
Подготовка серьезных исследований и научных работ не обходится без применения первоисточников иностранного происхождения. В данном случае у автора нового проекта возникает потребность в качественном переводе иностранного труда, но в значительной степени можно облегчить процесс применения ресурса с помощью использования официального перевода. Предлагаем Вам разобраться с данным понятием.
Что это такое?
Официальный перевод представляет собой текст, изложенный в рамках требуемого (отличного от родного) языка с тотальным соблюдением принципов точности, осмысленности, авторской позиции и научности. Фактически, это заверенный экспертом перевод иностранной работы (материала), не требующий перепроверки и заверения, который можно смело использовать в качестве первоисточника при написании НИР или в иных целях.
Официальный перевод – это уникальная возможность без особых усилий получить доступ к иностранным трудам на понятном или необходимом языке. Но важно отметить, что далеко не все исследования и письменные проекты подлежат обязательному официальную переводу. Чаще всего с такой потребностью сталкиваются авторы научных статей и работ, желающих опубликовать их в международном издании, где есть требование по предоставлению рукописей на иностранном и ином языке (двух языках).
В большинстве случаев официальный перевод делается на вынужденной основе с определенной целью:
- Личные документы подлежат обязательному транскрипту на иной язык для пересечения границы, проживания или обучения за рубежом и пр.;
- Документы о статусе и образовании: свидетельство о рождении/браке/смерти, диплом об образовании, аттестат, сертификаты и пр.;
- Медицинские документы для лечения за рубежом: история болезни, результаты медицинских анализов и обследований, диагноз, справки и пр.;
- Научные работы, патенты для использования в качестве первоисточника в серьезных изысканиях при разработке инноваций и пр.
Фактически, официальный перевод – это профессиональный перевод текста, не требующий дополнительной проверки. Он позволяет быстро вникнуть в сыть иностранной работы, определить возможности и уместность ее применения в собственных целях. Его можно использовать в новых проектах или по необходимости в качестве основы, но строго на легальной основе.
Возникли сложности?
Нужна помощь преподавателя?
Мы всегда рады Вам помочь!

В каких случаях студенты и исследователи полагаются на официальный перевод иностранной работы?
Необходимость поиска или подготовки официального перевода научной работы или статьи возникает далеко не во всех случаях. Чаще всего с данной потребностью сталкиваются опытные исследователи, стремящиеся к инновациям и инноваторству.
Официальный перевод предполагает поиск зарубежного первоисточника в русскоязычной (для российского автора) версии. В большинстве случаев студенты используют данный вид первоисточника в следующих целях:
- Для подготовки материала сравнительного плана: сравнение отечественных и зарубежных норм/достижений или иных аспектов в решении одного и того же вопроса с целью определения пробела, нестыковки или поиска нового пути по ее разрешению;
- Для учета опыта иностранных исследователей при разработке новейших подходов и методик, то есть с целью перенятия опыта и адаптации европейского или иного «чуда» под отечественные реалии. Изучение иностранных работ в данном случае минимизируют риск плагиата и повышают возможности разработки инноваций, оформления авторства на них или патентов;
- В теоретических исследованиях для расширения темы, границ исследования – более обширное описание объекта, пополнение информативной или доказательной, эмпирической базы и пр.

Потребность в официальном переводе иностранных работ чаще всего возникает у квалифицированных специалистов, в числе которых:
- Кандидаты и доктора наук, научные работники и сотрудники, исследователи, занимающиеся совершенствованием отрасли, науки с акцентом на интересуемый их вопрос/проблему;
- Исследователи, намеревающиеся оформить патент на собственную разработку;
- Административный аппарат организации, проходящий обучение в рамках МВА-курсов, где внедрение опыта иностранных коллег и его адаптация под отечественные нужды, апробация – обязательный момент.
Простому студенту или бакалавру нет явной и существенной надобности погружаться в сложные иностранные работы. Их исследования носят больше обзорный характер, не требуют глубокого исследования темы. Им достаточно описать лишь общие, базовые моменты с акцентом на отечественные реалии и проблемы. Поиск иностранной литературы и/или ее официального перевода осуществляется преимущественно по личной инициативе для расширения кругозора и повышения уровня эрудиции. Все остальные категории чаще всего основываются на научном развитии и построении академической и научной карьеры.
Где можно найти официальный перевод научной литературы?
Работать с зарубежными исследованиями, трудами подготовленными на иностранном языке может не каждый автор или исследователь. Для этого требуется владение и понимание соответствующей лингвистической среды, языка, культуры.
Для начала отметим, что далеко не каждый научный и исследовательский материал на иностранном языке подлежит обязательному (или простому) переводу на иной язык (в том числе русский). Во-первых, зачастую авторы стараются опубликовать свое изыскание на «родном» языке или общепринятом международном (английском). Во-вторых, далеко не все издательства требуют предоставления рукописей на нескольких языках. В-третьих, перевести иностранный текст в современных условиях нетрудно: для этих целей действуют онлайн-сервисы и приложения, квалифицированные переводчики и пр.
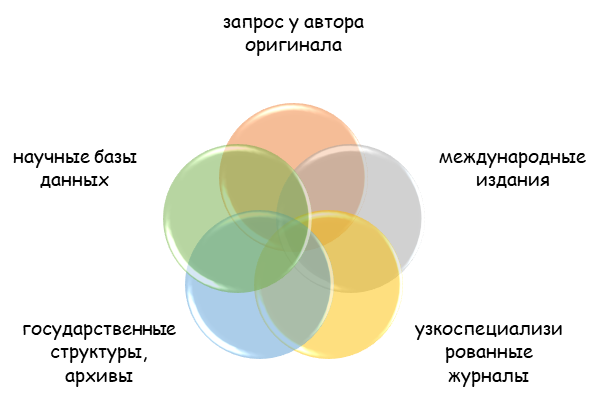
Найти официальный перевод зарубежного первоисточника, выполненного на иностранном языке, бывает непросто. Сейчас мы перечислим наиболее популярные и доступные для авторов варианты:
- Обращение к международным научным изданиям, выходящим в свет на нескольких языках. В этом случае рукописи предоставляются на нескольких языковых полях, притом автор либо лично занимается переносом сути на иной язык, ибо обращается к квалифицированным переводчикам. В редких случаях перевод осуществляются силами редакции.
- Обращение к международным научным базам данных и площадкам. К данной категории относят всемирно известные интернет-сети и базы данных: Академия Гугл, Scopus, WoS и пр. Здесь могут присутствовать как первоисточники на иностранном языке, так и их переводы, но не все материалы доступны на нескольких языках.
- Узкоспециализированные научные издания с международной репутацией. В данном случае речь идет о конкретных журналах, специализирующихся в рамках определенной научной области и имеющие глобальные масштабы, то есть действующие на территории различных государств. В большинстве случаев найти официальный перевод научной статьи можно в научных журналах по медицине, техническим, гуманитарным наукам и пр.
- Обращение к официальным ведомствам, контролирующим решение вопроса/проблемы, заинтересованным в эффективном исходе. Например, юридические документы и акты, статьи можно найти в соответствующих государственных структурах (министерства, суды, архивы и пр.);
- В издательстве, где был опубликован зарубежный труд в оригинале. Чаще всего такой ход применим по отношению к небольшим проектам – научным статьям, аннотациям, рефератам и авторефератам, научным докладам и тезисам. В частности, подобное требование может действовать при размещении материалов в сборнике по результатам научной конференции (международного формата).
В целом, вариантов для поиска иностранной литературы с официальным переводом немного. Чаще всего исследователям удается найти такой документ в отношении серьезных исследований и работ данным автора, ключевым словам, проблематике на научных площадках и базах данных.
Возникли сложности?
Нужна помощь преподавателя?
Мы всегда рады Вам помочь!
Специфика официального перевода научных работ
Официальный перевод текста научных исследований и проектов – это не просто письменный или устный вариант реализованного изыскания. В данном случае создается уникальный документ, который будет соответствовать конкретным параметрам:
- Выполняется только квалифицированным переводчиком, лингвистом, владеющим необходимым языком и разбирающимся в теме исследования;
- Подлежит письменному оформлению с целью дальнейшего обнародования через издательство (журнал, сайт, база данных и пр.);

