To quickly see the duplicate rows you can run a single simple query
Here I am querying the table and listing all duplicate rows with same user_id, market_place and sku:
select user_id, market_place,sku, count(id)as totals from sku_analytics group by user_id, market_place,sku having count(id)>1;
To delete the duplicate row you have to decide which row you want to delete. Eg the one with lower id (usually older) or maybe some other date information. In my case I just want to delete the lower id since the newer id is latest information.
First double check if the right records will be deleted. Here I am selecting the record among duplicates which will be deleted (by unique id).
select a.user_id, a.market_place,a.sku from sku_analytics a inner join sku_analytics b where a.id< b.id and a.user_id= b.user_id and a.market_place= b.market_place and a.sku = b.sku;
Then I run the delete query to delete the dupes:
delete a from sku_analytics a inner join sku_analytics b where a.id< b.id and a.user_id= b.user_id and a.market_place= b.market_place and a.sku = b.sku;
Backup, Double check, verify, verify backup then execute.
Сборник запросов для поиска, изменения и удаления дублей в таблице MySQL по одному и нескольким полям. В примерах все запросы будут применятся к следующий таблице:
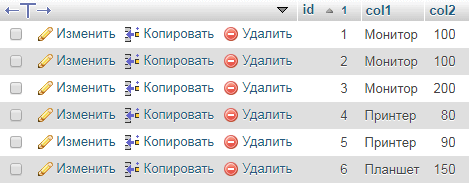
1
Поиск дубликатов
Подсчет дублей
Запрос подсчитает количество всех записей с одинаковыми значениями в поле `col1`.
SELECT
`col1`,
COUNT(`col1`) AS `count`
FROM
`table`
GROUP BY
`col1`
HAVING
`count` > 1SQL

Подсчет дубликатов по нескольким полям:
SELECT
`col1`,
`col2`,
COUNT(*) AS `count`
FROM
`table`
GROUP BY
`col1`,`col2`
HAVING
`count` > 1SQL

Все записи с одинаковыми значениями
Запрос найдет все записи с одинаковыми значениями в `col1`.
SELECT
*
FROM
`table`
WHERE
`col1` IN (SELECT `col1` FROM `table` GROUP BY `col1` HAVING COUNT(*) > 1)
ORDER BY
`col1`SQL
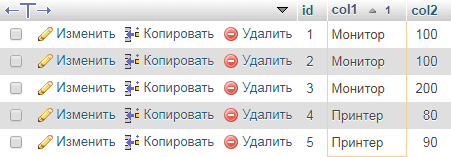
Для одинаковых значений в `col1` и `col2`:
SELECT
*
FROM
`table`
WHERE
`col1` IN (SELECT `col1` FROM `table` GROUP BY `col1` HAVING COUNT(*) > 1)
AND `col2` IN (SELECT `col2` FROM `table` GROUP BY `col2` HAVING COUNT(*) > 1)
ORDER BY
`col1`SQL
Получить только дубликаты
Запрос получит только дубликаты, в результат не попадают записи с самым ранним `id`.
SELECT
`table`.*
FROM
`table`
LEFT OUTER JOIN
(SELECT MIN(`id`) AS `id`, `col1` FROM `table` GROUP BY `col1`) AS `tmp`
ON
`table`.`id` = `tmp`.`id`
WHERE
`tmp`.`id` IS NULLSQL

Для нескольких полей:
SELECT
`table`.*
FROM
`table`
LEFT OUTER JOIN
(SELECT MIN(`id`) AS `id`, `col1`, `col2` FROM `table` GROUP BY `col1`, `col2`) AS `tmp`
ON
`a`.`id` = `tmp`.`id`
WHERE
`tmp`.`id` IS NULLSQL
2
Уникализация записей
Запрос сделает уникальные названия только у дублей, дописав `id` в конец `col1`.
UPDATE
`table`
LEFT OUTER JOIN
(SELECT MIN(`id`) AS `id`, `col1` FROM `table` GROUP BY `col1`) AS `tmp`
ON
`table`.`id` = `tmp`.`id`
SET
`table`.`col1` = CONCAT(`table`.`col1`, '-', `table`.`id`)
WHERE
`tmp`.`id` IS NULLSQL
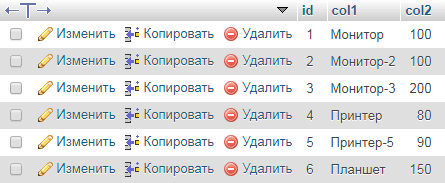
По нескольким полям:
UPDATE
`table`
LEFT OUTER JOIN
(SELECT MIN(`id`) AS `id`, `col1`, `col2` FROM `table` GROUP BY `col1`, `col2`) AS `tmp`
ON
`table`.`id` = `tmp`.`id`
SET
`table`.`col1` = CONCAT(`table`.`col1`, '-', `table`.`id`)
WHERE
`tmp`.`id` IS NULLSQL
3
Удаление дубликатов
Удаление дублирующихся записей, останутся только уникальные.
