![]()
Загрузить PDF
![]()
Загрузить PDF
С абсолютной частотой все довольно просто: она определяет, сколько раз конкретное число содержится в имеющемся наборе данных (объектов или значений). А вот относительная частота характеризует отношение количества конкретного числа в наборе данных. Другими словами, относительная частота – это отношение количества определенного числа к общему количеству чисел в наборе данных. Имейте в виду, что вычислить относительную частоту достаточно легко.
-

1
Соберите данные. Если вы решаете математическую задачу, в ее условии должен быть дан набор данных (чисел). В противном случае проведите эксперимент или исследование и соберите необходимые данные. Подумайте, в какой форме записать исходные данные.
- Например, нужно собрать данные о возрасте людей, которые посмотрели определенный фильм. Конечно, можно записать точный возраст каждого человека, но в этом случае вы получите довольно большой набор данных с 60-70 числами в пределах от 10 до 70 или 80. Поэтому лучше сгруппировать данные по категориям, таким как «Моложе 20», «20-29», «30-39» «40-49», «50-59» и «Старше 60». Получится упорядоченный набор данных с шестью группами чисел.
- Другой пример: врач собирает данные о температуре пациентов в определенный день. Если записать округленные числа, например, 37, 38, 39, то результат будет не слишком точным, поэтому здесь данные нужно представить в виде десятичных дробей.
-

2
Упорядочьте данные. Когда вы соберете данные, у вас, скорее всего, получится хаотичный набор чисел, например, такой: 1, 2, 5, 4, 6, 4, 3, 7, 1, 5, 6, 5, 3, 4, 5, 1. Такая запись кажется практически бессмысленной и с ней сложно работать. Поэтому упорядочьте числа по возрастанию (от меньшего к большему), например, так: 1,1,1,2,3,3,4,4,4,5,5,5,5,6,6,7.[1]
- Упорядочивая данные, будьте внимательны, чтобы не пропустить ни одного числа. Посчитайте общее количество чисел в наборе данных, чтобы убедиться, что вы записали все числа.
-

3
Создайте таблицу с данными. Собранные данные можно организовать в виде таблицы. Такая таблица будет включать три столбца и использоваться для вычисления относительной частоты. Столбцы обозначьте следующим образом:[2]
Реклама
-

1
Найдите количество чисел в наборе данных. Относительная частота характеризует, сколько раз конкретное число содержится в имеющемся наборе данных по отношению к общему количеству чисел. Чтобы найти относительную частоту, нужно посчитать общее количество чисел в наборе данных. Общее количество чисел станет знаменателем дроби, с помощью которой будет вычислена относительная частота.[3]
- В нашем примере набор данных содержит 16 чисел.
-
2
Найдите количество определенного числа. То есть посчитайте, сколько раз конкретное число встречается в наборе данных. Это можно сделать как для одного числа, так и для всех чисел из набора данных.[4]
- Например, в нашем примере число
встречается в наборе данных три раза.
- Например, в нашем примере число
-

3
Разделите количество конкретного числа на общее количество чисел. Так вы найдете относительную частоту для определенного числа. Вычисление можно представить в виде дроби или воспользоваться калькулятором или электронной таблицей, чтобы разделить два числа.[5]
Реклама
-

1
Результаты вычислений запишите в созданную ранее таблицу. Она позволит представить результаты в наглядной форме. По мере вычисления относительной частоты результаты записывайте в таблицу напротив соответствующего числа. Как правило, значение относительной частоты можно округлить до второго знака после десятичной запятой, но это на ваше усмотрение (в зависимости от требований задачи или исследования). Помните, что округленный результат не равен точному ответу.[6]
- В нашем примере таблица относительных частот будет выглядеть следующим образом:
- x : n(x) : P(x)
- 1 : 3 : 0,19
- 2 : 1 : 0,06
- 3 : 2 : 0,13
- 4 : 3 : 0,19
- 5 : 4 : 0,25
- 6 : 2 : 0,13
- 7 : 1 : 0,06
- Итого : 16 : 1,01
-

2
Представьте числа (элементы), которых нет в наборе данных. Иногда представление чисел с нулевой частотой так же важно, как и представление чисел с ненулевой частотой. Обратите внимание на собранные данные; если между данными имеются пробелы, их нужно заполнить нулями.
- В нашем примере набор данных включает все числа от 1 до 7. Но предположим, что числа 3 нет в наборе. Возможно, это немаловажный факт, поэтому нужно записать, что относительная частота числа 3 равна 0.
-