- Материал, подвергаемый переводу сохраняется в рамках изначальной структуры, содержания и смысловой нагрузки, авторского индивидуализма. Поэтому в основе официального перевода лежит комбинированный подход: смысловой перевод с акцентом на научные особенности текста, при необходимости задействование техники дословного перевода и пр.;
- Официальный перевод подлежит обязательной перепроверке независимым экспертом – квалифицированным и опытным переводчиком, который заверяет достоверность, точность и корректность «новоиспеченного текста». Делается это с помощью подписи эксперта и отражения его личных персональных данных и контактов для связи. Если перевод осуществлялся силами юридического лица – обязательно присутствие печати компании и подписи ее руководителя, а также непосредственного исполнителя (переводчика).
Таким образом, официальный перевод будет состоять из нескольких существенных «раздел». Первый – данные о первоисточнике, где отмечается настоящий автор иностранной научной литературы и общие сведения о труде (тема, аннотация и ключевые слова, место первичной публикации). Второй – основная часть, где приводится непосредственный перевод зарубежной научной работы. Третий раздел – сведения о переводчике с верификацией.
Возникли сложности?
Нужна помощь преподавателя?
Мы всегда рады Вам помочь!
Правила грамотного и эффективного поиска официального перевода иностранного первоисточника
Искать зарубежные труды непросто. Более того, найти научную работу или статью на иностранном языке недостаточно, ведь важно вникнуть в суть материала и определить возможности его применения в собственном исследовании.
Чтобы облегчить участь студентов и исследователей, у которых возникла необходимость в поиске и применении иностранных трудов, мы подготовили следующие сценарии.
Схема №1. Тематическая принадлежность. Для начала автору необходимо определить тематику и проблематику исследования и основные параметры поиска: какие именно материалы пригодны, какая проблема должна исследоваться в проекте и пр. На данном этапе целесообразно выделить ключевые слова и формулировку запросов для поиска информации. Для этого придется перевести тему и ключи текущего исследования на иностранный язык или вбить в поисковик наименование темы на русском языке и проштудировать все варианты.
Схема №2. Авторская принадлежность. Данный вариант поиска уместен в том случае, когда известен автор иностранного труда. В этом случае есть шанс найти, как оригинальный вариант, так и официально переведённый. Более того, как правило, каждый автор специализируется на изучении конкретной темы или проблемы. Поэтому данный вариант позволяет за один раз убить несколько зайцев: найти массу исследований по теме, изучить смежные и иные работы автора и подобрать более качественную и весомую доказательную базу и пр.

