Достаточные статистики и оптимальные оценки.
Если для любой оценки
![]() из
из
класса
![]()
![]() ,
,
для любого
![]() ,
,
то оценку Т* называют оценкой с
равномерно минимальной дисперсией.
Такая оценка
называется оптимальной
оценкой.
Итак, T*
– оптимальная оценка для параметрической
функции
![]() ,
,
если
![]() ,
,
![]() ,
,
![]() .
.
Статистика
![]() называется
называется
достаточной
для
параметрического семейства распределений
P=![]() (или
(или
достаточной для параметра
![]() ),
),
если условный закон распределения
выборки при условии, что статистика
T(X)
приняла некоторое фиксированное значение
t,
не зависит от параметра
![]() .
.
Теорема
Рао-Блекуэлла-Колмогорова: Оптимальная
оценка, если она существует, является
функцией от достаточной статистики.
Теорема:
Если существует полная достаточная
статистика, то всякая функция от неё
является оптимальной оценкой своего
математического ожидания.
То есть оптимальная
оценка однозначно определяется уравнением
![]() ,
,
где Т – полная достаточная статистика,
H(T)
– произвольная функция от Т.
Функция
![]() ,
,
рассматриваемая при фиксированной
реализации выборки
![]() как
как
функция от
![]() ,
,
называется функцией
правдоподобия.
Критерий
факторизации.
Для того, чтобы
статистика была достаточной для
параметрического семейства распределений
P,
необходимо и достаточно, чтобы функция
правдоподобия выборки
![]() в
в
нём допускала следующее представление:
![]()
Где множитель h(x)
от
![]()
не зависит, а функция g(.)
от реализации выборки
![]() зависит
зависит
через функцию T(x).
Если
![]() при
при
возрастании θ, то в этом случае существует
одномерная достаточная статистика
![]()
Аналогично, если
![]() при
при
возрастании θ, то одномерная достаточная
статистика существует и имеет вид
![]()
Этими двумя случаями
исчерпываются ситуации, когда в модели
![]()
существует одномерная достаточная
статистика.
Для модели
![]() достаточной
достаточной
статистикой является
![]() ,
,
а для моделей
![]() и
и
![]() минимальной
минимальной
достаточной статистикой является T.
Оценка методом моменов .
Пусть неизвестный
параметр распределения наблюдаемой
случайной величины
![]() векторный:
векторный:
![]()
и у случайной величины
![]() существует
существует
конечный r-ый
момент:
![]()
Оценкой неизвестного
параметра
![]() ,
,
полученной методом моментов (ОММ),
называется вектор
![]() ,
,
где
![]()
есть решение системы
уравнений:
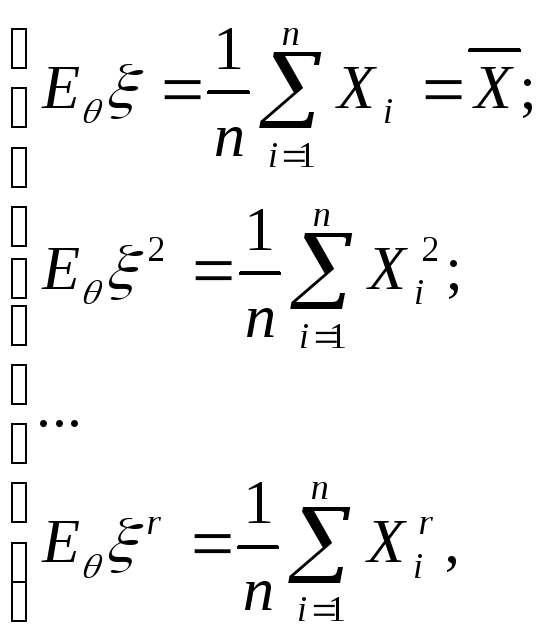
Теоретические
моменты, являющиеся функциями от
неизвестных параметров
![]() ,
,
приравниваются к
их статистическим аналогам – выборочным
моментам. Полученная система – это
система r
уравнений с r
переменными. Если решения системы
уравнений нет, оценки по методу моментов
не существует. Если имеется несколько
решений, то существует несколько таких
оценок. Если система уравнений имеет
единственное решение, то оценка по
методу моментов является состоятельной
оценкой параметра
![]() .
.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Виктория123 писал(а):
… чтобы доказать полноту, надо поссчитать мат.ожидание от какой то функции $$") ? И показать что оно равно
? И показать что оно равно  только в случае равенства нулю этой функции
только в случае равенства нулю этой функции  ?
?
Да.
Пусть оптимальной оценкой
называется несмещенная оценка с равномерно минимальной дисперсией. В зависимости от программы, возможно несколько способов построения оптимальной оценки  :
:
0. Угадать и проверить по определению.
1. Воспользоваться теоремой о том, что функция от полной достаточной статистики является оптимальной оценкой своего ожидания.
2. Воспользоваться критерием Бхаттачария.
