Skip to content
В этой статье мы рассмотрим разные подходы к одной из самых распространенных и, по моему мнению, важных задач в Excel – как найти в ячейках и в столбцах таблицы повторяющиеся значения.
Работая с большими наборами данных в Excel или объединяя несколько небольших электронных таблиц в более крупные, вы можете столкнуться с большим числом одинаковых строк.
И сегодня я хотел бы поделиться несколькими быстрыми и эффективными методами выявления дубликатов в одном списке. Эти решения работают во всех версиях Excel 2016, Excel 2013, 2010 и ниже. Вот о чём мы поговорим:
- Поиск повторяющихся значений включая первые вхождения
- Поиск дубликатов без первых вхождений
- Определяем дубликаты с учетом регистра
- Как извлечь дубликаты из диапазона ячеек
- Как обнаружить одинаковые строки в таблице данных
- Использование встроенных фильтров Excel
- Применение условного форматирования
- Поиск совпадений при помощи встроенной команды “Найти”
- Определяем дубликаты при помощи сводной таблицы
- Duplicate Remover – быстрый и эффективный способ найти дубликаты
Самой простой в использовании и вместе с тем эффективной в данном случае будет функция СЧЁТЕСЛИ (COUNTIF). С помощью одной только неё можно определить не только неуникальные позиции, но и их первые появления в столбце. Рассмотрим разницу на примерах.
Поиск повторяющихся значений включая первые вхождения.
Предположим, что у вас в колонке А находится набор каких-то показателей, среди которых, вероятно, есть одинаковые. Это могут быть номера заказов, названия товаров, имена клиентов и прочие данные. Если ваша задача – найти их, то следующая формула для вас:
=СЧЁТЕСЛИ(A:A; A2)>1
Где А2 – первая ячейка из области для поиска.
Просто введите это выражение в любую ячейку и протяните вниз вдоль всей колонки, которую нужно проверить на дубликаты.

Как вы могли заметить на скриншоте выше, формула возвращает ИСТИНА, если имеются совпадения. А для встречающихся только 1 раз значений она показывает ЛОЖЬ.
Подсказка! Если вы ищите повторы в определенной области, а не во всей колонке, обозначьте нужный диапазон и “зафиксируйте” его знаками $. Это значительно ускорит вычисления. Например, если вы ищете в A2:A8, используйте
=СЧЕТЕСЛИ($A$2:$A$8, A2)>1
Если вас путает ИСТИНА и ЛОЖЬ в статусной колонке и вы не хотите держать в уме, что из них означает повторяющееся, а что – уникальное, заверните свою СЧЕТЕСЛИ в функцию ЕСЛИ и укажите любое слово, которое должно соответствовать дубликатам и уникальным:
=ЕСЛИ(СЧЁТЕСЛИ($A$2:$A$17; A2)>1;”Дубликат”;”Уникальное”)
Если же вам нужно, чтобы формула указывала только на дубли, замените “Уникальное” на пустоту (“”):

=ЕСЛИ(СЧЁТЕСЛИ($A$2:$A$17; A2)>1;”Дубликат”;””)

В этом случае Эксель отметит только неуникальные записи, оставляя пустую ячейку напротив уникальных.
Поиск неуникальных значений без учета первых вхождений
Вы наверняка обратили внимание, что в примерах выше дубликатами обозначаются абсолютно все найденные совпадения. Но зачастую задача заключается в поиске только повторов, оставляя первые вхождения нетронутыми. То есть, когда что-то встречается в первый раз, оно однозначно еще не может быть дубликатом.
Если вам нужно указать только совпадения, давайте немного изменим:
=ЕСЛИ(СЧЁТЕСЛИ($A$2:$A2; A2)>1;”Дубликат”;””)
На скриншоте ниже вы видите эту формулу в деле.

Нетрудно заметить, что она не обозначает первое появление слова, а начинает отсчет со второго.
Чувствительный к регистру поиск дубликатов
Хочу обратить ваше внимание на то, что хоть формулы выше и находят 100%-дубликаты, есть один тонкий момент – они не чувствительны к регистру. Быть может, для вас это не принципиально. Но если в ваших данных абв, Абв и АБВ – это три разных параметра – то этот пример для вас.
Как вы могли уже догадаться, выражения, использованные нами ранее, с такой задачей не справятся. Здесь нужно выполнить более тонкий поиск, с чем нам поможет следующая функция массива:
{=ЕСЛИ(СУММ((–СОВПАД($A$2:$A$17;A2)))<=1;””;”Дубликат”)}
Не забывайте, что формулы массива вводятся комбиинацией Ctrl + Shift + Enter.
Если вернуться к содержанию, то здесь используется функция СОВПАД для сравнения целевой ячейки со всеми остальными ячейками с выбранной области. Результат возвращается в виде ИСТИНА (совпадение) или ЛОЖЬ (не совпадение), которые затем преобразуются в массив из 1 и 0 при помощи оператора (–).
После этого, функция СУММ складывает эти числа. И если полученный результат больше 1, функция ЕСЛИ сообщает о найденном дубликате.
Если вы взглянете на следующий скриншот, вы убедитесь, что поиск действительно учитывает регистр при обнаружении дубликатов:

Смородина и арбуз, которые встречаются дважды, не отмечены в нашем поиске, так как регистр первых букв у них отличается.
Как извлечь дубликаты из диапазона.
Формулы, которые мы описывали выше, позволяют находить дубликаты в определенном столбце. Но часто речь идет о нескольких столбцах, то есть о диапазоне данных.
Рассмотрим это на примере числовой матрицы. К сожалению, с символьными значениями этот метод не работает.