DELETE
`table`
FROM
`table`
LEFT OUTER JOIN
(SELECT MIN(`id`) AS `id`, `col1` FROM `table` GROUP BY `col1`) AS `tmp`
ON
`table`.`id` = `tmp`.`id`
WHERE
`tmp`.`id` IS NULLSQL
По нескольким полям:
DELETE
`table`
FROM
`table`
LEFT OUTER JOIN
(SELECT MIN(`id`) AS `id`, `col1`, `col2` FROM `table` GROUP BY `col1`, `col2`) AS `tmp`
ON
`table`.`id` = `tmp`.`id`
WHERE
`tmp`.`id` IS NULLSQL
I have a table with a varchar column, and I would like to find all the records that have duplicate values in this column. What is the best query I can use to find the duplicates?
asked Mar 27, 2009 at 4:22
Jon TackaburyJon Tackabury
47.4k50 gold badges129 silver badges167 bronze badges
3
Do a SELECT with a GROUP BY clause. Let’s say name is the column you want to find duplicates in:
SELECT name, COUNT(*) c FROM table GROUP BY name HAVING c > 1;
This will return a result with the name value in the first column, and a count of how many times that value appears in the second.
the Tin Man
158k41 gold badges214 silver badges302 bronze badges
answered Mar 27, 2009 at 4:24
12
SELECT varchar_col
FROM table
GROUP BY varchar_col
HAVING COUNT(*) > 1;
![]()
simhumileco
31.1k16 gold badges136 silver badges112 bronze badges
answered Mar 27, 2009 at 4:27
![]()
maxyfcmaxyfc
11.1k7 gold badges36 silver badges46 bronze badges
2
SELECT *
FROM mytable mto
WHERE EXISTS
(
SELECT 1
FROM mytable mti
WHERE mti.varchar_column = mto.varchar_column
LIMIT 1, 1
)
ORDER BY varchar_column
This query returns complete records, not just distinct varchar_column‘s.
This query doesn’t use COUNT(*). If there are lots of duplicates, COUNT(*) is expensive, and you don’t need the whole COUNT(*), you just need to know if there are two rows with same value.
This is achieved by the LIMIT 1, 1 at the bottom of the correlated query (essentially meaning “return the second row”). EXISTS would only return true if the aforementioned second row exists (i. e. there are at least two rows with the same value of varchar_column) .
Having an index on varchar_column will, of course, speed up this query greatly.
techtheatre
5,4887 gold badges31 silver badges51 bronze badges
answered Mar 27, 2009 at 10:54
QuassnoiQuassnoi
411k91 gold badges612 silver badges612 bronze badges
11
Building off of levik’s answer to get the IDs of the duplicate rows you can do a GROUP_CONCAT if your server supports it (this will return a comma separated list of ids).
SELECT GROUP_CONCAT(id), name, COUNT(*) c
FROM documents
GROUP BY name
HAVING c > 1;
![]()
Novocaine
4,6434 gold badges43 silver badges66 bronze badges
answered Feb 19, 2015 at 0:56
Matt R.Matt R.
2,1291 gold badge16 silver badges19 bronze badges
3
to get all the data that contains duplication i used this:
SELECT * FROM TableName INNER JOIN(
SELECT DupliactedData FROM TableName GROUP BY DupliactedData HAVING COUNT(DupliactedData) > 1 order by DupliactedData)
temp ON TableName.DupliactedData = temp.DupliactedData;
TableName = the table you are working with.
DupliactedData = the duplicated data you are looking for.
slfan
8,920115 gold badges65 silver badges78 bronze badges
answered May 8, 2019 at 8:40
udiudi
2413 silver badges5 bronze badges
2
Assuming your table is named TableABC and the column which you want is Col and the primary key to T1 is Key.
