Поиск печатей в документах
Время прочтения: 4 мин.
Предположим, что имеется цветное изображение формата А4, на котором может быть одна или несколько круглых печатей. Поставим задачу — определить координаты прямоугольников, ограничивающих области изображения с оттисками печати. Эта задача является задачей детекции объектов (object detection), и для её решения можно использовать разные подходы. Применим подход на основе поиска контуров с помощью преобразования Хафа. Это подход удобно использовать, поскольку у нас есть некоторые априорные знания об искомых объектах: круглая форма, преимущественно синий цвет, определенный размер.
Рассмотрим процесс решения поставленной задачи.
Шаг 1. Подключаем библиотеки opencv и numpy.
import cv2
import numpy as np
Шаг 2. Открываем исходное изображение. В качестве примера изображения используем лицензию, выданную Центробанком РФ.
im = cv2.imread('license.jpg')
Шаг 3. Выделяем области искомого цвета. Для этого преобразуем изображение из цветовой модели RGB в цветовую модель HSV (hue-saturation-value, или тон-насыщенность-значение). Если цветовую схему HSV представить в виде круга, где тон определяется углом от 0° до 360°, то можно обнаружить, что тон синей печати находится внутри сектора, приблизительно ограниченного значениями 160° и 280°.

С учетом того, что в соответствии с особенностями библиотеки opencv значение тона лежит в диапазоне от 0 до 180, выбранные нами границы примут значения 80 и 140 соответственно.
Выполняем преобразование изображения к цветовой модели HSV, задаём границы тона, насыщенности и значения, накладываем соответствующую маску на исходное изображение.
hsv = cv2.cvtColor(im, cv2.COLOR_BGR2HSV)
blue_lower = np.array([80, 30, 30])
blue_higher = np.array([140, 250, 250])
mask = cv2.inRange(hsv, blue_lower, blue_higher)
selection = cv2.bitwise_and(im, im, mask=mask)
В результате изображение selection будет содержать только те области, цвет которых соответствует заданным нам ограничениям.

Шаг 4. Преобразуем цветное изображение в серое, затем выполняем сглаживание для коррекции мелких артефактов на изображении.
gray = cv2.cvtColor(selection, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (5,5), 2)
Шаг 5. Находим круглые контуры с помощью функции HoughCircles. Предварительно рассчитываем минимальный и максимальный радиусы искомых окружностей в пикселах, а также задаем параметр minDist (минимальное расстояние между центрами контуров) равным диаметру самой маленькой печати. Отметим, что согласно ГОСТ Р 51511-2001, диаметр гербовой печати составляет от 40 до 50 мм, или от 19% до 24% от ширины листа формата А4. С учетом небольшого запаса задаём относительные диаметра печатей от 0,15 до 0,30.
h, w = gray.shape
r_min = int(w * 0.15 / 2)
r_max = int(w * 0.30 / 2)
contours = cv2.HoughCircles(blur, cv2.HOUGH_GRADIENT, dp=1, minDist=2 * r_min)
В результате переменная contours будет содержать перечень координат центров и радиусов всех обнаруженных контуров.
Шаг 6. Составляем список ограничивающих прямоугольников boxes, для чего проходим в цикле по всем обнаруженным контурам, отбираем окружности подходящего радиуса и рассчитываем координаты противоположных углов ограничивающих прямоугольников.
boxes = []
if contours is not None:
for contour in contours[0]:
xc, yc, r = np.uint16(np.around(contour))
if r_min <= r <= r_max:
x1 = xc - r
y1 = yc - r
x2 = xc + r
y2 = yc + r
boxes.append([x1, y1, x2, y2])
Для рассмотренного изображения найден один такой прямоугольник. Наложив найденный прямоугольник на исходное изображение, убеждаемся, что рассмотренный алгоритм позволил правильно решить поставленную задачу.