Идя первым путем, Вы доказали достаточность. Для доказательства полноты, попробуйте воспользоваться его определением (приведите свое определение; используемое мною может отличаться от принятого у Вас в курсе). После этого, попробуйте подобрать функцию этой статистики, математическое ожидание которой равно, возможно с точностью до постоянного коэффициента, .
Добавлено
Виктория123 писал(а):
В семействе биномиальных распределений $$") найти оптимальную(с равномерно минимальной дисперсией
найти оптимальную(с равномерно минимальной дисперсией
) оценку для параметрической функции ={theta}^2$$")
[Выделение цветом – GAA
]
Иногда, оптимальной
(в [1], и ряде других книг, принят термин эффективная
) называют несмещенную
оценку с равномерно минимальной дисперсией. Именно о построении такой оценки я писал выше.
[1] Боровков А.А. Математическая статистика. Оценка параметров, проверка гипотез. — М.: Наука, 1984.
14.4.1. Оптимальная оценка по критерию максимума апостериорной плотности.
Предположим теперь, что однородная независимая выборка  принадлежит распределению с плотностью
принадлежит распределению с плотностью  причем
причем  — случайный параметр с известной плотностью вероятности до
— случайный параметр с известной плотностью вероятности до  . При таких априорных данных оптимальный алгоритм оценивания параметра
. При таких априорных данных оптимальный алгоритм оценивания параметра  синтезируется по критерию максимума апостериорной плотности вероятности
синтезируется по критерию максимума апостериорной плотности вероятности  оцениваемого параметра [см. (12.26)]. По формуле Байеса находим [см. (2.61)]
оцениваемого параметра [см. (12.26)]. По формуле Байеса находим [см. (2.61)]
 (14.70)
(14.70)
где
 (14.70 а)
(14.70 а)
Так как логарифм — монотонная функция, то точки экстремумов функции  по
по  совпадают с точками экстремумов по
совпадают с точками экстремумов по  функции
функции
 (14.71)
(14.71)
Если функция  дифференцируема по
дифференцируема по  , то ее максимум определяет оптимальную оценку
, то ее максимум определяет оптимальную оценку  максимальной апостериорной плотности согласно уравнению
максимальной апостериорной плотности согласно уравнению
 (14.72)
(14.72)
при условии

Для независимой выборки из (14.72) следует
 (14.73)
(14.73)
Оценка максимальной апостериорной плотности вероятности состоятельная и асимптотическая эффективная. Распределение ее при  асимптотически нормальное с параметрами
асимптотически нормальное с параметрами  , где
, где  — информация по Фишеру [см. (14.39 а)].
— информация по Фишеру [см. (14.39 а)].
Если априорное распределение случайного параметра  равномерное на заданном интервале, то [см. (14.71)]
равномерное на заданном интервале, то [см. (14.71)]

и, следовательно, при этом оценка максимальной апостериорной плотности совпадает с оценкой максимального правдоподобия.
14.4.2. Байесовские оценки.
Предположим, что наряду с априорными данными, указанными в п. 14.4.1, задана также функция потерь  (см. п. 12.2.5). Тогда имеется полный комплект априорных данных, необходимый для синтеза байесовского алгоритма оценивания случайного скалярного параметра
(см. п. 12.2.5). Тогда имеется полный комплект априорных данных, необходимый для синтеза байесовского алгоритма оценивания случайного скалярного параметра  . Как показано в п. 12.4.2, байесовской оценкой, минимизирующей средний риск, является оценка минимального апостериорного риска [см. (12.20)]
. Как показано в п. 12.4.2, байесовской оценкой, минимизирующей средний риск, является оценка минимального апостериорного риска [см. (12.20)]
 (14.74)
(14.74)
Минимизация функционала (14.74) представляет задачу вариационного исчисления, Функционал  в правой части (14.74) зависит от вида функции
в правой части (14.74) зависит от вида функции  и необходимое условие минимума можно записать в виде
и необходимое условие минимума можно записать в виде
 (14.75)
(14.75)
Выбор функции потерь в известной мере субъективен и зависит от конкретной задачи оценивания параметра. Наиболее часто используются функции потерь, которые представляют четные функции ошибки  оценивания, монотонно возрастающие (неубывающие) при увеличении модуля ошибки.
оценивания, монотонно возрастающие (неубывающие) при увеличении модуля ошибки.
Далее рассматриваются байесовские ошибки при функциях потерь указанного вида.
14.4.3. Простая функция потерь.
Рассмотрим функцию потерь, которая равна постоянной с для всех значений ошибок и дает бесконечный «выигрыш» при точном оценивании
 (14.76)
(14.76)
Функция потерь (14.76) называется простой.
Подставляя (14.76) в (14.74), получаем

Из (14.77) следует, что байесовская оценка при простой функции потерь совпадает с оценкой максимальной апостериорной плотности вероятности оцениваемого параметра.
14.4.4. Квадратичная функция потерь.