3
Выразите результаты в процентах. Иногда результаты вычислений нужно преобразовать из десятичных дробей в проценты. Это общепринятая практика, потому что относительная частота характеризует процент случаев появления определенного числа в наборе данных. Чтобы преобразовать десятичную дробь в проценты, нужно десятичную запятую передвинуть на две позиции вправо и приписать символ процента.
- Например, десятичная дробь 0,13 равна 13%.
- Десятичная дробь 0,06 равна 6% (обратите внимание, что перед 6 стоит 0).
Реклама
Советы
- Относительная частота характеризует наличие или возникновение определенного события в наборе событий.
- Если сложить относительные частоты всех чисел из набора данных, вы получите единицу. Помните, что при сложении округленных результатов сумма не будет равна 1,0.
- Если набор данных слишком большой, чтобы обработать его вручную, воспользуйтесь программой MS Excel или MATLAB; это позволит избежать ошибок в процессе вычисления.
Реклама
Источники
Об этой статье
Эту страницу просматривали 144 719 раз.
Была ли эта статья полезной?
Мода и медиана
Модой ряда чисел называется число, наиболее часто встречающееся в данном ряду.
Обратимся снова к нашему примеру со сборной по футболу:
Чему в данном примере равна мода? Какое число наиболее часто встречается в этой выборке?
Все верно, это число ( displaystyle 181), так как два игрока имеют рост ( displaystyle 181) см; рост же остальных игроков не повторяется.
Тут все должно быть ясно и понятно, да и слово знакомое, правда?
Перейдем к медиане, ты ее должен знать из курса геометрии. Но мне не сложно напомнить, что в геометрии медиана (в переводе с латинского- «средняя») — отрезок внутри треугольника, соединяющий вершину треугольника с серединой противоположной стороны.
Ключевое слово – СЕРЕДИНА. Если ты знал это определение, то тебе легко будет запомнить, что такое медиана в статистике.
Медианой ряда чисел с нечетным числом членов называется число, которое окажется посередине, если этот ряд упорядочить (проранжировать, т.е. расположить значения в порядке убывания или возрастания).
Медианой ряда чисел с четным числом членов называется среднее арифметическое двух чисел, записанных посередине, если этот ряд упорядочить.
Ну что, вернемся к нашей выборке футболистов?
Ты заметил в определении медианы важный момент, который нам еще здесь не встречался? Конечно, «если этот ряд упорядочить»!
Для того, чтобы в ряду чисел был порядок, можно расположить значения роста футболистов как в порядке убывания, так и в порядке возрастания. Мне удобней выстроить этот ряд в порядке возрастания (от самого маленького к самому большому).
Вот, что у меня получилось:
Так, ряд упорядочили, какой еще есть важный момент в определении медианы? Правильно, четное и нечетное количество членов в выборке.
Заметил, что для четного и нечетного количества даже определения отличаются? Да, ты прав, не заметить – сложно. А раз так, то нам надо определиться, четное у нас количество игроков в нашей выборке или нечетное?
Все верно – игроков ( displaystyle 11), значит, количество нечетное! Теперь можем применять к нашей выборке менее заковыристое определение медианы для нечетного количества членов в выборке.
Ищем число, которое оказалось посередине в нашем упорядоченном ряду:
Ну вот, чисел у нас ( displaystyle 11), значит, по краям остается по пять чисел, а рост ( displaystyle 183) см будет медианой в нашей выборке.
Не так уж и сложно, правда?
Частота и относительная частота
Частота представляет собой число повторений, сколько раз за какой-то период происходило некоторое событие, проявлялось определенное свойство объекта либо наблюдаемый параметр достигал данной величины.
То есть частота определяет то, как часто повторяется та или иная величина в выборке.
Разберемся на нашем примере с футболистами. Перед нами вот такой вот упорядоченный ряд:
![]()
Частота – это число повторений какой-либо величины параметра. В нашем случае, это можно считать вот так. Сколько игроков имеет рост ( 176)?
Все верно, один игрок. Таким образом, частота встречи игрока с ростом ( 176) в нашей выборке равна ( 1).
Сколько игроков имеет рост ( 178)? Да, опять же один игрок. Частота встречи игрока с ростом ( 178) в нашей выборке равна ( 1).
Задавая такие вопросы и отвечая на них, можно составить вот такую табличку:
Ну вот, все довольно просто. Помни, что сумма частот должна равняться количеству элементов в выборке (объему выборки).
То есть в нашем примере: ( 1+1+1+2+1+1+1+1+1+1=11)
Перейдем к следующей характеристике – относительная частота.
Относительная частота – это отношение частоты к общему числу данных в ряду. Как правило, относительная частота выражается в процентах.
Обратимся опять к нашему примеру с футболистами. Частоты для каждого значения мы рассчитали, общее количество данных в ряду мы тоже знаем ( left( n=11 right)) .
Рассчитываем относительную частоту для каждого значения роста и получаем вот такую табличку:
А теперь сам составь таблицы частот и относительных частот для примера с 9-классниками, решающими задачи.
![]()
Download Article
Preparing, calculating, and reporting your data
![]()
Download Article
Absolute frequency is a simple concept to grasp: it refers to the number of times a particular value appears in a specific data set (a collection of objects or values). However, relative frequency can be a little trickier. It refers to the proportion of times a particular value appears in a specific data set. In other words, relative frequency is, in essence, how many times a given event occurs divided by the total number of outcomes. If you organize your data, calculating and presenting relative frequency can become a simple task.
-

1
Collect your data. Unless you are just completing a math homework assignment, calculating relative frequency generally implies that you have some form of data. Conduct your experiment or study and collect the data. Decide how precisely you wish to report your results.[1]
- For example, suppose you are collecting data on the ages of people who attend a particular movie. You could decide to collect and report the exact age of everyone who attends. But this is likely to give you 60 or 70 different results, being every number from about 10 through 70 or 80. You may instead wish to collect data in groups, like “Under 20,” “20-29,” “30-39,” “40-49,” “50-59,” and “60 plus.” This would be a more manageable set of six data groups.
- As another example, a doctor might collect body temperatures of patients on a given day. In this case, just collecting whole numbers, like 97, 98, 99, might not be precise enough. It might be necessary to report data in decimals in this case.
-

2
Sort the data. After you complete your study or experiment, you are likely to have a collection of data values that could look like 1, 2, 5, 4, 6, 4, 3, 7, 1, 5, 6, 5, 3, 4, 5, 1. In this form, the data appear almost meaningless and difficult to use. It is more helpful to sort the data in order from lowest to highest. This would result in the list 1,1,1,2,3,3,4,4,4,5,5,5,5,6,6,7.
- When you are sorting and rewriting your collection of data, be careful to include every point correctly. Count the data set to make sure you do not leave off any values.
Advertisement
-

3
Use a data table. You can summarize the results of your data collection by creating a simple data frequency table. This is a chart with three columns that you will use for your relative frequency calculations. Label the columns as follows:[2]
-
. This column will be filled with each value that appears in your data set. Do not repeat items. For example, if the value 4 appears several times in the list, just put
-
,
or
. In statistics, the variable
- Relative Frequency or
. This final column is where you will record the relative frequency of each data item or grouping. The label
-
Advertisement
-

1
Count your full data set. Relative frequency is a measure of the number of times a particular value results, as a fraction of the full set. In order to calculate relative frequency, you need to know how many data points you have in your full data set. The will become the denominator in the fraction that you use for calculating.[3]
- In the sample data set provided above, counting each item results in 16 total data points.
-

2
Count each result. You need to determine the number of times that each data point appears in your results. You may want to calculate the relative frequency of one particular item, or you may be summarizing the overall data for the full data set.[4]
- For example, in the data set provided above, consider the value
- For example, in the data set provided above, consider the value
-

3
Divide each result by the total size of the set. This is the final calculation to determine the relative frequency of each item. You can set it up as a fraction or use a calculator or spreadsheet to perform the division.[5]
Advertisement
-

1
Present your results in a frequency table. The frequency table that you began above can be used to present the results in a format that is easy to review. As you perform each of the calculations, fill in the results in the corresponding places in the table. It is common to round your answers to two decimal places, although you will need to decide this for yourself based on the needs of your study. Because of rounding the end result may total something close to , but not exactly 1.0.[6]
- For example, using the data set above, the relative frequency table would appear as follows:
- x : n(x) : P(x)
- 1 : 3 : 0.19
- 2 : 1 : 0.06
- 3 : 2 : 0.13
- 4 : 3 : 0.19
- 5 : 4 : 0.25
- 6 : 2 : 0.13
- 7 : 1 : 0.06
- total : 16 : 1.01
-