SELECT a.Key, b.Key, a.Col
FROM TableABC a, TableABC b
WHERE a.Col = b.Col
AND a.Key <> b.Key
The advantage of this approach over the above answer is it gives the Key.
answered Mar 27, 2009 at 4:29
TechTravelThinkTechTravelThink
2,9843 gold badges20 silver badges13 bronze badges
3
Taking @maxyfc’s answer further, I needed to find all of the rows that were returned with the duplicate values, so I could edit them in MySQL Workbench:
SELECT * FROM table
WHERE field IN (
SELECT field FROM table GROUP BY field HAVING count(*) > 1
) ORDER BY field
answered Aug 1, 2017 at 22:29
![]()
AbsoluteƵERØAbsoluteƵERØ
7,8162 gold badges24 silver badges35 bronze badges
SELECT *
FROM `dps`
WHERE pid IN (SELECT pid FROM `dps` GROUP BY pid HAVING COUNT(pid)>1)
demongolem
9,41036 gold badges90 silver badges105 bronze badges
answered May 22, 2014 at 14:48
strustamstrustam
1211 silver badge2 bronze badges
1
To find how many records are duplicates in name column in Employee, the query below is helpful;
Select name from employee group by name having count(*)>1;
davejal
5,97910 gold badges38 silver badges82 bronze badges
answered Nov 24, 2015 at 12:12
0
My final query incorporated a few of the answers here that helped – combining group by, count & GROUP_CONCAT.
SELECT GROUP_CONCAT(id), `magento_simple`, COUNT(*) c
FROM product_variant
GROUP BY `magento_simple` HAVING c > 1;
This provides the id of both examples (comma separated), the barcode I needed, and how many duplicates.
Change table and columns accordingly.
answered May 5, 2017 at 2:38
![]()
I am not seeing any JOIN approaches, which have many uses in terms of duplicates.
This approach gives you actual doubled results.
SELECT t1.* FROM my_table as t1
LEFT JOIN my_table as t2
ON t1.name=t2.name and t1.id!=t2.id
WHERE t2.id IS NOT NULL
ORDER BY t1.name
![]()
Mahbub
4,7321 gold badge31 silver badges34 bronze badges
answered Apr 20, 2018 at 10:33
Adam FischerAdam Fischer
1,07511 silver badges23 bronze badges
1
I saw the above result and query will work fine if you need to check single column value which are duplicate. For example email.
But if you need to check with more columns and would like to check the combination of the result so this query will work fine:
SELECT COUNT(CONCAT(name,email)) AS tot,
name,
email
FROM users
GROUP BY CONCAT(name,email)
HAVING tot>1 (This query will SHOW the USER list which ARE greater THAN 1
AND also COUNT)
davejal
5,97910 gold badges38 silver badges82 bronze badges
answered May 30, 2016 at 7:42
1
I prefer to use windowed functions(MySQL 8.0+) to find duplicates because I could see entire row:
WITH cte AS (
SELECT *
,COUNT(*) OVER(PARTITION BY col_name) AS num_of_duplicates_group
,ROW_NUMBER() OVER(PARTITION BY col_name ORDER BY col_name2) AS pos_in_group
FROM table
)
SELECT *
FROM cte
WHERE num_of_duplicates_group > 1;
DB Fiddle Demo
answered Jul 12, 2018 at 17:40
Lukasz SzozdaLukasz Szozda
159k23 gold badges221 silver badges263 bronze badges
SELECT t.*,(select count(*) from city as tt
where tt.name=t.name) as count
FROM `city` as t
where (
select count(*) from city as tt
where tt.name=t.name
) > 1 order by count desc
Replace city with your Table.
