![]()
Загрузить PDF
![]()
Загрузить PDF
С абсолютной частотой все довольно просто: она определяет, сколько раз конкретное число содержится в имеющемся наборе данных (объектов или значений). А вот относительная частота характеризует отношение количества конкретного числа в наборе данных. Другими словами, относительная частота – это отношение количества определенного числа к общему количеству чисел в наборе данных. Имейте в виду, что вычислить относительную частоту достаточно легко.
-

1
Соберите данные. Если вы решаете математическую задачу, в ее условии должен быть дан набор данных (чисел). В противном случае проведите эксперимент или исследование и соберите необходимые данные. Подумайте, в какой форме записать исходные данные.
- Например, нужно собрать данные о возрасте людей, которые посмотрели определенный фильм. Конечно, можно записать точный возраст каждого человека, но в этом случае вы получите довольно большой набор данных с 60-70 числами в пределах от 10 до 70 или 80. Поэтому лучше сгруппировать данные по категориям, таким как «Моложе 20», «20-29», «30-39» «40-49», «50-59» и «Старше 60». Получится упорядоченный набор данных с шестью группами чисел.
- Другой пример: врач собирает данные о температуре пациентов в определенный день. Если записать округленные числа, например, 37, 38, 39, то результат будет не слишком точным, поэтому здесь данные нужно представить в виде десятичных дробей.
-

2
Упорядочьте данные. Когда вы соберете данные, у вас, скорее всего, получится хаотичный набор чисел, например, такой: 1, 2, 5, 4, 6, 4, 3, 7, 1, 5, 6, 5, 3, 4, 5, 1. Такая запись кажется практически бессмысленной и с ней сложно работать. Поэтому упорядочьте числа по возрастанию (от меньшего к большему), например, так: 1,1,1,2,3,3,4,4,4,5,5,5,5,6,6,7.[1]
- Упорядочивая данные, будьте внимательны, чтобы не пропустить ни одного числа. Посчитайте общее количество чисел в наборе данных, чтобы убедиться, что вы записали все числа.
-

3
Создайте таблицу с данными. Собранные данные можно организовать в виде таблицы. Такая таблица будет включать три столбца и использоваться для вычисления относительной частоты. Столбцы обозначьте следующим образом:[2]
Реклама
-

1
Найдите количество чисел в наборе данных. Относительная частота характеризует, сколько раз конкретное число содержится в имеющемся наборе данных по отношению к общему количеству чисел. Чтобы найти относительную частоту, нужно посчитать общее количество чисел в наборе данных. Общее количество чисел станет знаменателем дроби, с помощью которой будет вычислена относительная частота.[3]
- В нашем примере набор данных содержит 16 чисел.
-
2
Найдите количество определенного числа. То есть посчитайте, сколько раз конкретное число встречается в наборе данных. Это можно сделать как для одного числа, так и для всех чисел из набора данных.[4]
- Например, в нашем примере число
встречается в наборе данных три раза.
- Например, в нашем примере число
-

3
Разделите количество конкретного числа на общее количество чисел. Так вы найдете относительную частоту для определенного числа. Вычисление можно представить в виде дроби или воспользоваться калькулятором или электронной таблицей, чтобы разделить два числа.[5]
Реклама
-

1
Результаты вычислений запишите в созданную ранее таблицу. Она позволит представить результаты в наглядной форме. По мере вычисления относительной частоты результаты записывайте в таблицу напротив соответствующего числа. Как правило, значение относительной частоты можно округлить до второго знака после десятичной запятой, но это на ваше усмотрение (в зависимости от требований задачи или исследования). Помните, что округленный результат не равен точному ответу.[6]
- В нашем примере таблица относительных частот будет выглядеть следующим образом:
- x : n(x) : P(x)
- 1 : 3 : 0,19
- 2 : 1 : 0,06
- 3 : 2 : 0,13
- 4 : 3 : 0,19
- 5 : 4 : 0,25
- 6 : 2 : 0,13
- 7 : 1 : 0,06
- Итого : 16 : 1,01
-

2
Представьте числа (элементы), которых нет в наборе данных. Иногда представление чисел с нулевой частотой так же важно, как и представление чисел с ненулевой частотой. Обратите внимание на собранные данные; если между данными имеются пробелы, их нужно заполнить нулями.
- В нашем примере набор данных включает все числа от 1 до 7. Но предположим, что числа 3 нет в наборе. Возможно, это немаловажный факт, поэтому нужно записать, что относительная частота числа 3 равна 0.
-