Схема №3. Издательская принадлежность. Данный вариант поиска также подходит только в конкретном случае. Журнал должен иметь международный формат и принимать рукописи на нескольких языках (в том числе требуемом – русском и пр.), студенту необходимо знать наименование издательства. Далее поиск производится в стандартной схеме – через поисковик браузера, в рамках научной базы данных (Скапус, Веб оф сайнс, РИНЦ , ВАК и пр.).
Схема №4. Архивный поиск. В данном случае найти актуальные первоисточники на иностранном языке конечно, вряд ли удастся. Но все страны практикуют «раскрытие» информации по истечении определенного времени или после снятия грифа «секретно». Многие исторические или ранние достижения открытия и разработки подвергаются рассекречиванию и переводу при архивах или государственных структурах. Для поиска подобной информации достаточно зайти на официальный сайт ведомства или организации (издания, научной организации, иностранные и отечественные вузы с научной площадкой и пр.), найти «архивные данные» и сделать соответствующий запрос.
Как можно получить официальный перевод?
Чтобы задействовать научный труд, выполненный на иностранном языке, важно иметь на руках качественный перевод. Притом в бакалаврских работах допускается применение простого перевода текста (если студент сам хорошо владеет иностранным языком, то он может сам перевести необходимый фрагмент, но в обязательном порядке указать оригинальный первоисточник).
При выполнении серьезных изысканий (магистерской, кандидатской, докторской диссертации и пр.) авторам требуется задействовать не простой (ручной) перевод, а официальный перевод – грамотный, корректный, заверенный.
В России нет строгих правил по проведению официального перевода иностранных текстов. Заниматься переводческой деятельностью могут только дипломированные лингвисты и переводчики, при этом работать в штате специального переводческого бюро им вовсе не обязательно. Достаточно иметь документ об образовании на руках. Поэтому получить официальный перевод на территории и РФ не составляет труда. Достаточно найти грамотного и надежного, а главное – компетентного переводчика и поручить ему столь непростое дело. Но в этом варианте к переводчику могут предъявляться дополнительные требования: помимо знания иностранного языка, он должен владеть азами по теме переводимого исследования (предмету, науке).
Поэтому официальный перевод в России можно получить только у дипломированного специалиста, имеющего за плечами высшее лингвистическое образование! Дополнительных разрешений, сертификатов и удостоверений не требуется.
Также заказать официальный перевод можно на базе действующих образовательных центров, предоставляющих услуги по переводу текстов. Аналогичные заказы принимают специальные бюро переводов.
Официальный перевод текста – это профессиональный полноценный перевод иностранного труда, который будет предоставлен по специальной заявке на платной основе (притом цена вопроса будет соответствующей) строго в письменном виде с учетом общих правил перевода, дополнительных требований заказчика.
Благодаря переводу результатов поиска вы можете просматривать больше материалов на своем языке. Если по запросу ничего не найдено на вашем языке, Google Поиск может показать переведенные результаты.
Важно! В настоящее время перевод результатов поиска доступен:
- на индонезийском, каннада, малаялам, тамильском, телугу и хинди;
- в мобильных браузерах с поддержкой Google Поиска.
Как посмотреть страницу на своем языке
- На телефоне или планшете откройте сайт google.com.
- Выполните поиск.
- Нажмите на переведенное название страницы в результатах.
Примечание. Когда вы нажмете на название страницы, она откроется в Google Переводчике. Любая страница, на которую вы перейдете по ссылке с переведенного сайта, будет автоматически переведена.
Как посмотреть страницу на исходном языке
В нижней части переведенного результата нажмите на стрелку вниз ![]()
![]() коснитесь названия страницы на исходном языке.
коснитесь названия страницы на исходном языке.
Как работает перевод результатов поиска
Названия и описания результатов поиска переводятся автоматически. Вы можете посмотреть перевод страницы, выполненный Google Переводчиком, или прочитать ее на исходном языке.
Ресурсы по теме
- Как управлять переведенными результатами для своих веб-страниц
- Как настроить рекламную сеть для работы с функциями Google Поиска, связанными с переводом
Эта информация оказалась полезной?
Как можно улучшить эту статью?
Трудности перевода: как найти плагиат с английского языка в русских научных статьях
Время на прочтение
11 мин
Количество просмотров 61K
В нашей первой статье в корпоративном блоге компании Антиплагиат на Хабре я решил рассказать о том, как работает алгоритм поиска переводных заимствований. Несколько лет назад возникла идея сделать инструмент для обнаружения в русскоязычных текстах переведенного и заимствованного текста из оригинала на английском языке. При этом важно, чтобы этот инструмент мог работать с базой источников в миллиарды текстов и выдерживать обычную пиковую нагрузку Антиплагиата (200-300 текстов в минуту).
 “
“
В течение 12 лет своей работы сервис Антиплагиат обнаруживал заимствования в рамках одного языка. То есть, если пользователь загружал на проверку текст на русском, то мы искали в русскоязычных источниках, если на английском, то в англоязычных и т. д. В этой статье я расскажу об алгоритме, разработанном нами для обнаружения переводного плагиата, и о том, какие случаи переводного плагиата удалось найти, опробовав это решение на базе русскоязычных научных статей.
Я хочу расставить все точки над «i»: в статье речь пойдёт только о тех проявлениях плагиата, которые связаны с использованием чужого текста. Всё, что связано с воровством чужих изобретений, идей, мыслей, останется за рамками статьи. В тех случаях, когда мы не знаем, насколько правомерным, корректным или этичным было такое использование, мы будем говорить «заимствование текста» или «текстовое заимствование». Слово «плагиат» мы используем только тогда, когда попытка выдать чужой текст за свой очевидна и не подлежит сомнению.
Над этой статьей мы работали вместе с Rita_Kuznetsova и Oleg_Bakhteev. Мы решили, что образы Пиноккио и Буратино служат прекрасной иллюстрацией к проблеме поиска плагиата из иностранных источников. Сразу оговорюсь, что мы ни в коем случае не обвиняем А.Н.Толстого в плагиате идей Карло Коллоди.
Для начала я коротко расскажу, как работает «обычный Антиплагиат». Мы построили своё решение на основе т.н. «алгоритма шинглов», который позволяет быстро находить заимствования в очень больших коллекциях документов. Этот алгоритм основан на разбиении текста документа на небольшие перекрывающиеся последовательности слов определенной длины – шинглы. Обычно используется шинглы длиной от 4 до 6 слов. Для каждого шингла рассчитывается значение хэш-функции. Поисковый индекс формируется как отсортированный список значений хэш-функции с указанием идентификаторов документов, в которых встретились соответствующие шинглы.
Проверяемый документ также разбивается на шинглы. Затем по индексу находятся документы с наибольшим количеством совпадений по шинглам с проверяемым документом.
Этот алгоритм успешно зарекомендовал себя в поиске заимствований как на английском, так и на русском языке. Алгоритм поиска по шинглам позволяет быстро обнаруживать заимствованные фрагменты, при этом он позволяет искать не только полностью скопированный текст, но и заимствования с небольшими изменениями. Подробнее о задаче обнаружения нечетких текстовых дубликатов и методах её решения можно узнать, например, из статьи Ю. Зеленкова и И. Сегаловича.
По мере развития системы поиска «почти дубликатов» становилось недостаточно. У многих авторов возникала потребность быстро повысить процент оригинальности документа, или, говоря иначе, тем или иным способом «обмануть» действующий алгоритм и получить более высокий процент оригинальности. Естественно, самый действенный способ, который приходит на ум, – это переписать текст другими словами, то есть перефразировать его. Однако основной недостаток такого способа – на реализацию уходит слишком много времени. Поэтому нужно что-то более простое, но гарантированно приносящее результат.
Тут на ум приходит заимствование из иностранных источников. Стремительный рост современных технологий и успехи машинного перевода позволяют получить оригинальную работу, которая при беглом взгляде выглядит так, как будто её написали самостоятельно (если не вчитываться внимательно и не искать ошибки машинного переводчика, которые, впрочем, легко исправить).
До недавнего времени обнаружить такой вид плагиата было можно, только обладая широкими знаниями по тематике работы. Автоматического инструмента детектирования заимствований такого рода не существовало. Это хорошо иллюстрирует случай со статьей «Корчеватель: Алгоритм типичной унификации точек доступа и избыточности». Фактически «Корчеватель» — это перевод автоматически сгенерированной статьи «Rooter: A Methodology for the Typical Unification of Access Points and Redundancy». Прецедент был создан искусственно с целью проиллюстрировать проблемы в структуре журналов из списка ВАК в частности и в состоянии российской науки в целом.
Увы, но переведённая работа «обычным Антиплагиатом» не нашлась бы – во-первых, поиск осуществляется по русскоязычной коллекции, а во-вторых, нужен иной алгоритм поиска таких заимствований.