Replace name with your field name
![]()
AbsoluteƵERØ
7,8162 gold badges24 silver badges35 bronze badges
answered Jan 25, 2013 at 5:59
0
SELECT ColumnA, COUNT( * )
FROM Table
GROUP BY ColumnA
HAVING COUNT( * ) > 1
AsgarAli
2,2011 gold badge20 silver badges32 bronze badges
answered Mar 27, 2009 at 4:28
Scott FergusonScott Ferguson
7,6707 gold badges41 silver badges64 bronze badges
1
I improved from this:
SELECT
col,
COUNT(col)
FROM
table_name
GROUP BY col
HAVING COUNT(col) > 1;
answered Oct 29, 2020 at 22:57
As a variation on Levik’s answer that allows you to find also the ids of the duplicate results, I used the following:
SELECT * FROM table1 WHERE column1 IN (SELECT column1 AS duplicate_value FROM table1 GROUP BY column1 HAVING COUNT(*) > 1)
answered Feb 24, 2021 at 1:07
![]()
SELECT
t.*,
(SELECT COUNT(*) FROM city AS tt WHERE tt.name=t.name) AS count
FROM `city` AS t
WHERE
(SELECT count(*) FROM city AS tt WHERE tt.name=t.name) > 1 ORDER BY count DESC
![]()
Moseleyi
2,5161 gold badge22 silver badges45 bronze badges
answered Feb 21, 2013 at 8:37
![]()
1
CREATE TABLE tbl_master
(`id` int, `email` varchar(15));
INSERT INTO tbl_master
(`id`, `email`) VALUES
(1, 'test1@gmail.com'),
(2, 'test2@gmail.com'),
(3, 'test1@gmail.com'),
(4, 'test2@gmail.com'),
(5, 'test5@gmail.com');
QUERY : SELECT id, email FROM tbl_master
WHERE email IN (SELECT email FROM tbl_master GROUP BY email HAVING COUNT(id) > 1)
![]()
kodabear
3401 silver badge14 bronze badges
answered Mar 4, 2016 at 7:55
![]()
SELECT DISTINCT a.email FROM `users` a LEFT JOIN `users` b ON a.email = b.email WHERE a.id != b.id;
![]()
answered Jul 1, 2013 at 18:17
Pawel FurmaniakPawel Furmaniak
4,6203 gold badges29 silver badges33 bronze badges
5
For removing duplicate rows with multiple fields , first cancate them to the new unique key which is specified for the only distinct rows, then use “group by” command to removing duplicate rows with the same new unique key:
Create TEMPORARY table tmp select concat(f1,f2) as cfs,t1.* from mytable as t1;
Create index x_tmp_cfs on tmp(cfs);
Create table unduptable select f1,f2,... from tmp group by cfs;
answered Feb 4, 2016 at 9:58
2
One very late contribution… in case it helps anyone waaaaaay down the line… I had a task to find matching pairs of transactions (actually both sides of account-to-account transfers) in a banking app, to identify which ones were the ‘from’ and ‘to’ for each inter-account-transfer transaction, so we ended up with this:
SELECT
LEAST(primaryid, secondaryid) AS transactionid1,
GREATEST(primaryid, secondaryid) AS transactionid2
FROM (
SELECT table1.transactionid AS primaryid,
table2.transactionid AS secondaryid
FROM financial_transactions table1
INNER JOIN financial_transactions table2
ON table1.accountid = table2.accountid
AND table1.transactionid <> table2.transactionid
AND table1.transactiondate = table2.transactiondate
AND table1.sourceref = table2.destinationref
AND table1.amount = (0 - table2.amount)
) AS DuplicateResultsTable
GROUP BY transactionid1
ORDER BY transactionid1;
The result is that the DuplicateResultsTable provides rows containing matching (i.e. duplicate) transactions, but it also provides the same transaction id’s in reverse the second time it matches the same pair, so the outer SELECT is there to group by the first transaction ID, which is done by using LEAST and GREATEST to make sure the two transactionid’s are always in the same order in the results, which makes it safe to GROUP by the first one, thus eliminating all the duplicate matches. Ran through nearly a million records and identified 12,000+ matches in just under 2 seconds. Of course the transactionid is the primary index, which really helped.
![]()
answered Sep 6, 2016 at 13:52
0
Select column_name, column_name1,column_name2, count(1) as temp from table_name group by column_name having temp > 1
answered Dec 18, 2015 at 18:21
Vipin JainVipin Jain
3,67816 silver badges35 bronze badges
If you want to remove duplicate use DISTINCT
Otherwise use this query:
SELECT users.*,COUNT(user_ID) as user FROM users GROUP BY user_name HAVING user > 1;
benc
1,3435 gold badges31 silver badges39 bronze badges
answered Jan 14, 2019 at 7:21
Thanks to @novocaine for his great answer and his solution worked for me. I altered it slightly to include a percentage of the recurring values, which was needed in my case. Below is the altered version. It reduces the percentage to two decimal places. If you change the ,2 to 0, it will display no decimals, and to 1, then it will display one decimal place, and so on.
SELECT GROUP_CONCAT(id), name, COUNT(*) c,
COUNT(*) OVER() AS totalRecords,
CONCAT(FORMAT(COUNT(*)/COUNT(*) OVER()*100,2),'%') as recurringPecentage
FROM table
GROUP BY name
HAVING c > 1
answered Sep 21, 2021 at 14:36
![]()
Iwan RossIwan Ross
1962 silver badges10 bronze badges
Try using this query:
SELECT name, COUNT(*) value_count FROM company_master GROUP BY name HAVING value_count > 1;
answered Nov 15, 2018 at 9:16
Summary: in this tutorial, you will learn how to find duplicate values of one or more columns in MySQL.