3
Выразите результаты в процентах. Иногда результаты вычислений нужно преобразовать из десятичных дробей в проценты. Это общепринятая практика, потому что относительная частота характеризует процент случаев появления определенного числа в наборе данных. Чтобы преобразовать десятичную дробь в проценты, нужно десятичную запятую передвинуть на две позиции вправо и приписать символ процента.
- Например, десятичная дробь 0,13 равна 13%.
- Десятичная дробь 0,06 равна 6% (обратите внимание, что перед 6 стоит 0).
Реклама
Советы
- Относительная частота характеризует наличие или возникновение определенного события в наборе событий.
- Если сложить относительные частоты всех чисел из набора данных, вы получите единицу. Помните, что при сложении округленных результатов сумма не будет равна 1,0.
- Если набор данных слишком большой, чтобы обработать его вручную, воспользуйтесь программой MS Excel или MATLAB; это позволит избежать ошибок в процессе вычисления.
Реклама
Источники
Об этой статье
Эту страницу просматривали 145 121 раз.
Была ли эта статья полезной?
Мода и медиана
Модой ряда чисел называется число, наиболее часто встречающееся в данном ряду.
Обратимся снова к нашему примеру со сборной по футболу:
Чему в данном примере равна мода? Какое число наиболее часто встречается в этой выборке?
Все верно, это число ( displaystyle 181), так как два игрока имеют рост ( displaystyle 181) см; рост же остальных игроков не повторяется.
Тут все должно быть ясно и понятно, да и слово знакомое, правда?
Перейдем к медиане, ты ее должен знать из курса геометрии. Но мне не сложно напомнить, что в геометрии медиана (в переводе с латинского- «средняя») — отрезок внутри треугольника, соединяющий вершину треугольника с серединой противоположной стороны.
Ключевое слово – СЕРЕДИНА. Если ты знал это определение, то тебе легко будет запомнить, что такое медиана в статистике.
Медианой ряда чисел с нечетным числом членов называется число, которое окажется посередине, если этот ряд упорядочить (проранжировать, т.е. расположить значения в порядке убывания или возрастания).
Медианой ряда чисел с четным числом членов называется среднее арифметическое двух чисел, записанных посередине, если этот ряд упорядочить.
Ну что, вернемся к нашей выборке футболистов?
Ты заметил в определении медианы важный момент, который нам еще здесь не встречался? Конечно, «если этот ряд упорядочить»!
Для того, чтобы в ряду чисел был порядок, можно расположить значения роста футболистов как в порядке убывания, так и в порядке возрастания. Мне удобней выстроить этот ряд в порядке возрастания (от самого маленького к самому большому).
Вот, что у меня получилось:
Так, ряд упорядочили, какой еще есть важный момент в определении медианы? Правильно, четное и нечетное количество членов в выборке.
Заметил, что для четного и нечетного количества даже определения отличаются? Да, ты прав, не заметить – сложно. А раз так, то нам надо определиться, четное у нас количество игроков в нашей выборке или нечетное?
Все верно – игроков ( displaystyle 11), значит, количество нечетное! Теперь можем применять к нашей выборке менее заковыристое определение медианы для нечетного количества членов в выборке.
Ищем число, которое оказалось посередине в нашем упорядоченном ряду:
Ну вот, чисел у нас ( displaystyle 11), значит, по краям остается по пять чисел, а рост ( displaystyle 183) см будет медианой в нашей выборке.
Не так уж и сложно, правда?
Частота и относительная частота
Частота представляет собой число повторений, сколько раз за какой-то период происходило некоторое событие, проявлялось определенное свойство объекта либо наблюдаемый параметр достигал данной величины.
То есть частота определяет то, как часто повторяется та или иная величина в выборке.
Разберемся на нашем примере с футболистами. Перед нами вот такой вот упорядоченный ряд:
![]()
Частота – это число повторений какой-либо величины параметра. В нашем случае, это можно считать вот так. Сколько игроков имеет рост ( 176)?
Все верно, один игрок. Таким образом, частота встречи игрока с ростом ( 176) в нашей выборке равна ( 1).
Сколько игроков имеет рост ( 178)? Да, опять же один игрок. Частота встречи игрока с ростом ( 178) в нашей выборке равна ( 1).
Задавая такие вопросы и отвечая на них, можно составить вот такую табличку:
Ну вот, все довольно просто. Помни, что сумма частот должна равняться количеству элементов в выборке (объему выборки).
То есть в нашем примере: ( 1+1+1+2+1+1+1+1+1+1=11)
Перейдем к следующей характеристике – относительная частота.
Относительная частота – это отношение частоты к общему числу данных в ряду. Как правило, относительная частота выражается в процентах.
Обратимся опять к нашему примеру с футболистами. Частоты для каждого значения мы рассчитали, общее количество данных в ряду мы тоже знаем ( left( n=11 right)) .
Рассчитываем относительную частоту для каждого значения роста и получаем вот такую табличку:
А теперь сам составь таблицы частот и относительных частот для примера с 9-классниками, решающими задачи.
Продолжаем изучать элементарные задачи по математике. Сегодня мы поговорим о статистике.
Статистика — это раздел математики в котором изучаются вопросы сбора, измерения и анализа информации, представленной в числовой форме. Происходит слово статистика от латинского слова status (состояние или положение дел).
Так, с помощью статистики мы можем узнать свое положение дел, касающихся финансов. С начала месяца можно вести дневник расходов и по окончании месяца, воспользовавшись статистикой, узнать сколько денег в среднем мы тратили каждый день или какая потраченная сумма была наибольшей в этом месяце либо узнать какую сумму мы тратили наиболее часто.
На основе этой информации можно провести анализ и сделать определенные выводы: следует ли в следующем месяце немного сбавить аппетит, чтобы тратить меньше денег, либо наоборот позволить себе не только хлеб с водой, но и колбасу.
Выборка. Объем. Размах
Что такое выборка? Если говорить простым языком, то это отобранная нами информация для исследования. Например, мы можем сформировать следующую выборку — суммы денег, потраченных в каждый из шести дней. Давайте нарисуем таблицу в которую занесем расходы за шесть дней

Выборка состоит из n-элементов. Вместо переменной n может стоять любое число. У нас имеется шесть элементов, поэтому переменная n равна 6
n = 6
Элементы выборки обозначаются с помощью переменных с индексами ![]() . Последний
. Последний ![]() элемент является шестым элементом выборки, поэтому вместо n будет стоять число 6.
элемент является шестым элементом выборки, поэтому вместо n будет стоять число 6.