При помощи формулы массива
{=ИНДЕКС(НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11);СТРОКА($1:$100)); НАИМЕНЬШИЙ(ЕСЛИОШИБКА(ЕСЛИ(ПОИСКПОЗ(НАИМЕНЬШИЙ(ЕСЛИ( СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11);СТРОКА($1:$100)); НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11); СТРОКА($1:$100));0)=СТРОКА($1:$100);СТРОКА($1:$100));””);СТРОКА()-1))}
вы можете получить упорядоченный по возрастанию список дубликатов. Для этого введите это выражение в нужную ячейку и нажмите Ctrl+Alt+Enter.
Затем протащите маркер заполнения вниз на сколько это необходимо.
Чтобы убрать сообщения об ошибке, когда дублирующиеся значения закончатся, можно использовать функцию ЕСЛИОШИБКА:
=ЕСЛИОШИБКА(ИНДЕКС(НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11); СТРОКА($1:$100));НАИМЕНЬШИЙ(ЕСЛИОШИБКА(ЕСЛИ(ПОИСКПОЗ( НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11); СТРОКА($1:$100));НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11); СТРОКА($1:$100));0)=СТРОКА($1:$100);СТРОКА($1:$100));””);СТРОКА()-1));””)
Также обратите внимание, что приведенное выше выражение рассчитано на то, что оно будет записано во второй строке. Соответственно выше него будет одна пустая строка.
Поэтому если вам нужно разместить его, к примеру, в ячейке K4, то выражение СТРОКА()-1 в конце замените на СТРОКА()-3.
Обнаружение повторяющихся строк
Мы рассмотрели, как обнаружить одинаковые данные в отдельных ячейках. А если нужно искать дубликаты-строки?
Есть один метод, которым можно воспользоваться, если вам нужно просто выделить одинаковые строки, но не удалять их.
Итак, имеются данные о товарах и заказчиках.
Создадим справа от наших данных формулу, объединяющую содержание всех расположенных слева от нее ячеек.
Предположим, что данные хранятся в столбцах А:C. Запишем в ячейку D2:
=A2&B2&C2
Добавим следующую формулу в ячейку E2. Она отобразит, сколько раз встречается значение, полученное нами в столбце D:
=СЧЁТЕСЛИ(D:D;D2)
Скопируем вниз для всех строк данных.
В столбце E отображается количество появлений этой строки в столбце D. Неповторяющимся строкам будет соответствовать значение 1. Повторам строкам соответствует значение больше 1, указывающее на то, сколько раз такая строка была найдена.
Если вас не интересует определенный столбец, просто не включайте его в выражение, находящееся в D. Например, если вам хочется обнаружить совпадающие строки, не учитывая при этом значение Заказчик, уберите из объединяющей формулы упоминание о ячейке С2.
Обнаруживаем одинаковые ячейки при помощи встроенных фильтров Excel.
Теперь рассмотрим, как можно обойтись без формул при поиске дубликатов в таблице. Быть может, кому-то этот метод покажется более удобным, нежели написание выражений Excel.
Организовав свои данные в виде таблицы, вы можете применять к ним различные фильтры. Фильтр в таблице вы можете установить по одному либо по нескольким столбцам. Давайте рассмотрим на примере.
В первую очередь советую отформатировать наши данные как «умную» таблицу. Напомню: Меню Главная – Форматировать как таблицу.
После этого в строке заголовка появляются значки фильтра. Если нажать один из них, откроется выпадающее меню фильтра, которое содержит всю информацию по данному столбцу. Выберите любой элемент из этого списка, и Excel отобразит данные в соответствии с этим выбором.
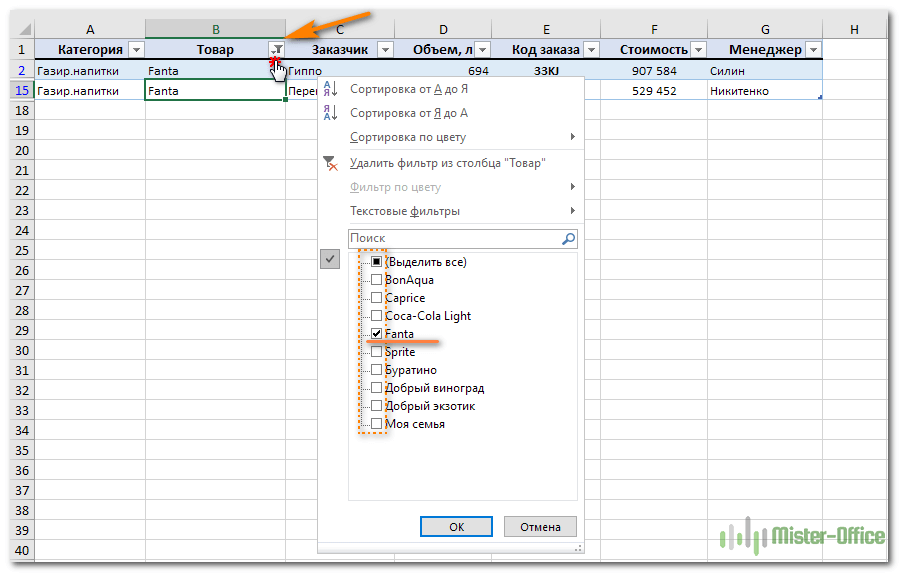
Вы можете убрать галочку с пункта «Выделить все», а затем отметить один или несколько нужных элементов. Excel покажет только те строки, которые содержат выбранные значения. Так можно обнаружить дубликаты, если они есть. И все готово для их быстрого удаления.
Но при этом вы видите дубли только по отфильтрованному. Если данных много, то искать таким способом последовательного перебора будет несколько утомительно. Ведь слишком много раз нужно будет устанавливать и менять фильтр.
Используем условное форматирование.
Выделение цветом по условию – весьма важный инструмент Excel, о котором достаточно подробно мы рассказывали.
Сейчас я покажу, как можно в Экселе найти дубли ячеек, просто их выделив цветом.
Как показано на рисунке ниже, выбираем Правила выделения ячеек – Повторяющиеся. Неуникальные данные будут подсвечены цветом.
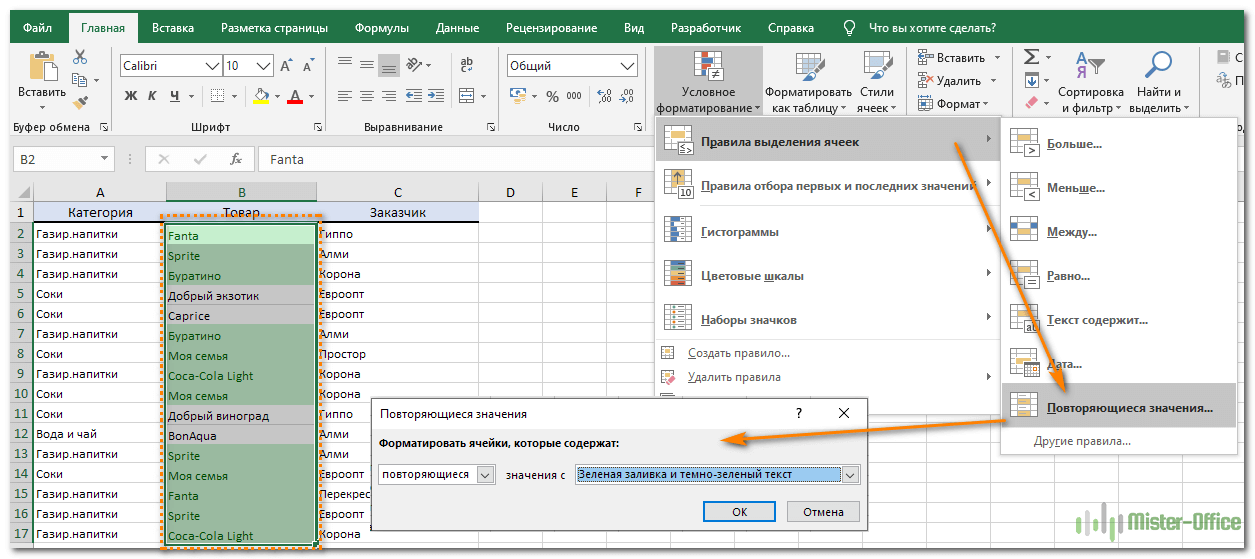
Но здесь мы не можем исключить первые появления – подсвечивается всё.
Но эту проблему можно решить, использовав формулу условного форматирования.
=СЧЁТЕСЛИ($B$2:$B2; B2)>1

Результат работы формулы выденения повторяющихся значений вы видите выше. Они выделены зелёным цветом.
Чтобы освежить память, можете руководствоваться нашим материалом «Как изменить цвет ячейки в зависимости от значения».
Поиск совпадений при помощи команды «Найти».
Еще один простой, но не слишком технологичный способ – использование встроенного поиска.
Зайдите на вкладку Главная и кликните «Найти и выделить». Откроется диалоговое окно, в котором можно ввести что угодно для поиска в таблице. Чтобы избежать опечаток, можете скопировать искомое прямо из списка данных.
Затем нажимаем «Найти все», и видим все найденные дубликаты и места их расположения, как на рисунке чуть ниже.

В случае, когда объём информации очень велик и требуется ускорить работу поиска, предварительно выделите столбец или диапазон, в котором нужно искать, и только после этого начинайте работу. Если этого не сделать, Excel будет искать по всем имеющимся данным, что, конечно, медленнее.
Этот метод еще более трудоемкий, нежели использование фильтра. Поэтому применяют его выборочно, только для отдельных значений.
Как применить сводную таблицу для поиска дубликатов.
Многие считают сводные таблицы слишком сложным инструментом, чтобы постоянно им пользоваться. На самом деле, не все так запутано, как кажется. Для новичков рекомендую к ознакомлению наше руководство по созданию и работе со сводными таблицами.
Для более опытных – сразу переходим к сути вопроса.
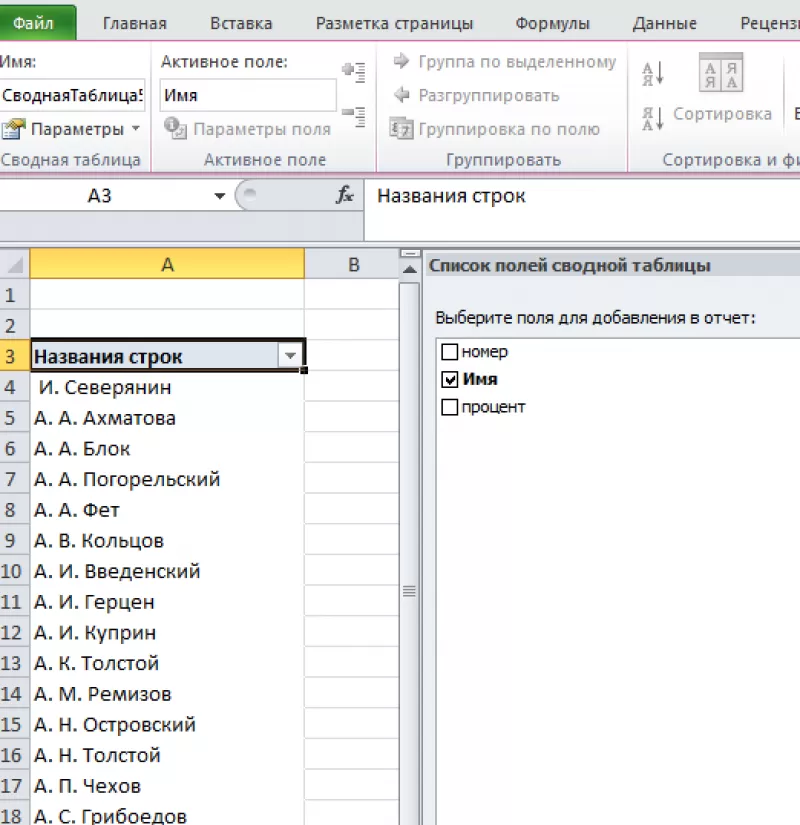
Создаем новый макет сводной таблицы. А затем в качестве строк и значений используем одно и то же поле. В нашем случае – «Товар». Поскольку название товара – это текст, то для подсчета таких значений Excel по умолчанию использует функцию СЧЕТ, то есть подсчитывает количество. А нам это и нужно. Если будет больше 1, значит, имеются дубликаты.

