вес одного символа и информационный объём сообщения.
Материал для углубленного изучения темы.
Как текстовая информация выглядит в памяти компьютера.
Набирая текст на клавиатуре, мы видим привычные для нас знаки (цифры, буквы и т.д.). В оперативную память компьютера они попадают только в виде двоичного кода. Двоичный код каждого символа, выглядит восьмизначным числом, например 00111111. Теперь возникает вопрос, какой именно восьмизначный двоичный код поставить в соответствие каждому символу?
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код ‑ просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.Таблица для кодировки – это «шпаргалка», в которой указаны символы алфавита в соответствии порядковому номеру. Для разных типов компьютеров используются различные таблицы кодировки.
Таблица ASCII (или Аски), стала международным стандартом для персональных компьютеров. Она имеет две части.

В этой таблице латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений. Это правило соблюдается и в других таблицах кодировки и называется принципом последовательного кодирования алфавитов. Благодаря этому понятие «алфавитный порядок» сохраняется и в машинном представлении символьной информации. Для русского алфавита принцип последовательного кодирования соблюдается не всегда.
Запишем, например, внутреннее представление слова «file». В памяти компьютера оно займет 4 байта со следующим содержанием:
01100110 01101001 01101100 01100101.
А теперь попробуем решить обратную задачу. Какое слово записано следующим двоичным кодом:
01100100 01101001 01110011 01101011?
В таблице 2 приведен один из вариантов второй половины кодовой таблицы АSСII, который называется альтернативной кодировкой. Видно, что в ней для букв русского алфавита соблюдается принцип последовательного кодирования.

Вывод: все тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные для нас буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в форме двоичного кода.
Из памяти же компьютера текст может быть выведен на экран или на печать в символьной форме.
Сейчас используют целых пять систем кодировок русского алфавита (КОИ8-Р, Windows, MS-DOS, Macintosh и ISO). Из-за количества систем кодировок и отсутствия одного стандарта, очень часто возникают недоразумения с переносом русского текста в компьютерный его вид. Поэтому, всегда нужно уточнять, какая система кодирования установлена на компьютере.
Разбор решения заданий тренировочного модуля
№1. Определите информационный вес символа в сообщении, если мощность алфавита равна 32?
Варианты ответов:
3
5
7
9
Решение:
Информационный вес символа алфавита и мощность алфавита связаны между собой соотношением: N = 2i.
32 = 2i, 32 – это 25, следовательно, i =5 битов.
Ответ: 5 битов.
№2. Выразите в килобайтах 216 байтов.
Решение:
216 можно представить как 26 · 210.
26 = 64, а 210 байт – это 1 Кб. Значит, 64 · 1 = 64 Кб.
Ответ: 64 Кб.
№3. Тип задания: выделение цветом
8х = 32 Кб, найдите х.
Варианты ответов:
3
4
5
6
Решение:
8 можно представить как 23. А 32 Кб переведём в биты.
Получаем 23х=32 · 1024 ·8.
Или 23х = 25 · 210 · 23.
23х = 218.
3х = 18, значит, х=6.
Ответ: 6.