При квадратичной функции потерь
 (14.78)
(14.78)
апостериорный риск
 (14.79)
(14.79)
Подставляя (14.79) в (14.75) и разрешая уравнение относительно функции  , получаем
, получаем
 (14.80)
(14.80)
или
 (14.80 а)
(14.80 а)
Функцию правдоподобия  в (14.80 а) можно заменить статистикой отношения правдоподобия
в (14.80 а) можно заменить статистикой отношения правдоподобия
 (14.806)
(14.806)
где  — некоторое фиксированное значение параметра [ср. также с (14.64 а)].
— некоторое фиксированное значение параметра [ср. также с (14.64 а)].
Из (14.80) следует, что байесовская оценка при квадратичной функции потерь представляет условное среднее значение оцениваемого параметра  при заданной выборке
при заданной выборке  . Нетрудно убедиться, что (14.80) соответствует минимуму апостериорного риска, так как
. Нетрудно убедиться, что (14.80) соответствует минимуму апостериорного риска, так как 
Условное среднее (14.80) является несмещенной оценкой параметра
 (14.81)
(14.81)
и, следовательно, [см. (14.79)]
 (14.82)
(14.82)
В отличие от простой функции потерь, для которой байесовская оценка определяется локальными свойствами апостериорной плотности вероятности оцениваемого параметра  в окрестности ее максимума, байесовская оценка при квадратичной функции потерь зависит от изменения указанной апостериорной плотности во всем диапазоне измерения параметра
в окрестности ее максимума, байесовская оценка при квадратичной функции потерь зависит от изменения указанной апостериорной плотности во всем диапазоне измерения параметра  . Заметим, однако, что для унимодальной и симметричной относительно моды апостериорной плотности распределения условное среднее совпадает с модой и, следовательно, байесовская оценка при квадратичной функции потерь совпадает с оценкой по критерию максимума апостериорной плотности, т. е. с байесовской оценкой при простой функции потерь.
. Заметим, однако, что для унимодальной и симметричной относительно моды апостериорной плотности распределения условное среднее совпадает с модой и, следовательно, байесовская оценка при квадратичной функции потерь совпадает с оценкой по критерию максимума апостериорной плотности, т. е. с байесовской оценкой при простой функции потерь.
14.4.5. Функция потерь, равная модулю ошибки.
Для функции потерь
 (14.83)
(14.83)
апостериорный риск

откуда согласно условию (14.75)

или
 (14.84)
(14.84)
Из (14.84) следует, что байесовская оценка при функции потерь, равной модулю ошибки, совпадает с условной медианой оцениваемого параметра  при заданной выборке
при заданной выборке 
Если апостериорная плотность вероятности оцениваемого параметра унимодальна и симметрична относительно моды, то медиана и среднее значение этого распределения совпадают и равны его моде. В этом случае байесовские оценки при функции потерь, равной модулю ошибки, и при квадратичной функции потерь одинаковы и совпадают с оценкой максимальной апостериорной плотности вероятности.
14.4.6. Прямоугольная функция потерь.
Для функции потерь

апостериорный риск
 (14.85)
(14.85)
откуда из (14.75) получаем следующее трансцендентное уравнение для определения байесовской оценки при прямоугольной функции потерь:
 (14.86)
(14.86)
Если апостериорная плотность вероятности оцениваемого параметра унимодальна и симметрична относительно моды, то единственным решением уравнения (14.86) является такая оценка  , которая совпадает с модой указанной апостериорной плотности вероятности. В этом случае байесовская оценка при прямоугольной функции потерь совпадает с оценкой, соответствующей максимальной апостериорной плотности вероятности, т. е. с байесовской оценкой при простой и квадратичной функциях потерь.
, которая совпадает с модой указанной апостериорной плотности вероятности. В этом случае байесовская оценка при прямоугольной функции потерь совпадает с оценкой, соответствующей максимальной апостериорной плотности вероятности, т. е. с байесовской оценкой при простой и квадратичной функциях потерь.
14.4.7. Симметричная функция потерь.
Рассмотрим произвольную функцию потерь, четную относительно ошибки и неубывающую при увеличении модуля ошибки
 (14.87)
(14.87)
Все указанные в п.п. 14.4.3-14.4.6 функции потерь являются функциями такого вида. Предположим, что апостериорная плотность вероятности параметра  при заданной выборке
при заданной выборке  унимодальна и симметрична относительно моды. Из этого предположения следует, что условное среднее
унимодальна и симметрична относительно моды. Из этого предположения следует, что условное среднее  является модой апостериорной плотности, т. е.
является модой апостериорной плотности, т. е.  – четная функция аргумента
– четная функция аргумента 
Запишем уравнение (14.75)
 (14.88)
(14.88)
Так как  — четная функция, ее производная
— четная функция, ее производная  -нечетная функция аргумента
-нечетная функция аргумента 
Поэтому величина  тождественно обращается в нуль, если
тождественно обращается в нуль, если  , т. е. если оценка
, т. е. если оценка 
 (14.89)
(14.89)
потому что при выполнении равенства (14.89) подынтегральная функция становится нечетной функцией относительно новой переменной интегрирования  Таким образом, оценка (14.89) является решением уравнения (14.88) и, следовательно, байесовской оценкой.