Обозначим элементы нашей выборки через переменные ![]()
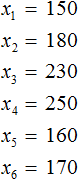
Количество элементов выборки называют объемом выборки. В нашем случае объем равен шести.
Размахом выборки называют разницу между самым большим и маленьким элементом выборки.
В нашем случае, самым большим элементом выборки является элемент 250, а самым маленьким — элемент 150. Разница между ними равна 100
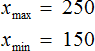
Среднее арифметическое
Понятие среднего значения часто используется в повседневной жизни.
Примеры:
- средняя зарплата жителей страны;
- средний балл учащихся;
- средняя скорость движения;
- средняя производительность труда.
Речь идет о среднем арифметическом — результате деления суммы элементов выборки на их количество.
Среднее арифметическое — это результат деления суммы элементов выборки на их количество.
![]()
Вернемся к нашему примеру
Узнаем сколько в среднем мы тратили в каждом из шести дней:
![]()
Средняя скорость движения
При изучении задач на движение мы определяли скорость движения следующим образом: делили пройденное расстояние на время. Но тогда подразумевалось, что тело движется с постоянной скоростью, которая не менялась на протяжении всего пути.
В реальности, это происходит довольно редко или не происходит совсем. Тело, как правило, движется с различной скоростью.
Когда мы ездим на автомобиле или велосипеде, наша скорость часто меняется. Когда впереди нас помехи, нам приходиться сбавлять скорость. Когда же трасса свободна, мы ускоряемся. При этом за время нашего ускорения скорость изменяется несколько раз.
Речь идет о средней скорости движения. Чтобы её определить нужно сложить скорости движения, которые были в каждом часе/минуте/секунде и результат разделить на время движения.
Задача 1. Автомобиль первые 3 часа двигался со скоростью 66,2 км/ч, а следующие 2 часа — со скоростью 78,4 км/ч. С какой средней скоростью он ехал?

Сложим скорости, которые были у автомобиля в каждом часе и разделим на время движения (5ч)
![]()
Значит автомобиль ехал со средней скоростью 71,08 км/ч.
Определять среднюю скорость можно и по другому — сначала найти расстояния, пройденные с одной скоростью, затем сложить эти расстояния и результат разделить на время. На рисунке видно, что первые три часа скорость у автомобиля не менялась. Тогда можно найти расстояние, пройденное за три часа:
66,2 × 3 = 198,6 км.
Аналогично можно определить расстояние, которое было пройдено со скоростью 78,4 км/ч. В задаче сказано, что с такой скоростью автомобиль двигался 2 часа:
78,4 × 2 = 156,8 км.
Сложим эти расстояния и результат разделим на 5
![]()
Задача 2. Велосипедист за первый час проехал 12,6 км, а в следующие 2 часа он ехал со скоростью 13,5 км/ч. Определить среднюю скорость велосипедиста.

Скорость велосипедиста в первый час составляла 12,6 км/ч. Во второй и третий час он ехал со скоростью 13,5. Определим среднюю скорость движения велосипедиста:
![]()
Мода и медиана
Модой называют элемент, который встречается в выборке чаще других.
Рассмотрим следующую выборку: шестеро спортсменов, а также время в секундах за которое они пробегают 100 метров

Элемент 14 встречается в выборке чаще других, поэтому элемент 14 назовем модой.
Рассмотрим еще одну выборку. Тех же спортсменов, а также смартфоны, которые им принадлежат

Элемент iphone встречается в выборке чаще других, значит элемент iphone является модой. Говоря простым языком, носить iphone модно.
Конечно элементы выборки в этот раз выражены не числами, а другими объектами (смартфонами), но для общего представления о моде этот пример вполне приемлем.
Рассмотрим следующую выборку: семеро спортсменов, а также их рост в сантиметрах:

Упорядочим данные в таблице так, чтобы рост спортсменов шел по возрастанию. Другими словами, построим спортсменов по росту:

Выпишем рост спортсменов отдельно:
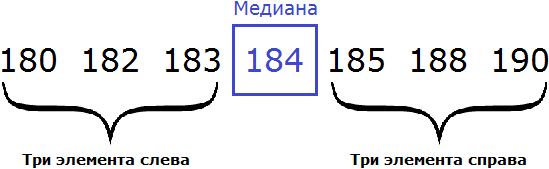
180, 182, 183, 184, 185, 188, 190
В получившейся выборке 7 элементов. Посередине этой выборки располагается элемент 184. Слева и справа от него по три элемента. Такой элемент как 184 называют медианой упорядоченной выборки.
Медианой упорядоченной выборки называют элемент, располагающийся посередине.
Отметим, что данное определение справедливо в случае, если количество элементов упорядоченной выборки является нечётным.
В рассмотренном выше примере, количество элементов упорядоченной выборки было нечётным. Это позволило нам быстро указать медиану
Но возможны случаи, когда количество элементов выборки чётно.
К примеру, рассмотрим выборку в которой не семеро спортсменов, а шестеро:

Построим этих шестерых спортсменов по росту:

Выпишем рост спортсменов отдельно:
180, 182, 184, 186, 188, 190
В данной выборке не получается указать элемент, который находился бы посередине. Если указать элемент 184 как медиану, то слева от этого элемента будут располагаться два элемента, а справа — три. Если как медиану указать элемент 186, то слева от этого элемента будут располагаться три элемента, а справа — два.
В таких случаях для определения медианы выборки, нужно взять два элемента выборки, находящихся посередине и найти их среднее арифметическое. Полученный результат будет являться медианой.
Вернемся к нашим спортсменам. В упорядоченной выборке 180, 182, 184, 186, 188, 190 посередине располагаются элементы 184 и 186

Найдем среднее арифметическое элементов 184 и 186
![]()
Элемент 185 является медианой выборки, несмотря на то, что этот элемент не является членом исходной и упорядоченной выборки. Спортсмена с ростом 185 нет среди остальных спортсменов. Рост в 185 см используется в данном случае для статистики, чтобы можно было сказать о том, что срединный рост спортсменов составляет 185 см.
Поэтому более точное определение медианы зависит от количества элементов в выборке.
Если количество элементов упорядоченной выборки нечётно, то медианой выборки называют элемент, располагающийся посередине.
Если количество элементов упорядоченной выборки чётно, то медианой выборки называют среднее арифметическое двух чисел, располагающихся посередине этой выборки.
Медиана и среднее арифметическое по сути являются «близкими родственниками», поскольку и то и другое используют для определения среднего значения. Например, для предыдущей упорядоченной выборки 180, 182, 184, 186, 188, 190 мы определили медиану, равную 185. Этот же результат можно получить путем определения среднего арифметического элементов 180, 182, 184, 186, 188, 190
![]()
Но медиана в некоторых случаях отражает более реальную ситуацию. Например, рассмотрим следующий пример:
Было подсчитано количество имеющихся очков у каждого спортсмена. В результате получилась следующая выборка:
0, 1, 1, 1, 2, 1, 2, 3, 5, 4, 5, 0, 1, 6, 1
Определим среднее арифметическое для данной выборки — получим значение 2,2
![]()
По данному значению можно сказать, что в среднем у спортсменов 2,2 очка
Теперь определим медиану для этой же выборки. Упорядочим элементы выборки и укажем элемент, находящийся посередине:
0, 0, 1, 1, 1, 1, 1, 1, 2, 2, 3, 4, 5, 5, 6
В данном примере медиана лучше отражает реальную ситуацию, поскольку половина спортсменов имеет не более одного очка.
Частота
Частота это число, которое показывает сколько раз в выборке встречается тот или иной элемент.
Предположим, что в школе проходят соревнования по подтягиваниям. В соревнованиях участвует 36 школьников. Составим таблицу в которую будем заносить число подтягиваний, а также число участников, которые выполнили столько подтягиваний.
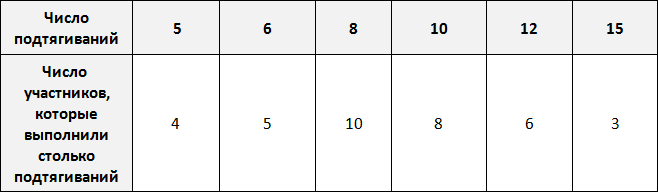
По таблице можно узнать сколько человек выполнило 5, 10 или 15 подтягиваний. Так, 5 подтягиваний выполнили четыре человека, 10 подтягиваний выполнили восемь человек, 15 подтягиваний выполнили три человека.
Количество человек, повторяющих одно и то же число подтягиваний в данном случае являются частотой. Поэтому вторую строку таблицы переименуем в название «частота»:

Такие таблицы называют таблицами частот.
Частота обладает следующим свойством: сумма частот равна общему числу данных в выборке.
Это означает, что сумма частот равна общему числу школьников, участвующих в соревнованиях, то есть тридцати шести. Проверим так ли это. Сложим частоты, приведенные в таблице:
4 + 5 + 10 + 8 + 6 + 3 = 36
Относительная частота
Относительная частота это в принципе та же самая частота, которая была рассмотрена ранее, но только выраженная в процентах.
Относительная частота равна отношению частоты на общее число элементов выборки.
Вернемся к нашей таблице:
Пять подтягиваний выполнили 4 человека из 36. Шесть подтягиваний выполнили 5 человек из 36. Восемь подтягиваний выполнили 10 человек из 36 и так далее. Давайте заполним таблицу с помощью таких отношений:

Выполним деление в этих дробях:

Выразим эти частоты в процентах. Для этого умножим их на 100. Умножение на 100 удобно выполнить передвижением запятой на две цифры вправо:

Теперь можно сказать, что пять подтягиваний выполнили 11% участников, 6 подтягиваний выполнили 14% участников, 8 подтягиваний выполнили 28% участников и так далее.
Понравился урок?
Вступай в нашу новую группу Вконтакте и начни получать уведомления о новых уроках
Возникло желание поддержать проект?
Используй кнопку ниже


The term ‘relative’ is used to denote that an act is being observed in comparison to something other. Frequency is a way to calculate how repeatedly a particular action takes place. Relative frequency is a way to find how regularly a particular action takes place against total events. To calculate relative frequency two things are important
1. Number of total events/occurrences
2. Frequency count for a subgroup/category
Relative frequency: Subgroup frequency/ total frequency
Relative frequency: f/n
Here,
f = Number of times an event occurred in an observation
n = frequency
How to Calculate Relative Frequency?
Frequencies can be converted into relative frequencies by following these steps
Step 1: Find the frequency in the given data
Step 2: Then the frequency should be divided by N (total number).
Suppose for example Gopal surveys a group of students in his college to find their favorite game. The data processed by him is represented in graphical form below. What will be the relative frequency of students whose favorite game is cricket?

The total number of students in the above-given data set is found by the addition of the heights of the bars
5+10+25+15 = 55
from the above graphical representation The number of students whose favorite game is cricket are 5
So, the relative frequency for the cricket will be = f/N = 5/55= 0.09 = 9%
Cumulative relative frequency
The addition of all of the previous relative frequencies to the relative frequency for the current row is called cumulative relative frequency
Sample Problems
Problem 1: A die is tossed 50 times and it falls 5 times on the number 6. Then find the relative frequency?
Solution:
Given, Number of times a die is tossed = 50
Number of times it falls on number 6 = 5
From the formula,
Relative frequency = Number of positive occurrences/Total Number of occurrences
f = 5/50 = 0.1
Therefore, the relative frequency of the die that fell on the number 6 is 0.1
Problem 2: A coin is tossed 90 times, and the coin falls on heads 24 times. What is the relative frequency of the coin falling on tails?
Solution:
Relative frequency = number of times an act has occurred / number of occurrences
The act taken into consideration is the coin falling on tails = 90 – 24 = 66 times
Relative frequency of the coin falling on tails = 66/90 = 0.733 = 73.3%
Problem 3: If 10 students travel to school by car, another 10 students travel to school by bus and another 10 students reach school through a van. Then find the relative frequency of students who reach school by bus?
Solution:
The total number of students in the above-given data set
10 + 10 + 10 = 30
graphical representation of given data
Number of students traveling through bus = 10
So, the relative frequency of students traveling through bus will be = f/N = 10/30= 0.33= 33%