2
Report items that do not appear. It may be just as meaningful to report items whose frequency is 0 as to report those items that do appear in your data set. Look at the kind of data you are collecting, and if you notice any gaps in your sorted data, you may need to report them as 0s.
- For example, the sample data set you have been working with includes all values from 1 to 7. But suppose that the number 3 never appeared. That could be important, and you would report the relative frequency of the value 3 as 0.
-

3
Show your results as percentages. You may wish to turn your decimal results into percentages. This is a common practice, as relative frequency is often used as a predictor of the percentage of times that some value will occur. To convert a decimal number to a percentage, simply shift the decimal point two spaces to the right, and add a percent symbol.[7]
- For example, the decimal result of 0.13 is equal to 13%.
- The decimal result of 0.06 is equal to 6%. (Don’t just skip over the 0.)
Advertisement
Add New Question
-
Question
What is frequency of the event?

It’s a measurement of how often the event occurs in a given time period.
-
Question
How can you calculate frequency from relative frequency?

The word “frequency” alone is not very clear. In statistics, there are absolute frequency (the number of times a data point appears), relative frequency (usually presented as a percentage), or cumulative frequency. Cumulative frequency begins at 0 and adds up the frequencies as you move through your list. If you are just asked for “frequency,” from the relative frequency, it probably means the absolute frequency. Take your relative frequency, and multiply it by the total number of items in the full data set, and you will have the absolute frequency.
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
-
Physically speaking, the relative frequency tells you the presence or occurrence of a particular event in a set of events.
-
If you add up the relative frequencies of all items in a data set, you should get a sum of 1. If you round off your values, the sum may not be exactly 1.0.
-
If your data set is too large for simple counting, you may need to use a software package like MS-Excel or MATLAB to avoid mistakes.
Thanks for submitting a tip for review!
Advertisement
References
About This Article
Article SummaryX