Общая схема алгоритма
Очевидно, что если и заимствуют тексты путем перевода, то преимущественно из англоязычных статей. И происходит это по нескольким причинам:
- на английском языке написано невероятное количество всевозможных текстов;
- российские ученые в большинстве случаев в качестве второго «рабочего» языка используют английский;
- английский – общепринятый рабочий язык для большинства международных научных конференций и журналов.
Исходя из этого, мы решили разрабатывать решения для поиска заимствований с английского на русский язык. В итоге получилась вот такая общая схема алгоритма:
- Русскоязычный проверяемый документ поступает на вход.
- Выполняется машинный перевод русского текста на английский язык.
- Происходит поиск кандидатов в источники заимствований по проиндексированной коллекции англоязычных документов.
- Производится сопоставление каждого найденного кандидата с английской версией проверяемого документа – определение границ заимствованных фрагментов.
- Границы фрагментов переносятся в русскоязычную версию документа. При завершении процесса формируется отчёт о проверке.
Шаг первый. Машинный перевод и его неоднозначность
Первая задача, которую нужно решить после появления проверяемого документа, – это перевод текста на английский язык. Для того, чтобы не зависеть от сторонних инструментов, мы решили использовать готовые алгоритмические решения из открытого доступа и обучать их самостоятельно. Для этого необходимо было собрать параллельные корпуса текстов для пары языков «английский – русский», которые есть в открытом доступе, а также попробовать собрать такие корпуса самостоятельно, анализируя веб-страницы двуязычных сайтов. Разумеется, качество обученного нами переводчика уступает лидирующим решениям, но ведь от нас никто и не требует высокого качества перевода. В итоге удалось собрать около 20 миллионов пар предложений научной тематики. Такая выборка подходила для решения стоявшей перед нами задачи.
Реализовав машинный переводчик, мы столкнулись с первой трудностью – перевод всегда неоднозначен. Один и тот же смысл может быть выражен разными словами, может меняться структура предложения и порядок слов. А так как перевод делается автоматически, то сюда накладываются ещё и ошибки машинного перевода.
Чтобы проиллюстрировать эту неоднозначность, мы взяли первый попавшийся препринт с arxiv.org

и выбрали небольшой фрагмент текста, который предложили перевести двум коллегам с хорошим знанием английского языка и двум известным сервисам машинного перевода.

Проанализировав результаты, мы сильно удивились. Ниже видно, насколько разными получились переводы, хотя общий смысл фрагмента сохранился:

Мы предполагаем, что текст, который на первом шаге нашего алгоритма мы автоматически перевели с русского на английский, ранее мог быть переведен с английского на русский. Естественно, каким именно образом был осуществлён исходный перевод, нам неизвестно. Но даже если бы мы это знали, шансы получить в точности исходный текст были бы ничтожно малы.
Здесь можно провести параллель с математической моделью «зашумленного канала» (noisy channel model). Допустим, какой-то текст на английском прошёл через «канал с шумом» и стал текстом на русском языке, который, в свою очередь, прошёл ещё через один «канал с шумом» (естественно, это уже был другой канал) и стал на выходе текстом на английском языке, который отличается от оригинала. Наложение такого двойного «шума» – одна из основных проблем поставленной задачи.

Шаг второй. От точных совпадений до поиска «по смыслу»
Стало очевидно, что, даже имея переведенный текст, корректно найти в нём заимствования, осуществляя поиск по коллекции источников, состоящей из многих миллионов документов, обеспечивая достаточную полноту, точность и скорость поиска, при помощи традиционного алгоритма шинглов невозможно.
И тут мы решили уйти от старой схемы поиска, основанной на сопоставлении слов. Нам однозначно нужен был другой алгоритм детектирования заимствований, который, с одной стороны, мог бы сопоставлять фрагменты текстов «по смыслу», а с другой, оставался таким же быстрым, как алгоритм шинглов.
Но что же делать с шумом, который дает нам «двойной» машинный перевод в текстах? Будут ли обнаружены тексты, порождённые разными переводчиками, как на примере ниже?