Problem 4: There are 36 students in a class, 20 boys and 16 girls. Then what are the frequency and relative frequency of boys in the classroom?
Solution:
The frequency of boys = Number of boys in the classroom = 20
Relative frequency of boys in classroom = Number of boys / Total students
= 20/36 = 0.5555 = 55.55 %
The frequency is 20 and the relative frequency in % is 55.55 %
Problem 5: Varun has conducted a survey in his village to study the diet habits of people. He obtained the results as given below. Then find
| Diet followed | Number of people |
| Vegetarian | 320 |
| Mixed diet | 430 |
| Non-vegetarian | 810 |
A) The relative frequency of vegetarians in Varun’s village.
B) The relative frequency of people taking a mixed diet in his village
Solution:
The relative frequency of vegetarians in Varun’s village.
Total population: 1560
Number of vegetarians: 320
From the formulaRelative frequency = Number of vegetarians / Total population
f = 320/1560
= 0.21 = 21%The relative frequency of the population taking a mixed diet in Varun’s village
Total population: 156
Number of people on mixed diet: 430
From the formulaRelative frequency = Number of population taking mixed diet/ Total population
f = 430/1560
= 0.28 = 28%
Last Updated :
28 Jun, 2022
Like Article
Save Article
Интервальный вариационный ряд и его характеристики
- Построение интервального вариационного ряда по данным эксперимента
- Гистограмма и полигон относительных частот, кумулята и эмпирическая функция распределения
- Выборочная средняя, мода и медиана. Симметрия ряда
- Выборочная дисперсия и СКО
- Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
- Алгоритм исследования интервального вариационного ряда
- Примеры
п.1. Построение интервального вариационного ряда по данным эксперимента
Интервальный вариационный ряд – это ряд распределения, в котором однородные группы составлены по признаку, меняющемуся непрерывно или принимающему слишком много значений.
Общий вид интервального вариационного ряда
| Интервалы, (left.left[a_{i-1},a_iright.right)) | (left.left[a_{0},a_1right.right)) | (left.left[a_{1},a_2right.right)) | … | (left.left[a_{k-1},a_kright.right)) |
| Частоты, (f_i) | (f_1) | (f_2) | … | (f_k) |
Здесь k – число интервалов, на которые разбивается ряд.
Размах вариации – это длина интервала, в пределах которой изменяется исследуемый признак: $$ F=x_{max}-x_{min} $$
Правило Стерджеса
Эмпирическое правило определения оптимального количества интервалов k, на которые следует разбить ряд из N чисел: $$ k=1+lfloorlog_2 Nrfloor $$ или, через десятичный логарифм: $$ k=1+lfloor 3,322cdotlg Nrfloor $$
Скобка (lfloor rfloor) означает целую часть (округление вниз до целого числа).
Шаг интервального ряда – это отношение размаха вариации к количеству интервалов, округленное вверх до определенной точности: $$ h=leftlceilfrac Rkrightrceil $$
Скобка (lceil rceil) означает округление вверх, в данном случае не обязательно до целого числа.
Алгоритм построения интервального ряда
На входе: все значения признака (left{x_jright}, j=overline{1,N})
Шаг 1. Найти размах вариации (R=x_{max}-x_{min})
Шаг 2. Найти оптимальное количество интервалов (k=1+lfloorlog_2 Nrfloor)
Шаг 3. Найти шаг интервального ряда (h=leftlceilfrac{R}{k}rightrceil)
Шаг 4. Найти узлы ряда: $$ a_0=x_{min}, a_i=1_0+ih, i=overline{1,k} $$ Шаг 5. Найти частоты (f_i) – число попаданий значений признака в каждый из интервалов (left.left[a_{i-1},a_iright.right)).
На выходе: интервальный ряд с интервалами (left.left[a_{i-1},a_iright.right)) и частотами (f_i, i=overline{1,k})
Заметим, что поскольку шаг h находится с округлением вверх, последний узел (a_kgeq x_{max}).
Например:
Проведено 100 измерений роста учеников старших классов.
Минимальный рост составляет 142 см, максимальный – 197 см.
Найдем узлы для построения соответствующего интервального ряда.
По условию: (N=100, x_{min}=142 см, x_{max}=197 см).
Размах вариации: (R=197-142=55) (см)
Оптимальное число интервалов: (k=1+lfloor 3,322cdotlg 100rfloor=1+lfloor 6,644rfloor=1+6=7)
Шаг интервального ряда: (h=lceilfrac{55}{5}rceil=lceil 7,85rceil=8) (см)
Получаем узлы ряда: $$ a_0=x_{min}=142, a_i=142+icdot 8, i=overline{1,7} $$
| (left.left[a_{i-1},a_iright.right)) cм | (left.left[142;150right.right)) | (left.left[150;158right.right)) | (left.left[158;166right.right)) | (left.left[166;174right.right)) | (left.left[174;182right.right)) | (left.left[182;190right.right)) | (left[190;198right]) |
п.2. Гистограмма и полигон относительных частот, кумулята и эмпирическая функция распределения
Относительная частота интервала (left.left[a_{i-1},a_iright.right)) – это отношение частоты (f_i) к общему количеству исходов: $$ w_i=frac{f_i}{N}, i=overline{1,k} $$
Гистограмма относительных частот интервального ряда – это фигура, состоящая из прямоугольников, ширина которых равна шагу ряда, а высота – относительным частотам каждого из интервалов.
Площадь гистограммы равна 1 (с точностью до округлений), и она является эмпирическим законом распределения исследуемого признака.
Полигон относительных частот интервального ряда – это ломаная, соединяющая точки ((x_i,w_i)), где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Накопленные относительные частоты – это суммы: $$ S_1=w_1, S_i=S_{i-1}+w_i, i=overline{2,k} $$ Ступенчатая кривая (F(x)), состоящая из прямоугольников, ширина которых равна шагу ряда, а высота – накопленным относительным частотам, является эмпирической функцией распределения исследуемого признака.
Кумулята – это ломаная, которая соединяет точки ((x_i,S_i)), где (x_i) – середины интервалов.
Например:
Продолжим анализ распределения учеников по росту.
Выше мы уже нашли узлы интервалов. Пусть, после распределения всех 100 измерений по этим интервалам, мы получили следующий интервальный ряд:
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| (left.left[a_{i-1},a_iright.right)) cм | (left.left[142;150right.right)) | (left.left[150;158right.right)) | (left.left[158;166right.right)) | (left.left[166;174right.right)) | (left.left[174;182right.right)) | (left.left[182;190right.right)) | (left[190;198right]) |
| (f_i) | 4 | 7 | 11 | 34 | 33 | 8 | 3 |
Найдем середины интервалов, относительные частоты и накопленные относительные частоты:
| (x_i) | 146 | 154 | 162 | 170 | 178 | 186 | 194 |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 |
| (S_i) | 0,04 | 0,11 | 0,22 | 0,56 | 0,89 | 0,97 | 1 |
Построим гистограмму и полигон:

Построим кумуляту и эмпирическую функцию распределения: 