Таким образом, оценка (14.89) является решением уравнения (14.88) и, следовательно, байесовской оценкой.
Сравнивая (14.89) с (14.80), приходим к выводу, что байесовская оценка при квадратичной функции потерь является также байесовской оценкой при симметричной функции потерь для целого класса апостериорных плотностей оцениваемого параметра, удовлетворяющих условиям унимодальности и симметричности относительно моды.
14.4.8. Байесовские оценки векторного параметра.
Предположим, что однородная независимая выборка  принадлежит распределению с плотностью
принадлежит распределению с плотностью  причем
причем  случайный векторный параметр с известной плотностью вероятности
случайный векторный параметр с известной плотностью вероятности  . Задана также функция потерь
. Задана также функция потерь  . Оптимальной байесовский оценкой
. Оптимальной байесовский оценкой  параметра
параметра  является оценка, минимизирующая апостериорный риск (см. п. 12.4.2):
является оценка, минимизирующая апостериорный риск (см. п. 12.4.2):
 (14.90)
(14.90)
Апостериорный риск  представляет многомерный функционал, зависящий от
представляет многомерный функционал, зависящий от  функций (статистик)
функций (статистик)  Система уравнений
Система уравнений
 (14.90 а)
(14.90 а)
определяет необходимое условие экстремума этого функционала. Для простой функции потерь
 (14.91)
(14.91)
апостериорный риск
 (14.92)
(14.92)
При этом из (14.92) следует, что байесовская оценка векторного параметра  является оценкой максимальной апостериорной плотности
является оценкой максимальной апостериорной плотности  , компоненты коюрой определяются системой уравнений [ср. с (14.73)]
, компоненты коюрой определяются системой уравнений [ср. с (14.73)]
 (14.93)
(14.93)
Для квадратичной функции потерь
 (14.94)
(14.94)
байесовские оценки компонент векторного параметра  равны апостериорному среднему
равны апостериорному среднему
 (14.95)
(14.95)
From Wikipedia, the free encyclopedia
In applied statistics, optimal estimation is a regularized matrix inverse method based on Bayes’ theorem.
It is used very commonly in the geosciences, particularly for atmospheric sounding.
A matrix inverse problem looks like this:

The essential concept is to transform the matrix, A, into a conditional probability and the variables,  and
and  into probability distributions by assuming Gaussian statistics and using empirically-determined covariance matrices.
into probability distributions by assuming Gaussian statistics and using empirically-determined covariance matrices.
Derivation[edit]
Typically, one expects the statistics of most measurements to be Gaussian. So for example for  , we can write:
, we can write:
![P(vec y|vec x) = frac {1} {(2 pi)^{m n/2} | boldsymbol{S_y}|}
exp left [ -frac{1}{2} (boldsymbol{A} vec{x} - vec{y})^T
boldsymbol {S_y}^{-1}
(boldsymbol{A} vec{x} - vec{y}) right ]](https://wikimedia.org/api/rest_v1/media/math/render/svg/b2f191f37ccb7c58571658ce7baa6aa772b8d300)
where m and n are the numbers of elements in and respectively  is the matrix to be solved (the linear or linearised forward model) and
is the matrix to be solved (the linear or linearised forward model) and  is the covariance matrix of the vector . This can be similarly done for :
is the covariance matrix of the vector . This can be similarly done for :
![P(vec x) = frac {1} {(2 pi)^{m/2} | boldsymbol {S_{x_a}}|}
exp left [-frac {1}{2} (vec{x}-widehat{x_a})^T
boldsymbol {S_{x_a}}^{-1} (vec{x}-widehat{x_a}) right ]](https://wikimedia.org/api/rest_v1/media/math/render/svg/b771725bb9ca3d58a99621e5561eef14d9bfbe99)
Here  is taken to be the so-called “a-priori” distribution:
is taken to be the so-called “a-priori” distribution:  denotes the a-priori values for while
denotes the a-priori values for while  is its covariance matrix.
is its covariance matrix.
The nice thing about the Gaussian distributions is that only two parameters are needed to describe them and so the whole problem can be converted once again to matrices. Assuming that  takes the following form:
takes the following form:
![P(vec x|vec y) = frac {1} {(2 pi)^{m n/2} | boldsymbol {S_x} |}
exp left [ -frac{1}{2} (vec{x} - widehat{x}) ^T
boldsymbol {S_x}^{-1} (vec{x} - widehat{x}) right ]](https://wikimedia.org/api/rest_v1/media/math/render/svg/51116a3995d5c9920e45ccdabae128f8c9c6e67a)
 may be neglected since, for a given value of , it is simply a constant scaling term. Now it is possible to solve for both the expectation value of ,
may be neglected since, for a given value of , it is simply a constant scaling term. Now it is possible to solve for both the expectation value of ,  , and for its covariance matrix by equating and
, and for its covariance matrix by equating and  . This produces the following equations:
. This produces the following equations:


Because we are using Gaussians, the expected value is equivalent to the maximum likely value, and so this is also a form of maximum likelihood estimation.