Data duplication happens because of many reasons. Finding duplicate values is one of the important tasks that you must deal with when working with the databases.
Setting up a sample table
First, create a table named contacts with four columns: id, first_name, last_name, and email.
CREATE TABLE contacts (
id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(255) NOT NULL
);
Code language: SQL (Structured Query Language) (sql)Second, inserts rows into the contacts table:
INSERT INTO contacts (first_name,last_name,email)
VALUES ('Carine ','Schmitt','carine.schmitt@verizon.net'),
('Jean','King','jean.king@me.com'),
('Peter','Ferguson','peter.ferguson@google.com'),
('Janine ','Labrune','janine.labrune@aol.com'),
('Jonas ','Bergulfsen','jonas.bergulfsen@mac.com'),
('Janine ','Labrune','janine.labrune@aol.com'),
('Susan','Nelson','susan.nelson@comcast.net'),
('Zbyszek ','Piestrzeniewicz','zbyszek.piestrzeniewicz@att.net'),
('Roland','Keitel','roland.keitel@yahoo.com'),
('Julie','Murphy','julie.murphy@yahoo.com'),
('Kwai','Lee','kwai.lee@google.com'),
('Jean','King','jean.king@me.com'),
('Susan','Nelson','susan.nelson@comcast.net'),
('Roland','Keitel','roland.keitel@yahoo.com');
Code language: SQL (Structured Query Language) (sql)Third, query data from the contacts table:
SELECT * FROM contacts
ORDER BY email;Code language: SQL (Structured Query Language) (sql)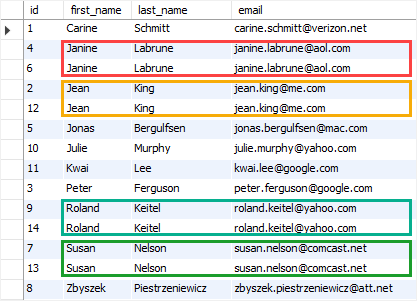
In the contacts table, we have some rows that have duplicate values in the first_name, last_name, and email columns. Let’s learn how to find them.
Find duplicate values in one column
The find duplicate values in on one column of a table, you use follow these steps:
- First, use the
GROUP BYclause to group all rows by the target column, which is the column that you want to check duplicate. - Then, use the
COUNT()function in theHAVINGclause to check if any group have more than 1 element. These groups are duplicate.
The following query illustrates the idea:
SELECT
col,
COUNT(col)
FROM
table_name
GROUP BY col
HAVING COUNT(col) > 1;
Code language: SQL (Structured Query Language) (sql)By using this query template, you can to find rows that have duplicate emails in the contacts table as follows:
SELECT
email,
COUNT(email)
FROM
contacts
GROUP BY email
HAVING COUNT(email) > 1;
Code language: SQL (Structured Query Language) (sql)This picture shows the output of the query that shows the duplicate emails:

Find duplicate values in multiple columns
Sometimes, you want to find duplicate rows based on multiple columns instead of one. In this case, you can use the following query:
SELECT
col1, COUNT(col1),
col2, COUNT(col2),
...
FROM
table_name
GROUP BY
col1,
col2, ...
HAVING
(COUNT(col1) > 1) AND
(COUNT(col2) > 1) AND
...
Code language: SQL (Structured Query Language) (sql)Rows are considered duplicate only when the combination of columns are duplicate therefore we used the AND operator in the HAVING clause.
For example, to find rows in the contacts table with duplicate values in first_name, last_name, and email column, you use the following query:
SELECT
first_name, COUNT(first_name),
last_name, COUNT(last_name),
email, COUNT(email)
FROM
contacts
GROUP BY
first_name ,
last_name ,
email
HAVING COUNT(first_name) > 1
AND COUNT(last_name) > 1
AND COUNT(email) > 1;
Code language: SQL (Structured Query Language) (sql)The following illustrates the output of the query:

In this tutorial, you have learned how to find duplicate rows based on value of one or more columns in MySQL.
Was this tutorial helpful?
Introduction
MySQL is a database application that stores data in rows and columns of different tables to avoid duplication. Duplicate values can occur, which can impact MySQL performance.
This guide will show you how to find duplicate values in a MySQL database.