Вы наблюдаете на скриншоте выше, что несколько товаров дублируются. И что нам это дает? А далее мы просто можем щелкнуть мышкой на любой из цифр, и на новом листе Excel покажет нам, как получилась эта цифра.
К примеру, откуда взялись 3 дубликата Sprite? Щелкаем на цифре 3, и видим такую картину:

Думаю, этот метод вполне можно использовать. Что приятно – никаких формул не требуется.
Duplicate Remover – быстрый и эффективный способ найти дубликаты в Excel
Теперь, когда вы знаете, как использовать формулы для поиска повторяющихся значений в Excel, позвольте мне продемонстрировать вам еще один быстрый, эффективный и без всяких формул способ: инструмент Duplicate Remover для Excel.
Этот универсальный инструмент может искать повторяющиеся или уникальные значения в одном столбце или же сравнивать два столбца. Он может находить, выбирать и выделять повторяющиеся записи или целые повторяющиеся строки, удалять найденные дубли, копировать или перемещать их на другой лист. Я думаю, что пример практического использования может заменить очень много слов, так что давайте перейдем к нему.
Как найти повторяющиеся строки в Excel за 2 быстрых шага
Сначала посмотрим в работе наиболее простой инструмент — быстрый поиск дубликатов Quick Dedupe. Используем уже знакомую нам таблицу, в которой мы выше искали дубликаты при помощи формул:

Как видите, в таблице несколько столбцов. Чтобы найти повторяющиеся записи в этих трех столбцах, просто выполните следующие действия:
- Выберите любую ячейку в таблице и нажмите кнопку Quick Dedupe на ленте Excel. После установки пакета Ultimate Suite для Excel вы найдете её на вкладке Ablebits Data в группе Dedupe. Это наиболее простой инструмент для поиска дубликатов.
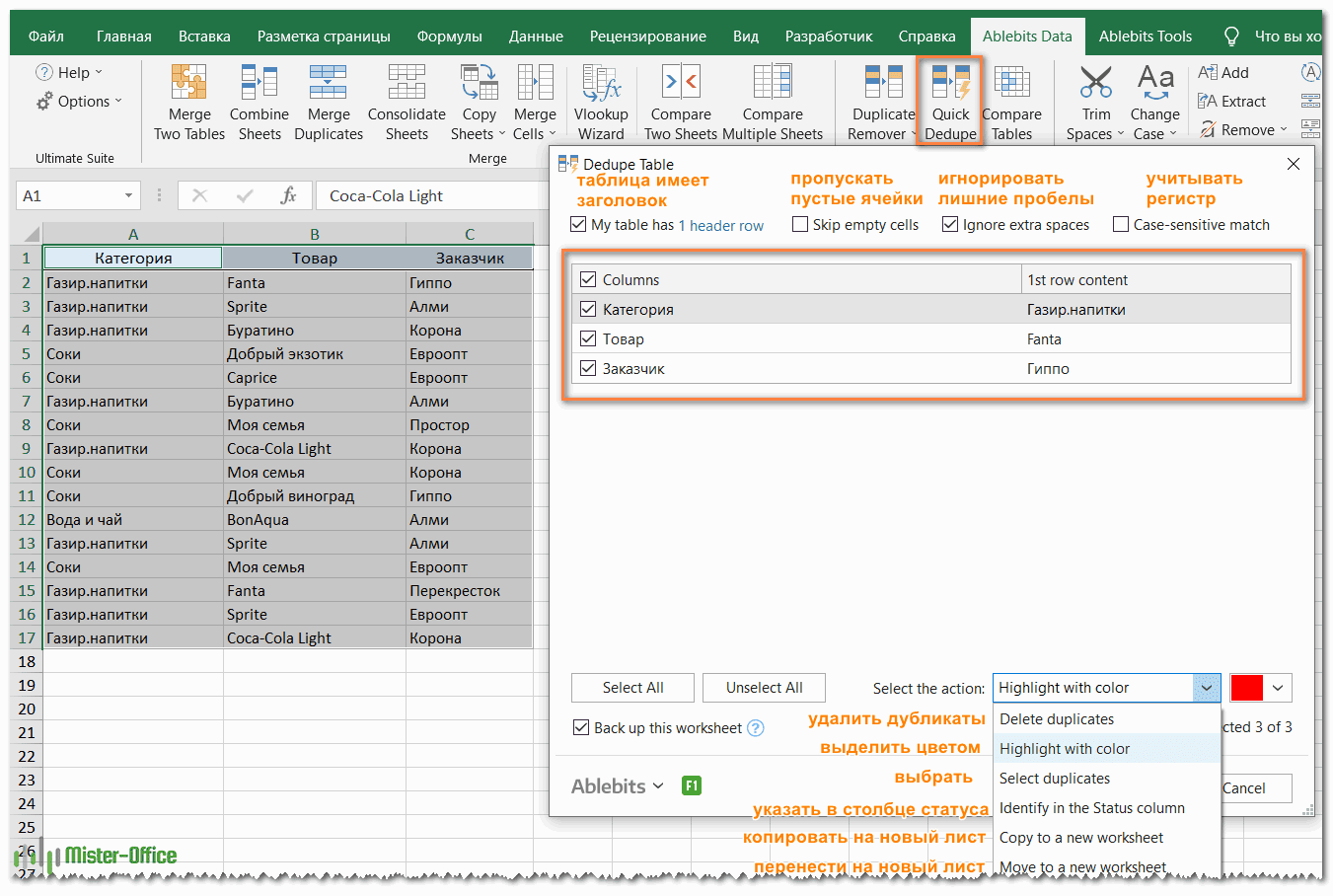
- Интеллектуальная надстройка возьмет всю таблицу и попросит вас указать следующие две вещи:
- Выберите столбцы для проверки дубликатов (в данном примере это все 3 столбца – категория, товар и заказчик).
- Выберите действие, которое нужно выполнить с дубликатами. Поскольку наша цель – выявить повторяющиеся строки, я выбрал «Выделить цветом».
Помимо выделения цветом, вам доступен ряд других опций:
- Удалить дубликаты
- Выбрать дубликаты
- Указать их в столбце статуса
- Копировать дубликаты на новый лист
- Переместить на новый лист
Нажмите кнопку ОК и подождите несколько секунд. Готово! И никаких формул 😊.
Как вы можете видеть на скриншоте ниже, все строки с одинаковыми значениями в первых 3 столбцах были обнаружены (первые вхождения не идентифицируются как дубликаты).