Эмпирическая функция распределения (относительно середин интервалов): $$ F(x)= begin{cases} 0, xleq 146\ 0,04, 146lt xleq 154\ 0,11, 154lt xleq 162\ 0,22, 162lt xleq 170\ 0,56, 170lt xleq 178\ 0,89, 178lt xleq 186\ 0,97, 186lt xleq 194\ 1, xgt 194 end{cases} $$
п.3. Выборочная средняя, мода и медиана. Симметрия ряда
Выборочная средняя интервального вариационного ряда определяется как средняя взвешенная по частотам: $$ X_{cp}=frac{x_1f_1+x_2f_2+…+x_kf_k}{N}=frac1Nsum_{i=1}^k x_if_i $$ где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Или, через относительные частоты: $$ X_{cp}=sum_{i=1}^k x_iw_i $$
Модальным интервалом называют интервал с максимальной частотой: $$ f_m=max f_i $$ Мода интервального вариационного ряда определяется по формуле: $$ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h $$ где
(h) – шаг интервального ряда;
(x_o) – нижняя граница модального интервала;
(f_m,f_{m-1},f_{m+1}) – соответственно, частоты модального интервала, интервала слева от модального и интервала справа.
Медианным интервалом называют первый интервал слева, на котором кумулята превысила значение 0,5. Медиана интервального вариационного ряда определяется по формуле: $$ M_e=x_o+frac{0,5-S_{me-1}}{w_{me}}h $$ где
(h) – шаг интервального ряда;
(x_o) – нижняя граница медианного интервала;
(S_{me-1}) накопленная относительная частота для интервала слева от медианного;
(w_{me}) относительная частота медианного интервала.
Расположение выборочной средней, моды и медианы в зависимости от симметрии ряда аналогично их расположению в дискретном ряду (см. §65 данного справочника).
Например:
Для распределения учеников по росту получаем:
| (x_i) | 146 | 154 | 162 | 170 | 178 | 186 | 194 | ∑ |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 | 1 |
| (x_iw_i) | 5,84 | 10,78 | 17,82 | 57,80 | 58,74 | 14,88 | 5,82 | 171,68 |
$$ X_{cp}=sum_{i=1}^k x_iw_i=171,68approx 171,7 text{(см)} $$ На гистограмме (или полигоне) относительных частот максимальная частота приходится на 4й интервал [166;174). Это модальный интервал.
Данные для расчета моды: begin{gather*} x_o=166, f_m=34, f_{m-1}=11, f_{m+1}=33, h=8\ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h=\ =166+frac{34-11}{(34-11)+(34-33)}cdot 8approx 173,7 text{(см)} end{gather*} На кумуляте значение 0,5 пересекается на 4м интервале. Это – медианный интервал.
Данные для расчета медианы: begin{gather*} x_o=166, w_m=0,34, S_{me-1}=0,22, h=8\ \ M_e=x_o+frac{0,5-S_{me-1}}{w_me}h=166+frac{0,5-0,22}{0,34}cdot 8approx 172,6 text{(см)} end{gather*} begin{gather*} \ X_{cp}=171,7; M_o=173,7; M_e=172,6\ X_{cp}lt M_elt M_o end{gather*} Ряд асимметричный с левосторонней асимметрией.
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|}=frac{2,0}{0,9}approx 2,2lt 3), т.е. распределение умеренно асимметрично.
п.4. Выборочная дисперсия и СКО
Выборочная дисперсия интервального вариационного ряда определяется как средняя взвешенная для квадрата отклонения от средней: begin{gather*} D=frac1Nsum_{i=1}^k(x_i-X_{cp})^2 f_i=frac1Nsum_{i=1}^k x_i^2 f_i-X_{cp}^2 end{gather*} где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Или, через относительные частоты: $$ D=sum_{i=1}^k(x_i-X_{cp})^2 w_i=sum_{i=1}^k x_i^2 w_i-X_{cp}^2 $$
Выборочное среднее квадратичное отклонение (СКО) определяется как корень квадратный из выборочной дисперсии: $$ sigma=sqrt{D} $$
Например:
Для распределения учеников по росту получаем:
| $x_i$ | 146 | 154 | 162 | 170 | 178 | 186 | 194 | ∑ |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 | 1 |
| (x_iw_i) | 5,84 | 10,78 | 17,82 | 57,80 | 58,74 | 14,88 | 5,82 | 171,68 |
| (x_i^2w_i) – результат | 852,64 | 1660,12 | 2886,84 | 9826 | 10455,72 | 2767,68 | 1129,08 | 29578,08 |
$$ D=sum_{i=1}^k x_i^2 w_i-X_{cp}^2=29578,08-171,7^2approx 104,1 $$ $$ sigma=sqrt{D}approx 10,2 $$
п.5. Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
Исправленная выборочная дисперсия интервального вариационного ряда определяется как: begin{gather*} S^2=frac{N}{N-1}D end{gather*}
Стандартное отклонение выборки определяется как корень квадратный из исправленной выборочной дисперсии: $$ s=sqrt{S^2} $$
Коэффициент вариации это отношение стандартного отклонения выборки к выборочной средней, выраженное в процентах: $$ V=frac{s}{X_{cp}}cdot 100text{%} $$
Подробней о том, почему и когда нужно «исправлять» дисперсию, и для чего использовать коэффициент вариации – см. §65 данного справочника.
Например:
Для распределения учеников по росту получаем: begin{gather*} S^2=frac{100}{99}cdot 104,1approx 105,1\ sapprox 10,3 end{gather*} Коэффициент вариации: $$ V=frac{10,3}{171,7}cdot 100text{%}approx 6,0text{%}lt 33text{%} $$ Выборка однородна. Найденное значение среднего роста (X_{cp})=171,7 см можно распространить на всю генеральную совокупность (старшеклассников из других школ).
п.6. Алгоритм исследования интервального вариационного ряда
На входе: все значения признака (left{x_jright}, j=overline{1,N})
Шаг 1. Построить интервальный ряд с интервалами (left.right[a_{i-1}, a_ileft.right)) и частотами (f_i, i=overline{1,k}) (см. алгоритм выше).
Шаг 2. Составить расчетную таблицу. Найти (x_i,w_i,S_i,x_iw_i,x_i^2w_i)
Шаг 3. Построить гистограмму (и/или полигон) относительных частот, эмпирическую функцию распределения (и/или кумуляту). Записать эмпирическую функцию распределения.
Шаг 4. Найти выборочную среднюю, моду и медиану. Проанализировать симметрию распределения.
Шаг 5. Найти выборочную дисперсию и СКО.
Шаг 6. Найти исправленную выборочную дисперсию, стандартное отклонение и коэффициент вариации. Сделать вывод об однородности выборки.
п.7. Примеры
Пример 1. При изучении возраста пользователей коворкинга выбрали 30 человек.
Получили следующий набор данных:
18,38,28,29,26,38,34,22,28,30,22,23,35,33,27,24,30,32,28,25,29,26,31,24,29,27,32,24,29,29
Постройте интервальный ряд и исследуйте его.
1) Построим интервальный ряд. В наборе данных: $$ x_{min}=18, x_{max}=38, N=30 $$ Размах вариации: (R=38-18=20)
Оптимальное число интервалов: (k=1+lfloorlog_2 30rfloor=1+4=5)
Шаг интервального ряда: (h=lceilfrac{20}{5}rceil=4)
Получаем узлы ряда: $$ a_0=x_{min}=18, a_i=18+icdot 4, i=overline{1,5} $$
| (left.left[a_{i-1},a_iright.right)) лет | (left.left[18;22right.right)) | (left.left[22;26right.right)) | (left.left[26;30right.right)) | (left.left[30;34right.right)) | (left.left[34;38right.right)) |
Считаем частоты для каждого интервала. Получаем интервальный ряд:
| (left.left[a_{i-1},a_iright.right)) лет | (left.left[18;22right.right)) | (left.left[22;26right.right)) | (left.left[26;30right.right)) | (left.left[30;34right.right)) | (left.left[34;38right.right)) |
| (f_i) | 1 | 7 | 12 | 6 | 4 |
2) Составляем расчетную таблицу:
| (x_i) | 20 | 24 | 28 | 32 | 36 | ∑ |
| (f_i) | 1 | 7 | 12 | 6 | 4 | 30 |
| (w_i) | 0,033 | 0,233 | 0,4 | 0,2 | 0,133 | 1 |
| (S_i) | 0,033 | 0,267 | 0,667 | 0,867 | 1 | – |
| (x_iw_i) | 0,667 | 5,6 | 11,2 | 6,4 | 4,8 | 28,67 |
| (x_i^2w_i) | 13,333 | 134,4 | 313,6 | 204,8 | 172,8 | 838,93 |
3) Строим полигон и кумуляту