Prerequisites
- An existing installation of MySQL
- Root user account credentials for MySQL
- A command line / terminal window
Setting up a Sample Table (Optional)
This step will help you create a sample table to work with. If you already have a database to work on, skip to the next section.
Open a terminal window, and switch to the MySQL shell:
mysql –u root –pNote: If you get ‘ERROR 1698’, try opening MySQL using sudo mysql instead. This error occurs on some Ubuntu installations and is caused by authentication settings.
List existing databases:
SHOW databases;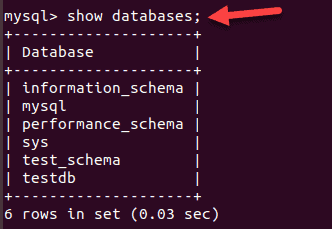
Create a new database that doesn’t already exist:
CREATE database sampledb;Select the table you just created:
USE sampledb;Create a new table with the following fields:
CREATE TABLE dbtable (
id INT PRIMARY KEY AUTO_INCREMENT,
date_x VARCHAR(10) NOT NULL,
system_x VARCHAR(50) NOT NULL,
test VARCHAR(50) NOT NULL
);Insert rows into the table:
INSERT INTO dbtable (date_x,system_x,test)
VALUES ('01/03/2020','system1','hard_drive'),
('01/04/2020','system2','memory'),
('01/10/2020','system2','processor'),
('01/14/2020','system3','hard drive'),
('01/10/2020','system2','processor'),
('01/20/2020','system4','hard drive'),
('01/24/2020','system5','memory'),
('01/29/2020','system6','hard drive'),
('02/02/2020','system7','motherboard'),
('02/04/2020','system8','graphics card'),
('02/02/2020','system7','motherboard'),
('02/08/2020','system9','hard drive');Run the following SQL query:
SELECT * FROM dbtable
ORDER BY date_x;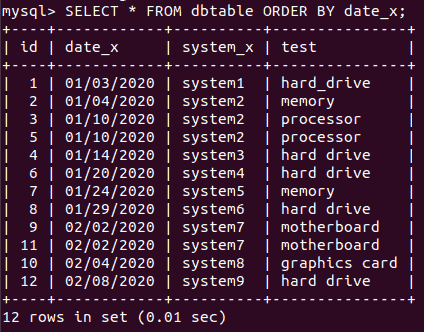
Finding Duplicates in MySQL
Find Duplicate Values in a Single Column
Use the GROUP BY function to identify all identical entries in one column. Follow up with a COUNT() HAVING function to list all groups with more than one entry.
SELECT
test,
COUNT(test)
FROM
dbtable
GROUP BY test
HAVING COUNT(test) > 1;
Find Duplicate Values in Multiple Columns
You may want to list exact duplicates, with the same information in all three columns.
SELECT
date_x, COUNT(date_x),
system_x, COUNT(system_x),
test, COUNT(test)
FROM
dbtable
GROUP BY
date_x,
system_x,
test
HAVING COUNT(date_x)>1
AND COUNT(system_x)>1
AND COUNT(test)>1;

This query works by selecting and testing for the >1 condition on all three columns. The result is that only rows with duplicate values are returned in the output.
Check for Duplicates in Multiple Tables With INNER JOIN
Use the INNER JOIN function to find duplicates that exist in multiple tables.
Sample syntax for an INNER JOIN function looks like this:
SELECT column_name
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column name;
To test this example, you need a second table that contains some information duplicated from the sampledb table we created above.
SELECT dbtable.date_x
FROM dbtable
INNER JOIN new_table
ON dbtable.date_x = new_table.date_x;
This will display any duplicate dates that exist between the existing data and the new_table.
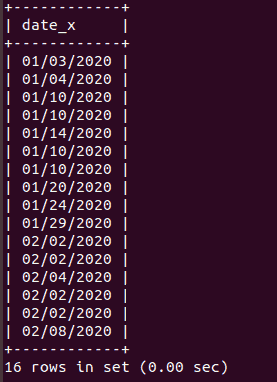
Note: The DISTINCT command can be used to return results while ignoring duplicates. Also, newer versions of MySQL use a strict mode, which can affect operations that attempt to select all columns. If you get an error, make sure that you’re selecting specific individual columns.
Conclusion
Now you can check for duplicates in MySQL data in one or multiple tables and understand the INNER JOIN function. Make sure you created the tables correctly and that you select the right columns.
Now that you have found duplicate values, learn how to remove MySQL duplicate rows.