Таким образом, рассмотренный алгоритм можно использовать для поиска печатей в документах. Исходный код ноутбука приведен в репозитории — ссылка
Ответы на вопрос (2):
Взять там, где оттиски успели сделать до утери печатей. Например, в банке, где открывали счет.
Спросить
Добрый день! Самое простое – трудовые договоры работников, т.к. их срок хранения 50 (75) лет. Или приказ о вступлении в должность генерального директора – на нем тоже часто ставят оттиск печати. Договоры предприятия (услуги, закупки и прочее), счета – если бухгалтерия хранит у себя второй экземпляр.
Спросить
Похожие вопросы
Где взять оттиск печати?
Вводные данные: имеется учредитель и директор в одном лице, у которого нет на руках ни документов на организацию ни печати.
Требуется изготовить печать по оттиску организации, но где этот оттиск можно отыскать, есть ли в налоговой на каких-либо документах такой оттиск организации, за дубликатом которого можно сходить в налоговую?
Читать ответы: 1
Вопрос от 29.08.2018
Как быть, и как грамотно юридически оформить/заверить печать (если она конечно возможна)?
Печать для документов для представителя непосредственной формы самоуправления многоквартирным домом (самоуправление без образования ТСЖ/Юр лица), возможно и законно ли её иметь? При оформлении документов на жилищную субсидию, требуют документов с печатью, но у непосредственного самоуправления, печати нет, представитель самоуправления не знает законно ли будет оформлять такую печать, и вообще возможно ли её иметь при непосредственной форме самоуправления. Как быть, и как грамотно юридически оформить/заверить печать (если она конечно возможна)?
Читать ответы: 2
Вопрос от 28.02.2017
Перед нами часто стоят задачи — проанализировать печатные документы. При этом анализу может подвергаться как текст документа, так и его графические элементы (например — штрих-коды и печати). Для проверки наличия печати в документе или для анализа соответствия печати некоторому образцу необходимо найти области документа, содержащие изображения печатей. Предположим, что имеется цветное изображение формата А4.
На нем может быть одна или несколько круглых печатей. Поставим задачу — определить координаты прямоугольников, ограничивающих области изображения с оттисками печати. Эта задача является задачей детекции объектов (object detection), и для её решения можно использовать разные подходы. Применим подход на основе поиска контуров с помощью преобразования Хафа. Это подход удобно использовать, поскольку у нас есть некоторые априорные знания об искомых объектах: круглая форма, преимущественно синий цвет, определенный размер.
Рассмотрим процесс решения поставленной задачи.
Шаг 1. Подключаем библиотеки opencv и numpy.
import cv2
import numpy as np
Шаг 2. Открываем исходное изображение. В качестве примера изображения используем лицензию, выданную Центробанком РФ.
im = cv2.imread(‘license.jpg’)
Шаг 3. Выделяем области искомого цвета. Для этого преобразуем изображение из цветовой модели RGB в цветовую модель HSV (hue-saturation-value, или тон-насыщенность-значение). Если цветовую схему HSV представить в виде круга, где тон определяется углом от 0° до 360°, то можно обнаружить, что тон синей печати находится внутри сектора, приблизительно ограниченного значениями 160° и 280°.
С учетом того, что в соответствии с особенностями библиотеки opencv значение тона лежит в диапазоне от 0 до 180, выбранные нами границы примут значения 80 и 140 соответственно.
Выполняем преобразование изображения к цветовой модели HSV, задаём границы тона, насыщенности и значения, накладываем соответствующую маску на исходное изображение.
hsv = cv2.cvtColor(im, cv2.COLOR_BGR2HSV)
blue_lower = np.array([80, 30, 30])
blue_higher = np.array([140, 250, 250])
mask = cv2.inRange(hsv, blue_lower, blue_higher)
selection = cv2.bitwise_and(im, im, mask=mask)
В результате изображение selection будет содержать только те области, цвет которых соответствует заданным нам ограничениям.
Шаг 4. Преобразуем цветное изображение в серое, затем выполняем сглаживание для коррекции мелких артефактов на изображении.
gray = cv2.cvtColor(selection, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (5,5), 2)
Шаг 5. Находим круглые контуры с помощью функции HoughCircles. Предварительно рассчитываем минимальный и максимальный радиусы искомых окружностей в пикселах, а также задаем параметр minDist (минимальное расстояние между центрами контуров) равным диаметру самой маленькой печати. Отметим, что согласно ГОСТ Р 51511-2001, диаметр гербовой печати составляет от 40 до 50 мм, или от 19% до 24% от ширины листа формата А4. С учетом небольшого запаса задаём относительные диаметра печатей от 0,15 до 0,30.
h, w = gray.shape
r_min = int(w * 0.15 / 2)
r_max = int(w * 0.30 / 2)
contours = cv2.HoughCircles(blur, cv2.HOUGH_GRADIENT, dp=1, minDist=2 * r_min)
В результате переменная contours будет содержать перечень координат центров и радиусов всех обнаруженных контуров.
Шаг 6. Составляем список ограничивающих прямоугольников boxes, для чего проходим в цикле по всем обнаруженным контурам, отбираем окружности подходящего радиуса и рассчитываем координаты противоположных углов ограничивающих прямоугольников.
boxes = []
if contours is not None:
for contour in contours[0]:
xc, yc, r = np.uint16(np.around(contour))
if r_min <= r <= r_max:
x1 = xc – r
y1 = yc – r
x2 = xc + r
y2 = yc + r
boxes.append([x1, y1, x2, y2])
Для рассмотренного изображения найден один такой прямоугольник. Наложив найденный прямоугольник на исходное изображение, убеждаемся, что рассмотренный алгоритм позволил правильно решить поставленную задачу.
Таким образом, рассмотренный алгоритм можно использовать для поиска печатей в документах. Исходный код ноутбука приведен в репозитории — ссылка
Где можно посмотреть печать компании по инн?
Ser S.
9 ноября 2018 · 3,3 K
ОтветитьУточнить
Евгений З.28,2 K
Aequĭtas sequĭtur legem · 14 нояб 2018
Печать компании по ИНН посмотреть не получится, на данный момент печати не регистрируются в отдельных реестрах, а кроме того, организация вообще может не иметь печати.
3,2 K
Евгений Матяшов
14 июля 2022
есть реестр печатей. но, к сожалению, это не автоматизированная БД в интернете. надо заявление отправлять
Комментировать ответ…Комментировать…
Вы знаете ответ на этот вопрос?
Поделитесь своим опытом и знаниями
Войти и ответить на вопрос
Привет, Хабр! Сегодня мы расскажем, как делали в нашей группе анализа данных прототип для уже успешно работающего внутри DLP-системы Solar Dozor движка детектирования графических объектов на изображениях. Покажем это на примере одного его представителя – оттисков печатей на изображениях документов. Вспомним о противоречивых требованиях к решению задачи и очертим бизнес-метрики, определяющие успешное решение. В процессе подберем фильтр наличия печатей из арсенала компьютерного зрения, сравним подходы к детектированию объектов и поговорим о популярных движках CNN, SIFT и их вариациях. А также поведаем об интересных находках в части создания датасетов. Здесь, как оказалось, немало места для творчества и экспериментов. В общем, запасайтесь попкорном.