Поиск «по смыслу» мы решили обеспечить через кластеризацию английских слов так, чтобы семантически близкие слова и словоформы одного и того же слова попали в один кластер. Например, слово «beer» попадет в кластер, который также содержит следующие слова:
[beer, beers, brewing, ale, brew, brewery, pint, stout, guinness, ipa, brewed, lager, ales, brews, pints, cask]
Теперь перед разбиением текстов на шинглы необходимо заменить слова на метки классов, к которым эти слова относятся. При этом за счёт того, что шинглы строятся с перекрытием, можно не обращать внимания на определенные неточности, присущие алгоритмам кластеризации.
Несмотря на погрешности кластеризации, поиск документов-кандидатов происходит с достаточной полнотой – нам достаточно, чтобы совпало всего несколько шинглов, и по-прежнему с высокой скоростью.
Шаг третий. Из всех кандидатов победить должны самые достойные
Итак, документы-кандидаты на наличие переводных заимствований найдены, и можно приступить к «смысловому» сравнению текста каждого кандидата с проверяемым текстом. Здесь нам шинглы уже не помогут – этот инструмент для решения этой задачи слишком неточен. Мы попробуем реализовать такую идею: каждому фрагменту текста поставим в соответствие точку в пространстве очень большой размерности, при этом будем стремиться к тому, чтобы фрагменты текстов, близкие по смыслу, были представлены точками, расположенными в этом пространстве неподалеку (были близки по некоторой функции расстояния).
Рассчитывать координаты точки (или чуть более научно – компоненты вектора) для фрагмента текста мы будем с помощью нейронной сети, а обучать эту сеть будем с помощью данных, размеченных асессорами. Роль асессора в этой работе – создать обучающую выборку, то есть указать для некоторых пар фрагментов текста, являются ли они близкими по смыслу или нет. Естественно, что чем больше удастся собрать размеченных фрагментов, тем лучше будет работать обученная сеть.
Ключевая задача во всей работе — правильно выбрать архитектуру и обучить нейронную сеть. Наша сеть должна отображать текстовый фрагмент произвольной длины в вектор большой, но фиксированной размерности. При этом она должна учитывать контекст каждого слова и синтаксические особенности текстовых фрагментов. Для решения задач, связанных с какими-либо последовательностями (не только текстовыми, но и, например, биологическими) существует целый класс сетей, которые называются рекуррентными. Основная идея этой сети состоит в том, чтобы получать вектор последовательности, итеративно добавляя информацию о каждом элементе этой последовательности. На практике такая модель имеет множество недостатков: её сложно тренировать, и она достаточно быстро «забывает» информацию, которая была получена из первых элементов последовательности. Поэтому на основе этой модели было предложено множество более удобных архитектур сетей, которые исправляют эти недостатки. В нашем алгоритме мы используем архитектуру GRU. Эта архитектура позволяет регулировать, сколько информации должно быть получено из очередного элемента последовательности и сколько информации сеть может «забыть».
Для того, чтобы сеть хорошо работала с разными видами перевода, мы обучали её как на примерах ручного, так и машинного перевода. Сеть обучалась итеративно. После каждой итерации мы изучали, на каких фрагментах она ошибалась сильнее всего. Такие фрагменты мы также давали сети для обучения.
Интересно, но использование готовых нейросетевых библиотек, таких как word2vec, успеха не принесло. Их результаты мы использовали в работе в качестве оценки базового уровня, ниже которого опускаться было нельзя.
Стоит отметить ещё один немаловажный момент, а именно — размер фрагмента текста, который будет отображаться в точку. Ничто не мешает, например, оперировать с полными текстами, представляя их в виде единого объекта. Но в этом случае близкими будут только тексты, полностью совпадающие по смыслу. Если же в тексте будет заимствована только какая-то часть, то нейронная сеть расположит их далеко, и мы ничего не обнаружим. Хорошим, хотя и не бесспорным, вариантом является использование предложений. Именно на нём мы решили остановится.
Давайте попробуем оценить, какое количество сравнений предложений нужно будет выполнить в типичном случае. Допустим, и проверяемый документ, и документы кандидаты содержат по 100 предложений, что соответствует размеру средней научной статьи. Тогда на сравнение каждого кандидата нам потребуется 10 000 сравнений. Если кандидатов будет всего 100 (на практике из многомиллионного индекса иногда поднимаются и десятки тысяч кандидатов), то нам потребуется 1 миллион сравнений расстояний для поиска заимствований всего в одном документе. А поток проверяемых документов часто переваливает за 300 в минуту. При этом сам по себе расчёт каждого расстояния – тоже не самая простая операция.
Чтобы не сравнивать все предложения со всеми, используем предварительный отбор потенциально близких векторов на основе LSH-хэширования. Основная идея этого алгоритма в следующем: каждый вектор мы умножаем на некоторую матрицу, после чего запоминаем, какие компоненты результата умножения имеют значение больше нуля, а какие – меньше. Такую запись про каждый вектор можно представить двоичным кодом, обладающим интересным свойством: близкие векторы имеют схожий двоичный код. Таким образом, при правильном подборе параметров алгоритма мы сокращаем количество требуемых попарных сравнений векторов до небольшого числа, которое можно провести за приемлемое время.
Шаг четвертый. «Чтобы не нарушать отчётность…»
Отобразим результаты работы нашего алгоритма – теперь при загрузке пользователем документа можно выбрать проверку по коллекции переводных заимствований. Результат проверки виден в личном кабинете:

Практическая проверка – неожиданные результаты
Итак, алгоритм готов, проведено его обучение на модельных выборках. Удастся ли нам найти что-то интересное на практике?
Мы решили поискать переводные заимствования в крупнейшей электронной библиотеке научных статей eLibrary.ru, основу которой составляют научные статьи, входящие в Российский индекс научного цитирования (РИНЦ). Всего мы проверили около 2,5 млн научных статей на русском языке.
В качестве области поиска мы проиндексировали коллекцию англоязычных архивных статей из фондов elibrary.ru, сайты журналов открытого доступа, ресурс arxiv.org, англоязычную википедию. Общий объем базы источников в боевом эксперименте составил 10 миллионов текстов. Может показаться странным, но 10 миллионов статей – это очень небольшая база. Количество научных текстов на английском языке исчисляется, как минимум, миллиардами. В этом эксперименте, располагая базой, в которой находилось менее 1% потенциальных источников заимствований, мы считали, что даже 100 выявленных случаев будут удачей.
В результате мы обнаружили более 20 тысяч статей, содержащих переводные заимствования в значительных объемах. Мы пригласили экспертов для детальной проверки выявленных случаев. В результате удалось проверить чуть меньше 8 тысяч статей. Результаты анализа этой части выборки представлены в таблице:
Часть результатов относится к легальным заимствованиям. Это переводные работы тех же авторов или выполненные в соавторстве, часть результатов — корректные срабатывания одинаковых фраз, как правило, одних и тех же юридических законов, переведённых на русский язык. Но значительная часть результатов — это некорректные переводные заимствования.
Исходя из анализа, можно сделать несколько интересных выводов, например, о распределении процента заимствований:

Видно, что чаще всего заимствуют небольшие фрагменты, однако встречаются работы, заимствованные целиком и полностью, включая графики и таблицы.