Если вам нужны дополнительные возможности для работы с дубликатами и уникальными значениями, используйте мастер удаления дубликатов Duplicate Remover, который может найти дубликаты с первыми вхождениями или без них, а также уникальные значения. Подробные инструкции приведены ниже.
Мастер удаления дубликатов – больше возможностей для поиска дубликатов в Excel.
В зависимости от данных, с которыми вы работаете, вы можете не захотеть рассматривать первые экземпляры идентичных записей как дубликаты. Одно из возможных решений – использовать разные формулы для каждого сценария, как мы обсуждали в этой статье выше. Если же вы ищете быстрый, точный метод без формул, попробуйте мастер удаления дубликатов — Duplicate Remover. Несмотря на свое название, он не только умеет удалять дубликаты, но и производит с ними другие полезные действия, о чём мы далее поговорим подробнее. Также умеет находить уникальные значения.
- Выберите любую ячейку в таблице и нажмите кнопку Duplicate Remover на вкладке Ablebits Data.
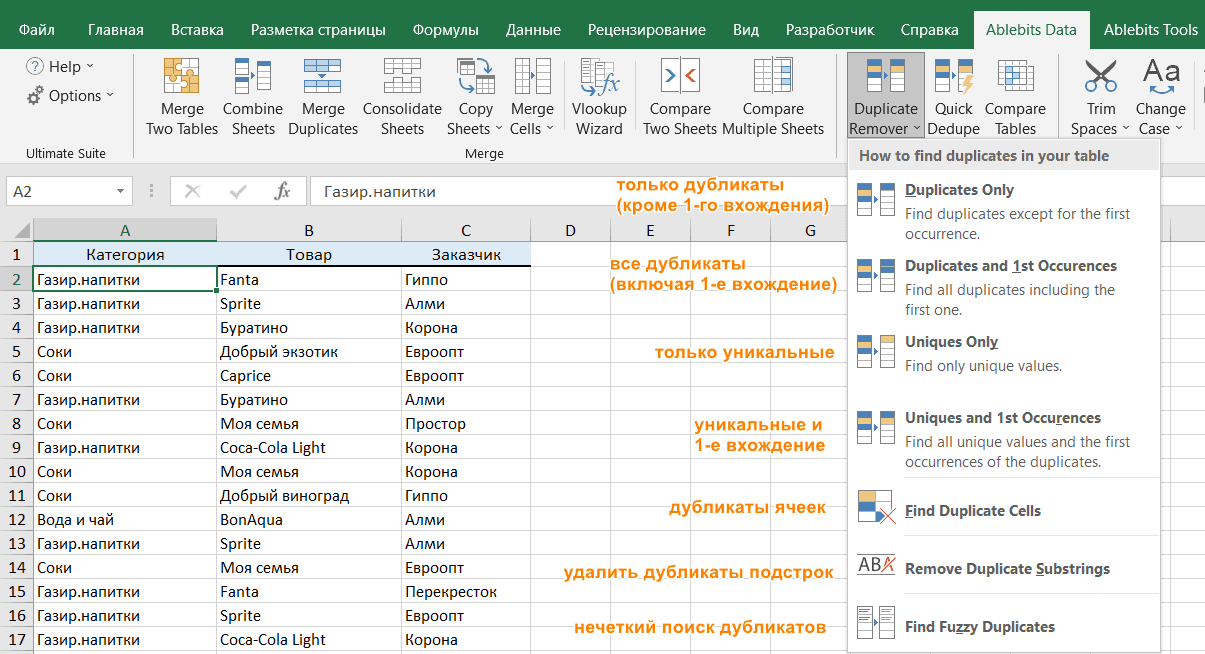
- Вам предложены 4 варианта проверки дубликатов в вашем листе Excel:
- Дубликаты без первых вхождений повторяющихся записей.
- Дубликаты с 1-м вхождением.
- Уникальные записи.
- Уникальные значения и 1-е повторяющиеся вхождения.
В этом примере выберем второй вариант, т.е. Дубликаты + 1-е вхождения:

- Теперь выберите столбцы, в которых вы хотите проверить дубликаты. Как и в предыдущем примере, мы возьмём первые 3 столбца:
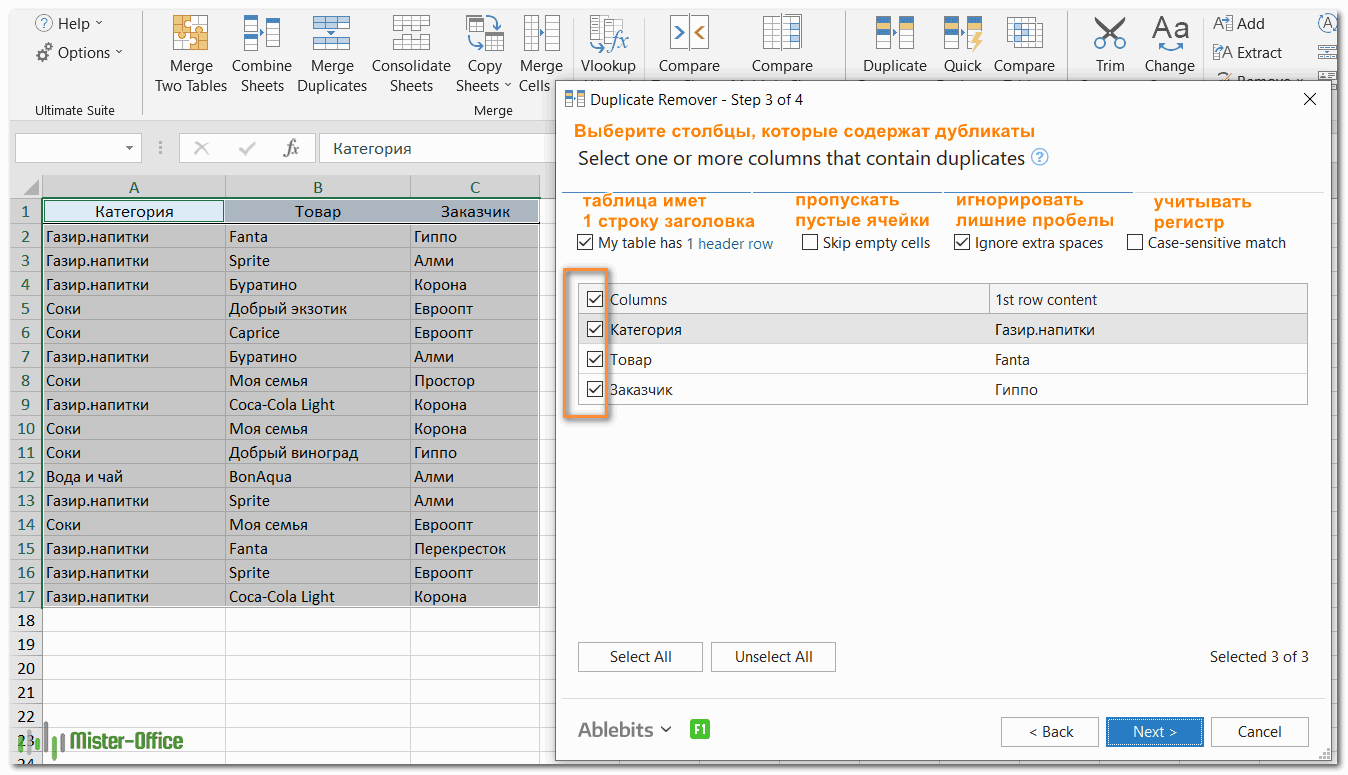
- Наконец, выберите действие, которое вы хотите выполнить с дубликатами. Как и в случае с инструментом быстрого поиска дубликатов, мастер Duplicate Remover может идентифицировать, выбирать, выделять, удалять, копировать или перемещать повторяющиеся данные.

Поскольку цель этого примера – продемонстрировать различные способы определения дубликатов в Excel, давайте отметим параметр «Выделить цветом» (Highlight with color) и нажмите Готово.
Мастеру Duplicate Remover требуется всего лишь несколько секунд, чтобы проверить вашу таблицу и показать результат:

Как видите, результат аналогичен предыдущему. Но здесь мы выделили дубликаты, включая и первое появление повторяющихся записей.
Никаких формул, никакого стресса, никаких ошибок – всегда быстрые и безупречные результаты 🙂
Итак, мы с вам научились различными способами обнаруживать повторяющиеся записи в таблице Excel. В следующих статьях разберем, что мы с этим можем полезного сделать.
Если вы хотите попробовать эти инструменты для поиска дубликатов в таблицах Excel, вы можете загрузить полнофункциональную ознакомительную версию программы. Будем очень признательны за ваши отзывы в комментариях!
При совместной работе с таблицами Excel или большом числе записей накапливаются дубли строк. Ста…
При совместной работе с
таблицами Excel или большом числе записей
накапливаются дубли строк. Статья
посвящена тому, как выделить
повторяющиеся значения в Excel,
удалить лишние записи или сгруппировать,
получив максимум информации.