Оглавление
-
Зачем распознавать печати?
-
Что, кстати, хочет пользователь?
-
Немного общей теории
-
Классификация
-
Детектирование
-
Сегментация
-
-
Алгоритмы, алгоритмы, а я маленький такой
-
Что с датасетами?
-
Сбор данных для задачи «Любая печать»
-
Поисковики
-
Kaggle
-
Госзакупки
-
-
Данные для задачи «Моя печать»
-
-
Обучение
-
Технические аспекты
-
Обучение оптимальной модели для задачи «Любая печать».
Немного простой теории
-
Выбор алгоритма для задачи «Моя печать»
-
-
Комплексное решение
-
Попробуем подвести итоги и сделать выводы
-
Источники литературы
Зачем распознавать печати?
Печать используется для подтверждения подлинности документа, а если быть точнее – подлинности подписи должностного лица. Часто заверенная печатью информация должна быть доступна только определенным лицам и ни в коем случае не должна выходить за пределы компании. Если нарушаются границы, в пределах которых должен «путешествовать» документ, важно как можно раньше обратить на это внимание.
Чтобы детектировать печати, надо понять, какими они бывают. Выделяют три вида печатей: гербовые, приравненные к гербовым и простые. Гербовые отличаются от всех остальных наличием изображения герба РФ и используются в государственных органах власти. Приравненные к гербовым печати используются коммерческими фирмами или индивидуальными предпринимателями. Они похожи на гербовые, но содержат логотип компании или ФИО частного предпринимателя. Для этих двух видов определены свои требования (в отличие от простой печати). Последняя не содержит в себе какого-либо логотипа и используется она обычно для документов, подтверждение подлинности которых не является критичным. Таких печатей в компании может быть несколько, а количество гербовых или приравненных к ней ограничивается одной.
Важно также понимать, что задач детектирования печати на самом деле две. Они разные как по смыслу, так и по решению, как это мы в дальнейшем определим.
-
Первая – это находить любые печати в документе независимо от того, к какой организации они относятся.
Эта задача предполагает возможность предобучения на хорошем датасете модели распознавания и пользователю решения уже не нужно будет заморачиваться с обучением.
Назовем эту задачу для простоты «Любая печать».
-
Вторая задача – находить экземпляры печати какой-то конкретной организации. И решается она иначе.
От пользователя уже требуется наличие примера такой печати, но не стоит рассчитывать на объемлющий датасет с примерами, а ограничиться одним примером.
Будем называть эту задачу «Моя печать».
|
«Любая печать» –Распознавать любую печать |
«Моя печать» – Распознавать конкретную (заданную) печать |
|
|
Датасет: учебная выборка |
Не ограничена |
Ограничена одним примером |
|
Датасет: тестовая выборка |
Не ограничена |
|
|
Классификатор |
Бинарный |
|
|
Бизнес польза |
Находит любые заверенные документы. |
Находит документы, заверенные конкретной организацией. |
|
Минусы для пользователей |
Нельзя отличить важные печати от неважных |
Пользователю требуется сделать пример конкретной печати и тем самым самостоятельно обучить модель. |
Таблица 1: Различие решаемых задач «Любая печать» и «Моя печать»
Что, кстати, хочет пользователь?