Из гистограммы, приведенной ниже, видно, что заимствовать предпочитают из недавно опубликованных статей, хотя встречаются работы, где источник датируется, например, 1957 г.
Мы использовали метаданные, предоставленные eLibrary.ru, в том числе о том, к какой области знания относится статья. Используя эту информацию, можно определить, в каких российских научных областях чаще всего заимствуют путём перевода с английского.

Самый наглядный способ убедиться в корректности результатов – это сравнить тексты обеих работ – проверяемой и источника, положив их рядом.

Сверху – работа на английском языке с arxiv.org, снизу – русскоязычная работа, которая целиком и полностью, включая графики и результаты, является переводом. Соответствующие блоки отмечены красным. Примечательным является и тот факт, что авторы пошли ещё дальше – оставшиеся куски оригинальной статьи они тоже перевели и опубликовали ещё пару «своих» статей. На оригинал авторы решили не ссылаться. Информация обо всех найденных случаях переводных заимствований передана в редакции научных журналов, выпустивших соответствующие статьи.
Таким образом, результат не мог нас не порадовать – система «Антиплагиат» получила новый модуль для обнаружения переводных заимствований, который проверяет русскоязычные документы теперь и по англоязычным источникам.
Творите собственным умом!
Как переводчику искать информацию в интернете
Всемирная сеть как источник информации — палка о двух концах: вы получаете беспрепятственный доступ к миллионам текстов на самые разные темы, благодаря чему можете искать любые данные. В то же время каждый может выложить в интернет любой бред, сознательно или бессознательно. Учитывая это, данные следует искать в сети осторожно и дополнительно подтверждать полученные результаты: нельзя полагаться на найденную в сети информацию без подтверждения, поскольку уровень надежности в этом случае такой же, как у слов вроде «я это услышал от незнакомца на улице».
Методы поиска терминов
В своей работе «Перевод и поиск информации в сети» (Translation and Web Searching) Ванесса Энрикез Райдо (Vanessa Enriquez Raido) советует такой алгоритм поиска:
- Найдите нужное выражение на языке оригинала и/или ограничьте поиск правительственными вебсайтами либо страницами, которые вызывают доверие.
- Зафиксируйте варианты перевода (обычно их несколько).
- Проверьте найденный перевод и сравните частотность вариантов.
Поиск словосочетаний
Если вы будете искать не слово, а словосочетание в кавычках (в таком случае будет осуществляться поиск абсолютных соответствий), количество результатов будет значительно меньше по сравнению с поиском отдельных слов. Поэтому этот способ поиска более надежный. Если словосочетание содержит неправильное или менее широко употребляемое слово, вы найдете немного результатов (от нескольких десятков до сотен).
Второй способ поиска нужного термина или словосочетания, например, в биологии или зоологии, предусматривает такие шаги:
- Поиск названия вида животного или растения на языке оригинала, чтобы выяснить соответствующее научное название (на латинском языке).
- Поиск информации по научному названию в целевом языке.
Описанные выше способы опираются на предположение, что большинство текстов написаны носителями соответствующих языков и не содержат ошибок. Однако, так же как в случае с работой с корпусами, результаты следует обработать.
К сожалению, Google пока не имеет механизмов одновременного поиска по разным запросам. Однако можно, например, одновременно открыть две вкладки для поиска двух различных вариантов термина/словосочетания.
Сравнение вариантов
Это можно сделать на сайте Googlefight, который был разработан с развлекательной целью: нужно просто ввести нужные термины в соответствующие поля, и программа выполнит их одновременный поиск в Google. В результате вы получите две цифры — количество случаев вхождения каждого варианта:

Этот способ имеет два недостатка: во-первых, поиск можно выполнять только на английском. При использовании других языков результаты искажены, поскольку пользователь может только указать нужные домены сайтов (например «site :. Fr») в окне поиска. Во-вторых, программа выдает только количество случаев без дополнительных данных. Поэтому истолковать их надлежащим образом невозможно. Имейте этот инструмент в виду как вспомогательный.
Перевод материала extraspeech.com

Специалист по обучению бюро переводов «Профпереклад».
Преподаватель кафедры английского языка факультета переводоведения Киевского национального лингвистического университета (КНЛУ), переводчик и редактор с 15+ годами опыта.
Ключевые компетенции:
лингвистика, переводоведение, CAT-инструменты.
Образование:
магистратура и аспирантура КНЛУ.
Автор статьи:
Лилия Линник
Специалист по обучению бюро переводов «Профпереклад».
Преподаватель кафедры английского языка факультета переводоведения Киевского национального лингвистического университета (КНЛУ), переводчик и редактор с 15+ годами опыта.
Ключевые компетенции:
лингвистика, переводоведение, CAT-инструменты
Образование:
магистратура и аспирантура КНЛУ.
Читайте также
Как реагировать на негативный отзыв о своем переводе
Читать статью
Ложные друзья переводчика в переводе экономических текстов
Читать статью