Поиск
одинаковых значений в Excel
Выберем
одну из ячеек в таблице. Рассмотрим, как
в Экселе найти повторяющиеся значения,
равные содержимому ячейки, и выделить
их цветом.
На
рисунке – списки писателей. Алгоритм
действий следующий:
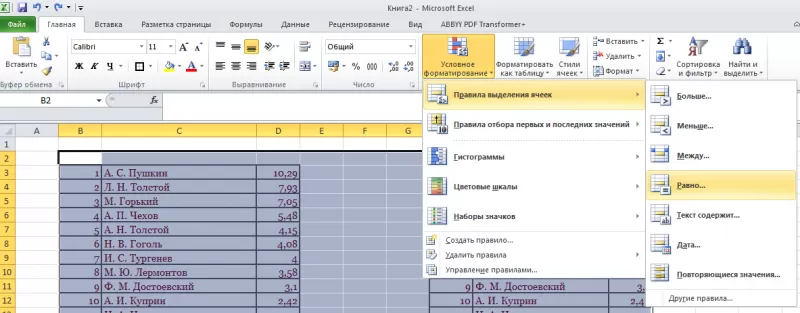
- Выбрать
ячейку I3
с записью «С. А. Есенин». - Поставить
задачу – выделить цветом ячейки с
такими же записями. - Выделить
область поисков. - Нажать
вкладку «Главная». - Далее
группа «Стили». - Затем
«Условное форматирование»; - Нажать
команду «Равно».
- Появится
диалоговое окно:
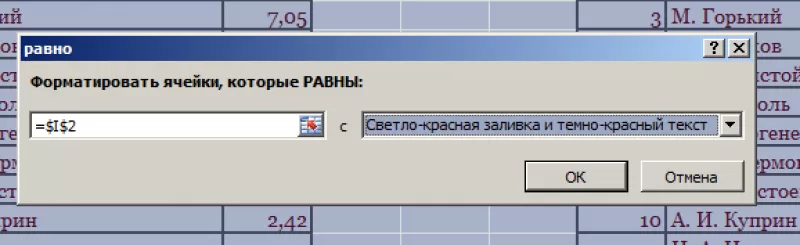
- В
левом поле указать ячейку с I2,
в которой записано «С. А. Есенин». - В
правом поле можно выбрать цвет шрифта. - Нажать
«ОК».
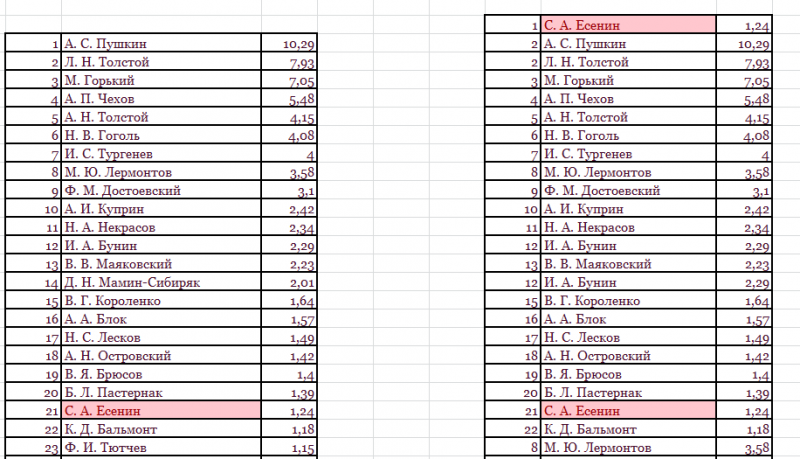
В
таблицах отмечены цветом ячейки, значение
которых равно заданному.
Несложно
понять, как
в Экселе найти одинаковые значения в
столбце.
Просто выделить перед поиском нужную
область – конкретный столбец.
Ищем в таблицах Excel
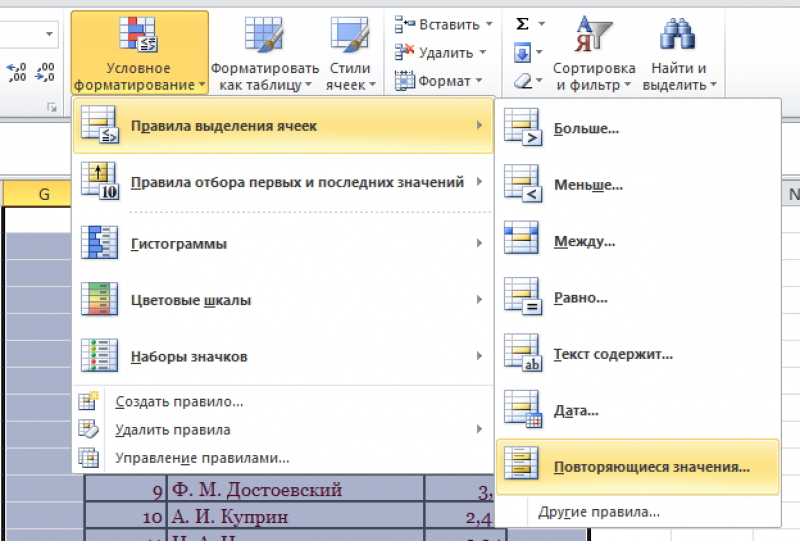
все повторяющиеся значения
Отметим
все неуникальные записи в выделенной
области. Для этого нужно:
- Зайти
в группу «Стили». - Далее
«Условное форматирование». - Теперь
в выпадающем меню выбрать «Правила
выделения ячеек». - Затем
«Повторяющиеся значения».
- Появится
диалоговое окно:
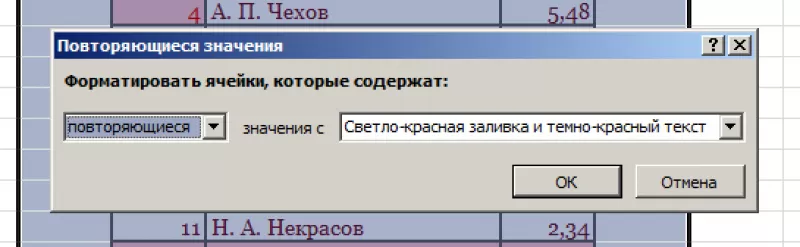
- Нажать
«ОК».
Программа
ищет повторения во всех столбцах.
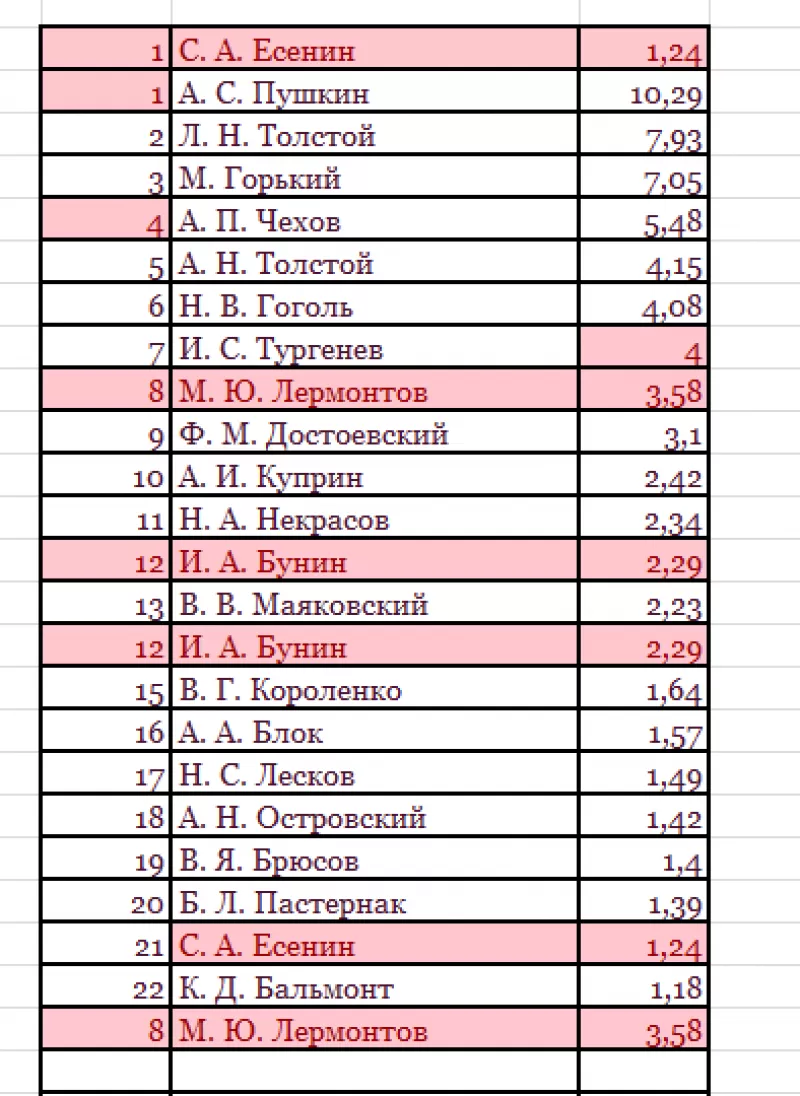
Если
в таблице много неуникальных записей,
то информативность такого поиска
сомнительна.
Удаление одинаковых значений
из таблицы Excel
Способ
удаления неуникальных записей:
- Зайти
во вкладку «Данные». - Выделить
столбец, в котором следует искать
дублирующиеся строки. - Опция
«Удалить дубликаты».
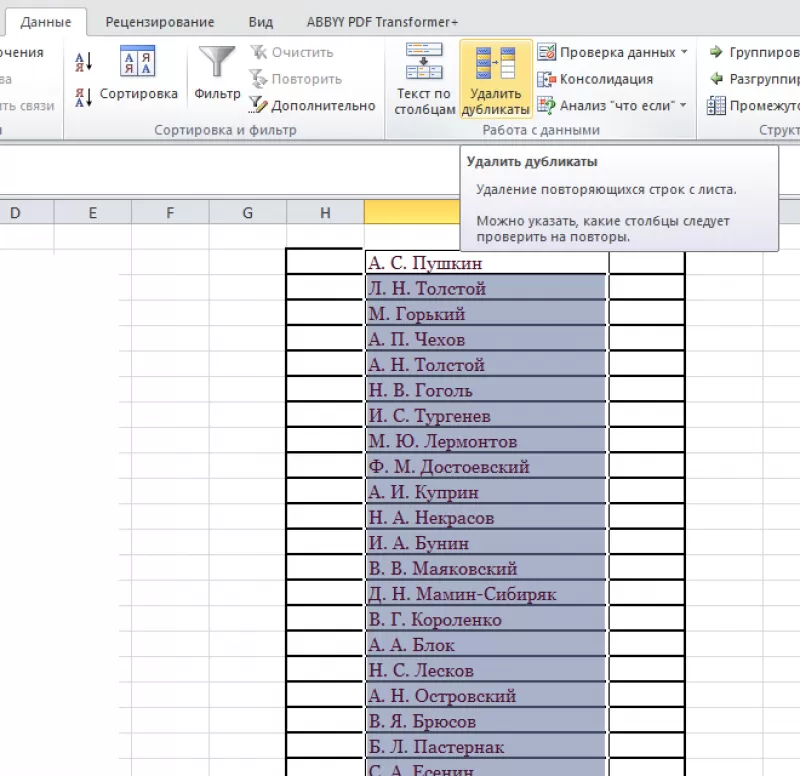
В
результате получаем список, в котором
каждое имя фигурирует только один раз.
Список
с уникальными значениями:

Расширенный фильтр: оставляем
только уникальные записи
Расширенный
фильтр – это инструмент для получения
упорядоченного списка с уникальными
записями.
- Выбрать
вкладку «Данные». - Перейти
в раздел «Сортировка и фильтр». - Нажать
команду «Дополнительно»:
- В
появившемся диалоговом окне ставим
флажок «Только уникальные записи». - Нажать
«OK»
– уникальный список готов.
Поиск дублирующихся значений
с помощью сводных таблиц
Составим
список уникальных строк, не теряя данные
из других столбцов и не меняя исходную
таблицу. Для этого используем инструмент
Сводная таблица:
Вкладка
«Вставка».
Пункт
«Сводная таблица».
В
диалоговом окне выбрать размещение
сводной таблицы на новом листе.
В
открывшемся окне отмечаем столбец, в
котором содержатся интересующие нас
значений.
Получаем
упорядоченный список уникальных строк.
Простой алгоритм для поиска всех совпадающих под-текстов в двух текстах
Время на прочтение
4 мин
Количество просмотров 28K
По долгу службы мне часто нужно находить все пересечения между текстами (например, все цитаты из одного текста в другом). Я достаточно долго искал стандартное решение, которое бы позволило бы это делать, но найти его мне так и не удалось — обычно решается какая-то совсем или немного другая задача. Например, класс SequenceMatcher из difflib в стандартной библиотеке Питона находит самую длинную общую подпоследовательность в двух последовательностях hashable элементов, а потом рекурсивно повторяет поиск слева и справа от нее. Если в одном из текстов будет более короткая подпоследовательность, которая содержится внутри уже найденной (например, если кусок длинной цитаты где-то был повторен еще раз), он ее пропустит. Кроме того, когда я загнал в него «Войну и мир» и «Анну Каренину» в виде списков слов и попросил для начала найти самую длинную подпоследовательность, он задумался на семь минут; когда я попросил все совпадающие блоки, он ушел и не вернулся (в документации обещают среднее линейное время, но что-то в прозе Льва Толстого, по-видимому, вызывает к жизни worst-case квадратичное).
В конечном итоге я придумал свой алгоритм, тем самым наверняка изобретя велосипед, который надеюсь увидеть в комментариях. Алгоритм делает ровно то, что мне нужно: находит все совпадающие последовательности слов в двух текстах (за исключением тех, что в обоих текстах входят в состав более крупных совпадающих последовательностей) и сравнивает «Войну и мир» с «Анной Карениной» за минуту.
Принцип следующий: сначала из каждого текста извлекаются все биграммы и создается хэш-таблица, где для каждой биграммы указан ее порядковый номер. Затем берется более короткий текст, его биграммы перебираются в любом порядке, и если какая-то из них есть в словаре для второго текста, то в отдельно созданный массив добавляются все пары вида (№ биграммы из первого словаря, № биграммы из второго словаря). Например, если в тексте 1 биграмма «А Б» встречается на позициях 1, 2 и 3, а во втором тексте она же встречается на позициях 17, 24 и 56, в массив попадут пары (1, 17), (1, 24), (1, 56), (2, 17)… Это самое слабое место алгоритма: если оба текста состоят из одинаковых слов, то в массив попадет n на m пар цифр. Такие тексты, однако, нам вряд ли попадутся (алгоритм ориентирован на тексты на естественном языке), а чтобы снизить количество бессмысленных совпадений, можно заменить биграммы на любые n-граммы (в зависимости того, какие минимальные совпадения нужны) или выкинуть частотные слова.
Каждая пара цифр в массиве — это совпадение на уровне биграммы. Теперь нам надо получить оттуда совпадающие последовательности, причем если у нас есть совпадение вида «А Б Б В», то тот факт, что ровно эти же фрагменты текста совпадают по «А Б», «Б Б» и «Б В» т. д. надо проигнорировать. Все это очень легко сделать за линейное время при помощи умеренно нетривиальной структуры данных — упорядоченного множества. Оно должно уметь помещать в себя и выкидывать из себя элементы за константное время и помнить, в каком порядке элементы в него добавлялись. Имплементация такого множества для Питона есть здесь: code.activestate.com/recipes/576694-orderedset Для наших нужд оно должно уметь выплевывать из себя элементы не только из конца, но и из начала. Добавляем туда сделанный на скорую руку метод popFirst:
def popFirst(self):
if not self:
raise KeyError('set is empty')
for item in self:
i = item
break
self.discard(i)
return i
Остальное совсем просто: вынимаем из множества первый элемент, кладем во временный массив и, пока можем, добавляем к нему такие элементы из множества, что у каждого следующего и первый и второй индексы на один больше, чем у предыдущего. Когда таких больше не оказывается, отправляем найденную параллельную последовательность в итоговый массив и повторяем заново. Все добавленные элементы тоже выкидываются из множества. Таким образом мы одновременно получаем макисмальные по длине параллельные последовательности, игнорируем совпадения подпоследовательностей в длинных последовательностях и не теряем связи между найденными последовательностями и другими местами в тексте (такие совпадения будут отличаться на первый или второй индекс). В конечном итоге на выходе имеем массив массивов, где каждый подмассив — совпадающая последовательность слов. Можно отсортировать эти подмассивы по длине или по индексу начала (чтобы узнать все параллельные места к тому или иному фрагменту) или отфильтровать по минимальной длине.
Код на Питоне без OrderedSet и с биграммами. compareTwoTexts сразу возвращает результат. Чтобы по номерам биграмм понять, какие именно фрагменты текста совпадают, нужно отдельно сделать словарь биграмм и из него обратный словарь (extractNGrams, getReverseDic) или просто взять список слов (extractWords): каждая биграмма начинается со слова, стоящего в той же позиции, что и она сама.
from OrderedSet import OrderedSet
russianAlphabet = {'й', 'ф', 'я', 'ц', 'ы', 'ч', 'у', 'в', 'с', 'к', 'а', 'м', 'е', 'п', 'и', 'н', 'р', 'т', 'г', 'о', 'ь', 'ш', 'л', 'б', 'щ', 'д', 'ю', 'з', 'ж', 'х', 'э', 'ъ', 'ё'}
def compareTwoTexts(txt1, txt2, alphabet = russianAlphabet):
# txt1 should be the shorter one
ngramd1 = extractNGrams(txt1, alphabet)
ngramd2 = extractNGrams(txt2, alphabet)
return extractCommonPassages(getCommonNGrams(ngramd1, ngramd2))
def extractNGrams(txt, alphabet):
words = extractWords(txt, alphabet)
ngrams = []
for i in range(len(words)-1):
ngrams.append(
(words[i] + ' ' + words[i+1], i)
)
ngramDic = {}
for ngram in ngrams:
try:
ngramDic[ngram[0]].append(ngram[1])
except KeyError:
ngramDic[ngram[0]] = [ngram[1]]
return ngramDic
def extractWords(s, alphabet):
arr = []
temp = []
for char in s.lower():
if char in alphabet or char == '-' and len(temp) > 0:
temp.append(char)
else:
if len(temp) > 0:
arr.append(''.join(temp))
temp = []
if len(temp) > 0:
arr.append(''.join(temp))
return arr
def getReverseDic(ngramDic):
reverseDic = {}
for key in ngramDic:
for index in ngramDic[key]:
reverseDic[index] = key
return reverseDic
def getCommonNGrams(ngramDic1, ngramDic2):
# ngramDic1 should be for the shorter text
allCommonNGrams = []
for nGram in ngramDic1:
if nGram in ngramDic2:
for i in ngramDic1[nGram]:
for j in ngramDic2[nGram]:
allCommonNGrams.append((nGram, i, j))
allCommonNGrams.sort(key = lambda x: x[1])
commonNGramSet = OrderedSet((item[1], item[2]) for item in allCommonNGrams)
return commonNGramSet
def extractCommonPassages(commonNGrams):
if not commonNGrams:
raise ValueError('no common ngrams')
commonPassages = []
temp = []
while commonNGrams:
if not temp:
temp = [commonNGrams.popFirst()]
if not commonNGrams:
break
if (temp[-1][0]+1, temp[-1][1]+1) in commonNGrams:
temp.append((temp[-1][0]+1, temp[-1][1]+1))
commonNGrams.discard((temp[-1][0], temp[-1][1]))
else:
commonPassages.append(temp)
temp = []
if temp:
commonPassages.append(temp)
return commonPassages
Поиск и удаление повторений
Excel для Microsoft 365 Excel 2021 Excel 2019 Excel 2016 Excel 2013 Excel 2010 Excel 2007 Excel Starter 2010 Еще…Меньше
В некоторых случаях повторяющиеся данные могут быть полезны, но иногда они усложняют понимание данных. Используйте условное форматирование для поиска и выделения повторяющихся данных. Это позволит вам просматривать повторения и удалять их по мере необходимости.
-
Выберите ячейки, которые нужно проверить на наличие повторений.
Примечание: В Excel не поддерживается выделение повторяющихся значений в области “Значения” отчета сводной таблицы.
-
На вкладке Главная выберите Условное форматирование > Правила выделения ячеек > Повторяющиеся значения.