Typically with optimal estimation, in addition to the vector of retrieved quantities, one extra matrix is returned along with the covariance matrix. This is sometimes called the resolution matrix or the averaging kernel and is calculated as follows:

This tells us, for a given element of the retrieved vector, how much of the other elements of the vector are mixed in. In the case of a retrieval of profile information, it typical indicates the altitude resolution for a given altitude. For instance if the resolution vectors for all the altitudes contain non-zero elements (to a numerical tolerance) in their four nearest neighbours, then the altitude resolution is only one fourth that of the actual grid size.
References[edit]
- Clive D. Rodgers (1976). “Retrieval of Atmospheric Temperature and Composition From Remote Measurements of Thermal Radiation”. Reviews of Geophysics and Space Physics. 14 (4): 609. doi:10.1029/RG014i004p00609.
- Clive D. Rodgers (2000). Inverse Methods for Atmospheric Sounding: Theory and Practice. World Scientific.
- Clive D. Rodgers (2002). “Atmospheric Remote Sensing: The Inverse Problem”. Proceedings of the Fourth Oxford/RAL Spring School in Quantitative Earth Observation. University of Oxford.
Содержание:
Оценки и методы их получения:
Приближенные значения параметров, входящих в законы распределения, определяемые каким-либо способом по выборкам, называются оценками или статистиками. Оценки бывают точечными и интервальными. Точечные оценки представляются одним числом, интервальные – двумя числами 
Метод моментов
Пусть генеральная случайная величина X имеет плотность распределения 
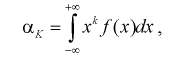 (8.1)
(8.1)
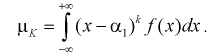 (8.2)
(8.2)
По выборке 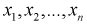 определяем выборочные начальные и центральные моменты:
определяем выборочные начальные и центральные моменты:
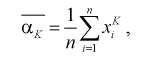 (8.3)
(8.3)
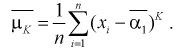 (8.4 )
(8.4 )
Метод моментов состоит в том, что генеральные моменты (8.1, 8.2), в которые входят оцениваемые параметры, приблизительно приравниваются к соответствующим выборочным моментам (8.3), (8.4). Составляется система уравнений:
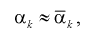 (8.5)
(8.5)
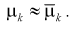 (8.6)
(8.6)
Решая систему (8.5), (8.6), находим оцениваемые параметры.
Особо важную роль играет 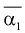 – выборочный начальный момент 1-го по рядка, он называется выборочным средним и обозначается
– выборочный начальный момент 1-го по рядка, он называется выборочным средним и обозначается 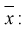
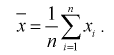 (8.7)
(8.7)
Следующим по важности выборочным моментом является выборочный центральный момент 2-го порядка 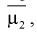 который называется выборочной дисперсией и обозначается
который называется выборочной дисперсией и обозначается 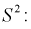
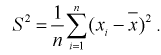 (8.8)
(8.8)
Наиболее часто используются две формулы метода моментов.
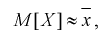 (8.9)
(8.9)
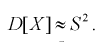 (8.10)
(8.10)
Сформулируем метод моментов в общем виде.
Пусть 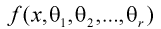 плотность распределения случайной величины
плотность распределения случайной величины 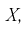 где
где 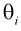 – неизвестные параметры. Чтобы найти оценки
– неизвестные параметры. Чтобы найти оценки 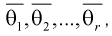 выражаем первые
выражаем первые 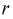 начальных или центральных моментов случайной величины X через параметры
начальных или центральных моментов случайной величины X через параметры 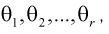 затем генеральные моменты аппроксимируем соответствующими выборочными. В результате имеем систему из
затем генеральные моменты аппроксимируем соответствующими выборочными. В результате имеем систему из 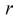 уравнений с
уравнений с 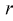 неизвестными, откуда и получаем
неизвестными, откуда и получаем 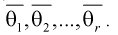
Пример:
Пусть генеральная случайная величина X имеет показательный закон распределения с плотностью 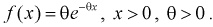 По выборке
По выборке 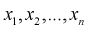 методом моментов найти оценку параметра
методом моментов найти оценку параметра 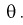
1. Определяем 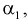 используя (8.1):
используя (8.1):
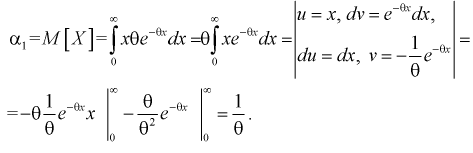
2. По (8.3) или (8.7) находим выборочный начальный момент 1-го порядка или 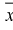 и составляем выражение вида (8.5) или (8.9):
и составляем выражение вида (8.5) или (8.9):
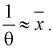
3. Заменяя в п. 2 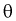 на оценку
на оценку 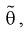 составим уравнение:
составим уравнение: 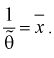
4. Откуда определим оценку параметра 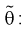
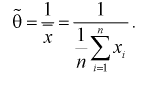
Метод наибольшего правдоподобия
Этот метод предложен математиком Фишером в 1912 г.