Где найти статьи на английском языке, сегодня интересует многих российских ученых, которые хотят добиться признания в мире науки. Чтобы быть специалистом в определенной области, необходимо интересоваться актуальными разработками и постоянно расширять кругозор, активно взаимодействовать с международной аудиторией.
Для поиска достоверных источников информации нужно пользоваться надежными сервисами, простые поисковые системы для этого не подойдут. К счастью, существует много разнообразных сервисов, открывающих доступ к трудам исследователей со всего мира на любые темы.
Зачем и как правильно искать англоязычные публикации, а также перечень достойных внимания поисковых площадок – обо всем этом читайте в статье.
Содержание статьи
- 1. Когда возникает необходимость в поиске статей на английском языке?
- 2. Где искать качественный материал?
- 3. Подборка 20-ти проверенных ресурсов
- 4. Специализированные площадки: 7 сайтов
- 5. Ресурсы по отдельным дисциплинам: 16 источников
- Заключение
1. Когда возникает необходимость в поиске статей на английском языке?
Искать научные статьи на английском языке может понадобиться любому человеку, имеющему отношение к научно-исследовательской деятельности – от студента до профессора. При написании курсовых, магистерских и дипломных проектов учащимся приходится перечитывать много материала по своей теме. Часто русскоязычных источников оказывается недостаточно, особенно если работа пишется по узконаправленной специфической тематике, на которую проводилось мало исследований. Тогда на помощь придут англоязычные публикации.
Другая ситуация – соискатель ученой степени пишет диссертацию или статью. Использование зарубежных источников поможет расширить кругозор, посмотреть на описываемую проблему под другим углом, так как у иностранных исследователей может быть совсем другой подход и способы решения проблемы.
Помимо этого, упоминание источников на иностранном языке в списке литературы при сдаче квалификационной работы или диссертации станет весомым плюсом и повысит шансы на успешную защиту.
Каждый ученый, который хочет занимать достойное место в мире науки и иметь авторитет среди коллег, должен следить за появлением новых разработок и усовершенствованием существующих технологий. Чтобы идти в ногу со временем, необходимо постоянно интересоваться новейшими исследованиями и их результатами. Для этого обязательно нужно знать, где найти статьи на английском языке.
Сегодня уже недостаточно быть в курсе новостей только из отечественных областей знаний, международное сотрудничество и поддержание связей с единомышленниками из других стран – обязательная составляющая успеха ученого.
2. Где искать качественный материал?
Чтобы найти статьи на английском языке достойного качества, недостаточно перевести на иностранный и ввести интересующий запрос в обычной поисковой системе интернета, такой как Яндекс или Google. Конечно, при таком подходе возможно найти полезные источники, но процесс отнимет много времени и сил, ведь среди качественных материалов будет попадаться немало «мусора».
Надежней пользоваться специализированными ресурсами, направленными на поиск нужной информации среди научных работ. Поиск англоязычных публикаций в интернете осуществляется по нескольким направлениям:
- реферативные базы Scopus и Web of Science;
- специализированные базы данных по разным дисциплинам;
- образовательные поисковые системы;
- базы диссертаций и архивы с полнотекстовыми документами;
- репозитории;
- сервисы крупнейших мировых издательств;
- приложения и расширения;
- социальные сети.
3. Подборка 20-ти проверенных ресурсов
Официальный сайт Scopus
База одного из первых европейских издательств Elsevier. Scopus содержит сведения о научных трудах в авторитетных международных журналах, книгах. На сайте приводятся результаты исследований из любых отраслей знаний по всему миру. Сервис платный.
Web of Knowledge
Площадка Web of Science открывает доступ к индексам цитирования по различным направлениям. Полезная система для написания автореферата или диссертации от разработчика Clarivate Analytics. Для пользования базой необходимо оформить платную подписку.
Google Scholar

Специализированный портал от Google, где ищут научные документы. Достаточно ввести в окно нужную тему и выбрать интересующий материал, если он в открытом доступе. На платформе есть отечественные и зарубежные публикации, но многие из них с ограничениями.
Mendeley

Универсальный сервис Mendeley, где можно найти статьи на английском языке, сотрудничать с иностранными коллегами и хранить документы как в облаке с возможностью продолжения работы в любом месте. Удобный помощник при написании исследовательских текстов.
ResearchGate

Ресурс позволяет найти статьи на английском и других языках из огромной электронной научной библиотеки. Часть материалов в бесплатном доступе с возможностью их скачивания, другие требуют платной подписки. Некоторые списки литературы с активными ссылками на источники, при просмотре работы сайт автоматически предлагает ознакомиться с публикациями на схожие тематики.
FreeFullPDF

Бесплатная система по поиску документов в формате PDF. Работает аналогично популярным поисковым системам, но результаты показывает исключительно по научным материалам. Содержит колоссальную базу.
ScienceDirect

Система поиска статей по ключевым словам, ФИО автора, названию работы. Разработка нидерландского издательства Elsevier. Есть платные и бесплатные материалы. Платформа позволяет свободно перемещаться между публикациями.
Academia

Простой и удобный поисковик, разработан для обмена полезной информацией между учеными. Чтобы найти статьи на английском языке, достаточно ввести тему интересующих работ. Материалы доступны к чтению в режиме онлайн и для скачивания в виде PDF-файла. Можно зайти на страничку определенного автора и посмотреть его публикации.
Wikipedia

Англоязычный портал развивается лучше и активней, чем русскоязычная версия. Здесь в публикациях приводится достоверная информация по интересующей дисциплине. Несмотря на это, в своих трудах лучше не ссылаться на источники Википедии, а использовать ссылки на материалы, приведенные в конце каждой статьи.
Unpaywall
На сайте можно скачать расширение Unpaywall, которое устанавливается для браузеров Chrome и Firefox. Оно помогает находить полные тексты научных трудов в интернете. При переходе на страницу с публикацией в правом верхнем углу появляется замок. Открытый замок зеленого цвета позволяет перейти на страницу с полным текстом в PDF-формате.
ArXiv

Бесплатный крупный проект, разработанный Корнелльским университетом, который дает доступ к более чем 1,5 млн. публикаций по разнообразным дисциплинам. На сайте исследователи выкладывают черновые варианты своих работ, которые в дальнейшем немного редактируются.
Tandfonline

Составляющая издательской группы Informa plc с платной подпиской. Тесно сотрудничает с редакторами, научными сообществами и институтами для образования обширной базы статей из разных областей науки.
Wiley