-
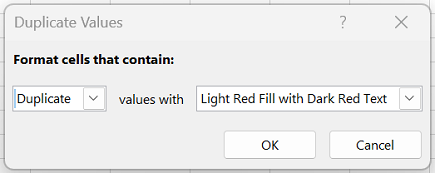
В поле рядом с оператором значения с выберите форматирование для применения к повторяющимся значениям и нажмите кнопку ОК.
Удаление повторяющихся значений
При использовании функции Удаление дубликатов повторяющиеся данные удаляются безвозвратно. Чтобы случайно не потерять необходимые сведения, перед удалением повторяющихся данных рекомендуется скопировать исходные данные на другой лист.
-
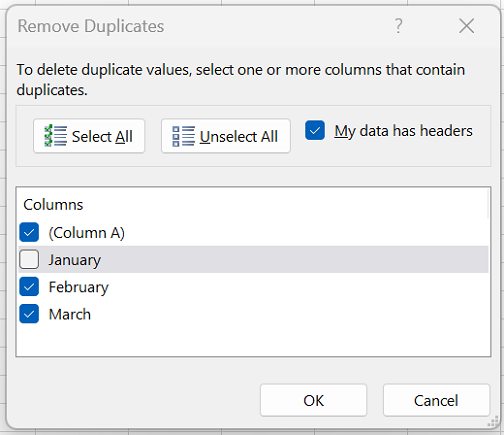
Выделите диапазон ячеек с повторяющимися значениями, который нужно удалить.
-
На вкладке Данные нажмите кнопку Удалить дубликаты и в разделе Столбцы установите или снимите флажки, соответствующие столбцам, в которых нужно удалить повторения.
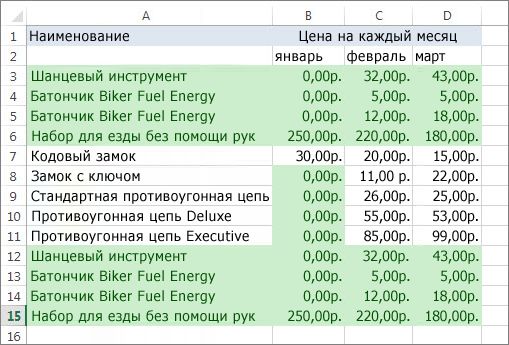
Например, на данном листе в столбце “Январь” содержатся сведения о ценах, которые нужно сохранить.
Поэтому флажок Январь в поле Удаление дубликатов нужно снять.
-
Нажмите кнопку ОК.
Примечание: Количество повторяющихся и уникальных значений, заданных после удаления, может включать пустые ячейки, пробелы и т. д.
Дополнительные сведения