Сами эти задачи, конечно, не свалились с потолка. Запрос на них пришел к нам в группу анализа данных от владельца продукта. С ним-то и определялись основные критерии хорошего решения задач. Причем у нас в группе анализа данных используется Lean DS в качестве подхода управления задачами. И важная составляющая в нем – это определение связи: бизнес выгода – ML метрики.
Мы определили бизнес-метрики и связанные ML-метрики:
-
Пользователь (аналитик безопасности) за рабочий день может обрабатывать до 1000 артефактов и не готов тратить более 10 минут на обработку ложных срабатываний, что говорит о требовании к высокой точности. Мы выяснили, что среднее время работы в системе – 2 часа в сутки, и, что ложное срабатывание обрабатывается, как минимум, в 2 раза быстрее. Несложно оценить требуемую точность детектирования, она должна быть не ниже 84%.
-
Крайне нежелательно упускать из виду объекты, они могут свидетельствовать об утечках данных, по стоимости значительно превышающих 10 минут работы аналитика безопасности. Поэтому полнота детектирования, можно сказать, важнее чем точность. Мы приняли решение выбрать оптимальный алгоритм, а затем постепенно снижать до приемлемого порога точность в угоду высокой полноте.
-
Одновременно с требованием к высокому качеству распознавания мы имели ограничение к ресурсам железа, требуемым для обработки.
-
Также у нас было требование к скорости обработки не менее 1000 изображений произвольного размера за час.
Так у нас родился треугольник успешности 99% решений подобного рода (аналог треугольника управления проектами).

Немного общей теории
Итак, нам нужен некий фильтр наличия печатей. Но как должен работать этот фильтр?
Он должен просто выдавать изображения, на которых есть хотя бы одна печать, или, может быть, от него также требуется информация о количестве этих печатей?
Или что-то еще? Здесь необходимо сделать введение в задачи компьютерного зрения. В различной литературе они описаны по-разному, однако следующие три, как правило, упоминаются везде:
-
классификация;
-
детектирование;
-
сегментация.
Поговорим о каждой из них.
Классификация
Классификатор – алгоритм, который отвечает на вопрос, есть ли заданный нами объект на изображении (не более того). Допустим, у нас есть несколько объектов, о существовании которых на изображениях мы хотели бы знать. Пусть это будут печать, подпись и печатный текст. У нас есть несколько изображений:
")
Что получится на выходе? Обычно для каждого изображения это словарь следующего вида:
{
объект_1: вероятность_нахождения_на_изображении_объекта_1,
объект_2: вероятность_нахождения_на_изображении
… ,
объект_n: вероятность_нахождения_на_изображении
}
Но просто вероятность не дает нам ответа «ДА, НА ЭТОМ ИЗОБРАЖЕНИИ ЕСТЬ ЭТОТ ОБЪЕКТ» или «НЕТ, НА ЭТОМ ИЗОБРАЖЕНИИ НЕТ ЭТОГО ОБЪЕКТА». Для этого необходимо использовать порог – специальное значение, вероятность выше которого означала бы положительный ответ, а ниже – отрицательный.
Что получится в таком случае для изображений выше? Примерно следующее:

Детектирование
Обнаружение объектов (object detection) – важная задача компьютерного зрения. Она связана с обнаружением экземпляров визуальных объектов определенного класса (например, люди, животные или автомобили) на цифровых изображениях [1]. Постановка задачи детекции объектов состоит в том, чтобы определить, где именно расположены интересуемые объекты на конкретном изображении (локализация объекта) и к какой категории принадлежит каждый объект (классификация объектов) [2].
На изображениях это выглядит следующим образом:

Сегментация
Сегментация заходит еще дальше. Это алгоритм, который отвечает на вопрос, какие из заданных нами объектов есть на изображении, сколько их и где они находятся (точные границы). Изображение в качестве примера:

Как можно заметить, решение каждой из задач подошло бы для реализации фильтра. Однако сегментация была сразу отброшена – знание точных границ являлось излишней информацией. Поэтому встал выбор между классификацией и детектированием, из которых выбор пал на последнее, поскольку для задач защиты данных важно знать сколько объектов на изображении документа.
Алгоритмы, алгоритмы, а я маленький такой
За последние десять лет зоопарк решений по детектированию объектов настолько вырос, что нам пришлось проводить отдельный НИР по выявлению вариантов подходящих моделей.
Выбор стоял между наиболее актуальными на сегодняшний день нейронными сетями и давно зарекомендовавшими себя вариациями SIFT-алгоритма. А с учетом того, что последний не так давно просрочил свой патент, стало возможным его использовать в коммерческих решениях свободно.