Пусть 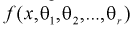 – плотность распределения генеральной случайной величины X, где
– плотность распределения генеральной случайной величины X, где 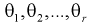 – неизвестные параметры. Согласно методу, наилучшими оценками
– неизвестные параметры. Согласно методу, наилучшими оценками 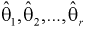 параметров
параметров 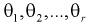 являются такие, для которых функция правдоподобия L принимает наибольшее значение.
являются такие, для которых функция правдоподобия L принимает наибольшее значение.
Для непрерывной случайной величины
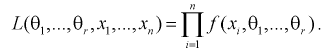 (8.11)
(8.11)
Для дискретной случайной величины
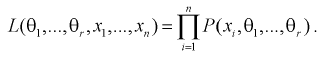 (8.12)
(8.12)
Здесь 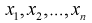 – выборка из генеральной случайной величины X.
– выборка из генеральной случайной величины X.
Априорные выборочные значения 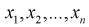 – являются независимыми случайными величинами, закон распределения которых совпадает с законом распределения генеральной случайной величины X. Тогда правую часть (8.11) на основании теоремы умножения законов распределений (см. раздел 3.5) можно рассматривать как плотность распределения вероятности
– являются независимыми случайными величинами, закон распределения которых совпадает с законом распределения генеральной случайной величины X. Тогда правую часть (8.11) на основании теоремы умножения законов распределений (см. раздел 3.5) можно рассматривать как плотность распределения вероятности  мерного вектора
мерного вектора 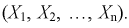 Согласно методу, для наилучших оценок
Согласно методу, для наилучших оценок 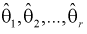 случайный вектор
случайный вектор 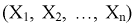 будет иметь наибольшую плотность распределения. То есть надо найти такие оценки
будет иметь наибольшую плотность распределения. То есть надо найти такие оценки 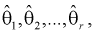 для которых функция правдоподобия L – максимальна. Для этого составляют и решают такую систему уравнений:
для которых функция правдоподобия L – максимальна. Для этого составляют и решают такую систему уравнений:
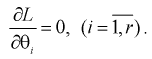 (8.13)
(8.13)
Так как функция и ее логарифм достигают экстремума в одной точке, то часто для упрощения решения задачи используют логарифмическую функцию правдоподобия. В случае логарифмической функции правдоподобия составляется система следующих уравнений:
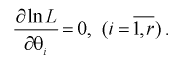 (8.14)
(8.14)
Пример:
Пусть генеральная случайная величина X имеет показательный закон распределения с плотностью 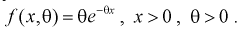 По выборке
По выборке 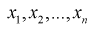 методом наибольшего правдоподобия найти оценку параметра
методом наибольшего правдоподобия найти оценку параметра 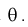
1. Так как нам необходимо оценить один параметр 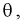 то надо составить и решить одно уравнение. Найдем функцию правдоподобия, используя (8.11):
то надо составить и решить одно уравнение. Найдем функцию правдоподобия, используя (8.11):
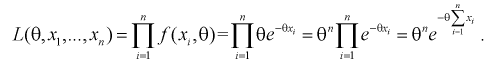
2. Составим логарифмическую функцию правдоподобия:
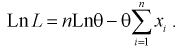
3. Для определения максимума логарифмической функции правдоподобия составляем и решаем следующее уравнение:
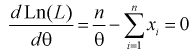
Откуда оценка 0 параметра 0 определяется так:
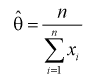
При сравнение это выражение с оценкой 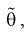 полученной по методу моментов (см. раздел 8.1), мы понимаем, что они одинаковы. Методы, рассмотренные нами, как видим, абсолютно разные. Это свидетельствует о их достоверности.
полученной по методу моментов (см. раздел 8.1), мы понимаем, что они одинаковы. Методы, рассмотренные нами, как видим, абсолютно разные. Это свидетельствует о их достоверности.
Свойства оценок
Пусть 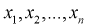 – выборка из генеральной совокупности. Обозначим оценку параметра
– выборка из генеральной совокупности. Обозначим оценку параметра 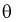 через
через 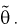 Ранее мы показали, что эта оценка определяется с помощью различных методов по полученной выборке , т. е. являляется функцией от
Ранее мы показали, что эта оценка определяется с помощью различных методов по полученной выборке , т. е. являляется функцией от 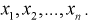
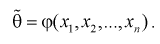
Так как любая выборка типа 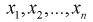 – случайна, то и выборочные функции
– случайна, то и выборочные функции 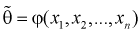 – тоже являются случайными. Следовательно, она тоже имеет свои характеристики.
– тоже являются случайными. Следовательно, она тоже имеет свои характеристики.
1. Оценка 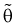 называется несмещенной, если ее математическое ожидание совпадает с самим оцениваемым параметром:
называется несмещенной, если ее математическое ожидание совпадает с самим оцениваемым параметром:
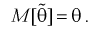
В противном случае оценка называется смещенной.