Эмпирическая функция распределения: $$ F(x)= begin{cases} 0, xleq 20\ 0,033, 20lt xleq 24\ 0,267, 24lt xleq 28\ 0,667, 28lt xleq 32\ 0,867, 32lt xleq 36\ 1, xgt 36 end{cases} $$ 4) Находим выборочную среднюю, моду и медиану $$ X_{cp}=sum_{i=1}^k x_iw_iapprox 28,7 text{(лет)} $$ На полигоне модальным является 3й интервал (самая высокая точка).
Данные для расчета моды: begin{gather*} x_0=26, f_m=12, f_{m-1}=7, f_{m+1}=6, h=4\ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h=\ =26+frac{12-7}{(12-7)+(12-6)}cdot 4approx 27,8 text{(лет)} end{gather*}
На кумуляте медианным является 3й интервал (преодолевает уровень 0,5).
Данные для расчета медианы: begin{gather*} x_0=26, w_m=0,4, S_{me-1}=0,267, h=4\ M_e=x_o+frac{0,5-S_{me-1}}{w_{me}}h=26+frac{0,5-0,4}{0,267}cdot 4approx 28,3 text{(лет)} end{gather*} Получаем: begin{gather*} X_{cp}=28,7; M_o=27,8; M_e=28,6\ X_{cp}gt M_egt M_0 end{gather*} Ряд асимметричный с правосторонней асимметрией.
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|} =frac{0,9}{0,1}=9gt 3), т.е. распределение сильно асимметрично.
5) Находим выборочную дисперсию и СКО: begin{gather*} D=sum_{i=1}^k x_i^2w_i-X_{cp}^2=838,93-28,7^2approx 17,2\ sigma=sqrt{D}approx 4,1 end{gather*}
6) Исправленная выборочная дисперсия: $$ S^2=frac{N}{N-1}D=frac{30}{29}cdot 17,2approx 17,7 $$ Стандартное отклонение (s=sqrt{S^2}approx 4,2)
Коэффициент вариации: (V=frac{4,2}{28,7}cdot 100text{%}approx 14,7text{%}lt 33text{%})
Выборка однородна. Найденное значение среднего возраста (X_{cp}=28,7) лет можно распространить на всю генеральную совокупность (пользователей коворкинга).