Ресурс от Wiley дает возможность почитать или купить тексты публикаций по разным дисциплинам. Больше всего материалов по точным наукам, но есть немало статей и по гуманитарным.
Sciencemag

Science – один из самых популярных журналов в мире, разработан Американской ассоциацией содействия развитию науки. Через него ученые из любых стран узнают о последних значимых исследованиях и открытиях. С платным доступом.
Dart

DART-Europe – платформа, созданная при партнерстве европейских исследовательских центров. Открывает доступ к 800 тысячам научных работ для исследователей и обычных читателей на разных языках бесплатно.
PQDTOpen

Проект разработан компанией ProQuest LLC для поддержки научно-исследовательской деятельности в мире. Здесь можно бесплатно найти и прочитать диссертацию по точным и гуманитарным наукам на различных языках. Портал полезен аспирантам и научным сотрудникам.
Theses and Dissertations

Архив с содержанием более 5 млн. диссертаций и других работ по самым разным направлениям. OATD сотрудничает с научными и исследовательскими учреждениями, колледжами из разных стран. Доступ к документам бесплатный.
Paperity

На площадке Paperity хранится более 1,5 млн. публикаций по разнообразным дисциплинам. Найти статьи на английском языке можно также через мобильное приложение. Сервис бесплатный.
SciGuide

Русскоязычная платформа по поиску зарубежных научных ресурсов в открытом доступе. Продукт Сибирского отделения РАН.
Annual Reviews

Независимая платформа с ежегодным ростом числа публикаций. Цель сервиса – обобщить и интегрировать знания по биологии, биомедицине, физике, экономии, социологии. Доступ платный.
4. Специализированные площадки: 7 сайтов
Помимо этого, существует немало специализированных площадок с полными текстами статей в открытом доступе:
- PubMed – большинство работ по биологии и медицине, бесплатный доступ к полным текстам частично;
- Jstor – крупная база с английскими статьями, журналами, научными трудами по разным направлениям;
- MedLine – самая большая платформа по поиску материалов на медицинские темы;
- Psyjournals – сайт содержит электронные версии популярных журналов по психологии и педагогике;
- SciFinder – самый полный и достоверный ресурс, содержащий публикации по химии, биологии и биомедицине, инженерии;
- Frontiers – сборники статей с подборками на любые темы;
- Scientific Commons – информационный портал из различных областей знаний на английском и немецком языках.
5. Ресурсы по отдельным дисциплинам: 16 источников
Также есть ресурсы по отдельным дисциплинам:
- Osapublishing – содержит материалы по физике из профессиональных журналов и сборников OSA с платным доступом;
- Spiedigitallibrary – хранилище с 500 000 отчетов с конференций и около 370 электронных книг по оптике и фотонике с частично платным доступом;
- AipScitation – некоммерческая организация от Американского института физики, ознакомиться со сборниками можно бесплатно без регистрации;
- IOPScience – площадка с книгами по биофизике, квантовой механике, астрофизике, инженерии, космологии, нанотехнологиям и так далее;
- ScienceResearch – платформа поддерживает открытость и доступность знаний для каждого, бесплатный поиск материалов по зоологии, ботанике, астрономии, математике, компьютерным разработкам;
- IEEExplore – хранилище научных статей на английском языке по электротехнике и электронике, вычислительной технике, телекоммуникациям, доступ платный;
- NanoNature – содержит публикации по нанотехнологиям с пробным периодом;
- SciFinder – собирает и систематизирует информацию, проверяет результаты исследований по химии, тут можно искать чужие и размещать свои материалы;
- RSCJournals – бесплатное хранилище научных англоязычных статей по химии, биологии, биофизике, энергетике, физике, инженерии;
- NCBI – ценный бесплатный ресурс для исследователей, интересующихся биомедициной;
- CochraneLibrary – собрана информация по здравоохранению из 130 стран, сервис дает возможность узнать новости из мира медицины, будет полезен как медикам, так и простым читателям;
- PLOS ONE – на платформе можно найти статьи на английском языке по медицине, технике, инженерии, полезный портал для тех, кто занимается исследованиями в сфере генетики, иммунологии, клинических испытаний, вычислительной биологии;
- DOAJ – на площадке можно искать и размещать свои труды из области медицины, техники, естественных наук бесплатно;
- JURN – бесплатный сервис по поиску и загрузке полных текстов статей по гуманитарным дисциплинам и искусству;
- ERIC – инструмент создан Институтом педагогических наук США для преподавателей, ученых, политиков, содержит тысячи англоязычных публикаций по образованию и педагогике с бесплатным доступом;
- CogPrints – хранилище полнотекстовых документов по психологии, философии, искусственному интеллекту, математике, компьютерным технологиям.
Если не получается найти определенную статью на английском языке, можно попробовать обратиться к автору или его коллегам напрямую. Таким способом довольно часто пользуются в научном мире. Для этого используют социальную сеть Твиттер – нужно написать пост с хештегом #ICanHazPDF и указать, что именно ищете и куда отправить полный текст. Также найти определенную работу можно через профиль автора на сайте ResearchGate или Academia.edu. Обычно ученые охотно отвечают в течение недели, при этом можно еще и обсудить с автором его работу.
Заключение
Невозможно эффективно развиваться и строить карьеру в сфере образования, науки и исследований без понимания, где найти статьи на английском языке. Необходимо интересоваться современными разработками и новинками, актуальными исследованиями в различных отраслях со всего мира.
Ссылки на источники, приведенные в данной статье, помогут быстро и легко находить достоверную информацию по самым разным дисциплинам. Есть как универсальные площадки, где размещены научные труды на любые темы, так и узкоспециализированные, платные и бесплатные.
Если не получается найти полный текст конкретной публикаций, есть смысл пообщаться с автором напрямую (например, через специализированную научную соцсеть) заодно обсудив с ним интересующие вопросы по теме исследований. Большинство ученых легко идут на контакт с единомышленниками.
Присоединяйтесь, чтобы моментально узнавать о новых статьях в нашем научном блоге, акциях и получать только полезные материалы!