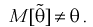
Полную погрешность 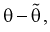 возникшую от замены 0 на 0, можно представить так:
возникшую от замены 0 на 0, можно представить так:
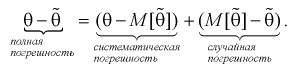
Таким образом, если оценка несмещенная, то систематическая погрешность равна нулю, т. е. 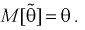
Наиболее опасна систематическая ошибка, если она заранее неизвестна или среднее квадратичное отклонение не очень большое. Среднее значение случайной ошибки 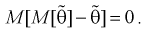
Мы уже отмечали, что 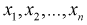 – независимые случайные величины, имеющие тот же закон распределения, что и
– независимые случайные величины, имеющие тот же закон распределения, что и 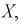 генеральная случайная величина, в частности, выборочное математическое ожидание и дисперсия имеет те же числовые характеристики, т. е. справедливы тождества:
генеральная случайная величина, в частности, выборочное математическое ожидание и дисперсия имеет те же числовые характеристики, т. е. справедливы тождества:
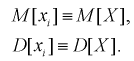 (*)
(*)
Проверим смещенность оценки математического ожидания выборочной средней 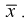 Используя обычные свойства математического ожидания, найдем
Используя обычные свойства математического ожидания, найдем 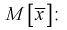
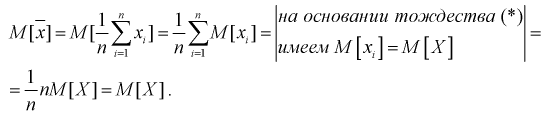
Обозначим 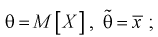 видим, что
видим, что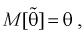 значит, выборочное среднее
значит, выборочное среднее 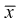 является несмещенной оценкой математического ожидания.
является несмещенной оценкой математического ожидания.
Проверим смещенность оценки дисперсии выборочной дисперсией 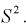 Найдем математическое ожидание от выборочной дисперсии:
Найдем математическое ожидание от выборочной дисперсии:
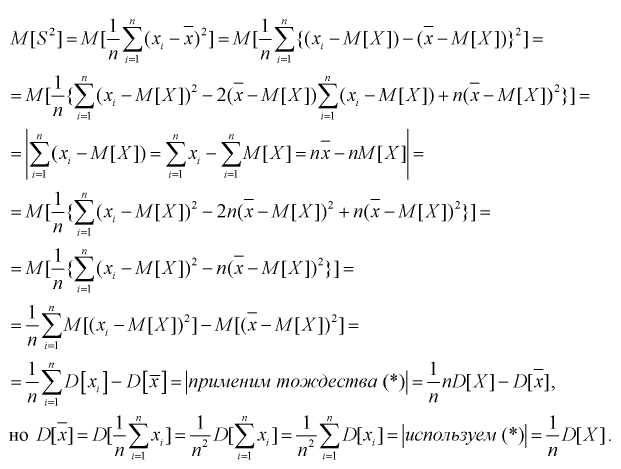
То есть дисперсия выборочной средней в 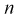 раз меньше дисперсии генеральной случайной величины. Тогда
раз меньше дисперсии генеральной случайной величины. Тогда
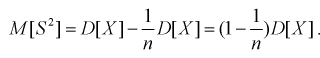
Обозначим 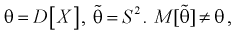 значит, выборочная дисперсия
значит, выборочная дисперсия 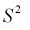 является смещенной оценкой дисперсии. Можно отметить, что выборочная дисперсия
является смещенной оценкой дисперсии. Можно отметить, что выборочная дисперсия 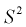 является асимптотически несмещенной оценкой, т. к. при
является асимптотически несмещенной оценкой, т. к. при 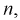 стремящемся к бесконечности, смещение стремится к нулю.
стремящемся к бесконечности, смещение стремится к нулю.
При решении практических задач часто используется несмещенная оценка дисперсии – это модифицированная выборочная дисперсия:
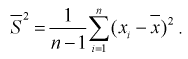
Найдем математическое ожидание от 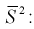
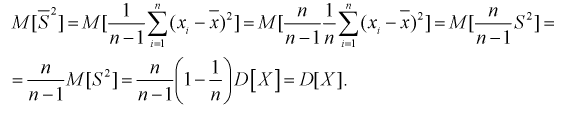
Обозначим 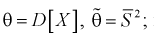 как видим,
как видим, 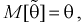 значит, оценка
значит, оценка 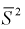 уже несмещенная. При малых
уже несмещенная. При малых 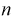 этой формулой пользоваться лучше (при и > 30 оценки совпадают). На практике используют еще одну несмещенную оценку дисперсии – когда известно математическое ожидание:
этой формулой пользоваться лучше (при и > 30 оценки совпадают). На практике используют еще одну несмещенную оценку дисперсии – когда известно математическое ожидание:
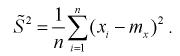
Найдем 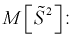
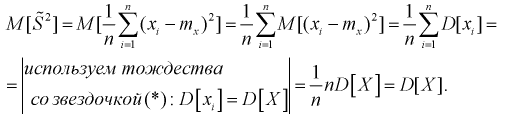
Обозначим 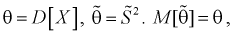 значит, оценка
значит, оценка 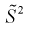 несмещенная.