Нужна дополнительная помощь?
Нужны дополнительные параметры?
Изучите преимущества подписки, просмотрите учебные курсы, узнайте, как защитить свое устройство и т. д.
В сообществах можно задавать вопросы и отвечать на них, отправлять отзывы и консультироваться с экспертами разных профилей.
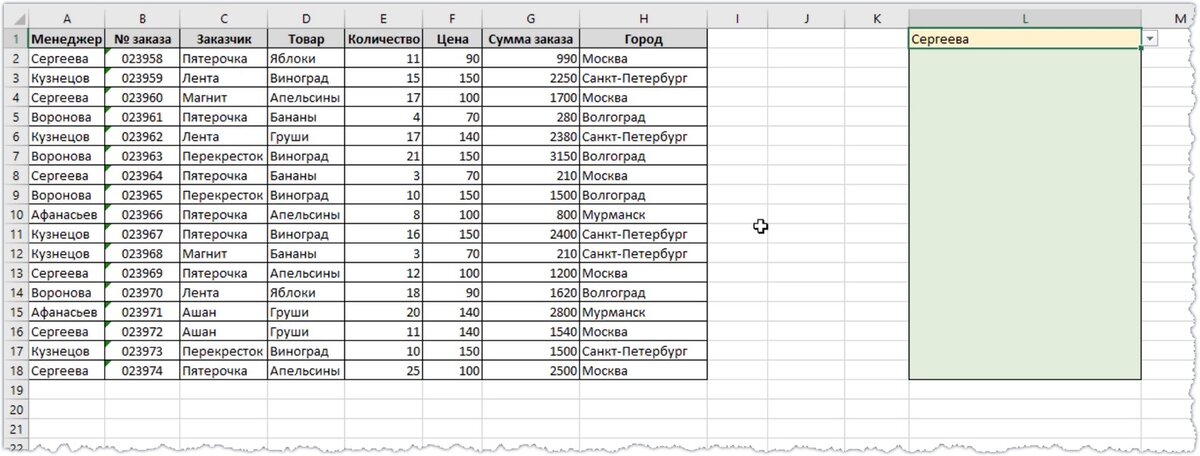
При анализе данных с помощью Excel очень часто приходится искать некоторые значения по определенным критериям и подставлять их в другие таблицы. В таких задачах на помощью приходит функция ВПР, но у нее есть два существенных недостатка. Во-первых, функция ВПР возвращает только первое найденное значение. Например, у меня есть перечень заказов и необходимо получить номера всех заказов, которые оформил конкретный менеджер. Фамилия менеджера выбирается из выпадающего списка (выделено желтым) и ниже должны выводиться соответствующие номера заказов (зеленая область).
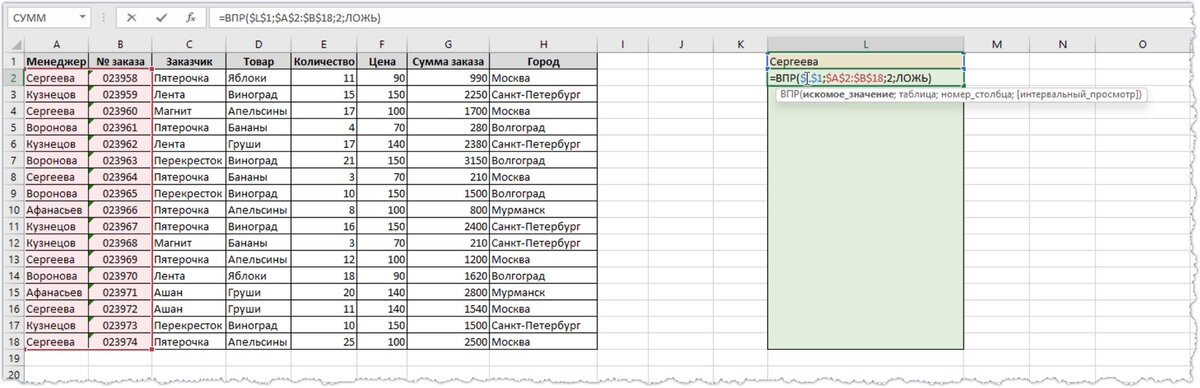
Если использовать стандартную функцию ВПР, то она найдет первый подходящий заказ и вернет ТОЛЬКО его номер.
Еще одним недостатком функции ВПР является то, что она ищет значения только в левом крайнем столбце выделенного диапазона. То есть если бы столбец с фамилиями менеджеров находился правее столбца с номерами заказов, то функцию ВПР вообще не удалось бы использовать.
Этот недостаток устраняется с помощью сочетания функций ИНДЕКС и ПОИСКПОЗ, которые являются более гибкой альтернативой функции ВПР, но и эти функции не решают поставленную задачу.
Как же быть, если нужно вернуть все значения, соответсвующие определенному критерию? В этом также поможет функция ИНДЕКС.
Напомню, что функция ИНДЕКС возвращает значение, которое находится в указанном номере строки выделенного диапазона. То есть мы должны выбрать некоторый диапазон значений и вторым аргументом указать номер строки в этом диапазоне. Подчеркиваю, не номер строки листа Эксель, а номер строки выделенного диапазона значений.
Функция ИНДЕКС может возвращать не только одно значение, а массив значений. И именно это нам и нужно. Чтобы функция вернула массив значений, мы должны в нее подставить массив номеров нужным нам строк. Поэтому основной задачей для нас сейчас как раз и будет получение этого массива.
Давайте рассмотрим упрощенную таблицу, чтобы в ней не было отвлекающей информации. У нас есть таблица, состоящая из двух столбцов – Менеджер и Номер заказа. Также есть выпадающий список с фамилиями менеджеров и некоторая область листа, в которую мы будем выводить все заказы, связанные с выбранным менеджером.
Итак, сначала мы должны определить все строки в основной таблице, относящиеся к выбранному в списке менеджеру. Давайте сделаем это с помощью вспомогательного столбца и функции ЕСЛИ.
Если значение из текущей ячейки первого столбца таблицы (А2) равно значению, выбранному в выпадающем списке (L1), то определим номер строки, в котором это значение находится. Для этого воспользуемся функцией СТРОКА, которая как раз и предназначена для решения этой задачи. Так как формулу мы будем протягивать по диапазону, то не забываем зафиксировать ссылку на ячейку с выпадающем списком.
Протягиваем формулу.
Так как мы не указали в функции ЕСЛИ значение, которое появится в случае невыполнения условия, то в соответствующих ячейках выводится логическое выражение ЛОЖЬ. Это неважно, так как нас будут интересовать только цифры.
Мы получили номера строк листа Эксель, но в функцию ИНДЕКС необходимо подставить номер строки в выделенном диапазоне. В данном примере основная таблица располагается в верху листа и в первой строке находится шапка с названиями столбцов, поэтому, чтобы получить необходимые значения, мы можем откорректировать формулу и отнять единицу от полученного значения. В итоге во вспомогательном столбце появится массив необходимых нам чисел.
Если же таблица находится в другой части листа, то нужно будет либо вручную прописать необходимое корректировочное значение (то есть отступ от первой строки листа), либо можно автоматизировать этот процесс с помощью все той же функции СТРОКА, но об этом я расскажу чуть позже, чтобы сейчас не усложнять формулу.
Итак, теперь нам нужно отсортировать столбец, чтобы в начале были цифры. Сделать это можно, например, с помощью функции НАИМЕНЬШИЙ, которая возвращает указанное по счету наименьшее значение в выбранном диапазоне.
Выбираем диапазон (С2:С18) и затем необходимо указать цифру, определяющую, какое по порядку наименьшее число нужно вывести. Если укажем 1, то получим первое наименьшее значение в диапазоне, если 2, то второе, и так далее. Именно таким образом мы и сможем отсортировать полученный список с помощью формулы. Создадим вспомогательный столбец со значениями по порядку и подставим эти значения в функцию НАИМЕНЬШИЙ.
Мы получили необходимый нам перечень номеров строк и можем вернуться к функции ИНДЕКС. Фактически нам нужно подтянуть значения из второго столбца основной таблицы, поэтому в качестве диапазона указываем его. В качестве строки, соответственно, только что рассчитанные значения.
Чтобы избавиться от ошибки ЧИСЛО! воспользуемся функцией ЕСЛИОШИБКА. Обернем ей полученную функцию и в случае ошибки выведем пустоту.
Мы достигли необходимого результата, но для этого пришлось создать несколько вспомогательных столбцов. Давайте свернем все промежуточные вычисления в одну формулу, но это будет не простая формула, а формула массива, поэтому нам нужно будет поменять некоторые ссылки на диапазоны, к которым они относятся. А если точнее, то в функции ЕСЛИ нужно будет заменить относительные ссылки на ячейки столбца А соответствующим диапазоном и не забываем зафиксировать его. Также не забываем сделать формулу формулой массива, нажав сочетание клавиш Ctrl + Shift + Enter. Растянем формулу на весь зарезервированный диапазон таблицы и получаем необходимый результат.
Все вспомогательные столбцы, кроме столбца с нумерацией (столбец F) можно удалить. Давайте сделаем так, чтобы и этот столбец был не нужен. Значения столбца F используются в функции НАИМЕНЬШИЙ и нам нужно сделать так, чтобы подобный ряд чисел создавался автоматически и не зависел от того, где находится таблица с формулами. Для этого можно воспользоваться функцией СТРОКА и определить номер строки листа Эксель первой ячейки основной таблицы. Затем этот номер будем вычитать из номера последующих строк. Чтобы значения «не сползали» при протягивании формулы, зафиксируем ссылку на первую ячейку диапазона.
Все отлично, кроме того, что все значения нужно увеличить на единицу. Дополним формулу и получим нужный нам результат.
Осталось скопировать формулу и подставить ее в формулу массива, после чего и последний вспомогательный столбец можно будет удалить.
Ну и по аналогии можно решить проблему зависимости формулы от расположения исходной таблицы. Сейчас ее заголовки расположены в первой строке листа и поэтому формула четко привязана к этому положению.
Мы можем внести в функцию ЕСЛИ аналогичную формулу с двумя функциями СТРОКА. То есть отнимем от уже имеющейся функции СТРОКА со всем диапазоном столбца номер строки первой ячейки этого диапазона и прибавим единицу.
Теперь формула никак не привязана к положению исходной таблице на листе и она выполняет поставленную задачу – возвращает все искомые значения из указанного диапазона.
Ссылки на мои ресурсы по Excel
★ YouTube-канал по Excel
★ Телеграм
★ Серия видеокурсов “Microsoft Excel Шаг за Шагом”
★ Авторские книги и курсы