To stop face sweating, try applying an astringent containing tannic acid, like witch hazel, to your face twice a day using a cotton ball. Additionally, apply an antiperspirant spray to your scalp, temples, and upper forehead to temporarily block your sweat glands. Alternatively, try using a dry shampoo to manage scalp sweating by holding it 8 inches from your head, then spraying it in 2 inch sections of your hair at a time. After that, massage the dry shampoo into your scalp for even distribution. For more tips, like how to show your results as percentages, read on!
Did this summary help you?
Thanks to all authors for creating a page that has been read 102,834 times.
Did this article help you?
17 авг. 2022 г.
читать 2 мин
Таблица частот — это таблица, в которой отображается информация о частотах. Частоты просто говорят нам, сколько раз произошло определенное событие.
Например , в следующей таблице показано, сколько товаров было продано магазином в разных ценовых диапазонах за данную неделю:
| Цена товара | Частота | | — | — | | $1 – $10 | 20 | | $11 – $20 | 21 | | 21 – 30 долларов США | 13 | | $31 – $40 | 8 | | $41 — $50 | 4 |
В первом столбце отображается ценовой класс, а во втором столбце — частота этого класса.
Также можно рассчитать относительную частоту для каждого класса, которая представляет собой просто частоту каждого класса в процентах от целого.
| Цена товара | Частота | Относительная частота | | — | — | — | | $1 – $10 | 20 | 0,303 | | $11 – $20 | 21 | 0,318 | | 21 – 30 долларов США | 13 | 0,197 | | $31 – $40 | 8 | 0,121 | | $41 — $50 | 4 | 0,061 |
Всего было продано 66 штук. Таким образом, мы нашли относительную частоту каждого класса, взяв частоту каждого класса и разделив ее на общее количество проданных товаров.
Например, было продано 20 товаров по цене от 1 до 10 долларов. Таким образом, относительная частота класса $1 – $10 составляет 20/66 = 0,303 .
Затем был продан 21 предмет в ценовом диапазоне от 11 до 20 долларов. Таким образом, относительная частота класса $11 – $20 составляет 21/66 = 0,318 .
В следующем примере показано, как найти относительные частоты в Excel.
Пример: относительные частоты в Excel
Сначала мы введем класс и частоту в столбцах A и B:
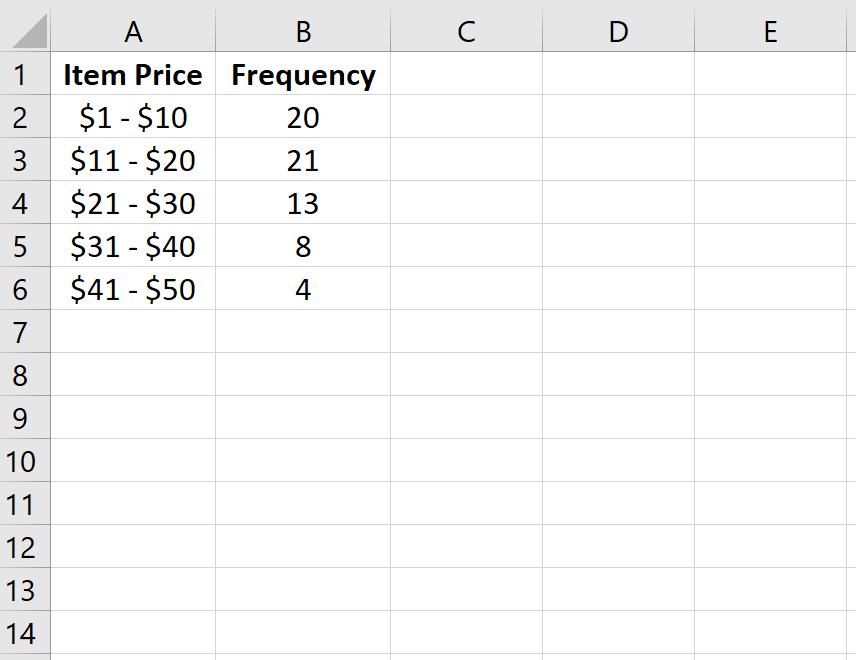
Далее мы рассчитаем относительную частоту каждого класса в столбце C. В столбце D показаны формулы, которые мы использовали:
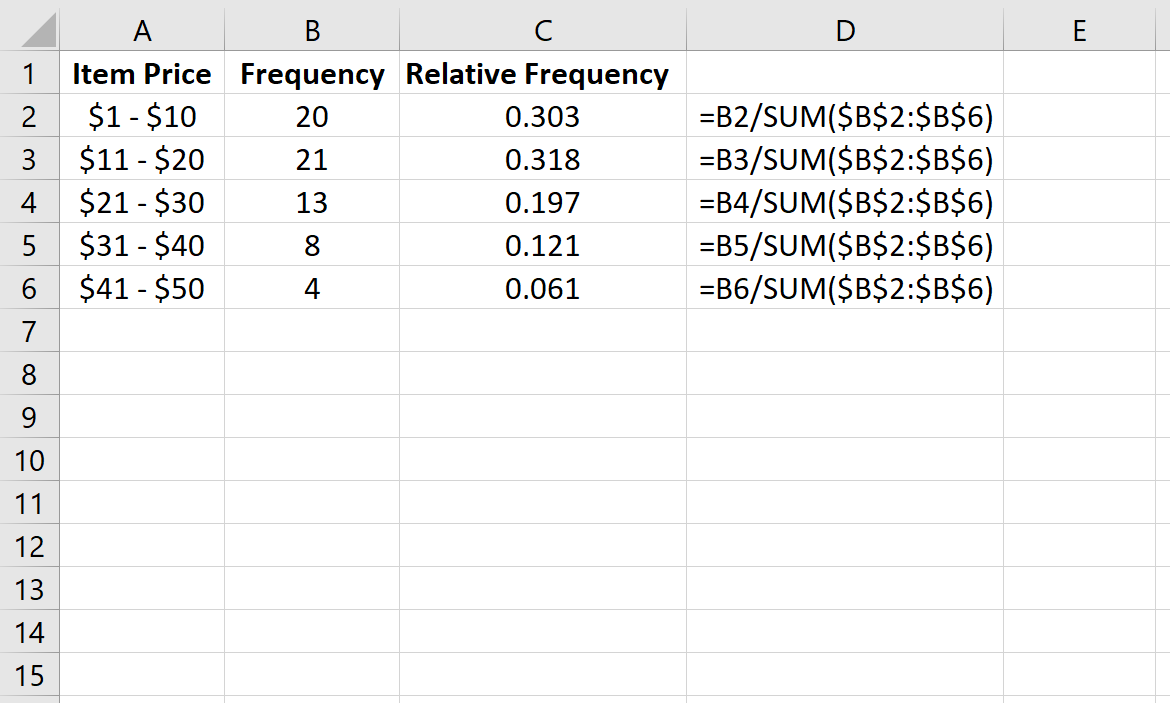
Мы можем проверить правильность наших расчетов, убедившись, что сумма относительных частот равна 1:
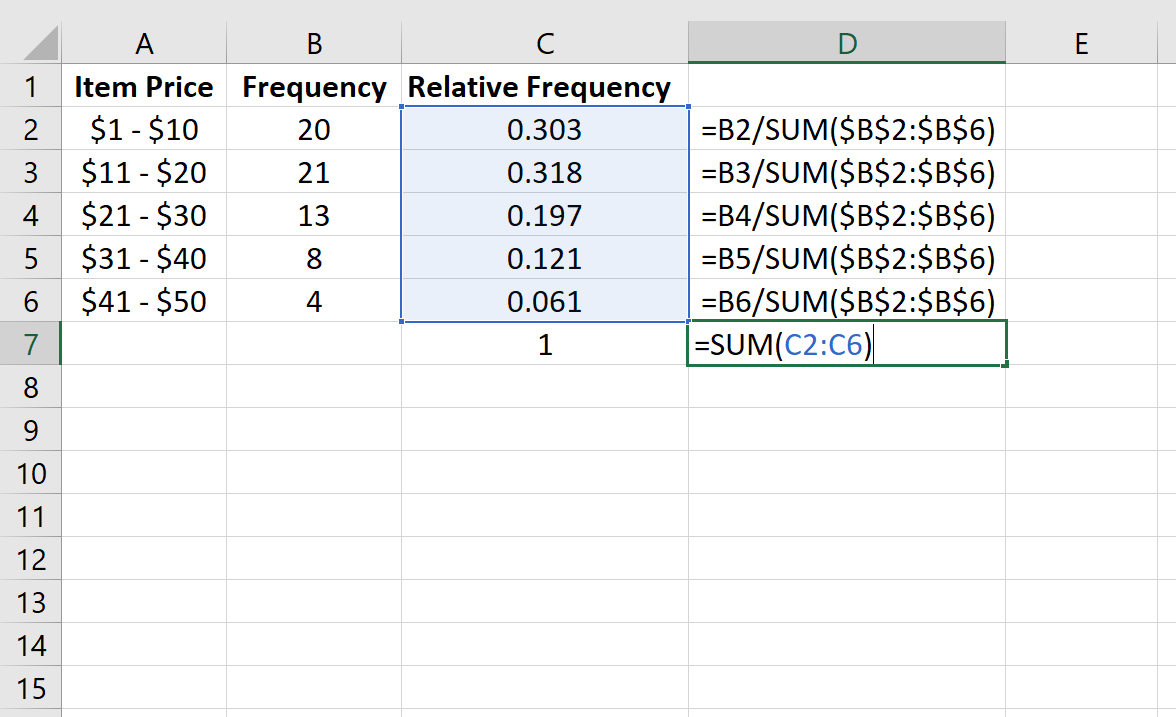
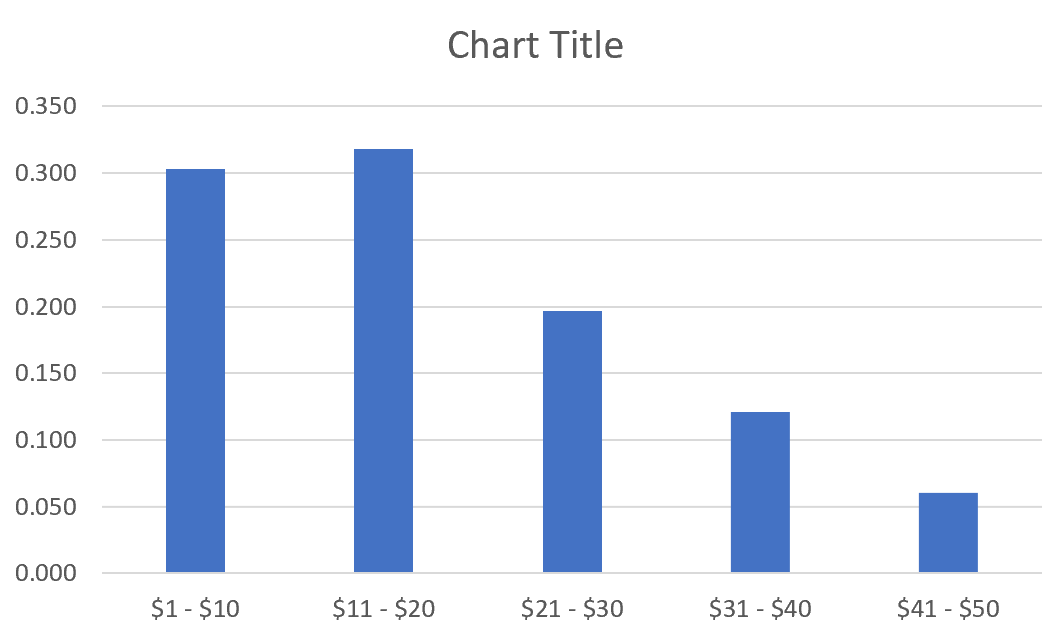
Мы также можем создать гистограмму относительной частоты для визуализации относительных частот.
Просто выделите относительные частоты:

Затем перейдите в группу « Диаграммы » на вкладке « Вставка » и щелкните первый тип диаграммы в « Вставить столбец» или «Гистограмма» :
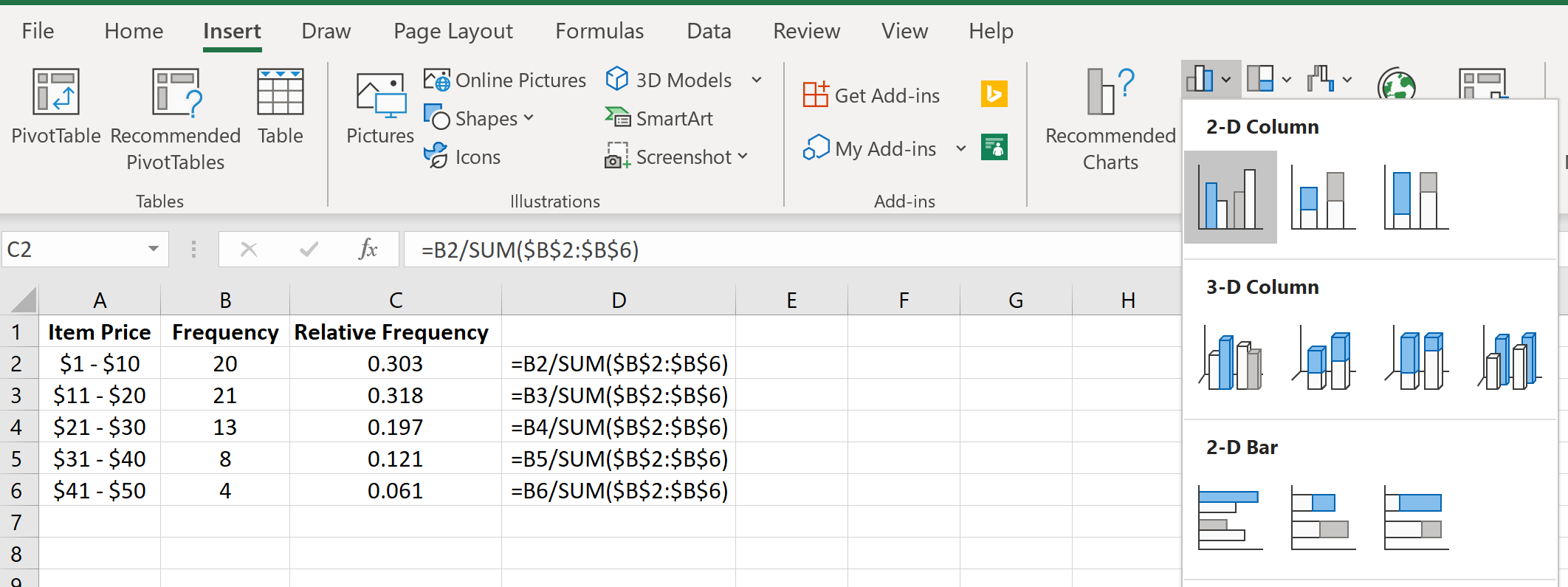
Автоматически появится гистограмма относительной частоты:
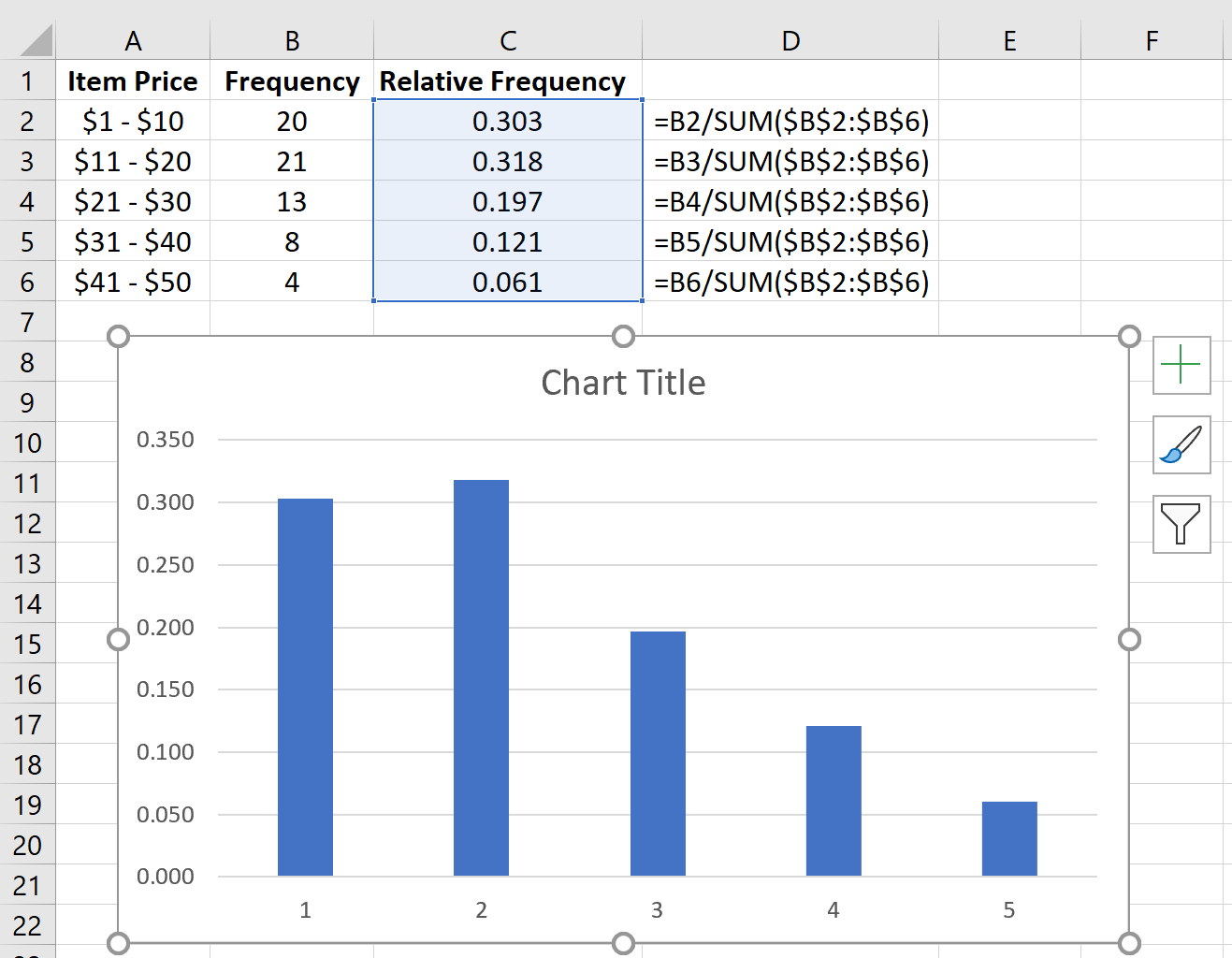
Измените метки оси X, щелкнув правой кнопкой мыши диаграмму и выбрав Выбрать данные.В разделе « Ярлыки горизонтальной (категории) оси » нажмите « Изменить » и введите диапазон ячеек, содержащий цены на товары. Нажмите OK , и новые метки осей появятся автоматически:
Дополнительные ресурсы
Калькулятор относительной частоты
Гистограмма относительной частоты: определение + пример
Интервальный вариационный ряд и его характеристики
- Построение интервального вариационного ряда по данным эксперимента
- Гистограмма и полигон относительных частот, кумулята и эмпирическая функция распределения
- Выборочная средняя, мода и медиана. Симметрия ряда
- Выборочная дисперсия и СКО
- Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
- Алгоритм исследования интервального вариационного ряда
- Примеры
п.1. Построение интервального вариационного ряда по данным эксперимента
Интервальный вариационный ряд – это ряд распределения, в котором однородные группы составлены по признаку, меняющемуся непрерывно или принимающему слишком много значений.
Общий вид интервального вариационного ряда
| Интервалы, (left.left[a_{i-1},a_iright.right)) | (left.left[a_{0},a_1right.right)) | (left.left[a_{1},a_2right.right)) | … | (left.left[a_{k-1},a_kright.right)) |
| Частоты, (f_i) | (f_1) | (f_2) | … | (f_k) |
Здесь k – число интервалов, на которые разбивается ряд.
Размах вариации – это длина интервала, в пределах которой изменяется исследуемый признак: $$ F=x_{max}-x_{min} $$
Правило Стерджеса
Эмпирическое правило определения оптимального количества интервалов k, на которые следует разбить ряд из N чисел: $$ k=1+lfloorlog_2 Nrfloor $$ или, через десятичный логарифм: $$ k=1+lfloor 3,322cdotlg Nrfloor $$
Скобка (lfloor rfloor) означает целую часть (округление вниз до целого числа).
Шаг интервального ряда – это отношение размаха вариации к количеству интервалов, округленное вверх до определенной точности: $$ h=leftlceilfrac Rkrightrceil $$
Скобка (lceil rceil) означает округление вверх, в данном случае не обязательно до целого числа.
Алгоритм построения интервального ряда
На входе: все значения признака (left{x_jright}, j=overline{1,N})
Шаг 1. Найти размах вариации (R=x_{max}-x_{min})
Шаг 2. Найти оптимальное количество интервалов (k=1+lfloorlog_2 Nrfloor)
Шаг 3. Найти шаг интервального ряда (h=leftlceilfrac{R}{k}rightrceil)
Шаг 4. Найти узлы ряда: $$ a_0=x_{min}, a_i=1_0+ih, i=overline{1,k} $$ Шаг 5. Найти частоты (f_i) – число попаданий значений признака в каждый из интервалов (left.left[a_{i-1},a_iright.right)).
На выходе: интервальный ряд с интервалами (left.left[a_{i-1},a_iright.right)) и частотами (f_i, i=overline{1,k})