Изучили наиболее известные статьи по сравнению двух подходов. Наиболее содержательными видятся статьи, проводящие сравнение двух подходов:
-
SIFT Meets CNN: A Decade Survey of Instance Retrieval, Liang Zheng, Yi Yang, and Qi Tian, Fellow, IEEE
-
CNN vs. SIFT for Image Retrieval: Alternative or Complementary, Ke Yan, Yaowei Wang, Dawei Liang, Tiejun Huang, Yonghong Tian
-
Object Recognition. SIFT vs Convolutional Neural Networks, Josip Josifovski
Общий вывод исследователей следующий. Алгоритмы SIFT-based хорошо справляются с поиском очень похожих дубликатов и менее пригодны для детектирования более широких классов объектов.
Тогда как сверточные нейронные сети, напротив, лучше справляются с обнаружением похожих, не обязательно идентичных объектов. При этом начинают чаще путаться при задаче отделения дубликатов от просто похожих изображений.
|
Алгоритм |
Хорошо |
Плохо |
|
SIFT |
Задачи идентификации, поиска дубликатов. Легко встроить в продукт. Быстрый |
Плохо обобщает объекты. Плохо справляется с нелинейными искажениями |
|
CNN |
Задачи классификации, поиска объектов определенного типа. Очень хорошо ищет похожие объекты, обобщает |
Потребляет много ресурсов. Требует большого датасета для обучения. Требует настройки |
Таблица 3: анализ преимуществ и недостатков SIFT и CNN
Для прототипа решения обеих наших задач были выбраны несколько моделей из Tensorflow Object Detection, реализация SIFT в OpenCV, а также его аналог ORB.
Для справки
Масштабно-инвариантное преобразование признаков (Scale Invariant Feature Transform, SIFT) – это детектор признаков, впервые
представленный Дэвидом Лоу в 2004 году в работе «Distinctive Image Features from Scale-Invariant Keypoints». Наряду с тем, что SIFT является очень эффективным в приложениях для распознавания объектов, он требует большой вычислительной мощности, что является серьезным недостатком, особенно для приложений реального времени [4].
SIFT решает проблему поворота изображения, аффинных преобразований, интенсивности и изменения точки обзора в соответствующих объектах. Алгоритм состоит из 4 основных шагов. Во-первых, оцениваются масштабные пространственные экстремумы с использованием разности Гаусса. Во-вторых, локализуются ключевые точки. На этом же шаге ключевые точки уточняются путем устранения точек с низкой контрастностью. В-третьих, определяется ориентация ключевой точки на основе локального градиента изображения и, наконец, применяется генератор дескрипторов для вычисления локального дескриптора изображения для каждой ключевой точки на основе величины и ориентации градиента изображения.
Oriented FAST and Rotated BRIEF (ORB) был предложен Итаном Р., Куртом К. и Гарри Б. в 2011 году, в качестве эффективной альтернаты SIFT и SU
RF [5]. ORB представляет собой синтез так называемого «FAST» детектора ключевых точек и «BRIEF» дескриптора с некоторыми
модификациями. На первом шаге, для определения ключевых моментов алгоритм использует FAST. Затем применяется мера угла Харриса, чтобы найти верхние N точек. FAST вычисляет центроид, взвешенный по интенсивности, для пятна с расположенным углом в центре. Направление вектора от этой угловой точки к центроиду определяет ориентацию. BRIEF плохо работает, если происходит вращение в плоскости [4].
А теперь расскажем про отдельные интересные особенности решения обеих задач.
Что с датасетами?
Сначала пара слов о требованиях к датасету. Напомню, что датасет – это некоторая случайная выборка из генеральной совокупности всех примеров. На языке математики от такой совокупности требуется равномерное распределение по генеральной совокупности. И, конечно, необходимо следить за снижением размерности задачи машинного обучения и нормализацией данных. Но, как говорили классики, «есть один нюанс». Получить представление о генеральной совокупности примеров непросто и требует знания бизнес-специфики и задач пользователей. И эта задача находится на пересечении компетенции датасайентиста и бизнес-аналитика. По-хорошему, им обоим надо сильно подружиться (поработать вместе), чтобы сформировать полное представление о генеральной совокупности.
В нашем случае мы совместно с бизнес-аналитиком провели больше двух десятков интервью с конечными пользователями, чтобы понять, в каких сценариях могут возникать задачи перехвата оттиска печатей, какими могут быть эти оттиски и как часто подвергаться тем или иным искажениям. Например, оттиски печатей могут находиться на:
-
Программно-конвертируемых изображениях,
-
Скриншотах экранов, сделанных на всевозможных типах сканеров,
-
Сфотографированных оригиналах документов,
-
Сфотографированных фотографиях и копиях документов,
-
Снимках с веб-камеры.
Помимо этого, изображение может быть искажено по различным причинам:
-
Поворот, растяжение, сжатие,
-
Сворачивание исходного документа,
-
Смятие исходного документа,
-
Частичное отображение искомого объекта,
-
Размытие и смазывание,
-
Наложение на текст, другие печати, водяные знаки.
Сами печати могут относиться к разным степеням коммерческой значимости. Эти факторы и их распределение должны формировать сбалансированную равномерно распределенную выборку из генеральной совокупности – датасет.
Сбор данных для задачи «Любая печать»
Пойдем по первому пути – будем детектировать любые печати на документах. Сначала необходимо обучить алгоритм, для чего нужно собрать датасет – набор изображений с размеченными на них печатями.
Напомню, что для обучения в датасет должны входить учебная и тестовая выборки.
И поскольку мы как разработчики обучаем модель, нам необходимо собрать как можно больший по информативности датасет и учебную и тестовую выборки. Мы рассматривали любые возможные источники наполнения датасета.
Поисковики
Самый очевидный вариант. Документы с печатями в поиске по картинкам найти можно, особенно в Яндексе, и их много. Проблема в том, что довольно большая масса изображений – различного рода дипломы, отзывы, поздравительные открытки и так далее. В общем, на серьезные бумаги не очень похоже. И явно не подходит под требования к датасету, обозначенные выше.
Kaggle
Это знаменитая платформа для соревнований в области исследования данных. К соревнованиям обычно прикладываются данные с хорошим источником датасетов. Однако печатей на момент поиска там найдено не было. И это ожидаемо. Вряд ли кто-то будет выкладывать без причины свои юридические признаки в общий доступ.
Где же брать примеры для датасета?
Немного потренировавшись на изображениях из поисковиков, мы решили поискать дополнительные источники. Кое-что нам удалось взять по своим каналам лояльности. Но этого все равно было мало. Мы даже задумали заказать разработку оттисков печатей у специальной организации и даже уже начали обсуждать с ней условия. Но вовремя посетила гениальная по простоте идея – взять примеры печатей с реальных и официально открытых документов на открытой площадке «Госзакупки».
Госзакупки
На «Госзакупках» присутствовали те самые желаемые нами реальные данные, причем в большом количестве.
После сбора изображений датасет был размечен (на картинках были обозначены области, в которых находятся печати). Для этого использовался специальный инструмент под названием labelImg (Ссылка).
")
В итоге мы получили датасет с более чем 1000 примеров объектов для учебной и тестовой выборки.
Во время формирования датасета нужно помнить о необходимой предобработке или очистке от некорректных примеров как с технической, так и с пользовательской точки зрения.
Данные для задачи «Моя печать»
Вторая задача заключалась в том, чтобы научиться находить конкретную печать на документах. Правда обучение здесь уже имеет привязку к пользовательскому сценарию работы с продуктом.
В учебной выборке у нас всегда только один пример, а тестовая по-прежнему должна быть большой. С учебной выборкой просто – берем печать своей организации. А вот тестовую пришлось делать своими руками. Мы взяли несколько аппаратов с печатью и проставили как можно больше печатей на документы со всевозможными деформациями и искажениями.
Еще часть учебной выборки сделали в цифровом виде. Сделали png образ печати с прозрачностью и в фотошопе «шлепали» ее на разные документы, при этом деформируя ее разными способами.
Часть документов дополнительно преобразовали в сканы с помощью сканера, а часть – отфотографировали в разных положениях. Вышла тоже приличная учебная выборка из более 200 верных примеров.
Обучение
Технические аспекты
Как говорится в одном известном фильме: «У нас была NVIDIA GTX 1080 и 2080, 32 гигабайта оперативной памяти и еще множество ноутбуков разных размеров и окрасов…»
Сначала нужно было установить TensorFlow версии 1.* с поддержкой видеокарты. Но не все так просто. Установка на GPU это вам не просто написать pip install tf.