несмещенная.
2. Оценка 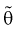 параметра
параметра 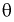 называется состоятельной, если она сходится по вероятности к параметру
называется состоятельной, если она сходится по вероятности к параметру 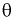 , т. е. если
, т. е. если 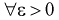 выполняется:
выполняется:
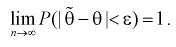
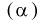
Условие 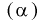 на практике проверить трудно. Поэтому для проверки состоятельности оценок применяют более простые условия:
на практике проверить трудно. Поэтому для проверки состоятельности оценок применяют более простые условия:
а) 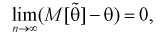
б) 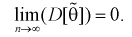
Как видим, оценка 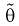 будет состоятельной, если при
будет состоятельной, если при 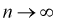 смещение устраняется и дисперсия оценки стремится к нулю.
смещение устраняется и дисперсия оценки стремится к нулю.
Пример:
Проверим состоятельность оценки математического ожидания выборочной средней 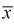 . Ранее мы показали, что
. Ранее мы показали, что 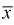 является несмещенной оценкой математического ожидания, т. е. условие а) выполняется и без вычисления предела. Проверим условие б), найдем
является несмещенной оценкой математического ожидания, т. е. условие а) выполняется и без вычисления предела. Проверим условие б), найдем 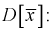
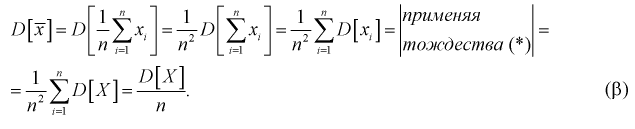
Видим, что при 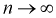 предел
предел 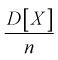 будет стремиться к нулю, значит условие б) выполняется. Следовательно,
будет стремиться к нулю, значит условие б) выполняется. Следовательно, 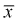 является состоятельной оценкой математического ожидания.
является состоятельной оценкой математического ожидания.
3. Несмещенная оценка 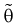 параметра
параметра 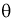 называется эффективной, если она имеет наименьшую дисперсию среди всех оценок при одном и том же объеме выборки
называется эффективной, если она имеет наименьшую дисперсию среди всех оценок при одном и том же объеме выборки 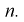
Для определения наименьшей дисперсии эффективной оценки 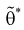 параметра
параметра 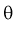 применяется формула Рао-Крамера:
применяется формула Рао-Крамера:
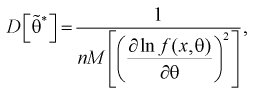 (8.15)
(8.15)
где 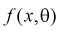 – плотность распределения генеральной случайной величины X.
– плотность распределения генеральной случайной величины X.
Отметим, если оценка 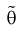 смещенная, то малость ее дисперсии еще не говорит о ее эффективности. Например, если в качестве оценки
смещенная, то малость ее дисперсии еще не говорит о ее эффективности. Например, если в качестве оценки 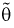 взять любую постоянную величину с, то ее дисперсия будет равна нулю, а ошибка может быть какой угодно большой.
взять любую постоянную величину с, то ее дисперсия будет равна нулю, а ошибка может быть какой угодно большой.
Пример:
Задана нормальная случайная величина 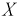 с плотностью распределения
с плотностью распределения
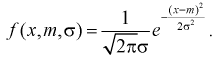
Проверим эффективность оценки математического ожидания выборочной средней 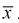 .
.
Найдем дисперсию эффективной оценки параметра 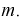 Обозначим эффективную оценку
Обозначим эффективную оценку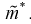 Чтобы воспользоваться формулой Рао-Крамера (8.15), вычислим
Чтобы воспользоваться формулой Рао-Крамера (8.15), вычислим
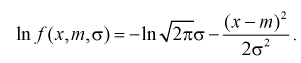
Найдем производную:
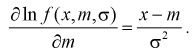
Подставим полученное выражение в (8.15):
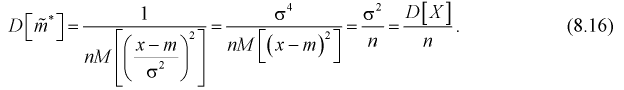
Ранее мы показали, что такую же дисперсию имеет 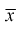 (см. формулу
(см. формулу 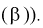
Видим, что правые части формул (8.16) и 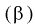 совпадают, следовательно, выборочное среднее
совпадают, следовательно, выборочное среднее 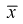 является эффективной оценкой параметра
является эффективной оценкой параметра 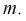
Отметим, что оценки, полученные методом наибольшего правдоподобия, являются состоятельными. Если существуют эффективная оценка, то метод наибольшего правдоподобия позволяет найти ее, но не всегда оценки, полученные этим методом, являются несмещенными.
- Теория статистической проверки гипотез
- Линейный регрессионный анализ
- Вариационный ряд
- Законы распределения случайных величин
- Статистические решающие функции
- Случайные процессы
- Выборочный метод
- Статистическая проверка гипотез