Заметим, что поскольку шаг h находится с округлением вверх, последний узел (a_kgeq x_{max}).
Например:
Проведено 100 измерений роста учеников старших классов.
Минимальный рост составляет 142 см, максимальный – 197 см.
Найдем узлы для построения соответствующего интервального ряда.
По условию: (N=100, x_{min}=142 см, x_{max}=197 см).
Размах вариации: (R=197-142=55) (см)
Оптимальное число интервалов: (k=1+lfloor 3,322cdotlg 100rfloor=1+lfloor 6,644rfloor=1+6=7)
Шаг интервального ряда: (h=lceilfrac{55}{5}rceil=lceil 7,85rceil=8) (см)
Получаем узлы ряда: $$ a_0=x_{min}=142, a_i=142+icdot 8, i=overline{1,7} $$
| (left.left[a_{i-1},a_iright.right)) cм | (left.left[142;150right.right)) | (left.left[150;158right.right)) | (left.left[158;166right.right)) | (left.left[166;174right.right)) | (left.left[174;182right.right)) | (left.left[182;190right.right)) | (left[190;198right]) |
п.2. Гистограмма и полигон относительных частот, кумулята и эмпирическая функция распределения
Относительная частота интервала (left.left[a_{i-1},a_iright.right)) – это отношение частоты (f_i) к общему количеству исходов: $$ w_i=frac{f_i}{N}, i=overline{1,k} $$
Гистограмма относительных частот интервального ряда – это фигура, состоящая из прямоугольников, ширина которых равна шагу ряда, а высота – относительным частотам каждого из интервалов.
Площадь гистограммы равна 1 (с точностью до округлений), и она является эмпирическим законом распределения исследуемого признака.
Полигон относительных частот интервального ряда – это ломаная, соединяющая точки ((x_i,w_i)), где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Накопленные относительные частоты – это суммы: $$ S_1=w_1, S_i=S_{i-1}+w_i, i=overline{2,k} $$ Ступенчатая кривая (F(x)), состоящая из прямоугольников, ширина которых равна шагу ряда, а высота – накопленным относительным частотам, является эмпирической функцией распределения исследуемого признака.
Кумулята – это ломаная, которая соединяет точки ((x_i,S_i)), где (x_i) – середины интервалов.
Например:
Продолжим анализ распределения учеников по росту.
Выше мы уже нашли узлы интервалов. Пусть, после распределения всех 100 измерений по этим интервалам, мы получили следующий интервальный ряд:
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| (left.left[a_{i-1},a_iright.right)) cм | (left.left[142;150right.right)) | (left.left[150;158right.right)) | (left.left[158;166right.right)) | (left.left[166;174right.right)) | (left.left[174;182right.right)) | (left.left[182;190right.right)) | (left[190;198right]) |
| (f_i) | 4 | 7 | 11 | 34 | 33 | 8 | 3 |
Найдем середины интервалов, относительные частоты и накопленные относительные частоты:
| (x_i) | 146 | 154 | 162 | 170 | 178 | 186 | 194 |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 |
| (S_i) | 0,04 | 0,11 | 0,22 | 0,56 | 0,89 | 0,97 | 1 |
Построим гистограмму и полигон:

Построим кумуляту и эмпирическую функцию распределения: 

Эмпирическая функция распределения (относительно середин интервалов): $$ F(x)= begin{cases} 0, xleq 146\ 0,04, 146lt xleq 154\ 0,11, 154lt xleq 162\ 0,22, 162lt xleq 170\ 0,56, 170lt xleq 178\ 0,89, 178lt xleq 186\ 0,97, 186lt xleq 194\ 1, xgt 194 end{cases} $$
п.3. Выборочная средняя, мода и медиана. Симметрия ряда
Выборочная средняя интервального вариационного ряда определяется как средняя взвешенная по частотам: $$ X_{cp}=frac{x_1f_1+x_2f_2+…+x_kf_k}{N}=frac1Nsum_{i=1}^k x_if_i $$ где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Или, через относительные частоты: $$ X_{cp}=sum_{i=1}^k x_iw_i $$
Модальным интервалом называют интервал с максимальной частотой: $$ f_m=max f_i $$ Мода интервального вариационного ряда определяется по формуле: $$ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h $$ где
(h) – шаг интервального ряда;
(x_o) – нижняя граница модального интервала;
(f_m,f_{m-1},f_{m+1}) – соответственно, частоты модального интервала, интервала слева от модального и интервала справа.
Медианным интервалом называют первый интервал слева, на котором кумулята превысила значение 0,5. Медиана интервального вариационного ряда определяется по формуле: $$ M_e=x_o+frac{0,5-S_{me-1}}{w_{me}}h $$ где
(h) – шаг интервального ряда;
(x_o) – нижняя граница медианного интервала;
(S_{me-1}) накопленная относительная частота для интервала слева от медианного;
(w_{me}) относительная частота медианного интервала.
Расположение выборочной средней, моды и медианы в зависимости от симметрии ряда аналогично их расположению в дискретном ряду (см. §65 данного справочника).
Например:
Для распределения учеников по росту получаем:
| (x_i) | 146 | 154 | 162 | 170 | 178 | 186 | 194 | ∑ |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 | 1 |
| (x_iw_i) | 5,84 | 10,78 | 17,82 | 57,80 | 58,74 | 14,88 | 5,82 | 171,68 |
$$ X_{cp}=sum_{i=1}^k x_iw_i=171,68approx 171,7 text{(см)} $$ На гистограмме (или полигоне) относительных частот максимальная частота приходится на 4й интервал [166;174). Это модальный интервал.
Данные для расчета моды: begin{gather*} x_o=166, f_m=34, f_{m-1}=11, f_{m+1}=33, h=8\ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h=\ =166+frac{34-11}{(34-11)+(34-33)}cdot 8approx 173,7 text{(см)} end{gather*} На кумуляте значение 0,5 пересекается на 4м интервале. Это – медианный интервал.
Данные для расчета медианы: begin{gather*} x_o=166, w_m=0,34, S_{me-1}=0,22, h=8\ \ M_e=x_o+frac{0,5-S_{me-1}}{w_me}h=166+frac{0,5-0,22}{0,34}cdot 8approx 172,6 text{(см)} end{gather*} begin{gather*} \ X_{cp}=171,7; M_o=173,7; M_e=172,6\ X_{cp}lt M_elt M_o end{gather*} Ряд асимметричный с левосторонней асимметрией.
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|}=frac{2,0}{0,9}approx 2,2lt 3), т.е. распределение умеренно асимметрично.
п.4. Выборочная дисперсия и СКО
Выборочная дисперсия интервального вариационного ряда определяется как средняя взвешенная для квадрата отклонения от средней: begin{gather*} D=frac1Nsum_{i=1}^k(x_i-X_{cp})^2 f_i=frac1Nsum_{i=1}^k x_i^2 f_i-X_{cp}^2 end{gather*} где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Или, через относительные частоты: $$ D=sum_{i=1}^k(x_i-X_{cp})^2 w_i=sum_{i=1}^k x_i^2 w_i-X_{cp}^2 $$
Выборочное среднее квадратичное отклонение (СКО) определяется как корень квадратный из выборочной дисперсии: $$ sigma=sqrt{D} $$
Например:
Для распределения учеников по росту получаем:
| $x_i$ | 146 | 154 | 162 | 170 | 178 | 186 | 194 | ∑ |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 | 1 |
| (x_iw_i) | 5,84 | 10,78 | 17,82 | 57,80 | 58,74 | 14,88 | 5,82 | 171,68 |
| (x_i^2w_i) – результат | 852,64 | 1660,12 | 2886,84 | 9826 | 10455,72 | 2767,68 | 1129,08 | 29578,08 |
$$ D=sum_{i=1}^k x_i^2 w_i-X_{cp}^2=29578,08-171,7^2approx 104,1 $$ $$ sigma=sqrt{D}approx 10,2 $$
п.5. Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
Исправленная выборочная дисперсия интервального вариационного ряда определяется как: begin{gather*} S^2=frac{N}{N-1}D end{gather*}
Стандартное отклонение выборки определяется как корень квадратный из исправленной выборочной дисперсии: $$ s=sqrt{S^2} $$
Коэффициент вариации это отношение стандартного отклонения выборки к выборочной средней, выраженное в процентах: $$ V=frac{s}{X_{cp}}cdot 100text{%} $$
Подробней о том, почему и когда нужно «исправлять» дисперсию, и для чего использовать коэффициент вариации – см. §65 данного справочника.
Например:
Для распределения учеников по росту получаем: begin{gather*} S^2=frac{100}{99}cdot 104,1approx 105,1\ sapprox 10,3 end{gather*} Коэффициент вариации: $$ V=frac{10,3}{171,7}cdot 100text{%}approx 6,0text{%}lt 33text{%} $$ Выборка однородна. Найденное значение среднего роста (X_{cp})=171,7 см можно распространить на всю генеральную совокупность (старшеклассников из других школ).
п.6. Алгоритм исследования интервального вариационного ряда
На входе: все значения признака (left{x_jright}, j=overline{1,N})
Шаг 1. Построить интервальный ряд с интервалами (left.right[a_{i-1}, a_ileft.right)) и частотами (f_i, i=overline{1,k}) (см. алгоритм выше).
Шаг 2. Составить расчетную таблицу. Найти (x_i,w_i,S_i,x_iw_i,x_i^2w_i)
Шаг 3. Построить гистограмму (и/или полигон) относительных частот, эмпирическую функцию распределения (и/или кумуляту). Записать эмпирическую функцию распределения.
Шаг 4. Найти выборочную среднюю, моду и медиану. Проанализировать симметрию распределения.
Шаг 5. Найти выборочную дисперсию и СКО.
Шаг 6. Найти исправленную выборочную дисперсию, стандартное отклонение и коэффициент вариации. Сделать вывод об однородности выборки.
п.7. Примеры
Пример 1. При изучении возраста пользователей коворкинга выбрали 30 человек.
Получили следующий набор данных:
18,38,28,29,26,38,34,22,28,30,22,23,35,33,27,24,30,32,28,25,29,26,31,24,29,27,32,24,29,29
Постройте интервальный ряд и исследуйте его.
1) Построим интервальный ряд. В наборе данных: $$ x_{min}=18, x_{max}=38, N=30 $$ Размах вариации: (R=38-18=20)
Оптимальное число интервалов: (k=1+lfloorlog_2 30rfloor=1+4=5)
Шаг интервального ряда: (h=lceilfrac{20}{5}rceil=4)
Получаем узлы ряда: $$ a_0=x_{min}=18, a_i=18+icdot 4, i=overline{1,5} $$
| (left.left[a_{i-1},a_iright.right)) лет | (left.left[18;22right.right)) | (left.left[22;26right.right)) | (left.left[26;30right.right)) | (left.left[30;34right.right)) | (left.left[34;38right.right)) |
Считаем частоты для каждого интервала. Получаем интервальный ряд:
| (left.left[a_{i-1},a_iright.right)) лет | (left.left[18;22right.right)) | (left.left[22;26right.right)) | (left.left[26;30right.right)) | (left.left[30;34right.right)) | (left.left[34;38right.right)) |
| (f_i) | 1 | 7 | 12 | 6 | 4 |
2) Составляем расчетную таблицу:
| (x_i) | 20 | 24 | 28 | 32 | 36 | ∑ |
| (f_i) | 1 | 7 | 12 | 6 | 4 | 30 |
| (w_i) | 0,033 | 0,233 | 0,4 | 0,2 | 0,133 | 1 |
| (S_i) | 0,033 | 0,267 | 0,667 | 0,867 | 1 | – |
| (x_iw_i) | 0,667 | 5,6 | 11,2 | 6,4 | 4,8 | 28,67 |
| (x_i^2w_i) | 13,333 | 134,4 | 313,6 | 204,8 | 172,8 | 838,93 |
3) Строим полигон и кумуляту