Это надо скачать правильные драйвера под правильную версию TF, таблица в помощь.

Но, признаться, чтобы все завелось и работало, как надо, мы потратили где-то неделю. Из технических моментов интересен следующий случай.
Как-то между нашими обучениями произошел казус, GTX1080 на пару недель вышла из строя и нам пришлось обучать алгоритм на CPU (процесс установки, по секрету, НАМНОГО ПРОЩЕ).
Что интересно, модель из Tensorflow с высоким батчсайзом наш CPU + 32 ОЗУ смог переварить, хоть и очень долго, а GPU с 11 Гб вывалился по памяти.
С учетом нетривиального развертывания, капризов tensorflow, а также того, что наша команда работала в удаленном режиме (хоть и совместно), очень выручило использование докера.
Экспериментировать с разными версиями стало намного легче.
Обучение оптимальной модели для задачи «Любая печать»
Поговорим про обучение. Можно ли с первого раза получить модель, выдающую хорошие результаты? Вероятность есть, но она невысока. Кроме того, имея на руках только одну модель, нельзя сказать, что она наилучшая из возможных. Поэтому в данном случае необходимы эксперименты. С чем можно поэкспериментировать:
-
Разные варианты разметки
Печать на тексте можно отметить как просто печать, а можно ей выдать отдельное название. Точно так же, как и размазанной печати. Никогда заранее не знаешь, с каким вариантом разметки детектор будет лучше работать.
-
Разные модели
У Object Detection есть свой зоопарк моделей (и здесь нужно быть осторожным, так как для каждой версии Tensorflow свой зоопарк). Модели в нем самые разные. От быстрых, нетребовательных, но с косяками в детектировании, до тех, которые доведут одну-другую машину до перезагрузки.
-
Настройка гиперпараметров
Оптимальная настройка может, например, помочь модели детектировать объекты чуть быстрее без ущерба качеству или же улучшить качество (правда и повлиять на скорость).
Когда модель получена, необходимо понять, насколько хорошо она работает.
Немного простой теории
Оценку лучше всего получать в числовом виде, чтобы была возможность сравнивать модели. В машинном обучении часто для определения качества результатов используются метрики precision (точность) и recall (полнота). Чтобы понять, как они рассчитываются в общем случае, введем понятие матрицы ошибок. Допустим, в нашем наборе данных есть только два вида объектов. Пусть это будут животные (они будут помечаться меткой “Positive”) и растения (они будут помечаться – “Negative”). Распознающий алгоритм может правильно увидеть животное в коте, а может ошибочно посчитать его за растение. Дерево точно так же может быть переведено по ошибке в разряд животных, или же будет распознано правильно. В итоге получается четыре группы результатов:
|
Правильно распознанные (True) как животные (Positive) |
Неправильно распознанные (False) как животные (Positive) |
|
Неправильно распознанные (False) как растения (Negative) |
Правильно распознанные (True) как растения (Negative) |