Эмпирическая функция распределения: $$ F(x)= begin{cases} 0, xleq 20\ 0,033, 20lt xleq 24\ 0,267, 24lt xleq 28\ 0,667, 28lt xleq 32\ 0,867, 32lt xleq 36\ 1, xgt 36 end{cases} $$ 4) Находим выборочную среднюю, моду и медиану $$ X_{cp}=sum_{i=1}^k x_iw_iapprox 28,7 text{(лет)} $$ На полигоне модальным является 3й интервал (самая высокая точка).
Данные для расчета моды: begin{gather*} x_0=26, f_m=12, f_{m-1}=7, f_{m+1}=6, h=4\ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h=\ =26+frac{12-7}{(12-7)+(12-6)}cdot 4approx 27,8 text{(лет)} end{gather*}
На кумуляте медианным является 3й интервал (преодолевает уровень 0,5).
Данные для расчета медианы: begin{gather*} x_0=26, w_m=0,4, S_{me-1}=0,267, h=4\ M_e=x_o+frac{0,5-S_{me-1}}{w_{me}}h=26+frac{0,5-0,4}{0,267}cdot 4approx 28,3 text{(лет)} end{gather*} Получаем: begin{gather*} X_{cp}=28,7; M_o=27,8; M_e=28,6\ X_{cp}gt M_egt M_0 end{gather*} Ряд асимметричный с правосторонней асимметрией.
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|} =frac{0,9}{0,1}=9gt 3), т.е. распределение сильно асимметрично.
5) Находим выборочную дисперсию и СКО: begin{gather*} D=sum_{i=1}^k x_i^2w_i-X_{cp}^2=838,93-28,7^2approx 17,2\ sigma=sqrt{D}approx 4,1 end{gather*}
6) Исправленная выборочная дисперсия: $$ S^2=frac{N}{N-1}D=frac{30}{29}cdot 17,2approx 17,7 $$ Стандартное отклонение (s=sqrt{S^2}approx 4,2)
Коэффициент вариации: (V=frac{4,2}{28,7}cdot 100text{%}approx 14,7text{%}lt 33text{%})
Выборка однородна. Найденное значение среднего возраста (X_{cp}=28,7) лет можно распространить на всю генеральную совокупность (пользователей коворкинга).