А если абстрагироваться от названий объектов, получится так:
|
True Positive (TP) |
False Positive (FP) |
|
False Negative (FN) |
True Negative (TN) |
Если на место каждого названия группы поставить количество соответствующе распознанных объектов, получится та самая матрица ошибок. На основе значений этой матрицы рассчитываются точность и полнота (варианты для Positive-группы)
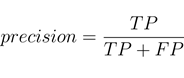


В Object Detection эти метрики также используются, только в чуть измененном виде. Есть несколько препятствий этому. Во-первых, не совсем ясно, как понять, к чему из TP, TN, FP, FN относится полученная детектором область. Классически область считается TP, если она удовлетворяет трем условиям:
-
предсказанная вероятность выше порога;
-
предсказанный класс совпадает с размеченным классом по названию;
-
IoU предсказанной области и размеченной области выше порога (по умолчанию 0.5).
Для того, чтобы предсказание стало FP, достаточно не соблюсти хотя бы одно их двух последних условий. Если два последних условия соблюдаются, но предсказанная вероятность ниже порога, детектирование причисляется к FN. К TN относятся результаты, для которых не соблюдено первое условие, плюс они находятся на области, не относящейся ни к одному классу.
Здесь мелькает новое понятие – Intersection over Union (IoU). Чтобы его получить для предсказанной области (predicted bounding box), потребуются размеченные человеком области объекта (ground-truth bounding box).
")
Вычисляться эта метрика будет следующим образом:
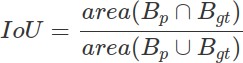
Где Bp – predicted bounding box, Bgt – ground-truth bounding box.

Когда TP, FP и FN найдены, можно считать precision и recall. Однако просто полнота и точность не используются для оценки. Вместо них берутся Average Precision (AP), mean Average Precision (mAP), Average Recall (AR), mean Average Recall (mAR).
Average Precision (AP) получается для каждого из класса в детекторе. Для ее получения сначала строится кривая precision-recall (precision-recall curve). Строится она следующим образом:
-
По абсциссе (X) откладывается recall (полнота), по ординате (Y) – precision (точность).
-
Постепенно уменьшая порог для предсказанной вероятности от единицы к нулю, для каждого из его рассматриваемых значений получаем recall (всегда уменьшается вместе с порогом) и precision (не обязательно всегда уменьшается, но в целом идет на спад).
-
Отмечаем все полученные значения точности и полноты на графике, соединяем линиями.

Далее график «сглаживается», и ищется площадь под ним – это и будет Average Precision.

Мean Average Precision (mAP) получается путем нахождения среднего из AP по всем классам детектора.
Для получения Average Recall используется другая кривая – recall-IoU curve. Строится она следующим образом:
-
По абсциссе (X) откладывается Intersection over Union (IoU∈[0.5,1.0]), по ординате (Y) – recall (полнота).
-
Меняя IoU, вычисляется recall (полнота) для заранее выбранного порога вероятности предсказания (по дефолту 0.5).
-
Все точки IoU + recall отмечаются на графике и соединяются.
Построив recall-IoU кривую, можно вычислить площадь под ней, и, умножив получившееся значение на два, узнать Average Recall для класса. Mean Average Recall (mAP), как и mean Average Precision (mAP) вычисляется как среднее из AR по всем классам.

Перечисленные метрики – неплохой способ дать оценку модели, однако стоит помнить, что это не весь арсенал для оценивания. Кроме того, AP и AR описаны выше в классическом варианте, существуют и их переопределения.
Когда модели получены, необходимо выбрать лучшую – здесь уже все зависит от личных предпочтений. Если рассматривать одну модель, обученную по-разному, можно сравнивать AP и AR для определения лучшей. Если модели разные, можно также рассматривать скорость распознавания.
Выбор алгоритма для задачи «Моя печать»
Итак, имея «на руках» рабочую модель-детектор, обнаруживающую на документе произвольную печать (штамп), оставалось найти способ распознавания конкретно-определенного объекта по одному-единственному образцу, который будет загружаться в систему пользователем.
Из всех имевшихся вариантов для обнаружения признаков на изображениях нами были выбраны два алгоритма – SIFT и ORB. SURF был более желаемым вариантом, поскольку он менее затратен в вычислительных мощностях и одновременно более точен, по сравнению с тем же SIFT, однако он запатентован и его применение в коммерческих приложениях не допускается.
Оба алгоритма (SIFT, ORB) были протестированы на нашем датасете и SIFT продемонстрировал лучшую точность в сопоставлении печатей на изображениях документов по заданному образцу. Однако SIFT работает значительно дольше, чем ORB:
 и ORB (справа)")
Кроме этого, скорость нахождения ключевых точек у обоих алгоритмов зависит от размера изображения и количества информации на нем. Так, например, полностью белое изображение будет обрабатываться быстрее, чем изображение с какими-нибудь объектами на нем.
")
Комплексное решение
Определившись с алгоритмом сопоставления заданной печати с детектированным объектом, необходимо было найти способ выделять данную область с печатью в отдельное изображение. Это позволило бы значительно улучшить точность алгоритма сопоставления, а также сократить время распознавания, поскольку в данной операции участвовало бы не все изображение документа, а лишь конкретные его участки, там, где обнаружена печать (штамп).
Для решения этой задачи был написан скрипт на языке Python. После того, как загруженная в оперативную память компьютера модель-детектор (наша обученная модель) выполняет свою часть работы, связанную с обнаружением на входных изображениях документов участков с печатями (штампами), выполняется операция вырезания данных участков. Далее каждое вырезанное изображение поочередно сопоставляется с заданной печатью (образцом).
Результаты работы скрипта выглядят следующим образом:


Таким образом, была реализована программа, объединившая в себе два алгоритма, – детектирование объектов и сопоставление изображений. В качестве альтернативы возможно применение другой обученной модели-детектора либо замена алгоритма SIFT на BRIEF или ORB. По итогам тестирования получившееся решение показало достаточно хорошие результаты в распознавании конкретных печатей на документах.
Попробуем подвести итоги и сделать выводы
Ну вот! Мы объединили два алгоритма – нейронные сверточные сети CNN и SIFT и получили прототип, подходящий для коммерческого решения. Но не тут-то было. Для того, чтобы он стал рабочим решением, необходимо было защитить его перед владельцем продукта и архитекторами и еще не раз подтвердить обозначенные вначале бизнес-метрики. Во время обсуждений с архитекторами и разработчиками были обнаружены проблемы в архитектуре и библиотеках, которые несколько раз корректировали исходную алгоритмическую схему, что снова меняло ML-метрики. Так было принято решение использовать в продукте два режима (точности и полноты), поскольку разным бизнес-пользователям могут быть важны несбалансированные точность и полнота.
На создание бизнес-успешно работающего прототипа у нас ушло суммарно 3 месяца работы трех человек с учетом бизнес-аналитика. Два месяца на задачу распознавания любой печати и один месяц на задачу распознавания заданной печати.
Много это или мало, что думаете?)
Авторы
Исследовательская группа центра продуктов Dozor «Ростелеком-Солар»:
Анна Яковленко, аналитик данных,
Никита Туляков, аналитик,
Анвар Баширов, аналитик данных,
Максим Бузинов, руководитель
Источники литературы
-
Object detection in 20 years: A Survey // Zhengxia Zou, Zhenwei Shi, Member, IEEE, Yuhong Guo, and Jieping Ye, Senior Member, IEEE.
-
Object detection with deep learning: A Review // Zhong-Qiu Zhao, Member, IEEE, Peng Zheng, Shou-Tao Xu, and Xindong Wu, Fellow, IEEE.
-
Shaharyar A., Zahra S. A comparative analysis of SIFT, SURF, KAZE, AKAZE, ORB, and BRISK // 2018 International Conference on Computing, Mathematics and Engineering technologies – iCoMET 2018.
-
Karami E., Prasad S., Shehata M. Image matching using SIFT, SURF, BRIEF and ORB: performance comparison for distorted images //arXiv preprint arXiv:1710.02726. – 2017.
-
Ethan Rublee, Vincent Rabaud, Kurt Konolige and Gary Bradski, “ORB: and efficient alternative to SIFT or SURF,” IEEE International Conference on Computer Vision, 2011.
